
Abstract
Brain emotional learning (BEL) model has been used frequently for predicting a quantity or modeling complex and nonlinear systems in recent years. In this research, two methods proposed for improving the efficiency of original BEL model using fuzzy rules, learning automata concepts and optimization algorithms. In the first proposed method, different optimization algorithms and continuous action-set learning automata (CALA) were used for finding the weights of BEL model, while in the second proposed model, the weights obtained using original rules of BEL model. In fact, in the second model finite action-set learning automata, CALA and different optimization algorithms were used for calibrating the learning parameters of the model. Also in the both proposed methods after extracting frequency features in thalamus, deep belief network is used in the sensory cortex for reducing the size of features. In addition, ANFIS is used for making fuzzy rules in the amygdala. The proposed models were used for magnitude and consequently fear prediction of the earthquakes. The results show that although both proposed methods are more accurate than original BEL model and could be used successfully, the second proposed model is more precise and reliable than the first proposed model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Artificial neural networks are developed based on the analogy of human’s brain for making decision or learning different activities. Recently, a new model is under consideration, which is inspired by the emotional process of brain’s limbic system of mammalian. The brain emotional learning model has the advantages of lower computational complexity, high speed of convergence, and its stability. Moren and Balkenius proposed one of the famous computational models of brain emotional learning (BEL) [1, 2]. This model or modified version of it was used in different engineering applications [3,4,5,6,7,8,9,10]. Fakhrmoosavy et al. proposed an intelligent method for generating artificial earthquake records based on hybrid PSO-parallel brain emotional learning inspired model [10]. In spite of high ability of ANNs to simulate complex nonlinear problems, appropriate selection of learning parameters and initial weights have an important role on the training convergence of the model. Suitable selection of these parameters could lead the model to more results that are accurate and making it more reliable model. Different modified version of BEL proposed by researchers and used in real applications. Lotfi and akbarzadeh proposed the brain emotional learning-based pattern recognizer by extending the computational model of human brain limbic system. The authors used the proposed model for solving classification and chaotic time series prediction problems. The proposed model has advantages of more accuracy, less complexity, and more speed of training in comparison with standard MLP [11]. Parsapoor combined emotionally inspired structure with neuro-fuzzy inference system to propose a new model for solar activity prediction. The author found that the predictor model has a faster convergence than ANFIS and is reliable model for predicting the solar activity and other similar prediction problems [12]. Lotfi used the model of emotional process in the brain and proposed an image classifier model named brain emotional learning-based picture classifier. The author applied the activation function in the brain emotional model to improve the efficiency of proposed model. The results of simulation show the high speed of proposed model in comparison with multilayer perceptron neural network in training [13]. Parsapoor merged the model of brain emotional learning-based fuzzy inference system with radial basis function network and tested it by complex systems [14]. Lotfi and Keshavarz introduced the fuzzy mathematical model of brain system and used it for predicting the chaotic activity of earth’s magnetosphere. The authors fuzzified the connections in the limbic system model and implemented the inhibitory task of orbitofrontal cortex as a fuzzy decision making layer. The simulation showed the higher correlation of obtained results of fuzzy model in comparison with non-fuzzy models [15]. Lucas and Moghimi used a modified version of brain emotional learning model for designing an intelligent controller for auto landing system of aircrafts. As the existing automotive landing systems are activated only in a well-specified wind speed lamination condition, the proposed controller was more robust and had a better performance in the condition of strong wind gusts [16]. Parsapoor and Bilstrup proposed a new model of brain emotional learning-based prediction model by assigning adaptive networks to the different parts of original brain emotional learning model. The author used proposed model for predicting geomagnetic storms using the disturbance storm time index [12].
In this study, we combined optimization algorithms and learning automata with original model of BEL to propose modified new models to increase the accuracy and performance. This article is organized as follows: the concepts of brain emotional learning inspired model are presented in Sect. 2. Learning automata is described in Sect. 3. The optimization methods, which are used in this research, are expressed in Sect. 4. Power spectral density function as the frequency feature of earthquake record is presented in Sect. 5. Adaptive neuro-fuzzy inference system is explained in Sect. 6. Deep belief network for size reduction of features is described in Sect. 7. Two methods for improving the efficiency of original BEL model are proposed in Sect. 8. Numerical examples are illustrated in Sect. 9. Finally, concluding and remarks are presented in Sect. 10.
