
Abstract
This study explores the potential of adaptive neuro-fuzzy inference systems (ANFIS) for prediction of the ultimate axial load bearing capacity of piles (Pu) using cone penetration test (CPT) data. In this regard, a reliable previously published database composed of 108 datasets was selected to develop ANFIS models. The collected database contains information regarding pile geometry, material, installation, full-scale static pile load test and CPT results for each sample. Reviewing the literature, several common and uncommon variables have been considered for direct or indirect estimation of Pu based on static pile load test, cone penetration test data or other in situ or laboratory testing methods. In present study, the pile shaft and tip area, the average cone tip resistance along the embedded length of the pile, the average cone tip resistance over influence zone and the average sleeve friction along the embedded length of the pile which are obtained from CPT data are considered as independent input variables where the output variable is Pu for the ANFIS model development. Besides, a notable criticism about ANFIS as a prediction tool is that it does not provide practical prediction equations. To tackle this issue, the obtained optimal ANFIS model is represented as a tractable equation which can be used via spread sheet software or hand calculations to provide precise predictions of Pu with the calculated correlation coefficient of 0.96 between predicted and experimental values for all of the data in this study. Considering several criteria, it is represented that the proposed model is able to estimate the output with a high degree of accuracy as compared to those results obtained by some direct CPT-based methods in the literature. Furthermore, in order to assess the capability of the proposed model from geotechnical engineering viewpoints, sensitivity and parametric analyses are done.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Deep foundations are mainly used in situations that the underlying soil layer is not enough capable of bearing the applied loads where it is not possible to use shallow foundations. The main objective of using piles is to transfer structural loads to a strong layer which is able to support the applied loads. Thus, the safety and stability of pile supported structures depend on the behavior of piles. In order to ensure the stability of the foundation, it is necessary to make an accurate estimation of the pile bearing capacity, particularly for pre-design purposes. This problem has been challenging for many geotechnical engineers and not yet entirely been handled due to many factors and uncertainties affecting the system behavior including complicated behavior of piles in soil, soil disturbance due to pile installation and sampling, and pile load transfer mechanism (Kiefa 1998).
Based on characteristics of load transfer to the underlying layer, the staticaxial load bearing capacity of the pile (Qu) can be generally considered as the sum of end-bearing capacity of the pile (Qt), i.e. the bearing capacity of the compact stratum or a stiff layer where applied loads are transferred onto and the shaft friction capacity (Qs) that loads are carried through friction of the surrounding soil along the shaft and can be represented as the equation as follows (Niazi and Mayne 2013):
where qt is the unit end bearing capacity, At is the area of the pile at tip, fs unit shaft resistance of the ith soil layer through which the pile shaft is embedded; Asi is the area providing frictional resistance with the adjacent soil in the ith layer against axial displacement
It is worth mentioning that the end-bearing capacity (Qt) plays the overriding role in granular soils, whereas in cohesive soils the shaft friction capacity (Qs) dominates. In this regard, considering the type of pile is an important issue for the design and analysis of piles (Tomlinson and Woodward 2014).
The most usually utilized approaches to determine the bearing capacity of piles can be classified into following groups: (1) full scale pile load tests (2) analytical and semi empirical methods (3) correlation with in situ tests. Pu may be obtained using laboratory testing methods; however, it is necessary to conduct several field and laboratory experimentations such as standard penetration test (SPT), unconfined compression test, soil classification, etc. due to the variability and large number of soil properties which are needed as input variables for the static analysis. Hence, laboratory methods would have some certain drawbacks such as being cumbersome, expensive and time consuming. On the one hand, full scale pile load tests cannot be used for other engineering purposes to assess the pile behavior as they are highly expensive. On the other hand, dynamic load tests require special equipment expertise for monitoring, recording and interpreting the obtained data. Among various in situ experimentations, cone penetration test (CPT) may be regarded as the most frequently utilized method for characterization of geo-materials properties at different depth. Besides, CPT is the most commonly used method for soil investigation in Europe as it is rapid, economical and is able to continuously obtain information from soil (Omer et al. 2006). CPT is basically composed of a cylindrical rod with a cone tip which is driven into the soil and measure the tip resistance and sleeve friction due to this intrusion which can be considered as a model pile. Two main parameters obtained from the CPT test, cone resistance and sleeve friction, can be regarded as base and shaft resistance of the pile respectively. In addition, the resistance parameters are used to classify soil strata and to estimate strength and deformation characteristics of soils at different depth. CPT is a simple, quick, and economical test that provides reliable information about undistributed in situ continuous soundings of subsurface soil (Abu-Farsakh and Titi 2004; Eslami 1996; Niazi and Mayne 2013; Omer et al. 2006). Furthermore, it is recently possible to apply this test for a wide range of geotechnical applications adding up different devices to cone penetrometer.
Quite a few approaches are proposed for calculating the axial pile capacity using CPT data. These methods may be mainly classified into two methods (Niazi and Mayne 2013):
- (1)
Direct approach The unit toe bearing capacity of the pile (qt) is evaluated from the cone tip resistance (qc), and the unit skin friction of the pile is evaluated from either the sleeve friction (fs) profile or qc profile.
- (2)
Indirect approach The CPT data, qc and fs, are firstly used to evaluate the soil strength parameters such as the undrained shear strength (Su) and the angle of internal friction ϕ. These parameters are then used to evaluate the qt and the unit skin friction of the pile ϕ using formulas derived based on semi-empirical or analytical methods. In this major quite a few models have been proposed by various researchers.
1.1 Schmertmann (1978) Method
The Schmertmann (1978) method is based on the result of the 108 load tests on pile carried out by Nottingham (1975). The ultimate tip resistance (Qp) of pile can be calculated as:
where Atip is pile tip area; qc1 and qc2 are the minimum of the average cone tip resistances of zones ranging from 0.7 to 4 D below the pile tip, and over a distance 8 D above the pile tip, respectively. The average cone resistance values are obtained from the graphical representation of the failure surface, which is assumed to follow a logarithmic spiral as introduced by Begemann (1963). The method limits the average of qc1 and qc2 to 15 MPa.
