
Abstract
In recent years, the energy consumption and associated carbon emissions from household consumption are increasing rapidly. It is an essential indicator to evaluate the extent of building a low-carbon society in China under the background of carbon peaking and carbon neutrality. Thus, we firstly calculate the information entropy of direct household consumption-induced carbon emission structure (IDHCES) in China during 2005–2019. Secondly, the spatial association network of the IDHCES is constructed by using the modified gravity model. Finally, we apply the social network analysis (SNA) to investigate spatial association characteristics of the spatial association network and explore influential factors by constructing the quadratic assignment procedure (QAP) model. There are four primary discoveries: (1) The balance of inter-provincial direct carbon emission structure from residential consumption is quite different. And the spatial linkage of the IDHCES is not just geographical proximity, but shows the complex network pattern. The extent of this network linkage is getting higher over time. (2) The spatial association network of the IDHCES presents an evident core-edge distribution. Most of the eastern provinces situated at the core of this network, such as Shanghai, Beijing and Tianjin, play essential roles, while most of the central and western provinces such as Qinghai, Guizhou, Xiangjiang and Ningxia are on the edge and have slight influence to this network. (3) The spatial association network for the IDHCES can be divided into four blocks, which are strongly related to each other and have obvious stepwise spillover effects. (4) The expansion of differences in per capita GDP, energy consumption per unit of GDP, family size and government investment in science and technology promotes the formation of the spatial association network of the IDHCES. While, the expansion of differences in geographical distance, population density and engel coefficient acts as a barrier. Based on the above analysis, we put forward some related suggestions for optimizing the information entropy of the direct carbon emission structure from Chinese residents’ consumption.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
With the deepening of reform and opening-up, the economy of China, the level of social development has improved significantly. Moreover, the energy consumption and associated carbon emissions from household consumption are increasing rapidly. The carbon emissions statistics in 2007 indicated that the carbon emissions of China exceeded the United States to become the largest carbon emitter in the world(Dong et al. 2013). As a result, China is under increasing pressure from the international community to address the environmental problems as soon as possible.
In fact, China has been moving hand in hand in solving the problem of environmental pollution to create a bright future in the past few years. In 2020, China proposed many targets in the UN General Assembly aiming to peak carbon dioxide emissions by 2030 and striving for carbon neutrality by 2060 (Jiang and Fu 2021). In order to achieve the goal of low-carbon development, China has put forward many relevant policies and measures(Zhang et al. 2019).
The primary source of carbon emissions is fossil fuels. The use of fossil energy is mainly concentrated in chemical industry, steel, construction and other industrial fields, so many policies and measures are targeted at the production sector. Thus, a large number of scholars also concentrated on carbon emissions in the production sector and obtained lots of research results in the past few years, please see references (Sassani et al. 2018; Zhou et al. 2019a, b; Jary et al. 2016). However, numerous previous studies pointed out that the carbon emissions from the household sector were also growing with the continuous improvement of residents’ living standards. Wei et al. (2007) suggested that the carbon emissions generated by residents’ energy consumption accounted for \(30\% \) of total carbon emissions in China during 1996–2006. Wang and Shi (2009) found the proportions of energy consumption and associated carbon emissions caused by the household sector increased substantially with a trend of rapid growth. Subsequently, Lu and Liu (2014) indicated that the household sector is the second largest energy consumer in China, after the industrial sector. Numerous research by other scholars also verified this view, please see references (Feng et al. 2011; Liu et al. 2011; Wang and Liu 2017; Streimikiene 2015; Das and Paul 2014). To a large extent, household consumption-induced carbon emissions can reflect residents’ consumption level and living quality, which is an important basis for building a green, energy-saving and low-carbon society. Thus, it is urgent to study the carbon emissions of household energy consumption.
Based on study by Qu et al. (2013), the household consumption-induced carbon emissions (HCE) included those both from direct and indirect energy consumption. The direct household consumption-induced carbon emissions (DHCE) referred to the carbon emissions generated by household direct energy consumption, such as lighting, heating, cooling, lighting, cooking, transportation and other activities. And the indirect household consumption-induced carbon emissions (IHCE) referred to the carbons emission generated by the energy consumed by the products and services used by residents in the process of processing and production. Reinders et al. (2003) and Li et al. (2015) introduced the carbon emission coefficient method to calculate household consumption-induced carbon emissions. Shan et al. (2017) proposed the carbon emission accounting method based on energy balance sheet. In addition, many studies (Nansai et al. 2012; Kadian et al. 2007) also indicated that the carbon emission coefficient method provided by the Intergovernmental Panel on Climate Change (2006) was more suitable and widely accepted to measure carbon emissions generated by household consumption than other methods.
Current analysis of carbon emissions can fall into the following three categories (Bai et al. 2020; Wei et al. 2020).
-
(1)
Calculation of carbon emissions and analysis of influencing factors. Cao et al. (2019) calculated the household consumption-induced carbon emissions and analyzed the influencing factors and found that residents’ income level and urbanization level were the main influencing factors. Tian et al. (2016) studied the changing trend and influencing factors of carbon emissions from household consumption in Shanghai and found residential consumption pattern was the main influence. Song et al. (2008) analyzed the relationship between industrial pollutants and economic growth, found that the trend meets the environmental Kuznets curve (EKC) hypothesis. Shortly afterwards, Wang et al. (2011) investigated the relationship between economic growth and energy consumption. Their research manifested a causal relationship among energy consumption, capital, employment and economic growth. For more information, please refer to (Barrett et al. 2014; Dong et al. 2019; Zhou et al. 2018; Zheng et al. 2018; Liao et al. 2011).
-
(2)
The trend analysis and forecast of carbon emissions. Xia et al. (2019) studied the influencing factors by multiple regression analysis and input-output analysis, and predicted the trend of inter-provincial domestic indirect carbon emissions in the future. They found that the growth rate of carbon emissions would slow down under the effective guidance of national policies. Wang and Ye (2017) forecasted carbon emissions from fossil energy consumption in China based on the improved grey model. Pao and Tsai (2011) predicted Brazil’s carbon emissions from energy consumption by using time series analysis.
-
(3)
The spatial-temporal evolution analysis of carbon emissions. With the development of spatial econometrics, spatial factors were gradually taken into consideration in the analysis of influencing factors of carbon emissions in the past few years. Wang et al. (2020) studied the temporal and spatial characteristics of the relationship between transportation carbon emissions and economic growth in China. Kang et al. (2020) quantified the impact of the development of Chinese express delivery industry on carbon emissions. It is evident from the studies that numerous scholars have shifted their research perspective from temporal analysis to spatial analysis. For more information, please see(Danish and Baloch 2018; Rong et al. 2020; Dou et al. 2016; Wang and Feng 2017; Chen et al. 2018).
There are still three deficiencies in the previous literature as shown in the following.
-
(1)
Many studies are conducted on the household consumption-induced carbon emissions from national level instead of regional level. In fact, different regions have significant differences in resource endowment, economic level, residents’ living habits and other aspects in China, so the inter-provincial household energy consumption carbon emissions are also different.
-
(2)
Much research describes the spatial distribution characteristics and spatial correlation of carbon emissions based on “attribute” data rather than “relational data”, which may fail to reflect the spatial structural characteristics and the effect of each region in the network.
-
(3)
The previous research for household consumption-induced carbon emissions mainly focuses on carbon emissions, which can not reflect the uniformity of carbon emission distribution and the balance of carbon emission structure generated by various types of energy consumption.
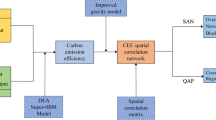
According to the above results, in this paper we first calculate the inter-provincial carbon emissions from the household sector in China during 2005–2019. Secondly, the information entropy of the household consumption-induced carbon emissions can be derived based on the information entropy theory. Thirdly, the association network for information entropy of household consumption-induced carbon emissions can be studied by utilizing the social network analysis (SNA) method. Finally, the quadratic assignment procedure (QAP) model can be constructed to find out the influencing factors.
The uniqueness of this paper is presented in the following. Firstly, we deeply study the differences of inter-provincial household energy consumption structure, the proportion of carbon emissions generated by various types of energy, and the balance and stability of carbon emissions structure among residents of different provinces in China based on the information entropy theory in thermodynamics. Secondly, we utilize the SNA method to study the association of inter-provincial household consumption-induced carbon emissions from the perspective of complex network. SNA derived from graph theory is a method usually used in investigating the spatial network characteristics of a certain system based on “relational data”. For more information, please see (Wei et al. 2020; Liu et al. 2021, 2022; Liu and Xiao 2021; Sun et al. 2019). In recent years, it is widely used in the study of complex inter-regional relationship structure, but few studies apply it to inter-provincial household carbon emissions. So, our study can enrich the literature.
The remainder is as follows. Section 2 concludes the methodology description and data sources. Section 3 applies social network analysis to investigate spatial association characteristics of the spatial association network and explores influential factors by constructing the QAP model. Section 4 summarizes the entire text and makes appropriate recommendations.
2 Methodology and data sources
In this section, we will introduce the basic principles of the research method, the construction of the research model, the selection of research variables and the source of research data, which can provide theoretical basis for the empirical analysis below.
2.1 The calculation of IDHCES
In this part, the information entropy of direct household consumption-induced carbon emission structure (IDHCES) can be calculated. Based on the Intergovernmental Panel on Climate Change (2006) power system carbon emissions measurement method, we estimate the direct household consumption-induced carbon emissions (DHCE) by using the terminal consumption of 12 kinds of energy, namely raw coal, cleaned coal, other washed coal, gangue, coke, coke oven gas, gasoline, kerosene, diesel, liquefied petroleum gas, natural gas and electricity. Except electricity, the formula of carbon emissions generated by 11 kinds of fossil energy consumption from household sector can be derived as shown
where \(C_{it}\) denotes the total carbon emissions of province i in the t year, \(E_j\) is the consumption of energy j. \(\alpha _j\) is the conversion factor of energy j and \(\beta _j\) is the carbon emission factor of energy j, as shown in Table 1.
Since the electricity consumption varies significantly among regions and different provinces belong to different grids, in this paper we utilize the emission factors of regional grids published by the National Development and Reform Commission (NDRC) in 2012 for measuring the carbon emissions of electricity consumed in residential life. The regional power grids can be divided into six regional grids. The division range and emission factors of each region are shown in Table 2.
