
Abstract
In the structural dynamic optimization procedure, many repeated analyses are conducted to evaluate vibration performance of successively modified structural designs. A new procedure for structural vibration (or eigenproblem) reanalysis is developed based on iteration and inverse iteration method with frequency-shift and linear combination acceleration to reduce the high computational cost of structure reanalysis. With a suitable frequency-shift factor, the Frequency-Shift Combined Approximations (FSCA) method allows to calculate higher modes accurately. Three numerical examples are presented to demonstrate the accuracy of the proposed method. Excellent results can be obtained in cases where large modifications are made and higher modes are needed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Changes of structure are often necessary to satisfy predetermined demands in various design and optimization problems, and in each step, structural response problems have to be solved in cases where limited modifications are made in large structures. In structural dynamic optimization, repeated vibration analysis with modifications is one of the most costly computations. Many approximate and exact reanalysis methods were intended to analyze structures which are modified due to changes without the full computation in design and optimization (Kirsch 2010; Kirsch et al. 2007b). The need for efficient and accurate reanalysis technique in modern structural design is crucial because the design becomes more complex and large.
Structural reanalysis methods for linear static problems have been well-developed since the 1970s (Arora 1976; Phansalkar 1974). Combined Approximations (CA) method developed by Kirsch is one of the effective methods (Kirsch 2000). Research of vibration reanalysis methods were well discussed in the early 2000s (Chen and Rong 2002; Kirsch and Bogomolni 2007; Chen et al. 2000). Kirsch re-deduced the CA approach for eigenproblems (Kirsch 2003a). These approximations are obtained by analyzing eigenproblems in a reduced Krylov subspace composed of several approximation vectors. According to numerical examples, CA method is efficient even in cases where the series of basis vectors is diverges, but it is less suitable for calculating eigenproblems with global large modifications or in cases where higher eigenvalues are needed. Based on the CA method and the Rayleigh quotient, an extended CA method of eigenproblem reanalysis for large modifications was developed by Suhuan Chen (Chen and Yang 2000). Epsilon algorithm was first used for static displacement reanalysis as a acceleration approach in iteration (Wu et al. 2007), and then it was applied in the eigenproblem reanalysis associated with the Neumann series expansion (Chen et al. 2006). Based on matrix inverse power iteration and CA method, a Modified Combined Approximations (MCA) method for reanalysis of dynamic problems with many dominant mode shapes was discussed by Geng Zhang (Zhang et al. 2009). Although the methods for large structural modifications have been developed, reanalysis method, in cases where higher eigenvalues are needed, has seldom been discussed yet.
In this study, a novel reanalysis method, the Frequency-Shift Combined Approximations (FSCA) method, is developed for vibration reanalysis, and a new set of basis vectors is calculated by the FSCA method. With the basis vectors, a much smaller eigenproblem is solved, and then approximate solution of the modified eigenproblem is achieved. The formula of vibration reanalysis is shown in Section 2, and then CA method and MCA method are given in Section 3. Two Frequency-Shift Combined Approximations (FSCA) algorithms are first presented and discussed in Section 4. Three numerical examples with large modifications are demonstrated for the accuracy of FSCA method, and the results of FSCA method are compared with those of CA and MCA approximations in Section 5. Conclusions are drawn in Section 6.
2 Structural vibration reanalysis
The aim of vibration analysis is to find the free-vibration frequencies and the modes of the system, which plays an important role in the dynamic analysis. The solution of large structural eigenproblem is one of the most costly computations in the vibration analysis. In many applications, not all of the eigenvalues and corresponding eigenvectors of a structure are needed. It is common for only the eigenvalues which are largest or smallest in modulus to be required.
For an undamped structure with stiffness and mass matrices \(\mathop {{{\bf K}}^{(0)}}\limits_{n\times n} \) and \(\mathop {{{\bf M}}^{(0)}}\limits_{n\times n} \) respectively, the equation of the first m eigenproblems for structure is
where \(\mathop {{{\boldsymbol \Lambda }}^{(0)}}\limits_{m\times m} \) and \(\mathop {{{\boldsymbol \Phi }}^{(0)}}\limits_{n\times m} \) denote the matrix of eigenvalues for initial structure and the corresponding matrix of eigenvectors, n is the number of degrees of the structural freedom, \(\mathop {{{\bf U}}_0 }\limits_{n\times n} \) in (2) is an upper triangular matrix obtained with Cholesky decomposition of \(\mathop {{{\bf K}}^{(0)}}\limits_{n\times n} \). In structural reanalysis \(\mathop {{{\bf U}}_0 }\limits_{n\times n} \) can be given by the original analysis.
