
Abstract
The existing grey wolf optimization algorithm has some disadvantages, such as slow convergence speed, low precision and so on. So this paper proposes a grey wolf optimization algorithm combined with particle swarm optimization (PSO_GWO). In this new algorithm, the Tent chaotic sequence is used to initiate the individuals’ position, which can increase the diversity of the wolf pack. And the nonlinear control parameter is used to balance the global search and local search ability of the algorithm and improve the convergence speed of the algorithm. At the same time, the idea of PSO is introduced, which utilize the best value of the individual and the best value of the wolf pack to update the position information of each grey wolf. This method preserves the best position information of the individual and avoids the algorithm falling into a local optimum. To verify the performance of this algorithm, the proposed method is tested on 18 benchmark functions and compared with some other improved algorithms. The simulation results show that the proposed algorithm can better search global optimal solution and better robustness than other algorithm.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
One of the salient features of the development of modern science and technology is that life sciences and engineering sciences cross, interpenetrate, and influence each other. The vigorous development of swarm intelligence algorithm reflects this characteristic and trend of scientific development. In recent years, swarm intelligence algorithm has gradually become the focus of scholars. Due to its simplicity, flexibility, non-derivation mechanism and avoidance of local optimality, swarm intelligence algorithm is applied to not only computers but also agriculture (Zou et al. 2016), metallurgy (Reihanian et al. 2011), military (Zheng et al. 2017), civil, and hydraulic engineering (Quiniou et al. 2014), etc.
Recently, many nature inspired optimization algorithm are proposed. Artificial fish swarm algorithm (AFSA) (Xian et al. 2017) imitates the foraging, gathering, and rear-tailing behaviour of fish group by constructing artificial fish to achieve optimal results; ant colony optimization (ACO) (Chen et al. 2017) is inspired by the behaviour of ants in finding the path during the search for food; butterfly optimization algorithm (BOA) (O’Neil et al. 2010) is a natural heuristic algorithm that mimics butterfly foraging behaviour; cuckoo search (CS) (Rakhshani and Rahati 2017) effectively solves the optimization problem by simulating some of the cuckoo species’ brood parasitism. At the same time, CS also use the relevant Levy flight search mechanism; firefly algorithm (FA) (Nekouie and Yaghoobi 2016) is mainly to use the characteristics of firefly luminescence for random optimization; krill herd algorithm (KH) (Gandomi and Alavi 2012) simulates the response behaviour of krill for the biochemical processes and environments evolve; fruit fly optimization algorithm (FOA) (Pan 2012) is a method for seeking global optimization based on fruit fly foraging behaviour; flower pollination algorithm (FPA) (Yang 2013) is a stochastic global optimization algorithm developed to mimic the biological characteristics of self-pollination and cross-pollination of flowering plants in nature; chicken optimization algorithm (COA) (Meng et al. 2014) simulates the chicken hierarchy and chicken behaviour.
The above metaheuristic algorithms show that many swarm intelligence technologies have been proposed. Some of them simulate animal predatory behaviour. However, they ignored the grey wolf, which is a predator in the top of the food chain. Researchers have not established a mathematical model of grey wolf social hierarchy and predatory behaviour. Therefore, Mirjalili et al. (2014) proposed a novel metaheuristic algorithm, which imitated leadership hierarchy and hunting process of grey wolves. Based on nature of grey wolves, they proposed a grey wolf optimization algorithm (GWO). GWO is a heuristic algorithm based on population. It mainly simulates the leadership hierarchy of wolves and grey wolf predation behaviour. Through a series of standard test functions, GWO algorithm can converge to a better quality near-optimal solution, possesses better convergence characteristics than other prevailing population-based techniques, such as genetic algorithm (GA), particle swarm optimization (PSO), firefly algorithm (FA), artificial fish swarm algorithm (AFSA) and differential evolution algorithms (DE). At the same time, the GWO algorithm is simple to operate in the optimization process, easy to implement, and has few adjustment parameters. Therefore, the GWO algorithm is widely concerned and is applied to solve many practical problems, such as multilevel thresholding problem (Khairuzzaman and Chaudhury 2017), chemistry experiment (Bian et al. 2018), multi-objective optimal reactive power dispatch (Nuaekaew et al. 2017), etc.
