
Abstract
Beta regression models are employed to model continuous response variables in the unit interval, like rates, percentages, or proportions. Their applications rise in several areas, such as medicine, environment research, finance, and natural sciences. The maximum likelihood estimation is widely used to make inferences for the parameters. Nonetheless, it is well-known that the maximum likelihood-based inference suffers from the lack of robustness in the presence of outliers. Such a case can bring severe bias and misleading conclusions. Recently, robust estimators for beta regression models were presented in the literature. However, these estimators require non-trivial restrictions in the parameter space, which limit their application. This paper develops new robust estimators that overcome this drawback. Their asymptotic and robustness properties are studied, and robust Wald-type tests are introduced. Simulation results evidence the merits of the new robust estimators. Inference and diagnostics using the new estimators are illustrated in an application to health insurance coverage data. The new R package robustbetareg is introduced.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Beta regression is a flexible and popular tool for modeling proportions, rates, and other continuous response variables restricted to the open unit interval. Beta regression models are employed to model the relationship between predictors and a continuous response variable that is assumed to follow a beta distribution. The beta regression model with constant precision was introduced by Ferrari and Cribari-Neto (2004) and was extended in various directions. For instance, in Smithson and Verkuilen (2006) and Simas et al. (2010), both the mean and precision parameters are modeled using predictors. There are numerous applications involving beta regression in different areas such as medicine (Guolo and Varin 2014; Swearingen et al. 2011), environment research (Silva et al. 2015), finance (Cook et al. 2008), and natural sciences (Geissinger et al. 2022).
The probability density function of the beta distribution in the mean-precision parameterization is
where \(0<\mu <1\), \(\phi >0\), and \(B(\cdot ,\cdot )\) is the beta function, and we write \(y\sim \text {Beta}(\mu ,\phi )\). We have \(\mathbb {E}\left( y\right) =\mu \) and \(\mathbb {V}\textrm{ar}\left( y\right) =\mu (1-\mu )/(1+\phi )\), hence \(\mu \) is the mean parameter and \(\phi \) can be interpreted as a precision parameter. If \(\mu \phi >1\) and \((1-\mu ) \phi >1\), the beta density (1) is bounded, has a single mode in (0, 1), and decreases to zero as \(y \downarrow 0\) or \(y \uparrow 1\). When \(\mu \phi <1\) or \((1-\mu ) \phi <1\), the beta density is unbounded at one or both boundaries.
The beta regression model considered here is defined as follows. Let \(y_1,\ldots ,y_n\) be independent random variables such that \(y_{i}\sim \text {Beta}(\mu _i,\phi _i)\), for \(i=1,\ldots ,n\), with
where \(\varvec{\beta }=(\beta _1,\ldots ,\beta _{p_{1}})^{\top }\) and \(\varvec{\gamma }=(\gamma _1,\ldots ,\gamma _{p_{2}})^{\top }\) are vectors of unknown regression coefficients (\(p=p_1+p_2<n\)); \(\varvec{X}_{i}=(x_{i1},\ldots ,x_{ip_{1}})^{\top }\) and \(\varvec{Z}_{i}=(z_{i1},\ldots ,z_{ip_{2}})^{\top }\) are vectors of the covariates, and \(\varvec{\theta } = (\varvec{\beta }^\top , \varvec{\gamma }^\top )^\top \in \mathbb {R}^{p}\) is the unknown parameter vector. The link functions \(g_\mu :(0,1)\rightarrow \mathbb {R}\) and \(g_\phi :(0,\infty )\rightarrow \mathbb {R}\) are strictly increasing and, at least, twice differentiable.
The maximum likelihood approach is usually employed for estimating \(\varvec{\theta }\). However, the maximum likelihood estimator (MLE) is highly sensitive to outliers. Recently, Ghosh (2019) and Ribeiro and Ferrari (2022) proposed robust estimators for the beta regression model (1)–(2). These estimators require suitable restrictions in the parameter space. If all the beta densities in model (1)–(2) are bounded, the robust estimators and their respective asymptotic covariance matrices are well-defined. Note that the boundedness of all the beta densities assumption requires implicit, non-trivial restrictions in the parameter space of the regression parameters \(\varvec{\beta }\) and \(\varvec{\gamma }\). Moreover, these restrictions depend on the covariate vectors \(\varvec{X}_{i}\) and \(\varvec{Z}_{i}\) for all \(i=1,\ldots ,n\). If the restrictions are not satisfied, relevant numerical problems may arise when employing the robust estimators in empirical applications.
This paper introduces two new robust estimators for the beta regression model (1)–(2). They are derived using methods similar to those employed by Ghosh (2019) and Ribeiro and Ferrari (2022), with the advantage of not requiring restrictions in the parameter space.
The remaining of this paper is organized as follows. Section 2 briefly describes the estimators developed by Ghosh (2019) and Ribeiro and Ferrari (2022). Section 3 presents two new robust estimators that overcome the limitations of the current robust estimators. Robustness and asymptotic properties of the new estimators and the new package robustbetareg are also presented in Sect. 3. Section 4 shows simulation results that evidence the merits of the new estimators over the MLE and the current robust estimators. An application of the proposed methods is discussed in Sect. 5. The paper closes with some remarks and directions for future works.
