
Abstract
Piles are widely applied to substructures of various infrastructural buildings. Soil has a complex nature; thus, a variety of empirical models have been proposed for the prediction of the bearing capacity of piles. The aim of this study is to propose a novel artificial intelligent approach to predict vertical load capacity of driven piles in cohesionless soils using support vector regression (SVR) optimized by genetic algorithm (GA). To the best of our knowledge, no research has been developed the GA-SVR model to predict vertical load capacity of driven piles in different timescales as of yet, and the novelty of this study is to develop a new hybrid intelligent approach in this field. To investigate the efficacy of GA-SVR model, two other models, i.e., SVR and linear regression models, are also used for a comparative study. According to the obtained results, GA-SVR model clearly outperformed the SVR and linear regression models by achieving less root mean square error (RMSE) and higher coefficient of determination (R2). In other words, GA-SVR with RMSE of 0.017 and R2 of 0.980 has higher performance than SVR with RMSE of 0.035 and R2 of 0.912, and linear regression model with RMSE of 0.079 and R2 of 0.625.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Literature consists of many experimental and theoretical studies into the prediction of the load-bearing capacity and behavior of piles though the mechanisms have not yet clarified completely for scholars of the field. In case of the piles that are driven into cohesionless soil, the problem is of high complexity and this is because of the sensitive nature of the factors that have impact on the behaviors of the pile. These factors can not only be quantified easily, but also involve extensive uncertainties. These factors include the stress and strain history of the soil, the impacts of soil fabric and compressibility, installation effects, and the difficulty of attaining undisturbed samples of soil.
To address effectively these complexities, the correlations with in situ experiments, e.g., the cone penetration test, the standard penetration test, and the pressure meter, are applied to numerous cases. Such tests show, to some degree, the natural conditions of soil though they suffer from many limitations. For instance, the standard penetration tests have considerably inherent variability, and they do not show the compressibility of the soil. On the other hand, if such tests are correlated with load test data upon a regional basis, instead of employing general correlations, they can deliver acceptable predictions [1, 2].
The limitations of the correlations that are attained with the in situ tests have made the researchers to develop numerous empirical relations between pile capacity and soil parameters in both end-bearing and friction piles, on the basis of load test results. The aim is providing rapid and yet practically accurate estimations regarding the pile capacity. Four of the most popular empirical methods in the literature have been introduced by Meyerhof [3], Coyle and Castello [4], the American Petroleum Institute [5], and Randolph [6]. However, they either oversimplify or inappropriately consider the impacts of given factors. The factors include residual stresses, the stress history, and actual soil parameters that exist following the pile driving operation. The designing recommendations these methods provide for users have an inconsistency with the physical processes that dictate the actual pile capacity [6]. As a result, a substitute method needs to be developed in a way to resolve the uncertainties that we face in the prediction process of the pile load capacity [2].
In recent years, in the geotechnical engineering fields of study, artificial neural networks (ANNs) have been implemented effectively to a variety of applications [7,8,9,10,11,12,13]. A multivariate adaptive regression spline (MARS) approach was used by Samui [14] for the purpose of determining the ultimate capacity of the driven piles that are installed in sands. In MARS, a variety of parameters are used as the input variables, including driven pile area (A), effective vertical stress at the tip of the pile (\(\sigma_{v}^{\prime }\)), soil at the tip of the derived pile (\(\phi_{\text{tip}}\)) and angle of shear resistance of the soil surrounding the shaft (\(\phi_{\text{shaft}}\)), and pile length (L). The pile ultimate bearing capacity is set as the MARS output. Samui [14] compared the results obtained from MARS to those of other ANN-based models, e.g., the generalized regression neural network (GRNN) model. In addition, an equation was eventually proposed on the basis of the proposed MARS. On the other hand, the driven pile bearing capacity in clay was studied by Dzagov and Razvodovskii [15]. Depending on the surrounding soil properties and the length of pile, the driven piles are capable of providing basic characteristics to be recognized as both end bearing and/or friction piles. Having integrated the artificial neural networks (ANNs) and genetic algorithm (GA), Momeni et al. [16] attempted to develop a hybrid model applicable to the prediction of the pile bearing capacity. Literature also contains other AI techniques effectively applied to the prediction of the bearing capacities of a variety of piles by means of ANN [17,18,19], functional networks (FN) [20], relevance vector machines (RVM) [21], support vector machines (SVM) [22], extreme learning machines (ELM) [23], and MARS [20, 24]. ANN has been applied not only to the load-bearing capacity of piles, but also to the prediction of the settlement of piles on the basis of the cone penetration tests (CPT) [25]. On the other hand, ANN suffers from the drawback of poor generalization, which is due to the fact that, during the training process, it attains local minima and it requires iterative learning steps to achieve learning performances of a higher quality.
