
Abstract
This paper proposes a linear approximation of the nonlinear Threshold AutoRegressive model. It is shown that there is a relation between the autoregressive order of the threshold model and the order of its autoregressive moving average approximation. The main advantage of this approximation can be found in the extension of some theoretical results developed in the linear setting to the nonlinear domain. Among them is proposed a new order estimation procedure for threshold models whose performance is compared, through a Monte Carlo study, to other criteria largely employed in the nonlinear threshold context.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The complexity of nonlinear time series models often makes it difficult to analyze the main features of their dynamics, the derivation of their statistical properties and the identification and estimation of the models. In this case the issues developed in the linear domain cannot be further adapted and new tools need to be introduced.
We herein propose a bridge between the linear AutoRegressive Moving Average (ARMA) model and the nonlinear Self-Exciting Threshold AutoRegressive (SETAR) model (Tong and Lim 1980; Tong 1990). We introduce a linear approximation of the threshold model that offers the opportunity to investigate the dynamics of the generating process.
In more detail, we show that the proposed linear approximation of the nonlinear SETAR process is given by an ARMA model. Even though one might expect that this approximation is given by an autoregressive (AR) process, we show that there is also a moving average (MA) component.
The linear approximation is obtained using the best (in \(L^2\) norm) one-step-ahead predictor of the SETAR process, and the corresponding coefficients of the ARMA approximation are theoretically derived.
Then, leveraging these results which allow us to derive the ARMA model that best approximates the threshold structure, we introduce a new procedure by which to estimate the order of the SETAR process, in what can be considered one of the potential applications of the proposed linear approximation.
Before going into the details of our proposal and to better introduce our contribution, we need to clarify the distinction between linear representation and linear approximation of a nonlinear process. The linear representation of nonlinear models was extensively presented in Francq and Zakoïan (1998), and in the references therein. It is based on a new parametrization of the nonlinear model that leads to a weak ARMA representation, where the adjective weak relates to the fact that the assumptions, usually given on the noises of the ARMA model (such as independence), are not satisfied by the linear ARMA representation. (For an example of linear representation of the subdiagonal bilinear model, see Pham 1985).
In this domain, more recently, Kokoszka and Politis (2011) used the definition of weak linear time series, and even showed that Autoregressive Conditional Heteroscedasticity-type and Stochastic Volatility-type processes do not belong to this class.
The definition of linear approximation of \(X_t\) is instead based on different issues. The aim is to introduce of an approximation that allows one to distinguish two components in the process \(X_t\):
with \(X_t^L\) the linear approximation and \(Y_t\) the nonlinear component, where \(X_t^L\) is given by the linear causal process:
with \(\psi _0=1\), \(\sum _{j=0}^\infty |\psi _j|<\infty\) and \(\{\varepsilon _t\}\) a sequence of independent and identically distributed (i.i.d.) random variables, with \(E[\varepsilon _t]=0\) and \(E[\varepsilon _t^2]=\sigma ^2\).
The derivation of the linear approximation \(X_t^L\) is associated in the literature with the use of the Volterra series expansion of \(X_t\), where \(X_t^L\) is obtained considering the first-order term of the expansion of \(X_t\). (For an example of the bilinear model, see Priestley 1988, p. 58.)
The spirit of the Volterra expansion has inspired various contributions to linear approximation, with applications in many domains (among others see Huang et al. 2009 and Schoukens et al. 2016).
In this study we obtain a linear approximation of \(X_t\) by borrowing the definition of the best mean square one-step-ahead predictor (see among others Brockwell and Davis 1991, Sect. 2.7).
The first results are presented in Proposition 1, whereas the elements included in \(X_t^L\) are further discussed in Remark 1 that leads to the proposed linear approximation of \(X_{t}\). Moreover, we show that the proposed linear approximation is an ARMA process and we use this result in the order estimation of the threshold process, thus confining the computational effort needed to estimate the order of a nonlinear process to the linear domain.
In particular, in Sect. 2 we establish the conditions under which a linear approximation of \(X_t\) can be obtained. In Sect. 3 the linear approximation is used to implement a new order estimation procedure whose consistency property is shown; in Sect. 4 some extensions of the linear approximation are given after removing some conditions fixed in the previous pages, and the role played by the SETAR parameters in the approximation is discussed; in Sect. 5 the order estimation procedure is evaluated and compared to other information criteria, through a Monte Carlo study. Some final comments are given at the end, and all proofs are given in the Appendix.
2 Linear approximation of the SETAR process: main results
Let \(\{X_t\}_{t\in \mathbb Z}\) be a SETAR nonlinear process, given by:
where \(\{\varepsilon _t \}\) is a sequence of continuous i.i.d. \(\mathbb R\)-valued random variables with mean zero and \(E[\varepsilon _t^2]=\sigma _{\varepsilon }^2<\infty\), \(\mathbb I(\cdot )\) is the indicator function, k is the number of regimes, \(p_j\) is the order of the autoregressive regimes, \(X_{t-d}\) is the threshold variable, d is an integer representing the threshold delay, \(p_j\) is a nonnegative integer, k and d are positive integers, \(\mathbb R_j=(r_{j-1}, r_j]\) for \(j=1, \ldots , k-1\) with \(-\infty =r_0<r_1<\ldots<r_{k-1}<r_k=\infty\), and \(\mathbb R_k=(r_{k-1}, +\infty )\) are subsets of the real line such that \(\mathbb R=\bigcup _{j=1}^k\mathbb R_j\).
In the following, to find a stochastic linear approximation of the process \(X_t\), we use the \(L^2\) norm given by \(\Vert X_t-X_t^L|\mathcal I_{t-1}\Vert _{L^{2}}=E\left[ (X_t-X_t^L)^2|\mathcal I_{t-1}\right] ^{1/2}\), with \(\mathcal I_{t-1}\) the set of information on \(X_t\) available up to time \(t-1\).
To show the theoretical results, we take advantage of an alternative representation of the threshold process that, to avoid heavy notation (which would not help in understanding the issues), is assumed to have \(k=2\) regimes (the case with \(k>2\) is discussed in Sect. 4.3) and null intercepts (\(\phi _0^{(j)}=0\), for \(j=1,2,\ldots , k\)). This guarantees the following form to process (2):
where
with \({\varvec{ I}}\) the identity matrix, \(\varvec{ 0}\) the null vector, and the autoregressive order p (the assumption that the two regimes have the same autoregressive order simplifies the presentation of results and can be easily met including null coefficients in the model (see Sect. 4.2)). Without loss of generality, we can suppose that \(d=1\) and \(r_1=0\) (these assumptions will be further discussed in Sect. 4.1); then, the process (3) can be written as
where
Note that all results given in the following are based on the assumptions of strict stationarity (refereed to as stationarity in the next pages) and ergodicity of the process. In the threshold domain the milestone in this framework is given by Petruccelli and Woolford (1984), who state a set of sufficient and necessary conditions for the stationarity and ergodicity of a SETAR(2;1) model; sufficient conditions for the more general SETAR(2;p) process, are given in Chan and Tong (1985) and Bec et al. (2004).
There are at least two difficulties inherent in obtaining the linear approximation of the SETAR model; these make this model different from other nonlinear models, such as Markov Switching structures (Hamilton 1989). First, the SETAR process (5) has stochastic coefficients that depend on the process \(X_t\) itself: it implies, among others things, that it is not easy to obtain its moments (whose sufficient conditions for their existence are given in Lemma 2 in the Appendix). Second, the SETAR process does not fulfil many regularity conditions that can assist in obtaining the linear approximation. (For example, the first derivative of \(X_t\), carried out to derive the coefficients of the first-order Volterra expansion (see Priestley 1988, p. 26), may not exist when the skeleton of the process assumes a value equal to the threshold value.)
Starting from these two points, to derive a linear approximation of a SETAR(2; p) process, we need to introduce an additional notation that simplifies the presentation.
Let \(X_t=\mathbf {e}_1^T\mathbf {X}_t\) be the SETAR(2;p) process (5), with \(\mathbf {e}_1\) a \((p\times 1)\) vector with 1 as its first element and all remaining \((p-1)\) elements are zero, whereas \(\mathbf{A}^\top\) is the transpose of \(\mathbf{A}\). Further, let
be two matrices where \(\varvec{\pi }\) is a \((2p\times p)\) matrix, with \(\pi =Pr(X_t\le 0)\), \(\mathbf{I}_p\) is an identity matrix of order p and \(\otimes\) is the Kronecker product, whereas \(\mathbf{P}\) is a \((2\times 2)\) matrix, with \(\pi _{ij}=Pr(X_t\in \mathbb {R}_j|X_{t-1}\in \mathbb {R}_i)\), for \(i,j=1,2\) and \(\mathbb {R}_1=(-\infty ,0]\), \(\mathbb {R}_2=(0,\infty )\). Moreover, consider the following matrix:
with \(\varvec{\Phi }_i\), for \(i=1,2\), defined in (4).
