
Abstract
Given the multi-model and nonlinear characteristics of photovoltaic (PV) models, parameter extraction presents a challenging problem. This challenge is exacerbated by the propensity of conventional algorithms to get trapped in local optima due to the complex nature of the problem. Accurate parameter estimation, nonetheless, is crucial due to its significant impact on the PV system’s performance, influencing both current and energy production. While traditional methods have provided reasonable results for PV model variables, they often require extensive computational resources, which impacts precision and robustness and results in many fitness evaluations. To address this problem, this paper presents an improved algorithm for PV parameter extraction, leveraging the opposition-based exponential distribution optimizer (OBEDO). The OBEDO method, equipped with opposition-based learning, provides an enhanced exploration capability and efficient exploitation of the search space, helping to mitigate the risk of entrapment in local optima. The proposed OBEDO algorithm is rigorously verified against state-of-the-art algorithms across various PV models, including single-diode, double-diode, three-diode, and photovoltaic module models. Practical and statistical results reveal that the OBEDO performs better than other algorithms in estimating parameters, demonstrating superior convergence speed, reliability, and accuracy. Moreover, the performance of the proposed algorithm is assessed using several case studies, further reinforcing its effectiveness. Therefore, the OBEDO, with its advantages in terms of computational efficiency and robustness, emerges as a promising solution for photovoltaic model parameter identification, making a significant contribution to enhancing the performance of PV systems.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Addressing climate change and shaping effective energy policies have become urgent global priorities. In this context, the value of photovoltaic (PV) power generation cannot be overstated. It offers a pathway to harness electricity from solar radiation, all while bypassing greenhouse gas emissions1,2. The usage of PV systems has witnessed a substantial rise, despite their relative costliness, as part of the solution to these global issues. Recent research has concentrated on crafting precise models to maximize the productivity of renewable energy (RE) sources. These endeavours aim to provide viable alternatives to traditional fossil fuels, whose usage is tied to environmental pollution. Among various renewable sources, solar energy stands out. Its capacity to generate electricity through PV power is a green alternative that causes no environmental harm. PV systems, pivotal in renewable energy development, transform solar energy into electrical power3,4,5. However, they face challenges due to environmental influences like dust, weather changes, and temperature variations. These elements can decrease the efficiency of solar cells, making the need for accurate PV models crucial. Such models can help optimize the energy conversion process and mitigate these challenges. Solar energy is a significant renewable source, capable of generating electricity without excessive resource consumption or environmental pollution. Yet, the practical application of this source faces obstacles, including low photoelectric conversion and the need for precise PV cell modelling. Furthermore, the veracity of simulation results in various power systems relies heavily on correct PV module modelling. Therefore, developing robust mathematical models is essential for predicting solar cell parameters and understanding their behaviour6,7,8.
In PV equivalent circuits, the single-diode-model (SDM) is formed with one diode and two resistors9, while introducing two diodes results in the double-diode model (DDM)10, and so forth. As diodes increase, so do the uncertain variables within the photovoltaic models. For example, a single-diode PV model contains five unknown parameters, a DDM has seven, and a Triple-Diode Model (TDM) possesses nine11,12, and this progression continues. This illustrates that the complexity of the model grows with the increasing count of diodes. Parameters such as shunt-resistor, shunt-resistance current, series resistor, and saturation current, among others, are unaccounted for in these PV models. They must be computed and recovered from the PV characteristic curves. An accurate estimation of such parameters is vital for the optimal operation of solar cell models. Any misestimation can introduce significant discrepancies in the system output, leading to errors in the manufacturers' data. Therefore, determining these parameters is an essential task that significantly enhances the PV system's optimization and performance. The PV mathematical model equations are inherently implicit, nonlinear, multivariable, and multimodal. It is widely accepted among researchers that solving PV models presents substantial challenges. As such, multiple methods have been proposed to extract, evaluate, and simulate PV parameters in a precise, reliable, and timely manner6,7,13,14. The literature reveals that various PV models are typically utilized to examine the I–V characteristics of PV cells, with the SDM forming the fundamental basis. However, the SDM fails to account for recombination losses occurring in the depletion region. For this reason, besides SDM, this study considered the DDM and the TDM to model solar cells effectively. The DDM is acknowledged to provide more precise outcomes than the single-diode model because it factors in the effects of low current. Meanwhile, the TDM addresses the PV cell's intricate nonlinear behaviour and is perceived as a high precise model than the ideal, SDM, and DDMs. Furthermore, it depicts solar cell characteristics in situations involving leakage current. However, the TDM's mathematical resolution presents challenges due to its nonlinear equations. Therefore, the problems associated with the TDM are typically addressed by transforming them into optimization problems15,16,17.
Accuracy in parameter estimation for solar PV systems is crucial for several reasons: (i) Accurate parameter values are essential for optimizing the performance of PV systems. They ensure that the system operates at its maximum efficiency, thereby maximizing energy output; (ii) Precise parameters help in predicting the behaviour of PV systems under different conditions, which is vital for ensuring their reliability and longevity; (iii) Accurate estimation impacts the economic feasibility of PV installations. Overestimation or underestimation of system capabilities can lead to financial losses or underutilization of resources, and (iv) As solar technology evolves, the need for precise parameter estimation becomes even more critical to leverage advancements in PV materials and designs fully. Over the past several decades, researchers have made significant strides in understanding, optimizing, and estimating the parameters of various PV mathematical models. A range of methods has been proposed in the literature to handle and analyze the non-linearity of PV models, focusing on accuracy and efficiency. These solutions largely depend on the information sourced from the manufacturer's datasheet, which can be divided into two main categories: the I–V characteristic approach and the key point technique18,19. The key point-based technique extracts uncertain variables from the experimental samples offered by manufacturers. This approach simplifies the models by minimizing the expressions and incorporating a few experimental data. It identifies variables through significant points such as maximum power point (MPP) and data derived from the slopes of the experimental curves for the open-circuit voltage and short-circuit current points. However, this simplification of equations compromises the method's efficiency and accuracy. Recent research indicates that this method lags behind the I–V characteristic method in extracting parameters. The I–V characterization curve-based approach uses numerical optimization methods to determine the PV variables by minimizing the differences between experimental and calculated current data. Using this strategy, parameters can be identified in a variety of ways. Analytical, numerical, and technological approaches based on intelligent/metaheuristic methods have recently been classified as existent solutions in the scientific community for obtaining and determining PV characteristics from the I–V curves20,21,22.
In the analytical technique, a PV solar cell's precise mathematical model and its parameters are established using explicit equations. These equations use data from datasheets or significant points from the experimental I–V curve, such as open circuit voltage, short circuit current, and MPP current and voltage, to directly calculate the model parameters. Although straightforward to use, this approach is based on some simplifying presumptions that compromise the entire model's reliability and produce wildly exaggerated projections of economic returns14,23. Furthermore, these methods lack flexibility and are particularly sensitive to measurement noise. Another approach is numerical parameter identification methods, such as the widely-used Newton method24. These gradient-based algorithms have a straightforward procedure to accurately and quickly find the optimal model parameters. Nevertheless, they are highly sensitive to the initial parameter assumptions. If the technique starts from an initial solution distant from the optimal point, it may converge to a local optimal. Similar methods, like the Lambert W-based analytical method25,26, have been proposed for accurately determining the PV model parameters. This method is more effective in ease of implementation, robustness, efficiency, and accuracy than other methods. Yet, its application scope is limited and can easily fall into a local optimum point. Given that the PV cell model is generally nonlinear, the parameter estimation of the PV cell model exhibits multivariable and nonlinear characteristics. Consequently, numerical and analytical optimization methods may struggle to handle such nonlinear optimizations effectively. To address these weaknesses, intelligent algorithms have been introduced27,28. These aim to improve the parameter identification performance by minimizing the overall error between all experimental and simulated I–V curve data points.
Over the years, researchers have found that traditional methods, such as the I–V characteristic curve and key point approaches, may not be the most efficient means of deriving PV variables from equivalent PV models. In response, a shift towards adopting metaheuristic methods has been observed, as these methods demonstrate superior abilities in parameter extraction and analysis6,29,30. Unlike analytical and numerical methods subject to strict constraints and assumptions, metaheuristic methods offer a more flexible and accurate approach. The growing interest in meta-heuristic methods has led to the exploration of various algorithms, many of which are inspired by natural phenomena. These algorithms have consistently outperformed previous methods in terms of accuracy and efficiency. However, these methods are not without their challenges. High computation time is often required, and due to their stochastic nature, finding the optimal solution can still be elusive. Several techniques, such as genetic algorithm (GA)31, differential evolution (DE) algorithm32,33, cuckoo search (CS)34,35, artificial bee colony (ABC)36, teaching–learning-based optimization (TLBO)37, and particle swarm optimization (PSO)38, have been leveraged to minimize discrepancies between experimental and simulated current data in PV models. Despite their effectiveness, these techniques could benefit from enhancements in computational time efficiency. The GA, one of the most commonly used evolutionary algorithms, has been employed to solve many optimization problems, including extracting electrical parameters from various PV cells. Researchers have gone a step further by merging GA with other techniques, such as the Newton–Raphson or the interior point technique, to intensify the precision of PV variables39,40. Similarly, the DE and PSO algorithms, another popular evolutionary algorithm, have been modified and improved to cater to the PV model parameter extraction needs. However, like all stochastic algorithms, their accuracy and reliability can be unpredictable. Introducing hybrid algorithms has revolutionized extracting parameters from photovoltaic models in recent years. These innovative solutions include combinations of DE and reinforcement learning41, the gaining-sharing knowledge-based algorithm (GSK)42, the comprehensive learning Rao-1 algorithm43, hybrid PSO and grey wolf optimizer (HPSOGWO)44, the modified honey badger algorithm (HBA)45, and an adaptive harris hawk optimization (HHO) algorithm that employs sine–cosine transformations46. Each hybrid method is designed to strike a balance between exploration and exploitation in the extraction process. Moreover, an array of unique methods such as the chaotic tuna swarm algorithm (CTSA)47, gradient-based optimizer (GBO)48,49,50, slime mould algorithm (SMA)51, artificial hummingbird optimizer52, butterfly optimization algorithm (BOA)53, improved arithmetic optimization algorithm (IAOA)15, mountain gazelle optimizer (MGO)54, resistance–capacitance optimizer55, and a war strategy optimization (WSO) algorithm56 inspired by ancient warfare tactics have also been proposed for the extraction of unknown parameters of solar PV systems. Table 1 additionally encompasses pertinent information, including the specific performance criteria, enhanced method, electrical model, solar cell/panel type, and the data employed to estimate parameters. This table offers a thorough evaluation of numerous studies.
Furthermore, various hybrid approaches have been suggested to address the limitations of single algorithms and enhance the efficiency of parameter estimation for photovoltaic models. These include the ABC algorithm with DE70, teaching–learning-based ABC (TLBABC)71, collaborative intelligence of different swarms72, Opposition-Based Flower Pollination Algorithm and Nelder-Mead simplex (OBFPA-NM)73, hybrid GWO and PSO44,74, Levenberg–Marquardt algorithm combined with simulated annealing algorithm (LMSAA)75, and hybrid firefly and pattern search algorithm (HFFPSA)76, hybrid GWO and CS algorithm77, etc. These approaches combine different techniques to achieve more effective results. The RMSE between the experimental and calculated current for the PV model is lower in OBFPA-NM compared to TLBABC and LMSAA. While the OBFPA-NM and HFFPSA methods yield the same RMSE value for both the SDM and DDM models, the estimated parameters obtained from these two approaches are distinct. When comparing the DDM, OBFPA-NM demonstrates superior performance over TLBABC. It was noted that the RMSE of OBFPA-NM was marginally lower than that of HFFPSA while predicting parameters for an SDM of the PV module. The effectiveness of these strategies varies depending on the task at hand, and their ability to produce accurate results quickly is heavily influenced by selecting the appropriate algorithm parameters. These approaches have recently garnered increased interest due to their lack of stringent requirements.
Despite the plethora of meta-heuristic algorithms available to researchers seeking to extract PV model parameters, achieving accurate and reliable results remains a complex and challenging task. This persistent challenge underscores the need for continual refinement and innovation in developing algorithms and methods for PV parameter extraction. This brings us to an essential conundrum: Can we effectively address this issue using current algorithms without sacrificing accuracy and stability? The “no-free-lunch (NFL)” theorem provides a fitting response to this query78. This theorem posits that no single algorithm can optimally resolve all optimization issues, as the superior performance of an algorithm in solving one specific problem does not guarantee an equivalent level of success in tackling other issues. Consequently, the quest for an ideally suitable meta-heuristic algorithm remains an ongoing research topic. The NFL theorem has laid the groundwork for numerous studies and allowed for the customization of existing algorithms to cater to novel problem classifications.
Historically, precise extraction of PV model parameters has been a complex task. This has motivated our development of the opposition-based exponential distribution optimizer (OBEDO). The original exponential distribution optimizer (EDO)—an algorithm known for its simplicity, efficiency, and fast convergence—demonstrated its strength in addressing global optimization issues79. However, despite its success in global optimization problems, the EDO faced limitations when dealing with local optima. To overcome these limitations, this study introduced OBEDO, an advanced EDO version incorporating an opposition-based learning approach. These strategies ensure a more accurate and precise extraction of parameters from various PV models. One pivotal strategy, opposition-based learning (OBL), is a memory repository that records prior positions80. These records are then compared with newly generated positions to inform positioning adjustments. The result is a system better equipped to navigate local optima and identify promising new positions. The main contributions of this paper can be summarized as follows:
-
The introduction of OBEDO, engineered to extract PV model parameters effectively.
-
Incorporating the OBL technique is designed to enhance the quality of positions by utilizing a history of prior positions.
-
The comparison of OBEDO with other recognized algorithms using various PV models.
-
Through comprehensive experimental results and statistical analyses, this study demonstrates the superior performance of OBEDO.
The rest of this document is organized as follows: Section “Photovoltaic modelling and problem formulation” delves into the various photovoltaic models, meticulously explaining their mathematical aspects, and explores the crafting of the objective function. Section “Proposed opposition-based exponential distribution optimizer” provides a succinct overview of the exponential distribution optimizer, thoroughly elaborating on the structure of the suggested OBEDO methodology. Section “Results and discussions” examines the results of various case studies, providing a profound analysis of the experiments. The final section wraps up the study, offering future research directions.
Photovoltaic modelling and problem formulation
This section details the various photovoltaic modes and their respective mathematical modelling. Furthermore, the objective function construction is also deliberated.
Photovoltaic modelling
Photovoltaic devices translate sunlight straight into electricity utilizing the photovoltaic effect. Accurately depicting these mechanisms is crucial to predicting their performance, designing systems, and undertaking thorough analysis. The three main models applied in PV system representation are SDM, DDM, and TDM16,81,82,83. Typically, a cell is represented through a singular current source, denoted as \({I}_{ph}\). The photocurrent, \({I}_{ph}\), is reliant on the intensity of solar radiation.
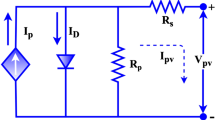
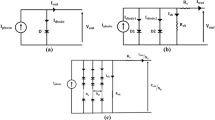
The single-diode model is the most elementary and prevalently employed model for assessing PV systems. This model encompasses one semiconductor junction and the subsequent photovoltaic effect. Despite its simplicity, this model can effectively depict the function of a solar cell across diverse operational conditions. In the framework of the SDM, we engage a sole non-ideal diode, integrated into parallel alignment with the current source, a scenario visually represented in Fig. 1. As was broached earlier, \({R}_{sh}\) symbolizes the parallel resistance, \({R}_{se}\) stands for the series resistance, and the current traversing through the diode is designated as \({I}_{d}\). However, a contrasting approach is adopted in the DDM, wherein a pair of imperfect diodes are collaboratively connected in a parallel manner to one unique current source, a setup graphically elucidated in Fig. 2. In this configuration, \({I}_{d1}\) and \({I}_{d2}\) denote the currents that flow through the first and second diodes, respectively, with \({I}_{d2}\) in particular, corresponding to losses experienced within the space charge region. The fundamental mathematical formula for the single-diode model is as follows84,85.

