
Abstract
Mental stress is an issue that creates functional limitations in the workplace. Chronic stress leads to a number of psychophysiological sicknesses. For instance, it raises the risk of depression, heart attack, and stroke. According to the most recent findings in neuroscience, the human brain is the primary focus of mental stress. Perception of biological motion in the human brain determines the risky and stressful situations. Neural signaling of the human brain is used as an objective measure for determining the stress level of a subject. The oscillations of electroencephalography (EEG) signals are utilized for classifying human stress. EEG signals have a higher temporal resolution and are rapidly distorted with unwanted noise, resulting in a variety of artifacts. This study utilizes Extended Independent Component Analysis based approach for artifacts removal. A Multiclass Common Spatial Pattern-based moving window technique is proposed here to obtain the most distinguishable time segment of EEG trials. BiLSTM is used to improve classification results. In order to validate the model performance, two publically available datasets (i.e., DEAP and SEED) are utilized. Employing these datasets, the proposed model achieves state-of-the-art results (93.1, 96.84%) for EEG signal classification to identify stress.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Stress is described as an impression of being overwhelmed or unable to deal with emotional or mental pressure. Human body is sensitivity to any form of pressure and threats it as stress. A number of situations or life events can cause this. It occurs when we are stuck with something new and unexpected. Stress is the source of many mental infections. Various ways of stress exist which have negative influence on human life. It has a harsh effect on the subject's working relationships and on job performance. It also contributes to the risk of anxiety and depression (Sharma et al. 2020). The circumplex model proposed in (Russell JA, 1980) located stress in the left quadrant of the emotional space as shown in Fig. 1. Arousal varies from inactive state (like tired, sleepiness) to active state (e.g., alert, excited). Whereas, valence scales from unpleasant (like sad, stressed) to pleasant (e.g., happy, elated) (Koelstra et al. 2011).

Circumplex model of emotions
Humans are subjected to two forms of stress: acute stress and perceived stress. Acute stress is a rare complication likely to be the result of events such as an accident, a severe career mistake, or a conflict with relatives/friends. Perceived stress is a long-term illness that may be caused by socioeconomic conditions like a boring job, an unsuccessful marriage, family problems, or poverty (Arsalan et al. 2019). The analysis of stress has been done using bio-signals of the human brain (Mukherjee and Roy 2019). A Brain Computer Interface (BCI) based on EEG signals, empowers the humans to communicate directly with computers using their brain impulses (Ullah et al. 2021). EEG data is exploited in brain computer interfaces to trigger actions using computational intelligence approaches. (Halim, Baig, and Bashir 2007). The reliable measure of brain activity is the EEG alpha variability index, which tends to be lower in stressful conditions (Giannakakis et al. 2019). These signals are time-variant measures (Bhavsar et al. 2018) of individual body functions that occur in two sections, physical and physiological bio-signals. Muscle activity, eye blinking, head movements, facial expressions, and speech are examples of physical bio-signals related to external body movements. The body's internal activities such as heart rate (electrocardiogram ECG), blood volume pulse (BVP), brain activity (EEG), and muscle excitability (electromyography EMG) are related to physiological signals. To investigate the relationship between brain function and emotional responses, the current brain waves are captured as EEG signals (Halim and Rehan 2020). Stress has been shown to have a wide range of adverse effects on the brain, ranging from mental illnesses to brain shrinkage. The activation of neurons in the brain generates electrical impulses in response to a combination of multiple stimuli (Zou et al. 2014).
EEG signal contains detailed information about individual mental states as well as objective assessments. EEG is exploited to measure brain functions, abnormalities, and physiological dynamics (Sun, Liu, and Beadle 2005). Pattern recognition in EEG signals can reliably differentiate a range of emotional states. The electrical signals produced by brain activity are minuscule (amplitude of around 10 to 100 µV), on the scale of a millionth of a volt. It also has a lower frequency spectrum of 4 to 60 Hz. The electrical signal on the scalp is made up of both actual brain signals and noise artifacts. The other body parts such as eye movements and blinking (electrooculography, EOG), heart activity (ECG), facial muscle movements (facial electromyography, fEMG), muscle movements (electromyography, EMG), produce attenuation in the EEG signals (Mannan et al. 2018). The EEG signals generated from various parts of the body are shown in Fig. 2. Non-physiological distortions, such as power-line noise and rapid impedance changes caused by electrode movement, arise outside the body.

EEG signals contributed by multiple body parts
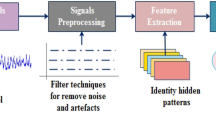
In medical research, the retrieval of individual brain signals from a distorted EEG signal is the most challenging task (Sharma et al. 2020). The most demanding aspect of EEG analysis is detecting and eliminating artifacts. Artifact removal, which involves removing all unwanted signals from the signals released by the brain, is the first step in any EEG data processing. It is important to eliminate noise from the EEG signals, to make the neural activity better analyzable. First, the desired brain signals must be extracted from the raw EEG data (Oosugi et al. 2017). In this study, a detailed investigation of separating artifacts from EEG signals, dividing it into time segments, representing it through feature vectors, and finally its classification is proposed. Splitting a multivariate signal into related subcomponents is done using ICA. This is accomplished by suggesting that the individual components are non-Gaussian signals which are statistically distinct from each other. Adaptive filters with Least Mean Squares (LMS) and Recursive least squares (RLS) are utilized to filter noise from the EEG signals. The coefficients of the filters vary in time due to a reference signal (noise), with the intention of causing the filter to converge to an ideal state. The M-CSP technique is used to derive features from EEG signals. It makes use of spatial filters to increase discriminability in the form of variances between several features. Various characteristics are used as features to distinguish the different levels of stress.
