
Abstract
We introduce a generalized framework for sampling and reconstruction in separable Hilbert spaces. Specifically, we establish that it is always possible to stably reconstruct a vector in an arbitrary Riesz basis from sufficiently many of its samples in any other Riesz basis. This framework can be viewed as an extension of the well-known consistent reconstruction technique (Eldar et al.). However, whilst the latter imposes stringent assumptions on the reconstruction basis, and may in practice be unstable, our framework allows for recovery in any (Riesz) basis in a manner that is completely stable.
Whilst the classical Shannon Sampling Theorem is a special case of our theorem, this framework allows us to exploit additional information about the approximated vector (or, in this case, function), for example sparsity or regularity, to design a reconstruction basis that is better suited. Examples are presented illustrating this procedure.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The Shannon Sampling Theorem, or the Nyquist–Shannon Sampling Theorem as it is also called (we will refer to it as the NS-Sampling Theorem throughout the paper), is a mainstay in modern signal processing and has become one of the most important theorems in mathematics of information [32]. The list of applications of the theorem is long, and ranges from Magnetic Resonance Imaging (MRI) to sound engineering. We will in this paper address the question on whether or not the NS-Sampling Theorem can be improved. In particular, given the same set of information, can one design a reconstruction of a function that would be better than that provided by the NS-Sampling Theorem? The answer to such a question will obviously depend on the type of functions considered. However, suppose that we have some extra information about the functions to be reconstructed. One may, for example, have information about a basis that is particularly suited for such functions. Could this information be used to improve the reconstruction given by the NS-Sampling Theorem, even if it is based on the same sampling procedure? Although such a question has been posed before, and numerous extensions of the NS-Sampling Theorem have been developed [7, 8, 15, 16, 33], the generalization we introduce in this paper is, to the best of our knowledge, a novel approach for this problem.
The well known NS-Sampling Theorem [24, 26, 29, 30, 34] states that if
where \(\mathcal{F}\) is the Fourier transform and supp(g)⊂[−T,T] for some T>0, then both f and g can be reconstructed from point samples of f. In particular, if \(\epsilon\leq\frac{1}{2T}\) then

The quantity \(\frac{1}{2T}\), which is the largest value of ϵ such that the theorem holds, is often referred to as the Nyquist rate [29]. In practice, when trying to reconstruct f or g, one will most likely not be able to access the infinite amount of information required, namely, {f(kϵ)} k∈ℤ. Moreover, even if we had access to all samples, we are limited by both processing power and storage to taking only a finite number. Thus, a more realistic scenario is that one will be given a finite number of samples {f(kϵ)}|k|≤N , for some N<∞, and seek to reconstruct f from these samples. The question is therefore: are the approximations
optimal for f and g given the information {f(kϵ)}|k|≤N ? To formalize this question consider the following. For N∈ℕ and ϵ>0, let

(C(ℝ) denotes the set of continuous functions on ℝ). Define the mappings (with a slight abuse of notation)

The question is, given a class of functions Θ⊂L 2(ℝ), could there exist mappings Ξ N,ϵ,1:Ω N,ϵ →L 2(ℝ) and Ξ N,ϵ,2:Ω N,ϵ →L 2(ℝ) such that

As we will see later, the answer to this question may very well be yes, and the problem is therefore to find such mappings Ξ N,ϵ,1 and Ξ N,ϵ,2.
As motivation for this work, consider the following reconstruction problem. Let g be defined by
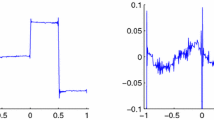
This is the well-known Haar wavelet. Due to the discontinuity, there is no way one can exactly reconstruct this function with only finitely many function samples if one insists on using the mapping Λ N,ϵ,2. We have visualized the reconstruction of g using Λ N,ϵ,2 in Fig. 1. In addition to g not being reconstructed exactly, the approximation Λ N,ϵ,2(g) is polluted by oscillations near the discontinuities of g. Such oscillations are indicative of the well-known Gibbs phenomenon in recovering discontinuous signals from samples of their Fourier transforms [23]. This phenomenon is a major hurdle in many applications, including image and signal processing. Its resolution has, and continues to be, the subject of significant inquiry [31].

The figure shows Λ N,ϵ,2(f) for \(f = \mathcal {F}g\), N=500 and ϵ=0.5 (left) as well as g (right)
It is tempting to think, however, that one could construct a mapping Ξ N,ϵ,2 that would yield a better result. Suppose for a moment that we do not know g, but we do have some extra information. In particular, suppose that we know that g∈Θ, where
for some finite number M and where {ψ k } are the Haar wavelets on the interval [0,1]. Could we, based on the extra knowledge of Θ, construct mappings Ξ N,ϵ,1:Ω N,ϵ →L 2(ℝ) and Ξ N,ϵ,2:Ω N,ϵ →L 2(ℝ) such that

Indeed, this is the case, and a consequence of our framework is that it is possible to find Ξ N,ϵ,1 and Ξ N,ϵ,2 such that

provided N is sufficiently large. In other words, one gets perfect reconstruction. Moreover, the reconstruction is done in a completely stable way.
The main tool for this task is a generalization of the NS-Sampling Theorem that allows reconstructions in arbitrary bases. Having said this, whilst the Shannon Sampling Theorem is our most frequent example, the framework we develop addresses the more abstract problem of recovering a vector (belonging to some separable Hilbert space \(\mathcal{H}\)) given a finite number of its samples with respect any Riesz basis of \(\mathcal{H}\).
1.1 Organization of the Paper
We have organized the paper as follows. In Sect. 2 we introduce notation and idea of finite sections of infinite matrices, a concept that will be crucial throughout the paper. In Sect. 3 we discuss existing literature on this topic, including the work of Eldar et al. [13, 14, 33]. The main theorem is presented and proved in Sect. 4, where we also show the connection to the classical NS-Sampling Theorem. The error bounds in the generalized sampling theorem involve several important constants, which can be estimated numerically. We therefore devote Sect. 5 to discussions on how to compute crucial constants and functions that are useful for providing error estimates. Finally, in Sect. 6 we provide several examples to support the generalized sampling theorem and to justify our approach.
2 Background and Notation
Let i denote the imaginary unit. Define the Fourier transform \(\mathcal{F}\) by
where, for vectors x,y∈ℝd, x⋅y=x 1 y 1+⋯+x d y d . Aside from the Hilbert space L 2(ℝd), we now introduce two other important Hilbert spaces: namely,
and
with their obvious inner products. We will also consider abstract Hilbert spaces. In this case we will use the notation \(\mathcal{H}\). Note that {e j } j∈ℕ and {e j } j∈ℤ will always denote the natural bases for l 2(ℕ) and l 2(ℤ) respectively. We may also use the notation \(\mathcal{H}\) for both l 2(ℕ) and l 2(ℤ) (the meaning will be clear from the context). Throughout the paper, the symbol ⊗ will denote the standard tensor product on Hilbert spaces.
The concept of infinite matrices will be quite crucial to what follows, and also finite sections of such matrices. We will consider infinite matrices as operators from both l 2(ℕ) to l 2(ℤ) and l 2(ℕ) to l 2(ℕ). The set of bounded operators from a Hilbert space \(\mathcal{H}_{1}\) to a Hilbert space \(\mathcal{H}_{2}\) will be denoted by \(\mathcal{B}(\mathcal{H}_{1},\mathcal{H}_{2})\). As infinite matrices are unsuitable for computations we must reduce any infinite matrix to a more tractable finite-dimensional object. The standard means in which to do this is via finite sections. In particular, let

