
Abstract
Changes in overall observed precipitation have been recognized in many parts of the world in recent decades, leading to the argument on climate change and its impact on extreme precipitation. However, the concept of natural variations and the complex physical mechanisms hidden in the observed data sets must also be taken into consideration. This study aims to examine the matter further with reference to inter-decadal variability in extreme precipitation quantiles appropriate for risk analysis. Temporal changes in extreme precipitation are assessed using a parametric approach incorporating a regional method in region-of-influence form. The index-flood method with the application of generalized extreme value distribution is used to estimate the decadal extreme precipitation. The study also performs a significance test to determine whether the decadal extremes are significant. A case study is performed on the Yangtze River Basin, where annual maximum 1-day precipitation data for 180 stations were analyzed over a 50-year period from 1961 to 2010. Extreme quantiles estimated from the 1990s data emerged as the significant values on several occasions. The immediate drop in the quantile values in the following decade, however, suggested that it is not practical to assign more weight to recent data for the quantile estimation process. The temporal patterns identified are in line with the previous studies conducted in the region and thus make it an alternative way to perform decadal analysis with an advantage that the scheme can be transferred to ungauged conditions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The assessment of decadal variability in extreme precipitation has an important role in climate change research and subsequently in water resources management. The natural variability within the climate system as well as future changes can be evaluated with such assessment (IPCC 2001). In addition, the trends and oscillations in past extremes can indicate whether any additional assumptions are needed when estimating return period values of extreme precipitation for engineering purposes.
Over the past few decades, a large number of studies appear to find precipitation variability in various parts of the world. Initial attention was given to changes in mean precipitation (Turkes 1996; Tsonis 1996; Gong and Wang 2000; Nichols et al. 2002). However, lately, a considerable number of studies have been carried out on precipitation extremes (Wang and Zhou 2005; Zhai et al. 2005; Feng et al. 2007; Ntegeka and Willems 2008; Zhang et al. 2008; Su et al. 2008; Chen et al. 2012; Das et al. 2013; Bengtsson and Rana 2014; Tabari et al. 2014; Bülow et al. 2015; Tabari and Willems 2016), as extremes in the form of heavy precipitation are responsible for destructive hydrometeorological phenomena. Two perspectives have emerged from the analysis with respect to extreme precipitation. Some studies found significant changes in some regions, while a number of studies in other regions found little variation that proved to be significant. For example, Alexander et al. (2006) analyzed 600 precipitation stations worldwide for the period between 1901 and 2003. Extreme precipitation changes, in the form of maximum 1-day precipitation, showed a widespread and in some cases significant increase. The analysis revealed that 28% of the stations had exhibited significant increases, and were located mainly in North America, Central Europe, Russia and Southern Australia. About 50% of the stations showed nonsignificant changes, mainly in Northern and Southern Europe, and Northeast Australia. In recent decades, a number of regions have experienced a significant rise in extreme precipitation, including regions in Denmark (Bülow et al. 2015), Switzerland (Scherrer et al. 2016), northwestern and southeastern Iran (Tabari et al. 2014), the northeastern United States (Huang et al. 2017) and Southern Brazil (Pedron et al. 2017). On the other hand, studies by Soltani et al. (2016) in Iran and Jung et al. (2017) in South Korea found no significant changes in extreme precipitation when they analyzed trends in annual maximum precipitation.
In the case of China, several studies (e.g. Wang and Zhou 2005; Zhai et al. 2005; Feng et al. 2007; Zhang et al. 2008) have identified a significant increase in extreme precipitation in East China, in particular in the middle-lower reaches of the Yangtze River Basin. However, Guo et al. (2013), who analyzed the regional characteristics of several extreme precipitation indices in the Yangtze River Basin for the period 1961–2010 using the non-parametric Mann–Kendall (M–K) trend test, argued that there was no general significant increasing or decreasing trend based on their analysis of extreme precipitation indices.
The above illustrates the need to acknowledge the concept of natural variations and the complex physical mechanisms hidden in the observed data sets. Several issues have been noted that must be addressed when evaluating the soundness of fundamental assumptions for detecting meaningful trends in hydrometeorological analysis. Serial correlations (Tabari et al. 2014) and size of records (Ntegeka and Willems 2008; Willems 2013; Bengtsson and Rana 2014) were identified as components that can affect the results. A regional response was also reported on many occasions (Wang and Zhou 2005; Zhai et al. 2005; Alexander et al. 2006; Zhang et al. 2007; Guo et al. 2014), which highlights the importance of conducting such studies within a regional framework.
The most common way to evaluate temporal variability is to apply statistical tools on time series data. The M–K test (e.g. Alexander et al. 2006; Gocic and Trajkovic 2013; Jiang et al. 2007; Zhang et al. 2008) and Spearman's rho (e.g. Yilmaz et al. 2014) are widely employed methods in hydrometeorological studies. The presence of correlation between successive observations that affects the outcomes is a common problem with such methods (Tabari et al. 2014; Serinaldi and Kilsby 2016). Another approach is the quantile perturbation method introduced by Ntegeka and Willems (2008). The method is designed to evaluate the temporal variability associated with changes in the extreme quantiles. The technique uses peak-over-threshold data in order to accumulate a longer peak series in a decade. Although the method has shown promising results, the uncertainty in estimates can be large in some cases, in particular for decadal analysis.
