
Abstract
Face as a biometric attribute has been extensively studied over the past few decades. Even though, satisfactory results are already achieved in controlled environments, the practicality of face recognition in realistic scenarios is still limited by several challenges, such as, expression, pose, occlusion, etc. Recently, the research direction is concentrating on the prospects of complementing face recognition systems with facial soft biometric traits. The ease of extracting facial soft biometrics under several varying conditions has mainly resulted in the ability of using the traits to, either improve the performance of traditional face recognition systems, or performing recognition solely based on many facial soft biometrics. This paper presents state-of-the-art techniques in facial soft biometrics research by describing the type of traits, feature extraction methods, and the application domains. It indicates the most recent and valuable results attained, while also highlighting some possible future scientific research directions to be investigated.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The domain of computer vision has witnessed tremendous and innovative developments over the past few decades. A particular area of research that has been specifically focused on by researchers is biometrics, because of the consciousness of the need to find solutions to the increasing security challenges. Biometrics mainly involves using physical attributes of humans such as face, iris, fingerprint, or using behavioral attributes like signature, voice, and gait for recognition [1]. These are usually regarded as the traditional biometrics, and intensive studies carried out on these attributes have yielded optimum results in various research areas [2–4]. However, recently, a new recognition method termed soft biometrics [5–9], has been proposed and implemented with some successful outcomes. Soft biometrics can be simply defined as physical or behavioral characteristics which provide detailed descriptions of humans. The characteristics can be extracted in form of labels, measurements, and descriptors that can mainly be used for recognition [9]. Although, the characteristics possess distinctiveness and permanence issues [10], they can be applied in scenarios whereby the constraints of pose, human compliance, and intrusiveness are more relaxed. Research work on soft biometrics remains largely in the areas of computer vision and machine learning, and has been studied from various perspectives.
Previous works have investigated the possibility of fusing both traditional and soft biometrics to increase the accuracy of the recognition systems [11–13]. There are also other studies concentrating on designing robust techniques for extracting soft biometric traits from images and videos [14]. In addition, some studies have focused on utilizing computational approaches for combining numerous soft biometrics for human identification and data retrieval (such as, image and video retrieval) [15]. However, soft biometrics has been mainly categorized into three categories, which are face, body, and accessory-related attributes [16, 17].
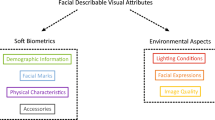
Considering the wide perspective in which researches on soft biometrics have extended to, in recent years, therefore, we limit the scope of this survey to only facial soft biometrics. To the best of our knowledge, there is currently no survey dedicated to facial soft biometrics. Moreover, we present the descriptions of relevant facial soft biometric literatures. The main objective of this survey is to highlight the prospects of previous researches on facial soft biometrics, and to point out the possible directions that could be exploited in future studies. The paper is structured to describe the techniques adopted for extracting the facial soft biometric attributes, coupled with the methods of application of the attributes in previous literatures, as represented in the Fig. 1.

Structure of the literature survey
With regard to the recent trends in studies on soft biometrics, the research aspect can be mainly grouped from two perspectives, which are based on extracting the features as measured descriptors or semantic descriptors, as shown in Fig. 1. Although, the application aspect involves using the descriptors to either improve traditional biometrics or perform recognition solely based on multiples of such descriptors. As a result, this paper mainly describes the techniques proposed in previous studies with respect to the feature extraction type utilized (either measured or semantic).
2 Measured descriptors
The study of facial features in traditional and soft biometrics is carried out with the same prime objective, which is to extract prominent facial attributes with high identifying and/or discriminating capabilities.
This implies that both domains share similar fundamental steps, but focus on different facial traits. Measured descriptors are usually generated by exploiting the continuous pixel distribution of the image, and then quantifying the pixels in a more discrete manner. In this section, we point out some feature extraction techniques for facial soft biometrics and their application methods.
2.1 Exploiting micro-features as facial soft biometrics
The human face is one the most reliable and widely researched biometric attributes because of its uniqueness, distinctiveness, and permanence. In fact, it was described by, Lin [18], as an attribute which encodes different structures and information when viewed from different scales. Traditional biometric systems were developed using low-resolution images in to provide solutions to the challenges usually encountered in real applications. Thus, in traditional biometrics, the possibilities of extracting other discriminating micro-features are often overlooked [18].
But, through manipulation of high-resolution images, discovery of several new traits has been achieved. Though these microscopic features are not permanent enough, they are temporarily invariant, which classifies them under soft biometrics. Lin [18], segmented the face into local regions, before applying Scale Invariant Feature Transform (SIFT) to extract face irregular features. As claimed by Jain and Park [19], the irregularities extracted were not specifically mentioned. So in their work, the authors used active appearance model [20], to first annotate the shape of the face before using Laplace of Gaussian (LoG) to extract micro-features such as moles, scars, and freckles for face recognition. An example of facial mark detection is depicted in Fig. 2. Also, Zhang et al. [21] presented the possibility of improving the baseline Principal Component Analysis (PCA) face recognition algorithm with facial marks. They examined the statistical distribution of facial marks on each face image-based on, color intensity, location, and size of the features. Hence, they adopted a region growing algorithm to detect the micro-features. Similarity matching of facial marks alone showed the reliability of the features for face recognition. Furthermore, a combination of the facial marks score with PCA face recognition significantly improved the recognition rate of their system.

