
Abstract
This paper presents a derivative-free method for computing approximate solutions to the uncertain Lambert problem (ULP) and the reachability set problem (RSP) while utilizing higher-order sensitivity matrices. These sensitivities are analogous to the coefficients of a Taylor series expansion of the deterministic solution to the ULP and RSP, and are computed in a derivative-free and computationally tractable manner. The coefficients are computed by minimizing least squared error over the domain of the input probability density function (PDF), and represent the nonlinear mapping of the input PDF to the output PDF. A non-product quadrature method known as the conjugate unscented transform is used to compute the multidimensional expectation values necessary to determine these coefficients with the minimal number of full model propagations. Numerical simulations for both the ULP and the RSP are provided to validate the developed methodology and illustrate potential applications. The benefits and limitations of the presented method are discussed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The classical Lambert problem is a well-known two-point boundary value problem, where the solution is the initial velocity vector that connects two known position vectors for a given time of flight. This problem and its many variants have a rich history in academic research and has been solved in an equally diverse range of methods. A good overview of the Lambert problem is given in Battin (1999), Battin and Vaughan (1984), Prussing and Conway (2013) and Vallado (2001). A complimentary but equally important problem in astrodynamics is the Reachability Set Problem (RSP). The RSP is the determination of the set of all possible final positions of a satellite given some range of initial positions and velocities. Similar to the Lambert problem, reachability sets have a robust background in the literature of mathematics, dynamics, optimization, control and game theory (Kurzhanski and Varaiya 2001; Bicchi et al. 2002; Patsko et al. 2003; Lygeros 2004; Mitchell et al. 2005; Hwang et al. 2005). The reachability set problem has been investigated in many different contexts, often interpreting the reachability set as an envelope of possible future states generated by some analytically derived boundaries (Vinh et al. 1995; Dan et al. 2010; Li et al. 2011; Gang et al. 2013; Wen et al. 2018). The Lambert problem and the reachability set problem have many important applications in space operations including but not limited to: satellite tracking, maneuver detection, orbit determination, track correlation, collision probability determination, and rendezvous planning. Both problems are deterministic; however, the real world does not reflect the idealized conditions of these problems. Due to limited accuracy in measurement and dynamic models, the characterization of uncertainty in the Lambert problem as well as the RSP is an important operational concern for many Space Situational Awareness (SSA) problems.
Typically, uncertainty is analyzed by assigning a state covariance matrix and propagating the mean and covariance through a dynamic system using a linearized solution; however, the solution using this method can rapidly break down in the presence of highly nonlinear dynamics. It is desirable to propagate the covariance matrix to a high degree of accuracy, and if possible, to gain some information about the higher-order moments (HOM’s) of the state or even the full state probability density function (PDF). Obtaining HOM’s or the state PDF can enable satellite operators to be better informed about potentially high impact decisions regarding valuable space assets.
Uncertainty characterization and propagation in nonlinear dynamical systems are active areas of research in control theory (Junkins and Singla 2004; Ramdani and Nedialkov 2011; Ghanem and Red-Horse 1999; Terejanu et al. 2008; Vishwajeet and Singla 2013), and have been useful in astrodynamics applications (Fujimoto et al. 2012; Vishwajeet et al. 2014; Park and Scheeres 2006) due to the high uncertainties inherent in space operations. Luo and Yang (2017) provides a concise summary of many existing methods for linear and nonlinear uncertainty propagation in orbital mechanics. Luo’s review concludes that many nonlinear methods which require computation of statistical HOM’s still face technical challenges associated with high computational expense in the face of practical limitations in onboard computational capabilities.
The uncertain Lambert problem was first introduced by Schumacher et al. (2015), where a linear state transition matrix was solved analytically. A similar analytic approach to characterize the uncertainty associated with the Lambert solution involves linearizing the Lambert solution using first-order partial derivatives about the nominal orbit (Arora et al. 2015; McMahon and Scheeres 2016). These linear variational approximations to the Lambert solution are computationally efficient; however, linear analyses are only valid if initial and final state uncertainties are relatively small, and they may not provide insight into the exact distribution of error associated with the Lambert solution. Armellin et al. (2012) utilized differential algebra implemented in automatic differentiation package COSY-Infinity Makino and Berz (2006) to compute the Taylor series expansion of the Lambert problem solution as a part of the initial orbit determination. The obtained Taylor series expansion of the Lambert problem is used as a surrogate model to consider the effect of uncertainties in input variables.
Rather than considering linear perturbations to the Lambert Problem inputs, or deterministic maneuvers for the RSP, this paper will substitute stochastic variables with a prescribed PDF for the input variables. In the Uncertain Lambert Problem (ULP), uncertainty is assigned to the initial and final position vectors, and in the RSP, uncertainty is assigned to the initial position and velocity. Specifically for the RSP, uncertainty in initial velocity is often facilitated by the effects of uncertainty in maneuver parameters. Using a similar idea, the method of transformation of variables has been recently used to find the density function corresponding to solution of the Lambert problem in two different efforts (Healy et al. 2020; Adurthi and Majji 2020). While Healy et al. (2020) used the transformation of variable formulation to obtain a velocity distribution from a point source via Housen’s method, Adurthi and Majji (2020) exploited the solution of uncertain Lambert problem for initial orbit determination and data association problem. However, both of these approaches either use a grid-based sampling or Monte Carlo sampling to compute the PDF of a velocity along a particular sample point which can be a computationally expensive procedure.
The motivation behind this paper is to develop a nonlinear method to map the input PDF to the output PDF by computing any arbitrary order sensitivity matrix numerically for both the ULP and the RSP. This method is termed the higher-order sensitivity matrix (HOSM) method, and involves computing the least squares polynomial coefficients which correspond to the higher-order terms of a Taylor series expansion. These polynomial coefficients represent the elements of the sensitivity matrices and are synonymous with polynomial chaos expansion coefficients in estimation literature (Jones et al. 2015; Prabhakar et al. 2010; Dutta and Bhattacharya 2010; Madankan et al. 2013). Traditionally in the polynomial chaos theory, the computation of higher-order sensitivity coefficients for high dimensional systems is computationally expensive due to the exponentially increasing cost of evaluating expectation integrals with increasing state dimension. To alleviate the computational burden associated with multi-dimensional expectation integral evaluation, this work utilizes a non-product quadrature method known as the Conjugate Unscented Transformation (CUT) Adurthi et al. (2018) to compute the necessary multidimensional expectation integrals in a computationally attractive manner. The CUT method provides the minimal quadrature points in n-dimensional space and can be seen as the extension of the celebrated unscented transformation Julier et al. (2000) to compute higher-order statistical moments. The unscented transformation captures the mean and covariance of the input PDF while the CUT method provides the sigma points to capture the higher-order moments (up to order 8) of the input PDF. A set of samples drawn according to the CUT approach called sigma points or quadrature points are used to compute the solution of deterministic Lambert problem or reachability set problem. The deterministic solution corresponding to these sigma points is utilized to compute statistical moments corresponding to the PDF of ULP and RSP. These same points are also used to compute polynomial coefficients representing the sensitivity of the Lambert problem and reachability set problem to the input variables.
The structure of the paper is as follows: Sect. 2 provides a brief description of ULP and RSP problem. Section 3 describes an approach to compute the desired order statistical moments in a computationally efficient manner followed by the details of polynomial surrogate model in the Sect. 4. Section 5 provides results corresponding to numerical experiments considered and finally, Sect. 6 provides concluding remarks regarding the utility of the developed methodology.
2 Problem description
This section provides the mathematical description of the ULP and RSP problem. Figure 1 shows a schematic diagram of the ULP (left) and the RSP (right). In Fig. 1a, initial position \({\mathbf {r}}^*_1\) and final position \({\mathbf {r}}^*_2\) are nominal system inputs and initial velocity \({\mathbf {v}}^*_1\) is the nominal system output. In Fig. 1b, initial position \({\mathbf {r}}^*_1\), initial velocity \({\mathbf {v}}^*_1\) and control \({\mathbf {u}}^*\) are nominal system inputs and final position \({\mathbf {r}}^*_2\) is the nominal system output. Notice that both problems can be formulated as input-output systems where the nonlinear function \(f\) maps the \((n\times 1)\) input vector \({\mathbf {x}}\) to a \((m\times 1)\) nominal output vector \({\mathbf {y}}\).
In the ULP case, \(f(\mathbf {x})\) represents a Lambert solver algorithm with inputs \({\mathbf {r}}_1,{\mathbf {r}}_2\) and output \({\mathbf {v}}_1\), and in the RSP case, \(f(\mathbf {x})\) represents the integration of the system dynamics to map uncertain inputs \({\mathbf {r}}_1,{\mathbf {v}}_1\), and control \({\mathbf {u}}\) to output \({\mathbf {r}}_2\). Table 1 summarizes the variables in each problem. To formulate this as a stochastic system, the deterministic input vector \(\mathbf {x}^*\) is replaced by the continuous random (\(n\times 1\)) vector \(\mathbf {x}\) with associated probability density function \(\rho (\mathbf {x})\). The objective is to find the PDF of output \(\rho (\mathbf {y})\) given the nonlinear mapping function \(f\) and \(\rho (\mathbf {x})\).

