
Abstract
In this paper, a joint restoration convolutional neural network (JRCNN) is proposed to produce a visually pleasing super resolution (SR) image from a single low-quality (LQ) image. The LQ image is a low resolution (LR) image with ringing, blocking and blurring artifacts arising due to compression. JRCNN consists of three deep dense residual blocks (DRB). Each DRB comprises of parallel convolutional layers with cross residual connections. The representational power of JRCNN is improved by depth-wise concatenation of feature representations from each of the DRBs. Moreover, these connections mitigate the problem of vanishing of gradients. Different from the previous networks, JRCNN exploits the contextual information directly in the LR image space without using any interpolation. This strategy improves the training efficiency of the network. The exhaustive experimentation on different datasets show that the proposed JRCNN produces state-of-the-art performance. Furthermore, ablation experiments are performed to assess the effectiveness of JRCNN. In addition, individual experiments are conducted for SR and compression artifact removal on benchmark datasets.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction

Super resolution by \(\times \)2 for a JPEG compressed image with a quality factor of 10
In this era of information explosion, transfer of multimedia content among different networks and devices have become more popular. Compression and down sampling are the most common image degradations. Images are available in degraded form on the web due to the availability of low storage space. Furthermore, images are compressed while being transmitted through low bandwidth channels. Down sampling exploits the spatial redundancy (duplicate pixels) in an image while compression further exploits the correlation in frequency (DCT coefficients) and temporal domains for frames in a video. Even though the degraded image requires less storage space, it contains unpleasant visual artifacts, i.e., ringing, blocking and blurring. These complex visual artifacts severely affect the user experience (e.g., Fig. 1). Accurate reconstruction of the super resolution (SR) image from a single LQ image is a challenging task. There is a huge requirement for improvement in visual quality of reconstructed SR image.

Artifacts removal from a JPEG compressed image with a quality factor of 10
The lossy Joint Photographic Experts Group (JPEG) compression [32] standard introduces blocking artifacts (e.g., Fig. 2) due to discontinuities between the adjacent 8\(\times \)8 pixel blocks, while the ringing and blurring artifacts occur during the coarse quantization of high frequency details. The JPEG 2000 compression standard uses wavelet transform and avoids the blocking artifacts but still suffers from the ringing and the blurring artifacts. The main objective of this paper is to address super resolution (SR), compression artifact removal (CAR) and compressed image super resolution (CISR) from a single low-quality image. SR focuses mainly on the estimation of missing high frequency details (e.g., Fig. 3), while CAR focuses on the removal of ringing and blocking artifacts from the images compressed using the JPEG standard that’s widely adopted on the internet. CISR focuses on the SR of low resolution (LR) compressed images. In this paper, a joint restoration convolutional neural network (JRCNN) architecture is proposed to address all the three tasks, i.e., SR, CAR and CISR.

Super resolution by \(\times \)4
Figure 1 represents the SR of a LQ image for a JPEG quality factor (QF) of 10 and an up scaling factor of 2 (\(\times \)2). From Fig. 1, one can notice that the LQ image is an LR and compressed image. Bicubic interpolation amplifies the compression artifacts and produces visually unpleasant outputs, whereas the image produced by JRCNN is visually pleasant. Figure 2 represents the CAR of a JPEG compressed image with a quality factor of 10. The lower quality factors represent the higher compression. From Fig. 2, one can observe that the visually annoying artifacts are present in the JPEG decompressed image. These artifacts are removed in the image produced by the JRCNN. Similarly, Fig. 3 represents the SR of a LR image for \(\times \)4. Blurring artifacts can be clearly observed in the bicubic interpolated image. These blurring artifacts are removed using the JRCNN. In all Figures 1, 2 and 3, it can be observed that the outputs of the JRCNN are much more visually pleasant than the LR input image and the bicubic interpolated image.
Nowadays deep learning-based methods are able to produce state-of-the-art performance. An end-to-end learning strategy is adopted in this paper using deep convolutional neural network (DNN). The CISR involves two different tasks, i.e., removal of complex artifacts and increasing the spatial resolution of the image. If these operations are performed one after the other, i.e., SR followed by CAR or CAR followed by SR, perceptually unpleasant images will be produced. In SR followed by CAR strategy, the complex artifacts are amplified in the SR stage and CAR stage is not able to remove these artifacts. Similarly, in CAR followed by SR, the CAR stage removes some of the essential information like edges and textures which are required in SR stage for accurate reconstruction. So, in this paper a joint restoration DNN is proposed to learn an end-to-end mapping function between LQ image \(I_\mathrm{LQ}\) and the corresponding residual image \(I_\mathrm{Res}\) formed by subtracting bicubic interpolated image \(I_\mathrm{Bic}\) [15] from the original image \(I_\mathrm{HR}\). The \(I_\mathrm{LQ}\) can be obtained from compression and down sampling of \(I_\mathrm{HR}\) and is formulated as follows:
where C is the composite operator of compression and decompression and H is the down sampling operator. The aim of CISR is to obtain \(I_\mathrm{HR}\) from \(I_\mathrm{LQ}\). Out of many existing compression standards for still images, the JPEG is one of the widely used compression standard. In this paper, the JPEG compression standard is taken as an example. In JPEG compression standard, quality factor (QF) decides the amount of compression and perceptual quality of an image. Lower value of QF corresponds to higher compression and reduced storage size of the image.