The use of micro-features, such as, moles, freckles, and patches was investigated for differentiating between identical twins, by Srinivas et al. [23]. One of the main challenges of state-of-the-art biometric recognition algorithms is differentiating between identical twins. The work in [23], establishes the possibility of differentiating twins using these facial marks. The features were manually annotated by human observers using a dedicated annotation application, and comparison was made by matching the annotated description using Bipartite Graph Matching with Euclidean distance metric. Manual annotation degraded the performance of their system due to the variations in annotation. However, the authors extended their work, by proposing an automatic facial mark detection system [24]. The authors adopted active shape model [25], for localizing the primary features of the face, like, eyes, nostril, and mouth. Thus, an independent facial mask was generated for each image. Further, fast radial symmetry transform [26], was applied to highlight regions with high radial symmetry, before thresholding to output potential facial marks. In addition, Pierrard and Vetter [27], proposed the use of moles and birthmarks as face irregularities for face identification. The method is quite invariant to pose and illumination because it is based on 3D morphing model. But, the technique may require a high-computational complexity which can influence its application in realistic environments.
Facial wrinkle is another micro-feature that was recently introduced for facial recognition. Literally, the curvature of facial wrinkles around the head, eye, and mouth regions are not distinctive enough for recognition purposes. However, Batool et al. [28], have proven that a set of wrinkles as a pattern may indeed be unique to each individual. Majority of the feature extractions were performed manually in [28]. This is due to several challenges, such as intra user-variability, low-quality image resolution, pose, and expression variations, as shown in Fig. 3. Moreover, Bipartite Graph Matching was adopted for finding correspondence between curve of wrinkles and Hausdorff distance metric was applied for curve-to-curve pattern matching. They attained 65 % rank-1 and 90 % rank-4 retrieval recognition rate.

2.2 Utilizing facial geometric measurements for face recognition
The shape of the human face is also another attribute that can be used to describe a person. In asmuchas facial shapes are not very discriminating in the context of 2D image representation, they are valuable features for recognition when properly extracted. Facial shape is a more established method of face detection and feature extraction in 2D and 3D face recognition. In this case, landmark points are usually annotated around the local geometry of the face, such as eyes, mouth, nose, and chin regions. Some examples of algorithms used for localizing landmark points for facial shape extraction are; Active Appearance Model, Active Shape Model, Deformable Shape Model [29–32]. Ramanathan and Wechsler [33], have developed a face authentication system that incorporates 19 geometric measurements of the face. The authors adopted decision fusion strategy for fusing anthropometric measures with PCA and Linear Discriminant Analysis (LDA), based on neural network, as well as feature level fusion, using boosting techniques. Their system tends to provide significant recognition rates, even on degraded images, and in the presence of occlusion. Several geometric measurements, such as relative distance between the mouth, eyes, and nose, were part of the feature extraction performed to build a feature space with other attributes proposed by Ghalleb et al. [34]. The 87.33 % accuracy achieved solely based on soft biometric traits proved the reliability of these features which was only slightly less than the 91.85 % attained with traditional face recognition technique.
Afterwards, the facial measurements were combined with conventional face recognition in a decision fusion scheme, which increased the performance of the system to 93.74 %. Table 1 summarizes some previous micro-features and geometric techniques found in the literatures.
2.3 Face-based color soft biometrics
Color is a fundamental feature used in identification, because of its importance in a wide variety of applications, such as gesture analysis, face detection, human–machine interaction, video surveillance, image retrieval, etc. Color features include: eye, skin, and hair color. In this section, we present descriptions of research works on color information related to facial soft biometrics. Majority of the studies related to skin color were performed for the purpose of developing face detection algorithms [35–37]. As a result, the outcome is only a binary classification of regions of the human face into skin or non-skin. Nevertheless, building a robust feature extraction mechanism for face detection remains a challenging task, particularly due to varying pose and illumination conditions. To represent the color features, different color spaces can be adopted for different real application problems. Each color space has its own advantages and disadvantages. For instance, using \(RGB\) color space, Boaventura et al. [38], proposed a fuzzy logic method for classifying skin tone based on the subjects’ ethnicity. The \(RGB\) colors were represented with three membership functions, which contain the average pixel color at each band, and were mapped with their respective skin tones using 27 inference rules. Likewise, more recently, \(RGB\) was utilized for deriving skin color information as soft biometrics to aid human–robot interaction [39]. Also, Dantcheva [40] investigated the reliability of eye color as a soft biometric information. They mainly evaluated the influence of varying ambient lighting, color space, and eye glasses on the automatic detection of the eye color. Their system attained its best performance using \(RGB\) for color representation. In addition, Niinuma et al. [41], have developed a form of continuous authentication system, which combines face recognition and soft biometric information such as skin and cloth color. Color information was represented with quantized \(RGB\) histograms, and Bhattacharya coefficient was used for similarity measures. The experiment involved 20 users under varying illumination, who were continuously moving in front of a web cam to depict pose, expression variation, and occlusion. Incorporating color information into their system did not only ease constraint of human compliance, it reduced the false acceptance and false rejection rates of their system to 0 and 4.17 % respectively.
Although \(RGB\) has been used in different applications, it is worth noting that there is no clear separation between its luminance and chrominance, thus making \(RGB\) not robust enough for modeling skin color under varying illumination [42, 43]. Alternatively, a normalized \(RGB\) has been popularly considered by researchers [44, 45], to reduce this problem, based on its invariance to illumination changes. The normalization process is performed, by dividing each color band by a summation of \(R, G, B,\) as they all sum to 1, (R + G + B = 1), using the following expression:
Despite the normalization of \(RGB\), it is still difficult to offer adequate description of colors that fall outside the specified \(RGB\) band.
