
Abstract
Land use land cover (LULC) classification using remote sensing images is a valuable resource in various fields such as climate change, urban development, and land degradation monitoring. The city of Madurai in India is known for its diverse geographical elements and rich heritage, which includes the cultural sport of “Jallikattu”: whose main competitor, the zebusare deeply affected by the conversion of their waterbodies and pastures into concrete jungles. Hence, monitoring land degradation is vital in preserving the geography and cultural heritage of the study area, Madurai. The “Landsat 8 Operational Land Imager tier_2 collection_2 Level_2 Surface Reflectance” image was taken for this study. The LULC classification is performed based on the following classes: forest, agriculture, urban, water bodies, uncultivated land, and bare land. The objective of the study is to incorporate auxiliary features to spectral and textural features along with a simple non-iterative clustering (SNIC) segmentation algorithm and implement a boundary-specific two-level learning approach based on support vector machines (SVM) and k nearest neighbors (kNN) classification algorithms. The overall accuracy (OA) of 95.78% and 0 .94 Kappa score (K) were obtained using a boundary-specific two-level model augmented with auxiliary feature and SNIC algorithm in comparison to PB, OB, and OBS, which achieve OA (K) of 81% (0.76), 91% (0.89), and 94.42% (0.92), respectively. The results demonstrate a notable enhancement in overall classification accuracy when augmenting the features and refining classification decisions using a boundary-specific two-level learning approach.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Remote sensing (RS) satellites collect vital information from the earth for mapping and monitoring the Earth’s surface (Rogan & Chen, 2004). To effectively monitor and document the Earth’s surface, remote sensing data is commonly utilized for the collection of information about LULC (Sowmya et al., 2017). Land use refers to the human use of landscapes such as urban, building, and agriculture (Kim, 2016). Land cover is a natural element that appears on the landscape like water, mountains, and forests (Lv et al., 2019). LULC classification refers to the process of assigning and classifying land cover classes to pixels. Waterbody, urban, cultivation, building, forests, agriculture, plains, mountains, bare land, and highlands are a few example classes for LULC (Talukdar et al., 2020). According to recent studies, LULC classification is an essential tool for finding the effect on a variety of characteristics of the Earth’s surface, including terrestrial ecosystems, water balance, biodiversity, and climate (Alshari & Gawali, 2021). For the LULC classification, Landsat 8 images are the most commonly used dataset from the United States Geological Survey (USGS). USGS imagery includes Landsat, MODIS, and Sentinel 2. Among them, the Landsat time series spanning nearly 40 years is of particular note. Kulkarni and Vijaya (2021a) used Landsat 8 imagery to identify the LULC changes that occurred in Bangalore during 2013, 2016, and 2019. They chose the study area of Bangalore because of urban sprawl and the city’s significant increase in built-up areas. Similarly, the study area of Madurai in the southeastern region of India was chosen for this research. Data were gathered by the Landsat 8 satellite in 11 different bands using two different sensors. The information required for LULC classification may come from any band. However, if the bands themselves have a high degree of correlation, the information provided by each band will be redundant. As a result, only a subset of all accessible bands may be utilized. The selection of spectral, texture, and vegetation indices features is a more important step in LULC classification (Kulkarni & Vijaya, 2021b). Numerous vegetation indicators were used in the current study to achieve consistent accuracy. It also ensures a comprehensive analysis of vegetation conditions and characteristics (Qu et al., 2021). These indices offer a more exact view of vegetation dynamics to differentiate forest, agriculture, and uncultivated regions.
Traditionally, most LULC classifications were based on PB classification from remotely sensed images (Varma et al., 2016). They either used supervised or unsupervised categorization or both. Several supervised machine-learning algorithms have been used for LULC classification, including SVM (Heumann, 2011), maximum likelihood (ML) (Sinha et al., 2015), kNN (Hudait & Patel, 2022), and random forests (RF) (Hütt et al., 2016). There are also several unsupervised machine-learning algorithms commonly used for LULC classification, including a priori (Lee et al., 2018), principle component analysis (PCA) (Deng et al., 2008), and independent component analysis (ICA) (Lu et al., 2019). A PB takes into account the spatial and contextual information associated with the particular pixel. As higher-resolution imagery becomes more available, it may be possible to use this spatial information to produce more accurate LULC classifications (Willhauck, 2000). To address these issues, remote-sensing image analysis increasingly uses segment-based classification instead of pixel-based classification. By analyzing objects individually, it is possible to minimize the spectral variability within a class, as well as classification errors caused by pixel artifacts due to spectral differences in atmospheric corrections. OB classification offers another advantage when it comes to broad-area mapping, in that it reduces computational complexity, although segmentation may be a time-consuming process (Blaschke, 2010).
Many studies have compared the performance of PB and OB approaches for classifying land use. Gholoobi et al. (2010) examined the performance of PB classification and OB classification of land use in mountainous regions. Based on their findings, the OB classification approach yields no noisy results. According to Johansen et al. (2010), the OB approach reduces the following effects: differences in sensor view, shadows of clouds, high spatial frequency noise, and unregistered images. Based on Aggarwal et al. (2016) work, it is possible to accomplish OB classification without the limitations of PB classification, which is dependent solely on the spectral values of the data collected through remote sensing. The limitation of OB classification was discussed by Zhou et al. (2008a) in which the OB method requires greater computational power than PB classification, and the effectiveness of the rule is heavily dependent on the expertise of the experts. Several OB LULC classification problems can be successfully solved using SVM classification algorithms (Shao & Lunetta, 2012). It is important to note that one of the issues with SVM is that while the classification training data set is divided by the class boundary line, many misclassifications occur near this boundary line. In order to refine the classification decision near the boundary line of SVM, in second level, kNN distance measure is used. Thus, the misclassification rate of the data classification is reduced as a result of the two-level classification (SVM-kNN). The papers (Garcia-Gutierrez et al., 2010; Rithesh, 2017) proposed and discussed a two-step SVM-kNN classification approach, which uses both SVM and kNN classifiers sequentially to solve classification problems. During the OB classification process, similar pixels are grouped into clusters, and objects are generated based on the clustering and segmentation of the pixels. The accuracy of OB LULC classification has improved significantly since the segmentation process was developed.
