
Abstract
Unsupervised domain adaptation (UDA) aims to explore the knowledge of labeled source domain to help training the model of unlabeled target domain. By now, while most existing UDA approaches typically learn domain-invariant representations by directly matching the distributions across the domains, they pay less attention on respecting the cross-domain similarity and discrimination exploration. To address these issues, this article designs a kind of UDA with dynamic bias alignment and discrimination enhancement (UDA-DBADE). Specifically, in UDA-DBADE we define a dynamic balance factor by the ratio of the normalized cross-domain discrepancy to the discrimination, which decreases gradually in the process of UDA-DBADE. Afterward, we construct domain alignment with adversarial learning as well as distinguishable representations through advancing the discrepancy of multiple classifiers, and dynamically balance them with the defined dynamic factor. In this way, a larger weight is originally assigned on the domain alignment and then gradually on the discrimination enhancement in the learning process of UDA-DBADE. In addition, we further construct a bias matrix to characterize the discrimination alignment between the source and target domain samples. Compared to current state-of-the-art methods, UDA-DBADE achieves an average accuracy of 88.8% and 89.8% on Office-31 dataset and ImageCLEF-DA dataset, respectively. Finally, extensive experiments demonstrate that UDA-DBADE has an excellent performance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, machine learning models especially deep networks have achieved wide success, as in image classification [1] and semantic segmentation [2]. Nevertheless, these methods typically follow the assumption that both the training and test data are collected from the same distributions. In real applications, it frequently does not hold because of the distribution discrepancy between the domains, i.e., domain shift. To address this issue, the paradigm of domain adaptation (DA) [3,4,5,6] was proposed to match the domains. On the other hand, the methods aforementioned typically reply on large numbers of labeled data; however, labeling data is time-consuming and laborious, or even difficult to obtain. To further address such challenges, unsupervised DA (UDA) was raised. The UDA methodology exploits source domain knowledge to handle unlabeled target tasks. The modeling strategies of existing UDA works can be mainly divided into two categories. On the one hand, it seeks to match the source and target domains by reducing their distribution discrepancy [7,8,9,10]. On the other hand, it performs domain adaptation by learning domain-invariant representations encouraged by adversarial domain discriminator [3, 4, 11], conditional domain discriminator [5, 12] or task classifier [13, 14]. The former usually uses the momentum distance [15, 16], or second-order correlation [9, 17, 18], between the source and target domains to align their distributions. The latter learns domain-invariant feature representations to achieve UDA via the generative adversarial network [19] or domain-adversarial training. Among them, Xiao et al. [20] introduced the notions of alignment degree and discriminability degree to dynamically weight the learning losses of alignment and discriminability. Wei et al. [21] proposed treating domain alignment objectives and classification objectives as meta-training and meta-testing tasks in a meta-learning framework. Huang et al. [22] devised a novel adversarial learning strategy between domain-level and class-level feature representations. Most of these UDA methods with adversarial learning [4, 11, 23,24,25,26,27,28] can effectively learn domain-invariant representations for better generalization to the target domain. Moreover, the flexibility and diversity provided by some GAN models [3, 28] enable them to adapt to multiple target domains, thus enhancing the applicability of UDA in complex scenarios. Although most of these methods have achieved promising results on UDA tasks, they still suffer from the following limitations. Firstly, they have not considered the quantity imbalance issue between the domains, since the domain with more samples affects more on the process of UDA. Even worse, this issue tends to result in an undesirably biased UDA model. Thirdly, these methods usually directly align the source and target domains without preserving the class diversity, which may lead to excessive domain alignment. Finally, such methods like [29,30,31] usually assume that the model trained on source domain data generalizes well on the target domain tasks and consequently only aligns the cross-domain marginal distributions but ignores the data classes bias across domains, which easily leads to misclassification. As shown in Fig. 1b, even though the marginal distributions of the source and target domains are aligned well, the target samples are still misclassified seriously by the source classifier.

Comparison of existing and the proposed DA methods. a Domain adaptation to the previous source and target domains. b Most of the existing domain adaptation methods directly align the Marginal distribution, which often leads to noise near the classification boundary. c UDA-DBADE firstly uses the balance factor \(\omega\) to control the degree of domain alignment to prevent negative migration caused by excessive domain alignment. Secondly, the sample similarity loss is calculated using sample bias matrix \(\text {S}\) to narrow the similar samples and push the dissimilar samples
In order to address the issues aforementioned, in this article we propose a kind of UDA model via dynamic bias alignment and discrimination enhancement (UDA-DBADE). Specifically, we firstly construct a dynamic balance factor by the ratio of the normalized cross-domain discrepancy to the inter-/intra-class discrimination, whose value decreases gradually with iterated process of UDA-DBADE. Then, with the balance factor, we dynamically regulate the adversarial domain alignment and distinguishable representations. As a result, UDA-DBADE pays more attention on domain alignment and then gradually more on the discrimination enhancement in the learning process of domain adaptation. In addition, we design a bias matrix to characterize the discrimination alignment between the source and target domains. In summary, our main contributions are fourfold as follows:
-
Proposing a novel kind of unsupervised domain adaptation (UDA) model via dynamic bias alignment and discrimination enhancement (UDA-DBADE), which jointly achieves the goal of domain alignment and discrimination enhancement.
-
In UDA-DBADE, a dynamic balance factor is constructed by the ratio of the normalized cross-domain discrepancy to the target domain inter-/intra-class discrimination, which encourages the model pay more attention on domain alignment and then gradually more on the discrimination enhancement in the learning process of domain adaptation.
-
A bias matrix is designed to characterize the discrimination alignment between the source and target domain samples to further regularize the performance of UDA-DBADE.
-
Extensive experiments validate the effectiveness and superiority of the proposed UDA-DBADE over the current state-of-the-art methods with average accuracy improvement of 0.4% on digital datasets and with average accuracy improvement of 0.5% on Office-Home dataset.
The rest of this article is organized as follows. In Sect. 2, we give a brief overview of the related work. Section 3 introduces the method in details. Then, experiments and analyses are presented in Sect. 4. Finally, conclusions and future directions are given in Sect. 5.
