
Abstract
We study the nonparametric regression estimation problem with a random design in \({\mathbb{R}}^{p}\) with \(p\ge 2\). We do so by using a projection estimator obtained by least squares minimization. Our contribution is to consider non-compact estimation domains in \({\mathbb {R}}^{p}\), on which we recover the function, and to provide a theoretical study of the risk of the estimator relative to a norm weighted by the distribution of the design. We propose a model selection procedure in which the model collection is random and takes into account the discrepancy between the empirical norm and the norm associated with the distribution of design. We prove that the resulting estimator automatically optimizes the bias-variance trade-off in both norms, and we illustrate the numerical performance of our procedure on simulated data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
We consider the following random design regression model:
where the variables \({\varvec{X}}_i\in {\mathbb {R}}^p\) are independent but not necessarily identically distributed, the noise variables \(\varepsilon _i\in {\mathbb {R}}\) are i.i.d. centered with finite variance \(\sigma ^2\) and independent from the \({\varvec{X}}_i\)s, and \(b:{\mathbb {R}}^p\rightarrow {\mathbb {R}}\) is a regression function. We seek to recover the function b on a domain \(A\subset {\mathbb {R}}^p\) from the observations \(({\varvec{X}}_i, Y_i)_{i=1,\dotsc ,n}\).
More precisely, we consider the following framework. We assume that the variance of the noise \(\sigma ^2\) is known. We assume that the variables \({\varvec{X}}_i\) are independent but not identically distributed, we call \(\mu _i\) the distribution of \({\varvec{X}}_i\), but we do not assume that \(\mu _i\) is known. However, we fix \(\nu \) a reference measure on A and we assume that \(\mu {:}{=} \frac{1}{n} \sum _{i=1}^{n} \mu _i\) admits a bounded density with respect to \(\nu \), so that we have \(\textrm{L}^2(A,\mu )\subset \textrm{L}^2(A,\nu )\). In particular, this assumption implies that \({{\,\textrm{supp}\,}}(\mu )\subset A\). Finally, we consider domains \(A\subset {\mathbb {R}}^p\) of the form \(A_1\times \cdots \times A_p\) where \(A_k\subset {\mathbb {R}}\) and we consider a measure \(\nu \) on A that is of the form \(\nu _1\otimes \cdots \otimes \nu _p\) with \(\nu _k\) supported on \(A_k\). Our goal is to estimate the regression function b on the domain A and to control the expected error with respect to the norm \(\left| \left| \cdot \right| \right| _\mu \) associated with the distribution of the \({\varvec{X}}_i\)s:
We can interpret the error with respect to this norm as a prediction risk: if \({\varvec{X}}_1',\dotsc ,{\varvec{X}}'_n\) are independent copies of \({\varvec{X}}_1,\dotsc ,{\varvec{X}}_n\), then we have:
which is the mean quadratic error of a new observation drawn uniformly from one of the distributions \(\mu _i\).
Nonparametric regression problems have a long history, and a large number of methods have been proposed. In this introduction, we focus on two main families of methods: kernel estimators and projection estimators. For reference books on the subject, see Efromovich (1999) regarding the projection method and Györfi et al. (2002) for the kernel method.
The classical estimator of Nadaraya (1964) and Watson (1964) consists of a quotient of estimators \({\widehat{bf}} /{\hat{f}}\), where \({\widehat{bf}}\) and \({\hat{f}}\) are kernel estimators of the functions bf and f (the function f being the common density of the \({\varvec{X}}_i\)s in the i.i.d case). This estimator can also be interpreted as locally fitting a constant by averaging the \(Y_i\)s, the locality being determined by the kernel, see the book of Györfi et al. (2002) or Tsybakov (2009). This method can then be generalized by replacing the local constant by a local polynomial, leading to the so-called local polynomial estimator.
The main drawback of the Nadaraya–Watson estimator is that it relies on an estimator of the density of the \({\varvec{X}}_i\)s. As such, the rate of convergence depends on the regularity of f, and two smoothing parameters have to be chosen. A popular solution is to choose the same bandwidth for both estimators using leave-one-out cross-validation. This method works well in practice and has been proven consistent by Härdle and Marron (1985) (see also Chapter 8 in Györfi et al. (2002)). Recently, Comte and Marie (2021) have proposed to use the Penalized Comparison to Overfitting method (PCO), a bandwidth selection method developed by Lacour et al. (2017) for kernel density estimation, to select separately the bandwidths of the numerator and the denominator of the Nadaraya–Watson estimator. Their estimator matches the performances of the single bandwidth CV estimator when the noise is high, but the latter is better when the noise is small. Other bandwidth selection methods exist such as plug-in or bootstrap; see Köhler et al. (2014) for an extensive survey and comparison of the different bandwidth selection methods for the local linear estimator.
Another approach is to use a projection estimator. The idea is to minimize a least squares contrast over finite-dimensional spaces of functions \(\{S_{{\varvec{m}}}:{{\varvec{m}}\in {\mathscr {M}}_n}\}\) called models:
the model collection \({\mathscr {M}}_{n}\) being allowed to depend on the number of observations. This method overcomes the problems of the Nadaraya–Watson estimator: it does not need to estimate the density of the \({\varvec{X}}_i\)s, and only one model selection procedure is required. Moreover, it can provide a sparse representation of the estimator. This approach was developed in a fixed design setting by Birgé and Massart (1998); Barron et al. (1999) and Baraud (2000). In particular, the papers of Baraud (2000, 2002) provide a model selection procedure that optimizes the bias-variance compromise under weak assumptions on the moments of the noise distribution. They obtain an estimator that is adaptive both in the fixed and random design setting when the domain A is compact.
The non-compact case has been studied recently in the simple regression setting (\(p=1\)) by Comte and Genon-Catalot (2020a, 2020b). They use non-compactly supported bases, specifically the Hermite basis (supported on \({\mathbb {R}}\)) and the Laguerre basis (supported on \({\mathbb {R}}_+\)), to construct their estimator. Significant attention has been paid to these bases in the past years since they exhibit nice mathematical properties that are useful for solving inverse problems (Mabon, 2017; Comte and Genon-Catalot, 2018; Sacko, 2020). Non-compactly supported bases also avoid issues concerning the choice of support. When A is compact, the theory assumes it is fixed a priori. In practice, however, the support is generally determined using the data, although this dependency between data and support is not taken into account in the theoretical development. Working with a non-compact domain, for example \({\mathbb {R}}\) or \({\mathbb {R}}_+\), allows us to bypass this issue.
Concerning the regression problem, difficulties arise when we go from the compact case to the non-compact case. When A is compact, it is usual to assume that the density of the \({\varvec{X}}_i\)s is bounded from below by some positive constant \(f_0\). In the non-compact case, this assumption fails. Instead, the study of the minimum eigenvalue of some random matrix must be done. This question has been studied in the simple regression case (\(p=1\)) by Cohen et al. (2013) by using the matrix concentration inequalities of Tropp (2012). However, their results are obtained under the assumption that the regression function is bounded by a known quantity and they do not provide a model selection procedure.
We make the following contributions in our paper. We extend the results of Comte and Genon-Catalot (2020a) to the multiple regression case (\(p\ge 2\)) with more general assumptions on the design, and we improve their result on the oracle inequality under the empirical norm (see Theorem 2). Our work generalizes the results of Baraud (2002) to the non-compact case and improves their results in the compact case (see Theorem 3). We do so by combining the fixed design results of Baraud (2000) with a more refined study of the discrepancy between the empirical norm and the \(\mu \)-norm. This discrepancy is expressed in terms of the deviation of the minimum eigenvalue of a random matrix, of which we control the probability with the concentration inequalities of Tropp (2012) and Gittens and Tropp (2011). Finally, our estimator is constructed as a projection estimator on a tensorized basis whose coefficients are computed using hypermatrix calculus and can be implemented in practice. This feasibility is illustrated in Sect. 5 which also shows that the procedure works well.
Outline of the paper In Sect. 2, we define the projection estimator. In Sect. 3, we study the probability that the empirical norm and the \(\mu \)-norm depart from each other and we derive an upper bound on the \(\mu \)-risk of our estimator. In Sect. 4, we propose a model selection procedure and we prove that it satisfies an oracle inequality both in empirical norm and in \(\mu \)-norm. Finally, in Sect. 5, we study numerically the performance of our estimator. All the proofs are gathered in Sect. 7.
Notations
-
\({\mathbb {E}}_{{\varvec{X}}} {:}{=} {\mathbb {E}}\left[ {\,\cdot }|{{\varvec{X}}_1,\dotsc ,{\varvec{X}}_n}\right] \), \({\mathbb {P}}_{{\varvec{X}}} {:}{=} {\mathbb {P}}\left[ {\,\cdot }|{{\varvec{X}}_1,\dotsc ,{\varvec{X}}_n}\right] \), \({{\,\textrm{Var}\,}}_{{\varvec{X}}} {:}{=} {{\,\textrm{Var}\,}}( \,\cdot \,\vert \,{\varvec{X}}_1,\dotsc ,{\varvec{X}}_n )\), where \({\varvec{X}} = ({\varvec{X}}_1,\dotsc ,{\varvec{X}}_n)\).
-
If \(\pi \) is a measure on A, we write \(\left| \left| \cdot \right| \right| _\pi \) and \({\langle }{ \cdot , \cdot }{\rangle }_\pi \) the norm and the inner product weighted by the measure \(\pi \).