Like other swarm intelligent optimization algorithms, the grey wolf optimization algorithm also has some disadvantages. For example, the original GWO algorithm is easy to fall into stagnation when attacking prey, and the speed of convergence gradually slows down in the late search period. Therefore, Saremi et al. (2015) and Mirjalili et al. (2016) proposed the combination of dynamic evolutionary population and grey wolf algorithm to improve the local search ability of the algorithm. But it neglects the algorithm’s global search ability. Mittal et al. (2016) presented a modified GWO(mGWO) to balance exploration and exploitation ability. Long et al. (2016) proposed a hybrid grey wolf optimization (HGWO), which utilizes chaotic sequence to strengthen the diversity of global searching. Zhu et al. (2015) and Yao and Wang (2016) introduced differential evolution algorithm to improve the searching ability of wolf algorithm. In order to increase the diversity of the population, Long and Wu (2017), Zuo et al. (2017) and Guo et al. (2017) proposed the good point set theory to update the grey wolves individuals’ position, so that the initial population is evenly distributed. Kohli and Arora (2017) presented the chaos theory into the GWO algorithm and aimed at accelerating its global convergence speed. Tawhid and Ali (2017) combined grey wolf optimization and genetic algorithm to improve the convergence performance of the algorithm. Jitkongchuen (2016) proposed a hybrid differential evolution algorithm with grey wolf optimizer, which solves function optimization problem. But, the above algorithms do not consider the influence of the individual wolves’ experience on the whole population when studying the grey wolf predation process. So Singh and Singh (2017) presented a newly hybrid nature inspired algorithm called HPSOGWO. This algorithm improves the ability of exploitation in particle swarm optimization with the ability of exploration in grey wolf optimizer to produce both variants’ strength.
On this basis, this paper presents a grey wolf optimization algorithm combined with particle swarm optimization (PSO_GWO). This algorithm contains three main improvement concepts. Firstly, it initializes the population by using Tent mapping; secondly, it adopts nonlinear control parameter strategy to coordinate the exploration and exploitation ability; thirdly, inspired by the particle swarm optimization (PSO) algorithm, a new position update equation of individuals by incorporating the information of individual historical best solution into the position update equation is designed to speed up convergence.
The rest of this paper is organized as follows. Section 2 presents a brief description of GWO. Section 3 illustrates the proposed approach. Section 4 comprises benchmark test functions and experimental results. Section 5 concludes the work and outlines some ideas for future works.
2 Grey wolf optimization algorithm
2.1 Grey wolf social rank and hunting behaviour
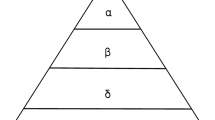
Grey wolf is a predator in the top of the food chain. Most of the wolves live in groups, which has 5–12 wolves per population on average. And each wolf has its own role in the population, so they have a very strict social hierarchy, as shown in Fig. 1.

The leadership hierarchy of wolves
The first layer is the highest leader of the grey wolves, called \(\alpha \), which is mainly responsible for making decisions about hunting, habitat and so on; the second layer is the grey wolf in the subordinate leader of the grey wolf, called \(\beta \), which is mainly responsible for assisting leadership management group or other wolf pack activities; the third layer is \(\delta \), which is mainly responsible for watching the boundaries of the territory, warning the wolf pack in case of any danger and caring for the weak and wounded grey wolves. The fourth layer is the lowest level grey wolf in the population, called \(\upomega \), which has to submit to all the other dominant grey wolves. It may seem that the \(\upomega \) wolves are not an important character in the wolf pack, but indispensable for balancing the internal relations of the population.
