
Abstract
The echo state network (ESN) has been widely applied for nonlinear system modeling. However, the too large reservoir size of ESN will lead to overfitting problem and reduce generalization performance. To balance reservoir size and training performance, the multi-objective sparse echo state network (MOS-ESN) is proposed. Firstly, the ESN design problem is formulated as a two-objective optimization problem, which is solved by the decomposition-based multi-objective optimization algorithm (MOEA/D). Secondly, to accelerate algorithm convergence, the local search strategy is designed, which combines the l1 or l0 norm regularization and coordinate descent algorithm, respectively. Thirdly, to produce more solutions around the knee point, an adaptive weight vectors updating method is proposed, which is based on decision maker interest. Experimental results show that the MOS-ESN outperforms other methods in terms of network sparseness and prediction accuracy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Time series prediction is widely existed in all aspects of life [1,2,3,4], such as forecasting the number daily discharged inpatients of hospital, wind power prediction, global financial situation prediction, and so on. Typical methods include statistical regression [5], gray prediction [6] and machine learning [7]. The autoregressive moving average [8] is a commonly used statistical regression method, but it cannot solve nonlinear problems. Gray prediction [9] is suitable for time series prediction with uncertain partial information, but it is not suitable for the static dataset. Therefore, the prediction method based on machine learning [10] has been widely concerned, which requires no assumptions about the data or model.
In the field of machine learning, the commonly used methods include decision tree (DT) [11], support vector machine (SVM) [12] and artificial neural networks (ANN) [13,14,15,16,17], among which the ANN has drawn many attentions due to its nonlinear approximation ability. The most classical ANN is feed-forward neural network (FNN) [16], which can simulate any nonlinear system. However, it is difficult for FNN to capture the hidden sequence information of time series data. Therefore, the recurrent neural network (RNN) [17] is proposed to solve complex time series problems. However, its network structure and training method may lead to low training efficiency and memory loss. Therefore, Jaeger has proposed a new type of RNN, named as echo state network (ESN) [18].
Nowadays, ESN has been successfully applied in the field of time series prediction [18,19,20,21,22,23,24,25]. Unlike the traditional RNN, the ESN uses a reservoir to store and manage information. The input weights and internal weights of ESN are generated randomly and remain unchanged, only the output weights (also called readout) should be trained. In [21], the generation of reservoirs and training of readouts are reviewed. In [22], the hierarchical ESN is proposed, which is trained by stochastic gradient descent. In [23], the ESN with leaky integrator neurons is designed, which can easily adapt to time characteristics.
In reservoir initialization phase, hundreds of sparsely connected neurons are generated, and some neurons may have little influence on training performance. If all reservoir nodes are connected with network outputs, the ESN will perform very well on training data, but not good on testing data, leading to the overfitting problem. Hence, how to design a suitable reservoir size to improve the performance of ESN has always been the focus of research. In [24], the singular value decomposition-based growing ESN is proposed, which can weaken the coupling among reservoir neurons. In [25], the reservoir pruning method is designed, in which the mutual information between reservoir states is used to delete nodes. However, the pruning method may destroy the echo state characteristics of ESN [26].
To avoid overfitting problem, the regularization techniques are widely applied to sparse the readout of ESN, rather than control the size of reservoir directly [27, 28]. In [29], the reservoir nodes are dynamically added or deleted according to their importance to network performance, the l2 regularization is used to update the output weights. However, the l2 regularization is not able to generate the sparse ESN. In [30], the l1 penalty term is added into the objective function to shrink some irrelevant output weights as small values, such that the readout is sparse. In [31], the l0 regularization is used for sparse signal recovery, which is able to reduce computation complexity and improve classification ability, simultaneously. In [32], the online sparse ESN is designed, in which the l1 and l0 norms are respectively used as penalty terms to control the network size, the sparse recursive least squares and sub-gradient algorithm are combined to estimate output weights. This method has shown superior performance than other ESNs in prediction accuracy and network sparseness. Hence, the l0 and l1 regularization are the focus of this paper.
In traditional regularization approaches [27,28,29,30,31,32], the regularization coefficient is used to introduce the penalty term into the objective function,
where the first term and the second term are the training error and penalty term, respectively,\(\mu\) is regularization coefficient, Wout is the output weight of ESN, p = 0,1 represent the l0-norm or l1-norm, respectively. The regularization coefficient is used to balance training error and sparseness of Wout. Different \(\mu\) will lead to different optimal solutions [33], and a small change of the regularization coefficient will have a great influence on the training results. Thus, it is important to choose an appropriate regularization coefficient.
To avoid choosing regularization coefficient, in this paper, the optimization of Eq. (1) is formulated as a multi-objective optimization problem (MOP), in which the two conflicting objectives can be optimized [34]. From the view point of optimization, many Pareto-optimal solutions can be obtained by multi-objective optimization algorithms, and thus it is difficult to determine which solution can obtain the best network structure and training error. To select the appreciate solution, the preferences of decision maker should be considered [35]. The knee point is proposed in [36], in which a small change of one objective will generate a big change on the other [37,38,39]. Although the solutions in knee points does not provide the best result for some problems, they still be Pareto solutions which has the optimal performance for MOP.
In this paper, the multi-objective sparse ESN (MOS-ESN) is proposed, in which the training error and network size are treated as two optimization objectives. The main contribution is as follows. Firstly, the MOEA/D-based multi-objective optimization algorithm is designed to optimize network structure and network performance. Secondly, to improve algorithm convergence, the l1 or l0 regularization and coordinate descent algorithm-based local search strategy is designed. Thirdly, the preference information of knee point is integrated into weight vectors updating method, which guides the evolution of population toward knee region. Simulation results prove that MOS-ESN can improve the training accuracy and network sparseness without involving any regularization parameters.
The paper organization is as follows. Section 2 introduces the basic description of ESN, MOP and MOEA/D. The proposed MOS-ESN is given in Sect. 3. The simulations are discussed in Sect. 4. The paper is summarized in Sect. 5
2 Background
2.1 Original ESN
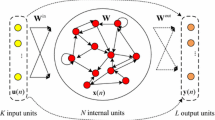
The original ESN (OESN) in Fig. 1 is constructed with an input layer, a reservoir and an output layer. The OESN has n input neurons in input layer, N nodes in reservoir and one output node. The input layer and reservoir are connected by the input weight matrix Win ∈ \(\mathbb{R}^{{N \times N}}\) the elements in reservoir are tied by the internal weight matrix W ∈ \(\mathbb{R}^{{N \times N}}\) while the input layer and reservoir are related with the output layer through the output weight matrix Wout ∈ \(\mathbb{R}^{{\left( {N + n} \right) \times 1}}\). Consider L distinct samples {u(k), t(k)}, where u(k) = [u1(k), u2(k), …, un(k)]T ∈ \(\mathbb{R}^{{\left( {N + n} \right) \times 1}}\) and t(k) are input and target, respectively, and the reservoir state x(k) is updated as below,
where g (·) = [g1(·), …, gN (·)T are the activation functions. The output y(k) is equal to (Wout)T[x(k); u(k)], where [x(k); u(k)] ∈ $$ \mathbb{R}^{{1 \times \left( {1 + n} \right)}} $$ is the concatenation of reservoir states and input matrix.

