
Abstract
In categorization tasks, two memory systems may be involved in the learning of categories: one explicit and rule-based system and another implicit and procedure-based system. Learning of rule-based categories relies on some form of explicit reasoning, whereas procedural memory underlies information–integration category-learning tasks, in which performance is maximized only if information of two (or more) dimensions is integrated. The present study aimed at investigating the role of how feedback is administered, whether differential or non-differential, in procedural learning. An information–integration category-learning task was designed, where the to-be-categorized stimuli differed in two dimensions. Participants were randomly assigned to two groups: one group received the reinforcers for correct categorizations differentially, one for each category (the differential outcomes procedure, DOP), and the other group received the reinforcers randomly (the non-differential outcomes procedure, NOP). The participants of the DOP group showed better procedural learning in the categorization task, compared to the NOP group. Moreover, the analysis of learning strategies revealed that more participants developed more optimal strategies in the DOP group than in the NOP group. These results extend the benefits of the differential outcomes-based feedback to non-declarative memory tasks and help better understand the role of feedback in procedural learning.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Categorization refers to the process by which people assign different responses to different groups of stimuli. This process reduces the complexity that characterizes our environment and is governed by the evolutionary history of our organism, the experience resulting from our relationship with the environment, and the consequences of the decisions we make at each moment ((Maddox & Ashby, 2004; Maddox, Ashby, & Bohil, 2003).
Several studies have demonstrated the involvement of multiple memory systems in learning categories (for a review, see Ashby & O’Brien, 2005). One influential model that integrates those memory systems with their neuroanatomic correlates is the competition between verbal and implicit systems (COVIS) model (Ashby, Alfonso-Reese, & Waldron, 1998; Cantwell, Crossley, & Ashby, 2015). The model proposes the existence of two systems involved in category learning: one explicit and rule-based system and another implicit and procedure-based system. Evidence for the existence of those two systems comes from the dissociations found in behavioral tasks of perceptual categorization (Maddox & Ashby, 2004).
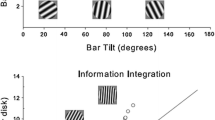
Rule-based category-learning tasks (RB) are based on some explicit reasoning that treats each stimulus dimension separately, as it is illustrated in Fig. 1b. The stimuli depicted are Gabor patches, which are defined by two dimensions: orientation and spatial frequency (width of the bars, see Fig. 1a). The rule that a participant must follow to achieve high performance in this task can be described verbally in a simple way, since only one of the two dimensions is relevant for categorization. Studies with functional magnetic resonance imaging (fMRI) suggest that this memory system, that recruits working memory and executive attention, is mediated by fronto-striatal circuits (anterior cingulate, prefrontal cortex, and the head of the caudate nucleus; Elliott & Dolan, 1998). On the other hand, procedural learning is involved in information–integration category-learning tasks (II), in which performance is maximized only if information of two (or more) dimensions is integrated at some predecisional stage (Ashby & Gott, 1988). The rule by which participants classify these stimuli is at least rather difficult to describe verbally, because it requires integrating information from both dimensions (see Fig. 1c). Performance in II tasks appears to be mediated by the striatum, and more specifically by the tail of the caudate nucleus (Ashby & Ell, 2001; Ashby & Ennis, 2006; Filoteo, Maddox, Salmon, & Song, 2005).

Example of Gabor patch (a), and spatial distributions that might be used in a rule-based category-learning experiment (b), and in an information-integration category-learning experiment (c)
An additional source of dissociation between the two types of category-learning tasks refers to the role of feedback. In contrast to RB tasks, II tasks have been found to be highly sensitive to how feedback is administered (Dunn, Newell, & Kalish, 2012; Maddox, Love, Glass, & Filoteo, 2008). For instance, the absence or delay of the feedback hinders performance just in II tasks. However, despite the existence of extensive literature illustrating the effects of feedback on II tasks, no study has examined whether performance in those tasks can be modulated by administering feedback in either a category specific differential or a category non-specific non-differential way. In the present study, we aimed at extending the role of differential feedback in II category-learning tasks, where procedural memory is involved.
