
Abstract
In this study, the flood hazards susceptibility map of an area in Turkey which is frequently exposed to flooding was predicted by training 70% of inventory data. For this, statistical, and hybrid methods such as frequency ratio (FR), evidential belief function (EBF), weight of evidence (WoE), index of entropy (IoE), fuzzy logic (FL), principal component analysis (PCA), analytical hierarchy process (AHP), technique for order preference by similarity to an ideal solution (TOPSIS), and VlseKriterijumska optimizacija I Kompromisno Resenje (VIKOR) were adapted. Values at both 70% and 30% of inventory data from the generated maps were extracted to validate the training and testing processes by receiver operating characteristics (ROC) analysis and seed cell area index (SCAI). Sensitivity, specificity, accuracy, and kappa index were calculated from ROC analysis, and SCAI was computed from the classification of map by natural break method and flood pixels in that classification. Since the predicted results of the methods applied did not point out the same model for each criterion, a simple method was selected to determine the most preferable method. Analysis showed that, IoE model was found to be the best model considering the ROC parameters, while PCA and AHP methods gave more reliable results considering SCAI. This study may be considered as a comprehensive contribution to the hybridization methods in predicting accurate flood hazards susceptibility maps.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In developing world, as the needs of human beings increase, new residential areas and commercial facilities expand near the waterfront sides. Hence, this brings a direct confinement of the waterway and leads to increasing of flood hazards. Floods are one of the major natural hazards which seriously threaten the infrastructures, cultivated agricultural lands, transportation networks in both urban and countryside areas and cause losses of significant economic activities and lives (Akay 2021). So, policymakers have to face challenging decisions on irresistible and increasing economic activities and its conflicting results of flooding hazards. Being aware of this problem, researchers are working on finding solutions to predict the spatial distribution of flood susceptibility. Flood susceptibility maps in terms of the risk groups may be considered as a design criterion or input to assess the flood vulnerability of the structures to be constructed, where necessary. For instance, an engineer could decide about the construction site of a new residential area by taking into consideration of the flood susceptibility maps.
Watershed characteristics are spatially obtained by the extraction of the available data using geographic information system (GIS) which is an important and effective tool, and adopted the contribution as an attribute in susceptibility assessment. Researchers focus on different techniques, based on statistical, fuzzy logic (FL), multi-criteria decision making (MCDM), machine learning, and meta-heuristic algorithms etc. to estimate the spatial distribution of flood susceptibility of flooded and non-flooded zones. Moreover, those methods have attracted attention and been employed for not only flood susceptibility but also for landslide susceptibility, groundwater potential, avalanche susceptibility, and wildfire probability mapping etc. (Mogaji et al. 2015; Arabameri et al. 2019; Choubina et al. 2019; Jaafari et al. 2019; Rahmati et al. 2019; Moayedi et al. 2020).
Researchers performed various methods including frequency ratio (FR) (Tehrany et al. 2019; Arabameri et al. 2019; Sahana and Patel 2019; Vafakhah et al. 2020; Mirzaei et al. 2021; Wang et al. 2021), weights of evidence (WoE) (Tehrany et al. 2014), index of entropy (IoE) (Haghizadeh et al. 2017; Wang et al. 2021), evidential belief function (EBF) (Tehrany and Kumar 2018; Arabameri et al. 2019; Bui et al. 2019), logistic regression (LR) (Nandi et al. 2016; Tehrany and Kumar 2018; Tehrany et al. 2019), statistical index (SI) (Tehrany et al. 2019), support vector machine (SVM) (Tehrany et al. 2014; Shafapour Tehrany et al. 2019), naïve Bayes tree (NBT) (Khosravi et al. 2019; Chen et al. 2020), random forest (RF) (Chen et al. 2020; Vafakhah et al. 2020; Mirzaei et al. 2021), fuzzy logic (FL) (Sahana and Patel 2019), fuzzy DEMATEL ANP (Kanani-Sadat et al. 2019), artificial neural network (ANN) (Kia et al. 2012), analytical hierarchy process (AHP) (Hammami et al. 2019; Kanani-Sadat et al. 2019), Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS) (Arabameri et al. 2019; Khosravi et al. 2019), VlseKriterijumska optimizacija I Kompromisno Resenje (VIKOR) (Arabameri et al. 2019; Khosravi et al. 2019), SAW (Khosravi et al. 2019), adaptive neuro-fuzzy inference system (ANFIS) (Hong et al. 2018; Vafakhah et al. 2020), and gradient boosting tress and multilayer perception algorithms (Costache et al. 2020; Ahmadlou et al. 2021; Wang et al. 2021) for flood susceptibility assessment.
In recent years, results of flood susceptibility mapping studies obtained from aforementioned methods were compared with each other, accuracy of prediction results were discussed and the methods giving the best accuracy were determined, accordingly (Khosravi et al. 2016; Arabameri et al. 2019; Kanani-Sadat et al. 2019; Shafapour Tehrany and Kumar 2018; Shafapour Tehrany et al. 2019; Shana and Patel 2019; Al-Abadi and Al-Najar 2020; Chen et al. 2020). Since there is yet no consensus worldwide on the accuracy of the model structure and limitations of the models and the characteristics of the study area, flood susceptibility mapping studies are still ongoing to improve the accuracy of the spatially predicted results (Costache et al. 2020). Hence, those methods are integrated creating the hybrid or ensemble models to get higher prediction performance (Shafapour Tehrany et al. 2014; Bui et al. 2019; Shafapour Tehrany et al. 2019; Costache et al. 2020). Researchers studying on flash flood susceptibility mapping coupled the EBF with LR, SVM, and other methods in order to improve the accuracy of the predictions and also avoid computational affords (Bui et al 2019; Chowdhuri et al 2020; Costache et al 2020; Talukdar et al 2020). Vafakhah et al. (2020) compared FR, ANFIS, and RF models in predicting flood susceptibility mapping, and the authors found RF model as the best predicting model. Mirzaei et al. (2021) adapted FR, RF, generalized additive model (GAM), and extreme gradient boosting (EGB) models to estimate the spatial distribution of flood susceptibility. Results indicated that RF and GAM models gave the best performance. Ahmadlou et al. (2021) implemented multilayer perceptron (MLP) and autoencoder–MLP models in flood susceptibility mapping. Authors stated that autoencoder-MLP gave outperformed. Wang et al. (2021) hybridized FR, IoE, and probability density (PD) models with MLP, and classification and regression tree (CART) models. MLP-PD was found as the most efficient model in flood susceptibility prediction in the study. Pham et al. (2021) employed best first decision tree (BFT), and bagging, decorate and random subspace ensemble models of BFT. Decorate-BFT was identified as superior model in flood susceptibility predictions. Dodangeh et al. (2020), Mehrabi et al. (2020), Pourghasemi et al. (2020), Arora et al. (2021), and Shahabi et al. (2021) adopted ensemble meta-heuristic algorithms and ANFIS, SVM machine learning techniques in order to optimize parameters in development of their predictions. All the researchers concluded that hybrid or ensemble techniques changed the predictions and contributed the accuracy of the model results. Researches on improvement of the model predictions using optimization and ensemble machine learning algorithms are still ongoing.
The main objective of this study is to contribute to the recent efforts on comprehensive comparison of statistical, FL and MCDM methods. To the best knowledge of the author, a comprehensive study was not implemented using this methodology. For this, some fundamental statistical approaches such as FR, WoE, EBF, IoE, and principal component analysis (PCA) were used. Moreover, some hybridization techniques using those methods in FL and MCDM methods such as AHP, TOPSIS, and VIKOR were tested in order to further understand the capability of the model outcomes. Flood hazards susceptibility maps were predicted separately and compared with each other.
2 Materials and methods
2.1 Study area
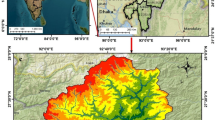
Gokirmak Basin sited in the northern part of Turkey has a drainage area of 1375 km2, drains through Ulus town and Bartin city center and then discharges into the Black Sea. The annual rainfall of the basin varies between 850–1250 mm; and the average slope of the basin is 35%. Increase in population and economic activities in the region leads to rapid urbanization causing the curve number of the region to increase, as well. So, the basin frequently faces flash floods due to increase in excessive rainfall, steep topography, deterioration in the basin, and the characteristics of the basin. Some major flash flood disasters took place in the study area, one of which occurred in 1998 that is still in the memories of the local people who experienced it (Akay and Baduna Koçyiğit 2020). Several studies including hydrologic modeling of the hydrological processes in the basin were conducted to further increase the understanding of the runoff of excessive rainfall (Baduna Koçyiğit et al. 2017; Akay et al. 2018). Flash floods occurring in Gokirmak Basin might seriously damage the residential areas, infrastructures, and suspend commercial activities and transportation services causing economic loss each year.
Rapid urbanization also requires infrastructure investments that should be insured against flash flood hazards. Engineers should consider the hydrologic vulnerability and risk assessment of flash floods regarding the safety of any structure in design stage, as well. Hence, a reliable flood hazards susceptibility mapping obtained using different statistical and hybrid MCDM models for Gokirmak Basin carried out in this study is thought to be crucial for especially local authorities for water management activities in the area.
2.2 Methodology
The methodology adopted in this study to obtain flood hazards susceptibility maps is given in Fig. 1.

