
Abstract
In this paper, we consider the problem of estimating the \(d\)-th order derivative \(f^{(d)}\) of a density \(f\), relying on a sample of \(n\) i.i.d. observations \(X_{1},\dots,X_{n}\) with density \(f\) supported on \({\mathbb{R}}\) or \({\mathbb{R}}^{+}\). We propose projection estimators defined in the orthonormal Hermite or Laguerre bases and study their integrated \({\mathbb{L}}^{2}\)-risk. For the density \(f\) belonging to regularity spaces and for a projection space chosen with adequate dimension, we obtain rates of convergence for our estimators, which are optimal in the minimax sense. The optimal choice of the projection space depends on unknown parameters, so a general data-driven procedure is proposed to reach the bias-variance compromise automatically. We discuss the assumptions and the estimator is compared to the one obtained by simply differentiating the density estimator. Simulations are finally performed. They illustrate the good performances of the procedure and provide numerical comparison of projection and kernel estimators
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 INTRODUCTION
1.1 Motivations and Content
Let \(X_{1},\dots,X_{n}\) be \(n\) i.i.d. random variables with common density \(f\) with respect to the Lebesgue measure. The problem of estimating \(f\) in this simple model has been widely studied. In some contexts, it is also of interest to estimate the \(d\)th order derivative \(f^{(d)}\) of \(f\), for different values of the integer \(d\). Density derivatives provide information about the slope of the curves, local extrema or saddle points, for instance. Several examples of use of derivatives are developed in [33, 39]. The most common cases are those with \(d\in\{1,2\}\). The first order density derivative permits to reach information, such as mode seeking in mixture models and in data analysis, see e.g., [10, 12]. The second order derivative of the density can be used to estimate one parameter scale of exponential families (see [17]), to develop tests for mode (see [12]), to select the optimal bandwidth parameter for density estimation (see [37]). Let us detail two specific contexts.
(1) The question arises when considering regression models. The estimation of the so-called ‘‘average derivative’’ defined by \(\delta={\mathbb{E}}[Y\psi(X)]\), with \(\psi(x)=f^{(1)}(x)/f(x),\) and \(f\) is the marginal distribution of \(X\) (see [19, 21]) relies on the estimation of the derivative of the density of \(X\). This quantity enables to quantify the relative impact of \(X\) on the variable of interest \(Y\). In an econometric context, the average derivative is also used to verify empirically the law of demand: it allows to compare two economies with different price systems (see [19, 20], Section 3). In [7], the study of sea shore water quality leads the authors to estimate the derivative of the regression function, and the derivative of a Nadaraya–Watson estimator involves the derivative of a density estimator. Regression curves (see [30]) also involve derivatives of densities, consider \(r(x)={\mathbb{E}}(Y|X=x)\), [39] (see Eq. (2.1)) establishes that for specific families of conditional distributions of \(Y\) given \(X\), on can express \(r(x)=\psi(x)\) as \(\psi(x)=f^{(1)}(x)/f(x)\), where \(f\) is a density (see (2.1) in [39]).
(2) Derivatives also appear in the study of diffusion processes. Let \((X_{t})_{t\geqslant 0}\) be the solution of
where \(W_{t}\) is a standard Brownian independent of \(\eta\). There exists a solution under standard assumptions on \(b\) and \(\sigma\). The model is widely used, for example in finance and biology. One related statistical problem is to estimate the drift function \(b\), from discrete time observations of the process \(X\). Under additional conditions (see [34]), the model is stationary, admits a stationary distribution \(f\) and it holds that
If the variance \(\sigma\) is either a constant or known, estimating \(f\) and \(f^{(1)}\) lead to an estimator of \(b\).
These examples illustrate the interest of the mathematical question of nonparametric estimation of derivatives as a general inverse problem.
Most proposals for estimating the derivative of a density are built as derivatives of kernel density estimators, see [8, 10, 11, 28, 32, 35, 37] or [18], either in independent or in \(\alpha\)-mixing settings, in univariate or in multivariate contexts. A slightly different proposal still based on kernels can be found in [38]. The question of bandwidth selection is only considered in the more recent papers. For instance, [10] proposes a general cross-validation method in the multivariate case for a matrix bandwidth, see also the references therein. Most recently, [27] proposed a general original approach to bandwidth selection, and applies it to derivative estimation in a multivariate \(\mathbb{L}^{p}\) setting and for anisotropic Nikol’ski regularity classes. This paper is, to the best of our knowledge, the first to study the risk of an adaptive kernel estimator.
Projection estimators have also been considered for density and derivatives estimation. More precisely, using trigonometric basis, [15] proposes a complete study of optimality and sharpness of such estimators, on Sobolev periodic spaces. Lately, [18] proposes a projection estimator and provide an upper bound for its \(\mathbb{L}^{p}\)-risk, \(p\in[1,\infty]\). In a dependent context, [34] studies projection estimators in a compactly supported basis constrained on the borders or a non compact multi-resolution basis: she considers dependent \(\beta\)-mixing variables and a model selection method is proposed and proved to reach optimal rates on Besov spaces. In most results, the rate obtained for estimating \(f^{(d)}\) the \(d\)th order derivative assumed to belong to a regularity space associated to a regularity \(\alpha\), is of order \(n^{-2\alpha/(2\alpha+2d+1)}\). Recently, a bayesian approach has been investigated in [36] relying on a \(B\) spline basis expansion, the procedure requires the knowledge of the regularity of the estimated function.
In the present work, we consider projection estimators on projection spaces generated by Hermite or Laguerre basis, which have non compact supports, \({\mathbb{R}}\) or \({\mathbb{R}}^{+}\). When using compactly supported bases, one has to choose the basis support: it is generally considered as a fixed interval say \([a,b]\), but the bounds \(a\) and \(b\) are in fact determined from the data. Hermite and Laguerre bases do not require this preliminary choice. Moreover, in a recent work, [6] proves that estimators represented in Hermite basis have a low complexity and that few coefficients are required for a good representation of the functions: therefore, the computation is numerically fast and the estimate is parsimonious. If the \(X_{i}\)’s are nonnegative, then one should use the Laguerre basis: thus, this basis is of natural use in survival analysis where most functions under study are \({\mathbb{R}}^{+}\)-supported. Lastly, we mention that derivatives of Laguerre or Hermite functions have interesting mathematical properties: their derivatives are simple and explicit linear combination of other functions of the bases. This property is fully exploited to construct our estimators.
The integrated \({\mathbb{L}}^{2}\)-risk of such estimators is classically decomposed into a squared bias and a variance term. The specificity of our context is threefold.
(1) The bias term is studied on specific regularity spaces, namely Sobolev Hermite and Sobolev Laguerre spaces, as defined in [9], enabling to consider non compact estimation support \({\mathbb{R}}\) or \({\mathbb{R}}^{+}\).
(2) The order of the variance term depends on moment assumptions. This explains why, to perform a data driven selection of the projection space, we propose a random empirical estimator of the variance term, which has automatically the adequate order.
(3) In standard settings, the dimension of the projection space is the relevant parameter that needs to be selected to achieve the bias-variance compromise. In our context, this role is played by the square root of the dimension.
We also mention that our procedure provides parsimonious estimators, as few coefficients are required to reconstruct functions accurately. Moreover, our regularity assumptions are naturally set on \(f\) and not on its derivatives, contrary to what is done in several papers. Our random penalty proposal is new, and most relevant in a context where the representative parameter of the projection space is not necessarily its dimension, but possibly the square root of the dimension. We compare our estimators with those defined as derivatives of projection density estimators, which is the strategy usually applied with kernel methods. Finally, we also propose a numerical comparison between our projection procedure and a sophisticated kernel method inspired by the recent proposal in density estimation of [25].
The paper is organized as follows. In the remaining of this section, we define the Hermite and Laguerre bases and associated projection spaces. In Section 2, we define the estimators and establish general risk bounds, from which rates of convergence are obtained, and lower bounds in the minimax sense are proved. A model selection procedure is proposed, relying on a general variance estimate; it leads to a data-driven bias-variance compromise. Further questions are studied in Section 3: the comparison with the derivatives of the density estimator leads in our setting to different developments depending on the considered basis: interestingly Hermite and Laguerre cases happen to behave differently from this point of view. Lastly, a simulation study is conducted in Section 4, in which kernel and projection strategies are compared.
1.2 Notations and Definition of the Basis
The following notations are used in the remaining of this paper. For \(a\), \(b\) two real numbers, denote \(a\vee b=\max(a,b)\) and \(a_{+}=\max(0,a)\). For \(u\) and \(v\) two functions in \(\mathbb{L}^{2}(\mathbb{R})\), denote \(\langle u,v\rangle=\int_{-\infty}^{+\infty}u(x)v(x)dx\) the scalar product on \(\mathbb{L}^{2}(\mathbb{R})\) and \(||u||=\big{(}\int_{-\infty}^{+\infty}u(x)^{2}dx\big{)}^{1/2}\) the norm on \(\mathbb{L}^{2}(\mathbb{R})\). Note that these definitions remain consistent if \(u\) and \(v\) are in \(\mathbb{L}^{2}(\mathbb{R}^{+})\).