Moayedi and Jahed Armaghani [26] offered a combination of ANN and imperialism competitive algorithm (ICA) to predict bearing capacity of driven pile. Their results indicated that the performance of ICA–ANN was comparable with higher accuracy in prediction of K of the bearing capacity of driven pile than ANN one.
In other study, Moayedi and Hayati [27] predicted the friction capacity of driven piles through SVM, genetic programming (GP) and adaptive neuro-fuzzy inference system (ANFIS). Performance assessment indicated that the ANFIS possessed superior predictive ability than the GP and SVM models.
The ANFIS model was compared with hybrid ICA–ANN for the prediction of bearing capacity of driven pile in the study conducted by Shaik et al. [28]. They showed the superiority of ICA–ANN over ANFIS in terms of performance measures.
Recently, Harandizadeh et al. [29] presented a hybrid intelligent model based on ANFIS in combination with group method of data handling (GMDH) to predict bearing capacity of driven pile. Then the developed ANFIS–GMDH was optimized by particle swarm optimization (PSO). They compared the performance of proposed model with ANN performance, and indicated the effectiveness of ANFIS–GMDH–PSO model to predict the bearing capacity of driven pile.
This research is mainly aimed to present a new artificial intelligent approach to predict the total bearing capacity of the driven pile that is installed inside the cohesionless soil using support vector regression (SVR) optimized by genetic algorithm (GA). In other words, the main contribution of this study is to propose a new GA-SVR model in the field of driven piles. To the best of our knowledge, no research has developed the GA-SVR model to predict vertical load capacity of driven piles in different timescales as of yet. Additionally, SVR and linear regression models are also used for comparison.
2 Dataset
To develop the models capable of predicting the vertical capacity of piles, the dataset of Darrag [1] was used in this study. This database comprises in situ tests carried out on soil together with the pile load test data coming from various parts of the world. In this database, there are input parameters such as \(\phi_{\text{tip}}\), \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A, whereas the output is set to be the total pile capacity (Qm). In the used database, \(\phi_{\text{tip}}\), \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), A and Qm were varied in the ranges of 31–41, 28–39, 3–47.2 m, 38–475 KN/m2, 0.0061–0.6568 m2 and 75–5604 KN, respectively. In modeling processes of GA-SVR, SVR and linear regression, the datasets were separated into two parts in a random way: training (47 data samples) and testing (12 data samples). A part of datasets used in this study is given in Table 1.
3 Optimizing the SVR parameters by GA
3.1 Support vector regression (SVR)
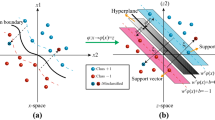
Support vector machines (SVM) have been recognized as a proper tool for predicting aims [30, 31]. The basis of SVM is the principle of structural risk minimization, and it enjoys an acceptable generalization with only a few number of data samples. SVM is actually a generation learning system that has been developed on the basis of developments that occurred in statistical learning theory. It helps researchers to map non-linear form of an n-dimensional input space and change it to a high-dimensional feature space in which, for instance, a linear classifier is applicable. SVM is capable of training the non-linear models on the basis of the principles of structural risk minimization, whose main aim is the minimization of an upper bound of the generalization errors, not the minimization of the empirical errors (as aimed by other neural networks). The basis of such induction principle is the fact that generalization error is bounded by the sum of the empirical error and a confidence interval term, which is dependent upon the Vapnik–Chervonenkis (VC) dimension. In accordance with this principle, SVM can attain an optimal model structure through the establishment of an appropriate balance between the VC confidence interval and the empirical error, which finally results in a generalization performance with a higher quality compared to that of the other ANN [32]. An added bonus of SVM is that its training is an exclusively solvable quadratic optimization problem, and in SVM, the solution complexity is only dependent upon the intricacy of the desired solution, not upon the dimensionality of the input space. As a result, SVM employs a non-linear mapping (on the basis of a kernel function) for the transformation of an input space into a high-dimensional space; then, within such space, it seeks for a non-linear relation between inputs and outputs. Note that SVM enjoys a rigorous theoretical background and, additionally, it is capable of finding global optimal solutions to the problems that have small training samples, non-linearity, high dimension, and local optima. In the beginning, SVM was developed to be applied to the pattern recognition problems [33], and it is only in the recent years that it has demonstrated a high capacity in solving a wide range of problems, e.g., non-linear regression. Support vector regression (SVR) employs the same principles as the SVM for classification, with only a few minor differences such as the margin of tolerance is set in approximation to the SVM which would have been requested from the problem [34]. For more detailed information about the SVR, please refer to [34,35,36,37,38]. Figure 1 shows a view of SVR structure. In this figure, \(a_{i}^{*} - a_{i}\) and B parameters are the weights of support vectors and polarization, respectively.