EEG data is susceptible to a variety of noise patterns, which reduces the model accuracy of identification. We propose the use of a Recurrent Neural Network (RNN) based technique that learns the discriminative EEG characteristics to overcome these issues. Specifically, from time-series EEG data, to demonstrate the association between subsequent data samples. In comparison to other techniques, this network has internal memory, which allows it to remember past information and have a higher understanding of time series data and its context. An extension of a long short-term memory network called BiLSTM is utilized to learn and classify the features into the desired labeled classes.
2 Related work
EEG signals are electric impulse produced by a set of particular pyramid nerve cells indicating neural activity. Based on the functioning condition of the brain, numerous types of rhythms can be seen in neural signals. Very small alterations in the frequency patterns of these signals may help in the early prediction of neurological problems or identifying that some neural activity is occurring in response to the external environment (Khosla et al. 2020). A comprehensive and domain-specific information pool is necessary to create an appropriate model for stress detection using EEG data (Hasan and Kim 2019).
In the domain of human behavior prediction, the study of emotion recognition, as well as other associated problems, is gaining interest (Halim et al. 2017). Psychological stress is a major health issue that has to be handled with proper measures in order to keep society healthy. The nervous system is made up of millions of neurons that play an important role in controlling the behavior of the body. Information will be sent from the human body to the brain via these neurons. To examine cognitive activities, brain imaging or signals are needed. Biosignals that could be accurately recorded in connection to such behavior are ECG, EEG, and EMG signals. The physical measures that could be used are eye activity, pupil size, respiratory rate, speech, and skin temperature (Giannakakis et al. 2019). Arsalan et al. (2019) presented an experimental study employing EEG data to make the right phase for characterizing perceived mental stress. The subject's stress is recorded using a benchmark stress scale questionnaire, which is then employed to annotate the EEG data. They suggested a novel feature selection method based on classification accuracy, which chooses characteristics from the relevant EEG frequency band. Stress levels are classified using three classifiers, such as SVM, naïve Bayes, and multilayer perceptron. Driving a vehicle during a stress condition decreases the driver's command over the vehicle, which often leads to road accidents. Halim et al. (2020) proposed a model to identify the ongoing neural activity using EEG signals. The relationship between neural activity and emotional states is discovered in this paradigm.
Early diagnosis of psychological stress is essential for successful treatment. In comparison to conventional methods, automation techniques are effective and beneficial in respect of diagnostics speed. Xia et al. (2018) provide a robust approach for the early diagnosis of psychological stress by analyzing differences in both EEG and ECG signals, collected from 22 male participants. They observed that the results obtained demonstrate significant physiological variations between the stress-free and stress situation at an individual scale. Following the recent developments in wearable EEG technology, EEG's capacity to detect stress can be expanded to field employees. Jebelli et al. (2018) suggest a method for automatically identifying employees' stress on work sites. This study collected EEG recordings of construction workers and manipulated them to obtain high-quality data. Salivary cortisol, which is a stress hormone, is also acquired from workers at various places to determine their stress levels. The frequency and time domain characteristics of EEG data are computed employing static and moving windowing techniques. Next, the authors employed SVM algorithms to detect workers’ stress level.
The EEG is a non-invasive brain imaging technique that may be used to evaluate various cognitive functions. It has the benefits of portability, reduced cost, and higher spatial resolution (Mannan et al. 2018). Literature shows that different features of EEG signals are indicative of different states of neural activity that depict people's emotions and behaviors (Bhavsar et al. 2018). Emotions are psychological conditions, characterized by personal experience, physiological reactions, and behavioral responses. These are a collection of various overlapped sensations that do not remain in isolation (Halim et al. 2020). However, EEG signals are continually contaminated with artifacts, which makes their decoding challenging. Therefore, detecting and eliminating artifacts are critical (Zou et al. 2014). To address the issues of EEG signal processing, artifact removal, and source localization, studies have explored EEG sources via spatial segregation and source activity localization (Sun, Liu, and Beadle 2005). The concept of source identification and source localization was studied using the ICA method. Which statistically generates separate sources from highly correlated EEG data. It fragments EEG recordings into a number of artifact-related and event-related components and is used to clean EEG recordings.