For n∈ℕ, define P n to be the projection onto span{e 1,…,e n } and, for odd m∈ℕ, let \(\widetilde{P}_{m}\) be the projection onto \(\mathrm{span}\{e_{-\frac{m-1}{2}},\ldots, e_{\frac{m-1}{2}}\}\). Then \(\widetilde{P}_{m} U P_{n}\) may be interpreted as

an m×n section of U. Finally, the spectrum of any operator \(T \in\mathcal{B}(\mathcal{H})\) will be denoted by σ(T).
3 Connection to Earlier Work
The idea of reconstructing signals in arbitrary bases is certainly not new and this topic has been subject to extensive investigations in the last several decades. The papers by Unser and Aldroubi [7, 33] have been very influential and these ideas have been generalized to arbitrary Hilbert spaces by Eldar [13, 14]. The abstract framework introduced by Eldar is very powerful because of its general nature. Our framework is based on similar generalizations, yet it incorporates several key distinctions, resulting in a number of advantages.
Before introducing this framework, let us first review some of the key concepts of [14]. Let \(\mathcal{H}\) be a separable Hilbert space and let \(f \in\mathcal{H}\) be an element we would like to reconstruct from some measurements. Suppose that we are given linearly independent sampling vectors {s k } k∈ℕ that span a subspace \(\mathcal{S} \subset\mathcal{H}\) and form a Riesz basis, and assume that we can access the sampled inner products c k =〈s k ,f〉, k=1,2…. Suppose also that we are given linearly independent reconstruction vectors {w k } k∈ℕ that span a subspace \(\mathcal{W} \subset \mathcal{H}\) and also form a Riesz basis. The task is to obtain a reconstruction \(\tilde{f} \in\mathcal{W}\) based on the sampling data {c k } k∈ℕ. The natural choice, as suggested in [14], is
where the so-called synthesis operators \(S, W:l^{2}(\mathbb{N})\rightarrow\mathcal{H}\) are defined by
and their adjoints \(S^{*}, W^{*}:\mathcal{H} \rightarrow l^{2}(\mathbb{N})\) are easily seen to be
Note that S ∗ W will be invertible if and only if
Equation (3.1) gives a very convenient and intuitive abstract formulation of the reconstruction. However, in practice we will never have the luxury of being able to acquire nor process the infinite amount of samples 〈s k ,f〉, k=1,2…, needed to construct \(\tilde{f}\). An important question to ask is therefore:
What if we are given only the first m∈ℕ samples 〈s k ,f〉, k=1,…,m? In this case we cannot use (3.1). Thus, the question is, what can we do?
Fortunately, there is a simple finite-dimensional analogue to the infinite dimensional ideas discussed above. Suppose that we are given m∈ℕ linearly independent sampling vectors {s 1,…,s m } that span a subspace \(\mathcal{S}_{m} \subset\mathcal{H}\), and assume that we can access the sampled inner products c k =〈s k ,f〉, k=1,…,m. Suppose also that we are given linearly independent reconstruction vectors {w 1,…,w m } that span a subspace \(\mathcal{W}_{m} \subset \mathcal{H}\). The task is to construct an approximation \(\tilde{f} \in\mathcal{W}_{m}\) to f based on the samples \(\{c_{k}\}_{k=1}^{m}\). In particular, we are interested in finding coefficients \(\{d_{k}\}_{k=1}^{m}\) (that are computed from the samples \(\{c_{k}\}_{k=1}^{m}\)) such that \(\tilde{f} = \sum_{k=1}^{m} d_{k} w_{k}\). The reconstruction suggested in [12] is
where the operators \(S_{m}, W_{m} : \mathbb{C}^{m} \rightarrow\mathcal{H}\) are defined by
and their adjoints \(S^{*}, W^{*}:\mathcal{H} \rightarrow\mathbb{C}^{m}\) are easily seen to be
From this it is clear that we can express \(S_{m}^{*}W_{m}: \mathbb{C}^{m}\rightarrow\mathbb{C}^{m}\) as the matrix

Also, \(S_{m}^{*}W_{m}\) is invertible if and only if and ([12, Prop. 3])
Thus, to construct \(\tilde{f}\) one simply solves a linear system of equations. The error can now conveniently be bounded from above and below by
where \(P_{\mathcal{W}_{m}}\) is the projection onto \(\mathcal{W}_{m}\),
is the cosine of the angles between the subspaces \(\mathcal{S}_{m}\) and \(\mathcal{W}_{m}\) and \(P_{\mathcal{S}_{m}}\) is the projection onto \(\mathcal{S}_{m}\) [12].
Note that if \(f \in\mathcal{W}_{m}\), then \(\tilde{f} = f \) exactly—a feature known as perfect recovery. Another facet of this framework is so-called consistency: the samples \(\langle s_{j},\tilde{f}\rangle\), j=1,…,m, of the approximation \(\tilde{f}\) are identical to those of the original function f (indeed, \(\tilde {f}\), as given by (3.2), can be equivalently defined as the unique element in \(\mathcal{W}_{m}\) that is consistent with f).
Returning to this issue at hand, there are now several important questions to ask:
-
(i)
What if \(\mathcal{W}_{m} \cap\mathcal{S}_{m}^{\perp} \neq\{0\}\) so that \(S_{m}^{*}W_{m}\) is not invertible? It is very easy to construct theoretical examples such that \(S_{m}^{*}W_{m}\) is not invertible. Moreover, as we will see below, such situations may very well occur in applications. In fact, \(\mathcal{W}_{m} \cap\mathcal{S}_{m}^{\perp} = \{0\}\) is a rather strict condition. If we have that \(\mathcal{W}_{m} \cap \mathcal{S}_{m}^{\perp} \neq\{0\}\) does that mean that is impossible to construct an approximation \(\tilde{f}\) from the samples \(S_{m}^{*}f\)?
-
(ii)
What if \(\|(S_{m}^{*}W_{m})^{-1}\|\) is large? The stability of the method must clearly depend on the quantity \(\|(S_{m}^{*}W_{m})^{-1}\|\). Thus, even if \((S_{m}^{*}W_{m})^{-1}\) exists, one may not be able to use the method in practice as there will likely be increased sensitivity to both round-off error and noise.
Our framework is specifically designed to tackle these issues. But before we present our idea, let us consider some examples where the issues in (i) and (ii) will be present.
Example 3.1
As for (i), the simplest example is to let \(\mathcal{H} = l^{2}(\mathbb {Z})\) and {e j } j∈ℤ be the natural basis (e j is the infinite sequence with 1 in its j-th coordinate and zeros elsewhere). For m∈ℕ, let the sampling vectors \(\{s_{k}\}_{k=-m}^{m}\) and the reconstruction vectors \(\{w_{k}\}_{k=-m}^{m}\) be defined by s k =e k and w k =e k+1. Then, clearly, \(\mathcal{W}_{m} \cap\mathcal{S}_{m}^{\perp} =\mathrm{span}\{e_{m+1}\}\).
Example 3.2
For an example of more practical interest, consider the following. For 0<ϵ≤1 let \(\mathcal{H} = L^{2}([0,1/\epsilon])\), and, for odd m∈ℕ, define the sampling vectors
(this is exactly the type of measurement vector that will be used if one models Magnetic Resonance Imaging) and let the reconstruction vectors \(\{w_{k}\}_{k=1}^{m}\) denote the m first Haar wavelets on [0,1] (including the constant function, w 1=χ [0,1]). Let S ϵ,m and W m be as in (3.3), according to the sampling and reconstruction vectors just defined. A plot of \(\|(S_{\epsilon,m}^{*}W_{m})^{-1}\|\) as a function of m and ϵ is given in Fig. 2. As we observe, for ϵ=1 only certain values of m yield stable reconstruction, whereas for the other values of ϵ the quantity \(\|(S_{\epsilon,m}^{*}W_{m})^{-1}\|\) grows exponentially with m, making the problem severely ill-conditioned. Further computations suggest that \(\|(S_{\epsilon,m}^{*}W_{m})^{-1}\|\) increases exponentially with m not just for these values of ϵ, but for all 0<ϵ<1.