1.2.1. The Laguerre basis. Define the Laguerre basis by:
where \(L_{j}\) is the Laguerre polynomial of degree \(j\). It satisfies: \(\int_{0}^{+\infty}L_{k}(x)L_{j}(x)e^{-x}dx=\delta_{k,j}\) (see [1], 22.2.13), where \(\delta_{k,j}\) is the Kronecher symbol. The family \((\ell_{j})_{j\geqslant 0}\) is an orthonormal basis on \(\mathbb{L}^{2}(\mathbb{R}^{+})\) such that \(||\ell_{j}||_{\infty}=\sup_{x\in\mathbb{R}^{+}}|\ell_{j}(x)|=\sqrt{2}\). The derivative of \(\ell_{j}\) satisfies a recursive formula (see Lemma 8.1 in [13]) that plays an important role in the sequel:
1.2.2. The Hermite basis. Define the Hermite basis \((h_{j})_{j\geqslant 0}\) from Hermite polynomials \((H_{j})_{j\geqslant 0}\) :
The family \((H_{j})_{j\geqslant 0}\) is orthogonal with respect to the weight function \(e^{-x^{2}}\): \(\int_{\mathbb{R}}H_{j}(x)H_{k}(x)e^{-x^{2}}dx=2^{j}j!\sqrt{\pi}\delta_{j,k}\) (see [1], 22.2.14). It follows that \((h_{j})_{j\geqslant 0}\) is an orthonormal basis on \(\mathbb{R}\). Moreover, \(h_{j}\) is bounded by
(see [1], Chap. 22.14.17 and [22]). The derivatives of \(h_{j}\) also satisfy a recursive formula (see [13], Eq. (52) in Section 8.2),
In the sequel, we denote by \(\varphi_{j}\) either for \(h_{j}\) in the Hermite case or for \(\ell_{j}\) in the Laguerre case. Let \(g\in\mathbb{L}^{2}(\mathbb{R})\) or \(g\in\mathbb{L}^{2}(\mathbb{R}^{+})\), \(g\) develops either in the Hermite basis or the Laguerre basis:
Define, for an integer \(m\geqslant 1\), the space
The orthogonal projection of \(g\) on \(S_{m}\) is given by: \(g_{m}=\sum_{j=0}^{m-1}a_{j}(g)\varphi_{j}\).
2 ESTIMATION OF THE DERIVATIVES
2.1 Assumptions and Projection Estimator of \(f^{(d)}\)
Let \(X_{1},\dots,X_{n}\) be \(n\) i.i.d. random variables with common density \(f\) with respect to the Lebesgue measure and consider the following assumptions. Let \(d\) be an integer, \(d\geqslant 1\).
(A1) The density \(f\) is \(d\)-times differentiable and \(f^{(d)}\) belongs to \(\mathbb{L}^{2}(\mathbb{R}^{+})\) in the Laguerre case or \(\mathbb{L}^{2}(\mathbb{R})\) in the Hermite case.
(A2) For all integer \(r\), \(0\leqslant r\leqslant d-1\), we have \(||f^{(r)}||_{\infty}<+\infty\).
(A3) For all integer \(r\), \(0\leqslant r\leqslant d-1\), it holds \(\lim_{x\to 0}f^{(r)}(x)=0\).
Assumption (A3) is specific to the Laguerre case and avoids boundary issue. In particular, it permits to establish Lemma 2.1 below that is central to define our estimator. This assumption can be removed at the expense of additional technicalities, see Section 3. Under (A1), we develop \(f^{(d)}\) in the Laguerre or Hermite basis, its orthogonal projection on \(S_{m}\), \(m\geqslant 1\), is
The estimator is built by using the following result, proved in Appendix A.
Lemma 2.1. Suppose that (A1) and (A2) hold in the Hermite case and that (A1), (A2), and (A3) hold in the Laguerre case. Then \(a_{j}(f^{(d)})=(-1)^{d}\mathbb{E}[\varphi_{j}^{(d)}(X_{1})],\) \(\forall j\geqslant 0.\)
Remark 1. If the support of the density \(f\) is a strict compact subset \([a,b]\) of the estimation support (here \({\mathbb{R}}\) and \(a<b\) or \({\mathbb{R}}^{+}\) and \(0<a<b\)), then the regularity condition (A1) implies that \(f\) must be null in \(a,b\), as well as its derivatives up to order \(d-1\)( i.e. \(f(x_{0})=f^{(1)}(x_{0})=\dots=f^{(d-1)}(x_{0})=0\) for \(x_{0}\in\{a,b\}\)). On the contrary, Assumption (A3) in the Laguerre case can be dropped out (see Section 3) and this shows that a specific problem occurs when the density support coincides with the estimation interval. This point presents a real difficulty and is either not discussed in the literature, or hidden by periodicity conditions.
We derive the following estimator of \(f^{(d)}\) (see also [18] p. 402): let \(m\geqslant 1\),
For \(d=0\), we recover an estimator of the density \(f\).
2.2 Risk Bound and Rate of Convergence
We consider the \(\mathbb{L}^{2}\)-risk of \(\widehat{f}_{m,(d)}\), defined in (7),
where \(f_{m}^{(d)}:=\sum_{k=0}^{m-1}a_{j}(f^{(d)})\varphi_{j}.\) The study of the second right-hand-side term of the equality (variance term) leads to the following result.
Theorem 2.1. Suppose that (A1) and (A2) hold in the Hermite case and that (A1), (A2), and (A3) hold in the Laguerre case. Assume that
Then, for sufficiently large \(m\geqslant d\), it holds that
for a positive constant \(C\) depending on the moments in condition (9) (but not on \(m\) nor \(n\)).
Remark 2. In the Laguerre case, condition (9) is a consequence of (A3) and \(f^{(d)}(0)<+\infty\). Indeed, (A3) imposes that \(f(x)\underset{x\to 0}{\sim}x^{d}f^{(d)}(x)\) which, under \(f^{(d)}(0)<+\infty\), ensures integrability of \(x^{-d-1/2}f(x)\) around \(0^{+}\) (i.e., \(\int_{0}x^{-d-1/2}f(x)dx<\infty\)); integrability near \(\infty\) is a consequence of \(f\in\mathbb{L}^{1}([0,\infty))\).
The bound obtained for \(\widehat{f}_{m,(d)}\) in Theorem 2.1 is sharp. Indeed, we can establish the following lower bound.
Proposition 2.1. Under the assumptions of Theorem 2.1, it holds, for some constant \(c>0\), that
2.3 Definition of Regularity Classes and Rate of Convergence
The first two terms in the right hand side of (10) have an antagonistic behavior with respect to \(m\): the first term, \(||{f^{(d)}_{m}}-f^{(d)}||^{2}\) is a squared bias term which decreases when \(m\) increases, while the second \(m^{d+1/2}/n\) is a variance term which increases with \(m\). Thus, the optimal choice of \(m\) requires a bias-variance compromise which allows to derive the rate of convergence of \(\widehat{f}_{m,(d)}\). To evaluate the order of the bias term, we introduce Sobolev–Hermite and Sobolev–Laguerre regularity classes for \(f\) (see [9, 13]).
2.3.1. Sobolev–Hermite classes. Let \(s>0\) and \(D>0\), define the Sobolev–Hermite ball of regularity \(s\)
where \(a_{k}^{2}(\theta)=\langle\theta,h_{k}\rangle\) and \(k^{s}\) is to be understood as \((\sqrt{k})^{2s}\), see Remark 3 below. The following Lemma 2.2 relates the regularity of \(f^{(d)}\) and the one of \(f\).
Lemma 2.2. Let \(s\geqslant d\) and \(D>0\), assume that \(f\) belongs to \(W_{H}^{s}(D)\) and (A1), then there exist a constant \(D_{d}>D\) such that \(f^{(d)}\) is in \(W_{H}^{s-d}(D_{d}).\)
2.3.2. Sobolev–Laguerre classes. Similarly, consider the Sobolev–Laguerre ball of regularity \(s\)
where \(a_{k}(\theta)=\langle\theta,\ell_{k}\rangle\). If \(s\geqslant 1\) an integer, there is an equivalent norm of \(|\theta|_{s}^{2}\) (see Section 7.2 of [4]) defined by
This inspires the definition, for \(s\in\mathbb{N}\) and \(D>0\), of the subset \(\widetilde{W}_{L}^{s}(D)\) as
It is straightforward to see that \(\widetilde{W}_{L}^{s}(D)\subset W_{L}^{s}(D)\). Moreover, we can relate the regularity of \(f^{(d)}\) and the one of \(f\).
Lemma 2.3. Let \(s\in\mathbb{N},\) \(s\geqslant d\geqslant 1\), \(D>0\) and \(\theta\in\widetilde{W}_{L}^{s}(D)\), then, \(\theta^{(d)}\in\widetilde{W}_{L}^{s-d}(D_{d})\) where \(D\leqslant D_{d}<\infty\).
2.3.3. Rate of convergence of \(\widehat{\boldsymbol{f}}_{\boldsymbol{m,(d)}}\). Assume that \(f\in W_{H}^{s}(D)\) or \(f\in\widetilde{W}_{L}^{s}(D)\), then Lemmas 2.2 and 2.3 enable a control of the bias term in (10)
Injecting this in (10) yields
Remark 3. We stress that the squared bias and variance terms have orders specific to the use of Laguerre or Hermite bases. For instance if \(d=0\), the latter bound becomes \(m^{-s}+c\sqrt{m}/n\) showing that the associated spaces are represented by the square root of their dimension and not their dimension. Analogously in the context of derivatives, the role of the dimension in [34] is played in our case by \(\sqrt{m}\).
Consequently, selecting \(m_{\textrm{opt}}=[n^{2/(2s+1)}]\) gives the rate of convergence
where \(C(s,d,D)\) depends only on \(s\), \(d\), and \(D\), not on \(m\). This rate coincides with the one obtained by [34] in the dependent case and by [18]. Contrary to [32] and [27], we set the regularity conditions on the function \(f\) and not on its derivatives: for a regularity \(s\) of \(f^{(d)}\), they obtain a quadratic risk \(n^{-2(s-d)/(2s+1)}\) (case \(p=2\) in [27] and dimension 1). Interestingly, \(m_{\textrm{opt}}\) does not depend on \(d\). This is in accordance with [27]’s strategy, which consists in plugging in the derivative kernel estimator the bandwidth selected for the direct density estimation problem. Note that, for \(d=0\) in (15), we recover the optimal rate for estimation of the density \(f\).
Remark 4. If \(f\) is a mixture of Gaussian densities in the Hermite case or a mixture of Gamma densities in the Laguerre case, it is known from Section 3.2 in [13] that the bias decreases with exponential rate. The computations therein can be extended to the present setting and imply in both Hermite and Laguerre cases that \(m_{\textrm{opt}}\) is then proportional to \(\log(n)\). Therefore the risk has order \([\log(n)]^{d+\frac{1}{2}}/n\): for these collections of densities, the estimator converges much faster than in the general setting.
