
Abstract
Based on the Hermitian and skew-Hermitian splitting (HSS), we come up with a generalized HSS iteration method with a flexible shift-parameter for solving the non-Hermitian positive definite system of linear equations. This iteration method utilizes the optimization technique to obtain the optimal value of the flexible shift-parameter at iteration process. Both theory and experiment have shown that the new strategy is efficient.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this study we focus on solving the large sparse non-Hermitian and positive definite system of linear equations
where \(A \in \mathbb {C}^{n\times n}\) is nonsingular and \(x,b\in \mathbb {C}^n\). Based on the Hermitian/skew-Hermitian (HS) splitting [25]
of the coefficient matrix A, where
Bai et al. [9] first proposed the efficient Hermitian and skew-Hermitian splitting (HSS) iteration method with a fixed shift-parameter in 2003 for solving the system (1.1). The method was designed as follows: Given an initial guess \(x_0\in {\mathbb {C}^n}\), for \(k=0,1,2,\ldots \) until the sequence of iterates \(\{x_k\}_{k=0}^\infty \subset {\mathbb {C}^n} \) converges, compute the next iterate \(x_{k+1}\) according to the following formulation:
where I is the identity matrix and \(\alpha \) is a fixed shift-parameter (a given positive constant).
Note that the HSS iteration (1.2) may also be considered as a splitting iteration induced from the splitting of the matrix A as follows,
where
It was proved in [9] that the HSS iteration method converges unconditionally to the unique solution of the linear system (1.1), and the upper bound of the convergence rate of the method is about the same as that of the conjugate gradient method applied to a linear system of the coefficient matrix H. The optimal shift-parameter [9] is estimated as
where \(\lambda _{\text {min}}\) and \(\lambda _{\text {max}}\) are the minimum and the maximum eigenvalues of the matrix H, respectively.
Because of its outstanding performance and elegant mathematical properties, the HSS iteration method obtains widespread attention. For instance, it is extended to solve non-Hermitian positive semi-definite matrices [7, 11], the saddle point problems [2, 4, 6, 23], complex symmetric linear systems [5, 16] and so on. Many modifications and generalizations of the HSS iteration method can be found in [1, 10, 12, 18–21] and the references therein. On the other hand, some effective algorithms use the HSS iteration as a preconditioner or use the preconditioning variants of the HSS iteration, which often work out excellent results; see [13–15] and their references.
However, we have noticed that the shift-parameter \(\alpha \) is a constant throughout the iteration process in all discussed above, which reduces the effectiveness of the methods from one point of view.
For the Hermitian positive definite linear system, Pearcy [22] has designed the device of changing iteration shift-parameters on the half-steps
where D is a positive definite normalizing matrix, \(V_1, V_2\) are Hermitian positive definite matrices such that \(A=V_1+V_2\), \(\alpha _{\frac{1}{2}}\ge \alpha _{1}\ge \alpha _{1+\frac{1}{2}}\ge \cdots \ge \alpha _{t-\frac{1}{2}}\ge \alpha _{t}\), and \(\alpha _{k}=\alpha _{k(\text {mod}\;t)}\) for \(k>t\). But the convergence of this alternating direction implicit (ADI) iteration method depends on the positive definiteness of the splitting matrices \(V_1\) and \(V_2\). Furthermore, for the case \(V_1V_2=V_2V_1\) and \(D=I\), Douglas [17] showed that ADI was always convergent and the problem of choosing an optimal parameter sequence [24] has also been solved for this case. Unfortunately, the problems of practical interest are usually with \(V_1V_2\ne V_2V_1\). So we propose the generalized HSS iteration method with a flexible shift-parameter. Moreover, motivated by the optimization models [26], shift-parameters \(\alpha _k,k=1,2,\ldots \) are constructed by the minimization of residuals.