2 Related work
In this section, we briefly review some representative UDA approaches mostly related to our work.
UDA with discrepancy measurement These approaches mainly match the source and target domains though reducing their distribution discrepancy. Representative measures include maximum mean difference (MMD) [8, 32], correlation alignment (CORAL) [9] and central moment difference (CMD) [16], etc. In articles [8] and [32], the distribution divergence between the source and target domains were measured with variants of MMD, such as multi-core MMD (MK-MMD) and joint maximum mean difference (JMMD). The authors of [33] designed a weighted MMD by assigning class-specific weights into the MMD measure. In D-CORAL [18], the CORAL was improved by incorporating the correlations between the active layers of the deep networks. Moreover, the central moment difference (CMD) [16] was also used to UDA by matching higher-order central moments across domain distributions.
UDA with domain-adversarial learning This kind of UDA is inspired by Generative Adversarial Network (GAN) [19], which uses adversarial training to learn domain-invariant representations. Along this line, the methods as domain adversarial training of neural networks (DANN) [3], adversarial discriminative domain adaptation (ADDA) [4] and conditional domain adversarial network (CDAN) [5] adopted a domain discriminator to distinguish the divergence among domain representations. Moreover, Wasserstein distance guided representation learning (WDGRL) [34] and re-weighted adversarial adaptation network (RAAN) [35] predicted the distribution distance between the source and target domain samples via a domain critical network with adversarial learning. Maximum classifier discrepancy (MCD) [13] and sliced Wasserstein discrepancy (SWD) [14] performed domain alignment through building task-specific classifiers as domain discriminators to train domain-invariant representations. Recently, domain-symmetric networks (SymNets) [36] was modeled with an improved adversarial learning objective with a two-layer domain obfuscation structure. Moreover, in view of the intermediate and image distortion caused by the instability of the generation network, in the article [37], the authors apply an end-to-end transfer framework to improve the image quality of the intermediate domain of adversarial generation network. In addition, transferable adversarial training (TAT) [38] was modeled to reduce the cross-domain gap by performing UDA with the generated transferable samples, as well as the reverse-trained depth classifier to make consistent predictions on the transferable samples.
UDA with metric learning To facilitate the alignment across domain samples, the methodology of distance metric has been introduced in UDA. Most of related works were modeled with metric loss on the samples [39,40,41,42] or proxies [43,44,45,46] to learn class distinction boundary, in which the key issue is how to characterize both the intra- and inter-class differences. In the article [47], the authors apply clustering-based self-supervised learning to classify pseudo-labels into positive and negative classes, forming a set of clusters through the similarity of pseudo-labels. Finally, the classification results are given based on two confidence scores for each label from the detector backbone and multi-expert fusion. Furthermore, in the article [48], the authors employ a memory mechanism and develop two types of nonparametric classifiers that assign pseudo-labels to target samples using only target data. Different from [48], we use the source domain data, then follow the K-nearest neighbors algorithm and employ a ratio test to assign the target sample pseudo-labels. In articles [49] and [50], the authors use soft-max contrast loss and noise contrast loss to characterize intra- and inter-class differences, respectively. We use the useful sample pair relation of pair domain adaptation classification to construct the sample pair similarity loss as processing multiple positive and negative sample pair information at one time. Although domain adaptation algorithms based on metric learning have been proposed by many previous studies, the principle of metric learning is rarely considered to improve conventional domain adaptation problems. Wang et al. [51] applied a triplet loss utilizing both source and unlabeled target samples on the confusion domain in order to achieve class-level alignment. Furthermore, considering the different importance of pairwise samples for feature learning and domain alignment, Wang et al. [52] derived a BP-triplet Loss that adjusts the weights of pairwise samples within and between domains from the perspective of Bayesian learning. Nevertheless, previous related work either required triplet losses with complex sampling strategies or did not use sample-level similarity relationships. In this article, we calculate the sample pair similarity loss from the sample level, which makes the close similarity more compact and the dissimilar samples more discrete.
3 Proposed methodology
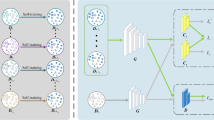
In this section, we describe the details of our approach, and the overall architecture of our model is shown in Fig. 2. The symbols used in this article are defined in Table 1. Firstly, in order to prevent the deviation of the trained model due to the large difference in the number of samples in the two domains, we weight the samples in the source domain and target domain. Secondly, we calculate the equilibrium factor \(\omega\) according to the degree of domain alignment and class differentiability and use it to adjust the domain alignment and class difference loss to prevent excessive domain alignment. Finally, we construct the sample pair bias matrix to calculate the sample similarity loss and optimize the sample similarity loss to make the intra-class more compact and the inter-class more discrete.

Overall architecture of the UDA-DBADE method in this article. Our network architecture is divided into three modules: feature extractor (F), domain discriminator (D), the classifier (\({C_1},{C_2},{C_3}\)) and related parameters \({\phi _f},{\phi _d}\), (\({\phi _{c1}},{\phi _{c2}},{\phi _{c3}}\)). The balance factor \(\omega\) acts on the loss of domain alignment, and \((1 - {\omega _t})\) acts on the loss of class discrepancy to balance the degree of domain alignment. Additionally, we use source domain features and target domain features to construct a sample pair bias matrix \({{{\varvec{S}}}}\), which preserves the similarity between samples. Then, we use the value of bias matrix \({{{\varvec{S}}}}\) to calculate the sample similarity loss
Consider the classification of image X in class C problems. For UDA, we are typically given a source domain \({{X}_{s}}\text { = }\left\{ ({{{\varvec{x}}}}_{{{{\varvec{s}}}}}^{{{{\varvec{i}}}}}{,{{\varvec{y}}}}_{{{{\varvec{s}}}}}^{{{{\varvec{i}}}}}) \right\} _{i=1}^{{{N}_{s}}}\) with \({{N}_{s}}\) labeled examples and a target domain \({{X}_{t}}\text { = }\left\{ {{{\varvec{x}}}}_{{{{\varvec{t}}}}}^{{{{\varvec{j}}}}} \right\} _{j=1}^{{{N}_{t}}}\) with \({{N}_{t}}\) unlabeled examples.