2 Current robust estimators
Ghosh (2019) proposed the minimum density power divergence estimator (MDPDE) for the beta regression model, a robust estimator based on the density power divergence that involves a tuning constant, \(\alpha \ge 0\) (Basu et al. 1998; Ghosh and Basu 2013). It solves the estimating equation
where \(f_{\varvec{\theta }}(y_i; \mu _i, \phi _i)\) denotes the beta density (1) with \(\mu _i\) and \(\phi _i\) given by (2), \(\varvec{U}(y_i; \varvec{\theta })=\nabla _{\varvec{\theta }}\log (f_{\varvec{\theta }}(y_i; \mu _i, \phi _i))\), and \(\mathcal {E}_{i,1-\alpha }(\varvec{\theta }) = \mathbb {E}\left[ \varvec{U}(y_i; \varvec{\theta })f_{\varvec{\theta }}(y_i; \mu _i, \phi _i)^\alpha \right] \). The factor \(f_{\varvec{\theta }}(y_i; \mu _i, \phi _i)^\alpha \) acts as the weight of the i-th observation in the estimation procedure. If \(\alpha =0\), we have the maximum likelihood estimator. Choices of \(\alpha \in (0,1)\) leads to a robust procedure because observations that are inconsistent with the postulated model receive smaller weights. If \(\alpha \ge 1\), the estimator is highly robust but severely inefficient. Hence, from now on, we will restrict \(\alpha \in [0,1)\). The role of \(\mathcal {E}_{i,1-\alpha }(\varvec{\theta })\) is to center the weighted score, ensuring Fisher-consistency. However, \(\mathcal {E}_{i,1-\alpha }(\varvec{\theta })\) is not well-defined unless \(\mu _i \phi _i>\alpha /(1+\alpha )\) and \((1-\mu _i) \phi _i>\alpha /(1+\alpha )\). Moreover, the asymptotic covariance matrix of the MDPDE is not well-defined unless \(\mu _i \phi _i>2\alpha /(1+2\alpha )\) and \((1-\mu _i) \phi _i>2\alpha /(1+2\alpha )\) (see Ribeiro and Ferrari (2022) for details).
Ribeiro and Ferrari (2022) proposed an estimator based on the maximization of a reparameterized L\(_q\)-likelihood. The L\(_q\)-likelihood (Ferrari and Yang 2010) is
where \(q=1-\alpha \in (0,1]\) is the tuning constant and \(L_q(u) = (u^{1-q} - 1)/(1-q)\), for \(q \in (0,1)\), and \(L_q(u) = \log (u)\), for \(q=1\). The estimator that comes from the maximization of (3) solves the estimating equation
Note that the estimating function is not unbiased unless \(\alpha =0\), hence the resulting estimator is not Fisher-consistent. In Ghosh (2019), the Fisher-consistency is achieved by centering the weighted score. Ribeiro and Ferrari (2022) obtained a Fisher-consistent estimator through a reparametrization of the L\(_q\)-likelihood, named surrogate maximum likelihood estimator (SMLE). The estimating equation is given in Ribeiro and Ferrari (2022, eq. (10)); it is not well-defined unless \(\mu _i \phi _i>\alpha \) and \((1-\mu _i) \phi _i>\alpha \). Also, the validity of its asymptotic covariance matrix requires that \(\mu _i \phi _i>2\alpha /(1+\alpha )\) and \((1-\mu _i) \phi _i>2\alpha /(1+\alpha )\).
A sufficient condition for the MDPDE and the SMLE and their respective asymptotic covariance matrices to be well-defined is that all the beta densities in model (1)–(2) are bounded. Under such assumption, the MDPDE and the SMLE have good properties such as B-robustness, V-robustness, and asymptotic normality. A crucial issue for the use of the proposed estimators is the choice of the tuning constant. Higher values of \(\alpha \) increase robustness and decrease efficiency. Ribeiro and Ferrari (2022) developed an effective data-driven algorithm for selecting the optimal \(\alpha \). Simulation results and real data applications in Ribeiro and Ferrari (2022) evidence the superior performance of these estimators relative to the MLE for datasets containing outlier observations.
The findings in Ghosh (2019) and in Ribeiro and Ferrari (2022) are guaranteed for bounded beta densities but not necessarily otherwise. As we will show later, simulations for unbounded beta densities reveal serious numerical problems of the MDPDE and the SMLE. In the next section we propose alternative robust estimators which have the advantage of being well-defined for all beta densities.
3 Robust estimators through the logit transformation
The limitation of the MDPDE and the SMLE discussed in the previous section comes from the fact that the beta densities are not closed under power transformations. Given a density v and a constant \(\xi \in (0,\infty )\), the power transformations is
provided that \(\int v(y)^{\xi } \textrm{d}y<\infty \). For the beta density (1),
which is integrable for all \(\xi \in (0, \infty )\) if and only if \(\mu \phi \ge 1\) and \((1-\mu ) \phi \ge 1\). Hence, the class of the bounded beta densities is closed under power transformations, unlike the complete class of the beta densities.
To overcome this problem, consider the logit transformation \(y^\star =\log [y/(1-y)]\). If \(y \sim \text {Beta}(\mu , \phi )\), the density function of \(y^\star \) is given by
The distribution of \(y^\star \) is called exponential generalized beta of the second type (Kerman and McDonald 2015) and we write \(y^\star \sim \text {EGB}(\mu ,\phi )\). Note that \(h(y^\star ;\mu ,\phi )^\xi \propto h(y^\star ;\mu ,\xi \phi )\), for all \(y^\star \in \mathbb {R}\), \(\mu \in (0,1)\), and \(\phi , \xi >0\). That is, the class of the EGB densities is closed under power transformations.
We will construct robust estimators for the parameters of the beta regression model (1)–(2) using the density function of the logit transformed response variable. These estimators are based on Ghosh (2019) and Ribeiro and Ferrari (2022) methods and will be described in the following.