Given the previous notation, we can now introduce the linear approximation of \(X_t\). Let \(X_t(1)\) be the best (in \(L^2\) norm) one-step-ahead predictor for the SETAR(2;p) process, \(X_t(1)=E[X_{t}|\mathcal I_{t-1}]\); we can now state the following results.
Proposition 1
Let \(X_t\), \(t\in \mathbb Z\), be a stationary and ergodic SETAR(2;p) process with \(E(\varepsilon _t^2)<\infty\) and \(\gamma _2<1\) (with \(\gamma _2\) given in Lemma 2 in the Appendix); then, given the linear process \(X_t^L\) as in (1), we have the following results in \(L^2\) norm:
-
(i)
\(\arg \min _{\{g_j\}}||X_t-X_t^L|\mathcal {I}_{t-1}||_{L^2}^2=g_j(\mathcal {I}_{t-1})=\mathbf {e}_1^T\prod _{s=0}^{j-1}\mathbf {A}_{I_{t-1-s}}\mathbf {e}_1,\forall j\ge 1\), -
that is, the minimizer - say, \(X_{t|t-1}^L\), is given by \(X_{t|t-1}^L=\sum _{j=1}^{\infty }g_j(\mathcal {I}_{t-1})\varepsilon _{t-j}\);
-
(ii)
\(X_t(1)=\sum _{j=1}^{\infty }g_j(\mathcal {I}_{t-1})\varepsilon _{t-j}\),
where \(\mathcal {I}_{t-1}=\{X_{t-1},X_{t-2},\ldots \}\) and the subscript \(t-1\) in \(X_{t|t-1}^L\) is due to the conditional set \(\mathcal {I}_{t-1}\).
Proof
See the Appendix.
The result of Proposition 1 is twofold. First it gives, for the SETAR(2; p) model, a representation of the optimal one-step-ahead predictor, \(X_t(1)\), which is a generalized linear process with coefficients \(g_j(\mathcal I_{t-1})\) that relate to the process itself. Second, this optimal predictor corresponds to \(X_{t|t-1}^L\) when the minimization is done with respect to the linear process \(X_t^L\).
Now we need to emphasize the following key remark.
Remark 1
Proposition 1 gives a representation of the best one-step-ahead predictor for the SETAR(2;p) process. However, the quantities \(g_j(\mathcal {I}_{t-1})\) are not easly managed because they are nonlinear functions of the observations. An easy way to derive a linear process, as defined in (1), is to consider the expectation of \(g_j(\mathcal {I}_{t-1})\) - that is
If we suppose that \(\gamma _1<1\) (see Lemma 2) and use the same arguments as in the proof of Lemma 2, we have that \(g_j^{(2)}=O(\gamma _1^j)\), \(\forall j\ge 1\). So, it follows that \(\sum _{j=0}^{\infty }|g_j^{(2)}|<\infty\). Then, we have the following linear approximation of the SETAR(2;p) process
\(\square\)
Further note that Proposition 1 gives the best (in \(L^2\) norm) one-step-ahead predictor for the SETAR(2;p) process, whereas the linear process in (10) is a projection of the SETAR(2;p) predictor in the space of the linear predictors. Many features of this linear process will be analysed in the following; the extension to the SETAR(2;\(p_1, p_2\)) case, with \(p_1\ne p_2\), is discussed in Sect. 4.2.
First of all, we provide an example to illustrate the linear approximation in (10).
Example 1
Let \(X_t\) be a stationary and ergodic SETAR(2;1) process given by
To simplify the computations, we suppose that the transition matrix \(\mathbf {P}=\left( \begin{array}{ll}0 &{} 1\\ 1 &{} 0\end{array}\right)\), which implies that \(\pi =1/2\) and that the two parameters \(\phi _1\) and \(\phi _2\) are negative. Moreover, the matrix \(\mathbf {K}\), defined in (8), is
Set \(j=2u\) and \(j=2u-1\) for even and odd cases of j, respectively. Since
it follows that
Finally, note that the coefficients \(g_j^{(2)}\) derived through Proposition 1 and Remark 1 exhibit the same ergodic conditions given in Petruccelli and Woolford (1984). \(\blacksquare\)
The next theorem shows a more precise characterization of the linear approximation (10) of the SETAR(2;p) process.
Theorem 1
Let \(X_t\), \(t\in \mathbb Z\), be a stationary and ergodic SETAR(2;p) process with \(E(\varepsilon _t^2)<\infty\) and \(\gamma _2<1\); then the linear approximation (10) is the ARMA(2p, 2p) process.
Proof
See the Appendix.
What is stated in Theorem 1 allows us to make some interesting remarks.
Remark 2
The assumptions in Theorem 1, \(E(\varepsilon _t^2)<\infty\) and \(\gamma _2<1\), are sufficient to have a finite second moment, \(E(X_t^2)<\infty\) (see Lemma 2 in the Appendix). Further, \(\gamma _r\) given by \(\gamma _r=\pi \Vert \varvec{\Phi }_1\Vert ^r+(1-\pi )\Vert \varvec{\Phi }_2\Vert ^r\) is always less than one when the two regimes are also stationary, with \(\Vert \varvec{\Phi }_1\Vert <1\) and \(\Vert \varvec{\Phi }_2\Vert <1\); in the other cases, however, this condition needs to be verified case by case.\(\square\)
Remark 3
Theorem 1 provides the linear approximation of the SETAR(2;p) process, given by the ARMA(2p,2p) model. Looking at the proof of Theorem 1 in the Appendix (Eq. (30)) we have the exact expression of the linear process \(X_t^{(2)}\) in (10) that even allows to theoretically derive the coefficients of the ARMA(2p,2p) model. For simplicity, suppose that the matrix \(\mathbf{K}\), in (8), has different eigenvalues - say \(\lambda _1,\ldots ,\lambda _{2p}\). By (30) and after some easy but long algebra, we have two polynomials of degree 2p related to the autoregressive and moving average component of \(X_t^{(2)}\) whose coefficients are given respectively by:
with \(|\mathbf{v}|=\sum _{u=1}^{2p}v_u\), \(|\mathbf{v}_{-k}|=\sum _{\begin{array}{c} u=1 \\ u\ne k \end{array}}^{2p}v_u\) for \(v_u\in \{0;1\}\) and where the sums in (11) are made with respect to all different i and \(j-1\) groups of ones in the vectors \(\mathbf{v}\) and \(\mathbf{v}_{-k}\), respectively. \(\square\)
To emphasize the issues in Theorem 1 and illustrate how the coefficients (11) can be used, consider the following example.
Example 2
Let \(X_t\) be a stationary and ergodic SETAR(2;1) process with the matrices of the coefficients \(\varvec{\Phi }_1=\{\phi _1\}\) and \(\varvec{\Phi }_2=\{\phi _2\}\).
The matrix \(\mathbf {K}\) in (8) becomes
For simplicity, suppose that the matrix \(\mathbf {K}\) has two different eigenvalues - say \(\lambda _1\) and \(\lambda _2\). Write \(\mathbf {K}=\varvec{\Gamma }\varvec{\Delta }\varvec{\Gamma }^{-1}\) and set \(\mathbf {P}_1^T=\varvec{\pi }^T\varvec{\Gamma }\) and \(\mathbf {P}_2=\varvec{\Gamma }^{-1}\left( \begin{array}{c}\phi _1\\ \phi _2\end{array} \right)\) as in the proof of Theorem 1. Let \(c_k\), \(k=1,2\), be the component-wise product of the elements in the vectors \(\mathbf {P}_1\) and \(\mathbf {P}_2\). By Theorem 1, we have that the linear approximation of \(X_t\) is given by an ARMA(2,2) model - that is,
where \(a_1=\lambda _1+\lambda _2\), \(a_2=-\lambda _1\lambda _2\), \(b_1=-a_1+c_1+c_2\), and \(b_2=-(a_2+c_1\lambda _2+c_2\lambda _1)\) by using (11) in Remark 3. \(\qquad \blacksquare\)
Furthermore note that from Remark 1 it follows that the coefficients of the approximation (10) are based on the expectation (9) that makes \(X_t^{(2)}\) a suboptimal linear approximation, in the sense that it is not the best linear one-step-ahead predictor of \(X_t\) (see Proposition 1). Moreover, it has the great advantage of establishing a clear correspondence between the ARMA and SETAR orders, as stated in Theorem 1. This correspondence is the key element that overshadows the need to evaluate how \(X_t^{(2)}\) approximates \(X_t\), which becomes only a theoretical issue lacking any empirical application in identifying the SETAR model (as discussed in Sect. 3).