3.1 Weight Adaptation
Sample Weighting: In the process of model training, when the sample number difference between the two domains is too large, it will lead to a deviation in model training, and the model will be biased toward the domain with a large sample number. In order to avoid such problems, we intuitively weight the samples before they are input into the model to prevent the model deviation caused by the unbalanced number of samples. For each domain, the weight of the sample should be inversely proportional to its total sample size in both domains. Specifically, we weight the samples of each domain as follows:
where \(\alpha \in (0,1]\) is the hyperparameter controlling the degree of sample weighting.
Domain Alignment and Class Discriminability Weighting: During the optimization process of domain alignment loss and class discrepancy loss, excessive domain alignment or class discrimination is easy to occur, leading to the occurrence of negative transfer. In order to avoid this situation and make the domain alignment and class differentiability be optimized together, we calculate the domain alignment degree and class discrepancy during each iteration and get the balance factor \(\omega\) of the current iteration. \(\omega\) is used as the weight of domain alignment loss and class discrepancy to control the degree of domain alignment. We use maximum mean discrepancy (MMD) and linear discriminant analysis (LDA) [53] to calculate the degree of domain alignment and class differentiability of the current network model. As one of the widely used distance measures for domain adaptation, MMD can express the difference in cross-domain distribution between the source domain and target domain after mapping:
In addition, the definition of linear class discriminator \(LDA({{{{{\varvec{W}}}}}})\) based on LDA is as follows:
where \({{{{{\varvec{W}}}}}} \in {R^{n{\times }d}}\) is the projection matrix, \({{{\varvec{d}}}}\) is the dimension projected into low-dimensional space, \({{{{{{\varvec{S}}}}}}_{{{{{\varvec{b}}}}}}}\) is the inter-class divergence matrix and \({{{{{{\varvec{S}}}}}}_{{{{{\varvec{w}}}}}}}\) is the intra-class divergence matrix. By maximizing the inter-class divergence matrix and minimizing the intra-class divergence matrix, the larger \(LDA({{{{{\varvec{W}}}}}})\) value is obtained. A larger \(LDA({{{{{\varvec{W}}}}}})\) value represents the smallest difference within a class and the largest difference between classes, that is, the class is more distinguishable. We normalize the original values obtained from Eq. (3) and Eq. (4) by using the min–max standardization method. In order to balance the complexities of \(MMD({X_S},{X_T}){}\) and \(LDA({{{{{\varvec{W}}}}}})\), we normalize them, respectively, in Eq. (5) and Eq. (6):
where \(\delta\) is an infinitesimal value (e.g., 1e-3) to guarantee the denominator not equal to zero, \(t \in [1,T]\) indicates current iteration number. \(MMD{{({X_S},{X_T})}_t}\) represents the domain alignment degree at current tth iteration. \(MMD{{({X_S},{X_T})}_{\min }}\) and \(MMD{{({X_S},{X_T})}_{\max }}\), respectively, indicate the minimal value and maximal value of \(MMD{{({X_S},{X_T})}}\) in previous iterations of the model training process and are updated at each iteration.
where \(LDA{{({{{{{\varvec{W}}}}}})}_t}\) represents the class discrepancy at current tth iteration. \(LDA{{({{{{{\varvec{W}}}}}})}_{\min }}\) and \(LDA{{({{{{{\varvec{W}}}}}})}_{\max }}\), respectively, indicate the minimal value and maximal value of \(LDA({{{{{\varvec{W}}}}}})\) in previous iterations of the model training process and are also updated at each iteration. We can easily draw the conclusion from Eq. (5) and Eq. (6) that \(MM{D}{({X_S},{X_T})_t^*} \in [0,1]\) and \(LDA({{{{{\varvec{W}}}}}})_t^* \in [0,1]\). For the sake of dynamically balancing between domain alignment and cross-domain discrimination, with the normalized \(MM{D}{{({X_S},{X_T})}_t^*}\) and \(LDA({{{{{\varvec{W}}}}}})_t^*\), we design the balancing factor \({\omega _t}\) for the tth iteration as follows:
The smaller the value of \(MM{D}{({X_S},{X_T})_t^*}\), the better the alignment of the current domain, and the larger the value of \(LDA({{{{{\varvec{W}}}}}})_t^*\), the stronger the distinguishability of the current class. When the degree of domain alignment is far worse than the degree of class discrimination, the \(MM{D}{({X_S},{X_T})_t^*}\) approaches 1, the \((1 - LDA({{{{{\varvec{W}}}}}})_t^*)\) approaches 0, and the \({\omega _t}\) approaches 1. When the degree of domain alignment is far better than the class discriminability, the \(MM{D}{({X_S},{X_T})_t^*}\) approaches 0, the \((1 - LDA({{{{{\varvec{W}}}}}})_t^*)\) approaches 1, and the \({\omega _t}\) approaches 0. Then, \({\omega _t}\) gradually converges to the value of 0.5 with increased iteration epochs.
