
Abstract
Correctly estimating the speed-up of a parallel embedded application is crucial to efficiently compare different parallelization techniques, task graph transformations or mapping and scheduling solutions. Unfortunately, especially in case of control-dominated applications, task correlations may heavily affect the execution time of the solutions and usually this is not properly taken into account during performance analysis. We propose a methodology that combines a single profiling of the initial sequential specification with different decisions in terms of partitioning, mapping, and scheduling in order to better estimate the actual speed-up of these solutions. We validated our approach on a multi-processor simulation platform: experimental results show that our methodology, effectively identifying the correlations among tasks, significantly outperforms existing approaches for speed-up estimation. Indeed, we obtained an absolute error less than 5 % in average, even when compiling the code with different optimization levels.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Nowadays, creating Multiprocessor System-on-Chip (MPSoC) architectures is a well-established solution for the design of efficient embedded systems [1]. On one hand, these architectures can deliver significant computational power thanks to a variety of processing elements, like general purpose processors, digital signal processors and specialized hardware accelerators. On the other hand, designing the applications for these systems is challenging due to several complex and interdependent steps to be performed [2–5]. First, the application has to be decomposed into multiple tasks that can be potentially executed in parallel or accelerated by dedicated components (partitioning). Then, these tasks need to be assigned to the available processing elements (mapping) and, finally, it is necessary to determine the execution order of the tasks assigned to the same resources (scheduling). When exploring this large design space (either by hand or by automatic methodologies), these combined solutions demand an accurate performance estimation before taking the final decisions [4].
Different approaches have been proposed for estimating the performance of parallel applications running on the top of MPSoCs. Accurate evaluations can be obtained by running the design solutions directly on the target platforms, but in most of the cases these are not available in the early stages of the design. Alternatively, it is possible to use cycle-accurate simulators [6, 7], but they can be too slow to be adopted during the design exploration phase, when multiple solutions have to be evaluated and compared. Fast estimation techniques, based on mathematical models [8, 9], are thus usually preferred in this phase. They are indeed less accurate but much faster, allowing the possibility of exploring more solutions in less time.
Additionally, depending on the nature of the application, different representations can be used to describe the solutions and to estimate the performance. Applications running on embedded systems can be dominated either by data (e.g. audio/video/image processing, digital communications) or by control (e.g. device control, packet processing). Data-oriented applications are often represented through data-flow models and their analysis methods usually focus more on architectural aspects rather than on the application behavior, which is assumed to be highly predictable [10]. However, there is a wide range of applications that cannot be well represented by these models, mainly due to the large presence of coarse-grained parallelism and conditional constructs (e.g. data-dependent loops, branches, function calls), which can significantly vary the execution time of the single parts of the application. In this scenario, task graph models [11] are widely adopted to represent partitioned solutions and derive mapping decisions [2, 5].
Multiple techniques have been proposed for estimating the performance of a task graph and most of them model the task execution time as a constant value [12] or as a stochastic variable [9]. These task estimations are then combined to estimate the execution time of the entire application, but without considering code correlations that may exist [13]. This can easily lead to wrong estimations that can, in turn, lead to the adoption of sub-optimal solutions. Conversely, the application behavior can be collected dynamically through code profiling [14], but this information is usually exploited only at task level, reducing the accuracy of the task graph estimation.
In this paper we present a methodology to accurately estimate the performance of control-dominated applications for heterogeneous embedded systems. To collect precise information about the control flow of the application (e.g. how many times the different sequences of branch transitions are executed), we extend the well-known Efficient Path Profiling [15] with a novel technique, called Hierarchical Path Profiling, which allows us to better correlate the profiling information with the structure of the partitioned application. Since the behavior and the correlations of the control constructs depend only on the input data, the profiling is independent from any parallel implementations or target architectures. For this reason, the profiling can be performed only once, on the sequential specification, and on a generic host machine, which is usually much faster than the target architecture. Our approach then combines these profiling data with task graph information to accurately estimate the speed-up of multiple parallel solutions with respect to the sequential version. We also integrate performance models of the different processing elements [16] and predictions of the synchronization costs [17] to have more accurate estimations of the specific target architecture. We applied our methodology to multiple embedded applications in several scenarios, which have been obtained by varying the number of processors in the target architecture and the compiler optimization levels. We then validated our estimations by comparing them with the benchmark execution on an MPSoC simulation platform. This shows that our methodology is effectively able to accurately predict the speed-up with an absolute error that is smaller than 5 % in average.
The rest of this paper is organized as follows. Section 2 presents a motivating example, which clearly shows why classical techniques are inadequate for estimating the performance of control-dominated applications running on MPSoCs. Section 3 discusses previous work, while Sect. 4 provides preliminary definitions and discusses the applicability of the approach to different architectures. Our methodology is then detailed in Sect. 5 and evaluated in Sect. 6. Finally, Sect. 7 concludes the paper.
2 Motivation
Estimating the speed-up introduced by a parallel implementation of a control-dominated application is challenging since the execution times of the tasks can vary significantly and, additionally, control constructs in distinct portions of the code can be correlated. To exemplify this problem, let us consider the function fun_0 shown in Fig. 1a. One of its parallelization is described through some annotations borrowed from the OpenMP formalism [18] and shown in Fig. 1b, while the corresponding task graph is shown in Fig. 2. Let us also assume that the target architecture is composed of two processors (i.e. \(CPU_\alpha \) and \(CPU_\beta \)), and the following information is known:
-
the estimated execution time of each statement \(o_i\) (including the calls to functions fun_1, fun_2 and fun_3) is fixed and known, as reported in Table 1 (the identifier i of \(o_i\) is reported on the left-hand side of Fig. 1a);
-
the probability of condition c1 being true is 0.5, the probability of condition c2 being true is 0.5 and the condition c3 is always true;
-
the architecture requires 50 cycles to create the tasks and 10 cycles for either synchronizing or destructing the created tasks.
Finally, let us also assume that there exists a correlation between c1 and c2, which controls the execution of fun_1 and fun_3, respectively. The following situations are considered:
-
 c1 and c2 always have the same value (either true or false) during an execution of fun_0: fun_1 and fun_3 are both invoked (true) or none of them is invoked (false).
c1 and c2 always have the same value (either true or false) during an execution of fun_0: fun_1 and fun_3 are both invoked (true) or none of them is invoked (false). -
 c1 and c2 always have opposite values during the same execution of fun_0: fun_1 and fun_3 are called in mutual exclusion.
c1 and c2 always have opposite values during the same execution of fun_0: fun_1 and fun_3 are called in mutual exclusion.


Table 2 reports the maximum and the average execution time for all the tasks. It is important to note how the execution of fun_1 and fun_3 heavily impacts on the execution time of Task1 and Task3.

Implementation of the example function fun_0. On each line, the number on the left-hand side is the identifier associated with the statement, while the number on the right-hand side is the identifier of the basic block to which the statement belongs. a Sequential implementation of function fun_0. b Parallel implementation of function fun_0

Task Graph extracted from function fun_0
Now we consider the two following mapping and scheduling solutions to be evaluated:
-
SolA: Task1 and Task2 are mapped onto \(CPU_\alpha \) (with Task1 scheduled before Task2) and Task3 is mapped onto \(CPU_\beta \);
-
SolB: Task1 and Task3 are mapped onto \(CPU_\alpha \) (with Task1 scheduled before Task3) and Task2 is mapped onto \(CPU_\beta \).
Right part of Table 3 (Real) reports the different real speed-ups of fun_0 in each of the possible cases obtained by combining the two conditions situations ( and
and  ) with the two mapping solutions (SolA and SolB). Results show that SolA has a larger speed-up in situation
) with the two mapping solutions (SolA and SolB). Results show that SolA has a larger speed-up in situation  , while SolB is the best solution in situation
, while SolB is the best solution in situation  . Table 3 also reports the estimations that can be obtained by using traditional techniques [19] based on average (AT) and maximum (MT) execution times. The former technique averages the different execution times of each task in all the situations, while the latter adopts the maximum execution time for each of them. These techniques present the same results for the two situations
. Table 3 also reports the estimations that can be obtained by using traditional techniques [19] based on average (AT) and maximum (MT) execution times. The former technique averages the different execution times of each task in all the situations, while the latter adopts the maximum execution time for each of them. These techniques present the same results for the two situations  and
and  and these results may also lead to choose inefficient mapping and scheduling solutions. Specifically, the MT technique always suggests to choose SolA, which is not correct in situation
and these results may also lead to choose inefficient mapping and scheduling solutions. Specifically, the MT technique always suggests to choose SolA, which is not correct in situation  . On the contrary, the AT technique always leads to slightly prefer SolB, which is not the best solution in situation
. On the contrary, the AT technique always leads to slightly prefer SolB, which is not the best solution in situation  .
