
Abstract
Accurately estimated highway traffic flow info plays a decisive role in dynamic and real-time road management, planning, and preventing frequent/recurring traffic jams, traffic rule violations, and chain/fatal traffic accidents. Traffic flow information is extracted by processing raw camera images via vehicle detection and tracking algorithms. Object detectors including the Yolo, single-shot detector, and EfficientNet algorithms are used for vehicle detection; however, You only look once version 5 (Yolov5) has a clear advantage in terms of real-time performance. Due to this reason, the pre-trained Yolov5 models were utilized in the vehicle detection part, and in the vehicle tracking module, a novel tracker algorithm was developed using vehicle detection features. The performance of the proposed approach was measured by comparing it to the Kalman filter-based tracker. The evaluation results show that the proposed tracking approach outperformed the Kalman filter-based tracker with 5.82% (Buses), 2.24% (Cars), 36.50% (Trucks), and overall 2.58% better traffic counting accuracy for the 12 nighttime case study videos captured from the highways with different horizontal and vertical angle-of-views.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
An essential component of traffic analysis and planning in urban areas is the road participant categorization (classifying vehicles such as bicycles, buses, cars, motorcycles, and trucks) on highways, as well as the estimation of statistical traffic flow information (traffic flow frequency and the proportion of each vehicle by its type and its trajectory data). However, in this contemporary era of expanding technology and population, real-time highway traffic flow monitoring is a difficult problem on urban areas. According to Luque-Baena et al. (2015), improper highway traffic management contributes to frequent traffic bottlenecks/congestion, traffic rule infringements or road ridges, and deadly road accidents. It takes a lot of time, money, and effort to solve this problem using conventional methods such as RADAR, LIDAR, RFID, or LASAR (Khan et al. 2018; Jeon et al. 2016). Human observers visit the area and tally the number of passing vehicles when these sensors are insufficient. Nevertheless, manual traffic data collecting is not a reasonable solution, and these techniques are unable to produce real-time traffic flow data. Additionally, they fall short when it comes to categorizing vehicles or getting data about the number of vehicles by their kind and direction of travel (Zhao et al. 2019).
However, state-of-the-art approaches to artificial intelligence (specifically machine vision techniques) have been utilized in real-time video/image data processing applications. Particularly, vision-based vehicle detection and vehicle tracking algorithms that are based on deep image processing and machine learning techniques are being used in a wide range of application areas of Intelligent Transportation Systems. These systems typically compose of vehicle detection, tracking (associating the best-matching peers in consecutive frames), spatio-temporal trajectory data, and estimation of traffic flow information. Traffic flow information includes speed, the categorical or total number of vehicles and vehicle entrances and exits in the specified area, and time period data. All this information is extracted from the vehicle trajectory data by utilizing vehicle recognition and vehicle re-identification approaches (Lu et al. 2020). Therefore, high-performance and accurate vehicle detection and tracker algorithms play an important role in this type of systems (Yang and Pun-Cheng 2018; Feng et al. 2019).
Vehicle detection is an approach for recognizing the label of interest (object class) and re-identifying the targeted objects through successive frames of a video stream. General-purpose object detection techniques such as conventional machine/deep learning methods are widely used for the vehicle recognition tasks. Conventional vision-based vehicle detection approaches include background subtraction and a classification algorithm like support vector machines (SVM), blob extraction via a classifier like K-nearest neighbor (KNN), edge-like feature extraction and a classification algorithm, or other kinds of classical detection techniques based on Scale-Invariant Feature Transform (SIFT) and Speeded Up Robust Features (SURF) utilize manually and hand-crafted feature vectors (Pillai et al. 2021). On the one hand, the aforementioned approaches necessitate in-depth knowledge and expertise to select representative features or feature vectors of a certain object type (Chauhan and Singh 2018). On the other hand, deep neural networks do not have to utilize manually extracted features or feature vectors, which are defined with the strict rules that require a low-level imaging expertise. Besides, they do not require deep knowledge about object content since the deep neural network architectures automatically extract deep and hidden features with user-defined activation functions such as Rectified Logic Unit (ReLU), Sigmoid, and Tanh, and the optimization functions like Adam, AdaDelta or Stochastic Gradient Descent (SGD). So these architectures are capable to extract deep and hidden vehicle features that help to recognize and re-identify objects on a video frame or an input image (Zhao et al. 2019).
Vehicle tracking is re-identifying the detected objects and associating them with their best-matched peers across a series of frames of an input video. In simple terms, all the detected vehicles are associated first; the detections are tracked with the assigned unique IDs in vehicle tracking part. In this way, unique vehicle trajectory data per vehicle are estimated. Trajectory data extraction algorithms use pixel, shape, color, and bounding box (Bbox) information to associate vehicles. Although pixel, shape, and color-based tracking techniques are considered to be reliable for tracking objects through subsequent frames, they are too sluggish for real-time video analysis applications. Even though the vehicle trackers that were built on pixel, shape, and color-like features are thought to be reliable for tracking objects through subsequent frames, they are extremely slow for real-time video analysis applications. On the other hand, vehicle tracking algorithms that are based on the Kalman filter or Particle filter approach simply process the coordinate information of the Bbox data of the recognized vehicles. Hence, these algorithms are a little faster than pixel, shape, or color-based approaches. Nevertheless, when the number of vehicles on a video frame increases, these methods also get failed to run in real time. Sudha and Priyadarshini (2020). As an example, the Kalman filter and particle filter-based tracking approaches struggle on high-speed roads where vehicles go very fast. In addition, if the number of vehicles is above 30 on a certain frame, the performance of these algorithms drops sharply. Moreover, vehicle recognition and re-identifying have been challenging tasks of classical machine-vision research due to the problems such as partial or full occlusion of vehicles, light illusion, camera shaking, extremely high- or low-quality picture, distinct weather conditions including rain, snow and wind, and especially nighttime issues, which can complicate the vehicle detection, tracking, and data association processes, and in some cases, these problems make such systems completely fail (Datondji et al. 2016). Due to these reasons, a robust and real-time tracking algorithm is necessary for the effective and efficient real-time video analysis tools.
