
Abstract
This study compared two machine learning techniques, support vector machines (SVM), and artificial neural network (ANN) in modeling monthly precipitation fluctuations. The SVM and ANN approaches were applied to the monthly precipitation data of two synoptic stations in Hamadan (Airport and Nojeh), the west of Iran. To avoid overfitting, the data were divided into two parts of training (70 %) and test sets (30 %). Then, monthly data from July 1976 to June 2001 and data from April 1961 to November 1996 were considered as training set for the Hamadan and Nojeh stations, respectively, and the remaining were used as test set. The results of the SVM model were compared with those of the ANN based on the root mean square errors, mean absolute errors, determination coefficient, and efficiency coefficient criteria. Based on the comparison, it was found that the SVM model outperformed the ANN, and the estimated precipitation values were in good agreement with the corresponding observed values.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Forecasting precipitation as a main ingredient of the hydrological cycle is of primary importance in water resources planning and management (Kaheil et al. 2008). Especially, it is substantial to estimate and forecast rainfall accurately for reservoir operation and flooding prevention since it can provide an extension of lead-time of the flow forecasting, larger than the response time of the watershed (Wu et al. 2010). Also, as part of the modernization of the National Weather Service (NWS), more affirmation is being placed on the local generation of quantitative precipitation forecasts and their application in hydrological models (Hall et al. 1999). Nevertheless, precipitation forecasting issue is quite difficult due to the tremendous variation of rainfall over the wide range of scales both in space and time (Kaheil et al. 2008). Therefore, accurate modeling and forecasting this phenomenon are two of the greatest challenges in operational hydrology, despite many advances in weather forecasting in recent decades (Hung et al. 2009).
Several methods have been developed for modeling time series data like precipitation, including autoregressive (AR), moving-average (MA), AR moving-average (ARMA), and AR integrated moving-average (ARIMA). In this model, the correlated data will be used while limited to forecast temporary changes. However, these techniques do not seem to be able to deal with nonstationary time series. Therefore, it would be necessary to implement updated models with higher capacities. In recent years, several progressive techniques have been introduced as new tools for modeling. Thus, the best technique for prediction needs to be chosen among them. In this regard, recently soft computing techniques including support vector machines (SVMs) and artificial neural networks (ANNs) have been utilized in various areas of science including time series forecasting.
Due to the significant progress in the fields of pattern recognition methodology, the ANN has been applied to model various nonlinear hydrological processes including time series forecasting. Satisfactory performance of the ANN has been verified by several studies such as predicting the flood (Kisi 2003), suspended sediment estimation (Wang et al. 2008; Gao et al. 2002), reservoir inflow forecasting (Bae et al. 2007), rainfall runoff (Solaimani 2009), as well as the precipitation prediction (Hung et al. 2009; Valverde Ramírez et al. 2005). Valverde Ramírez et al. (2005) applied the multi-layer feed-forward perception neural network to predict daily precipitations. Results indicated that the performance of the ANN approach was better than that of the linear regression model. Saplioglu et al. (2010) used three-layer feed-forward neural networks to predict precipitations and indicated that ANN model was well-linked as compared to general methods of weighted and harmonic means. El-Shafie et al. (2011) (El-Shafie et al. 2011) investigated the accuracy of an ANN technique in precipitation forecasting and demonstrated that the ANN works better than other linear methods.
Furthermore, support vector machines (SVMs) which are based on the structural risk minimization, instead of the empirical risk minimization of the ANN, have been successfully used in different research areas. Utilizing the empirical risk minimization can cause the overfitting problem of the network due to capturing the solution in a local minimum. The empirical error and model complexity are minimized simultaneously by the structural risk minimization. Then, the generalization ability of the SVM for classification or regression problems can be improved in many disciplines.
Recently, the SVMs have been widely utilized to predict water resource variations especially on predicting the rainfalls, floods, and water reservoirs. Several authors have investigated the SVM performance for the prediction of the rainfall runoff (Dibike et al. 2001), the lake water levels (Khan and Coulibaly 2006; Asefa et al. 2005; Khalil et al. 2006), the flood and stream flow (Yu et al. 2006), and the atmospheric temperature (Radhika and Shashi 2009).