The traditional segmentation algorithm works based on the following algorithms, that are region growth, threshold, level set and active contours. Many segmentation algorithms such as fractal net evolution (Zhou et al., 2008b), bottom‐up region‐merging (Im et al., 2008), multitemporal segmentation (Civco et al., 2002), hierarchical segmentation (Tassi & Vizzari, 2020), and multiresolution segmentation (Atik & Ipbuker, 2021) are achieving good results in the object, but most traditional segmentation algorithms need to achieve decent improvement in the segmentation speed. In the current state of technology, the superpixel segmentation (Wang et al., 2017) algorithm is widely applicable to image segmentation and classification in various fields because of its low calculation quantity, faster processing speed, and better anti-noise characteristics. Achanta and Süsstrunk (2017) presented simple linear iterative clustering (SLIC) and SNIC segmentation algorithms in 2012 and 2017, respectively, based on the concept of superpixel segmentation. Several approaches were developed according to the original SLIC segmentation technique, and these algorithms have the advantage of being quick and simple to compute.
Increasing the accessibility of geographical imagery has recently made it possible to create and develop cloud-based spatial analysis frameworks such as the Google Earth Engine (GEE). Previously, a large-volume spatial analysis such as LULC was impossible to implement because of the complexity of the algorithm. The GEE interface provides users with the opportunity to state, create, and execute the algorithms according to their needs using an intuitive interface. Furthermore, it offers a publicly accessible dataset that encompasses a comprehensive archive of Landsat 6, 7, 8, and 9 images, along with the MODIS dataset, and Sentinel 1, 2, and 3 imagery. Because of the factors outlined above, the proposed work will be implemented and executed over a GEE platform for simplicity and efficiency.
In the present study, a novel boundary-specific two-level learning approach augmented with auxiliary features is used to evaluate LULC classification systems. The primary contribution lies in the comparison between PB classification and OB classification methods using SVM classification within the GEE environment. To enhance OB classification accuracy, auxiliary features are incorporated alongside traditional features, and the SNIC segmentation algorithm is utilized for segmentation instead of the previously employed multiresolution segmentation. Finally, a boundary-specific classification algorithm combining SVM and kNN is employed to minimize SVM’s misclassification rate. These findings provide valuable insights for improving LULC classification techniques.
Material and methods
Methodological framework
The boundary-specific two-level classification framework for the LULC classes is shown in Fig. 1 along with a comparison of the classification accuracy of PB and two OB techniques with and without SNIC (OBS and OB) using Landsat 8 datasets. The typical workflow comprises the following steps: (i) data composition, (ii) creation of PB and OB data, (iii) boundary-specific two-level classification, and (iv) accuracy evaluation. In the first step of the methodology, a data composition approach is a process of merging data from several sources, such as spectral bands, dates, and resolutions, to produce a more complete image of the study area. The data composition helps to increase the quantity and quality of information available from Landsat 8 data. In the pre-processing step to increase the quantitative and qualitative information, Landsat 8 data is included with date, ROI (region of interest masking), and cloud coverage filter. Then, the features are collected from the preprocessed image and the features are mainly three types: spectral, textural, and indices. Following this, the next step of the methodology is the creation of PB and OB data. PB data is the combination of bands Surface Reflectance_Band7 (SR_B7), SR_B5, and SR_B3. In OB, that spectral composite image is segmented into an object (group of similar pixels) by applying multi-resolution segmentation. Based on these objects, the spectral and textural information of the image is used for the classification. After that to implement the second OBS approach, auxiliary features are added and compared with the existing spectral features as well a new SNIC segmentation approach is used for the object creations.

Flowchart illustrating the proposed methodology’s data processing and analysis implemented in GEE
The final methodological step is boundary-specific two-level classification; here, the first level dataset is divided into two parts, training and testing, then it is classified with SVM classification. Based on the classification result the training data is labeled and compared with the user-defined class labels. kNN classification is implemented to refine the training set and improve the accuracy of the SVM classification. Based on the classification output and the ground truth value the confusion matrix is generated for each method. The accuracy level of the output LULC map is interpreted and generated using these matrices, which are used to create a number of qualitative and quantitative measures helpful for comparing the performance of the various techniques.
Study area
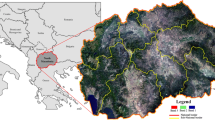
Tamilnadu’s district of Madurai (study area) is situated in the southern part of India and is one of the districts of that state. In the north, it is bordered by the districts of Dindigul and Thiruchirapalli, in the east by Sivagangai, in the west by Theni, and in the south by Virudhunagar. There are 3,038,252 residents in the city, which covers an area of 3710 km2. In terms of geographical location, it lies between the North Latitudes of 9°30.00 and 10°30.00 and the East Latitudes of 77°00.00 and 78°30.00 (Alaguraja et al., 2010). The study region is bounded by the Southeast Ghats and several mountain spurs of the Western Ghats. During the 8 months of the year, the climate of the study area is predominantly hot and dry. As a result of the difficult patterns of topography and climate that dictate the locations of Madurai LULC, a great deal of biodiversity is created as well as unique landscapes (Rajesh et al., 2020). Forestry, agriculture, urban, water bodies, uncultivated land, and bare land are the most common land uses and land cover patterns in the study area and these six classes are used for the LULC classification. The selected classes, their codes, and the description of the class information are present in the Table 1. The number of classes is chosen based on the characteristics of the study area and the importance of the problem that was desired to be solved. The study area is carefully examined depending on how the various classes were distributed in the data (Mohideen, 2017). The study area location map is shown in Fig. 2.