The critical aspects in developing a highly effective BCI system for emotion identification from EEG signals are features extractions and classification. Rahman et al. (2020) introduce a new feature extraction approach that combines Principal Component Analysis (PCA) with t-statistics. To categorize emotional states, four classifiers are used such as SVM, ANN, k-NN, and linear discriminant analysis (LDA). CSP algorithm is a successful approach for categorizing two-class EEG data, but its strength is dependent on the frequency range used by the subject (Ang et al. 2012a, b). In conventional CSP approach, a sample-based covariance-matrix estimate is employed. As a result, if the amount of training data is limited, its efficiency in EEG classification decreases. A regularized algorithm called R-CSP is proposed by (Lu et al. 2010), in which the covariance-matrix estimating is normalized by two variables to reduce the estimate bias while decreasing the estimated variance. The R-CSPs are then integrated to provide an ensemble-based outcome. They matched their proposed technique to four other participating techniques using dataset IVa of BCI Competition III. The outcomes of three sets of tests conducted in various testing conditions show that it outperforms the other techniques in terms of average classification results. For obtaining discriminant features, CSP is an effective feature extraction technique. However, CSP features, on the other hand, are compact, and feature sequences in the feature map are selected frequently. Fu et al. (2020) present a sparse method that incorporates sparse approaches and recursive searches into the CSP, which can filter out certain EEG channels with its most noticeable characteristics. To enhance classification accuracy, two regularization factors are applied to the linear discriminant analysis. The empirical results from the BCI competition dataset show that the proposed technique is 10.75% more accurate than the traditional algorithm.
In EEG signals processing, conventional methods involve wavelet, chaos analysis, matching and tracking etcetera, however, they all require custom design, and retrieval of EEG characteristics. These techniques have a lot of inconsistency and do not take into consideration the temporal aspects of EEG data, which are essential for emotion detection (Yang et al. 2020). The BiLSTM network used in this study has the ability to handle traditional deep learning algorithm's shortcomings in interacting with temporal data.
3 Proposed work
Previous investigations describe that the EEG signals and artifacts possess a high-frequency overlap with each other. M-CSP has better discriminative capabilities, however, it is prone to noise artifacts. Therefore, the E-ICA method is employed to retain the stress-related EEG signals while separating the remaining unwanted signals from the raw EEG data and removing the artifacts. Therefore, even if the raw EEG signals have poor quality, the proposed method still has the capacity to produce accurate classification results.
3.1 Raw EEG signals
The potential difference between both the active and reference electrodes over time is the observed EEG signal, and its amplitude is recorded in micro-volts (μV) (Rashid et al. 2020). These potential changes are caused by ionic current flows within the brain's neurons. EEG is a powerful tool for obtaining brain waves from the scalp surface area that correspond to distinct brain states. These signals are further classified on the basis of their frequency ranges (0.1 Hz to 100 Hz) into different classes, such as delta (1–4 Hz), theta (4–8 Hz), alpha (8–13 Hz), beta (13–30 Hz), and gamma (30–80 Hz) respectively (Kumar and Bhuvaneswari 2012). The frequency, amplitude, or shape of a pulse is analyzed to identify whether the subject is normal or pathological. DEAP (Koelstra et al. 2011), a publically available dataset, is used to evaluate performance of the proposed model.
In this data, the EEG signal of 32 subjects was collected where each subject watched 40 one-minute-long music video clips. The subjects rated every video using the four scales (arousal, valence, like/dislike, and dominance). Each dimension has a continuous rating score ranging from 1 to 9. EEG was captured using 32 AgCl electrodes at a sampling frequency of 512 Hz. The 10/20 international system was adopted for electrode placement on the scalp, in EEG data collection. The EEG 32-channel data was then split into 63-s trials, where the three-second pre-trials discarded and the 60-s trials are maintained for further analysis. The captured electrical signals get corrupted with artifacts, which has an adverse effect on EEG signal analysis. Therefore, there is a need to develop methods for detecting and retrieving clean EEG data from encephalogram samples. The other signal sources which contaminated EEG signals are separated in the pre-processing step. The datasets employed in this study are shown in Table 1.
3.2 Pre-processing
Deep neural networks learn from data in a hierarchical manner. Therefore, unlike traditional machine learning approaches, it reduces the requirement for domain expertise and the need for intensive feature extraction. However, the acquisition of EEG signals provides us with a large amount of data to examine. For example, each participant in the DEAP dataset has 40 trials, each of which comprises information from 40 EEG channels. In a single trial, there are 322,560 measurements since each channel includes 8064 data points. Due to the scanty of hardware sources, evaluating such data is challenging, and this may also include data that does not significantly contribute to the validity of the simulation results. As a solution, we start by normalizing our data with the help of suitable preprocessing approaches.
Pre-processing is performed to eliminate artifacts from EEG data. Broadly, two types of EEG artifact sources exist; environmental/external sources and physiological sources. In this study, the external noise sources are kept constant. Physiological noise is generated by a variety of body functions, such as eye activity EOG, heart activity ECG, muscle activity EMG, and breathing are just a few examples (Chen et al. 2017).
The multi-channel EEG signals \(x\left[ t \right] \in {\mathbb{R}}^{M}\) at sample time \(t\) can be represented as,
where, \(a\left[ t \right] \in {\mathbb{R}}^{M}\) represents artifacts and \(e\left[ t \right] \in {\mathbb{R}}^{M}\) shows the EEG signals. The artifacts signals \( a\left[ t \right]\) contain different types of noise signals. The signals \(x\left[ t \right], a\left[ t \right]\) and \(e\left[ t \right]\) are modeled as m-dimensional stochastic variables that appear at specific sampling intervals \( t \in N\).