Let \(C_{ij t}\) be the carbon emissions generated by energy j of province i in the t year and \(R_{ijt}\) be the ratio of carbon emissions generated by energy j of province i in the t year with calculation formula as below:
Then \(H_{it}\) represents IDHCES of province i in the t year derived as
H reflects the distribution of various types of energy’s carbon emissions and the balance of carbon emission structure in household consumption. The larger H is, the lower the proportion of carbon emissions from single energy consumed by residents. In other words, the larger H is, the more balanced the household consumption-induced carbon emissions from different energy sources are and the more stabilized the household consumption-induced carbon emission structure is.
2.2 Spatial association network of IDHCES
The association network of IDHCES is composed of the aggregate among provinces. Nodes represent provinces and directed line segments represent the correlation relationships between any two provinces in China. According to the law of universal gravitation and previous studies, please see (Barrios et al. 2012; Ma et al. 2019), the optimized gravity model for spatial correlation network of IDHCES can be constructed as shown in the following:
where \(\psi _{ij}\) reflects the correlation between information entropy of direct household consumption-induced carbon emission structure between provinces i and j, \(H_i\) and \(H_j\) are respectively the information entropy of direct household consumption-induced carbon emission structure of provinces i and j, \(P_i\) and \(P_j\) are respectively represents the total population of provinces i and j at the end of the year, \(G_i\) and \(G_j\) are respectively the regional GDP of provinces i and j, \(d_{ij}\) is the real spherical distance between capital cities of provinces i and j, \(g_i\) and \(g_j\) are the per capita GDP of provinces i and j.
Then, the matrix of association network of IDHCES between 30 provinces can be obtained from Formula (2.3), shown as follows
In order to indicate whether the degree of correlation is significant clearly and intuitively, we transform the spatial correlation matrix into relational matrix, namely 0-1 matrix. The specific method of constructing 0-1 matrix can be seen in Wei et al. (2020).
Based on the above changes, the spatial association matrix of IDHCES can be derived. A directed line segment can be drawn to connect the provinces i and j which have a spatial correlation.
2.3 Characterization index analysis in the network of IDHCES
In this section, we will introduce the selection of research variables and the source of research data, which can provide theoretical basis for the empirical analysis below.
2.3.1 Integral network analysis
According to previous studies, we reflect the integral structure characteristics of IDHCES through four indicators: network connectedness, network density, network efficiency and network hierarchy.
Network connectedness indicates robustness of the network (Scott 2007). The greater the value of network connectedness is, the fewer outliers exist and the higher the overall network correlation degree is. The calculation formula of network connectedness is:
where \(C_N\) is the network connectedness, n and v are the number of nodes and mutually unreachable node pairs in the network, respectively.
Network density shows tightness of the network (Scott 2007). Its value ranges from 0 to 1. The closer the value of network density is to 1, the closer the connection between different nodes in the network is. It is defined as follows:
where \(D_N\) is the network density, l is the amount of edges that really exist.
Network efficiency aims to reflect the degree of redundant connections in the network (Scott 2007). The lower the network efficiency, the more redundant connections between nodes, the more obvious the spillover effect, and the more stable the network. Its calculation formula is as follows:
where \(E_N\) is the network efficiency, R is the number of redundant connections between nodes, and max(R) is the maximum number of redundant connections that can exist.
Network hierarchy shows importance and control of the nodes in the overall network (Scott 2007). The higher the network hierarchy , the more distinct the classes among the nodes in the network, and the more difficult it is for the nodes at the edge of the network to integrate into the center of the network. Therefore, the more uneven the distribution of the whole network. The formula for calculating network hierarchy is:
where \(H_N\) is the network hierarchy, Q is the logarithm of the symmetric reachable nodes, and max(Q) is the logarithm of the largest possible reachable nodes.
2.3.2 Individual network analysis
According to previous studies, in this paper we reflect the individual structure characteristics of the association network for IDHCES through centrality. Centrality can reflect the position of one or some nodes in the overall network. The stronger the centrality of the node, the closer the node is to the center of the network, and the more influence and control the node has over other nodes. The indices commonly used to characterize centrality are point centrality, closeness centrality and betweenness centrality.
Point centrality measures the number of nodes directly connected to the node irrespective of nodes indirectly connected, so the point centrality reflects the node’s centrality on a localised scale of the whole network. The higher the node’s point centrality, the more the node tends to be at the center of the network, and the greater the influence of the node. Point centrality is divided into absolute point centrality and relative point centrality. The former is applicable to the case where the size of the network is the same, and the latter is applicable to the case where the size of the network is different. In this paper, absolute point centrality is used. Since the network studied in this paper is a directed network, point centrality is also divided into in-degree and out-degree. The in-degree of a node is the number of direct relations obtained from that node, and the out-degree is the number of relations issued directly from that node(Scott 2007). The formulas for calculating in-degree and out-degree are shown in the following:
where n is total number of nodes in the network, \(x_{ji}\) is the number of relationships from node j to node i, and \(x_{ij}\) is the number of relationships from node i to node j.
Closeness centrality, obtained by measuring the shortest distance from a node to other nodes, reflects the proximity of the node to others (Borgatti et al. 2009). The higher the closeness centrality of the node, the shorter the distance between the node with others, the faster and greater the node’s influence on others(Freeman 1979). It’s calculated as follows:
where \(s_{ij}\) denotes the shortest distance between node i and node j.
Betweenness centrality is divided into the point-betweenness centrality and the edge-betweenness centrality. This paper studied the point-betweenness centrality with each province as a node. The point-betweenness centrality reflects the node’s control and mediation capability in the network. In other words, if the node is on the shortest path of many pairs of nodes, it means that this node has a strong control ability(Freeman 1979). Its formula is:
where \(g_{pq}\) is the number of shortest paths between nodes i and j, \(g_{pq}(i)\) is the number of shortest paths between nodes p and q through node i.
2.3.3 Block model analysis
The purpose of the block model analysis method is to reduce a complex network to a block model or image matrix, which can more intuitively reflect the properties and roles of the nodes in the network. According to previous studies, network can be divided into four blocks, namely “Main outflow”, “Main inflow”, “Agent” and “Bidirectional spillover”. The “Main outflow” block has few internal correlations and receives few relationships from other blocks, but sends many relationships outward to other blocks(Zhou et al. 2021). On the contrary, the “Main inflow” block has many internal affiliations but few external affiliations, receives many relationships from others but sends few to others. The “Agent” block both sends and accepts external relations, but has fewer links with others(Lv et al. 2019). The “Bidirectional spillover” block both receives contacts and sends contacts to others in internally and externally. Wasserman and Faust (1994) obtained a method to measure intra-location relationships, as shown in Table 3, where \(f_i\) is the amount of nodes in block i, and f represents the amount of all nodes in the network.
2.3.4 QAP model
Independent variables should satisfy the basic assumption of mutual independence in the traditional multiple linear regression analysis, otherwise, multicollinearity will occur, which makes the regression results have serious errors. In this paper we study the relationship matrix, which is not independent, so the traditional multiple linear regression analysis is not appropriate now. However, the QAP model can avoid the above undesirable effects, which is often used together with the SNA method to explore the regression relationship between relationship variables. The QAP regression model is as follows:
where \(\Omega \) refers to the network relationship matrix, \(X_i (i=1,2, \ldots , m) \) is the influence matrix.
2.3.5 Data sources
For the reason of the serious short of energy consumption data of provinces before 2005 as well as the serious lack of data of Tibet Autonomous Region and Hong Kong, Macao and Taiwan, in this paper we take 2005–2019 as the research interval and 30 Chinese provinces as the research objects for analysis. The consumption data of 11 kinds of energy are obtained from the China Energy Statistical Yearbook and the National Data Center on the official website of China Statistics Bureau. The data of QAP regression impact factors are taken from China Statistical Yearbook, China Energy Statistical Yearbook, etc. Among them, the individual missing data of some provinces are uniformly processed by regression difference method.
3 Results and discussions
In the following, we will present the main points of this section. Firstly, we calculate inter-provincial information entropy of household consumption-induced carbon emission structure during 2005–2019. Secondly, the spatial correlation network of the IDHCES among provinces can be constructed by using the improved gravity model. Thirdly, the overall characteristic indicators and individual characteristic indicators of above network are analyzed based on the SNA. Finally, the influencing factors are analyzed by building QAP model.
3.1 Spatial distribution analysis of the IDHCES
According to formulas (2.1) and (2.2), the average direct carbon emissions from household consumption and the average information entropy of direct carbon emission structure from household consumption from 2005 to 2019 in 30 provinces can be calculated. The results are exhibited in Fig. 1. On the one hand, the distribution of household consumption-induced direct carbon emissions was uneven among the 30 provinces in China. Hebei, Guangdong, Shandong and Henan were the four provinces with the highest household consumption-induced direct carbon emissions. These provinces have one thing in common: large populations. In other words, people need more energy for their daily lives, which can lead to large amounts of carbon emissions. Guangdong is the most populous province in China with more than 100 million people, followed by Shandong and Henan with nearly 100 million, respectively. From Fig. 1, most of the provinces with small carbon emissions are remote, economically backward and sparsely populated, such as Ningxia, Qinghai, etc. On the other hand, the gap in information entropy of direct household consumption-induced carbon emission structure among the 30 provinces in China was also large. The seven provinces with the highest information entropy were Jiangxi, Shandong, Liaoning, Fujian, Zhejiang, Hunan and Shanghai. The seven provinces with the lowest information entropy were Guizhou, Qinghai, Xinjiang, Ningxia, Sichuan, Gansu and Hainan. It is straightforward to find that provinces with higher information entropy of direct household consumption-induced carbon emission structure are mainly located in the eastern regions with higher level of economic development but relatively scarce resources. The proportion of single energy in the residential energy consumption structure of these provinces is relatively low, the energy consumption is diversified and the energy consumption structure is reasonable, so the carbon emission structure is more balanced than other provinces. On the contrary, provinces with lower information entropy of direct carbon emissions structure from household consumption are mainly in western regions which have a relatively low level of economic development. These provinces have good resource endowment but lack of diversity in energy utilization.