The present study uses a parametric approach in a novel way to assess the temporal variability in precipitation extremes. A key problem in conducting such analysis in a parametric framework is that a limited number of data sets are available in a decade, which is often inadequate for successful fitting with the chosen statistical distribution function, producing a considerable amount of uncertainty. This study opts for a regional approach in which a large number of gauged stations can be grouped for analysis, and thus uncertainty can be minimized in a decadal estimate. The L-moment-based regional approach is used, as it is found to be adequate for the handling of correlations and existence of outliers (Hosking and Wallis 1997). Using this method, the present study examines the temporal behavior of decadal quantiles and whether these quantiles are statistically significant in comparison with the natural temporal variability.
The Yangtze River Basin, a key economic center of China, is used as a case study in this research. A range of studies have been conducted in this region to examine trends and behavior in extreme precipitation (Wang and Zhou 2005; Zhai et al. 2005; Su et al. 2006, 2008; Feng et al. 2007; Jiang et al. 2007; Qian et al. 2007; Zhang et al. 2008; Liu et al. 2011; Chen et al. 2012; Fu et al. 2013). The general outcome reveals that the basin has a complex spatiotemporal extreme precipitation structure. Also, assessment of the changes in extreme precipitation is difficult because of the dynamic nature of the underlying mechanisms that control the overall precipitation patterns of the region. Thus, the decadal quantile pattern, which was not given much attention in earlier studies, will provide new insight into the temporal behavior of the Yangtze River Basin.
2 Study Area and Data
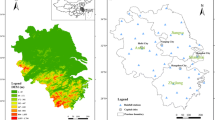
The Yangtze River Basin, which occupies one-fifth of the land area of China, is located primarily in the subtropical zone. The basin is divided longitudinally into three segments—upper, middle and lower regions— from west to east in order to better categorize both the climatic and the hydrological behavior of the region (Ju et al. 2014). The divided regions correspond reasonably well with the decrease in altitude. The regions, as displayed in Fig. 1 (station 57545 indicates roughly the beginning of the middle region, and station 58424 indicates the beginning of the lower region), have an average altitude of 2551, 627 and 113 m above mean sea level, respectively.

Location of gauged meteorological stations in the Yangtze River Basin. The highlighted stations were used for significance assessment. The different colors indicate the positioning of stations in different zones of the basin (green for upper, blue for middle and red for lower basin)
The climate of the basin is largely dominated by the southwest and southeast monsoons and their intersection with the northern cold air, which causes variations in precipitation and produces heavy precipitation in some cases. Flooding due to extreme precipitation is common in this region and causes severe damage to society and property. The average annual precipitation in the basin is approximately 1100 mm, but the spatial distribution of the precipitation is highly asymmetrical, varying from 300–500 mm in the western region to 1600–1900 mm in the eastern region (Guo et al. 2012). The length of the basin’s primary stream (Yangtze River), which originates from the Tanggula Mountains in the Tibetan Plateau and flows east into the East China Sea, is around 6300 km, and the total drainage area is about 1,800,000 km2 (Ju et al. 2014).
Daily precipitation data are available for 180 stations in the Yangtze River Basin (see Fig. 1). Data for five decades from 1961 to 2010 were obtained from the National Meteorological Information Center of the China Meteorological Administration. The annual maximum (AM) 1-day precipitation series were extracted from the data sets. It should also be noted that the years with missing data were omitted from the analysis where necessary. Not all the data sets have the full five decades of data. Table 1 reports the number of stations that are recorded for each decade. It was found that 144 stations have the full five decades of AM data.
3 Methodologies
This study aims to determine the temporal effect on the quantile estimates obtained by data divided into decades. The quantiles are estimated based on annual maximum (AM) data series which is standard in hydrological frequency analysis (Hosking and Wallis 1997; Institute of Hydrology 1999; Svensson and Jones 2010; Das 2018a). The AM series which is defined as \(P_{1} , \;P_{2} , \ldots , \;P_{n}\), where Pi is the maximum precipitation of a certain duration occurring in the ith year, is assumed to be a random sample from some underlying distribution. As limited data sets are available from which to estimate quantiles for a decade, a regional frequency analysis is considered. A region-of-influence (ROI)-based regional approach (Burn 1990) is employed to assess the temporal behavior with reference to decadal quantile values. The ROI method is attractive because it minimizes the uncertainty of the estimates compared with cases when an at-site method is used based on limited data sets (Institute of Hydrology 1999; Das 2017). The procedures related to the method are given in the following subsections (Sects. 3.1–3.3).
3.1 ROI Method of Forming Groups
The ROI approach is a site-specific approach where a homogeneous pooling group of gauged stations is delineated for that particular site. It is recognized as being superior to the traditional geographical approach (Institute of Hydrology 1999; Das 2017) in the sense that the traditional one selects fixed homogeneous regions in which each gauging station in a region has the same regional information except for a site-specific scaling factor (i.e. index precipitation). In that case, stations at the border line between regions may face some inconsistencies. The ROI approach, on the other hand, was designed primarily to avoid such inconsistencies at the boundaries of regions involved in the traditional approach.