Based on this method, the ultimate shaft resistance (Qs) of pile is given by:For clay:
For sand:
where D and As are pile width or diameter, pile-soil surface area, respectively; ac and as are the ratio of pile shaft resistance to the sleeve friction for sand and clay; ac varies from 0.2 and 1.2 and is a function of the values of the sleeve friction, while as depends on the ratio of the embedment length of pile to the pile width or diameter and varies from 0.4 to 2.4; fs is the average sleeve friction; product of fs and αc must not exceed 120 kPa.
1.2 deRuiter and Bringen (1979) Method
The method proposed by de Ruiter and Beringen (1979) is based on the experience gained in the North Sea. In clay, both unit tip resistance and shaft resistance are determined from undrained shear strength using following equations:
Unit tip resistance in clay:
Unit shaft resistance in clay:
where \(\alpha^{\prime }\) is adhesion factor (0.5 for OC clays and 1 for NC clays); Nc is bearing capacity factor and Su is the undrained shear strength obtained from the following equation:
where Nk is the cone factor and varies from 15 to 20.
For unit shaft resistance of a pile in sand, the following equation is used:
where qc and fs are cone resistance and sleeve friction, respectively. Calculation of pile tip resistance in sand with this method is similar to Schmertman (1978) method.
1.3 Bustamante and Gianeselli (1982) (LPC) Method
LPC method, also called French method, is based on the experiments conducted by Bustamante and Gianselli (1982) for the French highway department. According to this method, both unit tip and shaft resistance are determined from the cone resistance, neglecting sleeve friction. The unit tip resistance is estimated using following equation:
where qca is the average of the qc values over the influence zone which ranges between 1.5 D below and above the pile tip (D is pile diameter); kb is a factor depending on soil material and pile installation type. The ultimate shaft resistance in this method can be calculated by the following formula:
where Ks is a factor that depends on pile material and installation method, and qc is the average cone resistance value over the pile embedment length.
Furthermore, codes and guidelines, e.g. Eurocode-7 (1997) and ERTC3 (1999), suggest different methods for direct or indirect estimation of pile load bearing capacity based on CPT data (Niazi and Mayne 2013; Omer et al. 2006). Although great efforts have been made to develop appropriate models using analytical methods and assumptions, they often made their conclusions by optimizing the analytical results with their obtained experimental data through empirical methods. In other words, such models are designated through simplifying assumptions and more important they are initiated from few observations and controlling few models through simple statistical regression analyses to find the appropriate model. Besides, the suggested values by guidelines are often too conservative and general. This is highly related to the complex parameters affecting the system behavior which cannot thoroughly be considered for producing constitutive models considering information obtained from CPT results.
Recently, Shahin (2010) have utilized artificial neural networks (ANNs), Alkroosh and Nikraz (2011)and Alkroosh and Nikraz (2012) demonstrated the capability of gene expression programming (GEP) and Kordjazi et al. (2014) used support vector machines (SVM) for prediction of ultimate axial load-carrying capacity of piles through experimental CPT data. It is worth mentioning that the models obtained by those artificial intelligence based approaches represented better performance in comparison with the traditional analytical formulas. Such soft computing techniques may be considered as good alternatives to traditional methods for tackling real world problems as they can automatically learn from observed data to construct a prediction model. Besides, these techniques have become more attractive because of their capability of information processing such as non-linearity, high parallelism, robustness, fault and failure tolerance and their ability to generalize models. Also, they have been successfully applied to many civil engineering prediction problems (Alavi and Sadrossadat 2016; Fattahi and Babanouri 2017; Khandelwal and Armaghani 2016; Sadrossadat et al. 2013, 2016a, b, 2017; Tajeri et al. 2015; Xue et al. 2017; Ziaee et al. 2015; Žlender et al. 2012).
This paper explores the capability of adaptive neuro-fuzzy inference system paradigm to find an optimal model for indirect estimation of the ultimate load bearing capacity of piles through a reliable collection of CPT results. The major criticism associated with ANFIS in comparison to some other soft computing is the fact that it produces black-box models as such techniques usually do not provide practical prediction equations. To cope with these issues, the calculations required for input processing output and model development by ANFIS are explicitly explained and the derived model is represented in present study. In order to verify the robustness of the obtained model several validation and verification study phases are conducted.
2 Adaptive Neuro-Fuzzy Inference Systems
ANFIS combines the advantages of fuzzy inference systems (FIS) with the learning ability of ANN and presents all their benefits in a single framework. The selection of the FIS is the main concern in designating the ANFIS model (Jang et al. 1997). Several FIS systems have been already developed in the literature based on fuzzy reasoning and the employed fuzzy if then rules e.g. (Mamdani 1977; Takagi and Sugeno 1985; Tsukamoto 1979). There are two types of commonly utilized fuzzy inference systems: Mamdani and Takagi–Sugeno (TS) or Sugeno. In Mamdani model both input and output variables are fuzzy (Mamdani 1977), whereas, in TS or the sugeno inference system the output is expressed as a linear function of the input variables which takes a numerical value (Takagi and Sugeno 1985).The main difference between them is the fact that while the Mamdani model uses the human expertise and linguistic knowledge to design the membership functions and if–then rules, TS model uses optimization and adaptive techniques to establish the system modeling and also uses less number of rules. Furthermore, when a numerical or crisp output is required, then, the data-driven rule generation with TS model is selected. Also the output membership function in TS is simpler designed as either linear or constant (Sadrossadat et al. 2016b; Takagi and Sugeno 1985). This inference system is more commonly used in ANFIS for modeling problems (Sugeno and Kang 1988). Considering two input variables (x, y) and one output (f), the two if–then rules in first-order TS type can be represented as follows:
- Rule 1:
if x = A1 and y = B1, then f1 = p1x + q1y + r1
- Rule 2:
if x = A2 and y = B2, then f2 = p2x + q2y + r2
where pi, qi, and ri are the consequent parameters obtained from the training, A and B labels of fuzzy set defined suitable membership function.
ANFIS optimizes the model parameters using the ANN architecture. In ANFIS, the input variables are propagated forward in a network similar to the MLP architecture layer by layer. Best consequent parameters are determined by the least-squares method (LSM), while the premise parameters are assumed to be fixed for the current cycle through the training set. Next, the error values propagate backward to adjust the premise parameters, using back propagation gradient descent method (Sadrossadat et al. 2016b; Žlender et al. 2012). In this algorithm, the weighted values are changed to minimize the following error function (E):
where \(t_{k}^{n}\) and \(h_{k}^{n}\) are, respectively, the calculated output and the actual output value, n is the number of samples and k is the number of output neurons.