Location map for the study area
Data composition
Landsat 8 Operational Land Imager (OLI) images are used in this study and the images are collected from the Landsat 8 satellite which was operated by the National Aeronautics and Space Administration (NASA) and USGS. On average, Landsat 8 produces a 30-m resolution image every 2 weeks, and its categories with three tiers (tier_1, tier_2, and tier_RT), two collections (collection_1, and collection_2), and three different processing methods (surface reflectance, top of atmosphere, and raw images) (Knight & Kvaran, 2014). Among the categories, “Landsat 8 Level_2 tier_2 collection_2 Surface Reflectance” images are collected from the GEE archive and these images are already atmospherically corrected datasets. The input parameters of the data insertion in GEE are shown in Table 2. The images comprise five visible and near-infrared bands (VNIR) and two short-wave infrared bands (SWIR) (Barsi et al., 2014). To minimize the impact of cloud coverage and the most suitable time for vegetation growth, the data set is filtered with the appropriate time intervals from June 2015 to October 2015. Moreover, the image is filtered with the geometric boundary based on the study area, and the filtered image is shown in Fig. 3a and b.

The study area’s multispectral image is shown in a prior to cloud and ROI masking, and in b after applying the masking process
Feature collection
According to earlier research, the different remote sensing feature sets are responsive to various forms of LULC. As a result, there is no comprehensive feature set for LULC. In the feature set collection process, 7 spectral characteristics, 4 texture features, and 4 spectral indices were extracted from preprocessed Landsat 8 OLI images (Table 3). In order to create the PB classification data composition, SR_B7, SR_B5, and SR_B3 are linearly combined. The combination of these bands is perfect for tracking agricultural crops, which tend to appear in bright green hues (Acharya & Yang, 2015). A similar combination of bands is used for the classification of OB. In addition to this, gray level co-occurrence matrix (GLCM) and entropy are added in order to create the feature set for OB classification. For OBS classification auxiliary dataset is added with the earlier feature (F2, F3, F4, and F5). Here auxiliary dataset is a geospatial dataset not derived from the Landsat 8 satellite. A global forest/non-forest map (FNF) (F2) is created by categorizing backscattering coefficients in a 25-m resolution mosaic, differentiating “forest” and “non-forest” using variable thresholds (Altunel et al., 2020). The auxiliary feature, “Inland water bodies—GLCF: Landsat Global Inland Water,” (F3) aids in identifying water bodies with Landsat imagery (Chen et al., 2015). Soil texture auxiliary feature (F4) characterizes soil properties and influences vegetation growth globally, including numeric properties at different depths and soil class distribution (De Lannoy et al., 2014). The global population dataset (F5) enhances predictions for dense classes and reduces confusion between similar urban classes (Chen et al., 2020). These datasets are open access datasets in GEE shown in Fig. 4, and this dataset provides variation and spatial distribution of human settlements, soil features, inland water bodies, and forest cover.

The auxiliary dataset used in study. A Global human settlements white pixels denote the human settlements. B Forest cover green pixels denote the forest regions. C Soil features green and gray pixels denote the different textures of the soil. D Inland water bodies blue pixel denotes the water bodies regions
SNIC segmentation
In the OBS method, a SNIC segmentation algorithm is used for image segmentation. Simple linear iterative clustering (SLIC) acts as a base for SNIC, an advanced super-pixel segmentation method. Compared with the SLIC segmentation algorithm, the SNIC segmentation algorithm has more advantages, since it reduces the computation time of segmentation by using non-iterative procedures. The main parameters of SNIC segmentation in the GEE environment are super-pixel size, connectivity, compactness, neighborhood size, and seed shape. Figure 5 shows the input parameters and output image of the SNIC segmentation algorithm for the study area.

The outcome of SNIC segmentation in GEE environment with parameter list
In SNIC, K initial centroids in the image plane are generated using a regular grid. The grid matches with K corresponding elements in the input image and here K is the user-specified number of super-pixels. The main user-defined parameter of SNIC is K, which stands for the number of initial centroids. It establishes a super-pixel size s, which may be computed as follows:
where N is the image’s pixel count and the Image \({\left\{{I}_{i}\right\}}_{i=0}^{N}\). Each element in SNIC consists of the spatial position of the candidate pixel, the CIELAB color of the pixel, and the label of the super-pixel centroid. The priority queue Q is interleaved with K elements, and it checks to see if Q is not empty first, then it pops out the minimum distance element from the queue. For each linked neighbor pixel of the popped element, a new element is formed and the distance from the connected centroid and the label of the connected centroid are assigned. Repeat this procedure until the centroid has been assigned or all of the image’s pixels have been popped. The result is an image where each pixel is mapped to the nearest centroid.
Boundary-specific two-level classification
This methodology utilizes a two-level boundary-specific classification method to compute the LULC Classification. The earlier investigations have shown that, as a consequence of the uniqueness and limitations of the tools, no classifier can be categorically regarded as superior to other classifiers since it cannot guarantee high-quality classification for all datasets (Vivekananda et al., 2021; Alshari & Gawali, 2021). The binary SVM classification provides satisfactory classification results in complex multidimensional datasets. In complex multidimensional datasets, binary SVM classification can provide satisfactory classification results. On the other hand, it does not work when applied to large and imbalanced datasets. It is necessary to perform another classification at the second level in order to reduce the misclassification rate. A kNN classifier is implemented in the second level to reduce the misclassifications caused by the SVM classifier. Therefore, the boundary-specific two-level classification method combines the strengths of the two classifiers to increase LULC classification accuracy. This method has proven to be reliable and accurate in various applications. Figure 6 illustrates the algorithm steps for implementing the boundary-specific two-level classification. Figure 7 illustrates the boundary-specific two-level approach in a two-dimensional space, which utilizes the cascade learning method. In the first level of classification, the SVM classifier is applied to the dataset, forming a hyperplane based on the support vectors and kernel function. This hyperplane separates the dataset into two classes with labels + 1 and − 1. The objects falling inside the strip line are considered as a dataset for the kNN classifier. To develop a training set for the kNN classifier, objects from the boundary region are selected, assuming that the SVM classifier will continue to correctly classify objects outside the area, but may make mistakes inside this area. The kNN classifier works differently from the SVM classifier and can improve the overall data classification quality in some cases.