The grouping of stations in the ROI is completed by a similarity distance measure which defines the closeness of the subject and pooled sites in the site descriptor space. The Euclidean distance in the site descriptor space is commonly used to estimate similarity between sites (Burn 1990; Institute of Hydrology 1999; Das and Cunnane 2012). The distance (dij) is measured from site j (pooled site) to site i (subject site) as follows:
where n is the number of descriptor variables, Xk,i, i is the value of the kth variable at the ith site and wk is the weight applied to descriptor k, reflecting its relative importance.
Geographical (e.g. location coordinates, elevation) and climatological descriptors (e.g. annual average precipitation) are generally used in the distance measure calculation (Institute of Hydrology 1999; Gaál and Kyselý 2009; Das 2017). Another important thing to consider regarding the ROI procedure is the size of the group. The 5T rule suggested by the Institute of Hydrology (1999) is a common practice, which is the total number of data in terms of station years to be included when estimating that the T-year return period value should be at least 5T.
3.2 Homogeneity Assessment
The delineated group, however, needs to pass a homogeneity test as the homogeneity criterion improves the accuracy of the estimates (Hosking and Wallis 1997; Viglione et al. 2007). The heterogeneity measure, H1 by Hosking and Wallis (1993), is generally used to test the homogeneity in such cases. The test is based on the L-coefficient of variation (t2) which is an L-moment statistic. A detailed description about the L-moments can be obtained from Hosking and Wallis (1997). The test evaluates the sample variability of t2 among the samples in the pooling group and compares it with the variation that would be expected in a homogeneous pooling group. The measure of the sample variability, V1, is defined as follows:
where \(t_{2}^{R}\) is the group average of t2; \(t_{2}^{i}\) and ni are the values of the L-coefficient of variation and the sample size for site i, respectively; and M is the number of sites in the pooling group.
The expected variation in the homogeneous group is calculated by carrying out a simulation based on kappa distribution. The heterogeneity measure, H1, is then evaluated as follows:
where \(\mu \upsilon_{1}\) and \(\sigma \upsilon_{1}\) are the expected mean and the standard deviation, respectively, of V1 for the homogeneous group.
According to Hosking and Wallis (1997), a pooling group is considered to be “acceptably homogeneous” if H1 < 1, “possibly heterogeneous” if 1 < H1 < 2, and “definitely heterogeneous” if H1 > 2. However, dealing with extreme precipitation data, Wallis et al. (2007) suggested a revised guideline: an H1 value less than 2.0 may be considered acceptably homogeneous, and an H1 value greater than 3.0 would be indicative of heterogeneity.
3.3 Quantile Estimation
Upon formation of a homogeneous group, the pooled AM precipitation series were used to perform frequency analysis based on the index-flood method (Dalrymple 1960). With this method, the extremes in terms of return periods, PT, are calculated by multiplying the growth curve, XT (dimensionless variate), with the index rainfall, PI, as follows:
In this study, the median (median value of the subject site’s AM series) is used as the index value (PI) which is recommended by the Institute of Hydrology (1999). The estimation of XT, which shows the relation between XT and the return period (T), requires a suitable probability distribution function to be identified. The L-moment ratio (LMR) diagram (Hosking and Wallis 1997) is often used as a diagnostic tool to identify an appropriate distribution in hydrometeorological studies. The AM data sets were investigated with the LMR diagram which is shown in Fig. 2. The diagram identified generalized extreme value (GEV) as the most suitable distribution for describing the AM precipitation data for the Yangtze River Basin. Hence, the GEV is used to complete the estimation procedure in this study.

L-moment ratio diagram for annual maximum (AM) 1-day precipitation series for 180 stations in the Yangtze River Basin. Theoretical lines for five 3-parameter distributions, namely generalized logistic (GLO), generalized extreme (GEV), Pearson type 3 (PE3), generalized normal (GNO) and generalized Pareto (GPA), and theoretical points for two 2-parameter distributions, normal (N) and Gumbel (G), are indicated in the diagram. The average value of the L-moment ratios falls on the theoretical line of the GEV distribution
The XT is derived based on the data from stations of an ROI pooling group. The estimation of growth factor (XT) at a particular return period using the GEV distribution has the following form (Das and Cunnane 2011):
The two parameters \(\beta\) and k are estimated using the method of L-moments (Hosking and Wallis 1997):
where \(t_{2}^{R}\) is the pooled/regional L-coefficient of variation (LCV), \(t_{3}^{R}\) the pooled L-skewness and \(\varGamma\) the complete gamma function.
The pooled estimate of LMRs based on the ROI method is derived as follows:
where t(i)R is the pooled LMR (either t2 or t3) for the target site, i; t(j) is the LMR for the ith most similar site and wij is a weighting coefficient. The weight is estimated based on dij values (Kay et al. 2007):
4 Analysis
4.1 Decadal Quantile Estimation
A step-by-step procedure based on the ROI regional method for estimating decadal quantile values is described below:
- 1.
Annual maximum (AM) precipitation of 1-day duration (measured in depth in mm) is extracted from a daily precipitation data series. The decadal series are then obtained from the full-length AM series.
- 2.