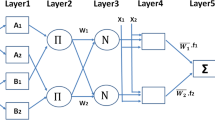
As illustrated in Fig. 1, there are five essential layers in which the mathematical computations in ANFIS are performed. The process in each layer may be described as follows (Sadrossadat et al. 2016b):

A typical first-order TS model reasoning and the basic ANFIS architecture
Layer one Each node in this layer modifies the values of the crisp input variables by using membership functions (fuzzification step). Every node i in this layer is an adaptive node. Parameters in this layer determine the final shape of the membership function and are called premise parameters. The output of the ith node of the first layer may be MFs such as linear, triangular, trapezoidal, Gaussian, generalized bell or several other functions. Here, MFs are described by Gaussian functions as selected for the qult modeling.
In equations above, x is the input to node i, and Ai is the linguistic label associated with this node function. So, the O1, i (x) is essentially the membership grade for x and y which is assumed to be a Gaussian function. ci and σi are respectively the center and width of the ith fuzzy set Ai or Bi. These parameters are adjusted during model optimization and are referred to as premise parameters.
Layer two The antecedent parts of rules are computed in this layer. This layer consists of the nodes labelled ∏, which multiplies the incoming signals and sends the product out.
Layer three Each node in this layer is a fixed node labeled N. The ith node calculates the ratio of the ith ratio of the firing strengths of the rules as follows:
Layer four The fourth layer is the second adaptive layer of ANFIS architecture, i.e., defuzzification layer. The nodes in this layer are adaptive with linear node functions. Parameters in this layer are called consequent parameters which are parameters of output membership functions. These parameters are adjusted during the training of the model considering the utilized datasets.
The parameters in this layer (pi, qi, ri) are to be determined and are called consequent parameters.
Layer five The node in this layer is a single fixed node and computes the final model output as the combination of all incoming signals from every fired rule. It is a weighted average combination which is indicated as follows:
3 Experimental Database
A comprehensive database including the results of the 108 extensive load tests on axially loaded piles has been drawn from the earlier studies by Eslami (1996) and Pooya Nejad (2009). The database consists of information about load test results and pile geometry along with the CPT measurements along the pile embedment length and pile tip. The CPT data consist of cone tip resistance (qc1, qc2, qc3) and sleeve friction values (fs1, fs2, fs3) along the pile embedded length as well as the average cone tip resistance (\(\bar{q}_{c - t}\)) around the pile failure zone. The pile embedded length is divided into three equal segments with the same thickness, and the average values of qc and fs are calculated to consider the variability of the soil properties. Piles are either driven or bored, made up of different materials (concrete, steel, composite), with various shapes (square, round, octagonal, triangle, pipe and H section), and different tip conditions (open and closed). The soil types include sands, clays and silts and mixture of them, in single and multiple layers (Kordjazi et al. 2014).The maintained load test was conducted on most of the cases in the study, in which the pile is loaded in several increments equal to 15% of the design load, each maintained for 5 min. The loading is then continued until reaching 300% of the design load (Fellenius 1975).
The results of the compression load test were plotted in the form of curves describing foundation displacement as a function of applied load. The failure is defined as the point in which excessive displacements take place under a relatively small increase in loading, typically associated with an abrupt change in the load–displacement curve characteristics. In the database, the 80% criterion interpretation method was used in the cases that the failure point was not easily defined (Hansen 1963). It is worth mentioning that various part of the database have been used by various researchers (Alkroosh and Nikraz 2011, 2012; Kordjazi et al. 2014; Shahin 2010). The utilized data and descriptive statistics of variables for developing the ANFIS model are given in Tables 1 and 2, respectively.
4 Numerical Simulation of Bearing Capacity
After reviewing the literature and the structure of the existing models in this field, the main influential parameters which are considered in the database include: type of pile static load test (maintained or constant rate of penetration), pile material (steel, concrete and composite), pile installation method (driven or bored), pile tip condition (close or open), embedment length of pile (Lemb), perimeter of the pile (O), cross sectional area of the pile tip (At), the average pile tip resistance along the pile embedded length (qc1, qc2 and qc3), average sleeve friction along the embedded length of the pile (fs1, fs2 and fs3), average cone tip resistance about pile tip failure zone (\(\bar{q}_{c - t}\)). Among these variables, the average CPT measurements are included in the model to account for the soil properties variability. These values have been used as input variables for establishing various models by researchers (Alkroosh and Nikraz 2011, 2012; Kordjazi et al. 2014; Shahin 2010). The selected variables as independent input variables in present study are different from those provided by other AI based approaches. At and As are considered to be as input variables in the model development in order to account for the pile geometry as well as the fact that these parameters have direct influence on the bearing capacity in terms of physical behavior and from geotechnical engineering viewpoints. It is worth mentioning that the As is calculated by multiplying the perimeter and the pile embedded length, and has not been considered in the previously published models in the literature for indirect estimation of Pu of piles through interpreting information obtained by CPT methods which can be taken into account as a highly significant input variable. Thus, the proposed formulation of Pu is considered as a function in terms of following parameters:
where, At is the pile tip cross sectional area, As is the shaft area, \(\bar{q}_{c - s}\) is the average cone tip resistance along the embedded length of the pile,\(\bar{q}_{c - t}\) is the average cone tip resistance over influence zone, and \(\bar{f}_{s}\) is the average sleeve friction along the embedded length of the pile. It should be noted that the failure zone is defined in accordance with Eslami (1996), in which it extends to 4 D below and above the pile tip when soil tip is located in homogenous soil; 4 D below and 8 D above the pile tip in the case that the pile tip is located in a nonhomogeneous strong layer underneath a weak layer; and 4 D below and 2 D above the pile tip when the pile tip is situated in a weak layer with a strong layer above in which D is the equivalent diameter of pile cross section.
