
Abstract
Divergence measure is a significant tool for evaluating the amount of discrimination for IFSs. Since then it has acquired concentration for their applications in different areas. In this paper, we utilize the conception of Jensen–Shannon divergence to propose new measures called Jensen-exponential divergence for measuring the discrimination between intuitionistic fuzzy sets (IFSs) and demonstrate some very elegant properties, which show its strength for applications point of view. Next, a multi-criteria decision-making (MCDM) problem for IFSs that describes information about options with respect to criteria is studied. A technique that employs the relative comparisons for IFSs (that uses all the constraints, viz. membership, non-membership and hesitancy degrees) based on the advantage and disadvantage scores of the options with respect to criterion, where criterion weights are completely unknown, is used. In addition, the score functions are applied to evaluate the strength and worst scores leading to the satisfaction degree of the options. A multi-objective optimization model for optimal weights of the criterion that maximizes the satisfaction degree of each option is constructed. Energy resources play an important role in the social and economic development of the countries. Due to the industrialization, population growth and urbanization, the demand of energy is increasing gradually and this requires the selection of most suitable energy resource for economic development of the countries. The proposed MCDM method is presented to choose the most appropriate energy alternative among set of renewable energy alternatives. In this real case study, the decision makers provide their opinions in terms of linguistic variables because it is tricky to portray exact numerical values during the evaluation of energy alternatives. Finally, a comprehensive comparison is prepared to express the effectiveness of the technique over the existing techniques for the IF MCDM problems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the few decades, divergence measures have been extensively employed to determine the discrimination between two probability distributions, introduced by Kullback and Leibler [18], and extensively utilized in various disciplines. Afterwards, different generalizations of divergence have been introduced by various authors [41, 44] and deliberated their properties and applications in different areas. Another important information-theoretic divergence measure, introduced by Lin [22], is the Jensen–Shannon divergence (JSD) which has attracted quite some attention from researchers and fruitfully executed in various disciplines [1, 9, 33, 38].
Inspired by the notion of divergence between two probability distributions, Bhandari and Pal [4], Shang and Jiang [42], Fan and Xie [7] and Montes et al. [35] introduced different divergence measures for fuzzy sets (FSs). Bhandari and Pal [4] and Shang and Jiang [42] divergence measures for FSs are based on logarithmic information gain functions, and that of Fan and Xie [7] is derived from exponential information gain functions with the same approach being followed in Mishra et al. [10, 27,28,29]. As for FSs, divergence measures for intuitionistic fuzzy sets (IFSs) are proposed by Vlachos and Sergiadis [49], Hung and Yang [11], Zhang and Jiang [61], Xia and Xu [53], Junjun et al. [12], Mishra et al. [30, 31], Ansari et al. [2], Mishra and Rani [32] and these measures are utilized in pattern recognition, medical diagnosis, MCDM and image processing. Recently, Montes et al. [34] proposed an axiomatic definition of the notion of divergence for IFSs and recommended some new approaches for building divergence measures for IFSs.
The concept of IFSs [3] considered as an extension of FSs [60] considered by a membership, non-membership and hesitancy functions. Subsequently, various authors implemented IFSs to the multi-criteria decision-making (MCDM). Tan and Chen [46] introduced a technique for MCDM based on IF-correlated averaging operators with intuitionistic fuzzy information. Zhao and Wei [62] presented MCDM problems with intuitionistic fuzzy numbers (IFNs). Next, there are various real-world decision-making circumstances such that the weight information is either partially known or completely unknown. Li and Wan [20] proposed a fuzzy linear programming method for MCDM problems with incomplete weight. Xu and Cai [54] developed various nonlinear optimization models to evaluate the optimal weights of criterion when no weight information is available. Xu [56] proposed a linear programming model to determine optimal attribute weights where the information about attribute weights is partially known. Wei [52] initiated grey relational analysis technique to solve IF MCDM problem with partial weight information. Xu [55] discussed an interactive method for IF MADM problem where the weight information is not completely known. Li [19] proposed TOPSIS-based nonlinear programming technique for MCDM with IVIFSs. Chen and Li [5] introduced a method to determine weights using IF entropy measures. Wan and Dong [50] pioneered a possibility degree technique for IVIF MCGDM.
In this paper, we develop new Jensen-exponential divergence measures for IFSs. These measures have some elegant properties, which are revealed to enhance the applicability of these measures. The vitality of these extensions has been established by a technique for multi-criteria decision-making problem. Next, we study IF MCDM problem where the weight information on the criterion is completely or partially unknown using relative comparisons among the available options on each criterion. To evaluate the optimal weight vector, we first achieve the advantage and disadvantage scores of each option and with the help of advantage and disadvantage scores of an option with respect to the criterion are then used to find the strength and weakness scores of the option as a function of the weight vector. To find the optimal criteria weights, the satisfaction degree of each option is used to formulating a multi-objective optimization model. The optimal weights determine the overall criterion value of each option. Finally, a ranking technique is implemented to rank the options on the basis of overall criterion values.
2 Prerequisite
Throughout this paper, let \(\mathbf{{{\mathbb R}}}=[0,\,\infty [,\) let FSs (X) and IFSs(X) be the sets of all fuzzy sets and intuitionistic fuzzy sets on a universal set X, respectively, and P(X) be the set of all crisp sets on the universal set X. Further, we roughly introduce some basic knowledge about entropy, divergence measure, FSs and IFSs.
Let \(\varDelta _{n} =\left\{ P=(p_{1} ,p_{2} ,\ldots ,p_{n} ):p_{i} \ge 0;\sum _{i=1}^{n}p_{i} =1 \right\} ,\, \, n>2\) be a set of discrete probability distributions. For a probability distribution \(P=(p_{1} ,p_{2} ,\ldots ,p_{n} )\in \varDelta _{n},\) Shannon’s entropy [43] is defined as
Pal and Pal [39] scrutinized Shannon entropy and proposed another measure called exponential entropy as follows:
Note that (2) has an advantage over (1). For the uniform probability distribution \(P=\left( 1/n,\, \, 1/n,\, \ldots ,\, \, 1/n\right),\) exponential entropy has an upper bound
which is not the case for Shannon’s entropy (1).
