
Abstract
This paper studies the polynomial optimization problem whose feasible set is a union of several basic closed semialgebraic sets. We propose a unified hierarchy of Moment-SOS relaxations to solve it globally. Under some assumptions, we prove the asymptotic or finite convergence of the unified hierarchy. Special properties for the univariate case are discussed. The application for computing (p, q)-norms of matrices is also presented.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
We consider the optimization problem
where each \(K_l\) is the basic closed semialgebraic set given as
Here, all functions f, \(c_i^{(l)}\), \(c_j^{(l)}\) are polynomials in \(x := (x_1, \ldots , x_n)\); all \(\mathcal {E}^{(l)}\) and \(\mathcal {I}^{(l)}\) are finite labeling sets. We aim at finding the global minimum value \(f_{min}\) of (1.1) and a global minimizer \(x^*\) if it exists. It is worthy to note that solving (1.1) is equivalent to solving m standard polynomial optimization problems by minimizing f(x) over each \(K_l\) separately, for \(l = 1, \ldots , m\). When K is nonempty and compact, \(f_{min}\) is achievable at a feasible point, and (1.1) has a minimizer. When K is unbounded, a minimizer may or may not exist. We refer to [28, Section 5.1] for the existence of optimizers when the feasible set is unbounded.
The optimization (1.1) contains a broad class of problems. For the case \(m=1\), if all functions are linear, then (1.1) is a linear program (LP); if f is quadratic and all \(c_i^{(l)}\), \(c_j^{(l)}\) are linear, then (1.1) is a quadratic program (QP); if all f, \(c_i^{(l)}\), \(c_j^{(l)}\) are quadratic, then (1.1) is a quadratically constrained quadratic program (QCQP). Polynomial optimization has wide applications, including combinatorial optimization [4, 18], optimal control [8], stochastic and robust optimization [34, 35, 44], generalized Nash equilibrium problems [30, 31, 33], and tensor optimization [5, 26, 32, 36].
When the feasible set K is a single basic closed semialgebraic set (i.e., \(m=1\)) instead of a union of several ones, the problem (1.1) becomes a standard polynomial optimization problem. There exists much work for solving standard polynomial optimization problems. A classical approach for solving them globally is the hierarchy of Moment-SOS relaxations [12]. Under the archimedeanness for constraining polynomials, this hierarchy gives a sequence of convergent lower bounds for the minimum value \(f_{min}\). The Moment-SOS hierarchy has finite convergence if the linear independence constraint qualification, the strict complementarity and the second order sufficient conditions hold at every global minimizer [25]. When the equality constraints define a finite set, this hierarchy is also tight [14, 16, 24]. We refer to the books and surveys [8, 9, 13, 17, 28] for introductions to polynomial optimization.
Contributions
When \(m > 1\), the difficulty for solving the optimization problem (1.1) increases. A straightforward approach to solve (1.1) is to minimize f(x) over each \(K_l\) separately, for \(l = 1, \ldots , m\). By doing this, we reduce the problem (1.1) into m standard polynomial optimization problems.
In this paper, we propose a unified Moment-SOS hierarchy for solving (1.1). The standard kth order moment relaxation for minimizing f(x) over the subset \(K_l\) is (for \(l = 1, \ldots , m\))
We refer to Section 2 for the above notation. The unified moment relaxation we propose in this paper is
For \(k = 1, 2, \ldots \), this gives a unified hierarchy of relaxations.
A major advantage of (1.3) is that it gives a unified convex relaxation for solving (1.1) instead of solving it over each \(K_l\) separately. It gives a sequence of lower bounds for the minimum value \(f_{min}\) of (1.1). Under the archimedeanness, we can prove the asymptotic convergence of this unified hierarchy. Moreover, under some further local optimality conditions, we can prove its finite convergence. We, in addition, study the special properties for the univariate case. When \(n = 1\), there are nice representations for polynomials that are nonnegative over intervals. The resulting unified Moment-SOS relaxations can be expressed in a more mathematically concise manner. We also present numerical experiments to demonstrate the efficiency of our unified Moment-SOS hierarchy.
An application of (1.1) is to compute the (p, q)-norm of a matrix A:
where p, q are positive integers. When p and q are both even, this is a standard polynomial optimization problem. If one of them is odd, the norm \(\Vert A \Vert _{p,q}\) can be expressed as the optimal value of a problem like (1.1). For instance, when \(p=4\) and \(q=3\), we can formulate this problem as
The feasible set of the above can be expressed in the union form as in (1.1). It is interesting to note that the number of sets in the union is \(2^n\), so the difficulty of (1.4) increases substantially as n gets larger. More details are given in Section 5.
The paper is organized as follows. Section 2 introduces the notation and some preliminary results about polynomial optimization. Section 3 gives the unified hierarchy of Moment-SOS relaxations; the asymptotic and finite convergence are proved under certain assumptions. Section 4 studies some special properties of univariate polynomial optimization. Section 5 gives numerical experiments and applications. Section 6 draws conclusions and makes some discussions for future work.
2 Preliminaries
Notation
The symbol \(\mathbb {N}\) (resp., \(\mathbb {R}\)) stands for the set of nonnegative integers (resp., real numbers). For an integer \(m>0\), denote \([m] := \{1, 2, \ldots , m\}\). For a scalar \(t \in \mathbb {R}\), \(\lceil t \rceil \) denotes the smallest integer greater than or equal to t, and \(\lfloor t \rfloor \) denotes the largest integer less than or equal to t. For a polynomial p, \(\deg (p)\) denotes its total degree and vec(p) denotes its coefficient vector. For two vectors a and b, the notation \(a \perp b\) means they are perpendicular. The superscript \(^T\) denotes the transpose of a matrix or vector. For a symmetric matrix X, \(X \succeq 0\) (resp., \(X \succ 0\)) means that X is positive semidefinite (resp., positive definite). The symbol \(S^n_+\) stands for the set of all n-by-n real symmetric positive semidefinite matrices. For two symmetric matrices X and Y, the inequality \(X\succeq Y\) (resp., \(X\succ Y\)) means that \(X-Y\succeq 0\) (resp., \(X-Y\succ 0\)). For \(x := (x_1, \ldots , x_n)\) and a power vector \(\alpha := (\alpha _1, \ldots , \alpha _n) \in \mathbb {N}^n\), denote \(|\alpha | := \alpha _1 + \cdots + \alpha _n\) and the monomial \(x^{\alpha } := x_1^{\alpha _1}\cdots x_n^{\alpha _n}\). For a real number \(q\ge 1\), the q-norm of x is denoted as \(\Vert x\Vert _q := (|x_1|^q + \cdots + |x_n|^q)^{1/q}\). The notation
denotes the set of monomial powers with degrees at most d. The symbol \(\mathbb {R}^{\mathbb {N}_d^n}\) denotes the space of all real vectors labeled by \(\alpha \in \mathbb {N}_d^n\). The column vector of all monomials in x and of degrees up to d is denoted as
The notation \(\mathbb {R}[x] := \mathbb {R}[x_1, \ldots , x_n]\) stands for the ring of polynomials in x with real coefficients. Let \(\mathbb {R}[x]_d\) be the set of real polynomials with degrees at most d. Denote by \(\mathscr {P}(K)\) the cone of polynomials that are nonnegative on K and let
In the following, we review some basics of polynomial optimization. For a tuple \(h := (h_1, \ldots , h_s)\) of polynomials in \(\mathbb {R}[x]\), let
The 2kth truncation of Ideal[h] is
The real variety of h is
A polynomial \(\sigma \in \mathbb {R}[x]\) is said to be a sum of squares (SOS) if there are polynomials \(q_1, \ldots , q_t \in \mathbb {R}[x]\) such that \(\sigma = q_1^2 + \cdots + q_t^2\). The convex cone of all SOS polynomials in x is denoted as \(\Sigma [x]\). We refer to [8, 13, 17, 28] for more details. For a tuple of polynomials \(g := (g_1, \ldots , g_t)\), its quadratic module is (let \(g_0 := 1\))
For a positive integer k, the degree-2k truncation of QM[g] is
The quadratic module QM[g] is said to be archimedean if there exists \(q \in \text {QM}[g]\) such that the set
is compact.