Assuming that there are changes in the design, the eigenproblem of the modified structure is expressed as follows:
where \(\mathop {{\bf K}}\limits_{n\times n} =\mathop {{{\bf K}}^{(0)}}\limits_{n\times n} +\mathop {\Delta {{\bf K}}}\limits_{n\times n} \) and \(\mathop {{\bf M}}\limits_{n\times n} =\mathop {{{\bf M}}^{(0)}}\limits_{n\times n} +\mathop {\Delta {{\bf M}}}\limits_{n\times n} \) are the global stiffness and mass matrices of the modified structure, \(\mathop {\Delta {{\bf K}}}\limits_{n\times n} \) and \(\mathop {\Delta {{\bf M}}}\limits_{n\times n} \) are the stiffness and mass modification matrices, \(\mathop {{\boldsymbol \Lambda }}\limits_{m\times m} \) and \(\mathop {{\boldsymbol \Phi }}\limits_{n\times m} \) represent the matrix of eigenvalues and the matrix of corresponding eigenvectors for the modified structure, respectively. \(\mathop {{\bf U}}\limits_{n\times n} \) in (4) is an upper triangular matrix obtained with Cholesky decomposition of \(\mathop {{\bf K}}\limits_{n\times n} \).
3 CA and MCA method
3.1 CA
In the CA method (Kirsch 2003b), the matrix of eigenvectors \(\mathop {{\boldsymbol \Phi }}\limits_{n\times m} \) is assumed to be approximated by a linear combination of preselected s basis vectors, and a subspace with basis vectors is formed as follows:
where s is the number of basis vectors \(\mathop {{{\bf r}}^{(i)}}\limits_{n\times 1}\), i = 1, 2, ⋯ , s, and \(\mathop {{\bf R}}\limits_{n\times s} \) is the matrix formed by basis vectors.
The basis vectors is given by (6) and (7).
Using (2), Cholesky decomposition of \(\mathop {{{\bf K}}^{(0)}}\limits_{n\times n}\) can be obtained with the original analysis, calculation of \(\mathop {{{\bf r}}^{(i+1)}}\limits_{n\times 1} \) involve only forward and backward substitutions. We first solve for \(\mathop {{\bf z}}\limits_{n\times 1} \) by the forward substitution
Then \(\mathop {{{\bf r}}^{(i+1)}}\limits_{n\times 1} \) is calculated by the backward substitution
Similarly, the \(\mathop {{{\bf r}}^{{(1)}}}\limits_{n\times 1} \) is calculated from
The stiffness matrix \(\mathop {{\bf K}}\limits_{n\times n} \) and mass matrix \(\mathop {{\bf M}}\limits_{n\times n} \) are condensed as (11), respectively.
where \(\mathop {{{\bf K}}_R }\limits_{s\times s} \) and \(\mathop {{{\bf M}}_R }\limits_{s\times s} \) denote condensed stiffness matrix and mass matrix, respectively.
The modified analysis equations are approximated by a small eigenproblem of (12) with a new unknown \(\mathop {{{\bf y}}_1 }\limits_{s\times 1} \).The kth eigenvector \(\mathop {{{\boldsymbol \varphi}}_k }\limits_{n\times 1} \) can be calculated by (13).
3.1.1 Gram–Schimidt orthogonalizations of the approximate modes
To improve the accuracy of the results in the higher mode shapes calculation, the \({{\bf r}}^{(i+1)}_{n\times 1} \) is orthogonalized by \(\mathop {{{\bf r}}^{(1)}}\limits_{n\times 1} ,\cdots{\kern-.4pt} ,\mathop {{{\bf r}}^{(i)}}\limits_{n\times 1} \), using the expression below (Kirsch et al. 2007a).