SDM of the photovoltaic cell.

DDM of the photovoltaic cell.
The diode current \({I}_{d}\) is deduced using the Shockley diode formula, and the leakage current \({I}_{sh}\) is attributed to the shunt resistance, which reflects power losses in the PV cell. By including the expressions for \({I}_{d}\) and \({I}_{sh}\), Eq. (1) is expanded as follows.
where \({I}_{sd}\) represents the diode saturation current, \({V}_{pv}\) denotes the PV cell output voltage, \({I}_{pv}\) denotes the PV cell output current, \(n\) denotes the ideality factor, \({V}_{t}\) is the thermal voltage, \(k\) denotes Boltzmann’s constant, \(q\) denotes the electron charge, and \(T\) denotes the cell temperature.
Examining Eq. (2) reveals five undetermined variables: \({I}_{ph}\), \(n\), \({I}_{sd}\), \({R}_{se}\), and \({R}_{sh}\). Accurate estimation of these parameters from the I–V characteristic of the PV cell is crucial for successful PV modelling. However, the SDM does not consider losses in the depletion region. This has led to the proposition of the DDM by researchers who have asserted that the DDM yields more precise results. The DDM is a more intricate model accounting for recombination losses in both the depletion and quasi-neutral regions of the solar cell, phenomena not represented in the SDM. The equivalent circuit of the DDM is shown in Fig. 2. Essentially, it embodies two single-diode models functioning in parallel, hence “double-diode”. The equation for the DDM becomes more sophisticated, incorporating two diode currents (\({I}_{d1}\) and \({I}_{d2}\)) is as follows86.
By replacing the expression for \({I}_{d1}\) and \({I}_{d2}\) using the Shockley equation, Eq. (4) is rewritten as follows.
where \({I}_{sd1}\) and \({I}_{sd2}\) are the saturated currents of diode 1 and diode 2, respectively, and \({n}_{1}\) and \({n}_{2}\) are the ideality factors of diode 1 and diode 2, respectively.
Examining Eq. (5) reveals seven undetermined variables: \({I}_{ph}\), \({n}_{1}\), \({n}_{2}\), \({I}_{sd1}\), \({I}_{sd2}\), \({R}_{se}\), and \({R}_{sh}\). Accurate estimation of these parameters from the I–V characteristic of the PV cell is crucial for successful PV modelling. Each diode current in DDM possesses its ideality factor, which enhances the precision of this model and its complexity compared to the single-diode model. The TDM incorporates a third diode to signify the recombination losses in the space-charge region, consequently achieving an even more precise representation of the actual behaviour of the solar cell. The equivalent circuit of the TDM is shown in Fig. 3. However, it also significantly elevates the complexity of the model, with the formula involving three diode currents \(({I}_{d1}\), \({I}_{d2}\) and \({I}_{d3}\)) is as follows87,88.