Description of OESN
Denote T = [t(1), t(2),…, t(L)]T as target data matrix and represent H = [X(1), X(2), …, X(L)]T as internal state matrix as below
The output weight matrix Wout can be calculated by
where H† is the Moore–Penrose pseudoinverse of H. H† can be computed by orthogonal projection methods [40], single-value decomposition, and so on. However, if the input data contain unknown random noise, the inverse calculation of H may lead to an ill-posed problem, i.e., an unstable solution is obtained.
2.2 MOPs
MOPs contain many conflicting objective functions that should be optimized at the same time. Generally speaking, the minimized MOPs can be expressed as below:
subject to W ∈ Ωwhere W is the decision variable, m is the number of objective functions, Ω is the decision space, F: Ω → Rm is consisted of m objective functions, and Rm is named as the objective space.
For two solutions W1 and W2, W1 is said to dominate W2 (denoted as W1 ≺ W2), if and only if fi(W1) ≤ fi(W2) for each objective i ∈ {1,…,m}, and fj(W1) < fj(W2) for at least one value j ∈ {1,…,m} [40].
Furthermore, the solution W∗ ∈ Ω is defined as Pareto-optimal if there is no other feasible solution W ≺ W∗. Particularly, the set of W∗ is named as Pareto-optimal set (PS) and the union of all PS is called the Pareto-optimal front (PF) [34].
2.3 MOEA/D
MOEA/D decomposes a MOP into several single-objective subproblems by multiple weight vectors, and all the subproblems can be optimized at the same time [40]. The main steps of MOEA/D are given:
Step 1: Generate the initial population, x1, x2, …, xP, and a group of uniformly weight vectors λ = (λ1, …, λP), where P is the population size.
Step 2: Compute the Euclidean distance between any two weight vectors, find the nearest T vectors of each vector, which are denoted the neighborhood of λi and represented as B(i) = {i1, i2, …, iT}.
Step 3: Choose two index k,l from B(i) randomly. Apply genetic operators on xk and xl to generate a new individual y.
Step 4: Update neighboring solutions. When the aggregate function value of y is smaller or equal to xj, update xj = y, where j ∈ B(i).
Step 5: Determine the non-dominated solutions of population and update the external population (EP), which saves the non-dominated solutions.
The main feature of MOEA/D is its decomposition method [40], such as the weighted sum approach, Tchebycheff approach and boundary intersection approach. In the following, the form of weighted sum approach is shown
where λi = {λi,1, λi,2, …, λi,m} represents the weight vector corresponding to each objective function, and it is noted that \(\sum\nolimits_{k = 1}^{m} {\lambda_{i,k} = 1}\).
3 MOS-ESN
To optimize the network size and training error simultaneously, the MOS-ESN is proposed. Firstly, the design of ESN is formulated as a bi-objective optimization problem, which is solved by MOEA/D. Secondly, to improve algorithm convergence, the l1 and l0 regularization-based local search strategy is designed. Furthermore, to find more solutions around the knee point, the decision maker preference-based weight vectors updating method is proposed.
3.1 Problem Formulation
The network size of ESN is closely related to training performance. To prove their relationship, a simple experiment is designed. Firstly, an ESN with 200 nodes is randomly initialized. Then, several sparse output weights are generated, and the corresponding training errors are recorded. Finally, the training error (denoted as f1) and the number of nonzero elements of output weights (denoted as f2) are drawn in Fig. 2. Obviously, the training error decreases as the network size increases, the too large network will lead to overfitting problem. However, if the network is too small, the training of ESN will be insufficient. Hence, how to achieve a balance between network size and training error becomes the key to research.