Theorem 2.1
[39] If \(\textrm{QM}[g]\) is archimedean and a polynomial \(f > 0\) on S(g), then \(f \in \textrm{QM}[g]\).
A vector \(y := \left( y_{\alpha }\right) _{\alpha \in \mathbb {N}^n_{2k}}\) is said to be a truncated multi-sequences (tms) of degree 2k. For \(y \in \mathbb {R}^{\mathbb {N}^n_{2k}}\), the Riesz functional determined by y is the linear functional \(\mathscr {L}_y\) acting on \(\mathbb {R}[x]_{2k}\) such that
For convenience, we denote
The localizing matrix and localizing vector of p generated by y are respectively
In the above, the linear operator is applied component-wisely and
We remark that \(L_p^{(k)}[y] \succeq 0\) if and only if \(\mathscr {L}_y \ge 0\) on \(\text {QM}[p]_{2k}\), and \(\mathscr {V}_{p}^{(2k)}[y]=0\) if and only if \(\mathscr {L}_y = 0\) on \(\text {Ideal}[p]_{2k}\). More details for this can be found in [13, 17, 28]. The localizing matrix \(L_p^{(k)}[y]\) satisfies the following equation
for the degree \(s := k - \lceil \deg (p)/2 \rceil \) and for every vector v of length \(n+s \atopwithdelims ()s\). For instance, when \(n = 3\), \(k = 3\) and \(p = x_1x_2x_3 - x_3^3\),
In particular, for \(p=1\), we get the moment matrix \(M_k[y] := L_1^{(k)}[y]\). Similarly, the localizing vector \(\mathscr {V}_{p}^{(2k)}[y]\) satisfies
for \(t := 2k - \deg (p)\). For instance, when \(n = 3\), \(k = 2\) and \(p = x_1^2 + x_2^2 + x_3^2 - 1\),
It is worthy to note that if \(L_{g_i}^{(k)}[y] \succeq 0\) and \(f \in \text {QM}[g]_{2k}\), then \(\langle f , y \rangle \ge 0\). This can be seen as follows. For \(f = \sum _{i=0}^{t} g_i\sigma _{i}\) with \(\sigma _{i} = \sum _j p_{ij}^2 \in \Sigma [x]\) and \(\deg ( g_i\sigma _{i}) \le 2k\), we have
A tms \(y\in \mathbb {R}^{\mathbb {N}_{2k}^n}\) is said to admit a Borel measure \(\mu \) if
Such \(\mu \) is called a representing measure for y. The support of \(\mu \) is the smallest closed set \(S \subseteq \mathbb {R}^n\) such that \(\mu (\mathbb {R}^n \setminus S) = 0\), denoted as \(\textrm{supp}(\mu )\). The measure \(\mu \) is said to be supported in a set K if \(\textrm{supp}(\mu ) \subseteq K\).
2.1 Moment Relaxation
Consider the polynomial optimization problem
where f, \(c_i\), \(c_j\) are polynomials in x. The kth order moment relaxation for (2.1) is
Suppose the tms \(y^*\) is a minimizer of above. Denote the degree
We can extract minimizers if \(y^*\) satisfies the flat truncation condition: there exists an integer \(k \ge t \ge \max \{d, \deg (f)/2\}\) such that
Interestingly, if () holds, we can extract \(r := \textrm{rank}\,M_t[y^*]\) minimizers for the optimization problem (2.1).
The following result is based on work by Curto and Fialkow [3] and Henrion and Lasserre [6]. The form of the result as presented here can be found in book [28, Section 2.7].
Theorem 2.2
[3, 6] If \(y^*\) satisfies (), then there exist \(r := \textrm{rank}\,M_t[y^*]\) distinct feasible points \(u_1, \ldots , u_r\) for (2.1) and positive scalars \(\lambda _1, \ldots , \lambda _r\) such that
In the above, the notation \(y^*|_{2t}\) stands for its subvector of entries that are labeled by \(\alpha \in \mathbb {N}_{2t}^n\).
2.2 Optimality Conditions
Suppose u is a local minimizer of (2.1). Denote the active labeling set
The linear independence constraint qualification condition (LICQC) holds at u if the gradient set \(\{\nabla c_i(u)\}_{i \in \mathcal {E} \cup J(u)}\) is linearly independent. When LICQC holds, there exists a Lagrange multiplier vector
satisfying the Karush–Kuhn–Tucker (KKT) conditions
The equation (2.3) is known as the first order optimality condition (FOOC), and (2.4) is called the complementarity condition (CC). If, in addition, \(\lambda _j + c_j(u) > 0\) for all \(j \in \mathcal {I}\), the strict complementarity condition (SCC) is said to hold at u. For the \(\lambda _i\) satisfying (2.3)–(2.4), the Lagrange function is
The Hessian of the Lagrangian is
If u is a local minimizer and LICQC holds, the second order necessary condition (SONC) holds at u:
where \(\nabla c_i(u)^{\perp } := \{v \in \mathbb {R}^n ~|~ \nabla c_i(u)^Tv = 0\}\). Stronger than SONC is the second order sufficient condition (SOSC):
If a feasible point u satisfies FOOC, SCC, and SOSC, then u must be a strict local minimizer. We refer to the book [1] for optimality conditions in nonlinear programming.