Mean inter-provincial direct household consumption-induced carbon emissions and carbon emission structure information entropy in 2005–2019

Inter-provincial direct household consumption-induced carbon emission structure information entropy (2005, 2012, 2019)
Figure 2 depicts the trend of information entropy of the inter-provincial household consumption-induced direct carbon emissions structure in 2005, 2012 and 2019. As shown in Fig. 2, the information entropy of inter-provincial household consumption-induced direct carbon emissions structure shows a trend of fluctuation influenced by the type and level of energy consumption. The fluctuation can be roughly divided into three types: (1) Information entropy decreased year by year, such as Beijing, Shanghai, Tianjin, Jiangsu, etc. (2) Information entropy increased year by year, such as Chongqing, Inner Mongolia, Gansu, Ningxia, Qinghai, etc. (3) Information entropy fell after rose or shook after rose, such as Heilongjiang, Shanxi, Hubei, etc. Evidently, the first wave trend was mostly concentrated in the eastern region, the second was mostly concentrated in the western region and the third was mostly concentrated in the central region. The results of these three fluctuation trends may narrow the information entropy gap of the inter-provincial household consumption-induced carbon emissions structure. Therefore, we plot the annual change trend of the information entropy of inter-provincial household consumption-induced carbon emissions structure covered by eastern region, central region and western region in 2005–2019, as shown in Fig. 3, which proving the above speculation is correct.

Different regions’ inter-provincial direct household consumption-induced carbon emission structure information entropy in 2005–2019
In order to more intuitively reflect the spatial distribution characteristics and temporal change trends of the information entropy of the direct carbon emission structure of residential consumption in each province in China, in this paper we also select 2005, 2012 and 2019 as examples to draw the spatial distribution of the information entropy of the direct carbon emission structure of residential consumption in each province in China, as shown in Figs. 4, 5 and 6 below.