The leadership hierarchy of wolves plays a crucial role in hunting of prey. Firstly, the grey wolves search and track the prey; secondly, the \(\alpha \) grey wolf leads the other wolves to encircle the prey in all directions; thirdly, \(\alpha \) grey wolf commands the \(\beta \) and \(\delta \) wolves to attack the prey. If the prey escapes, the other wolves which are supplied from the rear will continue to attack the prey; finally, grey wolves catch the prey.
2.2 Grey wolf optimization algorithm description
Grey wolf optimization algorithm simulates the leadership hierarchy of wolves and predatory behaviour, and then utilizes the grey wolf abilities, which are search, encirclement, hunting and other activities in the predation process, to achieve the purpose of optimization. Assuming that the number of wolves is N and the search area is d, the position of the ith wolf can be expressed as: \(X_{i}=(X_{{i1}},X_{{i2}}, X_{{i3}}, {\ldots }, X_{{id}})\). In order to mathematical model the social hierarchy of wolves, the fittest solution is considered as the alpha (\(\alpha )\) wolf. Consequently, the second- and third-best solutions are named beta (\(\beta \)) and delta (\(\delta \)) wolves, respectively. The rest of the candidate solutions are assumed to be omega (\(\upomega \)) wolves. In the algorithm, the location of the prey corresponds to the position of the alpha wolf.
The encircling behaviour of grey wolves can be mathematically modelled as follows:
where the set t indicates the current iteration, and the set \(X_{p}(t)\) represents the position vector of the prey, the set X(t) is the position vector of a grey wolf, the set C is a control coefficient, which is determined by the following formula:
where the set \(r_{1}\) is the random variable in the range of [0, 1]. The set A is convergence factor, which is calculated as follows:
where the set \(r_{2}\) is the random variable in the range of [0, 1]. The set a is the control coefficient, which linearly decreases from 2 to 0 over the course of iterations, that is (Sahoo and Chandra 2016), \(a_{\max }=2, a_{\min }=0\).
When the grey wolves catch prey, firstly, the leader wolf \(\alpha \) leads the other wolves to surround the prey. Then, the \(\alpha \) wolf leads \(\beta \) and \(\delta \) wolves to capture the prey. In the grey wolves, \(\alpha ,\beta \) and \(\delta \) wolves are the closest to the prey, so the location of the prey can be calculated by their positions. The specific mathematical model is as follows:
The distance between X(t) and \(\alpha ,\beta , \upomega \) wolves is calculated by formula (6)–(11), and then, the position of the wolves move to the prey is calculated by formula (12). The flowchart of GWO is given in Fig. 2.

GWO algorithm optimization process
3 Improved hybrid grey wolf algorithm
3.1 Chaos initialization
GWO algorithm usually solves function optimization problem by using randomly generated data as the initial population information, which will not retain the diversity of the population and lead to the poor optimization result of the algorithm. Therefore, this paper proposes Tent chaotic map to initialize the population.
Chaotic motion has the characteristics of randomness, regularity, and ergodicity. When solving function optimization problems, these features can lead algorithm to escape local optima, so as to maintain the diversity of the population and improve the global search ability. Chaotic maps include Tent maps, Logistic maps and so on. However, different chaotic mappings have different search characteristics. So far logistic map is mostly used in the literature. But it has a higher value rate in [0, 0.1] and [0.9, 1] that leads to inhomogeneous distribution of values. Shan et al. (2005) proves that the Tent map can perform better than the Logistic mapping in traversal homogeneity and generate a more uniform initial value between [0, 1], so as to improve the optimization speed of the algorithm.
Therefore, this paper proposes Tent chaos initialization, that is, we use Tent chaos to initialize the grey wolves. The mathematical model of Tent chaos map is as follows:
When \(u= 1/2\), the Tent map has the most typical form. At this time, the resulting sequence has a uniform distribution and has an approximately uniform distribution density for different parameters.