-
We denote by \({\langle }{ \cdot , \cdot }{\rangle }_n\) and \(\left| \left| \cdot \right| \right| _n\) the empirical inner product and the empirical normFootnote 1, defined as \({\langle }{ t, s }{\rangle }_n {:}{=} \frac{1}{n} \sum _{i=1}^{n} t({\varvec{X}}_i)s({\varvec{X}}_i)\) and \( \left| \left| t\right| \right| _n^2 {:}{=} \frac{1}{n} \sum _{i=1}^{n} t({\varvec{X}}_i)^2\). If \({\textbf{u}} \in {\mathbb {R}}^n\) is a vector, we also write \(\left| \left| {\textbf{u}}\right| \right| _n^2 {:}{=} \frac{1}{n} \sum _{i=1}^{n} u_i^2\).
2 Projection estimator
In our setting, the domain is a Cartesian product \(A=A_1\times \cdots \times A_p\) and \(\nu =\nu _1\otimes \cdots \otimes \nu _p\) where \(\nu _k\) is supported on \(A_k\). For each \(i\in \{1,\dotsc ,p\}\), we consider \((\varphi ^i_{j})_{j\in {\mathbb {N}}}\) an orthonormal basis of \(\textrm{L}^2(A_i, \textrm{d}\nu _i)\) and we form an orthonormal basis of \(\textrm{L}^2(A, \textrm{d}\nu )\) by tensorization:
For \({\varvec{m}}\in {\mathbb {N}}_+^p\), we set \(S_{{\varvec{m}}} {:}{=} {{\,\textrm{Span}\,}}(\varphi _{{\varvec{j}}} : {\varvec{j}}\le {\varvec{m}}-\textbf{1})\) and we write \(D_{{\varvec{m}}} {:}{=} m_1\cdots m_p\) its dimension. We estimate b by minimizing a least squares contrast on \(S_{{\varvec{m}}}\):
If we expand \({\hat{b}}_{{\varvec{m}}}\) on the basis \((\varphi _{{\varvec{j}}})_{{\varvec{j}}\in {\mathbb {N}}^p}\), this problem can be written as:
where \({\textbf{Y}} {:}{=} (Y_1,\dotsc , Y_n) \in {\mathbb {R}}^n\) and \(\widehat{{\varvec{\varPhi }}}_{{\varvec{m}}} \in {\mathbb {R}}^{n\times {\varvec{m}}}\) is defined as:
Using Lemma 8 in Appendix, the problem (1) has a unique solution if and only if \(\widehat{{\varvec{\varPhi }}}_{{\varvec{m}}}\) is injective and in that case:
where \([\widehat{{\varvec{\varPhi }}}_{{\varvec{m}}}^*]_{{\varvec{j}}, i} = [\widehat{{\varvec{\varPhi }}}_{{\varvec{m}}}]_{i,{\varvec{j}}}\) and where \({\widehat{\textbf{G}}}_{{\varvec{m}}}\) is the Gram hypermatrix of \((\varphi _{{\varvec{j}}})_{ {\varvec{j}}\le {\varvec{m}}-\textbf{1}}\) relatively to the empirical inner product \({\langle }{ \cdot , \cdot }{\rangle }_n\):
Notice that \(\widehat{{\varvec{\varPhi }}}_{{\varvec{m}}}\) is injective if and only if \({\widehat{\textbf{G}}}_{{\varvec{m}}}\) is invertible, that is if and only if \(\left| \left| \cdot \right| \right| _n\) is a norm on \(S_{{\varvec{m}}}\).
3 Bound on the risk of the estimator
Let us start with the classical bias-variance decomposition of the empirical risk. In our context, this result is given by the next Proposition.
Proposition 1
If \({\widehat{\textbf{G}}}_{{\varvec{m}}}\) is invertible, then we have:
As a consequence, if \({{\widehat{\textbf{G}}}}_{{\varvec{m}}}\) is invertible a.s, then we have:
Hereafter, we always assume that \({\hat{\textbf{G}}}_{{\varvec{m}}}\) is invertible a.s.
If we want to obtain a similar result for the \(\mu \)-norm, we need to understand how the empirical norm can deviate from the \(\mu \)-norm. More generally, we need to understand the relations between the different norms we have on the subspace \(S_{{\varvec{m}}}\) (\(\left| \left| \cdot \right| \right| _n\), \(\left| \left| \cdot \right| \right| _\mu \), \(\left| \left| \cdot \right| \right| _\nu \) and \(\left| \left| \cdot \right| \right| _\infty \)). It is well known that all norms are equivalent on finite-dimensional spaces; our question concerns the constants in this equivalence. We introduce the following notation: if \(\left| \left| \cdot \right| \right| _\alpha \) and \(\left| \left| \cdot \right| \right| _{\beta }\) are two norms on a space S, we define:
and when \(S=S_{{\varvec{m}}}\), we use the notation \(K^\alpha _\beta ({\varvec{m}}) {:}{=} K^\alpha _\beta (S_{{\varvec{m}}})\). The next lemma gives the value of \(K_\alpha ^\beta (S)\) when the norms are Euclidean.
Lemma 1
Let \((S, {\langle }{ \cdot , \cdot }{\rangle }_\alpha )\) be a d-dimensional Euclidean vector space equipped with an orthonormal basis \((\phi _1, \dots , \phi _d)\). Let \({\langle }{ \cdot , \cdot }{\rangle }_\beta \) be another inner product on E and let \(\textbf{G}\) be the Gram matrix of the basis \((\phi _1,\dotsc ,\phi _d)\) relatively to \({\langle }{ \cdot , \cdot }{\rangle }_\beta \), that is:
We have:
The proof of Lemma 1 is identical to the proof of Lemma 3.1 in Baraud (2000), so we leave it out.
The next lemma provides a way to compute \(K_\alpha ^\infty (S)\) from an orthonormal basis when \(\left| \left| \cdot \right| \right| _\alpha \) is Euclidean. It is essentially the same as Lemma 1 in Birgé and Massart (1998).
Lemma 2
Let S be a space of bounded functions on A such that \(d{:}{=}\dim (S)\) is finite. Let \({\langle }{ \cdot , \cdot }{\rangle }_\alpha \) be an inner product on S. If \((\psi _1,\dotsc ,\psi _d)\) is an orthonormal basis of S, then we have:
The question we are interested in is how close are the norms \(\left| \left| \cdot \right| \right| _n\) and \(\left| \left| \cdot \right| \right| _\mu \) on \(S_{{\varvec{m}}}\). Following a similar idea of Cohen et al. (2013), let us define the event:
The key decomposition of the \(\mu \)-risk of \({\hat{b}}_{{\varvec{m}}}\) is given by the following Proposition.
Proposition 2
For all \(\delta \in (0,1)\), we have:
where \(K_n^\mu ({\varvec{m}})\) and \(K_\mu ^\infty ({\varvec{m}})\) are given by Lemmas 1 and 2.
We see that we need an upper bound on the probability of the event \(\varOmega _{{\varvec{m}}}(\delta )^c\). The following proposition is a consequence of the matrix Chernoff bound of Tropp (2012) (Theorem 5 in Appendix) .
Proposition 3
For all \(\delta \in (0,1)\), we have:
where \(h(\delta ){:}{=} \delta + (1-\delta )\log (1-\delta ) \) and \(K_\mu ^\infty ({\varvec{m}})\) is given by Lemma 2.
Remark 1
The quantity \(K_\mu ^\infty ({\varvec{m}})\) is unknown but we have the following upper bound using Lemmas 1 and 2:
The quantity \(\left| \left| \textbf{G}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}\) is still unknown but can be estimated by plugging in \({{\widehat{\textbf{G}}}}_{{\varvec{m}}}\).
Comte and Genon-Catalot (2020a) show in their Proposition 8 that, when one uses the Hermite or the Laguerre basis, the inverse of the Gram matrix is unbounded (it satisfies \(\Vert {\textbf{G}}_m^{-1}\Vert _{\textrm{op}} \gtrsim \sqrt{m}\)), while it is bounded in the compact case:
where \(f_0\) is a positive lower bound of the covariates density. Hence, the least squares minimization problem will become highly unstable as the dimension of the projection space grows. That is why a form of regularization is needed if we want to control the \(\mu \)-risk of the estimator. For \(\alpha \) a positive constant, let us consider the following model collection:
Gathering Propositions 2 and 3, we obtain the following bound on the \(\mu \)-risk of \({\hat{b}}_{{\varvec{m}}}\) when \({\varvec{m}}\) belongs to \({\mathscr {M}}^{(1)}_{n,\alpha }\).
Theorem 1
Let us assume that \(b\in \textrm{L}^{2r}(\mu )\) for some \(r \in (1, +\infty ]\) and let \(r'\in [1,+\infty )\) be the conjugated index of r, that is: \(\frac{1}{r} + \frac{1}{r'} = 1\). For all \(\alpha \in (0, \frac{1}{2r'+1})\) and for all \({\varvec{m}}\in {\mathscr {M}}^{(1)}_{n,\alpha }\) we have:
where the constants \(C_n(\alpha , r')\) and \(C'(\alpha , r')\) are given by:
where \(\delta (\alpha , r')\in (0,1)\) tends to 1 as \(\alpha \) tends to \(\frac{1}{2r'+1}\), and where \(C''\big (b, \sigma ^2, \alpha ,r\big )\) is defined by (18).
Remark 2
Let us make some statements concerning the behavior of \(C_n(\alpha ,r')\) and \(C'(\alpha ,r')\):
-
\(C_n(\alpha , r')\) is bounded relatively to n;
-
\(C_n(\alpha , r')\ge 1\) and \(C'(\alpha , r')\ge 2\);
-
as \(\alpha \rightarrow \frac{1}{2r'+1}\) with n fixed, \(C_n(\alpha , r')\) and \(C'(\alpha , r')\) tend to \(+\infty \);
-
as \(n\rightarrow +\infty \) with \(\alpha \) and \(r'\) fixed, \(C_n(\alpha , r')\) tends to 1.