2 Brain emotional learning inspired model (BELIM)
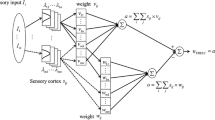
The emotional part of mammalian’s brain has an important role of making a rapid response to the environmental stimuli. This part, which is called limbic system, includes different sections such as Thalamus, Sensory Cortex, Amygdala, and Orbitofrontal Cortex. Each section has a role in analyzing the input stimuli and making emotional response. The thalamus receives input information from environment. Pre-processing of signals is done in this section. The amygdala receives information of initial signals from thalamus that has not yet entered to the sensory cortex. Information of the other parts of the limbic system is also entered to the amygdala. Sensory cortex acts as a transition area in which signals through it from the rest of the cerebral cortex transmitted to the limbic system and vice versa. Therefore, it works as a communication area of the brain for controlling the behaviour. The orbitofrontal cortex (OFC) receives information from the sensory cortex. It has an important role in decision-making by its cognitive processors. In this area, learning is done by processing the stimuli and applying positive and negative reinforcement in the sense of reward and penalty. The other duty of OFC is controlling amygdala’s irrelevant responses.
Many researchers recently studied and used brain emotional learning inspired model to solve complex and nonlinear problems of mapping and making decision in the engineering science and industrial applications [4,5,6,7,8,9,10, 14]. Moren and Balkenius proposed one of the most important computational models in the field of emotional learning. This model shows the relationship between different parts of limbic system as shown in Fig. 1 with emphasize on interaction between amygdala and orbitofrontal cortex [2].

Different parts of limbic system in the BEL model [2]
The sensory inputs enter to the thalamus, which is a pathway for sending the input stimuli to sensory cortex and amygdala. In fact, the noise reduction and pre-processing will be done in the thalamus. In the case of having \(n\)inputs, they will be pre-processed in the thalamus. Then, it sends n normalized stimuli to the sensory cortex and one stimulus to the amygdala, which are as follows [2]:
Sensory cortex is a transition area which transmits the sensory inputs to both amygdala and orbitofrontal cortex. Amygdala, which has the role of final decision-making, contains n + 1 A-nodes. For each A-node, there is a connection weight \({V_i}\). The output of each node is made by multiplying inputs \({S_i}\) to weights \({V_i}\):
The output of amygdala is obtained by the summation of weighted inputs [2]:
The connection weights \({V}_{i}\) are modified monotonically based on the difference between the reinforcer \(R\) and summation of \(A-\)nodes:
where \(\alpha\) is the learning rate in the interval of \(\left[\text{0,1}\right]\). If emotional reaction is learned by amygdala, it should be permanent; thus, the modification of weights \({V}_{i}\) is monotonically based on Eq. (2.4). There is another important part in the limbic system, called orbitofrontal cortex, which controls amygdala’s irrelevant responses. There is \(n\)o-node in the orbitofrontal cortex, which is obtained by multiplying sensory inputs \({S}_{i}\) by connection weights \({W}_{i}\) [2]:
Summation of O i makes the output of orbitofrontal cortex:
Connection weights of \({W}_{i}\) are updated as a function of the input and internal reinforcer for the orbitofrontal cortex:
where β is a learning rate parameter and internal reinforcer \({R_0}\) could be calculated by the following equation:
The final output of limbic system will be calculated by the following equation [2]:
3 Learning automata
A stochastic learning automaton is a useful tool for making decision under uncertain conditions. It has been used in many engineering problems with a nondeterministic nature. Learning automata is an iterative process of selecting an action randomly, based on a probability density function and applying the action to the environment. The environment responses to the action and this response change the probability vector for selecting the next action. This process will be repeated to find the best action for finding an optimum or goal response of environment. Learning automata is divided to two main categories, finite action-set learning automata and continuous action-set learning automata, which are described in the following [17,18,19].
3.1 Finite action-set learning automata (FALA)
The action-set in FALA is always considered to be finite and predefined. Let \(A=\left\{ {{\alpha _1}, \ldots ,{\alpha _r}} \right\},~~r<\infty\) be the set of actions available at each instant n, the automaton selects an action \(\alpha \left( n \right)\) randomly based on its probability distribution, \(p\left( n \right)=\left\{ {{p_1}\left( n \right), \ldots ,{p_r}\left( n \right)} \right\}.\) The selected action is applied to the environment. Then, the environment responds to this action by stochastic reinforcement signal, \(\beta \left( n \right)\) as shown in Fig. 2. Afterward, the LA updates the probability distribution \(p\left( n \right)\) based on the selected action and reinforcement signal. The process of updating is done using different learning algorithms. Two kinds of fixed and variable structure FALA exist.