Flood susceptibility mapping methodology
2.3 Data
Data used in this study consist of flood inventory and spatial distribution of flood conditioning factors. Flood inventory data include hazards occurred at past flood events reported by experts and local authorities while flood conditioning factors are the parameters that directly affect occurrence of flash floods.
2.3.1 Flood inventory
Past floods are one of the most important indicators, which show that similar consequences or hazards may be experienced as a result of future possible floods in the same environment depending on the meteorological, climatological, hydrological conditions of the watershed at that time. So, past flood hazards reported by the authorities at different time intervals were considered in this study to increase the estimation capability of flood hazards susceptibility spatial modeling using various techniques. Besides, flood inventory data also provide high flood susceptible zones in the watershed. On the other hand, non-flooded zones which are generally constituted from hills contribute to test the accuracy of the generated flood hazards susceptibility mapping (Tehrany and Kumar 2018). In the study, flooded and non-flooded points collected from past flood events were introduced into ArcGIS and analyzed, accordingly. 139 flooded and 140 non-flooded points were considered for the generation of flood hazards susceptibility maps, of which randomly selected 98 points were used for training while the rest were used for testing of the generated map (Fig. 2).

Study area and flooding pixels
2.3.2 Flood conditioning factors
To determine the dominant flood conditioning factors is a crucial issue regarding the flood hazards susceptibility mapping. Accuracy of both inventory data and well-defined flood condition factors plays an important role on the accuracy of generated flood hazards susceptibility maps since they are involved directly. Analysis of flooded or non-flooded points is based on the extraction of attributes of relevant flood conditioning factors, and then processing and incorporating by overlapping those attributes. In the literature, some common physical characteristics such as lithology, land use, land cover, geological conditions, precipitation, and drainage characteristics of the watershed are considered in assessment of the landslides or flash floods susceptibility and ground water potential. Three meteorological observation stations collect meteorological data in the basin (Akay et al. 2018). According to the report analyzed from those stations, the basin takes average annual precipitation of 850 mm, but sometimes it increased to 1250 mm. However, unfortunately, these stations seriously suffer from the scarce and lack of continuous data. Such kind of basins is called as poorly gauged or ungauged basins. Moreover, this is a systematic problem that does not significantly change, even reversely affect the flood hazard maps, in poorly gauged watersheds, worldwide. Since the watershed is poorly gauged, precipitation which is the main component of flood hazards could not be used in prediction of spatial distribution of flood hazards. In similar studies, precipitation was left out in prediction of flood susceptibility (Mirzaei et al. 2021; Pham et al. 2021). So, in this study, available aforementioned types of data of the study area which are compatible with similar studies conducted in the literature were selected as flood conditioning factors to estimate the flood susceptibility maps (Mirzaei et al. 2021). Those data may be categorized as local and concentrated characteristics of the watershed. Local attributes of the watershed that are independent of the upstream characteristics are considered to capture the heterogeneities in the watershed while concentrated characteristics of the watershed consider the contribution of the most upstream points. In this study, local parameters such as elevation, slope, aspect, plan curvature, distance from stream and soil groups, and concentrated characteristics such as topographic wetness index (TWI), sediment transport index (STI), drainage density (Dd), elongation ratio (Er), and stream order were considered as flood conditioning factors. Elevation, slope, aspect, plan curvature, land cover, and distance from stream, TWI, STI, and Dd parameters are commonly utilized to assess flood, landslide susceptibility and groundwater potential of the watershed. Er; just as Dd; or stream order are related with shape and drainage properties of the watershed and reflect the flash flood vulnerability, but those parameters have not been used in flash flood susceptibility mapping studies to the best knowledge of the author. All flood conditioning factors except soil groups were processed in ArcGIS using digital elevation model (DEM) with a resolution of 10 m obtained from 1:25,000 scaled topographic maps. Watershed consists of alluvial (A), gray brown podzolic (G), colluival (K), brown forest (M), non-calcareous brown forest (N), and red yellow podzolic (P) great soil groups. Slope, aspect and plan curvature grids were obtained by using only DEM of the watershed, itself. Flow direction and flow accumulation cells were determined from DEM after operation of fill sinks. TWI and STI concentrated factors were calculated as a function of flow accumulation and slope grids. Stream network of the watershed was extracted based on the value of threshold cells, taken as 1000 in this study, of flow accumulation (Arabameri et al. 2019). Studies in close watersheds indicated that the drainage network is sensitive to the threshold value of flow accumulation. However, it does not improve the model accuracy when the threshold value decreases more (Akay 2021). Stream order of the extracted network was designated based on Strahler’s method. Concentrated cells of each designated stream order were defined as a domain of the class. Line density of the extracted stream following the stream segmentation, and drainage line processing, respectively, was used for determination of the drainage density spatial distribution of the watershed. Elongation ratio of the watershed could be spatially calculated by combining the flow accumulation and flow length obtained using flow direction of the watershed. Elongation ratio presented as a grid format herein is one of the most important parameters in determining the flash flood characteristics of the watershed. Previous studies on morphometric analysis emphasized the vital contribution of watershed shape characteristics (Akay and Baduna Koçyiğit 2020).
Multicollinearity test of flood conditioning factors was conducted to detect if repeating variables may occur in independent variables. In case of occurrence, one of the repeating variables may be left out considering the value of variance inflation factor (VIF). VIF value more than 10 is accepted to be exist multicollinearity problem (Talukdar et al. 2020). In ArcGIS, elevation, slope, distance from stream, TWI, STI, Er and Dd conditioning factors were classified based on natural break method in five sub-classes while aspect, curvature, soil groups and order conditioning factors were classified based on supervised classification method. Since Strahler’s order of the main stream is seven, while the number of soil groups in the watershed is six, the number of sub-classes of the relevant factors was classified, accordingly. Aspect in nine classes based on the surface gradient direction and curvature in three classes based on the tangent to the DEM were created. Figure 3 indicates the flood conditioning factors in the watershed.