4 Adaptive estimator
We consider the empirical version of the model collection \({\mathscr {M}}_{n,\alpha }\) defined by (4):
with \(\beta \) a positive constant. We choose \({\varvec{{\hat{m}}}}_1 \in {{\widehat{{\mathscr {M}}}}}^{\ (1)}_{n,\beta }\) by minimizing the following penalized least squares criterion:
Based on a result of Baraud (2000) for fixed design regression, we prove that \({\hat{b}}_{{\varvec{{\hat{m}}}}_1}\) automatically optimizes the bias-variance compromise in empirical norm on \({\mathscr {M}}_{n,\alpha }\), up to a constant and a remainder term.
Theorem 2
If \(b \in \textrm{L}^{2r}(\mu )\) for some \(r\in (1,+\infty ]\) and if \({\mathbb {E}}\left| \varepsilon _1 \right| ^q\) is finite for some \(q>6\), then there exists a constant \(\alpha _{\beta , r'}>0\) depending on \(\beta \) and \(r'\) (the conjugated index of r) such that for all \(\alpha \in (0, \alpha _{\beta , r'})\), the following upper bound on the risk of the estimator \({\hat{b}}_{{\varvec{{\hat{m}}}}_1}\) with \({\varvec{{\hat{m}}}}_1\) defined by (5) holds:
where \(C(\theta ) {:}{=} (2+8\theta ^{-1})(1+\theta )\), and where:
with \(\kappa (\alpha ,\beta )\) a positive constant satisfying \(\frac{\kappa (\alpha ,\beta )}{r'} > 1\) and \(\frac{\kappa (\alpha ,\beta )}{r'}\rightarrow 1\) as \(\alpha \rightarrow \alpha _{\beta , r'}\).
Remark 3
The term \(\varSigma (\theta ,q)\) is finite if \(q>6\). Indeed, let \(2\epsilon {:}{=} (\frac{q}{2}-2)-1>0\), we have:
where we use Theorem 7 in Appendix.
Remark 4
The constant \(\alpha _{\beta , r'}\) is increasing with \(\beta \) and goes from 0 to \(\frac{1}{2r'+1}\). It is also decreasing with \(r'\) (so increasing with r) and tends to 0 as \(r'\rightarrow +\infty \) (as \(r\rightarrow 1\)).
To transfer the previous adaptive result from the empirical norm into the \(\mu \)-norm, we use once again concentration inequalities on the matrix \({{\widehat{\textbf{G}}}}_{{\varvec{m}}}\). However, we need to make a distinction between the compact case and the non-compact case. Indeed, when A is compact, we can make the usual assumption that the density \(\frac{\textrm{d}\mu }{\textrm{d}\nu }\) is bounded from below and apply the matrix Chernoff bound of Gittens and Tropp (2011), see Lemma 6. This lemma relies critically on the “bounded from below” assumption so it cannot work in the non-compact case.
To handle the non-compact case, we make use of the matrix Bernstein bound of Tropp (2012) instead (Theorem 6 in appendix), see Lemma 7. This inequality is different from the matrix Chernoff bounds we have used so far, so we have to consider smaller model collections to make it work. In the following, we consider two cases:
-
1.
Compact case. We assume that there exists \(f_0>0\) such that for all \(x\in A\), \(\frac{\textrm{d}\mu }{\textrm{d}\nu }(x)>f_0\). In that case, \(\textbf{G}_{{\varvec{m}}}\) is always invertible and we have \(\left| \left| \textbf{G}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}\le \frac{1}{f_0}\), see (3).
-
2.
General case. We consider smaller model collections:
$$\begin{aligned}{} & {} {\mathscr {M}}_{n,\alpha }^{(2)} {:}{=} {\lbrace }{ {\varvec{m}}\in {\mathbb {N}}_+^p \,\vert \, K_{\nu }^\infty ({\varvec{m}}) \left( \left| \left| \textbf{G}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}^2 \vee 1 \right) \le \alpha \frac{n}{\log n} }{\rbrace },\\{} & {} \quad {{\widehat{{\mathscr {M}}}}}_{n,\beta }^{\ (2)} {:}{=} {\lbrace }{ {\varvec{m}}\in {\mathbb {N}}_+^p \,\vert \, K_{\nu }^\infty ({\varvec{m}}) \left( \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}^2 \vee 1 \right) \le \beta \frac{n}{\log n} }{\rbrace }, \end{aligned}$$where \(\alpha \) and \(\beta \) are positive constants and we choose \({\varvec{{\hat{m}}}}_2 \in {{\widehat{{\mathscr {M}}}}}_{n,\beta }^{\ (2)}\) as:
$$\begin{aligned} {\varvec{{\hat{m}}}}_2 {:}{=} {{\,\mathrm{arg\, min}\,}}_{{\varvec{m}}\in {{\widehat{{\mathscr {M}}}}}_{n,\beta }^{\ (2)}} \left( -\left| \left| {\hat{b}}_{{\varvec{m}}}\right| \right| _n^2 + (1+\theta )\sigma ^2 \frac{D_{{\varvec{m}}}}{n} \right) ,\quad \theta > 0. \end{aligned}$$(6)
Theorem 3
Let \(r\in (1,+\infty ]\), let \(r'\in [1,+\infty )\) be its conjugated index and let us assume that b belongs to \(\textrm{L}^{2r}(\mu )\) and that \({\mathbb {E}}\left| \varepsilon _1 \right| ^q\) is finite for some \(q>6\).
\(\bullet \) Compact case. Let \(f_0>0\) such that \(\frac{\textrm{d}\mu }{\textrm{d}\nu }(x)\ge f_0\) for all \(x\in A\), there exists \(\beta _{f_0,r'}>0\) such that for all \(\beta \in (0, \beta _{f_0,r'})\), there exists \(\alpha _{\beta , r'}>0\) such that for all \(\alpha \in (0, \alpha _{\beta , r'})\), the following upper bound on the risk of the estimator \({\hat{b}}_{{\varvec{{\hat{m}}}}_1}\) with \({\varvec{{\hat{m}}}}_1\) defined by (5) holds:
where the remainder term is given by:
with \(\lambda (\beta ,r,f_0)>1\) and \(\frac{\kappa (\alpha , \beta )}{r'} >1\).
\(\bullet \) General case. Let \(B{:}{=} (\left| \left| \frac{\textrm{d}\mu }{\textrm{d}\nu }\right| \right| _\infty + \frac{2}{3})^{-1}\), there exists \(\beta _{B,r'}>0\) such that for all \(\beta \in (0, \beta _{B,r'})\), there exists \({\tilde{\alpha }}_{\beta , r'}>0\) such that for all \(\alpha \in (0, {\tilde{\alpha }}_{\beta , r'})\), the following upper bound on the risk of the estimator \({\hat{b}}_{{\varvec{{\hat{m}}}}_2}\) with \({\varvec{{\hat{m}}}}_2\) defined by (6) holds:
where the remainder term is given by:
with \(\lambda (\beta ,r,B)>1\) and \(\frac{{\tilde{\kappa }}(\alpha , \beta )}{r'} >1\).
This result shows that there is a range of values for the constant \(\beta \) that depends on the integrability of b and on \(f_0\) (compact case) or \(\left| \left| \frac{\textrm{d}\mu }{\textrm{d}\nu }\right| \right| _\infty \) (general case), such that for the \(\mu \)-norm, the estimator \({\hat{b}}_{{\varvec{{\hat{m}}}}}\) automatically optimizes the bias-variance trade-off (up to a constant and a rest) on \({\mathscr {M}}_{n,\alpha }\) for all \(\alpha \) in a range that depends on \(\beta \).
Remark 5
Theorem 3 improves previous results in the literature:
-
1.
In the compact case, we improve the result of Baraud (2002). Indeed in this article, the model collections considered are built by picking an “envelope model”, that is a linear space \({\mathscr {S}}_n\) with finite dimension \(N_n\), whose all models are a subspace. Their assumptions concern the space \({\mathscr {S}}_n\): they assume that \(K_\nu ^\infty ({\mathscr {S}}_n) \le C^2 N_n\) for some constant \(C>0\) and they require that \(N_n \le C^{-1} \sqrt{ n/(\log n)^3 }\). In comparison, our procedure avoids the choice a priori of an envelope model, and uses a looser constraint on the dimension of the models.
-
2.
In the non-compact case, we extend the results of Comte and Genon-Catalot (2020a) to the case \(p\ge 2\) without losing much on the assumptions: their result requires a moment of order 6 on the noise whereas our result is obtained with a moment of order q, with \(q>6\). We also generalize their result by considering a non i.i.d. design and by using a more general moment assumption on the regression function.
Remark 6
(Unknown variance) During all of our work, we assume that \(\sigma ^2\) is known. To handle the case of an unknown variance, we can use the same method proposed by Baraud (2000) in the fixed design setting. Using a residual least-squares estimator of \(\sigma ^2\) in the penalized criterion for choosing the model, they prove (Theorem 6.1) that the resulting estimator of the regression function satisfies an oracle inequality. Starting from Baraud’s result, and using the same arguments we used in this paper, we think one can obtain an oracle inequality for a projection estimator, in the random design framework with unknown variance. We omit such development for the sake of conciseness.
5 Numerical illustrations
In this section, we compare our estimator with the Nadaraya–Watson estimator on simulated data in the case \(p=1\) and \(p=2\).
Regression function We consider the following regression functions:
-
1.
\(b_1(x) = \exp ((x-1)^2) + \exp ((x+1)^2)\),
-
2.
\(b_2(x) {:}{=} \frac{1}{1+x^2}\),
-
3.