In Eq. 1, if C is an identity matrix then \(I_\mathrm{LQ}\) is just the down sampled version of \(I_\mathrm{HR}\). SR of \(I_\mathrm{LQ}\) produces \(I_\mathrm{HR}\). If H is an identity matrix then \(I_\mathrm{LQ}\) is just the compressed and decompressed version of \(I_\mathrm{HR}\). In this case different artifacts must be removed from \(I_\mathrm{LQ}\) occurred during compression and decompression operations on \(I_\mathrm{HR}\). If none of C and H are identity matrices then the operation is simultaneous removal of compression artifacts and SR. To perform all these operations individually, a joint restoration convolutional neural network (JRCNN) is proposed in this paper. The novel contributions in this paper are as follows;
-
Deep dense residual blocks (DRB) with parallel convolutional layers (PCL) are proposed for efficient training of the JRCNN.
-
Cross residual connections (CRC) are introduced in each dense residual block to ease the training and to improve the training efficiency. Moreover, these connections mitigate the problem of gradient explosion.
-
Skip connections are introduced among different deep dense residual blocks to improve the representational power of the JRCNN. Furthermore, skip connections avoid the problem of vanishing of gradients by creating short paths for efficient flow of gradients. In addition, feature redundancy is avoided by using skip connections.
-
Different ablation experiments have been conducted on benchmark datasets to access the superiority of the JRCNN.
-
Different experiments like super resolution (SR), compression artifact removal (CAR) and compressed image super resolution (CISR) have been performed using the JRCNN on standard datasets.
The rest of the paper is organized as follows: Sect. 2 reviews the related works for SR, CAR and CISR. Section 3 presents the network architecture of JRCNN and the training methodology. Section 4 shows the extensive experiments on different datasets along with ablation studies. Finally, Sect. 5 is the conclusion.
2 Related work
Recently, deep learning-based methods have gain popularity due to the availability of modern GPUs and they can produce state-of-the-art performance. Different methods have been proposed for SR, CAR and CISR using DNNs. A three-layered DNN named SRCNN has been proposed for SR [8] with lightweight. The SRCNN cannot perform multi-scale SR. Moreover, SRCNN takes interpolated LR image as input. To accelerate the SRCNN, a network named FSRCNN [9] has been proposed. The FSRCNN improved the speed of training and testing by directly performing SR of LR image using deconvolution layer as output layer without needing any interpolation. The FSRCNN also cannot provide multi-scale SR. To provide multi-scale SR, a very deep network named VDSR [16] has been proposed with 20 layers. However, the VDSR requires bicubic interpolation of LR image to support multi-scale SR. Similar to the VDSR, a denoising network named DnCNN [36] has been proposed with batch-normalization layers. The DnCNN can perform multiple tasks like SR, CAR and denoising. Densely connected DNN with deep dilation filters has been proposed in DenseDbSR [2] to perform SR, deblocking and simultaneous deblocking, SR. To control the number of parameters, recursive learning has been proposed with local and global residual connections in DRRN [28] for SR. The DRRN contains up to 52 convolutional layers. In LapSRN [18], the sub-band residuals of HR images are reconstructed at multiple pyramid levels. Furthermore, the LapSRN uses recursive learning for parameter sharing across as well as within pyramid levels.
A persistent memory network [29] consisting of recursive units and gate units has been proposed for three image restoration tasks, i.e., JPEG deblocking, SR and denoising. The optimal balance between the accuracy and the speed for SR has been achieved with balanced two-stage residual network (BTSRN) [10] with constrained depth. Different from other methods, SRMD network [37] has been proposed for SR with multiple degradations by considering blur kernel and noise level. A multi-level wavelet DNN (MWCNN) has been proposed [21] to reduce the computational cost by adopting U-Net architecture for SR. The MWCNN consists of contracting sub-network for reducing the size of feature maps by applying wavelet transform and expanding the sub-network for constructing the HR images by deploying inverse wavelet transform. A cascading residual network (CARN) has been proposed [1] for accurate SR with multiple local and global cascading connections which allow efficient flow of data and gradients. An enhanced deep SR (EDSR) network has been proposed [20] for performance improvement by removing the batch-normalization layer in the residual block.
A combination of cascading residual network (CRN) and an enhanced residual network (ERN) has been proposed [19] for SR. The CRN contains several locally sharing groups (LSGs) to promote propagation of information and gradients. The ERN enhances the image resolution. A residual dense network (RDN) has been proposed [39] for SR to fully exploit the hierarchical features from all the layers. The RDN uses a contiguous memory (CM) mechanism to improve the SR performance. A residual channel attention network (RCAN) has been proposed [38] for SR to learn high frequency information and low frequency information is bypassed through multiple skip connections with residual in residual (RIR) structure. Very recently, progressive growing methodologies have been proposed [22] for SR using a generative adversarial network (PG-GAN). In the PG-GAN, the training has been stabilized and accelerated by adopting progressive growing methodologies. An embedded block residual network (EBRN) has been proposed [26] with shallower modules for low frequency estimation and deeper modules for estimation of high frequency information.