Algorithm steps for boundary-specific two-level classification using SVM and kNN

Boundary-specific two-level classificationin two-dimensional space
In the GEE environment, the important parameters for the SVM and kNN classifier are shown in Table 4.
Accuracy assessment
In the GEE environment for testing and training of the boundary-specific two-level classification, 200 polygons are randomly collected from the study area. The number of sample polygons is chosen based on the study area size and previous studies (Avci et al., 2023). To create the ground truth points, the polygons is overlaid with the Google Earth high-resolution base map, and manually labeled each polygon as FAC, UAC, WBC, BLC, ULC, and ALC (Al-Abdulrazzak & Pauly, 2014). According to a random selection, 70% of these points are used for training and 30% for validation. The confusion matrix is used to assess the accuracy of PB, OB, and OBS LULC classification. To assess the LULC classification accuracy quantitatively producers’ accuracy (PA), users’ accuracy (UA), OA, and K were calculated (by calculating the confusion matrix). A confusion matrix based on the number of pixels was calculated in the PB classification methods. Object-based classification methods can be applied either based on the number of objects or based on the area of the objects to determine the confusion matrix.
Results
Figure 8 shows the step-by-step outcome of PB LULC classification. The initial step of the classification is masking and creating the true color composite image. The true-color composite layer is used to examine how pixels are visualized for each band. To generate a true-color composite image, the “SR_B4,” “SR_B3,” and “SR_B2” bands are utilized. In the next step, spectral features and indices are collected. As a result of the feature collection, the study area is classified into one of the PB LULC classes such as FAC, UAC, WBC, BLC, ULC, and ALC using the supervised classification method.

The step-by-step outcome of PB LULC classification
The findings of the OB and OBS LULC categorization are displayed in stages in Figs. 9 and 10. In the classification of OB and OBS approaches, the processing stages are similar, but the segmentation methodologies differ. As part of the OB LULC classification approach, a multiresolution segmentation algorithm is employed to construct the objects, and the contextual information is added to the feature collection. The OBS LULC classification process uses the SNIC segmentation approach for segmentation and auxiliary features are introduced during the feature-collecting stage. These results suggest that object-based classifiers take into account smoothness, form, and texture in addition to spectral values, whereas PB classifiers simply take into account spectrum values.

The step-by-step outcome of OB LULC classification

The step-by-step outcome of OBS LULC classification
Figure 11 illustrates the significance of augmenting auxiliary feature sets using the OBS method. In this context, F1 represents the accuracy (92.45%) of the OBS method when using the earlier feature set, comprising spectral features (7), texture (4), and indices (4). F2 corresponds to the inclusion of the auxiliary feature forest cover alongside the earlier feature set, resulting in an accuracy of 93.36%. Furthermore, when incorporating the inland water bodies feature with F1, the accuracy increases to 93.60% (F3). Similarly, the simultaneous addition of soil feature and population feature to the F1 feature yields accuracies of 94.25% (F4) and 94.39% (F5), respectively. Finally, by augmenting all auxiliary features with the earlier feature set, the overall accuracy reaches 94.42%. It is worth noting that each feature provides marginal improvement over its predecessor, but the combined augmentation leads to a notable 2% increase in accuracy.

Auxiliary feature augmentation
In GEE, a confusion matrix was developed to statistically compare the ground truth points to the validation points with the output classifications to assess the accuracy of both LULC classifications. In addition to providing information about the OA and K, the confusion matrix also indicates the LULC classes that produce errors (quantified by the UA and PA, respectively). These errors can be used to identify potential areas of improvement in the analysis for more accurate results. Furthermore, the confusion matrix can be used to identify the most and least accurate LULC classes. Table 5 lists the OA and K values of the PB, OB, and OBS LULC classifications. The results from the OBS LULC classification accurately depicted the land cover of the study area. The table showed that the OA and K values of the OBS LULC classification (OA: 94.42% and K: 0.92) were higher than those of the PB (OA: 81% and K: 0.76) and OB (OA: 91% and K: 0.89) LULC classifications. Therefore, the OBS LULC classification is more accurate than the other two.
Based on the classification methodologies employed in this study, Fig. 12 shows the proportion of the total area filled by each class. Based on OBS’s highest accuracy methodology, BLC is the biggest area class and ULC is the second biggest area. Following UAC occupies nearly 14% of the total study area. The remaining classes occupy lesser areas of the total study area, with the smallest proportion being occupied by the ALC class. This is followed by the FAC and WBC classes, which occupy nearly 7% and 1.7% of the total area, respectively. Overall, the results show that BLC is the most dominant class in the study area.

Distribution of 6 LULC classes for the study area
The SVM classification in the OBS method produced an OA of 94.42% and a K of 0.92, which was a marked improvement over the PB and OB methods. However, when it came to PA and UA, the accuracy of ULC and UAC classes remained quite low due to misclassification between them. The maximum rate of misclassification occurs between the following pairs of classes ULC and UAC, UAC, and BLC. To improve the accuracy of the OBS method, special attention should be paid to these misclassifications.
The proposed two-level boundary-specific SVM-kNN classifiers could increase the accuracy of the classification. It may be possible to reduce the number of misclassified objects by applying the kNN classifier to objects that are near the separating hyperplane found by the SVM classifier. As a result of this method, the OA is increased by 3%, and the K is 0.94. There is also a slight increase in the PA and UA of ULC and UAC when compared with SVM. The confusion matrix of the OBS method, employing SVM classification and a boundary-specific two-level classification, is displayed in Tables 6 and 7.