Relationship between training error and network size
To solve this problem, the regularization methods are introduced by using the l1 or l0 norm penalty term, and then the design of ESN is realized by optimizing the following objective function
where \(\mu\) is regularization parameters. Actually, the selection of regularization parameters is a difficult problem, because the large \(\mu\) means a small reservoir with large training error, while the small \(\mu\) has the opposite effect [33].
To avoid choosing regularization coefficient, the problem in Eq. (9) is treated as a multi-objective optimization problem,
where the first term is training error and the second is network size. To minimize the training error and network size simultaneously, the MOEA/D is used, in which the weighted sum approach is applied to generate a set of subproblems
where λ1 and λ2 represent the weight of f1 and f2, respectively, and λ1 + λ2 = 1.
3.2 Local Search Method
To accelerate the convergence speed of MOEA/D, the local search strategy is proposed, in which the l1 or l0 regularization term is applied to ensure network sparsity, and the coordinate descent algorithm is introduced to update the elements of Wout.
3.2.1 The l1 regularization-based local search method
By using the l1 regularization, the problem in Eq. (8) is formulated as below:
where \({\Vert {\text{W}}^{\text{out}}\Vert }_{1}\text{=}\sum_{\text{i} = {1}}^{\text{N+n}}\text{|}{\text{w}}_{\text{i}}\text{|}\) represent the l1-norm of Wout. The subproblem in Eq. (9) is described as
To facilitate computational analysis, \({{\lambda_{1} } \mathord{\left/ {\vphantom {{\lambda_{1} } 2}} \right. \kern-\nulldelimiterspace} 2}\) is applied in Eq. (11) instead of λ1. Because the two objectives in Eq. (11) are differentiable, the coordinate descent algorithm is selected to calculate the value of Wout, which has shown strong local search ability. Under the framework of coordinate descent algorithm, in each iteration, the ith variable wi (i = 1, 2, …, N + n)of Wout is updated, while the other elements remain the same. Thus, Eq. (11) becomes
It can be found that\(\frac{{\lambda _{1} }}{2}\sum\nolimits_{{{\text{k = 1}}}}^{{\text{L}}} {\left[ {\left( {{\text{t}}\left( {\text{k}} \right) - \sum\limits_{{{\text{j}} \ne {\text{i}}}}^{{{\text{N + n}}}} {{\text{X}}_{{{\text{kj}}}} } {\text{w}}_{{\text{j}}} } \right)^{2} } \right]}\) is irrelevant to wi, thus minimizing E(Wout( wi)) in Eq. (12) is equal to minimizing Z(Wout( wi)),
The sub-gradient of l1-norm is shown as below
When the derivative of Z(Wout( wi)) respect to wi is equal to zero, the minimize of Z(Wout( wi)) can be obtained. The derivative of Z(Wout( wi)) is given as
To simplify the calculation, two parameters D and C are introduced
Thus, the derivative of Z(Wout( wi)) is given,
By setting \(\frac{{\partial {\text{Z(Wout( wi))}}}}{{\partial {\text{w}}_{{\text{i}}} }} = {0}\), the update equation of wi is shown in Eq. (19), the corresponding threshold function is shown in Fig. 3a.