However, in Hue, Saturation, and Value (HSV) color space, more perceptual colors are better accommodated. Hue is composed of dominant colors, such as yellow, red, and purple. Saturation depicts the level of colorfulness, while V contains the brightness of the image [43]. In this color space, the difference between chrominance and luminance can be easily achieved. Besides, the \(V\) band can be discarded, if necessary, for color representation. Therefore, it makes HSV more invariant to illumination changes. HSV was exploited by Hashem [46], for detecting skin region with neural networks for different scales of the face. Dermikus et al. [47], have utilized HSV for skin tone and hair color representation as session soft biometrics in surveillance human categorization scenario. The authors formed a 2D color histogram by discarding the \(V\) band, and retaining only the HS band. This is very useful in maintaining the short-term correspondence of people in multi-camera network environment.
Furthermore, \(YC_{b}C_{r, }\)which is a common video display color space in European studios, has been examined in some literatures. \(YC_{b}C_{r}\) is better suited for image compression work, as it reduces the redundancy in basic color space like \(RGB\). The \(Y\) band is Luma, while \(C_{b}\) is blue difference, and \(C_{r}\) is red difference. \(YC_{b}C_{r}\) is another form of encoding \(RGB\) non-linearly, using the following expression:
Meanwhile, luminance and Chrominance are always well separated in this color space, therefore, making \(YC_{b}C_{r}\) more suitable for modeling skin color [48, 49]. It was applied for skin detection in head-to-shoulder images with complex backgrounds, by Chai and Ngan [50]. Since, luminance can be clearly separated in \(YC_{b}C_{r}\) color space, the authors made use of the chrominance component to detect the pixels that belong to the skin. Subsequently, they used region regularization to suppress objects that have close similarity to skin color in the background, thereby, refining to the facial region to be detected. Marcialis et al. [51] represented the hair color in \(YC_{b}C_{r, }\)coupled with ethnicity information to verify the face identity of subjects in a group-specific application scenario. In this situation, it should be noted that, soft biometrics alone functioned efficiently in terms of False Rejection Rate (FRR) and False acceptance Rate (FAR), when the soft features are very distinctive among some subjects. Some studies on face-based color soft biometrics are presented in Table 2.
2.4 Face gender and ethnicity recognition
Gender and ethnicity recognition has recently become an area of research that provides many interesting applications. For instance, it can be applied in human computer interaction, person categorization, database search filtering, and passive demographic data collection. Furthermore, it is also useful in the commercial world, particularly in providing automatic assistance in market analysis. For humans, gender and ethnicity recognition is relatively an easy task. However, for electronic systems, it is a daunting task, performing accurate gender recognition, mainly when facial features cannot be easily extracted due to low resolution, variation in pose, expression, and illumination. The task of face gender and ethnicity classification can be grouped into two levels:
-
Face detection and feature extraction
-
Classification
The first step in gender and ethnicity recognition system is the detection or localization of face [52]. Face detection is an important phase in gender recognition, especially in the process of attempting to locate important features on the face. For instance, Yang et al. [53] claimed that in many researches, the general assumption is that the face has already been localized or identified in an image. The authors also extended further to claim that the general notion should not be accepted, because there is a need to develop fast and robust algorithms that efficiently detect and differentiate face from non-face [53]. The techniques of detecting face in an image can be divided into four, namely; knowledge-based, feature invariant, template matching, and appearance-based techniques [53].
Many methods have been proposed for feature extraction purpose, some examples are highlighted in Table 3. Normally, the two levels of face detection and feature extraction go hand-in-hand. According to Khan et al. [54], feature vectors can be extracted using two methods: Geometric-based (local) features and Appearance-based.
Appearance-based (Global) features use the whole face for feature extraction [55]. Usually a set of sample faces are used to train the classifier, then during testing, gender classification is performed using new face samples. In this technique, it is not necessary to accurately extract feature points, since it utilizes the raw pixels of the whole face. However, a popular problem in pattern recognition is the length of the feature vector. Having too many features does not necessarily result in high success rate in classification [56]. The essence is to reduce the dimension of data after the pre-processing level and extraction of relevant features that are categorical and characteristic enough to differentiate two images, without losing too much information about the image. Therefore, it is important to reduce the dimensionality of features in this technique [55].
Geometric-based feature extraction attempts to locate some salient local attributes, such as eyebrow, nose, mouth, and lips as features [57]. This approach tends to be more computationally wise because of the reduced features dimension. In [54, 73], it was also confirmed that these are the main techniques for feature extraction in gender and ethnicity classification. Examples of geometric and appearance-based feature extraction techniques include; discrete cosine transform, wavelet and radon transform, local directional pattern, local binary pattern, principal component analysis. Given below is a summary of some techniques found in the literatures.
Discrete cosine transform (DCT): is an image transformation algorithm that is commonly used for data compression. The part containing the most visually significant information of an image is usually concentrated in just few coefficients of the DCT. This is the main reason, why the DCT is often adopted in the compression of images. The most significant DCT coefficients are selected by determining the variance of the DCT coefficients [59]. DCT was applied in [59–61], for reducing the dimensionality of data and for feature extraction. It was noted that even though the technique is robust to illumination changes, variation in the size of feature vectors, especially local features, affected classification accuracy.
Radon and wavelet transform: combines the radon transform and discrete wavelet transform for dimensionality reduction and feature vector extraction. Given an image \(I, \) radon and wavelet transform basically compute the projection of the image along specified angles which results in the sum of intensities in different directions [62]. This technique was applied by Rai and Khanna [62] for data dimensionality reduction and extraction of important feature vectors. The advantage of this technique is the ease of computation, robustness, and insensitivity to various distortions, pose variation and illumination changes. The authors claimed that Radon and wavelet transform is an improvement over DCT [62].
Local directional pattern (LDP): in this method, each pixel of an image is assigned an 8-bit binary code. The relative edge response values of each pixel in different directions are used to calculate the LDP. Jabid et al. [58], used local directional pattern for face representation and feature extraction. This method enhanced result because it is invariant to changes in pixel intensity. However, since LDP has to represent each pixel of an input image with an 8-bit binary code, the computation tends to be a lot slower.