Let \(P=(p_{1} ,p_{2},\ldots ,p_{n} )\) and \(Q=(q_{1} ,q_{2},\ldots ,q_{n} )\in \varDelta _{n}\) be probability distribution. Then, Kullback and Leibler [18] introduced the divergence measure of P from Q as follows:
Lin [22] proposed that the Jensen–Shannon divergence between P and Q is given by
where H(.) is Shannon entropy given in (1).
Definition 2.1
(Zadeh [60]): A fuzzy set \(\tilde{M}\) on a finite discourse set \(X=\left\{ x_{1} ,\, \, x_{2} ,\, \, \ldots ,\, \, x_{n} \right\}\) is defined as
where \(\mu _{\tilde{M}} (x_{i} )\left( 0\le \mu _{\tilde{M}} (x_{i} )\le 1\right)\) represents the degree of membership of \(x_{i}\) to \(\tilde{M}\) in X.
De Luca and Termini [25] introduced first entropy for FS \(\tilde{M}\) corresponding to (1) as follows:
Based on (2), exponential entropy for FS \(\tilde{M}\) has also been introduced by Pal and Pal [39] which is given by
Let \(\tilde{M} ,\tilde{N}\in\) FSs, then Bhandari and Pal [4] introduced divergence measure for FSs based on (3) as follows:
Fan and Xie [7] initiated the divergence measure for FSs based on exponential function which is given by
Definition 2.2
(Atanassov [3]): An IFS M on discourse set \(X=\left\{ x_{1} ,\, \, x_{2} ,\, \, \ldots ,\, \, x_{n} \right\}\) is given by
where \(\mu _{M} :X \rightarrow [0, 1]\) and \(\nu _{M} :X \rightarrow [0, 1]\) are the degrees of membership and non- membership of \(x_{i}\) to M in X, respectively, such that \(0\le \mu _{M} (x_{i} )\le 1,\)\(0\le \nu _{M} (x_{i} )\le 1\) and \(0\le \mu _{M} (x_{i} )+\nu _{M} (x_{i} )\le 1\), \(\forall \, \, x_{i} \in X.\) For an IFS M in X, we call the intuitionistic index (hesitancy degree) of an element \(x_{i} \in X\) to M the following expression: \(\pi _{M} (x_{i} )=1-\mu _{M} (x_{i} )-\nu _{M} (x_{i} )\) and \(0\le \pi _{M} (x_{i} )\le 1, \, \forall \,\, x_{i} \, \in X.\)
Let X be a discourse set such that \(X=\left\{ x_{1} ,\, \, x_{2} ,\, \, \ldots ,\, \, x_{n} \right\}\) and \(M,\, N \in \, \mathrm{IFSs}(X)\) defined by
then operations on IFSs are defined as follows:
-
1.
\(M\subseteq N\) iff \(\,\mu _{M}(x_{i})\le \mu _{N}(x_{i})\) and \(\nu _{M}(x_{i})\ge \nu _{N}(x_{i}) \, \forall \,\, x_{i} \in X;\)
-
2.
\(M=N\) iff \(M\subseteq N\) and \(N\subseteq M;\)
-
3.
\(M\cup N=\{\langle x_{i}, (\mu _{M}(x_{i})\vee \mu _{N}(x_{i})), (\mu _{M}(x_{i})\wedge \mu _{N}(x_{i}))\rangle | x_{i} \in X\};\)
-
4.
\(M\cap N=\{\langle x_{i}, (\mu _{M}(x_{i})\wedge \mu _{N}(x_{i})), (\mu _{M}(x_{i})\vee \mu _{N}(x_{i}))\rangle | x_{i} \in X\}.\)
Divergence measure is concerned to measure the discrimination information, based on Shannon’s inequality [43], Vlachos and Sergiadis [49] introduced a definition of divergence measure for IFSs.
Definition 2.3
(Vlachos and Sergiadis [49]): Let \(M,N\in \mathrm{IFSs},\) then \(J:\mathrm{IFS}(X)\times \mathrm{IFS}(X)\rightarrow \mathbf{{\mathbb R}}\) is called a divergence measure or cross-entropy, if it fulfils the following axioms:
-
(C1).
\(J(M || N)\ge 0;\)
-
(C2).
\(J(M || N)=0,\) if and only if \(M=N.\)
2.1 Method for transforming IFSs into FSs
Li et al. [21], as briefly delineated underneath, introduced a method for transforming ‘intuitionistic fuzzy sets (IFSs)’ into ‘fuzzy sets (FSs)’ by distributing hesitation degree equally with membership and non-membership.
Definition 2.4
(Li et al. [21]): Let \(M \in \mathrm{IFS}(X),\) then the fuzzy membership function \(\mu _{\tilde{M}} (x_{i})\) to \(\tilde{M}\) ( \(\tilde{M}\) be the fuzzy set corresponding to intuitionistic fuzzy set M) is defined as
3 Divergence measure for IFSs
In the present section, the some existing divergence measures for IFSs are reviewed. Inspired by the concept of Jensen–Shannon divergence, we develop new Jensen-exponential divergence measures for IFSs and some refined properties of the developed measures are also studied here.
3.1 Existing divergence measure for IFSs
There are three measures to assess the difference for two IFSs viz. IF-dissimilarity, IF-distance and IF-divergence. Out of which IF-divergence is the most elegant one for applications due to the following reasons. Though a dissimilarity measure holds some enviable axioms of difference for IFSs, it is too general in nature, while a distance measure is not necessarily a measure of dissimilarity. A distance measure for IFSs is not expected to be useful for applications, i.e. image processing, because when an image is represented by an IFS, the triangular inequality may not reflect a enviable relation. Conversely, an IF-divergence measure is also a measure of dissimilarity and it holds a set of enviable axioms, which are useful for assessing differences for IFSs [34].