TDM of the photovoltaic cell.
By replacing the expression for \({I}_{d1}\), \({I}_{d2}\) and \({I}_{d3}\) using the Shockley equation, Eq. (6) is rewritten as follows.
where \({I}_{sd1}\), \({I}_{sd2}\) and \({I}_{sd3}\) are the saturated currents of diode 1, diode 2, and diode 3, respectively, and \({n}_{1}\), \({n}_{2}\), and \({n}_{3}\) are the ideality factors of diode 1, diode 2, and diode 3, respectively. Examining Eq. (7) reveals nine undetermined variables: \({I}_{ph}\), \({n}_{1}\), \({n}_{2}\), \({n}_{3}\), \({I}_{sd1}\), \({I}_{sd2}\), \({I}_{sd3}\), \({R}_{se}\), and \({R}_{sh}\). Accurate estimation of these parameters from the I–V characteristic of the PV cell is crucial for successful PV modelling. Each diode current in the TDM also has its ideality factor. Despite being the most precise model, its complexity can lead to more challenging parameter extraction and increased computational burden.
These models support the comprehension and prediction of PV cells' behaviour under diverse illumination and temperature conditions. The SDM is ideal for applications where simplicity and computational speed are key, whereas the DDM and TDM offer greater accuracy and detail and are more suited for in-depth research and comprehensive analysis of PV cell operations. Building a PV module around the principles of the SDM involves integrating SDM-based PV cells arranged in series and parallel networks as key components. A PV module is structured using multiple parallel strings of PV cells (\({N}_{sh}\)), each containing an equivalent number of series-aligned PV cells (\({N}_{se}\)). The I–V characteristics of the module are derived using Eq. (8).
Problem formulation
The PV system, with its nonlinear, intuitive, and transcendental traits, makes the PV cells/modules an appealing choice for optimization tasks. An error function that assesses the precision of parameter estimates can feasibly be established by synthesizing Eqs. (2, 5, 7, and 8). When employing optimization algorithms for this task, creating an error or fitness function is a must; this function must be minimized to secure the best parameter estimation values. The selection of an error function is crucial since it has a substantial impact on the general effectiveness of the final model. Root mean square error (RMSE), as outlined in Eq. (12), is used as the objective function, providing a comprehensive overview of the performance of the estimated model across all characteristics.
The corresponding functions for the SDM, DDM, and TDM, along with the solution vector, denoted as \(x\), for each PV model, are presented as follows.
By utilizing experimental data drawn from the I–V characteristic of the PV cell, it is possible to diminish the value of the RMSE. As a result, extracting parameters from the solar PV cell becomes a process geared towards reducing the RMSE value. This reduction is achieved by carefully adjusting the values of the solution variables. In other words, the goal of the extraction process is to find those values of the solution variables that would minimize the RMSE value, thus enhancing the accuracy of the PV model.
Ethical approval
The authors have confirmed that no ethical approval is required.
Proposed opposition-based exponential distribution optimizer
This section briefly introduces the concepts of the EDO algorithm and its mathematical modelling. Later, the discussion has been extended to formulating the proposed algorithm.
Exponential distribution optimizer
The exponential distribution optimizer (EDO) is a metaheuristic algorithm rooted in mathematics that addresses intricate optimization problems79. The algorithm is founded on Exponential Distribution, a specific form of the continuous probability distribution that models the time between events in a Poisson point process. EDO effectively solves diverse optimization problems, including continuous, linear, nonlinear, and constrained problems. The idea of EDO is to employ a population of individuals (solutions) to explore the search space. Each solution represents a point in the search space, and the objective function value determines the quality of the solution. The algorithm exploits the balance between exploration (global search) and exploitation (local search) to direct the search procedure towards the global optima. In the phase of exploitation, the EDO leverages three fundamental constituents intrinsic to the exponential probability distribution (EPD). These constituents encompass the memoryless attribute, the directive solution, and the exponential dispersion, all essential to retain the contemporaneity of the innovative solution. Conversely, during the phase of exploration, a model optimized based on two solutions, both derived from the ED present within the initial population, is selected. Concurrently, the arithmetic average solution is utilized to effectuate an update to the promising solution.
The main inspiration of EDO, the ED, is a continuous probability distribution that describes the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. The probability density function (PDF) of an exponential distribution is given by:
where \(\lambda =\frac{1}{Mean}\). The ED has the property of being memoryless. In the context of the EDO algorithm, this implies that the quality of a solution does not depend on how the solution was obtained in previous iterations. In adherence to the memoryless property, there is no retention or consideration of the prior history of the solutions. This is due to the independence of past failures, rendering them empty of any impact on subsequent outcomes. Updated solutions are duplicated into the memoryless matrix to emulate the memoryless attribute intrinsic to the ED, irrespective of their fitness levels. This is premised on the understanding that historical data doesn’t influence future developments. Consequently, the memoryless matrix becomes a repository for two categories of solutions: successful ones and those that fall short. Initially, the memoryless matrix is assigned a value identical to the original population, designated as \({X}_{w}\). Like all metaheuristic algorithms, the initialization phase is done random population solution, i.e., the populations are randomly aligned, and the solutions are generated randomly using the random populations. Equation (14) can be employed to stochastically generate each exponential random parameter that is part of the candidate ED within the domain of the problem.
where \(lb\) and \(ub\) denote the lower and upper bounds of the control vectors, \(rand\) denotes the uniform random number varies between [0,1], \({N}_{p}\) signifies the population size, and \(dim\) denotes the problem dimension.
The exploitation stage leverages numerous features of the ED model, including the memoryless attribute, mean, standard deviation, and exponential rate. Furthermore, a directive solution is utilized to steer the exploration phase towards the global optima. The vicinity of a proficient solution often holds the potential for identifying the global optima. This is why several procedures delve into the search bounds near effective solutions by drawing in the lesser-performing ones. Hence, the quest for the global optima is centred on the guiding solution \({X}_{g}\). The \({X}_{g}\) is characterized as the average of the top three solutions from an organized population, designed as follows:
where \(t\) represents the current iterations, the guiding solution is chosen over the best solution because it incrementally leads the solutions towards the optimum one. Even if the best solution is ensnared in local optimum, all other outcomes persistently gravitate towards this best solution. The area surrounding an effective solution often harbours the potential for uncovering the global optimum. Consequently, numerous algorithms take advantage of the search space near high-performing solutions by drawing in the less successful ones. The exploitation stage of the EDO practices several features of the ED model, such as the memoryless feature, mean, and standard variance, to update the solution as follows.
where \({ML}_{i}^{t}\) denotes the ith solution of the memoryless matrix, \(\varphi\) signifies the uniform random number between [0, 1], \(b\) and \(a\) denote adaptive variables and \(f\) denotes the random number in the range of [− 1, 1]. The expression for exponential variance is provided as follows.
The exponential mean \(\mu\) is determined as the mean value between the \({X}_{g}^{t}\) and the \(i\)th memoryless parameter, which could either be a winning or a losing solution.
The algorithm's exploration stage pinpoints areas within the search bound that are considered likely to contain the globally optimal results. The optimization framework for the EDO's exploration stage is constructed around two successful solutions from the initial agents in adherence to the ED. Following this, the solution is updated using Eqs. (23–27).
where \({M}^{t}\) denotes the mean solutions obtained in the actual population, \(c\) denotes the tunable parameter signifying the ratio of information shared among \({Y}_{2}\) and \({Y}_{1}\) to the current solution, \(T\) denotes the maximum number of iterations, and \({X}_{{w}_{rand1}}^{t}\) and \({X}_{{w}_{rand2}}^{t}\) denote the winners concerning the randomly selected ED from the population. An approach based on a greedy method is utilized for the solution update obtained during the exploration and exploitation stages within the initial population. Any updated solution is integrated into the original population only if it meets the criteria of being considered good. The pseudocode of the EDO algorithm exists in Algorithm 1.

Pseudocode of the EDO algorithm.
Opposition-based exponential distribution optimizer
The mutation operations in the EDO algorithm are based on the ED parameters and two control parameters (\(a\) and \(b\)) derived from a uniformly distributed random variable f. This ensures diversity in the population and facilitates exploration and exploitation of the search space. Opposition-based learning (OBL) is an additional strategy that can be incorporated into EDO to enhance performance80,89. The foundational concept of OBL is based on De Morgan's laws in Boolean logic, which state that the complement of a conjunction is the disjunction of the complements, and the complement of a disjunction is the conjunction of the complements. It is used to calculate the “opposite” of a solution.
In optimization algorithms, a point and its opposite define an axis that bisects the solution space. The point lies on one side of the space, and its opposite is equidistant from the centroid but on the opposite side of the space. This geometric interpretation offers the key insight of OBL: for each point considered by the algorithm, there exists an unexplored point that is as far from the centroid as the original point but in the opposite direction. If a solution is a point in the search space, its opposite is another point in the space such that the line connecting the solution and its opposite passes through the centroid of the search space. The primary advantage of considering both a solution and its opposite is that it can double the useful information obtained from each fitness evaluation. Furthermore, because the opposite points are spread throughout the solution space, OBL can widen the search scope, enhancing exploration capabilities and accelerating convergence to the global optimum. Therefore, the proposed algorithm can explore the search space more effectively by evaluating both a solution and its opposite. The OBL is a strategy used to enhance the performance of optimization algorithms by exploring the search space more efficiently. The central concept of OBL is the simultaneous consideration of an estimate (a solution) and its opposition during the search process. In mathematical terms, for a problem defined in the \(dim\)-dimensional real space, a point \({X}_{w}\) in the search space is represented as a vector of \(dim\) real numbers. Given a real-valued solution “\({X}_{w}\)” in the interval \([lb, ub]\), the opposite solution “\({X}_{w,opp}\)” is calculated as follows.
where \(lb\) and \(ub\) represent the lower and upper bounds of the search space, respectively. The fitness of both \({X}_{w}\) and \({X}_{w,opp}\) are evaluated, and the point with the better fitness is selected, i.e., \({\text{if}} f({X}_{w,opp}) < f({X}_{w}), {\text{then}} {X}_{w} = {X}_{w,opp}\).
The main idea of this strategy is to consider the current estimate and its opposite to obtain a better approximation for the global optimal solution. In other words, for each candidate solution, the algorithm generates its opposite solution and evaluates both. The algorithm tries to keep the one with better fitness for the next generation. This can be especially useful in the initial stages of the algorithm's run, where it can significantly increase the convergence speed. The reason is that, with OBL, the algorithm can simultaneously consider two “opposite” points in the solution space. This is akin to exploring two different directions simultaneously, potentially leading to a broader and more efficient search. This OBL strategy is incorporated into EDO during the initialization and mutation phases. As discussed, during initialization, each randomly generated solution \({X}_{w}\) is accompanied by its opposite \({X}_{w,opp}\), and the one with better fitness is selected for the initial population. An offspring solution is created, and its opposite is generated during mutation. Again, the one with the better fitness is selected to replace its parent. This way, in each iteration, the algorithm explores the vicinity of the solutions and their opposite points in the search space. This strategy significantly enhances the exploratory capability of the algorithm, making it more robust and potentially faster in finding the global optimal solution. By applying this strategy, the OBEDO can benefit from an enhanced exploration capability, potentially improving its effectiveness and efficiency in solving complex optimization problems. The pseudocode of the proposed OBEDO algorithm is presented in Algorithm 2. The flowchart of the OBEDO is shown in Fig. 4.

Flowchart of the proposed OBEDO algorithm.

Pseudocode of the proposed OBEDO algorithm.
The OBEDO algorithm, as discussed, likely integrates two key concepts: OBL and EDO algorithm. OBL is a concept used in optimization algorithms to speed up the convergence rate. It works on the principle that considering a candidate solution and its opposite can provide a better approximation of the global optimum. In OBL, for every estimated solution, the opposite solution is also considered. This means if a solution is at a point \(x\) in the search space, its opposite \(-x\) is also evaluated. This approach increases the chances of finding better solutions in fewer iterations as it explores the search space more effectively. When integrated into the OBEDO framework, OBL could help in quickly identifying more promising regions of the search space for parameter estimation, thereby improving the efficiency and accuracy of the optimization process. OBL enhances the global search capability, ensuring diverse and comprehensive exploration, while the exponential distribution method fine-tunes the search, allowing for efficient exploitation of promising areas. This synergy could make OBEDO particularly effective in navigating complex, high-dimensional search spaces typical in solar PV model parameter estimation, where traditional methods might struggle due to local optima or slow convergence. The effectiveness of OBEDO in outperforming other methods could stem from its ability to balance exploration and exploitation in the optimization process. This balance is crucial in parameter estimation problems, where finding the global optimum in a complex search space is essential for accurate and reliable results.
Complexity of the proposed OBEDO algorithm
The algorithm creates an initial population of solutions \({{X}_{w}}_{i}\). The complexity of the initialization phase should be \(O({N}_{p}\times dim)\), where \({N}_{p}\) is the number of individuals, and \(dim\) is the dimension of the solution space. The algorithm performs a series of computations for each individual in the population (\({N}_{p}\)), and this is done for each iteration. Thus, the complexity within the loop could be considered as \(O({N}_{p}\times dim)\). This includes fitness computation, memory updates, and solution modifications. Assuming the complexity of the fitness function is \(O(dim)\), this would still give a complexity of \(O({N}_{p}\times dim)\) for the whole iteration. The sorting operations would add a complexity of \(O({N}_{p}\times log({N}_{p}))\) per iteration. However, since \({N}_{p}\times log({N}_{p})\) is smaller than \({N}_{p}\times dim\) for large enough \({N}_{p}\) and \(dim\), ignore it in the final complexity assessment. Therefore, the time complexity of the OBEDO can be approximated as \(O({N}_{p}\times dim\times T)\), which is the same as the original EDO algorithm.
Results and discussions
In this section of the paper, we present the experimental results obtained to assess the performance of the proposed OBEDO algorithm. The OBEDO determines the parameters of four benchmarked PV cell/module models: RTC France silicon cell, PVM752 GaAs PV cell, Photowatt PWM201 module, commercial Sharp ND-R250A5 PV module, and commercial SM55 PV module. To evaluate the effectiveness of the OBEDO, it is applied to three PV models, namely the SDM, DDM, and TDM. For each model, the OBEDO and other seven algorithms, such as opposition-based GBO (OBGBO), opposition-based marine predator algorithm (OBMPA), MGTO, ADHHO, IAOA, HDE, and original EDO, are employed to obtain the optimal parameters that best fit the experimental data. The application of the proposed OBEDO and other algorithms to estimate PV parameters is pictorially represented in Fig. 5.