Household consumption-induced direct carbon emission structure information entropy distribution in 2005

Household consumption-induced direct carbon emission structure information entropy distribution in 2012

Household consumption-induced direct carbon emission structure information entropy distribution in 2019
From Figs. 4, 5 and 6, we can clearly see that: in 2005, the information entropy of the direct carbon emission structure of residential consumption in most regions of China, especially in the western regions was very low, showing that the energy structure of residential consumption in these provinces was overly dominated by a single energy source and lacked diversity in energy use. In the following years, with the strengthening of the relatedness of the association network of IDHCES, the direct carbon emission structure of residential consumption was optimized in most provinces.
Based on the above analysis, we can derive that the information entropy of inter-provincial direct carbon emission structure from household consumption may be related to regional economic development level and regional resource endowment.
3.2 Network characterization for spatial association network of IDHCES
3.2.1 Integral structural characteristics for spatial association network of IDHCES
Based on the the optimized gravity model of the network for IDHCES shown as formula (2.3), in this paper we derive the gravity matrices for spatial association network of IDHCES in 2005–2019 and draw the spatial correlation structures by using the visualization tool NetDraw in UCINET software. It is motivating to observe that the spatial correlation of the network of IDHCES is not simply geographic proximity, but presents complex network structure pattern, which also indicates the necessity of using SNA method for further analysis. Due to limited space, this paper takes the spatial correlation for the network of IDHCES diagrams in 2005, 2012 and 2019 as examples, shown in Figs. 7, 8 and 9. In Figs. 7, 8 and 9, directed line segments are used to connect provinces with spatial correlation. There are 30 provinces studied in this paper, namely, there are 30 nodes in the spatial association network diagram. The size of the node is divided based on the value of its point centrality, which can reflect the spatial association strength of the province. On the whole, there is no isolated province in the spatial association networks during 2005–2019, indicating that existed correlation between provinces and the form of the spatial association networks are relatively stable.

Spatial correlation network diagram of the information entropy of the household consumption-induced carbon emission structure in China in 2005

Spatial correlation network diagram of the information entropy of the household consumption-induced carbon emission structure in China in 2012

Spatial correlation network diagram of the information entropy of the household consumption-induced carbon emission structure in China in 2019
From Figs. 7, 8 and 9, we can evidently find the following two points:
-
(1)
The spatial association network of information entropy of the household consumption-induced direct carbon emission structure was centered around Shanghai, Beijing, Zhejiang, Jiangsu, Tianjin, Guangdong and Shandong in 2005. Shanghai, Jiangsu, Beijing, Tianjin, Shandong and Zhejiang were the center in 2012, and Beijing, Shanghai, Jiangsu, zhejiang and Fujiang were the center in 2019. These provinces formed a radiation network. Some provinces have always been situated at the core of above network, like Shanghai, Beijing and Jiangsu, indicating that these provinces exert a very important influence in the association network of information entropy of the household consumption-induced direct carbon emission structure. Most of these provinces have developed economy, high consumption level and good quality of life, but lack of natural resources. On the contrary, most of the central and western provinces like Qinghai, Guizhou and Xiangjiang are at the edge of above network and have slight influence to the network.
-
(2)
The blue nodes indicated that these provinces both received and sent contacts from others, while red nodes indicated the provinces sent contacts but didn’t receive contacts from others. In 2005, eleven provinces, including Sichuan, Qinghai, Guizhou, Gansu, Ningxia, Shaanxi, Xinjiang, Fujian, Heilongjiang and Inner Mongolia, did not receive contact from other provinces. Most of these provinces are economically backward, with underdeveloped transportation and low consumption level, but rich in natural resources. In 2012, three provinces, namely Xinjiang, Ningxia and Qinghai, did not receive contact from others. In 2019, only two provinces, namely Ningxia and Xinjiang, didn’t receive contacts. It is motivating to observe that the association of information entropy of carbon emission structure of residents’ direct consumption among provinces had been increasing in 2005–2019.
Based on the formulas (2.5)–(2.8), we analyse the integral structural characteristics of the spatial association network of the IDHCES through five indicators, namely network density, network contacts, network hierarchy, network efficiency and connectedness, as shown in Figs. 10, 11.

Evolution of network density and network contacts of the information entropy of the household consumption-induced carbon emission structure