Let \(y_i^\star =\log [y_i/(1-y_i)]\), where \(y_i\), for \(i=1, \ldots , n\), follow the postulated beta regression model (1)–(2). We denote the density function of \(y_i^\star \) by \(h_{\varvec{\theta }}(\cdot ; \mu _i, \phi _i)\). The first proposed robust estimator, named logit minimum density power divergence estimator (LMDPDE), minimizes the empirical version of the density power divergence given by
where
and
for \(0\le \alpha <1\). Note that the integral is finite for all \(0\le \alpha <1\). The estimating equation \(\nabla _{\varvec{\theta }} \mathcal {H}_n(\varvec{\theta }) = \varvec{0}\) is given by
in which
where \(y_i^\dagger = \log (1-y_i)\),
with \(\mu _i^\star = \mathbb {E}({y}_i^\star ) = \psi (\mu _{i}\phi _i)-\psi ((1-\mu _{i})\phi _i)\), \(\mu _i^\dagger = \mathbb {E}(y_i^\dagger ) = \psi ((1-\mu _{i})\phi _i)-\psi (\phi _i)\), \(\mu _{i, \alpha }^{ \star } = \psi (\mu _{i} \phi _{i, \alpha }) - \psi ((1-\mu _{i}) \phi _{i, \alpha })\), \(\mu _{i, \alpha }^{ \dagger } = \psi ((1-\mu _{i}) \phi _{i, \alpha }) - \psi ( \phi _{i,\alpha })\), \(\psi (\cdot )\) denoting the digamma function, and \(\phi _{i, \alpha } = \phi _i \alpha \).
The weight of the i-th observation in the estimating equation (4) of the LMDPDE is \(h_{\varvec{\theta }}(y_i^\star ; \mu _i, \phi _i)^\alpha \). In contrast, the corresponding weight for the MDPDE is \(f_{\varvec{\theta }}(y_i; \mu _i, \phi _i)^\alpha \). If \(\alpha =0\), \(h_{\varvec{\theta }}(y_i^\star ; \mu _i, \phi _i)^\alpha =1\) and \(E_{i,1-\alpha }(\varvec{\theta }) = 0\), for all \(i=1, \ldots , n\); hence the LMDPDE coincides with the MLE. Unlike the estimating function of the MDPDE, that of the LMDPDE is well-defined for all \(\alpha \in [0,1)\) and \(\varvec{\theta } \in \mathbb {R}^p\).
The second robust estimator is based on Ribeiro and Ferrari (2022) method, and is named logit surrogate maximum likelihood estimator (LSMLE). The L\(_q\)-likelihood based on the density \(h_{\varvec{\theta }}(\cdot ; \mu _i, \phi _i)\) is given by (3) with \(f_{\varvec{\theta }}(y_i; \mu _i, \phi _i)\) replaced by \(h_{\varvec{\theta }}(y_i^\star ; \mu _i, \phi _i)\). As expected, the estimator that comes from the maximization of the L\(_q\)-likelihood is not Fisher-consistent. In other words, the estimating function is biased. Since the class of the EGB densities is closed under power transformations, Fisher-consistency can be achieved by maximizing the L\(_q\)-likelihood in the parametrization \(\tau _{1/(1-\alpha )}(\varvec{\theta })\) (Ferrari and La Vecchia 2012; La Vecchia et al. 2015), where \(\tau _\omega (\varvec{\theta }): \varvec{\Theta } \longmapsto \varvec{\Theta }\) is a continuous function satisfying \(h_{\tau _\omega (\varvec{\theta })}(y^\star ;\mu , \phi ) = h_{\varvec{\theta }}^{(\omega )}(y^\star ;\mu , \phi )\), for all \(y^\star \in \mathbb {R}\). The LSMLE is the maximizer of
where \(h_{\varvec{\theta }}^{\left( \frac{1}{1-\alpha }\right) }(y_i^\star ; \mu _i, \phi _i) = h_{\varvec{\theta }}\left( y_i^\star ; \mu _i, {\phi }_{i, (1-\alpha )^{-1}}\right) \), with \(0\le \alpha <1\), and \(\mu _i\) and \(\phi _i\) satisfying (2). Note that \(h_{\varvec{\theta }}\left( y_i^\star ; \mu _i, {\phi }_{i, (1-\alpha )^{-1}}\right) \) is the density function of the logit transformation of a variable that follows a modified beta regression model with mean and precision submodels given respectively by
which will be denoted by \(h^*_{\varvec{\theta }}(y_i^\star ; \mu _{i}, \phi _{i})\). Thus, the LSMLE is the maximizer of
It solves the estimating equation
where \(\varvec{U}^*(y_i^\star ; \varvec{\theta }) = \nabla _{\varvec{\theta }}\log h^*_{\varvec{\theta }}(y_i^\star ; \mu _i, \phi _i)\) is the modified score vector for the i-th observation given by
In the Supplementary Material (Section 1) we show that the LSMLE is Fisher-consistent.
