
Abstract
Recent studies have demonstrated the high efficiency of metaheuristic algorithms for various optimization engineering problems. The main focus of the present study is to apply a novel notion of stochastic search methods, namely evaporation rate-based water cycle algorithm (ER-WCA) to the problem of soil shear strength (SSS) prediction. The ER-WCA, as the name indicates, is a modified version of the water cycle algorithm that is used to computationally modify an artificial neural network (ANN) for the mentioned purpose. The sensitivity analysis showed that the most proper values for the number of rivers + sea and the population size are 5 and 300, respectively. The performance of the ER-WCA–ANN hybrid is compared to an ANN typically trained by the Levenberg–Marquardt algorithm to evaluate the effectiveness of the proposed metaheuristic technique. The findings showed that incorporation of the ER-WCA results in reducing the root-mean-square error by 5.87% and 4.92% in the training and testing phases, respectively. Meanwhile, the coefficient of determination rose from 84.27 to 86.11% and from 78.80 to 80.83% in these phases. It indicates that the weights and biases suggested by the ER-WCA can construct a considerably more reliable ANN. Therefore, the introduced method is recommended for practical uses in the early prediction of the SSS in civil engineering projects.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The resistance of the soil for sustaining load (against shearing stresses) reflects soil shear strength (SSS). In many civil/geotechnical engineering projects, the safety and cost of the work are highly dependent on the SSS parameters [1, 2]. Various analytical and numerical methods, up to now, have been proposed for analyzing the SSS and its parameters [3, 4]. Gao et al. [5] investigated the impact of soil type on the SSS. Also, they proposed new equations for unsaturated soil by taking the relationship between the average skeleton stress and the suction over a wide suction range. Likewise, the effect of water content and fractal dimension on the SSS (for red soil in southern China) was evaluated by Zhang et al. [6]. Zhai et al. [7] used soil–water characteristic curve for estimating the SSS. Regarding the complicated relationship between the soil parameters and shear strength, many scholars have recommended the use of machine learning models as more reliable predictors, due to their high capability in the nonlinear analysis [8, 9].
In this sense, different types of artificial intelligence techniques have been successfully used for predicting many geotechnical parameters [9,10,11,12,13,14,15]. Mola-Abasi and Eslami [16] evaluated the efficiency of group method of data handling (GMDH) artificial neural network (ANN) for estimating two parameters of cohesion and friction angle, which are essential in measuring the SSS. Jokar and Mirasi [17] compared the neuro-fuzzy system with empirical approaches in SSS prediction and found that the results of both “c-mean” and “subtractive” clustering models of this system are more accurate than empirical ones. Various attempts for proving the efficiency of ANNs can be found in earlier literature [18,19,20,21,22,23,24,25]. But utilizing the ANNs, sometimes, meets with some computational drawbacks like trapping in local minima. To remedy this problem, scholars have suggested employing metaheuristic search schemes.
By combining metaheuristic algorithm, scholars have achieved powerful predictors for the simulation of soil parameters [26,27,28,29,30,31,32,33,34,35]. Moayedi et al. [9] suggested four wise metaheuristic optimizers including elephant herding optimization (EHO), shuffled frog leaping algorithm (SFLA), wind-driven optimization (WDO), and salp swarm algorithm (SSA) for optimizing the performance of ANN to predict the SSS. Their case study was a local project in Vietnam. Evaluation of the results revealed that the SSA (with the error of 0.0386 and around 82% correlation) is the most powerful optimizer. The foraging behavior of animals (like grasshopper and Harris hawk), invasive weed growing process, and sports league scheduling were studied by Moayedi et al. [36], Nagaraju et al. [37], and Moayedi et al. [38] for predicting the compression coefficient of soil. Samui et al. [39] investigated the efficiency of artificial bee colony algorithm for the same objective and showed that the proposed hybrid model (with a mean absolute percentage error of 12.58% and correlation of 84.1%) outperforms typical ANN. Bui et al. [40] tested the applicability of cuckoo search optimization for adjusting the hyperparameters of an SVM-oriented model. The proposed ensemble was fed by data collected from an expressway project in Vietnam to estimate the SSS. The findings proved the superiority of the algorithm over popular predictors like ANN and regression tree. Further attempts in the field of metaheuristic algorithms for SSS modeling can be found in studies like [41, 42].