3.2.1 E-ICA
The ICA approach has seen a lot of growth over the years, notably in domains like biomedicine, radar signals, and pattern recognition etcetera. The classic EEG artifacts removal methods involve eliminating noise from observed data having clear artifacts features like frequency and peak amplitude exceeding a certain limit. This might result in a significant quantity of data loss, particularly in studies examining brain activity (Chen et al. 2021). While on the other hand, the ICA technique is an interactive optimization strategy that is characterized by high-order statistics. This technique is primarily employed to identify and retrieve the potential portion of the multidimensional signal and to separate it into statistically independent components. The eye movement distortions in EEG signals are considered to be created by distinct signal sources. Using ICA fragmentation, the eye movement artifacts may be eliminated and the original EEG data can be recovered.
The cognitive functions are not linked to just one portion of the brain, therefore a single event may impact numerous brain activities. A single channel's EEG signals are made up of a combination of various sources. The objective of this step is to separate EEG signals associated with varying degrees of stress levels from other signals. This study utilizes an E-ICA-based approach to decompose the superposed signals and to eliminate a wide range of artifacts from multichannel EEG recordings. This approach assumes that the time series recorded on the scalp are spatially stable mixtures of the activities of temporally independent cerebral and artifactual sources. At the electrodes, the summation of potentials from various areas of the brain, scalp, and body is assumed linear. The transmission latencies between the sources and the electrodes are considered to be negligible. The components will be first detected and classified as neural or artifacts sources using hard thresholding. Eye movements largely project to frontal areas using a lowpass spatial pattern. The proposed E-ICA is combined with Singular Spectrum Analysis (SSA) developed by (Noorbasha, Sudha, and Control 2021) for removal of EOG artifacts. Joint Blind Source Separation (JBSS) models introduced by (Liu et al. 2021) is employed to remove muscle artifacts.
Utilizing ICA, the multi-channel EEG data \(X\) is segmented into isolated components \( S\) with higher-order spatial moments (Chen et al. 2018). After recognizing the artifact components, they are eliminated, and the residual EEG signal components are projected back to their native spatial domain. This approach results in the regeneration of an EEG signal, which is free of artifacts. Infomax algorithm is used for EEG signal processing that retrieves independent signals by exploiting entropy component (Urigüen and Garcia-Zapirain 2015). It states that a function mapping collection of input data \(I\) to a set of output values \(O\) should be selected or learned in such a way that the Mutual Information (MI) between \(I\) and \(O\) is optimized, this is subject to a set of noise processes. Infomax is built on a neural network containing three columns of neurons, each indicating a different type of information; like the input data (\(I\)), the registered data (\(r)\) and estimated independent data (\(Y\)). Every column of neurons in a matrix is merged in a linear way. Using a neural network technique based on information maximizing, we can blindly distinguish the super-Gaussian sources. The assumption is that we can separate a source, \(s_{i}\) from mixtures \(x_{i}\) such that, the activity of every source is regarded statistically unrelated of the other sources. This implies that the input time ensemble is used to calculate their joint probability density function. It is worth mentioning that the mutual information between any two sources, \(s_{i}\) and \(s_{j}\), is assumed zero such as,
where, \(E\left[ . \right]\) indicates expectation function. The main goal of the blind separation task is to calculate a matrix \(W\) that may be used to establish the corresponding linear equation:
If the situation is re-established like by estimating, \(I_{s} \left( {u_{i} ,u_{j} } \right) = \) 0 for all \(i \ne j\). For example, suppose the mutual entropy of two nonlinearly converted components of \(y\) such as
where, \(y_{i} = g\left( {u_{i} } \right)\) and \(g()\) is an integrable and limited nonlinear function that offers the higher-order statistics required to demonstrate independent criterion through its Taylor expansion. The strategy for increasing the overall entropy includes increasing individual entropies \(H\left( {y_{i} } \right)\) and \(H\left( {y_{2} } \right)\). Hence increasing \(H\left( {\text{y}} \right)\) in common, is comparable to lessen the value of \(I\left( {\text{y}} \right)\). When the latter reaches 0, the two variables are considered statistically independent of each other. We want to optimize the entropy \(H\left( {\text{y}} \right)\) by iteratively altering the components of the square matrix \(W\) via smaller quantities of data vectors taken randomly from \(\left\{ {\text{x}} \right\}\)without replacement.
A priori information of the source distribution is provided by the logistic sigmoid such as:
In ideal situation, the type of nonlinearity would be the accumulative density function of distributions of independent sources such as;
The natural gradient infomax algorithm's initial version is expressed as;
where,\({ }W^{T} W\). is the “natural gradient” term which prevents matrix inversions and accelerates convergence. The cumulative density function of the distributions of different sources is commonly used to represent the weight matrix. The function \(\phi \left( u \right)\) is the log-likelihood gradient vector, often known as the score function, which is defined as the relationship between \(u\) probability density function and its derivative.