Asymptotic normality. Let \(\widehat{\varvec{\theta }}_\alpha = (\widehat{\varvec{\beta }}_\alpha ^\top , \widehat{\varvec{\gamma }}_\alpha ^\top )^\top \) and \(\widetilde{\varvec{\theta }}_\alpha = (\widetilde{\varvec{\beta }}_\alpha ^\top , \widetilde{\varvec{\gamma }}_\alpha ^\top )^\top \) be the LMDPDE and the LSMLE, respectively, for fixed \(\alpha \in [0,1)\). Since they are M-estimators, under suitable regularity conditionsFootnote 1, we have that \(\widehat{\varvec{\theta }}_\alpha {\mathop {\sim }\limits ^{a}} \text {N}(\varvec{\theta }, \varvec{V}_{1, \alpha }(\varvec{\theta })) \) and \(\widetilde{\varvec{\theta }}_\alpha {\mathop {\sim }\limits ^{a}} \text {N}(\varvec{\theta }, \varvec{V}_{2, \alpha }(\varvec{\theta })) \), where \({\mathop {\sim }\limits ^{a}}\) denotes asymptotic distribution,
and the expressions for \(\varvec{\Lambda }_{j, \alpha }(\varvec{\theta })\) and \(\varvec{\Sigma }_{j, \alpha }(\varvec{\theta })\), \(j=1,2\), are given in the Appendix; see the Supplementary Material (Section 2) for details. The covariance matrices \(\varvec{V}_{1, \alpha }(\varvec{\theta })\) and \(\varvec{V}_{2, \alpha }(\varvec{\theta })\) are well-defined for all \(\alpha \in [0,1)\) and \(\varvec{\theta } \in \mathbb {R}^p\) unlike those of the SMLE and MDPDE (Ribeiro and Ferrari 2022). In addition, the asymptotic covariance matrices are equal to the asymptotic covariance matrix of the MLE for \(\alpha =0\).
Robustness properties. In the context of robust estimators, the influence function plays an important role. Introduced by Hampel (1974), the influence function represents the first-order measure of the effect on the asymptotic bias caused by a slight contamination in a data point. Since the LMDPDE and the LSMLE are M-estimators, their influence functions are respectively given by
where \(E_{1-\alpha }(\varvec{\theta }) = \mathbb {E}\left[ \varvec{U}(y; \varvec{\theta })h_{\varvec{\theta }}(y^\star ; \mu , \phi )^\alpha \right] \). The influence functions of the LMDPDE and the LSMLE are bounded, that is they are B-robust. We also extend the robustness analysis to the change-of-variance function, which measures the bias on the covariance matrix due to an infinitesimal contamination in a data point. We show that the change-of-variance functions of the LMDPDE and the LSMLE are bounded, that is they are V-robust (Hampel et al, 2011, Section 2.5); see the Supplementary Material, Section 3, for details. These robustness properties do not hold for the MLE and are guaranteed for the MDPDE and SMLE for bounded beta densities; see Ribeiro and Ferrari (2022).
Robust Wald-type tests. Let \(m:\mathbb {R}^p\rightarrow \mathbb {R}^{d}\), with \(d\le p\), be a continuously differentiable function of \(\varvec{\theta }\). Assume that its Jacobian \(d \times p\) matrix, \(\varvec{J}_{m}(\varvec{\theta })\), has rank d. Consider the null hypothesis \(m(\varvec{\theta }) = \varvec{\eta }_0\), for a fixed \(\varvec{\eta }_0 \in \mathbb {R}^d\), to be tested against a two sided alternative. Let
for \(j=1,2\). The Wald-type test statistics that use the LMDPDE and the LSMLE are, respectively, given by \(W_{1,\alpha }(\widehat{\varvec{\theta }}_\alpha )\) and \(W_{2,\alpha }(\widetilde{\varvec{\theta }}_\alpha )\). Under the null hypothesis, both statistics are asymptotically \(\chi _d^2\)-distributed. They coincide with the usual Wald test statistic if \(\alpha =0\).
Selecting the tuning constant. Ribeiro and Ferrari (2022, Section 3) proposed a data-driven algorithm to select the tuning constant for the MDPDE and the SMLE. The idea is to select \(\alpha \), in an ordered grid from \(\alpha =0\) to \(\alpha =\alpha _{\text {max}}\), that is closest to zero such that the estimates of the parameters are sufficiently stable, ensuring full efficiency for non-contaminated data. If the algorithm does not reach stability up to \(\alpha _{\text {max}}\), it returns the MLE (\(\alpha =0\)). Here, the algorithm is implemented for selecting \(\alpha \) for the LMDPDE and the LSMLE.
For the sake of completeness, we provide the steps of the Ribeiro and Ferrari (2022) algorithm. Let \(\alpha _0 = 0< \alpha _1< \alpha _2 < \cdots \le 1\) be an ordered grid of values for \(\alpha \), and let \(z_{\alpha _k}\) be the vector of standardized estimates with tuning constant \(\alpha _k\), i.e.,
where \(\text{ se }(\cdot )\) denotes the asymptotic standard error.
We define the standardized quadratic variation (SQV) for \(\widehat{{\varvec{\theta }}}_{\alpha _k}\) as \(\text{ SQV}_{\alpha _k} = p^{-1}|| {\varvec{z}}_{\alpha _k} - {\varvec{z}}_{\alpha _{k+1}}||.\) If \(\text{ SQV}_{\alpha _k}\) is small, the estimation with \(\alpha =\alpha _k\) and \(\alpha =\alpha _{k+1}\) are similar.
-
1.
Define an ordered, equally spaced grid for \(\alpha \): \(\alpha _0 = 0< \alpha _1< \alpha _2 < \cdots \le \alpha _{m_1} = 0.2\).