The remained of the paper is organized as follows. In Sect. 2, we describe the proposed iteration method. In Sect. 3, we use some numerical experiments to show the effectiveness of the new iteration method. Finally, we end the paper with a conclusion in Sect. 4.
2 The generalized HSS method with a flexible shift-parameter
In this section, we present a generalized HSS method to solve the system of linear equations (1.1) and it is stated as follows.
Method 2.1
(The generalized HSS method with a flexible shift-parameter) Let \(x_{0}\in {\mathbb {C}^n}\) be an arbitrary initial guess and \(\varepsilon > 0\) be a given tolerance. The splitting matrices \(M(\alpha )\) and \(N(\alpha )\) are defined by (1.3). For \(k=0,1,2,\ldots \) until the sequence of iterates \(\{x_{k}\}_{k=0}^ \infty \subset {\mathbb {C}^n}\) converges, compute the next iteration \(x_{k+1}\) according to the following procedure.
-
(1)
Compute \(r_{k}=b-Ax_{k}\).
-
(2)
Solve the following system of linear equations:
$$\begin{aligned} \left\{ \begin{array}{ll} (\alpha _{k+1} I +H)x_{k+{\frac{1}{2}}}=(\alpha _{k+1} I-S)x_{k}+b,\\ (\alpha _{k+1} I +S)x_{k+1}=(\alpha _{k+1} I-H)x_{k+\frac{1}{2}}+b,\\ \end{array} \right. \end{aligned}$$(2.1)where \(\alpha _{k+1}\) is the solution of the following optimization problem
$$\begin{aligned} \min _{\alpha } r_{k+1}^{*}\left( \alpha I-H\right) ^{-2}r_{k+1}, \end{aligned}$$(2.2)here, \(r_{k+1}=N(\alpha )M(\alpha )^{-1}r_k\).
-
(3)
If \(\Vert r_{k+1}\Vert _2 \le \varepsilon \), stop; otherwise, \(k\Leftarrow k+1\) and go to (1).
If \(\alpha =\alpha _1=\alpha _2=\cdots \) in (2.1), Method 2.1 reduces to the HSS iteration method with a fixed shift-parameter. So we only consider the situation that the shift-parameters \(\alpha _k\), \(k=1,2,\ldots \) are not all equal, which is said the generalized HSS method with a flexible shift-parameter.
In matrix-vector form, the scheme (2.1) can be equivalently written as
where
and
Evidently, we can express \(x_{k+1}\) as
where
and
Lemma 2.1
Let \(x_{k}\) be generated by Method 2.1, \(M(\alpha )\) and \(N(\alpha )\) be given by (1.3). Then at the (k+1)-st step it holds that
where \(\alpha \) is obtained by the optimization model (2.2). Furthermore,
Proof
Let \(\varPhi (\alpha )=(\alpha I-S)(\alpha I+S)^{-1}\), we see that \(\varPhi (\alpha )^{*}\varPhi (\alpha )=I\), which means that \(\varPhi (\alpha )\) is a unitary matrix. Since
we have
Note that
Then,
\(\square \)
Theorem 2.1
Let A be a non-Hermitian positive definite matrix. Then the iteration sequence \(\left\{ x_k\right\} \) generated by Method 2.1 converges to the unique solution \(x_*\) of the system of linear equations (1.1). Furthermore, if A is a normal matrix, then the 2-norm of the error vector \(e_k=x_k-x_*\) is strictly decreasing, i.e., \(\Vert e_{k+1}\Vert _2<\Vert e_{k}\Vert _2\), \(k=0,1,2,\ldots \).
Proof
Let \(e_k=x_k-x_{*}\) be the error at the kth step of Method 2.1. If \(\alpha _{k+1}\) is obtained by the minimization model (2.2), then for any \(\alpha _k>0\) it holds that
From (2.7), we have
It is noted that there exists a positive number \(\gamma \) such that for any \(\alpha _k>0\) the inequality \(\max _{\lambda _i \in \lambda (H)} \left| \ \frac{\alpha _k-\lambda _i}{\alpha _k+\lambda _{i}}\right| \le 1-\gamma \) is valid. Thus we have
Moreover,
For any \(\alpha >0\), the matrix \((\alpha I-H)^{-1}\) is of full rank. Hence, we have \(\lim \limits _{k\rightarrow \infty }r_{k+1}=0\).