Diagram of ULP and RSP
The input variable PDF’s are typically specified to be either Gaussian or uniform. Hence, the random variable \(\mathbf {x}\) is defined in terms of a (\(n\times 1\)) normalized Gaussian or uniform random vector \(\varvec{\zeta }\) with \(\rho (\varvec{\zeta })\). The normalized PDF can then be linearly scaled to the desired input PDF and propagated through the mapping function \(f\) as shown in Fig. 2.

Characterization of uncertainty
This transformation is given as follows:
where \({\mathbf {S}}\) is a linear scaling matrix dependent on \(\rho (\varvec{\zeta })\). \(\varvec{\zeta }\) is unit variance, zero mean for a Gaussian distribution, and on the domain \([-1,1]\) for a uniform distribution. The linear scaling matrix \({\mathbf {S}}\) for Gaussian and uniform distributions is given as:
where \(\varvec{\Sigma }\) is the \((n\times n)\) input covariance matrix for Gaussian \(\rho (\varvec{\zeta })\), and \({\mathbf {a}},{\mathbf {b}}\) are the lower and upper boundary vectors, respectively, for uniform \(\rho (\varvec{\zeta })\). For a Gaussian random variable, all the higher-order moments and hence the PDF is completely defined by the mean and covariance matrix; however, this is not the case when the output has been transformed by a nonlinear function \(f\). The objective of this work is to describe the output PDF, i.e., \(\rho (\mathbf {y})\) as a function of input PDF, i.e., \(\rho (\mathbf {x})\). Given the fact that the characteristic function of the PDF is a Fourier transformation of the PDF and hence the statistical moments provide the spectral content of the PDF, we describe this PDF in terms of higher-order statistical moments. The ith order statistical moment will be ith order tensors defined as:
Furthermore, we are also interested in finding a polynomial model which captures the nonlinear function \(\varvec{f(\mathbf {x})}\) in the domain of \(\rho (\mathbf {x})\). The coefficients of this polynomial model define the sensitivities of the output with respect to the input variables.
3 Computation of statistical moments
As discussed the in last section, we are interested in the computation of statistical moments corresponding to the PDF of output variable, i.e., \(\rho (\mathbf {y})\). Conventionally, the random sampling Monte Carlo (MC) method is used to numerically evaluate statistical moments. Although the MC sampling scheme is easily implemented, it suffers from slow convergence such that increasing the accuracy of an integral by one decimal place requires increasing the number of sampled points by a factor of 100. Figure 3 demonstrates the convergence of the Monte Carlo method in evaluating the mean and covariance of a zero mean, unit variance Gaussian distribution. The left side of Fig. 3 shows the mean vs number of Monte Carlo points and the right side shows the 2-norm of the error between the computed covariance and the unit covariance (identity) matrix.