This paper suggests the application of a novel notion of recently developed optimizers, namely evaporation rate-based water cycle algorithm (ER-WCA) for the problem of soil shear strength modeling. Going through the literature shows that recent studies have been mostly dedicated to testing new methodologies (e.g., shuffled frog leaping algorithm [43], ant lion optimization [44], genetic algorithm [45]) in order to find the best-fitted SSS predictive model. This paper, therefore, provides supplementary information by evaluating the ER-WCA algorithm. According to the best knowledge of the authors, in spite of high capability [46,47,48,49,50,51], this algorithm has been previously used neither for neural network optimization, nor SSS analysis.
2 Methodology
The steps that need to be taken for fulfilling the objective of the study are shown in Fig. 1. In this regard, after a field survey and providing the soil information, the data are arranged in Excel format. As will be explained in the following, they are then divided into two sets for training and testing the models. On the other side, the WCA algorithm which is modified by evaporation-based relationships is applied to an ANN to create the proposed hybrid tool. After sensitivity analysis and complexity optimization, this model, along with typical ANN, is implemented to predict the SSS. The results are evaluated by popular accuracy criteria, and the effects of the applied metaheuristic algorithm are assessed.

Methodology applied in the current research
2.1 Artificial neural network
Recent advances in soft computing have resulted in the advent of capable predictive models. ANN is almost the most well-known notion of intelligent models, designed by simulating the mechanism of the biological neural system [52, 53]. The main neural processors are called neurons which are completely connected by weights. An ANN originally benefits the Levenberg–Marquardt training algorithm [54] and backpropagation adjustment method [55] for tuning the parameters. In this method, after each completed epoch, the error is calculated and propagated in a backward direction to be reduced. This enhancement in accuracy is achieved by adjusting the weights and biases.
Multilayer perceptron (MLP) [56] is a capable type of ANNs with at least three layers. The neurons are embedded in these layers. Figure 2 shows the calculation process in a neuron. As is seen, after receiving the input (I), a weight factor (W) is assigned, and then, the bias term (b) is added. Depending on the selected activation function (f), the resulted value is then released as the neuron output (O). The structure of the used MLP network will be better discussed in the next section.

General structure of the MLP neural network
2.2 Evaporation rate-based water cycle algorithm
Evaporation rate-based water cycle algorithm (ER-WCA) is one of the most recent search schemes proposed by Sadollah et al. [47]. It presents a modified version of the WCA algorithm [57]. The WCA is a nature-inspired algorithm based on the water cycle process and flowing of water streams toward the sea. In the water (or hydrologic) cycle, water in streams is evaporated and plants transpire it by doing photosynthesis. The vapor moves to the air and generates clouds. Under weather conditions, the water returns to the earth in different forms [58]. The rivers, in this algorithm, are chosen as individuals with high goodness, and the remaining streams are called streams. Assuming K as the problem dimension, the candidate streams will be x1, x2,…, xK. The initial population is randomly generated as follows:
where \(K_{{{\text{pop}}}}\) gives the size of the population. The flow intensity is then calculated for each algorithm using Eq. 2:
Among the elite individuals, \(K_{{{\text{sr}}}}\) are selected as rivers, as well as a sea. The number of the rest of the population which may flow to the rivers or the sea is represented by \(K_{{{\text{Stream}}}}\). The volume of the water attracted by the river/sea is varied based on their flow power. The streams assigned to each river and sea are determined as follows:
where \({\text{NS}}_{n}\) shows the number of streams flowing to the specific sea or rivers. Since the larger number of streams tends to flow to the sea, the fitness function is defined to proportionally hand out the streams among the sea and rivers. In nature, however, some streams join each other and make new rivers.