Application of the OBEDO and other algorithms for parameter estimation.
For the RTC France silicon cell with a diameter of 57 mm, experimental data is collected under specific conditions, with a solar irradiance of 1000 W/m2 and a temperature of 33 °C. A total of 26 sets of current and voltage measurements are gathered to determine the cell variables by optimizing the RMSE, a common metric for evaluating the accuracy of models. The goal is to find the best-fitting parameters that minimize the RMSE and, thus, enhance the accuracy of the PV cell model. For the PVM752 GaAs PV cell, the experimental data is gathered under 1000W/m2 irradiation and 25 °C temperature. Similarly, for the Photowatt PWM201 module, experimental data is gathered under specific conditions with a solar insolation of 1000 W/m2 and a temperature of 45 °C. For the commercial Sharp ND-R250A5 PV module, the experimental data is gathered under 1040W/m2 irradiation and 59 °C temperature. In addition, the data for the commercial SM55 PV module under different operating conditions are also collected. To ensure realistic parameter estimates, \(lb\) and \(ub\) limits for the cells and the modules parameters are provided in Table 2. These limits constrain the optimization process during the execution of all algorithms and ensure that the resulting parameters fall within physically meaningful ranges.
The simulation tests were conducted on a laptop running Windows 11 with specific hardware specifications. The laptop has an Intel(R) Core (TM) i5-10300H CPU operating at a clock frequency of 2.44 GHz and 8 GB of RAM. For the simulation tests, this study considered a population size of 40, and the maximum number of iterations was set to 1000 for all the PV models under consideration. Additionally, other control parameters for all the algorithms utilized in the experiments are documented in Table 3, providing transparency and reproducibility of the study. To ensure a fair comparison among all the selected algorithms, each method was executed 30 times independently. This repetition helps account for any potential variability in the results and allows us to draw robust conclusions regarding the algorithms' performance. This study employed MATLAB R2020b software to conduct the simulation tests. By running the experiments on the specified laptop and using the common platform of MATLAB R2020b, this study ensures consistency and comparability of the results across all algorithms and PV models. This systematic approach allows us to make well-informed evaluations of the algorithms' efficiency and effectiveness in optimizing the PV model parameters.
In this study, the performance comparison among all the selected algorithms is carried out using various statistical measures and performance metrics to assess their effectiveness in optimizing the PV model parameters. The statistical measures considered include Minimum (Min), Maximum (Max), Mean, and Standard Deviation (STD). These measures help us understand the range and distribution of the results obtained by each algorithm. On the other hand, performance metrics provide specific quantitative evaluations of the algorithms' accuracy in predicting the PV model parameters. The metrics used in this comparison are Relative Error (RE), Integral Absolute Error (IAE), and Root Mean Square Error (RMSE). The runtime (RT) of each algorithm is also analyzed, which represents the average running time of all 30 independent runs for each case study. This information is crucial for understanding the computational efficiency of the algorithms and their feasibility for practical applications. The metrics RE and IAE are computed as follows: (i) IAE represents the integral absolute error for a particular trial, which is calculated as the absolute difference between the estimated current \({I}_{es}\) and the measured current \({I}_{ex}\) value for that trial, and (ii) RE denotes the relative error, which quantifies the percentage difference between the estimated current and the measured current value. It is computed as the ratio of the difference between the measured and estimated current to the measured current value. The IAE is designed to penalize errors equally, regardless of the direction, while the RE provides insight into the magnitude of the absolute error with respect to the measured data. When an exact measurement is unavailable, using the measured value to calculate relative inaccuracy is common. Finally, a Friedman's Ranking Test (FRT) is performed to validate the statistical significance of the results. This test allows for comparing multiple algorithms across different metrics and identifies whether any algorithm significantly outperforms the others. By employing these statistical measures, performance metrics, runtime analysis, and Friedman's Ranking Test, the study comprehensively evaluates the selected algorithms' performance and provides valuable insights into their capabilities in accurately estimating the PV model parameters. Such detailed comparisons are essential for researchers and practitioners to decide on the most suitable algorithm for specific PV modelling applications.
Scenario 1—RTC France Si PV cell
This sub-section details the results obtained by the proposed algorithm and other algorithms for scenario 1, i.e., SDM, DDM, and TDM of the RTC France Si PV cell. The bounds for all the PV models are provided in Table 2. As deliberated earlier, all algorithms are executed 30 times for a fair comparison.
Tables 4, 5, and 6 display a comprehensive overview of the five, seven, and nine parameters estimated through the SDM, DDM, and TDM employment pertaining to the RTC of France Si solar cell. It is imperative to emphasize that these parameters were determined within the precise confines, as elucidated in Table 2. A graphical representation of the I–V (Current–Voltage) and P–V (Power–Voltage) characteristic curves pertinent to the SDM, DDM, and TDM of the RTC France Si solar cell obtained by all algorithms have been expounded in Figs. 6, 7, and 8. These elucidate the outcomes engendered by the proposed OBEDO that was instituted as part of this study. It is crucial to underline that the quantitative values encapsulating the IAE and the RE have been meticulously documented in Table 7. To visually portray the paramount significance of the RE and IAE values ascertained through the instrumentality of the OBEDO and other algorithms, this study has deviously created error graphs as showcased in Figs. 9, 10, and 11. A cursory examination of Figs. 6, 7, 8, 9, 10, and 11 unfolds a noticeably harmonious alignment between the projected estimated and empirically derived experimental curves. This alignment strengthens the inference that the curve fitting has yielded a commendable equivalence. To offer a comprehensive assessment, meticulous cataloguing of statistical indicators including, but not limited to, Min, Mean, Max, RT, and STD values has been meticulously undertaken. These values have been scrupulously logged within Table 8 to facilitate in-depth data comprehension. Furthermore, it is noteworthy that salient achievements, exemplified by the most remarkable outcomes gleaned from the diverse tables, have been judiciously highlighted through the distinctive formatting of boldfaces.

Characteristics curves obtained by algorithms for Scenario 1 (SDM); (a) I–V curves, (b) P–V curves.

Characteristics curves obtained by algorithms for Scenario 1 (DDM); (a) I–V curves, (b) P–V curves.

Characteristics curves obtained by algorithms for Scenario 1 (TDM); (a) I–V curves, (b) P–V curves.

Error curves obtained by algorithms for Scenario 1 (SDM); (a) IAE, (b) RE.

Error curves obtained by algorithms for Scenario 1 (DDM); (a) IAE, (b) RE.

Error curves obtained by algorithms for Scenario 1 (TDM); (a) IAE, (b) RE.
The IAE value resulting from using the OBEDO in the context of the SDM, DDM, and TDM for scenario 1 is notably below the threshold of 3.01E−03. This indicates a remarkably precise alignment between the predicted and observed values. Similarly, the RE value, which gauges the degree of dissimilarity between the predicted and actual values, demonstrates significant conformity as it remains under the stringent limit of 1.51E−01. A broader assessment of the performance metrics sheds light on the collective behaviour for scenario 1 under the purview of the OBEDO algorithm. The average RE and IAE values of SDM, DDM, and TDM are 4.74E−03, 4.50E−03, 4.51E−03, 8.28E−04, 8.19E−04, and 8.18E−04respectively, further reinforcing the efficacy of the optimization algorithm in achieving a robust convergence between the simulated and empirical outcomes. The comprehensive data showcased in Table 5 and Figs. 9, 10, and 11 corroborates the capability of the OBEDO to precisely extract the intricate characteristics of the PV cell within the specific framework. This affirmation of accuracy underscores the algorithm's competence in capturing the nuanced behaviour and performance attributes of the PV cell, thereby contributing to a deeper and more comprehensive understanding of its indefinite characteristics.
Table 8 summarizes the performance of various algorithms across three models: SDM, DDM, and TDM. The metrics assessed include Min, Max, Mean, Median, STD, and RT for each algorithm. Across all three models, the OBEDO algorithm consistently achieves low RMSE values, indicative of accurate predictions. Notably, it maintains a narrow RMSE range, resulting in stable and reliable outcomes. The EDO algorithm displays more variability in RMSE, particularly in the DDM and TDM models, where it reaches higher maximum RMSE values. This suggests that EDO performs well on average but may produce less precise predictions occasionally. ADHHO demonstrates generally consistent performance, maintaining moderate RMSE values and standard deviations. Its RMSE range remains relatively stable across the different models. OBMPA consistently produces moderate RMSE values with low standard deviations, indicating dependable performance. Its RMSE range is also relatively stable across models. MGTO consistently achieves low RMSE values with minimal variability, suggesting accurate and reliable predictions. Notably, its runtime is consistent across models. IAOA displays wider variability in RMSE, particularly in the SDM and DDM models, where it reaches higher maximum values. While its mean RMSE is reasonable, the variability suggests some potential for less accurate predictions. HDE generally maintains low and consistent RMSE values, with minor fluctuations. Its RMSE range remains stable across models, indicating dependable performance. OBGBO stands out with extremely low RMSE values, particularly in the SDM model. However, it comes with higher runtimes, especially in the TDM model. The OBEDO, OBGBO, and MGTO algorithms consistently exhibit accurate and reliable performance across the three models. OBMPA, EDO, ADHHO, IAOA, and HDE also show reasonable performance but with some variability. OBGBO demonstrates good accuracy, though at the cost of longer runtimes.
The progression trajectories, characterizing the convergence behaviour, intricately unravel the dynamics of the SDM, DDM, and TDM for Scenario 1. These complex patterns of convergence are portrayed in the comprehensive Fig. 12. As the gaze fixes upon this graphical representation, the remarkably accelerated convergence of the OBEDO becomes noticeably apparent. This swift trajectory toward convergence, markedly outpacing its algorithmic counterparts, is a testament to the superior efficiency of the OBEDO. The unfolding narrative takes an artistic turn as we venture into Fig. 13, which, rather than opting for the conventional boxplot approach, ingeniously employs the visually captivating violin plot technique. Within this illustration, the distinct strategies outlined for the SDM, DDM, and TDM emerge as leading roles, each contributing its unique melodic note to the symphony of data visualization. In the symphony of violin plots, a striking revelation comes to the fore—OBEDO's reliability emerges as a true virtuoso. A harmonious refrain of low STD values resonates across all the photovoltaic models in Scenario 1.

Convergence curves (Scenario 1); (a) SDM, (b) DDM, (c) TDM.