Convergence of Monte Carlo method
It is apparent from Fig. 3 that the convergence of statistical moments using the Monte Carlo method is quite slow and can quickly cause accurate moment evaluation to become computationally infeasible. This fact is greatly exacerbated considering that the moments computed in this toy example are for a normalized Gaussian distribution which is trivial to sample quickly. In a generic case however, every sampled point potentially involves a computationally intensive operation depending on the function \(f(\mathbf {x}_i)\). Fortunately, there are alternatives designed to alleviate this issue.
3.1 Moment mapping
With the goal of finding an expression for statistical moments of \(\mathbf {y}\) as a function of statistical moments of \(\mathbf {x}\), let us consider the \(d\)th order Taylor series expansion of nonlinear mapping between input and output variables given by Eq. (1):
This formulation expresses \(\mathbf {y}\) as polynomials in powers of the departure \(\delta \mathbf {x}\) from mean value \(\mathbf {x}^*\) with constant coefficients corresponding to partial derivatives of \(\mathbf {y}\) evaluated at \(\mathbf {x}^*\). The statistical characteristics of output \(\mathbf {y}\) are determined by computing the output moments defined by \(E[y_1^{\alpha _1}y_2^{\alpha _2}\ldots y_m^{\alpha _m}]\). If we truncate the Taylor series expansion of \(\mathbf {y}\) to the first order, then analytical expressions can be obtained to compute the moments of \(\mathbf {y}\). For example, the mean and covariance of \(\mathbf {y}\) can be approximated as:
This Jacobian approach is used in linear methods such as the Extended Kalman Filter (EKF) and is valid in a small region around the mean, however, the approximation quickly breaks down as input uncertainty and/or nonlinearity increases. One way to correct for this error is to use an iterative EKF scheme, in which the first order term is used to differentially correct the approximation Anderson and Moore (1979). An alternative method to improve accuracy for inputs far from the mean is to include the higher-order Taylor series terms. In this respect, let us consider the second-order Taylor series expansion \(\mathbf {y}^{(2)}\):
Once again, the first two statistical moments of \(\mathbf {y}^{(2)}\) are given as:
It should be noticed that the \(\varvec{\mu }_y\) is a function of covariance of \(\mathbf {x}\) while covariance of \(\mathbf {y}\) is a function of fourth-order moments of \(\mathbf {x}\). The process of computation of statistical moments while considering higher-order Taylor series expansion has been discussed in Ref. Majji et al. (2008) and lead to the formulation of Jth Moment Extended Kalman Filter (JMEKF). The computation of statistical moments of \(\mathbf {y}^{(d)}\) requires knowledge of the higher-order partial derivatives of \(f(\mathbf {x})\) which may not be rapidly available or difficult to compute in the absence of explicit analytical expression for the nonlinear function \(f(\mathbf {x})\). For example, it is difficult to compute the expression for these Jacobians for the ULP.
3.2 Taylor series equivalent numerical approximation
As an alternative to analytically computing statistical moments of \(\mathbf {y}\), we seek a derivative-free numerical approach which provides these moments estimates with the same accuracy as the dth order Taylor series approximation of \(f(\mathbf {x})\) will provide. In this respect, it is desired to evaluate the expectation value of \(f(\mathbf {x})\) as the sum of discrete function evaluations \(f(\mathbf {x}_i)\) multiplied by weights \(w_i\):
Substituting the \(d\)th Taylor series expansion of \(f(\mathbf {x})\) into Eq. (9) provides the following expression:
Realizing that the partial derivative terms on each side of the equation are equal and independent of both the expectation value and summation operators leads to the following simplification of the aforementioned expression:
For the above equality to hold, the coefficients of the partial derivative terms must be equal which leads to the following constraints on the points and weights:
A direct implication of this result is that it is necessary for the points \(\delta \mathbf {x}_i\) and weights \(w_i\) to match the moments of the input variable \(\delta \mathbf {x}\) in order to evaluate the integral up to \(d\)th order accuracy. Such a set of points, often referred to as quadrature points or sigma points, satisfy the moment constraints of input variable \(\delta \mathbf {x}_i\) up to the accuracy of a dth order Taylor series expansion. The application of these sigma points to the propagation of random variables is the motivation behind many well-known nonlinear filtering methods including the Unscented Kalman Filter (UKF), Gauss–Hermite Kalman Filter (GHKF), and sparse filters.
The difference between various numerical integration methods exists only in the manner in which the points \(\delta \mathbf {x}_i\) and weights \(w_i\) are selected. Gaussian quadrature methods provide the deterministic points and weights to exactly replicate the moment constraints given by Eq. (12). In \(1-D\) space, the Gaussian quadrature scheme provides minimal N points for the exact computation of \(d=2N-1\) order polynomials, i.e., moments (Stroud and Secrest 1966). However, one needs to take a tensor product of the points \(\mathbf {x}_i\) in a multi-dimension space and hence, increasing the necessary number of points exponentially to \(N^n\).
Several methods exist to alleviate the exponential growth of points with increasing dimension. One popular method is sparse grid quadratures, in particular Smolyak quadrature, which takes the sparse product of one-dimensional quadrature points enabling multidimensional integral evaluation with fewer points than an equivalent Gaussian quadrature rule (Gerstner and Griebel 1998). Although the Smolyak quadrature method drastically reduces the number of function evaluations, it comes at the cost of potentially introducing negative weights which can adversely impact the accuracy (Stroud and Secrest 1966).

A schematic of CUT axes

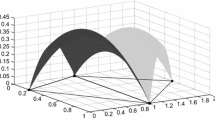
Comparison of quadrature schemes for same order of accuracy Adurthi et al. (2018)
The Unscented Transform (UT) which forms the basis of celebrated UKF Julier et al. (2000) and Julier et al. (1995) is a 3rd order minimal quadrature scheme. According to the UT formulation, one can exactly replicate expectation integrals involving 3rd order polynomials with respect to the Gaussian PDF for any dimension \(n\) with \(2n+1\) points on the eigenvectors of the covariance matrix also known as the principal axes. In our earlier work Adurthi (2013) and Adurthi et al. (2018), it has been shown that the UT cannot reproduce higher-order moments (\(d>3\)) by just increasing the number of points on the principal axes. The Conjugate Unscented Transformation (CUT) extends the conventional UT rules by selecting symmetric points on specially defines axes in multidimensional space to construct higher-order quadrature rules (Adurthi 2013; Adurthi et al. 2018). The location and weights of these points are computed through the solution of moment constrained equations of Eq. (12). Figure 4 illustrates the CUT axes for \(n=2\) and \(n=3\). The symmetry of the selected points automatically satisfies the odd order moments, and even order moment constraints are used to compute the points and weights. Construction of quadrature points in this manner enables the exact replication of any arbitrary expectation value order using the minimal number of points. Figure 5 shows a comparison of the number of points required to achieve the same integral accuracy for various quadrature schemes, and clearly shows the advantage of CUT over other existing methods. For more details on CUT, and for the tabulated points and weights for 4th, 6th, and 8th order CUT for selected \(n\) values (Adurthi 2013; Adurthi et al. 2012a, 2013, 2012b, 2018; Adurthi and Singla 2015).
All simulations in this work utilize the 8th order CUT points. With the computational savings afforded by the CUT method, the determination of higher-order moments with dth order accuracy is now a computationally tractable problem. Furthermore, one can exploit this moment information to construct the PDF while making use of the principle of maximum entropy (Adurthi and Singla 2015). An alternative is to create a surrogate model which can be used in conjunction with Monte Carlo methods to create histogram representation of PDF. In the next section, a least squares method is discussed to construct a polynomial surrogate model representing the solution of the Lambert as well as the reachability set problem while making use of the CUT runs.
4 Polynomial approximation
In this section, we discuss a least square based method to find the polynomial approximation of the nonlinear mapping valid over the domain of input PDF, i.e., \(\rho (\mathbf {x})\). The least square formulation utilizes the CUT method discussed in the previous section to find the coefficients of this polynomial expression. The Taylor series expansion given by Eq. (5) can be re-written as follows by grouping the partial derivative terms into \((m\times b_i)\) coefficient matrices \({\mathbf {C}}^{(i)}\), and the deviation terms of all possible ith order combinations of \(\delta x_{}\) into \((b_i\times 1)\) vectors \(\delta \mathbf {x}^{(i)}\).
Note that the size of the coefficient matrices and deviation vectors will vary depending on the number of \(\delta x_{}\) permutations in the \(i\)th order. The first two \(\delta \mathbf {x}\) vectors are given as:
The total number of polynomial basis functions, \(M\) in n-dimensional space up to degree d follows the following factorial relationship:
From Eq. (15), it can be deduced that the number of basis functions \(b_i\) belonging to the \(i\)th order is given by
In general, the deviation vectors in Eq. (13) can be re-arranged into any linear combination of \(\delta \mathbf {x}^{(i)}\) to provide an arbitrary set of polynomial basis functions \(\varvec{\phi }(\varvec{\zeta })\), and a set of new unknown coefficients. Recalling the normalized scaling of input \(\mathbf {x}\) given by Eq. (2), the new basis functions are expressed in terms of the normalized variable \(\varvec{\zeta }\). Defining the Taylor series in terms of normalized variable \(\varvec{\zeta }\) helps to avoid numerical error during coefficient calculation due to taking high order exponents of the variable \(\mathbf {x}\), which can potentially have a large raw magnitude. Collecting the \({\mathbf {C}}^{(i)}\) matrices and \(\varvec{\phi }^{(i)}(\varvec{\zeta })\) vectors, the Taylor series approximation can be expressed as
where the total \((m\times M)\) coefficient matrix \({\mathbf {C}}\) and \((M\times 1)\) basis function vector \(\varvec{\phi }(\varvec{\zeta })\) are given by
These coefficient matrices are the sensitivity matrices which map the input uncertainty in \(\varvec{\zeta }\) to output uncertainty in \(\mathbf {y}\). Note that the zeroth order \({\mathbf {C}}^{(0)}\) term is a vector representing output mean \(\mathbf {y}^*\), and the first-order coefficient matrix \({\mathbf {C}}^{(1)}\) is analogous to the state transition matrix. For convenience, index notation is adopted to express the approximation for the \(j\)th element of \(\mathbf {y}\)
A continuous least squares error minimization procedure is used to determine the coefficients which best approximates the output.
Notice that \(\left\langle a,b\right\rangle =E[ab]\). The minimization of J results in the following normal equations:
where \(\mathbf {A}\) and \(\mathbf {B}\) are matrices of inner products of dimension (\(m\times M\)) and (\(M\times M\)), respectively. If the polynomial basis functions \(\varvec{\phi }\) are intelligently selected to be orthogonal polynomials with respect to \(\rho (\varvec{\zeta })\), the \(\mathbf {B}\) matrix will be a diagonal matrix and can be re-written as:
For a given distribution \(\rho (\varvec{\zeta })\), the orthogonal polynomials \(\phi _l(\varvec{\zeta })\) can be computed through the application of the Gram–Schmidt process (Singla and Junkins 2008; Luenberger 1968). For a standard zero mean, unit variance Gaussian PDF the orthogonal polynomials are the Hermite polynomials, and for a standard uniform PDF between \([-1,1]\) the orthogonal polynomials are the Legendre polynomials. An example of the first three \(\varvec{\phi }^{(i)}\) vectors for \(d=3\), \(n=3\), and a Gaussian distribution (Hermite basis) is given as:
For diagonal \(\mathbf {B}\), the least squares coefficients \(c_{j,l}\) become linearly independent and can be written in the convenient analytical form given by Eq. (24)
The integrals in \(\mathbf {B}\) are purely polynomial and can be integrated with relative ease; however, it important to note that the integration technique used to evaluate the elements in \(\mathbf {B}\) must be able to replicate moments of \(\varvec{\zeta }\) up to two times the maximum basis function order. The main challenge comes in evaluating the multi-dimensional integrals in \(\mathbf {A}\). In general, there is not an analytical expression for \(y_j\), so the \(A_{j,l}\) terms must be evaluated numerically as follows:
The computational burden of evaluating \(A_{j,l}\) is dictated by chosen quadrature scheme to numerically approximate the aforementioned integral. As discussed in the previous Section, the CUT methodology enable the accurate computation of \(A_{j,l}\) with significantly fewer points than other quadrature methods such as the Gaussian quadrature and the Smolayak scheme. Once the coefficients are computed, it is trivial to sample random points from \(P(\varvec{\zeta })\), evaluate the orthogonal basis functions \(\varvec{\phi }(\varvec{\zeta })\) and compute the solution given by Eq. (17). Figure 6 illustrates the procedure of creating polynomial surrogate model for the ULP problem. The application of CUT methodology allows us to compute both desired order statistical moments as well as the polynomial surrogate model from minimal sampling of the input variable space.