A suitable site descriptor is selected in the Euclidian distance measure to pool data sets from available stations. Geographical proximity (geographical coordinates) is used in this case. Similar types of descriptors have shown promising results in delineating homogeneous groups in several ROI-based extreme precipitation studies (Reed et al. 1999; Kyselý et al. 2011; Das 2018b). The use of such descriptors has several advantages in this study context. Firstly, it would not change over time, thus making it suitable for decadal analysis. Secondly, the procedure can be transferred to ungauged conditions, as location is the only requirement for pooling of data sets.
- 3.
A pooling/regional group of a particular decade for a subject station is selected from gauged stations that are available in that particular decade. The heterogeneity measure in terms of H1 is then used to assess homogeneity for that particular group. Although the delineation of a homogeneous group is recommended, a moderately delineated heterogeneous group (H1 < 4.0) has still proved to be advantageous with such regional approach (Das and Cunnane 2012).
- 4.
Upon successful formation of a group, the frequency analysis is performed for a specific decade for that subject site. With this technique, a sufficient number of AM data are available for a specific decade to achieve an accurate estimate. This study uses a quantile at a 50-year return period value for the temporal assessment. The 5T rule in this context will require accumulating about (5 × 50) 250 years of records in a group, which will necessitate the inclusion of at least 25 stations per group for decadal analysis. The estimation beyond T = 50 years will require a large number of stations, which may compromise the homogeneity of the group, according to Hosking and Wallis (1997). Thus, extreme values at a 50-year return period are assessed in this study.
- 5.
A suitable probability distribution, in this case, GEV, is employed to estimate growth factor (X50) at a 50-year return period using Eq. (5). Finally, the quantile estimation (P50) is completed using Eq. (4).
4.2 Significance Assessment
The assessment is conducted to examine whether the estimated decadal values are statistically significant compared with the natural variability exhibited at an individual station. In this study, confidence intervals are constructed to test the hypothesis of observed changes being solely caused by natural variability. Confidence intervals outline a region of natural variability in precipitation extremes. Thus, any value outside the confidence bounds is considered to be statistically significant, whereas the value within the bounds is statistically nonsignificant. A parametric Monte Carlo method is used to outline the confidence intervals. The Monte Carlo simulation is performed with the GEV distribution which is suitable for the region. With this approach, the confidence intervals are outlined for a full-length (long) historical series which is taken as the baseline series. The use of long historical series is assumed to provide a true representation of the population data in this experiment. After assessing the decadal values using the ROI regional approach, the confidence intervals are estimated based on baseline data and plotted on the same chart. Hence it is visually feasible to detect periods that demonstrate significant departures under the hypothesis of no trend.
5 Results
The primary goal of this study is to assess the temporal effects on quantiles estimated using data divided into decades. The method described in the previous sections is applied to identify anomalies in the decadal estimates. The study uses a dimensionless growth factor (see Eq. 4) to identify any general trends and oscillations in the estimates for the whole region. The decadal quantile, on the other hand, is used to detect whether these estimated values are significant for a particular station. In all cases, the effect on the growth factor at a 50-year return period (X50) and associated quantile (P50) have been assessed.
The ROI-based estimation is carried out by forming groups for each subject station using the geographical proximity criterion. The heterogeneity measure is then evaluated for each group. An illustration of the ROI procedure in forming groups is described in Fig. 3 for station 57545. Group members in each decade and their heterogeneity measures are shown there. According to this ROI scheme (i.e. grouping based on geographical proximity), every decadal group should have the same group members. However, because not all the stations have the full decadal series (see Table 1), a slight variation is found in each case, which is ultimately reflected in the heterogeneity measure. Because of this, it can be said that this approach allows for good use of the available decadal data a station possesses.

An illustration of ROI groups formed for each decade for station 57545. The subject station 57545 is indicated by a red circle, while pooling group members are indicated by a green circle. The heterogeneity measure, H1, is also reported for each group
Growth factors are estimated for each decade for 144 stations. Figure 4 presents X50 values for each decade as well as the H1 values in a box-plot arrangement. Each box plot contains 144 values. The average value displays an oscillation pattern, with decade 1970 experiencing the lowest average value and decade 1990 experiencing the largest average value. The upward trend in the average value of X50 in decade 1990 is the result of the occurrence of extreme precipitation caused by climate factors, such as the southwest and southeast monsoons during that period in the Yangtze River Basin. This explains to some degree the intensification of flooding in the 1990s as noted by several studies (Jiang et al. 2007; Su et al. 2008).

Box plots of decadal variation in the growth factor at a 50-year return period (X50) and the associated heterogeneity measure (H1). The average value is indicated by a blue circle in both cases. Each box plot consists of values obtained from each individual station’s pooling group
Similar temporal behavior through the 1990s was observed in several studies (Gong and Wang 2000; Zhang et al. 2008), in which a negative precipitation (mean as well as extreme) trend was identified for the 1960s–1970s, and subsequently a positive trend for the 1980s–1990s. The trend, however, as this study found, decreased in the following decade (2001–2010). The illustration of the oscillation pattern in extremes over the whole region demonstrates what may occur in the coming decades. Given the nature of the extreme variation, it is suggested not to assign more weight to recent data for estimating return period values of extreme precipitation. The overall results highlight that the precipitation extremes have experienced strong decadal variability over the past 50 years.