5 Data Preprocessing for Model Development
Artificial intelligence based computing techniques as well as statistical regression approaches generally use datasets for developing models. Thus, some issues regarding the data preprocessing must be taken into account for providing more accurate models considering the limited range of data (Sadrossadat et al. 2016a; Ziaee et al. 2015). In fact, the correlation between independent input variables and the output, different scales of data, distributions of variables considering their range in the employed database highly affect the prediction accuracy obtained by modeling techniques. In this regard, normalization techniques may be used to adjust the scale of the data. Normalization of data may be regarded as adjusting data values provided on different scales to a notionally common scale. It increases the speed of training in machine learning algorithms and is especially efficient where the range of raw data vary widely. More, it is recommended to normalize or standardize the inputs in order to reduce the chances of getting stuck in local optima or unchanged outputs (Xue et al. 2017; Ziaee et al. 2015). Feature scaling is a method can be used to standardize the range of variables or features of data. Feature standardization makes the values of each feature in the data have mean close to 0 the unit-variance. In addition, this technique can be used to restrict the range of values in the dataset between any arbitrary values a and b. the general form of the formula used for feature scaling to normalize the raw data of variables to a range of [a, b]:
where Xmax and Xmin are the maximum and minimum values of the variable and Xn is the normalized value. In the present study, a = 0.05 and b = 0.95.
A major problem in generalization of the obtained models is the overfitting. It is the case in which the error on the datasets obtained by the model is driven to a very small value, but when new datasets are presented to the model, the error becomes very large. A commonly used approach to avoid overfitting is to test the model on another group of data which are not used in the training process. To avoid overfiting, It is recommended that the available database should be classified into three sets: (1) training, (2) validation, and (3) test subsets (Alavi and Sadrossadat 2016; Sadrossadat et al. 2016a, b; Shahin et al. 2004; Ziaee et al. 2015). The training set is utilized to fit the models, the validation set is used to estimate prediction error for model selection and the test set which is a group of unseen datasets is used for the evaluation of the generalization error of the selected model. In present study, 70% of the data sets are taken for the training and validation processes. The remaining 30% of the data sets are used for the testing of the obtained ANFIS models.
6 ANFIS Model Development
In order to develop prediction models through ANFIS algorithm, a code was written in MATLAB 2011b environment based on genfis3 which is an advanced fuzzy inference technique used in MATLAB. There are many difficulties in developing fuzzy models due to the large number of degrees of freedom which needs expert knowledge. During the input processing output modeling, quite a few parameters are required to be found e.g. the number and the type of MFs, rules, selection of the logical operations and etc. These values may be achieved using the process of trial and error or using optimization algorithm based approaches.
Considering the complexity and complicated behavior of Pu the determination of MFs would be difficult. In addition, a TS model is needed to fuzzify crisp or numerical values. On the other hand, simplification of fuzzy models is important to make the rule simple and interpretable. This can be achieved by optimizing the number of fuzzy sets for each input variable and or reducing the number of rules (Sadrossadat et al. 2016b). Besides, these values directly affect the complexity of the obtained ANFIS models which is a significant aim of this paper. Herein, the fuzzy c-means clustering (FCM), is chosen due to its efficiency and simplicity (Sadrossadat et al. 2016b). In present study, the number of clusters is considered to be 4 in order to generate simpler formulation ANFIS-based model which is obtained after several run. It is worth mentioning that the number of clusters, MFs and rules are considered to be equal in genfis3. Besides, input MFs are considered to be Gaussian functions as follows, where linear functions were used as output MFs as was mentioned in Sect. 2. In inference method, AND is prod, OR is probor, implication is prod and aggregation is sum. The detailed definitions of these represented expressions are described in Matlab functions.
The structure of ANFIS model for predicting the Pu of piles is represented in Fig. 2.

The structure of ANFIS model for predicting the ultimate axial load bearing capacity of the pile
The general form of fuzzy rule extracted from ANFIS model can be represented as follows where i varies between 1 to 4:
If At is in1cluster(i) and As is in2cluster(i) and \(\bar{q}_{c - s}\) is in3cluster(i) and \(\bar{q}_{c - t}\) is in4cluster(i) and \(\bar{f}_{s}\) is in5cluster(i) then Pu is out1cluster(i).
In expression above, At is in1cluster1 indicates that At is considered as the first input variable which is selected from the first cluster. As was mentioned, in present study and is used in constructing rules in inference method which means MFs should be multiplied.
Consequently, the weighted average method (wave) is utilized as the defuzzification method. It is one of the most frequently used methods in fuzzy applications (Lee 1990; Mishra et al. 2015; Sadrossadat et al. 2016b; Yilmaz and Yuksek 2009). Wave is typically applied to symmetrical output MFs such as those provided in this study, i.e. the Gaussian MF. It is formed by weighing each MF, using its respective maximum membership value which is the center of symmetrical MF. The algebraic expression of wave is given as follows:
In equation above, c* is the defuzzified real-valued output where µAi(x) is the ith MF and ci is the center of the ith fuzzy set Ai, respectively.
7 Explicit Formulation of the Obtained ANFIS Model
Considering the aforementioned issues for development of the models and the process of input processing output in ANFIS in addition to the ANFIS architecture, the obtained model can be explicitly represented via a complex formula as the following equations. It is noteworthy that normalized variables are used as input and output variables in the training process as explained before. Therefore, the first step is to normalize values input variables and accordingly, in order to obtain a real value of Pu, the output should be denormalized. Herein, the normalization is calculated through following equation:
where Xmax and Xmin are the maximum and minimum values of the variable and Xn is the normalized value. Considering input variables in this study, wi can be represented as follows:
in which n means the normalized value of the variable, ci and σi are the center and width of the ith Gaussian membership function for the corresponding input variable which can be calculated through the obtained values after training process summarized in Table 3. It should be noted that the number of MFs, clusters and rules are obtained to be 4 for the optimal model presented in present study. Therefore, i varies between 1 and 4.
Accordingly, the firing strengths of weights and the output variable which gives normalized values can be calculated using Eqs. (23) and (24):
where ai to di are the linear function coefficients which are obtained after training process and are summarized in Table 4.
Finally, considering the maximum and minimum values of Pu in the range of datasets used for ANFIS model development in this paper, the de normalization function can be calculated as follows:
In order to precisely assess this complex formula, an example is provided in this paper. The values of sample number 39 in Table 1 are assumed to be calculated via the obtained ANFIS model. In that sample, At, As, \(\bar{q}_{c - s}\), \(\bar{f}_{s}\), and \(\bar{q}_{c - t}\) are 960 cm2, 13.92 m2, 3.587 MPa, 97.75 kPa and 8.15 MPa respectively.
