
Abstract
Shadow removal is a challenging problem due to its sensitivity to lighting and material conditions. In this paper, we propose a shading-aware shadow processing algorithm, which can automatically detect and remove complex shadows from a single color image. Our framework consists of two key steps. We firstly conduct a shadow-preserving filter upon the image which will effectively remove the image texture while preserving the shadow and shading information. Shadow regions are estimated by establishing a confidence map from the filtered image incorporating depth cue. We then develop a shading-aware optimization framework to remove shadows and recover shading in these regions. The extensive experimental results show that the proposed algorithm produces visually compelling results in a series of challenging images and it can handle complex shadows in both indoor and outdoor scenes. Quantitative and qualitative comparisons with current state-of-the-art methods strongly demonstrate the efficacy of our proposed approach.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Shadow is a ubiquitous natural phenomenon in our daily life. Although shadows can provide useful clues for illumination estimation [46], scene depiction [20] and object shapes [32], shadows also degrade the performance of some applications, such as object recognition [7], object tracking [29] and intrinsic image decomposition [25]. Therefore, it is a fundamental problem to detect and remove shadows from single images and will definitely be beneficial for computer vision and graphics communities.
Shadow removal involves three main challenges. First, for the image with complex shadows like a surface with both soft and hard shadow, accurate shadow detection is challenging. Second, there are usually texture details losing on hard shadow boundaries, which will induce visual artifacts on these boundaries during shadow removing [40, 48]. Finally, to obtain visually consistent shadow removal results, the shading information should be preserved in the shadow-free image [42].

Our visualization results of shadow detection and removal. From left to right are a input images, b shadow confidence maps and c shadow removal results.
To overcome the above challenges, we propose an automatic shadow detection and removal method by jointly exploring color cues as well as depth information. First, based on the observation that shadows essentially appear as smooth and continuous regions, we develop a shadow-preserving filter which effectively removes the image texture while preserving the shadow and shading information. This filter enables to estimate more accurate shadow confidence map and benefits better shadow detection results. Second, to effectively detect the complex shadow including both hard/soft shadow and local/global shadow, we develop a shadow confidence propagation scheme for shadow detection, which works well on detecting shadows in various environments. Finally, based on the shadow confidence, we present a novel shading-aware shadow removal optimization model. It can effectively remove the shadows while preserving the shading information of the shadow regions well. Moreover, the chromaticity and texture details under the shadow regions are well recovered, as illustrated in Fig. 1.
In summary, our major contributions are threefold as follows:
-
We propose a novel shadow-preserving texture filter. Such a filter is immune to texture, boundary and noise, and enhances shadow and shading information which enables to better shadow confidence estimation.
-
We design a shadow confidence propagation scheme, which propagates the local shadow boundary confidence to the global scene adaptively, enabling to detect both local and global complex shadows.
-
We propose a shading-preserving shadow removal framework which can effectively remove the complex shadow as well as recovering the shading, chromaticity and texture details under the shadow regions.
Our proposed method have been demonstrated on a series of challenging images, including indoor and outdoor scenes with hard and soft shadows. We also compare it with current state-of-the-art methods and show its superior performance in both shadow detection and removal.

Overview of the proposed shadow detection and removal
2 Related work
Shadow detection methods Several user assistance-based shadow detection methods [2, 14, 48] work well on simple shadow scenes, whereas they often require extra tedious user interaction for complex scenarios. Many automatic shadow detection methods have been proposed. For example, Lalonde et al. [22] built a shadow detector for photographs of outdoor scenes, and this method focused on detecting ground shadow. Guo et al. [15] compared pairs of regions and determined whether they were in the same illumination conditions. Nevertheless, this detector may group soft shadows with non-shadow regions and may fail in the case of multiple light sources. Shadow detection for complex shadows is still a challenging problem.
Recently, deep learning based on convolutional neural network has achieved great success in computer vision community and also has been exploited in shadow detection [17, 24, 31, 49]. For example, Nguyen et al. [31] detected shadow using conditional generative adversarial networks. Hu et al. [17] analyzed image context and detected shadow in direction-aware manner. To obtain satisfying results, deep learning methods depend on large and good training data. For some complex scenes, the training data are difficult to collect, and the results are not satisfactory.
Shadow removal methods Traditional shadow removal methods were proposed mainly based on gradient domain manipulation [11, 26, 30]. To receive satisfactory results, these methods depend on accurate shadow edges detection for shadow-free image reconstruction. Shadow matting was also exploited in shadow detection and removal [6, 14, 23, 39], while these methods do not preserve the shading well in the shadow-free image. Inspired by the color transfer theory [34], several shadow removal methods have been proposed based on illumination or color transferring [35, 41, 47, 48]. To generate good results, for each patch in the shadow regions, these methods need to find corresponding non-shadow regions for illumination transferring.