Principal component analysis: is commonly used for reducing the dimension of data in various areas of computer vision. It is basically a statistical method that converts a set of correlated samples into a new linearly uncorrelated subspace using orthogonal transformation. The principal components are the most significant variables. In gender identification, an increase in the number of PCA features decreases the classification accuracy. Dhamecha and Sankaran [63], have performed gender identification using three discriminant functions; LDA, PCA and Sub-class discriminant analysis. But, as the features increased, the classification accuracy decreased significantly.
Other global and local feature extraction techniques used in other literatures are:
For classification, the output is either male or female. Popular classifiers used in gender and ethnicity identification from human face image are, Neural Networks, Support Vector Machine, and Adaboost, as shown in Table 3. One of the earliest major attempts on face gender classification was reported by Golomb et al. [70]. The authors introduced SEXNET based on a back-propagation neural network classification (BPNN), developed with 30 by 30 resolution face image. Their neural network approach showed that, even in a very low resolution image, they were able to identify gender with a classification rate of 93 %. Using similar classification approach, Mitsumoto et al. [71] used 8 \(\times \) 8 and 8 \(\times \) 6 low-resolution face images for gender identification with 90 % accuracy.
While neural network was the pioneer classifier used for gender classification, it has been criticized for taking a longer computational time. Support Vector Machine (SVM) is now the most commonly used classification technique, simply because of its high classification rate and reduced computational time [72–74]. SVM is a pattern classification algorithm that is structured to find a separating hyperplane that discriminates two dataset, so as to minimize the classification error for data that are not used during the training process. SVM kernels include linear, Polynomial, Radial basis Function, and Sigmoid [75]. Yang and Moghaddam [76, 77], used linear SVM to classify gender in low-resolution images. The results obtained outperformed human perception test, as well as exceeding the performance of other linear classifiers, such as Fisher Linear Discriminant, Nearest Neighbor, and even Radial Basis Function-based classifiers with average error rate of 6.7 %.
Makinen and Raisamo [78] have also performed a comparative experiment on four different gender classification methods using SVM. Likewise, Farinella and Dugelay [79] studied the influence of gender and ethnicity on each other using SVM classifier. They used leave-one cross validation for each gender-specific ethnicity classifier. They deduced that the two attributes do not influence the performance of each other. In addition, Adaboost, which is a combination of several weak learners for building a strong classifier has been suggested in [78, 80]. A brief summary of some related works on gender recognition is illustrated in Table 3.
3 Semantic descriptors
Semantics involves using verbal descriptions for performing recognition. This means that, the use of words is adopted feature representation, after which the feature vectors are converted to numerical values. The descriptions can either be manually or automatically annotated. The basic idea behind the use of semantics is to minimize the level of inaccuracy of descriptions offered by a human observer. Mainly, when humans predict measurements, the outcome can be very inaccurate. As a result, the use of labels are deemed rather more convenient way of describing a person. In previous studies, two basic approaches have been attempted, which include categorical and comparative labeling, as shown in Table 4.
Although detailed literatures on this technique for facial soft biometric recognition are quite limited. We gain some insight into few related studies, with regard to the form of labels they have utilized. Bhatia et al. [81], have investigated on developing a means of describing the overall shape of the face in categorical descriptive terms, rather than using measured descriptors. They assumed that humans take into consideration the relative measurements, shapes, and appearance of the face in a holistic manner, when trying to recognize faces in degraded images [82]. Descriptive terms were used to represent the ratio between geometry of the face. For instance, the ratio of the length of the nose to the length of the face was labeled as short, normal or long.
Dantcheva et al. [83] proposed using a bag of facial soft biometrics, such as skin color, hair color, eye color, glasses, mustache, and beard for face recognition. The color soft biometrics embedded in their system were detected using HSV color space. Then skin and hair color were divided into various number of instances for categorizing the subjects in the database. For instance, hair color was labeled with terms such as black, blonde, red, gray white. Also, a similar approach was exploited for labeling skin, hair, and eye color [84, 85]. The problem associated with using categorical labels is that the user or human observer can be subjective when providing descriptive terms. According to Reid and Nixon [86], the perception of the distribution of population average around the user or observer can negatively influence the descriptions provided using categorical labels.
However, the use of comparative verbal description of the face for image retrieval was introduced by Reid and Nixon [87]. The authors proposed a technique of facial comparison through verbal descriptions or semantic annotation of facial features, such as, eyes, eyebrow, ear, nose, chin, and jaw. This technique is more suitable for policing, whereby an offender is searched and retrieved by comparing his descriptions with other subjects in the database. They attained a rank-1 recognition of 96.7 % using only three comparisons, which was boosted by adding more comparison, resulting in 100 % rank-1 recognition rate for 20 verbal descriptions. Generally, using labels for identification can be very useful to some extent in criminal investigation or short-term image retrieval such as “Can you describe the offender for me”. However, in the context of biometric identification, using labels theoretically lead into categorization, and as a result, it makes the biometric system unable to provide a conclusive identification, since many subjects would share common labels.