Firstly the values should be normalized using Eq. 21. The normalized values of At, As,\(\bar{q}_{c - s}\), \(\bar{f}_{s}\), and \(\bar{q}_{c - t}\) are 0.12, 0.0448, 0.1153, 0.2597, 0.2941, respectively. Considering Eq. 22 and the obtained values of ci and σi for each variable and corresponding MF, w1, w2, w3 and w4 are calculated 0.008, 0.163, 0.866, and 0.177, respectively. Accordingly, \(\bar{w}_{1}\) to \(\bar{w}_{4}\) can be calculated. The Pu factor is obtained equal to 0.097 through Eq. 24 and considering the aforementioned values of coefficients in Table 4. After denormalizing the obtained value, the final value of Pu is calculated equal to 1113.5 kN.
8 Results and Discussions
8.1 Performance Analysis of ANFIS Model
Although There would be several models obtained by ANFIS prediction technique; however, an optimal model should meet some criteria before the selection. In this regard, quite a few procedures and statistical criteria have been suggested by researchers in the literature. In this paper, correlation coefficient (R), root mean square error (RMSE) and mean absolute error (MAE) are employed to assess the accuracy of the ANFIS model. It is suggested that there is a strong correlation between the predicted and observed values if R > 0.8 or R2 > 0.64 which means the prediction capability of the model is acceptable (Sadrossadat et al. 2013, 2016a, b; Smith 1986). It is noteworthy that only considering R as a model performance evaluation criterion would not be sufficient to examine the accuracy of a model because it is insensitive to additive and proportional differences between model predictions and observed values. Therefore, RMSE and MAE are considered as additive criteria to obtain a robust model. The lower the RMSE and MAE values, the better the model performance would be. These parameters are calculated using the following equations:
where oi and pi are the actual and predicted output values for the ith output, respectively, \(\bar{o}_{i}\) and \(\bar{p}_{i}\) are the average of the actual and predicted outputs, and n is the number of samples.
In order to represent the capability of the obtained ANFIS models, the predicted versus observed values are demonstrated in Fig. 3. It can be figured out that the ANFIS-based model with high R and low RMSE and MAE values is able to predict the actual values with a high degree of accuracy. Besides, close R, RMSE and MAE values on the training and testing data suggests that it has both good predictive abilities and generalization performance in addition to the fact that overfitting is avoided.

Predicted versus experimental Pu values using the optimal ANFIS model: a training (learning and validation) datasets, b testing datasets
Furthermore, in order to ensure about the prediction performance of the ANFIS model, its prediction capability should be assessed and compared with those of other conventional models. In this regard, the same test datasets employed for producing ANFIS model are considered and the comparative analyses results are represented in Fig. 4. It should be noted that test data are unseen in input processing output procedure which means that they have not been employed for producing the ANFIS model. Therefore, they can be considered as new data for the generated ANFIS model and the predictability and generalization performance of the ANFIS model can be check using them. It is worth mentioning that the obtained values made by CPT-based methods are extracted from the previously published research by Eslami (1996) as these methods cannot estimate Pu factor using the available information which can be regarded as a negative point of those approaches as they require further information to estimate the Pu factor. It has also been shown that the results obtained by different methods vary differently for the same case (Briaud 1988; Abu-Farsakh and Titi 2004).

A comparative plot of experimental and predicted Pu (kN) values using different models for test data
As can be seen, the obtained ANFIS model with higher R value and less RMSE and MAE outperforms other models. This way of observing mismatches or differences between predicted and measured values made by different models can also represent how models can estimate the target value, e.g. Schertmann’s model overestimates the Pu factor in many cases.
Moreover, another statistical analysis procedure is employed here for evaluating external capability of the ANFIS model on testing datasets which has been proposed by various researchers (Abu-Farsakh and Titi 2004; Alkroosh and Nikraz 2011, 2012; Kordjazi et al. 2014). This procedure can be done based on four criteria:
- (1)
The equation of the best fit line of estimated (Pu) versus measured pile capacity (Pm) with the corresponding coefficient of determination.
- (2)
The arithmetic mean (μ) and standard deviation (σ) of Pup/Pum. It can be suggested that a model is highly capable of predicting the target values when μ (Pup/Pum) is closer to 1 and σ (Pup/Pum) is closer to 0.
- (3)
The 50% cumulative probability (P50%) of Pup/Pum. The closer the value of P50% to 1, the better model would be. In order to calculate P50%, Pup/Pum values estimated by the model should be arranged in an ascending order (1, 2, 3,…, i,…, n). Thereafter, the cumulative probability can be calculated using the following equation:
$$P = \frac{i}{n + 1}$$(29)where i is the order number given for the calculated ratio of Pup/Pum, n is the number of data which is considered to be the number of testing data here.
- (4)
The coefficient of efficiency (E) which compares the predicted and observed values of ultimate axial bearing capacity and evaluates how well the model is able to explain the total variance of the data. This parameter can be calculated through the following equations:
$$E = \frac{{E_{1} - E_{2} }}{{E_{1} }}$$(30)$$E_{1} = \sum\limits_{t = 1}^{r} {(P_{um} - \bar{P}_{um} )^{2} }$$(31)$$E_{2} = \sum\limits_{t = 1}^{r} {(P_{up} - P_{um} )^{2} }$$(32)
The overall performance of the ANFIS model and each traditional CPT-based model may be considered as an overall rank index (RI) which is defined as the sum of the ranks from the different criteria (i.e. RI = R1 + R2 + R3 + R4). The lower the RI, the better the estimation performance of the model is. The results of the statistical analysis are summarized in Table 5.