This figure shows \(\log_{10}\|(S^{*}_{\epsilon,m}W_{m})^{-1}\|\) as a function of m and ϵ for m=1,2,…,100. The left plot corresponds to ϵ=1, whereas the right plot corresponds to ϵ=7/8 (circles), ϵ=1/2 (crosses) and ϵ=1/8 (diamonds)
Example 3.3
Another example can be made by replacing the Haar wavelet basis with the basis consisting of Legendre polynomials (orthogonal polynomials on [−1,1] with respect to the Euclidean inner product).
In Fig. 3 we plot the quantity \(\| (S_{\epsilon,m}^{*}W_{m})^{-1} \|\). Unlike in the previous example, this quantity now grows exponentially and monotonically in m. Whilst this not only makes the method highly susceptible to round-off error and noise, it can also prevent convergence of the approximation \(\tilde{f}\) (as m→∞). In essence, for convergence to occur, the error \(\| f - P_{\mathcal{W}_{m}} f \|\) must decay more rapidly than the quantity \(\| (S_{\epsilon,m}^{*} W_{m})^{-1} \|\) grows. Whenever this is not the case, convergence is not assured. To illustrate this shortcoming, in Fig. 3 we also plot the error \(\| f -\tilde{f} \|\), where \(f(x) =\frac{1}{1+16 x^{2}}\). The complex singularity at \(x = \pm\frac{1}{4} \mathrm{i}\) limits the convergence rate of \(\| f - P_{\mathcal{W}_{m}} f \|\) sufficiently so that \(\tilde {f}\) does not converge to f. Note that this effect is well documented as occurring in a related reconstruction problem, where a function defined on [−1,1] is interpolated at m equidistant pointwise samples by a polynomial of degree m−1. This is the famous Runge phenomenon. The problem considered above (reconstruction from m Fourier samples) can be viewed as a continuous analogue of this phenomenon.

The left figure shows \(\log_{10}\|(S_{\epsilon,m}^{*}W_{m})^{-1}\|\) as a function of m for m=2,4,…,50 and \(\epsilon= 1,\frac {7}{8},\frac{1}{2},\frac{1}{8}\) (squares, circles, crosses and diamonds respectively). The right figure shows \(\log_{10}\| f - P_{\mathcal {W}_{m}} f \|\) (squares) and \(\log_{10}\| f - \tilde{f} \|\) (circles) for m=2,4,6,…,100, where \(f(x) = \frac{1}{1+16 x^{2}}\)
Actually, the phenomenon illustrated in Examples 3.2 and 3.3 is not hard to explain if one looks at the problem from an operator-theoretical point of view. This is the topic of the next section.
3.1 Connections to the Finite Section Method
To illustrate the idea, let {s k } k∈ℕ and {w k } k∈ℕ be two sequences of linearly independent elements in a Hilbert space \(\mathcal{H}\). Define the infinite matrix U by

Thus, by (3.4) the operator \(S_{m}^{*}W_{m}\) is simply the m×m finite section of U. In particular
where \(P_{m}UP_{m}\vert_{P_{m} l^{2}(\mathbb{N})}\) denotes the restriction of the operator P m UP m to the range of P m (i.e. the m×m finite section of U). The finite section method has been studied extensively over the last several decades [9, 18, 19, 27]. It is well known that even if U is invertible then \(P_{m}UP_{m}\vert_{P_{m} l^{2}(\mathbb{N})}\) may never be invertible for any m. In fact one must have rather strict conditions on U for \(P_{m}UP_{m}\vert_{P_{m} l^{2}(\mathbb{N})}\) to be invertible with uniformly bounded inverse (such as positive self-adjointness, for example [27]). In addition, even if U:l 2(ℕ)→l 2(ℕ) is invertible and \(P_{m}UP_{m}\vert_{P_{m} l^{2}(\mathbb{N})}\) is invertible for all m∈ℕ, it may be the case that, if
then
Suppose that {s k } k∈ℕ and {w k } k∈ℕ are two Riesz bases for closed subspaces \(\mathcal{S}\) and \(\mathcal{W}\) of a separable Hilbert space \(\mathcal{H}\). Define the operators \(S, W:l^{2}(\mathbb{N}) \rightarrow\mathcal{H}\) by
Suppose now that (S ∗ W)−1 exists. For m∈ℕ, let the spaces \(\mathcal{S}_{m}, \mathcal{W}_{m}\) and operators \(S_{m}, W_{m} : \mathbb{C}^{m}\rightarrow\mathcal{H}\) be defined as in Sect. 3 according to the vectors \(\{s_{k}\}_{k=1}^{m}\) and \(\{w_{k}\}_{k=1}^{m}\) respectively. As seen in the previous section, the following scenarios may well arise:
-
(i)
\(\mathcal{W} \cap\mathcal{S}^{\perp} = \{0\}\), yet
$$\mathcal{W}_m \cap\mathcal{S}^{\perp}_m \neq\{0\}, \quad\forall\, m \in\mathbb{N}.$$ -
(ii)
∥(S ∗ W)−1∥<∞ and the inverse \((S_{m}^{*}W_{m})^{-1}\) exists for all m∈ℕ, but
$$\bigl\|\bigl(S_m^*W_m\bigr)^{-1}\bigr\| \longrightarrow \infty, \quad m \rightarrow\infty.$$ -
(iii)
\((S_{m}^{*}W_{m})^{-1}\) exists for all m∈ℕ, however
$$W_m\bigl(S_m^*W_m\bigr)^{-1}S_m^*f\nrightarrow f, \quad m \rightarrow\infty,$$for some \(f \in\mathcal{W} \).
Thus, in order for us to have a completely general sampling theorem we must try to extend the framework described in this section in order to overcome the obstacles listed above.
4 The New Approach
4.1 The Idea
One would like to have a completely general sampling theory that can be described as follows:
-
(i)
We have a signal \(f \in\mathcal{H}\) and a Riesz basis {w k } k∈ℕ that spans some closed subspace \(\mathcal{W} \subset\mathcal{H}\), and
$$f = \sum_{k=1}^{\infty} \beta_kw_k, \quad\beta_k \in\mathbb{C}.$$So \(f \in\mathcal{W}\) (we may also typically have some information on the decay rate of the β k s, however, this is not crucial for our theory).
-
(ii)
We have sampling vectors {s k } k∈ℕ that form a Riesz basis for a closed subspace \(\mathcal{S} \subset\mathcal{H}\), (note that we may not have the luxury of choosing such sampling vectors as they may be specified by some particular model, as is the case in MRI) and we can access the sampling values {〈s k ,f〉} k∈ℕ.
Goal
Reconstruct the best possible approximation \(\tilde{f} \in \mathcal{W}\) based on the finite subset \(\{\langle s_{k},f\rangle\}_{k=1}^{m}\) of the sampling information {〈s k ,f〉} k∈ℕ.
We could have chosen m vectors {w 1,…,w m } and defined the operators S m and W m as in (3.3) (from {w 1,…,w m } and {s 1,…,s m }) and let \(\tilde{f}\) be defined by (3.2). However, this may be impossible as \(S_{m}^{*}W_{m}\) may not be invertible (or the inverse may have a very large norm), as discussed in Examples 3.2 and 3.3.
To deal with these issues we will launch an abstract sampling theorem that extends the ideas discussed above. To do so, we first notice that, since {s j } and {w j } are Riesz bases, there exist constants A,B,C,D>0 such that