In the past decade, several methods have been proposed for the reduction of JPEG compression artifacts. Most of the existing methods have been proposed to remove blocking artifacts. Recently, the DNN-based methods have been proposed to remove visually dominating artifacts occurred during JPEG compression and decompression, i.e., blocking, ringing and blurring. Shape adaptive discrete cosine transformation (SA-DCT) in conjunction with local polynomial approximation (LPA) has been used [11] for deblocking and deringing. To address JPEG compression artifacts a DNN named ARCNN has been proposed [7] with large-stride convolutional and deconvolutional layers. The ARCNN has a compact structure with just four convolutional layers but multi-scale CAR is not possible. A filter-based deblocking method [14] has been proposed by treating the blocking artifacts as an outlier random variable. This method aims at preserving the edge structures while removing the artifact outliers. CONstrained non-COnvex LOw-Rank (CONCOLOR) model has been proposed [35] by formulating deblocking as an optimization problem within maximum a posteriori framework.
A flexible learning framework has been proposed [6] based on trainable nonlinear reaction diffusion (TNRD) for various image restoration problems, i.e., SR, CAR and denoising. A 12-layer DNN named CAS-CNN has been proposed [4] with hierarchical skip connections and a multi-scale loss function to suppress compression artifacts. A slight modified version of CONCOLOR has been proposed with two new priors, i.e., structural sparse representation (SSR) prior and quantization constraint (QC) prior [40] for efficient deblocking. In the SSRQC method, the SSR prior is used for simultaneous enforcement of the intrinsic local sparsity and the nonlocal self-similarity of natural images and QC is used to ensure a more reliable and robust estimation. An adaptive distribution estimation and QC in DCT domain has been used in addition to patch sparse modeling in PCA domains on external images for robust deblocking [27]. A residual encoder–decoder (RED) network has been proposed [23] with dense skip connections among different convolutional and deconvolutional layers for multiple image restoration tasks. A modified inception module-based artifact removal DNN (IACNN) has been proposed [17] for blind and non-blind CAR. In IACNN, the compression quality factor is estimated first from the real compressed image and then the corresponding trained model has been used for CAR.
A highly compressed image is usually not only of low resolution but also contains visually annoying complex artifacts. Direct SR of these images would also magnify the artifacts. To solve this problem, a learning-based joint SR and deblocking (LJSRDB) method has been proposed [13]. In the LJSRDB method, sparse representation of LR and HR image patches with and without blocking artifacts have been exploited for joint SR and deblocking. Furthermore, morphological component analysis (MCA)-based image decomposition is also employed. Adjusted Anchored Neighborhood Regression (A+) [30] method has been proposed to increase the spatial resolution of an image with compression noise. SR in compressed domain based on field of experts (SRCDFOE) has been proposed [33] to produce visually pleasing images from compressed and LR images. In SRCDFOE method, HR image is modeled as a high-order Markov random field while compression is modeled as an additive and spatially correlated Gaussian noise. Recently, an end-to-end learning-based DNN has been proposed [5] with the name CISRDCNN to address SR of a compressed as well as LR image. The proposed JRCNN is also an end-to-end learning framework which is used to enhance the spatial resolution of the compressed low resolution images.
3 Methodology
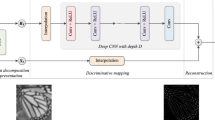
In this section, the architecture and the structural components proposed for compressed image SR are discussed. The architecture of the JRCNN is shown in Fig. 4. The JRCNN takes \(I_\mathrm{LQ}\) image as input and produces the corresponding \(I_\mathrm{Res}\) of \(I_\mathrm{HR}\) image. In SR, the input and the output images are highly correlated. Moreover, residual learning eases the training of the JRCNN. As shown in Fig. 4, the JRCNN consists of 47 convolutional layers and 2 transposed convolutional layers. Each of these layers are followed by a LeakyReLu layer with a scaling factor of 0.2 except the last convolutional layer which reconstructs \(I_\mathrm{Res}\) of \(I_\mathrm{HR}\) image. As shown in Fig. 4, the JRCNN mainly consists of four parts: first convolutional layer (Conv1) for low-level feature extraction, three dense residual blocks for high level feature extraction, two transposed convolutional layers for up scaling operation and the final convolutional layer for reconstruction.

Architecture of the JRCNN

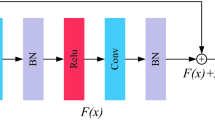
Structure of dense residual block
3.1 Low-level feature representations
The input to the Conv1 layer is a single channel \(I_\mathrm{LQ}\) image. The Conv1 layer extracts the low-level features like edges and blobs from the \(I_\mathrm{LQ}\) image. The Conv1 layer has 64 filters each of size \(3\times 3\). The output of Conv1 layer is 64 low-level feature representations (\(F_O\)) of \(I_\mathrm{LQ}\) image. The learned \(F_O\) is represented as follows:
where \(H_\mathrm{LF}{(.)}\) is the convolution operation. \(F_O\) is then used for high-level feature extraction with DRB.
3.2 Dense residual block
Dense residual block (DRB) is shown in Fig. 5. The DRB takes \(F_O\) as input and produces high-level feature representations (\(F_H\)). The \(F_H\) can be formulated as follows:
where \(H_{\mathrm{DRB}}(.)\) is the proposed DRB structure which contains parallel convolutional layers (PCL). The PCL contains two categories of convolutional layers. The first category contains seven convolutional layers each consisting of 64 filters of size \(1\times 1\). Similarly, the second category contains seven convolutional layers each consisting of 64 filters of size \(3\times 3\). There are residual connections between each convolutional layers in the two categories of PCL. Furthermore, cross residual connections (CRC) are provided between two categories to share feature representations from different convolutional layers. This type of structure eases the training and can help to increase the depth of DNN. A total of three DRBs are used in the JRCNN. Moreover, skip connections are used between each DRB to improve the representational power of the JRCNN by learning diverse sets of features. The feature representations learned from the previous layer are skipped to the current layer and then transferred to the next layer. All the feature representations are concatenated channel-wise. This strategy mitigates the feature redundancy by avoiding feature relearning.