8.2 Parametric Analysis
Quite a few studies were done in order to evaluate the generalization, validation and prediction capability of the proposed ANFIS model through some statistical criteria in addition to the fact that the results were compared with those of obtained by some CPT-based methods proposed by various researchers in the literature. Although the ANFIS model results represented that the ANFIS model is of great prediction capability, the ANFIS model is required to be assessed from engineering viewpoints in terms of physical behavior. For this purpose, the response and behavior of the models may be evaluated to different input variables and should be compared with those experimentally or theoretically provided in the literature. To cope with this issues, a parametric analysis can be performed as recommended by several researchers (Alavi and Sadrossadat 2016; Sadrossadat et al. 2013; Tajeri et al. 2015; Ziaee et al. 2015). The parametric analysis represents the response of the ANFIS-based Pu model to variations of variables. The mentioned method can be done through varying only one independent input variable while the other variables are remained constant at their mean values. Thereby, a set of artificial data is generated for each variable according to their range in the employed database. The obtained values are then presented to the model and the output is calculated. This procedure is repeated using other variable, one by one, until the model response is obtained for all of the predictor variables.
It is expected that Pu must increase with increasing the amount of At, As, \(\bar{q}_{c - s}\), \(\bar{f}_{s}\), \(\bar{q}_{c - t}\) as have been represented by researchers in the literature (Abu-Farsakh and Titi 2004; Alkroosh and Nikraz 2011, 2012; Eslami 1996; Kordjazi et al. 2014). As is represented in Fig. 5, the obtained results of the parametric study conform that the ANFIS model can predict the Pu factor regarding the physical behavior and from engineering viewpoints.

A parametric analysis of proposed ANFIS model for indirect estimation of Pu
8.3 Sensitivity Analysis
Another significant issue to assess a model is to find out the contribution and importance of each parameter which can be achieved through a sensitivity analysis (SA). The results of SA on model represent how much a model is affected by the variation of each independent input variable. The SA conducted in the present study is based on varying each input from its minimum to maximum value regarding to its range in the utilized database and the model output is calculated while the other inputs are fixed at their means (Kiani et al. 2016). According to the strictly increasing tendency of all variables as represented in Fig. 6, this type of SA is used here. The percent of each obtained output difference for each variable is computed which is often referred to as the sensitivity index (SI). The SI (%) values can be calculated using the following equations:
where f(xmax) and f(xmin) are the predicted values of maximum and minimum of the independent input variable over the ith input domain, and n is the number of involved variables.

The significance of each input variable in ANFIS model
The process of SA was conducted and the obtained SI (%) results for each variable are demonstrated in Fig. 6. As is illustrated, the obtained ANFIS model is more sensitive to the variation of the considered input variable, i.e. the shaft area of pile (As), followed by \(\bar{f}_{s}\), \(\bar{q}_{c - t}\), \(\bar{q}_{c - s}\) and At. The obtained results can be verified by those obtained by (Abu-Farsakh and Titi 2004; Eslami 1996; Kordjazi et al. 2014). All in all, the SI value for each variable used in an equation or a model is unique. Besides, it would be recommended that engineers are required to highly know about the significance and effect of each variable on models and equations they use for design purposes.
9 Summary and Conclusion
This paper aimed at investigating the robustness of ANFIS method for estimating the ultimate axial load bearing capacity of piles using CPT data which is a crucial problem in geotechnical engineering. In this regard, a collection of data was used for the development of the models. The selected database contained information about the pile installation method, pile material, full-scale pile load test and CPT data. However, the model was developed to simultaneously take into account At, As, \(\bar{q}_{c - s}\), \(\bar{f}_{s}\), \(\bar{q}_{c - t}\) as input variables obtained from pile load test and CPT results due to the fact that these variables are more meaningful from geotechnical engineering viewpoints. It is well-known that there exist some practical equations to estimate the ultimate axial load bearing capacity of piles based on experimental results obtained by CPT, as was presented in the paper. It should be highlighted that the strength of ANFIS algorithm, as a predictive tool, absolutely lies in its high precision for prediction and approximation purposes; however, the main weakness of ANFIS modeling technique which has scholarly been visited in the existing literature is the fact that it has not been able to generate explicit models or equations which can be used for hand-calculation aims. In other words, ANFIS has been considered as a black-box predictive tool. In this paper, the obtained optimal ANFIS model was converted to an explicit tractable formula which can be used for pile design uses. Additionally, engineers are required to know about the degree of accuracy, the physical behavior of the model, the relative significance of each variable and the validation and verification of the models they use in their computations or calculations. In this regard, several criteria were offered to assess the generalization performance of the model and sensitivity and parametric analyses are conducted and discussed. The parametric analysis results demonstrated that the obtained model output, i.e. Pu, increases with increasing At, As, \(\bar{q}_{c - s}\), \(\bar{f}_{s}\), \(\bar{q}_{c - t}\) as it was expected. The relative importance values of input variables obtained by the sensitivity analysis indicate the all input variables influence on the output to a large extent the obtained ANFIS takes into account all input variables. However, the sensitivity analysis results obtained by each model would be unique and the proposed ANFIS model is more sensitive to As variation followed by \(\bar{f}_{s}\), \(\bar{q}_{c - t}\), \(\bar{q}_{c - s}\) and At. The obtained results of the parametric and sensitivity studies approve that the ANFIS model can accurately predict the Pu factor regarding the physical behavior and from engineering viewpoints. The results of several comparative performance analyses of existing models confirmed that the proposed ANFIS model is up to standard for indirect estimation of the ultimate load bearing capacity of piles as it notably outperformed traditional models in terms of generalization and predictability. Finally, numerical models highly depend on the data used in their process of model development. The capability of such models is mostly limited to the range of the data, information and soil strata used for their calibration, and also the formulation depends on the available variables, in the database. To rise above this, the model should be retrained and improved to make more accurate predictions for a wider range, more variables or other types of soils.