Another key remark needs to be introduced to discuss the order of the ARMA approximation.
Remark 4
The order 2p of the ARMA approximation is the maximum value of the AR and MA components, and this correspondence between the order of the ARMA approximation and the order of the autoregressive regimes of the SETAR process could be used to estimate the autoregressive order of the threshold process (usually left to information criteria).\(\square\)
To emphasize this last remark and to give empirical evidence that 2p is the maximum order of the ARMA approximation (where 2p could be greater than the “true” ARMA order), consider the following example.
Example 3
Let \(X_t\sim\)SETAR(2;1) with coefficients \(\phi _1^{(1)}=\phi _1^{(2)}=\phi _1\), with \(|\phi _1|<1\). It is easy to note that this last equality implies the degeneration of the SETAR(2;1) model to an AR(1) structure, and that this degeneration needs to be found even in (10). This can be verified because, in this case, the transpose of the vector \(\varvec{\pi }\) in (7) becomes (1, 0) (or (0, 1)), whereas \(\mathbf{P}=\mathbf{I}_2\) and then \(\mathbf{K}=\phi _1\mathbf{I}_2\). From (27) it follows that \(g_j^{(2)}=\phi _1^j\) for \(j=1,2,\ldots ,\) and so:
which is the MA(\(\infty\)) representation of the AR(1) process.\(\qquad \blacksquare\)
The result given in Example 3 leads to an important evaluation: when \(X_t\) is a linear autoregressive process then \(X_t^{(2)}\) is identically equal to \(X_t\) and is no longer an approximation.
Another important consequence of the result of Theorem 1 and Remark 4 is the fact that we can build a SETAR(2;p) process whose linear approximation is null. This is important for two reasons. First we can subtract from \(X_t\) the linear approximation, and then we can mainly focus on the structure of the residuals. Second, by a proper parametrization, we can find a SETAR(2;p) process whose linear approximation (10) is null.
This last evaluation is summarized in the following Corollary.
Corollary 1
Let \(X_t\), \(t\in \mathbb Z\), be a stationary and ergodic SETAR(2;p) process. Under the assumptions of Theorem 1, there exists a SETAR(2;p) process such that its linear approximation (10) is null - that is \(g_j^{(2)}=0\), \(\forall j\ge 1\).
Proof
See the Appendix.
To illustrate the result of this Corollary consider the following example.
Example 4
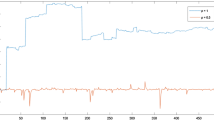
Let \(X_t\) be an ergodic SETAR(2;1) process. As shown in the proof of Corollary 1, a sufficient condition to obtain a SETAR(2; p) process with null linear approximation, is given by \(\phi _1=-\phi _2\), with \(\pi _{11}=\pi _{22}=0.5\). To give empirical evidence of this result, we generated \(n=200\) artificial data from a SETAR(2;1) model with autoregressive coefficients \(\phi _1=-0.58\) and \(\phi _2=0.58\). The correlogram on the left side of Fig. 1 clearly shows the absence of the linear component whereas the correlogram of \(X^2_t\) on the right side, gives evidence of nonlinearity in the generating process. \(\qquad \blacksquare\)

Plot of the autocorrelation function of \(X_t\) (left) and \(X_t^2\) (right)
Corollary 1 also plays an important role in the order estimation presented in the next section, because if we have a SETAR(2;p) model with \(p>0\), it can happen that the linear approximation in Theorem 1 is a white noise, and then the 2p order of the ARMA process will not match that of the SETAR(2;p) model (as discussed in Remark 4). This implies that in this case, the results of Theorem 1 cannot be used in the order estimation. To manage this problem and broadly use the results of Theorem 1 to estimate the autoregressive order of the threshold model, some additional conditions need to be added (see Theorem 2).
In the following Remark we give a bound for the residual part, coming out from the proposed linear approximation, \(X_t^{(2)}\), in \(L^2\) norm.
Remark 5
First, for simplicity, suppose that \(X_t^{(2)}=\varepsilon _t\), that is the linear approximation is null. Otherwise, we can always consider the process \(X_t-X_t^{(2)}\). So, we have to evaluate the following quantity
By using the representation of the SETAR process as in Lemma 1, if \(\gamma _4<1\) the main upper bound (in the sense that we take into account the series of the squared terms) of (13) is
for some positive constant C, \(\mathbf {K}_2=\left( \begin{array}{cc} \varvec{\Phi }_1^2&{}\mathbf {0}\\ \mathbf {0}&{}\varvec{\Phi }_2^2 \end{array} \right) \left( \mathbf{P}\otimes \mathbf {I}_p\right)\) whereas the other quantities correspond to those defined in (8). This result follows by using the same arguments as in the proof of Theorem 1. \(\qquad \blacksquare\)
Then, by focusing on the proposed linear approximation, the threshold autoregressive order can be consistently estimated, thus restricting attention to the linear time series domain. As will be discussed in Sect. 3, this has remarkable advantages not only from a theoretical point of view but even empirically, because the computational burden of the order estimation procedure of a nonlinear time series model is restricted to its linear (and less complex) approximation.
3 Order estimation
Identify the time series models is a crucial step in the ‘iterative stages in the selection of a model’ (Box and Jenkins 1976) that needs to preserve the parsimony of the model and makes a heavy impact on the computational effort needed to estimate the parameters.
In the linear domain, and in particular in the ARMA context, the identification has well-established results based on the relation between the ARMA parameters and the total/partial autocorrelation (at different lags) of the generating process.
As expected, these results - which relate strictly to the linear dependence - cannot be extended to the nonlinear domain. The complexity of the nonlinear time series structures has led to the model selection and identification largely discussed in the literature, which often focuses on information criteria and their performance (see Psaradakis et al. 2009; Emiliano et al. 2014; Rinke and Sibbertsen 2016). If we focus on order estimation in the SETAR domain, we find it looks different: Kapetanios (2001) proposes a consistent information criterion by which to estimate the lag order of the autoregressive regimes; Wong and Li (1998) introduce a correction to the Akaike Information Criterion (AIC; Akaike 1974) to correct its bias in the presence of SETAR models; and De Gooijer (2001) proposes cross-validation criteria to select the autoregressive order of these nonlinear structures. Galeano and Peña (2007), modifying the model selection criteria introduced by Hurvich et al. (1990), propose the inclusion of a determinant term related to the estimated parameters of each regime; furthermore, more recently, Fenga and Politis (2015) evaluated a bootstrapped version of the AIC in the SETAR domain, and defined the procedure step by step.
The results given in Sect. 2 could be used in this context to introduce a new approach to estimating the autoregressive order of the threshold regimes. For simplicity, assume that both regimes have the same order. (As noted before, this is not a limitation because zeroes could be included in the vector of parameters.) The proposed procedure is based on the linear approximation of the SETAR model as given in Theorem 1. We call this procedure Linear AIC (L-AIC) and it is based on the two main steps that are discussed below and summarized with the pseudo-code in Algorithm 1.
Let \(X_t\) be a stationary SETAR(2; p) process. The first step starts by fixing the maximum order for p (\(p_{max}\)) and then for each \(p=1,2,\ldots , p_{max}\):
-
(1.a)
estimate the parameters of the SETAR(2; p) model;
-
(1.b)
compute the eigenvalues of the matrix \(\mathbf{K}\) in (8)
-
(1.c)
compute the estimates of the autoregressive parameters - say \(\hat{a}_{j}\) - for \(j=1,2,\ldots , 2p\), of the linear approximation
$$\begin{aligned} X_t^{(2)}=a_{1} X_{t-1}^{(2)}+\ldots +a_{2p} X_{t-2p}^{(2)}+\varepsilon _t, \end{aligned}$$(14)using the results in (11).