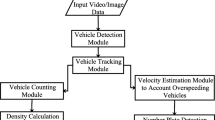
General-purpose object detectors including Yolov(1–5), Single Shot Detector, EfficientNet, RetinaNet, Residual Networks (ResNets), Region-based Convolutional Neural Networks (R-CNN), and Faster R-CNN, which are based on CNN architectures, are utilized for real-time vehicle recognition, but, Yolov5 has clear advantages with high-performance and strong vehicle localization functionality. Therefore, the pre-trained Yolov5 models (nano, small, medium, large, X-large) were used for the vehicle detection task. For the vehicle tracking part, a novel Bbox-based and nighttime-adopted vehicle tracker algorithm was developed in this study. Besides, the Kalman filter-based vehicle tracker was implemented to compare the results of the proposed tracker in this paper. The main flow-chart of the system is illustrated in Fig. 1 Then, 10 traffic (vehicle) counting systems were developed using Yolov5 architectures with the Kalman filter-based and the new Bbox-based trackers, see Fig. 2. The evaluation results of the vehicle counting systems show that the proposed tracker algorithm outperformed with overall 2.58% better accuracy than the Kalman filter-based tracker.
2 Related works

The illustration of the whole process of the main system

The interface of the real-time traffic flow monitoring system

Tracking by detection (up) and detection-free (down)
Smart cities are built in the basement of several smart applications including intelligent transportation systems, intelligent medicine, smart energy, smart environment, etc. At the same time, intelligent transportation systems have seven sub-application areas such as dynamic traffic flow and road network management, traveler information systems, public transport systems, commercial vehicle applications, vehicle safety applications maintenance & construction management applications, emergency management, and archived data management. Dynamic traffic flow and road network management are the most critical and crucial application field of the seven applications since it has a huge impact on reducing or preventing traffic congestion, managing roads & intersections in real-time, planning, and preventing frequent/recurring traffic jams, traffic rules violations, and chain/fatal traffic accidents (Azimjonov and Özmen 2021). Online traffic flow monitoring and control systems are developed using traffic flow information such as total and categorical traffic counts, traffic speed, and other traffic environmental variables. The system fully relies on vehicle recognition and extraction of vehicle trajectories. Recognizing vehicles and extraction of their trajectory data generally uses vehicle detection and tracking approaches (Song et al. 2018). Vehicle detection methods are divided into two main types, namely traditional machine learning and modern deep neural network-based approaches. Vehicle tracking approaches are also categorized into two groups such as trackers that utilize bounding box features (tracking by detection) and appearance-based tracking (tracking by detection free), see Fig. 3. In the following, we describe vehicle detection and tracking approaches in detail (Azimjonov and Özmen 2022).
Vehicle detection. Vehicle recognition (localization and classification) techniques, which utilizes classical machine learning algorithms, completely depend on hand-crafted and manually determined vehicle features/features vectors. The feature vector is extracted from the appearance or motion features of pixels in an image (Sivaraman and Trivedi 2013). The detection algorithms, which detect and classify vehicles based on the content (appearance and shape characteristics) of vehicle images on a video frame, mainly compose of three stages. In the first stage, background modeling (background subtraction) is performed by removing the background (Cabido et al. 2012). In the second stage, after background removal, the blobs and their locations are determined. Next, the desired (user-defined) features are extracted using the detected blobs and their locations (Fernández-Sanjurjo et al. 2019; Kavukcuoglu et al. 2010). In the third stage, the detected blobs and extracted features are fed to classification algorithms to form robust rules to identify vehicle labels. These algorithms perform well for offline videos with the constant background and good weather conditions. However, they are very weak against fast background changes, different weather conditions, color and shape problems; specifically, these algorithms fall short in processing of nighttime videos (Mandellos et al. 2011). Motion-based algorithms such as dynamic background modeling (Zhu et al. 2006), optical flow (Franke et al. 2005), occupancy grid (Badino et al. 2007), and tracking pixels (Erbs et al. 2011) have been developed to overcome the issues, which image/object content-based (appearance, shape, and disparity) algorithms faced in the past. The motion-based vehicle detecting relies on moving blobs/pixels, and they are robust against different weather conditions. However, due to the variety of partial or full occlusions, slowness, appearances, illumination, and background changes, it is difficult to manually design a robust feature descriptor to perfectly describe all kinds of vehicles (Rathore et al. 2018). Especially, it is very difficult to manually extract robust features from nighttime video images, which describes traffic objects features well. But, thanks to the recently emerged deep learning architectures, robust and accurate algorithms on object recognition have been developed to address the problems that the conventional machine vision techniques had in the past. These techniques include three major models including artificial neural networks (ANNs), deep neural networks (DNN), and convolutional neural networks (CNNs). These methods detect vehicles using automatically extracted deep and hidden features. CNN is a widely utilized and most representative model among the deep learning architectures (LeCun et al. 2015) due to its high-accuracy classification ability (Girshick et al. 2014). There have been conducted many research studies based on CNN architecture. For example, Region-based (RCNN) (Girshick 2015), Faster Region-based (FRCNN) (Ren et al. 2017), Single Shot Detector (SSD) (Liu et al. 2016), ResNet, RetinaNet, and Yolo (You Only Look Once, v1, v2, v3) (Redmon et al. 2016; Redmon and Farhadi 2017, 2018) are the most successful and widely utilized approaches. The detection and classification accuracy of the RCNN, FRCNN, SSD, ResNet, RetinaNet are slightly higher than Yolo; however, in real-time time video analysis tools such as traffic monitoring, only Yolo can be used because of its high-speed detection. The maximum fps rate of other methods is 8, whereas a minimum of 20 FPS and a maximum of 150 FPS can be obtained with Yolo (Redmon and Farhadi 2018). Due to its high-speed detection, and accuracy in real time, strong localization functionality unlike EfficientNet/Det, it is the only option for real-time traffic flow monitoring applications. However, the vehicle classification accuracy of this algorithm is below 57% since Yolo performs the object localization and classification tasks on an input image with a single neural network only one time. Hence, it causes such a low level of classification accuracy. Fifty-seven percentage of classification accuracy is not enough for traffic flow extraction systems on urban roads/highways. Thus, the classification accuracy of the Yolo-based vehicle detection algorithms should be improved by combing a robust classifier layer into the algorithm.