Several deep learning-based shadow removal methods have also been proposed [9, 18, 33, 37, 45]. Ding et al. [9] removed the shadow in an attentive recurrent way, and Wei et al. [38] preprocessed the shadow image with inpainting method. To address the lack of training data, Hu et al. [18] adopted unpaired data to diverse the samples, and Cun et al. [8] designed a shadow matting generative adversarial network to synthesize realistic shadow images. Obviously, the performance of those learning-based methods heavily depend on the training dataset. However, for images with complex shadows, it is difficult to construct the ground-truth shadow-free images, which makes these methods not sufficiently adept at processing complex shadows. In contrast, the optimization-based methods do not depend on those training dataset and have better generalization ability to handle complex scenes.
As the depth acquisition devices become more and more popular, some researchers have resorted to depth cues for shadow removal [42] and intrinsic image decomposition [3, 4, 16, 19]. Xiao et al. [42] applied depth information to remove shadows in RGB-D image and produced impressive shadow detection and removal results. However, this method is not immune to image texture when performing shadow detection and does not work well for preserving shading in shadow removal results. In this work, we also fall into this category with depth cues. To address existing defects, we make a shadow-preserving texture filter before shadow detection and design a shading-preserving shadow removal framework to get the final result.
3 Shadow detection and removal
Our goal in this paper is to accurately detect the shadows in a single image as well as to effectively remove them while keeping the texture and shading in it. To this end, we first propose an effective shadow detection algorithm that utilize a shadow-preserving filter to effectively remove the textures while preserving the shadow and shading information, and shadow regions are estimated by establishing a confidence map from the filtered image incorporating the depth map (Sect. 3.1). Then, we develop a shading-aware optimization algorithm to remove the shadows and recover the shading in these regions. The details of the image will be recovered by adding the detail layers in a weighted average way (Sect. 3.2). The framework of the overall algorithm is shown in Fig. 2.
3.1 Automatic shadow detection
Natural photographs usually contain complex textures which will affect the accuracy of shadow detection. Inspired by [5, 43], we propose a shadow-preserving bilateral filter for shadow detection. The pipeline of our proposed automatic shadow detection is shown in Fig. 3.
For a complex image, the depth map of the scene would be helpful for shadow confidence estimation. To obtain more accurate shadow confidence map, we apply the depth information of the image into our method. We can acquire the depth map using low-cost depth sensors, such as MS Kinect, or via learning-based methods. Recently, many image depth estimation methods have been proposed [12, 13, 21, 27, 43]. In this paper, for input image without depth map, we apply the method [12] to estimate the depth map.

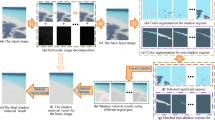
Overview of our shadow detection. Given an input image (a), we first compute the initial shadow confidence (b) and the initial non-shadow confidence (c) with the method in [42], and further estimate the initial shadow boundary (d). Then we estimate the shadow confidence map (f) and the non-shadow confidence map (g) of the filtered image (e) obtained by our shadow-preserving texture filter. Finally, we design a structure-aware confidence propagation scheme to interpolate (f) and (g) around the boundary to other pixels, and obtain the final shadow confidence map (h)
3.1.1 Shadow-preserving texture filter
The proposed shadow-preserving texture filter is defined as
where p represents the current pixel, \(\Omega _{p}\) is the local neighborhood of p, q represents a pixel in \(\Omega _{p}\), S is the shadow-aware texture measure of input image I and \(k_p\) is a normalizing parameter. The spatial kernel f and the range kernel g are Gaussian functions. This is a modification of the bilateral texture filter [5] with the shadow-aware texture similarity instead of structure-aware texture similarity. With the guidance of S, our filter can preserve the shadow boundaries, as shown in Fig. 4.
We assume that texture signal usually has smaller amplitude than shadow boundary. So we first find the patches which contain the shadow boundary, and compute the likelihood of these patches \(\Omega _{p}\) via estimating its shadow range \(\Psi (\Omega _{p})=C_{B}^{\max }(\Omega _{p})-C_{B}^{\min }(\Omega _{p})\). \(C_{B}\) is the shadow boundary confidence and it will be introduced in the next section. \(C_{B}^{\max }(\Omega _{p})\) and \(C_{B}^{\min }(\Omega _{p})\) denote the maximum and the minimum shadow boundary confidence in \(\Omega _{p}\). Intuitively, a patch with the maximum shadow range means a maximal probability of containing the shadow boundary. The shadow-aware texture measure \(S_p\) at p is:
where the pixel q has the largest \(\Psi (\Omega _{q})\) among the neighbor pixels of p. \(C_{B}^\mathrm{{avg}}(\Omega _{q})\) is the average shadow boundary confidence of the region \(\Omega _{q}\), and \(\Omega _{q}\) is the local neighborhood of q.