During a normal brain activity, the EEG signal follows the pattern of super-Gaussian distribution. An abnormal brain activity, such as epileptic seizures and nonepileptic attacks, event-related potentials, or other physiological artifacts, is indicated by a high positive normalized kurtosis value (more than 5). Non-physiological artifacts and slow brain activity exhibit sub-Gaussian distributions. Therefore, an improved infomax method is suggested for the separation of EEG data, which can separate both kindsf distributions using a parametric density model:
\(K\). is an n-dimensional matrix containing the \(k_{ii}\) entries. Where, \(k_{ii} = 1\) for super-Gaussian and \(k_{ii} = - 1\) for sub Gaussian process, respectively. Downsampling to 128 Hz and a bandpass frequency filter from 4.0–45.0 Hz has been used to preprocess the EEG data. Different types of artifacts were removed using preprocessing step. During preprocessing ICA does not know anything about artifacts like eye blinks and EMG. It separates signals into components based on a statistical measure. It transforms \(N\) channels into at most \(N\). components. We have to feed all EEG channels into the ICA. Whave to manually remove the components that contain artifacts and reconstruct the cleared EEG signal using the inverse transform.
3.3 Feature Extraction
The EEG signals recorded by the BCI device are weak, non-stationary, time-varying, and non-linear. A robust feature extraction approach is essential for boosting identification accuracy (Geng et al. 2021). EEG signals are often complex and include a significant amount of data. Therefore, the potential to retrieve the relevant aspects from EEG data is crucial. The goal of the feature extraction stage is to reduce the data to a low-dimensional space while keeping the valuable information provided by the EEG signals (Saeidi et al. 2021). The EEG signals have varying natures, and their statistical properties shift rapidly over time. Therefore, in this study, we start with M-CSP-based features extraction. Here, we employ spatial filters that optimize the discrimination capacity of the signals classes in order to derive optimal features. The preprocessed EEG data is transformed into a sequence of \(p\) features employing feature extraction approaches such that, \(x = \left( {x_{1} , \cdots ,x_{p} } \right)^{T} \in { }X_{p} { }\) that are suited for classification.
3.3.1 M-CSP
The CSP is a feature extraction approach, which employs spatial filters \(w\), that have a maximum variance for one class and a minimum variance for the other class (Dong et al. 2020). Therefore, the variance features enlarge the gap between the two signal categories. The benefit of this method is that it does not need to choose a frequency band in advance. It distinguishes between distinct classes of EEG data based on various types of motor activity using spatial filters. This method is prone to outliers since it needs the estimation of covariance matrices. In this study, we have extended CSP to multiclass M-CSP with a different optimization criteria. We develop a set of spatial filters (i.e., a spatial transform) with the variance of the filter signal maximal for one class and minimal for the other, and vice versa.
Let \({\text{X}}_{1}\) of size \(\left( {n,t_{1} } \right)\) and \({\text{X}}_{2}\) of size \(\left( {n,t_{2} } \right)\) be two multivariate signal windows, where \(n\) shows the number of signals and \(t_{1}\) and \(t_{2}\) show the number of samples. The CSP approach is used to identify the component \({\text{w}}^{{\text{T}}}\), which maximizes the fraction of variance (second-order moment) between the located windows:
Computing the two covariance matrices produces the solution:
To extend it for multiclass common spatial pattern (M-CSP), we have to expend it such as, let \({\text{X}}^{c} = \left[ {{\text{x}}_{1}^{c} ,{\text{x}}_{2}^{c} , \ldots ,{\text{x}}_{{t_{c} }}^{c} } \right],{\text{ where }}c = 1,2, \ldots N\), where \(N\) is the number of classes. \({\text{x}}_{i}^{c} \in R^{D \times S}\) is a \(D \times S\) matrix that describe the raw EEG data of the \(i^{th}\) trial for class \(c,i = 1,2, \ldots ,t_{c}\), and \(t_{c}\) represents the total trial number for class \(c.\). Here \(D\) shows the number of channels and \(S\) represents the number of samples. For each class, the normalized spatial covariance matrices are described as:
where \({\text{tr}}\) (⋅) represents the trace of matrix, and \({\text{X}}^{cT}\) indicates the transpose of \({\text{X}}^{c}\). The matrices are diagonalised simultaneously (also known as generalized eigenvalue decomposition). The eigenvector matrix is found such that \(P = \left[ {p_{1} \cdots p_{n} } \right]\). and the eigenvalues \(\left\{ {\lambda_{1} , \cdots ,\lambda_{n} } \right\}\). are placed in decreasing order in the diagonal matrix \({\text{D}}\).:
and
where \({\text{I}}_{n}\) shows the identity matrix. This is equal to the Eigen decomposition of \({\text{R}}_{2}^{ - 1} {\text{R}}_{1}\):
\({\text{w}}^{{\text{T}}}\) corresponding to the first column of \({\text{P}}\):
channels are rebuilt for each frequency by linearly combining the electrode outputs using two fourth-order CSPs. The aim of this process is to find the optimum channel linear combination for detecting certain frequencies based on previously recorded training data. The M-CSP-based extracted features can be employed as input to the classifiers.