Given the \(p_{max}\)-estimated SETAR models, the second step is based on a parametric bootstrap approach with B bootstrap replications. In particular, for \(b=1,\ldots B\):
-
(2.a)
generate the bootstrap independent innovations \(\{\varepsilon _t^*\}\), \(t=1,\ldots ,n+2p_{max}\), from a random variable with mean 0, variance \(\sigma ^2\), and with n the time series length;
for \(i=1,\ldots ,p_{max}\) run the steps 2.b) and 2.c):
-
(2.b)
generate the artificial time series from the AR(2i) models by using the innovations \(\{\varepsilon _t^*\}\) in 2.a) and the coefficients estimated in 1.c). Then we have \(X_t^{*(2)}\) as
$$\begin{aligned} X_t^{*(2)}=\hat{a}_{1} X_{t-1}^{*(2)}+\ldots +\hat{a}_{2i} X_{t-2i}^{*(2)}+\varepsilon _t^*; \end{aligned}$$(15) -
(2.c)
for each artificial time series i, select the autoregressive order \(\hat{p}_{b}^{(i)}\) such that \(\hat{p}_{b}^{(i)}=\arg \underset{ j\in \{1,\ldots ,2i\}}{\min }AIC(j)\), with j the order of the autoregressive process fitted to \(X_t^{*(2)}\), whose coefficients are obtained through the Yule-Walker estimators;
-
(2.d)
using the \(\hat{p}_b^{(i)}\) obtained from steps 2.b) and 2.c), estimate the autoregressive order of the SETAR(\(2;\hat{p}_b\)) model such that:
$$\begin{aligned} \hat{p}_b=\max \{i: |\hat{p}_{b}^{(i)}-\hat{p}_{b}^{(i+1)}|\ne 0\}, \quad \text {for } i=1,2,\ldots , p_{max}-1. \end{aligned}$$
Given the B selected orders (one for each bootstrap replication), the SETAR model has autoregressive order \(\hat{p}\) such that
with \(\# \hat{p}_b\) being the empirical frequency of \(\hat{p}_b\).
Note that: in step 1.b), given the ergodicity of the process \(X_t\), the probabilities included in the matrix \(\mathbf{P}\) of (8) can be consistently estimated using the empirical frequencies \(n_{ij}=\sum _{t=2}^n\mathbb {I}\left( X_t\in \mathbb {R}_i|X_{t-1}\in \mathbb {R}_j\right)\), for \(i,j=1,2\), such that \(\hat{\pi }_{ij}=n_{ij}/\sum _{j=1}^2n_{ij}\) (see among others Anderson and Goodman 1957); in step 1.c)) and all the elements included in the second step of the procedure, only the linear AR model is involved; this is because, given the results of Theorem 1 and Remark 3, the AR and MA components have the same order 2p. Moreover, the AR part of the ARMA approximation shares all the elements used in order estimation. Therefore, to simplify the procedure, we can only choose the AR component. (The extension to SETAR models with different autoregressive order is discussed in Sect. 4.2.)
Further, from the computational point of view, the use of theoretical issues related to linear models (instead of to nonlinear ones) in the second step, makes the algorithm quite fast.

This procedure has two important aspects. First, the linear approximation process, \(X_t^{(2)}\), is not observable, and so it is a sort of latent process. For this reason, in step 2.a) we generate for each p a sequence of i.i.d. innovations (for example, from the standard Gaussian distribution) and we estimate the parameters of the linear approximation by using (11). In this way, we build the process in (15) that is always a well-defined AR(2i) for each i; this is the key point for using the selection rule in step 2.d).
Moreover, our procedure is motivated by two main considerations. First, when we estimate a linear model in the SETAR(2;p) data generating process, the residuals are not a sequence of i.i.d. random variables, because they also capture the nonlinear structure of the SETAR process. Second, even if we could estimate the parameters of the linear approximation by using the results in Francq and Zakoïan (1998), it is not easy to derive the variance-covariance matrix of the estimators, in which case, the results (11) should be preferred.
Before stating the next results about the consistency of the L-AIC procedure, we need to report some regularity assumptions that refer to the Assumptions of Theorem 1 of Chan (1993).
Assumptions (H1). Let \(X_t\) be a nondegenerate SETAR(2;p) process where the coefficients of the two regimes are not equal and \(0<\pi <1\). Moreover,
-
(1)
the process \(X_t\) is stationary and ergodic (see Chan and Tong 1985; Bec et al. 2004);
-
(2)
there exists the univariate density function of \(X_t\) with respect to its invariant distribution, which is positive everywhere. \(\square\)
Finally, starting with the AIC behaviour in Shibata (1976), we define an asymptotically type-AIC consistent procedure if the asymptotic distribution of the chosen order is
with \(p_0\) the true order and \(\hat{p}\) the estimator of the autoregressive order that depends on the series length n.
Theorem 2
Let \(X_t\), \(t\in \mathbb {Z}\), be a stationary and ergodic SETAR(2;\(p_0\)), defined in (2). Under Assumptions (H1) and if \(\pi _{11}\ne \pi\), \(E(\varepsilon _t^2)<\infty\) and \(\gamma _2<1\), then \(\hat{p}\) in (16) is type-AIC consistent.
Proof
See the Appendix.
Note that the assumption \(\pi _{11}\ne \pi\) in Theorem 2 is relevant because it guarantees that the autoregressive process in Theorem 1 is exactly of order 2p (see Remark 4) and then what stated in Corollary 1 is prevented.
The proposed procedure and its consistency were empirically evaluated in a Monte Carlo study (see Sect. 5) that considers various SETAR models characterized by various degrees of complexity and nonlinearity.
4 Extensions
In this section we examine the proposed linear approximation of the SETAR process and evaluate three different aspects. First, we show the role of the threshold and delay parameters in this linear approximation. Second, we study the case where regimes have different orders. Third, we generalize the result of Theorem 1 when the number of regimes is more than two.
4.1 Threshold and delay parameters
To write the linear approximation for any values of the threshold and delay parameters, we consider the results in Sect. 2 presented for the case of two regimes with the same order. For simplicity, we consider only the AR part of the linear approximation. So, the matrix K in (8) becomes
where the threshold and delay parameters are r and d, respectively. The matrix \(\mathbf {P}_{r,d}\) is defined as
with \(\pi _{ij,r}^{(d)}=Pr\left( X_t\in \mathbb {R}_j|X_{t-d}\in \mathbb {R}_i\right)\), \(i,j=1,2\) and \(\mathbb {R}_1=(-\infty ,r]\), \(\mathbb {R}_2=(r,+\infty )\). All the other quantities are the same as in (8).
First, note that the delay parameter has the role of the order for the transition probabilities in \(\mathbf {P}_{r,d}\). It follows that \(\mathbf {P}_{r,d}=\left( \mathbf {P}_{r,1}\right) ^d\). Then, the matrix \(\mathbf {K}_{r,d}\) can be written as
Now, looking at the form of the matrix \(\mathbf {K}_{r,d}\), we can note that:
-
1.
the parameters r and d involve only the probabilities in the matrix \(\mathbf {P}_{r,d}\);
-
2.
in general, assuming that the SETAR model does not degenerate into an AR process, the rank of the matrix \(\mathbf {K}_{r,d}\) depends only on the matrices of the coefficients \(\varvec{\Phi }_1\) and \(\varvec{\Phi }_2\);
-
3.
the procedure for the order estimation (proposed in Sect. 3) needs only evaluate the difference between two successive orders. Then, it mainly depends on the matrices of the coefficients and not on the matrix \(\mathbf {P}_{r,d}\).
By using the previous considerations, we can argue that our procedure for the order estimation is independent of the threshold and delay parameters. This means that in identifying the SETAR model, we can separate the estimation of the threshold and delay parameters from the order estimation of the regimes.
4.2 Different orders in the regimes
Suppose that we have a SETAR model with two regimes with two different autoregressive orders - say \(p_1\) and \(p_2\). Moreover, suppose that the threshold and delay parameters are zero and one, respectively. Set \(p_0=\max \{p_1,p_2\}\). Let \(p_1<p_2\) and \(p_2=p_1+m\). Then, the matrix K is the same as in (8), except that matrix \(\varvec{\Phi }_1\) becomes:
In this case, \(\mathbf{K}\) is a \(2p_0\) matrix with \(a_{2p_0}=a_{2p_0-1}=\ldots =a_{2p_0-m+1}=0\) by (11) and using the fact that the matrix \(\mathbf{K}\) has m eigenvalues equal to zero. This means that the AR part of the linear approximation is \(AR(p_1+p_2)\).
Note that the transition probabilities in the matrix P are well defined in the sense that the irreducibility property of the Markov Chain with respect to the two regimes is still valid.