Violin plots (Scenario 1); (a) SDM, (b) DDM, (c) TDM.
This explicit stability display strengthens the OBEDO's position as an unmatched performer, standing high amidst its algorithmic companions. Interestingly, the plot's narrative takes a dramatic twist as a few algorithms stumble upon the snares of local minima, their quest for optimal outcomes thwarted by the intricate labyrinth of possibilities. Yet, amidst this unfolding drama emerges the OBEDO as the triumphant protagonist. It directs the complex optimization landscape, ascending to the peak of achievement with incomparable accuracy.
Scenario 2—PVM752 GaAs PV Cell
This sub-section details the results obtained by the proposed algorithm and other algorithms for scenario 2, i.e., SDM, DDM, and TDM of the PVM752 GaAs PV cell. The bounds for all the PV models are provided in Table 2. Tables 9, 10, and 11 display a comprehensive overview of the five, seven, and nine parameters estimated through the SDM, DDM, and TDM employment pertaining to the PVM752 GaAs PV cell. A graphical representation of the I–V and P–V characteristic curves pertinent to the SDM, DDM, and TDM of the PVM752 GaAs PV cell obtained by all algorithms has been expounded in Figs. 14, 15, and 16. The quantitative values summarizing the IAE and the RE must be meticulously documented in Table 12. To visually portray the paramount significance of the RE and IAE values ascertained through the instrumentality of the OBEDO and other algorithms, this study has deviously created error graphs as showcased in Figs. 17, 18, and 19. A cursory examination of Figs. 14, 15, 16, 17, 18, and 19 unfolds a noticeably perfect alignment between the estimated and experimental curves. This alignment strengthens the inference that the curve fitting has yielded a worthy equivalence. To offer a comprehensive assessment, meticulous cataloguing of statistical indicators has been meticulously undertaken. These values have been carefully logged within Table 13 to facilitate in-depth data comprehension.

Characteristics curves obtained by algorithms for Scenario 2 (SDM); (a) I–V curves, (b) P–V curves.

Characteristics curves obtained by algorithms for Scenario 2 (DDM); (a) I–V curves, (b) P–V curves.

Characteristics curves obtained by algorithms for Scenario 2 (TDM); (a) I–V curves, (b) P–V curves.

Error curves obtained by algorithms for Scenario 2 (SDM); (a) IAE, (b) RE.

Error curves obtained by algorithms for Scenario 2 (DDM); (a) IAE, (b) RE.

Error curves obtained by algorithms for Scenario 2 (TDM); (a) IAE, (b) RE.
The IAE value resulting from using the OBEDO in the context of the SDM, DDM, and TDM for scenario 2 is notably below the threshold of 9.01E−04. This indicates a remarkably precise alignment between the predicted and observed values. Similarly, the RE value, which gauges the degree of dissimilarity between the predicted and actual values, demonstrates significant conformity as it remains under the stringent limit of 1.51E−02. The average RE and IAE values of SDM, DDM, and TDM are − 7.46E−03, − 5.84E−03, − 6.67E−03, 2.02E−04, 1.63E−04, and 1.36E−04, respectively, further reinforcing the efficacy of the optimization algorithm in achieving a robust convergence between the simulated and empirical outcomes. The comprehensive data showcased in Table 12 and Figs. 17, 18, and 19 corroborates the capability of the OBEDO to precisely extract the intricate characteristics of the PV cell within the specific framework. This affirmation of accuracy underscores the algorithm's competence in capturing the nuanced behaviour and performance attributes of the PV cell, thereby contributing to a deeper and more comprehensive understanding of its indefinite characteristics.
Table 13 summarizes the performance of various algorithms across three models: SDM, DDM, and TDM. Across all the PV models, the algorithms exhibit notable variations in their capabilities. The OBEDO algorithm consistently demonstrates commendable accuracy, as reflected by its frequently low IAE values, ensuring precise predictions. Contrasting this, the EDO algorithm presents a broader spectrum of RMSE values, potentially indicating instances where predictions may be less precise. The ADHHO algorithm maintains consistent and moderate RMSE values, reflecting stable performance across the PV models. Similarly, the OBMPA algorithm displays uniform RMSE values, suggesting reliable outcomes across different scenarios. The MGTO algorithm consistently produces low RMSE values with minimal variability, indicating its potential for reliable predictions. Meanwhile, the IAOA algorithm exhibits more variability in RMSE, especially in the SDM and DDM models. Remarkably, the HDE algorithm consistently maintains low and consistent IAE values across all PV models. The OBGBO algorithm stands out for its exceptional accuracy, albeit with longer runtimes. In summary, the algorithms' performance reveals a diverse landscape of accuracy, convergence, and efficiency. While some algorithms shine in specific models, the OBEDO, MGTO, and HDE algorithms consistently exhibit robust and dependable performance across various photovoltaic models. The findings highlight the crucial interplay between accuracy and efficiency, underscoring the necessity for a comprehensive evaluation of optimization algorithms in photovoltaic modelling. The IAOA and OBMPA failed to trace the I–V and curves for the SDM because both get trapped by the local optima.
The convergence dynamics of the SDM, DDM, and TDM for Scenario 2 are meticulously unveiled through intricate progression trajectories, portrayed vividly in Fig. 20. Upon inspecting this visual depiction, the rapid and impressive convergence of OBEDO becomes clearly evident. This accelerated trajectory surpasses its algorithmic counterparts, underscoring OBEDO's exceptional efficiency. The narrative takes an artistic turn with Fig. 21, which employs the visually captivating violin plot.

Convergence curves (Scenario 2); (a) SDM, (b) DDM, (c) TDM.

Violin plots (Scenario 2); (a) SDM, (b) DDM, (c) TDM.
The strategies defined for SDM, DDM, and TDM play leading roles, each contributing a distinct note to the symphony of data visualization. Within the realm of the symphony of violin plots, a remarkable revelation unfolds—OBEDO emerges as a virtuoso of reliability. The attentive observer discerns the delicate undercurrents of STD values. The low STD values resonate across all photovoltaic models in Scenario 2. This steadfast stability further solidifies OBEDO's stature as an unmatched performer, towering among its algorithmic peers.
Scenario 3—Photowatt PWP-201 PV module
This sub-section details the results obtained by the proposed algorithm and other algorithms for scenario 3, i.e., SDM, DDM, and TDM of the Photowatt PWP-201 PV module. The bounds for all the PV models are provided in Table 2. Tables 14, 15, and 16 display a comprehensive overview of the five, seven, and nine parameters estimated through the SDM, DDM, and TDM employment pertaining to the Photowatt PWP-201 PV module. A graphical representation of the I−V and P–V characteristic curves pertinent to the SDM, DDM, and TDM of the Photowatt PWP-201 PV module obtained by all algorithms has been expounded in Figs. 22, 23, and 24. The quantitative values summarizing the IAE and the RE must be meticulously documented in Table 17. To visually portray the paramount significance of the RE and IAE values ascertained through the instrumentality of the OBEDO and other algorithms, this study has deviously created error graphs as showcased in Figs. 25, 26, and 27. A cursory examination of Figs. 22, 23, 24, 25, 26, and 27 unfolds a noticeably perfect alignment between the estimated and experimental curves. This alignment strengthens the inference that the curve fitting has yielded a worthy equivalence. To offer a comprehensive assessment, meticulous cataloguing of statistical indicators has been meticulously undertaken. These values have been carefully logged within Table 18 to facilitate in-depth data comprehension.

Characteristics curves obtained by algorithms for Scenario 3 (SDM); (a) I–V curves, (b) P–V curves.

Characteristics curves obtained by algorithms for Scenario 3 (DDM); (a) I–V curves, (b) P–V curves.

Characteristics curves obtained by algorithms for Scenario 3 (TDM); (a) I–V curves, (b) P–V curves.

Error curves obtained by algorithms for Scenario 3 (SDM); (a) IAE, (b) RE.

Error curves obtained by algorithms for Scenario 3 (DDM); (a) IAE, (b) RE.

Error curves obtained by algorithms for Scenario 3 (TDM); (a) IAE, (b) RE.
The IAE value resulting from using the OBEDO in the context of the SDM, DDM, and TDM for scenario 2 is notably below the threshold of 5.12E−04. This indicates a remarkably precise alignment between the predicted and observed values. Similarly, the RE value, which gauges the degree of dissimilarity between the predicted and actual values, demonstrates significant conformity as it remains under the stringent limit of 2.41E−02. The average RE and IAE values of SDM, DDM, and TDM are − 3.253E−04, 3.253E−04, 3.253E−04, 1.957E−03, 1.957E−03, and 1.957E−03, respectively, further reinforcing the efficacy of the optimization algorithm in achieving a robust convergence between the simulated and empirical outcomes. The comprehensive data is showcased in Table 17 and Figs. 25, 26, and 27 corroborates the capability of the OBEDO to precisely extract the intricate characteristics of the PV module within the specific framework. This affirmation of accuracy underscores the algorithm's competence in capturing the nuanced behaviour and performance attributes of the PV module, thereby contributing to a deeper and more comprehensive understanding of its indefinite characteristics.
Table 18 provides a comprehensive overview of algorithmic performance across three photovoltaic models: SDM, DDM, and TDM. Key metrics are presented for each algorithm within these models. Across the PV models, a diverse array of algorithmic behaviour is evident. OBEDO consistently demonstrates remarkable accuracy with low RMSE values, indicating precise predictions. EDO shows broader variability in RMSE values, suggesting varying predictive precision. ADHHO and OBMPA both exhibit stable RMSE values, implying reliable performance. MGTO's consistently low RMSE values suggest accurate predictions, while IAOA displays variability, particularly in SDM and DDM. HDE consistently maintains low RMSE values across models, reflecting dependable performance. Notably, OBGBO presents low RMSE values, albeit with higher runtimes. Within the DDM model, OBEDO stands out with its low RMSE values and efficient runtime. In TDM, OBEDO showcases impressive accuracy, while EDO displays variability. ADHHO and OBMPA offer stable and reliable performance. MGTO and IAOA present varying precision, while HDE demonstrates consistent accuracy. OBGBO maintains its performance pattern with higher runtimes. Overall, OBEDO, MGTO, and HDE consistently exhibit robust performance across various PV models, with OBEDO excelling in accuracy and efficiency. The findings emphasize the intricate interplay between accuracy and runtime, underscoring the significance of a comprehensive evaluation of algorithmic efficacy in PV modelling.
The convergence dynamics of the SDM, DDM, and TDM for Scenario 3 are meticulously unveiled through intricate progression trajectories, portrayed vividly in Fig. 28. Upon inspecting this visual depiction, the rapid and impressive convergence of OBEDO becomes clearly evident. This accelerated trajectory surpasses its algorithmic counterparts, underscoring OBEDO's exceptional efficiency. The narrative takes an artistic turn with Fig. 29, which employs the visually captivating violin plot.

Convergence curves (Scenario 3); (a) SDM, (b) DDM, (c) TDM.