Among \(K_{{{\text{pop}}}}\) individuals, assuming the presence of one sea and \(K_{{{\text{sr}} - 1}}\) rivers, Fig. 3 depicts how a stream flows toward a river along their connecting paths.

Way in which the stream flows to a specific river
More details about the proposed technique are presented in similar studies like [59,60,61].
3 Data and statistical analysis
For training intelligent models, providing proper data samples is an essential step. In this work, a set of real-world data is used to train the ANN and its hybrid (i.e., ER-WCA–ANN). The soil information is collected by a field survey in the Vinhomes Imperia housing project, constructed in Hai Phong city, Vietnam [42].
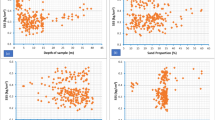
The shear strength (target variable) is considered to be a function of 12 influential factors, namely depth of sample (DOP), sand percentage (SP), loam percentage (LP), clay percentage (CP), percentage of moisture content (PMC), wet density (WD), dry density (DD), void ratio (VR), liquid limit (LL), plastic limit (PL), plastic index (PI), and liquidity index (LI). These factors are taken as input data during the training process. The distribution of these parameters versus the SSS is illustrated in Fig. 4. Descriptive statistics are also shown in Table 1. A total of 496 data are provided. With respect to the division ration of 80:20, 397 samples are used to discover the relationship between the SSS and input factors, and the remaining 99 samples are considered as unseen soil conditions to evaluate the generalization power of the applied models.

Graphical description of the used dataset
4 Results and discussion
A multilayer perceptron is selected to represent the neural network in this study. This network is supposed to be trained by the ER-WCA algorithm. The MLP, as is known, is composed of at least three layers with a fixed/variable number of computational neurons in them. The number of neurons in the input and output layer is fixed and equals to the number of these variables. But when it comes to the middle layer, this value needs to be determined by a trial and error process. By testing ten different neural networks, it was shown that the MLP which contains seven hidden neurons reflects the most suitable structure. Hence, the structure of the used MLP is depicted in Fig. 5.

Optimal structure of the used LM-ANN
4.1 Hybridizing the MLP using the ER-WCA
The selected MLP is converted to the equation form and fed by considered training data. The variables of this equation are the connecting weights and biases. The ER-WCA is then applied to adjust these parameters according to the relationship between the SSS and influential factors. The ER-WCA is a population-based metaheuristic algorithm that tries to minimize the training error by updating the solution at each iteration. A total of 1000 iterations are set for the created ensemble [62, 63], and root-mean-square error (RMSE) plays the role of the objective function to measure the error. Assuming Zi predicted and Zi observed, respectively, as the modeled and measured SSSs, this function is defined as follows:
where K shows the number of samples.
The size of the acting population (population size), as well as “the number of rivers + sea (RS),” is an important parameter that affects the goodness of the optimization by the ER-WCA algorithm. Like the number of hidden neurons in the MLP, a sensitivity analysis is carried out for each one to achieve the best-fitted ER-WCA–ANN. Nine different population sizes of 10, 25, 50, 75, 100, 200, 300, 400, and 500 are tested where the RS is set 4. The results are shown in Fig. 6. As is seen, the lowest objective function is recorded for the population size = 300. Next, the ER-WCA–ANN with this population size is tested for ten different RS values (1, 2,…, 10). It can be seen that the RS = 5 gives the most accurate understanding of the SSS pattern. Figure 7 illustrates the convergence curve of the selected ER-WCA–ANN. Like many other optimization algorithms, the majority of the error is minimized before the 500th iteration. The obtained RMSE is 0.0433082113478439 for that.