.
These results show that, especially in case of control-dominated applications, the best mapping and scheduling solution can depend on the correlations that may exist among control constructs in the source code. For this reason, a methodology for a correct performance estimation of such applications has to necessarily take this aspect into account.
3 Related Work
Performance estimation is a crucial step in the design of efficient MPSoCs, where multiple design solutions have to be properly compared to determine the best decisions. Several methodologies have been proposed for evaluating the performance of parallel applications on MPSoCs. These methods can be roughly divided into three categories: direct measures, estimations by simulations, estimations by use of mathematical models.
Most of methodologies based on direct measures (e.g. [17]) are not affordable since integrating direct measurements in a design exploration framework is a long, difficult and error-prone task. Additionally, it cannot be completely automated and most of the work is thus manually performed by the designers, limiting the number of solutions that can be effectively evaluated. Techniques based on estimations are thus usually preferred.
In simulation-based methods, the single components or the entire system are estimated with simulations at different levels of accuracy (e.g. with ARMn [20], MPARM [6], ReSP [7], gem5 [21]). For example, in [22], a complete simulation is required to evaluate each design solution. However, accurate simulators are usually quite slow, especially in case of MPSoCs where they need to simulate multiple architectural aspects. For this reason the estimation problem is usually decomposed into sub-problems, where the simulation is performed only at a higher level of abstraction. For example, in [23], the performance of the single tasks is estimated by accurately annotating the source code, while the entire application is estimated through TLM simulations.
Estimations can be also obtained by exploiting mathematical models that correlate some numerical features of a design solution, which are collected through static or dynamic analyses, with its performance. In general, they are less accurate than the ones based on simulators, but they are much faster so they allow the designer to compare much more solutions. Also in this case, these techniques adopt a two-stage approach to perform first the estimation of the single tasks and then of the entire application. For example, [12] exploits the intermediate representation of the SUIF compiler [24] to estimate the execution time of each task and, then, interval analysis to predict the execution time of the whole application. In a similar way, in [25], GCC is modified to automatically generate the workload models of the tasks, while [26] combines performance estimation of single processors to estimate the performance of JPEG encoder and decoder applications on a pipelined MPSoC. [27] considers an ILP formulation for automatically parallelizing a hierarchical task graph representation, but the cost estimation is performed by simply associating a weight with each instruction, without analyzing the correlations between the control constructs.
While all these approaches model the execution time of a task as a constant, there are performance models where the execution times of tasks and task graphs are variable. In [28], the execution time of single tasks is modeled as a function of the variations in memory accesses count and requests rate, but ignoring any other details of its internal behavior, such as conditional constructs correlations. Finally, also stochastic variables have been used in the performance models of both tasks and task graphs. For example, [8] estimates the performance of a task graph as a stochastic variable, which is based on the stochastic variables associated with the execution times of the single tasks. Similarly, in [29], stochastic variables are used to model the access time of different tasks to resources in contention, while in [19] they are used to model the execution time of the single tasks, based on multiple profiling runs executed with different data sets. The authors suggest also two possible deterministic techniques: the worst-case estimation, which considers the 99.9’th percentile of the execution time of each task, and the average-case estimation, which considers the average execution time. In [30] Distributionally Robust Monte Carlo Simulation (DRMCS) is combined with a task-accurate performance estimation method to guarantee a robust task graph estimation. It requires to annotate each task with an interval estimation of its execution time. DRMCS is then applied to compute the worst-case execution time of the entire task graph, along with a confidence level for this estimation.
However, all these approaches are based on the assumption that the execution times of the tasks are independent and this can lead to a wrong evaluation of the design solutions, as shown in Sect. 2. The correlation effects among the workload of parallel tasks have been actually examined in [13], but only to correctly model the energy consumption of the analyzed solution and not for an accurate performance analysis.
To correctly model the tasks correlations induced by control constructs, we rely on path profiling [15]. Path profiling is a well-known technique that adopts an instrumentation of the branch constructs, followed by a series of executions of the resulting code with different data sets. This allows the designer to collect information about the dynamic behavior of the application. For this reason, several estimation methods have been based on this technique, but they are usually applied only to sequential applications. Ernst and Ye [31] discusses the performance estimation of sequential applications for real-time embedded systems. This work exploits the concept of path-based analysis to determine best and worst execution times. Similarly, Malik et al. [32] describes several static timing analysis techniques targeting embedded systems composed of a single processor. However, all the discussed techniques have high computational complexity, since they aim at verifying hard or soft constraints of real time systems. Moreover, these techniques are limited by the number of generated paths, since they do not exploit any techniques for path decomposition as proposed by [15]. For this reason, they cannot be applied to large applications. In [33], the path information is used instead to analyze the synchronizations among the threads: the synchronization operations are speculatively anticipated if they are on the most executed paths. The path profiling information has been thus used to optimize the communication between the threads, rather than to estimate the performances of parallelized specifications.
To the best of our knowledge, none of the existing approaches is able to estimate the performances of entire task graphs by analyzing the correlations among the task executions due to conditional constructs. In [34], we proposed a preliminary approach that is able to consider such correlations by leveraging path profiling information. However, it does not consider heterogeneous architectures nor information about mapping and scheduling. It is thus not possible to take into account the effects of executing the code on different processing elements, as well as the overhead introduced by resource contention. This paper extends this approach with the following main contributions:
-
we provide the support to heterogeneous embedded systems by integrating performance models of different processing elements, along with information about mapping and scheduling decisions;
-
we present a comprehensive validation of our approach by comparing the estimated speed-up with the one obtained with an open-source simulation platform for MPSoCs, and by considering different architectures and compiler optimization levels for the applications.
4 Preliminaries
This section introduces the concepts we leverage for estimating the performance of partitioned control-oriented applications. Specifically, Sect. 4.1 presents some basic definitions to better understand our approach, while Sect. 4.2 discusses its applicability to different architectural templates.
4.1 Definitions
Our methodology works on the top of the following intermediate representations, which are built for each function of the input application:
-
Control Flow Graph (CFG) [35], a directed graph \(G_{CFG} = (V,E_{CFG})\), which is an abstract representation of the paths (i.e. the sequences of branches) that might be traversed during the execution of the function; each vertex \(v_i \in V\) represents a basic block \(BB_i\); two additional vertices Entry and Exit are introduced to represent entry and exit points of the function execution, respectively; edges that close a loop of a path starting from the Entry node are named feedback edges [36];
-
Control Dependence Graph (CDG) [37], a directed graph \(G_{CDG}=(V,\) \(E_{CDG})\), which represents the control dependences of the basic blocks;
-
Control Dependence Region (CDR) [37], a partitioning of the basic blocks such that two basic blocks are in the same region if and only if they have the same set of control dependences in the CDG; the function \(\gamma : C_c=\gamma (BB_i)\) returns the Control Dependence Region \(C_c\) to which the basic block \(BB_i\) belongs;
-
Loop Forest [36], a representation of the loop hierarchy inside the CFG;
-
Hierarchical Task Graph [38], a representation of the application decomposition induced by the partitioning specified by the designer.
Given the example of Fig. 1a, its CFG is represented in Fig. 3; the only feedback edge is the dashed edge \(e_{9,5}\). The CDG and the CDRs of the same example are shown in Fig. 4, where, for example, \(e_{1,2}\) represents that \(BB_2\) is executed if and only if \(BB_1\) has completed its execution and the value of its final condition is true. Conversely, \(BB_4\) has no control dependences with \(BB_1, BB_2\) and \(BB_3\), so they can be executed in parallel provided that data dependences are satisfied. The example contains one loop, which has \(BB_5\) as header and includes basic blocks \(BB_5, BB_6, BB_7\) and \(BB_8\). In the rest of the paper, we identify a loop with the number of its basic block header (e.g. \(L_5\)). The entire function fun_0 is considered as a main loop, called \(L_0\).