Structure of the SVR [39]
3.2 Model development
To have a high precision and efficiency in estimations made by SVR models, it is of high importance to accurately select the following SVR parameters: the regularization parameter (C), Kernel parameter (\(\gamma\)), and epsilon (\(\varepsilon\)) [40]. The values set for the above-noted parameters have a great impact on the model performance as explained in the following.
The C parameter (or box constraints) designates the penalty of the approximation function. The C value is recommended not to be too small or too large. In case it is too small, it considers an inadequate penalty upon the fitting of the training data, while in case it is selected too large, it can result in overfitting problems upon the training data [40]. The responsibility of the insensitivity loss function (\(\varepsilon\)) is controlling the number of support vectors; this parameter also affects the SVR performance. On the other hand, the \(\gamma\) parameter is for mapping non-linear function into higher dimensional space; in other words, it measures the SVR capacity of handling the problems of non-linearity [40, 41]. This is worth mentioning that numerous studies carried out previously into SVR performance still make use of manual or grid search for the purpose of choosing the hyperparameters of SVR [42]. The problem is that in cases where there is a broad parameter searching range, such approaches get computationally demanding and, at the same time, the achievement of the best parameters is of no guarantee in these approaches. Because of such shortages, researchers have designed some other techniques of searching aiming at solving the optimization problems. Remember that GA is a prevailing global optimization technique first introduced by Holland in 1975. It is highly attractive for scholars of numerous scientific fields because of its outstanding global searching capacity [41,42,43,44]. The present study makes the use of GA to find the optimal combination of SVR parameters. Figure 2 clearly depicts a flowchart of the optimization of SVR hyperparameters by means of GA.

GA-SVR structure [45]
3.2.1 The proposed GA-SVR
Here is proposed the GA-SVR model using the MATLAB 2018b platform. The MATLAB SVM toolbox containing SVR was utilized to develop the model. This toolbox was integrated with Global Optimization Toolbox in MATLAB to optimize the parameters of SVR. In a random way, 80% of whole data were classified into training dataset and the remaining 20% were assigned to the testing dataset. In other words, 47 and 12 data samples were used for training and testing parts. The former was applied to developing the proposed model.
In the training process, an algorithm is utilized to establish the functional relationship between the inputs and the corresponding target. Such process is normally done to explore the suitable set of SVR parameters, which decreases the cross-validation errors as far as possible. Before the beginning of model training, a normalization process was done on the training data in a way to make sure that it is computationally efficient. After that, the training data (inputs and target), the SVR parameter range, the population size and the number of generation were inserted into GA. In the present paper, the upper bound and lower bounds of the SVR parameters were specified as C (1e−08, inf), \(\varepsilon\) (1e−6, 8), \(\gamma\) (1e−8, inf), whereas the maximum iteration and the population size were set to 300. Also, the values of 0.8 and 0.25 were assigned for the crossover and mutation rates, respectively, based on trial and error method. When the functional relationships are learnt from the training dataset by the model in a successful way, it is the turn for the testing dataset to be employed for the purpose of validating the precision of the proposed model in its predictions. Table 2 lists the most proper set of SVR parameters that were achieved in the course of model training; they would be utilized later for testing upon the new dataset (testing dataset). Note that, the GA-SVR explained here was trained and tested based on five input parameters, i.e., \(\phi_{\text{tip}}\), \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A. The performance of the proposed GA-SVR model to predict Qm is discussed in Sect. 4.