where \(\mathop {{{\bar {\bf r}}}^{(i+1)}}\limits_{n\times 1} \) is the normalized vector. The coefficients α k are obtained from the condition
where δ kj is the Kronecker delta. Premultiplying (9) by \({\mathop {{{\boldsymbol \varphi}}_k^{(0)} }\limits_{n\times 1}} ^T\mathop M\limits_{n\times n} \). Equation (17) is obtained
3.1.2 Gram–Schimidt orthogonalizations of the basis vectors
Numerical errors might occur in case of the basis vectors are linearly dependent. To improve this, Gram–Schimidt orthogonations are used to generate a new set of orthogonal basis vectors \(\mathop {{{\tilde {\bf r}}}^{(k)}}\limits_{n\times 1} , ({k=1,\cdots{\kern-.4pt} ,s})\). The normalized basis vector is determined by (18) and (19).
3.1.3 Shift of the basis vectors
With the shift of the basis vector, the accuracy of higher modes can be improved. A shift μ is defined in CA method, and the modified eigenvalue \({\bf \widehat{\lambda}}\) and stiffness matrix \(\widehat{\bf K}\) are expressed as
where \(\mathop {\Delta {{\bf K}}}\limits_{n\times n} -\mu \mathop {{\bf M}}\limits_{n\times n} \) is regarded as the new modification \(\mathop {\Delta \widehat{{\bf K}}}\limits_{n\times n}\), and the sift μ is defined by (22) in each iteration.
3.2 MCA
In the MCA method (Zhang et al. 2009), the CA method is modified by using the columns of the subspace basis given by following recursive process (23) and (24) instead of (6) and (7).
where \(\mathop {{{\boldsymbol \Phi }}^{(0)}}\limits_{n\times m} \) and \(\mathop {{{\bf T}}_i }\limits_{n\times m} ,i=1,2,\cdots{\kern-.4pt} ,s-1\) are the matrix of eigenvectors corresponding to the first m smallest eigenvalues in modulus and matrices of basis vectors, respectively. Cholesky decomposition of \(\mathop {{\bf K}}\limits_{n\times n} \) by (4) is first needed, and then calculations of (23) and (24) involves forward and backward substitutions similarly to the (8), (9) and (10).
The matrix of subspace basis is expressed as follows:
The Gram–Schimidt orthogonalizations of subspace basis vectors are used in MCA method according to the process in Section 3.1.2.
4 FSCA method
A new approximate method, the FSCA method, which is developed based on the iteration and inverse iteration method (Gourlay and Watson 1973) with frequency-shift and linear combination acceleration, is first proposed in this work as an efficient reanalysis method.
4.1 Algorithm 1
To evaluate the matrix of eigenvectors \(\mathop {{\boldsymbol \Phi }}\limits_{n\times m} \), postmultiplying (3) by \(\mathop {{{\boldsymbol \Lambda }}^{-1}}\limits_{m\times m} \), then (26) is given.
To improve the iteration method, (26) is translated with a frequency-shift factor μ. Subtracting (26) on both sides with \(\mu ^{-1}\mathop {{\bf K}}\limits_{n\times n} \mathop {{\boldsymbol \Phi }}\limits_{n\times m} \) gives
Equation (27) is transformed into another formation as follows:
Precisely, given \(\mathop {{{\boldsymbol \Phi }}^{(i)}}\limits_{n\times m}\), one can compute \(\mathop {{{\boldsymbol \Phi }}^{(i+1)}}\limits_{n\times m} \) by solving iterative formula as (29).
To accelerate the convergence of \(\mathop {{{\boldsymbol \Phi }}^{(i+1)}}\limits_{n\times m} \), assuming that a linear combination of \(\mathop {{{\boldsymbol \Phi }}^{(i)}}\limits_{n\times m} \), where i = 0, 1, ⋯ , s − 1, is closer to the exact solution than \(\mathop {{{\boldsymbol \Phi }}^{(i)}}\limits_{n\times m} \). The linear combination acceleration is shown as follows:
where a i , i = 1, 2, ⋯ , s − 1 are defined as undetermined relaxation factors in linear combination. \(\mathop {{\bf R}}\limits_{n\times ms} \) and \(\mathop {{\bf X}}\limits_{ms\times m} \) are given by (31) and (32), respectively.