3 A Unified Moment-SOS Hierarchy
In this section, we give a unified hierarchy of Moment-SOS relaxations to solve (1.1). Under some assumptions, we prove this hierarchy has asymptotic or finite convergence.
3.1 Unified Moment-SOS relaxations
For convenience of description, we denote the equality and inequality constraining polynomial tuples for \(K_l\) as
Recall that Ideal[\(c^{(l)}_{eq}\)] denotes the ideal generated by \(c^{(l)}_{eq}\) and QM[\(c^{(l)}_{in}\)] denotes the quadratic module generated by \(c^{(l)}_{in}\). We refer to Section 2 for the notation. The minimum value of (1.1) is denoted as \(f_{min}\) and its feasible set is K. We look for the largest scalar \(\gamma \) that is a lower bound of f over K, i.e., \(f - \gamma \in \mathscr {P}(K)\). Since
we have \(f - \gamma \ge 0\) on K if and only if \(f - \gamma \ge 0\) on \(K_l\) for every \(l = 1, \ldots , m\). Note that \(f - \gamma \ge 0\) on \(K_l\) is ensured by the membership (for some degree 2k)
The kth order SOS relaxation for solving (1.1) is therefore
The dual optimization of (3.1) is then the moment relaxation
The integer k is called the relaxation order. For \(k = 1,2, \ldots \), the sequence of primal-dual pairs (3.1)–(3.2) is called the unified Moment-SOS hierarchy. For each k, we denote by \(f_{sos, k}\) and \(f_{mom, k}\) the optimal values of (3.1) and (3.2), respectively. We remark that the moment relaxation (3.2) can be equivalently written in terms of Riesz functional. Let \(\mathscr {L}^{(l)}\) denote the Riesz functional given by \(y^{(l)}\), then (3.2) is equivalent to
Proposition 3.1
For each relaxation order k, it holds that
Moreover, both sequences \(\{f_{sos,k}\}_{k=1}^{\infty }\) and \(\{f_{mom,k}\}_{k=1}^{\infty }\) are monotonically increasing.
Proof
By the weak duality, we have \(f_{sos,k} \le f_{mom,k}\). For every \(\varepsilon >0\), there exist \(l' \in [m]\) and \(u \in K_{l'}\) such that \(f(u) \le f_{min}+\varepsilon \). Let \(y := (y^{(1)}, \ldots , y^{(m)})\) be such that \(y^{(l')} = [u]_{2k}\) and \(y^{(l)} = 0\) for all \(l \in [m] \setminus \{l'\}\). Then, y is feasible for (3.2) and
Since \(\varepsilon > 0\) can be arbitrary, \(f_{mom,k} \le f_{min}\). Therefore, we get (3.3). Clearly, if \(\gamma \) is feasible for (3.1) with an order k, then \(\gamma \) must also be feasible for (3.1) with all larger values of k, since the feasible set gets larger as k increases. So the sequence of lower bounds \(\{f_{sos,k}\}_{k=1}^{\infty }\) is monotonically increasing. On the other hand, when k increases, the feasible set of (3.2) shrinks, so the minimum value of (3.2) increases. Therefore, \(\{f_{mom,k}\}_{k=1}^{\infty }\) is also monotonically increasing. \(\square \)
3.2 Extraction of Minimizers
We show how to extract minimizers of (1.1) from the unified moment relaxation. This is a natural extension from the case \(m=1\) in Section 2.1. Suppose the tuple \(y^*:= (y^{(*,1)}, \ldots , y^{(*,m)})\) is a minimizer of (3.2). Denote the degree
We can extract minimizers by checking the flat truncation condition: there exists an integer \(t \ge \max _{l \in [m]}\{d_{l}, \deg (f)/2\}\) such that
where the labeling set
Interestingly, if (3.4) holds, we can extract
minimizers for the optimization problem (1.1).
Algorithm 3.2
To solve the polynomial optimization (1.1), do the following:
- Step 0::
-
Let \(k := \max _{l \in [m]}\{d_{l}, \lceil \deg (f)/2\rceil \}\).
- Step 1::
-
Solve the relaxation (3.2). If it is infeasible, output that (1.1) is infeasible and stop. Otherwise, solve it for a minimizer \(y^*:= (y^{(*,1)}, \ldots , y^{(*,m)})\).
- Step 2::
-
Check if the flat truncation (3.4) holds or not. If (3.4) holds, then the relaxation (3.2) is tight and for each \(l \in \mathcal {A}\), the truncation \(y^{(*,l)}|_{2t}\) admits a finitely atomic measure \(\mu ^{(l)}\) such that each point in \(\textrm{supp}(\mu ^{(l)})\) is a minimizer of (1.1). Moreover, \(f_{min} = f_{mom,k}\).
- Step 3::
-
If (3.4) fails, let \(k := k+1\) and go to Step 1.
The conclusion in Step 2 is justified by the following.
Theorem 3.3
Let \(y^*:= (y^{(*,1)}, \ldots , y^{(*,m)})\) be a minimizer of (3.2). Suppose (3.4) holds for all \(l\in \mathcal {A}\). Then, the moment relaxation (3.2) is tight and for each \(l \in \mathcal {A}\), the truncation
admits a \(r_l\)-atomic measure \(\mu ^{(l)}\), where \(r_l = \textrm{rank}\, M_t[y^{(*,l)}]\), and each point in \(\textrm{supp}(\mu ^{(l)})\) is a minimizer of (1.1). Therefore, the total number of minimizers is r as in (3.5).
Proof
By the assumption, the \(y^{(*,l)} \in \mathbb {R}^{\mathbb {N}^n_{2k}}\) satisfies (3.4) and
Then, by Theorem 2.2, there exist \(r_l\) distinct points \(u_1^{(l)}, \ldots , u_{r_l}^{(l)} \in K_l\) and positive scalars \(\lambda _1^{(l)}, \ldots , \lambda _{r_l}^{(l)}\) such that
The constriant \(\sum _{l=1}^{m} y_0^{(l)} = 1\) implies that \(\sum _{l=1}^{m} \sum _{i=1}^{r_l} \lambda _i^{(l)} = 1\), so
For each \(u_i^{(l)} \in K_l\), we have \(f(u_i^{(l)}) \ge f_{min}\), so
Hence, \(f_{mom,k} = f_{min}\) and
Since each \(\lambda _i^{(l)} > 0\), then each \(f(u_i^{(l)}) = f_{min}\), i.e., each \(u_i^{(l)}\) is a minimizer of (1.1). \(\square \)
In Step 2, the flat truncation condition (3.4) is used to extract minimizers. When it holds, a numerical method is given in [6] for computing the minimizers. We refer to [28, Section 2.7] for more details.