3.4 Classification
The proposed EEG classification workflow involves data preprocessing, feature extraction, partitioning the datasets for classifiers, determining the class of new data, and validating the performances of classification algorithms on the test datasets. Deep learning networks have resulted in various impressive solutions to a variety of modern problems. Its superiority over conventional statistical method is due to its layered architecture and better accuracy when trained on big datasets. We develop an RNN-based technique for automated identification of stress levels using EEG data to determine a subject's stress levels. We divide the time-series EEGs into short segments since the beginnings of a stress level appear at random in the EEG signals. The temporal associations between subsequent EEG data points are captured during the pre-processing stage. The features obtained from EEG signals are then sent into LSTM cells, which acquire the most reliable and discriminative EEG characteristics for detecting stress levels. The acquired features are then forwarded to the softmax layer, which computes cross-entropy among true and predicted outputs. The proposed model is then tested with well-known benchmark datasets such as DEAP and SEED. We test the model's detection accuracy in ideal settings when the EEG data has been processed for artifacts removal. The obtained results indicate that this technique outperforms various previous studies in terms of detection accuracy. However, to increase the accuracy, we employ BiLSTM to acquire information on previous EEG data too. Because regular LSTM can only handle unidirectional time signals. As illustrated in Fig. 3, BiLSTM is an extension of LSTM. It delivers both the positive and inverted EEG sequences to the learning technique, and it operates similar to merging the two LSTM together. We divide the data sequence into multiple input \(\left( {\text{X}} \right)\)/output \(\left( {\text{Y}} \right)\) patterns known as samples. Where multiple time steps are used as input and one-time step is employed as output. The input shape determines the size of time steps, samples, and number of features.

Block diagram of BiLSTM model
The context relationship in the input EEG feature sequence is extracted using the first layer of the LSTM. Each sequence has 125 frame characteristics, hence 125 LSTM cells are assigned to them in this layer. The second layer, i.e., the fully-connected layer acts as a classifier and incorporates information.
To categorize each subject's stress levels, we employ categories such as arousal, valence, and dominance. We use softmax to translate the values obtained via linear transformation into three probability values, which correspond to each category of stress levels. The highest probability value represents the relevant stress level for the tested EEG signal. For optimization, the mini-batch gradient descent technique is employed. The Minimum Square Error (MSE) is used as a loss function. To minimize overfitting, “dropout” was introduced to the LSTM layer and fully connected layer. The higher the dropout, the less LSTM cells will transmit their output to the next layer; the lower the dropout, the more LSTM cells in one layer will pass their output to the next layer. We set the dropout at 0.4 to avoid overfitting and reduce the model's complexity. Three thousand LSTM training epochs were determined. A high learning rate (0.01) is used for the first few hundred epochs to speed up the training process, and then it was gradually reduced to a lower rate (0.0003) to get more stable results.
3.4.1 Validation
Two publically available datasets, namely, DEAP (Koelstra et al. 2011), and SEED (Zheng et al. 2018), are used to validate the proposed frameworks. The validity of BiLSTM in a stress recognition task employing EEG signal characteristics is tested in two different ways, using both datasets. A tenfold cross-validation approach is employed to verify the classification results. All participants' data samples are randomly divided into 9 folds for training and onefold for testing. The validation procedure is performed ten times to get average results.
4 Results
This section presents the experimental results of the proposed model for stress level detection. Each dataset comprises of EEG signal recordings from various numbers of participants, with varying trails, channels, states, scale rate, and sampling rate.
The data is split into two parts in the experiments: 80% is used for training and 20% for testing. The EEG dataset contains \(N\) channels for trials \(\left( x \right)\). Using experiment on DEAP dataset each subject file contains a data array of 40 trials × 32 channels × 8064 data, and a label array of 40 trials × 4 subjective ratings. Three classification experiments using the DEAP dataset, of two classes (arousal, valence), three classes (arousal, valance, dominance), and four classes are performed as shown in Table 2. Each trial's data is split down into smaller portions using M-CSP by taking a narrower window of length \(l\) sample points with an overlap of \(t\). sample points, resulting in \(N\) segments. We select a reference duration of 63 s for each trial, with the first three seconds being spent in preparation and the remaining 60 s being recorded while watching the movie. As a result, for each channel, there are 63 s*128 Hz = 8,064 sample points in each trail. After that, a series of spatial filters are applied to all of the segments. Each trail's 63 s are subdivided into 1 s segments, with 128 sampling points in each segment. The data array is then formulated as 40 (trials) * 32 channels * 63 (time segments) * 128 (sampling points).
A feature matrix is created by computing the variance-based characteristics of each segment from a single trial. The features extracted are in the range of four frequency bands such as theta (4–7 Hz), alpha (8–13 Hz), beta (14–30 Hz), and gamma (31–45 Hz), respectively. BiLSTM is an advanced model based on LSTM that can process input data twice from different directions and therefore enhance training proficiency. Using this approach, the temporal and atial information of the segment data may be learnt and integrated. The dense layers preceding the softmax layers are normalized independently and added element-by-element to provide the final predicted class label, along with another softmax layer. The Adam optimizing algorithm is used to enhance the cross-entropy loss function with a final learning rate of 0.0003. In training using trials such as \(D^{i} = \left\{ {\left( {X^{1} ,y^{1} } \right), \ldots ,\left( {X^{{N_{i} }} ,y^{{N_{i} }} } \right)} \right\}\) are given as input to the model, where \(N_{i}\) represents the total number of conducted trials for \(i^{th}\) subject. During testing, we evaluate the models using trial data \(X^{j}\) and obtain prediction \(y^{j}\) for the trial-wise correctness. The efficiency of the classification method is evaluated using classification accuracy. It is calculated as correctly predicted outcomes divided by the total number of predictions. The accuracy of the proposed model is determined by applying it to each dataset and each participant independently. Using the number of classes generated, the average accuracy of all participants is determined for each dataset.
