
Abstract
Statistical downscaling is the technique of linking large-scale predictors and local-scale predictands through a relationship that is assumed to be helpful to generate local-scale climate change information from global climate model (GCM) driven large-scale future projection. The present study investigates downscaled seasonal and annual rainfall change scenarios over different locations of the Western Himalaya Region (WHR) of India using common predictors from ten GCMs of CMIP5 (Coupled Model Intercomparison Project phase 5) and reanalysis datasets from NCEP/NCAR (National Centers for Environmental Prediction/National Center for Atmospheric Research); and predictands from the IMD (India Meteorological Department) rain gauge stations. The combined EOF (Empirical Orthogonal Function) approach was used to develop location-specific statistical downscaling models over the WHR, and later on, some statistical skill scores based on error and agreement analysis were used to validate the model performance. Downscaled precipitation scenario using a multi-model ensemble of GCM under RCP4.5 (Representative Concentration Pathways 4.5) reveals a wetter climate during the 2020s, 2050s, and 2080s in the annual and monsoon time scale, whereas a drier climate is expected in the winter. Results show a possible intensification of the southwest monsoon and decrease in the frequency of western disturbances in the twenty-first century as the percentage changes of rainfall in monsoon will be higher than annual and winter time scale. The uncertainty in the monthly precipitation is projected to increase as time progresses from the 2020s to the 2080s. Higher uncertainty in precipitation is expected in the late pre-monsoon and early post-monsoon over WHR.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Under the context of global warming, the non-uniform and gradual increase in surface air temperature in different parts of the globe may lead to a change in precipitation patterns and their intensity, imposing a severe threat to agriculture and hydrological systems (Hoegh-Guldberg et al. 2018). The impact of warming over the mountainous areas covered with snow and ice, like the Himalayan region, is more severe than the plain area. Studies showed that the Himalayas are warming at a higher rate than the global average rate of warming (Xu et al. 2009; Das et al. 2018). Studies also reported that regional warmings in the Himalayas might increase the magnitude and frequency of extreme precipitation events (Tewari et al. 2017; Meher et al. 2018; Rafiq et al. 2022). Hence, accurate precipitation change information over this region is critical for the stakeholders to combat climate change and hydrological management. Along with precipitation, the climate change over the Himalayas also influences glaciers or snow cover, affecting rivers’ drainage patterns and tributaries that feed water from these glaciers (Tayal 2019). These rivers nourish the life and livelihood of > 500 million people living downstream in the Indo-Gangetic plains (IGP) and guarantee India’s energy security due to their role in producing hydel and thermoelectricity. Almost one-third of India’s electricity production capacity is located in IGP, and any variability in the flow pattern of Himalayan rivers can have profound consequences for the country’s energy security (Tayal 2019). The Himalayas are highly vulnerable to climate change among the youngest mountain ranges (Shrestha et al. 2012; IPCC 2013; Panwar 2021). Due to extreme local precipitation, several devastating floods have left their footprints over the Western Himalayan region (WHR) during the recent past, for example, Leh-Ladakh floods of 2010, Western Himalayan floods of 2012, Uttarakhand floods of 2013, Jammu and Kashmir flood of 2014, and Uttarakhand flood of 2021 (Ghawana and Minoru 2015; Sati and Gahalaut 2013; Kuloo 2021). These five floods wiped out ~ 7 thousand lives and ~ 614.45 billion worth of economic losses (Balaji 2011; Gupta et al. 2013; Balasubramanian and Kumar 2014; Stäubli et al. 2018). Studies show that the frequency of both extreme rainfall events (Chug et al. 2020) and extreme river flow events (Bharti 2015) has a significantly increasing trend over the WHR during 1980–2003 and 1998–2013, respectively. The extreme flow events have more than doubled during 1992–2003 compared to 1980–1991 (Chug et al. 2020). If such a trend persists, we might see more floods, especially flash floods, in the forthcoming decades (Saeed et al. 2017; Almazroui et al. 2021). So, the fundamental scientific question is, what will be the future of the Himalayan ecosystem under such natural disasters? The answer lies in taking proper flood mitigation measures to avoid future damage. Accurate assessment of future rainfall projection is one such flood mitigation technique that the scientific community should focus on.
Mishra (2015) and Almazroui et al. (2020) reported several climatic uncertainties in the Himalayan region about the changes coming from the observational datasets and the climate models. There is uncertainty in the observational finding of glacier melt and precipitation in different portions of the western Himalayan region. For example, Kehrwald et al. (2008) and Bolch et al. (2012) reported retreat in most Himalayan glaciers while advancing and stable glaciers were reported by Scherler et al. (2011) in the Karakoram Himalaya. A trilogy of studies by Archer and Fowler (2004), Bhutiyani et al. (2010), and Meher et al. (2018) reported three different nature of winter precipitation over the Himalayas, where the first study reported an increasing trend of winter precipitation during 1960–2000 in the upper Indus basin while the second and the third studies reported non-significant and significant declining trends of winter precipitation during 1866–2006 and 1902–2005 respectively. Like observational uncertainty, there is much uncertainty of future changes in precipitation coming from the global climate models (GCM) as they have failed to depict the Indian summer monsoon adequately (Pithan 2010; Meher et al. 2017). Contrasting findings were reported by Immerzeel et al. (2010) and Palazzi et al. (2013) on future precipitation projections where the former found a reduction in flow over the Indus and Brahmaputra basins under the projected future climate change; the latter reported wetter future conditions in the Himalayas from the investigations on CMIP5 GCMs. Despite these uncertainties, accurate assessment of precipitation over the Himalayas is necessary where weather events are pretty localized (Krishnan et al. 2019). Hence, downscaling techniques arose to bridge this gap (Benestad et al. 2007, 2008; Meher et al. 2017). It is essential to infer local precipitation through so-called downscaling in GCM studies. Downscaling is the process in which a natural and physical linkage is developed between the state of some variable representing a large space/scale (Predictor, e.g., Sea level pressure) and the state of some variable representing a smaller space/scale (Predictand, e.g., Local temperature of a weather station) (Chen et al. 2014). While the raw output of GCMs is practically of no use in high and complex topography regions because of their coarser resolution, inherent biases, and uncertainty to reproduce local scale features, the statistical downscaling approach of climate models can provide helpful information about the changes that are projected for the future climate.
Several literatures have emphasized the future climate prospects of the Indian region, where statistical downscaling has been used as an implicit technique (Tripathi et al. 2006; Salvi et al. 2011; Salvi and Ghosh 2013; Shashikanth et al. 2014; Shashikanth and Sukumar 2017). In a sub-regional context, several statistical and dynamic downscaling-based studies have reported possible changes of minimum, maximum, and mean temperatures as well as mean rainfall during different scales (i.e., monthly, seasonal, and annual) and different times (the 2020s, 2050s, and 2080s), and in different regions of the Himalayas. A brief literature review on downscaling of rainfall and temperature over different regions of the Himalayas is provided in Table 1. Uncertainties were seen in the future precipitation change over the WHR as several studies have come up with contradictory findings. For example, Sanjay et al. (2017) reported surplus (deficit) monsoon precipitation during 2036–2095 (2065–2095) under RCP8.5 (RCP4.5) over the entire WHR, while Banerjee et al. (2020) reported deficit precipitation (stagnant precipitation trend) during 2020–2100 in the Uttarakhand region. Over the Jhelum River Basin, Mahmood and Babel (2013) reported an increasing annual precipitation trend, while Akhter (2017) reported a decreasing trend in the future. Sabin et al. (2020) reported a non-significant moderate increasing trend of winter precipitation over the WHR region, while a significant increasing trend of winter rainfall was reported by Sanjay et al. (2017) and Almazroui et al. (2020).
Rainfall over the WHR is highly localized and is influenced by complex topography and large-scale circulations like summer monsoon and western disturbances (Meher et al. 2017, 2018). CMIP5 (Coupled Model intercomparison Project phase 5) GCMs over the WHR have shown improvement over CMIP3 in simulating the mean, interannual variability, and short-term trend of observed rainfall data (Meher et al. 2017). Improvement in the skill of GCMs across generations is a positive sign towards our advanced understanding of various parameterization schemes employed in the GCMs. Hence, they must be incorporated in the downscaling studies to better understand the region’s future climate (Almazroui et al. 2021). Several articles have investigated the precipitation change over the WHR through statistical downscaling studies. The earlier studies used satellite or reanalysis-based data, which never gives the ground reality due to their biases with the actual observation. Many uncertainties in the actual precipitation change in the future were seen when their findings were compared. The success of statistical downscaling depends on how accurate and how much volume of observational records were passed into the downscaling model. More than 400 meteorological stations are there over the WHR, but long-term data (> 100 years) is available for only 22 stations as taken in this study, which is the longest ever record of rain gauge data incorporated for any downscaling study over the WHR to date. In addition, as mentioned in Table 1, earlier studies only examined a specific portion of the WHR or an extensive area, of which WHR is a tiny part. Hence, to bridge these research gaps, the present study has been attempted to meet the following objectives.
-
I.
To develop and validate multiple stations-specific statistical downscaling models over the WHR.
-
II.
To construct local future annual and seasonal precipitation scenarios from existing CMIP5 GCMs using empirical statistical downscaling techniques over the WHR.