3.3 Convergence Analysis
Recall that \(f_{min}\), \(f_{sos,k}\) and \(f_{mom,k}\) denote the optimal values of (1.1), (3.1) and (3.2), respectively. The unified Moment-SOS hierarchy of (3.1)–(3.2) is said to have asymptotic convergence if \(f_{sos,k} \rightarrow f_{min}\) as \(k \rightarrow \infty \). If \(f_{sos,k} = f_{min}\) for some k, this unified hierarchy is said to be tight or to have finite convergence. The following theorem is a natural extension from the case \(m=1\).
Theorem 3.4
(Asymptotic convergence) If \(\textrm{Ideal}[c_{eq}^{(l)}] + \textrm{QM}[c_{in}^{(l)}]\) is archimedean for every \(l = 1, \ldots , m\), then the Moment-SOS hierarchy of (3.1)–(3.2) has asymptotic convergence:
Proof
For \(\varepsilon >0\), let \(\gamma = f_{min} - \varepsilon \). Then
on \(K_l\). Since \(\textrm{Ideal}[c_{eq}^{(l)}] + \text {QM}[c_{in}^{(l)}]\) is archimedean for every l, by Theorem 2.1,
for all k large enough. So
Since \(\varepsilon > 0\) can be arbitrary, \(\lim _{k \rightarrow \infty }f_{sos,k} = f_{min}\). By (3.3), we get the desired conclusion.
\(\square \)
Recall the linear independence constraint qualification condition (LICQC), the strict complementarity condition (SCC), and the second order sufficient condition (SOSC) introduced in Section 2.2. The following is the conclusion for the finite convergence of the unified Moment-SOS hierarchy of (3.1)–(3.2).
Theorem 3.5
(Finite convergence) Assume \(\textrm{Ideal}[c_{eq}^{(l)}] + \textrm{QM}[c_{in}^{(l)}]\) is archimedean for every \(l = 1, \ldots , m\). If the LICQC, SCC, and SOSC hold at every global minimizer of (1.1) for each \(K_l\), then the Moment-SOS hierarchy of (3.1)–(3.2) has finite convergence, i.e.,
for all k large enough.
Proof
We denote by \(f_{min,l}\) the minimum value of f on the set \(K_l\). Let
-
(i)
For the case \(l \notin \mathcal {B}\), \(f_{min,l} > f_{min}\),
$$ f(x) - f_{min} \ge f_{min,l} - f_{min} > 0 $$on \(K_l\). Since \(\text {Ideal}[c_{eq}^{(l)}] + \text {QM}[c_{in}^{(l)}]\) is archimedean, there exists \(k_0\) such that
$$ f- (f_{min} - \varepsilon ) \in \text {Ideal}[c_{eq}^{(l)}]_{2k_0} + \text {QM}[c_{in}^{(l)}]_{2k_0} $$for all \(\varepsilon >0\).
-
(ii)
For the case \(l \in \mathcal {B}\), \(f_{min,l} = f_{min}\). Since the LICQC, SCC, and SOSC hold at every global minimizer \(x^*\) of (1.1), there exists a degree \(k_0\) such that for all \(\varepsilon >0\), we have
$$ f - (f_{min} - \varepsilon ) \in \text { Ideal}[c_{eq}^{(l)}]_{2k_0} + \text { QM}[c_{in}^{(l)}]_{2k_0}. $$This is shown in the proof of Theorem 1.1 of [25].
Combining cases (i) and (ii), we know that \(\gamma = f_{min} - \varepsilon \) is feasible for (3.1) with the order \(k_0\). Hence, \(f_{sos,k_0} \ge \gamma = f_{min} - \varepsilon \). Since \(\varepsilon > 0\) can be arbitrary, we get \(f_{sos,k_0} \ge f_{min}\). By Proposition 3.1, we get \(f_{sos,k} = f_{mom, k} = f_{min}\) for all \(k \ge k_0\). \(\square \)
4 Univariate Polynomial Optimization
In this section, we consider the special case of univariate polynomial optimization, i.e., \(n=1\). The following results for the univariate case are extensions from the single interval case, and are presented here to provide a complete and thorough understanding for convenience of readers. The problem (1.1) can be expressed as
where \(K_l= [a_l,b_l]\) with \(a_l<b_l\) for \(l = 1, \ldots , m\). We still denote by \(f_{min}\) the minimum value of (4.1). For convenience, we only consider compact intervals. The discussions for unbounded intervals like \((-\infty , b]\) and \([a, +\infty )\) are similar (see [28, Chapter 3]).
Let \(y := (y_0, \ldots , y_d) \in \mathbb {R}^{d+1}\) be a univariate tms of degree d with \(d=2d_0+1\) or \(d=2d_0\). The \(d_0\)th order moment matrix of y is
For convenience of notation, we also denote that
It is well-known that polynomials that are nonnegative over an interval can be expressed in terms of sum of squares. The following results were known to Lukács [19], Markov [22], Pólya and Szegö [37], Powers and Reznick [38]. For each \(h \in \mathbb {R}[x]_d\) that is nonnegative on the interval \([a_l, b_l]\), we have:
-
(i)
If \(d=2d_0+1\) is odd, then there exist \(p,q \in \mathbb {R}[x]_{d_0}\) such that
$$\begin{aligned} h=(x-a_l)p^{2}+(b_l-x)q^{2}. \end{aligned}$$(4.2) -
(ii)
If \(d=2d_0\) is even, then there exist \(p \in \mathbb {R}[x]_{d_0}, q \in \mathbb {R}[x]_{d_0-1}\) such that
$$\begin{aligned} h=p^{2}+(x-a_l)(b_l-x)q^{2}. \end{aligned}$$(4.3)
The optimization problem (4.1) can be solved by the unified Moment-SOS hierarchy of (3.1)–(3.2). For the univariate case, they can be simplified. We discuss in two different cases of d.
4.1 The Case d is Odd (\(d=2d_0+1\))
When the degree \(d=2d_0+1\) is odd, by the representation (4.2), \(f_{min}\) equals the maximum value of the SOS relaxation
Its dual optimization is the moment relaxation
In the above,
Denote by \(f_{sos}\) and \(f_{mom}\) the optimal values of (4.4) and (4.5) respectively. For all \((X_l, Y_l)\) that is feasible for (4.4) and for all \(y^{(l)}\) that is feasible for (4.5), we have
This is because
which implies that
Indeed, we have the following theorem.
Theorem 4.1
For the relaxations (4.4) and (4.5), we always have
Proof
By the representation (4.2), for \(\gamma =f_{min}\), the subtraction \(f - f_{min}\) can be represented as in (4.4) for each \(l = 1, \ldots , m\), so \(f_{sos} = f_{min}\). By the weak duality, we have \(f_{sos} \le f_{mom} \le f_{min}\). Hence, they are all equal. \(\square \)
The optimizers for (4.1) can be obtained by the following algorithm.