2.4 Lower Bound
Contrary to the lower bound given in Proposition 2.1, which ensures that the upper bound derived in Theorem 2.1 for the specific estimator \(\widehat{f}_{m,(d)}\) is sharp, we provide a general lower bound that guarantees that the rate of the estimator \(\widehat{f}_{m,(d)}\) is minimax optimal. The following assertion states that the rate obtained in (15) is the optimal rate.
Let \(s\geqslant d\) be an integer and \(\widetilde{f}_{n,d}\) be any estimator of \(f^{(d)}\). Then for \(n\) large enough, we have
where the infimum is taken over all estimator of \(f^{(d)}\), \(c\) a positive constant depending on \(s\) and \(d\), and \(W^{s}(D)\) stands either for \(W_{L}^{s}(D)\) or for \(W_{H}^{s}(D)\).
We provide in Section 5.3 the key elements to establish (16). We emphasize that the proof relies on compactly supported test functions, implying that the lower bound on usual Sobolev spaces and the present one coincide, as these functions belong to both. This had to be checked since Hermite Sobolev spaces are strict subspaces of usual Sobolev spaces. Similar lower bounds were known for this model for different regularity spaces. We mention e.g., (7.3.3) in[16], which considers perdiodic Lispchitz spaces, or [27], which examines general Nikol’ski spaces.
2.5 Adaptive Estimator of \(f^{(d)}\)
The choice of \(m_{\textrm{opt}}=[n^{2/(2s+1)}]\) leading to the optimal rate of convergence is not feasible in practice. In this section we provide an automatic choice of the dimension \(m\), from the observations \((X_{1},\ldots,X_{n})\), that realizes the bias-variance compromise in (10). Assume that \(m\) belongs to a finite model collection \(\mathcal{M}_{n,d}\), we look for \(m\) that minimizes the bias-variance decomposition (8) rewritten as
Note that the bias is such that \(||{f^{(d)}_{m}}-f^{(d)}||^{2}=||f^{(d)}||^{2}-||f^{(d)}_{m}||^{2}\) where \(||f^{(d)}||^{2}\) is independent of \(m\) and can be dropped out. The remaining quantity \(-||f^{(d)}_{m}||^{2}\) is estimated by \(-||\widehat{f}_{m,(d)}||^{2}\). The variance term is replaced by an estimator of a sharp upper bound, given by
Finally, we set
where \(\kappa\) is a positive numerical constant. If we set \(V_{m,d}:=\sum_{j=0}^{m-1}\operatorname{\mathbb{E}}[(\varphi_{j}^{(d)}(X_{1})^{2})]\), it holds \(\mathbb{E}[\widehat{{\textrm{pen}}}_{d}(m)]=\kappa{V_{m,d}}/{n}\). In the sequel, we write \({\textrm{pen}}_{d}(m):=\kappa{V_{m,d}}/{n}\). To implement the procedure a value for \(\kappa\) has to be set. Theorem 2.2 below provides a theoretical lower bound for \(\kappa\), which is however generally too large. In practice this constant is calibrated by intensive preliminary experiments, see Section 4. General calibration methods can be found in [3] for theoretical explanations and heuristics, and in the associated package, for practical implementation.
Remark 5. Note that in the definition of the penalty, instead of (18), we can plug the deterministic upper bound on the variance and take \(c\,m^{d+\frac{1}{2}}/n\) as a penalty (see Theorem 2.1) as Proposition 2.1 ensures its sharpness. However, this upper bound relies on additional assumptions given in (9) and depends on non explicit constants (see [2]). This is why we choose to estimate directly the variance by \(\widehat{V}_{m,n}\) and use \(\widehat{V}_{m,n}/n\) as the penalty term.
Theorem 2.2. Let \(\mathcal{M}_{n,d}:=\{d,\dots,m_{n}(d)\}\), where \(m_{n}(d)\geqslant d\). Assume that (A1) and (A2) hold, and that (A3) holds in the Laguerre case, and that \(||f||_{\infty}<+\infty\).
AL. Set \(m_{n}(d)=\lfloor(n/\log^{3}(n))^{\frac{2}{2d+1}}\rfloor\), assume that \(\sup_{x\in\mathbb{R}^{+}}\frac{f(x)}{x^{d}}<+\infty\) in the Laguerre case.
AH. Set \(m_{n}(d)=\lfloor n^{\frac{2}{2d+1}}\rfloor\) in the Hermite case.
Then, for any \(\kappa\geqslant\kappa_{0}:=32\) it holds that
where C is a universal constant (\(C=3\) suits) and \(C^{\prime}\) is a constant depending on \(\sup_{x\in\mathbb{R}^{+}}\frac{f(x)}{x^{d}}<+\infty\) and \(\mathbb{E}[X_{1}^{-d-1/2}]<+\infty\) (Laguerre case) or \(||f||_{\infty}\) (Hermite case).
The constraint on the the largest element \(m_{n}(d)\) of the collection \(\mathcal{M}_{n,d}\) ensures that the variance term, which is upper bounded by \(m^{d+\frac{1}{2}}/n\) vanishes asymptotically. The additional \(\log\) term does not influence the rate of the optimal estimator: the optimal (and unknown) dimension \(m_{\textrm{opt}}\asymp n^{\frac{2}{2s+1}}\), with \(s\) the regularity index of \(f\), is such that \(m_{\textrm{opt}}\ll n^{\frac{2}{2d+1}}\) as soon as \(s>d\). For \(s=d\), a log-loss in the rate would occur in the Laguerre case, but not in the Hermite case.
Note that, in the Laguerre case, condition \(\sup_{x\in\mathbb{R}^{+}}\frac{f(x)}{x^{d}}<+\infty\) implies \({\mathbb{E}}(X_{1}^{-d-1/2})<+\infty\) (see condition (9)) and is clearly related to (A3). Inequality (19) is a key result and expresses that \(\widehat{f}_{\widehat{m}_{n},(d)}\) realizes automatically a bias-variance compromise and is performing as well as the best model in the collection, up to the multiplicative constant \(C\), since clearly, the last term \(C^{\prime}/n\) is negligible. Thus, for \(f\) in \(\widetilde{W}_{L}^{s}(D)\) or \(W_{H}^{s}(D)\) and under the assumptions of Theorem 2.2, we have \(\mathbb{E}\big{[}||\widehat{f}_{\widehat{m},(d)}-f^{(d)}||^{2}\big{]}=\mathcal{O}(n^{-2(s-d)/(2s+1)})\), which implies that the estimator is adaptive.
3 FURTHER QUESTIONS
We investigate here additional questions, and set for simplicity \(d=1\). Mainly, we compare our estimator to the derivative of a density estimator, and discuss condition (A3) in the Laguerre case.
3.1 Derivatives of the Density Estimator
When using kernel strategies, it is classical to build an estimator of the derivative of \(f\) by differentiating the kernel density estimator, as already mentioned in the Introduction. For projection estimators, we find more relevant to proceed differently. Indeed, our aim is to obtain an estimator expressed in an orthonormal basis; unfortunately, the derivative of an orthonormal basis is a collection of functions but not an orthonormal basis. So, our proposal (7) is easier to handle. Moreover, our estimator can be seen as a contrast minimizer, which makes model selection possible to settle up.
However, Laguerre and Hermite cases are somehow different and can be more precisely compared. Let us recall that the projetion estimator of \(f\) on \(S_{m}\) is defined by (see [13] or (7) for \(d=0\)):
As the functions \((\varphi_{j})_{j}\) are infinitely differentiable, both in Hermite and Laguerre settings, this leads to the natural estimator of \(f^{(d)}\), \(d\geqslant 1\),
For \(d=1\), we write \((\widehat{f}_{m})^{(1)}=(\widehat{f}_{m})^{\prime}\). We want to compare \((\widehat{f}_{m})^{\prime}\) to \(\widehat{f}_{m,(1)}\). In both Hermite and Laguerre cases, this estimator is consistent, under adequate regularity assumptions and for adequate choice of \(m\) as a function of \(n\).
3.2 Comparison of \(\widehat{f}_{m,(1)}\) with \((\widehat{f}_{m})^{\prime}\) in the Hermite Case
Using the recursive formula (5), in (20) and (7), respectively, straightforward computations give
whereas
Therefore, it holds that \(\mathbb{E}[||(\widehat{f}_{m})^{\prime}-\widehat{f}_{m,(1)}||^{2}]={m}/{2}\big{\{}\operatorname{\mathbb{E}}\big{[}(\widehat{a}^{(0)}_{m})^{2}\big{]}+\operatorname{\mathbb{E}}\big{[}(\widehat{a}^{(0)}_{m-1})^{2}\big{]}\big{\}}\) and
Using Lemma 8.5 in [13] under \({\mathbb{E}}[|X_{1}|^{2/3}]<+\infty\) and for \(f\) in \(W^{s}_{H}(D)\), \(s>1\), it follows for some positive constant \(C\) that,
Under the same assumptions, (10) for \(d=1\) implies
Therefore, by triangle inequality, this implies that \((\widehat{f}_{m})^{\prime}\) reaches the same (optimal) rate as \(\widehat{f}_{m,(1)}\), under the same assumptions.
3.3 Comparison of \(\widehat{f}_{m,(1)}\) with \((\widehat{f}_{m})^{\prime}\) in the Laguerre Case
In the Laguerre case, assumption (A3) is required for the estimator \(\widehat{f}_{m,(1)}\) to be consistent, while it is not for the estimator \((\widehat{f}_{m})^{\prime}\).