Figure 13 displays a map of the small section of the study area with a scale of 500 m, which clearly outlines the land use and land cover classes. It can be seen that this region is mainly composed of waterbodies along with some urban land, agricultural land, and uncultivated land. This output map from the OBS LULC classification method accurately differentiates the land within the waterbody and road as an urban area.

LULC classification outcome of Boundary-specific two-level classifications in the OBS method
Discussion
LULC classification is heavily dependent on the accuracy of the classification algorithms. Thus, improving the classification accuracy is of primary importance in remote sensing. Prior studies have attempted to increase the accuracy of the LULC classification, both by the traditional PB (Varma et al., 2016; Whiteside & Ahmad, 2005) and OB (Dorren et al., 2003; Kavzoglu & Yildiz, 2014) methods. In order to improve the accuracy of LULC classification existing in literature, Landsat8 OLI image is taken for the study area Madurai. The choice of Landsat 8 is based on the work by Chen et al., (2015) which proves that medium-resolution (Landsat-like, 10–30 m) sensors are more competent for detecting most human-nature interactions in high-resolution LULC classification. Landsat 8 is low to moderate-resolution sensors, which are not suitable for high-precision LULC classification studies at regional scales. The two leading platforms for medium-resolution satellite land imaging are Landsat and Sentinel. Due to Landsat’s compatibility with its earlier missions and extensive historical datasets compared to Sentinel satellites, Landsat is frequently used in research (Chander et al., 2009). The increased radiometric performance and the thermal band calibration of Landsat 8 also contribute to improved analyses of LULC classification (Roy et al., 2014). Thus, “Level 2 Surface Reflectance image from the Landsat 8 OLI (tier 2)” was employed. surface reflectance (SR) data from Landsat 8 Level-2 data products have already undergone certain radiometric and geometric adjustments (Acharya & Yang, 2015), under the direction of the United States Geological Survey (USGS). These corrections have been precisely applied to the Landsat 8 Level-2 data products, so using this dataset often does not require further radiometric and geometric corrections by individual researchers (Vermote et al., 2016).
The study aims to develop an OB LULC classification by combining auxiliary features, SNIC and boundary-specified two-level classification on a freely accessible GEE platform. Furthermore, the study also compares the LULC classifications of PB and OB. The OA for the PB classification achieved was 81%, whereas the OA for the OB classification without SNIC and auxiliary features was 91%. An accuracy improvement of 10% is observed for OB over the PB classification, which is a significant improvement over the accuracies achieved by Whiteside and Ahmad (2005) and Weih and Riggan (2010). In addition to the OB, Qu et al. (2021), Zhu et al. (2016), and Hurskainen et al. (2019) discuss the advantages of integrating the auxiliary features for better classification. The integration of freely available auxiliary features (F2, F3, F4, and F5) with spectral and textural features done in this paper has demonstrated a significant enhancement (2% improvement) in the OA of LULC classification (Fig. 11). The feature set F1 (7 spectral characteristics, 4 texture features, and 4 spectral indices) are selected based on the result obtained from the previous study (Rohini & Geraldine Bessie Amali, 2023).
In addition to addressing and analyzing the effect of the segmentation algorithms namely multiresolution and SNIC segmentation on OB classification, a comparison is also presented in this paper. The multi-resolution segmentation and SNIC segmentation provide an accuracy of 91% and 94.42%, respectively, in OB LULC classification. The implementation of the OBS approach resulted in a significant gain of almost 14% in the OA in comparison to the PB classification. The SNIC segmentation algorithm makes use of the “compactness factor” to define cluster shapes (with greater values leading to more condensed clusters), “connectivity” to decide how neighboring clusters merge (either four connections like queens or eight connections like rooks), and a “neighborhood size” to eliminate artifacts at tile boundaries when merging nearby clusters. The selection of compactness (0.1) and connectivity (8) parameters involves a methodical approach of experimentation and analysis. It was systematically assessed for compactness and connectivity through iterative testing.
Previous studies (Machhale et al., 2015; Zanchettin et al., 2012) improved the classification accuracy of SVM by using a hybrid SVM/kNN model. To implement this, researchers used SVM and kNN algorithms simultaneously on the complete dataset. However, in this study only a subset of data is considered for the second level of kNN based on the boundary condition of the SVM classification at the first level (Fig. 7). The results indicate that the boundary-specific two-level classification algorithm proposed in this paper provided better results than the existing literature despite the reduced dataset used at the training at the second level. A significant increase of 5% in terms of UA and PA for LULC classes was also observed (Tables 6 and 7).
Conclusion
This study offers valuable insights into LULC classification for monitoring the land degradation for the study area of Madurai. The primary focus of this research is to enhance classification accuracy through the integration of auxiliary features, utilization of the SNIC segmentation algorithm, and the implementation of a boundary-specific two-level classification approach using SVM and kNN. The evaluation of PB and OB classification techniques highlights the limitations of PB methods when compared to the OB. Advancements in the computational capabilities of platforms like GEE and improvements in the SNIC segmentation algorithm are poised to elevate LULC classification outcomes for Landsat 8 data, even at a 30-m resolution. The study effectively illustrates the efficiency of incorporating auxiliary features such as spanning forest cover, inland water bodies, soil characteristics, and population data. The study also develops a novel boundary-specific two-level classification methodology that synergistically combines the SVM and kNN techniques to reduce the misclassification rate. The proposed OBS method increases the OA and K from (94.42% to 95.78%) and (0.92 to 0.94). Overall, the present study provides a solid foundation for further research and opens avenues for improving LULC classification techniques, thereby enabling more accurate and reliable land cover information for various scientific and practical purposes. The limitation of the proposed method is that it does not take advantage of deep learning techniques, which can learn from large quantities of data and complex patterns that will be considered for future work. The proposed LULC classification can be extended and applied to different temporal data to identify the changes over a certain period of time.