In each of the DRBs, the feature representations from the previous convolutional layers are added element-wise in PCL to ease the training. All the feature representations from each of the DRBs are concatenated channel-wise to extract hierarchical features. All these features are extracted in the LR space. The goal of SR is to recover more useful information from the available abundant information in the LR inputs and the features. The skip connections make short paths for information and gradient flow thereby avoiding vanishing of gradients. Furthermore, feature representations from different layers are concatenated channel-wise to learn diverse set of features and improves the representational power of the model. In addition, feature redundancy is also avoided using skip connections.
The features learned from the DRB are then feed into bottleneck layer (1\(\times \)1 convolutional layer) introduced after the final DRB. The bottleneck layer reduces the number of feature representations that are extracted from the previous layers and reduces the burden on the transposed convolutional layer. The features extracted from bottleneck layer are formulated as follows:
where \(H_\mathrm{BNeck}(.)\) denotes the convolution operation in the bottleneck layer. These features are then upscaled using a upscale module.
3.3 Upscaling
The transposed convolutional layer upsamples the features extracted from the bottleneck layer to increase the spatial resolution of features. In the JRCNN, two transposed convolutional layers are used. The upscaled features extracted from the first transposed convolutional layer are formulated as follows:
where \(H_{UP_1}(.)\) and \(F_{UP_1}\) denote the upscale module and the upscaled features, respectively. Two additional convolutional layers are used after the first transposed convolutional layer to enhance the upscaled features. Different from the other networks [38, 39], the JRCNN has two transposed convolutional layers. Different upscaling factors are produced using two transposed convolutional layers as represented in Fig. 4. The stride of the first transposed convolutional layer is 2, 3 and 2 and the second transposed convolutional layer is 1, 1 and 2 for \(\times 2\), \(\times 3\) and \(\times 4\), respectively. The output of feature enhancement layers Conv3 and Conv4 are formulated as follows:
where \(H_{\mathrm{Conv}3}(.)\) and \(H_{\mathrm{Conv}4}(.)\) represent the convolution of features from enhancement layers Conv3 and Conv4, respectively. \(F_\mathrm{Enhance}\) is the enhanced feature representation of the enhancement layers. The first and second transposed convolutional layers have 64 filters each of size \(3\times 3\). Similarly, the two convolutional layers used for feature enhancement also have 64 filters each of size \(3\times 3\). To increase the spatial resolution further, one more transposed convolutional layer is introduced after the enhancement layers. The feature representations of second transposed convolutional layer are formulated as follows:
where \(H_{UP_2}(.)\) and \(F_{UP_2}\) denote the second upscale module and the upscaled features using second transposed convolutional layer, respectively. These features are then fed to the final reconstruction layer to extract the final reconstructed \(I_\mathrm{Res}\) image.
3.4 Reconstruction
The reconstruction layer is the final convolutional layer which has a single filter of size 3\(\times \)3 to reconstruct the required output. The reconstruction layer produces the residual of the required SR image. The reconstructed \(I_\mathrm{Res}\) image is formulated as follows:
where \(H_\mathrm{Res}(.)\) and \(I_\mathrm{Res}\) represent the reconstruction layer and the reconstructed image. The loss of high frequency information while interpolating an image results in a blurred image. The bicubic interpolation introduces blurring artifacts. Subtracting \(I_\mathrm{Bic}\) from \(I_\mathrm{HR}\) produces \(I_\mathrm{Res}\). So, \(I_\mathrm{Res}\) image contains only the high frequency information like edges, textures and complex patterns. The final SR image is obtained by adding \(I_\mathrm{Res}\) to the bicubic interpolated \(I_\mathrm{Bic}\) image of \(I_\mathrm{LQ}\) image. The \(I_\mathrm{SR}\) image is formulated as follows:
3.5 Training
An end-to-end mapping function is learned between the \(I_\mathrm{LQ}\) image and the \(I_\mathrm{Res}\) image by minimizing the mean squared error (MSE) using the JRCNN. Let \(\{{I_\mathrm{LQ}}^i,{I_\mathrm{Res}}^i\}\) represent the \(i^{th}\) training pair of N training samples and \(\Theta \) represent the network weight parameters of \(K^{th}\) layer. The MSE is formulated as follows:
where \(\lambda \) represents the weight decay (regularization) factor used to avoid under-or-over fitting. The MSE in Eq. 10 is minimized using Adam optimizer with 32 samples in each minibatch. Standard gradient descent method is used on each minibatch to optimize the error. The parameters \(\beta _1\) and \(\beta _2\) of Adam optimizer are set to 0.9 and 0.999, respectively.
4 Experimental analysis
In this section, a complete analysis of extensive experimental results on different datasets are provided quantitatively and qualitatively. Furthermore, the experimental settings and the structural comparison of the JRCNN with other methods are also provided.