Higher-order sensitivity method summary for ULP
5 Results
This section will present descriptions of all numerical simulations and analysis of the results. Test cases 1 and 2 are ULP cases while test cases 3 and 4 corresponds to RSP cases.
The two ULP test cases are (1) a Low Earth Orbit (LEO) case provided in Schumacher et al. (2015), and (2) a hypothetical Geosynchronous Transfer Orbit (GTO) orbit in the equatorial plane. The results for test case 1 will be compared to the linear variational solution in Ref. Schumacher et al. (2015) to validate the equivalency of the first-order sensitivity to the linear solution. Higher-order solutions will then be presented. The Lambert Problem solver used in this analysis is based on the universal variable formulation of the Battin–Vaughn algorithm (Battin and Vaughan 1984; Engels and Junkins 1981), and can be found in detail in Prussing and Conway (2013). The solver calculates an iterative solution to the initial and final position vectors for the given transfer time, and eliminates some of the singularities associated with traditional geometric solutions to the Lambert Problem.
The two RSP cases are based on (1) the optimal trajectory computed in Betts (1977), and (2) the first orbit insertion maneuver of the Korea Pathfinder Lunar Orbiter mission from Song et al. (2016). Each simulation models the nominal trajectory and maneuver sequence from the respective example in the literature, and adds uncertainty to the input variables to compute the final reachable space. Keplerian two body dynamics is assumed for all test cases.
5.1 Test case 1: LEO
Test case 1 will be presented differently than all other test cases, in that it will be used to validate the CUT approach to sensitivity matrix computation as well as demonstrate the effects of adding higher orders. Test case 1 corresponds to ULP as presented in Ref. Schumacher et al. (2015) and constitutes a satellite in a near-circular LEO orbit with a radius of \(|{\mathbf {r}}_1|\approx 7000\) km and inclination \(i=2^\circ \). The nominal initial and final state vectors for case 1 are shown in Table 2 and correspond to a time of flight \(dt=0.2059P\) where P is the orbital period. The input variables are the initial and final position vectors \({\mathbf {r}}_1\), \({\mathbf {r}}_2\), and are prescribed a Gaussian distribution with covariance matrix:
This corresponds to a standard deviation of 100 m in each dimension. The output variable is the initial velocity \({\mathbf {v}}_1\).
In addition to the mean and covariance, higher-order statistical central moments of the initial position and initial velocity are presented. Only the diagonal terms of these central moments will be considered, and can be calculated with Eq. (27)
where \(x_{i,j}\) and \(w_i\) are the 8th order CUT points and weights, respectively, and \(E[(x_j-E[x_j])^q]\) is the qth central moment. The first raw moment (mean) \(\mathbf {x}^*\), and the 2nd–4th central moments calculated using Eq. (27) are shown in Table 3. The third central moment is almost zero and the fourth central moment values are close to \(3\sigma ^4\) rule for the Gaussian random variable, with \(\sigma \) being the standard deviation. Hence, one can conclude that the distribution of \({\mathbf {v}}_1\) is near Gaussian. To directly compare the CUT8 results with the results in Schumacher et al. (2015), the covariance matrix for \({\mathbf {r}}_1\) and \({\mathbf {v}}_1\) is computed. This covariance matrix can be calculated by evaluating the deterministic Lambert problem at the CUT points, and using Eq. (28) for \(\mathbf {x}=[{\mathbf {r}}_1,\ {\mathbf {v}}_1]^T\).
As expected, the covariance matrix given in Schumacher et al. (2015) Table 3 matches the covariance calculated using the CUT8 method in Table 4 almost exactly to the precision given. Notably, in Schumacher et al. (2015) the off-diagonal terms are assumed to be uncorrelated and set to zero, however, no assumptions about correlation are made in evaluating the covariance matrix numerically. Thus, it is reassuring to see that the off-diagonal terms of the covariance matrix are indeed very small, further assuring us that the CUT8 method works properly.
To validate the equivalence of the first-order sensitivity matrix and state transition matrix, the following first-order sensitivity matrix is computed.
The State Transition Matrix given in Schumacher et al. (2015) matches the coefficients of \(\mathbf {C^{(1)}}\) given in Table 5 to the given precision. This demonstrates an approximate equivalency of the two methods.
The sensitivity matrices \({\mathbf {C}}_{V}^{(i)}\) corresponding to the initial velocities are now presented. The first three sensitivity matrices for initial velocity are computed
The magnitudes of the coefficients for various orders are summarized in Fig. 7. \(C_{V_x}\), \(C_{V_y}\), and \(C_{V_z}\) are the RMS values for all elements in the 1st, 2nd, and 3rd row of coefficients in each \({\mathbf {C}}_V^{(i)}\) matrix (see Eq. (13)).