On the other hand, if A is a normal matrix, we get
Thus, \(T(\alpha )=(\alpha I+ S)^{-1}(\alpha I-S)(\alpha I-H)(\alpha I+H)^{-1}\) is also a normal matrix, which implies that
Therefore, for the iteration matrix \(Q_{k+1}\) in (2.4), it holds that
Moreover,
So,
\(\square \)
It is worthy to note that the solution of the minimization model (2.2) is equivalent to compute the root of \(\frac{d}{d \alpha }\left( \Vert (\alpha I-H)^{-1}r_{k+1}\Vert ^2_2\right) =0\) in Theorem 2.1. However, the computational formula (2.6) is only of theoretical meaning and it is far away from actual applications, since the computational cost of the matrix \((\alpha I+H)^{-3}\) is expensive. Instead, we approximate the root of \(f(\alpha )=\Vert (\alpha I-H)^{-1}r_{k+1}\Vert ^2_2=0\) by the Newton method. An alternative procedure might be to approximate the value of \(f(\alpha )=\Vert (\alpha I+H)^{-1}r_{k}\Vert ^2_2=0\) by (2.5). Hence, Method 2.1 could be rewritten into a practical form stated in Method 2.2.
Method 2.2
(The practical generalized HSS method with a flexible shift-parameter) Let \(x_{0}\in {\mathbb {C}^n}\) be an arbitrary initial guess and \(\varepsilon > 0\) be a given precision. The splitting matrices \(M(\alpha )\) and \(N(\alpha )\) are defined by (1.3). For \(k=0,1,2,\ldots \) until the sequence of iterates \(\{x_{k}\}_{k=0}^ \infty \subset {\mathbb {C}^n}\) converges, compute the next iteration \(x_{k+1}\) according to the following procedure.
-
(1)
Compute \(r_{k}=b-Ax_{k}\).
-
(2)
Solve the systems of linear equations:
$$\begin{aligned} \left\{ \begin{array}{ll} (\alpha _{k+1} I +H)x_{k+{\frac{1}{2}}}=(\alpha _{k+1} I-S)x_{k}+b,\\ (\alpha _{k+1} I +S)x_{k+1}=(\alpha _{k+1} I-H)x_{k+\frac{1}{2}}+b,\\ \end{array} \right. \end{aligned}$$where \(\alpha _{k+1}\) is the root of the equation
$$\begin{aligned} f(\alpha )=\Vert (\alpha I+H)^{-1}r_{k}\Vert ^2_2=0. \end{aligned}$$ -
(3)
If \(\Vert r_{k+1}\Vert _2 \le \varepsilon \), stop; otherwise, \(k\Leftarrow k+1\) and go to (1).
Remark 2.1
For the sake of saving computational cost, we can perform a new update on the shift-parameter \(\alpha \) for every p iteration steps.
3 Numerical experiments
In this section, we provide numerical results to illustrate the effectiveness of Methods 2.1 and 2.2 in terms of the iteration steps (denoted as IT), the elapsed computing times in seconds (denoted as CPU), and the relative residual error (denoted as RES) defined by
All tests are started from the vector \(x_{0}=0\), and terminated when the current iteration satisfies RES\(\le 10^{-6}\). In addition, the numerical experiments are performed in MATLAB (version R2013a) on PC in double precision, which is 2.40 GHz central processing unit [Intel(R) Core(TM)i7-4500 CPU] with 8G memory and Microsoft Window 8 operating system. In actual computation, the \(\alpha _k\) is updated for every 5 iteration steps.