The Control flow graph of fun_0

The CDG of function fun_0; dashed boxes identify CDRs named with capital letters
Partitioned applications are usually represented through a task graph, which is a directed graph whose vertices are the tasks induced by the partitioning and the edges represent precedences among them. Similarly to [38] and [39], we adopt the Hierarchical Task Graph (HTG) as the intermediate representation of a partitioned application. Specifically, the HTG is an acyclic directed graph whose vertices can be: simple (i.e. a task with no sub-tasks), compound (i.e. a task that consists of other tasks in a HTG, for example higher-level structures such as subroutines) or loop (i.e. a task that represents a loop whose body is a HTG itself). In this work, to describe the parallelism, we adopt a sub-set of OpenMP formalism [18]. OpenMP is a C/C++/Fortran extension widely adopted to describe the application partitioning directly inside the source code by means of pragmas [4]. For this reason, it is possible to activate sequential or parallel execution with simple compiler flags. It is however important to note that a complete support of OpenMP is out of the scope of this work. On the contrary, we only selected few annotations (parallel sections and section) that allow the designer to statically specify which parts of the code are meant to be executed in parallel, that is the structure of the HTG. Indeed, other OpenMP pragmas (e.g., task) prevent the building of the task graphs at design time. We create the HTGs by analyzing the intermediate representation produced by the compiler after the optimization phase. In such a way, we are able to take into account the effects of compiler optimizations on the code associated with each task. For example, given the annotated code shown in Fig. 1b, we create the corresponding HTG, which is shown in Fig. 5, as follows. The HTGs associated with each function are created starting from the innermost ones. For this reason, the HTG associated with fun_0 is created after HTGs of all called functions. Then, a simple task is created for Task0 since it contains no function calls or loops. It also represents the fork of the OpenMP parallel sections, which is composed of three sections. The first section corresponds to a compound task (i.e. Task1) since it contains the call to function fun_1. The corresponding HTG is associated with the same task. The second section contains a loop, followed by a function call. For this reason, two distinct tasks are generated: Task2a, which is associated with \(HTG_5\) (i.e. the HTG associated with the loop), and Task2b, which contains the remaining code of the section. Note that both Task6 (i.e. the task representing the loop body) and Task2b are compound tasks since they contain function calls. Similarly to the first section, the third one corresponds to a compound task (i.e. Task3) due to the presence of a function call. An additional task is created to represent the join of the OpenMP parallel sections (i.e. Task4) and it contains the remaining code. Note that, in Fig. 5, dotted vertices identify compound tasks (i.e. Task1, Task2b, Task3, Task6), dashed vertices identify loop tasks (i.e. Task2b) and continue vertices identify simple tasks (i.e. Task0 and Task4).

Hierarchical Task Graph extracted from function fun_0. a Task Graph of \(L_0\). b Task Graph of \(L_5\)
Finally, mapping decisions are specified through custom code annotations, as in [39], and the information is associated with each task of graph.
4.2 Supported Target Architectures
This work targets embedded systems composed of a set of processors, which feature local memories for instructions and data [5, 39], and no operating system, but with a bare-metal synchronization, as in [39, 40]. We currently support ARM processors (with or without support for out-of-order execution) and DSPs. Supporting additional processors only requires to generate the proper model (see [16]), which can estimate the performance of the assigned tasks based on their source code. Our methodology then leverage any of these models, as described in the following sections, to estimate the performance of task graph solutions.
We support different communication infrastructures. The processing elements can be indeed interconnected through a shared bus, a network-on-chip or point-to-point links [40]. From the point of view of estimations, this simply corresponds to a different communication overhead for each data transfer based on the infrastructure adopted for its implementation.
Moreover, there is no communication between parallel tasks: communication between parallel tasks and other tasks (e.g. fork and join task) can be explicit (performed at the beginning and at the end of their execution through direct data transfers) or implicit (performed during all the execution through exploitation of shared memory). The delay for the first type of communication is well modeled by the proposed methodology since it is incorporated in task overhead cost. On the contrary, the second type of transfers can introduce approximations in the estimations since the proposed methodology does not take explicitly into account cache memories. We also assume that there is no synchronization during the execution of parallel tasks (e.g. shared variables protected by mutexes). These situations are managed only at task boundaries [17], when tasks are created or destroyed. In fact, this is a common practice to effectively allow the parallel execution of the tasks.
With these assumptions, we are able to target both commercial platforms (e.g. Atmel Diopsis 940HF [41], TI OMAP 4 [42]) and prototype architectures obtained with commercial system-level design tools (e.g. Xilinx Vivado IP Integrator [43]). These architectures are also supported by multiple MPSoC simulators, which can be adopted for virtual prototyping (e.g. [6, 7, 21, 44, 45]). These solutions can be thus easily combined to analyze the mutual effects of partitioned applications and architectural decisions (e.g. size of caches, number of processors, communication infrastructures). In this work, we adopt ReSP [7], an in-house simulation platform, to demonstrate this potentiality.
5 Proposed Methodology
Our methodology is composed of two consecutive steps, as shown in Fig. 6. First, we profile the sequential version of the application, which is obtained by ignoring any partitioning or mapping pragma annotations, in order to collect information about the behavior of the application, which is then associated with its internal representation. In this step, we adopt the Hierarchical Path Profiling (HPP) (i.e. our extension to the Efficient Path Profiling [15]) to collect path information in a way that is suitable to be combined with the HTG representation adopted in the subsequent task graph estimations. This part is detailed in Sect. 5.1. Then we estimate the speed-up introduced by any of its parallel implementations. Specifically, considering the partitioning solution to be analyzed, the methodology estimates the execution time of each path by computing the contribution of all the tasks and, then, by combining these contributions following the structure of the HTG. The final estimation is obtained by a weighted average of these estimations where the weights are the frequency of the corresponding paths. The process is repeated at each level of the hierarchy, starting from the innermost loops to the outermost ones, as detailed in Sect. 5.2.

Overview of the proposed methodology
5.1 Hierarchical Path Profiling
Before describing the HPP technique, we need to introduce the definition of path. Let \(G_{CFG}=(V,E_{CFG})\) be the CFG of a function. Note that our methodology does not have any requirements about the structure of the CFG nor about the structure of its loops. The path \(P_p\) is defined as the sequence of basic blocks \(BB_i\) \(\in V\):
where each pair of basic blocks \(BB_i\)–\(BB_j\) is connected by an edge \(e_{i,j} \in E_{CFG}\). Since the CFG represents all the paths that might be traversed during a program execution, it is possible to count their occurrences and so how many times the corresponding basic blocks are executed. This technique is usually called path profiling. According to this definition, the basic blocks that belong to a path are executed in sequence, without any interleaving.
However, it is worth noting that each cycle inside a cyclic CFG (i.e. a CFG with a feedback edge) is still a path. Then, any sequence composed of n repetitions of this path is again a path and so the number of paths may be infinite. For this reason, it is not possible to collect information about any admissible path. We thus need to select a subset of these paths, which we call valid paths, and collect information only about them. Our HPP considers as valid only the paths that correspond to an entire loop iteration (or function execution when considering the loop \(L_0\)). In particular, given the CFG \(G_{CFG}=(V,E_{CFG})\) and the set F of its feedback edges, a path \(P_{p} = \lbrace BB_i\) – \(BB_{i+1}\) – \(\dots \) – \(BB_j\rbrace \) is considered valid when it satisfies one of the following conditions:
-
\((BB_j,BB_i) \in F\): i.e. the last basic block \(BB_j\) is reconnected to the first basic block \(BB_i\) through a feedback edge;
-
\(BB_i = BB_{Entry} \wedge BB_j = BB_{Exit}\): i.e. the path starts from the initial basic block (\(BB_{Entry}\)) and terminates in the final basic block (\(BB_{Exit}\)).
Based on these conditions, the paths can be clustered in sets, called Hierarchical Paths (\(HP_i\)), according to the innermost loop \(L_i\) where they are completely contained. Specifically, the path \(P_{p}=BB_i\)–\(BB_{i+1}\)–\(\ldots \)–\(BB_j\) is contained into \(HP_{i}\) since it refers to loop \(L_i\), which has \(BB_i\) as header. In our example, the path \(BB_5\)–\(BB_6\)–\(BB_7\)–\(BB_9\) is contained into \(HP_{5}\) while the path \(BB_{Entry}\)–\(BB_1\)–\(BB_3\)–\(BB_4\)–\(BB_5\)–\(BB_{10}\)–\(BB_{11}\)–\(BB_{13}\)–\(BB_{Exit}\) is contained into \(HP_0\) since it refers to the loop \(L_0\) (i.e. the path starts from the function entry).
However, according to this definition of valid paths, cyclic paths are still admitted and, for this reason, the number of paths that can be identified in a cyclic CFG is still potentially infinite. To avoid this problem, given a path \(P_{p} \in HP_{i}\) that contains the execution of a nested loop \(L_j\), we replace the sequence of basic blocks belonging to \(L_j\) with the symbol \(L_j^*\). This represents that, during the execution of the path \(P_p\), a certain number of iterations of \(L_j\) may be executed. Following this definition, both the paths \(BB_{Entry}\)–\(BB_1\)–\(BB_3\)–\(BB_4\)–\(BB_5\)–\(BB_{10}\)–\(BB_{11}\)–\(BB_{13}\)–\(BB_{Exit}\) and \(BB_{Entry}\)–\(BB_1\)–\(BB_3\)–\(BB_4\)–\(BB_5\)–\(BB_6\)–\(BB_8\)–\(BB_9\)–\(BB_5\)–\(BB_{10}\)–\(BB_{11}\)–\(BB_{13}\)–\(BB_{Exit}\) can be represented with the same path \(BB_{Entry}\)–\(BB_1\)–\(BB_3\)–\(BB_4\)–\(L_5^*\)–\(BB_5\)–\(BB_{10}\)–\(BB_{11}\)–\(BB_{13}\)–\(BB_{Exit}\). Indeed, they provide the same information for computing the execution time of \(HTG_0\). Then, details about the basic blocks executed during the nested loop \(L_5\) are used to compute the execution time of \(HTG_5\) (i.e. the one associated with the loop).