We consider \(\mathop {{\boldsymbol \Phi }}\limits_{n\times m} =\mathop {{{\boldsymbol \Phi }}_c }\limits_{n\times m} \) in (3). Premultiplying (3) by \({\mathop {{\bf R}}\limits_{n\times ms}} ^T\), the condensed eigenproblem can be expressed as follows:
The matrices \({\mathop {{\bf R}}\limits_{n\times ms}} ^T\mathop {{\bf K}}\limits_{n\times n} \mathop {{\bf R}}\limits_{n\times ms} \) and \({\mathop {{\bf R}}\limits_{n\times ms} }^T\mathop {{\bf M}}\limits_{n\times n} \mathop {{\bf R}}\limits_{n\times ms} \) are symmetric and are much smaller than the matrices \(\mathop {{\bf K}}\limits_{n\times n} \) and \(\mathop {{\bf M}}\limits_{n\times n} \) in size, respectively. Rather than computing the exact solution by solving the large n×n eigenproblem in (3), we solve the smaller ms×ms system in (33) for \(\mathop {{\bf X}}\limits_{ms\times m} \) and \(\mathop {{\boldsymbol \Lambda }}\limits_{m\times m} \) firstly, and then evaluate the approximate matrix of eigenvactors by (34). The matrix of the first m eigenvalues of the n×n eigenproblem is given by \(\mathop {{\boldsymbol \Lambda }}\limits_{m\times m} \).
4.2 Algorithm 2
Equation (3) is translated with a frequency-shift factor μ. Subtracting (3) on both sides with \(\mu \mathop {{\bf M}}\limits_{n\times n} \mathop {{\boldsymbol \Phi }}\limits_{n\times m} \) gives
Premultiplying (35) by \(\Big( {\mathop {{\bf K}}\limits_{n\times n} -\,\mu \mathop {{\bf M}}\limits_{n\times n}}\Big)^{-1}\), then (36) is given.
Given \(\mathop {{{\boldsymbol \Phi }}^{(i)}}\limits_{n\times m} \), \(\mathop {{{\boldsymbol \Phi }}^{(i+1)}}\limits_{n\times m} \) can be computed by solving iterative formula as (37).
Assuming that a linear combination of \(\mathop {{{\boldsymbol \Phi }}^{(i)}}\limits_{n\times m} \), where i = 0, 1, ⋯ , s − 1, is closer to the exact solution than \(\mathop {{{\boldsymbol \Phi }}^{(i)}}\limits_{n\times m} \), the linear combination acceleration is presented as follows:
where b i , i = 1, 2, ⋯ , s − 1 are defined as undetermined relaxation factors in linear combination. \(\mathop {{\bf R}}\limits_{n\times ms} \) and \(\mathop {{\bf X}}\limits_{ms\times m} \) are given by (39) and (40), respectively.
A much smaller ms×ms system is solved in (33) for \(\mathop {{\bf X}}\limits_{ms\times m} \) and \(\mathop {{\boldsymbol \Lambda }}\limits_{m\times m} \) firstly, and then the approximate matrix of eigenvactors is evaluated by (34).
4.3 FSCA considerations
4.3.1 Frequency-shift considerations
For the purpose of improving the accuracy of the higher modes calculation and eliminate the numerical errors, the approximate modes and basis vectors are recalculated using Gram–Schimidt orthogonalizations in FSCA method according to the process in Sections 3.1.1 and 3.1.2.
The advantage of the shift factor is that more accuracy results are obtained. When the frequency response of large car-body structures are calculated using component mode synthesis, higher modes are usually needed (Ichikawa and Hagiwara 1996). In FSCA method, to improve the accuracy of higher modes calculation, the highest mode vector is chosen to generate the frequency shift factor.
where \(\mathop {\varphi _m ^{(i)}}\limits_{n\times 1} ,i=0,\cdots{\kern-.4pt} ,s-1\) is the highest mode in the ith iteration. Considering the increasing computational cost for μ (i + 1) calculations, the Rayleigh quotient (42) is chosen for the frequency-shift factor in FSCA method instead of (41). The numerical examples in Section 5 demonstrate that the frequency-shift factor is effective.