Vehicle tracking Extracting the trajectories of vehicle (X and Y trajectory vectors) from a roadway video scene for the particular time interval or in real time provides highly valuable traffic flow info such as vehicle speed, motion direction, total and categorical numbers, duration between entry and exit points of vehicles and other desired parameters. With these traffic data, one can easily monitor and manage the traffic condition of any desired region in a city or urban area. Although there exist several vehicle tracking methods which uses the pixel and bounding-box features such as optical flow, particle filter and Kalman filters, respectively, any of these approaches are not sufficient to solve the vehicle tracking problem accurately in real time on highways (Khalkhali et al. 2020). Optical flow and other pixel-based methods (Nguyen and Brilakis 2018) are very slow, which is inappropriate for real-time applications, while the Kalman filter algorithm struggles with many false predicted points. Additionally, the tracking performance of the Kalman filter-based trackers declines when the numbers of objects increase in a particular frame (Liu et al. 2019; Song et al. 2019). Besides, while testing Kalman filter with Yolo, it was observed that these two algorithms are not appropriate with each other, because Yolo does not determine the exact location of objects, but it estimates the bounding box information via minor shifts. In other words, the Yolo algorithm detects the same stationary or moving objects through successive frames in the slightly different positions from where they are exactly). The Kalman Filter tracking algorithm uses the motion information of Bboxes to predict new points such as motion velocity (\(v_{x} = v_{0_{x}} + at\)), \(v_{y} = v_{0_{y}} + at\)) and coordinate (\(x = x_{0} + v_{0_{x}}t + at^{2}/2\), \(y = y_{0} + v_{0_{y}}t + at^{2}/2\)), and several motion and direction state parameters (Xiao et al. 2020). These parameters make the Kalman filter too sensitive against minor movements/shifts of Bbox points. Additionally, the Kalman filter-based tracker predicts the new position using just one previous frame parameters when the observed object disappear from the certain frames. Predicting the new position of the disappeared object considering the state parameters from only one previous frame creates an uncertainty issue, which leads to failure of the tracker (Yang et al. 2019). Yolo’s unstable object position estimation nature, and the Kalman filter-based tracker’s motion-sensitive nature, and the uncertainty issue in vehicle tracking and data association make these two algorithms incompatible at some level. Consequently, they affect the accuracy and performance on the overall system negatively (Kanagamalliga and Vasuki 2018). Therefore, a robust vehicle tracking and data association algorithm, which is compatible with Yolo’s unstable object localization nature, are a need for a highway traffic flow monitoring and management system.
The contribution of the study: (i) fine-tuning and decreasing the number of classes by three from 90 classes, (ii) creating a testbed dataset to measure and evaluate the proposed traffic counter system with the 12 nighttime case study videos captured from the highways using different cameras with horizontal and vertical angle-of-views, (iii) developing real-time and high-accuracy vehicle detection system by Yolov5 models, (iv) developing a novel Bbox-based vehicle tracking algorithm and the implementing of the Kalman filter-based tracking algorithm. Next, applying the vehicle detectors and trackers to the vehicle trajectories extraction task, (v) estimating the categorical and total numbers of vehicles on the twelve nighttime case study highway videos using the extracted vehicle trajectories, and comparing the accuracy of the vehicle counting systems.
3 Methodology
The main system was built on four main parts, namely vehicle detection, vehicle tracking, vehicle trajectory data extraction, and traffic flow information estimation from the extracted trajectory data. In the vehicle detection part, Yolov5 (general-purpose object detector) was utilized by fine-tuning the algorithm. In the vehicle tracking part, a novel vehicle tracker algorithm was developed using vehicle detection features by adopting them to nighttime videos. Additionally, the Kalman filter-based tracking algorithm was also implemented to compare the performance of the proposed tracker. In the third module, a total of 10 vehicle trajectory data extraction systems were created using five models (Nano, Small, Medium, Large, and X-Large weight models) of Yolov5, and both trackers by pairing with them. For instance, the first vehicle trajectory extraction system was formed using the Yolov5 Nano model with the Bbox-based tracker, and the second one is created using the Yolov5 Nano model with the Kalman filter-based tracker. Other 8 trajectory extraction systems are developed in the same way.
