
Abstract
The regionalization methods, which “trade space for time” by pooling information from different locations in the frequency analysis, are efficient tools to enhance the reliability of extreme quantile estimates. This paper aims at improving the understanding of the regional frequency of extreme precipitation by using regionalization methods, and providing scientific background and practical assistance in formulating the regional development strategies for water resources management in one of the most developed and flood-prone regions in China, the Yangtze River Delta (YRD) region. To achieve the main goals, L-moment-based index-flood (LMIF) method, one of the most popular regionalization methods, is used in the regional frequency analysis of extreme precipitation with special attention paid to inter-site dependence and its influence on the accuracy of quantile estimates, which has not been considered by most of the studies using LMIF method. Extensive data screening of stationarity, serial dependence, and inter-site dependence was carried out first. The entire YRD region was then categorized into four homogeneous regions through cluster analysis and homogenous analysis. Based on goodness-of-fit statistic and L-moment ratio diagrams, generalized extreme-value (GEV) and generalized normal (GNO) distributions were identified as the best fitted distributions for most of the sub-regions, and estimated quantiles for each region were obtained. Monte Carlo simulation was used to evaluate the accuracy of the quantile estimates taking inter-site dependence into consideration. The results showed that the root-mean-square errors (RMSEs) were bigger and the 90 % error bounds were wider with inter-site dependence than those without inter-site dependence for both the regional growth curve and quantile curve. The spatial patterns of extreme precipitation with a return period of 100 years were finally obtained which indicated that there are two regions with highest precipitation extremes and a large region with low precipitation extremes. However, the regions with low precipitation extremes are the most developed and densely populated regions of the country, and floods will cause great loss of human life and property damage due to the high vulnerability. The study methods and procedure demonstrated in this paper will provide useful reference for frequency analysis of precipitation extremes in large regions, and the findings of the paper will be beneficial in flood control and management in the study area.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Changes in precipitation extremes are of great importance to the welfare of human beings as well as the entire ecosystem (Zhang et al. 2014; Li et al. 2014; Olsson and Foster 2014; Charles and Patrick 2015). One of the most significant consequences of climate change due to the increase in greenhouse gases would be an increase in the magnitude and frequency of extreme precipitation events (Rajeevan et al. 2008). On a global scale, Frich et al. (2002) found a significant increase in extreme precipitation amount, although the changes of spatial patterns were complex. Any positive or increasing trend in extreme rainfall events is a serious concern. Increases in heavy precipitation can increase river discharge and lead to more and worse floods and mudslides. The situation, particularly for those highly developed regions, will be worsened by rapid increases in population, unprecedented rise in living standards, and economic development (Xu and Singh 2004).
A number of studies on precipitation extremes have been undertaken using various statistical procedures, including regionalization techniques which can potentially reduce the uncertainties in quantile estimates that are inherent in the at-site approach. The index-flood method first suggested by Dalrymple (1960) of US Geological Survey has been one of the most widely utilized methods in regional flood frequency analysis. Hosking et al. (1985) and Lettenmaier and Potter (1985) indicated that the index-flood method can provide suitable, accurate, and robust quantile estimates. Hosking and Wallis (1993) proposed an index-flood method by assuming that the flood distributions at all stations within a homogeneous region are identical apart from the scale or index-flood parameter and used L-moments to conduct regional flood frequency analysis. Past research results (Vogel and Fennessey 1993; Lim et al. 2009) indicated that L-moment-based index-flood (LMIF) method has several advantages, such as better robustness and identifiability of the best fitted distribution than conventional moment methods, and this is particularly true for regional studies.
The LMIF method has been extensively applied in the regional frequency analysis of extreme precipitation in many countries (Fowler and Kilsby 2003; Norbiato et al. 2007; Hailegeorgis et al. 2013; Chen et al. 2014). However, most of the studies conducted regional frequency analysis without fully considering the assumptions given by Hosking (Yang et al. 2010a, b). Extensive tests for stationarity, serial correlation, and inter-site dependence should be conducted in the analysis to guarantee the reliability of estimates. In fact, both stationarity and independence are the major underlying assumptions of frequency analysis. Therefore, the analysis without the tests of stationarity and serial correlation may cause incorrect results and conclusions. Despite of its importance, in the literature, the inter-site dependence has rarely been considered in regional frequency analysis using LMIF method (Hussain 2011). Therefore, it will be desirable to draw sufficient concerns on the tests of stationarity, serial correlation, and inter-site dependence prior to the regional frequency analysis.
The objective of this paper is to promote the understanding of the spatial and temporal characteristics of extreme precipitation in the Yangtze River Delta (YRD) region, China, by using the state-of-the-art LMIF method. The main goal is achieved through the following steps: (1) extensive screening for stationarity, serial correlation, and inter-site dependence of the extreme precipitation time series and determining the homogeneous regions; (2) identifying the best probability distribution for different durations of extreme precipitation time series for each homogeneous sub-region, deriving the regional growth curves, and evaluating the accuracy of the estimated quintiles taking inter-site dependence into consideration; and (3) obtaining the map of the spatial patterns of extreme precipitation which can be served as an indicator of future flood risk in the YRD region by using the GIS technology. The study procedure demonstrated in this paper can provide a useful reference for regional frequency analysis of extreme precipitation in other regions of the world. This research can also be instrumental for further understanding of the unique and complex characteristics of extreme precipitation in the YRD region, which in turn will be beneficial to flood control and management in the study area.