Violin plots (Scenario 3); (a) SDM, (b) DDM, (c) TDM.
The strategies defined for SDM, DDM, and TDM play leading roles, each contributing a distinct note to the symphony of data visualization. Within the realm of the symphony of violin plots, a remarkable revelation unfolds—OBEDO emerges as a virtuoso of reliability. The attentive observer discerns the delicate undercurrents of STD values. The low STD values resonate across all photovoltaic models in Scenario 3. This steadfast stability further solidifies OBEDO's stature as an unmatched performer, towering among its algorithmic peers.
Scenario 4: commercial sharp ND− R250A5 polycrystalline PV module
The I–V characteristic of this panel has been measured at a temperature of 59 °C and an irradiation of 1040 W/m2. The results obtained for SDM of the commercial Sharp ND-R250A5 polycrystalline PV module are discussed in this sub-section. This PV panel consists of 60 polycrystalline silicon PV cells that are connected in series. Table 19 presents the optimized parameters of the commercial Sharp ND-R250A5 polycrystalline PV module by all selected algorithms. Table 20 presents the recorded data points, estimated data points using the OBEDO, and the corresponding errors. The average values for IAE and RE are stated as 9.41E−03 and − 3.93e−04. Table 2 displays the boundary values, and Table 19 displays the estimated optimal parameters of the PV module calculated by the OBEDO. The statistical measures for the SDM of this PV panel are presented in Table 21. The optimal RMSE is 1.12E−02, while the IAE is 9.41e−03. The results of five parameters derived by OBEDO were given in Table 19 and were compared with the other statE−of-thE−art algorithms. When comparing the outputs of the SDM, it is evident that the SDM obtained by OBEDO has lower RMSE values compared to the other algorithms. The error characteristics of this case are visualized in Fig. 30. Figure 30a illustrates the IAE with respect to the measured voltage, and Fig. 30b illustrates the RE with respect to the measured voltage. The measured and estimated I–V characteristics for the SDM of this PV panel are depicted in Fig. 31a. The P–V characteristics of this PV panel are shown in Fig. 31b, both measured and computed. The convergence of the objective function and violin plot analysis for OBEDO and seven other optimisation strategies is shown in Fig. 32. The convergence speed of the OBEDO surpasses that of the other algorithms, as demonstrated by Fig. 32a. The reliability of all the algorithms is visualized in Fig. 32b.

Error characteristics of Sharp ND-R250A5 PV module; (a) IAE, (b) RE.

Characteristics of Sharp ND-R250A5 PV module; (a) I–V characteristics, (b) P–V characteristics.

Statistical metrics of Sharp ND-R250A5 PV module; (a) convergence curves, (b) violin plots.
Scenario 5—commercial SM55 PV module
This sub-section details the results obtained by the proposed algorithm and other algorithms for scenario 5, i.e., the SDM of the SM55 PV module. The bounds for this scenario are provided in Table 2. To extract the parameters of scenario 5, a comprehensive analysis is conducted using experimental I–V samples. These samples are gathered under specific conditions, encompassing constant irradiance (G) of 1000 W/m2 and varying temperatures (T) of 25 °C, 50 °C, and 75 °C, as well as a constant temperature of 25 °C and diverse irradiation levels including 1000 W/m2, 800 W/m2, 600 W/m2, 400 W/m2, and 200 W/m2. The evaluation process encompasses various statistical measures and other pertinent performance indicators. Equation (30) is pivotal in this context, as it calculates the specific photovoltaic modules short-circuit current Isc across various operational scenarios.
In the context of this study, the variables T and G hold significance as they denote the prevailing temperature and irradiation levels. The parameter α signifies the temperature coefficient, while TSTC represents the temperature at STC, and GSTC corresponds to the irradiance at STC. Additionally, I(sc(STC)) represents the short-circuit current at STC. Through this meticulous examination, insights are gained into the behaviour and adaptability of the PV module model, facilitating a nuanced understanding of its performance under varying temperature and irradiance conditions. This analysis contributes to a comprehensive comprehension of the model's capabilities, aiding in optimizing and deploying photovoltaic systems across a spectrum of real-world scenarios.
Within this study, Tables 22 and 23 play a pivotal role in offering a comprehensive insight into the parameters estimated and optimized using the OBEDO, alongside several alternative methodologies employed to investigate the PV module model. Delving into the specifics, Table 22 meticulously catalogues the estimated variables associated with the SM55 photovoltaic module. The entries in this table pertain to scenarios where the irradiance remains constant at 1000 W/m2 while the temperature fluctuates across three distinct levels: 25 °C, 50 °C, and 75 °C. Meanwhile, Table 23 presents a similar compilation of estimated parameters for the SM55 PV module under differing conditions. In this instance, the temperature is maintained at a constant 25 °C while the irradiance levels are varied, spanning the range of 1000–200 W/m2.
The outcomes in Tables 22 and 23 witness the superior predictive prowess of the proposed OBEDO algorithm. These assertions are substantiated by observing significant RMSE values. This quantifiable measure of accuracy underscores the algorithm's efficacy in determining and predicting the parameters intrinsic to a PV system with enhanced precision. Augmenting the tabular data, Figs. 33 and 34 provide a graphical representation of the I–V and P–V curves, depicting the behaviour of the SM55 PV module as extracted through the OBEDO and other algorithms. These curves offer a tangible means to observe the alignment and coherence between the curves generated from the algorithm's predicted data and the actual empirical data. This visual correlation elucidates how much the algorithmic predictions harmonize with real-world observations, enhancing our understanding of the model's performance and predictive capabilities.

Characteristics of the SM55 PV module under different temperature conditions obtained by all algorithms; (a) I–V curves, (b) P–V curves.