2 Study region and data used
2.1 Study region
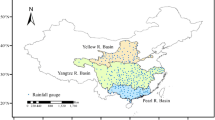
The study region is a part of the Hindu Kush Himalaya (HKH) region consists of two north India states—Himachal Pradesh and Uttarakhand, as shown in Fig. 1. Geographically, it is located between 28°43'–33°12'N and 75°47'–81°02'E (Meher et al. 2018). One of the major rivers of India—“The Ganga”—originates from the Gangotri glacier located in the Uttarakhand state. This region is a part of the “greater Himalayan” mountain range comprising an area of 1092.39 km2 (i.e., ~ 20.45% of the Indian Himalayan region). Glaciers present in the high topography of this region feed water to most rivers (e.g., The Chenab, The Yamuna, The Chandra, The Mandakini, The Pindari, The Ramganga, The Goriganga) flowing in Northern India (Das and Meher 2019). The local relief of the study region varies from 210 to 7817 m above mean sea level. The high altitude locations of this region are primarily cold deserts and record low annual rainfall compared to the foothills. The Lahul and Spiti region of Himachal Pradesh, and a tiny pocket in Garhwal beyond Badrinath and Neelang Region in Uttarkashi districts of Uttarakhand state fall under the cold deserts (Negi 2002). The climate of the study region is mainly dry to semi-humid; snowfall over this region starts during December and continues to March (Negi 2002). The rainfall over this region is highly erratic and is affected by Indian monsoon during June to September, WD during December to Early March and El Niño-Southern Oscillation (ENSO) (Meher et al. 2017, 2018).

(left) The location of the study region by highlighted box over the map of India. (right) The distribution of 22 numbers of meteorological stations (marked with station ID) over the study region. The station names corresponding to each station ID are mentioned in Table 2
2.2 Data used
2.2.1 Observational data or predictand
Twenty-two numbers of rain gauge stations (eight in Himachal Pradesh and fourteen in Uttarakhand) having monthly rainfall during the period 1901–2005 are taken in the present study. (However, the 1950–2005 time period was used for this study as a common time window for all the datasets.) These reference stations have long-term rainfall data procured from the India Meteorological Department (IMD) and were extensively used in earlier studies (Meher et al. 2014, 2017, 2018; Meher and Das 2019) for climate change and GCM evaluation. IMD high-resolution (0.25° × 0.25° latitude-longitude) gridded data developed by Pai et al. (2014a, 2014b) were used to fill the missing values in the mean monthly rainfall data. A detailed description of the missing value substitution in the original monthly rainfall data is available from Meher et al. (2017) and Meher and Das (2019). The location details of the rain gauge stations taken in this study are given in Table 2.
2.2.2 Large-scale fields or predictors
Large-scale predictors used for the present study are given in Table 3, comprising ten GCMs from the CMIP5 and four reanalysis predictors from the NCEP/NCAR (National Centers for Environmental Prediction/National Center for Atmospheric Research). The GCMs and the reanalysis data are available from the Web link of the Lawrence Livermore National Laboratory archives (https://esgf-node.llnl.gov/projects/esgf-llnl/) and the archives of Earth System Research Laboratory (ESRL) of National Oceanic and Atmospheric Administration (NOAA) (https://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanalysis.html) respectively. The reanalysis predictors were developed by the NCEP/NCAR (Kalnay et al. 1996). Two parameters, viz., monthly mean of relative humidity at 500 hPa (rhum500) and monthly precipitation (pr) for the GCMs and the reanalysis data, are taken in this study. NCEP data do not contain “precipitation” as a parameter while precipitation rate (unit: mm/day) was converted to monthly precipitation (unit: mm/month) for the present study.
The first ensemble runs with single initialization states, and the physical parameterization (r1i1p1) scheme was taken for the GCM datasets. All the GCMs and NCEP simulations containing monthly rainfall data from 1950 to 2005 were retrieved from their respective archives, while the future data for the GCMs were retrieved for a common period of 2006–2095 under the RCP4.5 scenario.
3 Methodology
There are two different ways of downscaling of GCMs firstly downscaling through a nested high-resolution regional climate model (RCM), often termed as “dynamical downscaling” illustrating the atmospheric and surface state in a smaller area with an enhanced spatial resolution than the GCM, and secondly, empirical-statistical downscaling (ESD) (Wilby and Wigley 1997; Benestad 2011; Chen et al. 2014). Some properties of GCMs are also common to the RCMs, like bias and parameterization. One of the significant difficulties in assessing RCMs is that they require extensive computer resources.
The purpose of ESD is particular, such as using GCMs to make an assumption about the local climate at a given location. ESD involves statistically representing appropriate fields from coarser-resolution GCMs. This method is more economical and less computer-intensive because it does not involve complex atmospheric physics (Salvi et al. 2013; Sachindra et al. 2014). However, ESD requires a large volume of accurate data, to begin with, a suitable set of predictors and the notion that the relationship between these predictors and the predictand will remain valid in the future climate (Benestad 2011; Blazak 2012). This approach is known as perfect prognosis (PP) (Maraun et al. 2010; Chen et al. 2014). There are three types of statistical downscaling schemes—(i) transfer function (based on regression models), (ii) weather typing/weather classification schemes, and (iii) weather generators (Benestad 2008; Blazak 2012; Chen et al. 2014). The first two types of the scheme may involve a pp-approach (Kanan et al. 2013) which uses empirical models that relate observation-based predictand and large-scale predictor during a common time period and then applied to simulated predictors (for example, GCM scenario runs) for the future (Kanan et al. 2013; Eden & Widmann 2014). In addition, a common attribute for many of these schemes is to apply an empirical orthogonal function (EOF) analysis to the large-scale variables (predictor) using few leading EOFs to train the empirical models (Zorita and von Storch 1999; Benestad 2001b, 2010; Benestad et al. 2008; Das et al. 2016). To be very specific, the “first scheme” deals with linking local-scale climate variables with the large-scale atmospheric field by using a linear or non-linear regression model (Blazak 2012; Chen et al. 2014; Das et al. 2016). Under this scheme, a statistical equation is developed to incorporate one or more large-scale predictor variables to estimate the local scale predictand. The “second scheme” groups days into similar synoptic events and relates those with local conditions such as temperature and precipitation (Blazak 2012). The third scheme uses stochastic models based on a gamma distribution for rainfall amounts and a Markov chain or semi-empirical distribution for transition probabilities between states. The present study deals with the first downscaling scheme, i.e., the transfer function.
The transfer function-based statistical downscaling is the most popular and widely used technique to project rainfall and temperature. The quality and the reliability of results obtained from ESD for successful implication in the local scale depends on various factors like long-term data with fewer missing records, local scale variable (predictand) to be downscaled, geography and circulation pattern of the site under consideration, and most importantly selection of a suitable predictor/s. Predictand, like temperature, shows > 70% variance in most downscale results, while the variance reduces to ~ 30% for rainfall (Wilby et al. 1999; Chen et al. 2014). The most frequently used predictors from GCM outputs for downscaling precipitation over the Indian and surrounding region include geopotential height, mean sea level pressure, air temperature, perceptible water content, precipitation rate, zonal and meridional velocity, relative humidity, and specific humidity (Huth et al. 1999; Goyal and Ojha 2010; Ojha et al. 2010; Huang et al. 2011; Blazak 2012; Mahmood and Babel 2012; Hu et al. 2013; Devak and Dhanya 2014; Pervez and Henebry 2014). The stepwise method for statistical downscaling used in this study is described below. The downscaling was carried out for three different time scales, i.e., annual, monsoon (June, July, August, September), and winter (December, January, February). In the case of the annual time scale, the total rainfall was used for downscaling, whereas the mean monthly rainfall was used in the monsoon and winter season.
Step 1: Common resolution of all data sets:
Horizontal resolutions of all the datasets were converted to a common grid resolution of 1.5° × 1.5° to avoid any systematic bias in the results. The selection of the common resolution depends on the user’s choice as per the original resolution of the datasets taken.
Step 2: Selection of predictand:
Twenty-two observational IMD rain gauge stations having rainfall data during 1950–2005 were selected as predictands based on our previous investigations (Meher and Das 2020).
Step 3: Selection of predictor domain and predictors:
This step is the crucial step of the statistical downscaling process. We have selected suitable predictors from the reanalysis data based on their statistical relationship with the predictand. In our earlier investigation (Meher and Das 2020) on the selection of suitable predictors and predictor domain over the WHR, geopotential height at 850 hPa, relative humidity at 500 and 1000 hPa, and precipitation rate emerged as good predictors for downscaling precipitation over different predictor domains over the WHR. We have used the two best predictors, viz., relative humidity at 500 hPa and precipitation rate, as predictors for the present study. Later on, the same predictor parameters from the GCMs were taken to employ them in the downscaling process.
Initially, a significantly larger domain of South Asia (10° S–40° N, 20°–120° E) was taken to see the spatial correlation, i.e., the correlation between observational data and the predictor data at each grid (using annual as well as seasonal data). The region where the spatial correlations were maximum was taken as the predictor domain (Meher and Das 2020). For the present study, a larger area between 27–38° N and 72–82° E around the study region was considered the predictor domain described in our earlier study (Meher and Das 2020).
The same study selected a suitable predictor in annual, monsoon, and winter time scales over the study domain using twenty-four potential predictors from the NCEP/NCAR reanalysis data. Meher and Das (2020) used two different skill scores to select the performance of the predictor. The skill scores were:
-
I.
Adjusted R2 of multiple regression between the seven-leading empirical orthogonal function (EOF) of predictor and regional averaged observational data.
-
II.
Correlation between the regional average data of the observation and the predictors.
Finally, all the predictors for a particular season were ranked using their skill score values. The top-ranked predictor was used as a suitable predictor for the downscaling study. After selecting suitable predictors from the reanalysis data, the same predictor parameters were taken from the GCM simulations and scenario runs.