2 Study area and data
The Yangtze River Delta (YRD) region is one of the major economic and cultural centers of China which undergoes the most rapid urbanization and economic development and has the densest population as well. In the current research, the YRD region is defined in a broad sense, comprising Jiangsu Province, Zhejiang Province, Anhui Province, and Shanghai City (Fig. 1). It has an area of 35.24 × 104 km2, accounting for 3.66 % of China’s territory, but produces 24.25 % of China’s GDP with 16.1 % of China’s population in the year 2012. The YRD region is located in the middle and northern subtropical regions; the topography is mainly plains (in the northern and eastern parts) and low mountains (distributed in the southwest and southern parts) (Fig. 1). Few studies conducted on the extreme precipitation in the YRD region showed that the Yangtze River Delta was dominated by positive extreme precipitation anomalies during 1961–2002 (Zhang et al. 2007), and a significant increasing trend of precipitation intensity was observed in YRD during 1960–2005 (Zhang et al. 2008). As for the spatial pattern, Gu and Sun (2013) demonstrated that annual extreme precipitation intensity decreased from south to north; the maximum was located in the southernmost part, while the minimum was located around Shanghai City. However, Dong et al. (2015) concluded that extreme precipitation showed an obviously higher level in southern Anhui, northern Jiangsu, and southern Zhejiang Provinces.

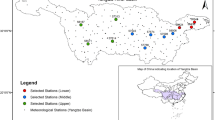
Location and the DEM of the YRD region (left, a), and the weather stations (right, b) used in the study
In this study, daily precipitation data of 44 stations in the YRD region from 1951 to 2010 were obtained from the Climate Data Center (CDC) of the National Meteorological Information Center, China Meteorological Administration (CMA). More detailed information about the weather stations can be found in Table 1. Figure 1b shows the locations of the weather stations in the YRD region. As for precipitation extremes, the following annual maximum time series are derived for analysis: annual maximum 1-day rainfall (AMS1), annual maximum 3-day rainfall (AMS3), annual maximum 5-day rainfall (AMS5), annual maximum 7-day rainfall (AMS7), annual maximum 10-day rainfall (AMS10), and annual maximum 15-day rainfall (AMS15).
The study area mainly belongs to the Meiyu rain belt. The seasonal torrential rain band usually lasts from mid-June to mid-July over the Yangtze and Huai River basin (28°–34° N and 110°–122° E) in East China. Meiyu is formed by torrential rain and drizzles along a persistent stationary front, and this causes the rain belt to linger and consequently gives rise to intermittent rain for about a month. We include AMS10 and AMS15 to get more information about the persistent rain in the study area.
3 Methods
Most of the analyses were performed with the free statistical software R (R Development Core Team 2013) in this paper. The LMIF method was performed by using the packages written by Hosking (2013) in R Software. They are lmom package, version 2.1 (http://CRAN.R-project.org/package=lmom), and lmomRFA package version 2.5 (http://CRAN.R-project.org/package=lmomRFA). For the sake of completeness, the analysis methods and the evaluation procedures used in this study are briefly described in the following sections.
3.1 L-moment
L-moments are expectations of certain linear combinations of order statistics. L stands for linear, which emphasizes that L-moments are a linear function of the order statistics. L-moments are more robust than conventional moments to the presence of outliers in the data. Therefore, L-moments provide more robust parameter estimates than conventional moments.
Let X 1:n ≤ X 2:n ≤… ≤ X n:n be the order statistics of a random sample of size n drawn from the distribution of X, and define the rth L-moment of variable X to be the quantities:
Here, EX r − k : r is the (r-k)th order statistics from a sample size of r. Because of the linearity of its moment statistics, L-moments method has been accepted as a more robust method for selecting and parameterizing representative probability distribution functions.
3.2 Index-flood method
The key assumption of an index-flood procedure is that the stations form a homogeneous region, meaning that the frequency distributions of the N stations are identical apart from a site-specific scaling factor, the index flood. We may then write
where Q i (F) for 0 < F < 1 is the quantile function of the frequency distribution at site i, μ i is the index flood (Hosking and Wallis 1997), N is the number of sites, and q(F) is the regional growth curve, a dimensionless quantile function common to every site.
The index flood is estimated by \( {\widehat{\mu}}_i={\widehat{Q}}_i \), the sample mean of the data at site i, and the dimensionless rescaled data are computed by \( {q}_{ij}={Q}_{ij}/{\widehat{\mu}}_i \), where Q ij is the observed data at site i, j = 1, 2, …, n i , and n i is the sample size at site i.
Hosking and Wallis (1993, 1997) considered an index-flood method where the parameters are estimated separately at each site. They suggested the use of a weighted average of the at-site estimates:
where \( {\widehat{\theta}}_k^{(i)} \) stands for the L-moment of interest. The estimated regional quantile \( \widehat{q}(F)=q\Big(F;{\widehat{\theta}}_1^R, \cdot s, {\widehat{\theta}}_P^R \) is obtained by substituting the estimates \( {\widehat{\theta}}_k^{(i)} \) into q(F) (Hosking and Wallis 1993). The quantile estimates at site i can be obtained using the estimates of μ i and q(F):
This index-flood procedure makes assumptions as follows: (i) observations at any given site are identically distributed, and independent both serially and spatially; (ii) frequency distributions at different sites are identical apart from a scale factor; and (iii) the mathematical form of the regional growth curve is correctly specified.
3.3 Data screening
Trend test is one of the most popular statistical methods in detecting the stationarity in time series. The rank-based Mann–Kendall method (MK) (Mann 1945; Kendall 1975) was highly recommended by the World Meteorological Organization to estimate the significance of monotonic trends in hydrometeorological series (Mitchell et al. 1966), because it possesses the advantage of requiring no distribution assumptions in the data while it has the same power as its parametric rivals.