3.1 Vehicle detection with Yolov5 models
Yolov5 models are fine-tuned and adopted to three vehicle classes. The fine-tuned parameters:
-
lr0: 0.009—initial learning rate (SGD=1E-2, Adam=1E-3)
-
lrf: 0.19—final OneCycleLR learning rate (lr0 * lrf)
-
momentum: 0.977—SGD momentum/Adam beta1
-
weight_decay: 0.00053—optimizer weight decay 5e-4
-
warmup_epochs: 3.0—warmup epochs (fractions ok)
-
warmup_momentum: 0.81—warmup initial momentum
-
warmup_bias_lr: 0.11—warmup initial bias lr
-
box: 0.057—box loss gain, cls: 0.57—cls loss gain
-
cls_pw: 1.0—cls BCELoss positive_weight
-
obj: 1.0—obj loss gain (scale with pixels)
-
obj_pw: 1.0—obj BCELoss positive_weight
-
iou_t: 0.45—IoU training threshold
-
anchor_t: 4.0—anchor-multiple threshold
-
anchors: 3—anchors per output layer (0 to ignore)
-
fl_gamma: 0.0—focal loss gamma (efficientDet default gamma=1.5)
-
hsv_h: 0.0155—image HSV-Hue augmentation (fraction)
-
hsv_s: 0.79—image HSV-Saturation augmentation (fraction)
-
hsv_v: 0.43—image HSV-Value augmentation (fraction)
-
degrees: 0.0—image rotation (± deg)
-
translate: 0.17—image translation (± fraction)
-
scale: 0.57—image scale (± gain)
-
shear: 0.0—image shear (± deg)
-
perspective: 0.0—image perspective (± fraction), range 0\(-\)0.001
-
flipud: 0.01—image flip up-down (probability)
-
fliplr: 0.51—image flip left-right (probability)
-
mosaic: 1.0—image mosaic (probability)
-
mixup: 0.01—image mixup (probability)
-
copy_paste: 0.0—segment copy-paste (probability)
-
angle: 0.15, saturation: 1.83, exposure: 1.85, hue: 0.5
-
nc: 3 [number of classes]
-
depth_multiple: 0.33 model depth multiple
-
width_multiple: 0.50 layer channel multiple
-
anchors: [10,13, 16,30, 33,23]-P3/8, [30,61, 62,45, 59,119]-P4/16, [116,90, 156,198, 373,326]-P5/32
-
classes names: 0—bus, 1—car, 2—truck
-
filters: filters=(num_classes + 5)*3.
So for 3 classes, filters = 24.
max_batches = 6000, classes=3, filters=24
where \(L_{\textrm{loc}}\) and \(L_{\textrm{cls}}\) are the loss functions for the localization and classification tasks, respectively. \(1_{i}^{\textrm{obj}}\): An indicator function of whether the cell i contains an object. \(1_{i}^{\textrm{obj}}\): It indicates whether the j-th Bbox of the cell i is ‘responsible’ for the object prediction. \(C_{ij}\): The confidence score of cell i, \(Pr(containing \; an \; object) * IoU (pred, truth)\), IoU > 0.5 for this study. \(\widehat{C_{ij}}\): The predicted confidence score. C: The set of all classes. \(p_{i}(c)\): The conditional probability of whether cell i contains an object of class \(c \in C\). \(\widehat{p_{i}}(c)\): The predicted conditional class probability.
The Yolov5-based vehicle detection architectures have been developed by utilizing the aforementioned hyper-parameters. The Yolo-based vehicle detection algorithm sees the vehicle recognition task as a single regression problem, and it performs localization and classification tasks in a single network. So, the Yolov5-based vehicle detection system predicts the Bbox (localization), and label (classification) information of objects. At its core, this equation is utilized as a loss function, see Eq. 1.
Yolov5 is a robust object detector by nature; nevertheless, it may detect several duplicate bounding boxes for the same vehicle on any frame of any video. The maximum number of duplicated detections in a certain object depends on the number of classes. For instance, if there are 80 class labels in a trained model, so maximum of 80 so-called detections (Bboxes) can be detected in a particular location for a certain object. These all detections can be considered as 80 objects if they are not handled accurately. In the vehicle tracking part, a unique ID is assigned to each object. If 80 detections come to the vehicle tracking module, it assigns 80 IDs and gives 80 tracks for just one object. Consequently, in the vehicle counting part, one object can be counted as 80 objects. This case is a big issue for the development of an accurate vehicle counting system. The duplicate-detection problem was addressed using our misdetection filtering algorithm. In this algorithm, we performed the bounding boxes matching in the same location of an input image using intersection over the union. All Bboxes are checked against overlapping via IoU, then vehicle detections (bounding boxes) of two objects those IoU value greater than 0.90 are ranked based on their prediction confidence levels. The one with the highest confidence level was kept, other object with a lower confidence level was removed for all detection of each video frame, the algorithm has been given in Algorithm 1.

A duplicate detection filtering algorithm to remove misdetections of a vehicle in a certain frame.