Step 4: Model setup and calibration:
The model setup was carried out using a combined EOF of the gridded reanalysis data and the GCM data as predictor while rain gauge data was the predictand as suggested by Benestad (2001b). The time series from reanalysis and GCM data represent the same spatial pattern in this approach. Here, the two data fields with data points on a common grid are combined along the time axis, and an EOF analysis was applied to the combined dataset. The EOF analysis was applied to the anomalies from the respective GCM and reanalysis climatologies. Each of the predictands and grid box values of the reanalysis data was detrended (i.e., original value minus the linear trend values) to reduce systematic bias towards the model calibration (Benestad 2001a).
Singular value decomposition (SVD) was used to calculate the EOFs used in this study. The EOFs used were estimated from a subsample of the data to avoid temporal autocorrelation, and the principal components have then been calculated according to the following inequality.
where, X, U, A, and V represent the data field (anomalies), EOFs, diagonal matrix of eigenvalues, and principal components respectively. Here, all the well-resolved EOFs were mutually orthogonal (UTU = I) and any spatial anomaly pattern will therefore be a specific combination of EOFs.
A statistical model describing the relation between predictors (x) and predictands (y) can be written as:
Here, Ω represents the statistical model, which was obtained by treating x as the principal components of the predictors used for model development and y as the IMD station rainfall record and then solving for Ω. The empirical downscaling models used in this study were developed using canonical correlation analysis.
All these model types were trained with the ten leading common EOFs through stepwise screening calibration (Wilks 1995; Kidson and Thompson 1998), in which the contribution of each predictor was evaluated through a cross-validation analysis (Wilks 1995). Only those contributing to the cross-validation skill were included in the predictor dataset.
Different statistical skill scores like Perkin score (Perkin et al. 2007), mean error or mean bias, and normalized root mean squared error (NRMSE) were used to calibrate the model over a 30-year window of 1951–1980. A short description of each skill score is as follows.
-
Perkin score (P):
This index (P) calculates the cumulative minimum value of two different distributions of each binned value. As a result, it calculates the common area between two probability distribution functions (PDFs). Values of P or the total sum of the probability at each bin center in a given PDF lie between 0 and 1. P = 1 represents the distribution of the model, and the observations are perfectly similar, i.e., both the distributions overlap each other. While P = 0 represents the model and the observed distributions are unique in their own way. The Perkin score is given by,
where, n, Zm, and ZO represent the number of bins used, frequency of values in a given bin from the model, and frequency of values in a given bin from the observed rainfall data respectively.
-
Normalized Root Mean Squared Error (NRMSE):
NRMSE is a measure of error when a distinct difference exists between the observed data and the model data. Here the normalization was achieved using the observed dataset. The normalization factor depends on the user’s choice, while common choices are the mean, standard deviation, or the range of the measured data. Lower NRMSE values indicate less residual variance. NRMSE is scale-dependent and is sensitive to outliers. The expression for NRMSE is as follows:
Here, the standard deviation of observation (σo) was used for normalization. M represents the model-generated values, O is the observed value, and N is the length of the common time window of modeled and observed data.
-
Mean error (me):
Mean error is the measure of average bias between the model and the observed datasets. It is expressed as
Here, M represents the model-generated values, O is the observed value, and N is the length of the common time window of modeled and observed data.
Step 5: Model validation:
The same statistical skill scores as mentioned above were also used to validate the model over a 25-year window of 1981–2005. In this step, the unused data from the GCMs during the period 1981–2005 were used in the model developed in step 4.
Step 6: Construction of future precipitation scenarios:
The same model developed in step 4 was used to project the GCM data during the three different 30-year time windows of 2006–2035, 2036–2065, and 2066–2095. The scenario data of the GCMs were used to downscale the local precipitation at each of the rain gauge stations taken in the study.
Both mean rainfall (at annual, monsoon, and winter time scales) and standard deviation of rainfall for each month (or the annual cycle of standard deviation) were downscaled at each of the station locations using the method mentioned above.
4 Results and discussion
The suitable predictor selected to downscale annual and monsoon rainfall from 1950 to 2005 was precipitation rate (pr), while relative humidity at 500 hPa (rhum500) was the best predictor during the winter season over the selected domain. These were the predictors which acquired top rank among the twenty-four predictors taken in our earlier study (Meher and Das 2020). The reason for getting two different predictors in the study region is that there exist two distinct seasons in the study region with distinct characteristics of prevailing circulation patterns. During the monsoon season, the study region gets ~ 80% of the annual rainfall (1250.1 ± 241.7 mm) from the large-scale southwest monsoon, while ~ 11% of the annual rainfall was received during the winter season from the eastward flowing western disturbances (Meher et al. 2017). In connection to the relative humidity parameter, it was shown in the literature that zonal and meridional structures of the relative humidity were an essential parameter of the vertical structure of western disturbances (Hunt et al. 2018) and can be taken as a parameter to simulate the precipitation and circulation pattern of the western disturbances in the model evaluation studies (Azadi et al. 2002; Thomas et al. 2018).
4.1 Performance of predictors during calibration
Figure 2 shows the performance hur500 and pr predictors for all the 22 rain gauge stations using different skill scores, viz., Perkin score, mean error, and NRMSE during the calibration period (1951–1980) in the monsoon and winter seasons. The predictor “hur500” was initially being selected to downscale the winter precipitation and “pr” for monsoon precipitation; nonetheless, both the predictors were used to calibrate the downscaled model to verify whether any of them is redundant (i.e., redundancy of pr in the winter season and hur500 in monsoon season). This is a simple assumption, which can be solved by analyzing agreement and error indices used in the study. The skill scores for a particular station represented the ensemble mean skill scores of all the GCMs. The skill scores of the calibration period for the annual time scale are not shown, as they are the same as the monsoon season.

Performance of selected predictors for all the rain gauge stations using different skill scores, viz., Perkin score, mean error, and NRMSE during the time window of 1951–1980 (calibration period) in the monsoon and winter seasons. Here, the skill scores represent the ensemble mean skill scores of all the GCMs
4.1.1 Analysis of Perkin score
The mean value of the agreement index, i.e., the Perkin score (P) in monsoon season, was ~ 0.50 for both predictors. 0.70 ≥ P ≥ 0.50 for stations like Banjar, Berinag, Dehra Gopipur, Hamirpur, Karnaprayag, Kasauli, Kashipur, Nurpur, Rajpur, and Ramnagar. Similarly, 0.50 ≥ P ≥ 0.40 for stations like Haldwani, Kangra, Kathgodam, Kotdwara, Kotkhai, Lansdowne, Palampur, and Srinagar. The P values for all the stations were > 0.35 except Ranikhet. In the winter season, the mean value of the Perkin score (P) was ~ 0.45 for both predictors. All the stations showed the value of 0.6 ≥ P ≥ 0.35 during the winter season. The result showed that downscaled PDFs of the monsoon season precipitation for most stations were quite similar to the observed PDFs, whereas, in the winter season, their performances were nominally lower than the monsoon season. Calculated P values for both predictors failed to explain the redundancy assumption proposed in the earlier paragraph.
4.1.2 Analysis of mean error
The mean value of the error index, i.e., the mean error (me) in the monsoon season, was ~ 4.62 for the pr, whereas it was higher for the hur500 (me ~ 29). The mean error indicated by pr was ~ 0 for most sites like Almora, Berinag, Bironkhol, Hamirpur, Kathgodam, Kotdwara, Lansdowne, Okhimath, Palampur, Ramnagar, Ranikhet, and Srinagar. Considerable differences lie among the two predictors’ mean error values (me of hur500 > me of pr) in a few sites like Dehra Gopipur, Kangra, Nurpur, Palampur, Rajpur, and Srinagar. In the winter season, the average mean error value was ~ 14 for the hur500, whereas it was higher for the pr (me ~ 55). The mean error shown by hur500 was ≤ 7 for the sites like Almora, Banjar, Berinag, Kangra, Kotkhai, Nurpur, Okhimath, Palampur, Rajpur, and Ranikhet. Considerable differences can be seen among the mean error values of the two predictors (me of pr > me of hur500) in all the sites over the study area. Altogether, the results showed that during the calibration period, the selected “suitable predictors” for the monsoon (pr) and winter (hur500) season showed a very negligible bias of downscaled precipitation with the observed precipitation. In contrast, a notable and higher bias was seen between the downscaled and observed precipitation during monsoon and winter seasons using hur500 and pr as predictors, respectively. Hence, the assumption of hur500 can also be taken as a suitable predictor to downscale monsoon and annual precipitation; and pr can be taken as a suitable predictor to downscale winter precipitation is false. Nonetheless, the trueness of this statement was also tested in the following paragraph using the NRMSE as another error index.
4.1.3 Analysis of normalized root mean squared error
The mean value of another error-index, i.e., the normalized root mean squared error (NRMSE) in the monsoon season, was ~ 75 for the pr, whereas it was higher for the hur500 (me ~ 79). The NRMSE values shown by pr were < 65 for some stations like Kangra, Lansdowne, Okhimath, Palampur, and Rajpur. Substantial differences lie among the NRMSE values of the two predictors (NRMSE of hur500 > NRMSE of pr) in some stations like Haldwani, Kangra, Kotdwara, Lansdowne, Nurpur, Okhimath, Palampur, and Rajpur. In the winter season, the mean value of NRMSE was ~ 85 for the hur500, whereas it was higher for the pr (me ~ 90). The calculated NRMSE values shown by hur500 were ≤ 80 for the stations like Kasauli, Okhimath, and Ranikhet. Notable differences lie among the NRMSE values of the two predictors (NRMSE of pr > NRMSE of hur500) in some sites in the study area like Berinag, Bironkhol, Karnaprayag, Kathgodam, Nurpur, Okhimath, Ramnagar, and Srinagar. Overall, the results showed that during the calibration period, the selected “suitable predictors” for the monsoon (pr) and winter (hur500) season showed lower normalized error values between the downscaled precipitation and the observed precipitation. In contrast, notable and higher normalized errors were seen between the downscaled and observed precipitation during monsoon and winter seasons using hur500 and pr as predictors, respectively. In addition, the assumption of hur500 can also be taken as a suitable predictor to downscale monsoon and annual precipitation; and pr can be taken as a suitable predictor to downscale winter precipitation is false. Hence, the trueness of this argument also holds using NRMSE as a skill score to evaluate the performance of both predictors during the calibration period.