It is worth noting that, in the EPP technique proposed in [15], the paths extracted from the execution trace are a complete partition of the trace itself; as a result, each execution of a basic block is counted as part of one and only one path. On the contrary, in the HPP, the execution of a basic block can be considered as part of multiple paths and, thus, overlapping paths are admitted. For example, the execution trace \(BB_{Entry}\)–\(BB_1\)–\(BB_3\)–\(BB_4\)–\(BB_5\)–\(BB_6\)–\(BB_8\)–\(BB_9\)–\(BB_5\)–\(BB_{10}\)–\(BB_{11}\)–\(BB_{13}\)–\(BB_{Exit}\) contains the execution of two different and valid paths: \(BB_{Entry}\)–\(BB_1\)–\(BB_3\)–\(BB_4\)–\(L_5^*\)–\(BB_5\)–\(BB_{10}\)–\(BB_{11}\)–\(BB_{13}\)–\(BB_{Exit}\) and \(BB_5\)–\(BB_6\)–\(BB_8\)–\(BB_9\). Then, for example, the execution of \(BB_6\) is included in both the paths. Indeed, while the latter naturally contains the basic block in the loop iteration, the former implicitly contains the contribution of \(BB_6\) through the contribution of \(L_5^*\). As a result, including the contribution of \(L_5^*\) in the outermost path automatically includes the performance estimation of the corresponding loop. We will use this observation to hierarchically build the performance estimation of the entire application.
The HPP keeps track of the current path in the same way of the EPP. Specifically, a variable is used to store the encoded representation of the path, which is updated every time an edge of the CFG is traversed. When a valid path terminates (i.e. the execution reaches its final basic block), the corresponding counter is incremented and a new path starts. However, while in EPP only one path is alive at a time, multiple paths can be simultaneously alive in the HPP, due to the path overlapping that has been described before. In this case, when a new loop starts (i.e. the execution reaches its header), the current path becomes “idle” and a new path starts to keep track of the loop execution. The idle path then returns active only after the termination of the nested loop. More details about this aspect can be found in [34].
Once HPP has been applied and all paths have been hierarchically clustered, they are projected onto the CDRs defined in Sect. 4: each path can be represented as the set of executed CDRs. We call this projection Control Region Path (CRP). In particular, let \(P_p \in HP_l\) be a path belonging to loop \(L_l\), the \(CRP_{p}\) associated with path \(P_p\) is defined as:
where \(\gamma \) is the function that associates a basic block with its CDR. Since the function \(\gamma \) is surjective (i.e. more basic blocks can belong to the same CDR), the size of a control region path \(CRP_{p}\) results equal or smaller than the size of the corresponding path \(P_p\), without loosing any information since the CDR represents all the basic blocks that have to be executed under the same control conditions.
By elaborating path profiling information, it is then possible to derive information about the average number of iterations for each loop. The average number \(N_l\) of iterations of a loop \(L_l\), which is nested in \(L_j\), can be computed as:
where \(f_p\) corresponds to the number of times that path \(P_p\) is executed. The numerator is the total number of iterations of \(L_l\), which is computed as the sum of the number of executions of all paths contained in \(HP_l\). The denominator corresponds to how many times the loop \(L_l\) is executed, which is computed as the sum of the number of executions of paths of \(L_j\) which enter \(L_l\).
Note that, we compute a unique speed-up for each partitioned solution. However, for many control-dominated applications, the behavior of the application and, in turn, the results of the path profiling depend on the input data. So, in case of multiple input data sets, the path profiling information will be obtained by averaging the results obtained on the single runs. Computing the single speed-up for each input data set is possible, but this approach has some criticalities. In fact, if we obtain that the best solution is different for each data set, multiple solutions have to be implemented at the same time in the final system, which can introduce resource problems (e.g. memory to be reserved for object code). Additionally, it would be necessary to implement a runtime mechanism to automatically determine the solution to be adopted based on the input data set and this is a challenging task.
Appendix 1 shows the results of applying the HPP to the example shown in Sect. 2.
5.2 Task Graph Estimation
This section shows how we combine the path profiling information obtained with the HPP with the HTG representation and the mapping and scheduling decisions in order to produce a performance estimation.
For doing this, given a HTG to be estimated, this is transformed into \(\overline{HTG}\) to take into account the mapping and scheduling information of each task, extracted from the design solution. Specifically, an edge is added from \(Task_i\) to \(Task_j\) when: \(Task_i\) and \(Task_j\) (or the tasks contained in them) share a processing element (mapping) and \(Task_i\) is scheduled before \(Task_j\) (scheduling).
Our methodology analyzes all the tasks of the application, starting from the task graphs at the innermost levels of the hierarchy. First, we estimate the execution time of each path by combining the contribution of its statements. Since each path may traverse multiple tasks during its execution and these tasks may be assigned to different processing elements, the contribution of each statement is computed according to the performance model of the processing element where the corresponding task has been mapped. Then, if the path contains one or more loops, their contributions are also taken into account. In this case, the average execution time of a loop iteration is multiplied by its average number of iterations, which is equal to one in case of \(L_0\) (i.e. the HTG associated with the entire function). Since different execution paths can be traversed during a loop iteration, the average execution time of the loop iteration is estimated by considering independently each execution path and then by performing a weighted average of their contributions according to their frequency. Finally, to compute the performance estimation \(HTC_0\) of \(\overline{HTG_0}\) (i.e. a function), \(\overline{HTG_0}\) is hierarchically analyzed with the procedure described by Algorithm 1. Three main steps can be identified:
-
1.
Task Analysis (lines 1–17): we compute the task contributions to the different paths;
-
2.
Task Graph Analysis (lines 18–23): we analyze the vertices of \(\overline{HTG_l}\) in topological order to compute start and end times of each task;
-
3.
Task Graph Performance Estimation (lines 24–27): the end time of task Exit is used to estimate the performance of the entire \(\overline{HTG_l}\).

Before analyzing a HTG, all nested HTGs have to be already analyzed since contributions of the innermost loops or of the called functions have to be taken into account. For example, the performance estimation of \(HTG_0\) can be computed only after estimating the performance of \(HTG_5\). Similarly, the HTGs associated with fun_1, fun_2, fun_3 and fun_4 must be estimated before estimating the HTG associated with fun_0. The contribution of a function call is estimated as fixed and not depending on the particular call site, potentially introducing an approximation in the estimated parallel solution. An alternative solution is to create a clone of the complete function HTG for each call site in order to produce better estimation results. However, this can significantly increase the complexity of the proposed methodology. Note that recursive functions are not supported by the proposed methodology.
Before estimating the performance \(HTC_l\) of the \(HTG_l\), several intermediate estimations need to be performed to compute the contribution of each task to each path and then of each path to the entire task graph. These contributions are computed starting from the contributions of the single statements which compose the path, aggregated according to the structure of the HTG and the CFG of the specification. To estimate the contribution of the statements, different methods can be adopted, such as analytical models [16, 46] or cycle-accurate simulators [20]. In this work, we adopt estimations based on analytical models. In particular, given a statement to be characterized, we adopt as features the sequence of low-level instructions (i.e. RTL instructions produced by compiler for the target processing element) that correspond to the specific statement and to the preceding ones in the execution flow. The performance model, which is built by means of linear regression on a set of characteristic applications, takes as input the sequence of low-level instructions associated with the statement and produces as output the estimation of the corresponding execution time. Additional details can be found in [16]. After the estimation of the execution time of the single instructions, we perform the following intermediate estimations:
-
1.
\(BC_{i,t}\) (line 2) is the contribution of a basic block to the execution time of a task. It is computed as the estimated execution time of the statements of \(BB_{i}\) which belong to the task \(v_t\):
$$\begin{aligned} BC_{i,t}=f(o_{s1}, o_{s2}, \ldots , o_{sn}) \end{aligned}$$(3)where \(o_{si}\) is a statement of \(BB_{i}\) which belongs to the task \(v_t\) and \(f(\dots )\) is the estimation of the execution time of the statements, which takes into account also the processing element where the task \(v_t\) has been mapped as described above.
-
2.