-
2.
if the stability condition \(\text{ SQV}_{\alpha _k} < L\), where \(L>0\) is a pre-defined threshold, holds for all \(k=0, 1, \ldots , m_1-1\), set the optimal value of \(\alpha \) at \(\alpha ^{*}= \alpha _0 = 0\); otherwise, set \(\alpha _\textrm{start}\) at the next point in the grid after the smallest \(\alpha _k\) for which the stability condition is not satisfied;
-
3.
define a new ordered, equally spaced grid for \(\alpha \) starting from \(\alpha _{\text {start}}\): \(\alpha _0 = \alpha _{\text {start}}< \alpha _1< \alpha _2< \cdots < \alpha _{m}\), where \(\alpha _m \le \alpha _{\text {max}}\);
-
4.
if the stability condition is satisfied for all \(k=0, 1, \ldots , m-1\), set the optimal value of \(\alpha \) at \(\alpha ^{*}= \alpha _0 = \alpha _{ \mathrm start}\); otherwise, set \(\alpha _\textrm{start}\) at the next point in the grid after the smallest \(\alpha _k\) for which the stability condition does not hold;
-
5.
repeat steps 3–4 until achieving stability of the estimates in the current grid or reaching the maximum value of \(\alpha \), \(\alpha _\textrm{max}\);
-
6.
if \(\alpha _{\text {max}}\) is reached without stability in the last grid, repeat steps 3-5 with \(\alpha _\textrm{start} = 0\);
-
7.
if \(\alpha _{\text {max}}\) is reached again without stability in the last grid, set \(\alpha ^{*}= 0\).
Ribeiro and Ferrari (2022) suggest setting \(\alpha _{\text {max}}=0.5\), \(L=0.02\), the grid spacings at 0.02 (hence \(m_1 = 10\)), and \(m=3\); refer to Section 3 in their paper for further details. These values are employed in our simulations and application.
R implementation. To enhance the practical utility of the current and proposed estimators, we developed the new R package robustbetareg, which is readily accessible on CRAN (https://CRAN.R-project.org/package=robustbetareg). Currently, four types of robust estimators are supported in the package: SMLE, MDPDE, LSMLE, and LMDPDE. The tuning constant may be fixed or selected by the data-driven algorithm presented in the previous paragraph. In addition, diagnostic tools associated with the fitted model, such as the residuals and goodness-of-fit statistics, are implemented. Robust Wald-type tests are available. Detailed instructions for utilizing the package and its functions, including model fitting, can be found within the package manual (Queiroz et al. 2022).
4 Simulation studies
In this section, we evaluate the performance of the robust estimators and the MLE for the beta regression model (1)–(2). We employ the logit and the logarithmic link functions for the mean and precision submodels, respectively. Both submodels include an intercept, i.e., \(x_{i,1} = z_{i,1} = 1\), \(i=1, \ldots , n\). The sample sizes are set at \(n=40,~80, ~160\), and 320. The covariate values for the mean submodel are set for the sample size \(n=40\) as random draws from a standard uniform distribution and replicated twice, four times and eight times for the other values of n. For the non-constant precision scenario, the covariate values for the mean submodel are used in the precision submodel. All the covariate values are kept constant over all the simulated samples. We consider non-contaminated and contaminated samples with a fixed contamination rate, namely 5%. All simulations were carried out using the R software (R Core Team 2022), and the results are based on 1000 Monte Carlo replications. The codes used to compute all the estimators are the same, with the corresponding maximization functions and respective score vectors and covariance matrices. Thus, the implementations have similar efficiency. The codes to reproduce all the simulation results are available at https://github.com/ffqueiroz/RobustBetareg.
We consider three different scenarios. Figure 1 shows scatter plots of a sample generated under each scenario for \(n=40\).
Scenario A: bounded beta densities; constant precision. The parameters are set at \(\beta _1=-1\), \(\beta _2=-2\) and \(\gamma _1=5\). The possible values for \(\mu \) range in (0.05, 0.27) and \(\phi =\exp (5) \cong 148\). For the contaminated samples, we replace the observations generated with the 5% smallest means by observations generated with mean \(\mu '_{i}=(1+\mu _i)/2\). All the beta densities in this scenario are bounded.
Scenario B: unbounded beta densities; constant precision. The parameters are set at \(\beta _1=-1\), \(\beta _2=-5.5\) and \(\gamma _1=5\). The possible values for \(\mu \) range in (0.001, 0.27) and \(\phi =\exp (5)\cong 1 48\). For the contaminated samples, the observations generated with the 5% highest means are replaced by observations generated with mean \(\mu '_{i}=0.002\). Some beta densities in this scenario are unbounded.
Scenario C: unbounded beta densities; varying precision. The parameters are set at \(\beta _1=-3\), \(\beta _2=7.5\), \(\gamma _1=1\), and \(\gamma _2=2\). The possible values for \(\mu \) and \(\phi \) range in (0.05, 0.98) and \(\phi \in (2.7,20.1)\), respectively. For the contaminated samples, the observations generated with the \(5\%\) highest means are replaced by observations generated with \(\mu '_{i}=\exp {(\beta _1)}/(1+\exp {(\beta _1)}) \cong 0.05\) and \(\phi '_{i}=\exp (\gamma _1+\gamma _2) \cong 20.1\). Some beta densities in this scenario are unbounded.

Scatter plots of contaminated samples generated as in Scenarios A, B, and C with \(n=40\). The contaminated observations are represented by solid black circles
First, we run simulations for the three scenarios with \(n=40\) for fixed values of the tuning constant \(\alpha \) ranging from 0 to 0.05 incremented by 0.05. For each \(\alpha \) value, we compute the failure rate over the 1000 simulated samples for the robust estimates: the MDPDE, the SMLE, the LMDPDE, and the LSMLE. We consider a failure whenever the optimization algorithm for computing the estimate does not reach convergence or the asymptotic standard error can not be calculated. In Scenario A, no sample resulted in failure for any of the estimators. Recall that all the beta densities in this scenario are bounded. Figure 2 displays plots of the failure rates for Scenarios B and C. The failure rate of SMLE and the MDPDE tend to increase as \(\alpha \) grows, more so in Scenario C. In contrast, for the new robust estimators, the failure rate is equal (or close) to zero for all values of \(\alpha \), both under non-contaminated or contaminated data. The high failure rate of SMLE and MDPDE has a theoretical reason. In fact, for beta densities that are not bounded, the SMLE and MDPDE may not even be well defined, unlike LSMLE and LMDPDE. This limitation of SMLE and MDPDE is reflected in our simulation results. Simulations for the other sample sizes reveal a similar pattern.