To our knowledge, a few studies have been conducted to compare ANN and SVM for predicting precipitation. Ingsrisawang et al. (2008) (Ingsrisawang et al. 2008) used and compared the three methods of Decision-tree, artificial neural network (ANN), and support vector machine (SVM) to predict short rainy days. They found that the SVM method showed less error in classifying precipitations of the rainy days with no rain, low rain, and the average raining. However, in predicting, ANN method showed less root mean square error. Yoon et al. (2011) compared SVM and ANN for modeling lake level fluctuations and concluded that SVM worked better than ANN. In addition, Çimen and Kisi (2009) compared SVM and ANN techniques for predicting lake water levels and groundwater levels and concluded that the SVM was superior to ANN.
The aim of this study was to compare two of the most promising and frequently used soft computing techniques of SVM and ANN for modeling the monthly precipitations. Therefore, both techniques were applied to estimate the precipitations in the central area of Hamadan City, the west of Iran, and the results were compared with each other.
2 Material and methods
2.1 Study area and data
The study site, Hamadan, is located at a mountainous area in the West of Iran. In this study, monthly precipitation data of 35 years (July 1976 to September 2011) from the Hamadan synoptic station (the airport station) and the data for 50 years (April 1961 to September 2011) from Nojeh station, another part of Hamadan Province, were used. Figure 1 shows the locations of the stations. The characteristics of the stations are listed in Table 1. To model precipitations, raw data for each year were extracted and registered. Before any calculations were carried out, the run test was performed to examine the accuracy and homogeneity of the data. The data were homogeneous and there was no gap. In order to avoid overfitting, the data was divided into two parts. Then, about 70 % of the data were considered as the training set, and the rest 30 % were utilized for the test set. Therefore, monthly data from July 1976 to June 2001 for the Hamadan station and data from April 1961 to November 1996 for the Nojeh station were considered as training set, and the remaining were used as test set.

Map of area showing the Hamadan in Iran
The monthly statistics of the data sets including mean, maximum, minimum, skewness, and the coefficient of autocorrelation (lag 1 to lag 2 which are shown as R1 and R12) are given in Table 1 for both meteorological stations. For two stations, the distribution of the training and testing data sets are slightly different from each other, thereby taken approximately similar. The precipitation data have significantly high autocorrelations for both stations (α < 0.05).
2.2 Method of study
2.2.1 Artificial neural networks
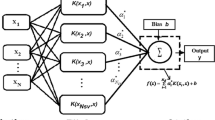
The ANN is a flexible mathematical structure pattern which is based on a model of emulating the processing of human neurological system to realize related spatial and temporal characteristics from the historical data patterns (especially for nonlinear and dynamic evolutions). In general, a common ANN, called a multilayer perceptron network (MLPN) includes input, hidden, and output layers with their nodes taking values in the range (0 to 1) and some activation functions. Each layer is fed with the previous layers. The model inputs functionally are mapped to the model outputs during optimization by using the hidden layers’ nodes (Yoon et al. 2011).
There are numerous ANN architectures and several methods for network training. The back-propagation algorithm (BPA) can effectively train the network for nonlinear problems. This study used an MLPN with one hidden layer trained by BPA to construct the ANN model. In the hidden and output layers, a log-sigmoid function and a linear function were utilized respectively as activation functions. It has been reported that extrapolation ability of the ANN model has been improved with this most commonly used configuration (Yoon et al. 2011).
The MLPN is mathematically represented by:
where the x i shows the ith nodal value in the previous layer, y j is the jth nodal value in the present layer, b j is the bias of the jth nodes in the present layer, W ji is a weight connecting x i and y j, N is the number of nodes in previous layer, and f is the activation function in the present layer (Yoon et al. 2011).
2.2.2 Support vector machine
Similar to ANNs, SVMs can be used for classification and regression problems. An SVM is a classifier derived from statistical learning theory based on structural risk minimization. Theoretically, it minimizes the expected error of a learning machine and reduces the problem of overfitting. That is, as this method minimizes the experimental error and the complexity simultaneously, it can improve its generalization for prediction (Yoon et al. 2011).
The basic idea is to map the input vector x into the high-dimensional feature space ϕ(x) (kernel function) in a nonlinear manner in which, theoretically, a simple linear regression can cope with the complex nonlinear regression of the input space.