The box plots of H1 values show that, in the majority of cases, the H1 values are less than 2, signifying that the pooling groups formed based on geographical proximity are homogeneous in nature, and thus offer reliable estimates. However, it is observed that the average values of H1 are slightly higher in decades 1990 and 2000 than the decades that precede 1990, suggesting that the variation in AM data in those decades (1990 and 2000) is slightly higher. This also implies that the extremes in those decades occur more frequently.
Whether these extremes in the case of an individual station are statistically significant can be tested using the procedure described in Sect. 4.2, which would support evaluating the possibility of climate change impacts during the most recent decades. A number of stations shown in bold in Fig. 1 were chosen to demonstrate the procedure. They are spatially positioned in various locations of the basin from west to east. This would help to determine whether any spatial variability exists in the extremes. The stations belong to the upper (ST56167, ST56571, ST57614, ST57313), middle (ST57545, ST57766, ST57574, ST57598, ST58506) and lower (ST58424, ST58345, ST58436) basin. The categorization of the Yangtze River Basin into upper, middle and lower can be found in Ju et al. (2014), which represents the varying climatic as well as hydrological behavior of the region. The heterogeneity measures of the groups formed for these stations are presented in Table 2, which shows their homogeneous nature according to the guidelines presented in Sect. 3.2. Except for station 56167’s group, which shows some degree of heterogeneity, the stations’ groups are quite homogeneous. The reason the groups formed for station 56167 became heterogeneous is due to the fact that the station is located in the far upper region, a distinct climatic region, where fewer gauged stations are available. This allows station 56167 to include a number of stations from other climatic regions to fulfill the 25-stations-per-group framework, which may introduce heterogeneity into the groups for the decades considered. For that reason, a modification is made to the heterogeneous groups formed for station 56167. The modification of a heterogeneous group to become a homogeneous group is a common practice in regional frequency analysis (Burn 1990; Hosking and Wallis 1997; Institute of Hydrology 1999). As it was observed that the homogeneity criterion was not met for decades 1980, 1990 and 2000, an adjustment was carried out in such cases. The station which just qualified as a member of the pooling group (geographically the farthest from the subject station 56167 in this ROI scheme) was excluded in each case, which sees the heterogeneity, H1 to fall below 3.0, thus satisfying the homogeneity. The H1 values based on the 24-member group in those cases are reported in Table 2.
The estimated decadal quantile as well as the growth factor and index precipitation (median value of AM series) are shown in Fig. 5. The greatest estimates were obtained in the middle part of the basin and in decade 1990. A similar pattern was observed for the growth factor. However, no noticeable pattern was found for the median value, indicating that the different statistical measures can influence the outcome of the temporal variability.

Decadal values of growth factor (X50), index precipitation (median value) and quantile estimate (P50) for selected stations shown in Fig. 1. Each decade is represented by a different color indicated in the plot
To test the significance, the decadal quantiles along with the confidence intervals are displayed in Fig. 6 for the considered stations. The confidence intervals represent the 95% bounds of natural variation under the null hypothesis of no trends. The hypothesis is rejected if the values fall outside these intervals. Based on this assessment, decades of statistically significant value can be identified. The variations in quantiles for the 1960s are within the confidence limits for the represented stations, indicating that nonsignificant anomalies in precipitation extremes are common in this decade for the Yangtze River Basin. Similarly, nonsignificant quantiles are found for the 1970s and 1980s. The decadal values for the 1990s provide the largest values for the middle region. In many cases, they are found to be significant, which explains the frequent occurrence of floods in the 1990s. These floods were documented in several studies (Gong and Ho 2002; Su et al. 2008), where it was reported that enhanced precipitation in the 1990s led to the occurrence of frequent flooding along the Yangtze River, such as floods that occurred in 1991, 1996, 1998 and 1999, causing huge losses to people and society. The estimated decadal values are statistically significant for ST57614, ST57545, ST57766 and ST57574, in which the extreme precipitation quantiles are more than 25% higher than those based on the full time series. The decadal quantile value for the decade 2000 was found to be the largest for ST58345 in the lower basin, but it did not prove to be significant. The extreme quantiles in the decade 2000 were not statistically significant in the remaining subbasins. Overall, there is evidence of significant decadal quantiles in precipitation extremes in the Yangtze River Basin which are generally observed in the 1990s and in the middle region, while in the far upper basin there are no such significant anomalies found for any decade. This is in line with the long-term trends reported for extreme precipitation observations in this region (Zhang et al. 2008; Liu et al. 2011; Fu et al. 2013).

Significance assessment for selected stations. 50-year decadal quantile (P50) values (red dots) together with baseline (green line) and associated 95% confidence intervals (blue and purple line) are displayed in the same plot. The baseline is constructed based on a full AM series for the particular station in question
6 Conclusion and Discussion
This study demonstrates how a regional frequency approach in ROI form, coupled with the index-flood method, can be used to examine the decadal variability in precipitation extremes. The methodology is applied to the Yangtze River Basin, where annual maximum 1-day precipitation data from 180 stations over a 50-year period from 1961 to 2010 were analyzed to study the decadal patterns.