4 Evaluation metrics
In any biometric application, the reliability of the system is determined by the variation within the samples of subjects (Intra-class variability) and the variation between the samples of subjects (Inter-class variability). Besides, a biometric attribute that possesses low intra-class variability is described to exhibit more permanence. While an attribute that has a high inter-class variability is described to be distinctive in distinguishing between subjects [88]. Therefore, the error observed in a biometric system can be analyzed in terms of the samples, that are correctly recognized and the samples that are wrongly recognizing. We briefly note here that, the domain of application determines the type of metrics used for evaluation. For instance, some biometric applications are used for verification. In this case, the aim is to perform a 1:1 comparison to classify subjects as genuine or impostor. As a result, the correctly identified samples that are genuine cases are counted as true positive (TP), and the correctly identified samples that are impostor cases are regarded as true negative (TN). The reverse is the case, for wrongly identified samples in both genuine and impostors, resulting in false positive (FP) and false negative (FN). Hence, the measure of error, calculates the false acceptance rate (FAR) and false rejection rate (FRR) with respect to the FP and FN, which is plotted using the receiver operating characteristic (ROC) curve, as shown in Fig. 4.

However, an identification system is a 1:\(N\) comparison, which focuses on finding the right target in a cluster of known and unknown individuals. Thus, the distribution of features of the target is compared with the rest of the subjects in the database to measure their similarity. The result of the comparison is used to rank the subjects in the database, based on the close resemblance they have with the target. Moreover, the position of the target is subsequently searched in the rank order list. The accumulation of the correct search is computed as the cumulative match score, and subsequently represented with the cumulative match characteristic (CMC) curve, as shown in Fig. 5.

Furthermore, some studies in soft biometrics have analyzed the level of identification error using probability of collision [83, 89]. Specifically, when categorical labels are used for representing the distribution of subjects in the database, the soft biometric system is limited in providing conclusive authentication, since many subjects belong to similar categories [90]. Therefore, the interest in this case is to measure the level of interference. Precisely, it evaluates the chances of a randomly chosen subject from an \(N\) authentication group to collide with any subject in the database [90]. Eventually, the identification error is plotted against the number of subjects in the database, as illustrated in Fig. 6.

Represent the probability of finding at least two subjects that collide in the authentication group, adapted from Dantcheva et al. [16]. Specifically, removing either skin color or eye color influences distinctiveness, while eye glasses has the least effect on detection results [16] (\(\copyright \)2011 Springer. Reprinted, with permission from [16])
5 Discussion and conclusion
We have performed a survey of the past and recent studies on face-based soft biometrics. The paper is outlined to cover two main perspectives, which include feature extraction techniques and methods of application of facial soft biometrics. The feature extraction covered the facial attributes that are within the scope of this paper, which include micro-features, facial color features, gender, and ethnicity. The methods of application pointed out various systems that have been developed with the aid of facial soft biometrics, while also highlighting the classification and evaluation techniques adopted.
Facial soft biometrics possesses several key benefits to complement the performance of the conventional face recognition systems.
In unconstrained situations, whereby the face image is captured in an off-frontal pose or limited by occlusion, these microscopic facial marks become very vital and provide more valuable information for matching the identities. The use of facial soft biometrics, such as gender, ethnicity, and facial marks improved the top rank performance of the popular commercial face matcher, FaceVACS [91] from 91.55 to 92.02 % [6]. In addition, the soft traits also reduced the equal error rate (EER) of the system from 3.853 to 3.839 %.
Based on the descriptive characteristics of soft biometrics, the advantage of using facial semantics is highlighted in the FIDA system, developed by Bhatia et al. [81]. Quite interestingly, the system does not require a reference image to perform recognition. This can be very useful in the law enforcement for forensic investigation and crime analysis. Moreover, it eliminates the effect facial variations such as pose, expression, and occlusion, while also minimizing the necessity of human compliance.
Furthermore, facial soft biometrics proved essential in pruning of search in the BIOFACE demonstrator, introduced by Quaret et al. [85]. Incorporating facial traits like eye color, skin color, beard, and mustache into BIOFACE, reduced the computational time and complexity of the traditional face recognition system.
Soft biometrics is still a developing area of research in the domain of computer vision. There remains massive improvements and contributions that can be still be made to the field from variety of perspectives. To this end, future studies should focus on proposing novel feature extraction techniques. This is more integral to the reliability of soft biometric system. Especially, proposing possible automatic methods for accurately extracting facial features from unconstrained low-resolution images or videos that are acquired from distance. It could be aided by utilizing multiple acquisition sensors, whereby a CCTV captures the full profile of the subjects, while an active sensor concentrates on the facial region. In this case, soft biometric information of the facial region, such as facial shapes can be represented with new descriptive features, similar to bag of words or bag of features. Also, the study of face gender and ethnicity on unconstrained face images is a very open area of research, which could be very useful in online image search.
Applications of soft biometrics can be easily adapted to many computer vision applications. As a result, novel applications in areas of soft biometrics should be studied. Some of the possible future prospect of soft biometrics could involve incorporating some soft traits, such as, color information, gender, and ethnicity into remote biometric identification systems for rapid image retrieval, whereby a large pool of data could be reduced to small entities through intelligent categorization. The problem of data storage could be eased using cloud servers for storage of the large amount data.
Furthermore, semantics face recognition research has been performed on still facial images, manually annotated from Gait dataset. This research area is still in its infancy, the influence of demographic distribution on description is yet to be evaluated. Since the distribution of average around the human observer influences the descriptions offered, it would be interesting to evaluate the correlation between intra and inter demographic descriptions, like the descriptions provided by a specific ethnic, gender, and age group. In addition, the exploit of semantics on video data retrieval of more challenging surveillance footage using automatic annotations is still an interesting possibility. For instance, the use of multiple semantics could be integrated together with the aid of fuzzy linguistic systems to offer a more precise description for forensic investigations.