Example 3.1
[8] Consider the two-dimensional convection-diffusion equation
on the unit square \((0,1)\times (0,1)\) with constant coefficient \(\beta \) and subject to Dirichlet-type boundary condition. By applying the five-point centered finite difference discretization, we get the system of linear equations (1.1) with the coefficient matrix
where \(h=\frac{1}{m+1}\) is the equidistant step-size (In this test, \(m=32\).), \( \otimes \) denotes the Kronecker product, and T is a tridiagonal matrix given by
where
is the mesh Reynolds number. Moreover, the right-hand side vector b is taken to be \(b=Ax_*\) with \(x_*=(1,1,\ldots ,1)^T\in \mathbb {R}^n\) being the exact solution.
Here and in the sequel, BGN-HSS means the HSS method by Bai et al. [9], and H-HSS means the new practical methods by Huang [19]. Correspondingly, Methods 2.1 and 2.2 are termed briefly as \(\hbox {MWZ}_1\)-HSS, and \(\hbox {MWZ}_2\)-HSS, respectively.
In Table 1, we give the iteration numbers, the CPU times and the RES values of BGN-HSS, H-HSS, \(\hbox {MWZ}_1\)-HSS and \(\hbox {MWZ}_2\)-HSS methods for Example 3.1 with respect to different choices of the problem parameter \(\beta \).
From Table 1, it can be seen that for different \(\beta \) the numbers of iteration steps of \(\hbox {MWZ}_1\)-HSS and \(\hbox {MWZ}_2\)-HSS methods are less than those of BGN-HSS and H-HSS methods at almost the same CPU times. The case \(\beta =50\) and \(\beta =5000\) of these observations can be further illustrated by the iteration pictures plotted in Fig. 1. Clearly, \(\hbox {MWZ}_2\)-HSS method outperforms both BGN-HSS and H-HSS methods.

Relative residual versus iteration step for the BGN-HSS, H-HSS and \(\hbox {MWZ}_2\)-HSS methods with \(m=32\)
Example 3.2
[8] We solve the linear system \(Ax = b\), where A is a 2-by-2 block matrix as follows:
where
with
and \(h=\frac{1}{m+1}\) being the discretization mesh-size.
In this example, the total number of variables is \(3m^2\), and the right-hand side vector b is taken to be \(b=Ax_*\) with \(x_*=(1,1,\ldots ,1)^T\in \mathbb {R}^n\) being the exact solution.
In Table 2, we provide the iteration numbers, the CPU times and the RES values of BGN-HSS, H-HSS, \(\hbox {MWZ}_1\)-HSS and \(\hbox {MWZ}_2\)-HSS methods for Example 3.2 with respect to different choices of the problem parameter \(\delta \) as well as the problem size m. Clearly, the iteration steps of \(\hbox {MWZ}_2\)-HSS method is much less than those of H-HSS and BGN-HSS methods. For the case \(\delta =1000\), when the problem size m becomes large the iteration steps of \(\hbox {MWZ}_2\)-HSS method unchange but those of BGN-HSS and H-HSS methods are increasing. As for the computing time, the situation is almost the same except for \(\hbox {MWZ}_1\)-HSS method.
Furthermore, we use the following singular linear system to further examine the effectiveness of \(\hbox {MWZ}_2\)-HSS method. Note that H-HSS method fails for this example. The generalized HSS method proposed by Li et al. [20] (as the above manner, denoted as LLP-GHSS) could be applied for comparison.
Example 3.3
[3] Consider the two-dimensional variable-coefficient second-order differential equation satisfying the periodic boundary condition given as follows:
The right-hand side vector is taken to be \(b=Ax_*\) with \(x_*=(1,2,\ldots ,n)^T\) being the exact solution.