The overall pattern was investigated by the growth factor estimated using the ROI approach. The average value showed a strong oscillation pattern, which was largest in decade 1990. The significance test was conducted on a selected number of stations in different areas of the basin to investigate whether the changes in the decadal quantile were significant. The quantile values in decade 1990 emerged as the largest in the middle region of the basin, with some values proving significant. Quantiles from other decades emerged as the largest in the upper and lower regions of the basin (e.g. ST56167, ST58345), but they were not found to be significant. The significant quantiles in the 1990s over the middle region were more than 25% higher than those based on the full time series. The overall results indicate that precipitation extremes have experienced strong decadal variability over the past 50 years. A possible reason for this variability, as pointed out by Liu et al. (2011) among others, may relate to changes in the monsoon circulation due to sea surface temperature (SST) warming over the Indian and western North Pacific oceans, and climate variation over the tropical Pacific region. However, it is also acknowledged that there is still a long way to go to achieve a comprehensive understanding of the laws of the inter-decadal changes. A potential future study could compare monsoon intensity over the decades. This may elucidate the main process (or mechanism) that contributes to extreme precipitation variation in this particular region.
Thus, although the results indicate that significant values were obtained in several cases when estimating extreme quantiles from data for the 1990s, the immediate decline in the quantile values in the following decade suggests that it is not practical to assign more weight to recent data sets for frequency analysis. It is therefore recommended not to exclude data for any decade from the quantile estimation process.
This study is based on precipitation measured at gauged locations. Recent studies show that measurement errors, specifically snow measurements (Rasmussen et al. 2012; Gultepe et al. 2017) and mountain observations (Gultepe et al. 2014), can influence the overall results in the assessment of extreme precipitation variability. Hence it is suggested that future studies should consider measurement errors in such analyses.
The advantage of the method is that the scheme presented in this study requires only location information to form pooling groups; thus, the method can be transferred to an ungauged site. Therefore, conducting similar studies at ungauged locations, particularly in remote areas, will lead to a better understanding of the trends and patterns of the quantiles in extreme precipitation. It is recommended that further studies be conducted on the reliability of the procedure in other regions and employing other historical series of hydrometeorological variables.
References
Alexander, L. V., Zhang, X., Peterson, T. C., et al. (2006). Global observed changes in daily climate extremes of temperature and precipitation. Journal of Geophysical Research: Atmospheres,111, 1–22. https://doi.org/10.1029/2005JD006290.
Bengtsson, L., & Rana, A. (2014). Long-term change of daily and multi-daily precipitation in southern Sweden. Hydrological Processes,28, 2897–2911. https://doi.org/10.1002/hyp.9774.
Bülow, I., Henrik, G., & Dan, M. (2015). Long term variations of extreme rainfall in Denmark and southern Sweden. Climate Dynamics. https://doi.org/10.1007/s00382-014-2276-4.
Burn, D. H. (1990). Evaluation of regional flood frequency analysis with a region of influence approach. Water Resources Research,26, 2257–2265.
Chen, H., Sun, J., & Fan, K. (2012). Decadal features of heavy rainfall events in eastern China. Acta Meteorologica Sinica,26, 289–303. https://doi.org/10.1007/s13351-012-0303-0.
Dalrymple, T. (1960). Flood frequency methods. U. S. Geological Survey,1543, 11–51.
Das, S. (2017). Performance of region-of-influence approach of frequency analysis of extreme rainfall in monsoon climate conditions. International Journal of Climatology,37, 612–623. https://doi.org/10.1002/joc.5025.
Das, S. (2018a). Goodness-of-fit tests for generalized normal distribution for use in hydrological frequency analysis. Pure and Applied Geophysics. https://doi.org/10.1007/s00024-018-1877-y.
Das, S. (2018b). Extreme rainfall estimation at ungauged sites: Comparison between region-of-influence approach of regional analysis and spatial interpolation technique. International Journal of Climatology. https://doi.org/10.1002/JOC.5819.
Das, S., & Cunnane, C. (2011). Examination of homogeneity of selected Irish pooling groups. Hydrology and Earth System Sciences,15, 819–830. https://doi.org/10.5194/hess-15-819-2011.
Das, S., & Cunnane, C. (2012). Performance of flood frequency pooling analysis in a low CV context. Hydrological Sciences Journal,57, 433–444. https://doi.org/10.1080/02626667.2012.666635.
Das, S., Millington, N., & Simonovic, S. P. (2013). Distribution choice for the assessment of design rainfall for the city of London (Ontario, Canada) under climate change. Canadian Journal of Civil Engineering,40, 121–129. https://doi.org/10.1139/cjce-2011-0548.
Feng, S., Nadarajah, S., & Hu, Q. (2007). Modeling annual extreme precipitation in China using the generalized extreme value distribution. Journal of the Meteorological Society of Japan,85, 599–613. https://doi.org/10.2151/jmsj.85.599.
Fu, G., Yu, J., Yu, X., et al. (2013). Temporal variation of extreme rainfall events in China, 1961–2009. Journal of Hydrology,487, 48–59. https://doi.org/10.1016/j.jhydrol.2013.02.021.
Gaál, L., & Kyselý, J. (2009). Comparison of region-of-influence methods for estimating high quantiles of precipitation in a dense dataset in the Czech Republic. Hydrology and Earth System Sciences,13, 2203–2219. https://doi.org/10.5194/hess-13-2203-2009.
Gocic, M., & Trajkovic, S. (2013). Analysis of changes in meteorological variables using Mann–Kendall and Sen’s slope estimator statistical tests in Serbia. Global and Planetary Change,100, 172–182. https://doi.org/10.1016/j.gloplacha.2012.10.014.