References
Jain, A.K., Ross, A., Prabhakar, S.: An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 14(1), 4–20 (2004)
Turk, M., Pentland, A.: Eigenfaces for recognition. J. Cogn. Neurosci. 3(1), 71–86 (1991)
Daugman, J.: How iris recognition works. IEEE Trans. Circuits Syst. Video Technol. 14(1), 21–30 (2004)
Maltoni, D., Maio, D., Jain, A.K., Prabhakar, S.: Handbook of Fingerprint Recognition. Springer-Verlag, New York (2009)
Jain, A., Nandakumar, K., Lu, X., Park, U.: Integrating faces, fingerprints, and soft biometric traits for user recognition. In: Proceedings of the Biometric Authentication Workshop, Lecture Notes in Computer Sciences, pp. 259–269 (2004)
Park, U., Jain, A.: Face matching and retrieval using soft biometrics. IEEE Trans. Inf. Forensics Secur. 5(3), 406–415 (2010)
Ross, A., Nandakumar, K., Jain, A.: Introduction to Multibiometrics. Handbook Biometrics. Springer, Berlin (2008)
Jr, K.R., Barbour, B.: What are soft can they be used? Computer 44(9), 106–108 (2011)
Jain, A.K., Dass, S.C., Nandakumar, K.: Soft biometric traits for personal recognition systems. In: Proceedings of the Biometric Authentication Workshop, Lecture Notes in Computer Sciences, pp. 1–7 (2004)
Jain, A.K., Dass, S.C., Nandakumar, K.: Can soft biometric traits assist user recognition? In: Proceedings of SPIE, pp. 561–572 (2004)
Zewail, R., Elsafi, A., Saeb, M., Hamdy, N.: Soft and hard biometrics fusion for improved identity verification. In: Proceedings of the 47th Midwest Symposium on Circuits and Systems, MWSCAS, pp. 225–228. (2004)
Ailisto, H., Vildjiounaite, E., Lindholm, M., Mäkelä, S.-M., Peltola, J.: Soft biometrics—combining body weight and fat measurements with fingerprint biometrics. Pattern Recogn. Lett. 27(5), 325–334 (2006)
Da Costa Abreu, M.C., Fairhurst, M.: Enhancing identity prediction using a novel approach to combining hard- and soft-biometric information. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 41(5), 599–607 (2011)
Ran, Y., Rosenbush, G., Zheng, Q.: Computational approaches for real-time extraction of soft biometrics. In: 19th International Conference on Pattern Recognition, ICPR, pp. 1–4 (2008)
Denman, S., Halstead, M.: Can you describe him for me? A technique for semantic person search in video. In: Proceedings of IEEE, Digital Image Computing? Techniques and Applications (DICTA), pp. 1–8 (2012)
Dantcheva, A., Velardo, C.: Bag of soft biometrics for person identification. Multimed. Tools Appl. 51(2), 739–777 (2011)
Ichino, M., Yamazaki, Y.: Soft biometrics and its application to security and business. In: Proceedings of the International Conference on Biometrics and Kansei, Engineering, pp. 314–319 (2013)
Lin, D.: Recognize high resolution faces: from macrocosm to microcosm. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 1355–1362 (2006)
Jain, A., Park, U.: Facial marks: soft biometric for face recognition. In: IEEE International Conference on Image Processing (ICIP), pp. 37–40 (2009)
Cootes, T.: Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 23(6), 681–685 (2001)
Zhang, Z., Tulyakov, S., Govindaraju, V.: Combining facial skin mark and eigenfaces for face recognition. In: Proceedings of Third International Conference on Biometrics (ICB’09), Heidelberg, Berlin. pp. 424–433 (2009)
Kim, M., Moon, H., Chung, Y., Pan, S.: A survey and proposed framework on the soft biometrics technique for human identification in intelligent video surveillance system. J. Biomed. Biotechnol. 2012, 1–7 (2012)
Srinivas, N., Aggarwal, G., Flynn, P.J., Bruegge, R.W.V.: Facial marks as biometric signatures to distinguish between identical twins. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, pp. 106–113 (2011)
Srinivas, N., Aggarwal, G., Flynn, P., Bruegge, R.V.: Analysis of facial marks to distinguish between identical twins. IEEE Trans. Inf. Forensics Secur. 7(5), 1536–1550 (2012)
Cootes, T., Taylor, C., Cooper, D., Graham, J.: Active shape models-their training and application. Comput. Vis. Image Underst. 61(1), 38–59 (1995)
Loy, G., Zelinsky, A.: A fast radial symmetry transform for detecting points of interest. IEEE Trans. Pattern Anal. Mach. Intell. 25(8), 959–973 (2003)
Pierrard, J.-S., Vetter, T.: Skin detail analysis for face recognition. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8 (2007)
Batool, N., Taheri, S., Chellappa, R.: Assessment of facial wrinkles as a soft biometrics. In: Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, pp. 1–7 (2013)
Wan, K., Lam, K., Ng, K.C.: An accurate active shape model for facial feature extraction. In: lnternational Symposium on Intelligent Multimedia. Video and Speech Processing, pp. 109–112 (2004)
Zlki, F., de Peter H.N.: Fast facial feature extraction using a deformable shape model with haar-wavelet based local texture attributes. In: Proceedings of the 2004 IEEE International Conference on Image Processing (ICIP), pp. 1425–1428 (2004)
Mahoor, M.H., Abdel-mottaleb, M.: Facial features extraction in color images using enhanced active shape model. In: Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition, pp. 1–5 (2006)
Niu, Z., Shan, S., Chen, X.: Facial shape localization using probability gradient hints. IEEE Signal Process. Lett. 16(10), 897–900 (2009)