Data availability
Landsat 8 OLI data was taken from the Google Earth Engine Data Catalog (Landsat 8 image courtesy of the US Geological Survey). The Google Earth Engine script, reference data, and LULC outputs may be made available on request from the authors.
References
Achanta, R., & Süsstrunk, S. (2017). Superpixels and polygons using simple non-iterative clustering. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4651–4660. https://doi.org/10.1109/CVPR.2017.520
Acharya, T. D. & Yang, I. (2015). Exploring landsat 8. International journal of IT, Engineering and Applied Sciences Research, 4(4), 8. https://www.researchgate.net/profile/Tri-Acharya/publication/311901147_Exploring_Landsat_8/links/589c0de6458515e5f4549e58/Exploring-Landsat-8.pdf. Accessed 5 Oct 2023
Aggarwal, N., Srivastava, M., & Dutta, M. (2016). Comparative analysis of pixel-based and object-based classification of high resolution remote sensing images – A review. International Journal of Engineering Trends and Technology, 38(1), 5–11. https://doi.org/10.14445/22315381/ijett-v38p202
Al-Abdulrazzak, D., & Pauly, D. (2014). Ground-truthing the ground-truth: reply to Garibaldi et al.’s comment on “Managing fisheries from space: Google Earth improves estimates of distant fish catches.” ICES Journal of Marine Science, 71(7), 1927–1931. https://doi.org/10.1038/278097a0
Alaguraja, P., Durairaju, S., Yuvaraj, D., Sekar, M., Muthuveerran, P., Manivel, M., & Thirunavukkarasu, A. (2010). Land use and land cover mapping – Madurai District, Tamilnadu, India using remote sensing and GIS techniques. International Journal of Civil and Strucutral Engineering, 1(1), 91–100.
Alshari, E. A., & Gawali, B. W. (2021). Development of classification system for LULC using remote sensing and GIS. Global Transitions Proceedings, 2(1), 8–17. https://doi.org/10.1016/j.gltp.2021.01.002
Altunel, A. O., Akturk, E., & Altunel, T. (2020). Examining the PALSAR-2 Global forest/non-forest maps through Turkish afforestation practices. International Journal of Remote Sensing, 41(16), 6071–6088. https://doi.org/10.1080/01431161.2020.1760397
Atik, S. O., & Ipbuker, C. (2021). Integrating convolutional neural network and multiresolution segmentation for land cover and land use mapping using satellite imagery. Applied Sciences, 11(12), 5551. https://doi.org/10.3390/app11125551
Avci, C., Budak, M., Yagmur, N., & Balcik, F. B. (2023). Comparison between random forest and support vector machine algorithms for LULC classification. International Journal of Engineering and Geosciences, 8(1), 1–10. https://doi.org/10.26833/ijeg.987605
Barsi, J. A., Lee, K., Kvaran, G., Markham, B. L., & Pedelty, J. A. (2014). The spectral response of the Landsat-8 operational land imager. Remote Sensing, 6(10), 10232–10251. https://doi.org/10.3390/rs61010232
Blaschke, T. (2010). Object based image analysis for remote sensing. ISPRS Journal of Photogrammetry and Remote Sensing, 65(1), 2–16. https://doi.org/10.1016/j.isprsjprs.2009.06.004
Chander, G., Markham, B. L., & Helder, D. L. (2009). Summary of current radiometric calibration coefficients for Landsat MSS, TM, ETM+, and EO-1 ALI sensors. Remote Sensing of Environment, 113(5), 893–903. https://doi.org/10.1016/j.rse.2009.01.007
Chen, J., Chen, J., Liao, A., Cao, X., Chen, L., Chen, X., He, C., Han, G., Peng, S., Lu, M., Zhang, W., Tong, X., & Mills, J. (2015). Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing, 103, 7–27. https://doi.org/10.1016/j.isprsjprs.2014.09.002
Chen, R., Yan, H., Liu, F., Du, W., & Yang, Y. (2020). Multiple global population datasets: Differences and spatial distribution characteristics. ISPRS International Journal of Geo-Information, 9(11), 637. https://doi.org/10.3390/ijgi9110637
Civco, D. L., Hurd, J. D., Wilson, E. H., Song, M., & Zhang, Z. (2002). A comparison of land use and land cover change detection methods. American Society for Photogrammetry and Remote Sensing/American Congress on Surveying and Mapping, Washington, DC, USA, November 2014, 12. https://www.researchgate.net/publication/228543190_A_comparison_of_land_use_and_land_cover_change_detection_methods. Accessed 5 Oct 2023
De Lannoy, G. J., Koster, R. D., Reichle, R. H., Mahanama, S. P., & Liu, Q. (2014). An updated treatment of soil texture and associated hydraulic properties in a global land modeling system. Journal of Advances in Modeling Earth Systems, 6, 957–979. https://doi.org/10.1002/2014MS000330.Received
Deng, J. S., Wang, K., Deng, Y. H., & Qi, G. J. (2008). PCA-based land-use change detection and analysis using multitemporal and multisensor satellite data. International Journal of Remote Sensing, 29(16), 4823–4838. https://doi.org/10.1080/01431160801950162
Dorren, L. K. A., Maier, B., & Seijmonsbergen, A. C. (2003). Improved Landsat-based forest mapping in steep mountainous terrain using object-based classification. Forest Ecology and Management, 183(1–3), 31–46. https://doi.org/10.1016/S0378-1127(03)00113-0