In this case, the procedure for the order estimation (see Sect. 3) is applied properly, changing Algorithm 1. The first step is modified by fixing a grid of candidate values for \(p_1\) and \(p_2\) such that \(p_1=1,\ldots , p_{1, \max }\) and \(p_2=1,\ldots , p_{2, \max }\). In the second step, the \(p_{1, \max }\times p_{2, \max }\) estimated SETAR models are used to carry out the bootstrap replications, with \(p_{1, \max }+p_{2, \max }\) innovations in row 13. A double cycle given by \(i=1,\ldots p_{1, \max }\) and \(s=1,\ldots p_{2, \max }\) is considered in row 14, whereas i is replaced by \(i+s\) in row 16. All these changes imply that the maximum in row 17 becomes:
for \(i=1,2,\ldots , p_{1,\max }-1\), \(s=1,2,\ldots , p_{2,\max }-1\) and with \(i_*\ge i\), \(s_*\ge s\), such that at least \(i_*\) or \(s_*\) is strictly greater than the corresponding i or s value. Finally, the computation of the empirical frequencies of \((\hat{p}_{b_1}, \hat{p}_{b_2})\) allows to conclude the algorithm.
4.3 More regimes
Suppose that we have k regimes with \(k\ge 2\). For simplicity, assume that all regimes have the same order - say p. Moreover, suppose that the delay is \(d=1\) and the thresholds are \(r_i\), for \(i=1, \ldots , k-1\), with \(-\infty<r_1<\ldots< r_{k-1}<\infty\). Then, the quantities in (7), become
with \(\sum _{i=1}^k\pi _i=1\). The matrix K in (8) becomes
where \(\varvec{\Phi }_i\), \(i=1,\ldots ,k\) are the matrices of coefficients of each regime.
Repeating the proof of Theorem 1, we get the expression in (30) as the sum of \(k\cdot p\) quantities instead of 2p. This implies that we have as a linear approximation the ARMA(\(k\cdot p,k\cdot p\)) process. Finally, in this case the procedure for the order estimation can be applied by replacing 2p with \(k\cdot p\) in Algorithm 1.
5 Simulation study
To evaluate the L-AIC procedure for the order estimation of the SETAR(2; p) process, we generated time series from four data generating processes:
\(M1: \quad X_t=-0.8X_{t-1}\mathbb I_{t-1}-0.2X_{t-1}(1-\mathbb I_{t-1})+\varepsilon _t\)
\(M2: \quad X_t=0.5X_{t-1}\mathbb I_{t-1}-0.5X_{t-1}(1-\mathbb I_{t-1})+\varepsilon _t\)
\(M3: \quad X_t=(-0.4X_{t-1}-0.5X_{t-2})\mathbb I_{t-1}+(0.2X_{t-1}-0.6X_{t-2})(1-\mathbb I_{t-1})+\varepsilon _t\)
\(M4: \quad X_t=(-0.7X_{t-1}-0.2X_{t-2})\mathbb I_{t-1}+(0.3X_{t-1}-0.6X_{t-2})(1-\mathbb I_{t-1})+\varepsilon _t\)
with threshold value \(r_1=0\), and \(\varepsilon _t\sim N(0,1)\). For each model we considered time series of length \(n={{50, 75, 150, 200, 500}}\) (with burn-in at 500 to discharge the effects of the initial conditions). The models M1 and M2 are those considered in Galeano and Peña (2007), where even for model M1 the condition of Theorem 2, \(\pi \ne \pi _{11}\), is satisfied; Models M3 and M4 were chosen to guarantee the assumptions of Theorem 1 and change the percentage of observations generated from each regime. (In M3 this percentage is almost identical in the two regimes, whereas in M4 the percentage of observations generated from the first regime is, on average, less than 40%.) Further, note that not all models include the intercepts: it makes it less easy to distinguishing between the two regimes, and the performance of the order estimation procedure could be affected from it.
After fixing \(p_{max}=5\), we estimated the SETAR(2;p) models, for \(p=1,\ldots , 5\) using conditional least squares estimators, with \(d=1\) and \(r_1=0\). For each estimated model we obtained the linear autoregressive approximation \(\hat{X}_{t}^{*(2)}\) and then we started, for each approximation, the \(B=125\) bootstrap replicates with \(\varepsilon _t\sim N(0,1)\). The number of Monte Carlo runs is 1000.
In the Monte Carlo study the L-AIC procedure has been compared to two other approaches.
The SETAR-AIC (Tsay 1989):
where \(T_j\), \(p_j\) and \(\hat{\sigma }^2_{\varepsilon _j}\) are the number of observations, the candidate autoregressive order, and the residual variance of regime j, for \(j=1,2\), respectively, whereas the second approach considered for the order estimation of the SETAR(2; p) model is the \(\beta\)AIC of Fenga and Politis (2015), which is a bootstrapped version of the SETAR-AIC.
Comparisons of the L-AIC with both the SETAR-AIC and the \(\beta\)AIC are presented in the left side of Table 1 where the relative empirical frequency of the selection of the true autoregressive orders of the SETAR(2; p) model are summarized. (The complement to one of the relative frequencies in the table is related to overparametrized models.)
It is widely known that the AIC tends to overfit models (see among others Koeher and Murphree 1988), whereas this overparametrization is penalized by the Bayesian Information Criterion (BIC), so we extended our procedure to the BIC domain giving rise to the Linear BIC (L-BIC) procedure.
For this purpose we considered steps 1.a) - 2.d) of the L-AIC procedure and replaced in step 2.c) the AIC with the BIC. Then we replicated the simulation study and compared the performance of the SETAR-BIC (Galeano and Peña 2007):
to that of the L-BIC procedure. (Note that Fenga and Politis 2015 do not consider the BIC.) The results of each model are presented in the right side of Table 1.
Finally note that the L-BIC procedure is made consistent by using the same arguments as in the proof of Theorem 2, together with the consistency of the BIC measure in the linear domain.
The results in Table 1 clearly show the improvement in the L-AIC procedure with respect to the SETAR-AIC and the \(\beta\)AIC approaches in all considered cases and correspondingly the good performance of the L-BIC if compared to the BIC criterion, mainly for small values of n. In particular, one can be note that when the distinction between the two regimes is more marked, as in model M2 where the autoregressive coefficients have opposite signs, there is an overall improvement in the competing order estimation approaches (mainly in the L-AIC case).
As the complexity of the data generating process grows with models M3 and M4, all procedures confirm their pertinence to estimating the autoregressive order of the nonlinear threshold processes, but even in this case the frequency with which the L-AIC procedure correctly detects is generally higher than that of the competing approaches based on the Akaike Criterion and this result is confirmed in the L-BIC case, even if with less marked differences between the L-BIC and the SETAR-BIC.
From the computational point of view, if we compare the L-AIC procedure with the Fenga and Politis (2015) criterion, we can note that, when \(r_1\), d are known and \(p_1=p_2=p\), the effort (measured in terms of computing time) is heavier for the \(\beta\)AIC criterion; this is because in the bootstrap iterations, for each candidate \(p=1,2,\ldots , p_{max}\), we need to estimate a nonlinear threshold model instead of a linear AR(2p) model, as in the L-AIC case. In practice, a further advantage of the L-AIC procedure is that the computationally intensive steps of the bootstrap iterations are confined to the linear domain characterized by reduced complexity relative to the nonlinear domain.
Finally, to evaluate how the variability of the SETAR(2; p) process is explained by the linear ARMA(2p, 2p) approximation, we have compared the variance of the SETAR generating process with the variance of its linear ARMA approximation. For all models, M1, M2, M3 and M4, we have generated 1000 artificial time series and for each of them we have computed the ratio between the two variances. In Table 2 the means of these ratios and the corresponding standard deviations, are presented for \(n=\{200, 500\}\). The variance explained by the ARMA approximation is higher for model M1 whereas this ratio is lower for model M4 that is characterized by high nonlinearity. The artificial time series have been further evaluated to investigate the dependence between \(X_t^{(2)}\) and the generating process \(X_t\). For this aim, in Table 2 we have considered, for each model, the mean of the correlations computed between the ARMA approximation \(X_t^{(2)}\) and \(Y_t=X_t-X_t^{(2)}\). The results show different correlations as the structure of the model changes.
6 Conclusion
It is widely known that when the behaviour of the autocorrelation function (ACF) is observed for a time series \(X_t\) generated by a SETAR(2; p) model, we can easily confuse the ACF of the threshold process with that of a linear ARMA structure. Different motivations can be cited for this empirical evaluation: among them is the fact that the linear autoregressive model is nested in the SETAR model because it can be seen as a degeneration of the SETAR structure when all data belong to the same regime.
In this study we investigated the relation between the SETAR and ARMA models. We showed that when \(X_t\sim\)SETAR(2; p), under proper conditions, the linear approximation (10) of \(X_t\) is \(X_t^{(2)}\sim\)ARMA(2p, 2p). We theoretically showed this result and even clarified when it could not be applied and how it can be generalized when the number of regimes is greater than two or the regimes have a different autoregressive order. Further, using linear approximation, we proposed an order estimation procedure called Linear-AIC to estimate the autoregressive order of the two regimes of \(X_t\); the consistency of this procedure was proved and the extension of these results to the BIC domain is discussed.