Ramanathan, V., Wechsler, H.: Robust human authentication using appearance and holistic anthropometric features. Pattern Recogn. Lett. 31(15), 2425–2435 (2010)
El Kissi Ghalleb, A., Sghaier, S., Essoukri Ben Amara, N.: Face recognition improvement using soft biometrics. In: 10th International Multi-Conferences on Systems, Signals & Devices, pp. 1–6 (2013)
Hsu, R., Abdel-Mottaleb, M., Jain, A.K.: Face detection in color images. IEEE Trans. Pattern Anal. Mach. Intell. 24(5), 696–706 (2002)
Garcia, C., Tziritas, G.: Face detection using quantized skin color regions merging and wavelet packet analysis. IEEE Trans. Multimed. 1(3), 264–277 (1999)
Wang, Z., Li, S., Ying, D.: The integration of skin color segmentation and self-adapted template matching for the robust face detection. Int. Rev. Comput. Softw. 6(5), 795–805 (2011)
Boaventura, I.A.G., Volpe, V.M., da Silva, I.N., Gonzaga, A.: Fuzzy classification of human skin color in color images. In: Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, pp. 5071–5075 (2006)
Martinson, E., Lawson, W., Trafton, J.G.: Identifying people with soft-biometrics at fleet week. In: Proceedings of 8th ACM/IEEE International Conference on Human–Robot, Interaction (HRI), pp. 49–56 (2013)
Dantcheva, A.: On the reliability of eye color as a soft biometric trait. In: Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), pp. 227–231 (2011)
Niinuma, K., Park, U., Jain, A.: Soft biometric traits for continuous user authentication. IEEE Trans. Inf. Forensics Secur. 5(4), 771–780 (2010)
Vezhnevets, V., Sazonov, V., Andreeva, A.: A survey on pixel-based skin color detection techniques. In: Proceedings of Graphicon, pp. 85–92 (2003)
Prema, C., Manimegalai, D.: Survey on skin tone detection using color spaces. Int. J. Appl. Inf. Syst. 2(2), 18–26 (2012)
Vijayanandh, R., Balakrishnan, G.: Performance analysis of human skin region detection techniques with face detection application. Int. J. Model. Optim. 1(3), 236–242 (2011)
Subban, R., Mishra, R.: Rule-based face detection in color images using normalized \(RGB\) color space—a comparative study. In: Proceedings of the 2012 IEEE International Conference on Computational Intelligence and Computing Research, pp. 1–5 (2012)
Hashem, H.: Adaptive technique for human face detection using HSV color space and neural networks. In: National Radio Science Conference, NRSC, pp. 1–7 (2009)
Demirkus, M., Garg, K., Guler, S.: Automated person categorization for video surveillance using soft biometrics. In: Proceedings of SPIE 7667, Biometric Technology for Human Identification VII, (2010)
Fu, Z.F.Z., Yang, J.Y.J., Hu, W.H.W., Tan, T.T.T.: Mixture clustering using multidimensional histograms for skin detection. In: Proceedings of the 17th International Conference on Pattern Recognition, pp. 1–4 (2004)
Xiang, F.: Fusion of multi color space for human skin region segmentation. Int. J. Inf. Electron. Eng. 3(2), 172–174 (2013)
Chai, D., Ngan, K.N.: Locating facial region of a head-and-shoulders color image. In: Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, pp. 124–129 (1998)
Marcialis, G.L., Roli, F., Muntoni, D.: Group-specific face verification using soft biometrics. J. Vis. Lang. Comput. 20(2), 101–109 (2009)
Zhao, W., Rosenfeld, A.: Face recognition? A literature survey. ACM Comput. Surv. 35(4), 399–458 (2003)
Yang, M., Kriegman, D.J., Member, S., Ahuja, N.: Detecting faces in images? A survey. IEEE Trans. Pattern Anal. Mach. Intell. 24(1), 34–58 (2002)
Khan, S.A., Nazir, M., Akram, S., Riaz, N.: Gender classification using image processing techniques: a survey. In: Proceedings of 2011 IEEE 14th International Multitopic Conference (INMIC), pp. 25–30 (2011)
Kim, H.-C., Kim, D., Ghahramani, Z., Bang, S.Y.: Appearance-based gender classification with Gaussian processes. Pattern Recogn. Lett. 27(6), 618–626 (2006)
Jain, A., Huang, J., Fang, S.: Gender identification using frontal facial images. In: Proceedings of IEEE International Conference on Multimedia and Expo, pp. 1082–1085 (2005)
Shih, H.: Robust gender classification using a precise patch histogram. Pattern Recogn. 46(2), 519–528 (2013)
Jabid, T., Kabir, M., Chae, O.: Gender classification using local directional pattern (LDP). In: Proceedings of 20th International Conference on Pattern Recognition (ICPR), pp. 2162–2165 (2010)
Majid, A., Khan, A., Mirza, A.: Gender classification using discrete cosine transformation: a comparison of different classifiers. In: 7th International Multi Topic Conference, pp. 59–64 (2003)
Nazir, M., Ishtiaq, M., Batool, A.: Feature selection for efficient gender classification. In: Proceedings of the 11th WSEAS International Conference on Neural Networks, Evolutionary Computing and Fuzzy Systems, pp. 70–75 (2010)
Berbar, M.A.: Three robust features extraction approaches for facial gender classification. Vis. Comput. 30(1), 19–31 (2013)
Rai, P., Khanna, P.: Gender classification using Radon and Wavelet Transforms. In: Proceedings of the 2010 International Conference on Industrial and Information Systems, pp. 448–451 (2010)
Dhamecha, T., Sankaran, A.: Is gender classification across ethnicity feasible using discriminant functions? In: 2011 International Joint Conference on Biometrics (IJCB), pp. 1–7 (2011)
Yousefi, S., Zahedi, M.: Gender recognition based on sift features. Int. J. Artif. Intell. Appl. 2(3), 87–94 (2011)