Feng, M., Sexton, J. O., Channan, S., & Townshend, J. R. (2016). A global, high-resolution (30-m) inland water body dataset for 2000: First results of a topographic–spectral classification algorithm. International Journal of Digital Earth, 9(2), 113–133. https://doi.org/10.1080/17538947.2015.1026420
Garcia-Gutierrez, J., Mateos-Garcia, D., & Riquelme-Santos, J. C. (2010). A SVM and k-NN restricted stacking to improve land use and land cover classification. International Conference on Hybrid Artificial Intelligence Systems; Springer: Berlin/Heidelberg, Germany, 6077, 493–500. https://doi.org/10.1007/978-3-642-13803-4_61
Gholoobi, M., Tayyebib, A., Taleyi, M., & Tayyebi, A. H. (2010). Comparing pixel based and object based approaches in land use classification in mountainous areas. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Science, 38(August), 789–794. https://doi.org/10.1109/JBHI.2016.2515993
Heumann, B. W. (2011). An object-based classification of mangroves using a hybrid decision tree-support vector machine approach. Remote Sensing, 3(11), 2440–2460. https://doi.org/10.3390/rs3112440
Hudait, M., & Patel, P. P. (2022). Crop-type mapping and acreage estimation in smallholding plots using Sentinel-2 images and machine learning algorithms: Some comparisons. Egyptian Journal of Remote Sensing and Space Science, 25(1), 147–156. https://doi.org/10.1016/j.ejrs.2022.01.004
Hurskainen, P., Adhikari, H., Siljander, M., Pellikka, P. K. E., & Hemp, A. (2019). Auxiliary datasets improve accuracy of object-based land use/land cover classification in heterogeneous savanna landscapes. Remote Sensing of Environment, 233(July), 111354. https://doi.org/10.1016/j.rse.2019.111354
Hütt, C., Koppe, W., Miao, Y., & Bareth, G. (2016). Best accuracy land use/land cover (LULC) classification to derive crop types using multitemporal, multisensor, and multi-polarization SAR satellite images. Remote Sensing, 8(8), 684. https://doi.org/10.3390/rs8080684
Im, J., Jensen, J. R., & Tullis, J. A. (2008). Object-based change detection using correlation image analysis and image segmentation. International Journal of Remote Sensing, 29, 399–423. https://doi.org/10.1080/01431160601075582
Johansen, K., Arroyo, L. A., Phinn, S., & Witte, C. (2010). Comparison of geo-object based and pixel-based change detection of riparian environments using high spatial resolution multi-spectral imagery. Photogrammetric Engineering & Remote Sensing, 76(2), 123–136. https://doi.org/10.14358/pers.76.2.123
Kavzoglu, T., & Yildiz, M. (2014). Parameter-based performance analysis of object-based image analysis using aerial and quikbird-2 images. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, II–7(October), 31–37. https://doi.org/10.5194/isprsannals-ii-7-31-2014
Kim, C. (2016). Land use classification and land use change analysis using satellite images in Lombok Island, Indonesia. Forest Science and Technology, 12(4), 183–191. https://doi.org/10.1080/21580103.2016.1147498
Knight, E. J., & Kvaran, G. (2014). Landsat-8 operational land imager design, characterization and performance. Remote Sensing, 6(11), 10286–10305. https://doi.org/10.3390/rs61110286
Kulkarni, K., & Vijaya, P. (2021a). NDBI based prediction of land use land cover change. Journal of the Indian Society of Remote Sensing, 49(10), 2523–2537. https://doi.org/10.1007/s12524-021-01411-9
Kulkarni, K., & Vijaya, P. A. (2021b). Separability analysis of the band combinations for land cover classification of satellite images. International Journal of Engineering Trends and Technology, 69(8), 138–144. https://doi.org/10.14445/22315381/IJETT-V69I8P217
Lee, J., Cardille, J. A., & Coe, M. T. (2018). BULC-U: Sharpening resolution and improving accuracy of land-use/land-cover classifications in Google Earth Engine. Remote Sensing, 10(9), 1455. https://doi.org/10.3390/rs10091455
Lu, P., Qin, Y., Li, Z., Mondini, A. C., & Casagli, N. (2019). Landslide mapping from multi-sensor data through improved change detection-based Markov random field. Remote Sensing of Environment, 231(June), 111235. https://doi.org/10.1016/j.rse.2019.111235
Lv, Z., Liu, T., Benediktsson, J. A., & Du, H. (2019). A novel land cover change detection method based on K-means clustering and adaptive majority voting using bitemporal remote sensing images. IEEE Access, 7, 34425–34437. https://doi.org/10.1109/ACCESS.2019.2892648
Machhale, K., Nandpuru, H. B., Kapur, V., & Kosta, L. (2015). MRI brain cancer classification using hybrid classifier (SVM-KNN). International Conference on Industrial Instrumentation and Control, ICIC 2015, May, 60–65. https://doi.org/10.1109/IIC.2015.7150592
Mohideen, S. (2017). Assessment on land use / land cover changes in madurai district, assessment on land use / land cover changes in Madurai District, Tamil Nadu, India. International Journal of Recent Innovation in Engineering and Research, 2(July), 6–14.