Structure of learning automata

Flowchart of GA for finding the weights or learning parameters of model
Examples of the fixed structure LA type are Tsetline, krinsky, and Krylov automata. Linear reward-inaction \({L_{R - I}}\), linear reward-ε-penalty \({L_{R - \varepsilon p}}\), linear reward-penalty \({L_{R - P}}\), and pursuit algorithm are examples of variable structure FALA. Variable structure FALA is used in this research. In the following, the algorithms, which are used in this study, will be described briefly [18, 19].
3.1.1 Linear reward-inaction algorithm, \({\varvec{L}}_{\varvec{R}-\varvec{I}}\)
The \({L_{R - I}}\) algorithm updates the action probabilities as described below. Let \(\alpha \left( n \right)={\alpha _i}\), then the action probability vector \(p\left( n \right)\) is updated as follows:
where λ is the learning (step-size) parameter satisfying \(0 <\)λ \(< 1\) [18].
3.1.2 Linear reward-penalty algorithm, \({\varvec{L}}_{\varvec{R}-\varvec{P}}\)
If \(\alpha \left( n \right)={\alpha _i},\) then the probability vector is updated as follows:
where λ 1 and λ 2 are learning parameters which usually λ 1 = λ 2 [18].
3.1.3 Pursuit Algorithm
The reward probabilities of actions are estimated in this algorithm by considering the history of selected actions and obtained reinforcement signal.
Let \(\alpha \left( n \right)={\alpha _i}\). The number of times which action \({\alpha _i}\) is chosen till instant \(n\)and the total reinforcement obtained in response to action \({\alpha _i}\) are saved in vectors \({\left( {{\eta _1}\left( n \right),~ \ldots ,{\eta _r}\left( n \right)} \right)^T} \, {\rm and} \, {\left( {{Z_1}\left( n \right),~ \ldots ,{Z_r}\left( n \right)} \right)^T},\) respectively. These vectors updates as follows:
where \(\hat {d}\) is the estimator vector, which is used for updating the probability of actions. Let \({\hat {d}_{M(n)}}\) be the highest estimated reward probability at instant. If the estimates are true, the value of p m (n) should be one and the rest of action probabilities should be zero. In other words, \(p\left( n \right)={e_{M\left( n \right),}}\) where \({e_{M\left( n \right)}}\) is a vector, which its mth element is one and the other elements are zero. This algorithm updates probability of actions by moving p(n) towards \({e_{M\left( n \right)}}\) by a small amount determined by a learning parameter as follows:
where \(0 <\)λ ≤ 1 is the learning parameter and the index \(M\left( n \right)\) is determined by the following [18, 19]:
3.2 Continuous action-set learning automata (CALA)
In the FALA, the actions are a finite set with predefined values. These actions could not be more suitable for finding optimal parameter values to maximize a performance index. In fact, in this case, a continuous action set is needed. The automaton, which uses continuous action set, is called CALA. In this algorithm, the probability distribution of actions at instant \(n\) is \(N\left( {\mu \left( n \right),\sigma \left( n \right)} \right),\) which is the normal distribution with mean \(~\mu \left( n \right)\) and standard deviation \(\sigma (n)\). By updating (n) and \(\sigma (n)\) in each instant, the CALA updates the probability distribution of actions. Let \(\alpha \left( n \right) \in {\mathbb{R}}\) be the action chosen and let \(\beta (n)\) be the reinforcement signal at instant n. A reward function \(f:~{\mathbb{R}} \to {\mathbb{R}}\) instead of reward probabilities is defined by \(f\left( x \right)={\text{{\rm E}}}\left[ {\beta \left( n \right)|\alpha \left( n \right)=x} \right].\) The reinforcement in response to action \(x\) denoted by \({\beta _x}\):
The role of CALA is finding the value of \(x\) to maximize the \(f\left( x \right).\) In this case, the \(N\left( {\mu \left( n \right),\sigma \left( n \right)} \right)\) converges to \(N\left( {{x_0},0} \right),\) where the reward function has its maximum value at \({x_0}.\) To avoid of being stuck at a non-optimal point the CALA, lets \(\sigma (n)\) converge to \({\sigma _l}\) instead of zero, which \({\sigma _l}\) has a very small value. CALA interact with the environment by choosing of two actions \(x\left( n \right)\) and \(~\mu \left( n \right)\) at each instant. The value of \(x\left( n \right)\) is generated randomly using probability distribution of \(N\left( {\mu \left( n \right),\phi \left( {\sigma \left( n \right)} \right)} \right).\) Two actions \(x\left( n \right)\) and \(~\mu \left( n \right)\) apply to the environment and CALA updates the probability distribution by updating mean and standard deviation of actions as follows [19]:
where
and, \(\lambda\): learning parameter \(\left( {0<\lambda \leqslant 1} \right),~c\): large positive constant.