Proceeding as previously and taking advantage of the recursive formula (2) in (20) and (7), respectively, straightforward computations give, for \(m\geqslant 1\),
Therefore, in the Laguerre case, the coefficients of \(\widehat{f}_{m,(1)}\) in the basis \((\ell_{j})_{j}\) do not depend on \(m\) while those of \((\widehat{f}_{m})^{\prime}\) do. Moreover, computing the difference between the estimators leads to \(\widehat{f}_{m,(1)}-(\widehat{f}_{m})^{\prime}=2\sum_{j=0}^{m-1}(\sum_{k=0}^{m-1}\widehat{a}_{k}^{(0)})\ell_{j}\) and
Heuristically, if \(f(0)=0\), as \(f(0)=\sqrt{2}\sum_{j\geqslant 0}a_{j}(f)=0\), it follows that \(\sum_{j=0}^{m-1}a_{j}(f)\) should be small for \(m\) large enough. Consequently, its consistent estimator \(\sum_{k=0}^{m-1}\widehat{a}_{k}^{(0)}\) should also be small. This would imply that, when \(f(0)=0\), the distance \(||\widehat{f}_{m,(1)}-(\widehat{f}_{m})^{\prime}||^{2}\) can be small; on the contrary, the distance should tend to infinity with \(m\) if \(f(0)\neq 0\). This is due to the fact that \(\widehat{f}_{m,(1)}\) is not consistent, while \((\widehat{f}_{m})^{\prime}\) is. Indeed, in the general case (\(f(0)\neq 0\)), the risk bound we obtain for \((\widehat{f}_{m})^{\prime}\) is the following.
Proposition 3.1. Assume that (A1) and (A2) hold for \(d=1\) and that \(f\) belongs to \(W_{L}^{s}(D)\). Then, it holds
Obviously, for suitably chosen \(m\) the estimator is consistent and by selecting \(m_{{\textrm{opt}}}\asymp n^{1/s}\), it reaches the rate: \(\mathbb{E}[||(\widehat{f}_{m_{{\textrm{opt}}}})^{\prime}-f^{\prime}||^{2}]\leqslant C(s,D)n^{-(s-2)/s}.\) This rate is worse than the one obtained for \(\widehat{f}_{m,(1)}\) but it is valid without (A3), and thus \(\widehat{f}_{m,(1)}\) is consistent to estimate an exponential density, or any mixture involving exponential densities. Note that both the order of the bias and the variance in (22) are deteriorated compared to (10), and we believe these orders are sharp.
In the following section, we investigate if the rate can be improved, if (A3) is not satisfied, by correcting our estimator (6).
3.4 Estimation of \(f^{\prime}\) on \(\mathbb{R}^{+}\) with \(f(0)>0\)
Assumption (A3) excludes some classical distribution such as the exponential distribution or Beta distributions \(\beta(a,b)\) with \(a=1\). If \(f(0)>0\), Lemma 2.1 no longer holds, and one has \(a_{j}(f^{\prime})=-f(0)\ell_{j}(0)-\mathbb{E}[\ell_{j}^{\prime}(X_{1})]\) instead. Therefore, \(f(0)\) has to be estimated and we consider
We estimate \(f^{\prime}\) as follows
Obviously, \(\widehat{a}_{j,K}^{(1)}\) is a biased estimator of \(a_{j}(f^{\prime})\), implying that \(\widetilde{f}_{m,K}^{\prime}\) is a biased estimator of \(f_{m}^{\prime}\). Now there are two dimensions \(m\) and \(K\) to be optimized. We can establish the following upper bound.
Proposition 3.2. Suppose (A1) is satisfied for \(d=1\), then it holds that
where \(f_{K}\) is the orthogonal projection of \(f\) on \(S_{K}\) defined by: \(f_{K}=\sum_{j=0}^{K-1}a_{j}(f)\ell_{j}\).
The first two terms of the upper bound seem similar to the ones obtained under (A3), but as we no longer assume \(f(0)=0,\) Assumption (9) for \(d=1\) cannot hold and the tools used to bound the variance term \(V_{m,1}\) by \(m^{3/2}\) no longer apply: we only get an order \(m^{2}\) for this term, under \(||f||_{\infty}<+\infty\).
The last two terms of (25) correspond to \(m\) times the pointwise risk of \(\widehat{f}_{K}(0)\). Then, using \(||\ell_{j}||_{\infty}\leqslant\sqrt{2}\), we obtain \(\textrm{Var}(\widehat{f}_{K}(x))\leqslant 4K^{2}/n\). If \(||f||_{\infty}<\infty\), this can be improved in \(\textrm{Var}(\widehat{f}_{K}(x))\leqslant||f||_{\infty}\,K/n,\) using the orthonormality of \((\ell_{j})_{j}\).
To sum up, if \(f\in\widetilde{W}_{L}^{s}(D)\), and \(||f||_{\infty}<\infty\), then
Choosing \(K_{{\textrm{opt}}}=cn^{1/s}\) and \(m_{{\textrm{opt}}}=cn^{1/s}\) gives the rate \(\mathbb{E}\big{[}||\widetilde{f}_{m_{{\textrm{opt}}},K_{{\textrm{opt}}}}^{\prime}-f^{\prime}||^{2}\big{]}\leqslant Cn^{-(s-2)/s}\), that is the same rate as the one obtained for \((\widehat{f}_{m_{{\textrm{opt}}}})^{\prime}\). Then, renouncing to Assumption (A3) has a cost, it renders the procedure burdensome and leads to slower rates.
We propose a model selection procedure adapted to this new estimator. Let
where \(\gamma_{n}(t)=||t||^{2}+\frac{2}{n}\sum_{i=1}^{n}t^{\prime}(X_{i})+2t(0)\widehat{f}_{K}(0).\) Here, we consider that \(K=K_{n}\) is chosen so that \(\widehat{f}_{K_{n}}\) satisfies
This assumption is likely to be fulfilled for a \(K\) selected in order to provide a squared bias/variance compromise, see the pointwise adaptive procedure for density estimation in [31]; however therein, the choice of \(K\) is random while we set \(K_{n}\) as fixed, here. Then, we select \(m\) as follows:
with
It is easy to ckeck that \(\gamma_{n}(\widehat{f^{\prime}}_{m,K})=-||\widehat{f^{\prime}}_{m,K}||^{2}\). We prove the following result.
Theorem 3.1. Let \(\widehat{f^{\prime}}_{m,K_{n}}\) be defined by (26) with \(m=\widehat{m}_{K_{n}}\) selected by (28), (29) and \(K_{n}\) such that (27) holds. Then for \(c_{1}\) and \(c_{2}\) larger than fixed constants \(c_{0,1},c_{0,2}\), we have
where \(C\) is a numerical constant and \(C^{\prime}\) depends on \(f\) .
Theorem 3.1 implies that the adaptive estimator \(\widehat{f^{\prime}}_{m,K_{n}}\) provides the adequate compromise, up to log terms.
4 NUMERICAL EXAMPLES
In this section, we provide a nonexhaustive illustration of our theoretical results.
4.1 Simulation Setting and Implementation
We illustrate the performances of the adaptive estimator \(\widehat{f}_{\widehat{m}_{n},(d)}\) defined in (7), with \(\widehat{m}\) selected by (17), (18), for different distributions and values of \(d\) (\(d=1,2\)). In the Hermite case we consider the following distributions which are estimated on the interval \(I\), which we fix to ensure reproducibility of our experiments:
(i) Gaussian standard \(\mathcal{N}(0,1)\), \(I=[-4,4],\)
(ii) Mixed Gaussian \(0.4\mathcal{N}(-1,1/4)+0.6\mathcal{N}(1,1/4)\), \(I=[-2.5,2.5],\)
(iii) Cauchy standard, density: \(f(x)=(\pi(1+x^{2}))^{-1}\), \(I=[-6,6],\)
(iv) Gamma \(\Gamma(5,5)/10\), \(I=[0,7],\)
(v) Beta \(5\beta(4,5)\), \(I=[0,5]\).
In the Laguerre case we consider densities (iv), (v) and the two following additional distributions
(vi) Weibull \(W(4,1)\), \(\textrm{I}=[0,1.5],\)
(vii) Maxwell with density \(\sqrt{2}x^{2}e^{-x^{2}/(2\sigma^{2})}/(\sigma^{3}\sqrt{\pi})\), with \(\sigma=2\) and \(\textrm{I}=[0,8].\)
All these distributions satisfy Assumptions (A1), (A2) and densities (iv)-(vii) satisfy (A3). The moment conditions given in (9) are fulfilled for \(d=1,2\), even by the Cauchy distribution (iii) which has finite moments of order \(2/3<1\). For the adaptive procedure, the model collection considered is \(\mathcal{M}_{n,d}=\{d,\dots,m_{n}(d)\}\), where the maximal dimension is \(m_{n}(d)=50\) in the Laguerre case and \(m_{n}(d)=40\) in the Hermite case, for all values of \(n\) and \(d\) (smaller values may be sufficient and spare computation time). In practice, the adaptive procedure follows the steps.
\(\bullet\) For \(m\) in \(\mathcal{M}_{n,d}\), compute \(-\sum_{j=0}^{m-1}(\widehat{a}_{j}^{(d)})^{2}+\widehat{{\textrm{pen}}}_{d}(m)\), with \(\widehat{a}_{j}^{(d)}\) given in (7) and \(\widehat{{\textrm{pen}}}_{d}(m)\) in (18).
\(\bullet\) Choose \(\widehat{m}_{n}\) via \(\widehat{m}_{n}=\underset{m\in\mathcal{M}_{n,d}}{\text{argmin }}\{-\sum_{j=0}^{m-1}(\widehat{a}_{j}^{(d)})^{2}+\widehat{{\textrm{pen}}}_{d}(m)\}\).