Gong, D.-Y., & Ho, C.-H. (2002). Shift in the summer rainfall over the Yangtze River valley in the late 1970s. Geophysical Research Letters,29, 78-1–78-4. https://doi.org/10.1029/2001gl014523.
Gong, D. Y., & Wang, S. W. (2000). Severe summer rainfall in China associated with the enhanced global warming. Climate Research,16, 51–59. https://doi.org/10.3354/cr016051.
Gultepe, I., Heymsfield, A. J., Gallagher, M., et al. (2017). Ice fog: The current state of knowledge and future challenges. Meteorological Monographs,58, 41–424. https://doi.org/10.1175/amsmonographs-d-17-0002.1.
Gultepe, I., Isaac, G. A., Joe, P., et al. (2014). Roundhouse (RND) mountain top research site: Measurements and uncertainties for winter alpine weather conditions. Pure and Applied Geophysics,171, 59–85. https://doi.org/10.1007/s00024-012-0582-5.
Guo, J., Chen, H., Xu, C. Y., et al. (2012). Prediction of variability of precipitation in the Yangtze River Basin under the climate change conditions based on automated statistical downscaling. Stochastic Environmental Research and Risk Assessment,26, 157–176. https://doi.org/10.1007/s00477-011-0464-x.
Guo, J., Guo, S., Li, Y., et al. (2013). Spatial and temporal variation of extreme precipitation indices in the Yangtze River basin, China. Stochastic Environmental Research and Risk Assessment,27, 459–475. https://doi.org/10.1007/s00477-012-0643-4.
Guo, P., Zhang, X., Zhang, S., et al. (2014). Decadal variability of extreme precipitation days over northwest China from 1963 to 2012. Journal of Meteorological Research,28, 1099–1113. https://doi.org/10.1007/s13351-014-4022-6.1.
Hosking, J. R. M., & Wallis, J. R. (1993). Some statistics useful in regional frequency analysis. Water Resources Research,29, 271–281.
Hosking, J. R. M., & Wallis, J. R. (1997). Regional frequency analysis: An approach based on L-moments. Cambridge: Cambridge University Press.
Huang, H., Winter, J. M., Osterberg, E. C., et al. (2017). Total and extreme precipitation changes over the Northeastern United States. Journal of Hydrometeorology,18, 1783–1798. https://doi.org/10.1175/JHM-D-16-0195.1.
Institute of Hydrology. (1999). Flood Estimation Handbook (Vol. 1-5). Wallingford: Institute of Hydrology.
IPCC. (2001). Climate Change 2001: The Scientific Basis. Contribution of Working Group I to the Third Assessment Report of the Intergovernmental Panel on Climate Change. New York: Cambridge University Press.
Jiang, T., Su, B., & Hartmann, H. (2007). Temporal and spatial trends of precipitation and river flow in the Yangtze River Basin, 1961–2000. Geomorphology,85, 143–154. https://doi.org/10.1016/j.geomorph.2006.03.015.
Ju, Q., Yu, Z., Hao, Z., et al. (2014). Response of hydrologic processes to future climate changes in the Yangtze River Basin. Journal of Hydrologic Engineering. https://doi.org/10.1061/(asce)he.1943-5584.0000770.
Jung, Y., Shin, J. Y., Ahn, H., & Heo, J. H. (2017). The spatial and temporal structure of extreme rainfall trends in South Korea. Water (Switzerland). https://doi.org/10.3390/w9100809.
Kay, A. L., Jones, D. A., Crooks, S. M., et al. (2007). An investigation of site-similarity approaches to generalisation of a rainfall–runoff model. Hydrology and Earth System Sciences,11, 500–515. https://doi.org/10.5194/hess-11-500-2007.
Kyselý, J., Gaál, L., & Picek, J. (2011). Comparison of regional and at-site approaches to modelling probabilities of heavy precipitation. International Journal of Climatology,31, 1457–1472. https://doi.org/10.1002/joc.2182.
Liu, Y., Huang, G., & Huang, R. (2011). Inter-decadal variability of summer rainfall in Eastern China detected by the Lepage test. Hydrology and Earth System Sciences. https://doi.org/10.1007/s00704-011-0442-8.
Nichols, M. H., Renard, K. G., & Osborn, H. B. (2002). Precipitation changes from 1956 to 1996 on the Walnut Gulch Experimental Watershed. Journal of the American Water Resources Association,38, 161–172.
Ntegeka, V., & Willems, P. (2008). Trends and multidecadal oscillations in rainfall extremes, based on a more than 100-year time series of 10 min rainfall intensities at Uccle, Belgium. Water Resources Research. https://doi.org/10.1029/2007wr006471.
Pedron, I. T., Silva Dias, M. A. F., de Paula, Dias S., et al. (2017). Trends and variability in extremes of precipitation in Curitiba—Southern Brazil. International Journal of Climatology,37, 1250–1264. https://doi.org/10.1002/joc.4773.
Qian, W., Fu, J., & Yan, Z. (2007). Decrease of light rain events in summer associated with a warming environment in China during 1961–2005. Geophysical Research Letters,34, 1–5. https://doi.org/10.1029/2007GL029631.