4 Used optimization methods
4.1 Genetic algorithm
Genetic algorithm is an evolutionary computing method for finding the optimum value of a simple to very complex and nonlinear function. This algorithm was inspired by the biological rules in the nature and has been used in many optimization problems especially in the engineering fields. The GA consists of three main operators, selection, crossover, and mutation [20,21,22]. Figure 3 shows the steps of GA and its application on this research. GA used two times in this study: first time, for finding the optimum value of BEL’s weights in one optimization problem and the second time for finding the best values of learning rate parameters.
4.2 Particle swarm optimization (PSO)
PSO algorithm was inspired by the social behaviour of animals, such as bird flocking or fish schooling. Each individual in this algorithm is called particle. Any particle moves to new position based on its past position and current velocity. Each particle updates its velocity based on the information which it gets by own and from other particles in the swarm [23, 24]. This algorithm was used in many areas of engineering fields [25,26,27,28,29,30,31,32]. PSO algorithm is used in this research for finding the optimum value of BEL weights or learning rate parameters as follows.

4.3 Artificial bee colony (ABC)
ABC was inspired by the behaviour of honeybees in the nature for finding food sources. In this algorithm, there are three groups of honeybees, which are named employee, onlooker, and scout bees. Scout bees find the food sources, which are the solution for each parameter randomly, and then, employee bees go to the food sources. They evaluate the amount of food source nectar (fitness function). Afterwards, the onlooker bees select the best food source after evaluating the information, which obtained from employee bees [33]. ABC algorithm is used in this research for finding the optimum value of BEL weights or learning rate parameters as follows.

5 Power spectral density function (PSDF)
If \(x\left( t \right)\) is a random variable, its time-history is not periodic, in general. Thus, it is not possible to show it by its discrete Fourier series. In addition, for a stationary process \(x\left( t \right)\), the condition below may not be satisfied:
Therefore, it is not possible to calculate the Fourier series of \(x\left( t \right)\). It may be overcome to this problem using autocorrelation function \({R_x}\left( \tau \right)\) instead of \(x\left( t \right)\). Autocorrelation function contains the frequency content of process indirectly and defined as the mean value of the product \(x\left( t \right)x\left( {t+\tau } \right)\), which \(\tau\) is a time difference between sampling. If \(x\left( t \right)\) is a stationary process, the value of \(E\left[ {x\left( t \right)x\left( {t+\tau } \right)} \right]\) is independent of time:
where \(E\left[ . \right]\) is the expected value.
Power spectral density function, \({S_x}\left( \omega \right)\), is the Fourier transform of autocorrelation function of \(x\) [34]:
6 Adaptive neuro-fuzzy inference system (ANFIS)
-
A fuzzy inference system with fuzzy if–then rules can model the qualitative aspects of human knowledge and reasoning processes without quantitative analysis. ANFIS acts in this way. Suppose that there is a system with two inputs x, y and one output z. The rule base contains two fuzzy if–then rules of Takagi and Sugeno type [35].
-
Ai, Bi and Fi are fuzzy sets and pi, qi and ri are the outputs of the system which obtains from the learning process. Figure 4 shows the type-3 ANFIS.
-
Layer 1 (fuzzification): in this layer, the membership grades are generated by Eqs. (6.1), (6.2), and (6.3) [35]:

Structure of the ANFIS with two inputs of x and y
-
\({\text{where}}~\,O_{i}^{1}\) is the membership function of A i . \(\mu {A_i}\left( x \right)\) is bell shaped with maximum of 1 and minimum of 0 such as
-
Or
-
which \(\left\{ {{a_i},{b_i},{c_i}} \right\}\) is the parameter set.