3.1.2 Shadow confidence estimation
For each pixel p, the shadow confidence is related to the feature similarity between the pixel and its neighbor pixels q, which is defined as:
where \(\alpha _{pq}^{c}\), \(\alpha _{pq}^{n}\) and \(\alpha _{pq}^{d}\) represent the similarity of chromaticity, normal and spatial location between p and q. \(\alpha _{pq}^{c}=\exp (-\frac{\left\| \hbox {ch}(I_{p})-\hbox {ch}(I_{q}) \right\| 2}{2\sigma _\mathrm{{ch}}^{2}})\) , \(\alpha _{pq}^{d}=1-\frac{\left\| \bar{p}-\bar{q} \right\| }{\underset{q\in \Omega _{p}}{\max }\left\| \bar{p}-\bar{q} \right\| }\), and \(\alpha _{pq}^{n}\) is estimated by solving the following optimization function:
\(\underset{\left\{ \alpha _{pq}^{n} \right\} }{\hbox {argmin}}\sum _{p\epsilon I}^{}\left\| n(p)-\sum _{q\in \Omega _p}^{}\alpha _{pq}^{n} n(q)\right\| ^2\) .
Here, \(\hbox {ch}(I_{p})\), n(p) and \(\bar{p}\) are the chromaticity, normal and 3D spatial location of the pixel p, \(\sigma _\mathrm{{ch}}\) is a positive parameter controlling the sensitivity of the similarity (typically is set to 0.1), and \(\Omega _p\) denotes the local neighborhood of p.
With the feature similarity between p and its neighbors, we calculate the corresponding weighted average intensity \(m_{p}=\frac{1}{\sum _{q\in \Omega _{p}}\alpha _{pq}}\sum _{q\in \Omega _p}\alpha _{pq}I_q\) and then estimate the initial shadow confidence \(C_{S}\) and the non-shadow confidence \(C_{U}\) using the method in [42]. The functions are as follows:
The visual maps of these two variables are shown in Fig. 3b, c, respectively. The shadow boundary confidence \(C_{B}\) (Fig. 3d) can be obtained by computing the windowed total variation and windowed inherent variation with \(C_{S}\) and \(C_{U}\).
The shadow-preserving filtered image (Fig. 3e) effectively removes the texture and noise. We can estimate more accurate shadow confidence \(C_{S}\) and non-shadow confidence \(C_{U}\) with the shadow-preserving filtered image, and the results are illustrated in Fig. 3f, g.

Image filtering comparisons. From left to right are a input images, b result using bilateral texture filter [5], c region of interest marked in blue in b, d result using multi-scale shadow-preserving texture filter, e region of interest marked in blue in d, f–h shadow detection results on a, b and d, respectively
3.1.3 Shadow confidence optimization
Due to the properties of feature similarity, the shadow confidence \(C_{S}\) is better estimated around the shadow boundaries. So as to enhance the estimation of the rest shadow regions far from the shadow boundaries, we apply a structure-aware confidence propagation to interpolate the confidence \(C_{S}\) and \(C_{U}\) around the boundary to other regions, and get a more comprehensive shadow confidence map.
Let n be the number of pixels in the image. The shadow confidence \(s_{i}\) of pixel \(p_{i}\) is then obtained by minimizing the following function:
The first term encourages the pixel \(p_i\) with large shadow confidence \(C_{S}(p_{i})\) to get a large value (close to 1). The second term enables the pixel \(p_i\) with large non-shadow confidence \(C_{U}(p_{i})\) to take a small value (close to 0). The last term is a smooth term. For every adjacent pixel pair (i, j), the weight \(w_{ij}\) is the element of matting Laplacian matrix [1]. As the filtered image J is piecewise smoothed with no oscillating texture variations, we can effectively propagate the shadow confidence and non-shadow confidence using the structure of J, and obtain higher-quality shadow confidence.
As shown in Fig. 3h, the optimized shadow confidence map \(C_{S}\) is more accurate than the initial one. The shadow regions are more highlighted, and the gradient information around shadow boundary is preserved as well, which will benefit our shadow removal in the next step.
To further remove the effects of noise and texture structures while detecting the shadows, we propose a multi-scale shadow confidence estimation method. In each filtering, by modifying the filter parameter (window size \(\Omega \) and standard deviation \(\sigma _{s}\)), the texture is progressively smoothed, and shadow boundary is progressively refined. The proposed method is summarized in Algorithm 1.