Thus, the formula for the Tent chaotic map cited in this article is:
The steps for generating a sequence of Tent chaos maps are as follows:
-
Step 1 Take the random initial value \(x_{\textit{0}}\) to avoid falling into the small cycles points{0.2, 0.4, 0.6, 0.8}. Mark the array \(y(1)=x_{\textit{0}},i=1, j=1\);
-
Step 2 According to formula (14) to produce a set of x sequences. After each iteration, \(i=i+1\);
-
Step 3 If the number of iterations reaches the maximum, jump Step 4; Else If there is \(x_{i}=\{0, 0.25, 0.5, 0.75\}\) or \(x_{i}=x_{i-k}, k=\{0, 1, 2, 3, 4\}\), replace the initial value of the iteration by the formula \(x(i)=y(j+1)=y(j)+c, j=j+1\); Else go to Step 2;
-
Step 4 Terminate the operation, save x sequence data.
3.2 Nonlinear control parameter strategy
The GWO algorithm is mainly composed of two steps: the prey positioning and the grey wolf individual’s predatory behaviour. According to formula (1), the parameter A plays a very crucial role in balancing the global exploration and local exploitation capability of the GWO algorithm. When \({\vert }A{\vert }>1\), the group will expand the search range to find a better candidate solution, which is the global exploration ability of the GWO algorithm. When \({\vert }A{\vert }<1\), the group will narrow the search range and perform detailed search in the local area, which is the local exploitation capability of the GWO algorithm. At the same time, we can see from formula (2) that in the process of iteration, the value of A changes continuously with the change of control parameter a. From formula (4), it can be seen that the control parameter a decreases linearly with the increase in the number of iterations. However, the optimization process of GWO algorithm is very complicated. The linear change of parameter a cannot reflect the actual optimization search process of the algorithm. Wei et al. (2016) and Yi-Tung and Erwie (2008) proposed that the control parameter a varies nonlinearly with the number of iterations. And through the standard test function optimization results show that the use of nonlinear change strategy is better than the linear strategy optimization. But they still cannot meet the needs of the algorithm.
Therefore, this paper presents a new nonlinear control parameters, as shown in the following formula:
where the set \(a_\mathrm{ini}\) and \(a_\mathrm{fin}\), respectively, represent the initial value and final value of the control parameter a. The set t is current iteration and the set Tmax is the maximum number of iterations.
In order to verify the validity of the control parameter a proposed in this paper, we compare it with the linear control parameters and the nonlinear control parameters which are proposed in Yang (2013) and Mirjalili et al. (2014), and the formula is as follows:
where the set \(\varepsilon \) is a nonlinear adjustment coefficient.
Four kinds of control parameters are simulated as shown in Fig. 3. It can be seen from Fig. 3 that the nonlinear control parameter as proposed in this paper slowly declines at the early stage and falls fast in the later period. So the nonlinearity of the proposed algorithm is better.

The change curve of the control parameter a
Meanwhile, the formula for the convergence factor A is as follows:

Convergence factor dynamic curve
The dynamic curve of the four kinds of convergence factor A is shown in Fig. 4. It can be seen that the decline speed of convergence factor A is slow in the early stage, which can increase the global search ability and avoid the algorithm falling into the local optimum. The decline speed of convergence factor A is quick in the later stage, which can improve local search and speed up algorithm optimization. Therefore, this improvement can further weigh the exploration and exploitation capabilities.
3.3 PSO thought
In the process of location updating, GWO algorithm takes into account only the location information of individual wolves and the optimal solution, second-best solution, and third-best solution location information of the wolf pack, which realizes the exchange of information between individuals and wolf pack. But it ignores the exchange of information between the wolf and its own experience. Therefore, the idea of PSO algorithm is introduced to improve the location updating process.