-
Layer 2 (production) : Each node in this layer is a circle node and multiplies the incoming signals. Each node output represents the firing strength of a rule [35]:
-
Layer 3 (normalization): The ith node calculates the ratio of the ith rule’s firing strength to the sum of all rules’ firing strengths [35]:
-
Layer 4 (defuzzification): Every node \(i\) in this layer is a square node with a function [35]:
-
where \({\bar {w}_i}\): Output of layer 3
-
\(\left\{ {{p_i},{q_i},{r_i}} \right\}\): Parameter set.
-
Layer 5 (output): The summation of all incoming signals is computed by the following [35]:
7 Deep belief network (DBN)
-
Artificial neural network is one of the most important tools in the field of artificial intelligence. It has many applications such as object recognition, mapping, signal analysis, and so on. According to the theoretical and biological reasons, it is recommended to use deep architecture including many nonlinear processing layers in the structure of ANNs. These deep models have many hidden layers and parameters, which should be trained. It increases the computational effort and decreases the speed of training significantly. In addition, it may cause to get into local minimum. Using DBN could overcome these problems [36, 37]. The layers of DBN consist of Restricted Boltzmann Machines (RBM) which are probabilistic models with one hidden layer. The DBN tries to reconstruct the inputs at the output layer. For this purpose, the hidden layer should be described the data of input layer, as well. Not only DBN is useable for classification, but also it is capable of extracting feature. In fact, DBN is able to extract the most important features of training data [38]. In addition, DBN could be used to reduce the dimensionality of data [38]. After extracting the features of earthquake records (PSDF) in the thalamus, the DBN is used in the sensory cortex to reduce the size of features. Therefore, the most effective features will be found. For this purpose, the number of neurons in the hidden layer should be less than the number of neurons in the input layer. If the reduced-dimension data could explain the input data, it could be used as representative of whole features. In this research, 101 features obtain for each earthquake record and considered as the inputs and outputs of DBN, as shown in Fig. 5. The number of hidden neurons is chosen 70, which are less than input and output neurons. The network will be trained. Therefore, the features in the hidden layer could be used as inputs of amygdala and orbitofrontal cortex.

Deep belief network for size reduction of features

Structure of First Proposed Model

Structure of Second Proposed Model

PSDF of four used samples as the input of models

Results of training first proposed model with different optimization algorithms

Training second proposed model with different learning algorithm of LA
8 Proposed method
-
Two methods are proposed in this research for predicting the level of fear encounter to an earthquake. In both methods, a modified BEL model is used. The input signal of the model is earthquake record, which shows the ground motion accelerations. As the ground accelerations are recorded in a short time steps (for example 0.02 s), there are many data points in each earthquake record, which increase the calculations of model. In addition, two earthquakes, which are similar in magnitude and intensity, could be completely different in acceleration–time diagram. Therefore, the feature extraction is considered in the thalamus to use a more relevant stimulus for sensory cortex. Frequency content is the most important feature of earthquake signals. In this research, power spectral density function is used as the frequency content of earthquake records for sending to sensory cortex. In this way, the calculations will be reduced significantly. Furthermore, more sensible stimulus will be used for predicting the fear induced by earthquake in the brain emotional model. In sensory cortex, we used a deep belief network for decreasing the size of PSDF. Afterwards, it sends the reduced features to orbitofrontal cortex and amygdala. It should be mentioned that the output of the model is the level of fear. In fact, the level of fear is a qualitative value, which could not be predicted directly using brain emotional learning (BEL) model. To make a relationship between the values, which calculate at amygdala and the level of fear, an adaptive neuro-fuzzy inference system, is used in the amygdala to make fuzzy rules. These fuzzy rules are used in the amygdala to find the level of fear caused by the earthquake.
8.1 First proposed method
-
In the first proposed method, the structure of BEL model is used without considering the original learning algorithm of BEL model. In this method, the weights are found and modified using different optimization algorithms such as GA, PSO, ABC, and CALA. In fact, this is an optimization problem, which its design variables are weights of modified BEL model and the goal is minimizing the error of model to find the fear. Different optimization algorithms are considered in the first proposed methods to find the most efficient algorithm for the kind of input–output data at hand. Figure Fig. 6 shows the structure of the first proposed method.