The advantages of the proposed shadow detection scheme are as follows: (1) Our method is more immune to texture, noise, and receives better shadow and shading information which enables to better shadow detection results; (2) with the local shadow boundary confidence and the global shadow propagation strategy, our method can detect not only local shadow areas, but more complex shadows in the scene. Figures 5 and 6 show the shadow confidence map comparisons with the method in [42].

Effect of the chromaticity term. From left to right are a input images, b, c shadow confidence maps of method [42] and our proposed method, d chromaticity images of a, e shadow removal results of method [42] with our shadow confidence maps c as input, and f, g our shadow removal results without and with chromaticity term, respectively

Effect of the shading-preserving term. From left to right are a input images, b depth maps, c, d shadow confidence maps of method [42] and our proposed method, e shadow removal results of method [42] with our shadow confidence maps d as input, f, g our shadow removal results without and with the shading-preserving term, respectively. Note that the yellow boxes are the part with poor shading, while the same place in the blue boxes preserve the shading well
3.2 Shading-aware shadow removal
3.2.1 Shadow removal
Like [39], the shadow factor can be modeled in the form of:
where F is the shadow-free image and \(\beta \) is a three-channel fractional shadow factor each in [0, 1] for scaling the respective color channel. In this paper, we use the normal information from depth for shadow detection and removal. Our aim is to achieve the shadow-free image F-preserving shading and the shadow factor \(\beta \) excluding shading, as shown in Fig. 6.
To estimate the shadow-free image F and the corresponding shadow factor \(\beta \), we propose the following energy equation for shadow removal:
This energy model contains four terms: data term \(E_\mathrm{{data}}\), shading-preserving smoothing term \(E_\mathrm{{smooth}}\), chromaticity term \(E_\mathrm{{chro}}\) and constant term \(E_\mathrm{{const}}\). The balanced weights \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) are set to 1, 0.5 and 1, respectively, in our experiments.
Data term As we aim to decompose the input image into a product of shadow-free and shadow factor components, we enforce this as a soft constraint via the data fitting term \(E_\mathrm{{data}}\). We assume monochromatic, white illumination and apply the fitting constraint to per color channel, i.e., \(I_{c}\approx F_{c}\cdot \beta _{c}\) , \(c\in \left\{ R,G,B \right\} \). To make the decomposition more robust to white illumination deviations, we use per-channel weights \(w_c\) in the constraint:
where \(\left\{ \omega _{R}, \omega _{G},\omega _{B}\right\} =\left\{ 0.299,0.587,0.114 \right\} \). In addition, based on the observation [28] that low-intensity pixels are more sensitive to the image noise, and pixels with higher intensity provide more decomposition reliability, we incorporate the image intensity weight \(\omega _{iw}(x)=1-\omega _\mathrm{{intensity}}\cdot (1-\left| I(x) \right| )\) in our data term, where \(\left| I(x) \right| \) is the image intensity and \(\omega _\mathrm{{intensity}}\) is the adjustable balance weight.
Shading-preserving smoothing term To obtain visually realistic result of shadow removal, the shading component should be preserved in the shadow-free image F. Our basic assumption is that pixels with similar features, including chromaticity, normal and spatial locations, are likely to have the same color or illumination. Let \(R_s\) be the shadow regions containing neighboring pixels, and two pixels p and q with a large similarity \(\alpha _{pq}\) tend to have the same shadow-free image F. We define the shading-preserving term as:
where \(C_{S}(p)\) is the shadow confidence for pixel p and \(\Omega _{p}\) denotes the local spatial neighbors of p.
When \(C_{S}(p)\) has a large value, which indicates the hard shadow, the smooth constraint on shadow-free image should be more enforced; thus, the recovered illumination could vary with the scene shape and produce more realistic results.
We also define shadow boundary-aware smoothness constraint on \(\beta \). Inspired by the Retinex theory, which have demonstrated that total variation has good performance in promoting illumination smoothness, we adopt the relative total variation (RTV) [44] for producing smooth \(\beta \). We define the shadow map smoothness regularizer as follows:
where \(H(\beta _{p})\) and \(V(\beta _{p})\) denote the horizontal and vertical relative total variation (RTV) measure. In this equation, when \(\left| C_{B}(p) \right| \) has a large value, which indicates the shadow boundary, the shading smoothness should be less enforced.