Characteristics of the SM55 PV module under different irradiance conditions obtained by all algorithms; (a) I–V curves, (b) P–V curves.
In order to conduct a more comprehensive evaluation of the performance of the newly introduced OBEDO, a detailed analysis of its statistical measures was carried out. This analysis specifically focused on Scenario 5 and involved the computation of various key metrics, including the Min, Max, Mean, Median and STD values. These statistical results were subsequently organized and presented in a tabular format, with Tables 24 and 25 dedicated to showcasing these values. The investigation was undertaken across various environmental factors, encompassing different temperature settings and varying irradiation conditions. The purpose of this exploration was to measure the algorithm's robustness and effectiveness under a variety of scenarios. Notably, the outcomes yielded by the OBEDO exhibited remarkable performance in terms of the computed statistical measures, specifically the Min, Max, Mean, and STD values. This notable achievement can be attributed to incorporating a unique enhancement technique, namely integrating OBL within the algorithmic framework. By infusing the algorithm with the principles of OBL, the inherent capacity of the OBEDO to explore and exploit the solution space was significantly augmented. This enhancement played a crucial role in the algorithm's ability to search for optimal PV module parameters under varying conditions efficiently.
The synergistic effect of the OBL strategy, alongside other optimization techniques embedded within the OBEDO, contributed to the algorithm's exceptional performance across different environmental contexts. In summary, the meticulous evaluation of the proposed OBEDO's performance in Scenario 5, through the assessment of statistical measures across distinct temperatures and irradiation conditions, underscored its effectiveness in achieving outstanding results. This success can be attributed to the successful integration of OBL, which bolstered both exploration and exploitation capabilities, ultimately identifying optimal PV module parameters across various conditions.
However, it is worth noting that the RT values acquired through utilizing the proposed algorithm across all operational conditions exhibit a marginal increase compared to those attained by the fundamental EDO. This observed difference in RT values can be attributed to amalgamating two distinct optimization strategies within the proposed algorithmic framework. Despite the slightly elevated RT values, the overall performance of the proposed algorithm surpasses that of the basic EDO by a notable margin, showcasing an improvement of over 75%. This significant enhancement can be attributed to the synergistic effect generated by the fusion of these diverse optimization strategies. The results obtained from the evaluation demonstrate a remarkable alignment between the I–V and P–V characteristics deduced from the estimated parameters and the experimental data, even under varying temperature and irradiance conditions. This alignment underscores the precision of the proposed algorithm in capturing the intricate nuances of the photovoltaic system's behaviour. Furthermore, the outcomes of the experimentation reveal an additional advantage of the OBEDO, namely its ability to attain a lower RMSE value. This improvement in accuracy highlights the algorithm's efficacy in modelling and predicting the behaviour of the photovoltaic module, thereby facilitating more reliable parameter estimations. The comprehensive discussions and analyses led to the clear conclusion that the efficiency of the OBEDO remains robust and dependable when confronted with dynamic shifts in environmental conditions. The amalgamation of optimization strategies, while contributing to a slight increase in RT values, offers substantial gains in performance, as evident from the substantial enhancement over the basic EDO. The alignment between simulated I–V and P–V characteristics and experimental data, coupled with the lower RMSE value achieved, attests to the algorithm's capability to handle the details of dynamic environmental variations.
Statistical performance
Milton Friedman, a renowned figure in statistics, is credited with conceiving a significant non-parametric statistical test known as the Friedman ranking test (FRT). This test holds a distinct purpose in the realm of statistical analysis—it serves as a valuable tool for detecting variations in treatments across multiple experimental runs, akin to the parameterized repeated measures ANOVA commonly employed in research. A comprehensive application of the FRT was conducted to establish the superiority of the OBEDO in terms of overall performance. In this endeavour, the objective was to substantiate that the OBEDO exhibits superior efficacy in generating aggregate results compared to a range of other algorithms. Among the algorithms subjected to analysis were not only the OBEDO and EDO but also an assortment of others, namely the ADHHO, OBMPA, MGTO, IAOA, HDE, and OBGBO. The process involved meticulously examining the FRT outcomes, which were carefully obtained by considering each algorithm's RMSE standard deviation values. These values, extracted and compiled in Table 26, provided a foundation for an extensive comparative analysis of the various algorithms under investigation. The resultant observations from this comparison laid bare a noteworthy revelation – the OBEDO emerged as a standout performer. By assessing the mean FRT values across four distinct case studies and comparing them against the benchmark set by preceding algorithms, the authors concluded that the recommended OBEDO showcases an exceptional ability to manage diverse scenarios with the lowest mean FRT values. In light of the compelling evidence amassed through this comprehensive analysis, it becomes evident that the OBEDO outshines its counterparts. The OBEDO's consistent superiority across multiple case studies firmly establishes its prowess as a premier algorithmic solution, further reinforcing its position as a robust and proficient tool for addressing various optimization challenges.
Table 26 presents a comparative analysis using the FRT across various scenarios and optimization models. The FRT aims to determine the relative performance of different optimization algorithms. The models evaluated in this study include OBEDO, EDO, ADHHO, OBMPA, MGTO, IAOA, HDE, and OBGBO. In Scenario 1, involving different data models (SDM, DDM, TDM), the FRT values indicate the algorithms' performance. The OBEDO algorithm achieved the lowest FRT value, followed by MGTO and OBGBO. Similar trends are observed in Scenario 2, which considers another set of data models, with OBEDO outperforming other models. Scenario 3 explores algorithms' performance across diverse conditions. Once again, OBEDO takes the lead in achieving the lowest FRT value, followed by ADHHO and IAOA. Scenario 4 explores algorithms' performance across diverse conditions. Once again, OBEDO takes the lead in achieving the lowest FRT value, followed by OBGBO and MGTO. In the fifth scenario, different temperature and irradiance conditions are analyzed. OBEDO consistently demonstrates the most favourable performance across varying environmental conditions. The mean FRT provides the average FRT values for each model, and the rank presents their ranking based on performance. Notably, OBEDO maintains the top rank with the lowest mean FRT value, emphasizing its consistent superiority. In summary, the FRT analysis across multiple scenarios and models underscores the exceptional performance of the OBEDO algorithm, which consistently achieves the lowest FRT values and the highest ranking. This suggests that OBEDO outperforms the other optimization models across diverse conditions and demonstrates its robustness and efficacy in optimization tasks.
Conclusions and future extension
The proposed OBEDO has demonstrated its prowess in efficiently, accurately, and rapidly extracting undefined parameters from diverse PV system models, as evidenced by the proposed study. The comprehensive analysis undertaken further substantiates the efficacy and potential of this framework in extrapolating parameters for commercial PV models. The evaluation sought to ascertain if the proposed methodology could successfully deduce the parameters of such intricate models, and the obtained results provide compelling evidence of the OBEDO's capability to precisely and effectively determine optimal parameters. Furthermore, it is noteworthy that the TDM exhibits the lowest model features in terms of RMSE, IAE, and RE, underscoring its accuracy. Additionally, the convergence speed of the OBEDO outperforms its counterparts across all test cases, indicating its superior efficiency. These attributes collectively position the proposed OBEDO as a cutting-edge, competitive, and advanced approach for parameter identification in PV models. The OBEDO attains stability and diversity, achieved through meticulous parameter tuning, which positions it favourably compared to its basic version. Nonetheless, as per the NFL theorem, it is crucial to recognize that while the OBEDO exhibits enhanced search results for parameter identification problems, its success might vary in problems with distinct characteristics. As a result, ongoing research and development are necessary to tailor meta-heuristic search approaches to specific problem domains.
In forthcoming research, the proposed algorithm can be evaluated within contemporary techniques for PV parameter identification and subsequently extended to real-world scenarios for various PV cells/modules. Moreover, the versatile applicability of the OBEDO can be harnessed to address challenging problems spanning water pollution prediction, disease diagnosis, binary optimization, feature selection/extraction, image processing tasks, scheduling optimization, wireless sensor networks, and medical image categorization. This underscores the algorithm's potential as a multifaceted solution with far-reaching implications across diverse domains.
Data availability
The datasets used during the current study are available from the corresponding author upon reasonable request.
References
Ravi, S., Premkumar, M. & Abualigah, L. Comparative analysis of recent metaheuristic algorithms for maximum power point tracking of solar photovoltaic systems under partial shading conditions. Int. J. Appl. Power Eng. 12(2), 196–217. https://doi.org/10.11591/IJAPE.V12.I2.PP196-217 (2023).
Hussin, F., Issabayeva, G. & Aroua, M. K. Solar photovoltaic applications: Opportunities and challenges. Rev. Chem. Eng. 34(4), 503–528. https://doi.org/10.1515/REVCE-2016-0058 (2018).
Vinod, Kumar, R. & Singh, S. K. Solar photovoltaic modeling and simulation: As a renewable energy solution. Energy Rep. 4, 701–712. https://doi.org/10.1016/J.EGYR.2018.09.008 (2018).
Podder, A. K., Roy, N. K. & Pota, H. R. MPPT methods for solar PV systems: A critical review based on tracking nature. IET Renew. Power Gener. 13(10), 1615–1632. https://doi.org/10.1049/IET-RPG.2018.5946 (2019).
Hegazy, E., Shokair, M. & Saad, W. Recursive bit assignment with neural reference adaptive step (RNA) MPPT algorithm for photovoltaic system. Sci. Rep. 13(1), 1–24. https://doi.org/10.1038/s41598-023-28982-6 (2023).
Kazem, H. A., Chaichan, M. T., Al-Waeli, A. H. A. & Gholami, A. A systematic review of solar photovoltaic energy systems design modelling, algorithms, and software. Energy Sources Part A Recovery Util. Environ. Effects 44(3), 6709–6736. https://doi.org/10.1080/15567036.2022.2100517 (2022).
Chin, V. J., Salam, Z. & Ishaque, K. Cell modelling and model parameters estimation techniques for photovoltaic simulator application: A review. Appl. Energy 154, 500–519. https://doi.org/10.1016/j.apenergy.2015.05.035 (2015).
Premkumar, M., Kumar, C. & Sowmya, R. Mathematical modelling of solar photovoltaic cell/panel/array based on the physical parameters from the manufacturer’s datasheet. Int. J. Renew. Energy Dev. 9(1), 7–22. https://doi.org/10.14710/ijred.9.1.7-22 (2020).
Xiao, W. B., Liu, W. Q., Wu, H. M. & Zhang, H. M. Review of parameter extraction methods for single-diode model of solar cell. Wuli Xuebao/Acta Phys. Sin. https://doi.org/10.7498/aps.67.20181024 (2018).
Yaqoob, S. J. et al. Comparative study with practical validation of photovoltaic monocrystalline module for single and double diode models. Sci. Rep. 11(1), 1–14. https://doi.org/10.1038/s41598-021-98593-6 (2021).
Houssein, E. H., Zaki, G. N., Diab, A. A. Z. & Younis, E. M. G. An efficient Manta ray foraging optimization algorithm for parameter extraction of three-diode photovoltaic model. Comput. Electr. Eng. 94, 107304. https://doi.org/10.1016/J.COMPELECENG.2021.107304 (2021).
Premkumar, M., Jangir, P. & Sowmya, R. Parameter extraction of three-diode solar photovoltaic model using a new metaheuristic resistance–capacitance optimization algorithm and improved Newton–Raphson method. J. Comput. Electron. 22(1), 439–470. https://doi.org/10.1007/S10825-022-01987-6/METRICS (2023).
Md Sabudin, S. N. & Jamil, N. M. Parameter estimation in mathematical modelling for photovoltaic panel. IOP Conf. Ser. Mater. Sci. Eng. https://doi.org/10.1088/1757-899X/536/1/012001 (2019).
Elkholy, A. & Abou El-Ela, A. A. Optimal parameters estimation and modelling of photovoltaic modules using analytical method. Heliyon 5(7), e02137. https://doi.org/10.1016/J.HELIYON.2019.E02137 (2019).
Mohammed Ridha, H. et al. Novel parameter extraction for single, double, and three diodes photovoltaic models based on robust adaptive arithmetic optimization algorithm and adaptive damping method of Berndt-Hall-Hall-Hausman. Sol. Energy 243, 35–61. https://doi.org/10.1016/J.SOLENER.2022.07.029 (2022).
Ridha, H. M. et al. Parameters extraction of three diode photovoltaic models using boosted LSHADE algorithm and Newton Raphson method. Energy 224, 120136. https://doi.org/10.1016/j.energy.2021.120136 (2021).