4.2 Validation results
Figure 3 shows the performance of individual GCM predictors during the validation period of 1981–2005 using the skill scores (P, me, and NRMSE). The GCM outputs of predictor pr were used in the downscaled model for annual and monsoon precipitation. In contrast, the GCM outputs of predictor hur500 were used in the downscaled model for the winter precipitation. Calculated values of the skill scores for all the 22 stations were used to generate Fig. 3 for the GCMs.

Performance of selected predictors for different GCMs using various skill scores, viz., Perkin score, mean error, and NRMSE during the time window of 1981–2005 (validation period) in the annual, monsoon season, and winter season. Here, the box plot for a particular GCM was generated using the calculated values of skill scores of all the station locations. For example, the box plot for the BNU-ESM GCM’s Perkin score in the winter season was calculated using the twenty-two Perkin score values of 22 stations downscaled using BNU-ESM GCM in the winter season
4.2.1 Validation from Perkin score
Perkin score (P) values in the annual time scale were 0.60 ≥ P ≥ 0.24 for all the GCMs. Except for seven sites—Kashipur, Kotdwara, Lansdowne, Palampur, Rajpur, Ramnagar, and Srinagar—all the other sites showed P values > 0.42 in most of the GCMs. Banjar, Kathgodam, and Okhimath sites have shown P > 0.55 for all the GCMs. Four GCMs (BNU-ESM, CMCC-CMS, MPI-ESM-LR, and NorESM1-ME) were the better performing GCMs having the median P-value of ~ 0.45. In the monsoon season, the P values were 0.54 ≥ P ≥ 0.26 for all the GCMs. In this season, all the stations except Berinag, Bironkhol, Palampur, Ramnagar, and Srinagar have shown P values > 0.40 in most GCMs. The calculated P values for six stations—Banjar, Dehra Gopipur, Karnaprayag, Kotkhai, Lansdowne, Nurpur, and Okhimath—were ~ 0.48 during the monsoon season. Most of the GCMs (except BNU-ESM and NorESM-ME) were the better performing GCMs this season, having a median value of P ~ 0.40. In the winter season, the P values were 0.51 ≥ P ≥ 0.20 for all the GCMs. All the stations except Bironkhol, Haldwani, Kashipur, Palampur, and Ramnagar have shown P values ≥ 0.30 in most GCMs. Three stations—Banjar, Karnaprayag, and Okhimath—have shown P values ~ 0.40 in all the GCMs during the winter season. The median value of P for four GCMs was bcc-csm1-1-m, and CNRM-CM5, MPI-ESM-MR, and NorESM1-ME were ~ 3.2; however, with a P-value of 3.6, MPI-ESM-MR was the best GCM in the winter season.
The above verification results based on the Perkin score indicated that precipitation distribution during the validation period was similar to the observed distribution to a certain extent in some sites like Banjar, Karnaprayag, Kotdwara, Lansdowne, Okhimath, Rajpur, and Srinagar. These stations have shown Perkin scores in the range 0.40–0.55 irrespective of time scale. One of the most notable features of rainfall distribution in the study region during the period 1951–2005 was a sudden shift of rainfall in most of the stations during 1960–1970. As a result, the rainfall distributions, before 1960–1970 and after 1960–1970, were distinct (Basistha et al. 2009; Kumar and Jaswal 2016; Meher et al. 2017, 2018); this may be a possible reason why the Perkin score in the validation period was less than the calibration period.
4.2.2 Validation from mean error
The calculated value of mean error (me) was revealed to be almost similar for all the GCMs in the individual time scale. In the annual time scale, the median value of the mean error was ~ 80. Stations like Bironkhol, Karnaprayag, Haldwani, Kashipur, Kathgodam, Lansdowne, Nurpur, and Ramnagar have shown a mean error value of ~ 130 in all the GCMs, whereas stations like Almora, Banjar, Berinag, Dehra, Gopipur, Kangra, Kasauli, Okhimath, Ranikhet, and Srinagar have shown a very low mean error value of ~ 21 to 27. The highest mean bias (~ 231) was seen in the Rajpur and Kotdwara stations in most GCMs. CanESM2 was the best performing GCM with a median value of the mean error of ~ 72. In the monsoon season, the median value of the mean error was between 26 and 38 in all the GCMs. Stations like Haldwani, Karnaprayag, Kashipur, Kotdwara, Kotkhai, and Nurpur have shown a mean error value in the range 45–76 in all the GCMs, whereas stations like Almora, Berinag, Dehra Gopipur, Kangra, Kasauli, and Srinagar have shown a very low mean error value between − 10 and 10. Higher mean error values were seen in the Palampur and Rajpur stations in most GCMs with a mean value of ~ − 109 and 140, respectively. Five stations, viz., Hamirpur, Kangra, Kasauli, Palampur, and Srinagar, have shown a dry bias in all the GCMs with a range of − 10 to 0 (− 109 in Palampur). CanESM2 was the best performing GCM with a median value of the mean error ~ 13. The mean error values were very low in the winter season, with a median value < 6 in all the GCMs. Three stations, namely Bironkhol, Nurpur, and Okhimath, have demonstrated higher mean bias values (~ 18) in all the GCMs compared to other stations. Some stations over the study region, viz., Almora, Banjar, Berinag, Haldwani, Hamirpur, Kathgodam, Palampur, Ranikhet, and Srinagar, have shown nominal wet bias (− 1 to − 11) concerning the observed rainfall. The performance of all the GCMs was quite similar; however, the NorESM-ME GCM with a median value of the mean error ~ 2 was the best performing GCM during the winter season.
The above validation results based on mean error showed a decreasing order of mean error values in different time scales: me in annual time scale > me in monsoon > mean error in winter season during the validation period. The higher mean error in annual is the higher magnitude of rainfall received in the annual time scale, whereas in winter, the rainfall received over the study region was lower.
4.2.3 Validation from normalized root mean squared error
Like the mean error, calculated values of NRMSE were also similar for all the GCMs in different time scales. In the annual time scale, the median value of the NRMSE was ~ 40. Stations like Berinag, Kasauli, Nurpur, Palampur, and Rajpur have shown an NRMSE value between 70 and 80 in all the GCMs. In contrast, stations like Almora, Dehra Gopipur, Hamirpur, Kathgodam, Kotkhai, Ranikhet, and Srinagar have shown a very low NRMSE value lying between ~ 25 and 35. The highest NRMSE (~ 80) was seen in the Rajpur and Berinag stations in most GCMs. NorESM1-M was the best performing GCM with a median value of the NRMSE ~ 39. In the monsoon season, the median value of the NRMSE was between 91 and 98 in all the GCMs. Stations like Haldwani, Kashipur, Kotkhai, and Ramnagar have shown an NRMSE value in the range 102–119 in all the GCMs. In contrast, stations like Dehra Gopipur, Hamirpur, Kangra, Lansdowne, and Okhimath have lower NRMSE values between 86 and 89. Higher NRMSE values were seen in the Kotkhai and Ramnagar stations in most GCMs, with a mean value of ~ 110 and 119. NorESM1-M was the best performing GCM with a median NRMSE value of ~ 91. In the winter season, the NRMSE values were < 109 in all the GCMs. Four stations, namely Bironkhol, Karnaprayag, Nurpur, and Ramnagar, have shown higher NRMSE values (between 112 and 115) in all the GCMs compared to other stations. CanESM2 and MPI-ESM-LR GCMs were the better performing GCMs with a median value of ~ 101.5 during the winter season.
4.3 Analysis of projected mean precipitation
The model developed by the combined EOF approach of the GCMs and reanalysis gridded predictors during the historical period was used for the future projection of rainfall in each of the stations. The RCP4.5 scenario data generated during the annual, monsoon, and winter time scales from each GCM was used in the calibration model to determine the change of rainfall during the twenty-first century. Three sub-periods, viz., 2006–2035 (the 2020s near future), 2036–2065 (2050s or mid future), and 2066–2095 (2080s or far future), were considered to calculate the percentage change of rainfall in the future. Table 4 shows the percentage (%) change (Δ) of 95th percentile rainfall estimates during different sub-periods, viz., the 2020s, 2050s, and 2080s in the twenty-first century calculated from the downscaled ensemble mean of ten GCMs (MME10). The historical time period of 1951–2005 was used as the baseline to calculate the percentage (%) change of rainfall in each sub-period. Palazzi et al. (2015) highlighted that no single CMIP5 model (out of 32 models) provides the best simulation in precipitation. The large spreads of individual models suggest considering a multi-model ensemble means approach to study past future climate change over the Hindu Kush Himalayan region. Hence, we considered limiting our analysis of future precipitation projection using the multi-model ensemble approach.