Here, various existing divergence measures for IFSs(X) are reviewed as follows:
Vlachos and Sergiadis [49]:
Hung and Yang [11]:
\(J_{HY} (M || N)=\frac{1}{1-\rho }\)
where \(\rho \ne 1\, \left( \rho >0\right) .\)
Zhang and Jiang [61]:
Xia and Xu [53]:
where \(t=(1+q)\ln (1+q)-(2+q)(\ln (2+q)-\ln 2)\) and \(q>0.\)
Junjun et al. [12]:
where \(\varDelta _{M} (x_{i} )=\left| \mu _{M} (x_{i} )-\nu _{M} (x_{i} )\right|\) shows the closeness of the membership and non-membership degree.
Example 3.1
Assume that IFSs(X) given by
The measures \(J_{VS} (M || N)\) and \(J_{C} (M || N)\) presume the values \(J_{VS} (M || N)=-0.00712\) and \(J_{JDC} (M || N)=-0.04547.\) Hence, the measures (11) and (15) do not satisfy the fundamental condition of non-negativity. The reason is that the measures (11) and (15) are based on the information-theoretic measure given by (Lin [22])
where \(\, 0\le p_{i} ,\, q_{i} \le 1;\, \sum _{i=1}^{n}p_{i} = \sum _{i=1}^{n}q_{i} = 1,\)\(P=\left( p_{1} ,\, p_{2} ,\ldots ,p_{n} \right)\) and \(Q=\left( q_{1} ,\, q_{2} ,\ldots ,q_{n} \right)\) are the finite discrete probability distribution.
Measure (16) is constantly non-negative by doctrine of Shannon inequality. However, measures (11) and (15), neither the duo \(\left( \mu _{M} (x_{i} ),\, \nu _{M} (x_{i} )\right)\) nor \(\left( \varDelta _{M} (x_{i} ),\, \pi _{M} (x_{i} )\right)\) spawn a probability distribution, because \(0\le \mu _{M} (x_{i} )+\nu _{M} (x_{i} )\le 1\) and \(0\le \varDelta _{M} (x_{i} )+\, \pi _{M} (x_{i} )\le 1,\, \forall \, \, x_{i} \in X.\) Hence, measures (11) and (15) do not hold the Shannon inequality compelling them to presume some negative values.
Example 3.2
Suppose that \(M,\, N\in \mathrm{IFSs}(X),\) then
Here, \(J_{VS} (M || N)=0,\) but M and N are not equal. Hence, postulate C2 is violated.
Example 3.3
Assume that \(M,\, N\in \mathrm{IFSs}(X)\) given by
We obtain \(J_{ZJ} (M || N)=0.\) Again postulate C2 is violated.
Example 3.4
Let us consider \(M,\, N\in {IFSs}(X)\) given by \(M=\left\{ \left\langle x_{1} ,\, 0.0,\, 0.5\right\rangle \right\}\) and \(N=\left\{ \left\langle x_{1} ,\, 0.5,\, 0.0\right\rangle \right\} ,\) we get \(J_{C} (M || N)=0.\) This is again a case of violation of postulate C2.
To avoid such a problem, in next subsection, we propose some new divergence measures for IFSs.
3.2 New Jensen divergence measures for IFSs
Definition 3.1
Let X be a discourse set such that \(X=\left\{ x_{1} ,\, \, x_{2} ,\, \,\ldots ,\, \, x_{n} \right\}\) and \(M,\, N \in \, \mathrm{IFSs}(X)\) given by
then corresponding to Verma and Sharma [48] measure, the Jensen-exponential divergence (JED) measure for IFSs M and N is defined as
and based on Mishra et al. [31] entropy measure, we introduce the following JED for IFSs as follows:
Theorem 3.1
For all \(L,M,\, N\in IFSs(X)\), then the exponential fuzzy cross-entropy measure \(J_{\alpha } \left( M||N\right) , (\alpha =1, 2)\) in (17) and (18) holds the following postulates:
-
1.
\(J_{\alpha } \left( M||N\right) \ge 0\) and \(0\le J_{\alpha } \left( M||N\right) \le 1,\)
-
2.
\(J_{\alpha } \left( M||N\right) =0\) if and only if \(M=N,\)
-
3.
\(J_{\alpha } \left( M||N\right) =J_{\alpha } \left( N||M\right) ,\)
-
4.
\(J_{\alpha } \left( M||M^{c} \right) =1,\) if and only if \(M\in P(X),\)
-
5.
\(J_{\alpha } \left( M||N\right) =J_{\alpha } \left( M^{c} ||N^{c} \right)\) and \(J_{\alpha } \left( M||N^{c} \right) =J_{\alpha } \left( M^{c} ||N\right) ,\)
-
6.
\(J_{\alpha } \left( L||M\right) \le J_{\alpha } \left( L||N\right)\) and \(J_{\alpha } \left( M||N\right) \le J_{\alpha } \left( L||N\right) ,\) for \(L\subseteq M\subseteq N.\)
Proof
Since \(f=x\exp (1-x)\) and \(0\le x\le 1,\) then \(f^{'} =\left( 1-x\right) \exp (1-x)\ge 0\) and \(f^{''} =-\left( 2-x\right) \exp (1-x)<0;\) thus, f is convex function of x and \(D_{1 } \left( M||N\right)\) is convex. Therefore, \(D_{1} \left( M||N\right)\) increases as \(\left\| M-N\right\| _{\gamma }\) increases, where \(\left\| M-N\right\| _{\gamma } =\left| \mu _{M} -\mu _{N} \right| +\left| \nu _{M} -\nu _{N} \right| +\left| \pi _{M} -\pi _{N} \right| .\) Hence, \(D_{\alpha } \left( M||N\right) \left( \alpha =1,\, 2\right) \,\) increases as \(\left\| M-N\right\| _{\gamma }\) increases. Then \(D_{\alpha } \left( M||N\right) \left( \alpha =1,\, 2\right) \,\) gets maximum value at \(M=\left\{ \left( 1,0,0\right) \right\} ,\)\(N=\left\{ \left( 0,1,0\right) \right\}\) or \(\left( \, M=\left\{ \left( 0,0,1\right) \right\} ,N=\left\{ \left( 0,1,0\right) \right\} \right.\) or \(M=\left\{ \left( 1,0,0\right) \right\} ,\)\(\left. N=\left\{ \left( 0,0,1\right) \right\} \right) ,\) i. e., \(M,N\in P(X)\) and reaches its minimum value \(M=N.\) Hence it follows that \(0\le J_{\alpha } (M||N)\le 1\) and \(J_{\alpha } (M||N)=0\) if and only if \(M=N.\)\(\square\)
Let \(L\subseteq M\subseteq N,\) i. e., \(\mu _{L} \le \mu _{M} \le \mu _{N}\) and \(\nu _{L} \ge \nu _{M} \ge \nu _{N} ,\) then \(\left\| M-N\right\| _{\gamma } \le \left\| L-N\right\| _{\gamma }\) and \(\left\| L-M\right\| _{\gamma } \le \left\| L-N\right\| _{\gamma }\).