When organisms deal with situations that involve discriminative learning, the way feedback (or reinforcement) is administrated has great impact on their performance. For instance, when in a discriminative learning task, each type of correct choice is followed by a unique outcome (reinforcer), discriminative learning is better compared to when either of each choice is followed by a common outcome, or if the alternative outcomes are administrated in a random way (Trapold, 1970). In the animal learning field, the association of a response with a unique outcome has been termed the differential outcomes procedure (DOP), and learning with the DOP has been frequently compared with learning obtained when outcomes are administered in a random way (the non-differential outcomes procedure, NOP). An increase in the rate of acquisition and improvement of the final level of performance in discriminative learning tasks are the hallmark of the DOP. Neuroanatomy also dissociates these two ways of discriminative learning, at least in animals. Whereas retrospective memory, a cholinergic-dependent memory system that involves the hippocampus, underlies performance under the NOP, prospective memory, a glutamatergic-dependent memory system that involves the basolateral amygdala and other fronto-parietal areas, underlies performance under the DOP (Savage, Buzzetti, & Ramirez, 2004; Savage & Ramos, 2009).
In humans, the DOP has demonstrated its usefulness beyond discriminative learning, mainly in the improvement of recognition memory in normal population (for a review, see López-Crespo & Estévez, 2013), and also in patients, whose pathology affects explicit memory such as Korsakoff syndrome (Hochhalter, Sweeney, Bakke, Holub, & Overmier, 2001), or Alzheimer’s disease ((Plaza, López-Crespo, Antúnez, Fuentes, & Estévez, 2012; Vivas et al., 2018). Despite the benefits of the DOP having been amply documented in relation to different memory systems and with different populations, to the best of our knowledge, we lack research that has addressed the effect of the DOP on procedural memory in humans. The aim of the present study was to investigate whether the benefits of the DOP can be extended to II tasks that have been thought to rely on non-declarative (procedural) memory system in humans.
Method
Participants
One hundred and eight undergraduate students from the University of Murcia (87 women and 21 men; M age = 21.3 years; SD age = 4.8) participated for course credit. All participants reported normal or corrected-to-normal vision. They were randomly assigned to one of the two outcome conditions, the differential outcomes condition (n = 54) and the non-differential outcomes condition (n = 54).
Materials
Stimuli were sinusoidal gratings with a Gaussian envelope (Gabor patches) defined by their spatial frequency values and orientation. Orientation and frequency values for stimuli belonging to categories A and B were sampled from two bivariate normal distributions with means μ = (40, 60) and μ = (60, 40), using the same covariance matrix for both distributions (covariance = 160; both variances = 170). We began generating random samples from each distribution. After that, exemplars that differed from the mean by more than three Mahalanobis distance units were considered outliers and discarded. By this procedure, we obtained two distributions of 122 items. Then, values of orientation and frequency, which were expressed in a normalized scale from 0 to 100, were linearly transformed into actual values, so that the values of 0 and 100 corresponded to 20 and 140 degrees clockwise in the orientation dimension (where 0 degrees = vertical orientation) and 3.5 and 9.5 cycles every 100 pixels in the frequency dimension. Gabor patches were 192 × 192 pixels in size, main colors were black and white, and background color was silver gray. Two Gabor patches from each distribution were randomly selected to be used in the practice trials.
We used two different positive reinforcers (see Fig. 2), which consisted of a thumb-up symbol within a green circle with the expression “¡Correcto!” (“Correct!”) written underneath in green letters; or a yellow smile icon holding a placard reading “¡Muy bien!” (“Alright!”) in yellow letters.

Schematic representation of the experimental procedure
A computer program generated by E-Prime (Schneider, Eschman, & Zuccolotto, 2002) controlled the experiment. Stimuli were presented on a TFT monitor and responses were collected via the keyboard. Screen background color was silver gray.