In the PSO algorithm, the current position of the particle is updated by using the best position information of the particle itself and the best position information of the group. This paper combining with PSO algorithm will introduce the optimal location of individual experience into the position updating formula, which enables it to keep its own optimal position information. The new location update formula is as follows:
where the set \(c_{1}\) is a social learning factor, the set \(c_{2}\) is a cognitive learning factor. They, respectively, represent the influence of the individual optimal value and the group optimal value. The value of \(c_{1}\) is large which can improve the global search capability; the value of \(c_{2}\) is large which can improve the local search capability. But if the \(c_{1}\) is too large, it will result in too many particles remain in the vicinity of the local. If the \(c_{2}\) is too large, it will cause the particles to reach the local optimum in advance and converge to this value. According to Clerc (2002), this paper selects \(c_{1}=c_{2}=2.05\). The set \(r_{1}\) and \(r_{2}\) are the random variable in the range of [0, 1]. The set \(X_{\mathrm{ibest}}\) indicates that the grey wolf has experienced the best position. The set \(w_{1},w_{2}, w_{3}\) are inertia weight coefficients. By adjusting weight ratio of the \(\alpha ,\beta ,\delta \) wolves, the global and local search ability of the algorithm can be balanced dynamically. The specific formula is as follows:
In Eq. (20), the first part is expressed as the mean value of the best prey position which utilizes \(\alpha ,\beta \) and \(\delta \) wolf to search, which expands the search interval to increase the global search ability of the algorithm; the second part is expressed as the effect of the personal historical best position on algorithm search, which preserves the optimal position experienced by the individual.
3.4 PSO_GWO algorithm flow
The specific implementation steps of the improved wolf algorithm are as follows:
-
Step 1 Set the size of the population to N, dimension d, and initialize the A, C, a values;
-
Step 2 Generate population individuals by using Tent mapping {\(X_{i}, i=1,2,3,\ldots ,N\}\), then calculate the individual fitness value {\(f_{i}, i=1,2,3,\ldots ,N\}\);
-
Step 3 Sort the order of fitness values by size, and take the first three fitness values corresponding to the individual as \(\alpha , \beta ,\delta \). The corresponding position information is: \(X_{\alpha },X_{\beta },X_{\delta }\);
-
Step 4 Use formula (15) to calculate the nonlinear control parameters a, and then update the value of A and C according to formula (2) and (19);
-
Step 5 Use formula (20) to update the location of individuals, then recalculate the fitness values and update values of \(\alpha , \beta ,\delta \);
-
Step 6 Judge whether t reaches Tmax value, if reached, the fitness value of \(\alpha \) is output, that is, the best solution. Else go to Step 3.
4 Experimental data and simulation analysis
4.1 Benchmark functions
In order to verify the effectiveness of the improved hybrid wolf algorithm, this paper selects 18 benchmark functions (Liu and Yin 2016; Lu et al. 2017) to do simulation, compares with the grey wolf optimization algorithm (GWO) (Mirjalili et al. 2014), the improved grey wolf optimization algorithm (IGWO) (Yao and Wang 2016) and the grey the wolf algorithm based on the third strategy (GWO_3) (Zuo et al. 2017). The specific benchmark functions are shown in Table 1, and Figs. 5, 6 and 7 illustrate the 2D versions of the benchmark functions used.


2-D versions of unimodal benchmark functions

2-D versions of multimodal benchmark functions

2-D version of fixed-dimension multimodal benchmark functions
4.2 Experimental parameters
The performances of the proposed algorithm have been evaluated by using 18 commonly used benchmark functions. For all the experimentation, population size is \(N=30\); dimensions are \(d=30\), 50, 100. The maximum number of iterations is \(T\max = 500\). In the IGWO algorithm, \(\varepsilon =5,b_{1}=0.5, b_{2}=0.5\). In the PSO_GWO algorithm, \(c_{1}=c_{2}=2.05; a_{\mathrm{ini}}=2, a_{\mathrm{fin}}=0; r_{1}=r_{2}=r_{3}=r_{4}=\hbox {rand } [0, 1]\).