Evolution of network hierarchy, network efficiency and connectedness of the information entropy of the household consumption-induced carbon emission structure
From Fig. 10, the network density and network contacts show an trend of first upward and then steady in general.
By 2019, the number of network contacts and the value of network density were 207 and 0.2379, respectively. This indicates that the association for the network of IDHCES has been increasing from 2005 to 2019. The larger the values of network contacts and network density are, the more complicated the spatial relationship of the information entropy of the household consumption-induced direct carbon emission structure between provinces will be. Moreover, there is still a large gap between the number of network contacts and the maximum possible network contacts, which shows that improving the above network is still necessary.
Figure 11 depicts the evolution of network hierarchy, network efficiency and connectedness of the spatial association network of IDHCES in 2005–2019. Both network hierarchy and efficiency demonstrate a downward trend in general with the former declining faster. From 2005 to 2019, the value of network hierarchy decreased from 0.5481 to 0.129 with an overall decrease of \(76.46\% \), indicating that the formerly relatively strict spatial correlation structure of the spatial association network of IDHCES was broken gradually, and the mutual influence and connection of the information entropy of carbon emission structure among provinces was deepened. The value of network efficiency gradually decreased from 2005 to 2012, showing that the correlation and mutual influence of the spatial correlation network of the household consumption-induced direct carbon emission structure’s information entropy among province were strengthened. After 2012, the network efficiency leveled off, showing that the efficiency of the spatial network was controlled reasonably. It also indicated that the establishment of the pilot carbon trading market in the 12th Five-Year Plan normalized the relationship of the carbon emission spatial correlation network, improved the efficiency of carbon emission, and optimized the spatial allocation of carbon emissions. The network connectedness was 1, indicating that the network structure was stable and there was spatial spillover effect and correlation effect among provinces.
3.2.2 Centrality analysis for the spatial association network of IDHCES
In this section, we will further study the individual structure characteristics for the spatial association network of IDHCES in order to find out the key provinces. In this paper we identify the key provinces by calculating the point centrality, betweenness centrality, and closeness centrality according to the formulas (2.9)–(2.13). The calculation results are shown in Table 4 and 5.
(1) Point centrality
The analysis reveals that the point centrality of each province in similar years didn’t change much although the point centrality of each province was fluctuated during 2005–2019. In recent years, Shanghai, Jiangsu, Beijing and Zhejiang are always on the head of the list of the point centrality among 30 provinces, indicating that these provinces play an absolute central role in the spatial association network of IDHCES. Moreover, more and more provinces’ point centrality were higher than the average with the passage of time, showing that the correlation of inter-provincial direct carbon emissions from household consumption was becoming more and more equal, and the number of core provinces was also increasing. For lack of space, the data for 2019 is analyzed in Table 4.
From the perspective of the in-degree and out-degree centrality, the top five provinces with the highest in-degree centrality in 2019 were Shanghai, Jiangsu, Beijing, Zhejiang and Fujian. And these provinces were also foremost among others in the ranking of point centrality in 2019. It is not difficult to find that most of these provinces are situated in the eastern region, with developed economy, convenient transportation and high living standards, need to receive energy from across China to meet their own needs. These provinces are benefited from the spatial spillovers of other provinces in the spatial association network of information entropy of direct carbon emissions from household consumption in China. The top five provinces with the highest out-degree centrality in 2019 were Gansu, Shanghai, Guangdong, Shannxi and Guizhou. As is known to all, Gansu province is rich in energy resources. It is an important comprehensive energy base and land energy transmission channel in China, and occupies an important position in the national energy development strategy. Shaanxi and Guizhou are rich in coal resources and both the top provinces in China in terms of coal output, with Shaanxi consistently topping the list in recent years. Guangdong province is rich in electricity resources.
(2) Closeness centrality and Betweenness centrality
The calculation results of closeness centrality and betweenness centrality of 30 provinces in 2019 are shown in Table 5. As seen from Table 5, the mean closeness centrality was 62.303. The eight provinces whose closeness centrality surpassed the average were Shanghai, Jiangsu, Beijing, Zhejiang, Fujian, Gansu, Guangdong and Hubei. These provinces have superior economic foundation, high technological level and developed transportation infrastructure, so the transmission of carbon emission correlation may don’t control and affect by other provinces to a large extent. The eight provinces whose closeness centrality at the bottom of the list of closeness centrality among 30 provinces were Tianjin, Anhui, Inner Mongolia, Hainan, Xinjiang, Guangxi and Jiangxi. Most of these provinces, like Xinjiang, Guangxi and Hainan, have few connections with other provinces due to their unfavorable geographical location, low economic development, low per capita income, low consumption level of residents and inconvenient transportation. They were at the edge of spatial correlation network, which was not conducive to the flow of carbon emission relations.
From the perspective of betweenness centrality, the mean value was 2.282 and the sum was 68.478. The six provinces whose betweenness centrality surpassed the average were Shanghai, Beijing, Jiangsu, Zhejiang, Fujian and Guangdong. The sum of these provinces’ the betweenness centrality was 58.058, accounting for 84.78% of the total national betweenness centrality. The six provinces whose betweenness centrality at the bottom of the list of betweenness centrality among 30 provinces were Inner Mongolia, Anhui, Hainan, Xinjiang, Ningxia and Jiangxi. The sum of these provinces’ betweenness centrality was 0.869, accounting for \(1.27\%\) of the total. Based on the above analysis, it can obtain that the network of information entropy of direct carbon emissions structure from household consumption in China had obvious unbalanced distribution characteristics. Therefore, this network mainly realized the flow of carbon emissions through several important provinces with the highest betweenness centrality. These provinces had strong influence and control over the carbon emission correlation among other provinces, acting as “bridge” in the association network, while other provinces with the lowest betweenness centrality were all in a controlled position.
(3) Block model analysis
According to the CONCOR tool in UCINET software, the maximum segmentation depth was set to 2, the centralised standard was set to 0.2, then 4 blocks can be formed. Due to limited space, in this paper we take 2005 and 2019 as examples to conduct block model analysis on the data of the above two years. The specific results are shown in Figs. 12, 13, 14 and 15 and Table 6.

Inter-provincial information entropy of the household consumption-induced carbon emission structure aggregation results in 2005

Inter-provincial information entropy of the household consumption-induced carbon emission structure block distribution in 2005
From Figs. 12 and 13, in 2005, Block 1 included 3 provinces, Beijing, Tianjin and Shangdong. The expected internal relationship was 6.90%, and the actual internal relationship was 16.44%. Block 1 received 52 contacts from other blocks and sent 9 contacts to other blocks. The number of contacts received was higher than sent. So, Block 1 was the “Main inflow” block. Block 2 included 4 provinces, Shanghai, Zhejiang, Guangdong and Jiangsu. The expected internal relationship was 10.34%, and the actual internal relationship was 10.10%. Block 2 received 76 contacts from other blocks but only received 5 from inside, showing that it had many contacts with other blocks but litter contacts from inside. Thus Block 2 belonged to the “Agents” block. Block 3 included 17 provinces, Jiangxi, Hunan, Guizhou, Hubei, Sichuan, Shaanxi, Gansu, Ningxia, Qinghai, Xinjiang, Anhui, Chongqing, Helongjiang, Hainan, Guangxi, Yunnan and Fujian. The expected internal relationship was 55.17%, and the actual internal relationship was 1.74%. Block 3 sent 101 contacts to other blocks but only received 12 from others, showing that the number of external contacts sent was far more than received. So, Block 3 was the “Main outflow” block. Block 4 included 6 provinces, Hebei, Shanxi, Henan, Jilin, Liaoning and Inner Mongolia. The expected internal relationship was 17.24%, and the actual internal relationship was 10.26%. Block 4 sent 26 contacts to other blocks but only sent 2 to inside, showing that it had many contacts with other blocks but litter contacts from inside. So Block 4 belonged to the “Agents” block.

Inter-provincial information entropy of the household consumption-induced carbon emission structure aggregation results in 2019