Procedure
The experiment consisted of ten blocks of 24 trials. The order of presentation of stimuli of the two categories was randomly determined with the restriction that six stimuli from each category were presented every 12 trials. As depicted in Fig. 2, each trial began with the presentation of a fixation point (a plus sign) in the center of the computer screen for 500 ms. Then, a Gabor patch replaced the fixation point and participants classified the stimulus into category A or B by pressing the Z or M key on the computer keyboard, respectively. Gabor stimuli remained visible until a response was made or a maximum of 3000 ms had elapsed. Feedback appeared 250 ms after the participants’ response and remained visible for 500 ms. Correct responses in the differential outcomes condition were consistently followed by one of the two positive reinforcers according to the category (the assignment of reinforcers to categories was counterbalanced across participants). In the non-differential outcomes condition, reinforcers were chosen randomly with the restriction that the two reinforcers were presented twice every four correct categorizations of stimuli belonging to each category. Incorrect responses were followed by the message “Error!” in red letters, whereas no response within the 3000 ms response window was followed by the message “No response” in black font. Finally, the screen went blank for 100 ms, and a new trial began. Participants completed four practice trials before the experimental trials (the four stimuli used in these practice trials were the same for all the participants). A brief rest period was provided after every two blocks. After completing the computer task, the participants were asked to put down in writing the rule they had been following to categorize the stimuli.
Results
Accuracy-based analysis
We first used a Bayesian multilevel approach to estimate the probability of correct categorization as a function of the outcomes condition and across the ten trial blocks (for a friendly introduction to Bayesian analysis, including the multilevel approach, see Kruschke, 2015; McElreath, 2016). We employed Stan 2.17.0, a programming language that implements Markov chain Monte Carlo algorithms (Carpenter et al., 2017), to fit a multilevel binomial model. This model included weakly informative regularizing priors and varying intercepts for both participants and stimuli. Thanks to these varying intercepts, we simultaneously modelled participants variability (the fact that some participants were better than others in the categorization task) and item variability (the fact that some stimuli were more easily categorizable than others). The possibility of considering these two sources of variation simultaneously is one of the main benefits of the multilevel approach (Rouder & Lu, 2005). The results we are about to describe are based on estimates derived from 12,000 samples, which were obtained after 12,000 warm-up samples. We performed the analysis in R 3.5.1 (R Core Team, 2017), which communicated with Stan via the Rethinking 1.88 package (McElreath, 2016). Trials with no response within the 3000 ms response window (0.6%) were discarded before fitting the model. Convergence was assessed by inspection of the trace plots, the R-hat values, and the number of effective samples (no convergence problems were detected, with all R-hats = 1).
After fitting the model, we obtained posterior distributions describing the plausibility of the different parameter values, according to the model and the observed data. From these distributions, and after back-transformed log-odds into probabilities, we estimated the posterior distribution of the probability of correct categorization across outcome conditions and trial blocks. Figure 3 depicts the mean of these estimations with 95% highest posterior density intervals (HPDI). These HPDIs can be directly interpreted as the intervals that include the most credible values of the probability of correct categorization (this possibility of direct interpretation of credible intervals is a prominent advantage of the Bayesian estimation approach). As shown in Fig. 3, the model predicted greater probability of correct categorization in the differential outcomes condition, especially for trial blocks 3, 5, 8, and 10, for which the corresponding 95% HPDIs did not overlap. To further determine if the probability of correct categorization in the differential outcomes condition was credibly greater than that in the non-differential condition, we examined the posterior distribution of the difference between these conditions across trial blocks. Table 1 shows the model estimates for these differences, along with the mean proportion of correct categorizations in each group.