Sensitivity analysis based on the RS and population size of the proposed ER-WCA–ANN

Convergence curve of the proposed ER-WCA–ANN with population size = 300 and RS = 5
4.2 Accuracy evaluation
After the optimization and implementation of the LM-ANN and ER-WCA–ANN models, the results are extracted and evaluated in this section. Along with the RMSE, two other popular accuracy indices of mean square error (MAE) and the coefficient of determination (R2) are defined to measure the learning/prediction error and the correlation between the modeled and measured SSSs. These criteria are expressed by Eqs. 6 and 7.
The training and testing results of the LM-ANN and ER-WCA–ANN models are first shown in the regression charts of Fig. 8. According to these charts, the correlation of the ANN results is increased from 84.27 to 86.11% in the training phase, as the effect of replacing the LM with ER-WCA. It means that the ANN optimized by the latter algorithm can analyze the relationship between the SSS and influential factors in a more accurate way. As for the testing data, the rise of R2 from 0.7880 to 0.8083 indicates that the hybrid model has produced more consistent results in this phase which indicates the higher capability of this model in predicting the SSS for unseen soil condition.

Correlation of the training and testing results for the a, b LM-ANN and c, d ER-WCA–ANN models
The training and prediction errors are also measured for both applied models. Figure 9 shows the results in three forms: (1) A comparison between the modeled and measured SSSs is shown to compare the real and simulated patterns, (2) the error is defined as the difference between the modeled and measured SSSs and is shown in the second part, and (3) the frequency of these error values is depicted by histogram charts. A comparison between Fig. 9a and Fig. 9c demonstrates that the training SSSs produced by the ER-WCA–ANN are more compatible with real data. The lower RMSE (0.0460 vs. 0.0433) and MAE (0.0370 vs. 0.0349) values confirm this statement. Also, Fig. 9b, d demonstrates that the prediction error of the ANN (RMSE = 0.0528 and MAE = 0.0419) is larger than ER-WCA–ANN (RMSE = 0.0502 and MAE = 0.0405). From this, it can be derived that the weights and biases suggested by the ER-WCA metaheuristic algorithm construct a more reliable MLP in comparison with those adjusted by the typical LM algorithm.

Obtained training and testing errors and a comparison between the results for the a, b LM-ANN and c, d ER-WCA–ANN models
Evaluating the obtained results showed the efficiency of the evaporation rate-based water cycle algorithm in optimal modification of ANN parameters that reveal the relationship between the SSS and DOP, SP, LP, CP, PMC, WD, DD, VR, LL, PL, PI, and LI as the key factors. In comparison with previous efforts, the method of the current study achieved more reliable results. In the study carried out by Moayedi et al. [64], four capable optimizers of elephant herding optimization (EHO), shuffled frog leaping algorithm (SFLA), salp swarm algorithm (SSA), and wind-driven optimization (WDO) were assessed and compared for the same objective. The training MAEs of the models were 0.0471, 0.0449, 0.0368, and 0.0402, respectively. This is while the MAE of our proposed ER-WCA–ANN was 0.0349. In the prediction phase, ER-WCA outperformed the EHO and SFLA algorithms (RMSE of 0.0502 vs. 0.0597 and 0.0546).
In this work, the solution was excerpt among a wide variety of candidates. Based on Fig. 6, (9 + 8 =) 17 different complexities were tested where each one performed for 1000 iterations. In other words, a total of 17,000 solutions were tested to find the most proper one. Also, referring to the structure of the used MLP (Fig. 5), the algorithm has found the optimal values of 99 hyperparameters (91 connecting weights and eight biases) at each iteration. Manually doing such calculations, definitely, is an impossible and time-consuming task. Therefore, we proposed an automatic search scheme which enables engineers to benefit more accurate and time-effective model for predicting the SSS. Figure 10 depicts the calculation time required for implementing the ER-WCA–ANN by different population sizes. As is seen, the time increases by enlarging the population. The used ER-WCA needed around 4017 s (on the operating system at 2.5 GHz and 6 Gigs of RAM) for optimizing the ANN.