Therefore, \(J_{\alpha } \left( L||M\right) \le J_{\alpha } \left( L||N\right)\) and \(J_{\alpha } \left( M||N\right) \le J_{\alpha } \left( L||N\right) ,\) for \(L\subseteq M\subseteq N.\)
Again, \(\mathrm{If}\, \, \mathrm{M}\, \mathrm{=\; M}^{c} \, \mathrm{and}\, \, N=N^{c},\) in (17), then
Thus, \(J_{1} (M^{c} ||N^{c} )=J_{1} \left( M||N\right) .\)
Similarly \(J_{2} (M^{c} ||N^{c} )=J_{2} \left( M||N\right) .\)
Hence \(J_{\alpha } (M^{c} ||N^{c} )=J_{\alpha } \left( M||N\right) .\)
Next,
Thus, \(J_{1} \left( M||N^{c} \right) =J_{1} (M^{c} ||N).\)
Similarly, \(J_{2} \left( M||N^{c} \right) =J_{2} (M^{c} ||N).\)
Hence, \(J_{\alpha } \left( M||N^{c} \right) =J_{\alpha } (M^{c} ||N).\)
Proposition 3.1
If \(N=M^{c} ,\) then the relation between \(J_{\alpha } \left( M||N\right) ,\, \left( \alpha =1,2\right)\) and entropy \(H_{\alpha } (M):\)
where \(H_{\alpha } (.)\) is entropy for IFSs [31].
Proposition 3.2
The mapping \(J_{\alpha } \left( M||N\right) ,\, \left( \alpha =1,2\right),\) is distance measures on IFSs(X).
Proposition 3.3
For all \(\, M,N\in IFSs(X),\)
-
1.
\(J_{\alpha } (M||M\cup N)=J_{\alpha } (N||M\cap N),\)
-
2.
\(J_{\alpha } (M||M\cap N)=J_{\alpha } (N||M\cup N),\)
-
3.
\(J_{\alpha } (M\cup N||M\cap N)=J_{\alpha } (M||N),\)
-
4.
\(J_{\alpha } (M||M\cup N)+J_{\alpha } (M||M\cap N)=J_{\alpha } (M||N),\)
-
5.
\(J_{\alpha } (N||M\cup N)+J_{\alpha } (N||M\cap N)=J_{\alpha } (M||N).\)
4 Proposed method for MCDM
Decision-making is a procedure of selecting the best option(s) from a finite number of feasible options. It is a prominent activity that generally happens in our daily life and plays a vital task in finance, management, business, social and political sciences, engineering and computer science, biology and medicine, etc.
An MCDM problem entails obtaining the optimal solution (i.e. an option) from the available options, which are assessed on multi-criteria. Consider the set of q alternatives, \(A=\left\{ a_{1} ,a_{2} ,\ldots ,a_{q} \right\} ,\) and a set of p criterion \(C=\left\{ c_{1} ,c_{2} ,\ldots ,c_{p} \right\} .\) Now, we try to find the weight vector \(w=\left( w_{1} ,w_{2} ,\ldots ,w_{p} \right) ^{T}\) of the criterion \(c_{r} \left( r=1(1)p\right)\) such that \(w_{r} >0,\, r=1(1)p,\, \sum _{r=1}^{p}w_{r} =1 ,\, w_{r} \in W,\) where W is the set of incomplete or uncertain weight information provided by the decision maker, which is illustrated via one or more of the cases [55]:
-
1.
A weak ranking: \(\left\{ w_{r} \ge w_{s} \right\} ,\, \, r\ne s.\)
-
2.
A strict ranking: \(\left\{ w_{r} -w_{s} \ge \beta _{i} \right\} ,\, \, r\ne s.\)
-
3.
A ranking of difference: \(\left\{ w_{r} -w_{s} \ge w_{t} -w_{l} \right\} ,\, \, r\ne s\ne t\ne l.\)
-
4.
A ranking with multiples: \(\left\{ w_{r} \ge \alpha _{r} w_{s} \right\} ,\, \, r\ne s.\)
-
5.
An interval form:\(\left\{ \beta _{r} \le w_{r} \le \beta _{r} -\varepsilon _{r} \right\} ,\, \,\) where \(\beta _{r}\) and \(\varepsilon _{r}\) are non-negative numbers.