Flood conditioning factors of the watershed
2.4 Flood susceptibility mapping
Besides the flood inventory data and values of flood conditioning factors at those points, accuracy of the generated flood hazards susceptibility maps also depends on how the flood conditioning factors incorporate with well-defined flood hazards. In similar studies, a basic assumption is that future flash flood hazards will occur under the same conditions as past flash floods. Flash floods are directly related with the spatial information of flood conditioning factors. The flood susceptibility maps of the study area were obtained by using various methods such as FR, EBF, WoE and IoE. Moreover, hybrid integration of those approaches with PCA, FL, AHP, TOPSIS and VIKOR was established in order to examine the accuracy of maps. For example, FL with FR and WoE, separately, PCA with EBF, AHP with IoE and EBF, and TOPSIS and VIKOR with AHP, and PCA weights, separately, were hybridized and flood susceptibility maps were estimated. This new challenge on preparation of accurate flood hazards susceptibility maps requires a detailed analysis.
2.4.1 Frequency ratio (FR)
FR is one of the most popular statistical methods used in mapping studies. FR approach is based on the observed relationships between the distribution of flash floods and each flash flood conditioning factor, to disclose the correlation between flood hazard pixels and the factors in the study area (Lee and Pradhan 2006). FR at a class of a flood conditioning factor is defined as the ratio of the flooded point percent at a class to the class pixel percent in the domain. FR values of each flood conditioning factor are computed and the flood susceptibility mapping is obtained by summing up the raster values of each FR of flood conditioning factors in ArcGIS.
2.4.2 Evidential belief function (EBF)
EBF is a bivariate statistical method which is dominated by four functions as belief (Bel), disbelief (Dis), uncertainty (Unc), plausibility (Pls), and based on the importance of class in a flood conditioning factor. EBF is a probability-based approach and bounded by Bel, and Pls functions as minimum and maximum probabilities, respectively. The EBF model was designed to process flood hazards information at different levels of knowledge. Moreover, no other assumptions are required to represent knowledge since the uncertainty responses is directly allowed directly in representation of system (Althuwaynee et al. 2012). Flood hazards probability of a class of a flood conditioning factor may be approximated by Bel and Pls functions while non-occurrence of flood at any classes of a flood conditioning factor is defined as Dis function. As the Bel value increases, the probability of flood occurrence also increases. Bel and Dis functions may be calculated as given in Eqs. 1–4.
where Cij is the jth class of conditioning factors (Ci), and wcij indicates the weight of Cij. N(T), N(Cij), N(D), and N(Cij ∩ D) denote the total pixel in the domain, total flood pixel in the domain, total pixel in the class, and total flood pixel in the class, respectively.
Since the summation of maximum occurrence and non-occurrence of flood hazard probabilities (Pls and Dis) are unity, and the difference of maximum and minimum occurrence probabilities are defined as uncertainty, the governing equations are represented as follows:
The Bel, Dis, Unc, and Pls functions at a prescribed class of each flood conditioning factor were calculated and processed in ArcGIS. The combination of each flood conditioning factor was conducted based on Dempster–Shafer theory using ArcGIS environment.
2.4.3 Weights of evidence (WoE)
WoE is a bivariate statistical method based on Bayesian likelihood theorem and combines information from all the flood hazards conditioning factors. In WoE method, in natural logarithm format, occurrence (Wi+) and non-occurrence (Wi−) of flood hazards considering the flood inventory data at a prescribed class of a flood conditioning factor are described as likely to occur and not to occur, respectively (Eqs. 7, 8).
where P is the conditional probability, A is the presence of flood pixels at B flood conditioning factor while over line bar denotes the absence of A and B.
The difference between Wi+ and Wi− is expressed as contrast (C). The variances of Wi+ and Wi− are calculated as given in Eqs. 9, and 10 in terms of the number of flooded and non-flooded pixels in a class (N). Standard deviation of the contrast (S(C)) is calculated by Eq. 11. So, weight of each class (W) can be calculated by Eq. 12.
W values of each class of flood conditioning factors were calculated and the flood hazards susceptibility map was created by summing all the flood conditioning factors in ArcGIS environment.
2.4.4 Index of entropy (IoE)
IoE proposed by Shannon (1948) is revealed to determine the disorderliness in the distribution of values of variables derived from information theory as a measure of redundancy in data (Arora et al. 2019). This approach was then adopted in flood susceptibility studies to understand the weight of contribution of conditioning factors (Haghizadeh et al. 2017). Given Eqs. (13–18) were followed to calculate the parameters, and the flood hazards susceptibility mapping is obtained by Eq. 19 in ArcGIS environment.
where Pij = frequency ratio, (Pij) = probability density, Hj and Hjmax = entropy values, Sj = number of classes, Ij = information coefficient, Wj = weight of the conditioning factor, i = number of particular conditioning factor map, z = number of classes within the conditioning factor with the greatest number of classes, mi = number of classes within particular conditioning factor map, and C = value of the class after secondary classification (Arora et al. 2019).
2.4.5 Principle component analysis (PCA)
PCA is generally conducted to understand the underlying structure in which how the data was contributed to the total variance explained by factor analysis. In this study, flood conditioning factors were extracted based on the initial eigenvalues of components using SPSS. Therefore, a sample of 500 random points in the study area was generated in ArcGIS (Arabameri et al. 2019). Values of flood conditioning factors at those points were extracted using ArcGIS, and the data were processed based on the initial eigenvalue of 0.95 which explains the total variance as 68%, in SPSS. So, five components were found to be more explanatory. Since the extracted components by PCA method did not have strong cross-correlation coefficients, the rotated factor loading matrices were used (Malik et al. 2019). Flood conditioning factors with the greatest correlation coefficient for each component were determined from the rotated component matrix. Weights of the component were determined as the ratio of the cross-correlation coefficient of that component and the total cross-correlation coefficients (Malik et al. 2019). Then, all classes of dominant flood conditioning factors were ranked starting from 2 to 10 based on the Bel value and raster maps were created, accordingly (Benjmel et al. 2020). So, flood hazard susceptibility map was processed by the summation of the multiplication of the ranks and factor weights.
2.4.6 Fuzzy logic (FL)