\(\bullet\) Compute \(\widehat{f}_{\widehat{m}_{n},(d)}=\sum_{j=0}^{\widehat{m}-1}\widehat{a}_{j}^{(d)}\varphi_{j}\).Then, we compute the empirical mean integrated squared errors (MISE) of \(\widehat{f}_{\widehat{m}_{n},(d)}\). For that, we first compute the ISE by Riemann discretization in 100 points: for the \(j\)th path, and the \(j\)th estimate \(\widehat{g}_{\widehat{m}}^{(j)}\) of \(g\), where \(g\) stands either for the density \(f\) or for its derivative \(f^{\prime}\), we set
for \(j=1,\dots R\). To get the MISE, we average over \(j\) of these \(R\) values of ISEs. The constant \(\kappa\) in the penalty is calibrated by preliminary experiments. A comparison of the MISEs for different values of \(\kappa\) and different distributions (distinct from the previous ones to avoid overfitting) allows to choose a relevant value. We take \(\kappa=3.5\) for the density and its first derivative and \(\kappa=5\) for the second order derivative in the Laguerre case or \(\kappa=4\) for the density and its first derivative and \(\kappa=6.5\) for the second order derivative in the Hermite case.
Comparison with kernel estimators. We compare the performances of our method with those of kernel estimators, and start by density estimation (\(d=0\)). The density kernel estimator is defined as follows
where \(h>0\) is the bandwidth and \(K\) a kernel such that \(\int K(x)dx=1\). These two quantities (\(h\) and \(K\)) are user-chosen. For density estimation, we use the function implemented in the statistical software R called density, where the kernel is chosen Gaussian and the bandwidth selected by plug-in (R-function bw.SJ), see Tables 2 and 4.
For the estimation of the derivative, the kernel estimator we compare with (see Tables 3 and 5) is defined by:
In that latter case there is no ready-to-use procedure implemented in R; therefore, we generalize the adaptive procedure of [25] from density to derivative estimation. To that aim, we consider a kernel of order 7 (i.e. \(\int x^{j}K(x)dx=0\), for \(j=1,\dots,7\)) built as a Gaussian mixture defined by:
where \(n_{j}(x)\) is the density of a centered Gaussian with a variance equal to \(j\): the higher the order, the better the results, in theory (see [42]) and in practice (see [14]). By analogy with the proposal of [25] for density estimation, we select \(h\) by:
where \(h_{\textrm{min}}=\min\mathcal{H}\), for \(\mathcal{H}\) the collection of bandwidths chosen in \([c/n,1]\) and \(K_{h}(x)=\frac{1}{h}K(\frac{x}{h})\). Note that
and this term can be explicitely computed with the definition of \(K\) in (30).
4.2 Results and Discussion
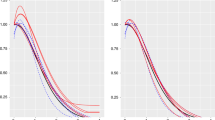
Figures 1 and 2 show 20 estimated \(f\), \(f^{\prime}\), \(f^{\prime\prime}\) in case (ii), for two values of \(n\), 500 and 2000. These plots can be read as variability bands illustrating the performance and the stability of the estimator. We observe that increasing \(n\) improves the estimation and, on the contrary, that increasing the order of the derivative makes the problem more difficult. The means of the dimensions selected by the adaptive procedure are given in Table 1. Unsurprisingly, this dimension increases with the sample size \(n\). In average, these dimensions are comparable for \(d\in\{0,1,2\}\), this is in accordance with the theory: the optimal value \(m_{\textrm{opt}}\) does not depend on \(d\).

20 estimates \(\widehat{f}_{\widehat{m}_{n},(d)}\) in the Hermite basis of a Mixed Gaussian distribution (ii), with \(n=500\) (first line) and \(n=2000\) (second line). The true quantity is in bold red and the estimate in dotted lines (left \(d=0\), middle \(d=1\), and right \(d=2\)).

20 estimates \(\widehat{f}_{\widehat{m}_{n},(d)}\) in the Laguerre basis of a Gamma distribution (iv), with \(n=500\) (first line) and \(n=2000\) (second line). The true quantity is in bold red and the estimate in dotted lines (left \(d=0\), middle \(d=1\), and right \(d=2\)).
Tables 2 and 4 for \(d=0\) and Tables 3 and 5 for \(d=1\) allow to compare the MISEs obtained with our method and the kernel method for different sample sizes and densities.The error decreases when the sample size increases for both methods. For density estimation (\(d=0\)), the results obtained with our Hermite projection method in Table 2 are better in most cases than the kernel competitor, except for smallest sample size \(n=100\) and Gamma (iv) and Beta (v) distributions. Table 3 gives the risks obtained for derivative estimation in the Hermite basis: our method is better for densities (i)–(iii) (except for \(n=100\) for Gaussian distribution (i)), but the kernel method is often better for densities (iv) and (v); they correspond to Gamma and beta densities which are in fact with support included in \({\mathbb{R}}^{+}\).
In Table 4, we compare the errors obtained for densities (iv)–(vii) with support in \({\mathbb{R}}^{+}\). Our method is always better than the R-kernel estimate. For the derivatives, in Table 5, our method and the kernel estimator seem equivalent. Lastly, Table 6 allows to compare Laguerre and Hermite bases for the estimation of the second order derivatives of functions (iv) and (v), for larger sample sizes. As expected, the risks are larger, because the degree of ill posedness increases and thus the rate deteriorates. For these \({\mathbb{R}}^{+}\)-supported functions, the Laguerre basis is clearly better. It is possible that scale of the functions themselves also increase (multiplicative factors appearing by derivation). Note that the same phenomenon is observed for the \({\mathbb{L}}^{1}\)-risk computed in [36], see their Table 1.
5 PROOFS
In the sequel \(C\) denotes a generic constant whose value may change from line to line and whose dependency is sometimes given in indexes.
5.1 Proof of Theorem 2.1
Following (8) we study the variance term, notice that \(\mathbb{E}\big{[}||\widehat{f}_{m,(d)}-{f^{(d)}_{m}}||^{2}\big{]}=\sum_{j=0}^{m-1}\textrm{Var}(\widehat{a}_{j}^{(d)})\). By definition of \(\widehat{a}_{j}^{(d)}\) given in (7), we have
Clearly, \(\sum_{j=0}^{m-1}a_{j}^{2}(f^{(d)})=||f_{m}^{(d)}||^{2}\). In the sequel we denote by \(V_{m,d}\) the quantity
The remaining of the proof consists in showing that under (9) we have \(V_{m,d}\leqslant cm^{d+1/2}.\) For that, write
where
To bound the second term in (33), we consider separately Hermite and Laguerre cases.
5.1.1. The Laguerre case. We derive from (1) that
Using [24], Eq. (2.10), we derive
Moreover, introduce the orthonormal basis on \(\mathbb{L}^{2}(\mathbb{R}^{+})\) \((\ell_{k,(\delta)})_{0\leqslant k<\infty}\) by
Therefore, \((L_{j}(2x))^{(k)}=2^{k}L_{j-k,(k)}(2x)\mathbf{1}_{j\geqslant k}\), so that
where \(\ell_{j,(\delta)}\) is defined in (35). Using the Cauchy Schwarz inequality in (36), we derive that
Now we rely on the following Lemma, proved in Appendix A.
Lemma 5.1. Let \(j\geqslant k\geqslant 0\) and suppose that \(\mathbb{E}[X^{-k-1/2}]<+\infty\), it holds, for a positive constant \(C\) depending only on \(k\), that
From Lemma 5.1, we obtain
Plugging this and (34) in (33), gives the result (10) and Theorem 2.1 in the Laguerre case.
5.1.2. The Hermite case. We first introduce a useful technical result, its proof is given in Appendix A.
Lemma 5.2. Let \(h_{j}\) given in (3), the dth derivative of \(h_{j}\) is such that
Using successively Lemma 5.2, the Cauchy Schwarz inequality and Lemma 8.5 in [13] (using that \(\operatorname{\mathbb{E}}[|X_{1}|^{2/3}]<\infty\)), we obtain, for \(k+j\) large enough,
Plugging (38) and (34) in (33) leads to inequality (10) and Theorem 2.1 in the Hermite case.
5.2 Proof of Proposition 2.1
We build a lower bound for (8). Recalling (31) and notation \(V_{m,d}=\sum_{j=0}^{m-1}\mathbb{E}[(\varphi_{j}^{(d)}(X_{1}))^{2}]\), to establish Proposition 2.1, we have to build a minorant for \(V_{m,d}.\) We consider separately the Laguerre and Hermite cases.
5.2.1. The Laguerre case. Using (36), we have
It follows that
For the first term, as (A1) ensures that \(f\) is a continuous density, there exist \(0\leqslant a<b\) and \(c>0\), such that \(\inf_{a\leqslant x\leqslant b}f(x)\geqslant c>0.\) We derive
By Theorem 8.22.5 in [40], for \(\delta>-1\) an integer, and for \(\underline{b}/j\leqslant x\leqslant\bar{b}\), where \(\underline{b}\), \(\bar{b}\) are arbitrary positive constants, it holds
where \(\mathcal{O}(1)\) is uniform on \([\underline{b}/j,\bar{b}]\) and \(\mathfrak{d}=2^{1/4}/\sqrt{\pi}\). It follows that,
We derive that \(\int_{a}^{b}\ell_{j-d,(d)}^{2}(x)dx\geqslant C(j-d)^{-1/2},\) after a change of variable \(y=\sqrt{x},\) for some positive constant \(C\) depending on \(a,b\), and \(d\). Consequently, it holds
where \(C^{\prime}\) depends on \(a\), \(b\), \(c\), and \(d\). For the second term, we have
By Lemma 5.1, it follows that
This together with (40), lead to \(\int_{0}^{+\infty}(\ell_{j}^{(d)})^{2}(x)f(x)dx\geqslant C^{\prime}j^{d-\frac{1}{2}},\quad j\geqslant 2d\) where \(C\) depends on \(a,b,c\), and \(d\). We derive
which ends the proof in the Laguerre case.