Serial correlation within a time series can decrease the effective sample size in comparison to independent data (Tallaksen et al. 2004). To detect the existence of possible serial correlation in the extreme precipitation time series, lag-1 autocorrelation coefficient was used.
Additionally, Hosking and Wallis (1997) proposed a discordancy measure in order to recognize the stations which are grossly discordant with the other stations. It is a single statistic based on the discordancy between the L-moment ratios of a station and the average L-moment ratios of a group as a whole, which can also be used to identify erroneous data.
3.4 Inter-site dependence
Inter-site dependence can increase the variability of estimates even though it can exert little effect on their bias (Hosking and Wallis 1997). Let Q ik be the data for station i at time point k, the sample correlation coefficient between stations i and j can be given by
where
and the sums over k extend over all time points for which stations i and j both have data, and \( {n}_{ij} \) is the number of such time points. The average inter-site correlation can then be given by
More elaborate correlation structures may also be used, if it is justified by physical reasoning about the similarity of different sites.
3.5 Identification of homogeneous regions
The first step in LMIF method is the determination of homogeneous regions. The cluster analysis by station characteristics is considered to be one of the most practical methods of forming regions from large data sets (Hosking and Wallis 1997). In the current research, the k-means algorithm was applied for cluster analysis. Suppose there are M sites in an N-dimensional space, the k-means algorithm allocates the sites into k clusters. Initial site allocation is made by locating the two closest centers. Then, every site is allocated to the cluster whose center (also known as centroid) is the nearest, i.e., such that the within-cluster sum of squares is the lowest. For every dimension (attribute), the center coordinates are the corresponding arithmetic mean over all the sites in the cluster. Once initial site allocations are finished, cluster centers are updated according to the attribute averages of the sites located within each cluster. The site transfer/reassignment process is repeated until the optimal combination of sites and clusters is achieved according to the criteria of minimum sum of square.
For the current research, two sets of dimensions (attributes) were utilized together with the k-means algorithm. The first attribute set was site information of longitude, latitude, and the elevation above sea level. The second set was the mean annual precipitation (MAP) of each site. The four variables (longitude, latitude, elevation, and MAP) were then scaled to values between 0 and 1 to avoid bias of those variables with large absolute values.
The output of the cluster analysis is usually not the final result. Subjective adjustments are often needed to enhance the physical coherence of regions and to decrease the heterogeneity of regions. Several adjustments of regions were recommended by Hosking and Wallis (1997): move a site or some sites from one region to another, remove a site or some sites from the data, subsplit the region, split the region by reallocate its sites to other regions, combine the region with another or others, combine two or more regions and reclassify groups, and obtain more data and reclassify groups.
3.6 Heterogeneity measure
To estimate the heterogeneity degree in a group of sites, a heterogeneity measure (H n , n = 1, 2, and 3) was proposed by Hosking and Wallis (1997). It is based on observed and simulated dispersion of L-moments for a group of sites under consideration. The regions are regarded as “acceptably homogeneous” when H n < 1, “possibly heterogeneous” when 1 < H n < 2, and “definitely heterogeneous” when H n > 2. A large positive value of H 1 implies that the observed L-moments are more scattered than what is consistent with the assumption of homogeneity. H 2 suggests whether the at-site and regional estimates are near to each other. A large value of H 2 implies a large difference between regional and at-site estimates. H 3 suggests whether the at-site and the regional estimates agree. Large values of H 3 imply a large deviation between at-site estimates and measured data. However, H 1 is the principal measure for the heterogeneity test because both H 2 and H 3 rarely can yield values bigger than 2 even for grossly heterogeneous regions (Hosking and Wallis 1997; Yang et al. 2010b). The details for the calculation of H n are given in Hosking and Wallis (1997).
3.7 Goodness of fit test
In order to aid in the choice of an appropriate distribution, Hosking and Wallis (1997) proposed a statistic named the Z-statistic, which is a goodness of fit measure for given distributions that measures how well the theoretical L-kurtosis of the fitted distribution matches the regional average L-kurtosis of the measured data. For each of the candidate distribution, the goodness of fit is measured by
as proposed by Hosking and Wallis (1993, 1997) using the L-kurtosis, where τ DIST4 indicates the L-kurtosis of the fitted distribution to the data using the candidate distribution, and
is the bias of estimated \( {\overline{t}}_4 \) with \( {\overline{t}}_4^{(m)} \) being the sample L-kurtosis of the mth simulation, and
The fit is regarded as adequate if |Z DIST| is sufficiently close to zero, and a reasonable criterion can be |Z DIST| ≤ 1.64. If there are more than one candidate distributions acceptable, the one with the smallest |Z DIST| is considered to be the most appropriate distribution. Moreover, the L-moment ratio diagram will also be utilized to inspect the distribution by the comparison of its closeness to the L-skewness versus L-kurtosis combination in the L-moment ratio diagram.