Model estimates (mean of the posterior distribution with 95% HPDIs) of the probability of correct categorization as a function of outcomes condition and trial block
To further characterize the results, mean proportions of correct categorizations (see Table 1) were submitted to a 2 × 10 mixed ANOVA with outcomes condition (differential and non-differential) as the between-participants factor and block (1–10) as the within-participants factor. There was a main effect of outcomes condition, F(1, 106) = 15.457, p < 0.001, showing that the proportion of correct categorization was higher in the differential outcomes condition than in the non-differential outcomes condition. There was also a main effect of block, F(9, 954) = 9.873, p < 0.001, which, according to post hoc tests with Bonferroni correction, was mainly due to lower proportion of correct categorizations in the first block compared to all the subsequent blocks (all p < 0.005). The interaction between outcomes condition and block did not reach statistical significance, F(9, 954) = 1.032, p = 0.412. Despite the non-significant interaction, a rather usual result is that the differences between the two outcomes conditions are not significant when both conditions are compared at the starting point of learning (first block/first trials) (e.g., see Estévez, Fuentes, Marí-Beffa, González, & Alvarez, 2001; Martínez, Flores, González-Salinas, Fuentes, & Estévez, 2013). In line with these previous findings, we did not observe any significant effect of outcomes condition in block 1, t(106) = 1.433, p = 0.155.
Model-based analysis
The results of the accuracy-based analyses showed that participants in the differential outcomes condition had a significantly better performance than those in the non-differential outcomes condition, and this improvement was more apparent as the participants had more practice with the task. However, it is also important to determine the decision strategies adopted by the participants, particularly whether those participants performing the task in the DOP condition were using optimal strategies in greater proportion than participants performing the task in the NOP condition. Following the Maddox and Ashby (1993) procedures, we determined the decision strategies adopted by the participants in the last two blocks. Three different types of decision bound models (DBM) were tested, fitting them to the responses of each participant. DBM assume that participants partition the perceptual space into response regions. The first model assumed an explicit one-dimensional rule-learning strategy (either orientation or bar width) and included two free parameters (a decision criterion on the relevant perceptual dimension and perceptual noise variance). The second model assumed a procedural learning strategy and included three free parameters (slope and intercept of the decision bound, and perceptual noise variance). The third model assumed random guessing strategy. The latter included one version that assumed that participants responded randomly without response bias (no free parameters) and another version that assumed that participants responded randomly but biased toward one response (with one free parameter).
All parameters were estimated using the maximum likelihood method and the statistic used for the model selection was the Akaike information criterion (AIC) (Akaike, 1974). To determine which model adjusted better to participants’ responses, the AIC statistic was computed for each model and the one that got the smallest AIC value was considered the winning model (see Table 2).
In a second step of the model-based analysis, we compared the best models fit with the guessing models fit for each participant, to determinate how well every model fitted the data. Note that the AIC values determine which bound model provides the best account of the participants’ responses, but it does not tell us whether the fit was good or bad. Following a Bayesian logic, if the prior probability that the DBM model (MDBM) is correct is equal to the prior probability that the random guessing model (MRG) is correct, then under certain technical conditions (e.g., Raftery, 1995), it can be shown that
where P (MDBM|Data) is the probability that the DBM is correct, assuming that either the DBM or the guessing model is correct. Thus, we computed those probabilities for each participant, where AICDBM was the AIC score of the best-fitting DBM. The mean value of P(MDBM|Data) was 0.97 for participants in DOP condition and 0.53 for participants in NOP condition, t(106) = 21.57, p < 0.001. A Bayesian independent samples t test (Rouder, Speckman, Sun, Morey, & Iverson, 2009) showed a Bayes factor BF10 = 8.603 × 1036, confirming that participants in the DOP group developed more optimal learning strategies than participants in the NOP group.
Participants’ explanation-based analysis
To check whether the participants were able to verbalize the rule they had followed to classify the stimuli, participants' written descriptions were analyzed by two researchers, who knew the categorization rule, but were blind regarding the experimental condition of each participant. They agreed (Cohen’s kappa = 1) that no participant had been able to guess the true classification rule.