A thorough analysis on how the uncertain or incomplete weight information is confined in implementation via the given cases [40]. Even if the principle idea of the communication is on incomplete weight information of criterion, it is admirable to mention that in several decision-making circumstances, the criteria weight can be fully unknown or is characterized by IFVs. Here, (1) the model of entropy weights might be employed to get the desirable weight vector [58, 59] and (2) the interval weights may be acquired via IFVs that confine the fuzzy doctrine of significance of criteria [23, 51] to describe the weight vector W. Let \(\mathbf{{\mathbb Z}}=\left( z_{rs} \right) _{p\times q}\) be an IF-decision matrix, where \(z_{rs} =\left( \mu _{rs} ,\nu _{rs} ,\pi _{rs} \right)\) is an IFV. In MCDM problem, the criteria are either of benefit type or of cost type. Considering their natures, a benefit attribute (the bigger the values better is it) and cost attribute (the smaller the values the better) are of rather opposite type. To deal both criterion sets concurrently, the criterion sets of the cost type are converted into the criterion sets of the benefit type by renovating \(\mathbf{{\mathbb Z}}=\left( z_{rs} \right) _{p\times q}\) into the IF-decision matrix \(\mathbf{{\mathbb R}}=\left( \ell _{rs} \right) _{p\times q} .\)
where \(\overline{z}_{rs}\) is the complement of \(z_{rs},\) and \(q=1(1)s.\) Here, the three parameters of IFVs are inferred as: (1) membership degree is referred as the more the better; (2) non-membership degree is referred as the less the better; and (3) hesitancy degree is also referred as the less the better. The advantage and disadvantage scores of an option on a criterion over the rest are evaluated as follows. To obtain advantage and disadvantage scores, we determine how much the first parameter is larger and the second and third parameters are smaller in comparison with others and vice versa. Analytically, the advantage and disadvantage scores \(m_{rs}\) and \(n_{rs}\) of the options \(a_{s}\) on the criteria \(c_{r},\) respectively, are constructed as
Next, the strength score \(\vartheta _{s} (w)\) and worst score \(\tau _{s} (w)\) of the option \(a_{s}\) are calculated as
If the \(\vartheta _{s} (w)\) is large, then the option \(a_{s}\) is enhanced, and if the \(\tau _{s} (w)\) is small, then the option \(a_{s}\) is improved. Taking into consideration solely either strength or worst scores in MCDM problems is not adequate to conclude how good or bad an option is on the given criteria. To estimate satisfaction degree of an option with respect to criteria, it is more suitable if we utilize both strength and worst scores. Hence, the satisfaction degree of option \(a_{s}\) with respect to p criteria is given by
It pursues that \(\eta \left( \xi _{s} (w)\right) \in [0,1]\) and greater value of \(\vartheta _{s} (w)\) and lesser value of \(\tau _{s} (w)\) (worst score) provide higher satisfaction degree \(\eta \left( \xi _{s} (w)\right)\) of the option \(a_{s}\) with respect to criteria. Hence, the option \(a_{s}\) is regarded as improved in comparison with existing ones. We observe that satisfaction degree \(\eta \left( \xi _{s} (w)\right)\) of the option \(a_{s}\) relies on the criteria weights, which are partially or completely unknown. Next, a multi-objective optimization model for desirable weight vector \(w^{*} =\left( w_{1}^{*} ,\, w_{2}^{*} ,\ldots ,w_{p}^{*} \right) ^{T}\) of the criterion is demonstrated as
subject to \(w=\left( w_{1} ,w_{2} ,\ldots ,w_{r} \right) ^{T} \in W \qquad\) (M-I)
where W is the set of incomplete weight vector given by the DMs. If weight vector W is contradictory, then W is an empty set and it desires to be amended by DM in order that the reassessed weight information is not contradictory. The model M-I is converted into the single-objective optimization model via weighted sums method with equal weights [8] as follows:
subject to \(w=\left( w_{1} ,w_{2} ,\ldots ,w_{r} \right) ^{T} \in W \qquad\) (M-II)
The model M-II is a linear fractional programming model. The evaluation of M-II offers the desirable weight vector \(w^{*} =\left( w_{1}^{*} ,\, w_{2}^{*} ,\ldots ,w_{p}^{*} \right) ^{T}.\) The overall criterion value of each option \(a_{s}\) is given by
where \(s=1(1)q.\)
Further, the options \(a_{s}\) are ranked based on the ranking of overall criteria \(\xi _{s} \left( w^{*} \right) , s=1(1)q.\) Ranking method [45] for ranking IFVs \(\gamma _{s} =\left( \mu _{s} , \nu _{s} , \pi _{s} \right) , \left( s=1(1)q\right)\) is implemented.
Define
where \(J_{\alpha } \left( \gamma ^{*} || \gamma _{r} \right) ,\alpha =1,2\) is divergence measure for IFVs given by (17) and (18) and
such that \(\left( \mu _{s}^{*} ,\, \nu _{s}^{*} \right) =\left( \mathop {\max \mu _{rs} }\limits _{r} ,\mathop {\min \nu _{rs} }\limits _{r} \right) ,\, s=1(1)q.\)
The smaller \(\mathrm{\phi }\left( \gamma _{r} \right) ,\) the improved the overall intuitionistic fuzzy preference value \(\gamma _{r}\) [45].

General implementation procedure for IF-decision-making model based on divergence measure
Algorithm 1
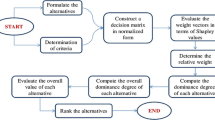
A fruitful classification of the method is discussed as follows (see Fig. 1):
-
Step 1
Generate the matrix \(\mathbf{{\mathbb Z}}=\left( z_{rs} \right) _{p\times q} ,\) weight vector W and transformation performed (20) if necessary.
-
Step 2
Evaluate the advantage \(m_{rs}\) and disadvantage \(n_{rs}\) scores according to each option \(a_{s} (s=1(1)q).\)
-
Step 3
Estimate the strength \(\vartheta _{s} (w)\) and worst \(\tau _{s} (w)\) scores of the option \(a_{s} (s=1(1)q).\)
-
Step 4
Apply the satisfaction degree \(\eta \left( \xi _{s} (w)\right)\) of the option \(a_{s} (s=1(1)q).\)
-
Step 5
Utilize model M-II to obtain the desirable weight vector \(w^{*} =\left( w_{1}^{*} ,\, w_{2}^{*} ,\ldots ,w_{p}^{*} \right) ^{T}.\) Compute overall criterion value \(\xi _{s} \left( w^{*} \right)\) of the option \(a_{s} (s=1(1)q).\)
-
Step 6
Corresponding to overall criterion values, implement (27) to rank the options \(a_{s} (s=1(1)q).\)
-
Step 7
Choose the optimal option(s) based on the ranking.
-
Step 8
End.