Qu, L., Chen, Z., Li, M., Zhi, J., & Wang, H. (2021). Accuracy improvements to pixel-based and object-based LULC classification with auxiliary datasets from Google Earth Engine. Remote Sensing, 13(3), 453. https://doi.org/10.3390/rs13030453
Rajesh, S., Nisia, T. G., Arivazhagan, S., & Abisekaraj, R. (2020). Land cover/land use mapping of LISS IV imagery using object-based convolutional neural network with deep features. Journal of the Indian Society of Remote Sensing, 48(1), 145–154. https://doi.org/10.1007/s12524-019-01064-9
Rithesh, R. N. (2017). SVM-KNN: A novel approach to classification based on SVM and KNN. International Research Journal of Computer Science, 4(8), 43–49. https://doi.org/10.26562/irjcs.2017.aucs10088
Rogan, J., & Chen, D. (2004). Remote sensing technology for mapping and monitoring land-cover and land-use change. Progress in Planning, 61(4), 301–325. https://doi.org/10.1016/S0305-9006(03)00066-7
Rohini, S., & Geraldine Bessie Amali, D. (2023). Assessment of object-based classification for mapping land use and land cover using Google Earth. https://doi.org/10.30955/gnj.004829
Roy, D. P., Wulder, M. A., Loveland, T. R., Woodcock, C. E., Allen, R. G., Anderson, M. C., Helder, D., Irons, J. R., Johnson, D. M., Kennedy, R., Scambos, T. A., Schaaf, C. B., Schott, J. R., Sheng, Y., Vermote, E. F., Belward, A. S., Bindschadler, R., Cohen, W. B., Gao, F., & Zhu, Z. (2014). Landsat-8: Science and product vision for terrestrial global change research. Remote Sensing of Environment, 145, 154–172. https://doi.org/10.1016/j.rse.2014.02.001
Shao, Y., & Lunetta, R. S. (2012). Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS Journal of Photogrammetry and Remote Sensing, 70, 78–87. https://doi.org/10.1016/j.isprsjprs.2012.04.001
Shimada, M., Itoh, T., Motooka, T., Watanabe, M., Shiraishi, T., Thapa, R., & Lucas, R. (2014). New global forest/non-forest maps from ALOS PALSAR data (2007–2010). Remote Sensing of Environment, 155(May), 13–31. https://doi.org/10.1016/j.rse.2014.04.014
Sinha, S., Sharma, L. K., & Nathawat, M. S. (2015). Improved land-use/land-cover classification of semi-arid deciduous forest landscape using thermal remote sensing. The Egyptian Journal of Remote Sensing and Space Science, 18(2), 217–233. https://doi.org/10.1016/j.ejrs.2015.09.005
Sowmya, D. R., Shenoy, P. D., & Venugopal, K. R. (2017). Remote sensing satellite image processing techniques for image classification: A comprehensive survey. International Journal of Computer Applications, 161(11), 24–37.
Talukdar, S., Singha, P., Mahato, S., Pal, S., Liou, Y.-A., & Rahman, A. (2020). Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sensing, 12(7), 1135. https://doi.org/10.3390/rs12071135
Tassi, A., & Vizzari, M. (2020). Object-oriented lulc classification in Google Earth learning algorithms. Remote Sensing, 12, 1–17. https://doi.org/10.3390/rs12223776
Varma, M. K. S., Rao, N. K. K., Raju, K. K., & Varma, G. P. S. (2016). Pixel-based classification using support vector machine classifier. Proceedings - 6th International Advanced Computing Conference, IACC 2016, February, 51–55. https://doi.org/10.1109/IACC.2016.20
Vermote, E., Justice, C., Claverie, M., & Franch, B. (2016). Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product. Remote Sensing of Environment, 185, 46–56. https://doi.org/10.1016/j.rse.2016.04.008
Vivekananda, G., Swathi, R., & Sujith, A. (2021). Multi-temporal image analysis for LULC classification and change detection. European Journal of Remote Sensing, 54(S2), 189–199. https://doi.org/10.1080/22797254.2020.1771215
Wang, M., Liu, X., Gao, Y., Ma, X., & Soomro, N. Q. (2017). Superpixel segmentation: A benchmark. Signal Processing: Image Communication, 56(January), 28–39. https://doi.org/10.1016/j.image.2017.04.007
Weih, R. C., & Riggan, N. D. (2010). Object-based classification vs. pixel-based classification: Comparitive importance of multi-resolution imagery. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, XXXVIII, 1–6.
Whiteside, T., & Ahmad, W. (2005). A comparison of object-oriented and pixel-based classification methods for mapping land cover in northern Australia. Spatial Intelligence, Innovation And Praxis: The National Biennial Conference of the Spatial Sciences Institute, September, 1225–1231.
Willhauck, G. (2000). Comparison of object oriented classification techniques and standard image analysis for the use of change detection between SPOT multispectral satellite images and aerial photos. International Archives of Photogrammetry and Remote Sensing, XXXIII, 214–221.
Zanchettin, C., Bezerra, B. L. D., & Azevedo, W. W. (2012). A KNN-SVM hybrid model for cursive handwriting recognition. The 2012 International Joint Conference on Neural Networks (IJCNN), 1–8. https://doi.org/10.1109/IJCNN.2012.6252719
Zhou, W., Troy, A., & Grove, M. (2008a). A comparison of object-based with pixel-based land cover change detection in the baltimore metropolitan area using multitemporal high resolution remote sensing data. IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2008), 4(1), 683–686. https://doi.org/10.1109/IGARSS.2008.4779814
Zhou, W., Troy, A., & Grove, M. (2008b). Object-based land cover classification and change analysis in the baltimore metropolitan area using multitemporal high resolution remote sensing data. Sensors, 8(3), 1613–1636. https://doi.org/10.3390/s8031613
Zhu, Z., Gallant, A. L., Woodcock, C. E., Pengra, B., Olofsson, P., Loveland, T. R., Jin, S., Dahal, D., Yang, L., & Auch, roger f. (2016). Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS Journal of Photogrammetry and Remote Sensing, 122, 206–221. https://doi.org/10.1016/j.isprsjprs.2016.11.004
Funding
No funding was obtained for this study.
Author information
Authors and Affiliations
Contributions
Rohini Selvaraj proposed the idea and prepared the draft. Geraldine Bessie Amali D refined the algorithm and revised the manuscript.
Corresponding author
Ethics declarations
Ethical approval
All authors have read, understood, and have complied as applicable with the statement on “Ethical responsibilities of Authors” as found in the Instructions for Authors.
Consent to participate and publish
This manuscript was drafted by all the authors and all of them consented to participate in its development. All authors have consented to the publication of this manuscript.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Selvaraj, R., Amali D, G.B. Accurate classification of land use and land cover using a boundary-specific two-level learning approach augmented with auxiliary features in Google Earth Engine. Environ Monit Assess 195, 1280 (2023). https://doi.org/10.1007/s10661-023-11903-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-023-11903-5