Let (x, y) be a set of N samples, where x ∈ ℝ m is an input vector of m components, and y is a corresponding outputvalue. An SVM estimator (f) on regression is mathematically represented by
where w is a weight vector, and b is a bias. The optimization issue can be written as a convex optimization problem with an ε -insensitivity loss function to obtain the solution to the above equation (Yoon et al. 2011). Then, the objective function
should be minimized subject to the following restrictions:
where C is a positive tradeoff parameter that determines the degree of the empirical error in the optimization problem and ξ i and ξ * i are slack variables that penalize training errors by the loss function over the error tolerance ε. This problem is usually solved in a dual form using Lagrangian multipliers. The data are usually assumed to have zero mean. The operations are performed in the input space rather than the potentially high-dimensional feature space by the kernel function. Therefore, an inner product in the feature space has an equivalent kernel in input space (Çimen and Kisi 2009). In general, the common kernel functions treated by the SVM are the functions with the polynomial, Gaussian radial basis (GRBF), exponential Radial basis, etc. This study utilized the GRBF which can be written as k(x i , x) = exp(−γ|x i − x|2)
2.3 Performance criteria
The root mean square error (RMSE), coefficient of efficiency (E), determination coefficient (R 2), and mean absolute error (MAE) were used for evaluating the prediction accuracy of SVM and ANN models. R 2 measures the degree of linear relation between two variables. The RMSE measures the goodness-of-fit relevant to high precipitation amounts and MAE yields a more balanced perspective of the goodness-of-fit at moderate precipitation amounts (Çimen and Kisi 2009). The coefficient of efficiency measures differences between the observations and predictions relative to the variability in the observed data. A value of 90 % and above indicates very satisfactory performance, but a value below 80 % indicates unsatisfactory performance (Çimen and Kisi 2009). The RMSE, E, and MAE are calculated as follows:
where n is the number of data, y is the under water level, and y mean is the average precipitation.
3 Results
The SVM and ANN models were implemented using clementine12. To choose appropriate inputs for these models, correlation analysis was used. Regarding the autocorrelation coefficients (Table 2), five inputs in Hamadan and four inputs in Nojeh stations were considered based on monthly precipitation amounts of previous periods. The autocorrelation statistics and the corresponding 95 % confidence bands from lag 0 to lag 12 were shown for the precipitation time series of both stations (Fig. 2). The SVM and the ANN inputs considered in the study were as follows: Lag1, Lag6, Lag7, Lag8, and Lag12 in the Hamadan station and Lag1, Lag6, Lag7, and Lag12 in the Nojeh station. To investigate the effect of lags as inputs on the predictive power of these models, the SVM and the ANN without inputs were also fitted, and models performance based on four criteria were evaluated.

The autocorrelations of the precipitation values
During the learning by SVM, optimum values of three parameters C, γ, and ε were determined using the trial and error method (Table 3). In addition, since neural networks with two and three hidden layers did not improve the prediction criteria, the ANN was used with one hidden layer with fewer parameters.
For two stations, the RMSE, MAE, E and R 2 statistics in training and test sets for all settings are given in Table 4. Table 4 indicates that for both stations, the SVM model comprising inputs performed much better than the SVM without inputs and the ANN with and without inputs.
It can be seen that the RMSE and MAE values of the SVM model with inputs are smaller than those of the other three models in both the training and testing stages, for both stations (RMSE = 8.01 and RMSE = 0.64 for the Hamadan and the Nojeh stations, respectively, in the test sets; MAE = 6.69 and MAE = 0.45 for Hamadan and Nojeh stations, respectively, in the test sets). On the other hand, the efficiency and the R 2 values of the SVM model with inputs are greater than those of the other three models in both the training and test sets (E = 0.87 and E = 0.97 for the Hamadan and the Nojeh stations, respectively; R 2 = 0.96 and R 2 = 0.99 for Hamadan and Nojeh stations, respectively, in the test sets). This implies that the SVM comprising inputs was better than that of the other three models for the given data.
The temporal variation of observed monthly precipitation values and the estimates of the SVM and ANN models with and without inputs for the test period are plotted in Fig. 3. In this figure, the four graphs on the right panel are related to the Nojeh station, and the left graphs are related to the Hamadan station. It is obviously seen from the graphs that the SVM estimates including inputs are closer to the corresponding observed values than those of the other three models especially for the peak values.