The soft thresholding function and the modified one
In Eq. (19), wi is related to, \({{\lambda_{1} } \mathord{\left/ {\vphantom {{\lambda_{1} } {\lambda_{2} }}} \right. \kern-\nulldelimiterspace} {\lambda_{2} }}\) which is a fixed value and not related to wi-1. Therefore, an adjustment is made on Eq. (19)
where wi-1 represents the weight at last iteration, ε is a small positive value and located in (0,1), and (x)+ equals 1/x when x ≤ 1 and is 1 otherwise.
The advantage of above method is its modifiable threshold \(\frac{{\lambda_{{2}} }}{{\lambda_{{1}} }}\left( {\varepsilon { + }\left| {{\text{w}}_{i - 1} } \right|} \right)_{ + }\). When wi-1 is small, C has a higher probability between \(- \frac{{\lambda_{{2}} }}{{\lambda_{{1}} }}\left( {\varepsilon { + }\left| {{\text{w}}_{i - 1} } \right|} \right)_{ + }\) and \(\frac{{\lambda_{{2}} }}{{\lambda_{{1}} }}\left( {\varepsilon { + }\left| {{\text{w}}_{i - 1} } \right|} \right)_{ + }\). Therefore, wi is attracted to zero with a higher possibility (show as Fig. 3b), while the increased threshold can reduce ||Wout||1 effectively. To the contrary, if wi−1 is large, the threshold will decrease to avoid becoming to zero.
3.2.2 The smoothed l0 regularization-based local search method
Actually, the l1 regularization always generates many components that are close but not equal to zero. To generate more sparse solution, the l0 regularization is considered
However, the minimization of Eq. (21) is NP-hard. To solve it, the ||Wout||0 is approximated by \({\text{||Wout||0 = g}}\left( {{\text{W}}_{{{\text{out}}}} } \right){\text{ = }}\sum\nolimits_{{{\text{i = 1}}}}^{{{\text{N + n}}}} {\left( {{\text{1}} - e^{{ - {\text{Q|w}}_{{\text{i}}} {\text{|}}}} } \right)}\)where Q is an appropriate positive constant. The subdifferential of \({\text{g}}\left({\text{W}}{\text{out}}\right)\) is as below
Transform e−Q|wi| by the first-order Taylor series expansion
Similar with l1 regularization, the subdifferential of objective function can be described as:
By setting \(\frac{{\partial {\text{Z}}\left( {{\text{Wout}}\left( {{\text{wi}}} \right)} \right)}}{{\partial {\text{w}}_{{\text{i}}} }} = {0}\), wi can be obtained by Eq. (25), and the threshold function is shown in Fig. 3(c).
To improve the zero-attraction effect, the modified l0 regularization method is proposed
which can modify the threshold based on the previous value of wi so that the small components are attracted to zeros with a higher probability (Fig. 3d).
3.3 Weight Vectors Updating Algorithm
By using MOEA/D, many non-dominated solutions can be obtained. However, only one solution is chosen to realize the nonlinear modeling problem. Generally speaking, the ESN with too large training error (λ1 is too small) or with too large network size (λ2 is too small) will not be chosen. As described in [41], the knee point is able to make a tradeoff between two objects. Thus, the knee point is selected as the final solution. In order to generate more solutions around the knee point, the weight vectors updating method is proposed, in which the information of knee point is incorporated.
3.3.1 Knee point
In this part, the distance-based method is introduced to find the knee point [41]. For a bi-objective optimization problem, a line L can be defined as ax + by + c = 0, where a, b, and c are determined by the two solutions that has minimize f1 and f2, respectively. Then, the distances d between solutions in PF and L can be calculated as
Considering the minimization problem in this paper, only the solutions in the convex region are of interesting. Thus, the above equation can be modified as
According to Eq. (28), the solution farthest from L is defined as knee point. For example, in Fig. 4, points A and B can determine the line L. By calculating the distance d between each point and L, the point E is the knee point obviously.

Example of knee point
3.3.2 Weight Vectors Updating Method
The weight vectors are updated according to the information of knee point and decision maker preference. As shown in Fig. 5, the red point K is the projection of the knee point on the line Lw and A and B are the boundary points where the updated weight vectors should be located, i.e., the line AB is divided into two subintervals by K. Then, the same number of weight vectors \(\frac{\text{P}}{{2}}\) will be generated in each subinterval. The distance between two weight vectors is called step size, which is calculated as

where d1 is the step size in line KA, d2 is the step size in line KB, and α > 0 is the step size parameter. The value of weight vector λi in line KA is,

The weight vectors updating method
Similarly, the value of weight vector \(\lambda_{j}\) in line KB is