3.8 Assessment of the accuracy of estimated quantiles
Hosking and Wallis (1997) proposed an assessment procedure which involves generation of regional average L-moments by using a Monte Carlo simulation. In the simulation, quantile estimates for various return periods are calculated. At the mth repetition, the estimated quantiles for nonexceedance probability F is \( {\hat{Q}}_i^{\left[m\right]}(F) \). The relative error of the estimate at station i for nonexceedance probability F is \( \left\{{\hat{Q}}_i^{\left[m\right]}(F)-{Q}_i(F)\right\}/{Q}_i(F) \). This quantity can be averaged over all the M repetitions in order to approximate the relative RMSE of the estimators. For large M, the relative RMSE is approximated by
A summary of the accuracy of quantile estimates over all of the stations in the region can be obtained by the regional average relative RMSE of the quantile estimates:
Analogous quantities can be computed for the estimates of growth curve, but with \( {\widehat{Q}}_i(F) \) and \( {\widehat{Q}}_i^{\left[m\right]}(F) \) substituted by \( {\widehat{q}}_i(F) \) and \( {\widehat{q}}_i^{\left[m\right]}(F) \), respectively. The 90 % error bounds for \( \widehat{q}(F) \) are
where L 0.05(F) and U 0.05(F) are the values where approximately 90 % of simulated values to true value ratio, i.e., \( {\widehat{q}}_i(F)/{q}_i(F) \), lies. Please refer to Hosking and Wallis (1997) for more details. To obtain the measures of absolute error, we just multiply the relative error measures by the estimated quantiles.
3.9 Spatial interpolation
Spatial patterns of the extreme precipitation with different return periods can be used as one of the most important indicators for flood control and management; thus, it is beneficial in quantifying the spatial associations of extreme precipitation between stations and mapping of extreme precipitation with different return periods across the YRD region using the ArcGIS interpolation technique. For this purpose, inverse distance weighted (IDW) was applied to generate surface in ArcGIS. Finally, isopluvial maps were generated using the ArcGIS.
4 Results and discussions
4.1 Data screening
Considerable efforts were taken in the screening and quality control of the data series, which aimed at removing false values associated with enormous data measurements, recording or transcription mistakes. Special attention was paid to the verification of the major assumptions of stationarity, serial independence, and inter-site dependence.
Trend analysis was first conducted. The Mann-Kendall trend test was conducted on the time series of precipitation extremes (AMS1, AMS3, AMS5, AMS7, AMS10, and AMS15) over the period 1951–2010 in the study region. The results are given in Fig. 2. It can be seen that about 5 % of the series present increasing (decreasing) trends (at the significance level of 0.05) and the remaining series show no significant trends. This implies that most of the precipitation extremes series in this study have no trends.

Mann-Kendall trend test results for different precipitation extreme series over the period 1951–2010. Asterisk indicates statistical significance at 0.05 level
Lag-1 autocorrelation coefficient (r 1) was used, and the value of r 1 for each station is given in Fig. 3, which implies that there is no evidence of significant serial correlation for most of the series at most of the sites. Hosking and Wallis (1997) came to the conclusion that a small quantity of serial dependence in annual time series may exert little influence on the quality of the estimates. Therefore, the assumption that the data series have no significant serial correlation is appropriate.

Lag-1 autocorrelation coefficients for different precipitation extreme series over the period 1951–2010. Asterisk indicates statistical significance at 0.05 level
The average inter-site correlation coefficients for each homogeneous sub-regions are shown in Table 2. As we can see, the study region has a moderate amount of inter-site dependence. Average correlation coefficients between sites in the homogeneous regions vary from 0.17 to 0.37, with an average of 0.26. And, the average correlation coefficients increase from AMS1 to AMS15. Therefore, the simulation accuracy of the estimated quantiles in this study will include inter-site dependence, using the algorithm described in Table 6.1 of Hosking and Wallis (1997).
4.2 Identification of homogeneous regions
In order to evaluate the proposed procedures, the entire study area was first assumed as one homogeneous group and the assumption was detected by using the discordancy measure D i and the heterogeneity measures H 1, H 2, and H 3. The YRD region did not pass the heterogeneity test because the stations of Tianmushan and Yinxian had values of D i > 3 (3.39 and 3.31, respectively). A check of the data at the two stations indicated no obvious inconsistencies. The heterogeneity measures for the whole YRD region were H 1 = 5.26, H 2 = 1.08, and H 3 = 1.10. The whole region should therefore be regarded as definitely heterogeneous for H 1 > 2, although the H 2 and H 3 values grouped it as possibly homogeneous. The region could not pass the tests even after the disposal of Tianmushan and Yinxian Stations, and cluster analysis was therefore performed.
First, the k-means cluster method was applied to divide the whole region into several clusters. The discordancy measure and heterogeneity measures were then calculated for each of the cluster, and the L-moment diagrams were drawn. However, some of the clusters did not show sufficient homogeneity according to heterogeneity test, indicating that there were some sites being discordant with the others within the cluster. As for these discordant stations, further subjective adjustments are needed to enhance the physical coherence of regions and to decrease the heterogeneity. We tried three clusters at first since the region is not large and the topography is not complex and finally decided to use four clusters because the heterogeneity test showed big heterogeneity when the southernmost stations of Yinxian, Shengxian, Hongjia, Shipu, and Wenzhou were included in the first cluster. In fact, this is because these stations are near the coast and located where typhoons often make landfall. We made some further adjustment proposed by Hosking and Wallis (1997) as follows: remove a site or some sites from the data (e.g., Kuocangshan and Wuhu were excluded here due to their relatively short time periods), subsplit the region or split the region by reallocating its sites to other regions (e.g., Yinxian, Shengxian, Hongjia, Shipu, Wenzhou, and Longquan were singled out as a new region), and move a site or some sites from one region to another (e.g., Longquan Station was moved to the new region). We also made adjustments according to the physical geographical conditions such as climate and topography of the study area. After several adjustments, the resulting identified homogeneous regions for each extreme precipitation time series were obtained and illustrated in Fig. 4, which indicates that the entire YRD region can be categorized into four homogeneous sub-regions. Moreover, Kuocangshan and Wuhu Stations were grouped to region 1 and region 3, respectively, just according to their location.