The L-AIC procedure is based on two main steps: in the first step we focus on the nonlinear generating process \(X_t\) and on its linear approximation \(X_t^{(2)}\), whereas in the second step we estimate the autoregressive order of the SETAR model using a parametric bootstrap approach.
Our Monte Carlo study gives evidence of the performance of the L-AIC procedure and of its BIC extension (called L-BIC). The results highlight that the L-AIC generally does a better job than both the competing SETAR-AIC in (17) and Fenga and Politis (2015) criterion (and, correspondingly, the L-BIC performs better than the SETAR-BIC criterion), even in the presence of the parametrization of the SETAR model that makes it difficult to distinguish among regimes.
The results presented herein will serve as the topic of future research that further investigates the extensions discussed in Sect. 4; future research can also study how the L-AIC and the L-BIC can be included in an overall identification procedure for SETAR models.
Change history
29 August 2022
Missing Open Access funding information has been added in the Funding Note.
References
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Automat Control AC 19:716–723
Anderson TW, Goodman LA (1957) Statistical inference about Markov chains. Ann Math Stat 28:89–110
Bec F, Salem BM, Carrasco M (2004) Tests for unit roots versus threshold specification with an application to the PPP. J Bus Econ Statist 22:382–395
Bickel PJ, Freedman DA (1981) Some asymptotic theory for the bootstrap. Ann Stat 3:1196–1217
Bougerol P, Picard N (1992) Strict stationarity of generalized autoregressive processes. Ann Probab 20:1714–1730
Box GEP, Jenkins GM (1976) Time series analysis: forecasting and control. Holden-Day, New York
Brockwell PJ, Davis RA (1991) Time series: theory and methods. Springer, New York
Chan KS (1993) Consistency and limiting of the least squares estimator of a threshold autoregressive model. Ann Stat 21:520–533
Chan KS, Tong H (1985) On the use of Lyapunov functions for the ergodicity of stochastic difference equations. Adv Appl Probab 17:666–678
De Gooijer J (2001) Cross validation criteria for SETAR model selection. J Time Ser Anal 22:267–281
Emiliano PC, Vivanco MJF, de Menezes FS (2014) Information criteria: How do they behave in different models? Comput Stat Data Anal 69:141–153
Fenga L, Politis DN (2015) Bootstrap order selection for SETAR models. J Stat Comput Simul 85:235–250
Francq C, Zakoïan JM (1998) Estimating linear representation of nonlinear processes. J Statist Plan Inference 68:145–165
Galeano P, Peña D (2007) Improved model selection criteria for SETAR time series models. J Statist Plan Inference 137:2802–2814
Hamilton JD (1989) A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica 57:357–384
Huang R, Xu F, Chen R (2009) General expression for linear and nonlinear time series models. Front Mech Eng China 4:15–24
Hurvich CM, Shumway R, Tsai C (1990) Improved estimators of Kullback-Leibler information for autoregressive model selection in small samples. Biometrika 77:709–719
Kapetanios G (2001) Model selection in threshold models. J Time Ser Anal 22:733–754
Koeher AB, Murphree ES (1988) A comparison of the Akaike and Schwarz criteria for selecting model order. J R Stat Soc Ser C 37:187–195
Kokoszka PS, Politis DN (2011) Nonlinearity of arch and stochastic volatility models and Bartlett’s formula. Probab Math Stat 31:47–59
Lütkepohl H (1996) Handbook of matrices. Wiley, Chichester
Petruccelli JD, Woolford SW (1984) A Threshold AR(1) model. J Appl Probab 21:270–286
Pham DT (1985) Bilinear Markovian representation and bilinear models. Stochast Process Appl 20:295–306
Priestley MB (1988) Non-linear and non-stationary time series analysis. Academic Press, London
Psaradakis Z, Sola M, Spagnolo F, Spagnolo N (2009) Selecting nonlinear time series models using information criteria. J Time Ser Anal 30:369–394
Rinke S, Sibbertsen P (2016) Information criteria for nonlinear time series models. Stud Nonlinear Dyn Econ 20:325–341
Schoukens J, Vaes M, Pintelon R (2016) Linear system identification in a nonlinear setting: nonparametric analysis of the nonlinear distortions and their impact on the best linear approximation. IEEE Control Syst Mag 36:38–69
Shibata R (1976) Selection of the order of an autoregressive order by Akaike information criterion. Biometrika 63:117–126
Stelzer R (2009) On Markov-switching ARMA processes - stationarity, existence of moments and geometric ergodicity. Economet Theor 25:43–62
Timmermann A (2000) Moments of Markov switching models. J Econ 96:75–111
Tong H (1990) Non-linear time series: a dynamical system approach. Oxford University Press, New York
Tong H, Lim KS (1980) Threshold Autoregression, limit cycles and cyclical data. J R Stat Soc (B) 42:245–292
Tsay R (1989) Testing and modeling threshold autoregressive processes. J Am Stat Assoc 84:231–240
Wong CS, Li WK (1998) A note on the corrected Akaike information criterion for threshold autoregressive models. J Time Ser Anal 19:113–124
Acknowledgements
The authors gratefully acknowledge the Editor, the Associate Editor and the two anonymous Referees for the insightful comments and constructive suggestions.
Funding
Open access funding provided by Università degli Studi di Salerno within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
We report the proof of all Theorems, Proposition and Corollary of the paper and two technical Lemmas.
Before proofing Theorem 1, we need to introduce the following Lemma on the iterative representation of the SETAR model:
Lemma 1
Let \(\mathbf {X}_t\), \(t \in \mathbb Z\), be a stationary and ergodic SETAR(2;p) process (4), with \(E[|\varepsilon _t|]<\infty\), \(\gamma =\pi \Vert \varvec{\Phi }_1\Vert +(1-\pi ) \Vert \varvec{\Phi }_2\Vert\) and \(E[\mathbb I\{X_{t-1}\le 0\}]=\pi\) (with \(0\le \pi \le 1\)), if \(\gamma <1\) then \(\mathbf {X}_t\) can be given by:
where \(\mathbf{A}_{I_{t-1-s}}\) is defined in (5) and \(\Vert \cdot \Vert\) is any matrix norm.
Proof
Using Theorem 1.1 in Bougerol and Picard (1992) and let
it is sufficient to show that \(c_k<0\), for any \(k\in \mathbb {N}\) and \(t\in \mathbb {Z}\).
Let \(\Vert \cdot \Vert\) any matrix norm, now we have that
Given the ergodicity and stationarity of \(X_t\) and considered the representation (5), then \(E\left( \Vert \mathbf{A}_{I_{t-1-s}}\Vert \right) =\gamma\), for any t and s. Noting that the assumptions of the present Lemma fit all conditions of Theorem 1.1 of Bougerol and Picard (1992), we have that \(\gamma <1\), for any k, and that this result holds for any matrix norm.\(\square\)
The next lemma proves the existence of moments of the SETAR process.
Lemma 2
Let \(X_t\), \(t\in \mathbb Z\), be a stationary and ergodic SETAR(2;p) process with \(E[|\varepsilon _t|^r]<\infty\), and \(\gamma _r<1\), where \(\gamma _r=\pi \left\| \varvec{\Phi }_1\right\| ^r+(1-\pi )\left\| \varvec{\Phi }_2\right\| ^r\), for \(r\in [1,\infty )\) and \(E[\mathbb I\{X_{t-1}\le 0\}]=\pi\) (with \(0\le \pi \le 1\)), then \(E[|X_t|^r]<\infty\) (where \(\left\| \cdot \right\|\) is any matrix norm).
Proof
Let \((\Vert \mathbf {X}_t\Vert )_{L^r}=E\left( \Vert \mathbf {X}_t\Vert \right) ^{1/r}\), be the \(L^r\) norm, as given in Stelzer (2009, Definition 4.1). We state with \(\Vert \cdot \Vert\) a generic matrix or vector norm on \(\mathbb {R}^p\), since the result of this lemma holds for any matrix or vector norm. By Lemma 1 and using the same arguments given in the first part of the proof of Theorem 4.1 in Stelzer (2009) , that can be applied even in this SETAR domain, we need to prove the sufficient condition that \(\mathbf{X}_t\) belongs to \(L^r(\mathbb {R}^p)\), that is given by:
Define
By using the same arguments as in the proof of Lemma 1, we have that
since \(E\left\| \mathbf {A}_{I_{t-1-s}}\right\| ^r=\gamma _r\) by stationarity and ergodicity of \(X_t\) and \(E|\varepsilon _t|^r<\infty\). Then, by (21)
where \(\eta _{i+1}=O\left( \frac{1}{i+1}\right)\).