In the above weight vectors updating method, the weight vectors have a denser distribution near the knee point and are sparser at the boundary. Hence, more weight vectors will be generated near the knee point, and fewer at the boundary. Moreover, the determination of points A and B can be made by decision maker preference, which makes the algorithm converge to the region of interest.
The weight vectors updating algorithm is presented in Algorithm 1. Firstly, the two solutions which minimize f1 and f2 are selected and the line L can be calculated. Then, the distance between each solution to L is computed to find the knee point, and the weight vectors corresponding to knee point are chosen. Finally, the weight vectors are updated according to Eqs. (31) and (32).
3.4 Framework of MOS-ESN
The pseudo code of MOS-ESN is described in Algorithm 2. In Step 1, the population is randomly initialized. In Steps 2 and 3, two individuals are randomly chosen to generate the offspring, the uniform crossover operation and polynomial mutation operator are applied. In Step 4, the neighborhoods of each weight vector are updated. In Step 5, the local search is operated loca iterations to improve algorithm convergence. In Step 6, the knee point is selected from EP. In Step 7, the weight vectors are updated by the weight vectors updating method.
4 4 Simulation
In this section, the proposed MOS-ESN models are tested on two simulated benchmark problems and one practical system modeling problem, including the Rossler chaotic time series prediction [29], the nonlinear system modeling problem [42] and the effluent ammonia nitrogen (NH4-N) prediction in wastewater treatment process (WWTP) [28]. It is noted that the MOS-ESN with l0 regularization is named as MOS-ESN-l0, while the MOS-ESN with l1 regularization is termed as MOS-ESN-l1.The MOS-ESN models are compared with OESN [29], the OESN with l1 norm regularization (OESN-l1) [33], the OESN with l0 norm regularization (OESN-l0) [32], the OESN whose output weight is updated by coordinate descent and l1 or l0 norm (CD-ESN-l1 [43], CD-ESN-l0), as well as the OESN whose output weights are directly calculated by MOEA/D (OESN-MOEA/D). For each algorithm, 50 independent runs are carried out in the MATLAB 2018b environment on a personal computer with i7 core 8.0 GB memory.
The training and testing RMSE values are applied to evaluate the learning and testing performance of ESNs. Furthermore, the sparsity degree (SP) of the output weight matrix [28] is also introduced. The SP and RMSE are defined as follows:
where Wout is the output weights matrix and y(k) and t(k) stand for actual and target output, respectively. A smaller RMSE means a better training or testing accuracy. Meanwhile, the smaller SP means, the ESN has the sparser structure.
To evaluate the searching ability of a multi-objective optimization, the C-matrix [45] is introduced, which can measure the ration of the non-dominated solutions in P that are not dominated by any other solutions in P*,
The larger C(P, P*) value means a better non-dominated solution set P.
The parameters setting of MOS-ESN-l0 and MOS-ESN-l1 are as below: the reservoir size, the population size, and the neighborhood size are set as 1000, 200, 15 in each test instance, which is suggested in [44]. The optimal value of loca, α is selected by the grid search method, the number of local search operations local is varied from 0 to 5 by the step of 1, and the step size α is set from 0 to 3 by the step of 1. For other algorithms, their corresponding parameter settings are described in Appendix.
4.1 Rossler chaotic time series prediction
To study the performance of MOS-ESN, the Rossler chaotic time series [29], a typical chaotic dynamical time series, is introduced as below:
where α = 0.2, β = 0.4, γ = 5.7. There are 2000 samples in the experiment, in which 1400 are used for training and the rest 600 are applied for testing. The White Gaussian noise, which has the signal-to-noise ratio (SNR) of 20 dB, is added into the original training and testing datasets.
The testing outputs and prediction error of MOS-ESN-l0, MOS-ESN-l1, OESN are illustrated in Figs. 6 and 7, respectively, in which the red, blue, black and cyan lines are the trends of MOS-ESN-l0, MOS-ESN-l1, target and OESN, respectively. It is easily found that both MOS-ESN-l0 and MOS-ESN-l1 can predict the trends of testing output, while the OESN shows missing outputs in a partial enlargement. Furthermore, the RMSE values of MOS-ESN-l0 are concentrated in [− 0.3,0.3], which is smaller than other methods, demonstrating its stable performance.

The prediction outputs for Rossler chaotic time series prediction

The prediction errors for Rossler chaotic time series prediction
Simulation results of all methods are presented in Table 1, including sparsity, CUP running time for one operation, the mean RMSE and standard deviation (Std. for short) RMSE of training and testing of 50 independent runs. It is easily found that the OESN has the smallest running time, while it has the largest testing RMSE, implying its poor generalization ability. Both OESN-l1 and OESN-l0 have smaller SP, which implies the regularization method could generate the sparse output weight matrix. Besides, the proposed MOS-ESN-l0 has the smallest testing RMSE and SP among all ESN models, which proves its effectiveness in terms of network sparseness and prediction accuracy.
4.1.1 Effect of loca
As introduced in Sect. 3.4, loca decides how many local search operators are conducted on each individual. The effects of loca on network performance are investigated through 50 independent experiments. By setting loca = 0, loca = 1 and loca = 3, the obtained non-dominated solutions of MOS-ESN-l1 and MOS-ESN-l0 are plotted in Figs. 8 and 9, respectively. The x-coordinate and y-coordinate are the objective function \({{\text{f}}_{2}\text\,=\,\Vert {\text{W}}^{\text{out}}\Vert }_{1/0}\) and \({\text{f}}_{1}\text\,=\,{\Vert {\text{T}}-{\text{H}}{\text{W}}^{\text{out}}\Vert }_{2}^{2}\), respectively. Obviously, the algorithm with loca = 3 can always generate more non-dominated solutions than the algorithms with loca = 0 or loca = 1, which implies that the local search algorithm can accelerate the algorithm convergence speed.