\(\overline{BC}_{i,t}\) (line 4 and line 6) is the contribution of a basic block to the execution of a task and includes also the contributions of nested loops. If a task is a loop and \(HTG_i\) is the nested HTG, the estimated loop performance \(HTC_i\) is added to the contribution of the header \(BB_i\):
$$\begin{aligned} \overline{BC}_{i,t}\left\{ \begin{array}{lll} BC_{i,t} + \textit{HTC}_i &{} \quad \text {if } v_t \text { is a loop task containing } HTG_i &{}\qquad \qquad \qquad \, \quad (4\hbox {a})\\ BC_{i,t} &{} \quad \text {otherwise}&{}\qquad \, \qquad \qquad \quad (4\hbox {b}) \end{array}\right. \end{aligned}$$ -
3.
\(\textit{CC}_{c,t}\) (line 9) is the contribution of a CDR to the execution time of a task. It is computed as the sum of the contributions of the basic blocks belonging to the CDR:
$$\begin{aligned} \textit{CC}_{c,t}=\sum _{\forall BB_i : c=\gamma (BB_i)} \overline{BC}_{i,t} \end{aligned}$$(5) -
4.
\(\textit{TPC}_{p,t}\) (line 13) is the execution time of the task t when the path \(P_p\) is executed. It is computed as the sum of the contributions of all the CDRs belonging to \(P_p\):
$$\begin{aligned} \textit{TPC}_{p,t} = \sum _{\forall c : CDR_c \in CRP_p} CC_{c,t} \end{aligned}$$(6) -
5.
\(\overline{\textit{TPC}}_{p,t}\) (line 15) is the overall execution time for the task t (including the task management overhead, if any) when the path \(P_p\) is executed. It is computed as the sum of the execution time plus the overhead cost:
$$\begin{aligned} \overline{\textit{TPC}}_{p,t} = \textit{TPC}_{p,t} + OC_t \end{aligned}$$(7) -
6.
\(START_{p,t}\) (line 20) is the time from the beginning of the execution of an iteration of \(L_l\) in which the task t starts the execution of the path \(P_p\), while \(STOP_{p,t}\) (line 21) is the time in which the task t ends the execution of the path \(P_p\). \(PC_p\) (line 25), is the contribution of each path \(P_p\) to the average performance of the task graph. The start time \(START_{p,t}\) is computed as:
$$\begin{aligned} \textit{START}_{p,t} = max_{v_u \in pred(v_t)} \textit{STOP}_{p,u} \end{aligned}$$(8)where \(pred(v_t)\) is the set of the predecessors of \(v_t\) in \(\overline{HTG_l}\). Equation 8 states that the start time of a task is the maximum between end times of the tasks that precede \(v_t\) in \(\overline{HTG_l}\). The end time \(STOP_{p,t}\) is computed as:
$$\begin{aligned} \textit{STOP}_{p,t} = \textit{START}_{p,t} + \overline{TPC}_{p,t} \end{aligned}$$(9)Equation 9 states that the end time of a task \(v_t\) during the execution of path \(P_p\) is the start time of the task plus the time required for its execution (\(\overline{TPC}_{p,t}\)). Finally, \(PC_p\) (i.e., the contribution of path \(P_p\) to \(\textit{HTC}_l\)) is computed as:
$$\begin{aligned} \textit{PC}_p = \textit{STOP}_{p,Exit} \end{aligned}$$(10)Equation 10 states that the contribution of each path is the end time of the task Exit.
-
7.
\(HTC_l\) (line 27) is the overall task graph execution time. It is computed as a weighted average of the contributions given by all paths:
$$\begin{aligned} \textit{HTC}_{l} = N_l\cdot \frac{\sum _{P_p \in HP_l} (PC_p\cdot f_p)}{\sum _{P_p \in HP_l} f_{p}} \end{aligned}$$(11)where \(N_l\) is the average number of iteration of \(L_l\) (\(N_0=1\)) and \(f_p\) represents how many times the path \(P_p\) is executed.
Let \(S_{0}\) be the performance of the sequential specification, the estimated speed-up \(\mu \) introduced with the parallelization is then computed as:
5.3 Analysis of the Proposed Methodology
It is worth noting that the estimation presents some approximations because of the simplifications that have been necessarily introduced. First, the execution time of each called function is estimated to be constant and equal to its average execution time: calling contexts and inter-functions correlations are not analyzed as discussed above. In the same way, the correlations between statements belonging to different loops are not taken into account and the execution time of the nested loops is estimated to be constant (i.e. the average execution time of an iteration multiplied by the average number of iterations). However, applying the proposed methodology to the two cases presented in Sect. 2, we obtain 2648.5 and 2122 cycles respectively (details are shown in Appendix 1), and these results have been confirmed by the execution times obtained with simulation. This shows that, by exploiting profiling information, the proposed methodology is able to take into account the contribution of each statement when estimating the overall performance of the application.
The algorithm complexity is \(O(|C| \cdot |HP_l| \cdot |V_l|)\) where C is the number of CDRs, \(HP_l\) is the set of paths for \(L_l\) and \(V_l\) is the set of tasks for \(HTG_l\), as it results from line 13 of Algorithm 1. In the Eqs. , 5, 6, a linear additive model is adopted to combine the contributions of the different path components. \(TPC_{p,t}\) is the estimation of the execution time for the task statements sequentially executed: it is possible to easily integrate more complex models for estimating the overall execution time of these sequences of statements, but this requires to compute independently all the \(TPC_{p,t}\) starting from the single statements, which may increase the complexity of the approach.
6 Experimental Evaluation
We tested our methodology on several C-based benchmarks mapped on different architectures. Section 6.1 describes the experimental setup, while Sect. 6.2 shows the results that have been obtained.
6.1 Experimental Setup
Our methodology has been integrated in PandA [47], a hardware/software co-design framework based on GCC [48]. We tested this methodology on several benchmarks, which have been extracted from different benchmark suites for embedded systems: MiBench [49], OpenMP Source Code Repository (OmpSCR) [50] and Splash 2 [51]. Their characteristics are reported in Tables 4 and 5. The parallelism has been described with OpenMP: some of these benchmarks already contain such annotations, while the remaining ones have been manually partitioned. We then applied our framework to the resulting code and we exploit the intermediate representation of the GCC to build the corresponding HTG representation as described in Sect. 4.1.
To implement the HPP, we added the proper instrumentations and we execute the resulting code on the host machine to collect information about the executed paths. Additional details can be found in [34]. Note that this instrumentation usually introduces an execution overhead that ranges from 20 to 200 % with respect to the non-instrumented execution on the same machine. However, since the profiling is performed directly on the host system, which is usually much faster than the target architecture or its cycle-accurate simulator, the actual overhead of the instrumented application with respect to the original application executed on the target architecture is significantly less. For some architectures, the instrumented execution on the host system can be even faster than non-instrumented execution on target. Additionally, the path profiling is performed only once on the sequential application and the evaluation of multiple parallel solutions does not require to perform multiple path profilings. For these reasons, the instrumentation overhead is acceptable. Applying the optimizations proposed in [15] (e.g. the use of registers to store intermediate results) would allow to further decrease this overhead, but this is out of the scope of this paper.
In our experiments, the target architectures are composed of ARM processors (from 1 to 4), with a shared 32 Mbyte memory connected through a shared bus. We adopted the ARM922T processors [52] with 333 Mhz clock frequency, based on ARM9TDMI core (ARMv4T architecture) with a 8KB instruction cache and a 8KB data cache. Different performance models have been created with the methodology proposed in [16] to consider the effects of different compiler optimizations sets on the application performance. In particular, we built performance models for applications compiled with no optimizations (-O0) and with a standard set of active optimizations (-O2). The task management costs have been obtained by applying the profiling technique proposed in [17]. Mapping decisions for these architectures have been obtained by applying the methodology proposed in [4] and then specified as source code annotations [39]. This approach automatically produces a partitioning of the resources among parallel tasks at each level of the hierarchy. The scheduling decisions are instead automatically computed by applying a topological sorting on the task graphs. Thanks to these assumptions, given a hierarchical task graph \(HTG_l\), there are no interferences between tasks at different levels of the hierarchy and the dependences added to create \(\overline{HTG_l}\) are sufficient to effectively compute the performance estimation.
To validate the speed-up estimations produced by our methodology, we adopt ReSP (Reflective Simulation Platform) [7], which is freely downloadable from [53]. ReSP is a highly configurable Virtual Platform targeted to the modeling and analysis of MPSoC systems and built on top of the SystemC and TLM libraries at different levels of abstraction. Note that, in our experiments, the cache coherence is guaranteed by a directory-based mechanism, which overhead is directly managed by the simulation platform itself.