4.3.1 Change of rainfall in annual time scale
Table 4 revealed a surplus of rainfall in most sites (i.e., 18 out of 22) in the study region during all the future sub-periods. In addition, few stations, viz., Karnaprayag, Kasauli, Lansdowne, and Rajpur, may face deficient rainfall during future sub-periods. Peculiar nature of positive/negative percentage change in rainfall (Δ) was found in most of the rain gauge sites where Δ2020s > Δ2050s > Δ2080s, whereas in a few sites like Almora, Berinag, Dehra Gopipur, Hamirpur, Kotdwara, Palampur, and Srinagar, the opposite trend of rainfall change was detected, i.e., Δ2020s < Δ2050s < Δ2080s. The stations, which recorded a surplus of rainfall in the future, have a mean Δ of 8.9% in the near future, 7.7% in the mid future, and 6.5% in the far future. Similarly, the stations that recorded a deficient future rainfall have a mean Δ of – 12.0% in the 2020s, − 10.9% in 2050s, and − 4.5% in 2080s. Minor change in Δ (i.e., 0.2 to 3%) was observed in Almora, Berinag, Kangra, and Ranikhet stations. Stations like Bironkhol, Haldwani, Kashipur, Kotdwara, and Nurpur may receive 10–16% surplus rainfall in different sub-periods. Ramnagar station may face the highest rainfall change, i.e., ~ 25–29% more rainfall during 2006–2065. On the other hand, Karnaprayag and Rajpur stations may face an acute deficit of rainfall during the twenty-first century, ranging from − 9 to − 14% and − 9 to − 22%, respectively. The overall analysis of projected rainfall change in the annual time scale revealed a wetter climate in the future in most of the locations of the study region under a changing climate with the highest radiative forcing scenario of RCP4.5.
Earlier studies on the change of annual rainfall in the twenty-first century through statistical downscaling approaches reported a wetter climate in different portions of the Western Himalaya region like the Sutlej river basin (Singh et al. 2015), Jhelum river basin (Mahmood and Babel 2013), Lidder river basin (Altaf et al. 2017), and different districts of Uttarakhand (in the monthly time scale) (Sharma et al. 2015). Panday et al. (2015) analyzed the simulated and projected precipitation over the western Himalaya-Karakoram using the CMIP3 and CMIP5 models. They also reported a wetter climate during the future over the study region. On the other hand, the model evaluation study by Wu et al. (2017) reported that future precipitation is projected to increase over most parts of the Hindu Kush Himalaya region, except for the northwestern part.
4.3.2 Change of rainfall in monsoon season
In the monsoon season, the projected rainfall at the majority of the stations may increase with respect to the baseline period. There are few stations (Hamirpur, Karnaprayag, Kasauli, Lansdowne, and Rajpur) where the projected rainfall revealed a deficit accumulation in all the sub-periods. The majority of the stations (12 out of 22 stations), namely Bironkhol, Kangra, Karnaprayag, Kasauli, Kathgodam, Kotkhai, Lansdowne, Nurpur, Okhimath, Rajpur, Ramnagar, and Ranikhet over the study region, have shown a decreasing trend of Δ across the three sub-periods, i.e., Δ2020s > Δ2050s > Δ2080s. On the other hand, the peculiar trend of increasing rainfall in some sites—Almora, Berinag, Dehra Gopipur, Haldwani, Hamirpur, Kashipur, and Kotdwara (as seen in the annual time scale) —was also seen across the different sub-periods, i.e., Δ2020s < Δ2050s < Δ2080s. The sites, which recorded a surplus of rainfall in the future, have a mean Δ of 10.4% in the near future, 11.2% in mid future, and 10.1% in the far future. Similarly, stations that recorded a deficient rainfall in the future have a mean Δ of – 17.6% during the 2020s, − 11.32% in the 2050s, and − 11.37% during the 2080s. Comparisons among the average value of percentage changes in annual and monsoon projected rainfall over WHR showed a clear difference, i.e., ΔMonsoon > ΔAnnual during all the sub-periods, hence depicting the intensification of southwest monsoon in future climate over the study region. The percentage change of rainfall in some stations like Nurpur, Okhimath, Palampur, and Ramnagar has shown a higher value, i.e., ~ 14–21.5% during the first two sub-periods (i.e., the 2020s and 2050s) compared to all the other stations. Rajpur station has shown the highest rainfall deficit among all the stations, with a Δ value of ~ 30% in the near future and ~ 18% in the mid future. Kangra, Kasauli, and Kathgodam stations have shown a nominal change in rainfall, having a Δ of 1.66% to 3.71%, − 1 to − 2.5%, and 1.7 to 6.8% respectively in the future. The overall analysis of projected rainfall change in the monsoon season revealed a wetter climate in the future in most of the locations of the study region under a changing climate.
Studies briefed that thermal contrast between the Tibetan plateau and the Indian ocean acts as an active driver of southwest monsoon rainfall over the Indian region, resulting in the transportation of water vapor from the tropical Indian Ocean to the Himalayas (Duan et al. 2006; Meher et al. 2017). Hence, higher monsoon rainfall may be attributed to strengthening the thermal contrast between the two regions of the planet in the future. Concerning future projection of monsoon rainfall over the study region, Kulkarni et al. (2013) reported that summer monsoon precipitation is expected to be 20–40% higher in 2071–2098 than that in the baseline period (1961–1990) over the Hindu Kush Himalayan region. Their findings were based on the study of high-resolution Regional Climate Model PRECIS (Providing Regional Climates for Impact Studies). Palazzi et al. (2013) also reported an increase in projected monsoon season mean precipitation with an increase in heavy rainfall days over the Hindu-Kush Karakoram Himalaya using a single CMIP5 model simulation. Kadel et al. (2018) studied the projection of future monsoon precipitation over the central Himalayas (including the present study region) using 38 CMIP5 GCMs. Their study reported increased summer monsoon mean precipitation in all future periods under RCP4.5.
4.3.3 Change of rainfall in winter season
Downscaled precipitation projections in the winter season have shown contrasting characteristics of what annual and monsoon precipitation projections were expected to show in the future over WHR. The WHR in the winter season is expected to be drier as all the stations revealed a deficient rainfall in all the three sub-periods of the near future (exception Kotdwara and Bironkhol stations), and the mid and far future. Like precipitation projection in monsoon season and annual time scales, in winter season also an increasing nature of mean percentage change of rainfall in future was observed across the three sub-periods, i.e., Δ2020s < Δ2050s < Δ2080s. The lowest precipitation stress is expected during the near future with a mean ∆ value of − 2%, whereas in the mid and far future, the calculated values of ∆ were − 10.4% and − 19.2%, respectively. Stations with the highest value of declining winter precipitation were Dehra Gopiur in the 2020s (∆ = − 3.4%), and Kotkhai in the 2050s and 2080s (∆ = − 15.4%, and − 28.4% respectively). The stations expected to face a higher precipitation deficit (∆ > 12.5%) during the 2050s are Dehra Gopipur, Kasauli, Kotkhai, Okhimath, Rajpur, and Ramnagar. Similarly, the stations expected to face a higher precipitation deficit (∆ > 25%) during the 2080s are Kasauli, Kotkhai, Okhimath, and Ramnagar. The overall analysis of winter rainfall projection from the downscaled data revealed that the study region is expected to get deficient precipitation in the twenty-first century under a changing climate with the highest radiative forcing scenario of RCP4.5. Nepal et al. (2021) also reported a deficit of winter precipitation over the Kabul river basin (in WHR) during the mid and far future under a warm and dry climatic condition.
During the winter season, precipitation in the study region is mainly attributed to the passage of eastward flowing western disturbances, which tend to develop over the Mediterranean Sea and the Atlantic Ocean. A decrease in the winter precipitation may be directly linked to the decreasing frequency of western disturbances in the future.
4.4 Analysis of the projected uncertainty of precipitation
Figure 4 illustrates the downscaled standard deviation of monthly precipitation in all the stations’ locations during different sub-periods. Both the predictors were used to downscale the standard deviation of precipitation. However, the predictor pr findings were only included in the text as both of them showed very similar results.

Downscaled standard deviation of monthly precipitation (using the predictor pr) in all the station locations during future sub-periods. Standard deviation values of the multi-model ensemble were portrayed through green color bars (first) for the 2020s, blue color bars (second) for 2050s, and red color bars (third) for 2080s. The observed standard deviation during the period 1951–2005 was represented through the black color bar (fourth)
UI Hasson et al. (2016) reported that the reliability of the climate model’s projections for future changes in the hydrology of the South and Southeast Asia region largely depends upon their realistic representation of both the monsoon precipitation regime and the westerly precipitation regime for the present-day climate. In Fig. 4, the downscaled results show a realistic representation of the standard deviation of precipitation in all the months. The essential features of Fig. 4 were that the monsoon precipitation regime and the winter/westerly precipitation regime were well reproduced through the downscaling method. The amplitude of standard deviation (σ) values in different sub-periods has shown a distinct pattern of the increasing trend from the 2020s to 2080s, i.e., σ2020s < σ2050s < σ2080s in ten out of twelve months (January, February, March, April, May, June, September, October, November, December). In July and August months, the increasing pattern of standard deviation was σ2050s < σ2020s < σ2080s and σ2050s < σ2080s < σ2020s respectively. The inclining trend of standard deviation across the different sub-periods represented an increasing uncertainty of projected precipitation with time progress. Results also showed five classes of standard deviation values (average value of σ of all the stations), i.e., 0–50 in November and December; 51–100 in January, February, March, April, and October; 101–150 in May, June, and September; 151–200 in July; and 201–250 in August. The higher value of standard deviation in July and August and an unfamiliar trend as discussed above represent that peak monsoon months were associated with random uncertainty of precipitation amount in the future. The stations that may face higher uncertainty of winter month’s rainfall in the future are Dehra Gopipur, Kasauli, Nurpur, Palampur, and Hamir.