With the above smoothing constraints on both shadow-free image F and the shadow matte \(\beta \), the smoothing constraint term is defined as:
Chromaticity term We assume that the chromaticity of the input image is not altered by illumination effects such as shading and shadows [10]. In this case, the chromaticity of the unknown shadow-free image F should be the same as that of the input image. With this assumption, we define the following soft constraint as:
where \(c(x)=I(x)/\left| I(x) \right| \) is the chromaticity of the input image and \(c_F\) is the chromaticity of the shadow-free image F, \(c_{F}(x)=F(x)/\left| F(x) \right| \). To avoid division by zero, we further rewrite this term as:
where \(\xi \) is a regularization parameter and is typically set 0.0001 in our experiments.
Constant term We pick out the reliable lit pixels that should maintain their \(\beta \) colors and enforce their values to be 1:
where the \(N_b\) is the reliable lit region that is neither high shadow confidence pixels nor their neighbors.
As illustrated in Fig. 5, using chromaticity prior, the texture and chromaticity under the shadow regions are better recovered. In Fig. 6, we can observe that using the shading-preserving term in the smooth term, the shading of the shadow regions is better reconstructed, and the recovered illumination varies with the scene shape. Figures 5 and 6 also show the shadow removal comparisons with method [42]. For fair comparisons on shadow removal step, both our method and method [42] use the same shadow confidence maps as input.
3.2.2 Image detail recovering
Although our shadow removal method can recover the texture detail well in most cases, for some extremely complicated cases, where the shadow regions are too dark and have heavy noise, or the edges information and texture details in the shadow regions have been weakened seriously due to the illumination occluding, our previous method may not work well, as illustrated in Fig. 7b. To make the method more robust and better recover the texture details, we add a multi-scale texture recovering in our method. In the previous steps, using the proposed shadow-preserving texture filter, we can extract a multi-scale detail levels \(D^{i}\) from the original image I and \(D^{i}=J^{i}-J^{i-1}\). We combine the details into the final results in a spatially varying manner using the weighted average.
Let \(I_\mathrm{{ini}}^\mathrm{{free}}\) be the initial shadow removal result and \(I_\mathrm{{enhance}}^\mathrm{{free}}\) be the enhanced image, then:
where m is the scale of the processing which is usually set to be 3, \(U^{i}=G_{\sigma }*e^{(|D_i - C_i|)}\) and \(C^i_p = \frac{\sum _{q\in \Omega _p}\nabla |I^i_q|}{n}\). \(\Omega _p\) is a local neighborhood of pixel p, and n is the number of pixels in \(\Omega _p\). \(G_{\sigma }\) is the Gaussian convolution, which is used to locally smooth the weight. \(C_{S}\) is the shadow confidence map, which reflects the density of shadow in each pixel. By multiplying \(C_{S}\), the details in shadow regions can be enhanced efficiently. In Fig. 7, we present the image detail recovering results. We can observe that the texture details are effectively recovered in the shadow region.

Visualization of the recovered texture detail. From left to right are a input images, b shadow removal results and c the detail-recovered results
4 Experiments
To illustrate the effectiveness of our method, we perform our shadow detection and removal on different datasets, and compare our method with other state-of-the-art methods quantitatively and qualitatively. All our results are implemented with MATLAB R2016a, and all our experiments are executed on the machine that equipped with Intel(R) Core(TM) i5-7400 CPU @ 3.00GHz with 8GB RAM. For an image of size \(640 \times 480\), our method generally takes 5–7 min for shadow removal and detection, where it spends 30–40 s for depth estimation and shadow detection, and takes about 4–6 min for performing shadow removal.

Visual comparison on shadow detection results. From left to right are a input images, b results of Guo [15], c results of Xiao [42], d results of Zhang [48] incorporating user interactivity, e results of Wang [37], f results of DSC [17], g our refined shadow confidence maps and h the binary results based on g
4.1 Datasets and evaluation metrics
Datasets for shadow detection Two benchmark datasets are employed in shadow detection. The first one is the SBU Shadow Dataset [36], which contains 4089 training images and 638 testing images. It includes a wide variety of scenes and covers various types of pictures. The second benchmark dataset we employed is the ISTD Shadow Dataset [37]. It includes 1340 training images and 530 testing images, and covers 135 different types of ground materials.
Evaluation metrics for shadow detection We employ the accuracy (ACC) and the balance error rate (BER) metrics to quantitatively evaluate the shadow detection performance, as defined in [17].
Datasets for shadow removal The comparison is conducted on SRD [33] and ISTD [37] datasets, and both of them have the shadow-free images. The first benchmark dataset [33] contains 3088 images, and the second benchmark dataset [37] contains 1870 images.
Evaluation metrics for shadow removal We conduct quantitative comparisons on shadow removal using the root mean square error (RMSE) between the produced shadow removal results and the corresponding ground-truth image in the LAB color space, and compute RMSE values.