3.2 Detection feature-based vehicle tracker approach
The proposed vehicle tracker approach uses the output of vehicle detection module. Vehicle detection module gets a video frame as an input, processes it. And it produces detection results. Next, the detection results are purified with the duplicate detection check algorithm. It removes the duplicate bounding boxes and produces output as in Eq. 2. Here, cl—class, conf—confidence and X1 and Y1—left and top, and X2 and Y2—right and bottom points.
The bounding box info as detection feature will be an input of the proposed tracker algorithm. The vehicle tracker generates time-dependent vehicle trajectory using Bbox information (X, Y, Width, Height) of two consecutive frames (\(frame_i\) and \(frame_j\)). The tracker calculates all distances among all object pairs from both frames. It keeps all distance values to the 2-dimensional array \(D_{ij}\), see Eq. 3. The structure of the array \(D_{ij}\) is given as Eq. 4.
The items by the rows of the Dist array correspond to the unique IDs of the vehicles on the ith (previous) frame and the items by the column of the Dist array indicate the newly assigned IDs of the same vehicles on the \({(i+1)}\)th frame on an input video, see Eq. 4.
where \(d_{11}\) is the distance between the first vehicles of the previous and new frames, and m and n are the total numbers of vehicles in these successive frames, respectively.
The Dist array is sorted by it rows and minimized by its columns, Eq. 5. The tracker algorithm updates the states of the vehicles by assigning new IDs based on the sorted row and minimized column IDs of the previous states of vehicles (Bbox coordinates) when the sorted and minimized distance value of a certain vehicle resides within the manually defined circled area. The radius of the user-defined circular area is 60 pixel units for this study. The radius of the circular area is determined after the thorough observation of vehicles’ behavior and velocity on a particular highway. If the speed is high, the radius of the area should be smaller than 2 times the fps (frames per second) rate of an input video. Otherwise, the algorithm cannot trace vehicles properly, because fast-moving vehicles cannot be detected with a high confidence level. Detections with less than a 60% confidence level were not considered as vehicles, and they were not included in the detection result array. A greater value should be assigned to the radius of a circular area if the velocity of the vehicles is low.
Here, Prev (as previous) is a set that keeps the unique IDs of the vehicles from the ith (previous) frame with the minimized distance values, and New (as new) holds the IDs of the vehicles from the \({(i+1)}\)th (new) frame with the minimized distance values. In case, any of the minimized distance values outside of the range of the manually defined circular area, the tracker algorithm computes the number of the appearance for the observed vehicles on the previous frames. If the appearance age for the particular vehicle satisfies the minimum appearance age (in our case, appearance and disappearance ages are 60), the current and next states of the vehicle are predicted by linear equations (Eq. 7) using the Bbox info from the 60 previous frames, then the predicted Bbox is assigned to the current vehicle, and at the same time the vehicle’s age is incremented by one for the each prediction step, Eq. 6. The appearance and disappearance ages were determined after the observation of movement speed of vehicles on the selected roads/highways videos.
If the disappeared object’s age is greater than the user-defined disappearance age, then it is considered as lost (disappeared) and de-registered immediately. The appearance and disappearance age thresholds provide robustness for the Bbox-based vehicle tracking algorithm by predicting the current or next state of the disappeared vehicles when the vehicles are lost because of partial or full occlusion, and illusion issues, or camera shaking, or harsh weather conditions. For the Bbox-based tracking algorithm, the prediction step (process) is critical because of the challenges including bad weather conditions such as heavy rain, snow or winds, or camera shaking, or illusion and partial or full occlusion, vehicle detection algorithm struggle at some level, or fails completely. In such conditions, vehicle tracking activates its prediction system to estimate the next state of the disappeared vehicle(s). The prediction functions based on linear equations are illustrated in Eq. 7.
where \(d_{X}\), \(d_{Y}\), \(d_{W}\), \(d_{H}\) are the average difference distances between the first and last points of a disappeared object, \(X_{n+1}\), \(Y_{n+1}\), \(W_{n+1}\), \(H_{n+1}\) are the new predicted states, and \(X_{n}\), \(Y_{n}\), \(W_{n}\), \(H_{n}\) are the last disappeared state of the trajectory of the lost vehicle. We have used linear equations to estimate the new state of disappeared objects since the motion of vehicles on highways are usually linear. For intersections, polynomial functions are better choice since the motion is nonlinear. To sum up, the proposed detection feature-based tracking algorithm is built on three main modules, namely new vehicle registering, vehicle state updating and vehicle deregistering. In the first module, all newly appeared vehicles are assigned with new unique IDs. Next, the vehicles with their unique IDs are tracked through the consecutive frames by updating their states in each step. In the last module, the disappeared vehicles are immediately removed from the tracks list. The algorithm is being illustrated via Algorithm.2.

A proposed detection feature-based tracker algorithm.