Homogeneous regions of the k-means cluster after adjustment in the study area
The discordance test of AMS1, AMS3, AMS5, AMS7, AMS10, and AMS15 was conducted for each homogeneous region. There are no discordant stations for each of the sub-region. The results for the heterogeneity test based on 1000 simulations for each of the four homogeneous regions are shown in Table 3. All the four sub-regions passed the heterogeneity test except for AMS1 of region 2. However, approximate homogeneity is sufficient to ensure that regional frequency analysis is much more accurate than at-site analysis (Hosking and Wallis 1997). Since the H 1 measurement of AMS1 of region 2 is close to 1, we can still consider it to be homogeneous.
The first region (the southeastern coastal region) has five stations and is located in the southeastern part of the study area. This region is the most prone to tropical cyclones and typhoons, which can bring large amount of heavy rain in summer and autumn. The region is homogeneous according to the heterogeneity test.
The second region (the southern hilly region) has ten stations, which are mainly located in the southern Anhui Province and the Zhejiang Province. The topography is mainly low mountains in the second region. The region is homogeneous except for AMS1 series according to the heterogeneity test.
The third region (the western hilly and plain region) has 13 stations, which are mostly located in Anhui Province, except Xuzhou Station in Jiangsu Province. The terrain of the third region is mainly plains with some low mountains in the southwest. The region is homogeneous for all the extreme precipitation series.
The fourth region (the eastern plain region) has the most stations (14 stations), of which 12 are located in Jiangsu Province. It is the most low-lying region of the study area and is also the most typical area of the Yangtze River Delta. The region is also homogeneous according to the heterogeneity test.
4.3 Goodness of fit test
In this section, the regional frequency distribution function for each region is identified mainly based on goodness of fit |Z DIST| statistics. In the LMIF method, distribution functions commonly used to fit data include three-parameter distributions such as the generalized extreme-value (GEV), the generalized normal (GNO), the generalized pareto (GPA), the generalized logistic (GLO), and the Pearson type III (PE3), the four-parameter kappa (KAP) distribution, and the five-parameter Wakeby (WAK) distribution. The four-parameter kappa and five-parameter Wakeby distributions are more general and flexible. The distributions of kappa and Wakeby will be used in case the choice of the above three-parameter candidate distributions is inconclusive. This normally occurs when the region is misspecified as being homogeneous. In this study, the sub-regions are correctly identified as homogeneous, so we can identify the best fit three-parameter distributions for them and do not need to use kappa and Wakeby distributions.
The results of the goodness of fit test are shown in Table 4. It can be observed that GEV and GNO perform very well in fitting regional precipitation extremes in the study region. GEV is found to be acceptable for all the four regions over all durations from AMS1 to AMS15. GNO is also acceptable very often except for AMS1 in region 4. PE3 is acceptable 11 times, and GLO is even less acceptable, only 8 times, whereas GPA is acceptable for none of the circumstances.
The best distributions were further determined mainly according to the minimum |Z D IST|.. What is more, L-moment ratio plots which demonstrate the location of regional average L-skewness versus L-kurtosis and their theoretical relation with different candidate distributions are shown in Fig. 5a–f. (For AMS7, the average L-skewness and L-kurtosis of region 2 and region 4 are so close to each other that the diamond cannot be seen.) In the end, GNO was chosen as the best parent distribution in 12 times, GEV in 8 times, and GLO was chosen to be the best only 2 times (Table 4). The L-moment ratio diagrams further verify the results obtained by minimum |Z DIST| value in which these distributions were actually nearest to the regional weighted L-moment means. As for region 2 of AMS7, the |Z DIST| values are the same for GEV and GNO; therefore, L-moment ratio plots were used to decide which one is the best distribution. The best distribution identified for each homogeneous region in this step will be used to estimate the regional growth curve.

L-moment ratio plots for the five candidate distributions with regional average L-skewness versus L-kurtosis. a AMS1, b AMS3, c AMS5, d AMS7, e AMS10, and f AMS15. Filled square, region 1; filled circle, region 2; filled triangle, region 3; filled diamond, region 4. For AMS7, the averages of L-skewness and L-kurtosis of region 2 and region 4 are so near to each other that the diamond cannot be seen
4.4 Regional growth curves and accuracy assessment
Once the delineated regions have demonstrated to be acceptably homogeneous and appropriate distributions have been determined for each sub-region, regional growth curves can then be derived based on the selected distributions. The regional growth curves of AMS1, AMS3, AMS5, AMS7, AMS10, and AMS15 for each homogeneous region were obtained respectively, and quantiles at each site were estimated for return periods of 2, 5, 10, 20, 50, and 100 years, etc.
The accuracy of the quantile estimates was assessed by RMSE and 90 % error bounds. These quantities cannot be calculated analytically so far since the regional L-moment quantile estimation procedure is too sophisticated. However, a Monte Carlo simulation procedure was applied, as described in Sect. 6.4 of Hosking and Wallis (1997). Simulated data were obtained for a region with the same number of stations and the same record lengths as the actual region and were derived from the distribution that was fitted to the actual regional data.