Algorithm 4.2
[28, Algorithm 3.3.6] Assume \(d=2d_0+1\) and \((y^{(1)}, \ldots , y^{(m)})\) is a minimizer for the moment relaxation (4.5). For each l with \(y_0^{(l)} > 0\) and \(r=\textrm{rank}\,M_{d_0}[y^{(l)}]\), do the following:
- Step 1::
-
Solve the linear system
$$ \begin{bmatrix} y_0^{(l)} &{} y_1^{(l)} &{} \cdots &{} y_{r-1}^{(l)} \\ y_1^{(l)} &{} y_2^{(l)} &{} \cdots &{} y_r^{(l)} \\ \vdots &{} \vdots &{} \ddots &{} \vdots \\ y_{2d_0-r+1}^{(l)} &{} y_{2d_0-r+2}^{(l)} &{} \cdots &{} y_{2d_0}^{(l)}\\ \end{bmatrix} \begin{bmatrix} g_0^{(l)} \\ g_1^{(l)} \\ \vdots \\ g_{r-1}^{(l)} \\ \end{bmatrix} = \begin{bmatrix} y_r^{(l)} \\ y_{r+1}^{(l)} \\ \vdots \\ y_{2d_0+1}^{(l)} \\ \end{bmatrix}. $$ - Step 2::
-
Compute r distinct roots \(t_1^{(l)}, \ldots , t_r^{(l)}\) of the polynomial
$$ g^{(l)}(x) := g_0^{(l)}+g_1^{(l)}x+\cdots +g_{r-1}^{(l)}x^{r-1}-x^r. $$ - Step 3::
-
The roots \(t_1^{(l)}, \ldots , t_r^{(l)}\) are minimizers of the optimization problem (4.1).
The conclusion in Step 3 is justified by Theorem 4.6. The following is an exposition for the above algorithm.
Example 4.3
Consider the constrained optimization problem
The moment relaxation is
The minimizer \(y^*= (y^{(*,1)}, y^{(*,2)})\) of the above is obtained as
Applying Algorithm 4.2, we get \(g_0^{(1)} = -1, g_0^{(2)} = -2, g_1^{(2)} = 3\) and the polynomials
Therefore, the minimizers are the distinct roots \(-1\), 1, 2 and the global minimum value \(f_{min} = 2\).
4.2 The Case d is Even (\(d=2d_0\))
When the degree \(d=2d_0\) is even, by the representation (4.3), \(f_{min}\) equals the maximum value of
Its dual optimization is the moment relaxation
We still denote by \(f_{sos}\) and \(f_{mom}\) the optimal values of (4.6) and (4.7), respectively. The same conclusion in Theorem 4.1 also holds here. The optimizers for (4.1) can be obtained by the following algorithm.
Algorithm 4.4
[28, Algorithm 3.3.6] Assume \(d=2d_0\) and \((y^{(1)}, \ldots , y^{(m)})\) is a minimizer for the moment relaxation (4.7). For each l with \(y_0^{(l)} > 0\) and \(r=\text {rank}\,M_{d_0}[y^{(l)}]\), do the following:
- Step 1::
-
If \(r\le d_0\), solve the linear system
$$ \begin{bmatrix} y_0^{(l)} &{} y_1^{(l)} &{} \cdots &{} y_{r-1}^{(l)} \\ y_1^{(l)} &{} y_2^{(l)} &{} \cdots &{} y_r^{(l)} \\ \vdots &{} \vdots &{} \ddots &{} \vdots \\ y_{2d_0-r}^{(l)} &{} y_{2d_0-r+1}^{(l)} &{} \cdots &{} y_{2d_0-1}^{(l)} \end{bmatrix} \begin{bmatrix} g_0^{(l)} \\ g_1^{(l)} \\ \vdots \\ g_{r-1}^{(l)} \end{bmatrix} = \begin{bmatrix} y_r^{(l)} \\ y_{r+1}^{(l)} \\ \vdots \\ y_{2d_0}^{(l)} \end{bmatrix}. $$ - Step 2::
-
If \(r=d_0+1\), compute the smallest value of \(y^{(l)}_{2d_0+1}\) satisfying
$$ b_lM_{d_0}[y^{(l)}] \succeq N_{d_0}[y^{(l)}] \succeq a_lM_{d_0}[y^{(l)}], $$then solve the linear system
$$ \begin{bmatrix} y_0^{(l)} &{} y_1^{(l)} &{} \cdots &{} y_{d_0}^{(l)} \\ y_1^{(l)} &{} y_2^{(l)} &{} \cdots &{} y_{d_0+1}^{(l)} \\ \vdots &{} \vdots &{} \ddots &{} \vdots \\ y_{d_0}^{(l)} &{} y_{d_0+1}^{(l)} &{} \cdots &{} y_{2d_0}^{(l)} \end{bmatrix} \begin{bmatrix} g_0^{(l)} \\ g_1^{(l)} \\ \vdots \\ g_{d_0}^{(l)} \end{bmatrix} = \begin{bmatrix} y_{d_0+1}^{(l)} \\ y_{d_0+2}^{(l)} \\ \vdots \\ y_{2d_0+1}^{(l)} \\ \end{bmatrix}. $$ - Step 3::
-
Compute r distinct roots \(t_1^{(l)}, \ldots , t_r^{(l)}\) of the polynomial
$$ g^{(l)}(x) := g_0^{(l)}+g_1^{(l)}x+\cdots +g_{r-1}^{(l)}x^{r-1}-x^r. $$ - Step 4::
-
The roots \(t_1^{(l)}, \ldots , t_r^{(l)}\) are minimizers of the optimization problem (4.1).
The conclusion in Step 4 is justified by Theorem 4.6. The following is an exposition for the above algorithm.
Example 4.5
Consider the constrained optimization problem
The moment relaxation is
The minimizer \(y^*= (y^{(*,1)}, y^{(*,2)})\) of the above is obtained as
Applying Algorithm 4.4, we get \(g_0^{(1)} = -2\), \(g_0^{(2)} = 0\), \(g_1^{(2)} = -1\) and the polynomials
Therefore, the minimizers are the distinct roots \(-2\), \(-1\), 0 and the global minimum value \(f_{min} = 0\).
The performance of the moment relaxations (4.5) and (4.7) can be summarized as follows.