Extracted vehicle trajectory data from the case study highways via the vehicle detection and the Bbox tracker
3.3 Datasets and case study nighttime highway videos
In the vehicle detection part, the COCO128 dataset was utilized by extracting three classes including buses, cars and trucks. In the vehicle counting system, 12 nighttime case study videos captured from 4 different highways with distinct vertical and horizontal angle-of-view were used. All nighttime videos have been acquired from YouTube channels. The detailed info is illustrated in Table 1
3.4 Accuracy calculation
The accuracy of traffic (vehicle) counters was measured based on Eq. 8. The total weighted average accuracy formula (Eq. 9) was utilized to evaluate the overall accuracy of the vehicle counting systems due to the reason that the number of vehicles by their types was not distributed normally. For instance, the total number of buses, cars, and trucks for all incoming and outgoing lanes of the 12 highway videos are 106, 16,591, and 166, respectively. This kind of abnormally distributed number of vehicles does not allow measuring the true accuracy of the entire system. However, it strongly recommended utilizing simple total average accuracy formula if the number of vehicles by their types is distributed normally. In future works, we are going to choose case study videos in which the number of vehicles is distributed normally.
where \(A_{\text {car}}\) is the accuracy of the estimated numbers of cars in incoming or outgoing direction. \(w_{\text {car}}\) is the weight for the cars and it is calculated in the following way, \(w_{\text {car}}\) = \(N_{\text {cars}}/T_{\text {num}\_\text {veh}}\), \(N_{\text {cars}}\) is the ground truth number of cars, \(T_{\text {num}\_\text {veh}}\) is the ground truth, total number of vehicles in a direction (incoming or outgoing). The other weights are calculated in the same way.
4 Results and discussion
4.1 Vehicle trajectory extraction results
Twelve nighttime highway case study videos have been processed with the Yolov5-based vehicle detection architectures and the developed vehicle tracking algorithm, and then, the time-dependent trajectory data of vehicles were extracted. The results can be seen in Fig. 4. Based on the figure and the vehicle counting results, it can be seen that the trajectories were extracted slightly accurately. Higher accurate trajectory data provide higher accurate traffic flow information such as total and categorical vehicle counts and speed, etc.
4.2 Traffic counting results of the entire system
4.2.1 Total weighted average accuracy results
The number of vehicles by their labels (class types) has been estimated with five Yolov5-based vehicle detectors and two vehicle trackers. In total, 10 traffic counters were developed, namely Yolov5n (Nano) vehicle detection model and the Bbox tracker, and Yolov5n (Nano) vehicle detection model and the Kalman filter-based vehicle tracker, etc. 12 case study videos were processed via the 10 vehicle counting systems. The vehicle count and accuracy results are illustrated in Table 2. The total weighted average accuracy (general accuracy) results of the traffic counting systems are shown in Fig. 5. Overall, the proposed vehicle tracker outperformed the Kalman filter-based tracker with 2.58% better total weighted average accuracy. The performance of the developed tracker for buses, cars, and trucks was 5.82%, 2.24%, and 36.5% better than the performance of the Kalman filter-based tracker. The main reason for this is the sensitivity of the Kalman filter approach.
The Kalman filter estimates the next state of a system based on a just previous state of it. This makes the Kalman filter very sensitive against instantaneous changes/minor shifts in the state of the observed vehicle/object; however, in a vehicle tracking system, the next state of the vehicles/objects should be estimated based on several previous states of the observed vehicle/objects. Estimating the next state of a system based on several previous states of it enables a tracker to underestimate the unintentional minor and instantaneous changes. The Yolo algorithm predicts vehicle/object locations with minor shifts on an input video frame. Therefore, a stationary or moving vehicle is detected with minor shifts/differences from its true location of the observed vehicle through consecutive frames. This case is considered by the Kalman filter-based tracker as a movement of the observed vehicle, and the tracker starts estimations for a moving vehicle, even though the observed vehicle is in a stationary state. With the incorrect estimation, it starts to produce vehicle IDs for nonexisted vehicles, and mistracking (incorrect tracking) of vehicles occurs. Due to this reason, the Kalman filter-based algorithm might have performed with less accuracy than its peer. However, the proposed tracker predicts disappeared vehicles based on their 60 previous states. Because of this, the Bbox tracker does not produce fake tracks like other tracker does.
Furthermore, cars were detected accurately in all videos with all traffic counters, that is because, in the vehicle detection dataset (COCO128), the number of cars is far greater than the number of both buses and trucks. During training, vehicle detection had seen more car samples than the other two classes, which results in more accurate car detection than bus or truck detection. So, the vehicle detection module recognizes more cars with slightly higher confidence levels than the other two vehicle types. Consequently, it affects negatively both trackers. It can be seen from Table 2.

Total weighted average accuracy of vehicle counters
4.2.2 Traffic counting outcomes for cars

Traffic counting accuracy outcomes for Cars
The bounding box-based tracker algorithm performed better with all Yolov5 models except the Yolov5n model. This is the lightest architecture via just 1.9 million parameters, so it is too prone to many false-positive vehicle detections, and its vehicle localization feature is the most unstable one than other Yolov5 models. Due to this reason, vehicles are detected with slightly different positions from their true locations on an input image. This leads the Kalman filter-based tracker to produce many false-positive tracks. The same cases occurred in almost all videos in both incoming and outgoing directions of the highways. Because of this reason, better accuracy outcomes than the Bbox-based tracker were obtained with the traffic counter system, which was built on Yolov5n and the Kalman tracker. This can be seen in Table 2 and Fig. 6.
However, vehicle counters that were built on the bounding box-based tracker and the other four models of Yolov5 outperformed the vehicle counters that were built on the Kalman filter-based tracker and four models of Yolov5. See for the detailed results Table 2 and Fig. 6. The vehicle detection based on Yolov5s architecture had also some false-positive car detections, which directly affected both trackers in which results slightly less traffic counting accuracy than other Yolov5 (medium, large, and X-large) architectures. However, the other three models with their better vehicle detection feature performed well; consequently, this case had a direct positive impact on the tracking accuracy of both trackers. However, the bounding box-based tracker outperformed its peer at a 2.24% better accuracy level for car counting.