Calculation time for different populations sizes of the ER-WCA–ANN
4.3 Presenting the neural predictive formula
Based on the accuracy improvement resulted from incorporating the ER-WCA metaheuristic algorithm, the hybrid model was found to be superior to the unreinforced ANN. Hence, the content of the proposed ER-WCA–ANN is presented in the form of a nonlinear formula to predict the SSS. In fact, the formula is composed of two parts: (1) Eq. 8 which reflects the weights and biases belonging to the unique output neuron of the MLP network and (2) Eq. 9 that gives the same parameters for the neurons in the hidden layer (see Fig. 5). As is seen, calculating the SSS requires obtaining seven middle parameters of R1, R2,…, R7 that represent the hidden neurons’ outputs. A Tansig function is also applied for calculating these parameters.
5 Conclusions
This work investigated the efficiency of a novel metaheuristic technique, namely the evaporation rate-based water cycle algorithm for predicting the soil shear strength which is a highly important geotechnical parameter. The model is applied to a neural network for the first time to modify its computational parameters. The ER-WCA–ANN hybrid model was created, and its results were compared to a typically trained ANN to evaluate the effect of the proposed metaheuristic model. The results of the sensitivity analysis showed that the best population size and the number of rivers and seas for the current problem are 300 and 5, respectively. In the training phase, it was shown that the learning RMSE of the ANN was reduced from 0.0460 to 0.0433 and the correlation rose from 0.8427 to 0.8611. It indicates that the ER-WCA algorithm has adjusted the weights and biases of the ANN more properly than the LM method. The same improvements in the testing phase also revealed the higher capability of the ER-WCA–ANN in predicting the SSS in stranger environments. Therefore, the proposed model can be reliably used for practical projects.
References
Chen L-H, Li X, Xu Y, Chen Z-Y, Deng G (2019) Accurate estimation of soil shear strength parameters. J Cent South Univ 26:1000–1010
Weidinger DM, Ge L (2009) Laboratory evaluation of the Briaud compaction device. J Geotech Geoenviron Eng 135:1543–1546
Motaghedi H, Eslami A (2014) Analytical approach for determination of soil shear strength parameters from CPT and CPTu data. Arab J Sci Eng 39:4363–4376
Cai J-S, Yan E-C, Yeh T-CJ, Zha Y-Y, Liang Y, Huang S-Y, Wang W-K, Wen J-C (2017) Effect of spatial variability of shear strength on reliability of infinite slopes using analytical approach. Comput Geotech 81:77–86
Gao Y, Da S, Zhou A, Li J (2020) Predicting shear strength of unsaturated soils over wide suction range. Int J Geomech 20:04019175
Zhang Y, Zhong X, Lin J, Zhao D, Jiang F, Wang M-K, Ge H, Huang Y (2020) Effects of fractal dimension and water content on the shear strength of red soil in the hilly granitic region of southern China. Geomorphology 351:106956
Zhai Q, Rahardjo H, Satyanaga A, Dai G (2019) Estimation of unsaturated shear strength from soil–water characteristic curve. Acta Geotech 14:1977–1990
Moavenian M, Nazem M, Carter J, Randolph M (2016) Numerical analysis of penetrometers free-falling into soil with shear strength increasing linearly with depth. Comput Geotech 72:57–66
Moayedi H, Bui DT, Ngo T, Thao P (2019) Neural computing improvement using four metaheuristic optimizers in bearing capacity analysis of footings settled on two-layer soils. Appl Sci 9:5264
Moayedi H, Mehrabi M, Mosallanezhad M, Rashid ASA, Pradhan B (2018) Modification of landslide susceptibility mapping using optimized PSO–ANN technique. Eng Comput 35(3):967–984