Effect of loca on MOS-ESN-l1

Effect of loca on MOS-ESN-l0
By setting loca = {1, 2, 3, 4, 5} and α = 2, the statistics results of training time, training and testing RMSE values, C-matrix and SP of MOS-ESN-l1 and MOS-ESN-l0 are reported in Tables 2 and 3, respectively. It is noted that during the calculation process of C-matrix, P* = (P1, P2, …, Pn), where Pi is the non-dominated solution set by the algorithm with loca = i (i = 1, …, 5). It is easily found that when loca is set as a small value, such as 0 or 1, the small value of C-matrix is obtained, which means the worse non-dominated solutions is obtained. When loca is set as a moderate value (loca = 3), the larger value of C-matrix, lower SP and testing RMSE values can be obtained. On the contrary, if loca is set as a too large value (loca = 5), the training and testing RMSE values are not best among all the models, because the too large value of loca may have a risk of converging to local regain. Furthermore, the too large loca will increase the computational complexity or training time.
4.1.2 Effect of α
For ESN design, the network with too small training error or too small network sparseness is not preferred, while the solution at the knee point maybe a good choice, which is a tradeoff between two objects. To help the algorithm converge to the knee point, the weight vectors updating algorithm is proposed, in which the weight updating step α is applied. A larger α implies that the updated weight vector is closer to the corresponding weight vector of knee point.
To show the influence of α on network performance, by setting α = {0, 1, 2}, the obtained non-dominated solution sets of MOS-ESN-l1 and MOS-ESN-l0 are compared in Figs. 10 and 11, respectively, and the x-coordinate and y-coordinate are the objective function \({{\text{f}}_{2}\text{=} \, \Vert {\text{W}}^{\text{out}}\Vert }_{1/0}\) and \({\text{f}}_{1}\text{=}{ \Vert {\text{T}}-{\text{H}}{\text{W}}^{\text{out}}\Vert }_{2}^{2}\), respectively. It is easily found that the non-dominated solutions sets with α = 1 or α = 2 are better than that with α = 0, which implies the effectiveness of weight vectors updating algorithm in terms of algorithm convergence.

Effect of α on MOS-ESN-l1

Effect of α on MOS-ESN-l0
With α = {0, 1, 2, 3} and loca = 3, the statistic results of 50 independent experiments of MOS-ESN-l1 and MOS-ESN-l0 are listed in Tables 4 and 5, respectively. Obviously, when α = 2, the obtained ESN has the most sparse network structure and the best testing RMSE values. However, when α = 3, the corresponding testing RMSE values become larger. Hence, the too large or too small value of α is not preferred.
4.2 Nonlinear dynamic system modeling
The proposed method is performed on the nonlinear dynamic system as below
where u(k) and y(k) are input and output, respectively. y(k + 1) is predicted by y(k), y(k − 1), u(k − 1), u(k − 2), u(k − 3). In the training phase, u(k) is 1.05sin(k/45). In the testing phase, u(k) is given as
In this experiment, 2000 samples are generated by Eq. (38). The first 1400 points are used in training stage, and the remaining 600 are used in testing phase. In addition, the 20-dB Gaussian noise is added to generate the noisy environment.
The prediction output and testing error of the resulted MOS-ESN-l1, MOS-ESN-l0 and OESN are plotted in Figs. 12 and 13, respectively. Actually, all the algorithms show similar predictive trend on nonlinear dynamic system. However, the prediction error of MOS-ESN-l0 is limited in [-0.4,0.4], which is smaller than other methods. Thus, the proposed MOS-ESN-l0 has the best prediction effect among all compared algorithms.

The prediction outputs for nonlinear dynamic system

The prediction errors for nonlinear dynamic system
The statistic results of 50 independent runs of compared algorithms are summarized in Table 6. Obviously, the OESN has shortest training time and smallest training error, but its testing error is largest, which indicates overfitting problem. Furthermore, the MOS-ESN-l0 obtains the smallest testing RMSE and SP values, which means the MOS-ESN-l0 has better prediction accuracy, sparser reservoir for nonlinear dynamic system modeling.
4.3 Effluent NH4 − N model in WWTP
Recently, the discharge of industrial and domestic wastewater has also increased sharply, and the phenomenon of water quality exceeding standard in the wastewater treatment process (WWTP) is serious. In WWTP, the excessive NH4 -N will lead to eutrophication of water body and affect human health. Thus, predicting NH4-N accurately is critical. However, the WWTP is a complex system with nonlinear, uncertainty, it is difficult to predict NH4-N. To solve this problem, the laboratory analytical techniques are used. However, these methods always require long time.
In this section, the proposed MOS-ESN models are applied to predict NH4-N in WWTP. This experiment contains 641 sets of data, which are collected from Chaoyang, Beijing in 2016. The first 400 groups are treated as training data and the rest 241 are set as testing data. The inputs of ESN include T, ORP, DO, TSS and pH, which are described in [29].
The prediction result of effluent NH4-N models of MOS-ESN-l0, MOS-ESN-l1 and OESN is demonstrated in Fig. 14, and the corresponding prediction error is shown in Fig. 15. Obviously, all the algorithms achieve the similar prediction accuracy. As compared with MOS-ESN-l0 and MOS-ESN-l1, it can be found that the l0 regularization can get sparser structure, and thus the MOS-ESN-l0-based effluent NH4-N model has smaller prediction error.