4.2.3 Traffic counting outcomes for buses

Traffic counting accuracy outcomes for Buses

Traffic counting accuracy outcomes for Trucks
There are a buses in all case study videos, in spite of the number of buses are few. Nevertheless, the vehicle detection models failed to detect them properly in most cases because of three reasons. The first reason is the COCO128 dataset. It includes less number of buses than the number of cars in it. It includes daytime and nighttime bus examples; however, the nighttime bus images are also very few in the dataset. So the nighttime bus image features could not be learned well by the Yolov5 architecture, which resulted in lower detection accuracy. The second reason is misclassification, in which buses were classified as cars and trucks that is because buses from the front side resemble car and truck objects at night time. The third one is the fast speed of vehicles in the video, because of the fast speed, the detectors failed. These issues led to the failure of the detectors. The failure of the detectors led to too many false positive tracks, which results in the failure or achieving lower accuracy of the entire traffic counting system for buses. See Table 2 and Fig. 7 for more details and insights. However, these misdetection and misclassification issues can be solved via the re-training of Yolov5 models on a new dataset that only contains nighttime vehicle images. In addition, the distribution of the samples of each class in the dataset should be distributed normally.
4.2.4 Traffic counting outcomes for trucks
For all video cases, there were trucks even though the number is few. But, because of the intense illusion cases of the headlights and taillights of vehicles, vehicle detectors performed with lower detection accuracy or failed. This led to the lower accuracy of vehicle trackers and traffic counters. However, the proposed algorithm performed with a 36.5% better traffic counting accuracy than the Kalman filter-based algorithm. Other details and more insight about the results can be seen in Table 2 and Fig. 8. The reason for the lower results in the Kalman filter-based tracker is its prediction algorithms. Kalman filter predicts the next state of an object based on only one previous state of the object. One state will not be sufficient for a proper estimation of an object’s new state in case the object disappears from the several frames of an input scene due to intense headlight or taillight illusion or partial or full occlusion issues. However, the Bbox-based tracker approach predicts the new state of a disappeared object based on 60 previous states of the current object. It makes the tracker robust against disappeared object data processing. The solution to the problem is the improvement of vehicle detection accuracy. It can be improved by training Yolov5 models via only nighttime vehicle samples.
5 Conclusion
In this study, real-time vehicle (traffic) counting systems were developed using vehicle detectors, which are based on the pre-trained Yolov5 architectures, and vehicle trackers such as Kalman filter-based and Bbox-based. The evaluation results show that the proposed tracker algorithm outperformed the Kalman filter-based tracker with 5.82% (Bus), 2.24% (Car), 36.50% (Truck), and overall 2.58% better traffic counting accuracy for the 12 nighttime case study videos captured from the highways with different horizontal and vertical angle-of-views. For buses and trucks, both vehicle trackers performed with lower accuracy due to the reason that vehicle detectors produced detection results with lower confidence levels or failed in most cases. This is called misdetection. The misdetection cases led to lower vehicle tracking accuracy, which results in lower traffic counting accuracy. In addition to the misdetection cases, buses and trucks were misclassified as cars in most cases because of the intense illusion of headlights and taillights of vehicles. The misdetection and misclassification issues impacted negatively both vehicle trackers for buses and trucks, but the proposed tracking algorithm was less affected by these negative cases than the Kalman filter-based tracker method. Hence, more accurate trajectory data were estimated with the Bbox-based tracker, which results in higher and better traffic counting accuracy. The misdetection/misclassification issues can be solved by the headlight and taillight illusion removal techniques or with re-training of the vehicle detectors. In the future work, we are planning to develop a headlight and taillight illusion removal module to the Yolov5-based vehicle detection algorithm to address the misdetection and misclassification problems.
Data availability
Enquiries about data availability should be directed to the authors.
References
Azimjonov J, Özmen A (2021) A real-time vehicle detection and a novel vehicle tracking systems for estimating and monitoring traffic flow on highways. Adv Eng Inform 50:101393
Azimjonov J, Özmen A (2022) Vision-based vehicle tracking on highway traffic using bounding-box features to extract statistical information. Comput Electr Eng 97:107560
Badino H, Franke U, Mester R (2007) Free space computation using stochastic occupancy grids and dynamic. In: Programming, proceedings of the international conference computer vision, workshop dynamical vision
Cabido R, Montemayor AS, Pantrigo JJ (2012) High performance memetic algorithm particle filter for multiple object tracking on modern GPUs. Soft Comput 16:217–230
Chauhan NK, Singh K (2018) A review on conventional machine learning vs deep learning. In: 2018 international conference on computing, power and communication technologies (GUCON), pp 347–352
Datondji SRE, Dupuis Y, Subirats P, Vasseur P (2016) A survey of vision-based traffic monitoring of road intersections. IEEE Trans Intell Transp Syst 17(10):2681–2698
Erbs F, Barth A, Franke U (2011) Moving vehicle detection by optimal segmentation of the dynamic stixel world. In: 2011 IEEE intelligent vehicles symposium (IV), pp 951–956