Theorem 4.6
Suppose f is a univariate polynomial of degree \(d=2d_0+1\) or \(d=2d_0\). Then, all the optimal values \(f_{min}\), \(f_{sos}\), \(f_{mom}\) are achieved for each corresponding optimization problem and they are all equal to each other. Suppose \(y^*:= (y^{(*,1)}, \ldots , y^{(*,m)})\) is a minimizer of (4.5) when \(d=2d_0+1\) or of (4.7) when \(d=2d_0\). Then, the tms
must admit a representing measure \(\mu ^*\) supported in K, and each point in the support of \(\mu ^*\) is a minimizer of (4.1). If f is not a constant polynomial, then f has at most \(2m + \lceil (d-1)/2 \rceil \) minimizers and the representing measure \(\mu ^*\) for \(z^*\) must be r-atomic with
Proof
Since each interval \([a_l,b_l]\) is compact, K is also compact. So the minimum value \(f_{min}\) is achievable, and it equals the largest \(\gamma \in \mathbb {R}\) such that \(f-\gamma \) is nonnegative on \([a_l,b_l]\) for every \(l = 1, \ldots , m\), so \(f_{min}=f_{sos}\) (see Theorem 4.1). Each of the moment relaxations (4.5) and (4.7) has a strictly feasible point, e.g., the tms \(\hat{y}^{(l)}=\int _{a_l}^{b_l} [x]_{2d_0+1} \,dx\) is strictly feasible and
The tms \(\tilde{y}^{(l)}=\int _{a_l}^{b_l} [x]_{2d_0} \,dx\) is strictly feasible and
By the strong duality, \(f_{sos}=f_{mom}\), and both (4.4) and (4.6) achieve their optimal values. By [28, Theorem 3.3.4], \(y^{(*,l)}\) must admit a representing measure \(\mu ^{(l)}\) supported in \([a_l,b_l]\). Hence, \(z^*\) must admit a representing measure \(\mu ^*=\mu ^{(1)}+\cdots +\mu ^{(m)}\) supported in K. The optimization problem (4.1) is then equivalent to the linear convex conic optimization
where \(\mathscr {B}(K)\) denotes the convex cone of all Borel measures whose supports are contained in K. We claim that if a Borel measure \(\mu ^*\) is a minimizer of (4.8), then each point in the support of \(\mu ^*\) is a minimizer of (4.1). Suppose \(E \subseteq K\) is the set of minimizers of (4.1). For any \(x^*\in E\), let \(\delta _{x^*}\) denote the unit Dirac measure supported at \(x^*\). Then, we have
Hence,
Thus, \(f=f_{min}\) on \(\textrm{supp}(\mu ^*)\). This implies that \(\textrm{supp}(\mu ^*) \subseteq E\). So, every point in \(\textrm{supp}(\mu ^*)\) is a minimizer of (4.1).
Note that f has degree d. If f is not a constant polynomial, it can have at most \(d-1\) critical points. Moreover, the local maximizers and minimizers alternate. Thus, at most \(\lceil (d-1)/2 \rceil \) of these critical points are local minimizers. On each interval \([a_l, b_l]\), two endpoints are possibly local minimizers. Since there are m intervals in total, f has at most \(2m + \lceil (d-1)/2 \rceil \) local minimizers on K. In the above, we have proved that each point in \(\textrm{supp}(\mu ^*)\) is a minimizer of (4.1). So the representing measure \(\mu ^*\) for \(z^*\) must be r-atomic with \(r \le 2m + \lceil (d-1)\) \(/2 \rceil \). \(\square \)
We refer to Algorithm 4.2 (when \(d = 2d_0+1\)) and Algorithm 4.4 (when \(d=2d_0\)) for how to determine the support of the representing measure \(\mu ^{(l)}\) for \(y^{(*,l)}\). The points in the support are all minimizers of (4.1). The upper bound for the number of minimizers is already sharp when \(m=1\). For instance, consider the optimization
There are 3 global minimizers \(-1\), 0, 1 and \(2m + \lceil (d-1)/2 \rceil = 2+1 =3\).
We would like to remark that the representations for nonnegative univariate polynomials have broad applications. In particular, it can be applied to the shape design of transfer functions for linear time invariant (LTI) single-input-single-output (SISO) systems [29]. Since the transfer function is rational, the optimization problem can be formulated in terms of coefficients of polynomials. We can then solve it by using representations of nonnegative univariate polynomials. For instance, we look for a transfer function such that it is close to a piecewise constant shape. That is, we want the transfer function to be close to given constant values \(\xi _1, \ldots , \xi _m\) in a union of m disjoint intervals \([a_l, b_l]\) with
As in [29], the transfer function can be written as \(p_1(x)/p_2(x)\). Specifically, we want to get \(p_1\), \(p_2\) such that
The above is equivalent to the linear conic constraints
We refer to [29] for more details.
5 Numerical Experiments
In this section, we present numerical experiments for how to solve polynomial optimization over the union of several basic closed semialgebraic sets. Algorithm 3.2 is applied to solve it. All computations are implemented using MATLAB R2022a on a MacBook Pro equipped with Apple M1 Max processor and 16GB RAM. The unified moment relaxation (3.2) is solved by the software Gloptipoly [7], which calls the SDP package SeDuMi [41]. For neatness, all computational results are displayed in four decimal digits.
Example 5.1
Consider the constrained optimization problem
where
The objective function is a dehomogenization of the Horn’s form [40]. For \(k=2\), we get \(f_{mom, 2} = 0\), and the flat truncation (3.4) is met for all \(l \in \mathcal {A}=\{1,4\}\). So, \(f_{mom,2}=f_{min}\). The obtained four minimizers are
For \(k=2\), the unified moment relaxation (3.2) took around 0.6 second, while solving the individual moment relaxations (1.2) for all \(K_1\), \(K_2\), \(K_3\), \(K_4\) took around 0.9 second.
Example 5.2
Consider the constrained optimization problem
where
The objective function is obtained from Robinson’s form [40] by changing \(x_i^2\) to \(x_i\) for each i. For \(k=2\), we get \(f_{mom, 2} = -1.3185\), and the flat truncation (3.4) is met for all \(l \in \mathcal {A}=\{1,2,3\}\). So, \(f_{mom,2}=f_{min}\). The obtained three minimizers are
For \(k=2\), the unified moment relaxation (3.2) took around 0.6 second, while solving the individual moment relaxations (1.2) for all \(K_1\), \(K_2\), \(K_3\) took around 1.1 seconds.
Example 5.3
Consider the constrained optimization problem
where
The objective function is obtained from Motzkin’s form [40] by adding the term \(x_1x_2x_3\). For \(k=3\), we get \(f_{mom, 3} = -1.0757\), and the flat truncation (3.4) is met for all \(l \in \mathcal {A} = \{2, 3\}\). So, \(f_{mom,3}=f_{min}\). The obtained four minimizers are
For \(k=3\), the unified moment relaxation (3.2) took around 0.7 second, while solving the individual moment relaxations (1.2) for all \(K_1\), \(K_2\), \(K_3\) took around 1.2 seconds.