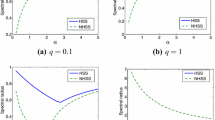
Relative residual versus iteration number for the BGN-HSS, LLP-HSS and \(\hbox {MWZ}_2\)-HSS iteration methods with respect to the different n
When \(c(x,y)\equiv 1\), the differential equation (3.2) is discretized by using the same approach as Example 3.1, with the equidistant stepsize \(h=\frac{1}{m}\) and \(n=m^2\). So we can get the real linear system with the singular and positive semi-definite n-by-n coefficient matrix
where \(\vartriangle \in \mathbb {R}^{m\times m}\) is given by
and \(R_e\) is defined by (3.1).
In Table 3, we list the numbers of iteration steps, the CPU times and the RES values of BGN-HSS, LLP-HSS, \(\hbox {MWZ}_1\)-HSS and \(\hbox {MWZ}_2\)-HSS methods for Example 3.3 with respect to different choices of the problem parameter \(\beta \) as well as the problem size m.
From Table 3, we see that \(\hbox {MWZ}_1\)-HSS method is not sensitive to the shift-parameter \(\alpha _{k+1}\). In this table, all methods can get a satisfactory approximation for solving this singular linear system. Evidently, the number of iteration steps tends to a constant when \(\beta \) becomes large. Table 3 shows that \(\hbox {MWZ}_2\)-HSS method requires less iteration steps and computing times than BGN-HSS and LLP-GHSS methods. It is also noted that \(\hbox {MWZ}_2\)-HSS method needs to compute the updated optimal shift-parameter for every 5 iteration steps, while BGN-HSS and LLP-GHSS methods do not require this additional computation. In Fig. 2, we further show the numerical advantages of \(\hbox {MWZ}_2\)-HSS method over the other three methods for different values of \(\beta \) and n.
4 Conclusion
In this paper, we propose a generalized HSS iteration method for solving the non-Hermitian positive definite system of linear equations. The numerical experiments show that the proposed \(\hbox {MWZ}_2\)-HSS method is superior to the methods given in [9, 19, 20]. Even though the coefficient matrix is singular and non-Hermitian positive semi-definite, the new iteration method can gain almost the same excellent properties as the HSS method.
References
Bai, Z.-Z.: Splitting iteration methods for non-Hermitian positive definite systems of linear equations. Hokkaido Math. J. 36, 801–814 (2007)
Bai, Z.-Z.: Optimal parameters in the HSS-like methods for saddle-point problems. Numer. Linear Algebra Appl. 16, 447–479 (2009)
Bai, Z.-Z.: On semi-convergence of Hermitian and skew-Hermitian splitting methods for singular linear systems. Computing 89, 171–197 (2010)
Bai, Z.-Z.: Block alternating splitting implicit iteration methods for saddle-point problems from time-harmonic eddy current models. Numer. Linear Algebra Appl. 19, 914–936 (2012)
Bai, Z.-Z., Benzi, M., Chen, F.: Modified HSS iteration methods for a class of complex symmetric linear systems. Computing 87, 93–111 (2010)
Bai, Z.-Z., Golub, G.H.: Accelerated Hermitian and skew-Hermitian splitting iteration methods for saddle-point problems. IMA J. Numer. Anal. 27, 1–23 (2007)
Bai, Z.-Z., Golub, G.H., Li, C.-K.: Convergence properties of preconditioned Hermitian and skew-Hermitian splitting methods for non-Hermitian positive semidefinite matrices. Math. Comput. 76, 287–298 (2007)
Bai, Z.-Z., Golub, G.H., Li, C.-K.: Optimal parameter in Hermitian and skew-Hermitian splitting method for certain two-by-two block matrices. SIAM J. Sci. Comput. 28, 583–603 (2006)
Bai, Z.-Z., Golub, G.H., Ng, M.K.: Hermitian and skew-Hermitian splitting methods for non-Hermitian positive definite linear systems. SIAM J. Matrix Anal. Appl. 24, 603–626 (2003)