According to FL theory, membership value of flood hazards conditioning factors has varying degrees of support and confidence in the range of 0 and 1. Fuzzy classes were obtained by considering the maximum and minimum FR and WoE values of a factor by corresponding that 0 is set for minimum and 1 is set for maximum. A value of one indicates full membership while zero demonstrates minimum membership of the class. Inner class values bounded with the minimum and maximum are computed based on the membership functions. In the study, flood conditioning factors at each class calculated using FR and WoE, separately, were transformed based on a linear membership type of raster maps varying between 0 and 1 in ArcGIS environment. Fuzzified raster maps of flood conditioning factors were overlaid by gamma method which is a function of fuzzy algebraic product and fuzzy algebraic sum in which a default value of gamma of 0.9 was used, converging to fuzzy and method.
2.4.7 Analytical hierarchy process (AHP)
In AHP method, criteria weights of the flood conditioning factors were implemented by hybridization of IoE and compound factor. Wj values of each conditioning factors were sorted in ascending order and then graded from 1 to 10 based on compound factor method. Pair-wise comparison matrix of flood conditioning factors was created based on those compound values and the classification scale proposed by Saaty (1980). The criteria weight vectors of flood conditioning factors were obtained from pair-wise comparison matrix.
The inconsistency index (Ii) of pair-wise comparison matrix was computed to examine the consistency of flood conditioning factors (Eqs. 20, 21).
where λmax = the largest eigenvalue of the pair-wise comparison matrix, n = number of flood conditioning factors, Ir = inconsistency ratio, and Ri = random index. For n = 11, Ri value can be approximated as 1.51. It should be noted that consistency of the factors is trustworthy when Ir is less than 0.10 (Saaty 1980). In this study, consistency of factors is satisfied since Ir value was calculated as 0.008.
Flood hazard susceptibility map was then processed by summing up the multiplication of the ranks, as mentioned in PCA section by criteria weights.
2.4.8 Technique for order preference by similarity to an ideal solution (TOPSIS)
Flood hazards susceptibility map of the study area was processed by TOPSIS method using the criteria weights obtained from AHP and PCA methods, separately. Decision matrix was created using flood conditioning factor values at generated random 500 points, as aforementioned in PCA sub-section, and then the decision matrix was normalized. Weighted normalized decision matrices were calculated using factor weights obtained from both AHP and PCA, separately. Of using Euclidean distance, positive and negative ideal solutions were computed considering the benefit or cost exhibition of the flood conditioning factors based on linear fitting of class number and Bel function. When the tendency line of the Bel value and the class number has positive slope, this factor was then thought to be cost. Watershed order, TWI and Er factors exhibited cost performance while the rest of the factors exhibited benefit performance. The closeness coefficients of random points were then determined. Flood susceptibility map of the study area was created by interpolating a raster surface from values of closeness coefficients of random points using Inverse Distance Weighting (IDW) method in ArcGIS since IDW method performed better results than Krigging method.
2.4.9 VlseKriterijumska optimizacija I Kompromisno Resenje (VIKOR)
Similar procedures adopted in TOPSIS method was followed, but some differences in techniques were employed in VIKOR method by definition. Instead of closeness coefficient determined from Euclidean distance of positive and negative ideal solutions, a compromising solution was introduced by using the utility, regret indexes, and the weight of the compromise strategy (Opricovic and Tzeng 2004).
2.5 Validation of flood hazards susceptibility maps
After creation of flood hazards susceptibility maps using various methods, the model results at flooded and non-flooded points were extracted from the model to obtain both training and testing data to be used in assessment of the prediction capability of the models using various statistical indicators. Thus, a receiver operating characteristic curve (ROC) analysis was conducted to examine the sensitivity, specificity, and accuracy of the estimated results involved assessment of not only more susceptible zones to flooding, but less susceptible zones, as well. In ROC analysis, 1-specificity in x-direction (Eq. 22) vs. sensitivity in y-direction (Eq. 23) was presented, and some statistical indicators as specificity, sensitivity, accuracy (Eq. 24), and kappa index (Eq. 25) were computed as follows:
where TN = true negatives, FP = false positives, TP = true positives, FN = false negatives, Pc = number of pixels to be classified correctly, and Pexp = expected agreement. As the ROC parameters increased, the prediction capability of the models implemented also increased. Furthermore, Kappa index was assessed quantitatively and qualitatively: poor (0–0.4), moderate (0.4–0.55), good (0.55–0.85), excellent (0.85–0.99), and perfect (0.99–1) (Monserud and Leemans, 1992; Kanani-Sadat et al. 2019).
The area under the ROC curve (AUC) is also associated with efficiency of the predicted susceptibility maps especially for flooded pixels. The AUC values can be interpreted as: weak (0.5–0.6), moderate (0.6–0.7), good (0.7–0.8), very good (0.8–0.9), and excellent (0.9–1) (Yesilnacar and Topal 2005).
Model results were also classified using natural break method in ArcGIS in five categories as very low (VL), low (L), moderate (M), high (H), and very high (VH) flood hazards susceptibility. This enabled to further understand the behavioral compatibility of spatial distribution of the predictions. So, another significant indicator, seed cell area index (SCAI) given in Eq. 26 was used to determine the categorized class density per flood pixel density in the class. Based on the SCAI values in a flood hazards susceptibility class, it is a reasonable judgment to make that the values of SCAI increase as the susceptibility class inversely decreases. Hence, a linear relationship between the susceptibility class and the SCAI values was fitted to decide about the method, which is more compatible with SCAI definition. It is also surmised that the greater negative inclined-fitted line with a reasonable coefficient of determination may give better classified maps.
3 Results and discussion
Multicollinearity test was conducted to specify the VIF values of each conditioning factor (Table 1). Since VIF values are less than 10, all the conditioning factors were considered in flood hazards susceptibility mapping. Class ranges of flood conditioning factors obtained from natural break method, pixels in domain and flooding pixels in the class are presented in Table 2 which also shows the results of FR and EBF methods. It can be said that flood pixels were concentrated on the specific class in elevation, slope, curvature, distance from river, TWI, and STI factors. For instance, there is a strong belief and high sensitivity that flood occurs in domain for elevation < 474.12, slope < 16.61º, curvature not convex, distance < 1589 m, TWI > 11.47, STI < 17.46. Moreover, flat surfaces, and Er > 0.50 pixels are found to be significant in producing flooding. Those results are also compatible with FR results. Greater FR or Bel values mean more prone area to flooding at that class. Flood hazards susceptibility maps obtained from FR, and EBF methods are given in Figs. 4 and 5, respectively.