4.1 Experimental settings
Number of filters and filter size are key factors which decide the performance of the JRCNN. The JRCNN has a total of 47 convolutional layers and 2 transposed convolutional layers all with 64 filters of size 3\(\times \)3. The convolutional layer which serves as a bottleneck layer that has filters of size 1\(\times \)1 only. The residual connections and the skip connections also improve the performance. Moreover in the JRCNN structure, cross residual connections are provided between the parallel convolutional layers (PCL) for efficient flow of feature representations.
Training is performed by optimizing MSE using Adam optimizer on minibatches of size 32. \(l_2\)-norm regularization with weight decay factor (\(\lambda \)) of \(10^{-5}\) is used. The JRCNN is trained for 100 epochs with initial learning rate set to \(10^{-4}\). After 50 epochs, the learning rate is reduced by 10\(\%\). Gradient clipping is not used as initial learning rate is very small. Patches of size 41\(\times \)41 are extracted from DIV2K dataset [31] images. A total of 16000 training pairs are extracted from 800 images of DIV2K training dataset. NVIDIA Tesla K40c GPU is used for training. For training and testing, MATLAB 2019b framework is used.
4.2 Degradation model
Bicubic degradation is used for SR. JPEG compression is used for CAR. In addition to bicubic degradation, JPEG compression is also used for CISR. The synthetic degraded images are formed by reducing the spatial resolution of image using bicubic interpolation and compressing the output image with JPEG coder. The color image is first transformed into YCbCr space. Only the luminance component (Y) is used for training. All the degradations are present in the Y channel only as Cb and Cr represent the chrome components. The following are the experiments performed on the synthesized image:
-
The SR with three different up scaling factors 2, 3 and 4.
-
The CAR with four different JPEG quality factors QF = {10, 20, 30 and 40}.
-
The CISR with three different JPEG quality factors QF = {10, 20 and 30} and an up scaling factor of 2.
4.3 Datasets
For comparison with state-of-the-art methods, different benchmark datasets have been used for different applications.
4.3.1 SR datasets
For training, 800 images from DIV2K [31] images are considered as all the methods [20, 37, 39] used the same dataset. For validation 100 images from validation set of DIV2K dataset are used. For testing, the benchmark datasets are: Set5 [3], Set14 [34], B100 [24], Urban100 [12] and Manga109 [25].
Training is performed with 400 images by combining 200 training and 200 testing images from BSDS500 [24] dataset. Validation is performed with 100 images from the validation set of BSDS500 dataset. For testing benchmark datasets are: classic5 [7], LIVE1 [7] and B100 [24]

Visual quality comparison for SR (\(\times \)4)
4.3.2 CAR datasets
Training is performed with 400 images by combining 200 training and 200 testing images from BSDS500 ([24]) dataset. Validation is performed with 100 images from the validation set of BSDS500 dataset. For testing benchmark datasets are: classic5 ([7]), LIVE1 ([7]) and B100 ([24])
4.3.3 CISR datasets
For CISR training and validation are performed on same datasets used for CAR. The testing is performed on Set10 [5] images considered in the CISRDCNN. Furthermore, three more datasets Set5 [3], Set14 [34] and B100 [24] are also used to assess the performance of the JRCNN.

Visual quality comparison for CAR (QF = 10

Visual quality comparison for CISR (\(\times \)2 and QF = 20)

Test time comparison on Set5 dataset for QF = 10 and \(\times \)2
4.4 Compared methods and metrics
The SR performance of the JRCNN is compared with SRCNN [8], FSRCNN [9], VDSR [16], DnCNN [36], DenseDbSR [2], DRRN [28], LapSRN [18], MemNet [29], BTSRN [10], SRMD [37], MWCNN [21], CARN [1], EDSR [20], CRN [19], ERN [19], RDN [39], RCAN [38], PG-GAN [22] and EBRN [26]. The CAR performance of the JRCNN is compared with SA-DCT [11], ARCNN [7], CONCOLOR [35], TNRD [6], CAS-CNN [4], SSRQC [40], EPCA [27], RED30 [23], DnCNN [36], IACNN [17] and DenseDbSR [2]. Similarly, the baseline methods used for CISR performance comparison of the JRCNN are LJSRDB [13], A+ [30], SRCDFOE [33], CONCOLOR-VDSR [16, 35], ARCNN-TNRD [6, 7], ARCNN-VDSR [7, 16], ARCNN-DnCNN [7, 36], FSRCNN [9], VDSR [16], DenseDbSR [2] and CISRDCNN [5]. The CONCOLOR-VDSR [16, 35], ARCNN-TNRD [6, 7], ARCNN-VDSR [6, 7] and ARCNN-DnCNN [7, 36] are cascading methods which consist of state-of-the-art CAR and SR methods.
In this paper, the widely used Peak Signal to Noise Ratio (PSNR) and Structural SIMilarity (SSIM) index [41] are used for objective performance comparison with the other state-of-the-art methods.
4.5 Objective evaluation on synthetic images
4.5.1 Quantitative analysis for SR
Table 1 represents the comparison of SR objective metrics on different benchmark datasets with the state-of-the-art methods. B100 [24] dataset consists of natural scenes. The JRCNN produces better performance on B100 [24] dataset. Urban100 dataset [12] contains 100 urban images with complex patterns and restoring these patterns while up scaling the images is a very challenging task. The proposed JRCNN outperforms the existing state-of-the-art methods on Urban100 dataset. The performance of the JRCNN is competitive with other recent state-of-the-art methods. For all the up scaling factors, i.e., \(\times \)2, \(\times \)3 and \(\times \)4, the JRCNN outperforms all the state-of-the-art methods.