Monthly estimations of precipitation based on neural network (NN) and support vector machine (SVM) models: a SVM predictions based on lags for Hamadan station. b SVM predictions without lags for Hamadan station. c NN predictions based on lags for Hamadan station. d NN predictions without lags for Hamadan station. a SVM predictions based on lags for Nojeh station. b SVM predictions without lags for Nojeh station. c NN predictions based on lags for Nojeh station. d NN predictions without lags for Nojeh station
In addition, the estimates of the SVM and ANN models are illustrated in the form of scatter plot (Fig. 4). As seen from the fit line equations (assume that the equation is y = a 0 x + a 1) in the scatter plots, the a 0 and a 1 coefficients for the SVM model with inputs are respectively closer to the 1and 0 than those of the other models at both stations.

Comparison of precipitation predictions (mm/month) from neural network (NN) and support vector machine (SVM) models with the observed values (mm/month): a SVM predictions based on lags for Hamadan station. b SVM predictions without lags for Hamadan station. c NN predictions based on lags for Hamadan station. d NN predictions without lags for Hamadan station. e SVM predictions based on lags for Nojeh station. f SVM predictions without lags for Nojeh station. g NN predictions based on lags for Nojeh station. h NN predictions without lags for Nojeh station
Based on these results, the SVM methodology comprising appropriate inputs was found to be better than the ANN ones in order to model precipitation fluctuations in these two particular stations.
4 Discussion
The results of this study indicated that the SVM is a beneficial method for the empirical forecasting of precipitation amount in Hamadan. The SVM model results were also compared with ANN model results. The performance measurements obtained from SVM comprising appropriate inputs were satisfactory. Also, with several performance criteria, the SVM model outperformed the ANN models with and without inputs and SVM without inputs.
Based on these results, the SVM methodology is found to be better than the ANN ones in order to model monthly precipitation fluctuations. There has been sufficient evidence from other studies in various fields of hydrology that indicates the superiority of SVM over the regular ANN modeling approach. For example, in a study conducted by Yoon et al. (2011), SVM and ANN performance was compared in ground water level modeling. Their results showed a better performance for SVM than for ANN. In addition, Çimen and Kisi (2009) compared SVM and ANN techniques for predicting lake water levels fluctuations and concluded that SVM is superior to ANN. However, the results of this study are inconsistent with the results of Ingsrisawang et al’s study. In their study, three methods of decision tree, artificial neural network (ANN), and support vector machine (SVM) were utilized to predict short rainy days. They reported that SVM method had less error in classifying precipitations of any rainy days with no rain, low rain, and the average raining categories, but in predicting rainfall, ANN method showed less root mean square error than the other methods.
Superior performance of SVM compared to ANN is due to the fact that the SVM model has greater generalization ability, relating the input to the desired output (Kalra and Ahmad 2012). Furthermore, the optimization algorithm utilized in SVM is more robust than the one utilized in ANN model (Kalra and Ahmad 2012).
The predicting techniques, utilized in this study, have a number of advantages and disadvantages. Among the appealing characteristics of SVMs are better generalization capabilities, low sensitivity to small training sets and noisy data and avoidance of overfitting (Kaheil et al. 2008). SVM can be a useful tool for nonlinear predicting problem especially with an unknown distribution.
If appropriate kernel function and related parameters are chosen, SVM can be robust even with some biases in training sample. However, a common drawback of SVMs is the lack of transparency of results. Because of very high dimension of SVMs, they cannot represent the score of all samples as a simple parametric function (Auria and Moro 2008). Another drawback of this technique is low speed of computation. In addition, the weakness of this study was lack of access to another data set for implementation and comparison. However, SVMs reduces forecasting errors theoretically as well as empirically (Hastie et al. 2005).
5 Conclusion
This study investigated the potential of SVM and ANN techniques to model the monthly precipitation amounts. The precipitation estimates of SVM were compared with the ANN model. The results indicated that the SVM outperformed the ANN model and confirmed the ability of this approach to provide a useful tool to solve specific problems in hydrology, such as precipitation modeling. The results suggested that the SVM model is a promising technique for predicting variations of precipitation. Also, the SVM can be used as an alternative of ANN models in the precipitation forecasting at this particular region. However, further studies are required to assess the strength and weakness of this method.