3.2 Domain alignment and class discrepancy
Adversarial learning has been widely used in domain adaptation tasks to learn domain-invariant representation. In adversity learning, weighted samples \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{\varvec{i}}}}\) and \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\) are used as the input of feature extractor F to obtain domain-invariant feature representation. By training model network, parameter \({\phi _f}\) of feature extractor F and parameter \({\phi _d}\) of domain discriminator D are updated to optimize the domain alignment loss in the following formula:
The domain alignment task can be achieved by optimizing Eq. (8). However, optimizing domain alignment loss does not guarantee class distinguishability. In order to get the feature representations which have good discriminability, we are inspired by MCD [13] to maximize the discrepancies between the classifiers, which benefits for generating more discriminative features. Therefore, the classification discrepancy measure is defined as Eq. (9):
where the classifiers \({C_1}\), \({C_2}\) and \({C_3}\) are obtained through pre-training on the source domain. In addition, \({p_1}\), \({p_2}\) and \({p_3}\) denote the probability labels predicted by the classifiers \({C_1}\), \({C_2}\) and \({C_3}\), respectively. The superscript K represents categories, for example, \(p_1^k\), \(p_2^k\) and \(p_3^k\) represent probability outputs of class k. In order to obtain class features with large discrepancy, we optimize the loss of class discrepancy as follows:
First, we train the feature extractor F by fixing \({C_2}\) and \({C_3}\) to minimize feature discrepancy. Then, we fix F and \({C_1}\) to maximize the discrepancy between classifiers \({C_2}\) and \({C_3}\) in the target domain. \({\phi _{c1}}\), \({\phi _{c2}}\) and \({\phi _{c3}}\) are parameters of classifiers \({C_1}\), \({C_2}\) and \({C_3}\), respectively. It is worth noting that different from MCD [13], we add a main classifier \({C_1}\), whose decision hyperplane is between \({C_2}\) and \({C_3}\), to make the distance between the classified samples and the decision boundary larger. Equation (7) shows that the larger the value of \({\omega _t}\), the worse the degree of domain alignment, and the larger the value of \((1 - {\omega _t})\), the worse the class difference. With this observation, we take \({\omega _t}\) as the weight of the domain alignment loss and \((1 - {\omega _t})\) as the weight of the class difference loss. The weighted model loss is as follows:
When the degree of domain alignment is less than the class distinguishability, we increase the weight of domain alignment loss. In contrast, when the class distinguishability is less than the domain alignment degree, we increase the weight of class distinguishability. With the iteration of training, we use \({\omega _t}\) to adjust the domain alignment and class discrepancy loss, and this weight enables the model to maintain the consistency of domain alignment and class differentiability, effectively avoiding negative migration.
3.3 Sample similarity loss
To constrain alignment at the class level, we explore the bias relationships between source and target sample pairs for each batch at the sample level and use them in calculating sample similarity losses. However, the target domain samples are unlabeled, if the classifier trained by source domain data is used to label the target domain with pseudo-labels, the sample bias relationship we get is wrong due to the influence of label noise. Therefore, we use the KNN classifier to assign pseudo-labels to the target domain samples. First of all, for each target domain sample, we take the first K source domain samples closest to it as pseudo-label samples. Secondly, the pseudo-label samples are labeled and voted, and the results are regarded as pseudo-label in the target domain. Finally, the label information is used to fill the sample bias matrix as follows: \({S_{ij}}{} = {}1,{}\) if \({{{{{\varvec{y}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}{} = {{ \hat{{{\varvec{y}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\); \({}{S_{ij}} = -1,\ {}otherwise\). The pseudo-label of the target sample obtained from the KNN algorithm also has noise sample. Therefore, after constructing sample bias matrix \({{{{{\varvec{S}}}}}}\), we filter out pseudo-labels that may be noise. We use the rejection confidence measure based on the neighborhood similarity test commonly used in KNN to filter noise labels. \({B_S}\) and \({B_T}\), respectively, represent the sample set of the current batch in the source and target domain. Define \(N_\mathrm{{j}}^p\) to represent the sample set of similar source domain near the target sample \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}} \in {B_T}\), which is obtained by \(N_j^p{} = {}\{ {{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}} \in {B_S}{}\vert {{ {{{\varvec{y}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}{} = \mathrm{{ \hat{{{\varvec{y}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\}\). Similarly, \(N_\mathrm{{j}}^n\) is defined to represent the dissimilar source domain sample set near the target domain sample \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}} \in {B_T}\), which is obtained by \(N_j^n{} = {}\{ {{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}} \in {B_S}{}\vert \mathrm{{ {{{\varvec{y}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}{} \ne \mathrm{{ \hat{{{\varvec{y}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\}\). We calculate the ratio of similar set to dissimilar set to serve as the consistency score \({\Omega _j}\) of pseudo-label prediction of sample \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\) in the target domain. The definition is as follows:
where \({{{{{\varvec{f}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}\) and \({{{{{\varvec{f}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\), respectively, represent the output features of the samples in the source domain and target domain calculated using feature extractor F, and d(., .) is the similarity score between features. After sorting \({\Omega _j}\) from large to small, the confidence factor \(\mu\) is used to select the sorted confidence samples, and the bias matrix value of the remaining target samples is set as \({S_{ij}} = 0\). For example, if our batch size is 64 and confidence factor \(\mu = 0.75\), the first 48 target domain samples are taken as confidence samples in order of consistency score predicted by pseudo-label. When we randomly sample batches from the source and target domains, it can happen that some classes cannot be selected in the source domain, which is problematic. For example, some target samples might not have a corresponding true source sample, leading to incorrect pseudo-labels. To address this issue, we perform class-balanced sampling for the mini-batch \(B_S\) on the source domain, and extract the same representations for all classes of the source domain. For the target domain, the instances are sampled randomly since they are unlabeled. In this way, the sample information with noise labels will not be involved in the calculation of sample similarity loss \({\mathcal{L}_S}\), to prevent the influence of noise labels on model training.
For each source domain sample \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}\), we divide the same batch of target domain samples into relevant sample set \(B_T^{S_i^ + }{} = {}\{ {{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}} \in {B_T}{}\vert {}{S_{ij}} = 1\}\) and unrelated sample set \(B_T^{S_i^ - }{} = {}\{ {{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}} \in {B_T}{}\vert {}{S_{ij}} = - 1\}\). Using the above two sets, we optimize Eq. (13) to make source domain sample \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}\) more compact with related samples and more separated from those irrelated:
The overall similarity loss of the current batch of source domain samples is defined as follows:
We use normalized inverse Euclidean distance [54] as the similarity measure, which is defined as follows:
If \({S_{ij}} = 1\), it means that \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}\) and \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\) are similar sample pairs, and the similarity degree is obtained by Eq. (15). Similarly, when \({S_{ij}} = - 1\), it means that \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{s}}}}}}^{{{{{\varvec{i}}}}}}\) and \({{\bar{{{\varvec{x}}}}}}_{{{{{\varvec{t}}}}}}^{{{{{\varvec{j}}}}}}\) dissimilar sample pairs, and the similarity degree value is close to 0.