Test case 1: RMS of coefficients for varying sensitivity order
Notice that the first-order coefficients in Fig. 7 are roughly 5 orders of magnitude higher than the second order and almost 10 orders of magnitude higher than the third-order coefficients. This indicates that the solution is overwhelmingly composed of first-order variational terms, further providing evidence that the distribution of \({\mathbf {v}}_1\) is approximately Gaussian given the input domain assumed in this test case.
To conduct an error analysis, 10,000 random points \(\varvec{\zeta }_i\) were sampled from the normalized Gaussian PDF \(\rho (\varvec{\zeta })\), and input to the full Lambert solver algorithm to determine the true \({\mathbf {v}}_1^{\star }\). These same points were also used to evaluate the polynomial approximation for \({\mathbf {v}}_1\approx {\mathbf {C}}\phi (\varvec{\zeta })\), and the percent error \(\%\epsilon \) for output magnitude was computed as follows
Table 6 summarizes the RMS of percent error in \({\mathbf {v}}_1\) for varying approximation order. Figure 8 summarizes the error for varying sensitivity approximation orders where the colorbar is \(\%\epsilon \) on a logarithm scale. Figures on the left show error scatter plots with \(v_{1,x},v_{1,y},\) and \(v_{1,z}\) on the axes, and figures on the right are error contour plots with Mahalanobis distances for \({\mathbf {r}}_1,{\mathbf {r}}_2\) on the x- and y-axes, respectively. Mahalanobis distance represents the distance of a given sample point from the mean in multiple dimensions and can be computed as follows

Test case 1: \(|{\mathbf {v}}_1|\) approximation % Error. The color of the particle corresponds to the logarithm of % error, i.e., \(\log \%\epsilon \). The cold blue color represents smaller values (\(\approx O(10^{-12})\)) for \(\%\epsilon \) while red color represents higher values (\(\approx O(10^{-7})\)) for \(\%\epsilon \)
Table 6 shows a decrease in error of 3 orders of magnitude between the first- and second-order sensitivity approximations, however, there is almost no improvement in error between second- and third-order sensitivities. This is reflected in the plots in Fig. 8. The fact that there is almost no improvement in accuracy between second- and third-order reflects that the distribution of \(\rho ({\mathbf {v}}_1)\) is almost perfectly captured by the second-order polynomial approximation. It is also notable that the error contours in the first-order Mahalanobis plot appear much more random than those in the higher orders, indicating that in addition to improving accuracy, adding higher-order sensitivities helps smooth out error variations in the domain of the approximation.
5.2 Test case 2: GTO
The second test case is a Geostationary Transfer Orbit (GTO) with longer time of flight (\(dt=0.4418P\)), and higher eccentricity than test case 1 to illustrate how this method performs when the dynamics introduce higher nonlinearities. The nominal orbit is an equatorial transfer \((i=0^\circ )\) between the LEO altitude in test case 1 (610.6 km) and GEO altitude (35786 km). The final position vector is at a true anomaly of \(5^\circ \) before the apoapsis \((\theta =175^\circ )\). The time of flight for test case 2 is \(dt=16936.7\)s. The nominal state vectors for test case 2 are given in Table 7. The PDF prescribed to both the initial and final position vectors is the same as in test case 1; Gaussian with 100m standard deviations (\(\varvec{\Sigma }=10,000\times I_{6\times 6}\ (m^2)\)).
Similar to test case 1, the results for test case 2 will be given as sensitivity coefficient magnitudes, RMS error table, and error distribution plots. The magnitude of the coefficients corresponding to each sensitivity matrix order is given in Fig. 9. Plots showing the spatial distribution of percent error in \({\mathbf {v}}_1\) as well as the Mahalanobis distance representation of percent error is given by Fig. 10. A summary of the RMS of percent error in \({\mathbf {v}}_1\) is given for each approximation order in Table 8.

Test case 2: RMS of coefficients for varying sensitivity order
The statistical moments of \({\mathbf {v}}_1\) are given in Table 9. It is notable that in this test case the skewness is roughly the same order of magnitude as the kurtosis. This indicates that there may be some non-Gaussian effects in the solution which require higher-order sensitivities to capture.

Test case 2: \(|{\mathbf {v}}_1|\) approximation % Error. The color of the particle corresponds to the logarithm of % error, i.e., \(\log \%\epsilon \). The cold blue color represents smaller values (\(\approx O(10^{-12})\)) for \(\%\epsilon \) while red color represents higher values (\(\approx O(10^{-5})\)) for \(\%\epsilon \)
The RMS error in the first-order sensitivity approximation for test case 2 is larger than it was in test case 1 by almost 2 orders of magnitude. Since each test case was prescribed the same uncertainty in input variables, this difference is largely due to the higher nonlinearities introduced due to a much longer time of flight. Despite the larger error for the first order approximation relative to the LEO case, adding higher order terms still significantly decreases the approximation error to the point where the 3rd order approximation errors for both cases are the same order of magnitude. Interestingly, Fig. 10 shows the same smoothing of the contour lines as in test case 1, but only once the third-order sensitivity matrix is included.
5.3 The reachability set problem
This section will present and discuss the results for the two reachability set test cases. The RSP test cases differ from the ULP cases because the satellite is no longer purely in two body motion and is now allowed to make maneuvers at intermediate times in the simulation. Each test case will use the NTW satellite coordinate system as defined in Vallado (2001) to describe the impulsive maneuvers. For this system, \({\hat{N}}\) is in the orbital plane and perpendicular to velocity, \({\hat{T}}\) is parallel to the velocity vector, and \({\hat{W}}\) is parallel to the angular momentum vector to complete the right handed system. The impulsive maneuvers are described by a magnitude \(|\Delta v|\), as well as pitch and yaw angles \(\psi \) and \(\theta \) as shown in Fig. 11.