Bai, Z.-Z., Golub, G.H., Ng, M.K.: On inexact Hermitian and skew-Hermitian splitting methods for non-Hermitian positive definite linear systems. Linear Algebra Appl. 428, 413–440 (2008)
Bai, Z.-Z., Golub, G.H., Pan, J.-Y.: Preconditioned Hermitian and skew-Hermitian splitting methods for non-Hermitian positive semidefinite linear systems. Numer. Math. 98, 1–32 (2004)
Benzi, M.: A generalization of the Hermitian and skew-Hermitian splitting iteration. SIAM J. Matrix Anal. Appl. 31, 360–374 (2009)
Bertaccini, D., Golub, G.H., Capizzano, S.S., Possio, C.T.: Preconditioned HSS methods for the solution of non-Hermitian positive definite linear systems and applications to the discrete convection-diffusion equation. Numer. Math. 99, 441–484 (2005)
Chan, L.-C., Ng, M.K., Tsing, N.-K.: Spectral analysis for HSS preconditioners. Numer. Math. Theor. Meth. Appl. 1, 57–77 (2008)
Chen, F., Jiang, Y.-L.: On HSS and AHSS iteration methods for nonsymmetric positive definite Toeplitz systems. J. Comput. Appl. Math. 234, 2432–2440 (2010)
Chen, F., Liu, Q.-Q.: On semi-convergence of modified HSS iteration methods. Numer. Algorithms 64, 507–518 (2013)
Douglas, J.: On the numerical integration \(\frac{\partial ^2u}{\partial x^2}+ \frac{\partial ^2u}{\partial y^2}=\frac{\partial u}{\partial t}\) by implicit methods. J. Soc. Indust. Appl. Math. 3, 42–65 (1955)
Guo, X.-X., Wang, S.: Modified HSS iteration methods for a class of non-Hermitian positive-definite linear systems. Appl. Math. Comput. 218, 10122–10128 (2012)
Huang, Y.-M.: A practical formula for computing optimal parameters in the HSS iteration methods. J. Comput. Appl. Math. 255, 142–149 (2014)
Li, W., Liu, Y.-P., Peng, X.-F.: The generalized HSS method for solving singular linear systems. J. Comput. Appl. Math. 236, 2338–2353 (2012)
Li, W.-W., Wang, X.: A modified GPSS method for non-Hermitian positive definite linear systems. Appl. Math. Comput. 234, 253–259 (2014)
Pearcy, C.: On convergence of alternating direction procedures. Numer. Math. 4, 172–176 (1962)
Simoncini, V., Benzi, M.: Spectral properties of the Hermitian and skew-Hermitian splitting preconditioner for saddle point problems. SIAM J. Matrix Anal. Appl. 26, 377–389 (2004)
Varga, R.S.: Matrix Iterative Analysis, 2nd edn. Springer, Berlin (2000)
Wang, C.-L., Bai, Z.-Z.: Sufficient conditions for the convergent splittings of non-Hermitian positive definite matrices. Linear Algebra Appl. 330, 215–218 (2001)
Wang, C.-L., Meng, G.-Y., Bai, Y.-H.: Practical convergent splittings and acceleration methods for non-Hermitian positive definite linear systems. Adv. Comput. Math. 39, 257–271 (2013)
Acknowledgments
The authors are very much indebted to the anonymous referees for their helpful comments and suggestions which greatly improved the original manuscript of this paper. This work is supported by the National Natural Science Foundation of China (No.11371275), the National Natural Science Foundation of Shanxi Province, China (No.2014011019-3) and the Key Construction Disciplines Project of Xinzhou Normal University, China (No.XK201301).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Meng, GY., Wen, RP. & Zhao, QS. The generalized HSS method with a flexible shift-parameter for non-Hermitian positive definite linear systems. Bit Numer Math 56, 543–556 (2016). https://doi.org/10.1007/s10543-015-0584-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-015-0584-7