3.4 The overall objective
In order to transfer the source knowledge to supervise target model training, we also need to incorporate the source domain classification in the UDA process. As a result, taking into account the source domain classification, domain alignment, class discrepancy and sample similarity aforementioned, we can naturally design the overall objective function of UDA with dynamic bias alignment and discrimination enhancement (UDA-DBADE) as follows:
where
denotes the classification loss on the source domain. As shown in Eq. (16), it mainly contains four parts: supervised classification loss \({\mathcal{L}_{\sup }}\) of the source domain, similar relationship loss \({\mathcal{L}_S}\) between samples, domain alignment loss \({\mathcal{L}_{dom}}\) and class difference loss \({\mathcal{L}_{cl}}\). For the sake of clarification, we summarize the complete steps of UDA-DBADE in Algorithm 1.

UDA-DBADE algorithm
4 Experiments
In this section, we conduct several experiments to evaluate the validity of the proposed method. First, we introduce four UDA datasets: Digits, Office-31, ImageCLEF-DA and Office-Home, along with their experimental settings. Then, we compare the proposed method with existing methods. Finally, we perform ablation experiments to verify the validity of each part of the model.
4.1 Datasets
Digital datasetsFootnote 1 We construct domain adaptive tasks among MNIST [55], USPS and SVHN [56] three digital datasets. Both MNIST (M) and USPS (U) datasets are handwritten numeric datasets from 0\(\sim\)9. SVHN (S) is a dataset of real images in Google Street View images. We perform domain adaptation experiments on M \(\rightarrow\) U, U \(\rightarrow\) M and S \(\rightarrow\) M tasks.
Office-31Footnote 2 [57] This dataset consists of three different domains, including Amazon (A), Webcam (W) and DSLR (D), each with 31 classes. We conduct experiments on all six domain adaptation tasks, namely A \(\rightarrow\) W, D \(\rightarrow\) W, W \(\rightarrow\) D, A \(\rightarrow\) D, D \(\rightarrow\) A and W \(\rightarrow\) A.
ImageCLEF-DAFootnote 3 [58] This dataset consists of three domains, including Caltech256 (C), ImageNet ILSVRC 2012 (I) and Pascal VOC 2012 (P), each with 12 classes
Office-HomeFootnote 4 This dataset is a large benchmark dataset containing around 15,500 images divided into 65 classes. The dataset comprises four domains: Artistic (Ar), Clip Art (Cl), Product (Pr) and Real-World (Rw).
4.2 Implementation details
We compare the proposed method with several state-of-the-art domain adaptation methods: DANN [3], ADDA [4], CDAN [5], DAN [8], MCD [13], DWL [20], TAT [38], JAN [32], LDC [66], GoGAN [70], CyCADA [59], CAT [60], SimNet [61], TPN [62], SAFN [67], LWC [63], ETD [64], CGDM [65], GSDA [69] and SCAL [68]. According to the standard protocol of UDA, all labeled source domain samples and unlabeled target domain samples participate in the training phase. For the domain adaptation task on the handwritten digit set, we follow the protocol in MCD [13]. We use 2K images from MNIST and 1.8K images on USPS to perform domain adaptation tasks between MNIST and USPS, and use the entire training set to perform domain adaptation between SVHN and MNIST. During the experiment, to train our model, we use ADAM whose weight attenuation of the learning rate is 0.0005 to optimize the network weight parameters. The learning rate is set as 0.0002, the sample batch size is set as 128, and the number of training iterations is set as 200. The classification accuracy of the target domain is adopted as the evaluation standard of the experiment. For image datasets such as Office-31, the original datasets are programmed on PyTorch, and the original features of the dataset are extracted by ResNet [19] network pre-trained on ImageNet [71]. The classifier network of the model in this article is set to be a two-layer network, and the domain discriminator is also composed of two-layer networks including ReLU and Dropout (0.5). We use small batches of SGD with a lot size of 32, a learning rate of 0.001 and a momentum of 0.9.

Model convergence and parameter sensitivity. a Model convergence analysis of UDA-DBADE on domain adaptation tasks M\(\rightarrow\)U, W\(\rightarrow\)A, A\(\rightarrow\)D and P\(\rightarrow\)C. b, c Sensitivity analysis of UDA-DBADE to parameters \(\mu\) and K of domain adaptation tasks M\(\rightarrow\)U, W\(\rightarrow\)A, A\(\rightarrow\)D and P\(\rightarrow\)C. d Iterative change analysis of UDA-DBADE to parameters \({\omega _t}\) of domain adaptation tasks M\(\rightarrow\)U, W\(\rightarrow\)A, A\(\rightarrow\)D and P\(\rightarrow\)C
4.3 Experimental results
In this section, we conduct extensive experiments to evaluate our model, and all comparative method results are taken from relevant literature. Experimental results on three datasets are shown in Tables 2, 3, 4 and 5. Our method is superior to many previous methods in different datasets. We present three-domain adaptation scenarios on handwritten numeral sets, and Table 2 reports the experimental results. The domain adaptation results of our method between MNIST and USPS reach 96.3% and 97.5%, respectively, and its classification accuracy is better than in previous work. The proposed method focuses on preventing excessive domain alignment and constructing a sample bias matrix by introducing metric learning to calculate sample similarity loss to make the classification boundary clearer and prevent negative migration. We show the results of the six preadaptation tasks on the Office-31 dataset and their averages in Table 3. We observe that the proposed method achieves the best results on two tasks with an average accuracy of 88.8%, which is superior to the previous comparison method. The accuracy of the model is 100% in W\(\rightarrow\)D and D\(\rightarrow\)W tasks. From the observation of classification accuracy, it can be seen that the proposed method can effectively balance the degree of domain alignment and class differentiation to prevent excessive domain alignment and smooth the classification boundary by using similarity loss among samples, thus improving the performance of the classifier in the target domain. For D\(\rightarrow\)A and W\(\rightarrow\)A tasks with large domain displacement and difficult domain adaptation, our model can still achieve 74.2% and 73.0% classification accuracy, which is better than 71.0% and 67.8% of the Enhanced Transport Distance (ETD) [64]. In Table 4, we show the results of six preadaptation tasks on the ImageCLEF-DA dataset and their average values. When training is stopped after 200 iterations, it is shown in Table 4 that our method is superior to the previous work and achieve the best average accuracy (89.8%). The evaluation results on Office-Home are reported in Table 5. It can be observed that the average accuracy of the proposed method UDA-DBADE achieves 70.8%, which is higher than 70.3% of GSDA. More importantly, UDA-DBADE achieves significant improvement on Pr\(\rightarrow\)Ar and Rw\(\rightarrow\)Ar tasks. It demonstrates the advantage of this method, especially when deal with transferring from a complicated scenario to a simple scenario. Moreover, when encountering a large domain discrepancy, UDA-DBADE still achieves promising results on complex transfer tasks such as Ar\(\rightarrow\)Rw, Cl\(\rightarrow\)Rw and Pr\(\rightarrow\)Rw, which further demonstrates its efficiency. In particular, Tables 2, 3, 4 and 5 show that compared with DWL, our method has achieved great advantages, especially on the Office-31 dataset, the average accuracy of our method is 3.3% higher than that of DWL. To this end, we analyze that, similar to DWL, we leverage adversarial learning to achieve domain alignment and build discriminative representations by boosting differences across multiple classifiers in this paper. In addition, we take into account the impact of label noise on the model, so we propose to use sample similarity loss to achieve sample-level alignment and reduce the impact of label noise on the model performance. Therefore, we consider that this is the superiority of our method over DWL.