Diagram of maneuver geometry in NTW frame
Maneuvers in the NTW frame can be computed using Eq. 34
The impulsive maneuver in the NTW frame must then be rotated to the Earth Centered Inertial (ECI) frame with rotation matrix (\({\mathbf {T}}\)) and combined with the pre-maneuver velocity (\({\mathbf {v}}^-\)) to compute the post-maneuver velocity (\({\mathbf {v}}^+\)).
5.4 Test case 3: two burn maneuver
Test case 3 is based on Betts (1977) which determines the optimal three burn transfer orbit from a LEO parking orbit to a final operations orbit of a specific inclination. This trajectory consists of three impulsive maneuvers to several target orbits with varying inclinations; however, this test case will only look at the first example with target \(i=63.4^{\circ }\). Additionally, test case 3 only considers the first two burns for the nominal optimal transfer orbit given in Ref. Betts (1977), and the end of the simulation is taken to be the position where the third burn would occur. The parking orbit is a circular LEO with \(i=37.4^{\circ }\), and the first burn is applied at an argument of latitude \(u=255^{\circ }\). The Right Ascension of the Ascending Node (RAAN) is not important for this analysis and is set to zero for simplicity. The nominal orbital elements for the coasting transfer orbits are given in Table 10.
The first burn occurs at the start of the simulation, and the second burn occurs at \(t=6078.2 (s)\). The nominal burn parameters (\(|\Delta v^*|,\ \theta ^*,\ \psi ^*\)) as well as the nominal argument of latitude (\(u^*\)) and time that each burn occurs are given in Table 11. Note that the time of the second burn is fixed regardless of the deviation from nominal orbit due to the initial burn.
The state at the first burn is assumed to be known exactly, and is determined by the position and velocity vectors of the parking orbit with argument of latitude \(u=255^\circ \). Thus, the uncertain input variables are the maneuver magnitudes and attitude angles. It is assumed that the pitch and yaw angles as well as the maneuver magnitude are normally distributed random variables with mean given by the nominal parameters given in Table 11, and standard deviations given by Table 12.
The sensitivity matrices corresponding to the reachable set at \(t_f=35,609.0 (s)\) are computed for approximation orders 1–4. Additionally, 4th order sensitivity matrices corresponding to the reachable set at intermediate times are computed and used to depict the evolution of the reachability set in Fig. 12

Test case 3: evolution of fourth-order reachability set

Test case 3: \(|{\mathbf {r}}_2|\) approximation % Error. The color of the particle corresponds to the logarithm of % error, i.e., \(\log \%\epsilon \). The cold blue color represents smaller values (\(\approx O(10^{-5})\)) for \(\%\epsilon \) while red color represents higher values (\(\approx O(10)\)) for \(\%\epsilon \)
10,000 points \(\varvec{\zeta }_i\) are randomly sampled and propagated through the full simulation, as well as approximated using the sensitivity matrices. The percent error in the magnitude of final position \(\%\epsilon _{{\mathbf {r}}_2}\) for each sample is computed and the RMS values for each sensitivity order are shown in Table 13. The colorbars in Fig. 13 show the percent error in final position \(\%\epsilon _{{\mathbf {r}}_2}\), and the axes show how the errors are spatially distributed. The axes of the plots in the left column show the final inertial X, Y and Z positions, and the plots in the right column show Mahalanobis distances of initial position and initial velocity on the x and y axes, respectively.
It is evident from inspection of Fig. 13 and Table 13 that the error in the final position decreases as the sensitivity matrix order is increased. This trend is consistent with the ULP results, however, the magnitude of percent error is considerably higher than that of both ULP test cases previously shown (Tables 6 and 8).
Table 14 lists the statistical moments of the final position \({\mathbf {r}}_2\). It is evident from the moments of \({\mathbf {r}}_2\), and particularly the third-order moment, that the distribution is strongly non-Gaussian. This fact coupled with the large covariance indicates that it is likely necessary to include higher-order terms to achieve any reasonable accuracy.
This result is perhaps unsurprising given the relatively high levels of uncertainty prescribed to the maneuvers and the length of the over which the simulation is propagated. It is visually apparent from Fig. 12 that the domain of the reachability set expands quite rapidly over time leading to a breakdown of the validity of the Taylor series expansion at lower order approximations. To continue to improve the approximation accuracy for simulations with such high uncertainties, even higher orders sensitivities would need to be computed; however, there is a point where the computational cost of computing the next sensitivity matrix may not be worth the diminishing return on accuracy.
5.5 Test case 4: Lunar orbit insertion
This test case simulates a Lunar Orbit Insertion (LOI) maneuver based on 1st orbit insertion maneuver of the Korea Pathfinder Lunar Orbiter mission described in Song et al. (2016). A similar example can be found in Houghton et al. (2007). It is assumed that the orbiter approaches the moon on a hyperbolic arrival trajectory with \(i=90^{\circ }\) such that the satellite can enter into a polar orbit. The nominal LOI maneuver is planned to execute at the periapsis of the arrival orbit such that the target insertion orbit has a period of 12 hours. A diagram showing the geometry of the arrival trajectory and insertion maneuver is shown in Fig. 14.

Test case 4: diagram of arrival geometry
The semi-major axis (\(a_0\)) and eccentricity (\(e_0\)) of the target orbit are defined by the relationships:
where P is the orbital period, \(\mu \) is the standard gravitational parameter of the Moon, \(R_m\) is the radius of the Moon, and \(h_p\) is the altitude above the lunar surface at periapses. It is assumed that the parameters \(i_0, \omega _0, \Omega _0, \nu _0, h_p\) and hyperbolic arrival velocity at periapsis \(v_{hyp}\) are design parameters that can be specified based on mission objectives. The current analysis will use the same target orbit as in Song et al. (2016): \(h_p=200\)km, \(|{\mathbf {v}}^*_{hyp}|=2.4\)km/s, time of maneuver \(t_i=0s\) and all other targeted orbit parameters shown in Table 15. The values given represent the nominal orbit of the spacecraft immediately after the burn. Given these target orbit specifications and the hyperbolic arrival velocity, the nominal maneuver is given by Eq. (38)
Uncertainty will be included in the (\(3\times 1\)) inertial cartesian position and velocity vectors \({\mathbf {r}}_{hyp}\) and \({\mathbf {v}}_{hyp}\), as well as in the (\(3\times 1\)) nominal maneuver vector \({\mathbf {u}}^*\). Figure 11 illustrates the geometry of the orbit insertion maneuver in the NTW frame. Note that all input variables are assumed to be normally distributed random variables and are represented in the NTW reference frame allowing more realistic initial uncertainties specifications. The input variables and their associated standard deviations are listed in Table 16.
To reduce the dimension of the input vector, and thus the computational expense of computing the sensitivity coefficients, the mean and covariance of the post-maneuver velocity in the NTW frame are computed using Eq. (39).
The covariance matrix for the hyperbolic arrival velocity \(\Sigma _{v_{hyp}}^{NTW}\) is given, however the covariance matrix for the maneuver in NTW frame \(\Sigma _{\Delta {\mathbf {v}}}^{NTW}\) is not directly specified from the burn magnitude and attitude uncertainties so we must calculate it. Using the maneuver model given by Eq. (34), the NTW frame covariance matrix can be computed with the CUT method.
Where \(w_i\) are the CUT weights and \(\Delta {\mathbf {v}}^{NTW}_i\) are the CUT points scaled to the post-maneuver velocity in the NTW frame. The post-maneuver velocity covariance matrix \(\Sigma _{{\mathbf {v}}_1}^{NTW}\) can now be calculated using Eq. (39). Assume that matrix \({\mathbf {T}}\) is the rotation matrix which maps the NTW frame to the Moon Centered Inertial (MCI) frame. To determine the mean velocity as well as position and velocity covariances in the MCI frame, the following relations are used:
Once a complete representation of the post-maneuver state mean and covariance has been computed in the MCI frame (Eq. (42)), the sensitivity coefficients can be calculated in the same manner as all previous test cases.
The final simulation time is \(t_f=2\) hours. The sensitivity coefficient matrices corresponding to the final time are computed up to fourth order. Additionally, fourth-order sensitivity matrices for some intermediate times are computed and used to depict the evolution of the reachability set in Fig. 15. The statistical moments of \({\mathbf {r}}_2\) are shown in Table 17.