The proposed JRCNN achieves 1.7dB improvement in the PSNR on Set5 dataset for \(\times \)2 when compared to SRCNN [8] method. The proposed JRCNN outperforms the recent state-of-the-art methods RDN [39], RCAN [38] and produces the competitive performance when compared to PG-GAN [22] and EBRN [26].
4.5.2 Quantitative analysis for CAR
Table 2 represents the comparison of CAR objective metrics on different benchmark datasets with the state-of-the-art methods. Overall, the DenseDbSR produces second best performance. The ARCNNN [7], CONCOLOR [35] and TNRD [6] are superior to SA-DCT [11] but the gains are limited to some extent. The DnCNN [36] and IACNN [17] are competitive to each other. The proposed JRCNN achieves the best performance for all the quality factors. A PSNR gain of 0.98dB is achieved with the JRCNN on classic5 dataset for QF = 10 when compared to the ARCNN [7].
4.5.3 Quantitative analysis for CISR
Table 3 represents the PSNR(dB) comparison of CISR objective metrics on Set10 dataset with the state-of-the-art methods. Overall, the CISRDCNN [5] generates the second-best results. The FSRCNN [9], ARCNN-VDSR [7, 16] and ARCNN-DnCNN [7, 36] achieve similar performance, and all of them are slightly inferior to the VDSR [16]. The A+ [30], CONCOLOR-VDSR [16, 35] and SRCDFOE [33] are superior to bicubic, but the gains are limited to some extent.
Table 4 represents the SSIM comparison of CISR objective metrics on Set10 dataset with the state-of-the-art methods. The SSIM measures the structural similarity between the restored image and the \(I_\mathrm{HR}\) image. The SSIM metric of the JRCNN is the highest when compared to the other methods for all the images of Set10 dataset. From Table 4, one can clearly observe that the structural content restoration of the JRCNN is the best.
4.6 CISR performance on benchmark datasets
To better assess the stability and robustness of the JRCNN, the performance metrics for four widely used benchmark datasets, i.e., Set5 [3], Set14 [34], B100 [24] and Urban100 [12] are shown in Table 5. The images in B100 [24] are cropped to generate test images of size 256\(\times \)256. Similarly, the images in Urban100 [12] dataset are cropped to generate test images of size 512\(\times \)512. From Table 5, one can see that the JRCNN consistently outperforms all of the compared methods. On an average the JRCNN achieves a PNSR gain of 0.3dB on all the datasets when compared to the next best CISRDCNN [5] method.
4.7 Subjective evaluation on synthetic images
In this section, the visual comparison analysis of images from standard datasets are performed. Different images from the different benchmark datasets for SR, CAR and CISR are considered. Figures 6, 7 and 8 represent the visual comparison for SR, CAR and CISR, respectively.
4.7.1 Qualitative analysis for SR
The visual comparison of restored images from different state-of-the-art methods for SR is shown in Fig. 6. A small patch from the barbara image of the Set14 [34] dataset is cropped. The cropped portion is super resolved by a factor of 4. The cropped portion has regular structures and complex patterns. The regular structures restored from all the state-of-the-art methods are distorted. The reconstructed patch by the JRCNN is visually pleasing and all the regular structures are restored accurately. The PSNR and SSIM values are also shown in Fig. 6. The EDSR [20], RDN [39] and RCAN [38] achieve better PNSR but the visual quality of the restored image is not good as it contains regular structure distortions. Quantitatively and qualitatively the JRCNN produces the best results for SR.
4.7.2 Qualitative analysis for CAR
The deblocking and deringing capability of the JRCNN is visually analyzed by extracting a small portion from the parrots image of LIVE1 [7] dataset. The zoomed version of the extracted patch is shown in Fig. 7. The JPEG decompressed patch contains blocking and ringing artifacts. A Small 8\(\times \)8 blocks can be observed in the restored patch. Similarly, ringing artifacts can be clearly observed around the edges. The JRCNN seamlessly attenuates the blocking and ringing artifacts which can be clearly observed in Fig. 7. The visual quality of the patches restored by the IACNN [17], DenseDbSR [2] and JRCNN are competitive.
4.7.3 Qualitative analysis for CISR
The visual quality of the restored image patches using different methods corrupted by compression and bicubic degradation is shown in Fig. 7. The visual quality of the image produced by the JRCNN is visually pleasing. Moreover, the JRCNN restores textures accurately. The visual quality of the CISRDCNN [5] and JRCNN are competitive. The bicubic interpolated image contains blurring, ringing and blocking artifacts. The DNN-based cascaded methods, i.e., ARCNN-TNRD [6, 7], ARCNN-VDSR [6, 7] and ARCNN-DnCNN [7, 36] produces blurred outputs. Basically, in cascaded methods, the CAR stage removes some of the information required for SR stage and produces blurred images. Similarly, the SR stage amplifies compression artifacts and CAR stage cannot suppress all the amplified artifacts and produces visually annoying output. The end-to-end learning frameworks, i.e., CISRDCNN [5] and the proposed JRCNN produces visually plausible images.