6.2 Experimental Results
We evaluated the benefits of considering profiling information by comparing our methodology with the following traditional techniques [19]:
-
Maximal Time (MT) the weight of each task is the estimation of its worst-case execution time and the profiling information is used to compute the maximum number of iterations for unbounded loops;
-
Average Time (AT) the weight of each task is the estimation of its average execution time and the profiling information is used to compute the average number of loop iterations, along with the branch probabilities.
Note that, in both the cases, the execution time of the task graph HTG is estimated as the longest path in the transformed task graph \(\overline{HTG}\).
These techniques have been applied to the benchmarks listed in Table 4, compiled with different levels of GCC optimizations (-O0 and -O2). The results have been compared with the results obtained with our path-based methodology (called PB) under the same conditions. For each application, we created eight situations to be analyzed: the two code optimization levels combined with the four considered architectures, i.e., from 1 to 4 processors. Each of these eight situations is analyzed with the three estimation techniques (i.e. MT, AT and PB) and then simulated with ReSP for validation.
Table 6 shows the average error produced by the three techniques when estimating the speed-up for the multiprocessor architectures with respect to the uniprocessor one. The error is computed as \(\frac{SU_{Est} - SU_{Real}}{SU_{Real}}\) where \(SU_{Est}\) is the estimated speed-up and \(SU_{Real}\) is the measured speed-up.
First, there are no significant differences in the accuracy of the estimations with different optimization levels for all the techniques. Indeed, applying code optimizations increases the error in estimating the performance of the single tasks, but the overall effects on the speed-up estimation are mitigated since the error is introduced in the estimations of both the sequential and the parallel versions of the applications. The results also show that our technique (i.e. PB), by properly adopting the complete path profiling information, is able to achieve better results (\(3.83\,\%\)) than state-of-the-art techniques (i.e. MT and AT). Additionally, the AT technique produces better estimations than the MT technique (22.60 vs. \(35.57\,\%\)) since it exploits more profiling information (e.g. the branch probabilities). The error introduced when estimating architectures with 4 processors with AT and MT techniques grows significantly, as explained in the following.
The results for each benchmark are reported in Tables 7, 8 and 9: the estimation error is reported for each combination of estimation technique, compiler optimization level and target architecture. Note that the error is positive when the technique overestimates the real speed-up, negative otherwise. For the PB technique, we report also the results obtained without taking into account the mapping information during the estimation: it is worth noting that this is equivalent to consider a target architecture composed of a number of processors equal or larger than the maximum degree of parallelism of the benchmark. In fact, in this case, there is no contention on the computational resources and the estimation computed considering mapping information corresponds to the one obtained by ignoring the mapping decisions. Results show that ignoring mapping and scheduling information introduces a large error in estimating the speed-up on the architectures with fewer processors (i.e. two or three) since, in this cases, the contention on the resources is much more relevant and ignoring this information leads to wrong estimations.
Analyzing the results, we can identify different classes of benchmarks. In particular, benchmarks like basicmath, grad and string search are characterized by a substantial data parallelism (e.g. parallel execution of different iterations of the same loop), which covers most of the application execution. These applications contain few conditional constructs, without any specific correlation among the execution times of their tasks. All techniques are thus able to estimate their speed-up with a good accuracy. Profiling information can be useful to obtain good speed-up estimations also in case of data parallelism and tasks with similar execution times that are executed in parallel. In fact, for example, benchmarks like array delay and blowfish are characterized by the presence of parallel sections consisting of parallelized loop iterations. In these benchmarks, the speed-up obtained in the single parallel sections can be easily estimated as their tasks have the same execution time. However, profiling information has to be necessarily considered also in this situation due to the proportion of the tasks composing sequential and parallel parts of the application, as stated by the well-known Amdahl’s Law. Since the MT technique is not able to correctly estimate this proportion, its speed-up estimation can lead to a significant error also in this case. In particular, for its intrinsic characteristics of adopting the maximum time, the MT technique systematically overestimates the execution time of the single tasks. Then, if the tasks composing the same parallel section are quite similar, as in the case of data parallel applications, all the tasks are overestimated in the same way. The MT technique thus overestimates the weight of the parallel part much more than the sequential one, overestimating the speed-up introduced by the parallelization. On the contrary, simple profiling information, such as the branch probabilities and the loop average iterations adopted by the AT technique, provides sufficient information to correctly estimate this proportion and, in turn, the overall speed-up. In these cases, the PB technique obtains almost the same results since the profiling of executed paths does not introduce any additional information to improve the estimation since no correlations are contained into the code. Conversely, when different tasks are correlated, adopting the path profiling information becomes critical. For example, in the susan benchmarks (corner detection and edge detection), there are parts of the code executed in parallel that are actually in mutual exclusion. Thus, the profiling information adopted by the AT technique is not sufficient and leads to optimistic estimations, as shown also in Sect. 2. Finally, consider the results about the dijkstra benchmark: in this case we introduced a false parallelism in the application since the code contained in parallel tasks is always in mutual exclusion. This situation has been artificially created to show how the proposed methodology is able to properly analyze also these situations. Indeed, our methodology correctly predicts a slow-down in the application due to the synchronization overhead of the tasks. The other techniques, instead, are not able to detect the mutual exclusion and, thus, they predict an incorrect positive speed-up.
Finally, Table 10 highlights how the estimation error changes when increaing the number of processors. In the benchmarks with substantial data parallelism (e.g. grad), there is no significant difference in the estimation error for all the techniques when considering more processors. Moreover, if the benchmark is characterized by parallel sections with four tasks that are equivalent from the performance point of view, there is not any benefit in increasing the number of processors from two to three. In fact, on the architecture with two processors, each processor has to execute two of the parallel tasks in sequence, while on the architecture with three processors, one of them has still to execute two tasks. For this reason, there is no difference in the speed-up. However, the additional cost required for creating more tasks induces a slow-down in the application execution, as correctly modeled by all techniques. On the contrary, if there is a correlation between the execution times of the parallel tasks, the errors in estimating the parallel version of the application and, in turn, of the speed-up increase when increasing the number of processors, as shown, for example, in the jpeg benchmark. When the tasks are completely correlated (e.g. they are in mutual exclusion as in dijkstra), these effects become very significant and can lead to large errors. On the contrary, the PB technique is able to take into account all these task correlations and, thus, the error is not significantly affected when increasing the number of processors.
7 Conclusions
In this paper, we proposed a methodology to better estimate the speed-up of a parallel code that takes into account the assignments of the tasks to the processing elements of the architecture and the correlation that may exist among their execution times. In particular, such estimation is computed by combining the HTG representation with a single profiling of the sequential version of the application, which is collected on a generic host machine. We applied our methodology to estimate the speed-up of a set of parallel benchmarks on different MPSoC architectures, which have been obtained by varying the number of processors, and we validated the results on a simulation platform. The results show that the proposed methodology is effectively able to produce much more accurate estimations with respect to classical approaches based on constant execution time for the tasks.