8.2 Second proposed method
-
In the second proposed method, learning automata is used for finding the learning parameters of modified BEL model (MBEL). In fact, MBEL model is used as the environment. The difference between the output of amygdala and target value shows the absolute error of the model. The relative error could be calculated and the response of environment will be defined as unity minus relative error. In the BEL model, the output and the target are scaled to be in the interval of [0, 1]. Therefore, the relative error could be in the interval of [0, 1], as well. If action selects properly in an ideal case, the relative error will be zero and the response of environment will be one, which shows a reward. In the other case: if an improper action selects, the relative error in the worth case will have its maximum value of one and the response of environment will be zero which shows a penalty. The response applies to LA for making decision of finding the best action, which are the learning parameters of network. These parameters are used in the weight correction algorithm of MBEL model. Three learning algorithm, \({L_{R - I}}\), \({L_{R - P}}\), \({L_{P - A}}\), are used in this research to find suitable algorithm for the data which are used in this study. These algorithms described in Sect. 3.
-
Selection of actions is done in three different methods:
-
selecting actions randomly (S 1)
-
selecting actions randomly with equal number of all actions (S2)
-
selecting actions based on their probability (S 3)
Figure Fig. 7 shows the second proposed method in detail.
9 Numerical examples
9.1 Data set
A data set consists of 100 real earthquake records, which is provided by the Pacific Earthquake Engineering Research Center (PEER) Website [39]. 70% of the data set are used for training the proposed model and the rest of data are used for testing the performance of trained model. Earthquakes are different in time duration, frequency content, magnitude, and peak ground acceleration. These records, which show the acceleration time-history of earthquakes, are used as the input of proposed models.
9.2 Example for the first proposed model
The earthquakes select randomly from the data set for applying to the model as the input. Feature extraction is done in the thalamus and PSDF is obtained for each earthquake record. In fact, PSDF shows the frequency content of earthquake which is one of the most important features of each earthquake record. Figure 8 shows four samples of PSDF which are used in this research.
The features entered into sensory cortex. DBN is used in this section for reducing the size of features. The training of the model is done using all specified training data. Figure 9 shows the comparison between original BEL and using different optimization algorithms for finding the appropriate weights of the first proposed method. According to Fig. 9, BEL-CALA is the best optimization algorithm for this example even better than original BEL.
To illustrate the ability of trained model, 30% of provided data were used as test data. The average relative error for BEL, BEL-GA, BEL-ABC, BEL-PSO, and BEL-CALA is 2.97, 3.82, 7.04, 1.92, and 1.21%, respectively. Table 1 demonstrates the results of ten samples of test data for different optimization algorithm and original BEL, which are used in the first proposed method.
As expected from the training results, BEL-CALA is the best model, which uses CALA algorithm for training the model. The level of fear is related to the amount of magnitude of the earthquakes. Table 2 illustrates the relationship between the earthquake magnitude and the level of fear, which is considered in this research.
Although there are small differences between the real and predicted magnitude using the PSO and CALA optimization algorithms in the first proposed model, the level of fear predicted successfully by these algorithms, as shown in Table 3.
Table 3 shows that the BEL-PSO and BEL-CALA models could exactly predict the level of fear and are reliable models for this purpose.
9.3 Example for the second proposed model
In this example, the second proposed method is used for training the model. In fact, the weights are corrected using BEL Formula and learning automata is used for finding the best values of learning parameters. Different learning algorithms are used for this purpose, which their results are shown in Fig. 10.
Three methods of selection are used in \({L_{R - I}}\) and \({L_{R - P}}\) learning algorithms, while \({L_{P - A}}\) works with \({S}_{3}\) method only. According to Fig. 10, the third method of selection is the best choice for all learning algorithms.
Figure 11 shows the comparison between different learning algorithms. Although Fig. 11 illustrates that \({L_{R - P}}\) has better training in the early epochs, but the results show that \({L_{R - I}}\)has the best training in overall.

Comparison between different learning algorithms of LA on training second proposed model

Performance of different algorithms on training second proposed model
For comparing the results, other algorithms such as CALA, GA, PSO, and ABC are used for finding the learning parameters. Figure 12 shows the performance of different algorithms on training second proposed model. The result shows that BEL-CALA and BEL-PSO have the minimum error, BEL, BEL-GA, and BEL-L_RI trained with a moderate amount of error, and BEL-ABC has the maximum error.