Plots of the failure rate versus the tuning constant \(\alpha \) for Scenario B (left) and Scenario C (right) for non-contaminated samples (first row) and contaminated samples (second row): SMLE (triangle), MDPDE (square), LSMLE (circle), and LMDPDE (star)

Boxplots of estimates of \(\beta _1\) (first row), \(\beta _2\) (second row), and \(\gamma _1\)(third row) for the MLE and the robust estimators. The red dashed line represents the true parameter value

Boxplots of estimates of \(\beta _1\) (first row), \(\beta _2\)(second row), and \(\gamma _1\)(third row) for the MLE and the robust estimators. The red dashed line represents the true parameter value

Boxplots of estimates of \(\beta _1\) (first row) and \(\beta _2\)(second row) for the MLE and the robust estimators. The red dashed line represents the true parameter value

Boxplots of estimates of \(\gamma _1\) (first row) and \(\gamma _2\)(second row) for the MLE and the robust estimators. The red dashed line represents the true parameter value
We now report simulation results using the data-driven algorithm for selecting the optimum value of \(\alpha \) proposed by Ribeiro and Ferrari (2022). Figures 3, 4, and 5-6 display the boxplots of the parameter estimates using the MLE, the SMLE, the MDPDE, the LSMLE, and the LMDPDE under Scenarios A, B, and C, respectively.
The MLE is highly affected by contaminated observations for all the scenarios and presents a severe bias. For instance, the maximum likelihood estimates of \(\gamma _1\) in Scenario B are around its true value, 5, for the non-contaminated data and around 2 for the contaminated data. In Scenario A, all the robust estimators present good performances for both contaminated and non-contaminated data. They behave similarly to the MLE under non-contaminated samples. Recall that all the beta densities in this scenario are bounded. In Scenarios B and C, which include unbounded beta densities, the MDPDE and the SMLE do not behave well for the non-contaminated data. In these cases, for almost all the samples, the selected optimum tuning constants are zero, resulting in non-robust estimates. It happens because the optimization fails; hence, the algorithm does not reach stability in the estimates and returns the MLE. In contrast, the LMDPDE and the LSMLE perform well in the presence and absence of contamination. Also, these estimators have similar behavior. For samples of moderate and large sizes (\(n=80, ~160, ~360\)), the performances of the LMDPDE and LSMLE are excellent. The simulation results indicate that the proposed estimators (LMDPDE and LSMLE) are robust in the presence of outliers, unlike the MLE. Also, the MDPDE and SMLE may not be useful in scenarios involving unbounded beta densities. In general, in the presence of contamination, the robustness obtained through the new proposed estimators comes at the cost of a slight increase in variability, especially in small sample sizes (\(n=40\)).
The data-driven algorithm to select the tuning constant \(\alpha \) had an excellent performance for the LMDPDE and the LSMLE (see Fig. 7). The selected optimum \(\alpha \) is zero for the LMDPDE and the LSMLE for non-contaminated data, except for a few samples when \(n=40\). Recall that \(\alpha =0\) corresponds to the MLE. For the contaminated data, the selected optimum values of \(\alpha \) are around 0.1 for Scenarios A and B and around 0.15 for Scenario C. Hence, the algorithm can identify the need to use a robust procedure. In Scenario A, the MDPDE and the SMLE behave like the LMDPDE and the LSMLE. On the other hand, for Scenarios B and C, the selected optimum \(\alpha \) values for the MDPDE and the SMLE are close to zero for both non-contaminated and contaminated data. This happens because the algorithm does not achieve stability under contaminated data for most of the samples.
We now report the empirical levels of the Wald test (that uses the MLE) and the robust Wald-type test based on the LMDPDE and the LSMLE. The considered nominal level is \(5\%\). The null hypotheses considered for Scenarios A and B are \(\text {H}_{0}^{1}:\beta _2=\beta _2^0\), \(\text {H}_{0}^{2}:(\beta _1,\beta _2)=(\beta _{1}^0,\beta _{2}^0)\), and \(\text {H}_{0}^{3}:(\beta _1,\beta _2,\gamma _1)=(\beta _{1}^0,\beta _{2}^0,\gamma _{1}^0)\). For Scenario C, we set \(\text {H}_{0}^{4}:(\beta _2,\gamma _2)=(\beta _{2}^0,\gamma _{2}^0)\), \(\text {H}_{0}^{5}:(\beta _1,\beta _2,\gamma _2)=(\beta _{1}^0,\beta _{2}^0,\gamma _{2}^0)\), and \(\text {H}_{0}^{6}:\gamma _2=\gamma _{2}^0\). The values of the parameters fixed at the null hypotheses are those used in the simulations above. The results are shown in Table 1. For non-contaminated data, the empirical levels of all the tests are close to the nominal levels. For contaminated data, the usual Wald test presents a type I error close to \(100\%\), being highly unreliable. In contrast, the robust Wald-type tests show to be reasonably reliable, with only slight inflation in the type I error relatively to non-contaminated situations.

Boxplots of the optimal values for the tuning parameter \(\alpha \) for the robust estimators under Scenario A (first row), B (second row), and C (third row)
Overall, our simulations suggest that the new robust estimators proposed in this paper, namely the LSMLE and the LMDPDE, exhibited the same performance as the SMLE and the MDPDE for bounded beta densities (Scenario A). For unbounded beta densities, as in Scenarios B and C, the MDPDE and the SMLE are unreliable, presenting severe bias for contaminated data. For all the scenarios, the new estimators behave as the MLE for non-contaminated data and prove to be robust in the presence of contamination. Hence, practitioners should employ the new proposed estimators in real data applications.