References
Wolf, W.: The future of multiprocessor systems-on-chips. In: Proceedings of the 41st Annual Design Automation Conference, DAC ’04, pp. 681–685 (2004)
Niemann, R., Marwedel, P.: An algorithm for hardware/software partitioning using mixed integer linear programming. Des. Autom. Embed. Syst. 2(2), 165–193 (1997)
Marwedel, P.: Embedded System Design: Embedded Systems Foundations of Cyber-Physical Systems, 2nd edn. Springer, Berlin (2010)
Ferrandi, F., Pilato, C., Tumeo, A., Sciuto, D.: Mapping and scheduling of parallel C applications with ant colony optimization onto Heterogeneous reconfigurable MPSoCs. In: Proceedings of the 15th IEEE Asia and South Pacific Design Automation Conference, ASP-DAC ’10, pp. 799–804, January 2010 (2010)
Ferrandi, F., Lanzi, P.L., Pilato, C., Sciuto, D., Tumeo, A.: Ant colony heuristic for mapping and scheduling task and communications on heterogeneous embedded systems. IEEE Trans. Comput. Aided Des. Integ. Circ. Syst. 29(6), 911–924 (2010)
Benini, L., Bertozzi, D., Bogliolo, A., Menichelli, F., Olivieri, M.: MPARM: Exploring the Multi-Processor SoC Design Space with SystemC. J. VLSI Sign. Process. 41(2), 169–182 (2005)
Beltrame, G., Fossati, L., Sciuto, D.: ReSP: A Nonintrusive Transaction-Level Reflective MPSoC Simulation Platform for Design Space Exploration. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 28(12), 1857–1869 (2009)
Li, Y.A., Antonio, J.K.: Estimating the execution time distribution for a task graph in a heterogeneous computing system. In Proceedings of the 6th Heterogeneous Computing Workshop, HCW ’97, pp. 172–184, (1997)
Manolache, S.: Analysis and optimisation of real-time systems with stochastic behaviour. Technical report, Linkoping University (2005)
Poplavko, P., Basten, T., Bekooij, M., van Meerbergen, J., Mesman, B.: Task-level timing models for guaranteed performance in multiprocessor networks-on-chip. In: Proceedings of the 2003 international conference on Compilers, architecture and synthesis for embedded systems, CASES ’03, pp. 63–72, (2003)
Coffman, E.G.: Computer and Job Shop Scheduling Theory. Wiley, New York (1976)
Sahu, A., Balakrishnan, M., Panda, P.R.: A generic platform for estimation of multi-threaded program performance on heterogeneous multiprocessors. In: Proceedings of the Conference on Design, Automation and Test in Europe, DATE ’09, pp. 1018–1023 (2009)
Yaldiz, S., Demir, A., Tasiran, S., Ienne, P., Leblebici, Y.: Characterizing and exploiting task-load variability and correlation for energy management in multi-core systems. In: ESTImedia, pp. 135–140 (2005)
Hubert, H., Stabernack, B., Wels, K.-I.: Performance and memory profiling for embedded system design. In: Proceedings of the International Symposium on Industrial Embedded Systems, SIES ’07, pp. 94–101 (July 2007)
Ball, T., Larus, J. R.: Efficient path profiling. In: MICRO-29: Proceedings of the 29th Annual ACM/IEEE International Symposium on Microarchitecture, pp. 46–57 (1996)
Lattuada, M., Ferrandi, F.: Performance modeling of embedded applications with zero architectural knowledge. In: Proceedings of the Eighth IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and Cystem Cynthesis, CODES/ISSS ’10, pp. 277–286 (2010)
Ferrandi, F., Lattuada, M., Pilato, C., Tumeo, A.: Performance modeling of parallel applications on MPSoCs. In: IEEE International Symposium on System-on-Chip, SOC ’09, pp. 64–67 (2009)
OpenMP. Application Program Interface, version 2.5 (May 2005)
Satish, N.R., Ravindran, K., Keutzer, K.: Scheduling task dependence graphs with variable task execution times onto heterogeneous multiprocessors. In: Proceedings of the 8th ACM international conference on Embedded software, EMSOFT ’08, pp. 149–158, New York, NY, USA. ACM (2008)
Zhu, X., Malik, S.: Using a communication architecture specification in an application-driven retargetable prototyping platform for multiprocessing. In: Proceedings of the Conference on Design, Automation and Test in Europe, DATE ’04, pp. 1244–1249 (2004)
Binkert, N., Beckmann, B., Black, G., Reinhardt, S.K., Saidi, A., Basu, A., Hestness, J., Hower, D.R., Krishna, T., Sardashti, S., Sen, R., Sewell, K., Shoaib, M., Vaish, N., Hill, M.D., Wood, D.A.: The Gem5 simulator. SIGARCH Comput. Archit. News 39(2), 1–7 (2011)
Miele, A., Pilato, C., Sciuto, D.: A simulation-based framework for the exploration of mapping solutions on heterogeneous MPSoCs. Int. J. Embed. Real Time Commun. Syst. 4(1), 22–41 (2013)
Lin, K.-L., Lo, C.-K., Tsay, R.-S.: Source-level timing annotation for fast and accurate tlm computation model generation. In: Design Automation Conference (ASP-DAC), 2010 15th Asia and South Pacific, pp. 235–240, (2010)
Wilson, R., French, R., Wilson, C., Amarasinghe, S., Anderson, J., T. S., Liao, S., Tseng, C., Hall, M., Lam, M., Hennessy, J.: The SUIF Compiler System: a Parallelizing and Optimizing Research Compiler. Technical report, Stanford, CA, USA (1994)
Kreku, J., Tiensyrjä, K., Vanmeerbeeck, G.: Automatic workload generation for system-level exploration based on modified GCC compiler. In: Proceedings of the Conference on Design, Automation and Test in Europe, Date ’10, pp. 369–374, (2010)
Javaid, H., Janapsatya, A., Haque, M.S., Parameswaran, S.: Rapid runtime estimation methods for pipelined MPSoCs. In: Proceedings of the Conference on Design, Automation and Test in Europe, DATE ’10, pp. 363–368 (2010)
Cordes, D., Marwedel, P., Mallik, A.: Automatic parallelization of embedded software using hierarchical task graphs and integer linear programming. In: Proceedings of the Eighth IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, CODES/ISSS ’10, pp. 267–276 (2010)
Kim, S., Ha, S.: System-level performance analysis of multiprocessor system-on-chips by combining analytical model and execution time variation. Microprocess. Microsyst. 38(3), 233–245 (2014)
Kumar, A., Mesman, B., Corporaal, H., Ha, Y.: Iterative probabilistic performance prediction for multi-application multiprocessor systems. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 29(4), 538–551 (2010)
Xu, Y., Wang, B., Hasholzner, R., Rosales, R., Teich, J.: On robust task-accurate performance estimation. In: Proceedings of the 50th Annual Design Automation Conference, DAC ’13, ACM, New York, NY, USA, pp. 171:1–171:6 (2013)
Ernst, R., Ye, W.: Embedded program timing analysis based on path clustering and architecture classification. In: Proceedings of the 1997 IEEE/ACM International Conference on Computer-Aided Design, ICCAD ’97, pp. 598–604, (1997)
Malik, S., Martonosi, M., Li, Y.S.: Static timing analysis of embedded software. In Proceedings of the 34th Annual Design Automation Conference, DAC ’97, pp. 147–152 (1997)
Zhai, A., Colohan, C.B., Steffan, J.G., Mowry, T.C.: Compiler optimization of scalar value communication between speculative threads. In: Proceedings of the 10th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS-X, pp. 171–183 (2002)
Ferrandi, F., Lattuada, M., Pilato, C., Tumeo, A.: Performance estimation for task graphs combining sequential path profiling and control dependence regions. In: Proceedings of the 7th IEEE/ACM International Conference on Formal Methods and Models for Codesign, MEMOCODE ’09, pp. 131–140 (2009)
Aho, A.V., Sethi, R., Ullman, J.D.: Compilers: Principles, Techniques, and Tools. Addison-Wesley Longman Publishing Co., Inc, Melbourne (1986)
Sreedhar, V.C., Gao, G.R., Lee, Y.: Identifying loops using DJ graphs. ACM Trans. Program. Lang. Syst. 18(6), 649–658 (1996)
Ferrante, J., Ottenstein, K.J., Warren, J.D.: The program dependence graph and its use in optimization. ACM Trans. Program. Lang. Syst. 9(3), 319–349 (1987)
Girkar, M., Polychronopoulos, C.: Automatic extraction of functional parallelism from ordinary programs. IEEE Trans. Parallel Distrib. Syst. 3(2), 166–178 (1992)
Bertels, K., Sima, V., Yankova, Y., Kuzmanov, G., Luk, W., Coutinho, G., Ferrandi, F., Pilato, C., Lattuada, M., Sciuto, D., Michelotti, A.: Hartes: Hardware-software codesign for heterogeneous multicore platforms. IEEE Micro. 30, 88–97 (2010)
Thompson, M., Nikolov, H., Stefanov, T., Pimentel, A.D., Erbas, C., Polstra, S., Deprettere, E.F.: A framework for rapid system-level exploration, synthesis, and programming of multimedia MP-SoCs. In: Proceedings of the IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, CODES+ISSS ’07, pp. 9–14 (2007)
Atmel Corporation. DIOPSIS 940HF. http://www.atmel.com (2009)
Texas Instruments. TI OMAP 4. http://www.ti.com (2011)
Xilinx. Vivado Design Suite. http://www.xilinx.com (2013)
Gerstlauer, A.: Host-compiled simulation of multi-core platforms. In: Proceedings of the IEEE International Symposium on Rapid System Prototyping (RSP), pp. 1–6 (June 2010)
Synopsys Inc. Platform Architect. http://www.synopsys.com/Systems/ArchitectureDesign (2012)
Oyamada, M.S., Zschornack, F., Wagner, F.R.: Applying neural networks to performance estimation of embedded software. J. Syst. Architect. 54(1–2), 224–240 (2008)
PandA. PandA framework. http://trac.ws.dei.polimi.it/panda
GNU Compiler Collection. GCC, version 4.3. http://gcc.gnu.org/
Guthaus, M.R., Ringenberg, J.S., Ernst, D., Austin, T.M., Mudge, T., Brown. R.B.: MiBench: A free, commercially representative embedded benchmark suite. In: Proceedings of the IEEE International Workshop on Workload Characterization, WWC ’01, pp. 3–14 (2001)
Dorta, A.J., Rodriguez, C., de Sande, F., Gonzalez-Escribano, A.: The OpenMP Source Code Repository. In: Proceedings of the 13th Euromicro Conference on Parallel, Distributed and Network-Based Processing, PDP ’05, pp. 244–250 (2005)
Woo, S.C., Ohara, M., Torrie, E., Singh, J.P., Gupta, A.: The SPLASH-2 programs: characterization and methodological considerations. In: Proceedings of the 22nd Annual International Symposium on Computer Architecture, ISCA ’95, pp. 24–36 (1995)
ARM922T. Technical Reference Manual. http://infocenter.arm.com
Politecnico di Milano. ReSP web-site. http://code.google.com/p/resp-sim/ (2010)
Author information
Authors and Affiliations
Corresponding author
Appendix 1: Example of Application of Task Graph Estimation Technique based on Path Profiling
Appendix 1: Example of Application of Task Graph Estimation Technique based on Path Profiling
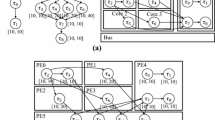
This appendix shows how the proposed methodology is applied to estimate the performance of the example presented in Sect. 2 when SolB is considered: Task1 and Task3 are assigned to \(CPU_\alpha , Task2a\) and Task2b are assigned to \(CPU_\beta \). The resulting \(\overline{HTG}\) is shown in Fig. 7: the edge \(<Task1,Task3>\) is added to represent the scheduling order, as discussed in Sect. 5.2. The estimation starts with the application of the Hierarchical Path Profiling on the host machine, which results are reported in Table 11. For the sake of readability, we report also the sequence of basic blocks which compose each path, even if this information is equivalent to the one provided by the corresponding CRP. The order of the Control Dependence Regions in a Control Region Path is not relevant since the basic blocks are interleaved during the execution. The table shows how HPP is able to profile the paths  and
and  and to collect correlations about the execution of basic blocks before and after a loop, even if it is executed, with a representation that can be easily mapped onto the HTG.