Rasmussen, R., Baker, B., Kochendorfer, J., et al. (2012). How well are we measuring snow: The NOAA/FAA/NCAR winter precipitation test bed. Bulletin of the American Meteorological Society,93, 811–829. https://doi.org/10.1175/BAMS-D-11-00052.1.
Reed, D. W., Faulkner, D. S., & Stewart, E. J. (1999). The FORGEX method of rainfall growth estimation II: Description. Hydrology and Earth System Sciences,3, 197–203. https://doi.org/10.5194/hess-3-205-1999.
Scherrer, S. C., Fischer, E. M., Posselt, R., Liniger, M. A., Croci-Maspoli, M., & Knutti, R. (2016). Emerging trends in heavy precipitation and hot temperature extremes in Switzerland. Journal of Geophysical Research: Atmospheres, 121(6), 2626–2637. https://doi.org/10.1002/2015JD024634.
Serinaldi, F., & Kilsby, C. G. (2016). The importance of prewhitening in change point analysis under persistence. Stochastic Environmental Research and Risk Assessment,30, 763–777. https://doi.org/10.1007/s00477-015-1041-5.
Soltani, M., Laux, P., Kunstmann, H., et al. (2016). Assessment of climate variations in temperature and precipitation extreme events over Iran. Theoretical and Applied Climatology,126, 775–795. https://doi.org/10.1007/s00704-015-1609-5.
Su, B., Gemmer, M., & Jiang, T. (2008). Spatial and temporal variation of extreme precipitation over the Yangtze River Basin. Quaternary International,186, 22–31. https://doi.org/10.1016/j.quaint.2007.09.001.
Su, B. D., Jiang, T., & Jin, W. B. (2006). Recent trends in observed temperature and precipitation extremes in the Yangtze River basin, China. Theoretical and Applied Climatology,83, 139–151. https://doi.org/10.1007/s00704-005-0139-y.
Svensson, C., & Jones, D. A. (2010). Review of rainfall frequency estimation methods. Journal of Flood Risk Management. https://doi.org/10.1111/j.1753-318x.2010.01079.x/abstract.
Tabari, H., AghaKouchak, A., & Willems, P. (2014). A perturbation approach for assessing trends in precipitation extremes across Iran. Journal of Hydrology,519, 1420–1427. https://doi.org/10.1016/j.jhydrol.2014.09.019.
Tabari, H., & Willems, P. (2016). Daily precipitation extremes in Iran: Decadal anomalies. Journal of the American Water Resources Association. https://doi.org/10.1111/1752-1688.12403.
Tsonis, A. A. (1996). Widespread increases in low-frequency variability of precipitation over the past century. Nature,382, 700.
Turkes, M. (1996). Spatial and temporal analysis of annual rainfall variations I. Journal of Climatology,1076, 1057–1076.
Viglione, A., Laio, F., & Claps, P. (2007). A comparison of homogeneity tests for regional frequency analysis. Water Resources Research. https://doi.org/10.1029/2006WR005095.
Wallis, J. R., Schaefer, M. G., Barker, B. L., & Taylor, G. H. (2007). Regional precipitation-frequency analysis and spatial mapping for 24-hour and 2-hour durations for Washington State. Hydrology and Earth System Sciences,11, 415–442. https://doi.org/10.5194/hess-11-415-2007.
Wang, Y., & Zhou, L. (2005). Observed trends in extreme precipitation events in China during 1961–2001 and the associated changes in large-scale circulation. Geophysical Research Letters,32, 1–4. https://doi.org/10.1029/2005GL022574.
Willems, P. (2013). Adjustment of extreme rainfall statistics accounting for multidecadal climate oscillations. Journal of Hydrology,490, 126–133. https://doi.org/10.1016/j.jhydrol.2013.03.034.
Yilmaz, A. G., Hossain, I., & Perera, B. J. C. (2014). Effect of climate change and variability on extreme rainfall intensity–frequency–duration relationships: A case study of Melbourne. Hydrology and Earth System Sciences,1, 1. https://doi.org/10.5194/hess-18-4065-2014.
Zhai, P., Zhang, X., Wan, H., & Pan, X. (2005). Trends in total precipitation and frequency of daily precipitation extremes over China. Journal of Climate,18, 1096–1108. https://doi.org/10.1175/JCLI-3318.1.
Zhang, Q., Xu, C. Y., Zhang, Z., et al. (2008). Spatial and temporal variability of precipitation maxima during 1960–2005 in the Yangtze River basin and possible association with large-scale circulation. Journal of Hydrology,353, 215–227. https://doi.org/10.1016/j.jhydrol.2007.11.023.
Zhang, X., Zwiers, F. W., Hegerl, G. C., et al. (2007). Detection of human influence on twentieth-century precipitation trends. Nature,448, 461–465. https://doi.org/10.1038/nature06025.
Acknowledgements
This study is supported by Nanjing University of Information Science and Technology in the form of a grant (grant no. 2243141501015) to the first author. Comments and suggestions from two anonymous reviewers are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Das, S., Zhu, D. & Cheng, CH. A Regional Approach of Decadal Assessment of Extreme Precipitation Estimates: A Case Study in the Yangtze River Basin, China. Pure Appl. Geophys. 177, 1079–1093 (2020). https://doi.org/10.1007/s00024-019-02354-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-019-02354-6