5.2.2. The Hermite case. The proof is similar to the Laguerre case. Consider the following expression of \(h_{j}\) (see [40], p. 248):
where \(\lambda_{j}=|h_{j}(0)|\) for \(j\) even or \(\lambda_{j}=|h_{j}^{\prime}(0)|/(2j+1)^{1/2}\) for \(j\) odd and
By Stirling formula, it holds
Differentiating (42), we get
Note that if \(d=2\) it holds
From (A1), there exists \(a<b\) and \(c>0\) such that \(\inf_{a\leqslant x\leqslant b}f(x)\geqslant c>0.\) It follows
For the first term, using \(\cos^{2}(x)=(1+\cos(2x))/2\) and (43), we get
For the second term we first show that
To establish (45) we first note, using (44), that for \(d\geqslant 2\), \(\forall x\in\mathbb{R}\),
Together with Lemma 5.2, one easily obtains by induction that \(\forall x\in[a,b]\), \(\forall j\geqslant 0\), \(\Psi_{j,d}(x)=\mathcal{O}(j^{\frac{d-1}{2}}).\) The latter result gives \(\xi_{j}^{(d)}=-j\xi_{j}^{(d-2)}+\Psi_{j,d}\) and an immediate induction on \(d\) leads to (45). Injecting this in \(E_{2}\) gives, together with (43), \(|E_{2}|\leqslant Cj^{d-\frac{3}{4}},\) for a positive constant \(C\) depending on \(a,\ b,\ c\), and \(d\). Gathering the bound on \(E_{1}\) and \(E_{2}\) lead to
and
which ends the proof of the Hermite case.
5.3 Proof of (16)
We apply Theorem 2.7 in [42]. We start by the construction of a family of hypotheses \((f_{\theta})_{\theta}\). The construction is inspired by [5]. Define \(f_{0}\) by
where \(P\) and \(Q\) are positive polynomials, for \(0\leqslant k\leqslant s,\) \(P^{(k)}(0)=Q^{(k)}(3)=0\), \(P^{(k)}(1)=\lim_{x\downarrow 1}(x/2)^{(k)}\), \(Q^{(k)}(2)=\lim_{x\uparrow 2}(x/2)^{(k)}\) and finally \(\int_{0}^{1}P(x)dx=\int_{2}^{3}Q(x)dx=\frac{1}{8}\). Consider \(f_{\theta}\) defined as a perturbation of \(f_{0}\)
for some \(\delta>0\), \({\theta}=(\theta_{1},\dots,\theta_{K})\in\{0,1\}^{K}\), \(\gamma>0\) and \(\psi\) which is supported on \([1,2]\), admits bounded derivatives up to order \(s\) and is such that \(\int_{1}^{2}\psi(x)dx=0\). The lower bound (16) is a consequence of the following Lemma 5.3.
Lemma 5.3. \((i)\). Let \(s\geqslant d\), \(\forall\text{ }\theta\in\{0,1\}^{K}\), there exist \(\delta\) small enough and \(\gamma>0\) such that \(f_{\theta}\) is density. There exists \(D>0\) such that \(f_{\theta}\) belongs to \(W_{H}^{s}(D)\). If in addition \(\gamma\geqslant s-d\), \(f_{\theta}\) belongs to \(W_{L}^{s}(D)\).
\((ii)\). Let \(M\) an integer, for all \(j<l\leqslant M\), \(\forall\theta^{(j)}\), \(\theta^{(l)}\) in \(\{0,1\}^{K}\), it holds \(||f^{(d)}_{\theta^{(j)}}-f^{(d)}_{\theta^{(l)}}||^{2}\geqslant C\delta^{2}K^{-2\gamma}\).
\((iii)\). For \(\delta\) small enough, \(K=n^{1/(2\gamma+2d+1)}\) and for all \((\theta^{(j)})_{1\leqslant j\leqslant M}\in(\{0,1\}^{K})^{M}\), it holds
where \(0<\alpha<1/8\) and \(\chi^{2}(g,h)\) denotes the \(\chi^{2}\) divergence between the distributions \(g\) and \(h\) .
Choosing \(\gamma=s-d\), \(K=n^{1/(2\gamma+2d+1)}\) and \(\delta\) small enough, we derive from Lemma 5.3 that,
The announced result is then a consequence of Theorem 2.7 in [42]. Proof of Lemma 5.3 is omitted, but can be found in the hal-preprint version of the paper.
5.4 Proof of Theorem 2.2
Consider the contrast function defined as follows:
for which \(\widehat{f}_{m,(d)}=\underset{t\in S_{m}}{\text{argmin}}\gamma_{n,d}(t)\) (see (7)) and \(\gamma_{n}(\widehat{f}_{m,(d)})=-||\widehat{f}_{m,(d)}||^{2}\). For two functions \(t,s\in\mathbb{L}^{2}(\mathbb{R})\), consider the decomposition:
where
By (18), it holds for all \(m\in\mathcal{M}_{n,d}\), that \(\gamma_{n,d}(\widehat{f}_{\widehat{m}_{n},(d)})+\widehat{{\textrm{pen}}}_{d}(\widehat{m}_{n})\leqslant\gamma_{n,d}({f^{(d)}_{m}})+\widehat{{\textrm{pen}}}_{d}(m).\) Plugging this in (49) yields, for all \(m\in\mathcal{M}_{n,d}\),
Note that for \(t\in\mathbb{L}^{2}(\mathbb{R})\), \(\nu_{n,d}(t)=||t||\nu_{n,d}\big{(}{t}/{||t||}\big{)}\leq||t||\sup_{s\in S_{m}+S_{\widehat{m}},||s||=1}|\nu_{n,d}(s)|.\) Consequently, using \(2xy\leqslant x^{2}/4+4y^{2}\), we obtain
It follows from (50) and (51) that:
Introduce the function \(p(m,m^{\prime})=4\frac{V_{m\vee m^{\prime},d}}{n}\), we get, after taking the expectation,
The remaining of the proof is a consequence of the following Lemma 5.4.
Lemma 5.4. Under the assumptions of Theorem 2.2, the following hold.
(i) There exists a constant \(\Sigma_{1}\) such that:
(ii) There exists a constant \(\Sigma_{2}\) such that:
Lemma 5.4 yields
Next, for \(\kappa\geqslant 32=:\kappa_{0}\), we have, \(4p(m,\widehat{m}_{n})\leq{\textrm{pen}}_{d}(\widehat{m}_{n})/2+{\textrm{pen}}_{d}(m)/2\). Therefore, we derive
Taking the infimum on \(\mathcal{M}_{n,d}\), \(C=3\) and \(C^{\prime}=2(4\Sigma_{1}+\Sigma_{2})/n\) completes the proof.
5.5 Proof of Proposition 3.1
First, it holds that
For the first bias term, we derive from (2) that \(\langle\ell_{j}^{\prime},\ell_{k}^{\prime}\rangle=2+4j\wedge k\) for \(j\neq k\) and \(\langle\ell_{j}^{\prime},\ell_{j}^{\prime}\rangle=1+4j\), and we derive that
First, for \(f\) in \(W_{L}^{s}(D)\), we have
and by the Cauchy–Schwarz inequality, it holds for a positive constant \(C\),
Thus, it comes
where \(C>0\) depends on \(D\). Second, for the variance term, straightforward computations lead to
By the orthonormality of \((\ell_{j})_{j}\) and (A2), we obtain
From this and (52), the result follows.
5.6 Proof of Proposition 3.2
By the Pythagoras Theorem, we have the bias-variance decomposition \(\mathbb{E}\big{[}||\widetilde{f}_{m,K}^{\prime}-f^{\prime}||^{2}\big{]}=||f^{\prime}-f_{m}^{\prime}||^{2}+\mathbb{E}\big{[}||\widetilde{f}_{m,K}^{\prime}-f_{m}^{\prime}||^{2}\big{]}.\) As \(\ell_{j}(0)=\sqrt{2}\), it follows that
From the orthonormality of \((\ell_{j})_{j}\), it follows
Finally, using that the \((X_{i})_{i}\) are i.i.d. lead to the result in the second variance term.
5.7 Proof of Theorem 3.1
We have the decomposition:
and as \(\langle t,f^{\prime}\rangle=-t(0)f(0)-\int t^{\prime}f,\) we get
First note that for
it holds that
Let us start by writing that, by definition of \(\widehat{m}_{K}\), it holds, \(\forall m\in{\mathcal{M}}_{n}\),
which yields, with (53) and notations introduced in (29),
To get the last line, we write that, for any \(t\in S_{m}\),
and we use that \(2xy\leqslant x^{2}/8+8y^{2}\) for all real \(x,y\). We obtain
where
The following Lemma 5.5 can be proved using the Talagrand inequality (see Appendix B.2).
Lemma 5.5. Under the assumptions of Theorem 3.1, and \({\texttt{b}}\geqslant 6\),
It follows that
This implies that \(8p_{1}(m\vee\widehat{m}_{K})\leqslant{\textrm{pen}}_{1}(m)+{\textrm{pen}}_{1}(\widehat{m}_{K})\) for \(c_{1}\)–defined in (29)–large enough.Moreover, let \({\texttt{a}}>0\) and
where \(Z_{i}^{K}:=\sum_{j=0}^{K-1}\ell_{j}(X_{i})\). To apply the Bernstein Inequality (see Appendix B.3), we compute \(s^{2}=||f||_{\infty}K\) and \(b=\sqrt{2}K\) and note that \(K\log(n)/n\leqslant 1\). Thus, we get that there exist constants \(c_{0}\), \(c\) such that
On \(\Omega_{K}\), it holds that
For any \(K_{n}\leqslant[n/\log(n)]\) satisfying condition (27), we have
Now we note that \(|\widehat{f}_{K}(x)|\leqslant 2K\) for all \(x\in{\mathbb{R}}^{+}\) and any integer \(K\) and by using the definition of (57), provided that \(c_{2}>2{\texttt{a}}+2\), we obtain
the term on \(\Omega_{K_{n}}\) being less than or equal to 0. Plugging this and (55) into (54), we get
which gives the result of Theorem 3.1. \(\Box\)
REFERENCES
M. Abramowitz and I. A. Stegun, Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, Volume 55 of National Bureau of Standards Applied Mathematics Series. For sale by the Superintendent of Documents (U.S. Government Printing Office, Washington, D.C, 1964).
R. Askey and S. Wainger, ‘‘Mean convergence of expansions in Laguerre and Hermite series,’’ Amer. J. Math. 87, 695–708 (1965).