Flood hazards susceptibility map using FR method

Flood hazards susceptibility map using EBF method
Table 3 shows the WoE and IoE results at prescribed classes. WoE results regarding the dominant and significant classes are also compatible with EBF and FR findings. However, some classes at a flood conditioning factor have a negative impact on flood. Final weights of IoE suggest that STI has a maximum weight of 25.87 while Dd has a minimum weight of 0.04 on flood conditioning. Flood hazards susceptibility maps processed with results of WoE and IoE methods are given in Figs. 6 and 7, respectively.

Flood hazards susceptibility map using WoE method

Flood hazards susceptibility map using IoE method
Since the extracted values of 500 random points in the study area had inadequate cross-correlation in PCA method, the rotated component matrix was considered to specify five significant components (Table 4). Distance from river, TWI, Er, Dd, and aspect were found to be more significant for components 1, 2, 3, 4, and 5, respectively. Moreover, these flood conditioning factors were found to be in a good correlation. The Spearman correlation coefficients of five components were used to determine the weights of flood conditioning factors (Table 5). Weights of the parameters were closer to each other and varied between 0.17 and 0.24. Flood hazards susceptibility map implemented with more significant flood conditioning factors is given in Fig. 8.

Flood hazards susceptibility map using PCA method
FR values and C/S(C) of WoE values at each class were fuzzified using linear membership type, separately. Flood hazards susceptibility maps of FL-FR and FL-WoE were overlaid using gamma and membership functions as shown in Figs. 9 and 10, respectively.

Flood hazards susceptibility map using FL-FR method

Flood hazards susceptibility map using FL-WoE method
Pair-wise comparison of flood conditioning factors in AHP method based on Wj values in IoE method, and compound factor, using Saaty’s scale (Saaty 1980), is given in Table 6. Weights of the flood conditioning factors given in Table 8 were computed by using ranks which varied between 2 and 10, given in Table 7. Flood hazards susceptibility maps based on AHP method were generated as shown in Fig. 11. In flood hazards susceptibility mapping, STI was found to have the most dominant impact while aspect and Dd had the least impact.

Flood hazards susceptibility map using AHP method
Flood hazards susceptibility maps determined by Euclidean distance-based TOPSIS method coupled with AHP and PCA weights were generated, as shown in Figs. 12, and 13, respectively. Flood hazards susceptibility maps obtained by VIKOR method also enabled comparison of the performance of two different decision models (Figs. 14, 15).

Flood hazards susceptibility map using TOPSIS-AHP method

Flood hazards susceptibility map using TOPSIS-PCA method

Flood hazards susceptibility map using VIKOR-AHP method

Flood hazards susceptibility map using VIKOR-PCA method
Figures 16 and 17 present the ROCs of flood hazards susceptibility maps estimated for training and testing processes generated from aforementioned methods. Sensitivity, specificity, accuracy, kappa index and AUC values computed from the extracted values from flooded and non-flooded points for both training and testing data are given in Table 9. Findings of the method which involved the training process based on statistical measures can be interpreted as follows: Sensitivity was calculated the best for IoE, and followed by AHP and EBF. Specificity of FL-FR for training and FL-WoE for testing was found to be the best performing model in their processes. Accuracy of EBF and IoE models for training, FR, and IoE for testing performed the best. Kappa index of IoE model gave the best result. AUC of PCA gave the best results. When excluding TOPSIS and VIKOR methods, AUC of other methods was assessed as excellent.