4.3 Simulation analysis
In order to verify the optimal performance of PSO_GWO, we use 18 benchmark functions to test the performance of four algorithms. These benchmark functions are described in Table 1 and classified in Figs. 5, 6 and 7.
First of all, we use 30 wolves as the grey wolf population and separately conduct simulation experiments on 30, 50 and 100 dimension. We separately simulate 30 times on unimodal and multimodal functions and record the average value and standard deviation. The specific results are shown in Table 2.
We use the mean and standard deviation as reliability criteria. It can be seen from Table 2 that when the dimension is same, the PSO_GWO can obtain better average in benchmark function F1–F9. Especially in the test function F8, the PSO_GWO algorithm can converge to zero. In addition, the standard deviation of the PSO_GWO algorithm is small in 9 benchmark functions experiments, which indicates that the robustness of this algorithm is better. This is because the PSO_GWO algorithm introduces nonlinear control parameters to balance the global exploration and local exploitation capability. However, the control parameters of other algorithms have poor nonlinearity, resulting in not balancing the local and global search ability well and easily fall into local optimum during the search period. Meanwhile, regardless of dimension \(d=30\), 50 or 100, PSO_GWO algorithm can get better optimal solution than the other three algorithms. But the optimization ability of PSO_GWO algorithm decreases slightly with the increase in dimension.
In addition, we also propose the next set of the benchmark functions analysed in this paper, which are the fixed-dimension multimodal benchmark functions. Then we separately simulate 30 times and record the average value and standard deviation. The results are shown in the following table.
Table 3 shows a comparison among GWO, GWO_3, IGWO, PSO_GWO four algorithms based on the average and standard deviation. It can be known from the above table data that the algorithm presented in this paper is not enough different with the simulation results of the other three algorithms.
Simultaneously, this paper calculates the algorithm’s time statistics from both CPU and TIC/TOC. The CPU reflects the time it takes to complete the process when the CPU is working at full speed, while the TIC/TOC is used to calculate the time the program is running. The calculation results are shown in Table 4.
The accuracy of the PSO_GWO algorithm can be verified by starting and ending time of algorithm (TIC and TOC), and CPU time. These experimental data are shown in Table 4. As it can be seen from Table 4, the PSO_GWO algorithm has lower computational complexity than IGWO algorithm. But comparing with the GWO algorithm, the PSO_GWO algorithm has a large computational complexity and has a long running time. This is because the PSO_GWO algorithm is based on the basic GWO algorithm to introduce PSO algorithm ideas, thereby increasing the computational complexity of the algorithm. Therefore, the PSO_GWO algorithm improves convergence accuracy at the expense of computational complexity. Figure 5 shows the eight test function optimization curve of the GWO, GWO_3, IGWO, PSO_GWO algorithm.
As can be seen from Figs. 8, 9 and 10, the search speeds of the four algorithms are roughly the same during the initial search, but as the number of iterations increases, the PSO_GWO algorithm proposed in this paper continues to search until the search for the optimal solution. However, the other three algorithms reach the stagnation state in advance, resulting in poor search results. Therefore, the proposed algorithm has better convergence performance on benchmark function. This is because the other three algorithms did not consider the impact of the individual experience of the grey wolf during the search process. However, the algorithm proposed in this paper uses its own experience to delay the algorithm into a local optimum during the predation process.
To sum up, all simulation results indicate the improved hybrid grey wolf optimization algorithm is very helpful in improving the efficiency of the GWO in the terms of result quality.