4.3.2 Basis vectors considerations
In MCA method, the most costly computation is calculating the Cholesky decomposition of \(\mathop {{\bf K}}\limits_{n\times n} \), when \(\mathop {{\bf K}}\limits_{n\times n} \) is sparse and symmetric, the algebraic operations number of which requires \({\displaystyle\frac{m}{2}}\sum\limits_{i=1}^n {r_i^{{\bf U}} \big( {r_i^{{\bf U}} +3} \big)}\), where \(r_i^{{\bf U}}\) denotes the number of nonzero elements in the ith row of U in (4) without the diagonal elements (Rose 1972). The inverse of \(\Big({\mathop {{\bf M}}\limits_{n\times n} -\,\mu ^{-1}\mathop {{\bf K}}\limits_{n\times n} } \Big)\) in Algorithm 1 and \(\Big({\mathop {{\bf K}}\limits_{n\times n} -\,\mu \mathop {{\bf M}}\limits_{n\times n}} \Big)\) in Algorithm 2 of FSCA method are calculated based on the Cholesky decomposition of \(\mathop {{{\bf K}}^{(0)}}\limits_{n\times n} \), which can be given from the initial analysis by (2).
\(\Big( {\mathop {{\bf M}}\limits_{n\times n} -\,\mu ^{-1}\mathop {{\bf K}}\limits_{n\times n} } \Big)^{-1}\) in Algorithm 1 is calculated similar to \(\Big(\mathop {{\bf K}}\limits_{n\times n} -\,\mu \mathop {{\bf M}}\limits_{n\times n}\Big)^{-1}\) in Algorithm 2 with deformation
where \(\Big({\mathop {{\bf K}}\limits_{n\times n} -\,\mu \mathop {{\bf M}}\limits_{n\times n}}\Big)^{-1}\) is received from the Neumann series expansion
The Neumann expansion is convergent only if \(\rho \Big( {{\mathop {{{\bf K}}^{(0)}}\limits_{n\times n}} ^{-1}}\) \(\times{\Big({\mu \mathop {{\bf M}}\limits_{n\times n} -\mathop {\Delta {{\bf K}}}\limits_{n\times n}}\Big)}\Big)\,<\,1\). Epsilon algorithm is used to improve the convergence even if the Neumann expansion is divergent, and the epsilon algorithm can yield a sufficient result after only a few order iterations (Chen et al. 2006).
The basis vectors of Algorithm 1 are received as follows.
where \(\mathop {{{\boldsymbol \varphi}}_j^{(i)} }\limits_{n\times 1} \) denotes the jth eigenvectors in the ith iteration, i = 0, ⋯ , s − 1, b i , j = 1, m.
Let \(\mathop {{{\bf s}}_0 }\limits_{n\times 1} ,\mathop {{{\bf s}}_1 }\limits_{n\times 1} ,\mathop {{{\bf s}}_2 }\limits_{n\times 1} ,\cdots\) be the partial sum of the sequence
The following iterative is constructed with the sequence \(\mathop {{{\bf s}}_0 }\limits_{n\times 1} ,\mathop {{{\bf s}}_1 }\limits_{n\times 1} ,\mathop {{{\bf s}}_2 }\limits_{n\times 1} ,\cdots\) to obtain the iterative table in the epsilon algorithm. Using (2), Cholesky decomposition of \(\mathop {{{\bf K}}^{(0)}}\limits_{n\times n} \) has been obtained with the original analysis, calculation of \(\mathop {{{\bf s}}_t }\limits_{n\times 1} \) involves only forward and backward substitutions.
The definition of the inverse of a real vector is given by Roberts (1996)
The epsilon algorithm is used to generate basis vectors with Table 1, where the sequence of the partial sum \(\mathop {{{\bf s}}_0 }\limits_{n\times 1} ,\mathop {{{\bf s}}_1 }\limits_{n\times 1} ,\mathop {{{\bf s}}_2 }\limits_{n\times 1} ,\mathop {{{\bf s}}_3 }\limits_{n\times 1} ,\mathop {{{\bf s}}_4 }\limits_{n\times 1} \) and \(\mathop {{{\boldsymbol \varepsilon }}_k^{(t)} }\limits_{n\times 1} \) are listed. Only the entries \(\mathop {{{\boldsymbol \varepsilon }}_{2k}^{(t)} }\limits_{n\times 1} \) with even subscript indices in the table are useful for extrapolation. It should be noted that the \({{\boldsymbol \varepsilon }}_4^{(t)}\) can usually converge to the exact solution (Chen et al. 2006).