5 A real application of selection of optimal energy source
Energy resources have been considered as a propeller in the socio-economic growth of any country. In the recent years, the renewable energy sources play vital role in the development of economic activity and have been utilized in the reduction of the fossil fuels, production costs [17], environmental pollutions, maintenance of non-renewable energies sources [26, 57] etc. Nowadays, the increasing demand of energy in various countries requires the determination of an optimal energy policy under different conflicting criteria. However, selecting the most appropriate energy resource with respect to different conflicting criteria is a critical and complex problem for decision makers. To deal with this issue, many authors have developed numerous decision-making methods based on FS theory to identify the most suitable energy policy under different criteria [13, 24]. Erdogan and Kaya [6] evaluated an integrated multi-criteria decision-making method to find an optimal energy alternative among set of energy alternatives in Turkey which is based on type-2 fuzzy sets. Mousavi and Tavakkoli-Moghaddam [36] presented a hesitant fuzzy hierarchal complex proportional assessment (HF-HCOPRAS) method to choose the best energy resource under 15 conflicting criteria. Presently, Mousavi et al. [37] developed a modified elimination and choice translating reality (ELECTRE) method under hesitant fuzzy environment for solving multi-attribute group decision-making (MAGDM) problems in energy sector. Here, a new modified preference selection method on uncertain environment under intuitionistic fuzzy divergence measure is proposed to demonstrate the relative importance of desirable energy attributes in renewable energy policy atmosphere by decision maker.
One of the problems facing the city development officer is to determine the best energy resource among set of renewable energy alternatives for their city. In this case, the officer tenders five renewable energy alternatives which are (1) wind energy \((E_{1}),\) (2) solar energy \((E_{2}),\) (3) geothermal energy \((E_{3}),\) (4) biomass energy \((E_{4})\) and (5) hydro-power energy \((E_{5}).\) A team of three decision makers (DMs) is established who have to select the most optimal energy resource. The preferred alternatives are assessed under 14 criteria which are (1) feasibility \((L_{1}),\) (2) economic risks \((L_{2}),\) (3) pollutant emission \((L_{3}),\) (4) land requirement \((L_{4}),\) (5) need of waste disposal \((L_{5}),\) (6) land disruption \((L_{6}),\) (7) water pollution \((L_{7}),\) (8) Investment costs \((L_{8}),\) (9) security of energy supply \((L_{9}),\) (10) source durability \((L_{10}),\) (11) sustainability of the energy resources \((L_{11} ),\) (12) compatibility with national energy policy objective \((L_{12}),\) (13) energy efficiency \((L_{13})\) and (14) labour impact \((L_{14})\) (see Fig. 2).

Decision hierarchy of selection of optimal energy source problem
Since it is not easy to provide an exact numerical value for the importance of the selected criteria, the decision makers define their judgements in linguistic variables. Now, Table 1 represents the relative importance of elected evaluation criteria and decision makers (DMs). In addition, the linguistic terms are adopted from Vahdani et al. [47] study for evaluating the candidates and weight of each criterion.
Tables 2 and 3 represent the importance degree of the DMs and weights of the criteria in terms of linguistic variables.
Table 4 characterizes the performance ratings of the energy alternatives given by DMs, and their importance with respect to each selected criteria is given in Table 5.
According to DM’s judgements, the aggregated intuitionistic fuzzy decision matrix is depicted in Table 6.
5.1 Implementation and discussion
In this section, proposed technique is applied in a real case study to select the most optimal energy alternative for city development. Now, the procedural steps are as follows:
Step 1 IF-decision matrix \({\mathbb R}\, =\, \left( l_{rs} \right) _{p\times q}\) (given by Table 6) and the weight vector of the criterion is given by
Step 2 By using (21) and (22), the advantage and disadvantage scores of the alternatives \(E_{s} \, (s=\, 1(1)\, 5)\) with respect to criteria \(L_{r} \, (r\, =1(1)\, 14)\) are obtained in Tables 7 and 8.
Step 3 The strength \(\upsilon _{s} (w)\) and worst \(\tau _{s} (w)\) scores of the alternatives \(E_{s} \, (s=\, 1(1)\, 5)\) are computed by using (23) and (24), which are given as
Step 4 By using (25), the satisfaction degrees \(\eta (\xi _{s} (w))\) of the alternatives \(E_{s} \, (s=\, 1(1)\, 5)\) are obtained as follows:
Step 5 To find the weight \(w^{*} =\, \left( w_{1} ,\, w_{2} ,\, \ldots ,\, w_{14} \right) ^{T} ,\) model M-II is given as follows:
subject to
By using MATHEMATICA software, the desirable weight vector is attained as follows:
Step 6 The overall criterion value \(\xi _{s} (w^{*} )\) of the alternatives \(E_{s} \, (s=\, 1(1)\, 5)\) is given as
Step 7 Using (17) and (27), we have \(\varphi (\xi _{1} (w^{*} ))\, =\, 0.0554,\)\(\varphi (\xi _{2} (w^{*} ))\, =\, 0.2059,\)\(\varphi (\xi _{3} (w^{*} ))\, =\, 0.1275,\)\(\varphi (\xi _{4} (w^{*} ))\, =\, 0.0806\) and \(\varphi (\xi _{5} (w^{*} ))\, =\, 0.0801,\) where
By using \(\varphi (\xi _{s} (w^{*} )),\) the overall criterion values \(\xi _{s} (w^{*} ) (s= 1(1)5)\) are ranked as
Therefore, the ranking of energy alternatives is \(E_{1} \, \succ \, E_{5} \, \succ \, E_{4} \, \succ \, E_{3} \, \succ \, E_{2} .\)
Step 8 Thus, wind energy \(E_{1}\) is the most suitable energy resource.
The ranking result of the energy alternatives obtained from proposed method is compared with existing methods in Table 9. The rank of the energy alternatives attained from proposed method is same as existing methods, and we observe that wind energy is the optimal energy alternative.
-
1.
In Kahraman et al. [14] and Kaya [15, 16], the weights of the selection criteria are determined by using fuzzy AHP method, whereas in our approach, all the three constraints of the intuitionistic fuzzy values are used to evaluate the decision maker’s opinions on the criteria weights, which is more realistic than existing methods.
-
2.
In Kaya [15, 16], the decision makers are not sure about the degree of importance of one parameter over other; therefore, the decision makers cannot give a definite scale to the comparison of the parameters, and thus, they are unable to obtain some valuable information due to the lack of sufficient information. In the proposed methodology, the advantage and disadvantage scores are used to determine the relative comparison of the parameters which avoid the drawbacks of existing methods.