References
Abu-Farsakh MY, Titi HH (2004) Assessment of direct cone penetration test methods for predicting the ultimate capacity of friction driven piles. Journal of Geotechnical and Geoenvironmental Engineering 130:935–944
Abu-Farsakh M, Titi H, Tumay M (1999) Prediction of bearing capacity of friction piles in soft Louisiana soils by cone penetration test transportation research record. J Transp Res Board, 32–39
Alavi AH, Sadrossadat E (2016) New design equations for estimation of ultimate bearing capacity of shallow foundations resting on rock masses. Geosci Front 7:91–99
Albiero J, Sacilotto A, Mantilla J, Telxeria J, Carvalho D (1995) Successive load tests on bored piles. In: Proceedings of the 10th Pan-American conference on soil mechanics and foundation Engineering, Mexico City, Mexico, pp 992–1002
Alkroosh I, Nikraz H (2011) Correlation of pile axial capacity and CPT data using gene expression programming. Geotech Geol Eng 29:725–748
Alkroosh I, Nikraz H (2012) Predicting axial capacity of driven piles in cohesive soils using intelligent computing. Eng Appl Artif Intell 25:618–627
Altaee A, Fellenius BH, Evgin E (1992) Axial load transfer for piles in sand. I. Tests on an instrumented precast pile Canadian Geotechnical Journal 29:11–20
Avasarala S, Davidson J, McVay A (1994) An evaluation of predicted capacity of single piles from SPILE and UNIPILE programs. In: Proceedings of the FHWA international conference on design and construction of deep foundations, Orlando, Fla, pp 712–723
Ballouz M, Nasr G, Briaud J-L (1991) Dynamic and Static testing of nine drilled shafts at Texas A and M University Geotechnical Research Sites. Geotechnical Engineering, Department of Civil Engineering, Texas A and M University
Begemann HP (1963) The use of the static soil penetrometer in Holland. NZ Eng 18:41
Briaud J-L, Tucker LM (1988) Measured and predicted axial response of 98 piles. Journal of Geotechnical Engineering 114:984–1001
Brown M, Hyde A, Anderson W (2006) Analysis of a rapid load test on an instrumented bored pile in clay. Geotechnique 56:627–638
Bustamante M, Gianeselli L (1982) Pile bearing capacity prediction by means of static penetrometer CPT. In: Proceedings of the 2-nd European symposium on penetration testing, pp 493–500
Campanella R, Robertson P, Davies M, Sy A (1989) Use of in situ tests in pile design. In: Proceedings 12th international conference on soil mechanics and foundation engineering, ICSMFE, Rio de Janeiro, Brazil, pp 199–203
de Ruiter J, Beringen F (1979) Pile foundations for large North Sea structures. Mar Georesour Geotechnol 3:267–314
ERTC3 (European Regional Technical Committee on Piles) (1999) Survey report on the present-day design methods for axially loaded piles, European practice, In F De Cock, C Legrand, B Lehane (eds) Published at the occasion of the XIIth ECSMGE, Amsterdam, June
Eslami A (1996) Bearing capacity of piles from cone penetration test data. Ph.D. thesis, University of Ottawa
Eurocode-7 (1997) Geotechnical Design, Part 1-General rules (together with UK National Application Document). British Standards Institution, Milton Keynes
Fattahi H, Babanouri N (2017) Applying Optimized Support Vector Regression Models for Prediction of Tunnel Boring Machine Performance. Geotech Geol Eng 35(3):1–13
Fellenius BH (1975) Test loading of piles and new proof testing procedure. J Geotech Geoenviron Eng, 101
Fellenius BH, Harris DE, Anderson DG (2004) Static loading test on a 45 m long pipe pile in Sandpoint. Idaho Canadian geotechnical journal 41:613–628
Fellenius BH, Santos JA, Fonseca AVd (2007) Analysis of piles in a residual soil—The ISC’2 prediction. Can Geotech J 44:201–220
Finno RJ (1989) Subsurface conditions and pile installation data: 1989 foundation engineering congress test section. In: Predicted and observed axial behavior of piles: results of a pile prediction symposium, ASCE, pp 1–74
Florida Department of Transportation (FDOT) Large diameter cylinder pile database (2003) Research Management Center
Gambini F (1985) Experience in Italy with centricast concrete piles. In: Proceedings of the international symposium on penetrability and drivability of piles, San Francisco, pp 97–100
Hansen JB (1963) Discussion on hyperbolic stress–strain response: cohesive soils. J Soil Mech Found Eng 89:241–242
Harris DE, Mayne P (1994) Axial compression behavior of two drilled shafts in Piedmont residual soils. In: Proceedings, international conference on design and construction of deep foundations. US Federal Highway Administration, pp 352–367
Haustorfer I, Plesiotis S (1988) Instrumented dynamic and static pile load testing at two bridge sites. In: Fifth Australia-New Zealand conference on geomechanics: prediction versus performance; preprints of papers. Institution of Engineers, Australia, p 514
Hill CM (1987) Geotechnical report on indicator pile testing and static pile testing, berths 225-229 at Port of Los Angeles CH2 M Hill. Los Angeles, Calif
Horvitz G, Stettler D, Crowser J (1981) Comparison of predicted and observed pile capacity. In: Cone penetration testing and experience. ASCE, pp 413–433
Jang J, Sun C, Mizutani E (1997) Fuzzy inference systems Neuro-fuzzy and soft computing: a computational approach to learning and machine intelligence, pp 73–91
Khandelwal M, Armaghani DJ (2016) Prediction of drillability of rocks with strength properties using a hybrid GA-ANN technique. Geotech Geol Eng 34:605–620
Kiani B, Gandomi AH, Sajedi S, Liang RY (2016) New formulation of compressive strength of preformed-foam cellular concrete: an evolutionary approach. J Mater Civ Eng 28:04016092
Kiefa MA (1998) General regression neural networks for driven piles in cohesionless soils. Journal of Geotechnical and Geoenvironmental Engineering 124:1177–1185
Kordjazi A, Nejad FP, Jaksa M (2014) Prediction of ultimate axial load-carrying capacity of piles using a support vector machine based on CPT data. Comput Geotech 55:91–102
Laier J (1994) Predicting the ultimate compressive capacity of long 12HP74 steel pile. In: Proceedings of the FHWA international conference on design and construction of deep foundations, Orlando, Fla, pp 1804–1818
Lee CC (1990) Fuzzy logic in control systems: fuzzy logic controller. II Systems, Man and Cybernetics, IEEE Transactions on 20:419–435