Now let U be defined as in (3.6). Instead of dealing with \(P_{m}UP_{m}\vert_{P_{m} l^{2}(\mathbb{N})} = S_{m}^{*}W_{m}\) we propose to choose n∈ℕ and compute the solution \(\{\tilde{\beta}_{1},\ldots, \tilde{\beta}_{n}\}\) of the following equation:

provided a solution exists (later we will provide estimates on the size of n,m for (4.2) to have a unique solution). Finally we let
Note that, for n=m this is equivalent to (3.2), and thus we have simply extended the framework discussed in Sect. 3. However, for m>n this is no longer the case. As we later establish, allowing m to range independently of n is the key to the advantage possessed by this framework.
Before doing so, however, we first mention that the framework proposed above differs from that discussed previously in that it is inconsistent. Unlike (3.2), the samples \(\langle s_{j},\tilde{f} \rangle\) do not coincide with those of the function f. Yet, as we shall now see, by dropping the requirement of consistency, we obtain a reconstruction which circumvents the aforementioned issues associated with (3.2).
4.2 The Abstract Sampling Theorem
The task is now to analyze the model in (4.2) by both establishing existence of \(\tilde{f}\) and providing error bounds for \(\|f-\tilde{f}\|\). We have
Theorem 4.1
Let \(\mathcal{H}\) be a separable Hilbert space and \(\mathcal{S}, \mathcal{W} \subset\mathcal{H}\) be closed subspaces such that \(\mathcal{W} \cap\mathcal{S}^{\perp} = \{0\}\). Suppose that {s k } k∈ℕ and {w k } k∈ℕ are Riesz bases for \(\mathcal{S}\) and \(\mathcal{W}\) respectively with constants A,B,C,D>0. Suppose that
Let n∈ℕ. Then there is an M∈ℕ (in particular \(M = \min\{k: 0 \notin\sigma(P_{n}U^{*}P_{k}UP_{n} \lvert_{P_{n}\mathcal{H}}) \}\)) such that, for all m≥M, the solution \(\{\tilde{\beta}_{1},\ldots, \tilde{\beta}_{n}\}\) to (4.2) is unique. Also, if \(\tilde{f}\) is as in (4.3), then
where
The theorem has an immediate corollary that is useful for estimating the error. We have
Corollary 4.2
With the same assumptions as in Theorem 4.1 and fixed n∈ℕ,

In addition, if U is an isometry (in particular, when {w k } k∈ℕ,{s k } k∈ℕ are orthonormal) then it follows that
Proof of Theorem 4.1
Let U be as in as in (3.6). Then (4.4) yields the following infinite system of equations:

Note that U must be a bounded operator. Indeed, let S and W be as in (3.7). Since
it follows that U=S ∗ W. However, from (4.1) we find that both W and S are bounded as mappings from l 2(ℕ) onto \(\mathcal{W}\) and \(\mathcal{S}\) respectively, with \(\|W\| \leq\sqrt{B}\), \(\|S\| \leq\sqrt{D}\), thus yielding our claim. Note also that, by the assumption that \(\mathcal{W} \cap\mathcal {S}^{\perp} = \{0\}\), (4.8) has a unique solution. Indeed, since \(\mathcal{W} \cap\mathcal{S}^{\perp} =\{0\}\) and by the fact that {s k } k∈ℕ and {w k } k∈ℕ are Riesz bases, it follows that inf∥x∥=1∥S ∗ Wx∥≠0. Hence U must be injective.
Now let η f ={〈s 1,f〉,〈s 1,f〉,…}. Then (4.8) gives us that
Suppose for a moment that we can show that there exists an M>0 such that \(P_{n}U^{*}P_{m}UP_{n}\lvert_{P_{n}\mathcal{H}}\) is invertible for all m≥M. Hence, we may appeal to (4.9), whence
and therefore, by (4.9) and (4.1),

where
Thus, (4.5) is established, provided we can show the following claim:
Claim
There exists an M>0 such that \(P_{n}U^{*}P_{m}UP_{n}\lvert_{P_{n}\mathcal{H}}\) is invertible for all m≥M. Moreover,
To prove the claim, we first need to show that \(P_{n}U^{*}UP_{n}\lvert_{P_{n}l^{2}(\mathbb{N})}\) is invertible for all n∈ℕ. To see this, let \(\Theta: \mathcal {B}(l^{2}(\mathbb{N})) \rightarrow\mathbb{C}\) denote the numerical range. Note that U ∗ U is self-adjoint and invertible. The latter implies that there is a neighborhood ω around zero such that σ(U ∗ U)∩ω=∅ and the former implies that the numerical range Θ(U ∗ U)∩ω=∅. Now the spectrum \(\sigma(P_{n}U^{*}UP_{n}\lvert_{P_{n}l^{2}(\mathbb{N})})\subset\Theta(P_{n}U^{*}UP_{n}\lvert_{P_{n}l^{2}(\mathbb{N})}) \subset\Theta (U^{*}U)\). Thus,
and therefore, \(P_{n}U^{*}UP_{n}\lvert_{P_{n}l^{2}(\mathbb{N})}\) is always invertible. Now, make the following two observations

where the last series converges at least strongly (it converges in norm, but that is a part of the proof). The first is obvious. The second observation follows from the fact that P m U→U strongly as m→∞. Note that
However, U ∗ P n U must be trace class since ran(P n ) is finite-dimensional. Thus, by (4.2) we find that

Hence, the claim follows (the fact that \(\Vert (P_{n}U^{*}UP_{n}\lvert_{P_{n}\mathcal{H}})^{-1}\Vert \leq \Vert (U^{*}U)^{-1}\Vert \) is clear from the observation that U ∗ U is self-adjoint), and we are done. □
Proof of Corollary 4.2
Note that the claim in the proof of Theorem 4.1 yields the first part of (4.7), and the second part follows from the fact that U=S ∗ W (where S,W are also defined in the proof of Theorem 4.1) and (4.1). Thus, we are now left with the task of showing that K n,m →0 as m→∞ when U is an isometry. Note that the assertion will follow, by (4.6), if we can show that
However, this is straightforward, since a simple calculation yields
which tends to zero by (4.12). To see why (4.13) is true, we start by using the fact that U is an isometry we have that
and therefore
And, by again using the property that U is an isometry we have that

Hence, (4.13) follows from (4.14). □
Remark 4.3
Note that the trained eye of an operator theorist will immediately spot that the claim in the proof of Theorem 4.1 and Corollary 4.2 follows (with an easy reference to known convergence properties of finite rank operators in the strong operator topology) without the computations done in our exposition. However, we feel that the exposition illustrates ways of estimating bounds for
which are crucial in order to obtain a bound for K n,m . This is demonstrated in Sect. 5.
Remark 4.4
Note that S ∗ W (and hence also U) is invertible if and only if \(\mathcal{H} = \mathcal{W} \oplus\mathcal{S}^{\perp}\), which is equivalent to \(\mathcal{W} \cap\mathcal{S}^{\perp} = \{0\}\) and \(\mathcal{W}^{\perp} \cap\mathcal{S} = \{0\}\). This requirement is quite strong as we may very well have that \(\mathcal{W} \neq\mathcal {H}\) and \(\mathcal{S} = \mathcal{H}\) (e.g. Example 3.2 when ϵ<1). In this case we obviously have that \(\mathcal{W}^{\perp} \cap\mathcal{S} \neq\{0\}\). However, as we saw in Theorem 4.1, as long as we have \(f \in\mathcal{W}\) we only need injectivity of U, which is guaranteed when \(\mathcal{W}\cap\mathcal{S}^{\perp} = \{0\}\).
If one wants to write our framework in the language used in Sect. 3, it is easy to see that our reconstruction can be written as
where the operators \(S_{m} : \mathbb{C}^{m} \rightarrow\mathcal{H}\) and \(W_{n} : \mathbb{C}^{n} \rightarrow\mathcal{H}\) are defined as in (3.3), and S m and W n corresponds to the spaces
where {w k } k∈ℕ and {s k } k∈ℕ are as in Theorem 4.1. In particular, we get the following corollary:
Corollary 4.5
Let \(\mathcal{H}\) be a separable Hilbert space and \(\mathcal{S}, \mathcal{W} \subset\mathcal{H}\) be closed subspaces such that \(\mathcal{W} \cap\mathcal{S}^{\perp} = \{0\}\). Suppose that {s k } k∈ℕ and {w k } k∈ℕ are Riesz bases for \(\mathcal{S}\) and \(\mathcal{W}\) respectively. Then, for each n∈ℕ there is an M∈ℕ such that, for all m≥M, the mapping \(W_{n}^{*}S_{m}S_{m}^{*}W_{n}:\mathbb {C}^{n} \rightarrow\mathbb{C}^{n}\) is invertible (with S m and W n defined as above). Moreover, if \(\tilde{f}\) is as in (4.15), then
where \(P_{\mathcal{W}_{n}}\) is the orthogonal projection onto \(\mathcal {W}_{n}\), and
Moreover, when {s k } and {w k } are orthonormal bases, then, for fixed n, C n,m →0 as m→∞.
Proof
The fact that \(W_{n}^{*}S_{m}S_{m}^{*}W_{n}:\mathbb{C}^{n} \rightarrow\mathbb{C}^{n}\) is invertible for large m follows from the observation that \(\mathcal{W} \cap\mathcal{S}^{\perp} = \{0\}\) and the proof of Theorem 4.1, by noting that \(S_{m}^{*}W_{n} = P_{m}UP_{n}\), where U is as in Theorem 4.1. Now observe that