4.2 Comparison with shadow detection methods
In Fig. 8, we compare our results with some state-of-the-art shadow detection methods [15, 17, 37, 42, 48] on the benchmark datasets and some other images. Among these methods, the method [15] is based on handcrafted features, the method [42] applies the RGB-D images, and the method [48] incorporates user interactivity; the last two [17, 37] are deep learning-based methods. In order to achieve the best results of those paper, the existing results in the paper are directly used as the comparison results, and the rest results are generated using implementations provided by the authors or reproduced according to the paper with recommended parameter setting. Also, note that, in these examples, the depth map used for both [42] and our method is estimated using [12]. It can be observed that incorporating shadow-preserving filtering techniques as well as depth maps, our methods work better for these images. Due to deep learning methods heavily depend on the variety of the training data, for some scenes that are hard to obtain the ground-truth training data, these methods do not work well.
Table 1 presents the quantitative comparisons with the state-of-the-art methods on the shadow detection accuracy for the two benchmark datasets. Note that we normalize the shadow confidence map and generate binary masks for [42] and our method for comparisons. We compare the binary mask against the ground truth on both the ISTD dataset [37] and SBU dataset [36]. The two datasets include lots of large-scale scenes, which can benefit to evaluate the performance of our algorithm comparatively and objectively. Our method has achieved one of the best performances on the both datasets.
4.3 Comparison with shadow removal methods
In Fig. 9, we compare our results with various kinds of state-of-the-art shadow removal methods [15, 33, 35, 37, 42, 48] on the benchmark datasets and some other images we collect. The last three [33, 35, 37] are deep learning-based shadow removal methods. For fair comparison, the shadow removal results of other methods are generated using implementations provided by the authors or reproduced according to the paper with recommended parameter setting.
In Table 2, we can see the quantitative comparisons on shadow removal using the root mean square error (RMSE) in the LAB color space. The comparison is conducted on SRD dataset [33] and ISTD dataset [37]. We evaluate the performance of different methods on shadow regions, non-shadow regions and the whole image, as shown in Table 2. The results demonstrate that our removal results perform better for illumination recovery in shadow regions and have the smallest difference from ground-truth shadow-free images.

Effect of parameters. a Result with default parameter setting described in our main paper (\(\sigma _\mathrm{{ch}}=0.3\), \(\lambda _1=1\), \(\lambda _2=0.5\), \(\lambda _3=1\)). b–j Results with different parameter settings. Note that we only change one parameter value at a time while keeping other parameter values fixed
User study As some images have no ground truths, we evaluated the quality of 40 shadow removal images by user tests. We performed a user study with 50 random volunteers to validate the effectiveness of our proposed method. For each volunteer, we randomly show them the shadow removal results of our approach and other six methods [15, 33, 35, 37, 42, 48]. All the results are labeled to avoid potential unfair comparison. Once a volunteer has finished browsing all the shadow removal results for each image, a survey is conducted to collect the feedbacks on the following questions:
-
Q1: Which one exhibits the best overall shadow removal result?
-
Q2: Which one best recovers the illumination of the shadow regions?
-
Q3: Which one introduces the least visual artifacts?
-
Q4: Which one has the least destruction on the non-shadow regions?
-
Q5: Which one preserves the clearest textures?
For each image, and for each question, the volunteer should select the best methods. Table 3 illustrates the survey results.
Discussions Deep learning-based shadow detection and removal methods have achieved convincing results for some input images. However, the performance of these methods heavily depends on the training dataset. The current training data usually contain images with simple shadow regions, as it is relatively easy to obtain the training data. For some complex scenes, the training data are difficult to collect. For example, as shown in Fig. 9, the shadow-free images (ground-truth data) are difficult to collect. In these cases, those deep learning methods do not work well. In contrast, our optimization-based method can produce satisfactory results just by tuning a small number of parameters.
Parameter influence We have explored the effect of changing the parameter setting, as shown in Fig. 10. To illustrate the effect of each parameter, we give each parameter a different value at a time while keeping other parameters unchanged and see how the shadow removal results vary with this parameter. Our method is not sensitive to parameter variations, and the default parameter setting we set in the main paper can be used to tackle images from other benchmarks well.
Limitations Our methods also have some limitations. One limitation is that as we do not incorporate the semantic object recognition in our shadow detection and removal system. Hence, some dark regions, such as the legs of the chair and dark textures of the floor, will be mistakenly detected as shadow regions. In this case, when we perform shadow removal on these regions, it will achieve unsatisfied results, as illustrated in the bottom of Figs. 7 and 9. In addition, computational cost is currently a bottleneck to our algorithm.