4 Results and discussion
In this study, SVR, and GA-SVR models are used to predict Qm. To demonstrate the effect of input parameters on Qm, the different SVR and GA-SVR models were constructed based on different combinations of input parameters. In other words, six different SVR models and six different GA-SVR models were constructed in this study. The inputs of the mentioned models were according to the following:
-
SVR model 1; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, \(\sigma_{v}^{\prime }\), and A
-
SVR model 2; inputs: \(\phi_{\text{tip}}\), L, \(\sigma_{v}^{\prime }\), and A
-
SVR model 3; inputs: \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A
-
SVR model 4; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, and A
-
SVR model 5; inputs: \(\phi_{\text{shaft}}\), \(\phi_{tip}\), \(\sigma_{v}^{\prime }\), and A
-
SVR model 6; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, and \(\sigma_{v} '\)
-
GA-SVR model 1; inputs: \(\phi_{tip}\), \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A
-
GA-SVR model 2; inputs: \(\phi_{\text{tip}}\), L, \(\sigma_{v}^{\prime }\), and A
-
GA-SVR model 3; inputs: \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A
-
GA-SVR model 4; input: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, and A
-
GA-SVR model 5; input: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), \(\sigma_{v}^{\prime }\), and A
-
GA-SVR model 6; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, and \(\sigma_{v}^{\prime } .\)
Apart from the mentioned SVR and GA-SVR models, six different linear regression models were also constructed based on different independent parameters as follows:
-
Linear regression model 1; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, \(\sigma_{v}^{\prime }\), and A
-
Linear regression model 2; inputs: \(\phi_{\text{tip}}\), L, \(\sigma_{v}^{\prime }\), and A
-
Linear regression model 3; inputs: \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A
-
Linear regression model 4; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, and A
-
Linear regression model 5; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), \(\sigma_{v}^{\prime }\), and A
-
Linear regression model 6; inputs: \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), L, and \(\sigma_{v}^{\prime } .\)
The generally form of linear regression can be formulated as
where \(X\), \(x_{1}\)…\(x_{5}\) are the coefficients of equation, and can be determined by SPSS software. Considering the analyses, the following equations were constructed based on different input parameters:
Note that Eqs. 2–7 were constructed based on normalized inputs and output. From Eq. 2, it can be found that \(Q_{\text{m}}\) has a direct relationship with \(\phi_{\text{shaft}}\), \(\phi_{\text{tip}}\), \(\sigma_{v}^{\prime }\) and A parameters, while it has an indirect relationship with the L parameter. To check the performance of all eighteen models (six SVR, six GA-SVR and six linear regression models), three well-known criteria, namely root mean square error (RMSE), coefficient of determination (R2) and mean absolute error (MAE) were used, which can be expressed as follows [46,47,48,49,50,51,52,53,54,55,56]:
where \(Qm_{a} \;\;{\text{and}}\;\; Qm_{p}\) are the actual and predicted Qm values, and n is the number of total data (here 59 data). A value closer to one for R2, and closer to zero for RMSE and MAE indicates a better model. The values of R2, RMSE and MAE obtained from linear regression, SVR and GA-SVR models are given in Table 3. It is worth mentioning that in the analysis of the predictive models, we only consider the results of the testing phase. According to Table 3, among the linear regression models, model 1 has the lowest MAE and RMSE values, while model 3 has the highest R2 value. Also, among the SVR models, model 1 has the lowest MAE and RMSE values, and the highest R2 value. On the other hand, GA-SVR model 1 has also the lowest MAE and RMSE values, and the highest R2 value among the other GA-SVR models. Considering all predictive models, it can be seen that model 1 of GA-SVR with R2 of 0.980, RMSE of 0.017 and MAE of 0.017 has the best performance compared to SVR and linear regression models, as bolded in Table 3. In other words, the results confirm the ability of GA to improve SVR results. Based on Table 3, model 6 of linear regression, SVR and GA-SVR models have the worst performance among the other models. In other words, when A, as an input parameter, was removed from the modeling, the highest RMSE and MAE, and the lowest R2 values were obtained. Consequently, the A parameter can be considered as the most effective parameter to predict Qm. According to Table 3, model 3 among the linear regression models, model 1 among the SVR models, and model 1 among the GA-SVR models have the highest R2 values in testing phase. For a better view, the R2 values obtained from the mentioned models are shown in Figs. 3, 4, and 5. From these figures, it was found that the GA-SVR possessed superior predictive ability than the SVR and linear regression models, since a very close agreement (R2 = 0.980) between the measured and the predicted values of Qm was obtained.