Najafi-Ghiri M, Mokarram M, Owliaie HR (2019) Prediction of soil clay minerals from some soil properties with use of feature selection algorithm and ANFIS methods. Soil Res 57:788–796
Samui P (2019) Application of artificial intelligence in geo-engineering. In: Proceedings of international conference on inforatmion technology in geo-engineering
Ebrahimi M, Taleshi AA, Abbasinia M, Arab-Amiri A (2016) Two and three-dimonsional ERT modelling for a buried tunnel. J Emerg Trends Eng Appl Sci 7:118–127
Ebrahimi M, Moradi A, Bejvani M, Davatgari Tafreshi M (2016) Application of STA/LTA based on cross-correlation to passive seismic data, pp 1–5. https://doi.org/10.3997/2214-4609.201600018
Amani M, Amani P, Bahiraei M, Wongwises S (2019) Prediction of hydrothermal behavior of a non-Newtonian nanofluid in a square channel by modeling of thermophysical properties using neural network. J Therm Anal Calorim 135:901–910. https://doi.org/10.1007/s10973-018-7303-y
Mola-Abasi H, Eslami A (2019) Prediction of drained soil shear strength parameters of marine deposit from CPTu data using GMDH-type neural network. Mar Georesour Geotechnol 37:180–189
Jokar MH, Mirasi S (2018) Using adaptive neuro-fuzzy inference system for modeling unsaturated soils shear strength. Soft Comput 22:4493–4510
Qiao W, Huang K, Azimi M, Han S (2019) A novel hybrid prediction model for hourly gas consumption in supply side based on improved whale optimization algorithm and relevance vector machine. IEEE Access 7:88218–88230. https://doi.org/10.1109/ACCESS.2019.2918156
Qiao W, Yang Z, Kang Z, Pan Z (2020) Short-term natural gas consumption prediction based on Volterra adaptive filter and improved whale optimization algorithm. Eng Appl Artif Intell 87:103323. https://doi.org/10.1016/j.engappai.2019.103323
Qiao W, Yang Z (2020) An improved dolphin swarm algorithm based on Kernel Fuzzy C-means in the application of solving the optimal problems of large-scale function. IEEE Access. https://doi.org/10.1109/ACCESS.2019.2958456
Qiao W, Yang Z (2019) Forecast the electricity price of U.S. using a wavelet transform-based hybrid model. Energy. https://doi.org/10.1016/j.energy.2019.116704
Zhou G, Moayedi H, Foong LK (2020) Teaching-learning-based metaheuristic scheme for modifying neural computing in appraising energy performance of building. Eng Comput. https://doi.org/10.1007/s00366-020-00981-5
Zhou G, Moayedi H, Bahiraei M, Lyu Z (2020) Employing artificial bee colony and particle swarm techniques for optimizing a neural network in prediction of heating and cooling loads of residential buildings. J Clean Prod. https://doi.org/10.1016/j.jclepro.2020.120082
Shahsavar A, Khosravi J, Mohammed HI, Talebizadehsardari P (2020) Performance evaluation of melting/solidification mechanism in a variable wave-length wavy channel double-tube latent heat storage system. J Energy Storage 27:101063. https://doi.org/10.1016/j.est.2019.101063
Liu W, Zhang ZX, Fan JY, Jiang DY, Daemen JJK (2020) Research on the stability and treatments of natural gas storage caverns with different shapes in bedded salt rocks. IEEE Access 8:000507. https://doi.org/10.1109/ACCESS.2020.2967078
Zhang Z, Jiang D, Liu W, Chen J, Li E, Fan J, Xie K (2019) Study on the mechanism of roof collapse and leakage of horizontal cavern in thinly bedded salt rocks. Environ Earth Sci 78:292. https://doi.org/10.1007/s12665-019-8292-2
Qiao W, Yang Z (2019) Modified Dolphin swarm algorithm based on chaotic maps for solving high-dimensional function optimization problems. IEEE Access 7:110472–110486. https://doi.org/10.1109/ACCESS.2019.2931910