Example 5.4
Consider the constrained optimization problem
where
The objective function is a dehomogenization of the Choi–Lam form [40]. For \(k=2\), we get \(f_{mom, 2} = -1\), and the flat truncation (3.4) is met for all \(l \in \mathcal {A}=\{1,2,3\}\). So, \(f_{mom,2}=f_{min}\). The obtained four minimizers are
For \(k=2\), the unified moment relaxation (3.2) took around 0.6 second, while solving the individual moment relaxations (1.2) for all \(K_1, K_2, K_3\) took around 1.1 seconds.
A class of problems like (1.1) has absolute values in the constraints. For example, we consider that
We can equivalently express K as
Example 5.5
Consider the constrained optimization problem
The constraining set can be equivalently expressed as \(\bigcup _{l=1}^4 K_l\) with
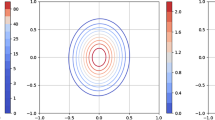
A contour of the objective over the feasible set is in Fig. 1. For \(k=2\), we get \(f_{mom, 2} = -6.3333\), and the flat truncation (3.4) is met for all \(l \in \mathcal {A}=\{1,2,3,4\}\). So, \(f_{mom,2}=f_{min}\). The obtained four minimizers are
For \(k=2\), the unified moment relaxation (3.2) took around 0.6 second, while solving the individual moment relaxations (1.2) for all \(K_1\), \(K_2\), \(K_3\), \(K_4\) took around 0.8 second.
Now we show how to compute the (p, q)-norm of a matrix \(A \in \mathbb {R}^{m\times n}\) for positive integers p, q. Recall that
When p and q are both even integers, this is a standard polynomial optimization problem. If one of them is odd, then we need to get rid of the absolute value constraints. When p is even and q is odd, we can equivalently express that
Here, the \(a_i^T\) is the ith row of A. When p is odd and q is even, we have
Similarly, when p and q are both odd, we have
The constraining sets in the above optimization problems can be decomposed in the same way as in (5.1).
Example 5.6
Consider the following matrix
Some typical values of the norm \(\Vert A\Vert _{p,q}\) and the vector \(x^*\) for achieving it are listed in Table 1.
The norms \(\Vert A\Vert _{p,q}\) are all computed successfully by the unified moment relaxation (3.2) for the relaxation order \(k=2\) or 3.

The contour is for the objective function in Example 5.5. The region outside the oval is the feasible set. The four diamonds are the minimizers
6 Conclusions and Future Work
This paper proposes a unified Moment-SOS hierarchy for solving the polynomial optimization problem (1.1) whose feasible set K is a union of several basic closed semialgebraic sets \(K_l\). Instead of minimizing the objective f separately over each individual set \(K_l\), we give a unified hierarchy of Moment-SOS relaxations to solve (1.1). This hierarchy produces a sequence of lower bounds for the optimal value \(f_{min}\) of (1.1). When the archimedeanness is met for each constraining subset \(K_l\), we show the asymptotic convergence of this unified hierarchy. Furthermore, if the linear independence constraint qualification, the strict complementarity and the second order sufficient conditions hold at every global minimizer for each \(K_l\), we prove the finite convergence of the hierarchy. For the univariate case, special properties of the corresponding Moment-SOS relaxation are discussed. To the best of the authors’ knowledge, this is the first unified hierarchy of Moment-SOS relaxations for solving polynomial optimization over unions of sets. Moreover, numerical experiments are provided to demonstrate the efficiency of this method. In particular, as applications, we show how to compute the (p, q)-norm of a matrix for positive integers p, q.
There exists relevant work on approximation and optimization about measures with unions of several individual sets. For instance, Korda et al. [11] consider the generalized moment problem (GMP) that exploits the ideal sparsity, where the feasible set is a basic closed semialgebraic set containing conditions like \(x_ix_j = 0\). Because of this, the moment relaxation for solving the GMP involves several measures, each supported in an individual set. Lasserre et al. [15] propose the multi-measure approach to approximate the moments of Lebesgue measures supported in unions of basic semialgebraic sets. Magron et al. [20] discuss the union problem in the context of piecewise polynomial systems. We would also like to compare the sizes of relaxations (1.2) and (1.3). To apply the individual relaxation (1.2), we need to solve it for m times. For the unified relaxation (1.3), we only need to solve it for one time. For a fixed relaxation order k in (1.2), the length of the vector \(y^{(l)}\) is \(n+2k \atopwithdelims ()2k\). For the same k in (1.3), there are m vectors of \(y^{(l)}\), and each of them has length \(n+2k \atopwithdelims ()2k\). The comparison of the numbers of constraints is similar. Observe that (1.2) has \(|\mathcal {E}^{(l)}|\) equality constraints, \(|\mathcal {I}^{(l)}|+1\) linear matrix inequality constraints, and one scalar equality constraint. Similarly, (1.3) has \(|\mathcal {E}^{(1)}|+\cdots +|\mathcal {E}^{(m)}|\) equality constraints, \( |\mathcal {I}^{(1)}|+\cdots +|\mathcal {I}^{(m)}|+m\) linear matrix inequality constraints, and one scalar equality constraint. It is not clear which approach is more computationally efficient. However, in our numerical examples, solving (1.3) is relatively faster.
There is much interesting future work to do. For instance, when the number of individual sets is large, the unified Moment-SOS relaxations have a large number of variables. How to solve the moment relaxation (3.2) efficiently is important in applications. For large scale problems, some sparsity patterns can be exploited. We refer to [10, 21, 42, 43] for related work. It is interesting future work to explore the sparsity for unified Moment-SOS relaxations. Moreover, how to solve polynomial optimization over a union of infinitely many sets is another interesting future work.