Convergence curve of GWO, GWO_3, IGWO, and PSO_GWO on unimodal functions

Convergence curve of GWO, GWO_3, IGWO, and PSO_GWO on multimodal functions

Convergence curve of PSO, GWO, IGWO and PSO_GWO variants on fixed-dimension multimodal functions

5 Conclusion
In this paper, we proposed an improved grey wolf algorithm. As described in Sect. 3, it first used Tent chaotic map to initialize grey wolf population, then used nonlinear control parameters to balance the local and global search capabilities of the algorithm and introduced PSO algorithm thought into the position update formula. And in Sect. 4, a series of experiments on the 18 benchmark test functions are executed to verify the effectiveness of the improved hybrid wolf algorithm. The experimental results show that the proposed algorithm is superior to other algorithms in the search capability. And it is evident that the proposed algorithm can improve the performance of GWO algorithm in terms of result quality and better robustness. In this work, we justify the problems that were used for testing benchmark test functions. Although the PSO_GWO algorithm improves result quality, the computational complexity is increased. So in the future, we will conduct research on the issue of reducing the computational complexity. At the same time, we will also apply the improved algorithm to solve wireless sensor networks coverage problem.
References
Bian XQ, Zhang L, Du ZM et al (2018) Prediction of sulfur solubility in supercritical sour gases using grey wolf optimizer-based support vector machine. J Mol Liq 261(1):431–438
Chen Z, Zhou S, Luo J (2017) A robust ant colony optimization for continuous functions. Expert Syst Appl 81:309–320
Clerc M (2002) The swarm and the queen: towards a deterministic and adaptive particle swarm optimization. In: Proceedings of the 1999 congress on evolutionary computation, CEC 99, vol 3. IEEE
Gandomi AH, Alavi AH (2012) Krill herd: a new bio-inspired optimization algorithm. Commun Nonlinear Sci Numer Simul 17(12):4831–4845
Guo Z, Liu R, Gong C et al (2017) Study on Improvement of grey wolf algorithm. Appl Res Comput 34(12):3603–3606
Jitkongchuen D (2016) A hybrid differential evolution with grey wolf optimizer for continuous global optimization. In: International conference on information technology and electrical engineering. IEEE, pp 51–54
Khairuzzaman AKM, Chaudhury S (2017) Multilevel thresholding using grey wolf optimizer for image segmentation. Expert Syst Appl 86(15):64–76
Kohli M, Arora S (2017) Chaotic grey wolf optimization algorithm for constrained optimization problems. J Comput Des Eng
Liu T, Yin S (2016) An improved particle swarm optimization algorithm used for BP neural network and multimedia course-ware evaluation. Multimed Tools Appl 76(9):11961–11974
Long W, Wu TB (2017) Improved grey wolf optimization algorithm coordinating the ability of exploration and exploitation. Control Decis 32(10):1–8
Long W, Cai SH, Jiao JJ et al (2016) Hybrid grey wolf optimization algorithm for high-dimensional optimization. Control Decis 31(11):1991–1997
Lu C, Gao L, Li X et al (2017) A hybrid multi-objective grey wolf optimizer for dynamic scheduling in a real-world welding industry. Eng Appl Artif Intell 57(C):61–79
Meng X, Liu Y, Gao X et al (2014) A new bio-inspired algorithm: chicken swarm optimization. In: Advances in swarm intelligence. Springer, pp 86–94
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69(3):46–61
Mirjalili S, Saremi S, Mirjalili SM et al (2016) Multi-objective grey wolf optimizer: a novel algorithm for multi-criterion optimization. Expert Syst Appl 47:106–119
Mittal N, Singh U, Sohi BS (2016) Modified grey wolf optimizer for global engineering optimization. Appl Comput Intell Soft Comput 2016(4598):1–16
Nekouie N, Yaghoobi M (2016) A new method in multimodal optimization based on firefly algorithm. Artif Intell Rev 46(2):267–287