EEG signals revealed a substantial reduction in alpha rhythmic power in all electrode points measured when subjects are stressed. A higher stress level in the Pre-Frontal Cortex (PFC) corresponds to a decreased EEG alpha rhythmic power. The results indicate that the subjects having depression produce abnormal brain signals. The proposed method's results are compared to those of other approaches that employed either the DEAP or SEED datasets or both, as shown in Table 3. We achieved the highest accuracy using DEAP dataset of 95.8% for two classes, 93.6% for three classes, and 93.1% for four classes respectively. The highest accuracy achieved for SEED dataset using three classes is 96.84%. Subjects that are in happy mode have high values of valence while those who are stressed have low values. The subjects who have high arousal values are excited while those having low values are calm.
The shortcoming of the proposed approach is that, unlike the conventional CSP approach, it is implemented in an iterative manner. Since an incorrect setting will keep the iterations in a local optimum. This approach also has the shortcoming of being noise-sensitive and relying on multi-channel analysis, which results in more computing efficiency.
5 Conclusion
EEG is a time series signal which requires the use of models like BiLSTM that can effectively process time sequence signals. To determine the spatial distribution of an EEG wave or activity. The reader must compare the appearance of the wave in all of the channels. To determine the frequency of an EEG rhythm, the reader must count the number of peaks per second. It is difficult to interpret EEG signals because of excessive artifacts present in the signals. The goal of this study was to investigate if E-ICA-based approaches, like Infomax, might be suitable choice for EEG artifacts removal. To apply the EEG signals to classification, we have to transform it into feature vectors. The key issue is how to extract the import features for best classification. In this study, we utilized spatial filter M-CSP that lead to optimal variances for the discrimination of multiple classes related to stress levels of EEG signals. In classification, through fine-tuning the BiLSTM model, we perform better than the past methods considered in this work.
In the future one may extend the proposed model to multi-modal emotion recognition. Other EEG-related areas where the proposed model can be used including BCI, brain illness diagnosis and assessment like epileptic seizures etcetera can be considered to evaluate the performance of the proposed approach.
Data availability
Enquiries about data availability should be directed to the authors.
References
Ang KK, Chin ZY, Wang C, Guan C, Zhang H (2012a) Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front Neurosci 6:39
Ang KK, Chin ZY, Wang C, Guan C, Zhang H (2012b) Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front Neurosci 6(39):1–9
Arsalan A, Majid M, Butt AR, Anwar SM (2019) Classification of perceived mental stress using a commercially available EEG headband. IEEE J Biomed Health Inform 23(6):2257–2264
Bhavsar R, Sun Y, Helian N, Davey N, Mayor D, Steffert T (2018) The correlation between EEG signals as measured in different positions on scalp varying with distance. Procedia Comp Sci 123:92–97
Chen X, Xu X, Liu A, McKeown MJ, Wang ZJ (2017) The use of multivariate EMD and CCA for denoising muscle artifacts from few-channel EEG recordings. IEEE Trans Instrum Meas 67(2):359–370
Chen X, Chen Q, Zhang Y, Wang ZJ (2018) A novel EEMD-CCA approach to removing muscle artifacts for pervasive EEG. IEEE Sens J 19(19):8420–8431
Chen Y, Xue S, Li D, Geng X (2021) The application of independent component analysis in removing the noise of EEG signal. In: 6th International Conference on Smart Grid and Electrical Automation ICSGEA IEEE: 138–141
Dong E, Zhou K, Tong J, Du S (2020) A novel hybrid kernel function relevance vector machine for multi-task motor imagery EEG classification. Biomed Sign Process Control. 60:1–12
Geng X, Li D, Chen H, Yu P, Yan H, Yue M (2021) An improved feature extraction algorithms of EEG signals based on motor imagery brain-computer interface. Alexandria Eng J. 61(6):4807–48020
Giannakakis G, Grigoriadis D, Giannakaki K, Simantiraki O, Roniotis A (2019) Review on psychological stress detection using biosignals. IEEE Transactions on Affective Computing. 1–22
Halim Z, Rehan M (2020) On identification of driving-induced stress using electroencephalogram signals: a framework based on wearable safety-critical scheme and machine learning. Information Fusion 1(53):66–79
Halim Z, Atif M, Rashid A, Edwin CA (2017) Profiling players using real-world datasets: clustering the data and correlating the results with the big-five personality traits. IEEE Trans Affect Comp 10(4):568–584
Halim Z, Waqar M, Tahir M (2020) A machine learning-based investigation utilizing the in-text features for the identification of dominant emotion in an email. Knowl-Based Syst 15(208):1–17
Halim Z, Baig R, Bashir S (2007) Temporal patterns analysis in eeg data using sonification. In: International Conference on Information and Emerging Technologies. IEEE: 1–6
Hasan MJ, Kim JM (2019) A hybrid feature pool-based emotional stress state detection algorithm using EEG signals. Brain Sci 9(12):1–15