Inter-provincial information entropy of the household consumption-induced carbon emission structure block distribution in 2019
From Figs. 13, 14, in 2019, Block 1 included 3 provinces, Beijing, Tianjin and Jiangsu. The expected internal relationship was 6.90%, and the actual internal relationship was 5.80%. Block 1 received 52 contacts from other blocks but only received 2 from inside. And it sent 13 contacts to other blocks but only sent 2 to inside. Thus, Block 1 belonged to the “Agents” block. Block 2 included 5 provinces, Shanghai, Zhejiang, Guangdong, Hubei and Fujian. The expected internal relationship was 13.79%, and the actual internal relationship was 13.45%. Similarly, Block 2 had plentiful contacts with other blocks, while the contacts among the inside block were a small amount, therefore it was the “Agents” block. Block 3 included 14 provinces, Jiangxi, Hunan, Fujian, Guizhou, Sichuan, Shaanxi, Gansu, Ningxia, Qinghai, Xinjiang, Hainan, Chongqing, Yunnan and Guangxi. The expected internal relationship was 41.38%, and the actual internal relationship was 27.07%. Block 3 sent 82 contacts to other blocks but only received 15 from others. So, Block 3 was the “Main outflow” block. Block 4 included 8 provinces, Anhui, Helongjiang, Hebei, Shandong, Henan, Jilin, Liaoning and Inner Mongolia. The expected internal relationship was 27.59%, and the actual internal relationship was 27.96%. Block 4 received 40 contacts and sent 53 contacts in total, showing that it both sent many to other blocks and received many from others, and had many internal relations. So, Block 4 belonged to the “Bidirectional spillover” block which played a role in diffusing, radiating and transferring carbon emissions in the overall network.
Comparing the above two figures, it can be found that: as time goes by, the links between the sections became closer and closer, the number of provinces in the “Main inflow” block was decreasing, the number of provinces in the “Agents” block and “Bidirectional spillover” block were increasing, and the number of provinces in ”Main outflow” block didn’t change much. This indicates that the network shows stepwise spillover effect.
In order to further investigate the correlation relationship and spillover effect among various blocks in the network of information entropy of direct carbon emissions from household consumption, we then calculate the image matrix. In 2005 and 2019, the total network density of the information entropy of the direct household consumption-induced carbon emission structure were 0.1885 and 0.2379, respectively. The image matrix is obtained by comparing the density of each block in the density matrix with that in the overall network. If the block’s density is greater than that in the overall network, then the block has a central tendency, denoted as “1”, otherwise, it means that the block has no central tendency, denoted as “0”. The image matrix can show the correlation and flow of information entropy of carbon emission structure inside and outside the four blocks more clearly. The density matrix and the image matrix in 2005 and 2019 are shown in Table 7.
From Table 7, in 2005, on the one hand, Block 1 and Block 2 not only were internally related but also received spillovers from Block 3 and Block 4. Block 1 and Block 2 are economically developed provinces, with high population density, high per capita income, much residents’ living consumption and a relative shortage of resources, which can lead to the large energy consumption and need energy supplies from other provinces. The regions from Block 3 and Block 4 are wealthy in energy sources, providing energy sources for other provinces. Thus, the spatial correlation of carbon emissions within plates was generated. On the other hand, Block 3 had neither the spatial relationships inside nor inflow relationships from external blocks. Block 4 was not internally relevant either, but inflowed relationships from Block 1. So the spatial association between provinces internal to block 4 should be enhanced in order to facilitate the flow of carbon emissions among provinces. In 2019, it can be find that the correlations between blocks was strengthened. The spatial correlation between Block 1, Block 2 and Block 4 was enhanced, reflecting that with the increasingly frequent economic exchanges, the energy mobility of these plates was better and the spillover effect of information entropy of carbon emission structure was more obvious.
3.3 Factors affecting the spatial association network of IDHCES
In this section, we will analyse the influencing factors of the association network of information entropy of direct household consumption-induced carbon emission structure. Firstly, we establish the QAP model, which contains 11 influential factors. Secondly, the QAP correlation and regression analysis are used to examine them. Finally, the extent of influence of different factors can be derived.
3.3.1 Model Construction
From the analysis of the association network for the information entropy of direct household consumption-induced carbon emission structure, it is evident that the spatial association network of IDHCES has spatial correlation and spatial spillover effect. Therefore, we study the influencing factors of the association network of IDHCES, which can provide effective reference for the proposal of carbon emission reduction measures.
Based on the above analysis, we derive that the factors affecting the above network may include geographical location, population size, economic level and the amount of household energy consumption. Referring to relevant literature, see (Druckman et al. 2012; Yu and Du 2019), it can be seen that in addition to the above factors, the amount of science and technology input and the government’s emission reduction intensity may also affect the spatial correlation of the above networks. Therefore, in this paper we assume that geographical distance, economic level, the amount of household energy consumption, the amount of science and technology input and the government’s emission reduction intensity are factors.
The specific observation targets in the model are as follows: the actual distance between the two provincial capitals, urbanization rate, population density, household size, per capita GDP, engel coefficient, per capita electricity consumption, the proportion of coal consumption to total household energy consumption, energy consumption per unit of GDP, the proportion of \( R \& D\) to GDP and the government expenditure on energy conservation and environmental protection. Then, the model can be constructed as follow:
where Net represents the association matrix of the information entropy of the household consumption-induced carbon emission structure; AD is the provincial geographic distance matrix; UR is the urbanization rate difference matrix; PD is the population density difference matrix; HS is the household size difference matrix; PAG is the per capita GDP difference matrix; EC is the engel coefficient difference matrix; PAE is the per capita electricity consumption difference matrix; PCT is the difference matrix of the percentage of coal consumption to total household energy consumption; EPG is the difference matrix of the power consumption per unit of GDP, RD is the difference matrix of the percentage of \( R \& D\) to GDP, GE is the government expenditure on energy conservation and environmental protection difference matrix, respectively. The above 11 difference matrices were obtained by the following methods: firstly, the mean of analysis indexes corresponding to influencing factors in each province from 2005 to 2019 were calculated, and then the difference matrices were derived by using the absolute differences of the relevant indexes among provinces. In order to eliminate the error caused by the difference of dimension, all the difference matrices were normalized by range. The variables of regression analysis are the relationship matrices between two provinces, so the commonly used numerical statistical test methods are not applicable. Therefore, the non-parametric method QAP correlation analysis and QAP regression analysis in social network are selected for study.
3.3.2 QAP correlation analysis
In this paper, the result can be shown in Table 8. AD, UR, PD, HS, PAG, EC and RD are significant at \(1\%\) level, indicating that the above variables have a very important impact on the construction of the correlation network of information entropy of direct carbon emissions structure from household consumption in China. PAE and GE are significant at \(10\%\) level, suggesting that the above variables have some influence on the construction of spatial correlation network of direct carbon emission structure information entropy of Chinese residents’ living consumption.
Among them, the correlation coefficients of urbanization rate, population density, household size, per capita GDP, per capita electricity consumption, the proportion of \( R \& D\) to GDP and the government expenditure on energy conservation and environmental protection are higher than “0”, showing that they contribute to the spatial association of the network of IDHCES. The correlation coefficient of spatial distance was less than “0”, indicating that the shorter the distance between provinces, the more likely to produce spatial relevancy. The correlation coefficient of engel coefficient was also less than “0”, reflecting that the gap in the engel coefficients of provinces hinders the spatial relevancy of the network of IDHCES. PCT and EPG fail the significance test, indicating the effects of the differences in the percentage of coal consumption to total household energy consumption and the power consumption per unit of GDP are not significant in the association network of IDHCES.