Nuaekaew K, Artrit P, Pholdee N et al (2017) Optimal reactive power dispatch problem using a two-archive multi-objective grey wolf optimizer. Expert Syst Appl 87(30):79–89
O’Neil M, Woolfe F, Rokhlin V (2010) An algorithm for the rapid evaluation of special function transforms. Appl Comput Harmon Anal 28(2):203–226
Pan W-T (2012) A new fruit fly optimization algorithm: taking the financial distress model as an example. Knowl Based Syst 26:69–74
Quiniou ML, Mandel P, Monier L (2014) Optimization of drinking water and sewer hydraulic management: coupling of a genetic algorithm and two network hydraulic tools. Procedia Eng 89:710–718
Rakhshani H, Rahati A (2017) Snap-drift cuckoo search: a novel cuckoo search optimization algorithm. Appl Soft Comput 52:771–794
Reihanian M, Asadullahpour SR, Hajarpour S et al (2011) Application of neural network and genetic algorithm to powder metallurgy of pure iron. Mater Des 32(6):3183–3188
Sahoo A, Chandra S (2016) Multi-objective grey wolf optimizer for improved cervix lesion classification. Appl Soft Comput 52:64–80
Saremi S, Mirjalili SZ, Mirjalili SM (2015) Evolutionary population dynamics and grey wolf optimizer. Neural Comput Appl 26(5):1257–1263
Shan L, Qiang H, Li J et al (2005) Chaotic optimization algorithm based on Tent map. Control Decis 20(2):179–182
Singh N, Singh SB (2017) Hybrid algorithm of particle swarm optimization and grey wolf optimizer for improving convergence performance. J Appl Math 2017(1–4):15
Tawhid MA, Ali AF (2017) A Hybrid grey wolf optimizer and genetic algorithm for minimizing potential energy function. Memet Comput 9(4):1–13
Wei Z, Zhao H, Li M et al (2016) A grey wolf optimization algorithm based on nonlinear adjustment strategy of control parameter. J Air Force Eng Univ (Nat Sci Ed) 17(3):68–72
Xian S, Zhang J, Xiao Y et al (2017) A novel fuzzy time series forecasting method based on the improved artificial fish swarm optimization algorithm. Soft Comput 10:1–11
Yang XS (2013) Flower pollination algorithm for global optimization. In: International conference on unconventional computation and natural computation. Springer, pp 240–249
Yao P, Wang HL (2016) Three-dimensional path planning for UAV based on improved interfered fluid dynamical system and grey wolf optimizer. Control Decis 31(04):701–708
Yi-Tung K, Erwie Z (2008) A hybrid genetic algorithm and particle swarm optimization for multimodal functions. Appl Soft Comput 8(2):849–857
Zheng YJ, Wang Y, Ling HF et al (2017) Integrated civilian-military pre-positioning of emergency supplies: a multiobjective optimization approach. Appl Soft Comput 58:732–741
Zhu A, Xu C, Li Z et al (2015) Hybridizing grey wolf optimization with differential evolution for global optimization and test scheduling for 3D stacked SoC. J Syst Eng Electron 26(2):317–328
Zou S, Fan Y, Tang Y et al (2016) Optimized algorithm of sensor node deployment for intelligent agricultural monitoring. Comput Electron Agric 127:76–86
Zuo J, Zhang C, Xiao Y et al (2017) Multi-machine PSS parameter optimal tuning based on grey wolf optimizer algorithm. Power Syst Technol 41(09):2987–2995
Acknowledgements
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions to improve this paper. Besides, this work is supported by the National Natural Science Foundation of China (No. 51277023), National Natural Science Foundation Youth Science Foundation Project (No. 61501107), “13th Five-Year” Scientific Research Planning Project of Jilin Province Department of Education (No. JJKH20180439KJ).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Ethical approval
This article does not contain any studies with animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Teng, Zj., Lv, Jl. & Guo, Lw. An improved hybrid grey wolf optimization algorithm. Soft Comput 23, 6617–6631 (2019). https://doi.org/10.1007/s00500-018-3310-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-018-3310-y