5 An application to health insurance coverage data
We shall now present and discuss an application of the new robust estimators to health insurance coverage data collected by the Institute of Applied Economic Research (Instituto de Pesquisa Econômica Aplicada, IPEA). The dataset includes information on 80 cities in the state of São Paulo, Brazil, in 2010. This application’s dataset and R codes are available at https://github.com/ffqueiroz/RobustBetareg.
The response variable (y) is the health insurance coverage index (HIC). The covariates are the percentage of the total population who lives in the city’s urban zone (Urb) and the per capita gross domestic product (GDP). We consider the beta regression model (1)–(2) with \(g_\mu (\cdot )\) and \(g_\phi (\cdot )\) being the logit and the log functions, respectively. First, both covariates and an intercept are included in the mean and precision submodels. We fit the model using the MLE and the robust estimators. The Wald-type tests based on all the estimators agree that the covariate Urb is not significant for the precision submodel (p-value greater than 0.3 for all the tests); see the Supplementary Material, Section 4. The postulated reduced model is the beta regression model with
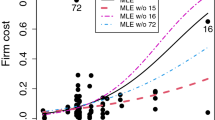
for \(i=1,\ldots ,80\). For some values of \(\alpha \), the SMLE and MDPDE could not be computed and the data-driven algorithm for selecting \(\alpha \) did not reach stability and returned \(\alpha =0\) (MLE). The estimates and standard errors for the LSMLE and LMDPDE are similar. Here, we present the results for the LSMLE and those for the LMDPDE are shown in the Supplementary Material (Section 4). Table 2 presents the estimates, asymptotic standard errors, z-statistics (estimate divided by the asymptotic standard error), and asymptotic p-values of the Wald-type tests of nullity of coefficients. It also reports the results without observation \(\#1\), which is the most evident outlier. This observation corresponds to a city with an atypical value for HIC, around 0.98.
For the full data, the data-driven algorithm for selecting the optimum \(\alpha \) returned \(\alpha =0.06\) for both LMDPDE and LSMLE, indicating that a robust fit is needed. For the data without observation \(\#1\), the algorithm returned \(\alpha =0\) (MLE) for both the new robust estimators. As we observe in Table 2, the MLE is highly influenced by observation \(\#1\). For instance, the estimated coefficient for Urb in the mean submodel moves from 3.429 (full data) to 4.854 (reduced data). Additionally, the covariate GDP in the precision submodel is non-significant (p-value equal to 0.648) for the full data and highly significant (p-value equal to 0.003) for the reduced data. In contrast, the results based on the LSMLE are not impacted by the exclusion of the outlier observation. The results for the LSMLE for the full data are close to those for the MLE for the reduced data.
Following Ribeiro and Ferrari (2022), Fig. 8 presents the normal probability plots with simulated envelopes of residuals for the MLE and the LSMLE and the plot of estimated weights against residuals for the LSMLE. We consider the ‘standardized weighted residual 2’ proposed by Espinheira et al. (2008). The residual plots of the MLE clearly evidence the lack of fit of the maximum likelihood estimation. As expected, observation \(\#1\) is highlighted as an outlier for both the MLE and the LSMLE fits. The residual plots for the LSMLE suggest a suitable fit for all the observations except for case \(\#1\). In fact, this observation receives a weight close to zero for the LSMLE fit.

Normal probability plots with simulated envelope of the residuals for MLE (first column) and LSMLE (second column) and plot of estimated weights for LSMLE (third column). The plots in the second row are zoomed versions of those in the first row
6 Concluding remarks
This paper introduces two new robust estimators for the beta regression models: the LSMLE and the LMDPDE. The proposed estimators overcome the limitations of the current robust estimators, the SMLE and the MDPDE. Simulation results and a real data application evidence the excellent performance of the new estimators even in situations where the existing estimators fail. The new robust estimators present similar behavior and are easily implemented. The new R package robustbetareg allows practitioners to apply the proposed estimators, as well as the current estimators, in their applications. The package manual contains several examples illustrating how to analyse new datasets using these estimators.
The development of robust estimators for inflated beta regression models (Ospina and Ferrari 2012) is a natural, although non-trivial, extension of our work. The second and third authors have been working on this topic. The findings will be reported elsewhere.
Notes
Specific regularity conditions required for the large sample properties of minimum power divergence estimators in non-i.i.d. settings are outlined in Ghosh and Basu (2013). However, it is worth noting that some of these conditions are particularly intricate to confirm within specific models. Similar conditions for surrogate maximum likelihood estimators may be stated. Remarkably, as of our current knowledge, they have not been explicitly listed in the statistical literature.