5 Conclusion and future work
In this paper, we have proposed a shading-aware shadow detection and removal algorithm. We first introduce a shadow-preserving texture filter and apply shadow confidence method for shadow confidence estimation. With the benefits of the shadow confidence map, we then develop a shading-aware shadow removal method. Our method can effectively remove the complex shadows, and in particular, our method works much better on recovering the shading of the shadow regions. In the future, we would like to extend our current method to handle video shadow detection and removal.
References
Anat, L., Dani, L., Yair, W.: A closed-form solution to natural image matting. IEEE TPAMI 30(2), 228–242 (2007)
Arbel, E., Helor, H.: Shadow removal using intensity surfaces and texture anchor points. IEEE TPAMI 33(6), 1202–1216 (2011)
Barron, J.T., Malik, J.: Intrinsic scene properties from a single rgb-d image. In: CVPR, pp. 17–24 (2013)
Chen, Q., Koltun, V.: A simple model for intrinsic image decomposition with depth cues. In: ICCV, pp. 241–248 (2013)
Cho, H., Lee, H., Kang, H., Lee, S.: Bilateral texture filtering. ACM TOG 33(4), 1–8 (2014)
Chuang, Y.Y., Goldman, D.B., Curless, B., Salesin, D.H., Szeliski, R.: Shadow matting and compositing. In: ACM SIGGRAPH, pp. 494–500 (2003)
Cucchiara, R., Grana, C., Piccardi, M., Prati, A., Sirotti, S.: Improving shadow suppression in moving object detection with HSV color information. In: Intelligent Transportation Systems, pp. 334–339 (2002)
Cun, X., Pun, C.M., Shi, C.: Towards ghost-free shadow removal via dual hierarchical aggregation network and shadow matting GAN. AAAI (2020)
Ding, B., Long, C., Zhang, L., Xiao, C.: Argan: attentive recurrent generative adversarial network for shadow detection and removal. In: ICCV, pp. 10213–10222 (2019)
Eh, L., Jj, M.: Lightness and retinex theory. J. Opt. Soc. Am. 61(1), 1–11 (1971)
Finlayson, G.D., Hordley, S.D., Lu, C., Drew, M.S.: On the removal of shadows from images. IEEE TPAMI 28(1), 59–68 (2006)
Godard, C., Aodha, O.M., Brostow, G.J.: Unsupervised monocular depth estimation with left-right consistency. In: CVPR, pp. 6602–6611 (2017)
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self-supervised monocular depth estimation. In: ICCV, pp. 3828–3838 (2019)
Gryka, M., Terry, M., Brostow, G.J.: Learning to remove soft shadows. ACM TOG 34(5), 1–15 (2015)
Guo, R., Dai, Q., Hoiem, D.: Single-image shadow detection and removal using paired regions. In: CVPR, pp. 2033–2040 (2011)
Hachama, M., Ghanem, B., Wonka, P.: Intrinsic scene decomposition from rgb-d images. In: ICCV, pp. 810–818 (2015)
Hu, X., Fu, C.W., Zhu, L., Qin, J., Heng, P.A.: Direction-aware spatial context features for shadow detection and removal. In: IEEE TPAMI, pp. 7454–7462 (2019)
Hu, X., Jiang, Y., Fu, C.W., Heng, P.A.: Mask-shadowgan: learning to remove shadows from unpaired data. In: ICCV, pp. 2472–2481 (2019)
Jeon, J., Cho, S., Tong, X., Lee, S.: Intrinsic image decomposition using structure-texture separation and surface normals. In: ECCV, pp. 218–233 (2014)
Karsch, K., Sunkavalli, K., Hadap, S., Carr, N., Jin, H., Fonte, R., Sittig, M., Forsyth, D.: Automatic scene inference for 3d object compositing. ACM TOG 33(3), 1–15 (2014)
Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., Navab, N.: Deeper depth prediction with fully convolutional residual networks. In: Fourth International Conference on 3D Vision, pp. 239–248 (2016)
Lalonde, J.F., Efros, A.A., Narasimhan, S.G.: Detecting ground shadows in outdoor consumer photographs. Lect. Notes Comput. Sci. 6312, 322–335 (2010)
Le, H., Samaras, D.: Shadow removal via shadow image decomposition. In: ICCV, pp. 8578–8587 (2019)
Le, H., Vicente, Y., Tomas, F., Nguyen, V., Hoai, M., Samaras, D.: A+ D net: training a shadow detector with adversarial shadow attenuation. In: ECCV, pp. 662–678 (2018)
Li, Z., Snavely, N.: Learning intrinsic image decomposition from watching the world. In: CVPR, pp. 9039–9048 (2018)