References
Bertsekas, D.: Nonlinear Programming, 2nd edn. Athena Scientific, Belmont, Massachusetts (1995)
Bochnak, J., Coste, M., Roy, M.-F.: Real Algebraic Geometry. Springer-Verlag, Berlin (1998)
Curto, R.E., Fialkow, L.A.: Truncated K-moment problems in several variables. J. Oper. Theory 54, 189–226 (2005)
de Klerk, E.: Aspects of Semidefinite Programming: Interior Point Algorithms and Selected Applications. Springer, New York (2002)
Dressler, M., Nie, J., Yang, Z.: Separability of Hermitian tensors and PSD decompositions. Linear Multilinear Algebra 70, 6581–6608 (2022)
Henrion, D., Lasserre, J.-B.: Detecting global optimality and extracting solutions in gloptipoly. In: Henrion, D., Garulli, A. (eds.) Positive Polynomials in Control. Lecture Notes in Control and Information Sciences, vol. 312, pp. 293–310. Springer, Berlin, Heidelberg (2005)
Henrion, D., Lasserre, J.B., Löfberg, J.: GloptiPoly 3: moments, optimization and semidefinite programming. Optim. Methods Softw. 24, 761–779 (2009)
Henrion, D., Korda, M., Lasserre, J.B.: The Moment-SOS Hierarchy. World Scientific, Singapore (2020)
Henrion, D.: Geometry of exactness of moment-SOS relaxations for polynomial optimization. arXiv:2310.17229 (2023)
Klep, I., Magron, V., Povh, J.: Sparse noncommutative polynomial optimization. Math. Program. 193, 789–829 (2022)
Korda, M., Laurent, M., Magron, V., Steenkamp, A.: Exploiting ideal-sparsity in the generalized moment problem with application to matrix factorization ranks. Math. Program. 205, 703–744 (2024)
Lasserre, J.B.: Global optimization with polynomials and the problem of moments. SIAM J. Optim. 11, 796–817 (2001)
Lasserre, J.B.: Introduction to Polynomial and Semi-Algebraic Optimization. Cambridge University Press, Cambridge (2015)
Lasserre, J.B., Laurent, M., Rostalski, P.: Semidefinite characterization and computation of zero-dimensional real radical ideals. Found. Comput. Math. 8, 607–647 (2008)
Lasserre, J.B., Emin, Y.: Semidefinite relaxations for Lebesgue and Gaussian measures of unions of basic semialgebraic sets. Math. Oper. Res. 44, 1477–1493 (2019)
Laurent, M.: Semidefinite representations for finite varieties. Math. Program. 109, 1–26 (2007)
Laurent, M.: Sums of squares, moment matrices and optimization over polynomials. In: Putinar, M., Sullivant, S. (eds.) Emerging Applications of Algebraic Geometry. The IMA Volumes in Mathematics and its Applications, vol. 149, pp. 157–270. Springer, New York (2009)
Laurent, M.: Optimization over polynomials: Selected topics. In: Jang, S.Y., Kim, Y.R., Lee, D.-W., Yie, I. (eds.) Proceedings of the International Congress of Mathematicians, pp. 843–869 (2014)
Lukács, F.: Verschärfung des ersten Mittelwertsatzes der Integralrechnung für rationale Polynome. Math. Z. 2, 295–305 (1918)
Magron, V., Forets, M., Henrion, D.: Semidefinite approximations of invariant measures for polynomial systems. Discrete Contin. Dyn. Syst. B 24, 6745–6770 (2019)
Mai, N.H.A., Magron, V., Lasserre, J.B.: A sparse version of Reznick’s Positivstellensatz. Math. Oper. Res. 48, 812–833 (2023)
Markov, A.: Lectures on functions of minimal deviation from zero (russian), 1906. Selected Works: Continued fractions and the theory of functions deviating least from zero, OGIZ, Moscow-Leningrad, pp. 244–291 (1948)
Nesterov, Y.: Squared functional systems and optimization problems. In: Frenk, H., Roos, K., Terlaky, T., Zhang, Z. (eds.) High Performance Optimization. Applied Optimization, vol. 33, pp. 405–440. Springer, New York (2000)
Nie, J.: Polynomial optimization with real varieties. SIAM J. Optim. 23, 1634–1646 (2013)
Nie, J.: Optimality conditions and finite convergence of Lasserre’s hierarchy. Math. Program. 146, 97–121 (2014)
Nie, J.: Symmetric tensor nuclear norms. SIAM J. Appl. Algebra Geom. 1, 599–625 (2017)
Nie, J.: Tight relaxations for polynomial optimization and Lagrange multiplier expressions. Math. Program. 178, 1–37 (2019)
Nie, J.: Moment and Polynomial Optimization. SIAM, Philadelphia, PA (2023)
Nie, J., Demmel, J.: Shape optimization of transfer functions. In: Hager, W.W., Huang, S.-J., Pardalos, P.M., Prokopyev, O.A. (eds.) Multiscale Optimization Methods and Applications. Nonconvex Optimization and Its Applications, vol. 82, pp. 313–326. Springer, New York (2006)
Nie, J., Tang, X.: Nash equilibrium problems of polynomials. Math. Oper. Res. 49, 1065–1090 (2024)
Nie, J., Tang, X.: Convex generalized Nash equilibrium problems and polynomial optimization. Math. Program. 198, 1485–1518 (2023)
Nie, J., Tang, X., Yang, Z., Zhong, S.: Dehomogenization for completely positive tensors. Numer. Algebra, Control Optim. 13, 340–363 (2023)
Nie, J., Tang, X., Zhong, S.: Rational generalized Nash equilibrium problems. SIAM J. Optim. 33, 1587–1620 (2023)
Nie, J., Yang, L., Zhong, S.: Stochastic polynomial optimization. Optim. Methods Softw. 35, 329–347 (2020)
Nie, J., Yang, L., Zhong, S., Zhou, G.: Distributionally robust optimization with moment ambiguity sets. J. Sci. Comput. 94, 12 (2023)
Nie, J., Zhang, X.: Real eigenvalues of nonsymmetric tensors. Comput. Optim. Appl. 70, 1–32 (2018)
Pólya, G., Szegö, G.: Problems and Theorems in Analysis: Series, Integral Calculus. Theory of Functions. Springer, Berlin, Heidelberg (1972)
Powers, V., Reznick, B.: Polynomials that are positive on an interval. Trans. Amer. Math. Soc. 352, 4677–4692 (2000)
Putinar, M.: Positive polynomials on compact semi-algebraic sets. Ind. Univ. Math. J. 42, 969–984 (1993)
Reznick, B.: Some concrete aspects of Hilbert’s 17th problem. In: Delzell, C.N., Madden, J.J. (eds.) Contemporary Mathematics, vol. 253, pp. 251–272. American Mathematical Society, Providence, RI (2000)
Sturm, J.F.: Using SeDuMi 1.02, a Matlab toolbox for optimization over symmetric cones. Optim. Methods Softw. 11, 625–653 (1999)
Wang, J., Magron, V., Lasserre, J.B.: TSSOS: A moment-SOS hierarchy that exploits term sparsity. SIAM J. Optim. 31, 30–58 (2021)
Wang, J., Magron, V., Lasserre, J.B., Mai, N.H.A.: CS-TSSOS: Correlative and term sparsity for large-scale polynomial optimization. ACM Trans. Math. Softw. 48, 1–26 (2022)
Zhong, S., Cui, Y., Nie, J.: Towards global solutions for nonconvex two-stage stochastic programs: a polynomial lower approximation approach. SIAM J. Optim. (2024). To appear
Acknowledgements
Jiawang Nie is partially supported by the NSF grant DMS-2110780. Linghao Zhang is partially supported by the UCSD School of Physical Sciences Undergraduate Summer Research Award.
Author information
Authors and Affiliations
Corresponding author
Additional information
This article is dedicated to Professor Tamás Terlaky’s 70th birthday.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nie, J., Zhang, L. Polynomial Optimization Over Unions of Sets. Vietnam J. Math. (2024). https://doi.org/10.1007/s10013-024-00700-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10013-024-00700-3