Actual vs. predicted Qm values using model 3 of linear regression models

Actual vs. predicted Qm values using model 1 of SVR models

Actual vs. predicted Qm values using model 1 of GA-SVR models
5 Conclusion
Achieving a high-precision model to predict vertical load capacity of driven piles is an important task in geotechnical field. This study investigates the ability of GA-SVR model to predict vertical load capacity of driven piles in cohesionless soils. Additionally, the SVR and linear regression models were also employed and their results were compared to GA-SVR results. In modeling processes of GA-SVR, SVR and linear regression models, \(\phi_{\text{tip}}\), \(\phi_{\text{shaft}}\), L, \(\sigma_{v}^{\prime }\), and A were adopted as the input parameters, while Qm was the output parameter. In total, 59 data samples were used in the modeling, categorized to training and testing parts. To check the effect of each input parameters on Qm, the different GA-SVR, SVR and linear regression models were constructed based on different combinations of input parameters. Accordingly, eighteen different models (six GA-SVR models, six SVR models and six linear regression models) were developed to predict Qm. After training and testing processes, the performance of the models was evaluated and compared using three common statistical performance metrics, namely R2, RMSE and MAE. According to the obtained results, it was demonstrated that the accuracy of the GA-SVR was higher compared with SVR and linear regression models. In other words, GA-SVR model with R2 of 0.980 can predict Qm better than the SVR and linear regression models with R2 of 0.912 and 0.625, respectively. From the results of this study, it can be concluded that the GA was an excellent optimization algorithm to improve the performance of SVR and has the potential to generalize. As a recommendation, other optimization algorithms such as Flower Pollination Algorithm, Gravitational Search Algorithm, Imperialistic Competitive Algorithm and Locust Swarm Algorithm may be trialed as well to optimize SVR model.
References
Darrag AA (1987) Capacity of driven piles in cohesionless soils including residual stresses. PhD thesis, Purdue Univ., West Lafayette, Ind
Abu Kiefa M (1998) General regression neural networks for driven piles in cohesionless soils. J Geotech Geoenviron Eng 124(12):1177–1185
Meyerhof GG (1976) Bearing capacity and settlement of pile foundations. J Geotech Eng 102(3):196–228
Coyle HM, Castello RR (1981) New design correlations for piles in sand. J Geotech Eng 107(7):965–986
RP2A (1991) Recommended practice for planning, designing and constructing fixed offshore platfonns, 19th edn. American Petroleum Institute, Washington, DC
Randolph MF, Dolwin J, Beck R (1994) Design of driven piles in sand. Geotech Lond 44(3):427–448
Monjezi M, Hasanipanah M, Khandelwal M (2013) Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Comput Appl 22(7–8):1637–1643
Amiri M, Bakhshandeh Amnieh H, Hasanipanah M, Mohammad Khanli L (2016) A new combination of artificial neural network and K-nearest neighbors models to predict blast-induced ground vibration and air-overpressure. Eng Comput 32:631–644
Hasanipanah M, Noorian-Bidgoli M, Armaghani DJ, Khamesi H (2016) Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng Comput 32(4):705–715
Taheri K, Hasanipanah M, Bagheri Golzar S, Abd Majid MZ (2016) A hybrid artificial bee colony algorithm-artificial neural network for forecasting the blast-produced ground vibration. Eng Comput 33(3):689–700
Armaghani DJ, Hasanipanah M, Mohamad ET (2016) A combination of the ICA-ANN model to predict air-overpressure resulting from blasting. Eng Comput 32(1):155–171
Mohamad ET, Armaghani DJ, Hasanipanah M, Murlidhar BR, Alel MNA (2016) Estimation of air-overpressure produced by blasting operation through a neuro-genetic technique. Environ Earth Sci 75(2):174