Note also that \(W^{*}_{n}W_{n}:\mathbb{C}^{n} \rightarrow\mathbb{C}^{n}\) is clearly invertible, since \(\{w_{k}\}_{k =1}^{n}\) are linearly independent. Now (4.17) yields
Thus,
which gives the first part of the corollary. The second part follows from similar reasoning as in the proof of Corollary 4.2. □
Remark 4.6
The framework explained in Sect. 3 is equivalent to using the finite section method. Although this may work for certain bases, it will not in general (as Example 3.2 shows). Computing with infinite matrices can be a challenge since the qualities of any finite section may be very different from the original infinite matrix. The use of uneven sections (as we do in this paper) of infinite matrices seems to be the best way to combat these problems. This approach stems from [20] where the technique was used to solve a long standing open problem in computational spectral theory. The reader may consult [17, 21] for other examples of uneven section techniques.
When compared to the method of Eldar et al., the framework presented here has a number of important advantages:
-
(i)
It allows reconstructions in arbitrary bases and does not need extra assumptions as in (3.5).
-
(ii)
The conditions on m (as a function of n) for \(P_{n}U^{*}P_{m}UP_{n}\lvert_{P_{n}\mathcal{H}}\) to be invertible (such that we have a unique solution) can be numerically computed. Moreover, bounds on the constant K n,m can also be computed efficiently. This is the topic in Sect. 5.
-
(iii)
It is numerically stable: the matrix \(A = P_{n} U^{*} P_{m} UP_{n} |_{P_{n} \mathcal{H}}\) has bounded inverse (Corollary 4.2) for all n and m sufficiently large.
-
(iv)
The approximation \(\tilde{f}\) is quasi-optimal (in n). It converges at the same rate as the tail \(\| P^{\perp}_{n} \beta\|_{l^{2}(\mathbb{N})}\), in contrast to (3.2) which converges more slowly whenever the parameter \(\frac{1}{\cos( \theta_{\mathcal{W}_{m}\mathcal{S}_{m}})}\) grows with n=m.
As mentioned, this method is inconsistent. However, since {s j } is a Riesz basis, we deduce that
for some constant c>0. Hence, the departure from consistency (i.e. the left-hand side) is bounded by a constant multiple of the approximation error, and thus can also be bounded by \(\| P^{\perp}_{n}\beta\|_{l^{2}(\mathbb{N})}\).
4.3 The Generalized (Nyquist–Shannon) Sampling Theorem
In this section, we apply the abstract sampling theorem (Theorem 4.1) to the classical sampling problem of recovering a function from samples of its Fourier transform. As we shall see, when considered in this way, the corresponding theorem, which we call the generalized (Nyquist–Shannon) Sampling Theorem, extends the classical Shannon theorem (which is a special case) by allow reconstructions in arbitrary bases.
Proposition 4.7
Let \(\mathcal{F}\) denote the Fourier transform on L 2(ℝd). Suppose that {φ j } j∈ℕ is a Riesz basis with constants A,B (as in (4.1)) for a subspace \(\mathcal{W} \subset L^{2}(\mathbb{R}^{d})\) such that there exists a T>0 with supp(φ j )⊂[−T,T]d for all j∈ℕ. For ϵ>0, let ρ:ℕ→(ϵℤ)d be a bijection. Define the infinite matrix

Then, for \(\epsilon\leq\frac{1}{2T}\), we have that U:l 2(ℕ)→l 2(ℕ) is bounded and invertible on its range with \(\|U\| \leq\sqrt{\epsilon^{-d}B}\) and ∥(U ∗ U)−1∥≤ϵ d A −1 . Moreover, if {φ j } j∈ℕ is an orthonormal set, then ϵ d/2 U is an isometry.
Theorem 4.8
(The Generalized Sampling Theorem)
With the same setup as in Proposition 4.7, set
and let P n denote the projection onto span{e 1,…,e n }. Then, for every n∈ℕ there is an M∈ℕ such that, for all m≥M, the solution to

is unique. Also, if
then
and
where K n,m is given by (4.6) and satisfies (4.7). Moreover, when {φ j } j∈ℕ is an orthonormal set, we have
for fixed n.
Proof of Proposition 4.7
Note that
Since ρ:ℕ→(ϵℤ)N is a bijection, it follows that the functions {x↦ϵ d/2 e −2πiρ(i)⋅x} i∈ℕ form an orthonormal basis for L 2([−(2ϵ)−1,(2ϵ)−1]d)⊃L 2([−T,T]d). Let
denote a new inner product on L 2([−(2ϵ)−1,(2ϵ)−1]d). Thus, we are now in the setting of Theorem 4.1 and Corollary 4.2 with C=D=ϵ d. It follows by Theorem 4.1 and Corollary 4.2 that U is bounded and invertible on its range with \(\|U\| \leq\sqrt{\epsilon^{-d}B}\) and ∥(U ∗ U)−1∥≤ϵ d A −1. Also, ϵ d/2 U is an isometry whenever A=B=1, in particular when {φ k } k∈ℕ is an orthonormal set. □
Proof of Theorem 4.8
Note that (4.18) now automatically follows from Theorem 4.1. To get (4.19) we simply observe that, by the definition of the Fourier transform and using the Cauchy–Schwarz inequality,

where the last inequality follows from the already established (4.18). Hence we are done with the first part of the theorem. To see that K n,m →0 as m→∞ when {φ j } j∈ℕ is an orthonormal set, we observe that orthonormality yields A=B=1 and hence (since we already have established the values of C and D) ϵ d/2 U must be an isometry. The convergence to zero now follows from Theorem 4.1. □
Note that the bijection ρ:ℕ→(ϵℤ)d is only important when d>1 to obtain an operator U:l 2(ℕ)→l 2(ℕ). However, when d=1, there is nothing preventing us from avoiding ρ and forming an operator U:l 2(ℕ)→l 2(ℤ) instead. The idea follows below. Let \(\mathcal{F}\) denote the Fourier transform on L 2(ℝ), and let \(f = \mathcal{F}g\) for some g∈L 2(ℝ). Suppose that {φ j } j∈ℕ is a Riesz basis for a closed subspace in L 2(ℝ) with constants A,B>0, such that there is a T>0 with supp(φ j )⊂[−T,T] for all j∈ℕ. For ϵ>0, let

Thus, as argued in the proof of Theorem 4.8, \(\widehat{U}\in\mathcal{B}(l^{2}(\mathbb{N}), l^{2}(\mathbb{Z}))\), provided \(\epsilon\leq\frac{1}{2T}\). Next, let \(P_{n} \in\mathcal{B}(l^{2}(\mathbb{N}))\) and, for odd m, \(\tilde{P}_{m} \in\mathcal{B}(l^{2}(\mathbb{Z}))\) be the projections onto
respectively. Define \(\{\tilde{\beta}_{1}, \ldots, \tilde{\beta}_{n}\}\) by (this is understood to be for sufficiently large m)