\(b_3(x) {:}{=} x\cos (x)\),
-
4.
\(b_4(x) {:}{=} \left| x \right| \),
-
5.
\(b_5(x_1,x_2) {:}{=} \exp (-\frac{1}{2} [(x_1-1)^2+(x_2-1)^2]) + \exp (-\frac{1}{2} [(x_1+1)^2+(x_2+1)^2])\),
-
6.
\(b_6(x_1,x_2) {:}{=} 1/({1+x_1^2+x_2^2})\),
-
7.
\(b_7(x_1,x_2) {:}{=} \cos (x_1)\sin (x_2)\),
-
8.
\(b_8(x_1,x_2) {:}{=} \left| x_1x_2 \right| \).
The functions \(b_2\) and \(b_6\) are smooth bounded functions and have a unique maximum at 0, so they should be an easy case. The functions \(b_1\) and \(b_5\) are smooth and bounded with two maximums. The functions \(b_3\) and \(b_7\) are smooth oscillating functions. Finally, the functions \(b_4\) and \(b_8\) are not smooth nor bounded, and should be a harder case.
Distribution of \({\varvec{X}}\) For the sake of simplicity, we consider the case where \({\varvec{X}}_1, \dotsc , {\varvec{X}}_n\) are i.i.d. and have a density with respect to Lebesgue measure (i.e. \(\nu = \textrm{Leb}\)). For the case \(p=1\), we consider the following distributions: \(X \sim {\mathscr {N}}(0, 1)\), and \(X\sim \textrm{Laplace}\). Both distributions are symmetric and centered at 0, but the normal distribution is more concentrated around its mean than the Laplace distribution. For the case \(p=2\), we use independent marginals for the distribution of the covariates: \({\varvec{X}} \sim {\mathscr {N}}(0, 1) \otimes {\mathscr {N}}(0, 1)\), and \({\varvec{X}} \sim \textrm{Laplace} \otimes \textrm{Laplace}\).
Noise distribution We consider the normal distribution: \(\varepsilon \sim {\mathscr {N}}(0, \sigma ^2)\). The variance \(\sigma ^2\) is chosen such that the signal-to-noise ratio is the same for each choice of regression function and distribution of \({\varvec{X}}\), where we define the signal-to-noise ratio as:
We consider the following values: \(\textrm{SNR}=2\) (High noise), and \(\textrm{SNR}= 20\) (Low noise).
Parameters of the projection estimator Since the distributions of \({\varvec{X}}\) are supported on \({\mathbb {R}}\) or \({\mathbb {R}}^2\), we choose the Hermite basis. The Hermite functions are defined as:
and form a basis of \(\textrm{L}^2({\mathbb {R}})\). We form a basis of \(\textrm{L}^2({\mathbb {R}}^2)\) by tensorizing the Hermite basis as explained in Sect. 2. We choose the parameter \({\varvec{{\hat{m}}}}\) with the model selection procedure (6). This procedure requires two additional parameters: the constant \(\theta \) in the penalty and the constant \(\beta \) in the model collection \({{\widehat{{\mathscr {M}}}}}_{n,\beta }^{\ (2)}\).
We choose \(\beta \) such that the model collection \({{\widehat{{\mathscr {M}}}}}_{n,\beta }^{\ (2)}\) is not too small, especially for small sample sizes. Indeed, we find that the operator norm \(\left| \left| {\widehat{\textbf{G}}}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}\) can grow very fast with \({\varvec{m}}\), which can result in model collections with very few models. In our case, we choose \(\beta =10^4\).
The constant \(\kappa {:}{=} 1+\theta \) in front of the penalty is chosen following the “minimum penalty heuristic” (Arlot and Massart 2009). On several preliminary simulations, we compute the selected dimension \(D_{{\varvec{{\hat{m}}}}}\) as a function of \(\kappa \) and we find \(\kappa _{\min }\) such that for \(\kappa < \kappa _{\min }\) the dimension is too high and for \(\kappa >\kappa _{\min }\) it is acceptable. Then, we choose \(\kappa _\star = 2\kappa _{\min }\). In our case, we find \(\kappa _\star =2\) when \(p=1\) and \(p=2\).
Nadaraya–Watson estimator Let us define the Nadaraya–Watson estimator in the case \(p=1\). For all \(h \in (0, 1)\), let \(K_{h}\) be the pdf of the \({\mathscr {N}}(0, h)\) distribution. The Nadaraya–Watson estimator is defined as:
The bandwidth h is selected by leave-one-out cross-validation, that is:
where \({\hat{b}}_{ h, -i}^{\textrm{NW}}\) is the Nadaraya–Watson estimator computed from the data set:
In the case \(p=2\), the definition of the estimator is the same but with a couple of bandwidths \({\varvec{h}} = (h_1, h_2)\in (0, 1)^2\), and with \(K_{{\varvec{h}}}\) the pdf of the \({\mathscr {N}}_2({\varvec{0}}, {\textbf{H}})\) distribution, where \({\textbf{H}} {:}{=} \textrm{diag}(h_1, h_2)\).
Computation of the risk We consider samples of size \(n=250\) and \(n=1000\) in the case \(p=1\), and samples of size \(n=500\) and \(n=2000\) in the case \(p=2\). For each choice of regression function, distribution of \({\varvec{X}}\) and \(\textrm{SNR}\), we generate \(N=100\) samples of size n. For each sample, we compute the Hermite projection estimator and the Nadaraya–Watson estimator; then, we compute the relative \(\mu \)-error of the estimators, that is:
where f is the density of the distribution \(\mu \). We compute an approximation of these integrals: we consider a compact domain \(I\times I\) with I an interval such that \({\mathbb {P}}\left[ X\in I \right] = 95\%\) in the case \(p=1\) and \({\mathbb {P}}\left[ {\varvec{X}}\in I\times I \right] = 95\%\) in the case \(p=2\). Then, we consider a discretization with 200 points of I. In the case \(p=1\), we use Simpson’s rule with this discretization of I to approximate the integrals. In the case \(p=2\), we approximate the integrals by a sum over the grid of \(I\times I\):
where \(\varDelta \) is the discretization step.
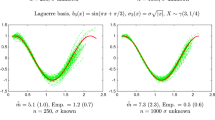
Results In the case \(p=1\), we show our results in Table 1. First of all, we see that the results are superior when X has a Normal distribution compared to a Laplace distribution. This can be explained by the fact that the Laplace distribution is less concentrated around 0 than the normal distribution, so the \(X_i\)s are more scattered and the mu-risk covers a larger range. In addition, in the normal setting, we see that the Hermite estimator is better than the Nadaraya–Watson estimator for estimating \(b_1\), \(b_2\) and \(b_3\), and both estimators are equivalent for estimating \(b_4\). In the Laplace setting, the Hermite estimator is still better for \(b_1\) and \(b_2\), but for \(b_3\) it has similar performances as the Nadaraya–Watson estimator. For estimating \(b_4\), the latter is better, although the difference becomes small as n increases.
In the case \(p=2\), we show our results in Table 2. In the normal setting, the Hermite projection estimator is better for estimating \(b_5\), \(b_6\) and \(b_7\). For \(b_8\), its performances are worse than the kernel estimator on small samples but they are equivalent on large samples. In the Laplace setting, our estimator is better for estimating \(b_5\) and \(b_6\), but it is worse for estimating \(b_7\). Moreover, the Hermite estimator has very poor performances for estimating \(b_8\). We think that the functions \(b_7\) and \(b_8\) are hard to approximate with the Hermite basis, so that the Hermite projection estimator performs poorly. This can be seen by looking at the mean selected dimension, which grows quickly as n grows, showing that the estimator needs a large number of coefficients to reconstruct the regression function. This is especially true for \(b_8\), as it is a non differentiable and unbounded function.
In addition, we observe that the Hermite estimator is faster to compute than the Nadaraya–Watson estimator with leave-one-out cross-validation. The difference is small when n is small, but for example, when \(n=2000\) and \(p=2\), the Hermite estimator is about 3 time faster. In conclusion, the Hermite projection estimator is a good alternative to the Nadaraya–Watson estimator.
6 Concluding remark
In this paper, we have considered the nonparametric regression problem with a random design. The covariates are assumed to be independent but not identically distributed, and the variance of the noise is assumed to be known. We estimate the regression function on a non-compact domain of \({\mathbb {R}}^p\) with a projection estimator, using tensorized orthonormal bases. The projection space is chosen by a penalized criterion, as in Birgé and Massart (1998) and Baraud (2000). Our model collection depends on the design and is thus random. Indeed, we consider subspaces \(S_{{\varvec{m}}}\) on which the operator norm of the Gram hypermatrix associated with the least squared minimization problem is constrained. This constraint on the operator norm comes from a refined study of the discrepancy between the norms \(\left| \left| \cdot \right| \right| _n\) and \(\left| \left| \cdot \right| \right| _\mu \) on \(S_{{\varvec{m}}}\). This study relies on Matrix concentration inequalities of Tropp (2012) and Gittens and Tropp (2011), as it has been suggested by the work of Cohen et al. (2013). Doing so, we obtain oracle bounds for the selected estimator, in both norms. Our work extends and improves the results of Baraud (2002) and Comte and Genon-Catalot (2020a), as explained by Remark 5.
Different extension of our work can be pursued. A natural extension would be to consider the heteroskedastic regression model, in which the observations \(({\varvec{X}}_i,Y_i)\) satisfy:
were \(\varepsilon _i\)s have unit variance. Using the same projection estimator, Comte and Genon-Catalot (2020b) have obtained similar results for this model in the one-dimensional case. The extension to the multivariate case could be done in two ways. The first way would be to generalize the fixed design results of Baraud (2000) to the case of noise variables with different variance, and then to apply the same arguments we used in this paper to deduce the results for the random design setting. The second way would be to follow the approach of Comte and Genon-Catalot (2020b), that is based on Talagrand’s inequality, and to see if it can be extended to the multivariate case.