The extreme precipitation series have a moderate amount of inter-site dependence which increases from AMS1 to AMS15 (Table 2). Here AMS15 in region 2 was taken as an example to analyze the influences of inter-site dependence on the accuracy of estimation. Correlation coefficients between sites have an average of 0.37 for AMS15 in region 2. Therefore, the inter-site dependence needs to be considered in the simulation algorithm. To specify the L-CV (one of the L-moment ratios being analogous to CV, coefficient of variation) range of the region which will be used as a base for simulations, 100 simulations of the correlated GNO regions with the same record lengths as the actual region indicate that when at-site L-CVs vary linearly over a range of 0.02, from 0.1762 at Cixi Station to 0.1962 at Tunxi Station and L-skewness equals 0.2143, the average H 1 of the simulated regions will be 0.23. Thus, the heterogeneity of the simulated region equals that of the actual region. Therefore, this region was used as a base in the simulation step. Ten thousand realizations of this region were made and the regional L-moment algorithm was applied to fit the GNO distribution to the generated data. The regional RMSEs for the assessed regional growth curves and quantiles were calculated based on these simulations.
The simulation results for the estimated quantiles of region 2 of AMS15 are presented in Table 5 A (regional growth curve) and B (Hangzhou Station, which belongs to region 2). Table 5 shows that the RMSEs with inter-site correlation coefficient R = 0.37 are bigger than those with R = 0 for both the regional growth curve and quantile curve. What is more, both of the two curves have wider 90 % error bounds, when inter-site dependence is taken into consideration. The differences between R = 0 and R = 0.37 become bigger with the increase of return periods. And, this kind of influence will be more significant with the increase of the correlation coefficients.
The results of Table 5 also show that the RMSEs of the estimated regional growth curve and the quantiles for Hangzhou Station vary from 0.01 (10.15) to 0.11(38.7) when return periods of AMS15 increase from 2 to 100 years, and these values increase to 0.24 (70.27) with the return period of 1000 years (inter-site dependence considered). This indicates that the RMSEs are so reliable that the quantile estimates can be used with confidence if return periods are within 100 years. Estimates of longer return periods (e.g., 1000 years) will require more historical records so that the reliability in the quantile estimation can be enhanced. Figure 6 shows the estimated regional growth curves of AMS15 for the four sub-regions together with the 90 % error bounds, which also verifies that the quantile estimates are accurate enough when return periods are shorter than 100 years.

Estimated regional growth curves of AMS15, with the 90 % error bounds for the four sub-regions. Panels (a), (b), (c), and (d) are for regions 1, 2, 3, and 4, respectively
4.5 At-site and regional estimates
In this part, the estimation accuracy based on at-site and regional methods was compared by using relative RMSE. The best fitted distributions of each station for at-site method are determined by extreme-value plot. For illustrative purpose, Fig. 7 demonstrates the results for Nanjing and Longhua Stations, and it can be seen that PE3 and GLO fit AMS1 well for both stations, respectively. The best fitted distributions for all the other series were determined accordingly. For the regional method, inter-site dependency was also considered in the estimation.

Extreme-value plot with fitted probability functions for AMS1 at Nanjing (a) and Longhua Stations (b). GLO, red; GEV, black; GNO, green; PE3, blue; GPA, orange
Lower relative RMSE values give an indication of better accuracy. Figure 8 gives the box plots of the estimated relative RMSE of at-site and regional methods for AMS1 and AMS15 of all the 42 stations except for Kuocangshan and Wuhu. First, the ranges of relative RMSE of at-site method are much wider than those of regional method; there are no evident differences in the range for regional method between different return periods, while the range became much wider for at-site method with the increase of return periods. This verifies the robustness of estimated quantiles of regional method. Second, the relative RMSE values of at-site method can be lower than those of the regional methods for periods under 50 years, while they will be much higher than those of the regional method for return periods over 50 years. And, this may indicate that estimated quantiles based on regional method have much better accuracy than those based on at-site method for longer return periods, but this may not be the case for shorter return periods.

Box plots of relative RMSE of AMS1 (a) and AMS15 (b) for different return periods by using at-site and regional methods
Kuocangshan and Wuhu Stations, which were excluded both in the identification of homogeneous region and in the estimation of the regional quantiles, will also be used to obtain the spatial pattern of extreme precipitation of the study area in Sect. 4.6. The estimated quantiles based on regional method have smaller uncertainty and better accuracy than those based on at-site method (Ngongondo et al. 2011); thus, we will use their quantile estimates based on regional method. The regional analysis used the regional growth curves of region 1 and region 3, to which Kuocangshan and Wuhu Stations belong, and estimated the index flood at each station by the sample mean.
4.6 Spatial patterns of extreme precipitation
In order to obtain the spatial patterns of extreme precipitation, isopluvial maps of the study area were drawn using the extreme precipitation for different return periods (10, 20, 50, and 100 years) (44 stations including Kuocangshan and Wuhu were used here). In this analysis, surface of extreme rainfall for each duration and return period was generated using IDW interpolation technique (Geostatistical Analyst tool) in ArcGIS. Then, contours (isopluvial) were generated from the surface, which indicates the precipitation for different durations and return periods with spatial variations. According to Sarkar et al. (2010), these isopluvial maps are more informative than the isopluvial maps generated by Central Water Commission report (CWC 1973). Isopluvial maps of the YRD region for different return periods of AMS1, AMS3, AMS5, AMS7, AMS10, and AMS15 were then obtained, which can be used to identify those areas with major flooding problems within the study area.