Test data are used to show the ability of trained model for predicting the magnitude of earthquakes. The mean relative error of BEL, BEL-GA, BEL-ABC, BEL-PSO, BEL-\({L}_{R-I}\), and BEL-CALA obtained 2.97, 2.43, 5.13, 1.18, 2.63, and 0.83%, respectively. Table 4 illustrates the results of ten samples of test data. According to Table (4), the BEL-CALA model has the best performance among different algorithms. In addition, BEL-PSO could predict the magnitude with acceptable amount of error.
Table 5 shows the result of different algorithms used in the second proposed model for predicting the level of fear for ten samples of test data. In spite of small errors in predicting the magnitude, Table (5) shows high accuracy of second model to predict the level of fear.
10 Conclusions
In this research, two modified BEL models proposed to improve the efficiency and accuracy of original BEL model. In both proposed models, ANFIS was used in amygdala to make fuzzy rules. Moreover, deep belief network was used in the sensory cortex for size reduction of features of earthquake record. GA, PSO, ABC, and learning automata were used in the first proposed model for finding the weights, and they were applied in the second proposed model to obtain learning parameters. The proposed models were used for magnitude and fear prediction of earthquakes to illustrate their performance. The following conclusions are drawn according to the results of numerical examples:
-
Both proposed methods are more accurate than original BEL model.
-
Except ABC, the other algorithms which were used in the first proposed model lead to improve the efficiency of original BEL model.
-
All algorithms which were used in the second proposed model could improve the accuracy of model in comparison with BEL model.
-
CALA algorithm in both proposed models illustrates the best accuracy among other used algorithms.
References
Moren J (2002) Emotion and Learning—a computational model of the amygdala, PhD dissertation. Cognitive studies, Lund University, Lund, Sweden
Moren J, Balkenius C (2000) A computational model of emotional learning in the amygdala. Cybern Syst 32(6):611–636
Parsapoor M, Bilstrup U (2013) Chaotic time series prediction using brain emotional learning based recurrent fuzzy system (BELRFS). Int J Reasoning-based Intell Syst 5(2):113–126
Lotfi E, Setayeshi S, Taimory S (2014) A neural basis computational model of emotional brain for online visual object recognition. Appl Artif Intell 28(8):814–834. https://doi.org/10.1080/08839514.2014.952924
Maleki M, Nourafza N, Setayeshi S (2016) A novel approach for designing a cognitive sugarscape cellular society using an extended moren network. Intell Autom Soft Comput 22(2):193–201. https://doi.org/10.1080/10798587.2015.1090720
Asadi Ghanbari A, Heidari E, Setayeshi S (2012) Brain emotional learning based brain computer interface. Int J Comput Sci Issues 9(5):146–154
Lotfi E, Akbarzadeh-T MR (2014) Adaptive brain emotional decayed learning for online prediction of geomagnetic activity indices. Neuro Comput 126:188–196. doi:https://doi.org/10.1016/j.neucom.2013.02.040
Lotfi E (2013) Mathematical modeling of emotional brain for classification problems. Proceedings of IAM 2(1):60–71
Lucas C (2010) Introducing BELBIC: Brain emotional learning based intelligent controller. Integrated Syst Design Technol 3:203–214
Fakhrmoosavy SH, Setayeshi S, Sharifi A (2017) An intelligent method for generating artificial earthquake records based on hybrid PSO-parallel brain emotional learning inspired model. Eng Comput (In Press)
Lotfi E, Akbarzadeh -T, M. R (2013) Brain emotional learning-based pattern recognizer. Cybernet Syst 44(5):402–421. https://doi.org/10.1080/01969722.2013.789652
Parsapoor M, Bilstrup U (2012) Brain emotional learning based fuzzy inference system (BELFIS) for solar activity forecasting. Paper presented at the Proceedings of the 2012 IEEE 24th International Conference on Tools with Artificial Intelligence, vol 01
Lotfi E (2013) Brain-inspired emotional learning for image classification. Majlesi J Multimed Process 2(3):21–26
Pasrapoor M, Bilstrup U (2013, 10–12 Sept. 2013) Brain emotional learning based fuzzy inference system (modified using radial basis function). Paper presented at the Eighth international conference on digital information management (ICDIM 2013)
Lotfi E, Keshavarz A (2014) A simple mathematical fuzzy model of brain emotional learning to predict kp geomagnetic index. Int J Intell Syst Appl Eng 2(2):22–25
Lucas C, Moghimi S (2004) Applying BELBIC (brain emotional learning based intelligent controller) to an autolanding system. WSEAS Transactions on Systems 3(1):284–290
Narendra KS, Thathachar MAL. (1974) Learning automata—a survey. IEEE Trans Syst Man Cybernet SMC -4:323–334
Narendra KS, Thathachar MAL (1989) Learning automata: an introduction: Prentice-Hall, Inc, Upper Saddle River
Thathachar MAL, Sastry PS (2002) Varieties of learning automata: an overview. IEEE Trans Syst Man Cybern B 32(6):711–722. https://doi.org/10.1109/TSMCB.2002.1049606
Lotfi E, Khosravi A, Akbarzadeh-T MR, Nahavandi S (2014) Wind power forecasting using emotional neural networks. Paper presented at the 2014 IEEE International Conference on Systems, Man, and Cybernet (SMC)
Goldberg DE (1989) Genetic algorithms in search, optimization and machine learning. Addison-Wesley Longman Publishing Co., Inc., Boston, MA.