Liu, F., Gleicher, M.: Texture-consistent shadow removal. In: ECCV, pp. 437–450 (2008)
Liu, F., Shen, C., Lin, G.: Deep convolutional neural fields for depth estimation from a single image. In: CVPR, pp. 5162–5170 (2015)
Meka, A., Richardt, C., Theobalt, C.: Live intrinsic video. ACM TOG 35(4), 109 (2016)
Mikic, I., Cosman, P.C., Kogut, G.T., Trivedi, M.M.: Moving shadow and object detection in traffic scenes. In: IEEE TPAMI, vol. 1, pp. 321–324 (2000)
Mohan, A., Tumblin, J., Choudhury, P.: Editing soft shadows in a digital photograph. IEEE Comput. Graph. Appl. 27(2), 23–31 (2007)
Nguyen, V., Vicente, T.F.Y., Zhao, M., Hoai, M., Samaras, D.: Shadow detection with conditional generative adversarial networks. In: ICCV, pp. 4520–4528 (2017)
Okabe, T., Sato, I., Sato, Y.: Attached shadow coding: estimating surface normals from shadows under unknown reflectance and lighting conditions. In: ICCV, pp. 1693–1700 (2009)
Qu, L., Tian, J., He, S., Tang, Y., Lau, R.W.H.: Deshadownet: a multi-context embedding deep network for shadow removal. In: CVPR, pp. 2308–2316 (2017)
Reinhard, E., Ashikhmin, M., Gooch, B., Shirley, P.: Color transfer between images. IEEE Comput. Graph. Appl. 21(5), 34–41 (2002)
Sidorov, O.: Conditional GANS for multi-illuminant color constancy: revolution or yet another approach? In: CVPR (2019)
Vicente, T.F.Y., Hou, L., Yu, C.P., Hoai, M., Samaras, D.: Large-scale training of shadow detectors with noisily-annotated shadow examples. In: ECCV, pp. 816–832 (2016)
Wang, J., Li, X., Yang, J.: Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In: CVPR, pp. 1788–1797 (2018)
Wei, J., Long, C., Zou, H., Xiao, C.: Shadow inpainting and removal using generative adversarial networks with slice convolutions. Comput. Graph. Forum 38, 381–392 (2019)
Wu, T.P., Tang, C.K., Brown, M.S., Shum, H.Y.: Natural shadow matting. ACM TOG 26(2), 8 (2007)
Xiao, C., Gan, J.: Fast image dehazing using guided joint bilateral filter. Vis. Comput. 28(6–8), 713–721 (2012)
Xiao, C., She, R., Xiao, D., Ma, K.L.: Fast shadow removal using adaptive multi-scale illumination transfer. Comput. Graph. Forum 32(8), 207–218 (2013)
Xiao, Y., Tsougenis, E., Tang, C.: Shadow removal from single rgb-d images. In: CVPR, pp. 3011–3018 (2014)
Xu, D., Ricci, E., Ouyang, W., Wang, X., Sebe, N.: Multi-scale continuous crfs as sequential deep networks for monocular depth estimation, pp. 161–169 (2017)
Xu, L., Yan, Q., Xia, Y., Jia, J.: Structure extraction from texture via relative total variation. ACM TOG 31(6), 1–10 (2012)
Zhang, L., Long, C., Zhang, X., Xiao, C.: Ris-gan: Explore residual and illumination with generative adversarial networks for shadow removal. In: AAAI (2020)
Zhang, L., Yan, Q., Liu, Z., Zou, H., Xiao, C.: Illumination decomposition for photograph with multiple light sources. IEEE Trans. Image Process. 26(9), 4114–4127 (2017)
Zhang, L., Yan, Q., Zhu, Y., Zhang, X., Xiao, C.: Effective shadow removal via multi-scale image decomposition. Vis. Comput. 35(6–8), 1091–1104 (2019)
Zhang, L., Zhang, Q., Xiao, C.: Shadow remover: image shadow removal based on illumination recovering optimization. IEEE Trans. Image Process. 24(11), 4623–4636 (2015)
Zheng, Q., Qiao, X., Cao, Y., Lau, R.W.: Distraction-aware shadow detection. In: CVPR, pp. 5167–5176 (2019)
Acknowledgements
Funding was provided by the Key Technological Innovation Projects of Hubei Province (Grant No. 2018AAA062), NSFC (Grant Nos. 61972298, 61672390, 61902286), National Key Research and Development Program of China (Grant No. 2017YFB1002600), China Postdoctoral Science Found (No. 2018M642933), and Wuhan University - Huawei GeoInformatics Innovation Lab.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Fan, X., Wu, W., Zhang, L. et al. Shading-aware shadow detection and removal from a single image. Vis Comput 36, 2175–2188 (2020). https://doi.org/10.1007/s00371-020-01916-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-020-01916-3