and to collect correlations about the execution of basic blocks before and after a loop, even if it is executed, with a representation that can be easily mapped onto the HTG.

\(\overline{HTG}\) created from HTG considering SolB. a Task Graph of \(L_0\). b Task Graph of \(L_5\)
Before estimating the execution time (\(HTC_0\)) of func_0, \(HTC_5\) is estimated as follows:
-
1.
the contribution \(BC_{i,t}\) of each basic block is computed (line 2 of Algorithm 1): the results are reported in Table 12a (e.g. \(BC_{9,6} = f(o_{13}) = 1\) since \(o_{13}\) is the only statement of \(BB_9\));
-
2.
the contribution \(\overline{BC}_{i,t}\) of each basic block including nested loops is computed (lines 4 and 6—Table 13a—e.g. \(\overline{BC}_{7,6} = BC_{7,6}\) since Task6 is simple);
-
3.
the contribution \(CC_{c,t}\) is computed summing the contribution of the single basic blocks (line 9—Table 14a—e.g. \(CC_{E,6} = \overline{BC}_{6,6} + \overline{BC}_{6,9} = 3\) since \(CDR_E\) is composed of \(BB_6\) and \(BB_9\));
-
4.
the contributions of the single Control Dependence Regions are summed to compute the contributions \(TPC_{p,t}\) (line 13—Table 15a—e.g. \(TPC_{ {{}}, 6} = CC_B + CC_E + CC_I = 6\) since path
 is composed of B, E and I);
is composed of B, E and I); -
5.
the overhead for the task management is added to \(TPC_{p,t}\) to compute \(\overline{TPC}_{p,t}\); since there is not any overhead cost in this task graph, \(\overline{TPC}_{p,t} = TPC_{p,t}\) (line 15—Table 16a—\(\overline{TPC}_{ {{}}, 6} = TPC_{ {{}}, 6}\) since Task6 has not overhead cost);
-
6.
the start and end times of each task are computed (lines 20 and 21—Table 17a—e.g. \(START_{ {{}}, 6} = STOP_{{{}}, Entry5}\) since \(Entry_5\) is the only predecessor of Task6; \(STOP_{ {{}}, 6} = START_{ {{}}, 6} + \overline{TPC}_{ {{}}, 6}\)); the execution times of the two paths are computed as the end time of task Exit (line 25—last line of Table 17a—e.g. \(PC_{{}} = STOP_{ {{}}, Exit_5}\));
-
7.
the estimation of the whole \(HTG_5\) can be computed (line 27):
$$\begin{aligned} HTC_5=N_5 \cdot \frac{PC_{{}}\cdot f_{{}}+PC_{{}}\cdot f_{{}}}{f_{{}}+f_{{}}}=10 \cdot \frac{105\cdot 100 + 6\cdot 0}{100+0}=1050 \end{aligned}$$(13)
 is composed of B, E and I);
is composed of B, E and I);After \(HTC_5\) has been estimated, \(HTC_0\) can be estimated in the same way and Fig. 8 shows how the different contributions are combined. These contributions are:
-
1.
the contribution of each basic block \(BC_{i,t}\) (lines 2), obtained from the clock cycles of Table 1; the results are reported in Table 12b;
-
2.
the contribution of each basic block including nested loops \(\overline{BC}_{i,t}\) (lines 4 and 6); the results are reported in Table 13b; note in particular that \(\overline{BC}_{5,2a}=BC_{5,2a} +HTC_5=1+1050\);
-
3.
the contribution of each Control Dependence Region \(CC_{c,t}\) (line 9); the results are reported in Table 14b;
-
4.
the contribution of each path to each task \(TPC_{p,t}\) (line 13); the results are reported in Table 15b;
-
5.
the contribution of each path to each task, along with the overhead cost, \(\overline{TPC}_{p,t}\) (line 15); the creation cost (50) is added to Task1 and Task2a; the synchronization and destruction cost (10) is added to Task3 and Task2b; the results are reported in Table 16b;
-
6.
\(START_{p,t}\) and \(STOP_{p,t}\) (lines 20 and 21); the results are reported in Table 17b, where the selected topological order is: \(Entry_0\)-Task0-Task1-Task2a-Task2b-Task3-Task4-\(Exit_0\);
-
7.
the contribution of each path \(PC_{p}\) (line 25): the results are reported in the last line of Table 17b;
-
8.
\(HPC_0\) in the two cases presented in Sect. 2:
-
 the CRPs executed are \(P_{{}}\) and \(P_{{}}\), so the execution time estimated for the parallel version is: $$\begin{aligned} HTC_{0} = \frac{PC_{{}} \cdot f_{{}} + PC_{{}} \cdot f_{{}}}{f_{{}} + f_{{}}} = \frac{4171 \cdot 5 + 1126 \cdot 5}{5 + 5} = 2648.5 \end{aligned}$$(14)
the CRPs executed are \(P_{{}}\) and \(P_{{}}\), so the execution time estimated for the parallel version is: $$\begin{aligned} HTC_{0} = \frac{PC_{{}} \cdot f_{{}} + PC_{{}} \cdot f_{{}}}{f_{{}} + f_{{}}} = \frac{4171 \cdot 5 + 1126 \cdot 5}{5 + 5} = 2648.5 \end{aligned}$$(14) -
 the CRPs executed are \(P_{{}}\) and \(P_{{}}\), so the execution time estimated for the parallel version is: $$\begin{aligned} HTC_{0} = \frac{PC_{{}} \cdot f_{{}} + PC_{{}} \cdot f_{{}}}{f_{{}} + f_{{}}} = \frac{2122 \cdot 5 + 2122 \cdot 5}{5 + 5} = 2122 \end{aligned}$$(15)
the CRPs executed are \(P_{{}}\) and \(P_{{}}\), so the execution time estimated for the parallel version is: $$\begin{aligned} HTC_{0} = \frac{PC_{{}} \cdot f_{{}} + PC_{{}} \cdot f_{{}}}{f_{{}} + f_{{}}} = \frac{2122 \cdot 5 + 2122 \cdot 5}{5 + 5} = 2122 \end{aligned}$$(15)
 the CRPs executed are
the CRPs executed are  the CRPs executed are
the CRPs executed are 
Composition of contributions to produce \(\textit{HTC}_0\) when c1 and c2 have always the same values; contributions (rounded rectangles) are computed from top to bottom of the graph using operations described in the proposed methodology (rhombuses); the corresponding levels are reported in the left of the figure
Finally, the speed-up for the two situations presented in Sect. 2 can be computed. The execution time of the sequential specification is 3123 cycles in both the cases, so the estimated speed-ups are 1.18 and 1.47, respectively.
Rights and permissions
About this article

Cite this article
Lattuada, M., Pilato, C. & Ferrandi, F. Performance Estimation of Task Graphs Based on Path Profiling. Int J Parallel Prog 44, 735–771 (2016). https://doi.org/10.1007/s10766-015-0372-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-015-0372-7