Moayedi H, Jahed Armaghani D (2017) Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng Comput. https://doi.org/10.1007/s00366-017-0545-7
Samui P (2012) Determination of ultimate capacity of driven piles in cohesionless soil: a multivariate adaptive regression spline approach. Int J Numer Anal Methods Geomech 36:1434–1439
Dzagov AM, Razvodovskii DE (2013) Bearing capacity of driven piles supported on slightly compressible soils. Soil Mech Found Eng 50:187–193
Momeni E, Nazir R, Armaghani DJ, Maizir H (2014) Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 57:122–131
Das SK, Basudhar PK (2006) Undrained lateral load capacity of piles in clay using artificial neural network. Comput Geotech 33(8):454–459
Shahin MA, Jaksa MB, Maier HR (2001) Artificial neural network applications in geotechnical engineering. Aust Geomech 36(1):49–62
Tarawneh B (2013) Pipe pile setup: database and prediction model using artificial neural network. Soils Found 53(4):607–615
Suman S, Das SK, Mohanty R (2016) Prediction of friction capacity of driven piles in clay using artificial intelligence techniques. Int J Geotech Eng 10(5):1–7
Samui P (2012) Application of relevance vector machine for prediction of ultimate capacity of driven piles in cohesionless soils. Geotech Geol Eng 30(5):1261–1270
Samui P (2011) Prediction of pile bearing capacity using support vector machine. Int J Geotech Eng 5(1):95–102
Muduli PK, Das SK, Das MR (2013) Prediction of lateral load capacity of piles using extreme learning machine. Int J Geotech Eng 7(4):388–394
Samui P (2012) Determination of ultimate capacity of driven piles in cohesionless soil: a multivariate adaptive regression spline approach. Int J Numer Anal Meth Geomech 36(11):1434–1439
Baziar MH, Azizkandi AS, Kashkooli A (2015) Prediction of pile settlement based on cone penetration test results: an ANN approach. KSCE J Civ Eng 19(1):98–106
Moayedi H, Jahed Armaghani D (2018) Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng Comput 34:347–356
Moayedi H, Hayati S (2018) Artificial intelligence design charts for predicting friction capacity of driven pile in clay. Neural Comput Appl. https://doi.org/10.1007/s00521-018-3555-5
Shaik S, Rama Krishna KS, Abbas M, Ahmed M, Mavaluru D (2018) Applying several soft computing techniques for prediction of bearing capacity of driven piles. Eng Comput. https://doi.org/10.1007/s00366-018-0674-7
Harandizadeh H, Jahed Armaghani D, Khari M (2019) A new development of ANFIS–GMDH optimized by PSO to predict pile bearing capacity based on experimental datasets. Eng Comput. https://doi.org/10.1007/s00366-019-00849-3
Hasanipanah M, Monjezi M, Shahnazar A, Armaghani DJ, Farazmand A (2015) Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement 75:289–297
Rad HN, Hasanipanah M, Rezaei M, Eghlim AL (2018) Developing a least squares support vector machine for estimating the blast-induced flyrock. Eng Comput 34(4):709–717
Khandelwal M (2011) Blast-induced ground vibration prediction using support vector machine. Eng Comput 27:193–200
Schmidt M (1996) Identifying speaker with support vector networks. In: Interface ‘96 proceedings, Sydney
Li XL, Li LH, Zhang BL, Guo QJ (2013) Hybrid self-adaptive learning based particle swarm optimization and support vector regression model for grade estimation. Neurocomputing 118:179–190
Safarzadegan Gilan S, Bahrami Jovein H, Ramezanianpour AA (2012) Hybrid support vector regression—particle swarm optimization for prediction of compressive strength and RCPT of concretes containing metakaolin. Constr Build Mater 34:321–329
Gunn S (1998) Support vector machines for classification and regression. In: ISIS Technical Report
Vapnik VN, Golowich S, Smola A (1997) Support vector method for function approximation, regression estimation and signal processing. In: Mozer M, Jordan M, Petsche T (eds) Advance in neural information processing system, vol 9. MIT Press, Cambridge, pp 281–287