-
3.
In Kaya [14], the distance of each alternative from PIS (1, 0, 0) and NIS (0, 0, 1) is calculated to evaluate the closeness coefficient of each alternative, and thus, the ranking of the energy alternatives is obtained on the basis of closeness coefficients. In our approach, the ranking of the alternatives is obtained on the basis of overall values which is more reasonable than Kaya [14].
6 Conclusions
In this paper, new Jensen-exponential divergence (JED) measures for IFSs have been proposed. Some elegant properties of JED measures have been discussed. The proposed measures are the outstanding complement to the existing divergence measures for IFSs. For future research, we look forward to extend the proposed measures to interval valued intuitionistic fuzzy sets (IVIFSs) and hesitant fuzzy sets (HFSs).
A technique to MCDM under the assumption that the criteria weight is completely unknown for IFSs, based on JED is introduced, and a real case study is presented on the selection of the most optimal energy alternative among the set of renewable energy alternatives. In the proposed methodology, the rating of each energy alternative with respect to criteria and the weight of the each criterion are expressed in terms of linguistic variables. Further, a satisfaction degree-based technique via strength and worst scores of options with respect to criteria for MCDM problems is discussed. The concepts of advantage, disadvantage, strength and worst scores are used.
To evaluate the optimal weights for criterion, a multi-objective optimization model via satisfaction degree of each option is constructed that are utilized to illustrate the overall criteria value and applied to choose the optimal option. To reveal the benefits of the developed technique, a realistic example of selecting the desirable financial organization is discussed and compared our results. The key advantage of the proposed technique is that the choice of optimal option is essentially based on relative comparison of performances of the options among each other rather than measuring the performance of each option via some hypothetical standards in real-world decision-making.
Based on the obtained result, wind energy is found to be the most appropriate energy alternative in this case. In comparison with some existing methods, we observe that the proposed method is more reasonable and different from the others in terms of relative importance of each alternative.
In addition, our future research will also focus on applications of IF MCDM in various vital disciplines of analysis, viz. portfolio selection, faculty recruitment, personnel examination, medical diagnosis, military system efficiency evaluation, supply chain management, marketing management.
References
Angulo JC, Antolin J, Rosa SL, Esquivel RO (2010) Jensen–Shannon divergence in conjugated spaces: entropy excess of atomic systems and sets with respect to their constituents. Phys A Stat Mech Appl 389:899–907
Ansari MD, Mishra AR, Ansari FT (2017) New divergence and entropy measures for intuitionistic fuzzy sets on edge detection. Int J Fuzzy Syst. doi:10.1007/s40815-017-0348-4
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96
Bhandari D, Pal NR (1993) Some new information measure for fuzzy sets. Inf Sci 67:209–228
Chen TY, Li CH (2010) Determining objective weights with intuitionistic fuzzy entropy measures: a comparative analysis. Inf Sci 180(21):4207–4222
Erdogan M, Kaya I (2015) An integrated multi-criteria decision making methodology based on type-2 fuzzy sets for selection among energy alternatives in Turkey. Iran J Fuzzy Syst 12:1–25
Fan J, Xie W (1999) Distance measure and induced fuzzy entropy. Fuzzy Sets Syst 104(2):305–314
French S, Hartley R, Thomas LC, White DJ (1983) Multiobjective decision making. Academic, New York
Ghosh M, Das D, Chakraborty C, Roy AK (2010) Automated lecukocyte recognition using fuzzy divergence. Micron 41:840–846
Hooda DS, Mishra AR (2015) On trigonometric fuzzy information measures. ARPN J Sci Technol 05:145–152
Hung WL, Yang MS (2008) On the J-divergence of intuitionistic fuzzy sets with its applications to pattern recognition. Inf Sci 178(6):1641–1650
Junjun M, Dengbao Y, Cuicui W (2013) A novel cross-entropy and entropy measures of IFSs and their applications. Knowl Based Syst 48:37–45
Kahraman C, Kaya I (2010) A fuzzy multicriteria methodology for selection among energy alternatives. Expert Syst Appl 37:6270–6281
Kahraman C, Kaya I, Cebi S (2009) A comparative analysis for multiattribute selection among renewable energy alternatives using fuzzy axiomatic design and fuzzy analytic hierarchy process. Energy 34:1603–1616
Kaya T, Kahraman C (2010) Multicriteria renewable energy planning using an integrated fuzzy VIKOR and AHP methodology: the case of Istanbul. Energy 35:2517–2527
Kaya T, Kahraman C (2011) Multicriteria decision making in energy planning using a modified fuzzy TOPSIS methodology. Expert Syst Appl 28:6577–6585
Keyhani A, Ghasemi-Varnamkhasti M, Khanali M, Abbaszadeh R (2010) An assessment of wind energy potential as a power generation source in the capital of Iran, Tehran. Energy 35:188–201
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Stat 22(1):79–86
Li DF (2010) TOPSIS-based nonlinear-programming methodology for multiattribute decision making with interval-valued intuitionistic fuzzy sets. IEEE Trans Fuzzy Syst 18(2):299–311
Li DF, Wan SP (2013) Fuzzy linear programming approach to multiattribute decision making with multiple types of attribute values and incomplete weight information. Appl Soft Comput 13(11):4333–4348
Li F, Lu ZH, Cai LJ (2003) The entropy of vague sets based on fuzzy sets. J Huazhong Univ Sci Tech 31:24–25
Lin J (1991) Divergence measure based on Shannon entropy. IEEE Trans Inf Theory 37(1):145–151
Lin L, Yuan XH, Xia ZQ (2007) Multicriteria fuzzy decision-making methods based on intuitionistic fuzzy sets. J Comput Syst Sci 73(1):84–88
Loken E (2007) Use of multicriteria decision analysis methods for energy planning problems. Renew Sustain Energy Rev 11:1584–1595