By exactly the same arguments as in the proof of Theorem 4.8, it follows that, if \(g = \sum_{j=1}^{\infty} \beta_{j} \varphi_{j}\), \(\tilde{g} = \sum_{j=1}^{n}\tilde{\beta}_{j} \varphi_{j}\), \(f = \mathcal{F}g\) and \(\tilde{f} = \sum_{j=1}^{n}\tilde{\beta}_{j}\mathcal{F} \varphi_{j}\), then

where K n,m is as in (4.6).
Remark 4.9
Note that (as the proof of the next corollary will show) the classical NS-Sampling Theorem is just a special case of Theorem 4.8.
Corollary 4.10
Suppose that \(f = \mathcal{F}g\) and supp(g)⊂[−T,T]. Then, for \(0 < \epsilon\leq\frac{1}{2T}\) we have that

Proof
Define the basis {φ j } j∈ℕ for L 2([−(2ϵ)−1,(2ϵ)−1]) by

Letting \(\widehat{U} = \{u_{k,l}\}_{k \in\mathbb{Z}, l \in\mathbb {N}}\), where \(u_{k,l} = (\mathcal{F}\varphi_{l})(k\epsilon)\), an easy computation shows that

By choosing m=n in (4.21), we find that \(\tilde{\beta}_{1} =\sqrt{\epsilon}f(0)\), \(\tilde{\beta}_{2} = \sqrt{\epsilon}f(\epsilon)\), \(\tilde{\beta}_{3} = \sqrt{\epsilon}f(-\epsilon)\), etc and that K n,m =0 in (4.22). The corollary then follows from (4.22). □
Remark 4.11
Returning to the general case, recall the definition of Ω N,ϵ from (1.1), the mappings Λ N,ϵ,1, Λ N,ϵ,2 from (1.2) and Θ from (1.3). Define Ξ N,ϵ,1:Ω N,ϵ →L 2(ℝ) and Ξ N,ϵ,2:Ω N,ϵ →L 2(ℝ) by
where \(\tilde{\beta}= \{\tilde{\beta}_{1}, \ldots, \tilde{\beta}_{N}\}\) is the solution to (4.21) with N=m. Then, for n>M (recall M from the definition of Θ (1.3)), and
it follows that

Hence, under the aforementioned assumptions on m and n, both f and g are recovered exactly by this method, provided g∈Θ. Moreover, the reconstruction is done in a stable manner, where the stability depends only on the parameter γ.
To complete this section, let us sum up several of the key features of Theorem 4.8. First, whenever m is sufficiently large, the error incurred by \(\tilde{g}\) is directly related to the properties of g with respect to the reconstruction basis. In particular, as noted above, g is reconstructed exactly under certain conditions. Second, for fixed n, by increasing m we can get arbitrarily close to the best approximation to g in the reconstruction basis whenever the reconstruction vectors are orthonormal (i.e. we get arbitrary close to the projection onto the first n elements in the reconstruction basis). Thus, provided an appropriate basis is known, this procedure allows for near-optimal recovery (getting the projection onto the first n elements in the reconstruction basis would of course be optimal). The main question that remains, however, is how to guarantee that the conditions of Theorem 4.8 are satisfied. This is the topic of the next section.
5 Norm Bounds
5.1 Determining m
Recall that the constant K n,m in the error bound in Theorem 4.1 (recall also U from the same theorem) is given by
It is therefore of utmost importance to estimate K n,m . This can be done numerically. Note that we already have established bounds on ∥U∥ depending on the Riesz constants in (4.1) and since we obviously have that
we only require an estimate for the quantity \(\|(P_{n}U^{*}P_{m}UP_{n}\lvert_{P_{n}\mathcal{H}})^{-1}\|\).
Recall also from Theorem 4.1 that, if U is an isometry up to a constant, then K n,m →0 as m→∞. In the rest of this section we will assume that U has this quality. In this case we are interested in the following problem: given n∈ℕ,θ∈ℝ+, what is the smallest m∈ℕ such that K n,m ≤θ? More formally, we wish to estimate the function \(\Phi: \mathcal{U}(l^{2}(\mathbb{N})) \times\mathbb{N} \times\mathbb {R}_{+} \rightarrow\mathbb{N}\),
where
Note that Φ is well defined for all θ∈ℝ+, since we have established that K n,m →0 as m→∞.
5.2 Computing Upper and Lower Bounds on K n,m
The fact that \(UP_{n}^{\perp}\) has infinite rank makes the computation of K n,m a challenge. However, we may compute approximations from above and below. For M∈ℕ, define

Then, for L≥M,

Clearly, \(K_{n,m} \leq \|U\| \widetilde{K}_{n,m}\) and, since P M ξ→ξ as M→∞ for all \(\xi\in\mathcal{H}\), and by the reasoning above, it follows that
Note that
has finite rank. Therefore we may easily compute K n,m,M . In Fig. 4 we have computed K n,m,M for different values of n,m,M. Note the rapid convergence in both examples.

The figure shows K n,m,M for n=75, m=350 and M=n+1,…,6000 (left) and K n,m,M for n=100, m=400 and M=n+1,…,6000 (right) for the Haar wavelets on [0,1]
5.3 Wavelet Bases
Whilst in the general case Φ(U,n,θ) must be computed numerically, in certain cases we are able to derive explicit analytical bounds for this quantity. As an example, we now describe how to obtain bounds for bases consisting of compactly supported wavelets. Wavelets and their various generalizations present an extremely efficient means in which to represent functions (i.e. signals) [10, 11, 28]. Given their long list of applications, the development of wavelet-based reconstruction methods using the framework of this paper is naturally a topic of utmost importance.
Let us review the basic wavelet approach on how to create orthonormal subsets {φ k } k∈ℕ⊂L 2(ℝ) with the property that L 2([0,a])⊂cl(span{φ k } k∈ℕ) for some a>0. Suppose that we are given a mother wavelet ψ and a scaling function ϕ such that supp(ψ)=supp(ϕ)=[0,a] for some a≥1. The most obvious approach is to consider the following collection of functions:
where
(The notation K o denotes the interior of a set K⊂ℝ.) Then we will have that
where T>0 is such that [−T,T] contains the support of all functions in Ω a . However, the inclusions may be proper (but not always, as is the case with the Haar wavelet.) It is easy to see that

Hence we get that
and we will order Ω a as follows:

We will in this section be concerned with compactly supported wavelets and scaling functions satisfying
for some
Before we state and prove bounds on Φ(U,n,θ) in this setting, let us for convenience recall the result from the proof of Theorem 4.1. In particular, we have that
Theorem 5.1
Suppose that {φ l } l∈ℕ is a collection of functions as in (5.2) such that supp(φ l )⊂[−T,T] for all l∈ℕ and some T>0. Let U be defined as in Proposition 4.7 with \(0 < \epsilon\leq \frac{1}{2T}\) and let the bijection ρ:ℕ→ϵℤ defined by ρ(1)=0,ρ(2)=ϵ,ρ(3)=−ϵ,ρ(4)=2ϵ,…. For θ>0,n∈ℕ define Φ(U,n,θ) as in (5.1). Then, if ϕ,ψ satisfy (5.3), we have that

where \(f(\theta) = (\sqrt{1+4\theta^{2}} -1)^{2}/(4\theta^{2})\).
Proof
To estimate Φ(U,n,θ) we will determine bounds on
Note that if r<1 and ∥P n U ∗ P m UP n −P n U ∗ UP n ∥≤r, then
(recall that U ∗ U=ϵ −1 I and that ϵ≤1). Also, recall (4.13), so that
when r and m are chosen such that
(note that \(\|U\| = 1/\sqrt{\epsilon}\)). In particular, it follows that
To get bounds on Ψ(U,n,θ) we will proceed as follows. Since ϕ,ψ have compact support, it follows that \(\mathcal{F}\phi, \mathcal{F}\psi\) are bounded. Moreover, by assumption, we have that
And hence, since
we get that
By the definition of U it follows that
And also, by (5.6) and (5.2) we have, for s>0,

thus we get that

Therefore, by using (5.4) we have just proved that
and by inserting this bound into (5.5) we obtain
which obviously yields the asserted bound on Φ(U,n,θ). □
The theorem has an obvious corollary for smooth compactly supported wavelets.
Corollary 5.2
Suppose that we have the same setup as in Theorem 5.1, and suppose also that ϕ,ψ∈C p(ℝ) for some p∈ℕ. Then
5.4 A Pleasant Surprise
Note that if ψ is the Haar wavelet and ϕ=χ [0,1] we have that
Thus, if we used the Haar wavelets on [0,1] as in Theorem 5.1 and used the technique in the proof of Theorem 5.1 we would get that