The basis vectors of Algorithm 2 are received as follows.
The sequence \(\mathop {{{\bf s}}_t }\limits_{n\times 1} \) is obtained with (50).
4.3.3 Efficiency considerations
The efficiency of reanalysis by the FSCA method, compared with CA method and MCA method, can be measured by the number of algebraic operations, which is possible to relate the computational effort to the bandwidth of the stiffness matrix, the number of basis vectors considered, and so on.
We list the approximate multiplications operations of the CA, MCA and FSCA method in Table 2, and the operation counts for numerical examples are list in Tables 7 and 10.
5 Numerical examples
To demonstrate the accuracy of the FSCA method, three numerical examples with different types of elements, mass-spring elements, beam elements, shell elements and solid elements, are presented.
5.1 Spring-mass system
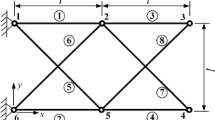
The example of spring-mass system shown in Fig. 1 is considered for illustrative purpose. The parameters of the initial system and changes are given as follows:

System of mass-spring
Given the first three eigenvectors of the initial system, with calculation, μ = 0.3598 is chosen for the frequency shift factor in FSCA. The first three eigenpairs of the modified structure and comparisons with the exact results are shown in Tables 3 and 4, which are achieved by the Algorithms 1 and 2 respectively. The exact solution is obtained by running simulations with MATLAB. Approximate eigenproblems are solved with the parameters s = 2 and s = 3, respectively. The operation counts for it is found that excellent results for eigenpairs can be got with the FSCA method.
5.2 Forty-storey structure
The example of a 40-storey frame structure, which has been calculated by another reanalysis method in Chen et al. (2006), is given to demonstrate the accuracy of FSCA method for global large modifications. The frame structure is modeled by beam elements as shown in Fig. 2. The parameters of the structure are as follows. The Young’s modulus of the material is \(E=2.1\times 10^{11}~\mbox{Pa}\); the mass density is \(\rho =7.8\times 10^3~\mbox{kg/m}^3\); the height and width of the cross-section of the vertical beams are H 1 = 0.8 m, and W 1 = 0.8 m; the corresponding values for horizontal beams are H 2 = 0.6 m and W 2 = 0.6 m.

Forty-storey frame with 202 nodes and 357 elements
In computations, the parameter modifications are given by
Given the first 10 eigenvectors of the initial 40-storey structure, with calculation, μ = 185.3567 is chosen for the frequency shift factor in FSCA. The solutions of the first 10 eigenvalues of the modified frame are shown in Tables 5 and 6, which are obtained by the CA method (with Gram–Schimidt orthogonalizations and shift of the basis vectors), MCA method (with Gram–Schimidt orthogonalizations), FSCA method and exact solution. The exact solution is obtained by solving a 1,212 × 1,212 eigenproblem with MATLAB. In cases where s = 2 and s = 3, approximate solutions are obtained by solving 20 × 20 and 30 × 30 eigenproblems for the first 10 eigenpairs with CA, MCA and FSCA methods respectively. The operation counts for CA, MCA and FSCA methods are list in Table 7. With comparison, it is found that the entire solution for s = 3 with the FSCA method is almost exact. Especially, results of higher eigenvalues with FSCA method are better than those of the CA and MCA method.
5.3 Truck body structure
The eigenproblem reanalysis of the truck body, as shown in Fig. 3, is given to demonstrate the accuracy of the FSCA method for large scale eigenproblems. The truck body contains 1,896 shell and solid elements, 1,944 nodes and 11,664 degrees of freedom. The Young’s modulus of the material is \(E=2.1\times 10^{11}~\mbox{Pa}\); the mass density is \(\rho =7.8\times 10^3~\mbox{kg/m}^3\); the Poisson’s ratio is 0.3. The modified departments and modifications of the truck body are signed in Fig. 4.