J.-P. Baudry, C. Maugis, and B. Michel, ‘‘Slope heuristics: Overview and implementation,’’ Stat. Comput. 22 (2), 455–470 (2012).
D. Belomestny, F. Comte, and V. Genon-Catalot, ‘‘Nonparametric Laguerre estimation in the multiplicative censoring model,’’ Electron. J. Stat. 10 (2), 3114–3152 (2016).
D. Belomestny, F. Comte, and V. Genon-Catalot, ‘‘Correction to: Nonparametric laguerre estimation in the multiplicative censoring model,’’ Electronic Journal of Statistics 11 (2), 4845–4850 (2017).
D. Belomestny, F. Comte, and V. Genon-Catalot, ‘‘Sobolev-Hermite versus Sobolev nonparametric density estimation on \(\mathbb{R}\),’’ Ann. Inst. Statist. Math. 71 (1), 29–62 (2019).
B. Bercu, S. Capderou, and G. Durrieu, ‘‘Nonparametric recursive estimation of the derivative of the regression function with application to sea shores water quality,’’ Stat. Inference Stoch. Process. 22 (1), 17–40 (2019).
P. Bhattacharya, ‘‘Estimation of a probability density function and its derivatives,’’ Sankhyā: The Indian Journal of Statistics, Series A, 373–382 (1967).
B. Bongioanni and J. L. Torrea, ‘‘What is a Sobolev space for the Laguerre function systems?’’ Studia Math. 192 (2), 147–172 (2009).
J. E. Chacón and T. Duong, ‘‘Data-driven density derivative estimation, with applications to nonparametric clustering and bump hunting,’’ Electronic Journal of Statistics 7, 499–532 (2013).
J. E. Chacón, T. Duong, and M. Wand, ‘‘Asymptotics for general multivariate kernel density derivative estimators,’’ Statistica Sinica, 807–840 (2011).
Y. Cheng, ‘‘Mean shift, mode seeking, and clustering,’’ IEEE transactions on pattern analysis and machine intelligence 17 (8), 790–799 (1995).
F. Comte and V. Genon-Catalot, ‘‘Laguerre and Hermite bases for inverse problems,’’ J. Korean Statist. Soc. 47 (3), 273–296 (2018).
F. Comte and N. Marie, ‘‘Bandwidth selection for the Wolverton–Wagner estimator,’’ J. Statist. Plann. Inference 207, 198–214 (2020).
S. Efromovich, ‘‘Simultaneous sharp estimation of functions and their derivatives,’’ Ann. Statist. 26 (1), 273–278 (1998).
S. Efromovich, ‘‘Nonparametric curve estimation: methods, theory, and applications,’’ Springer Series in Statistics (1999).
C. R. Genovese, M. Perone-Pacifico, I. Verdinelli, and L. Wasserman, ‘‘Non-parametric inference for density modes,’’ J. R. Stat. Soc. Ser. B. Stat. Methodol. 78 (1), 99–126 (2016).
E. Giné and R. Nickl, Mathematical Foundations of Infinite-Dimensional Statistical Models, Vol. 40 (Cambridge University Press. 2016).
W. Härdle, J. Hart, J. S. Marron, and A. B. Tsybakov, ‘‘Bandwidth choice for average derivative estimation,’’ Journal of the American Statistical Association 87 (417), 218–226 (1992).
W. Härdle, W. Hildenbrand, and M. Jerison, Empirical evidence on the law of demand (Econometrica: Journal of the Econometric Society, 1991), p. 1525–1549.
W. Härdle and T. M. Stoker, ‘‘Investigating smooth multiple regression by the method of average derivatives,’’ Journal of the American statistical Association 84 (408), 986–995 (1989).
J. Indritz, ‘‘An inequality for Hermite polynomials,’’ Proc. Amer. Math. Soc. 12, 981–983 (1961).
T. Klein and E. Rio, ‘‘Concentration around the mean for maxima of empirical processes,’’ Ann. Probab. 33 (3), 1060–1077 (2005).
R. Koekoek, ‘‘Generalizations of laguerre polynomials,’’ Journal of Mathematical Analysis and Applications 153 (2), 576–590 (1990).
C. Lacour, P. Massart, and V. Rivoirard, ‘‘Estimator selection: A new method with applications to kernel density estimation,’’ Sankhya A 79 (2), 298–335 (2017).
M. Ledoux, ‘‘On Talagrand’s deviation inequalities for product measures,’’ ESAIM Probab. Statist. 1, 63–87 (1995/1997).
O. V. Lepski, ‘‘A new approach to estimator selection,’’ Bernoulli 24 (4A), 2776–2810 (2018).
L. Markovich, ‘‘Gamma kernel estimation of the density derivative on the positive semi-axis by dependent data,’’ REVSTAT–Statistical Journal 14 (3), 327–348 (2016).
P. Massart, Concentration Inequalities and Model Selection, Vol. 1896 of Lecture Notes in Mathematics, Springer, Berlin, Lectures from the 33rd Summer School on Probability Theory Held in Saint-Flour, July 6–23, 2003, With a foreword by Jean Picard (2007).
C. Park and K.-H. Kang, ‘‘Sizer analysis for the comparison of regression curves,’’ Computational Statistics and Data Analysis 52 (8), 3954–3970 (2008).
S. Plancade, ‘‘Estimation of the density of regression errors by pointwise model selection,’’ Math. Methods Statist. 18 (4), 341–374 (2009).
B. L. S. P. Rao, ‘‘Nonparametric estimation of the derivatives of a density by the method of wavelets,’’ Bull. Inform. Cybernet. 28 (1), 91–100 (1996).
H. Sasaki, Y.-K. Noh, G. Niu, and M. Sugiyama, ‘‘Direct density derivative estimation,’’ Neural Comput. 28 (6), 1101–1140 (2016).
E. Schmisser, ‘‘Nonparametric estimation of the derivatives of the stationary density for stationary processes,’’ ESAIM Probab. Stat. 17, 33–69 (2013).
E. F. Schuster, ‘‘Estimation of a probability density function and its derivatives,’’ The Annals of Mathematical Statistics 40 (4), 1187–1195 (1969).
W. Shen and S. Ghosal, ‘‘Posterior contraction rates of density derivative estimation,’’ Sankhya A 79 (2), 336–354 (2017).
B. W. Silverman, ‘‘Weak and strong uniform consistency of the kernel estimate of a density and its derivatives,’’ The Annals of Statistics, 177–184 (1978).
R. Singh, ‘‘Mean squared errors of estimates of a density and its derivatives,’’ Biometrika 66 (1), 177–180 (1979).
R. S. Singh, ‘‘Applications of estimators of a density and its derivatives to certain statistical problems,’’ J. Roy. Statist. Soc. Ser. B 39 (3), 357–363 (1977).
G. Szegö, Orthogonal polynomials. American Mathematical Society Colloquium Publications, Vol. 23 (Revised ed. American Mathematical Society, Providence, R.I., 1959).
M. Talagrand, ‘‘New concentration inequalities in product spaces,’’ Invent. Math. 126 (3), 505–563 (1996).
A. B. Tsybakov, Introduction to Nonparametric Estimation. Springer Series in Statistics (Springer, New York. Revised and extended from the 2004 French original, Translated by Vladimir Zaiats, 2009).
Author information
Authors and Affiliations
Corresponding author
APPENDIX A
PROOFS OF AUXILIARY RESULTS
A.1. Proof of Lemma 2.1
In the Hermite case \(\varphi_{j}=h_{j}\) and \(f:\mathbb{R}\mapsto[0,\infty),\) allowing \(d\) successive integration by parts, it holds that
By definition for all \(j\geqslant 0\), \(h_{j}(x)=c_{j}H_{j}(x)e^{-\frac{x^{2}}{2}}\) where \(H_{j}\) is a polynomial. Then, its \(k\)th derivative, \(0\leqslant k\leqslant d-1\), is a polynomial multiplied by \(e^{-{x^{2}}/{2}}\) and \(\lim_{|x|\to+\infty}h_{j}^{(k)}(x)=0\). This together with (A2), gives that the bracket in (A.1) is null and the result follows.
Similarly in the Laguerre case, (A.1) holds integrating on \([0,\infty)\) instead of \(\mathbb{R}\) and replacing \(h_{j}\) by \(\ell_{j}\). The term in the bracket is null at 0 from (A3). It is also null at infinity using (A2) together with the fact that \(\ell_{j}\) are polynomials multiplied by \(e^{-x}\) leading similarly to \(\lim_{x\to\infty}f^{(d-1-k)}(x)\ell^{(k)}_{j}(x)=0\), \(0\leqslant k\leqslant d-1\), \(j\geqslant 0\). The result follows.
A.2. Proof of Lemma 2.2
We control the quantity
The first term is a constant which depending on \(d\). For the second term using Lemma 5.2, we obtain
Inserting this in (59), we obtain the announced result.
A.3. Proof of Lemma 2.3
We establish the result for \(d=1\), the general case is an immediate consequence. It follows from the definition of \(\widetilde{W}_{L}^{s}(D)\) that \((\theta^{\prime})^{(j)}\), \(0\leqslant j\leqslant s-1\) are in \(C([0,\infty))\). Moreover, it holds that \(x\mapsto x^{k/2}(\theta^{\prime})^{(j)}(x)\in\mathbb{L}^{2}(\mathbb{R}^{+})\) for all \(0\leqslant j<k\leqslant s-1\). The case \(k=j\) is obtained using that \(\theta^{(j)}\) is continuous on \(C([0,\infty))\) and that \(x\mapsto x^{(j+1)/2}(\theta^{\prime})^{(j)}(x)\in\mathbb{L}^{2}(\mathbb{R}^{+}).\) It follows that
where \(C\) depends on \(D\). Finally, using the equivalence of the norms \(|.|_{s}\) and \(|||.|||_{s}\), the value of \(D^{\prime}\) follows from the latter inequality.