References
Basu A, Harris I, Hjort N, Jones M (1998) Robust and efficient estimation by minimising a density power divergence. Biometrika 85:549–559
Cook OD, Kieschnick R, McCullough B (2008) Regression analysis of proportions in finance with self selection. J Empir Financ 15:860–867
Espinheira PL, Ferrari SLP, Cribari Neto F (2008) On beta regression residuals. J Appl Stat 35:407–419
Ferrari SLP, Cribari-Neto F (2004) Beta regression for modelling rates and proportions. J Appl Stat 31:799–815
Ferrari D, La Vecchia D (2012) On robust estimation via pseudo-additive information. Biometrika 99:238–244
Ferrari D, Yang Y (2010) Maximum L\(_q\)-likelihood estimation. Ann Stat 38:753–783
Geissinger EA, Khoo CL, Richmond IC, Faulkner SJ, Schneider DC (2022) A case for beta regression in the natural sciences. Ecosphere. https://doi.org/10.1002/ecs2.3940
Ghosh A (2019) Robust inference under the beta regression model with application to health care studies. Stat Methods Med Res 28:871–888
Ghosh A, Basu A (2013) Robust estimation for independent non-homogeneous observations using density power divergence with application to linear regression. Electron J Stat 32:2420–2456
Guolo A, Varin C (2014) Beta regression for time series analysis of bounded data, with application to Canada Google flu trends. Ann Appl Stat 8:74–88
Hampel FR (1974) Influence curve and its role in robust estimation. J Am Stat Assoc 69:383–393
Hampel F, Ronchetti EM, Rousseeuw P, Stahel W (2011) Robust statistics: the approach based on influence functions. Wiley, New York
Kerman S, McDonald JB (2015) Skewness-kurtosis bounds for EGB1, EGB2, and special cases. Communications in Statistics - Theory and Methods 44:3857–3864
La Vecchia D, Camponovo L, Ferrari D (2015) Robust heart rate variability analysis by generalized entropy minimization. Comput Stat Data Anal 82:137–151
Ospina R, Ferrari SLP (2012) A general class of zero-or-one inflated beta regression models. Comput Stat Data Anal 56:1609–1623
Queiroz FF, Maluf YS, Ferrari SLP (2022) Robustbetareg: robust beta regression. https://CRAN.R-project.org/package=robustbetareg, R package version 0.3.0
R Core Team (2022) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/
Ribeiro TKA, Ferrari SLP (2022) Robust estimation in beta regression via maximum L\(_q\)-likelihood. Stat Pap. https://doi.org/10.1007/s00362-022-01320-0
Silva CC, Madruga MR, Tavares HR, Oliveira TF, Saraiva ACF (2015) Application of the beta regression on the neutralization index of power equipment insulating oil. Int J Power Energy Syst 35:52–57
Simas AB, Barreto-Souza W, Rocha AV (2010) Improved estimators for a general class of beta regression models. Comput Stat Data Anal 54:348–366
Smithson M, Verkuilen J (2006) A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychol Methods 11:55–71
Swearingen CJ, Tilley CB, Adams RJ, Rumboldt Z, Nicholas SJ, Bandyopadhyay D, Woolson FR (2011) Application of beta regression to analyze ischemic stroke volume in NINDS rt-PA clinical trials. Neuroepidemiology 37:73–82
Acknowledgements
This work was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brazil (CAPES) - Finance Code 001 and by the Conselho Nacional de Desenvolvimento Científico e Tecnológico - Brazil (CNPq). The second author gratefully acknowledges the funding provided by CNPq (Grant No. 305963-2018-0). A special thank goes to Terezinha T.K.A. Ribeiro for helpful discussion and for sharing her R code on which we based our implementation of the estimators developed in this paper. We also thank the reviewer for constructive comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix
Appendix
The matrices \(\varvec{\Lambda }_{1, \alpha }(\varvec{\theta })\) and \(\varvec{\Sigma }_{1, \alpha }(\varvec{\theta })\) used in the covariance matrix of the LMDPDE are
and
where \(\gamma _{j}^{(\alpha )} = {\text {diag}}\{ \gamma _{j, i}^{(\alpha )}; i=1, \ldots , n \}\), for \(j=1, 2\), \(\gamma _{11}^{(\alpha )} = {\text {diag}}\{ \gamma _{11, i}^{(\alpha )}; i=1, \ldots , n \}\), \(\gamma _{12}^{(\alpha )} = {\text {diag}}\{ \gamma _{12, i}^{(\alpha )}; i=1, \ldots , n \}\), \(\gamma _{22}^{(\alpha )} = {\text {diag}}\{ \gamma _{22, i}^{(\alpha )}; i=1, \ldots , n \}\), with
and \(v_{i, \alpha } = \psi '(\mu _{i} {\phi }_{i, \alpha }) + \psi '((1-\mu _{i}) {\phi }_{i, \alpha })\).
For the LSMLE, the matrices \(\varvec{\Lambda }_{2, \alpha }(\varvec{\theta })\) and \(\varvec{\Sigma }_{2, \alpha }(\varvec{\theta })\) are given by
and
where \(\varvec{B}_j = {\text {diag}}\{b_{i, j}; i=1,\ldots , n \}\), \(j=1,2\),
\(\varvec{T}_\mu = {\text {diag}}\{t_{i, \mu }; i=1,\ldots , n \}\), \(\varvec{T}_\phi ^{ *} = {\text {diag}}\{t_{i, \phi }; i=1,\ldots , n \}\),
\(\varvec{\Phi } = {\text {diag}}\{\phi _{i}; i=1,\ldots , n \}\), \(\varvec{V} = {\text {diag}}\{v_i; i=1,\ldots , n \}\), \(\varvec{V}_{1+\alpha } = {\text {diag}}\{v_{i, 1+\alpha }; i=1,\ldots , n\}\), \(\varvec{C} = {\text {diag}}\{c_i; i=1,\ldots , n \}\), \(\varvec{C}_{1+\alpha } = {\text {diag}}\{c_{i, 1+\alpha }; i=1,\ldots , n \}\),
\(\varvec{D} = {\text {diag}}\{d_i; i=1,\ldots , n \}\), \(\varvec{D}_{1+\alpha } = {\text {diag}}\{d_{i, 1+\alpha }; i=1,\ldots , n \}\),
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Maluf, Y.S., Ferrari, S.L.P. & Queiroz, F.F. Robust beta regression through the logit transformation. Metrika (2024). https://doi.org/10.1007/s00184-024-00949-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00184-024-00949-1