Since \(\gamma _r<1\) and \(Q_i=O(\gamma _r^i)\), the result in (20) follows. Thus, we have that \(E[|X_t|^r]<\infty\). The proof is complete.\(\square\)
Proof of Proposition 1
Using the results of Lemma 1, we need to minimize the following quantity
\(Q(g_1,g_2,\ldots ;\mathcal {I}_{t-1})=||X_t-X_t^L|\mathcal {I}_{t-1}||_{L^2}^2=\)
Since by Lemma 2, the second moment exists, that is \(E(X_t^2)<\infty\), then \(Q(g_1,g_2\ldots ;\mathcal {I}_{t-1})\) is well defined.
Making the first partial derivatives of \(Q(g_1,g_2,\ldots ;\mathcal {I}_{t-1})\) with respect to \(g_k\), with \(k\ge 1\), and putting each equation equal to zero, we have
Since the process \(X_t\) is also measurable with respect to \(\tilde{\mathcal {I}}_{t-1}=\{\varepsilon _{t-1},\varepsilon _{t-2},\ldots \}\), then it is equivalent to consider either \(\tilde{\mathcal {I}}_{t-1}\) in place of \(\mathcal {I}_{t-1}\) in the conditional means. Now, it is sufficient to derive \(g_j\), \(\forall j\ge 1\), in the following equations.
Without loss of generality, we can consider both \(\varepsilon _{t-j}\) and \(\varepsilon _{t-k}\) different from zero. So, we can write (24) as
It follows that the solution in (25) is
Since (22) is a square function, if we replace the solution (26) in (22), then the latter is zero. This means that we have a minimum. Then, the proof of the first part of Proposition is complete.
Now, for the second part, we know that the optimal one step ahead \(L^2\) predictor of \(X_t\) is \(X_t(1)=E\left( X_t|\mathcal {I}_{t-1}\right)\). By using again Lemma 1, we have that
The proof is so complete. \(\square\)
Now we can prove Theorem 1.
Proof of Theorem 1
We start from the linear process (10) with coefficients, \(g_j^{(2)}=E\left( \mathbf {e}_1^T\prod _{s=0}^{j-1}\mathbf {A}_{I_{t-1-s}}\mathbf {e}_1\right)\), \(j\ge 1\), defined in (9).
By using the stationarity and ergodicity assumption on \(X_t\), it follows that also the indicator process, \(\mathbb {I}_t\), is stationary and ergodic. Moreover, we can apply, on the expression for \(g_j^{(2)}\), the Markov property and arguments similar to those given in Timmermann (2000) on the recursive representation and generation of moments of the regimes switching models. So, it follows that
where \(\varvec{\pi }\) and \(\mathbf {K}\) are defined in (7) and (8), respectively and \(\mathbf{K}^{j-1}=\mathbf{K}\cdot \mathbf{K}\cdot \ldots \cdot \mathbf{K}\), with the matrix \(\mathbf{K}\) multiplied \((j-1)\) times. Then, we can write the linear process in (10) as
where B is the back-shift operator such that \(B^j\varepsilon _t=\varepsilon _{t-j}\). For now, suppose that all the eigenvalues of the matrix \(\mathbf {K}\) are different. So, we can write \(\mathbf {K}=\varvec{\Gamma }\varvec{\Delta }\varvec{\Gamma }^{-1}\), where \(\varvec{\Delta }\) is a diagonal matrix with the eigenvalues on the main diagonal and \(\varvec{\Gamma }\) is the matrix with the corresponding eigenvectors. Therefore, we can write (28) as
By Remark 1, it follows that the series \(\sum _{j=1}^{\infty }|g_j^{(2)}|\) is convergent. Note that in (29) we have a power series and so it follows that \(\rho (\mathbf {K})<1\), with \(\rho (\mathbf {K})\) the maximum absolute eigenvalue of \(\mathbf {K}\).
Set \(\mathbf {P}_1^T=\mathbf {e}_1^T\varvec{\pi }^T\varvec{\Gamma }\) and \(\mathbf {P}_2=\varvec{\Gamma }^{-1}\left( \begin{array}{c} \varvec{\Phi }_1\\ \varvec{\Phi }_2 \end{array} \right) \mathbf {e}_1\) and let \(c_k\) be the component-wise product of the corresponding elements in the vectors \(\mathbf {P}_1\) and \(\mathbf {P}_2\), \(k=1,\ldots ,2p\). Now, we can write (29) as
where \(\lambda _k\), \(k=1,\ldots ,2p\), are the eigenvalues in the matrix \(\varvec{\Delta }\). So, we can conclude, that:
To complete the proof, we need to consider the case when two or more eigenvalues in the matrix \(\mathbf {K}\) are equal. In this case, we can apply the Jordan matrix decomposition of \(\mathbf{K}\) (among the others, see Lütkepohl (1996)) and the previous results still hold. The proof is so complete. \(\square\)
Corollary 1 states that the linear approximation of the SETAR model could be null. We here give the proof.
Proof of Corollary 1
Starting from (27) in the proof of Theorem 2, we have that
and so it is sufficient to find one case such that \(g_j^{(2)}=0\), \(\forall j \ge 1\). For this aim, suppose that the transition probability matrix (7) is
Then \(\pi =1/2\).
Further, suppose that the parameters in the first regime of the SETAR(2;p) model are the same, in absolute value, to the corresponding parameters of the second regime but with the opposite sign. It is easy to verify that \(g_1^{(2)}=2^{-1}\mathbf {e}_1^T\left( \mathbf {I}_p,\mathbf {I}_p\right) \left( \begin{array}{c} \varvec{\Phi }_1\\ \varvec{\Phi }_2 \end{array} \right) \mathbf {e}_1=0.\)
Now, by using the above assumptions, we can write \(g_j^{(2)}\) as
\(\forall j\ge 1\). Since the elements in the first row of the matrix \(\varvec{\Phi }_1\) have opposite sign with respect to the elements in the first row of the matrix \(\varvec{\Phi }_2\), we can write \(\varvec{\Phi }_1+\varvec{\Phi }_2=2\mathbf {C}\), where the matrix \(\mathbf {C}\) has all zeros in the first row and the same elements of \(\varvec{\Phi }_1\) or \(\varvec{\Phi }_2\) in the other rows. It is clear that the matrix \(\mathbf{C}\) is idempotent and so \(\mathbf{C}^j=\mathbf{C}\), \(\forall j\ge 1\). Then, we can write (31) as
So, the result follows.\(\square\)
We prove here the consistency of the identification procedure proposed.
Proof of Theorem 2
Before to enter into the details of the proof, we need to discuss the assumptions of Theorem 2. For simplicity, suppose that the eigenvalues of the matrix \(\mathbf{K}\), defined in (8), are all different. The assumption \(\pi _{11}\ne \pi\) guarantees that the linear approximation, \(X_t^{(2)}\), shows, at least, one coefficient different from zero (in fact, by Corollary 1, we could also have that \(X_t^{(2)}=\varepsilon _t\)).
In particular, from (11), it follows that \(a_{2p_0}=\prod _{k=1}^{2p_0}\lambda _k\), with \(\lambda _k\), \(k=1,\ldots , 2p_0\), the eigenvalues of \(\mathbf{K}\). Then \(a_{2p_0}\) is the determinant of \(\mathbf{K}\) and it is different from zero, if and only if all \(\lambda _k\) are different from zero. Further, \(|\mathbf{K}|=\phi _{p_0}^{(1)}\phi _{p_0}^{(2)}(\pi _{11}\pi _{22}-\pi _{12}\pi _{21})\), and then, given the generating process SETAR(\(2,p_0\)) where \(\phi _{p_0}^{(1)}\ne 0\) and \(\phi _{p_0}^{(2)}\ne 0\), \(|\mathbf {K}|\) is different from zero if and only if \(\pi _{11}\pi _{22}-\pi _{12}\pi _{21}\ne 0\), or in other words, if \(\pi _{11}\pi _{22}-(1-\pi _{11})(1-\pi _{22})\ne 0\) (where the term on the left is the determinant of \(\mathbf{P}\) in (8)). Using the ergodicity of the indicator process \(\mathbb I_{t-1}\) such that \(\varvec{\pi }^T=\varvec{\pi }^T\mathbf{P}\), it follows that the determinant of \(\mathbf{P}\) (and of \(\mathbf{K}\)) is different from zero if and only if \(\pi _{11}\ne \pi\). Then, we have that \(a_{2p_0}\ne 0\) iff \(\pi _{11}\ne \pi\).