Similarly, the uncertainty of monsoon month’s rainfall is expected to be higher in stations like Berinag, Dehra Gopipur, Haldwani, Kasauli, Kathgodam, Nurpur, Palampur, and Rajpur. In the rest of the sites, rainfall uncertainty is expected to be lower in winter and monsoon months. Palampur and Nurpur are the stations where the rainfall has consistently higher uncertainty in most of the months in the study region.
Month-wise percentage change of “average σ” of all the stations compared with the baseline period showed that in seven out of twelve months(Jan, and March to August), there was a positive change of σ. In contrast, from Oct to December, the change in σ was negative in all the sub-periods (Fig. 5). From Fig. 5, it is evident that later pre-monsoon months (dry seasons) and early post-monsoon months (dry season) will contribute maximum uncertainty to the rainfall in the study region, followed by the early post-monsoon month. However, this uncertainty may not impact the hydrological budget of the study region as rainfall during this time is significantly less in the past (< 5% of annual rainfall) over the WHR (Meher et al. 2017, 2018).

Month-wise percentage change of standard deviation (σ, average standard deviation values of all the stations) of downscaled precipitation during different sub-periods. The results were displayed for the downscaled precipitation using the pr predictor
5 Conclusion
Based on the results obtained from the present study, the downscale precipitation outputs from a multi-model ensemble of ten CMIP5 GCMs under the highest radiative forcing scenario of RCP4.5 revealed a wet climate in annual and monsoon, where a dry climate is expected in the future in the winter season over the Western Himalaya region. The total annual precipitation is expected to increase by 8.9% in the 2020s, 7.7% in 2050s, and 6.5% in 2080s compared to the baseline scenario. Similarly, mean monthly precipitation in the monsoon season may increase by 10.4% in the 2020s, 11.2% in the 2050s, and 10.1% in the 2080s. On the other hand, in the winter months, precipitation is expected to decline by 2% in the 2020s, 10.4% in the 2050s, and 19.2% in the 2080s. The downscaled standard deviation (σ) of monthly precipitation in different sub-periods has shown a distinct pattern of inclining trend from the 2020s to 2080s, representing an increasing uncertainty of projected precipitation with the progress of time. Downscaled precipitation projection during the twenty-first century showed higher precipitation uncertainty in pre-monsoon months (April and May) and early post-monsoon months (October) in the study region.
An increase in the monsoon rainfall over the WHR will positively impact the yield of the rainfed crop and ensure the nation’s energy security through increased hydroelectricity (Thadani 2015). WHR is highly prone to loss of fertile soil (for example, in Uttarakhand, the rate of loss of fertile soil is ten times higher than the national average) due to land degradation attributed to the intensity of precipitation (concentrated rainfall) (Thadani 2015; IHDI 2018). Uncertainty in the precipitation pattern may lead to flood-like conditions and infrastructure loss. Severe drought conditions in Uttarakhand in 2007–2008 were attributed to the uncertainty of precipitation patterns. Deficit precipitation in the winter season (also known as winter drought) can adversely affect the germination and yield of food crops (or rabi crops) like lentils, wheat, and mustard. Marginal and small landholders of rainfed areas are more vulnerable to food sufficiency due to this winter drought and precipitation uncertainty (Sharma et al. 2017). Priority action plans like drought and flood-tolerant crop varieties can boost crop production efficiency. Similarly, crop diversification and weather-based crop insurance can ensure economic viability in the WHR. Moreover, soil erosion check measures, rooftop water harvesting, and construction of ponds and tanks can meet the objective of in situ moisture conservation. In addition, research and development on the advanced forecasting model for yield and weather also need to be undertaken to reduce the impact of future precipitation uncertainty.
Data availability
The observational data were procured from IMD-Pune, India. They will be made available on request. The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code availability
The codes are available on reasonable request.
References
Akhter M (2017) Projection of future temperature and precipitation for Jhelum river basin in India using multiple linear regression. Int J Eng Res Appl 6(4):89–101. https://doi.org/10.9790/9622-07060489101
Almazroui M, Saeed F et al (2021) (2021) Projected changes in climate extremes using CMIP6 simulations over SREX regions. Earth Syst Environ 5(3):481–497. https://doi.org/10.1007/s41748-021-00250-5
Almazroui M, Saeed S, Saeed F, Islam MN, Ismail M (2020) Projections of precipitation and temperature over the South Asian countries in CMIP6. Earth Syst Environ 4(2):297–320. https://doi.org/10.1007/s41748-020-00157-7
Altaf Y, Ahmad AM, Mohd F (2017) MLR based statistical downscaling of temperature and precipitation in Lidder basin region of India. Environ Pollut Climate Change 1(109):2. https://doi.org/10.4172/2573-458x.1000109
Archer DR, Fowler HJ (2004) Spatial and temporal variations in precipitation in the upper Indus basin, global teleconnections and hydrological implications. Hydrol Earth Syst Sci 8(1):47–61. https://doi.org/10.5194/hess-8-47-2004
Azadi M, Mohanty UC, Madan OP, Padmanabhamurty B (2002) Prediction of precipitation associated with a western disturbance using a high-resolution regional model: role of parameterisation of physical processes. Meteorol Appl 9(3):317–326. https://doi.org/10.1017/S1350482702003055
Balaji B (2011) Dister management plan in Leh district. https://cdn.s3waas.gov.in/s3291597a100aadd814d197af4f4bab3a7/uploads/2018/10/2018100483.pdf . Accessed 16 March 2022
Balasubramanian M, Kumar PD (2014) Climate change, Uttarakhand, and the World Bank's message. Economic and Political Weekly 4:65–8. https://www.jstor.org/stable/24478458. Accessed 21 March 2022
Banerjee A, Dimri AP, Kumar K (2020) Rainfall over the Himalayan foot-hill region: present and future. J Earth Sys Sci 129(1):1–6. https://doi.org/10.1007/s12040-019-1295-2
Basistha A, Arya DS, Goel NK (2009) Analysis of historical changes in rainfall in the Indian Himalayas. Int J Climatol 29:555–572. https://doi.org/10.1002/joc.1706
Benestad RE (2001a) The cause of warming over Norway in the ECHAM4/OPYC3 GHG integration. Int J Climatol 21:371–387. https://doi.org/10.1002/joc.603
Benestad RE (2001b) A comparison between two empirical downscaling strategies. Int J Climatol 21(13):1645–1668. https://doi.org/10.1002/joc.703
Benestad RE (2010) Downscaling Precipitation Extremes. Theor Appl Climatol 100(1–2):1–21. https://doi.org/10.1007/s00704-009-0158-1
Benestad RE (2011) A new global set of downscaled temperature scenarios. J Climate 24(8):2080–2098. https://doi.org/10.1175/2010JCLI3687.1
Benestad RE, Hanssen-Bauer I, Chen D (2008) Empirical-statistical downscaling. World Scientific Publishing Company, New Jersey, London. https://doi.org/10.1142/6908
Benestad RE, Hanssen-Bauer I, Førland EJ (2007) An evaluation of statistical models for downscaling precipitation and their ability to capture long-term trends. Int J Climatol 27(5):649–665. https://doi.org/10.1002/joc.1421
Bharti V (2015) Investigation of extreme rainfall events over the Northwest Himalaya region using satellite data. Master's Thesis, University of Twente.
Bhutiyani MR, Kale VS, Pawar NJ (2010) Climate change and the precipitation variations in the northwestern Himalaya: 1866–2006. Int J Climatol 30(4):535–548. https://doi.org/10.1002/joc.1920
Blazak A (2012). Statistical downscaling of precipitation projections in Southeast Queensland Catchments. Doctoral dissertation, University of Southern Queensland.