4.8 Time analysis
For real time applications testing time is also one of the key factors which decides the robustness of any network. Test time comparisons of different DNN-based methods is shown in Fig. 9. For fair comparison with the JRCNN only DNN-based methods are considered. The test time plot shown in Fig. 9 represents the average PSNR in dB and the average test time in Sec of Set5 dataset images for QF = 10 and \(\times \)2. Out of all compared methods, the JRCNN is the fastest method. The JRCNN outperforms the next best CISRDNN [5] method by a margin of 0.32dB. When it comes to speed the FSRCNN [9] is the second best method after the JRCNN.
5 Conclusion
A deep learning-based joint restoration DNN is proposed with cross residual connections, dense skip connections and parallel convolutional layers for an efficient super resolution of compressed and low resolution images. The cross residual connections and dense skip connections helped to ease the training by mitigating the problem of gradient vanishing/exploding. The parallel convolutional layer structure improved the efficiency of the proposed network by performing parallel convolution operations. A notable gain is achieved in performance metrics when compared to the state-of-the-art methods. The visual quality of the restored images by the proposed network is good when compared to other existing methods. Using the proposed network, three different restoration tasks, i.e., super resolution, compression artifacts removal and compressed low resolution image super resolution are also performed. The robustness and the stability of the proposed network is assessed by performing restoration tasks on different benchmark datasets.
References
Ahn, N., Kang, B., Sohn, K.A.: Fast, accurate, and lightweight super-resolution with cascading residual network. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision—ECCV 2018, pp. 256–272. Springer International Publishing, Cham (2018)
Amaranageswarao, G., Deivalakshmi, S., Ko, S.-B.: Residual learning based densely connected deep dilated network for joint deblocking and super resolution. Appl. Intell. (2020). https://doi.org/10.1007/s10489-020-01670-y
Bevilacqua, M., Roumy, A., Guillemot, C.: line Alberi Morel M (2012) Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the British Machine Vision Conference, BMVA Press, pp 135.1–135.10, https://doi.org/10.5244/C.26.135
Cavigelli, L., Hager, P., Benini, L.: Cas-cnn: A deep convolutional neural network for image compression artifact suppression. In: 2017 International Joint Conference on Neural Networks (IJCNN), pp 752–759 (2017) https://doi.org/10.1109/IJCNN.2017.7965927
Chen, H., He, X., Ren, C., Qing, L., Teng, Q.: Cisrdcnn: super-resolution of compressed images using deep convolutional neural networks. Neurocomputing 285, 204–219 (2018). https://doi.org/10.1016/j.neucom.2018.01.043
Chen, Y., Pock, T.: Trainable nonlinear reaction diffusion: a flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1256–1272 (2017). https://doi.org/10.1109/TPAMI.2016.2596743
Dong, C., Deng, Y., Loy, C.C., Tang, X.: Compression artifacts reduction by a deep convolutional network. In: 2015 IEEE International Conference on Computer Vision (ICCV), pp. 576–584 (2015) https://doi.org/10.1109/ICCV.2015.73
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2016). https://doi.org/10.1109/TPAMI.2015.2439281
Dong, C., Loy, C.C., Tang, X.: Accelerating the super-resolution convolutional neural network. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision—ECCV 2016, pp. 391–407. Springer International Publishing, Cham (2016)
Fan, Y., Shi, H., Yu, J., Liu, D., Han, W., Yu, H., Wang, Z., Wang, X., Huang, T.S.: Balanced two-stage residual networks for image super-resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1157–1164 (2017) https://doi.org/10.1109/CVPRW.2017.154
Foi, A., Katkovnik, V., Egiazarian, K.: Pointwise shape-adaptive dct for high-quality denoising and deblocking of grayscale and color images. IEEE Trans. Image Process. 16(5), 1395–1411 (2007). https://doi.org/10.1109/TIP.2007.891788
Huang, J., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5197–5206 (2015) https://doi.org/10.1109/CVPR.2015.7299156
Kang, L., Hsu, C., Zhuang, B., Lin, C., Yeh, C.: Learning-based joint super-resolution and deblocking for a highly compressed image. IEEE Trans. Multimed. 17(7), 921–934 (2015)
Kayhan, S.K.: Efficient robust filtering technique for blocking artifacts reduction. Vis. Comput. (2015). https://doi.org/10.1007/s00371-015-1068-0
Keys, R.: Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 29(6), 1153–1160 (1981)
Kim, J., Lee, J.K., Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1646–1654 (2016) https://doi.org/10.1109/CVPR.2016.182
Kim, Y., Soh, J.W., Park, J., Ahn, B., Lee, H., Moon, Y., Cho, N.I.: A pseudo-blind convolutional neural network for the reduction of compression artifacts. IEEE Trans. Circuits Syst. Video Technol. (2019). https://doi.org/10.1109/TCSVT.2019.2901919
Lai, W., Huang, J., Ahuja, N., Yang, M.: Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 41(11), 2599–2613 (2019). https://doi.org/10.1109/TPAMI.2018.2865304