References
Asefa T, Kemblowski M, Lall U, Urroz G (2005) Support vector machines for nonlinear state space reconstruction: application to the Great Salt Lake time series. Water Resour Res 41, W12422
Auria L, Moro RA (2008) Support Vector Machines (SVM) as a technique for solvency analysis
Bae D-H, Jeong DM, Kim G (2007) Monthly dam inflow forecasts using weather forecasting information and neuro-fuzzy technique. Hydrol Sci J 52:99–113
Çimen M, Kisi O (2009) Comparison of two different data-driven techniques in modeling lake level fluctuations in Turkey. J Hydrol 378:253–262
Dibike YB, Velickov S, Solomatine D, Abbott MB (2001) Model induction with support vector machines: introduction and applications. J Comput Civ Eng 15:208–216
El-Shafie AH, El-Shafie A, El Mazoghi HG, Shehata A, Taha MR (2011) Artificial neural network technique for rainfall forecasting applied to Alexandria, Egypt. Int J Phys Sci 6:1306–1316
Gao JB, Gunn SR, Harris CJ, Brown M (2002) A probabilistic framework for SVM regression and error bar estimation. Mach Learn 46:71–89
Hall T, Brooks HE, Doswell CA III (1999) Precipitation forecasting using a neural network. Weather Forecast 14:338–345
Hastie T, Tibshirani R, Friedman J, Franklin J (2005) The elements of statistical learning: data mining, inference and prediction. Math Intell 27:83–85
Hung NQ, Babel MS, Weesakul S, Tripathi N (2009) An artificial neural network model for rainfall forecasting in Bangkok, Thailand. Hydrol Earth Syst Sci 13:1413–1425
Ingsrisawang L, Ingsriswang S, Somchit S, Aungsuratana P, Khantiyanan W (2008) Machine learning techniques for short-term rain forecasting system in the northeastern part of Thailand. Proceedings of World Academy of Science, Engineering and Technology
Kaheil YH, Rosero E, Gill MK, Mckee M, Bastidas LA (2008) Downscaling and forecasting of evapotranspiration using a synthetic model of wavelets and support vector machines. Geosci Remote Sens IEEE Trans 46:2692–2707
Kalra A, Ahmad S (2012) Estimating annual precipitation for the Colorado River Basin using oceanic-atmospheric oscillations. Water Resour Res 48
Khalil AF, Mckee M, Kemblowski M, Asefa T, Bastidas L (2006) Multiobjective analysis of chaotic dynamic systems with sparse learning machines. Adv Water Resour 29:72–88
Khan MS, Coulibaly P (2006) Application of support vector machine in lake water level prediction. J Hydrol Eng 11:199–205
Kisi Ö (2003) River flow modeling using artificial neural networks. J Hydrol Eng 9:60–63
Radhika Y, Shashi M (2009) Atmospheric temperature prediction using support vector machines. Int J Comput Theory Eng 1:1793–8201
Saplioglu K, Cimeny M, Akman B (2010) Daily precipitation prediction in Isparta station by artificial neural network. In: Proceedings of the 4th International Scientific Conference on Water Observation and Information System for Decision Support (BALWOIS), Ohrid, Republic of Macedonia
Solaimani K (2009) A study of rainfall forecasting models based on artificial neural network. Asian J Appl Sci 2:486–498
Valverde Ramírez MC, De Campos Velho HF, Ferreira NJ (2005) Artificial neural network technique for rainfall forecasting applied to the Sao Paulo region. J Hydrol 301:146–162
Wang Y-M, Traore S, Kerh T (2008) Using artificial neural networks for modeling suspended sediment concentration. WSEAS Computational Methods and Intelligent Systems, Sofia, pp 108–113
Wu C, Chau K, Fan C (2010) Prediction of rainfall time series using modular artificial neural networks coupled with data-preprocessing techniques. J Hydrol 389:146–167
Yoon H, Jun S-C, Hyun Y, Bae G-O, Lee K-K (2011) A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J Hydrol 396:128–138
Yu P-S, Chen S-T, Chang I-F (2006) Support vector regression for real-time flood stage forecasting. J Hydrol 328:704–716
Conflict of interest
The authors declare that there is no conflict of interests.
Funding
The authors received no funding for this study.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Hamidi, O., Poorolajal, J., Sadeghifar, M. et al. A comparative study of support vector machines and artificial neural networks for predicting precipitation in Iran. Theor Appl Climatol 119, 723–731 (2015). https://doi.org/10.1007/s00704-014-1141-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-014-1141-z