Table 9 shows the correlations among the 11 variables mentioned above. From Table 9, it can be found that multicollinearity exists among independent variables, which is difficult to be analyzed by linear regression method. Therefore, we next use QAP regression analysis which can avoid the above shortcoming.
3.3.3 QAP regression analysis
We eliminated the PCT and EPG which had no significant impact on the spatial correlation and used the remaining 9 variables for QAP regression analysis. Then, the regression results of the spatial associations and influencing factors can be obtained based on the selection of 10000 random permutations, as shown in Table 10. The \(R^2\) is 0.330 and the adjusted \(R^2\) is 0.324, which pass the significance level test of \(1\%\), indicating that these variables can explain \(32.4\%\) of the correlation of spatial correlation network of information entropy of the household consumption-induced carbon emission structure in China.
From the perspective of significance level, AD, PD, PAG and EC are significant at \(1\%\) level, RD is significant at \(5\%\) level, HS and PAE are significant at \(10\%\) level, UR and EG fail the significance test, indicating that the above variables affect the correlation of spatial correlation network of information entropy of direct carbon emissions from household consumption in China except urbanization rate and the government expenditure on energy conservation and environmental protection.
From the perspective of standardised regression coefficient, the absolute value of standardised regression coefficient of PAG is the largest, followed by AD, EC, PD, RD, PAE and HS. It indicates that the spatial relevance of IDHCES is most influenced by the per capita GDP factor, geographical position factor, engel coefficient factor and population density factor, followed by science and technology input factor, energy consumption factor and family size factor. The results show that provinces with larger gap in per capita GDP, regional investment in science and technology and residents’ living energy consumption have closer correlation with carbon emissions, and provinces with closer geographical distance, similar population density and engel coefficient have closer correlation with carbon emissions.
4 Conclusions and policy implications
In this section, we will show the results of this paper and present related suggestion.
4.1 Conclusions
Firstly, in this paper we calculated information entropy of the household consumption-induced carbon emission structure in 30 Chinese provinces and cities during 2005–2019 based on the carbon emission coefficient method. Secondly, the association network of information entropy of direct household consumption-induced carbon emissions structure among provinces was derived by the improved gravity model. Thirdly, the overall characteristic indicators and individual characteristic indicators of above network were analyzed according to the SNA method. Finally, the influencing factors of the association network of information entropy of direct household consumption-induced carbon emissions structure were analyzed.
Through the above analysis, we can gain several main conclusions including the following.
-
(1)
From the perspective of integral structural characteristics of the association network for the IDHCES, the IDHCES in China became more and more spatially connected and the overall network gradually became more robust during 2005–2019. The network density and network contacts showed an trend of first upward and then steady in general and network hierarchy and network efficiency demonstrated a downward trend in general.
-
(2)
From the perspective of centrality, Shanghai, Beijing and Jiangsu were always on the head of the list of the point centrality, indicating that these provinces played an absolute central role in the association network of IDHCES. The distribution of betweenness centrality was extremely uneven, suggesting that the association network for the information entropy of direct household consumption-induced carbon emissions structure was flowing through several major provinces such as Shanghai, Beijing, Jiangsu, etc.
-
(3)
From the perspective of spatial clustering, the provinces in the “Agent” block and the “Bidirectional spillover” block were mainly economically developed areas with high living standards, convenient transportation and good infrastructure, while the provinces in the “Main outflow” block were mainly economically backward areas with low consumption and inconvenient transportation. The blocks were increasingly connected, with the number of provinces in “Main outflow” block decreasing and the number of provinces in the “Agent” block and “Bidirectional spillover” block increasing.
-
(4)
From the perspective of influence factors, the relevance of direct carbon emissions structure information entropy is extremely influenced by the per capita GDP factor, geographical position factor, engel coefficient factor and population density factor, followed by science and technology input factor, energy consumption factor and family size factor. And the increase in differences in per capita GDP, energy consumption per unit of GDP, family size and government investment in science and technology promotes the formation of the spatial correlation of the IDHCES. On the contrary, the expansion of differences in geographical distance, population density and engel coefficient acts as a barrier.
4.2 Policy implications
Based on the analysis above, we present related suggestion and solution to implement as below.
-
(1)
There are obvious information entropy differences in the structure of carbon emissions caused by household consumption in China, so Chinese government departments should consider the actual situation of each region and pay attention to the spatial linkage effect of the association network of information entropy of direct carbon emission structure of residential consumption to formulate targeted and effective energy conservation and emission reduction policies.
-
(2)
In optimizing the structure of carbon emissions caused by residential consumption, Chinese government departments should consider the status and the role of each province in the spatial association network of IDHCES and give full play to the provinces’ unique advantages. For example, provinces which at the center of the spatial association network of IDHCES are as bridges in the spatial association of carbon emissions.
-
(3)
Provinces should improve their own innovation capacity. On the one hand, clean energy should be vigorously developed, and the policies of promoting energy transfer from provinces with abundant clean energy sources such as hydro, wind, solar and tidal energy should be proposed in order to reduce over-representation of a single energy source and the unstable structure of carbon emissions. On the other hand, new technologies should be utilized, and the exchange of new energy saving and emission reduction technologies between provinces should be enhanced to achieve the goal of improving energy efficiency and reducing carbon emissions.
-
(4)
Chinese government departments should formulate relevant policies to increase the population density of central and western provinces and improve the living standard of residents in economically backward provinces. Strengthening the relevance of the network of IDHCES by reducing the inter-provincial differences in population density and engel coefficient.
-
(5)
On the one hand, Chinese government departments should increase energy saving and emission reduction efforts and enhance financial expenditures on energy saving and environmental protection. On the other hand, it should actively advocate green travel and low-carbon life to achieve the purpose of raising residents’ awareness of energy conservation.
Data Availability
The data that support the findings of this study are available within the article. All relevant data are also available from the corresponding author upon reasonable request.
References
Bai C, Zhou L, Xia M, Feng C (2020) Analysis of the spatial association network structure of China’s transportation carbon emissions and its driving factors. J Environ Manage 253:109765
Barrett W, Evans EJ, Francis AE (2014) China’s regional industrial energy efficiency and carbon emissions abatement costs. Appl Energy 130:617–631
Barrios JM, Verstraeten WW, Maes P, Aerts J-M, Farifteh J, Coppin P (2012) Using the gravity model to estimate the spatial spread of vector-borne diseases. Int J Environ Res Public Health 9(12):4346–4364
Borgatti SP, Mehra A, Brass DJ, Labianca G (2009) Network analysis in the social sciences. Science 323(5916):892–895
Cao Q, Kang W, Xu S, Sajid MJ, Cao M (2019) Estimation and decomposition analysis of carbon emissions from the entire production cycle for Chinese household consumption. J Environ Manage 247:525–537
Chen J, Xu C, Li K, Song M (2018) A gravity model and exploratory spatial data analysis of prefecture-scale pollutant and \(CO_2\) emissions in China. Ecol Ind 90:554–563