Jebelli H, Hwang S, Lee S (2018) EEG-based workers’ stress recognition at construction sites. Autom Constr 1(93):315–324
Khateeb M, Anwar SM, Alnowami M (2021) Multi-domain feature fusion for emotion classification using DEAP dataset. IEEE Access. 9:12134–42
Khosla A, Khandnor P, Chand T (2020) A comparative analysis of signal processing and classification methods for different applications based EEG signals. Biocybern Biomed Eng 40(2):649–690
Koelstra S, Muhl C, Soleymani M, Lee JS, Yazdani A (2011) Deap: a database for emotion analysis; using physiological signals. IEEE Trans Affect Comp 3(1):18–31
Kumar JS, Bhuvaneswar P (2012) Analysis of electroencephalography EEG signals andits categorization a study. Procedia Eng 1(38):2525–2536
Lan Z, Sourina O, Wang L, Scherer R, Müller-Putz GR (2018) Domain adaptation techniques for EEG-based emotion recognition: a comparative study on two public datasets. IEEE Trans Cogn Develop Syst. 11(1):85–94
Liu J, Wu G, Luo Y, Qiu S, Yang S, Li W, Bi Y (2020) EEG-based emotion classification using a deep neural network and sparse autoencoder. Front Syst Neurosci 14:43
Liu A, Song G, Lee S, Fu X, Chen X (2021) A state-dependent IVA model for muscle artifacts removal from EEG recording. IEEE Trans Instr Measur 5(70):1–3
Mannan MM, Kamran MA, Jeong MY (2018) Identification and removal of physiological artifacts from electroencephalogram signals: a review. IEEE Access 31(6):30630–30652
Mukherjee P, Roy AH (2019) Detection of Stress in Human Brain. In: Second International Conference on Advanced Computational and Communication Paradigms ICACCP IEEE. 1–6
Noorbasha SK, Sudha GF (2021) Removal of EOG artifacts and separation of different cerebral activity components from single channel EEG—an efficient approach combining SSA–ICA with wavelet thresholding for BCI applications. Biomed Signal Process Control 1(63):1–12
Oosugi N, Kitajo K, Hasegawa N, Nagasaka Y, Okanoya K (2017) A new method for quantifying the performance of EEG blind source separation algorithms by referencing a simultaneously recorded ECoG signal. Neural Netw 1(93):1–6
Rahman MA, Hossain MF, Hossain M, Ahmmed R (2020) Employing PCA and t-statistical approach for feature extraction and classification of emotion from multichannel EEG signal. Egyptian Informatics Journal 21(1):23–35
Rashid M, Sulaiman N, Abdul Majeed PP, MusaBari RMBS (2020) Current status, challenges, and possible solutions of EEG-based brain-computer interface: a comprehensive review. Front Neurorobot 14:25
Russell JA (1980) A circumplex model of affect. J Pers Soc Psychol 39(6):1161–1178
Saeidi M, Karwowski W, Farahani FV, Fiok K, Taiar R (2021) Neural decoding of EEG signals with machine learning: a systematic review. Brain Sci 11(11):1–44
Sharma R, Pachori RB, Sircar P (2020) Automated emotion recognition based on higher order statistics and deep learning algorithm. Biomed Signal Process Control. 1(58):101867
Shon D, Im K, Park JH, Lim DS, Jang B, Kim JM (2018) Emotional stress state detection using genetic algorithm-based feature selection on EEG signals. Int J Environ Res Public Health 15(11):2461–2472
Sun L, Liu Y, Beadle PJ (2005) Independent component analysis of EEG signals. In: Proceedings of IEEE International Workshop on VLSI Design and Video Technology IEEE: 219–222
Tang H, Liu W, Zheng WL, Lu BL (2017) Multimodal emotion recognition using deep neural networks. International Conference on Neural Information Processing. Springer, Cham, pp 811–819
Ullah S, Halim Z (2021) Imagined character recognition through EEG signals using deep convolutional neural network. Med Biol Eng Compu 59(5):1167–1183
Urigüen JA, Garcia-Zapirain B (2015) EEG artifact removal, state-of-the-art and guidelines. J Neural Eng 12(3):1–23
Xia L, Malik AS, Subhani AR (2018) A physiological signal-based method for early mental-stress detection. Biomed Signal Process Control 1(46):18–32
Zhang Y, Zhang S, Ji X (2018) EEG-based classification of emotions using empirical mode decomposition and autoregressive model. Multim Tools and Appl 77(20):26697–26710
Zheng WL, Liu W, Lu Y, Lu BL, Cichocki A (2018) Emotionmeter: a multimodal framework for recognizing human emotions. IEEE Transactions on Cybernetics 49(3):1110–1122
Zou Y, Nathan V, Jafari R (2014) Automatic identification of artifact-related independent components for artifact removal in EEG recordings. IEEE J Biomed Health Inform 20(1):73–81
Acknowledgements
The authors are indebted to the editor and anonymous reviewers for their helpful comments and suggestions. The authors would like to thank GIK Institute for providing research facilities. This work was supported by the GIK Institute graduate program research fund under GA-4 scheme.
Author information
Authors and Affiliations
Contributions
The authors contributed to each part of this paper equally. All the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animal rights
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Communicated by Tiancheng Yang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rahman, A.U., Tubaishat, A., Al-Obeidat, F. et al. Extended ICA and M-CSP with BiLSTM towards improved classification of EEG signals. Soft Comput 26, 10687–10698 (2022). https://doi.org/10.1007/s00500-022-06847-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-022-06847-w