Prediction output of effluent NH4-N

Prediction errors of effluent NH4-N model
The comparison results of different models are shown in Table 7, including the network sparsity SP, training time, the mean and standard deviation of training and testing RMSE values of 50 independent experiments. Obviously, the OESN has small training but large testing RMSE values, which implies the overfitting problem occurs. Thus, the OESN has difficulty in predicting NH4-N in WWTP. In OESN-l1 and OESN-l0, the regularization technique is applied to make the network structure sparse, but the testing RMSE value is still large. In CD-ESN-l0 and CD-ESN-l1, the regularization technique and coordinate descent are used to updates the output weights, which can obtain better prediction performance than OESN-l1 and OESN-l0. As compared with OESN-MOEA/D, the local search and weight vectors updating algorithm are applied in MOS-ESN-l0 and MOS-ESN-l1, which helps to improve solution performance. Particularly, the MOS-ESN-l0 has the smallest testing error and the sparsest network structure, which can effectively predict NH4-N of WWTP.
5 Conclusion
In this paper, the multi-objective sparse ESN is proposed, in which the training error and network structure are optimized simultaneously. Firstly, instead of searching the regularization parameters, the design of ESN is treated as a bi-objective optimization problem. Secondly, to improve algorithm convergence performance, the local search strategy is designed, which incorporates the l1 or l0 norm regularization and coordinate descent algorithm. Furthermore, to make the algorithm converge to the region of interest, the weight vectors updating method is designed, which applies the information of knee point. The effectiveness and usability of the proposed algorithm are evaluated by experimental results. In future work, this method will be applied in other practical engineering fields, such as garbage classification and image recognition.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Zhu T, Luo L, Zhang XL et al (2017) Time-series approaches for forecasting the number of hospital daily discharged inpatients. IEEE J Biomed Health Inform 21(2):515–526
Zhang H, Cao X, John H, Tommy C (2017) Object-level video advertising: an optimization framework. IEEE Trans Industr Inf 13(2):520–531
Safari N, Chung CY, Price G (2018) A novel multi-step short-term wind power prediction framework based on chaotic time series analysis and singular spectrum analysis. IEEE Trans Power Syst 33(1):590–601
Lee R (2020) Chaotic type-2 transient-fuzzy deep neuro-oscillatory network (CT2TFDNN) for worldwide financial prediction. IEEE Trans Fuzzy Syst 28(4):731–745
Li JD, Tang H, Wu Z et al (2019) A stable autoregressive moving average hysteresis model in flexure fast tool servo control. IEEE Trans Autom Sci Eng 16(3):1484–1493
Zhou D, Al-Durra A, Zhang K et al (2019) A robust prognostic indicator for renewable energy technologies: a novel error correction grey prediction model. IEEE Trans Industr Electron 66(12):9312–9325
Ciprian C, Masychev K, Ravan M et al (2020) A machine learning approach using effective connectivity to predict response to clozapine treatment. IEEE Trans Neural Syst Rehabil Eng 28(12):2598–2607
Park YM, Moon UC, Lee KY (1996) A self-organizing power system stabilizer using fuzzy auto-regressive moving average (FARMA) model. IEEE Trans Energy Convers 11(2):442–448
Xie N, Liu S (2015) Interval grey number sequence prediction by using non-homogenous exponential discrete grey forecasting model. J Syst Eng Electron 26(1):96–102
Zhang K, Liu Z, Zheng L (2020) Short-term prediction of passenger demand in multi-zone level: temporal convolutional neural network with multi-task learning. IEEE Trans Intell Transp Syst 21(4):1480–1490
Kuang W, Chan YL, Tsang SH et al (2019) Machine learning-based fast intra mode decision for HEVC screen content coding via decision trees. IEEE Trans Circuits Syst Video Technol 30(5):1481–1496
Han SJ, Bae KY, Park HS et al (2016) Solar power prediction based on satellite images and support vector machine. IEEE Transactions on Sustainable Energy 7(3):1255–1263
Liu YT, Lin YY, Wu SL et al (2015) Brain dynamics in predicting driving fatigue using a recurrent self-evolving fuzzy neural network. IEEE Transactions on Neural Networks and Learning Systems 27(2):1–14
Zhang HJ, Li JX, Ji YZ, Yue H (2017) Subtitle understanding by character-level sequence-to-sequence learning. IEEE Trans Industr Inf 13(2):616–624
Zsuzsa P, Radu EP, Jozsef KT et al (2006) Use of multi-parametric quadratic programming in fuzzy control systems. Acta Polytechnica Hungarica 3(3):29–43
Rizvi SA, Wang LC (1997) Nonlinear vector prediction using feed-forward neural networks. IEEE Trans Image Process 6(10):1431–1436
Shi Z, Liang H, Dinavahi V (2017) Direct interval forecast of uncertain wind power based on recurrent neural networks. IEEE Transactions on Sustainable Energy 9(3):1177–1187
Jaeger H, Hass H (2004) Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 304:78–80
Wu Z, Li Q, Zhang HJ (2022) Chain-structure echo state network with stochastic optimization: methodology and application. IEEE Trans Neural Netw Learn Syst 33(5):1974–1985