A.4. Proof of Lemma 5.1
Consider the decomposition
where for \(\nu=4j-2k+2\), \(j\geqslant k\), we used the decomposition \((0,\infty)=(0,\frac{1}{\nu}]\cup(\frac{1}{\nu},\frac{\nu}{2}]\cup(\frac{\nu}{2},\nu-\nu^{1/3}]\cup(\nu-\nu^{1/3},\nu+\nu^{/13}]\cup(\nu+\nu^{1/3},3\nu/2]\cup(3\nu/2,\infty).\) Using [2] (see Appendix B.1) and straightforward inequalities give
Gathering these inequalities give the announced result.
A.5. Proof of Lemma 5.2
The result is obtained by induction on \(d\). If \(d=1\), \(h_{j}^{\prime}\) is given by (5), with \(b^{(1)}_{-1,j-1}=j^{1/2}/\sqrt{2}\), \(b_{0,j}=0\) and \(b^{(1)}_{1,j}=(j+1)^{1/2}/\sqrt{2}\), \(\forall j\geqslant 1\). Thus, it holds \(b_{k,j}^{(1)}=\mathcal{O}(j^{1/2})\) and (37) is satisfied for \(d=1\). Let \(\text{P}(d)\) the proposition given by Eq. (37) and assume \(\text{P}(d)\) holds and we establish \(\text{P}(d+1)\). It holds using successively \(\text{P}(d)\) and (5) that
where \(b^{(d)}_{k,j}=\mathcal{O}(j^{d/2})\), \(\forall j\geqslant d\geqslant|k|\) and \(b_{k,j}^{(d+1)}=b_{k+1,j}^{(d)}\frac{\sqrt{j+k+1}}{\sqrt{2}}\mathbf{1}_{|k|\leqslant d-1}-b_{k-1,j}^{(d)}\frac{\sqrt{j+k}}{\sqrt{2}}\mathbf{1}_{|k|\leqslant d+1}\). It follows that \(|b_{k,j}^{(d+1)}|\leqslant 2\sqrt{({j+d+1})/{2}}j^{\frac{d}{2}}\leqslant C_{d}j^{\frac{d+1}{2}},\) \(|k|\leqslant d\leqslant j\), which completes the proof.
Proof of Lemma 5.4
A.6.1. Proof of part (i). First, it holds that
which we bound applying a Talagrand Inequality (see Appendix B.2). Following notations of Appendix B.2, we have three terms \(H^{2},v\), and \(M_{1}\) to compute. Let us denote by \(m^{*}=m\vee m^{\prime}\), for \(t\in S_{m}+S_{{m^{\prime}}}\), \(||t||=1\), it holds
Computing \(\boldsymbol{H}^{\mathbf{2}}\). By the linearity of \(\nu_{n,d}\) and the Cauchy–Schwarz inequality, we have
One can check that the latter is an equality for \(a_{j}=\nu_{n,d}(\varphi_{j}).\) Therefore, taking expectation, it follows
Computing \(\boldsymbol{v}\). It holds for \(t\in S_{m}+S_{{m^{\prime}}}\), \(||t||=1\),
The first term of the previous inequality is a constant depending only on \(d\). For the second term, we consider separately the Laguerre and Hermite cases.
The Laguerre case (\(\varphi_{j}=\ell_{j}\)). Using (36) and the Cauchy–Schwarz inequality, it holds that
where we used the orthonormality of \((\ell_{j,(k)})_{j\geqslant 0}\) and where \(C(d)\) is a constant depending only on \(d\) and \(\sup_{x\in\mathbb{R}^{+}}\frac{f(x)}{x^{k}}\).
The Hermite case (\(\varphi_{j}=h_{j}\)). Similarly, using Lemma 5.2 and the orthonormality of \(h_{j}\), it follows
Plugging (A.5) or (A.6) in (A.4), we set in the two cases \(v:=c_{1}(m^{*})^{d}\) where \(c_{1}\) depends on \(d\) and either on \(\sup_{x\in\mathbb{R}^{+}}\frac{f(x)}{x^{k}}\) (Laguerre case) or \(||f||_{\infty}\) (Hermite case).
Computing \(\boldsymbol{M}_{\mathbf{1}}\). The Cauchy Schwarz Inequality and \(||t||=1\) give
The Laguerre case. We use the following Lemma whose proof is a consequence of (2) and an induction on \(d\).
Lemma A.1. For \(\ell_{j}\) given in (1), the \(d\)th derivative of \(\ell_{j}\) is such that \(||\ell_{j}^{(d)}||_{\infty}\leqslant C_{d}(j+1)^{d}\), \(\forall j\geqslant 0\) and where \(C_{d}\) is a positive constant depending on \(d\) .
Using Lemma A.1, we obtain
The Hermite case. The \(d\) first terms in the sum in (A.7) can be bounded by a constant depending only on \(d\). For the remaining terms, Lemma 5.2 and \(||h_{j}||_{\infty}\leqslant\phi_{0}\) (see (4)) give
where \(C\) is a positive constant depending on \(d\) and \(\phi_{0}\).
Injecting either (A.8) or (A.9) in (A.7), we set \(M_{1}=\mathcal{O}(m^{d+\frac{1}{2}})\) in the Laguerre case or \(M_{1}=\mathcal{O}(m^{\frac{d}{2}+\frac{1}{2}})\) in the Hermite case.
Now, we apply the Talagrand inequality see Appendix B.2 with \(\varepsilon=1/2\), it follows
The Laguerre case. We have
From (41) and the value of \(m_{n}(d)\), we obtain
Using the value \(m_{n}(d)\), it holds \((m^{*})^{d+1/2}\leqslant{n}/{\log^{3}(n)}\), which implies (recall \(m^{*}=m\vee m^{\prime}\))
where \(\Sigma_{d,2}\) is a constant depending only on \(d\). Next, it follows
The function \(m\mapsto m^{d+1}\exp(-C_{2}^{\prime}m^{\frac{1}{2}})\) is bounded and the sum is finite on \(m^{\prime}\), it holds
The Hermite case. Only the second term \(V_{d}(m^{*})\) changes. Here, it is given by
where we used (46) and the value of \(m_{n}(d)\). We derive that \(\sum_{m^{\prime}\in\mathcal{M}_{n,d}}V_{d}(m^{*})\leqslant\Sigma_{d,2}\).
Gathering all terms, it follows
Plugging this in (A.3) gives the announced result.
A.6.2. Proof of part (ii). We use the Bernstein Inequality (see Appendix B.3) to prove the result. Define
We select \(s^{2}\) and \(b\) such that \(\textrm{Var}(Z_{i}^{(m)})\leqslant s^{2}\) and \(|Z_{i}^{(m)}|\leqslant b\). By the computation of \(M_{1}\) (see proof of part (i)), we set \(b:=C^{*}m^{\alpha}\), with \(\alpha=2d+1\) (Laguerre case) or \(\alpha=d+1\) (Hermite case), where \(C^{*}\) depends on \(d\). For \(s^{2}\), using that \(\textrm{Var}(Z_{i}^{(m)})\leqslant\mathbb{E}[(Z_{i}^{(m)})^{2}]\leqslant b\sum_{j=0}^{m-1}\mathbb{E}\left[(\varphi_{j}^{(d)}(X_{i}))^{2}\right]=C^{*}m^{\alpha}V_{m,d}=:s^{2}\). Applying the Bernstein inequality, we have for \(S_{n}=n(\widehat{V}_{m,d}-V_{m,d})\)
Choose \(x=2\log(n)\) and define the set
Consider the decomposition,
Using \(2xy\leqslant x^{2}+y^{2}\), we have on \(\Omega\)
The constraint on \(m_{n}\) gives \(\widehat{m}^{d+1/2}\leqslant C{n}/{(\log(n))^{2}}\) together with (41) giving \(V_{\widehat{m},d}\geqslant c^{*}\widehat{m}^{d+1/2}\) give for \(\alpha=2d+1\) (Laguerre case) that \(\frac{8C^{*}}{3}\frac{\widehat{m}^{\alpha}\log(n)}{n}\leqslant\frac{8CC^{*}}{3c^{*}}\frac{V_{\widehat{m},d}}{\log(n)}\leqslant\frac{V_{\widehat{m},d}}{4},\) for \(n\) large enough and
In the Hermite case (\(\alpha=d+1\)) computations are similar as \(\widehat{m}^{d+1}\leqslant\widehat{m}^{2d+1}\). For the control on \(\Omega^{c}\), we write, using (A.10),
Gathering (A.11) and (A.12), we get the desired result.
Appendices
APPENDIX B
SOME INEQUALITIES
2.1 B.2. Asymptotic Askey and Wainger Formula
From [2], we have for \(\nu=4k+2\delta+2\), and \(k\) large enough
where \(\gamma_{1}\) and \(\gamma_{2}\) are positive and fixed constants.
2.2 B.2. A Talagrand Inequality
The Talagrand inequalities have been proven in [41] and reworked by [26]. This version is given in [23]. Let \((X_{i})_{1\leqslant i\leqslant n}\) be independent real random variables and
for \(t\) in \(\mathcal{F}\) a class of measurable functions. If there exist \(M_{1}\), \(H\), and \(v\) such that:
then, for \(\varepsilon>0\),
where \(C(\varepsilon)=(\sqrt{1+\varepsilon}-1)\wedge 1\), \(K_{1}=1/6\) and \(K_{1}^{\prime}\) a universal constant.
2.3 B.3. Bernstein Inequality ([29])
Let \(X_{1},\dots X_{n}\), \(n\) independent real random variables. Assume there exist two constants \(s^{2}\) and \(b\), such that \(\textrm{Var}(X_{i})\leqslant s^{2}\) and \(|X_{i}|\leqslant b\). Then, for all \(x\) positive, we have
About this article

Cite this article
Comte, F., Duval, C. & Sacko, O. Optimal Adaptive Estimation on \({\mathbb{R}}\) or \({\mathbb{R}}^{{+}}\)of the Derivatives of a Density. Math. Meth. Stat. 29, 1–31 (2020). https://doi.org/10.3103/S1066530720010020
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3103/S1066530720010020