Feng X, Jiang Y, Yang X, Du M, Li X (2019) Computer vision algorithms and hardware implementations: a survey. Integration 69:309–320
Fernández-Sanjurjo M, Bosquet B, Mucientes M, Brea VM (2019) Real-time visual detection and tracking system for traffic monitoring. Eng Appl Artif Intell 85:410–420
Franke U, Rabe C, Badino H, Gehrig S (2005) 6d-vision: fusion of stereo and motion for robust environment perception. In: Kropatsch WG, Sablatnig R, Hanbury A (eds) Pattern recognition. Springer, Berlin, pp 216–223
Girshick R (2015) Fast R-CNN. In: 2015 IEEE international conference on computer vision (ICCV), pp 1440–1448
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: 2014 IEEE conference on computer vision and pattern recognition, pp 580–587
Jeon D, Kim D-H, Ha Y-G, Tyan V (2016) Image processing acceleration for intelligent unmanned aerial vehicle on mobile GPU. Soft Comput 20:1713–1720
Kanagamalliga S, Vasuki S (2018) Contour-based object tracking in video scenes through optical flow and Gabor features. Optik 157:787–797
Kavukcuoglu K, Sermanet P, lan Boureau Y, Gregor K, Mathieu M, Cun YL (2010) Learning convolutional feature hierarchies for visual recognition. In: Lafferty JD, Williams CKI, Shawe-Taylor J, Zemel RS, Culotta A (eds) Advances in neural information processing systems 23. Curran Associates, Inc, pp 1090–1098
Khalkhali MB, Vahedian A, Yazdi HS (2020) Vehicle tracking with Kalman filter using online situation assessment. Robot. Auton. Syst. 131:103596
Khan S, Ali H, Ullah Z, Bulbul MF (2018) An intelligent monitoring system of vehicles on highway traffic. In: 2018 12th international conference on open source systems and technologies (ICOSST), pp 71–75
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436-444
Liu P, Wang G, Yu Z, Guo X, Lu W (2019) Vehicle tracking based on shape information and inter-frame motion vector. Comput Electr Eng 78:22–31
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, Berg AC (2016) SSD: single shot multibox detector. In: Leibe B, Matas J, Sebe N, Welling M (eds) Computer vision—ECCV 2016. Springer, Cham, pp 21–37
Lu S, Wang Y, Song H (2020) A high accurate vehicle speed estimation method. Soft Comput 24:1283–1291
Luque-Baena RM, López-Rubio E, Domínguez E, Palomo EJ, Jerez JM (2015) A self-organizing map to improve vehicle detection in flow monitoring systems. Soft Comput 19:2499–2509
Mandellos NA, Keramitsoglou I, Kiranoudis CT (2011) A background subtraction algorithm for detecting and tracking vehicles. Expert Syst Appl 38(3):1619–1631
Nguyen B, Brilakis I (2018) Real-time validation of vision-based over-height vehicle detection system. Adv Eng Inform 38:67–80
Pillai MS, Chaudhary G, Khari M, Crespo RG (2021) Real-time image enhancement for an automatic automobile accident detection through CCTV using deep learning. Soft Comput 25:11929
Rathore MM, Son H, Ahmad A, Paul A (2018) Real-time video processing for traffic control in smart city using Hadoop ecosystem with GPUs. Soft Comput 22:1533–1544
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: unified, real-time object detection. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 779–788
Redmon J, Farhadi A (2017) Yolo9000: better, faster, stronger. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 6517–6525
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement, pp 1–6. arXiv preprint arXiv:1804.02767
Ren S, He K, Girshick R, Sun J (2017) Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39(6):1137–1149
Sivaraman S, Trivedi MM (2013) Looking at vehicles on the road: a survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans Intell Transp Syst 14(4):1773–1795
Song H, Wang X, Hua C, Wang W, Guan Q, Zhang Z (2018) Vehicle trajectory clustering based on 3d information via a coarse-to-fine strategy. Soft Comput 22:1433–1444
Song D, Tharmarasa R, Florea MC, Duclos-Hindie N, Fernando XN, Kirubarajan T (2019) Multi-vehicle tracking with microscopic traffic flow model-based particle filtering. Automatica 105:28–35
Sudha D, Priyadarshini J (2020) An intelligent multiple vehicle detection and tracking using modified vibe algorithm and deep learning algorithm. Soft Comput 24:17417–17429
Xiao X, Sun Z, Shen W (2020) A Kalman filter algorithm for identifying track irregularities of railway bridges using vehicle dynamic responses. Mech Syst Signal Process 138:106582
Yang Z, Pun-Cheng LS (2018) Vehicle detection in intelligent transportation systems and its applications under varying environments: a review. Image Vis Comput 69:143–154
Yang T, Cappelle C, Ruichek Y, Bagdouri ME (2019) Online multi-object tracking combining optical flow and compressive tracking in Markov decision process. J Vis Commun Image Represent 58:178–186
Zhao Z, Zheng P, Xu S, Wu X (2019) Object detection with deep learning: a review. IEEE Trans Neural Netw Learn Syst 30(11):3212-3232
Zhu Y, Comaniciu D, Pellkofer M, Koehler T (2006) Reliable detection of overtaking vehicles using robust information fusion. IEEE Trans Intell Transp Syst 7(4):401–414
Funding
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (No. NRF-2022R1I1A3072355) and by the Scientific and Technological Research Council of Turkey under the Grant No. 119E077 and Title: “Development of a Customized Traffic Planning System for Sakarya City by Processing Multiple Camera Images with Convolutional Neural Networks (CNN) and Machine Learning Techniques”.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper. All authors of this research paper have directly participated in the planning, execution, or analysis of this study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Azimjonov, J., Özmen, A. & Kim, T. A nighttime highway traffic flow monitoring system using vision-based vehicle detection and tracking. Soft Comput 27, 13843–13859 (2023). https://doi.org/10.1007/s00500-023-08860-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08860-z