Discussion
In category learning that is based on procedural memory, categorization requires participants to integrate information from two or more dimensions. Our results show that performance is improved if differential outcomes-based feedback is administered to participants after correct responses. It is important to note that DOP benefits are mainly expected under conditions where learning is more difficult (Estévez et al., 2001, 2007). Thus, an II task, rather than a RB task, where the rule to classify the stimuli into categories could not be described by the participants, is deemed to be the most appropriate to observe DOP modulation on category-learning performance. Although performance was above chance in both outcomes conditions (see Fig. 3), likely due to the rather large number of trials that composed each block (24 trials) in comparison with the reduced number of trials per block in the previous studies (e.g., four trials in Martínez et al., 2013), both the rate of acquisition, as it is shown mainly in the two first blocks of trials, and the final level of performance was greater when the DOP was implemented compared to when random feedback was administered (the NOP) in the II task used here. Therefore, we successfully extended the benefits of the DOP to procedural learning. Taking the COVIS model as a framework, further research may extend the relevance of the DOP in the context of category learning by comparing its effects on both rule- and procedure-based tasks. As procedural learning requires immediate feedback (Ashby & O’Brien, 2005), the DOP might assist performance more in II tasks than in RB tasks or modulate the time window that makes feedback effective.
The results of the present study can be accounted for by the expectancy theory (Trapold & Overmier, 1972). With the DOP, participants activate expectancies about the upcoming outcomes because of the unique stimulus–outcome association. Such expectancies would have stimulus-like properties that exert control over the choice behavior (Holden & Overmier, 2014), and can be formed implicitly without participants intention and/or regardless of awareness of either the sample stimuli or their associated outcomes (Carmona, Marí-Beffa, & Estévez, 2019). Expectancies can have the form of a kind of prospective memory “representation” elicited by the particular stimuli that form part of each category, and such representation would be less affected by working memory demands. Prospective memory has been thought of as a glutamatergic-dependent memory system that involves the basolateral amygdala and other fronto-parietal areas (Mok, Thomas, Lungu, & Overmier, 2009; Savage et al., 2004; Savage & Ramos, 2009). With the NOP, as the associations between the stimuli and the outcomes are not unique, the sample stimuli cannot be used to predict what outcome will follow the correct choice, and therefore outcomes expectancies cannot guide choice behavior. Performance under the NOP is based on a cholinergic-dependent retrospective memory system, which mainly involves the hippocampus (Savage et al., 2004).
Although the specific neurocircuitry involved in the benefits attributed to the DOP in our II task is beyond the scope of the present study, the connections between the prefrontal cortex, mainly involved in creating a prospective representation of the outcomes (Mok et al., 2009), and the striatum, mainly involved in II tasks (Ashby & Ell, 2001; Ashby & Ennis, 2006; Filoteo et al., 2005), may well account for the present results. For instance, Filoteo et al., (2005) observed that patients with Parkinson’s disease show poor performance in II tasks. This deficit agrees with the role of basal ganglia in category learning (Ashby & Ennis, 2006), which confirms the involvement of the striatum in II tasks. A question for future research will be to assess the involvement of such corticostriatal circuitry in the DOP benefits observed here, in an II task (see Haber, 2016, for a review regarding such circuitry).
One other aspect of our results concerns the decision strategies adopted by the participants when performing the last block of trials. Strategies adopted by participants under the DOP were more optimal than those adopted by participants under the NOP. We suggest that the DOP improved the participants’ ability to integrate information coming from both dimensions in a more effective way. The differential feedback might have helped participants establish stronger associative links between the two dimensions, fostering individuated tokens for each category. Individuated tokens could then be successfully linked to unique outcomes under the DOP, yielding improved learning performance compared with the NOP. Note that this individuated process is mainly expected when the rule to differentiate between the two categories cannot be made explicit by the participant, as it happens in II tasks.
Finally, we would like to highlight two potential applications of the present results. First, typically developing school-age children are expected to show a transition from RB learning to the use of implicit learning strategies (Huang-Pollock, Maddox, & Karalunas, 2011). Importantly, the transition is compromised in attention-deficit/hyperactivity disorder (ADHD) children (Huang-Pollock, Maddox, & Tam, 2014), likely due to their suboptimal functioning in basal ganglia and frontostrial structures, which have been involved in several types of implicit learning (Nigg & Casey, 2005), and specifically in II tasks like the one used here (Ashby & Ennis, 2006). Therefore, school-aged children diagnosed with ADHD can greatly benefit of the use of differential feedback (the DOP) to overcome their implicit learning deficits. Second, the potential of the DOP has been demonstrated in the previous studies with patients with memory complaints, as it is the case of alcohol-induced amnesia that characterizes Korsakoff syndrome (Hochhalter et al., 2001) or Alzheimer’s disease (Plaza et al., 2012). Based on the present results, we suggest that patients with non-declarative memory impairment (e.g., Parkinson’s disease or Huntington’s chorea) could also benefit from the use of the DOP.