It is tempting to check numerically whether this bound is sharp or not. Let us denote the quantity in (5.8) by \(\widetilde{\Psi}(U,n,\theta)\), and observe that this can easily be computed numerically. Figure 5 shows \(\widetilde{\Psi}(U,n,\theta)\) for θ=1,2, where U is defined as in Proposition 4.7 with ϵ=0.5. Note that the numerical computation actually shows that
which is indeed a very pleasant surprise. In fact, due to the ‘staircase growth shown in Fig. 5, the growth is actually better than what (5.9) suggests. The question is whether this is a particular quality of the Haar wavelet, or that one can expect similar behavior of other types of wavelets. The answer to this question will be the topic of future work.

The figure shows sections of the graphs of \(\widetilde{\Psi}(U,\cdot,1)\) (left) and \(\widetilde{\Psi}(U,\cdot,2)\) (right) together with the functions (in black) x↦4.9x (left) and x↦4.55x. In this case U is formed by using the Haar wavelets on [0,1]
Note that Fig. 5 is interpreted as follows: provided m≥4.9n, for example, we can expect this method to reconstruct g to within an error of size \((1+\theta)\| P^{\top}_{n} \beta\|\), where θ=1 in this case. In other words, the error is only two times greater than the best approximation to g from the finite-dimensional space consisting of the first n Haar wavelets.
Having described how to determine conditions which guarantee existence of a reconstruction, in the next section we apply this approach to a number of example problems. First, however, it is instructive to confirm that these conditions do indeed guarantee stability of the reconstruction procedure. In Fig. 6 we plot \(\|(\epsilon\hat{A})^{-1} \|\) against n (for ϵ=0.5), where \(\hat{A}\) is formed via (4.21) using Haar wavelets with parameter m=⌈4.9n⌉. As we observe, the quantity remains bounded, indicating stability. Note the stark contrast to the severe instability documented in Fig. 2.

The quantity \(\| (\epsilon\hat{A})^{-1} \|\) against n=2,4,…,360
6 Examples
In this final section, we consider the application of the generalized sampling theorem to several examples.
6.1 Reconstruction from the Fourier Transform
In this example we consider the following problem. Let f∈L 2(ℝ) be such that
We assume that we can access point samples of f, however, it is not f that is of interest to us, but rather g. This is a common problem in applications, in particular MRI. The NS Sampling Theorem assures us that we can recover g from point samples of f as follows:
where the series converges in L 2 norm. Note that the speed of convergence depends on how well g can be approximated by the functions e 2πinϵ⋅, n∈ℤ. Suppose now that we consider the function
In this case, due to the discontinuity, forming
may be less than ideal, since the convergence g N →g as N→∞ may be slow.
This is, of course, not an issue if we can access all the samples {f(nϵ)} n∈ℤ. However, such an assumption is infeasible in applications. Moreover, even if we had access to all samples, we are limited by both processing power and storage to taking only a finite number.
Suppose that we have a more realistic scenario: namely, we are given the finite collection of samples
with N=900 and \(\epsilon= \frac{1}{2}\). The task is now as follows: construct the best possible approximation to g based on the vector η f . We can naturally form g N as in (6.1). This approximation can be visualized in the diagrams in Fig. 7. Note the rather unpleasant Gibbs oscillations that occur, as discussed previously. The problem is simply that the set {e 2πinϵ⋅} n∈ℤ is not a good basis to express g in. Another basis to use may be the Haar wavelets {ψ j } on [0,1] (we do not claim that this is the optimal basis, but at least one that may better capture the discontinuity of g). In particular, we may express g as
We will now use the technique suggested in Theorem 4.8 to construct a better approximation to g based on exactly the same input information: namely, η f in (6.2). Let \(\widehat{U}\) be defined as in (4.20) with ϵ=1/2 and let n=500 and m=1801. In this case

Define \(\tilde{\beta}= \{\tilde{\beta}_{1}, \ldots, \tilde{\beta}_{n}\}\) by (4.21), and let \(\tilde{g}_{n,m} = \sum_{j=1}^{n}\tilde{\beta}_{j} \psi_{j}\). The function \(\tilde{g}_{n,m}\) is visualized in Fig. 7. Although, the construction of g N and \(\tilde{g}_{n,m}\) required exactly the same amount of samples of f, it is clear from Fig. 7 that \(\tilde{g}_{n,m}\) is favorable. In particular, approximating g by \(\tilde{g}_{n,m}\) gives roughly four digits of accuracy. Moreover, had both n and m been increased, this value would have decreased. In contrast, the approximation g N does not converge uniformly to g on [0,1].

The upper figures show g N (left), \(\tilde{g}_{n,m}\) (middle) and g (right) on the interval [0,1]. The lower figures show g N (left), \(\tilde{g}_{n,m}\) (middle) and g (right) on the interval [0.47,0.57]
6.2 Reconstruction from Point Samples
In this example we consider the following problem. Let f∈L 2(ℝ) such that
for K=400, where {ψ j } are Haar wavelets on [0,1], and \(\{\alpha_{j}\}_{j=1}^{K}\) are some arbitrarily chosen real coefficients in [0,10]. A section of the graph of f is displayed in Fig. 8. The NS Sampling Theorem yields that
where the series converges uniformly. Suppose that we can access the following pointwise samples of f:
with \(\epsilon= \frac{1}{2}\) and N=600. The task is to reconstruct an approximation to f from the samples η f in the best possible way. We may of course form
However, as Fig. 9 shows, this approximation is clearly less than ideal as f(t) is approximated poorly for large t. It is therefore tempting to try the reconstruction based on Theorem 4.8 and the Haar wavelets on [0,1] (one may of course try a different basis). In particular, let
where
with m=2N+1=1201 and \(\widehat{U}\) is defined in (4.20) with ϵ=1/2. A section of the errors |f−f N | and \(|f - \tilde{f}|\) is shown in Fig. 9. In this case we have

In particular, the reconstruction \(\tilde{f}\) is very stable. Figure 9 displays how our alternative reconstruction is favorable especially for large t. Note that with the same amount of sampling information the improvement is roughly by a factor of ten thousand.