ROCs of training data of the applied methods

ROCs of testing data of the applied methods
A framework assessment should be conducted to determine the efficiency of the methods in generating flood hazards susceptibility maps using statistical measures since values of those are conflicting, and do not concentrate on the same model. A simple-relative approach based on the compound factor was adopted such that statistical measures for both training and testing were graded from one for the best model to twelve for the worst. In case the model results gave the same statistical measure values, they were successively ranked and re-ranked using the average of successive grades. Ranks of the statistical measure were taken as the average of training and testing grades. Final grades were determined by summing up the grades of statistical measures (Table 10). It can be concluded from that assessment, and the linear membership of the grades in four categories that it can be concluded that IoE method gave the best results of all (Arabameri et al. 2019). Moreover, other statistical methods, FR, EBF, PCA and AHP, also gave very good results like IoE that cannot be contradistinguished. On the other hand, results of WoE and FLs models might be evaluated as good while TOPSIS and VIKOR models gave the poorest results.
Another assessment criterion for the interpretation of generated flood hazards susceptibility maps is based on the classification of five susceptibility levels determined by natural break method in ArcGIS (Table 11). In a well-classified flood hazards susceptibility map, an increasing flood hazards potential trend of SCAI with decreasing susceptibility level is expected, and this may be measured by fitting a line whose negative slope tends to become perpendicular. IoE method was not successful at capturing flood hazard pixels since flood intensity concentrated on moderate susceptibility class. In FR method, flood hazard pixels concentrate on high class, but SCAI values are in the desired range. In EBF method, flood hazards pixels concentrate on very high class that is a huge amount of the drainage area. PCA or AHP methods may be evaluated as reasonable models predicting the susceptibility classes.
In overall assessment, hybridization of IoE and EBF with AHP and EBF with PCA gave very good results since IoE and EBF themselves predicted flood hazards susceptibility map very good. PCA method slightly improved the prediction of flood hazards susceptibility maps in comparison with AHP. However, hybridization of AHP and PCA did not contribute to TOPSIS- and VIKOR-based flood hazards susceptibility maps. Moreover, dimension reduction by PCA method in overlaying flood conditioning factor maps inversely impacted the results in TOPSIS and VIKOR methods. Relatively poor predictions of TOPSIS and VIKOR methods may be due to the number of random points implemented by Arabameri et al (2019) adopted in this study may not be compatible with grid cell size of DEM and scale of the map used. The model prediction capability may be improved by increasing the number of random points, implementing different distance measures in TOPSIS and changing strategy coefficients in VIKOR methods in order to overcome under-fitting problem. That may even be more reasonable to improve the PCA model results. Sensitivity analysis of criteria weights of AHP and PCA may also further contribute to optimize the results of flood conditioning factors. Adaption by hybridization of FR and WoE methods inversely impacted FL methods. Especially FR method was seriously influenced by fuzzification method. Extensive research on membership function type may help to improve the prediction results. Probabilistic approaches using various operators may also improve the fuzzy logic results.
It is assumed that future flash flood hazards would occur under the same conditions as past flash floods. Moreover, flash floods are correlated with the spatial information of flood conditioning factors. Using those assumptions in adaptation of some models in order to predict the spatial distribution of flood hazards susceptibility that is a very complex phenomenon may result in some errors. Those assumptions may also lead to previously unseen generalization errors. Model results may misclassify the training data that causes to decrease in accuracy of the predictions. Random selection of flood hazard pixels which may not be representative samples may not consider the internal dynamics of flood hazards in the watershed. So, it should be kept in mind that both the quality of conditioning factors, representativeness of flood hazard pixels and the implemented model are crucial in prediction of model results with low generalization and training error. A model may predict flood hazards susceptibility map with low training error, but high test error. This over-fitting problem may be overcome by increasing the number of representative training data with low generalization error (Han et al 2012). In the study, since adopted methods excluding TOPSIS and VIKOR gave good results and those results was improved in testing process, the predicted results were found to be satisfactory.
Many studies were conducted to improve prediction capability of flood susceptibility. Some of the researchers adapt hybridization techniques while some adapts ensemble models. Basic statistical models may be considered as a strong tool to develop prediction results and reduce computational efforts. Results of the recent studies also revealed that hybridization with statistical model improved predictions. For instance, Wang et al. (2021) stated that probability density model hybridized with MLP gave the most efficient prediction results based on considering ROC analysis. New ensemble models may enable to be constructed on these statistical models. It should be kept in mind that some of the ensemble algorithms were re-modified based on inclusion of new assumption of the existing algorithms. On the other hand, statistical representation of class values in order to improve prediction results, and avoid computational effort may be employed in ensemble machine learning models in natural hazards management studies. So, hybrid and ensemble models can be combined in order to estimate the susceptibility. The outcomes of such studies may be discussed and those basic studies may be addressed in near future.