References
Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19, 716–723.
Ashby, F. G., Alfonso-Reese, L. A., & Waldron, E. M. (1998). A neuropsychological theory of multiple systems in category learning. Psychological Review, 105, 442–481.
Ashby, F. G., & Ell, S. W. (2001). The neurobiology of human category learning. Trends in Cognitive Sciences, 5, 204–210.
Ashby, F. G., & Ennis, J. M. (2006). The role of the basal ganglia in category learning. Psychology of Learning and Motivation, 46, 1–36.
Ashby, F. G., & Gott, R. E. (1988). Decision rules in the perception and categorization of multidimensional stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition, 14, 33–53.
Ashby, F. G., & O’Brien, J. B. (2005). Category learning and multiple memory systems. Trends in Cognitive Sciences, 9, 83–89.
Cantwell, G., Crossley, M. J., & Ashby, F. G. (2015). Multiple stages of learning in perceptual categorization: Evidence and neurocomputational theory. Psychonomic Bulletin & Review, 22, 1598–1613.
Carmona, I., Marí-Beffa, P., & Estévez, A. F. (2019). Does the implicit outcomes expectancies shape learning and memory processes? Cognition, 189, 181–187.
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32.
Dunn, J. C., Newell, B. R., & Kalish, M. L. (2012). The effect of feedback delay and feedback type on perceptual category learning: The limits of multiple systems. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 840–859.
Elliott, R., & Dolan, R. J. (1998). Activation of different anterior cingulate foci in association with hypothesis testing and response selection. Neuroimage, 8, 17–29.
Estévez, A. F., Fuentes, L. J., Marí-Beffa, P., González, C., & Alvarez, D. (2001). The differential outcome effect as a useful tool to improve conditional discrimination learning in children. Learning and Motivation, 32, 48–64.
Estévez, A. F., Vivas, A. B., Alonso, D., Marí-Beffa, P., Fuentes, L. J., & Overmier, J. B. (2007). Enhancing challenged students’ recognition of mathematical relations through differential outcomes training. Quarterly Journal of Experimental Psychology, 60, 571–580.
Filoteo, J. V., Maddox, W. T., Salmon, D. P., & Song, D. D. (2005). Information-integration category learning in patients with striatal dysfunction. Neuropsychology, 19, 212–222.
Haber, S. N. (2016). Corticostriatal circuitry. Dialogues in Clinical Neuroscience, 18, 7–21.
Hochhalter, A. K., Sweeney, W. A., Bakke, B. L., Holub, R. J., & Overmier, J. B. (2001). Improving face recognition in alcohol dementia. Clinical Gerontologist, 22, 3–18.
Holden, J. M., & Overmier, J. B. (2014). Performance under differential outcomes: Contributions of reward-specific expectancies. Learning and Motivation, 45, 1–14.
Huang-Pollock, C. L., Maddox, W. T., & Karalunas, S. L. (2011). Development of implicit and explicit category learning. Journal of Experimental Child Psychology, 109, 321–335.
Huang-Pollock, C. L., Maddox, W. T., & Tam, H. (2014). Rule-based and information-integration perceptual category learning in children with attention-deficit/hyperactivity disorder. Neuropsychology, 28, 594–604.
Kruschke, J. (2015). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan (2nd ed.). Cambridge: Academic Press, Elsevier.
López-Crespo, G., & Estévez, A. F. (2013). Working memory improvement by the differential outcomes procedure. In S. H. Clair-Thompson (Ed.), Working memory: Developmental differences, component processes, and improvement mechanisms (pp. 145–157). New York: Nova Publishers.