Figure 9 illustrates the spatial patterns of extreme precipitation with return period of 100 years. It can be seen that there are two areas with the highest precipitation extremes: One is in the southeastern coastal area of Zhejiang Province (mainly region 1), and the other is in the southwest part of Anhui Province (between region 2 and region 3). Southeastern coastal area of Zhejiang Province is in the windward slope of landing typhoons, so that extreme precipitation is very high. The elevation in the south and southwest parts of Anhui Province is quite high, which will bring in large amount of orographic rain. There is also a small area with relatively high precipitation extremes in the northwest of Jiangsu Province for AMS1 and AMS3. What is more, there is another large area with low precipitation extremes in the north and middle parts of Zhejiang Province, Shanghai City, and Jiangsu Province (the rest of region 2 and most parts of region 4), and it is particularly the case for north Zhejiang, Shanghai, and south Jiangsu. This area with low precipitation extremes spreads in AMS5 and AMS7 and covers about two thirds of the whole study area in AMS10 and AMS15. The maps for the other return periods are similar to the pattern in Fig. 9 and are not shown here.

Spatial patterns of extreme precipitation with return period of 100 years. a AMS1, b AMS3, c AMS5, d AMS7, e AMS10, and f AMS15
The disaster situation depends not only on the disaster-driving factors but also on the human and social vulnerability. Extreme precipitation is the disaster-driving factor, while the population and economic conditions belong to the vulnerability. For the area with low precipitation extremes in the southern parts of Jiangsu Province, Shanghai City, and northern parts of Zhejiang Province, the dense population and advanced economy are most vulnerable to floods. What is more, the low-lying terrain and dense river network with decreasing storage capacity will aggravate the flood disaster situation. Consequently, floods in this area may cause greater losses of human life and property damage than in the upstream or mountainous regions, which must be paid enough attention by both the government and citizens.
5 Conclusions
Spatial-temporal characteristics of the extreme precipitation in the Yangtze River Delta region are explored based on daily precipitation data covering 1951–2010 by using L-moment-based index-flood (LMIF) method together with some other statistical tests and spatial analysis methods. The LMIF method in this study involves extensive data screening, identification of homogeneous regions, goodness of fit test, quantile estimates for each region, accuracy assessment including inter-site dependence, and mapping of the spatial patterns of extreme precipitation. According to the results of this study, we can draw some conclusions as follows:
-
1.
The statistical test results suggest that most observations of precipitation extremes in this study have no significant trends and it is also appropriate to conclude that the data series have no serious serial correlation. However, the four homogeneous regions have a moderate amount of inter-site dependence. Therefore, the simulation accuracy of the estimated quantiles needs to consider inter-site dependence.
-
2.
The entire YRD region was categorized into four homogeneous regions through cluster analysis and some further subjective adjustments. The best regional distribution function for each region was identified using the goodness of fit test measurement together with L-moment ratio diagrams. The results revealed that GEV and GNO are the dominant distribution functions for most of the sub-regions.
-
3.
Region 2 of AMS15 was used as an example to show the influences of inter-site dependence on the accuracy of estimated quantiles. The results indicated that the RMSEs with inter-site correlation coefficient R = 0.37 are bigger than those with R = 0 for both the regional growth curve and quantile curve. What is more, both of the two curves have wider 90 % error bounds when inter-site dependence was taken into consideration. The differences become bigger with the increase of return periods.
-
4.
Relative RMSEs were used to compare the accuracy of quantile estimates between at-site and regional methods. The results verified the robustness of estimated quantiles of regional method and showed that the estimated quantiles based on regional method have better accuracy than those based on at-site method especially for longer return periods.
-
5.
The spatial patterns of extreme precipitation with return period of 100 years indicate that there are two areas with the highest precipitation extremes: One is in the southeastern coastal area of Zhejiang Province (mainly region 1), and the other is in the southwest part of Anhui Province (between region 2 and region 3). There is also a large area with low precipitation extremes in the north and middle parts of Zhejiang Province, Shanghai City, and Jiangsu Province (mainly the rest of region 2 and most parts of region 4). However, the area with low precipitation extremes in the southern parts of Jiangsu Province, Shanghai City, and northern parts of Zhejiang Province are the most developed and densely populated regions with low-lying terrain; the flood in this specific area can cause great losses of human life and property damage due to the high vulnerability. So both the government and citizens should pay enough attention to it, especially when many researchers report that the precipitation is on the increase in this area recently.