4 Conclusion
It is important to guarantee an asset management in terms of expectation of return of investments in a projected life cycle. So, risk perception for assets and new investments may be introduced in planning and design stages coupled with a management strategy according to a risk category. Especially, natural hazards seriously threaten the infrastructures, and even lives of human beings. So, it is inevitable to estimate nationwide flood hazards susceptible zones. In this study, a study area which frequently exposed to flash flood hazards was chosen and flood hazards data and flood conditioning factors of the study area were coupled with GIS-based approach to generate flood hazards susceptibility maps.
It is also important and challenging to decide about the method and the data to be used, and how to combine these since the methods involve interpretation and processing of data. So, various methods such as FR, EBF, WoE and IoE, and hybrid integration of PCA, FL, AHP, TOPSIS, and VIKOR were used to generate flood hazards susceptibility maps. In the study, generated flood hazards susceptibility maps were validated for both training and testing data sets using sensitivity, specificity, accuracy, kappa index, AUC, and SCAI. Some methods gave very good results while the other methods gave relatively poor results. Since the whole statistical measures did not point out the same method, a simple approach was adopted to decide the most acceptable method. So, PCA and AHP methods were found to be more accurate at prediction of flood hazards susceptibility mapping with regard to ROC analysis and SCAI variation. This study may be evaluated as a contribution to the similar efforts on the estimation of accurate flood hazards susceptibility maps by hybridization methods and assists policymakers who have to face challenging decisions on land use. Strategies to improve TOPSIS and VIKOR predictions may be conducted using ensemble algorithms using non-stationary models. Generated flood hazards susceptibility maps may be commonly used in design, operation, and inspection stages of any structure.
References
Ahmadlou M, Al-Fugara AK, Al-Shabeeb AR, Arora A, Al-Adamat R, Pham QB, Al-Ansari N, Linh NTT, Sajedi H (2021) Flood susceptibility mapping and assessment using a novel deep learning model combining multilayer perceptron and autoencoder neural networks. J Flood Risk Manag 14(1):e12683
Akay H (2021) Mitigation of scour failure risk of a river bridge located in an ungauged basin. Baltic J Road Bridge Eng 16(1):37–56
Akay H, Baduna Koçyiğit M, Yanmaz AM (2018) Effect of using multiple stream gauging stations on calibration of hydrologic parameters and estimation of hydrograph of ungauged neighboring basin. Arab J Geosci 11(11):282
Akay H, Baduna Koçyiğit M (2020) Hydrologic assessment approach for river bridges in Western Black Sea Basin. Turkey J Perform Constr Fac 34(1):04019090
Al-Abadi AM, Al-Najar NA (2020) Comparative assessment of bivariate, multivariate and machine learning models for mapping flood proneness. Nat Hazards 100:461–491
Althuwaynee OF, Pradhan B, Lee S (2012) Application of an evidential belief function model in landslide susceptibility mapping. Comput Geosci 44:120–135
Arabameri A, Rezaei K, Cerdà A, Conoscenti C, Kalantari Z (2019) A comparison of statistical methods and multi-criteria decision making to map flood hazard susceptibility in Northern Iran. Sci Total Environ 660:443–458
Arora A, Pandey M, Siddiqui MA, Hong H, Mishra VN (2019) Spatial flood susceptibility prediction in Middle Ganga Plain: comparison of frequency ratio and Shannon’s entropy models. Geocarto Int. https://doi.org/10.1080/10106049.2019.1687594
Arora A, Arabameri A, Pandey M, Siddiqui MA, Shukla UK, Bui DT et al (2021) Optimization of state-of-the-art fuzzy-metaheuristic ANFIS-based machine learning models for flood susceptibility prediction mapping in the Middle Ganga Plain. India Science of the Total Environment 750:141565
Baduna Koçyiğit M, Akay H, Yanmaz AM (2017) Effect of watershed partitioning on hydrologic parameters and estimation of hydrograph of an ungauged basin: a case study in Gokirmak and Kocanaz. Turkey Arab J Geosci 10(15):331
Benjmel K, Amraoui F, Boutaleb S, Ouchchen M, Tahiri A, Touab A (2020) Mapping of groundwater potential zones in crystalline terrain using remote sensing, GIS techniques, and multicriteria data analysis (Case of the Ighrem Region, Western Anti-Atlas, Morocco). Water 12(2):471
Bui DT, Khosravi K, Shahabi H, Daggupati P, Adamowski JF, Melesse A, Pham BT, Pourghasemi HR, Mahmoudi M, Bahrami S, Pradhan B, Shirzadi A, Chapi K, Lee S (2019) Flood spatial modeling in Northern Iran using remote sensing and GIS: a comparison between evidential belief functions and its ensemble with a multivariate logistic regression model. Remote Sensing 11:1589
Chen W, Li Y, Xue W, Shahabi H, Li S, Hong H, Wang X, Bian H, Zhang S, Pradhan B, Ahmad BB (2020) Modeling flood susceptibility using data-driven approaches of naïve Bayes tree, alternating decision tree, and random forest methods. Sci Total Environ 701:134979
Choubina B, Borjia M, Mosavib A, Sajedi-Hosseinia F, Singhd VP, Shamshirband S (2019) Snow avalanche hazard prediction using machine learning methods. J Hydrol 577:123929
Chowdhuri I, Pal SC, Chakrabortty R (2020) Flood susceptibility mapping by ensemble evidential belief function and binomial logistic regression model on river basin of eastern India. Adv Space Res 65(5):1466–1489
Costache R, Pham QB, Avand M, Linh NTT, Vojtek M, Vojtekovà J, Lee S, Khoi DN, Nhi PTT, Dung TD (2020) Novel hybrid models between bivariate statistics, artificial neural networks and boosting algorithms for flood susceptibility assessment. J Environ Manage 265:110485
Dodangeh E, Panahi M, Rezaie F, Lee S, Bui DT, Lee CW, Pradhan B (2020) Novel hybrid intelligence models for flood-susceptibility prediction: meta optimization of the GMDH and SVR models with the genetic algorithm and harmony search. J Hydrol 590:125423
Haghizadeh A, Siahkamari S, Haghiabi AH, Rahmati O (2017) Forecasting flood-prone areas using Shannon’s entropy model. J Earth Syst Sci 126:39
Han J, Kamber M, Pei J (2012) Data mining: concepts and techniques. Morgan Kaufmann, USA