4.4 Experimental analysis
In this section, we further analyze the advantages and disadvantages of the model from the convergence, parameter sensitivity, feature visualization and ablation experiments of the proposed method.
Convergence Analysis
Since the objective of UDA-DBADE is optimized in iterative manner, we evaluate the classification accuracy with iterations. Specifically, Fig. 3a shows the experimental results of Digits domain adaptation task M\(\rightarrow\)U, ImageCLEF domain adaptation task P\(\rightarrow\)C and Office-31 domain adaptation tasks W\(\rightarrow\)A and A\(\rightarrow\)D, respectively. It can be seen that the accuracy ascends gradually and comes to stable with about 90 epochs.
Parameter Sensitivity Analysis
It can be concluded from Eq. (12) that a high \(\mu\) value will lead to the selection of many noisy pseudo-label samples, thus leading to the deviation of model classification. By comparison, a low \(\mu\) value will even filter out some confident samples that may be positive. In order to evaluate the influence of the confidence factor \(\mu\), we adjust its value and use it to predict the threshold of the consistency score \({\Omega _j}\) for target domain sample pseudo-labels. As shown in Fig. 3b, sensitivity evaluations in terms of the confidence factor \(\mu\) are conducted on the Digits domain adaptation task M\(\rightarrow\)U, ImageCLEF domain adaptation task P\(\rightarrow\)C and Office-31 domain adaptation tasks W\(\rightarrow\)A and A\(\rightarrow\)D, respectively. We observe that model reaches the optimum when \(\mu = 0.75\), which is equivalent to accepting two-thirds of the pseudo-label prediction.
We use the K-nearest neighbor algorithm to assign pseudo-labels to the target samples, but the value of K is closely related to the accuracy of the pseudo-labels of the target samples. Larger values of K lead to assigning wrong pseudo-labels to target samples, while lower values of K miss the correct pseudo-labels of target samples. In order to evaluate the influence of the K, we adjust its value and use it to select pseudo-labels for target samples. As shown in Fig. 3c, sensitivity evaluations in terms of the confidence factor K are conducted on the Digits domain adaptation task M\(\rightarrow\)U, ImageCLEF domain adaptation task P\(\rightarrow\)C and Office-31 domain adaptation tasks W\(\rightarrow\)A and A\(\rightarrow\)D, respectively. We observe that model reaches the optimum when \({K = 5}\). It is not difficult to understand that \(K > 1\) is beneficial to the pseudo-label of the target sample, because it helps to deal with the noise prediction of the classifier boundary.
For the balance factor \({\omega _t}\), its value changing rule in the model training process is shown in Fig. 3d. We observe that at the beginning, the value shakes seriously within the range of 0.4 to 0.8, and then gradually converges to the value of 0.5 with increased iteration epochs. It endorses the theoretical analysis Eq. (7).
4.5 Feature visualization
We use t-SNE to visualize the features learned by ResNet-50, DANN and the model UDA-DBADE in this article on the Digits domain adaptation task M\(\rightarrow\)U, ImageCLEF domain adaptation task P\(\rightarrow\)C and Office-31 domain adaptation tasks W\(\rightarrow\)A and A\(\rightarrow\)D, respectively, and the results are shown in Fig. 4. Figure 4 shows that the feature distribution of RESNET-50 is disordered, and the source and target domain are not aligned. DANN can alleviate this problem to some extent, but there are still big differences between the two domains. UDA-DBADE achieves the best adaptation results with clear class boundaries.

t-SNE on the tasks of M\(\rightarrow\)U and W\(\rightarrow\)A, where red circles and blue circles denote the samples of source and target domains, respectively
4.6 Ablation studies
To evaluate the contribution of different modules to the model in this article, we conduct ablation experiment, and the experimental results are shown in Tables 6 and 7. We select the Office-31 domain adaptation task W\(\rightarrow\)A and Digits domain adaptation task M\(\rightarrow\)U for the ablation experiments. We observe that sample weight, balance factor \({\omega _t}\) and sample similarity loss \({L_S}\) all play a key role in promoting the performance of the model.
5 Conclusion
This article proposed a kind of UDA through dynamic bias alignment and discrimination enhancement (UDA-DBADE). Specifically, in UDA-DBADE we define a dynamic balance factor by the ratio of the normalized cross-domain discrepancy to the discrimination. Afterward, we construct domain alignment with adversarial learning as well as distinguishable representations through advancing the discrepancy of multiple classifiers and dynamically balance them with the defined dynamic factor. Finally, we further construct a bias matrix to characterize the discrimination alignment between the source and target domain samples. Our experiments on multiple UDA datasets clearly showed that UDA-DBADE is superior to the most advanced methods. Although the proposed UDA-DBADE in this article has achieved outstanding results, it is only for the scenario of a single source domain and a single target domain, and does not consider the scenario of multiple source domains a single target domain. Therefore, in the future, we will try to extend the method to the scenario of multiple source domains and a single target domain.