Mamdani EH (1977) Application of fuzzy logic to approximate reasoning using linguistic synthesis IEEE transactions on computers 100:1182–1191
Matsumoto T, Michi Y, Hirano T (1995) Performance of axially loaded steel pipe piles driven in soft rock Journal of geotechnical engineering 121:305–315
Mayne P, Harris D (1993) Axial load-displacement behavior of drilled shaft foundations in Piedmont residuum FHWA. Georgia Tech Research Corp, Georgia Institute of Technology, Atlanta
McCabe B, Lehane B (2006) Behavior of axially loaded pile groups driven in clayey silt. Journal of Geotechnical and Geoenvironmental Engineering 132:401–410
Mishra D, Srigyan M, Basu A, Rokade P (2015) Soft computing methods for estimating the uniaxial compressive strength of intact rock from index tests. Int J Rock Mech Min Sci, 418–424
Nevels JB, Snethen DR (1994) Comparison of settlement predictions for single piles in sand based on penetration test results. In: Vertical and horizontal deformations of foundations and embankments ASCE, pp 1028–1038
Niazi FS, Mayne PW (2013) Cone penetration test based direct methods for evaluating static axial capacity of single piles. Geotech Geol Eng 31:979–1009
Nottingham LC (1975) Use of quasi-static friction cone penetrometer data to predict load capacity of displacement piles. Ph.D. thesis, University of Florida
O’Neill MW (1986) Reliability of pile capacity assessment by CPT in over consolidated clay. In: Use of in situ tests in geotechnical engineering. ASCE, pp 237–256
O’Neill M (1988) Pile group prediction symposium-summary of prediction results FHWA, draft report
Omer J, Delpak R, Robinson R (2006) A new computer program for pile capacity prediction using CPT data. Geotech Geol Eng 24:399–426
Paik K, Salgado R (2003) Determination of bearing capacity of open-ended piles in sand J Geotech Geoenviron Eng ASCE 129:46–57
Peixoto AS, Albuquerque PJd, Carvalho Dd (2000) Utilization of SPT-T, CPT and DMT tests to predict the ultimate bearing capacity of precast concrete pile in Brazilian unsaturated residual soil. In: Advances in unsaturated geotechnics, pp 32–39
Pooya Nejad F (2009) Prediction of pile settlement using artificial neural networks. Ph.D. thesis, Ferdowsi University of Mashhad, Mashhad, Iran
Reese J, O’Neill M, Wang S (1988) Drilled shaft tests, Interchange of West Belt Roll Road and US290 Highway. Texas Lymon C Reese and Associates, Austin
Sadrossadat E, Soltani F, Mousavi SM, Marandi SM, Alavi AH (2013) A new design equation for prediction of ultimate bearing capacity of shallow foundation on granular soils. Journal of Civil Engineering and Management 19:S78–S90
Sadrossadat E, Heidaripanah A, Ghorbani B (2016a) Towards application of linear genetic programming for indirect estimation of the resilient modulus of pavements subgrade soils. Road Mater Pavement Des, 1–15
Sadrossadat E, Heidaripanah A, Osouli S (2016b) Prediction of the resilient modulus of flexible pavement subgrade soils using adaptive neuro-fuzzy inference systems. Constr Build Mater 123:235–247
Sadrossadat E, Ghorbani B, Hamooni M, Moradpoor Sheikhkanloo MH (2017) Numerical formulation of confined compressive strength and strain of circular reinforced concrete columns using gene expression programming approach. Structural Concrete. https://doi.org/10.1002/suco.201700131
Schmertmann JH (1978) Guidelines for cone penetration test. (Performance and Design)
Shahin MA (2010) Intelligent computing for modeling axial capacity of pile foundations. Can Geotech J 47:230–243
Shahin MA, Maier HR, Jaksa MB (2004) Data division for developing neural networks applied to geotechnical engineering. Journal of Computing in Civil Engineering 18:105–114
Smith GN (1986) Probability and statistics in civil engineering Collins Professional and Technical Books 244
Sugeno M, Kang G (1988) Structure identification of fuzzy model Fuzzy sets and systems 28:15–33
Tajeri S, Sadrossadat E, Bazaz JB (2015) Indirect estimation of the ultimate bearing capacity of shallow foundations resting on rock masses. Int J Rock Mech Min Sci 80:107–117
Takagi T, Sugeno M (1985) Fuzzy identification of systems and its applications to modeling and control. IEEE Transactions on Systems, Man and Cybernetics 1:116–132
Tomlinson M, Woodward J (2014) Pile design and construction practice. CRC Press, Boca Raton
Tsukamoto Y (1979) An approach to fuzzy reasoning method Advances in fuzzy set theory and applications 137:149
Tucker LM, Briaud J-L (1988) Analysis of the pile load test program at the lock and dam 26 replacement project. DTIC Document
Tumay MT, Fakhroo M (1981) Pile capacity in soft clays using electric QCPT data. In: Cone penetration testing and experience. ASCE, pp 434–455
Urkkada Technology Ltd. Dynamic testing of piles and analysis (1995)
US Department of Transportation (2006) A laboratory and field study of composite piles for bridge substructures. Rep. No. FHWA-HRT-04-043
Viergever MA (1982) Relation between cone penetration and static loading of piles in locally strongly varying sand layers. Rijksdienst voor de IJsselmeerpolders
Xue X, Yang X, Li P (2017) Evaluation of Ground Vibration Due to Blasting Using Fuzzy Logic. Geotech Geol Eng 35(3):1–7
Yen T-L, Lin H, Chin C-T, Wang R (1989) Interpretation of instrumented driven steel pipe piles. In: ASCE proceedings of the foundation engineering congress, current principles and practice, Evanston, Ill, June, pp 25–29
Yilmaz I, Yuksek G (2009) Prediction of the strength and elasticity modulus of gypsum using multiple regression. ANN, and ANFIS models International Journal of Rock Mechanics and Mining Sciences 46:803–810
Ziaee SA, Sadrossadat E, Alavi AH, Shadmehri DM (2015) Explicit formulation of bearing capacity of shallow foundations on rock masses using artificial neural networks: application and supplementary studies. Environ Earth Sci 73:3417–3431
Žlender B, Jelušič P, Boumezerane D (2012) Planning geotechnical investigation using ANFIS. Geotech Geol Eng 30:975–989
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
About this article

Cite this article
Ghorbani, B., Sadrossadat, E., Bolouri Bazaz, J. et al. Numerical ANFIS-Based Formulation for Prediction of the Ultimate Axial Load Bearing Capacity of Piles Through CPT Data. Geotech Geol Eng 36, 2057–2076 (2018). https://doi.org/10.1007/s10706-018-0445-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10706-018-0445-7