Bolch T, Kulkarni A et al (2012) The state and fate of Himalayan glaciers. Science 336(6079):310–314. https://doi.org/10.1126/science.1215828
Chen J, Brissette FP, Leconte R (2014) Assessing regression-based statistical approaches for downscaling precipitation over North America. Hydrol Process 2(9):3482–3504. https://doi.org/10.1002/hyp.9889
Chug D, Pathak A, Indu J, Jain SK, Jain SK, Dimri AP, Niyogi D, Ghosh S (2020) Observed evidence for steep rise in the extreme flow of western Himalayan rivers. Geophy Res Lett 47(15):e2020GL087815. https://doi.org/10.1029/2020GL087815
Das L, Dutta M, Mezghani A, Benestad RE (2018) Use of observed temperature statistics in ranking CMIP5 model performance over the Western Himalayan Region of India. Int J Climatol 38(2):554–570. https://doi.org/10.1002/joc.5193
Das L, Meher JK (2019) Drivers of climate over the Western Himalayan region of India: a review. Earth-Sci Rev 198:102935. https://doi.org/10.1016/j.earscirev.2019.102935
Das L, Meher JK, Dutta M (2016) Construction of rainfall change scenarios over the Chilka Lagoon in India. Atmos Res 182:36–45. https://doi.org/10.1016/J.ATMOSRES.2016.07.013
Devak M, Dhanya CT (2014) Downscaling of precipitation in Mahanadi basin, India. Int J Civil Eng Res 5:111–120
Duan K, Yao T, Thompson LG (2006) Response of monsoon precipitation in the Himalayas to global warming. J Geophys Res 111:D19110. https://doi.org/10.1029/2006JD007084
Eden JM, Widmann M (2014) Downscaling of GCM-simulated precipitation using model output statistics. J Climate 27(1):312–324. https://doi.org/10.1175/JCLI-D-13-00063.1
Ghawana T, Minoru K (2015) Indian flood management: a report on institutional arrangements. Integrated Spatial Analytics Consultants, Delhi, India & International Centre for Water Hazard and Risk Management (ICHARM) under the auspices of UNESCO; Public Works Research Institute (PWRI). Available at http://whrm-kamoto.com/assets/files/TARUN%20MINORU-ICHARM%20REOPRT%20ON%20INDIAN%20FLOOD%20MANAGEMENT%20INSTITUTIONS%20JANUARY%202015.pdf. Accessed on 21 March 2022
Goyal MK, Ojha CSP (2010) Evaluation of various linear regression methods for downscaling of mean monthly precipitation in arid Pichola watershed. Nat Resources 1(01):11–18. https://doi.org/10.4236/nr.2010.11002
Gupta V, Dobhal DP, Vaideswaran SC (2013) August 2012 cloudburst and subsequent flash flood in the Asi Ganga, a tributary of the Bhagirathi river, Garhwal Himalaya. India Curr Sci 25:249–253
Ul Hasson S, Pascale S, Lucarini V, Böhner J (2016) Seasonal cycle of precipitation over major river basins in South and Southeast Asia: a review of the CMIP5 climate models data for present climate and future climate projections. Atmos Res 180:42–63
Hoegh-Guldberg O, Jacob D, Bindi M et al (2018) Impacts of 1.5 C global warming on natural and human systems. Global warming of 1.5 °C. An IPCC special report. https://www.ipcc.ch/site/assets/uploads/sites/2/2019/06/SR15_Chapter3_High_Res.pdf Accessed on 21 March 2022
Hu Y, Maskey S, Uhlenbrook S (2013) Downscaling daily precipitation over the Yellow River source region in China: a comparison of three statistical downscaling methods. Theor Appl Climatol 112(3–4):447–460. https://doi.org/10.1007/s00704-012-0745-4
Huang J, Zhang J, Zhang Z et al (2011) Estimation of future precipitation change in the Yangtze River basin by using statistical downscaling method. Stoch Environ Res Risk Assess 25(6):781–792. https://doi.org/10.1007/s00477-010-0441-9
Hunt KM, Turner AG, Shaffrey LC (2018) The evolution, seasonality and impacts of western disturbances. Q J R Meteorol Soc 144(710):278–290. https://doi.org/10.1002/qj.3200
Huth R (1999) Statistical downscaling in central Europe: evaluation of methods and potential predictors. Clim Res 13(2):91–101. https://doi.org/10.3354/CR013091
IHDI (2018) Uttarakhand: Vision 2030, Department of Planning, Government of Uttarakhand, p. 87. https://des.uk.gov.in/pages/display/154-uttarakhand-vision-2030 Accessed on 22 March 2022.
WW Immerzeel Droogers p, et al 2009 Large-scale monitoring of snow cover and runoff simulation in Himalayan river basins using remote sensing Remote Sens Environ 113 1 40 49 https://doi.org/10.1016/j.rse.2008.08.010
IPCC (2013), Climate change 2013: The Physical Science Basis, in Contribution on Working Group I to the Fifth Assessment Report of the IPCC, edited by T. F. Stocker et al. 1535 pp., Cambridge Univ. Press, Cambridge, U. K., and New York
Kadel I, Yamazaki T, Iwasaki T, Abdillah MR (2018) Projection of future monsoon precipitation over the central Himalayas by CMIP5 models under warming scenarios. Clim Res 75(1):1–21. https://doi.org/10.3354/cr01497
Kalnay E, Kanamitsu M, Kistler R et al (1996) The NCEP-NCAR 40-year reanalysis project. Bull Am Meteor Soc 77:437–471. https://doi.org/10.1175/1520-0477(1996)077%3C0437:TNYRP%3E2.0.CO;2
Kannan S, Ghosh S (2013) A nonparametric kernel regression model for downscaling multisite daily precipitation in the Mahanadi basin. Wat Resour Res 49(3):1360–1385. https://doi.org/10.1002/wrcr.20118
NM Kehrwald TLG Tandong Y et al 2008 Mass loss on Himalayan glacier endangers water resources Geophys Res Lett 35 L22503 https://doi.org/10.1029/2008GL035556
Kidson JW, Thompson CS (1998) A comparison of statistical and model-based downscaling techniques for estimating local climate variations. J Climate 11:735–753. https://doi.org/10.1175/1520-0442(1998)011%3C0735:ACOSAM%3E2.0.CO;2
Krishnan R, Shrestha AB, Ren G et al (2019) Unravelling climate change in the Hindu Kush Himalaya: rapid warming in the mountains and increasing extremes. In: Wester P, Mishra A, Mukherji A, Shrestha A (ed) The Hindu Kush Himalaya Assessment. Springer, Cham. pp. 57–97 https://doi.org/10.1007/978-3-319-92288-1_3
Kulkarni A, Patwardhan S, Kumar KK et al (2013) Projected climate change in the Hindu Kush-Himalayan region by using the high-resolution regional climate model PRECIS. Mt Res Dev 33(2):142–151. https://doi.org/10.1659/MRD-JOURNAL-D-11-00131.1
Kuloo M (2021) Deadly flash floods on the rise in the Himalayas. Earth Island Institute Publication. https://www.earthisland.org/journal/index.php/articles/entry/deadly-flash-floods-on-the-rise-in-the-himalayas/#eii-footer-block Accessed 16 March 2022
Kumar N, Jaswal AK (2016) Historical temporal variation in precipitation over western Himalayan region: 1857–2006. J Mt Sci 13:672–681. https://doi.org/10.1007/s11629-014-3194-y
Mahmood R, Babel MS (2013) Evaluation of SDSM developed by annual and monthly sub-models for downscaling temperature and precipitation in the Jhelum basin. Pakistan India Theor Appl Climatol 113(1–2):27–44. https://doi.org/10.1007/s00704-012-0765-0
Maraun D, Wetterhall F, Ireson AM et al. (2010) Precipitation downscaling under climate change: Recent developments to bridge the gap between dynamical models and the end user. Rev Geophys 48(3). https://doi.org/10.1029/2009rg000314.
Meher JK, Das L (2020) Selection of suitable predictors and predictor domain for statistical downscaling over the Western Himalayan region of India. Theor Appl Climatol 139(1):431–446. https://doi.org/10.1007/s00704-019-02980-z
Meher JK, Das L, Benestad RE, Mezghani A (2018) Analysis of winter rainfall change statistics over the Western Himalaya: the influence of internal variability and topography. Int J Climatol 38:e475–e496. https://doi.org/10.1002/joc.5385
Meher JK, Das L (2019) Gridded data as a source of missing data replacement in station records. J Earth Syst Sci 128(3):1–4. https://doi.org/10.1007/s12040-019-1079-8
Meher JK, Das L, Akhter J (2014) Future rainfall change scenarios simulated through AR4 and AR5 GCMs over the Western Himalayan Region. J Agrometeorology 16:53–58
Meher JK, Das L, Akhter J, Benestad RE, Mezghani A (2017) Performance of CMIP3 and CMIP5 GCMs to simulate observed rainfall characteristics over the Western Himalayan region. J Climate 30(19):7777–7799. https://doi.org/10.1175/JCLI-D-16-0774.1
Mishra V (2015) Climatic uncertainty in Himalayan water towers. J Geophy Res Atmos 120(7):2689–2705. https://doi.org/10.1002/2014JD022650
Negi SS (2002) Cold deserts of India. Indus Publishing, New Delhi
Nepal S, Khatiwada KR, Pradhananga S et al (2021) Future snow projections in a small basin of the Western Himalaya. Sci Tot Environ 795:148587. https://doi.org/10.1016/j.scitotenv.2021.148587
Ojha CS, Goyal MK, Adeloye AJ (2010) Downscaling of precipitation for lake catchment in arid region in India using linear multiple regression and neural networks. Int J Climatol 4(1):122–136. https://doi.org/10.1002/joc.2286
Pai DS, Sridhar L, Badwaik MR, Rajeevan M (2014a) Analysis of the daily rainfall events over India using a new long period (1901–2010) high resolution (0.25∘ × 0.25∘) gridded rainfall data set. Clim Dyn 45:755–776. https://doi.org/10.1007/s00382-014-2307-1
Pai DS, Sridhar L, Rajeevan M, Sreejith OP, Satbhai NS, Mukhopadhyay B. (2014a) Development of a new high spatial resolution (0.25 × 0.25) long period (1901–2010) daily gridded rainfall data set over India and its comparison with existing data sets over the region. MAUSAM 65(1): 1–8. https://doi.org/10.54302/mausam.v65i1.851
Palazzi E, Hardenberg J, Provenzale A (2013) Precipitation in the Hindu-Kush Karakoram Himalaya: observations and future scenarios. J Geophys Res Atmos 118:85–100. https://doi.org/10.1029/2012JD018697
Palazzi E, vonHardenberg J, Terzago S, Provenzale A (2015) Precipitation in the Karakoram-Himalaya: a CMIP5 view. Clim Dyn 45(1–2):21–45. https://doi.org/10.1007/s00382-014-2341-z