Data Availability
All data generated or analyzed during this study are included in this published article [and its supplementary information files].
References
Ding Y, Feng J, Chong Y, Pan S, Sun X (2021) Adaptive sampling toward a dynamic graph convolutional network for hyperspectral image classification. IEEE Trans Geosci Remote Sens 60:1–7
Xu H, Yang M, Deng L, Qian Y, Wang C (2021) Neutral cross-entropy loss based unsupervised domain adaptation for semantic segmentation. IEEE Trans Image Process 30:4516–4525
Ganin Y, Ustinova E, Ajakan H, Germain P, Larochelle H, Laviolette F, Marchand M, Lempitsky V (2016) Domain-adversarial training of neural networks. The Journal of Machine Learning Research 17(1):2096–2030
Tzeng E, Hoffman J, Saenko K, Darrell T (2017) Adversarial discriminative domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7167–7176
Long M, Cao Z, Wang J, Jordan MI (2017) Conditional adversarial domain adaptation. arXiv preprint arXiv:1705.10667
Tian Q, Sun H, Ma C, Cao M, Chu Y, Chen S (2021) Heterogeneous domain adaptation with structure and classification space alignment. IEEE Trans Cybernet 52(10):10328–10338
Geng B, Tao D, Xu C (2011) Daml: domain adaptation metric learning. Proc IEEE Trans Image Process 20(10):2980–2989
Long M, Cao Y, Wang J, Jordan M (2015) Learning transferable features with deep adaptation networks. In: international conference on machine learning, pp 97–105
Sun B, Feng J, Saenko K (2016) Return of frustratingly easy domain adaptation. In: proceedings of the AAAI conference on artificial intelligence, vol. 30
Tian Q, Sun H, Peng S, Ma T (2023) Self-adaptive label filtering learning for unsupervised domain adaptation. Front Comput Sci 17(1):1–3
Ganin Y, Lempitsky V (2015) Unsupervised domain adaptation by backpropagation. In: international conference on machine learning, pp 1180–1189
Tian Q, Zhu Y, Sun H, Chen S, Yin H (2022) Unsupervised domain adaptation through dynamically aligning both the feature and label spaces. IEEE Trans Circuits Syst Video Technol 32(12):8562–8573
Saito K, Watanabe K, Ushiku Y, Harada T (2018) Maximum classifier discrepancy for unsupervised domain adaptation. In: proceedings of the IEEE conference on computer vision and pattern recognition, pp 3723–3732
Lee CY, Batra T, Baig MH, Ulbricht D (2019) Sliced wasserstein discrepancy for unsupervised domain adaptation. In: proceedings of the IEEE conference on computer vision and pattern recognition, pp 10285–10295
Peng X, Bai Q, Xia X, Huang Z, Saenko K, Wang B (2019) Moment matching for multi-source domain adaptation. In: proceedings of the IEEE international conference on computer vision, pp 1406–1415
Zellinger W, Grubinger T, Lughofer E, Natschl T, Saminger-Platz S (2017) Central moment discrepancy (cmd) for domain-invariant representation learning. arXiv preprint arXiv:1702.08811
Peng X, Saenko K (2018) Synthetic to real adaptation with generative correlation alignment networks. In: proceedings of the IEEE winter conference on applications of computer vision, pp 1982–1991
Sun B, Saenko K (2016) Deep coral: correlation alignment for deep domain adaptation. In: European conference on computer vision, pp 443–450
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. Adv Neural Inf Process Syst 27:2672–2680
Xiao N, Zhang L (2021) Dynamic weighted learning for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 15242–15251
Wei G, Lan C, Zeng W, Chen Z (2021) Metaalign: coordinating domain alignment and classification for unsupervised domain adaptation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 16643–16653
Huang J, Xiao N, Zhang L (2022) Balancing transferability and discriminability for unsupervised domain adaptation. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2022.3201623
Bousmalis K, Silberman N, Dohan D, Erhan D, Krishnan D (2017) Unsupervised pixel-level domain adaptation with generative adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3722–3731
Sener O, Song HO, Saxena A, Savarese S (2016) Learning transferrable representations for unsupervised domain adaptation. In: Advances in neural information processing systems, pp 2110–2118
Bousmalis K, Trigeorgis G, Silberman N, Krishnan D, Erhan D (2016) Domain separation networks. Adv Neural Inf Process Syst 29:343–351
Zhang M, Wang H, He P, Malik A, Liu H (2022) Exposing unseen gan-generated image using unsupervised domain adaptation. Knowl-Based Syst 257:109905
Zhao D, Wang Z, Li H, Xiang J (2022) Gan-based privacy-preserving unsupervised domain adaptation. In: 2022 IEEE 22nd international conference on software quality, reliability and security (QRS), pp 117–126
Kalina B, Lee J (2023) Improving unsupervised domain adaptation with auxiliary classifier gans. In Proceedings of the 2023 international conference on research in adaptive and convergent systems, pp 1–6
Kang G, Jiang L, Yang Y, Hauptmann AG (2019) Contrastive adaptation network for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4893–4902 (2019)
Xie S, Zheng Z, Chen L, Chen C (2018) Learning semantic representations for unsupervised domain adaptation. In: International conference on machine learning, pp 5423–5432
Pei Z, Cao Z, Long M, Wang J (2018) Multi-adversarial domain adaptation. In: Thirty-second AAAI conference on artificial intelligence
Long M, Zhu H, Wang J, Jordan MI (2017) Deep transfer learning with joint adaptation networks. In: International conference on machine learning, pp 2208–2217
Yan H, Ding Y, Li P, Wang Q, Xu Y, Zuo W (2017) Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2272–2281
Shen J, Qu Y, Zhang W, Yu Y (2018) Wasserstein distance guided representation learning for domain adaptation. In: Thirty-second AAAI conference on artificial intelligence
Chen Q, Liu Y, Wang Z, Wassell I, Chetty K (2018) Re-weighted adversarial adaptation network for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7976–7985
Zhang Y, Tang H, Jia K, Tan M (2019) Domain-symmetric networks for adversarial domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5031–5040