Qiao W, Yang Z (2019) Solving large-scale function optimization problem by using a new metaheuristic algorithm based on quantum dolphin swarm algorithm. IEEE Access 7:138972–138989. https://doi.org/10.1109/ACCESS.2019.2942169
Qiao W, Tian W, Tian Y, Yang Q, Wang Y, Zhang J (2019) The forecasting of PM2.5 using a hybrid model based on wavelet transform and an improved deep learning algorithm. IEEE Access 7:142814–142825. https://doi.org/10.1109/ACCESS.2019.2944755
Alnaqi AA, Moayedi H, Shahsavar A, Nguyen TK (2019) Prediction of energetic performance of a building integrated photovoltaic/thermal system thorough artificial neural network and hybrid particle swarm optimization models. Energy Convers Manage 183:137–148. https://doi.org/10.1016/j.enconman.2019.01.005
Hamid R, Mohammad HB, Mahdi A (2018) Reevaluation of SPT-based liquefaction case history using earthquake demand energy. In: Geotechnical earthquake engineering and soil dynamics V, Austin, Texas, 10–13 June 2018. https://doi.org/10.1061/9780784481455.047
Pourya K, Abdolreza O, Brent V, Arash H, Hamid R (2020) Feasibility study of collapse remediation of illinois loess using electrokinetics technique by nanosilica and salt. In: Geo-Congress 2020, Minneapolis, Minnesota, 25–28 February 2020. https://doi.org/10.1061/9780784482780.066
Baziar MH, Rostami H (2017) Earthquake demand energy attenuation model for liquefaction potential assessment. Earthq Spectra 33(2):757–780. https://doi.org/10.1193/030816EQS037M
Hemmat Esfe M, Bahiraei M, Hajmohammad MH, Afrand M (2017) Rheological characteristics of MgO/oil nanolubricants: experimental study and neural network modeling. Int Commun Heat Mass Transfer 86:245–252. https://doi.org/10.1016/j.icheatmasstransfer.2017.05.017
Khosravi R, Rabiei S, Bahiraei M, Teymourtash AR (2019) Predicting entropy generation of a hybrid nanofluid containing graphene–platinum nanoparticles through a microchannel liquid block using neural networks. Int Commun Heat Mass Transfer 109:104351. https://doi.org/10.1016/j.icheatmasstransfer.2019.104351
Moayedi H, Gör M, Lyu Z, Bui DT (2019) Herding Behaviors of grasshopper and Harris hawk for hybridizing the neural network in predicting the soil compression coefficient. Measurement. 152:107389
Nagaraju TV, Prasad CD, Murthy N (2020) Invasive weed optimization algorithm for prediction of compression index of lime-treated expansive clays. In: Soft computing for problem solving. Springer, Singapore, pp 317–324
Moayedi H, Tien Bui D, Dounis A, Ngo PTT (2020) A novel application of league championship optimization (LCA): hybridizing fuzzy logic for soil compression coefficient analysis. Appl Sci 10:67
Samui P, Hoang N-D, Nhu V-H, Nguyen M-L, Ngo PTT, Bui DT (2019) A new approach of hybrid bee colony optimized neural computing to estimate the soil compression coefficient for a housing construction project. Appl Sci 9:4912
Bui DT, Hoang N-D, Nhu V-H (2019) A swarm intelligence-based machine learning approach for predicting soil shear strength for road construction: a case study at Trung Luong National Expressway Project (Vietnam). Eng Comput 35:955–965
Moayedi H, Tien Bui D, Dounis A, Kok Foong L, Kalantar B (2019) Novel nature-inspired hybrids of neural computing for estimating soil shear strength. Appl Sci 9:4643
Nhu V-H, Hoang N-D, Duong V-B, Vu H-D, Bui DT (2019) A hybrid computational intelligence approach for predicting soil shear strength for urban housing construction: a case study at Vinhomes Imperia project, Hai Phong city (Vietnam). Eng Comput pp 1–14
Moayedi H, Bui DT, Ngo PTT (2020) Shuffled frog leaping algorithm and wind-driven optimization technique modified with multilayer perceptron. Appl Sci 10(2):689
Moayedi H, Bui DT, Anastasios D, Kalantar B (2019) Spotted hyena optimizer and ant lion optimization in predicting the shear strength of soil. Appl Sci 9:4738