Hasanipanah M, Shahnazar A, Amnieh HB, Armaghani DJ (2017) Prediction of air-overpressure caused by mine blasting using a new hybrid PSO–SVR model. Eng Comput 33(1):23–31
Chen Y, Tan H (2017) Short-term prediction of electric demand in building sector via hybrid support vector regression. Appl Energy 204:1363–1374
Alade IO, Abd Rahman MA, Saleh TA (2019) Modeling and prediction of the specific heat capacity of Al2O3/water nanofluids using hybrid genetic algorithm/support vector regression model. Nano-Struct Nano-Objects 17:103–111
Jiang L, Diao M, Xue H, Sun H (2018) Energy dissipation prediction for stepped spillway based on genetic algorithm–support vector regression. J Irrig Drain Eng 144:04018003. https://doi.org/10.1061/(ASCE)IR.1943-4774.0001293
Liu S, Tai H, Ding Q, Li D, Xu L, Wei Y (2013) A hybrid approach of support vector regression with genetic algorithm optimization for aquaculture water quality prediction. Math Comput Model 58:458–465
Sajan KS, Kumar V, Tyagi B (2015) Genetic algorithm based support vector machine for on-line voltage stability monitoring. Int J Electr Power Energy Syst 73:200–208. https://doi.org/10.1016/j.ijepes.2015.05.002
Alade IO, Bagudu A, Oyehan TA, Rahman MAA, Saleh TA, Olatunji SO (2018) Estimating the refractive index of oxygenated and deoxygenated hemoglobin using genetic algorithm—support vector machine approach. Comput Methods Programs Biomed. https://doi.org/10.1016/J.CMPB.2018.05.029
Ghaedi M, Dashtian K, Ghaedib AM, Dehghanianc N (2016) A hybrid model of support vector regression with genetic algorithm for forecasting adsorption of malachite green onto multi-walled carbon nanotubes: central composite design optimization. Phys Chem Chem Phys 18:13310–13321
Zhou J, Li X, Shi X (2012) Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf Sci 50(4):629–644
Zhou J, Li X, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30(5):04016003
Zhou J, Li X, Mitri HS (2018) Evaluation method of rockburst: state-of-the-art literature review. Tunn Undergr Space Technol 81:632–659
Zhou J, Li E, Yang S, Wang M, Shi X, Yao S, Mitri HS (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118:505–518
Zhou J, Li E, Wang M, Chen X, Shi X, Jiang L (2019) Feasibility of Stochastic Gradient Boosting Approach for Evaluating Seismic Liquefaction Potential Based on SPT and CPT Case Histories. J Perform Constr Facil 33(3):04019024
Zhou J, Li X, Mitri HS (2015) Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat Hazards 79(1):291–316
Zhou J, Shi X, Du K, Qiu X, Li X, Mitri HS (2017) Feasibility of random-forest approach for prediction of ground settlements induced by the construction of a shield-driven tunnel. Int J Geomech 17(6):04016129
Zhou J, Shi X, Li X (2016) Utilizing gradient boosted machine for the prediction of damage to residential structures owing to blasting vibrations of open pit mining. J Vib Control 22(19):3986–3997
Yang HQ, Lan YF, Lu L, Zhou XP (2015) A quasi-three-dimensional spring- deformable-block model for runout analysis of rapid landslide motion. Eng Geol 185:20–32
Yang HQ, Zeng YY, Lan YF, Zhou XP (2014) analysis of the excavation damaged zone around a tunnel accounting for geostress and unloading. Int J Rock Mech Min 69:59–66
Yang H, Hasanipanah M, Tahir MM, Bui DT (2019) Intelligent prediction of blasting-induced ground vibration using ANFIS optimized by GA and PSO. Nat Resour Res. https://doi.org/10.1007/s11053-019-09515-3
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Luo, Z., Hasanipanah, M., Bakhshandeh Amnieh, H. et al. GA-SVR: a novel hybrid data-driven model to simulate vertical load capacity of driven piles. Engineering with Computers 37, 823–831 (2021). https://doi.org/10.1007/s00366-019-00858-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-019-00858-2