Test case 4: evolution of fourth order reachability set
10,000 points \(\varvec{\zeta }_i\) are sampled from \(\rho (\varvec{\zeta }_i)\) and both propagated through the full simulation as well as approximated using sensitivity matrices orders 1–4. Table 18 shows the RMS of percent error for each sensitivity order, and Fig. 16 depicts the distribution of errors over the samples. The plots on the left of Fig. 16 show a scatter plot of \({\mathbf {r}}_2\), and the plots on the right show error contours vs the Mahalanobis distances of the initial position and velocity on the x and y axes. The color scale of Fig. 16 is a log scale of percent error.

Test case 4: \(|{\mathbf {r}}_2|\) approximation % Error. The color of the particle corresponds to the logarithm of % error, i.e., \(\log \%\epsilon \). The cold blue color represents smaller values (\(\approx O(10^{-7})\)) for \(\%\epsilon \) while red color represents higher values (\(\approx O(10^{-1})\)) for \(\%\epsilon \)
The RMS errors given in Table 18 further reinforce the trend that including higher-order sensitivity matrices decreases the error in the approximation. Furthermore, the Mahalanbois distance plots show that even samples that are far from the mean have improved accuracy at higher order, implying that the approximation is valid for a larger domain of uncertainty.
6 Conclusions
The goal of this paper was to present the HOSM method and demonstrate its applicability to stochastic problems in orbital mechanics. Specific examples are presented for the ULP and RSP, however, the HOSM method is a generic uncertainty propagation method and can be applied to many other astrodynamics problems including orbit determination, conjunction analysis, and data association. The higher-order moments of the stochastic output variable up to dth order are computed using the CUT method, providing the same accuracy as a solution performing a dth order Taylor series expansion on the output. These moments are then used to construct a surrogate polynomial model of the output PDF, i.e., sensitivity matrix approximation. In both the ULP and the RSP, it has been demonstrated that increasing the order of sensitivity matrices decreases the approximation error and expands the domain over which the approximation is valid.
The HOSM method using first-order polynomials has been shown to be equivalent to a linear variational solution such as that given in Ref. Schumacher et al. (2015); however, the HOSM method is flexible in the sense that higher-order polynomials can be included to improve accuracy at the expense of increased computational time. In general, the approximation error for a given sensitivity matrix order depends on how much uncertainty there is in the inputs (size of the domain), and on how much nonlinearity is introduced to the output through other factors like the dynamics and time of flight. Unsurprisingly perhaps, higher uncertainty and nonlinearity results in lower accuracy, so as uncertainty increases, one must add higher-order derivatives to achieve the same accuracy. The CUT points and weights for up to 8th order for 6 dimensional polynomials have been computed and tabulated. This implies that a 4th order approximation is the maximum that can be found using these tabulated values due to the inner product of polynomial basis functions necessary to compute the sensitivity coefficients. However, in general the procedure for computing the CUT points and weights for higher orders and higher dimensional polynomials exists.
The novelty of this approach comes in the efficient computation of sensitivity matrices using the Conjugate Unscented Transformation numerical integration method. The CUT method allows for the computation of sensitivity matrices which satisfy higher order statistical moment constraints, enabling the non-Gaussian statistical mapping of the inputs to the solution space. An additional benefit of CUT is that the quadrature points are constructed without the need to take tensor products in multi-dimensional space. This enables the same accuracy as other quadrature methods with significantly lower computation time.
As is the case with any design problem, there are trade-offs between accuracy, computational time, and complexity that need serious consideration. The solution accuracy can theoretically always be improved by adding the next highest sensitivity matrix; however, it may be the case that including these terms is infeasible either due to available computational power or restrictive complexity involved in computing CUT points. A major benefit of this method is that it enables the analyst the flexibility to explore these trade-offs. In future works, authors are exploring the handshake of the CUT methodology with the transformation of variable method to obtain an expression for the output PDF.
References
Adurthi, N.: The Conjugate Unscented Transform—A Method to Evaluate Multidimensional Expectation Integrals. Master’s thesis, University at Buffalo (2013)
Adurthi, N., Majji, M.: Uncertain lambert problem: a probabilistic approach. J. Astronaut. Sci. 67, 1–26 (2020)
Adurthi, N., Singla, P.: A conjugate unscented transformation based approach for accurate conjunction analysis. AIAA J. Guid. Control Dyn. 38(9), 1642–1658 (2015)
Adurthi, N., Singla, P., Singh, T.: The conjugate unscented transform—an approach to evaluate multi-dimensional expectation integrals. In: Proceedings of the American Control Conference (2012a)
Adurthi, N., Singla, P., Singh, T.: Conjugate unscented transform and its application to filtering and stochastic integral calculation. In: AIAA Guidance, Navigation, and Control Conference (2012b)
Adurthi, N., Singla, P., Singh, T.: Conjugate Unscented Transform rules for uniform probability density functions. In: Proceedings of the American Control Conference (2013)
Adurthi, N., Singla, P., Singh, T.: Conjugate unscented transformation: applications to estimation and control. J. Dyn. Syst. Meas. Control 140(3), 030907 (2018)
Anderson, B.D.O., Moore, J.B.: Optimal Filtering, pp. 193–222. Prentice-Hall, Upper Saddle River (1979)
Armellin, R., Di Lizia, P., Lavagna, M.: High-order expansion of the solution of preliminary orbit determination problem. Celest. Mech. Dyn. Astron. 112(3), 331–352 (2012)
Arora, N., Russell, R.P., Strange, N., Ottesen, D.: Partial derivatives of the solution to the Lambert boundary value problem. J. Guid. Control Dyn. 38(9), 1563–1572 (2015)
Battin, R.: An Introduction to the Mathematics and Methods of Astrodynamics. AIAA Education Series. American Institute of Aeronautics & Astronautics. https://books.google.com/books?id=OjH7aVhiGdcC (1999). Accessed Sept 2019
Battin, R.H., Vaughan, R.M.: An elegant Lambert algorithm. J. Guid. Control Dyn. 7(6), 662–670 (1984)
Betts, J.T.: Optimal three-burn orbit transfer. AIAA J. 15(6), 861–864 (1977). https://doi.org/10.2514/3.7373