References
Charles O, Patrick W (2015) Uncertainty in calibrating generalised Pareto distribution to rainfall extremes in Lake Victoria basin. Hydrol Res. doi:10.2166/nh.2014.052
Chen YD, Zhang Q, Xiao MZ, Singh VP, Leung Y, Jiang LG (2014) Precipitation extremes in the Yangtze River Basin, China: regional frequency and spatial–temporal patterns. Theor Appl Climatol. doi:10.1007/s00704-013-0964-3
CWC (Central Water Commission), 1973 Estimation of design flood peak. Central Water Commission, Government of India, New Delhi. No. 1/73
Dalrymple T (1960) Flood frequency methods, U.S. geological survey, water supply paper, 1543A, 11–51
Dong HZ, Wu YJ, Xu HP (2015) Spatio temporal variation characteristics of extreme precipitation in the Yangtze River Delta during 1958–2012. doi:10.2495/ESBE140141. In: Weller K, Environmental Science and Biological Engineering, WIT Press, Southampton, UK
Fowler HJ, Kilsby CG (2003) A regional frequency analysis of United Kingdom extreme rainfall from 1961 to 2000. Int J Climatol 23:1313–1334
Frich P, Alexander LV, Della-Marta P, Gleason B, Haylock M, Klein Tank AMG, Peterson T (2002) Observed coherent changes in climatic extremes during the second half of the twentieth century. Clim Res 19:193–212
Gu C M, Sun W G. 2013. Extreme Precipitation Changes and Causes in Yangtze River Delta region. [EB/OL]. Beijing: Sciencepaper online [2013-08-19]. http://www.paper.edu.cn/releasepaper/content/201308-180
Hailegeorgis TT, Thorolfsson ST, Alfredsen K (2013) Regional frequency analysis of extreme precipitation with consideration of uncertainties to update IDF curves for the city of Trondheim. J Hydrol 498:305–318
Hosking JRM, Wallis JR (1993) Some statistics useful in regional frequency analysis. Water Resour Res 29(2):271–281
Hosking JRM, Wallis JR (1997) Regional frequency analysis: an approach based on L-moments. Cambridge University Press, Cambridge
Hosking JRM, Wallis JR, Wood EF (1985) Estimation of the generalized extreme-value distribution by the method of probability weighted moments. Technometrics 27(3):251–261
Hussain Z (2011) Application of the regional flood frequency analysis to the upper and lower basins of the Indus River, Pakistan. Water Res Manag 25:2797–2822. doi:10.1007/s11269-011-9839-5
Kendall MG (1975) Rank correlation methods. Griffin, London
Lettenmaier DP, Potter KW (1985) Testing flood frequency estimation methods using a regional flood generation model. Water Resour Res 21(12):1903–1914
Li JF, Zhang Q, Chen YD, Xu C-Y, Singh VP (2014) Changing spatiotemporal patterns of extreme precipitation regimes extremes in China during 2071–2100 based on Earth system models. Journal of Geophysical Research - Atmospheres, in press
Lim YH, Voeller DL (2009) Regional flood estimations in Red River using L-moment-based index-flood and bulletin 17B procedures. J Hydrol Eng 14(9):1002–1016
Mann HB (1945) Nonparametric tests against trend. Econometrica 13:245–259
Mitchell JM, Dzerdzeevskii B, Flohn H, Hofmeyr WL, Lamb HH, Rao KN, Wallen CC (1966) Climate Change. WMO Technical Note No. 79. World Meteorological Organization
Ngongondo C, Xu C-Y, Tallaksen LM, Alemaw B, Chirwa T (2011) Regional frequency analysis of rainfall extremes in Southern Malawi using the index rainfall and L-moments approaches. StochaS Environ Res Risk Asses 25:939–955
Norbiato D, Borga M, Sangati M, Zanon F (2007) Regional frequency analysis of extreme precipitation in the eastern Italian Alps and the August 29, 2003 flash flood. J Hydrol 345:149–166
Olsson J, Foster K (2014) Short-term precipitation extremes in regional climate simulations for Sweden. Hydrol Res 45(3):479–489. doi:10.2166/nh.2013.206
Rajeevan M, Bhate J, Jaswal AK (2008) Analysis of variability and trends of extreme rainfall events over India using 104 years of gridded daily rainfall data. Geophys Res Lett 35:L18707. doi:10.1029/2008GL035143
Sarkar S, Goel NK, Mathur BS (2010) Development of isopluvial map using L-moment approach for Tehri-Garhwal Himalaya. Stoch Env Res Risk A 24:411–423
Tallaksen LM, Madsen H, Hisdal H (2004) Frequency analysis, hydrological drought-processes and estimation methods for streamflow and groundwater, developments in water sciences, vol 48. Elsevier Science, The Netherlands
Vogel RM, Fennessey NM (1993) L moment diagrams should replace product moment diagrams. Water Resour Res 29(6):1745–1752
Xu C-Y, Singh VP (2004) Review on regional water resources assessment under stationary and changing climate. Water Res Manag 18(6):591–612
Yang T, Shao Q, Hao Z-C, Chen X, Zhang Z, Xu C-Y, Sun L (2010a) Regional frequency analysis and spatio-temporal pattern characterization of rainfall extremes in the Pearl River Basin China. J Hydrol 380:386–405
Yang T, Xu C-Y, Shao QX, Chen X (2010b) Regional flood frequency and spatial patterns analysis in the Pearl River Delta region using L-moments approach. Stochas Environ Res Risk Assess 24:165–182
Zhang ZX, Zhang Q, Jiang T (2007) Changing features of extreme precipitation in the Yangtze River basin during 1961–2002. J Geogr Sci 1:33–42
Zhang Q, Xu C-Y, Zhang ZX, Chen YQ, Liu C-L (2008) Spatial and temporal variability of precipitation maxima during 1960–2005 in the Yangtze River basin and possible association with large-scale circulation. J Hydrol 353:215–227
Zhang Q, Peng JT, Xu C-Y, Singh VP (2014) Spatiotemporal variations of precipitation regimes across Yangtze River Basin, China. Theor Appl Climatol 115:703–712
Acknowledgments
This work is financially supported by China Postdoctoral Science Foundation funded project (S1613002001), Jiangsu Planned Projects for Postdoctoral Research Funds (1301136C), Research Council of Norway projects JOINTINDNOR (203867), and Jiangsu Government Scholarship for Overseas Studies. Dr. Hosking J.R.M from IBM Research Division and Prof. Binzhang Lin from Nanjing University of Information Science and Technology are greatly acknowledged for their valuable suggestions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yin, Y., Chen, H., Xu, CY. et al. Spatio-temporal characteristics of the extreme precipitation by L-moment-based index-flood method in the Yangtze River Delta region, China. Theor Appl Climatol 124, 1005–1022 (2016). https://doi.org/10.1007/s00704-015-1478-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-015-1478-y