Wu Z, Li Q, Xia XH (2021) Multi-timescale forecast of solar irradiance based on multi-task learning and echo state network approaches. IEEE Trans Industr Inf 17(1):300–310
Mantas L, Jaeger H (2009) Reservoir computing approaches to recurrent neural network training. Computer science review 3:127–149
Jaeger H (2007) Discovering multiscale dynamical features with hierarchical echo state networks. Jacobs University Bremen, Bremen
Jaeger H, Lukosevicius M, Popovici D et al (2007) Optimization and applications of echo state networks with leaky integrator neurons. Neural Netw 20(2007):335–352
Qiao J, Li F, Han H et al (2017) Growing echo-state network with multiple subreservoirs. IEEE Trans Neural Netw Learn Syst 28(2):391–404
Wang HS, Ni CJ, Yan XF (2017) Optimizing the echo state network based on mutual information for modeling fed-batch bioprocesses. Neurocomputing 225:111–118
Xu M, Han M (2017) Adaptive elastic echo state network for multivariate time series prediction. IEEE Trans Cybern 46(10):2173–2183
Yang C, Nie K, Qiao J et al (2022) Robust echo state network with sparse online learning. Inf Sci 594:95–117
Luo X, Chang X, Ban X (2016) Regression and classification using extreme learning machine based on l1-norm and l2-norm. Neurocomputing 174:179–186
Yang CL, Qiao JF, Wang L et al (2019) Dynamical regularized echo state network for time series prediction. Neural Comput Appl 31(10):6781–6794
Han M, Ren W, Xu M (2014) An improved echo state network via l1-norm regularization. Acta Automatica Sinica 40(11):2428–2435
Dzati A, Ramli, et al (2017) Fast kernel sparse representation classifier using improved smoothed-l0 norm. Proc Comput Sci 112:494–503
Yang CL, Qiao JF, Ahmad Z et al (2019) Online sequential echo state network with sparse RLS algorithm for time series prediction. Neural Netw 118:32–42
Qiao JF, Wang L, Yang CL (2018) Adaptive lasso echo state network based on modified Bayesian information criterion for nonlinear system modeling. Neural Comput Appl 31(10):6163–6177
Huang HZ, Gu YK, Du X (2006) An interactive fuzzy multi-objective optimization method for engineering design. Eng Appl Artif Intell 19(5):451–460
Zhang HJ, Sun YF, Zhao MB et al (2020) Bridging user interest to item content for recommender systems: an optimization model. IEEE Transactions on Cybern 50(10):4268–4280
Lin L, Yao X, Stolkin R et al (2014) An evolutionary multiobjective approach to sparse reconstruction. IEEE Trans Evol Comput 18(6):827–845
Rachmawati L, Srinivasan D (2009) Multiobjective evolutionary algorithm with controllable focus on the knees of the pareto front. IEEE Trans Evol Comput 13(4):810–824
Branke J, Deb K, Dierolf H et al (2004) Finding knees in multiobjective optimization. In: International Conference on Parallel Problem Solving from Nature, LNCS 3242:722–731
Das I (1999) On characterizing the ‘knee’ of the pareto curve based on normal-boundary intersection. Struct Multidiscip Optimiz 18(2):107–115
Zhang Q (2007) MOEA/D: a multiobjective evolutionary algorithm based on decomposition. IEEE Transa Evolut Comput 11(6):712–731
Deb K, Gupta S (2011) Understanding knee points in bicriteria problems and their implications as preferred solution principles. Eng Optim 43(11):1175–1204
Weitian C, Brian DOA (2012) A combined multiple model adaptive control scheme and its application to nonlinear systems with nonlinear parameterization. IEEE Trans Autom Control 57(7):1778–1782
Yang CL, Wu ZH, Qiao JF (2020) Design of echo state network with coordinate descent method and l1 regularization. Commun Comput Inf Sci 1265:357–367
Dong ZM, Wang XP, Tang LX (2020) MOEA/D with a self-adaptive weight vector adjustment strategy based on chain segmentation. Inf Sci 521:209–230
Ishibuchi H, Yoshida T, Murata T (2003) Balance between genetic search and local search in memetic algorithms for multiobjective permutation flowshop scheduling. IEEE Trans Evol Comput 7(2):20
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (61973010, 61890930–5,62021003, 61533002), in part by the National Natural Science Foundation of Beijing (4202006), and in part by the National Key Research and Development Project (2021ZD0112302, 2019YFC1906002, 2018YFC1900802
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The parameters setting of different algorithms is given:
-
OESN: The reservoir has 1000 nodes. The reservoir sparsity s1 is chosen from the set (0.01, 0.015, …, 0.6), and the spectral radius of reservoir s2 is chosen from the set (0.1, 0.15, …, 0.95).
-
OESN-l1: The reservoir has same parameters as OESN. The regularization parameter λ1 is selected by (LASSO) method [33].
-
OESN-l0: The reservoir has same parameters as OESN. The regularization parameter λ0 is adaptively calculated [32].
-
CD-ESN-l1: The reservoir has same parameters as OESN. The regularization parameter λ is chosen from the set (0.05, 0.10, 0.15, …, 0.9) as suggested in [43].
-
CD-ESN-l0: The reservoir has same parameters as OESN. The regularization parameter λ is chosen from the set (0, 0.05, 0.15, …, 0.95).
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, C., Wu, Z. Multi-objective sparse echo state network. Neural Comput & Applic 35, 2867–2882 (2023). https://doi.org/10.1007/s00521-022-07711-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07711-6