Finite elements of truck body

Modifications of truck body
Given the first 10 eigenvectors of the initial 40-storey structure, with calculation, μ = 5556.28 is chosen for the frequency shift factor in FSCA. The solutions of the first 10 eigenvalues of the modified frame are shown in Tables 8 and 9, which are obtained by the CA method (with Gram–Schimidt orthogonalizations and shift of the basis vectors), MCA method (with Gram–Schimidt orthogonalizations), FSCA method and exact solution. The exact solution is obtained by solving an 11,664 × 11,664 eigenproblem with MATLAB. The operation counts for CA, MCA and FSCA methods are list in Table 10. It is found that results of higher eigenvalues with FSCA method are better than those of the CA and MCA method.
6 Conclusion
In this study, a new reanalysis technique, the FSCA method has been developed for vibration reanalysis with respect to improve the solution accuracy in case where global large modifications are made and higher modes are needed. Three numerical examples are shown for the demonstrations of accuracy in this work. It can be seen that the accuracy approximate solutions, especially for higher modes, were achieved with FSCA method with large changes and for large scale eigenproblems.
When general optimization problems are considered, a lot of research has been performed to reduce the computational cost in repeated analysis of modified structures. It is expected that the FSCA method could reduce the overall computational cost in problems where repeated analysis is needed.
References
Arora JS (1976) Survey of structural reanalysis techniques. ASCE Struct Div 102(4):783–802
Chen SH, Rong F (2002) A new method of structural modal reanalysis for topological modifications. Finite Elem Anal Des 38(11):1015–1028
Chen SH, Wu XM, Yang ZJ (2006) Eigensolution reanalysis of modified structures using epsilon-algorithm. Int J Numer Methods Eng 66(13):2115–2130. doi:10.1002/Nme.1612
Chen SH, Yang XW (2000) Extended kirsch combined method for eigenvalue reanalysis. AIAA J 38(5):927–930
Chen SH, Yang XW, Lian HD (2000) Comparison of several eigenvalue reanalysis methods for modified structures. Struct Multidisc Optim 20(4):253–259
Gourlay AR, Watson GA (1973) Computational methods for matrix eigenproblems. Wiley, London
Ichikawa T, Hagiwara I (1996) Frequency response analysis of large-scale damped structures using component mode synthesis. JSME Int J C 39(3):450–455
Kirsch U (2000) Implementation of combined approximations in structural optimization. Comput Struct 78(1):449–457
Kirsch U (2003a) Approximate vibration reanalysis of structures. AIAA J 41(3):504–511
Kirsch U (2003b) A unified reanalysis approach for structural analysis, design, and optimization. Struct Multidisc Optim 25(2):67–85. doi:10.1007/s00158-002-0269-0
Kirsch U (2010) Reanalysis and sensitivity reanalysis by combined approximations. Struct Multidisc Optim 40(1–6):1–15
Kirsch U, Bogomolni M (2007) Nonlinear and dynamic structural analysis using combined approximations. Comput Struct 85(10):566–578
Kirsch U, Bogomolni M, Sheinman I (2007a) Efficient dynamic reanalysis of structures. J Struct Eng-ASCE 133(3):440–448
Kirsch U, Bogomolni M, Sheinman I (2007b) Efficient structural optimization using reanalysis and sensitivity reanalysis. Eng Comput-Germany 23(3):229–239
Phansalkar SR (1974) Matrix iterative methods for structural reanalysis. Comput Struct 4(4):779–800
Roberts DE (1996) On the convergence of rows of vector padé approximants. J Comput Appl Math 70(1):95–109
Rose DJ (1972) A graph-theoretic study of the numerical solution of sparse positive definite systems of linear equations. In: Read R (ed) Graph theory and computing. Academic, New York, pp 183–217
Wu XM, Chen SH, Yang ZJ (2007) Static displacement reanalysis of modified structues using the epsilon algorithm. AIAA J 45(8):2083–2086. doi:10.2514/1.19767
Zhang G, Nikolaidis E, Mourelatos ZP (2009) An efficient re-analysis methodology for probabilistic vibration of large-scale structures. J Mech Des 131(5):051007.1–051007.13
Acknowledgements
This work is supported by the National Natural Science Foundation of China (50975121) and Specialized Research Fund for the Doctoral Program of Higher Education (No. 20090061110022).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Xu, T., Guo, G. & Zhang, H. Vibration reanalysis using frequency-shift combined approximations. Struct Multidisc Optim 44, 235–246 (2011). https://doi.org/10.1007/s00158-011-0624-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-011-0624-0