The remaining assumptions of this Theorem imply that the Conditional Least Squares estimators of the parameters for the SETAR(2;\(p_0\)) process, are consistent by Theorem 1 of Chan (1993). In order to apply this Theorem we need that \(E(X_t^2)<\infty\) which follows by the assumptions \(\gamma _2<1\) and \(E(\varepsilon _t^2)<\infty\) (see Lemma 2).
Since the eigenvalues of \(\mathbf{K}\) are all different and by using the Dini’s Theorem, it follows that the parameters \(a_i\), \(i=1,\ldots , 2p_0\) (given in (11)) are differentiable functions of the SETAR(2;\(p_0\)) parameters. So, they are also continuous functions of the SETAR(2;\(p_0\)) parameters. Then, we have that
where \(i=1,\ldots ,2p_0\).
Now we focus the attention on the consistency of \(\hat{p}\). Consider a \(\tilde{p}\) such that \(1\le \tilde{p}\le p_{max}\), where clearly \(\tilde{p}\) can be different from \(p_0\). Moreover, (32) holds when \(\tilde{p}\) is not equal to \(p_0\).
The second step of our procedure is based on a parametric bootstrap. In fact, we use the latter to estimate some quantities on the latent linear process \(X_t^{(2)}\) defined in (14). We build its bootstrap approximation as \(X_t^{*(2)}\) which is defined in (15). There are two main differences between \(X_t^{(2)}\) and \(X_t^{*(2)}\). Noting that we can fix any distribution function such that the random variables (drawn from it) have zero mean and variance \(\sigma ^2\), the first difference is that the random variables \(\varepsilon _t^*\) are not the same as \(\varepsilon _t\) even if they are independently drawn from the same distribution. The second difference is that \(X_t^{*(2)}\) includes the estimates \(\hat{a}_{i}\) instead of the true values \(a_i\), for \(i=1,\ldots , 2\tilde{p}\), as in \(X_t^{(2)}\). Now, we evaluate these two differences by using the Mallow’s metric of order 2 (see Bickel and Freedman 1981), say \(d_2(F_1,F_2)\), where \(F_1\) and \(F_2\) are two distributions . By Lemma 8.4 of Bickel and Freedman (1981), we have that
where \(F_{\varepsilon ,n}\) and \(F_{\varepsilon }\) are the empirical distribution and the true distribution function of \(\varepsilon _t\), respectively. Since we use a parametric bootstrap, then \(\{\varepsilon _t^*\}\) and \(\{\varepsilon _t\}\) are two different samples from the same distribution function. So, by (33) and using the triangular property of the Mallow’s metric, it follows that
with \(F_{\varepsilon ^*,n}\) the empirical distribution function of \(\varepsilon _t^*\).
By Remark 1, the linear process \(X_t^{(2)}\) is stationary and ergodic. Further by (), also the linear process \(X_t^{*(2)}\) is stationary and ergodic with probability tending to one when \(n\rightarrow \infty\), . Then the process \(X_t^{*(2)}-X_t^{(2)}\) is still stationary and ergodic with probability tending to one when \(n\rightarrow \infty\), since it is the difference of two (possibly different) AR(\(2\tilde{p}\)) process which are both stationary and ergodic, at least, in probability for large n.
Now, we evaluate the differences between the two linear processes \(X_t^{*(2)}\) and \(X_t^{(2)}\) by using \(d_2(F^*_n,F_n)\) where \(F_n^*\) and \(F_n\) are two univariate empirical distributions with respect to \(X_t^{*(2)}\) and \(X_t^{(2)}\), respectively. We show that \(d_2(F^*_n,F_n){\mathop {\longrightarrow }\limits ^{p}}0\). In order to get this result, it is sufficient that
Since in our procedure both \(X_t^{*(2)}\) and \(X_t^{(2)}\) are two (possibly different) AR(\(2\tilde{p}\)) processes, we can write
where \(\hat{a}_{i}\) and \(a_{i}\), \(i=1,\ldots ,2\tilde{p}\), are in (15) and (14), respectively.
By (32), it follows that
since \(\frac{1}{n-2\tilde{p}}\sum _{t=2\tilde{p}+1}^{n}\left( X_t^{(2)}\right) ^2{\mathop {\longrightarrow }\limits ^{p}}\gamma _X(0)<\infty\), which is the variance of \(X_t^{(2)}\). So, by (34) and (36), we can write
Since \(X_t^{*(2)}-X_t^{(2)}\) is a stationary and ergodic process with finite variance in probability, for large n, then \(\frac{1}{n-2\tilde{p}}\sum _{t=2\tilde{p}+1}^n\left( X_{t-i}^{*(2)}-X_{t-i}^{(2)}\right) ^2{\mathop {\longrightarrow }\limits ^{p}} Q_1\), for each integer \(i\ge 0\), with \(0\le Q_1<\infty\). For now, suppose that \(Q_1>0\), then, by (32), (37) asymptotically becomes \(Q_1\left[ 1-h(a_{1},\ldots ,a_{2\tilde{p}})\right] =0\) with \(h(a_{1},\ldots ,a_{2\tilde{p}})\) a continuous function and it is less than one because \(1-h(a_{1},\ldots ,a_{2\tilde{p}})\) is the same expression we get to derive \(\gamma _X(0)\). So, we can conclude that \(Q_1\) cannot be positive. The unique solution is \(Q_1=0\). Thus, (35) is shown.
By Bickel and Freedman (1981), this result implies that
for each integer \(i\ge 0\).
By Theorem 8.1.1 of Brockwell and Davis 1991, the Yule-Walker estimators of the parameters in \(X_t^{(2)}\), say \(\tilde{a}_{i}\), \(i=1,\ldots ,2\tilde{p}\), (we omit the order \(2\tilde{p}\)) are consistent as well as \(S^2_{\varepsilon }\), the estimator of \(\sigma ^2\), the variance of the innovation process. By (38) and using the continuous mapping Theorem, \(\tilde{a}_{i}^{*}-\tilde{a}_i{\mathop {\longrightarrow }\limits ^{p}}0\), \(i=1,\ldots ,2\tilde{p}\), where \(\tilde{a}_i^{*}\), \(i=1\ldots ,2\tilde{p}\), are the Yule-Waker estimators of parameters in \(X_t^{*(2)}\). Moreover, \(S^{2*}_{\varepsilon }-S^2_{\varepsilon }{\mathop {\longrightarrow }\limits ^{p}}0\), with \(S^{2*}_{\varepsilon }\) the estimator of \(\sigma ^2\) on \(X_t^{*(2)}\). Therefore, the AIC measure on the process \(X_t^{*(2)}\) is equal in probability, for large n, to the AIC measure on \(X_t^{(2)}\). Then, in the following, we can consider the \(X_t^{(2)}\) process.
First, suppose an AR(\(2\tilde{p}\)) process for \(X_t^{(2)}\) with \(\tilde{p}<p_0\) and \(2\tilde{p}\) the maximum order of the AR process. By Shibata (1976), it follows that \(\lim _{n\rightarrow \infty }P(2\hat{p}=2\tilde{p})=1\) but with \(\tilde{p}<p_0\).
Now, consider an AR(\(2\tilde{p}\)) process for \(X_t^{(2)}\), with \(\tilde{p}=p_0\) and \(2\tilde{p}\) the maximum order for the AR process. In this case we have that \(\lim _{n\rightarrow \infty }Pr(2\hat{p}=2 p_0)=1\) by Shibata (1976). So, we have the estimate of \(\hat{p}=p_0\) by step 3.c in our procedure with a probability tending to one.
Finally, suppose an AR(\(2\tilde{p}\)) process for \(X_t^{(2)}\) with \(\tilde{p}>p_0\) with \(2\tilde{p}\) the maximum order of the AR process. In this case, it follows that \(a_i=0\) for \(i=2\tilde{p},\ldots , 2p_{max}\) and by Shibata (1976), we have that \(\lim _{n\rightarrow \infty }Pr(2\hat{p}=2p_0)>0\).
Putting all together, we have that our procedure gives \(\lim _{n\rightarrow \infty }Pr(\hat{p}=\tilde{p})=0\) if \(\tilde{p}<p_0\) and \(\lim _{n\rightarrow \infty }Pr(\hat{p}=\tilde{p})>0\) if \(\tilde{p}\ge p_0\). So, \(\hat{p}\) is asymptotically type-AIC consistent. The proof is complete. \(\square\)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Giordano, F., Niglio, M. & Vitale, C.D. Linear approximation of the Threshold AutoRegressive model: an application to order estimation. Stat Methods Appl 32, 27–56 (2023). https://doi.org/10.1007/s10260-022-00638-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10260-022-00638-1