Danish MA, Baloch S (2018) Modeling the impact of transport energy consumption on \(CO_2\) emission in Pakistan: evidence from ARDL approach. Environ Sci Pollut Res 25:9461–9473
Das A, Paul SK (2014) \(CO_2\) emissions from household consumption in India between 1993–94 and 2006–07: a decomposition analysis. Ecol Econ 41:90–105
Dong F, Li X, Long R, Liu X (2013) Regional carbon emission performance in China according to a stochastic frontier model. Renew Sustain Energy Rev 28:525–530
Dong F, Yu B, Hadachin T, Dai Y, Wang Y, Zhang S, Long R (2019) Drivers of carbon emission intensity change in China resources. Conserv Recycl 129:187–201
Dou Y, Luo X, Dong L, Wu C, Liang H, Ren J (2016) An empirical study on transit-oriented low-carbon urban land use planning: exploratory Spatial data analysis (ESDA) on Shanghai, China. Habitat Int 53:379–389
Druckman A, Buck I, Hayward B, Jackson T (2012) Time, gender and carbon: a study of the carbon implications of British adults’ use of time. Ecol Econ 84:153–163
Feng Z-H, Zou L-L, Wei Y-M (2011) The impact of household consumption on energy use and \(CO_2\) emissions in China. Energy 36:656–670
Freeman LC (1979) Centrality in social networks: conceptual clarification. Social networks 1:215–239
Intergovernmental Panel on Climate Change (2006) 2006 IPPC Guidelines for National Greenhouse Gas Inventories, vol. 2. Institute for Global Environmental Strategies, Kanagawa, Japan. Energy. http://www.ipcc-nggip.iges.or.jp/public/2006gl/vol2.html
Jary H, Simpson H, Havens D, Manda G, Pope D, Bruce N, Mortimer K (2016) Household air pollution and acute lower respiratory infections in adults: a systematic review. PLoS ONE 11(12):e0167656
Jiang L, Fu X (2021) An Ammonia-Hydrogen energy roadmap for carbon neutrality: opportunity and challenges in China. Engineering 7(12):1688–1691
Kadian R, Dahiya R, Garg H (2007) Energy-related emissions and mitigation opportunities from the household sector in Delhi. Energy Policy 35(12):6195–6211
Kang P, Song G, Chen D, Duan H, Zhong R (2020) Characterizing the generation and spatial patterns of carbon emissions from urban express delivery service in China. Environ Impact Assess Rev 80:106336
Li Y, Zhao R, Liu T, Zhao J (2015) Does urbanization lead to more direct and indirect household carbon dioxide emissions? Evidence from China during 1996–2012. J Clean Prod 102:103–114
Liao C-H, Lu C-S, Tseng P-H (2011) Carbon dioxide emissions and inland container transport in Taiwan. J Transp Geogr 19(4):722–728
Liu S, Xiao Q (2021) An empirical analysis on spatial correlation investigation of industrial carbon emissions using SNA-ICE mode. Energy 224:120183
Liu LC, Wu G, Wang JN (2011) China’s carbon emissions from urban and rural households during 1992–2007. J Clean Prod 19(15):1754–1762
Liu J-B, Bao Y, Zheng W-T, Hayat S (2021) Network coherence analysis on a family of nested weighted n-polygon networks. Fractals 29(8):2150260–276
Liu J-B, Bao Y, Zheng W-T (2022) Analyses of some structural properties on a class of Hierarchical Scalefree networks. Fractals 30(7):2250136
Lu H, Liu G (2014) Spatial effects of carbon dioxide emissions from residential energy consumption: a county-level study using enhanced nocturnal lighting. Appl Energy 131:297–306
Lv K, Feng X, Kelly S, Zhu L, Deng M (2019) A study on embodied carbon transfer at the provincial level of China from a social network perspective. J Clean Prod 225:1089–1104
Ma F, Wang Y, Yuan KF, Wang W, Li X, Liang Y (2019) The evolution of the spatial association effect of carbon emissions in tansportation: a social network perspective. Int J Environ Res Public Health 16(12):2154
Nansai K, Kagawa S, Kondo Y, Suh S, Nakajima K, Inaba R, Oshita Y, Morimoto T, Kawashima K, Terakawa T, Tohno S (2012) Characterization of economic requirements for a carbon-debt-free country. Environ Sci Technol 46:155–163
Pao H-T, Tsai C-M (2011) Modeling and forecasting the \(CO_2\) emissions, energy consumption, and economic growth in Brazil. Energy 36(5):2450–2458
Qu J, Zeng J, Li Y, Wang Q, Maraseni T, Zhang L, Zhang Z, Clarke-Sather A (2013) Household carbon dioxide emissions from peasants and herdsmen in northwestern arid-alpine regions China. Energy Policy 57:133–140
Reinders AHME, Vringer K, Block K (2003) The direct and indirect energy requirement of households in the european union. Energy Policy 31(2):139–153
Rong P, Zhang Y, Qin Y, Liu G, Liu R (2020) Spatial differentiation of carbon emissions from residential energy consumption: a case study in Kaifeng China. J Environ Manag 271:110895
Sassani A, Arabzadeh A, Ceylan H, Kim S, Sadati SMS, Gopalakrishnan K, Taylor PC, Abdualla H (2018) Carbon fiber-based electrically conductive concrete for salt-free deicing of pavements. J Clean Prod 203:799–809
Scott J (2007) Social Network Analysis: A Handbook, 3rd edn. Sage Publication, London
Shan Y, Guan D, Liu J, Mi Z, Liu Z, Liu J, Schroeder H, Cai B, Chen Y, Shao S, Zhang Q (2017) Methodology and applications of city level \(CO_2\) emission accounts in China. J Clean Prod 161:1215–1225
Song T, Zheng T, Tong L (2008) An empirical test of the environmental Kuznets curve in China: a panel cointegration approach. China Econ Rev 19:381–392
Streimikiene D (2015) Assessment of reasonably achievable GHG emission reduction target in Lithuanian households. Renew Sustain Energy Rev 52:460–467
Sun L, Wang W, Zhou J, Bu C (2019) Study on the spatial correlation structure and synergistic governance development of the haze emission in China. Environ Sci Pollut Res 26:12136–12149
Tian X, Geng Y, Dai H, Fujita T, Wu R, Liu Z, Masui T, Yang X (2016) The effects of household consumption pattern on regional development: a case study of Shanghai. Energy 103:49–60
Wang M, Feng C (2017) Decomposition of energy-related \(CO_2\) emissions in China: an empirical analysis based on provincial panel data of three sectors. Appl Energy 190:772–787
Wang S, Liu X (2017) China’s city-level energy-related \(CO_2\) emissions: Spatiotemporal patterns and driving forces. Appl Energy 200:204–214
Wang Y, Shi M (2009) \(CO_2\) emission induced by urban household consumption in China. Chinese J Population Reasource and Environ 7(3):11–19
Wang Z-X, Ye D-J (2017) Forecasting Chinese carbon emissions from fossil energy consumption using non-linear grey multivariable models. J Clean Prod 142:600–612
Wang Y, Wang Y, Zhou J, Zhu X, Lu G (2011) Energy consumption and economic growth in China: a multivariate causality test. Energy Policy 39:4399–4406
Wang L, Fan J, Wang J, Zhao Y, Li Z, Guo R (2020) Spatio-temporal characteristics of the relationship between carbon emissions and economic growth in China’s transportation industry. Environ Sci Pollut Res 27:32962–32979
Wasserman S, Faust K (1994) Social Network Analysis: Methods and Applications. Cambridge University Press, Cambridge
Wei Y-M, Liu L-C, Fan Y, Wu G (2007) The impact of lifestyle on energy use and \(CO_2\) emission: an empirical analysis of China’s residents. Energy Policy 35:247–257
Wei Z-X, He Y-Y, Liu G-Q, Zhou P (2020) Spatial network analysis of carbon emissions from the electricity sector in China. J Clean Prod 262:121193
Xia Y, Wang H, Liu W (2019) The indirect carbon emission from household consumption in China between 1995–2009 and 2010–2030: a decomposition and prediction analysis. Comput Ind Eng 128:264–276
Yu Y, Du Y (2019) Impact of technological innovation on \(CO_2\) emissions and emissions trend prediction on New normal economy in China. Atmos Pollut Res 10(1):152–161
Zhang K, Xu D, Li S, Zhou N, Xiong J (2019) Has China’s pilot emissions trading scheme influenced the carbon intensity of output? Int J Environ Res Public Health 16(10):1854–1872
Zheng H, Shan Y, Mi Z, Meng J, Ou J, Schroeder H, Guan D (2018) How modifications of China’s energy data affect carbon mitigation targets. Energy Policy 116:337–343
Zhou Z, Guo X, Wu H, Yu J (2018) Evaluating air quality in China based on daily data: application of integer data envelopment analysis. J Clean Prod 198:304–311
Zhou Z, Wu H, Song P (2019) Measuring the resource and environmental efficiency of industrial water consumption in China: a non-radial directional distance function. J Clean Prod 240:118169
Zhou Z, Xu G, Wang C, Wu J (2019) Modeling undesirable output with a DEA approach based on an exponential transformation: an application to measure the energy efficiency of Chinese industry. J Clean Prod 236:117717
Zhou H, Ping W, Wang Y, Wang Y, Liu K (2021) China’s initial allocation of interprovincial carbon emission rights considering historical carbon transfers: program design and efficiency evaluation. Ecol Ind 121:106918
Acknowledgements
We would like to express sincere gratitude to the editor and the reviewers for helpful comments in improving the quality of the original manuscript.
Funding
This work was supported in part by Anhui Provincial Natural Science Foundation under Grant 2008085J01, and by Natural Science Fund of Education Department of Anhui Province under Grant KJ2020A0478.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, JB., Peng, XB. & Zhao, J. Analyzing the spatial association of household consumption carbon emission structure based on social network. J Comb Optim 45, 79 (2023). https://doi.org/10.1007/s10878-023-01004-x
Accepted:
Published:
DOI: https://doi.org/10.1007/s10878-023-01004-x