Pham BT, Hoang T-A, Nguyen D-M, Bui DT (2018) Prediction of shear strength of soft soil using machine learning methods. CATENA 166:181–191
Pahnehkolaei SMA, Alfi A, Sadollah A, Kim JH (2017) Gradient-based water cycle algorithm with evaporation rate applied to chaos suppression. Appl Soft Comput 53:420–440
Sadollah A, Eskandar H, Bahreininejad A, Kim JH (2015) Water cycle algorithm with evaporation rate for solving constrained and unconstrained optimization problems. Appl Soft Comput 30:58–71
Fan J, Jiang D, Liu W, Wu F, Chen J, Daemen J (2019) Discontinuous fatigue of salt rock with low-stress intervals. Int J Rock Mech Min Sci 115:77–86. https://doi.org/10.1016/j.ijrmms.2019.01.013
Liu W, Zhang Z, Chen J, Fan J, Jiang D, Jjk D, Li Y (2019) Physical simulation of construction and control of two butted-well horizontal cavern energy storage using large molded rock salt specimens. Energy 185:682–694. https://doi.org/10.1016/j.energy.2019.07.014
Chen J, Lu D, Liu W, Fan J, Jiang D, Yi L, Kang Y (2020) Stability study and optimization design of small-spacing two-well (SSTW) salt caverns for natural gas storages. J Energy Storage 27:101131. https://doi.org/10.1016/j.est.2019.101131
Jinlong L, Wenjie X, Jianjing Z, Wei L, Xilin S, Chunhe Y (2020) Modeling the mining of energy storage salt caverns using a structural dynamic mesh. Energy 193:116730. https://doi.org/10.1016/j.energy.2019.116730
Hassoun MH (ed) (1995) Fundamentals of artificial neural networks. MIT Press, Cambridge
Anderson D, McNeill G (1992) Artificial neural networks technology. Kaman Sci Corp 258:1–83
Moré JJ (ed) (1978) The Levenberg-Marquardt algorithm: implementation and theory. Numerical analysis. Springer, Berlin, pp 105–116
Hecht-Nielsen R (1992) Theory of the backpropagation neural network. Neural networks for perception. Elsevier, Amsterdam, pp 65–93
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Netw 2:359–366
Eskandar H, Sadollah A, Bahreininejad A, Hamdi M (2012) Water cycle algorithm—a novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput Struct 110:151–166
S David (1993) The water cycle (John Yates, Illus). Thomson learning. New York
Luo Q, Wen C, Qiao S, Zhou Y (2016) Dual-system water cycle algorithm for constrained engineering optimization problems. In: Proceedings of the international conference on intelligent computing
Heidari AA, Abbaspour RA, Jordehi AR (2017) An efficient chaotic water cycle algorithm for optimization tasks. Neural Comput Appl 28:57–85
Guo Y, Li B-Z (2018) Novel method for parameter estimation of Newton’s rings based on CFRFT and ER-WCA. Signal Process 144:118–126
Moayedi H, Nguyen H, Foong LK (2019) Nonlinear evolutionary swarm intelligence of grasshopper optimization algorithm and gray wolf optimization for weight adjustment of neural network. Eng Comput. https://doi.org/10.1007/s00366-019-00882-2
Moayedi H, Nguyen H, Rashid ASA (2019) Novel metaheuristic classification approach in developing mathematical model-based solutions predicting failure in shallow footing. Eng Comput pp 1–8
Moayedi H, Gör M, Khari M, Foong LK, Bahiraei M, Bui DT (2020) Hybridizing four wise neural-metaheuristic paradigms in predicting soil shear strength. Measurement p 107576
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Foong, L.K., Moayedi, H. & Lyu, Z. Computational modification of neural systems using a novel stochastic search scheme, namely evaporation rate-based water cycle algorithm: an application in geotechnical issues. Engineering with Computers 37, 3347–3358 (2021). https://doi.org/10.1007/s00366-020-01000-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-020-01000-3