Lan, R., Sun, L., Liu, Z., Lu, H., Su, Z., Pang, C., Luo, X.: Cascading and enhanced residual networks for accurate single-image super-resolution. IEEE Trans. Cybern. (2020)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1132–1140 (2017) https://doi.org/10.1109/CVPRW.2017.151
Liu, P., Zhang, H., Zhang, K., Lin, L., Zuo, W.: Multi-level wavelet-cnn for image restoration. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 886–88609 (2018) https://doi.org/10.1109/CVPRW.2018.00121
Ma, T., Tian, W.: Back-projection-based progressive growing generative adversarial network for single image super-resolution. In: Vis Comput (2020)
Mao, X., Shen, C., Yang, Y.B.: Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In: Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R. (eds.) Advances in Neural Information Processing Systems 29, Curran Associates, Inc., pp. 2802–2810 (2016)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, vol 2, vol. 2, pp. 416–423 (2001) https://doi.org/10.1109/ICCV.2001.937655
Matsui, Y., Ito, K., Aramaki, Y., Fujimoto, A., Ogawa, T., Yamasaki, T., Aizawa, K.: Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 76(20), 21811–21838 (2017). https://doi.org/10.1007/s11042-016-4020-z
Qiu, Y., Wang, R., Tao, D., Cheng, J.: Embedded block residual network: A recursive restoration model for single-image super-resolution. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4179–4188 (2019)
Song, Q., Xiong, R., Fan, X., Liu, X., Huang, T., Gao, W.: Compressed image restoration via external-image assisted band adaptive pca model learning. In: 2018 Data Compression Conference, pp. 97–106 (2018) https://doi.org/10.1109/DCC.2018.00018
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2790–2798 (2017) https://doi.org/10.1109/CVPR.2017.298
Tai, Y., Yang, J., Liu, X., Xu, C.: Memnet: A persistent memory network for image restoration. In: 2017 IEEE International Conference on Computer Vision (ICCV), pp. 4549–4557 (2017b) https://doi.org/10.1109/ICCV.2017.486
Timofte, R., DéSmet, V., Van Gool, L.: A+: adjusted anchored neighborhood regression for fast super-resolution. ACCV 9006, 111–126 (2015). https://doi.org/10.1007/978-3-319-16817-3_8
Timofte, R., Agustsson, E., Gool, L.V., Yang, M., Zhang, L., Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M., Wang, X., Tian, Y., Yu, K., Zhang, Y., Wu, S., Dong, C., Lin, L,, Qiao, Y., Loy, C.C., Bae, W., Yoo, J., Han, Y,, Ye, J.C., Choi, J., Kim, M., Fan, Y,, Yu, J., Han, W., Liu, D., Yu, H., Wang, Z., Shi, H., Wang, X,, Huang, T.S., Chen, Y., Zhang, K., Zuo, W., Tang, Z., Luo, L., Li. S., Fu, M., Cao, L., Heng, W., Bui, G., Le, T., Duan, Y., Tao, D., Wang, R., Lin, X., Pang, J., Xu, J., Zhao, Y., Xu, X., Pan, J., Sun, D., Zhang, Y., Song, X., Dai, Y., Qin, X., Huynh, X., Guo, T., Mousavi, H.S., Vu, T.H., Monga, V., Cruz, C., Egiazarian, K., Katkovnik, V., Mehta, R., Jain, A.K., Agarwalla, A., Praveen, C.V.S., Zhou, R., Wen, H., Zhu, C., Xia, Z., Wang, Z., Guo, Q.: Ntire 2017 challenge on single image super-resolution: Methods and results. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1110–1121 (2017) https://doi.org/10.1109/CVPRW.2017.149
Wallace, G.K.: The jpeg still picture compression standard. IEEE Trans. Consum. Electron. 38(1), xviii–xxxiv (1992)
Xiao, J., Wang, C., Hu, X.: Single image super-resolution in compressed domain based on field of expert prior. In: 2012 5th International Congress on Image and Signal Processing, pp. 607–611 (2012)
Zeyde, R., Elad, M., Protter M.: On single image scale-up using sparse-representations. 6920, 711–730 (2010). https://doi.org/10.1007/978-3-642-27413-8_47
Zhang, J., Xiong, R., Zhao, C., Zhang, Y., Ma, S., Gao, W.: Concolor: Constrained non-convex low-rank model for image deblocking. IEEE Trans. Image Process. 25(3), 1246–1259 (2016). https://doi.org/10.1109/TIP.2016.2515985
Zhang, K., Zuo, W., Chen, Y., Meng, D., Zhang, L.: Beyond a gaussian denoiser: residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 26(7), 3142–3155 (2017). https://doi.org/10.1109/TIP.2017.2662206
Zhang, K., Zuo, W., Zhang, L.: Learning a single convolutional super-resolution network for multiple degradations. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3262–3271 (2018) https://doi.org/10.1109/CVPR.2018.00344
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision—ECCV 2018, pp. 294–310. Springer International Publishing, Cham (2018)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2472–2481 (2018) https://doi.org/10.1109/CVPR.2018.00262
Zhao, C., Zhang, J., Ma, S., Fan, X., Zhang, Y., Gao, W.: Reducing image compression artifacts by structural sparse representation and quantization constraint prior. IEEE Trans. Circuits Syst. Video Technol. 27(10), 2057–2071 (2017). https://doi.org/10.1109/TCSVT.2016.2580399
Wang, Zhou, Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004). https://doi.org/10.1109/TIP.2003.819861
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Amaranageswarao, G., Deivalakshmi, S. & Ko, SB. Joint restoration convolutional neural network for low-quality image super resolution. Vis Comput 38, 31–50 (2022). https://doi.org/10.1007/s00371-020-01998-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-020-01998-z