Shan, C.: Learning local binary patterns for gender classification on real-world face images. Patt. Recogn. Lett. 33(4), 431–437 (2012)
Mayo, M., Zhang, E.: Improving face gender classification by adding deliberately misaligned faces to the training data. In: IEEE 3rd International Conference on Image and Vision Computing, pp. 1–5 (2008)
Wu, M., Zhou, J., Sun, J.: Multi-scale ICA texture pattern for gender recognition. Electron. Lett. 48(11), 629 (2012)
Lu, X., Jain, A.: Ethnicity identification from face images. In: Proceedings of SPIE Conference on Biometric Technology for Human Identification, pp. 114–123 (2004)
Bekios-Calfa, J., Buenaposada, J.M., Baumela, L.: Revisiting linear discriminant techniques in gender recognition. IEEE Trans. Patt. Anal. Mach. Intell. 33(4), 858–864 (2011)
Golomb, B., Lawrence, D., Sejnowski, T.: SEXNET: a neural network identifies sex from human faces. In: Lippmann, R.P., Moody, J.E., Touretzky, D.S.: (eds.) Proceedings of 1990 Conference on Advances in Neural Information Processing Systems 3 (NIP-3). Morgan Kaufmann Publishers Inc., San Francisco. pp. 572–577 (1990)
Tamura, S., Hideo, K., Mitsumoto, H.: Male/female identification from 8 x 6 very low resolution face images by neural network. Patt. Recogn. 29(2), 331–335 (1996)
Lu, L., Xu, Z., Shi, P.: Gender classification of facial images based on multiple facial regions. In: WRI World Congress on Computer Science and Information, Engineering, pp. 48–52 (2009)
Yang, W., Chen, C., Ricanek, K., Sun, C.: Gender classification via global–local features fusion. In: Biometric Recognition, Lecture Notes in Computer Sciences, pp. 214–220 (2011)
Chu, W.-S., Huang, C.-R., Chen, C.-S.: Gender classification from unaligned facial images using support subspaces. Inf. Sci. 221, 98–109 (2013)
Xu, Z., Lu, L., Shi, P.: A hybrid approach to gender classification from face images. In: Proceedings of the 19th International Conference on Pattern Recognition (ICPR), pp. 2–5 (2008)
Yang, M., Moghaddam, B.: Support vector machines for visual gender classification. In: Proceedings of the 15th International Conference on Pattern Recognition, pp. 1115–1118 (2000)
Moghaddam, B., Yang, M.: Learning gender with support faces. IEEE Trans. Patt. Anal. Mach. Intell. 24(5), 707–711 (2002)
Makinen, E., Raisamo, R.: Evaluation of gender classification methods with automatically detected and aligned faces. IEEE Trans. Patt. Anal. Mach. Intell. 30(3), 541–547 (2008)
Farinella, G., Dugelay, J.: Demographic classification: do gender and ethnicity affect each other? In: Proceedings of IEEE Intenational Conference on Informatics, Electronics & Vision, pp. 383–390 (2012)
Lu, H., Lin, H.: Gender recognition using adaboosted feature. In: Proceedings of Third International Conference on Natural Computation, ICNC, pp. 646–650 (2007)
Bhatia, N., Kumar, R., Menon, S.: FIDA: face recognition using descriptive input semantics. available: http://www.stanford.edu/class/cs229/proj2007/BhatiaKumarMenonFIDAFaceRecognitionusingDescriptiveInputSemantics.pdf (2007)
Sinha, B.P., Balas, B., Ostrovsky, Y., Russell, R.: Face recognition by humans? Nineteen results all computer vision researchers should know about. In: Proceedings of IEEE, pp. 1948–1962 (2006)
Dantcheva, A., Dugelay, J., Elia, P.: Person recognition using a bag of facial soft biometrics (BoFSB). In: Proceedings of IEEE International Workshop on Multimedia, Signal Processing (MMSP), pp. 511–516 (2010)
Dantcheva, A., Dugelay, J.: Frontal-to-side face re-identification based on hair, skin and clothes patches. In: Proceedings of the 8th IEEE International Conference on Advanced Video and Signal-Based Surveillance (AVSS), pp. 309–313 (2011)
Ouaret, M., Dantcheva, A., Min, R.: BIOFACE: a biometric face demonstrator. In: Proceedings of the International Conference on Multimedia (MM’ 10), ACM, New York, pp. 1613–1616 (2010)
Reid, D.A., Nixon, M.S.: Using comparative human descriptions for soft biometrics. In: International Joint Conference on Biometrics (IJCB), pp. 1–6 (2011)
Reid, D., Nixon, M.: Human identification using facial comparative descriptions. In: 6th International Conference on Biometrics, pp. 1–7 (2013)
Reid, D., Samangooei, S., Chen, C., Nixon, M., Ross, A.: Soft biometrics for surveillance: an overview. Handb. Stat. 31, 327–352 (2013)
DasGupta, A.: The matching, birthday and the strong birthday problem: a contemporary review. J. Stat. Plan. Inf. 130(1–2), 377–389 (2005)
Dantcheva, A., Dugelay, J., Elia, P.: Soft biometrics systems? Reliability and asymptotic bounds. In: Fourth IEEE International Conference on Biometrics: Theory Applications and Systems (BTAS), pp. 1–6 (2010)
FaceVACS software developer kit Cognitec Systems GmbH [Online]. Available: http://www.cognitec-systems.de
Acknowledgments
We would like to acknowledge the Malaysian Ministry of Higher Education for the provision of Exploratory Research Grant Schemes, through which this research was made possible.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Arigbabu, O.A., Ahmad, S.M.S., Adnan, W.A.W. et al. Recent advances in facial soft biometrics. Vis Comput 31, 513–525 (2015). https://doi.org/10.1007/s00371-014-0990-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-014-0990-x