Another extension of our work would be to investigate the use of more general approximation spaces \(S_m\), as does Baraud (2002). We want to know if the same method we used could handle approximation spaces that are not constructed from an orthonormal basis. A typical example we have in mind is splines approximation. We suspect that our results on the comparison between the norms \(\left| \left| \cdot \right| \right| _n\) and \(\left| \left| \cdot \right| \right| _\mu \) still hold in this context, so that adaptive strategies could be derived from it.
7 Proofs
7.1 Proofs of Sect. 2
Proposition 1
Let \(\varPi ^{(n)}_{{\varvec{m}}}\) be the projector on \(S_{{\varvec{m}}}\) for the empirical inner product. We have the decomposition:
Taking the expected value in this equality, we obtain:
\(\square \)
7.2 Proofs of Sect.3
Lemma 2
Let \(x\in A\) and let \(t = \sum _{j=1}^{d} a_j\, \psi _j\in S\). The family of functions \((\psi _1,\ldots , \psi _d)\) is orthonormal with respect to \({\langle }{ \cdot , \cdot }{\rangle }_\alpha \), so by the Cauchy–Schwarz inequality we have:
with equality if \((\alpha _1,\dotsc , \alpha _d)\) is proportional to \((\psi _1(x),\dotsc , \psi _d(x))\). Hence, we have:
Taking the supremum for \(x\in A\), we obtain:
that is:
\(\square \)
To prove Proposition 3 and Theorem 2, we need the following lemma.
Lemma 3
Let \((\psi _1,\dotsc ,\psi _{D_{{\varvec{m}}}})\) be an orthonormal basis of \(S_{{\varvec{m}}}\) relatively to an inner product \({\langle }{ \cdot , \cdot }{\rangle }_\alpha \). Let \(\widehat{{\textbf{H}}}_{{\varvec{m}}}\) be the Gram matrix of this basis relatively to the empirical inner product and let \({\textbf{H}}_{{\varvec{m}}} {:}{=} {\mathbb {E}}[\widehat{{\textbf{H}}}_{{\varvec{m}}}]\), that is:
For all \(\delta \in (0,1),\) we have:
with \(h(\delta ){:}{=} \delta + (1-\delta )\log (1-\delta )\) and where \(K_{\alpha }^\infty ({\varvec{m}})\) is given by Lemma 2.
Proof
We use Theorem 5 in Appendix. Indeed, \(\widehat{{\textbf{H}}}_{{\varvec{m}}}\) can be written as a sum \({\textbf{Z}}_1 + \dotsc + {\textbf{Z}}_n\) where
so we have using Lemma 2:
Therefore, applying inequality (29) of Theorem 5 with \(\mu _{\min } = \lambda _{\min }({\textbf{H}}_{{\varvec{m}}})\) and \(R = \frac{1}{n}K_\alpha ^\infty ({\varvec{m}})\) yields:
\(\square \)
Proposition 3
Let \(\psi _1,\dotsc ,\psi _{D_{{\varvec{m}}}}\) be an orthonormal basis of \(S_{{\varvec{m}}}\) relatively to the inner product \({\langle }{ \cdot , \cdot }{\rangle }_\mu \). Let \(\widehat{{\textbf{H}}}_{{\varvec{m}}}\) be their Gram matrix relatively to the empirical inner product. According to Lemma 1, we have \(K_n^\mu ({\varvec{m}}) = \left| \left| \widehat{{\textbf{H}}}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}= \lambda _{\min }(\widehat{{\textbf{H}}}_{{\varvec{m}}})^{-1}\) and we have \({\mathbb {E}}[\widehat{{\textbf{H}}}_{{\varvec{m}}}] = {\textbf{I}}_{{\varvec{m}}}\) because \((\psi _1, \dotsc , \psi _{D_{{\varvec{m}}}})\) is orthonormal for the inner product associated with \(\mu \), so the event \(\varOmega _{{\varvec{m}}}(\delta )^c\) can be written as:
Applying Lemma 3 yields the result.\(\square \)
Proposition 2
We start with the decomposition:
We consider these two terms separately. The expectation of the first term is controlled as in Theorem 3 in Cohen et al. (2013). On the event \(\varOmega _{{\varvec{m}}}(\delta )\) we have \((1-\delta )\left| \left| t\right| \right| _{\mu }^2 \le \left| \left| t\right| \right| _n^2\) for all \(t\in S_{{\varvec{m}}}\), so if \(b_{{\varvec{m}}}^{(\mu )}\) is the projection of b on \(S_{{\varvec{m}}}\) for the norm \(\left| \left| \cdot \right| \right| _\mu \), we have:
Taking the expectation, we obtain:
We give an upper bound on the last term in two ways. Firstly, we have:
since \(K_n^\mu ({\varvec{m}})\le \frac{1}{1-\delta }\) on the event \(\varOmega _{{\varvec{m}}}(\delta )\), see (2). Let \(\varPi _{{\varvec{m}}}^{(n)}\) be the empirical projector on \(S_{{\varvec{m}}}\), we have:
Thus, we have shown:
Secondly, let \(g {:}{=} b - b_{{\varvec{m}}}^{(\mu )}\) and let \(\varPi _{{\varvec{m}}}^{(n)}\) be the empirical projector on \(S_{{\varvec{m}}}\) we have:
Let \((\psi _1,\dotsc , \psi _{D_{{\varvec{m}}}})\) be an orthonormal basis of \(S_{{\varvec{m}}}\) for the inner product \({\langle }{ \cdot , \cdot }{\rangle }_\mu \), we have:
where \(\varPsi _{{\varvec{m}}} \in {\mathbb {R}}^{n\times D_{{\varvec{m}}}}\) is the matrix defined by \([\varPsi _{{\varvec{m}}}]_{i,j} {:}{=} \psi _{j}({\varvec{X}}_i)\), and where \({\textbf{g}}\) is the vector \(\big ( g({\varvec{X}}_1), \dotsc , g({\varvec{X}}_n) \big )\in {\mathbb {R}}^n\). By Lemma 8, \({\textbf{c}}^\star \) is given by:
where \({\textbf{H}}_{{\varvec{m}}}\) is the Gram matrix of \((\psi _1,\dotsc , \psi _{D_{{\varvec{m}}}})\) relatively to the empirical inner product. Using Lemma 1, we get:
Hence, on the event \(\varOmega _{{\varvec{m}}}(\delta )\) we obtain:
Since \(g=b-b_{{\varvec{m}}}^{(\mu )}\) is orthogonal to \(\psi _1,\dotsc ,\psi _{D_{{\varvec{m}}}}\) relatively to the inner product \({\langle }{ \cdot , \cdot }{\rangle }_\mu \), we have \({\mathbb {E}}[{\langle }{ g, \psi _j }{\rangle }_n] = {\langle }{ g, \psi _j }{\rangle }_\mu = 0\), so we get:
where the last equality comes from Lemma 2. Hence, we have shown:
Combining (9) and (10) yields:
For the second term in (7), we have:
We have the following upper bound on \(\left| \left| {\hat{b}}_{{\varvec{m}}}\right| \right| _\mu ^2\):
where the last inequality comes from the fact that \({\hat{b}}_{{\varvec{m}}}\) is the empirical projection of \({\textbf{Y}}\). Hence, we get:
The inequality of Proposition 2 is obtained using (8), (11) and (13) in (7).\(\square \)
Theorem 1
Let \({\varvec{m}}\in {\mathscr {M}}^{(1)}_{n,\alpha }\) and let \(\delta \in (0,1)\) (we choose it later in the proof). By Remark 1, we have by definition of \({\mathscr {M}}^{(1)}_{n,\alpha }\):
so Proposition 2 yields:
with \(C_n(\alpha , \delta ) {:}{=} \left( 1 + \frac{2}{1-\delta } \left[ \frac{\alpha }{(1-\delta )\log n} \wedge 1\right] \right) \), \(C'(\delta ) {:}{=} \frac{2}{1-\delta }\) and:
For the first term in \(R_n\), we apply Proposition 3 with (14):
For the second term in \(R_n\), since \(\left| \left| \cdot \right| \right| _\mu \le \left| \left| \cdot \right| \right| _\infty \) and \({\varvec{m}}\in {\mathscr {M}}^{(1)}_{n,\alpha }\) we have:
and we have using the independence of \(({\varvec{X}}_i)_{1\le i\le n}\) and \((\varepsilon _i)_{1\le i\le n}\):
We apply Hölder’s inequality with \(r,r'\in (1,+\infty )\) such that \(\frac{1}{r} + \frac{1}{r'} = 1\):
and if \(b\in \textrm{L}^\infty (\mu )\), the last inequality also holds for \(r=\infty \) and \(r'=1\) (just take the limit as \(r\rightarrow +\infty \)). Hence, we obtain:
If we choose \(\delta \) such that \(h(\delta ) \ge (2r'+1)\alpha \), then all the exponents of n in (15) and (17) are less than \(-1\). The function h is an increasing function from [0, 1] to itself so it is invertible on [0, 1]. Since \(\alpha \in (0, \frac{1}{2r'+1})\), we can choose \(\delta = \delta (\alpha , r') {:}{=} h^{-1}((2r'+1)\alpha )\). For this choice, we obtain:
where \(C_n(\delta ,\alpha )\) and \(C'(\delta )\) were defined at the beginning of the proof, and are as follows:
\(\square \)
7.3 Proof of Theorem 2
The proof of Theorem 2 is based on a result for fixed design regression of Baraud (2000). Let \({{\widehat{{\mathscr {M}}}}}_n\) be a finite collection of models, that may depend on \(({\varvec{X}}_1,\dotsc , {\varvec{X}}_n)\), such that for all \({\varvec{m}}\in {{\widehat{{\mathscr {M}}}}}_n\), \({{\widehat{\textbf{G}}}}_{{\varvec{m}}}\) is invertible. Let \({\varvec{{\hat{m}}}} \in {{\widehat{{\mathscr {M}}}}}_n\) be the minimizer of the following penalized least squares criterion:
Theorem 4
(Corollary 3.1 in Baraud (2000)) If \({\mathbb {E}}\left| \varepsilon _1 \right| ^q\) is finite for some \(q>4\), then the following upper bound on the risk of the estimator \({\hat{b}}_{{\varvec{{\hat{m}}}}}\) with \({\varvec{{\hat{m}}}}\) defined by (19) holds:
with:
where \(C(\theta ) {:}{=} (2+8\theta ^{-1})(1+\theta )\) and \(C'(\theta ,q)\) is a positive constant.