Maddox, W. T., & Ashby, F. G. (1993). Comparing decision bound and exemplar models of categorization. Attention, Perception, and Psychophysics, 53, 49–70.
Maddox, W. T., & Ashby, F. G. (2004). Dissociating explicit and procedural-learning based systems of perceptual category learning. Behavioural Processes, 66, 309–332.
Maddox, W. T., Ashby, F. G., & Bohil, C. J. (2003). Delayed feedback effects on rule-based and information-integration category learning. Journal of Experimental Psychology. Learning, Memory, and Cognition, 29, 650–662.
Maddox, W. T., Love, B. C., Glass, B. D., & Filoteo, J. V. (2008). When more is less: Feedback effects in perceptual category learning. Cognition, 108, 578–589.
Martínez, L., Flores, P., González-Salinas, C., Fuentes, L. J., & Estévez, A. F. (2013). The effects of differential outcomes and different types of consequential stimuli on 7-year-old children’s discriminative learning and memory. Learning & Behavior, 41, 298–308.
McElreath, R. (2016). Statistical rethinking: A Bayesian course with examples in R and Stan. Boca Raton: Chapman & Hall/CRC.
Mok, L. W., Thomas, K. M., Lungu, O. V., & Overmier, J. B. (2009). Neural correlates of cue-unique outcome expectations under differential outcomes training: An fMRI study. Brain Research, 1265, 111–127.
Nigg, J. T., & Casey, B. J. (2005). An integrative theory of attention-deficit/hyperactivity disorder based on the cognitive and affective neurosciences. Development and Psychopathology, 17, 785–806.
Plaza, V., López-Crespo, G., Antúnez, C., Fuentes, L. J., & Estévez, A. F. (2012). Improving delayed face recognition in Alzheimer’s disease by differential outcomes. Neuropsychology, 26, 483–489.
Raftery, A. E. (1995). Bayesian model selection in social research. Sociological Methodology, 25, 111–164.
Rouder, J. N., & Lu, J. (2005). An introduction to Bayesian hierarchical models with an application in the theory of signal detection. Psychonomic Bulletin & Review, 12, 573–604.
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16, 225.
Savage, L. M., Buzzetti, R. A., & Ramirez, L. R. (2004). The effects of hippocampal lesions on learning, memory, and reward expectancies. Neurobiology of Learning and Memory, 82, 109–119.
Savage, L. M., & Ramos, R. L. (2009). Reward expectation alters learning and memory: The impact of the amygdala on appetitive-driven behaviors. Behavioural Brain Research, 198, 1–12.
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-prime: User’s guide. Pittsburgh: Psychology Software Tools Inc.
R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/.
Trapold, M. A. (1970). Are expectancies based upon different positive reinforcing events discriminably different? Learning and Motivation, 1, 129–140.
Trapold, M. A., & Overmier, J. B. (1972). The second learning process in instrumental learning. In A. H. Black & W. F. Prokasy (Eds.), Classical conditioning II: Current theory and research (pp. 427–452). New York: Appleton-Cent.
Vivas, A. B., Ypsilanti, A., Ladas, A. I., Kounti, F., Tsolaki, M., & Estévez, A. F. (2018). Enhancement of visuospatial working memory by the differential outcomes procedure in mild cognitive impairment and Alzheimer’s disease. Frontiers in Aging Neuroscience, 10(239), 1–7.
Funding
This study was funded by the Spanish Ministry of Economy and Competitiveness (project PSI2017-84556-P, FEDER funds).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
Author Victor Martínez-Pérez declares that he has no conflict of interest. Author Luis J Fuentes declares that he has no conflict of interest. Author Guillermo Campoy declares that he has no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Martínez-Pérez, V., Fuentes, L.J. & Campoy, G. The role of differential outcomes-based feedback on procedural memory. Psychological Research 85, 238–245 (2021). https://doi.org/10.1007/s00426-019-01231-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-019-01231-0