Ojaghzadeh Mohammadi SD, Bahar A, Fakhrmoosavi SH, Setayeshi S (2010) Optimal column base plate design using a modified genetic algorithm based on Newton-Raphson method. In: 3rd International conference on advanced computer theory and engineering. Chengdu, China
Kennedy J, RC E (1995) Particle swarm optimization. Paper presented at the Proc. IEEE International Conference on Neural Networks (Perth, Australia), Piscataway
Kennedy J (2010) Particle Swarm Optimization. In: Sammut C, Webb GI (eds) Encyclopedia of machine learning. Springer, Boston, pp 760–766
Kumar N, Vidyarthi DP (2016) A novel hybrid PSO–GA meta-heuristic for scheduling of DAG with communication on multiprocessor systems. Eng Comput 32(1):35–47. https://doi.org/10.1007/s00366-015-0396-z
Hasanipanah M, Noorian-Bidgoli M, Jahed Armaghani D, Khamesi H (2016) Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng Comput 32(4):705–715. https://doi.org/10.1007/s00366-016-0447-0
Hasanipanah M, Armaghani Jahed, Amnieh D., Bakhshandeh, Majid H, M. Z. A., & Tahir M. M. D. (2016) Application of PSO to develop a powerful equation for prediction of flyrock due to blasting. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2434-1
Hasanipanah M, Naderi R, Kashir J, Noorani SA, Qaleh A. Z. A. (2017) Prediction of blast-produced ground vibration using particle swarm optimization. Eng Comput 33(2):173–179
Hasanipanah M, Amnieh HB, Arab H, Zamzam MS (2016) Feasibility of PSO-ANFIS model to estimate rock fragmentation produced by mine blasting. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2746-1
Ghasemi E, Kalhori H, Bagherpour R (2016) A new hybrid ANFIS–PSO model for prediction of peak particle velocity due to bench blasting. Eng Comput 32(4):607–614. https://doi.org/10.1007/s00366-016-0438-1
Zhang J, Xia P (2017) An improved PSO algorithm for parameter identification of nonlinear dynamic hysteretic models. J Sound Vib 389:153–167. https://doi.org/10.1016/j.jsv.2016.11.006
Gholizad A, Ojaghzadeh Mohammadi SD (2017) Reliability-based design of tuned mass damper using Monte Carlo simulation under artificial earthquake records. Int J Struct Stab Dyn 17(10):1750121
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization. Technical report-tr06, Erciyes university, engineering faculty, computer engineering department
Newland DE (1993) An introduction to random vibrations, spectral and wavelet analysis, 3rd edn. Wiley, New York
Jang J. S. R. (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybernet 23(3):665–685. https://doi.org/10.1109/21.256541
Liu Y, Zhou S, Chen Q (2011) Discriminative deep belief networks for visual data classification. Pattern Recognit 44(10):2287–2296. https://doi.org/10.1016/j.patcog.2010.12.012
Lee H, Ekanadham C, Ng AY (2007) Sparse deep belief net model for visual area V2. In: Proceedings of the 20th International Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada: Curran Associates Inc., 873–880
Hinton GE, Salakhutdinov RR (2006) Reducing the dimensionality of data with neural networks. Science 313(5786):504–507
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Fakhrmoosavy, S.H., Setayeshi, S. & Sharifi, A. A modified brain emotional learning model for earthquake magnitude and fear prediction. Engineering with Computers 34, 261–276 (2018). https://doi.org/10.1007/s00366-017-0538-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-017-0538-6