Theorem 2
Let \(\varDelta _{n,\alpha ,\beta } {:}{=} {\lbrace } {\mathscr {M}}^{(1)}_{n,\alpha }\subset {{\widehat{{\mathscr {M}}}}}^{\ (1)}_{n,\beta } {\rbrace }\), we have:
For the first term, on \(\varDelta _{n,\alpha ,\beta }\) we have \(\inf _{{\varvec{m}}\in {{\widehat{{\mathscr {M}}}}}^{\ (1)}_{n,\beta }} (\ldots ) \le \inf _{{\varvec{m}}\in {\mathscr {M}}^{(1)}_{n,\alpha }} (\ldots )\) so by applying Theorem 4 we obtain:
For the second term, we have:
Using Hölder’s inequality with \(r,r'\in (1,\infty )\) such that \(\frac{1}{r} + \frac{1}{r'}=1\), we obtain:
and if \(b\in \textrm{L}^\infty (\mu )\), the inequality also holds for \(r=\infty \) and \(r'=1\). Since \({\hat{b}}_{{\varvec{{\hat{m}}}}_1}\) is the empirical projection of \({\textbf{Y}}\) on \(S_{{\varvec{{\hat{m}}_1}}}\), we have \(\left| \left| {\hat{b}}_{{\varvec{{\hat{m}}}}_1}\right| \right| _n^2 \le \left| \left| {\textbf{Y}}\right| \right| _n^2\). Hence, we get:
To conclude, we give an upper bound on \({\mathbb {P}}\left[ \varDelta _{n,\alpha , \beta }^c\right] \):
Using the following inclusion of events:
we get:
Using Lemma 3 with the inequality \(K_\nu ^\infty ({\varvec{m}})\left| \left| \textbf{G}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}\le \alpha \frac{n}{\log n}\) for \({\varvec{m}} \in {\mathscr {M}}_{n,\alpha }^{(1)}\), we obtain:
Hence, we get:
Using Proposition 4 in appendix, we obtain:
with \(H_n {:}{=} \sum _{k=1}^{n} \frac{1}{k}\) and \(\kappa (\alpha ,\beta ) {:}{=} \frac{h(1-\frac{\alpha }{\beta })}{\alpha } - 2\). We know that \(H_n\sim \log n\), so we want a condition on \(\alpha \) such that the \(\kappa (\alpha ,\beta )\) is strictly greater than \(r'\). Let \(x {:}{=} \frac{\beta }{\alpha } \ge 1\), we have:
The function:
is decreasing on \([1,+\infty )\), we have \(f_{\beta , r'}(1)>1\) and \(f_{\beta , r'}(x) \rightarrow 0\) when \(x\rightarrow +\infty \), so there exists a unique \(x_{\beta , r'}\in (1,+\infty )\) such that \(f_{\beta , r'}(x_{\beta , r'})=1\). Thus, we have:
where \(\alpha _{\beta , r'} {:}{=} \frac{\beta }{x_{\beta , r'}}\). Hence, if \(\alpha \in (0, \alpha _{\beta , r'} )\) then we have:
with \(\frac{\kappa (\alpha ,\beta )}{r'}>1\) and \(\frac{\kappa (\alpha , \beta )}{r'} \rightarrow 1\) as \(\alpha \rightarrow \alpha _{\beta , r'}\).\(\square \)
Remark 7
If we use the collections \({\mathscr {M}}_{n,\alpha }^{(2)}\) and \({{\widehat{{\mathscr {M}}}}}_{n,\beta }^{\ (2)}\) instead, we obtain the inequality (21) with \(\alpha \) and \(\beta \) replaced by \(\alpha '{:}{=}\sqrt{\alpha }\) and \(\beta '{:}{=}\sqrt{\beta }\). The rest of the proof is unchanged.
Remark 4
We have \(\alpha _{\beta , r'} {:}{=} \frac{\beta }{x_{\beta , r'}}\) where \(x_{\beta , r'}\) is the unique solution in \((1,+\infty )\) of the equation \(f_{\beta , r'}(x) = 1\) with:
Hence, \(x_\beta \) satisfies the relation:
Since the functions \(f_{\beta , r'}\) are decreasing on \((1,+\infty )\) and since \(\forall x\), \(f_{\beta , r'}(x)\) is increasing with \(\beta \) and \(r'\), we see that \(x_{\beta , r'}\) is increasing with \(\beta \) and \(r'\). Thus, the limits of \(x_{\beta , r'}\) when \(\beta \rightarrow 0\) and \(\beta \rightarrow +\infty \) exist. Using the relation (23), we obtain:
and we have \(x_{\beta , r'} \sim (2+r')\beta \) when \(\beta \rightarrow +\infty \). Thus, the limits of \(\alpha _{\beta , r'}\) are:
Since \(x_{\beta , r'}\) is increasing with \(r'\), we see that \(\alpha _{\beta , r'}\) is decreasing with \(r'\). Finally, using the relation (23) again, we have:
It is easy to see that the function \(x\mapsto 1 - \frac{1}{x} - \frac{\log x}{x}\) is increasing on \([1,+\infty )\) so \(\alpha _{\beta , r'}\) is also increasing with \(\beta \). \(\square \)
7.4 Proof of Theorem 3
Before proving Theorem 3, we need some preliminary results.
Lemma 4
For all \(x> 0\) and all \({\varvec{m}}\in {\mathbb {N}}_+^p\) we have:
Proof
The set \(\{{ \varphi _{{\varvec{j}}}}:{{\varvec{j}}\le {\varvec{m}}-\textbf{1}}\}\) has cardinality \(D_{{\varvec{m}}}\) so let \({\lbrace } \phi _1, \dotsc , \phi _{D_{{\varvec{m}}}} {\rbrace }\) be its elements. We define the matrix \(\widehat{{\textbf{H}}}_{{\varvec{m}}}\) as:
and we denote its expectation \({\textbf{H}}_{{\varvec{m}}}\), of which the components are \({\langle }{ \phi _j, \phi _k }{\rangle }_\mu \). In other words, we have reshaped the hypermatrices \({{\widehat{\textbf{G}}}}_{{\varvec{m}}}\) and \(\textbf{G}_{{\varvec{m}}}\) into \(D_{{\varvec{m}}}\times D_{{\varvec{m}}}\) matrices. Moreover, this operation preserves the operator norm:
Indeed, let \(d{:}{=} D_{{\varvec{m}}}\), we have:
Since the sets \(\{{ \varphi _{{\varvec{j}}}}:{{\varvec{j}}\le {\varvec{m}}-\textbf{1}}\}\) and \({\lbrace } \phi _1, \dotsc , \phi _{d} {\rbrace }\) are equal, these two quantities are also equal. Hence, we have:
so we work on \(\widehat{{\textbf{H}}}_{{\varvec{m}}}\) and \({\textbf{H}}_{{\varvec{m}}}\) from now on. We write:
and we use the Matrix Bernstein bound (Theorem 6 in appendix).
-
1.
Bound on \(\left| \left| {\textbf{Z}}_i\right| \right| _\textrm{op}\):
$$\begin{aligned} \frac{1}{n}\left| \left| {\textbf{V}}_i {\textbf{V}}_i^\top \right| \right| _\textrm{op}= \frac{1}{n} \left| \left| {\textbf{V}}_i\right| \right| ^2 = \frac{1}{n} \sum _{j=1}^{D_{{\varvec{m}}}} \phi _j({\varvec{X}}_i)^2 \le \frac{K_\nu ^\infty ({\varvec{m}})}{n}, \end{aligned}$$where the last inequality comes from Lemma 2. Hence, \(\left| \left| {\textbf{Z}}_i\right| \right| _\textrm{op}\le R\), with \(R{:}{=} \frac{K_\nu ^\infty ({\varvec{m}})}{n}\).
-
2.