Luca AD, Termini S (1972) A definition of non-probabilistic entropy in the setting of fuzzy sets theory. Inf Control 20(4):301–312
Mehrzad Z (2007) Energy consumption and economic activities in Iran. Energy Econ 29:1135–1140
Mishra AR, Hooda DS, Jain D (2015) On exponential fuzzy measures of information and discrimination. Int J Comput Appl 119:01–07
Mishra AR, Jain D, Hooda DS (2016) On fuzzy distance and induced fuzzy information measures. J Inf Optim Sci 37(2):193–211
Mishra AR, Jain D, Hooda DS (2016) On logarithmic fuzzy measures of information and discrimination. J Inf Optim Sci 37(2):213–231
Mishra AR (2016) Intuitionistic fuzzy information measures with application in rating of township development. Iran J Fuzzy Syst 13(3):49–70
Mishra AR, Jain D, Hooda DS (2017) Exponential intuitionistic fuzzy information measure with assessment of service quality. Int J Fuzzy Syst 19(3):788–798. doi:10.1007/s40815-016-0278-6
Mishra AR, Rani P (2017) Shapley divergence measures with VIKOR method for multi-attribute decision making problems. Neural Comput Appl. doi:10.1007/s00521-017-3101-x
Molladavoudi S, Zainuddin H, Tim CK (2012) Jensen–Shannon divergence and non-linear quantum dynamics. Phys Lett A 376(26–27):1955–1961
Montes I, Pal NR, Janis V, Montes S (2015) Divergence measures for intuitionistic fuzzy sets. IEEE Trans Fuzzy Syst 23:444–456
Montes S, Couso I, Gil P, Bertoluzza C (2002) Divergence measure between fuzzy sets. Int J Approx Reason 30(2):91–105
Mousavi M, Tavakkoli-Moghaddam R (2015) Group decision making based on a new evaluation method and hesitant fuzzy setting with an application to an energy planning problem. Int J Eng C Asp 28:1303–1311
Mousavi M, Gitinavard H, Mousavi SM (2017) A soft computing based modified ELECTRE model for renewable energy policy selection with unknown information. Renew Sustain Energy Rev 68:774–787
Naghshvar M, Javidi T, Wigger M (2015) Extrinsic Jensen–Shannon divergence: applications to variable-length coding. IEEE Trans Inf Theory 61(4):2148–2164
Pal NR, Pal SK (1989) Object-background segmentation using new definitions of entropy. IEE Proc 136(4):284–295
Park KS (2004) Mathematical programming models for characterizing dominance and potential optimality when multicriteria alternative values and weights are simultaneously incomplete. IEEE Trans Syst Man Cybern A Syst Hum 34(5):601–614
Renyi A (1961) On measures of entropy and information. Proc Forth Berkeley Symp Math Stat Probab 1:547–561
Shang XG, Jiang WS (1997) A note on fuzzy information measures. Pattern Recognit Lett 18(5):425–432
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Sharma BD, Mittal DP (1977) New non-additive measures of relative information. J Comb Inf Syst Sci 2:122–133
Szmidt E, Kacprzyk J (2009) Ranking of intuitionistic fuzzy alternatives in a multi-criteria decision making problem. In: Proceedings of 28th annual conference on North American Fuzzy Information Processing Society, Cincinnati, OH, USA, pp 1–6
Tan CQ, Chen XH (2010) Intuitionistic fuzzy Choquet integral operator for multi-criteria decision making. Expert Syst Appl 37(1):149–157
Vahdani B, Mousavi SM, Tavakkoli-Moghaddam R, Hashemi H (2013) A new design of the elimination and choice translating reality method for multicriteria group decision-making in an intuitionistic fuzzy environment. Appl Math Model 37:1781–1799
Verma R, Maheshwari S (2016) A new measure of divergence with its application to multi-criteria decision making under fuzzy environment. Neural Comput Appl. doi:10.1007/s00521-016-2311-y
Vlachos K, Sergiadis GD (2007) Intuitionistic fuzzy information-applications to pattern recognition. Pattern Recognit Lett 28(2):197–206
Wan SP, Dong JY (2014) A possibility degree method for interval valued intuitionistic fuzzy multi-attribute group decision making. J Comput Syst Sci 80(1):237–256
Wang JQ, Zhang HY (2013) Multicriteria decision-making approach based on Atanassov’s intuitionistic fuzzy sets with incomplete certain information on weights. IEEE Trans Fuzzy Syst 21(3):510–515
Wei GW (2010) GRA method for multiple attribute decision making with incomplete weight information in intuitionistic fuzzy setting. Knowl Based Syst 23(3):243–247
Xia MM, Xu ZS (2012) Entropy/cross entropy-based group decision making under intuitionistic fuzzy environment. Inf Fusion 13(1):31–47
Xu ZS, Cai XQ (2010) Nonlinear optimization models for multiple attribute group decision making with intuitionistic fuzzy information. Int J Intell Syst 25(6):489–513
Xu ZS (2012) Intuitionistic fuzzy multiattribute decision making: an interactive method. IEEE Trans Fuzzy Syst 20(3):514–525
Xu ZS (2007) Multi-person multi-attribute decision making models under intuitionistic fuzzy environment. Fuzzy Optim Decis Mak 6(3):221–236
Yao H, Li W (2014) A new assessment method of new energy in regional sustainable development based on hesitant fuzzy information. J Ind Eng Manag 7:1334–1346
Ye J (2010) Fuzzy decision-making method based on the weighted correlation coefficient under intuitionistic fuzzy environment. Eur J Oper Res 205(1):202–204
Ye J (2010) Multicriteria fuzzy decision-making method using entropy weights-based correlation coefficients of interval-valued intuitionistic fuzzy sets. Appl Math Model 34(12):3864–3870
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353
Zhang QS, Jiang SY (2008) A note on information entropy measures for vague sets and its applications. Inf Sci 178(21):4184–4191
Zhao X, Wei G (2013) Some intuitionistic fuzzy Einstein hybrid aggregation operators and their application to multiple attribute decision making. Knowl Based Syst 37:472–479
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
About this article

Cite this article
Mishra, A.R., Kumari, R. & Sharma, D.K. Intuitionistic fuzzy divergence measure-based multi-criteria decision-making method. Neural Comput & Applic 31, 2279–2294 (2019). https://doi.org/10.1007/s00521-017-3187-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-017-3187-1