Bicchi, A., Marigo, A., Piccoli, B.: On the reachability of quantized control systems. IEEE Trans. Autom. Control 47(4), 546–563 (2002)
Dan, X., Junfeng, L., Hexi, B., Fanghua, J.: Reachable domain for spacecraft with a single impulse. J. Guid. Control Dyn. 33(3), 934–942 (2010)
Dutta, P., Bhattacharya, R.: Nonlinear estimation of hypersonic state trajectories in Bayesian framework with polynomial chaos. J. Guid. Control Dyn. 33(6), 1765–1778 (2010)
Engels, R., Junkins, J.: The gravity-perturbed Lambert problem: A KS variation of parameters approach. Celest. Mech. 24(1), 3–21 (1981)
Fujimoto, K., Scheeres, D., Alfriend, K.: Analytical nonlinear propagation of uncertainty in the two-body problem. J. Guid. Control Dyn. 35(2), 497–509 (2012)
Gang, Z., Xibin, C., Guangfu, M.: Reachable domain of spacecraft with a single tangent impulse considering trajectory safety. Acta Astronaut. 91, 228–236 (2013)
Gerstner, T., Griebel, M.: Numerical integration using sparse grids. Numer. Algorithms 18, 209–232 (1998). https://doi.org/10.1023/A:1019129717644
Ghanem, R., Red-Horse, J.: Propagation of probabilistic uncertainty in complex physical systems using a stochastic finite element approach. Physica D 133(1–4), 137–144 (1999)
Healy, L.M., Binz, C.R., Kindl, S.: Orbital dynamic admittance and earth shadow. J. Astronaut. Sci. 67, 427–457 (2020)
Houghton, M.B., Tooley, C.R., Saylor, R.S.: Mission design and operations considerations for NASA’s lunar reconnaissance orbiter. In: 58th International Astronautical Congress, Hyderabad, India 22-24 Sept 2007 (2007)
Hwang, I., Stipanovic, D.M.,Tomlin, C.J.: Polytopic approximations of reachable sets applied to linear dynamic games and to a class of nonlinear systems. In: Advances in Control, Communication Networks, and Transportation Systems. Systems and Control: Foundations and Applications, pp. 3–19. Birkhäuser, Boston (2005)
Jones, B.A., Parrish, N., Doostan, A.: Postmaneuver collision probability estimation using sparse polynomial chaos expansions. J. Guid. Control Dyn. 38(8), 1425–1437 (2015)
Julier, S.J., Uhlmann, J.K., Durrant-Whyte, H.F.: A new approach for filtering nonlinear systems. In: Proceedings of the American Control Conference, pp. 1628–1632. Seattle, WA (1995)
Julier, S., Uhlmann, J., Durrant-Whyte, H.: A new method for the nonlinear transformation of means and covariances in filters and estimators. IEEE Trans. Autom. Control AC–45(3), 477–482 (2000)
Junkins, J.L., Singla, P.: How nonlinear is it? A tutorial on nonlinearity of orbit and attitude dynamics. J. Astronaut. Sci. 52(1–2), 7–60 (2004). (Keynote paper)
Kurzhanski, A.B., Varaiya, P.: Dynamic optimization for reachability problems. J. Optim. Theory Appl. 108(2), 227–251 (2001)
Li, X., Xingsuo, H., Zhong, Q., Song, M.: Reachable domain for satellite with two kinds of thrust. Acta Astronaut. 68(11–12), 1860–1864 (2011)
Luenberger, D.G.: Optimization by Vector Space Methods. Wiley, New York (1968)
Luo, Y.Z., Yang, Z.: A review of uncertainty propagation in orbital mechanics. Prog. Aerosp. Sci. 89, 23–39 (2017)
Lygeros, J.: On reachability and minimum cost optimal control. Automatica 40(6), 917–927 (2004)
Madankan, R., Singla, P., Singh, T., Scott, P.D.: Polynomial-chaos-based bayesian approach for state and parameter estimations. J. Guid. Control Dyn. 36(4), 1058–1074 (2013)
Majji, M., Junkins, J.L., Turner, J.D.: A high order method for estimation of dynamic systems. J. Astronaut. Sci. 56(3), 401–440 (2008)
Makino, K., Berz, M.: Cosy infinity version 9. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 558(1), 346–350 (2006)
McMahon, J.W., Scheeres, D.J.: Linearized Lamberts problem solution. J. Guid. Control Dyn. 10, 2205–2218 (2016)
Mitchell, I.M., Bayen, A.M., Tomlin, C.J.: A time-dependent Hamilton–Jacobi formulation of reachable sets for continuous dynamic games. IEEE Trans. Autom. Control 50(7), 947–957 (2005)
Park, R.S., Scheeres, D.J.: Nonlinear mapping of Gaussian statistics: theory and applications to spacecraft trajectory design. J. Guid. Control Dyn. 29(6), 1367–1375 (2006)
Patsko, V., Pyatko, S., Fedotov, A.: Three-dimensional reachability set for a nonlinear control system. J. Comput. Syst. Sci. 42(3), 320–328 (2003)
Prabhakar, A., Fisher, J., Bhattacharya, R.: Polynomial chaos-based analysis of probabilistic uncertainty in hypersonic flight dynamics. J. Guid. Control Dyn. 33(1), 222–234 (2010)
Prussing, J.E., Conway, B.A.: Orbital Mechanics, p. 10016. Oxford University Press, 198 Madison Avenue, New York (2013)
Ramdani, N., Nedialkov, N.S.: Computing reachable sets for uncertain nonlinear hybrid systems using interval constraint-propagation techniques. Nonlinear Anal. Hybrid Syst. 5(2), 149–162 (2011)
Schumacher Jr., P.W., Sabol, C., Higginson, C.C., Alfriend, K.T.: Uncertain Lambert problem. J. Guid. Control Dyn. 38(9), 1573–1584 (2015)
Singla, P., Junkins, J.L.: Multi-Resolution Methods for Modeling and Control of Dynamical Systems. Applied Mathematics and Nonlinear Science. Chapman & Hall/CRC, Boca Raton (2008)
Song, Y.J., Bae, J., Kim, Y.R., Kim, B.Y.: Uncertainty requirement analysis for the orbit, attitude, and burn performance of the 1st lunar orbit insertion maneuver. J. Astron. Sp. Sci. 33(4), 323–333 (2016)
Stroud, A.H., Secrest, D.: Gaussian Quadrature Formulas. Prentice Hall, Englewood Cliffs (1966)
Terejanu, G., Singla, P., Singh, T., Scott, P.D.: Uncertainty propagation for nonlinear dynamic systems using Gaussian mixture models. J. Guid. Control Dyn. 31(6), 1623–1633 (2008)
Vallado, D.A.: Fundamentals of Astrodynamics and Applications, vol. 12. Springer, Berlin (2001)
Vinh, N.X., Gilbert, E.G., Howe, R.M., Sheu, D., Lu, P.: Reachable domain for interception at hyperbolic speeds. Acta Astronaut. 35(1), 1–8 (1995). https://doi.org/10.1016/0094-5765(94)00132-6
Vishwajeet, K., Singla, P.: Sparse approximation based Gaussian mixture model approach for uncertainty propagation for nonlinear systems. In: American Control Conference (ACC), 2013, pp. 1213–1218. IEEE (2013)
Vishwajeet, K., Singla, P., Jah, M.: Nonlinear uncertainty propagation for perturbed two-body orbits. J. Guid. Control Dyn. 37(5), 1415–1425 (2014)
Wen, C., Peng, C., Gao, Y.: Reachable domain for spacecraft with ellipsoidal delta-v distribution. Astrodynamics 2(3), 265–288 (2018). https://doi.org/10.1007/s42064-018-0025-x
Acknowledgements
This material is based upon work supported jointly by the AFOSR Grants FA9550-15-1-0313 and FA9550-17-1-0088.s.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hall, Z., Singla, P. Higher-order sensitivity matrix method for probabilistic solution to uncertain Lambert problem and reachability set problem. Celest Mech Dyn Astr 132, 50 (2020). https://doi.org/10.1007/s10569-020-09988-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10569-020-09988-y