Bound on \(\left| \left| \sum _{i=1}^{n} {\mathbb {E}}\left[ {\textbf{Z}}_i^2\right] \right| \right| _\textrm{op}\):
$$\begin{aligned} \left| \left| [\right| \right| \bigg ]{\sum _{i=1}^{n} {\mathbb {E}}\left[ {\textbf{Z}}_i^2\right] }_\textrm{op}= \sup _{\left| \left| {\textbf{a}}\right| \right| = 1} \sum _{i=1}^{n} {\mathbb {E}}\left[ \left| \left| {\textbf{Z}}_i\, {\textbf{a}}\right| \right| ^2 \right]&= \sup _{\left| \left| {\textbf{a}}\right| \right| = 1} \sum _{i=1}^{n} \sum _{j=1}^{D_{{\varvec{m}}}} {\mathbb {E}}\left[ ({\textbf{Z}}_i\, {\textbf{a}})_j^2 \right] \\&= \sup _{\left| \left| {\textbf{a}}\right| \right| = 1} \sum _{i=1}^{n} \sum _{j=1}^{D_{{\varvec{m}}}} {{\,\textrm{Var}\,}}\left[ ({\textbf{Z}}_i\, {\textbf{a}})_j \right] , \end{aligned}$$since \({\mathbb {E}}{\textbf{Z}}_i = {\textbf{0}}\). We compute the variance:
$$\begin{aligned} {{\,\textrm{Var}\,}}\left[ ({\textbf{Z}}_i\, {\textbf{a}})_j \right] = {{\,\textrm{Var}\,}}\left[ \frac{1}{n} \phi _j({\varvec{X}}_i)\sum _{k=1}^{D_{{\varvec{m}}}} \phi _k({\varvec{X}}_i)\, a_k \right]&\le \frac{1}{n^2} {\mathbb {E}}\left[ \left( \phi _j({\varvec{X}}_i)\sum _{k=1}^{D_{{\varvec{m}}}} \phi _k({\varvec{X}}_i)\, a_k \right) ^2 \right] \\&= \frac{1}{n} {\mathbb {E}}\left[ \phi _j({\varvec{X}}_i)^2 \, t_{{\textbf{a}}}({\varvec{X}}_i)^2 \right] , \end{aligned}$$where \(t_{{\textbf{a}}} {:}{=} \sum _{k=1}^{D_{{\varvec{m}}}} a_k \,\phi _k \). Using Lemmas 1 and 2 yields:
$$\begin{aligned} \sum _{i=1}^{n} \sum _{j=1}^{D_{{\varvec{m}}}} {{\,\textrm{Var}\,}}\left[ ({\textbf{Z}}_i\, {\textbf{a}})_j \right] \le \frac{1}{n^2} \sum _{i=1}^{n} {\mathbb {E}}\left[ \sum _{j=1}^{D_{{\varvec{m}}}} \phi _j({\varvec{X}}_i)^2\, t_{{\textbf{a}}}({\varvec{X}}_i)^2 \right]&\le \frac{1}{n} K_{\nu }^\infty ({\varvec{m}})\, \left| \left| t_{{\textbf{a}}} \right| \right| _\mu ^2 \\&\le \frac{1}{n} K_{\nu }^\infty ({\varvec{m}}) \, K_{\nu }^\mu ({\varvec{m}}) \, \left| \left| t_{{\textbf{a}}} \right| \right| _\nu ^2 \\&= \frac{1}{n} K_{\nu }^\infty ({\varvec{m}}) \,\left| \left| \textbf{G}_{{\varvec{m}}}\right| \right| _\textrm{op}\,\left| \left| {\textbf{a}}\right| \right| ^2. \end{aligned}$$Hence, \(\left| \left| \sum _{i=1}^{n} {\mathbb {E}}\left[ {\textbf{Z}}_i^2\right] \right| \right| _\textrm{op}\le \frac{1}{n} K_{\nu }^\infty ({\varvec{m}}) \left| \left| \textbf{G}_{{\varvec{m}}}\right| \right| _\textrm{op}{=}{:} v\).
Applying Theorem 6 yields:
which is the first inequality of Lemma 4. The second inequality follows from the following upper bound on \(\left| \left| \textbf{G}_{{\varvec{m}}}\right| \right| _\textrm{op}\):
\(\square \)
In order to prove Theorem 3, let us consider the events:
where \(\varOmega _{{\varvec{m}}}(\delta )\) is defined by (2).
Lemma 5
For \(\iota \in {\lbrace }1,2{\rbrace }\), we have for all \(\delta \in (0,1)\) and all \(\gamma >0\):
where \(H_n {:}{=}\sum _{k=1}^{n} \frac{1}{k}\) is the n-th harmonic number.
Proof
We use Proposition 3 with Remark 1:
where the last inequality comes from Proposition 4.\(\square \)
Lemma 6
(Compact case) We have for all \(\gamma>\beta >0\):
where \(h(\delta ) = \delta + (1-\delta )\log (1-\delta )\), \(f_0>0\) is such that \(\frac{\textrm{d}\mu }{\textrm{d}\nu }(x)\ge f_0\) for all \(x\in A\) and \(H_n {:}{=} \sum _{k=1}^{n} \frac{1}{k}\).
Proof
We start with a union bound:
We have the following inclusion of events:
hence we obtain:
We apply inequality (30) of Theorem 5 with \(R = \frac{1}{n} K_\nu ^\infty ({\varvec{m}})\):
In the compact case, we have \(\left| \left| \textbf{G}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}\le \frac{1}{f_0}\), see (3). Using Proposition 4, we obtain:
\(\square \)
Lemma 7
(General case) We have for all \(\gamma>\beta >0\):
where \(C(\beta ,\gamma ){:}{=} \left( 1 - \sqrt{\beta /\gamma } \right) ^2\), \(B{:}{=} \big ( \left| \left| \frac{\textrm{d}\mu }{\textrm{d}\nu }\right| \right| _\infty + \frac{2}{3}\big )^{-1}\) and \(H_n {:}{=} \sum _{k=1}^{n} \frac{1}{k}\).
Proof
We start with a union bound:
We have the following inclusion of events:
Let \(\eta {:}{=} \sqrt{\frac{\gamma }{\beta }}-1\) and let \(\epsilon \in (0,1)\). We consider the following decomposition:
with:
-
For \(E_1\), we apply Lemma 9 with \({\textbf{A}} {:}{=} {{\widehat{\textbf{G}}}}_{{\varvec{m}}}\) and \({\textbf{B}} {:}{=} \textbf{G}_{{\varvec{m}}} - {{\widehat{\textbf{G}}}}_{{\varvec{m}}}\):
$$\begin{aligned} E_1&\subset { \frac{ \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}^2 \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}} - \textbf{G}_{{\varvec{m}}}\right| \right| _{\textrm{op}}}{1 -\left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1} (\textbf{G}_{{\varvec{m}}} - {{\widehat{\textbf{G}}}}_{{\varvec{m}}})\right| \right| _\textrm{op}} \ge \eta \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1}\right| \right| _{\textrm{op}}} \cap { \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1} (\textbf{G}_{{\varvec{m}}} - {{\widehat{\textbf{G}}}}_{{\varvec{m}}})\right| \right| _\textrm{op}< \epsilon } \\&\subset { \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1}\right| \right| _\textrm{op}\left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}} - \textbf{G}_{{\varvec{m}}}\right| \right| _{\textrm{op}} \ge (1-\epsilon )\eta }. \end{aligned}$$ -
For \(E_2\), we have directly:
$$\begin{aligned} E_2 \subset {\lbrace } \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1} (\textbf{G}_{{\varvec{m}}} - {{\widehat{\textbf{G}}}}_{{\varvec{m}}})\right| \right| _\textrm{op}\ge \epsilon {\rbrace } \subset {\lbrace } \left| \left| {{\widehat{\textbf{G}}}}_{{\varvec{m}}}^{-1}\right| \right| \left| \left| \textbf{G}_{{\varvec{m}}} - {{\widehat{\textbf{G}}}}_{{\varvec{m}}}\right| \right| _\textrm{op}\ge \epsilon {\rbrace }. \end{aligned}$$
Thus, we obtain:
We now choose \(\epsilon \) maximizing \((1-\epsilon )\eta \wedge \epsilon \). This maximum is achieved when \(\epsilon = (1-\epsilon )\eta \), that is:
Thus, we obtain:
Let \(x{:}{=} c(\beta ,\gamma ) \sqrt{\frac{K_\nu ^\infty ({\varvec{m}})}{\beta } \frac{\log n}{n}}\) and notice that \(x\le 1\) if \(K_\nu ^\infty ({\varvec{m}}) \le \beta \frac{n}{\log n}\). We apply Lemma 4 and Proposition 4:
where \(B {:}{=} (\left| \left| \frac{\textrm{d}\mu }{\textrm{d}\nu }\right| \right| _\infty + \frac{2}{3})^{-1}\).\(\square \)
Now we can prove Theorem 3.
Theorem 3
Let \(\delta \in (0,1)\) and \(\gamma > \beta \) be constants to be chosen later. Let us introduce the event \(\varXi ^{(\iota )}_{n}(\beta ,\gamma ,\delta ){:}{=}\varLambda ^{(\iota )}_{n}(\beta ,\gamma ) \cap {\widetilde{\varOmega }}^{(\iota )}_{n}(\delta , \gamma )\) where \(\varLambda ^{(\iota )}_{n}(\beta ,\gamma )\) and \({\widetilde{\varOmega }}^{(\iota )}_{n}(\delta , \gamma )\) are defined by (24). On the event \(\varXi ^{(\iota )}_{n}(\beta ,\gamma ,\delta )\), for all \({\varvec{m}}\in {\mathscr {M}}^{(\iota )}_{n,\alpha }\), for all \(t\in S_{{\varvec{m}}}\) we have:
Taking the expectation yields for all \(t\in S_{{\varvec{m}}}\):
On the event \(\varXi ^{(\iota )}_{n}(\beta ,\gamma ,\delta )^c\), we use inequalities (12) and (16):
Using Hölder’s inequality as we did in (20), we obtain:
We see we need to control \({\mathbb {P}}\left[ \varXi ^{(\iota )}_n(\beta ,\gamma ,\delta )^c\right] \) by a term of order \(n^{-2r'}\).
We have decomposed the risk as the sum of (25) and (26). We give different upper bounds on these two terms depending on whether we are in the compact case or the general case.