Hammami S, Zouhri L, Souissi D, Souei A, Zghibi A, Marzougui A, Dlala M (2019) Application of the GIS based multi-criteria decision analysis and analytical hierarchy process (AHP) in the flood susceptibility mapping (Tunisia). Arab J Geosci 12:653
Hong H, Panahi M, Shirzadi A, Ma T, Liu J, Zhu AX, Chen W, Kougias L, Kazakis N (2018) Flood susceptibility assessment in Hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci Total Environ 621:1124–1141
Jaafari A, Mafi-Gholami D, Pham BT, Bui DT (2019) Wildfire probability mapping: bivariate vs. multivariate statistics. Remote Sensing 11:618
Kanani-Sadat Y, Arabsheibani R, Karimipour F, Nasseri M (2019) A new approach to flood susceptibility assessment in data-scarce and ungauged regions based on GIS-based hybrid multi criteria decision-making method. J Hydrol 572:17–31
Khosravi K, Nohani E, Maroufinia E, Pourghasemi HR (2016) A GIS-based flood susceptibility assessment and its mapping in Iran: a comparison between frequency ratio and weights-of-evidence bivariate statistical models with multi-criteria decision-making technique. Nat Hazards 83:947–987
Khosravi K, Shahabi H, Pham BT, Adamowski J, Shirzadi A, Pradhan B, Dou J, Ly HB, Gróf G, Ho HL, Hong H, Chapi K, Prakash I (2019) A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J Hydrol 573:311–323
Kia MB, Pirasteh S, Pradhan B, Mahmud AR, Sulaiman WNA, Moradi A (2012) An artificial neural network model for flood simulation using GIS: Johor River basin. Malaysia Environ Earth Sci 67(1):251–264
Lee S, Pradhan B (2006) Probabilistic landslide hazards and risk mapping on Penang Island, Malaysia. Earth Syst Sci 115(6):661–672
Malik A, Kumar A, Kushwaha DP, Kisi O, Salih SQ, Al-Ansari N, Yaseen ZM (2019) the implementation of a hybrid model for hilly sub-watershed prioritization using morphometric variables: case study in India. Water 11(6):1138
Mehrabi M, Pradhan B, Moayedi H, Alamri A (2020) Optimizing an adaptive neuro-fuzzy inference system for spatial prediction of landslide susceptibility using four state-of-the-art metaheuristic techniques. Sensors 20(6):1723
Mirzaei S, Vafakhah M, Pradhan B, Alavi SJ (2021) Flood susceptibility assessment using extreme gradient boosting (EGB). Iran Earth Science Informatics 14(1):51–67
Moayedi H, Khari M, Bahiraei M, Foong LK, Bui DT (2020) Spatial assessment of landslide risk using two novel integrations of neuro-fuzzy system and metaheuristic approaches; Ardabil Province, Iran. Geomatics Nat Hazards Risk 11(1):230–258
Mogaji KA, Lim HS, Abdullah K (2015) Regional prediction of groundwater potential mapping in a multifaceted geology terrain using GIS-based Dempster-Shafer model. Arab J Geosci 8:3235–3258
Monserud RA, Leemans R (1992) Comparing global vegetation maps with the kappa statistic. Ecol Model 62(4):275–293
Nandi A, Mandal A, Wilson M, Smith D (2016) Flood hazard mapping in Jamaica using principal component analysis and logistic regression. Environ Earth Sci 75(6):465
Opricovic S, Tzeng GH (2004) Compromise solution by MCDM methods: a comparative analysis of VIKOR and TOPSIS. Eur J Oper Res 156(2):445–455
Pham BT, Jaafari A, Van Phong T, Yen HPH, Tuyen TT, Van Luong V, Nguyen HD, Le HV, Foong LK (2021) Improved flood susceptibility mapping using a best first decision tree integrated with ensemble learning techniques. Geosci Front 12(3):101105
Pourghasemi HR, Razavi-Termeh SV, Kariminejad N, Hong H, Chen W (2020) An assessment of metaheuristic approaches for flood assessment. J Hydrol 582:124536
Rahmati O, Ghorbanzadeh O, Teimurian T, Mohammadi F, Tiefenbacher JP, Falah F, Pirasteh S, Ngo PTT, Bui DT (2019) Spatial modeling of snow avalanche using machine learning models and geo-environmental factors: comparison of effectiveness in two mountain regions. Remote Sensing 11:2995
Saaty TL (1980) The analytic hierarchy process. McGraw-Hill, New York
Shahabi H, Shirzadi A, Ronoud S, Asadi S, Pham BT, Mansouripour F et al (2021) Flash flood susceptibility mapping using a novel deep learning model based on deep belief network, back propagation and genetic algorithm. Geosci Front 12(3):101100
Sahana M, Patel PP (2019) A comparison of frequency ratio and fuzzy logic models for flood susceptibility assessment of the lower Kosi River Basin in India. Environ Earth Sci 78(10):289
Shafapour Tehrany MS, Kumar L, Shabani F (2019) A novel GIS-based ensemble technique for flood susceptibility mapping using evidential belief function and support vector machine: Brisbane, Australia. Peerj 7:e7653
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Talukdar S, Ghose B, Salam R, Mahato S, Pham QB, Linh NTT, Costache R, Avand M (2020) Flood susceptibility modeling in Teesta River basin, Bangladesh using novel ensembles of bagging algorithms. Stochastic Environ Res Risk Assess 34(12):2277–2300
Tehrany MS, Kumar L, Jebur MN, Shabani F (2019) Evaluating the application of the statistical index method in flood susceptibility mapping and its comparison with frequency ratio and logistic regression methods. Geomat Nat Haz Risk 10(1):79–101
Tehrany MS, Pradhan B, Jebur MN (2014) Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J Hydrol 512:332–343
Tehrany MS, Kumar L (2018) The application of a Dempster–Shafer-based evidential belief function in flood susceptibility mapping and comparison with frequency ratio and logistic regression methods. Environ Earth Sci 77:490
Wang Y, Fang Z, Hong H, Costache R, Tang X (2021) Flood susceptibility mapping by integrating frequency ratio and index of entropy with multilayer perceptron and classification and regression tree. J Environ Manage 289:112449
Vafakhah M, Mohammad Hasani Loor S, Pourghasemi H, Katebikord A (2020) Comparing performance of random forest and adaptive neuro-fuzzy inference system data mining models for flood susceptibility mapping. Arab J Geosci 13:417
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79:251–266
Acknowledgements
Author acknowledges the financial supports of Türkiye Bilimsel ve Teknolojik Araştırma Kurumu which fully funded this research (Project No. 114M292).
Author information
Authors and Affiliations
Contributions
Dr. HA performed all steps of the manuscript by himself.
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Akay, H. Flood hazards susceptibility mapping using statistical, fuzzy logic, and MCDM methods. Soft Comput 25, 9325–9346 (2021). https://doi.org/10.1007/s00500-021-05903-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-05903-1