The figure shows Re(f) (left) and Im(f) (right) on the interval [−5000,5000]

The figure shows the error |f−f N | (left) and \(|f - \tilde{f}|\) (right) on the interval [−5000,5000]
7 Concluding Remarks
The framework presented in this paper has been studied via the examples of Haar wavelets and Legendre polynomials. Whilst the general theory is now well developed, there remain many questions to answer within these examples. In particular,
-
(i)
What is the required scaling of m (in comparison to n) when the reconstruction basis consists of Legendre polynomials, and how well does the resulting method compare with more well-established approaches for overcoming the Gibbs phenomenon in Fourier series? Whilst there have been some previous investigations into this particular approach [22, 25], we feel that the framework presented in this paper, in particular the estimates proved in Theorem 4.1, are well suited for understanding this problem. We are currently investigating this possibility, and will present our results in future papers (see [2–5]).
-
(ii)
Whilst Haar wavelets have formed been the principal example in this paper, there is no need to restrict to this case. Indeed, Theorem 5.1 provides a first insight into using more sophisticated wavelet bases for reconstruction. Haar wavelets are extremely simple to work with, however the use of other wavelets presents a number of issues. In particular, it is first necessary to devise a means to compute the entries of the matrix U in a more general setting.
In addition, within the case of the Haar wavelet, there remains at least one open problem. The computations in Sect. 5.1 suggest that n↦Φ(U,n,θ) is bounded by a linear function in this case, meaning that Theorem 5.1 is overly pessimistic. This must be proven. Moreover, it remains to be seen whether a similar phenomenon holds for other wavelet bases.
-
(iii)
The theory in this paper has concentrated on linear reconstruction techniques with full sampling. A natural question is whether one can apply non-linear techniques from compressed sensing to allow for subsampling. Note that, due to the infinite dimensionality of the problems considered here, the standard finite-dimensional techniques are not sufficient (see [1, 6]).
References
Adcock, B., Hansen, A.C.: Generalized sampling and infinite dimensional compressed sensing. Technical report NA2011/02, DAMTP, University of Cambridge (submitted)
Adcock, B., Hansen, A.C.: Generalized sampling and the stable and accurate reconstruction of piecewise analytic functions from their Fourier coefficients. Technical report NA2011/12, DAMTP, University of Cambridge (submitted)
Adcock, B., Hansen, A.C.: Sharp bounds, optimality and a geometric interpretation for generalised sampling in Hilbert spaces. Technical report NA2011/10, DAMTP, University of Cambridge (submitted)
Adcock, B., Hansen, A.C.: Stable reconstructions in Hilbert spaces and the resolution of the Gibbs phenomenon. Appl. Comput. Harmon. Anal. (to appear)
Adcock, B., Hansen, A.C., Herrholz, E., Teschke, G.: Generalized sampling: extension to frames and ill-posed problems. Technical report NA2011/17, DAMTP, University of Cambridge (submitted)
Adcock, B., Hansen, A.C., Herrholz, E., Teschke, G.: Generalized sampling, infinite-dimensional compressed sensing, and semi-random sampling for asymptotically incoherent dictionaries. Technical report NA2011/13, DAMTP, University of Cambridge (submitted)
Aldroubi, A.: Oblique projections in atomic spaces. Proc. Am. Math. Soc. 124(7), 2051–2060 (1996)
Aldroubi, A., Feichtinger, H.: Exact iterative reconstruction algorithm for multivariate irregularly sampled functions in spline-like spaces: the L p-theory. Proc. Am. Math. Soc. 126(9), 2677–2686 (1998)
Böttcher, A.: Infinite matrices and projection methods. In: Lectures on Operator Theory and Its Applications, Waterloo, ON, 1994. Fields Inst. Monogr., vol. 3, pp. 1–72. Amer. Math. Soc., Providence (1996)
Candès, E.J., Donoho, D.L.: Recovering edges in ill-posed inverse problems: optimality of curvelet frames. Ann. Stat. 30(3), 784–842 (2002)
Candès, E.J., Donoho, D.L.: New tight frames of curvelets and optimal representations of objects with piecewise C 2 singularities. Commun. Pure Appl. Math. 57(2), 219–266 (2004)
Eldar, Y.: Sampling with arbitrary sampling and reconstruction spaces and oblique dual frame vectors. J. Fourier Anal. Appl. 9(1), 77–96 (2003)
Eldar, Y.: Sampling without input constraints: consistent reconstruction in arbitrary spaces. In: Zayed, A.I., Benedetto, J.J. (eds.) Sampling, Wavelets and Tomography, pp. 33–60. Birkhäuser, Boston (2004)
Eldar, Y., Werther, T.: General framework for consistent sampling in Hilbert spaces. Int. J. Wavelets Multiresolut. Inf. Process. 3(3), 347 (2005)
Feichtinger, H., Pesenson, I.: Recovery of band-limited functions on manifolds by an iterative algorithm. In: Wavelets, Frames and Operator Theory. Contemp. Math., vol. 345, pp. 137–152. Amer. Math. Soc., Providence (2004)
Feichtinger, H.G., Pandey, S.S.: Recovery of band-limited functions on locally compact abelian groups from irregular samples. Czechoslov. Math. J. 53(128), 249–264 (2003)
Gröchenig, K., Rzeszotnik, Z., Strohmer, T.: Convergence analysis of the finite section method and Banach algebras of matrices. Integral Equ. Oper. Theory 67(2), 183–202 (2010)
Hagen, R., Roch, S., Silbermann, B.: C ∗-Algebras and Numerical Analysis. Monographs and Textbooks in Pure and Applied Mathematics, vol. 236. Dekker, New York (2001)
Hansen, A.C.: On the approximation of spectra of linear operators on Hilbert spaces. J. Funct. Anal. 254(8), 2092–2126 (2008)
Hansen, A.C.: On the solvability complexity index, the n-pseudospectrum and approximations of spectra of operators. J. Am. Math. Soc. 24(1), 81–124 (2011)
Heinemeyer, E., Lindner, M., Potthast, R.: Convergence and numerics of a multisection method for scattering by three-dimensional rough surfaces. SIAM J. Numer. Anal. 46(4), 1780–1798 (2008)
Hrycak, T., Gröchenig, K.: Pseudospectral Fourier reconstruction with the modified inverse polynomial reconstruction method. J. Comput. Phys. 229(3), 933–946 (2010)
Jerri, A.: The Gibbs Phenomenon in Fourier Analysis, Splines, and Wavelet Approximations. Springer, Berlin (1998)
Jerri, A.J.: The Shannon sampling theorem: its various extensions and applications: A tutorial review. Proc. IEEE 65, 1565–1596 (1977)
Jung, J.-H., Shizgal, B.D.: Generalization of the inverse polynomial reconstruction method in the resolution of the Gibbs phenomenon. J. Comput. Appl. Math. 172(1), 131–151 (2004)
Kammler, D.W.: A First Course in Fourier Analysis, 2nd edn. Cambridge University Press, Cambridge (2007)
Lindner, M.: Infinite Matrices and Their Finite Sections. Frontiers in Mathematics. Birkhäuser, Basel (2006). An introduction to the limit operator method
Mallat, S.: A Wavelet Tour of Signal Processing. Academic Press Inc., San Diego (1998)
Nyquist, H.: Certain topics in telegraph transmission theory. Trans. AIEE 47, 617–644 (1928)
Shannon, C.E.: A mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423, 623–656 (1948)
Tadmor, E.: Filters, mollifiers and the computation of the Gibbs’ phenomenon. Acta Numer. 16, 305–378 (2007)
Unser, M.: Sampling—50 years after Shannon. Proc. IEEE 88(4), 569–587 (2000)
Unser, M., Aldroubi, A.: A general sampling theory for nonideal acquisition devices. IEEE Trans. Signal Process. 42(11), 2915–2925 (1994)
Whittaker, E.T.: On the functions which are represented by the expansions of the interpolation theory. Proc. R. Soc. Edinb. 35, 181–194 (1915)
Acknowledgements
The authors would like to thank Emmanuel Candès and Hans G. Feichtinger for valuable discussions and input.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Thomas Strohmer.
Rights and permissions
About this article
Cite this article
Adcock, B., Hansen, A.C. A Generalized Sampling Theorem for Stable Reconstructions in Arbitrary Bases. J Fourier Anal Appl 18, 685–716 (2012). https://doi.org/10.1007/s00041-012-9221-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00041-012-9221-x