Panday PK, Thibeault J, Frey KE (2015) Changing temperature and precipitation extremes in the Hindu Kush-Himalayan region: an analysis of CMIP3 and CMIP5 simulations and projections. Int J Climatol 35(10):3058–3077. https://doi.org/10.1002/joc.4192
Panwar TS (2021) IPCC report: Climate change and unregulated construction in the Himalayas. Deccan Herald. https://www.deccanherald.com/opinion/ipcc-report-climate-change-and-unregulated-construction-in-the-himalayas-1020301.html Accessed 16 March 2022
Parvaze S, Ahmad L, Parvaze S, Kanth RH (2017) Climate change projection in Kashmir Valley (J&K). Curr World Environ 12(1):107–115. https://doi.org/10.12944/CWE.12.1.13
Perkins SE, Pitman AJ, Holbrook NJ, McAneney J (2007) Evaluation of the AR4 climate models’ simulated daily maximum temperature, minimum temperature, and precipitation over Australia using probability density functions. J Climate 20(17):4356–4376. https://doi.org/10.1175/JCLI4253.1
Pervez MS, Henebry GM (2014) Projections of the Ganges-Brahmaputra precipitation—downscaled from GCM predictors. J Hydrol 517:120–134. https://doi.org/10.1016/j.jhydrol.2014.05.016
Pithan F (2010) Asian water towers: more on monsoons. Science 330(6004):584–585. https://doi.org/10.1126/science.330.6004.584-b
Rafiq M, Meraj G, Kesarkar AP, Farooq M, Singh SK, Kanga S (2022) Hazard mitigation and climate change in the Himalayas–policy and decision making. In: Kanga S, Meraj G, Farooq M et al (ed) Disaster management in the complex Himalayan terrains. Springer, Cham. pp 169–182 https://doi.org/10.1007/978-3-030-89308-8_12
Sabin TP, Krishnan R, Vellore R et al (2020) Climate change over the Himalayas. In: Krishnan R, Sanjay J, Gnanaseelan C et al (ed) Assessment of climate change over the Indian region. Springer, Singapore pp:207–222 https://doi.org/10.1007/978-981-15-4327-2_11
Sachindra DA, Huang F, Barton A, Perera BJC (2014) Statistical downscaling of general circulation model outputs to precipitation-part 1: calibration and validation. Int J Climatol 34(11):3264–3281. https://doi.org/10.1002/joc.3914
Saeed F, Almazroui M, Islam N, Khan MS (2017) Intensification of future heat waves in Pakistan: a study using CORDEX regional climate models ensemble. Nat Hazards 87(3):1635–1647. https://doi.org/10.1007/s11069-017-2837-z
Salvi K, Kannan S, Ghosh S (2013) High-resolution multisite daily rainfall projections in India with statistical downscaling for climate change impacts assessment. J Geophy Res Atmos 118(9):3557–3578. https://doi.org/10.1002/jgrd.50280
Salvi K, Kannan S, Ghosh S (2011). Statistical downscaling and bias-correction for projections of Indian rainfall and temperature in climate change studies. In 4th International Conference on Environmental and Computer Science (pp. 16–18). http://www.ipcbee.com/vol19/2-ICECS2011R00006.pdf Accessed on 21 March 2022
Sanjay J, Krishnan R, Shrestha AB, Rajbhandari R, Ren GY (2017) Downscaled climate change projections for the Hindu Kush Himalayan region using CORDEX South Asia regional climate models. Adv Clim Chang Res 8(3):185–198. https://doi.org/10.1016/j.accre.2017.08.003
Sati SP, Gahalaut VK (2013) The fury of the floods in the north-west Himalayan region: the Kedarnath tragedy. Geomat Nat Haz Risk 4(3):193–201 https://doi.org/10.1080/19475705.2013.827135
Scherler D, Bookhagen B, Strecker MR (2011) Spatially variable response of Himalayan glaciers to climate change affected by debris cover. Nat Geosci 4(3):156–159. https://doi.org/10.1038/ngeo1068
Sharma C, Arora H, Ojha CSP (2015) Assessment of the effect of climate change on historical and future rainfall in Uttarakhand. 20th International Conference on Hydraulics, Water Resour River Eng IIT Roorkee, India, 17–19 December, 2015. https://doi.org/10.13140/RG.2.1.4356.3286
Sharma S, Joshi R, Pant H, Dhyani PP (2017) Climate change & North-West Himalaya: prioritization of agriculture based livelihood actions. GB Pant National Institute of Himalayan Environ Sustain Develop Kosi-Katarmal, Almora, p. 27.
Shashikanth K, Sukumar P (2017) Indian monsoon rainfall projections for future using GCM model outputs under climate change. Adv Comput Sci Tech 10(5):1501–1516
Shashikanth K, Madhusoodhanan CG, Ghosh S et al (2014) Comparing statistically downscaled simulations of Indian monsoon at different spatial resolutions. J Hydrol 519:3163–3177. https://doi.org/10.1016/j.jhydrol.2014.10.042
Shrestha UB, Gautam S, Bawa KS (2012) Widespread climate change in the Himalayas and associated changes in local ecosystems. PLoS ONE 7(5):e36741. https://doi.org/10.1371/journal.pone.0036741
Singh D, Jain SK, Gupta RD (2015) Statistical downscaling and projection of future temperature and precipitation change in middle catchment of Sutlej River Basin, India. J Earth-Syst Sci, 124(4):843–860. https://springerlink.bibliotecabuap.elogim.com/journal/12040
Stäubli A, Nussbaumer SU, Allen SK et al (2018) Analysis of weather-and climate-related disasters in mountain regions using different disaster databases. In: Mal S, Singh RB, Huggel C (ed) Climate change, extreme events and disaster risk reduction. Springer, Cham. pp. 17–41. https://doi.org/10.1007/978-3-319-56469-2_2
Tayal S (2019) Climate change impacts on Himalayan glaciers and implications on energy security of India. TERI Discussion Paper. https://www.teriin.org/policy-brief/climate-change-impacts-himalayan-glaciers-and-implications-energy-security-india Accessed 15 March 2022.
Tewari VP, Verma RK, Von Gadow K (2017) Climate change effects in the Western Himalayan ecosystems of India: evidence and strategies. For Ecosyst 4(1):1–9. https://doi.org/10.1186/s40663-017-0100-4
Thadani R, Singh V, Chauhan DS et al (2015) Climate change in Uttarakhand: current state of knowledge and way forward. Center for Ecology Development and Research, India
Thomas L, Dash SK, Mohanty UC, Babu CA (2018) Features of western disturbances simulated over north India using different land-use data sets. Met App 25(2):246–253. https://doi.org/10.1002/met.1687
Tripathi S, Srinivas VV, Nanjundiah RS (2006) Downscaling of precipitation for climate change scenarios: a support vector machine approach. J Hydrol 330(3–4):621–640. https://doi.org/10.1016/j.jhydrol.2006.04.030
Wilby RL, Hay LE, Leavesley GH (1999) A comparison of downscaled and raw GCM output: implications for climate change scenarios in the San Juan River basin. Colorado J Hydrol 225(1–2):67–91. https://doi.org/10.1016/S0022-1694(99)00136-5
Wilby R, Wigley T (1997) Downscaling general circulation model output: a review of methods and limitations. Prog. Phys. Geogr., 21:530548. 10.1177%2F030913339702100403
Wilks DS (1995) Statistical methods in the atmospheric sciences. Academic Press, Orlando, FL
Wu J, Xu Y, Gao XJ (2017) Projected changes in mean and extreme climates over Hindu Kush Himalayan region by 21 CMIP5 models. Adv Clim Chang Res 8(3):176–184. https://doi.org/10.1016/j.accre.2017.03.001
Xu J, Grumbine RE, Shrestha A, Eriksson M, Yang X, Wang YU, Wilkes A (2009) The melting Himalayas: cascading effects of climate change on water, biodiversity, and livelihoods. Conserv Biol 23(3):520–530. https://doi.org/10.1111/j.1523-1739.2009.01237.x
Zambrano-Bigiarini M 2014 hydroGOF: Goodness-of-fit functions for comparison of simulated and observed hydrological time series; R package version 0.3–8. https://cran.r-project.org/web/packages/hydroGOF/hydroGOF.pdf Accessed on 21 March 2022
Zorita E, vonStorch H (1999) The analog method as a simple statistical downscaling technique: comparison with more complicated methods. J Climate 12:2474–2489. https://doi.org/10.1175/1520-0442(1999)012%3C2474:TAMAAS%3E2.0.CO;2
Acknowledgements
Jitendra Kumar Meher is thankful to Bidhan Chandra Krishi Viswavidyalaya for providing the basic lab facility to carry out the present work. The authors sincerely thank the Norway Research Council for funding the Indo-Norway international research project INDICE through which the present work has been carried out. The authors would like to acknowledge IMD, Pune, for providing the meteorological data used in the current research. The ESGF and NCEP/NCAR were duly acknowledged for their effort to make the GCM and reanalysis data publicly available for the present work. Authors would like to thank the anonymous reviewers for providing valuable suggestion to improve the quality of the article.
Funding
This work was supported by the fund received by Indo-Norway international research project INDICE. Jitendra Kumar Meher has received research support/fellowship from Norway Research Council during the preparation of the present work.
Author information
Authors and Affiliations
Contributions
All the authors contributed to the study conception and design. Data collection was done by Lalu Das. Material preparation and analysis were performed by Jitendra Kumar Meher. The first draft of the manuscript was written by Jitendra Kumar Meher and Lalu Das commented on previous versions of the manuscript. Both the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics declarations
The authors understand their ethical responsibility towards the present submission. There is no violations to the ethics as mentioned by Springer publications.
Consent to participate
Not applicable.
Consent for publication
No published data was taken from any third person. The authors give their consent for publication of this article upon acceptance by the journal.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Meher, J.K., Das, L. Is the Western Himalayan region vulnerable with respect to downscaled precipitation?. Theor Appl Climatol 149, 233–252 (2022). https://doi.org/10.1007/s00704-022-04048-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-022-04048-x