\(\bullet \) Compact case. In equation (25), we apply Theorem 2: for all \(\alpha \in (0, \alpha _{\beta , r'})\) we have:
with \(\frac{\kappa (\alpha ,\beta )}{r'}>1\). To obtain an upper bound on (26), we apply Lemmas 5 and 6:
where \(h(\delta ) {:}{=} \delta + (1-\delta )\log (1-\delta )\) and \(H_n{:}{=} \sum _{k=1}^{n} \frac{1}{k}\). In order to obtain a term of order \(n^{-2r'}\), we need:
Let us work on the last two conditions. Let \(x{:}{=} \frac{\gamma }{\beta }>1\), the conditions on \((\beta , \gamma )\) become:
The function \(x\mapsto x\log x - x +1\) is increasing on \((1,+\infty )\) and ranges from 0 to \(+\infty \), so there exists \(x_{f_0,\beta }>1\) such that for all \(x>x_{f_0,\beta }\) we have \(x\log x - x +1 > (2r'+1)\frac{\beta }{f_0}\). Hence, we need to choose x such that:
This is possible only if \(x_{f_0,\beta } < \frac{1}{(2r'+2)\beta }\), that is if:
Let us introduce a new variable \(y{:}{=} (2r'+2)\beta \) and let \(R = \frac{2r'+1}{2r'+2}\), the last inequality becomes:
The function \(y\mapsto \frac{R}{f_0} y + \frac{1+\log y}{y}\) is increasing on (0, 1), it tends to \(-\infty \) at 0 and for \(y=1\) it is greater than 1, so there exists \(y_{f_0,r'}\in (0,1)\) such that the condition (28) is satisfied on \((0, y_{f_0,r'})\). To sum up, we have shown that there exists \(\beta _{f_0,r'} \in (0, \frac{1}{2r'+2})\) such that for every \(\beta < \beta _{f_0,r'}\), the condition (27) is not empty. We choose:
and we obtain that:
where \(\lambda (\beta , r, f_0)>1\).
\(\bullet \) General case. In equation (25), if we follow the proof of Theorem 2 (see Remark 7), we see that if \(\alpha \in (0, \alpha _{\beta ^{1/2}, r'}^2)\) then we have:
with \(\frac{\kappa (\alpha ^{\frac{1}{2}},\beta ^{\frac{1}{2}})}{r'}>1\). Thus, we obtain:
To obtain an upper bound on (26), we apply Lemmas 5 and 7:
where \(C(\beta ,\gamma ){:}{=} \left( 1 - \sqrt{\beta /\gamma } \right) ^2\), \(B {:}{=} (\left| \left| \frac{\textrm{d}\mu }{\textrm{d}\nu }\right| \right| _\infty + \frac{2}{3})^{-1}\) and \(H_n{:}{=} \sum _{k=1}^{n} \frac{1}{k}\). To obtain a term of order \(n^{-2r'}\), we need:
Let \(x {:}{=} \sqrt{\beta /\gamma } \in (0,1)\), the conditions on \((\beta , \gamma )\) can be rewritten as:
We choose x maximizing this bound. This maximum is achieved when \(x^2 = (1-x)^2 \frac{B}{2}\), that is \(x = \frac{\sqrt{B/2}}{1 + \sqrt{B/2}}\). Finally, we choose:
and we obtain that for all \(\beta \in (0, \beta _{B,r'})\) with:
we have:
where \(\lambda (\beta , r, B)>1\).\(\square \)
Notes
in general, it is a semi-norm but we will only consider subspaces on which it is a norm.
References
Arlot, S., Massart, P. (2009). Data-driven calibration of penalties for least-squares regression. Journal of Machine Learning Research, 10(10), 245–279.
Baraud, Y. (2000). Model selection for regression on a fixed design. Probability Theory and Related Fields, 117(4), 467–493.
Baraud, Y. (2002). Model selection for regression on a random design. ESAIM: Probability and Statistics, 6, 127–146.
Barron, A., Birgé, L., Massart, P. (1999). Risk bounds for model selection via penalization. Probability Theory and Related Fields, 113(3), 301–413.
Birgé, L., Massart, P. (1998). Minimum contrast estimators on sieves: Exponential bounds and rates of convergence. Bernoulli, 4(3), 329–375.
Cohen, A., Davenport, M. A., Leviatan, D. (2013). On the stability and accuracy of least squares approximations. Foundations of Computational Mathematics, 13(5), 819–834.
Comte, F., Genon-Catalot, V. (2018). Laguerre and Hermite bases for inverse problems. Journal of the Korean Statistical Society, 47(3), 273–296.
Comte, F., Genon-Catalot, V. (2020a). Regression function estimation as a partly inverse problem. Annals of the Institute of Statistical Mathematics, 72(4), 1023–1054.
Comte, F., Genon-Catalot, V. (2020b). Regression function estimation on non compact support in an Heteroscesdastic model. Metrika, 83(1), 93–128.
Comte, F., Marie, N. (2021). On a Nadaraya-Watson estimator with two bandwidths. Electronic Journal of Statistics, 15(1), 2566–2607.
Efromovich, S. (1999). Nonparametric curve estimation: Methods, theory and applications. Springer series in statistics, New York: Springer.
Gittens, A., Tropp, J.A. (2011) Tail bounds for all eigenvalues of a sum of random matrices. ArXiv:1104.4513 [math].
Györfi, L., Kohler, M., Krzyżak, A., Walk, H. (2002). A distribution-free theory of nonparametric regression. Springer series in statistics, New York, NY: Springer New York.
Härdle, W., Marron, J. S. (1985). Optimal bandwidth selection in nonparametric regression function estimation. The Annals of Statistics, 13(4), 1465–1481.
Köhler, M., Schindler, A., Sperlich, S. (2014). A review and comparison of bandwidth selection methods for Kernel regression: Review of bandwidth selection for regression. International Statistical Review, 82(2), 243–274.
Lacour, C., Massart, P., Rivoirard, V. (2017). Estimator selection: A new method with applications to Kernel density estimation. Sankhya A, 79(2), 298–335.
Mabon, G. (2017). Adaptive deconvolution on the non-negative real line: Adaptive deconvolution on R+. Scandinavian Journal of Statistics, 44(3), 707–740.
Nadaraya, E. A. (1964). On estimating regression. Theory of Probability & Its applications, 9(1), 141–142.
Sacko, O. (2020). Hermite density deconvolution. Latin American Journal of Probability and Mathematical Statistics, 17(1), 419–443.
Tao, T. (2008). The divisor bound. https://terrytao.wordpress.com/2008/09/23/the-divisor-bound.
Tropp, J. A. (2012). User-friendly tail bounds for sums of random matrices. Foundations of Computational Mathematics, 12(4), 389–434.
Tsybakov, A. B. (2009). Introduction to nonparametric estimation. Series in statistics. London: Springer.
Watson, GS. (1964). Smooth regression analysis. Sankhyā: The Indian Journal of Statistics, Series A 26(4):359–372.
Acknowledgements
I want to thank Fabienne Comte and Céline Duval for their helpful advice and their support of my work. I also want to thank Florence Merlevède for her help with the second inequality of the Matrix Chernoff bound. Finally, I want to thank Herb Susmann for proofreading this article.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by a grant from Région Île-de-France.
Appendices
A Linear algebra
Lemma 8
Let E be a Euclidean vector space and let \(\ell :E\rightarrow {\mathbb {R}}^n\) be an injective linear map. For \(y\in {\mathbb {R}}^n\), the solution of the problem:
is given by:
where \(\ell ^*:{\mathbb {R}}^n\rightarrow E\) is characterized by the relation \({\langle }{ y, \ell (a) }{\rangle }_{{\mathbb {R}}^n} = {\langle }{ \ell ^*(y), a }{\rangle }_{E}\).
Lemma 9
Let \(\textbf{A}\), \(\textbf{B}\) be square matrices. If \(\textbf{A}\) is invertible and \(\left| \left| \textbf{A}^{-1}\textbf{B} \right| \right| _{\textrm{op}}<1\), then \(\textbf{A} +\textbf{B}\) is invertible and it holds:
B Concentration inequalities
You can find the proofs of the following bounds in Tropp (2012) and Gittens and Tropp (2011).
Theorem 5
(Matrix Chernoff bound) Let \({\textbf{Z}}_1, \dotsc , {\textbf{Z}}_n\) be independent random self-adjoint positive semi-definite matrices with dimension d, such that \(\sup _k \lambda _{\max }({\textbf{Z}}_k) \le R\) a.s. If we define:
then we have:
Theorem 6
(Matrix Bernstein bound) Let \({\textbf{Z}}_1, \dotsc , {\textbf{Z}}_n\) be independent random self-adjoint positive semi-definite matrices with dimension d, such that \({\mathbb {E}}[{\textbf{Z}}_k] = \textbf{0}\) and that \(\sup _k \lambda _{\max }({\textbf{Z}}_k) \le R\) a.s. If \(v>0\) is such that:
then for all \(x>0\) we have:
C Combinatorics
Proposition 4
For \(n\ge 1\) and \(p\ge 2\) we have:
where \(H_n {:}{=} \sum _{k=1}^{n} \frac{1}{k}\) is the n-th harmonic number.
Proof
We compute:
\(\square \)
Theorem 7
(Divisor bound) Let \(N\in {\mathbb {N}}_+\) and let \(\textrm{div}(N)\) be the set of divisors of N. We have for all \(\epsilon >0\):
As a consequence, we have for all \(\epsilon >0\):
A proof of this result can be found in Tao (2008).
About this article

Cite this article
Dussap, F. Nonparametric multiple regression by projection on non-compactly supported bases. Ann Inst Stat Math 75, 731–771 (2023). https://doi.org/10.1007/s10463-022-00863-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10463-022-00863-1