Shen G, Yu Y, Tang Z-R, Chen H, Zhou Z (2022) Hqa-trans: an end-to-end high-quality-awareness image translation framework for unsupervised cross-domain pedestrian detection. IET Comput Vision 16(3):218–229
Liu H, Long M, Wang J, Jordan M (2019) Transferable adversarial training: a general approach to adapting deep classifiers. In: International conference on machine learning, pp 4013–4022
Schroff F, Kalenichenko D, Philbin J (2015) Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 815–823
Oh Song H, Xiang Y, Jegelka S, Savarese S (2016) Deep metric learning via lifted structured feature embedding. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4004–4012
Sohn K (2016) Improved deep metric learning with multi-class n-pair loss objective. In: Advances in neural information processing systems, pp 1857–1865
Wang X, Han X, Huang W, Dong D, Scott MR (2019) Multi-similarity loss with general pair weighting for deep metric learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5022–5030
Aziere N, Todorovic S (2019) Ensemble deep manifold similarity learning using hard proxies. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7299–7307
Kim S, Kim D, Cho M, Kwak S (2020) Proxy anchor loss for deep metric learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3238–3247
Qian Q, Shang L, Sun B, Hu J, Li H, Jin R (2019) Softtriple loss: deep metric learning without triplet sampling. In: Proceedings of the IEEE international conference on computer vision, pp 6450–6458
Movshovitz-Attias Y, Toshev A, Leung TK, Ioffe S, Singh S (2017) No fuss distance metric learning using proxies. In: Proceedings of the IEEE international conference on computer vision, pp 360–368
Tang Z, Jiao Q, Zhong J, Wu S, Wong HS (2022) Source-free unsupervised cross-domain pedestrian detection via pseudo label mining and screening. In: 2022 IEEE international conference on multimedia and expo (ICME), pp 1–6. IEEE
Liang J, Hu D, Feng J (2021) Domain adaptation with auxiliary target domain-oriented classifier. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 16632–16642
Oord AVD, Li Y, Vinyals O (2018) Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748
Mnih A, Kavukcuoglu K (2013) Learning word embeddings efficiently with noise-contrastive estimation. In: Advances in neural information processing systems, pp 2265–2273
Wang S, Zhang L (2020) Self-adaptive re-weighted adversarial domain adaptation. In: Proceedings of the twenty-ninth international joint conference on artificial intelligence, pp 3181–3187
Wang S, Zhang L, Wang P, Wang M, Zhang X (2023) Bp-triplet net for unsupervised domain adaptation: a bayesian perspective. Pattern Recognit. 133:108993
Dorfer M, Kelz R, Widmer G (2015) Deep linear discriminant analysis. arXiv preprint arXiv:1511.04707
Van der Maaten L, Hinton G (2008) Visualizing data using t-sne. J Mach Learn Res 9(11):2579–2605
LeCun Y, Bottou Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY (2011) Reading digits in natural images with unsupervised feature learning
Saenko K, Kulis B, Fritz M, Darrell T (2010) Adapting visual category models to new domains. In: European conference on computer vision, pp 213–226
Long M, Zhu H, Wang J, Jordan MI (2017) Deep transfer learning with joint adaptation networks. In: International conference on machine learning, pp 2208–2217
Hoffman J, Tzeng E, Park T, Zhu JY, Isola P, Saenko K, Efros A, Darrell T (2018) Cycada: cycle-consistent adversarial domain adaptation. In: International conference on machine learning, pp 1989–1998
Deng Z, Luo Y, Zhu J (2019) Cluster alignment with a teacher for unsupervised domain adaptation. In: Proceedings of the IEEE international conference on computer vision, pp 9944–9953
Pinheiro PO (2018) Unsupervised domain adaptation with similarity learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8004–8013
Pan Y, Yao T, Li Y, Wang Y, Ngo CW, Mei T (2019) Transferrable prototypical networks for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2239–2247
Ye S, Wu K, Zhou M, Yang Y, Tan SH, Xu K, Song J, Bao C, Ma K (2020) Light-weight calibrator: a separable component for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 13736–13745
Li M, Zhai YM, Luo YW, Ge PF, Ren CX (2020) Enhanced transport distance for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 13936–13944
Du Z, Li J, Su H, Zhu L, Lu K (2021) Cross-domain gradient discrepancy minimization for unsupervised domain adaptation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3937–3946
Li S, Song S-J, Wu C (2018) Layer-wise domain correction for unsupervised domain adaptation. Front Inf Technol Electron Eng 19(1):91–103
Xu R, Li G, Yang J, Lin L (2019) Larger norm more transferable: an adaptive feature norm approach for unsupervised domain adaptation. In: Proceedings of the IEEE international conference on computer vision, pp 1426–1435
Wang H, Tian J, Li S, Zhao H, Wu F, Li X (2022) Structure-conditioned adversarial learning for unsupervised domain adaptation. Neurocomputing 497:216–226
Hu L, Kan M, Shan S, Chen X (2020) Unsupervised domain adaptation with hierarchical gradient synchronization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4043–4052
Liu M-Y, Tuzel O (2016) Coupled generative adversarial networks. Adv Neural Inf Process Syst 29:469–477
Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L (2009) Imagenet: A large-scale hierarchical image database. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 248–255
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant 62176128, the Natural Science Foundation of Jiangsu Province under Grant BK20231143, the Open Projects Program of State Key Laboratory for Novel Software Technology of Nanjing University under Grant KFKT2022B06, the Fundamental Research Funds for the Central Universities No. NJ2022028, the Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD) fund, as well as the Qing Lan Project of Jiangsu Province.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tian, Q., Yang, H. & Cheng, Y. Dynamic bias alignment and discrimination enhancement for unsupervised domain adaptation. Neural Comput & Applic 36, 7763–7777 (2024). https://doi.org/10.1007/s00521-024-09507-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-09507-2