Khanna, V., Das, B. K., Bisht, D., Vandana, & Singh, P. K. A three diode model for industrial solar cells and estimation of solar cell parameters using PSO algorithm. Renew. Energy 78, 105–113. https://doi.org/10.1016/J.RENENE.2014.12.072 (2015).
Khatib, T., Ghareeb, A., Tamimi, M., Jaber, M. & Jaradat, S. A new offline method for extracting I–V characteristic curve for photovoltaic modules using artificial neural networks. Sol. Energy 173, 462–469. https://doi.org/10.1016/J.SOLENER.2018.07.092 (2018).
Durán, E., Andújar, J. M., Enrique, J. M. & Pérez-Oria, J. M. Determination of PV generator I–V/P–V characteristic curves using a DC–DC converter controlled by a virtual instrument. Int. J. Photoenergy https://doi.org/10.1155/2012/843185 (2012).
Jordehi, A. R. Parameter estimation of solar photovoltaic (PV) cells: A review. Renew. Sustain. Energy Rev. 61, 354–371. https://doi.org/10.1016/j.rser.2016.03.049 (2016).
Venkateswari, R. & Rajasekar, N. Review on parameter estimation techniques of solar photovoltaic systems. Int. Trans. Electr. Energy Syst. 31(11), e13113. https://doi.org/10.1002/2050-7038.13113 (2021).
Humada, A. M., Hojabri, M., Mekhilef, S. & Hamada, H. M. Solar cell parameters extraction based on single and double-diode models: A review. Renew. Sustain. Energy Rev. 56, 494–509. https://doi.org/10.1016/j.rser.2015.11.051 (2016).
Cubas, J., Pindado, S. & Victoria, M. On the analytical approach for modeling photovoltaic systems behavior. J. Power Sources 247, 467–474. https://doi.org/10.1016/J.JPOWSOUR.2013.09.008 (2014).
Reis, L. R. D., Camacho, J. R. & Novacki, D. F. The newton raphson method in the extraction of parameters of PV modules. Renew. Energy Power Qual. J. https://doi.org/10.24084/repqj15.416 (2017).
Premkumar, M. et al. A reliable optimization framework for parameter identification of single-diode solar photovoltaic model using weighted velocity-guided grey wolf optimization algorithm and Lambert-W function. IET Renew. Power Gener. https://doi.org/10.1049/RPG2.12792 (2023).
Tripathy, M., Kumar, M. & Sadhu, P. K. Photovoltaic system using Lambert W function-based technique. Sol. Energy https://doi.org/10.1016/j.solener.2017.10.007 (2017).
Saxena, A., Sharma, A. & Shekhawat, S. Parameter extraction of solar cell using intelligent grey wolf optimizer. Evol. Intell. https://doi.org/10.1007/s12065-020-00499-1 (2020).
Irudayaraj, A. X. R. et al. Decentralized frequency control of restructured energy system using hybrid intelligent algorithm and non-linear fractional order proportional integral derivative controller. IET Renew. Power Gener. 17(8), 2009–2037. https://doi.org/10.1049/RPG2.12746 (2023).
Fahim, S. R., Hasanien, H. M., Turky, R. A., Aleem, S. H. E. A. & Ćalasan, M. A comprehensive review of photovoltaic modules models and algorithms used in parameter extraction. Energies 15(23), 8941. https://doi.org/10.3390/EN15238941 (2022).
Sharma, A. et al. Performance investigation of state-of-the-art metaheuristic techniques for parameter extraction of solar cells/module. Sci. Rep. 13(1), 1–41. https://doi.org/10.1038/s41598-023-37824-4 (2023).
Jervase, J. A., Bourdoucen, H. & Al-Lawati, A. Solar cell parameter extraction using genetic algorithms. Meas. Sci. Technol. 12(11), 1922–1925. https://doi.org/10.1088/0957-0233/12/11/322 (2001).
Premkumar, M. et al. A reliable optimization framework using ensembled successive history adaptive differential evolutionary algorithm for optimal power flow problems. IET Gener. Transm. Distrib. https://doi.org/10.1049/GTD2.12738 (2023).
Abido, M. A. & Khalid, M. S. Seven-parameter PV model estimation using differential evolution. Electr. Eng. 100(2), 971–981. https://doi.org/10.1007/s00202-017-0542-2 (2018).
Kang, T., Yao, J., Jin, M., Yang, S. & Duong, T. A novel improved cuckoo search algorithm for parameter estimation of photovoltaic (PV) models. Energies (Basel) 11(5), 1060. https://doi.org/10.3390/en11051060 (2018).
Ma, J. et al. Parameter estimation of photovoltaic models via cuckoo search. J. Appl. Math. https://doi.org/10.1155/2013/362619 (2013).
Oliva, D., Cuevas, E. & Pajares, G. Parameter identification of solar cells using artificial bee colony optimization. Energy 72, 93–102. https://doi.org/10.1016/j.energy.2014.05.011 (2014).
Li, S. et al. Parameter extraction of photovoltaic models using an improved teaching-learning-based optimization. Energy Convers. Manag. 186, 293–305. https://doi.org/10.1016/j.enconman.2019.02.048 (2019).
Wei, T., Yu, F., Huang, G. & Xu, C. A particle-swarm-optimization-based parameter extraction routine for three-diode lumped parameter model of organic solar cells. IEEE Electron. Device Lett. 40(9), 1511–1514. https://doi.org/10.1109/LED.2019.2926315 (2019).
Zagrouba, M., Sellami, A., Bouaïcha, M. & Ksouri, M. Identification of PV solar cells and modules parameters using the genetic algorithms: Application to maximum power extraction. Sol. Energy 84(5), 860–866. https://doi.org/10.1016/j.solener.2010.02.012 (2010).
Rong, J., Wang, B., Liu, B. & Zha, X. Parameter optimization of PV based on hybrid genetic algorithm. IFAC-PapersOnLine 48(28), 568–572. https://doi.org/10.1016/j.ifacol.2015.12.189 (2015).
Hosahalli, D. & Srinivas, K. G. Enhanced reinforcement learning assisted dynamic power management model for internet-of-things centric wireless sensor network. IET Commun. 14(21), 3748–3760. https://doi.org/10.1049/IET-COM.2020.0026/CITE/REFWORKS (2020).
Mohamed, A. W., Hadi, A. A. & Mohamed, A. K. Gaining-sharing knowledge based algorithm for solving optimization problems: a novel nature-inspired algorithm. Int. J. Mach. Learn. Cybern. 11(7), 1501–1529. https://doi.org/10.1007/S13042-019-01053-X/FIGURES/13 (2020).
Farah, A. et al. Parameter extraction of photovoltaic models using a comprehensive learning Rao-1 algorithm. Energy Convers. Manag. 252, 115057. https://doi.org/10.1016/J.ENCONMAN.2021.115057 (2022).
Premkumar, M., Sowmya, R., Umashankar, S. & Jangir, P. Extraction of uncertain parameters of single-diode photovoltaic module using hybrid particle swarm optimization and grey wolf optimization algorithm. Mater. Today Proc. 46, 5315–5321. https://doi.org/10.1016/J.MATPR.2020.08.784 (2021).
Hu, G., Zhong, J. & Wei, G. SaCHBA_PDN: Modified honey badger algorithm with multi-strategy for UAV path planning. Expert Syst. Appl. 223, 119941. https://doi.org/10.1016/J.ESWA.2023.119941 (2023).
Song, S., Wang, P., Heidari, A. A., Zhao, X. & Chen, H. Adaptive Harris hawks optimization with persistent trigonometric differences for photovoltaic model parameter extraction. Eng. Appl. Artif. Intell. 109, 104608. https://doi.org/10.1016/J.ENGAPPAI.2021.104608 (2022).
Kumar, C. & Magdalin Mary, D. A novel chaotic-driven tuna swarm optimizer with Newton–Raphson method for parameter identification of three-diode equivalent circuit model of solar photovoltaic cells/modules. Optik (Stuttgart) 264, 169379. https://doi.org/10.1016/J.IJLEO.2022.169379 (2022).
Yu, S. et al. Solar photovoltaic model parameter estimation based on orthogonally-adapted gradient-based optimization. Optik (Stuttgart) 252, 168513. https://doi.org/10.1016/J.IJLEO.2021.168513 (2022).
Premkumar, M. et al. An enhanced Gradient-based Optimizer for parameter estimation of various solar photovoltaic models. Energy Rep. 8, 15249–15285. https://doi.org/10.1016/J.EGYR.2022.11.092 (2022).
Zhou, W. et al. Random learning gradient based optimization for efficient design of photovoltaic models. Energy Convers. Manag. https://doi.org/10.1016/j.enconman.2020.113751 (2021).
Kumar, C., Raj, T. D., Premkumar, M. & Raj, T. D. A new stochastic slime mould optimization algorithm for the estimation of solar photovoltaic cell parameters. Optik (Stuttgart) 223(August), 165277. https://doi.org/10.1016/j.ijleo.2020.165277 (2020).
El-Sehiemy, R., Shaheen, A., El-Fergany, A. & Ginidi, A. Electrical parameters extraction of PV modules using artificial hummingbird optimizer. Sci. Rep. 13(1), 1–23. https://doi.org/10.1038/s41598-023-36284-0 (2023).
Long, W., Wu, T., Xu, M., Tang, M. & Cai, S. Parameters identification of photovoltaic models by using an enhanced adaptive butterfly optimization algorithm. Energy 229, 120750. https://doi.org/10.1016/J.ENERGY.2021.120750 (2021).
Chandrasekaran, K., Thaveedhu, A. S. R., Manoharan, P. & Periyasamy, V. Optimal estimation of parameters of the three-diode commercial solar photovoltaic model using an improved Berndt–Hall–Hall–Hausman method hybridized with an augmented mountain gazelle optimizer. Environ. Sci. Pollut. Res. https://doi.org/10.1007/S11356-023-26447-X/METRICS (2023).
Ravichandran, S., Manoharan, P., Jangir, P. & Selvarajan, S. Resistance–capacitance optimizer: A physics-inspired population-based algorithm for numerical and industrial engineering computation problems. Sci. Rep. 13(1), 1–40. https://doi.org/10.1038/s41598-023-42969-3 (2023).
Ayyarao, T. S. L. V. & Kumar, P. P. Parameter estimation of solar PV models with a new proposed war strategy optimization algorithm. Int. J. Energy Res. 46(6), 7215–7238. https://doi.org/10.1002/ER.7629 (2022).
Liang, J. et al. Classified perturbation mutation based particle swarm optimization algorithm for parameters extraction of photovoltaic models. Energy Convers. Manag. 203, 112138. https://doi.org/10.1016/J.ENCONMAN.2019.112138 (2020).
Premkumar, M., Babu, T. S., Umashankar, S. & Sowmya, R. A new metaphor-less algorithms for the photovoltaic cell parameter estimation. Optik (Stuttgart) 208, 164559. https://doi.org/10.1016/j.ijleo.2020.164559 (2020).
Ibrahim, I. A., Hossain, M. J. & Duck, B. C. A hybrid wind driven-based fruit fly optimization algorithm for identifying the parameters of a double-diode photovoltaic cell model considering degradation effects. Sustain. Energy Technol. Assess. 50, 101685. https://doi.org/10.1016/J.SETA.2021.101685 (2022).
Yu, Y. et al. A population diversity-controlled differential evolution for parameter estimation of solar photovoltaic models. Sustain. Energy Technol. Assess. 51, 101938. https://doi.org/10.1016/J.SETA.2021.101938 (2022).
Abdel-Basset, M., El-Shahat, D., Sallam, K. M. & Munasinghe, K. Parameter extraction of photovoltaic models using a memory-based improved gorilla troops optimizer. Energy Convers. Manag. 252, 115134. https://doi.org/10.1016/J.ENCONMAN.2021.115134 (2022).
Yu, S. et al. Parameter estimation of static solar photovoltaic models using Laplacian Nelder–Mead hunger games search. Sol. Energy 242, 79–104. https://doi.org/10.1016/J.SOLENER.2022.06.046 (2022).
Wang, D., Sun, X., Kang, H., Shen, Y. & Chen, Q. Heterogeneous differential evolution algorithm for parameter estimation of solar photovoltaic models. Energy Rep. 8, 4724–4746. https://doi.org/10.1016/J.EGYR.2022.03.144 (2022).
Bo, Q., Cheng, W., Khishe, M., Mohammadi, M. & Mohammed, A. H. Solar photovoltaic model parameter identification using robust niching chimp optimization. Sol. Energy 239, 179–197. https://doi.org/10.1016/J.SOLENER.2022.04.056 (2022).
Abbassi, A., Ben Mehrez, R., Touaiti, B., Abualigah, L. & Touti, E. Parameterization of photovoltaic solar cell double-diode model based on improved arithmetic optimization algorithm. Optik (Stuttgart) 253, 168600. https://doi.org/10.1016/J.IJLEO.2022.168600 (2022).
Premkumar, M., Jangir, P., Elavarasan, R. M. & Sowmya, R. Opposition decided gradient-based optimizer with balance analysis and diversity maintenance for parameter identification of solar photovoltaic models. J. Ambient Intell. Humaniz. Comput. 1, 1–23. https://doi.org/10.1007/S12652-021-03564-4/TABLES/16 (2021).
Abdel-basset, M., Mohamed, R., Mirjalili, S., Chakrabortty, R. K. & Ryan, M. J. Solar photovoltaic parameter estimation using an improved equilibrium optimizer. Sol. Energy 209, 694–708. https://doi.org/10.1016/j.solener.2020.09.032 (2020).
Yu, K. et al. A performance-guided JAYA algorithm for parameters identification of photovoltaic cell and module. Appl. Energy https://doi.org/10.1016/j.apenergy.2019.01.008 (2019).
Long, W. et al. Parameters estimation of photovoltaic models using a novel hybrid seagull optimization algorithm. Energy 249, 123760. https://doi.org/10.1016/J.ENERGY.2022.123760 (2022).
Hachana, O., Hemsas, K. E., Tina, G. M. & Ventura, C. Comparison of different metaheuristic algorithms for parameter identification of photovoltaic cell/module. J. Renew. Sustain. Energy https://doi.org/10.1063/1.4822054/286273 (2013).
Chen, X., Xu, B., Mei, C., Ding, Y. & Li, K. Teaching–learning-based artificial bee colony for solar photovoltaic parameter estimation. Appl. Energy 212, 1578–1588. https://doi.org/10.1016/J.APENERGY.2017.12.115 (2018).
Nunes, H. G. G., Pombo, J. A. N., Bento, P. M. R., Mariano, S. J. P. S. & Calado, M. R. A. Collaborative swarm intelligence to estimate PV parameters. Energy Convers. Manag. 185, 866–890. https://doi.org/10.1016/J.ENCONMAN.2019.02.003 (2019).
Xu, S. & Wang, Y. Parameter estimation of photovoltaic modules using a hybrid flower pollination algorithm. Energy Convers. Manag. 144, 53–68. https://doi.org/10.1016/J.ENCONMAN.2017.04.042 (2017).
Rezk, H., Arfaoui, J. & Gomaa, M. R. Optimal parameter estimation of solar PV panel based on hybrid particle swarm and grey wolf optimization algorithms. Int. J. Interact. Multimed. Artif. Intell. 6(Regular issue), 145–155. https://doi.org/10.9781/IJIMAI.2020.12.001 (2021).
Dkhichi, F., Oukarfi, B., Fakkar, A. & Belbounaguia, N. Parameter identification of solar cell model using Levenberg–Marquardt algorithm combined with simulated annealing. Sol. Energy 110, 781–788. https://doi.org/10.1016/J.SOLENER.2014.09.033 (2014).
Beigi, A. M. & Maroosi, A. Parameter identification for solar cells and module using a hybrid firefly and pattern search algorithms. Sol. Energy 171, 435–446. https://doi.org/10.1016/J.SOLENER.2018.06.092 (2018).
Long, W., Cai, S., Jiao, J., Xu, M. & Wu, T. A new hybrid algorithm based on grey wolf optimizer and cuckoo search for parameter extraction of solar photovoltaic models. Energy Convers. Manag. 203, 112243. https://doi.org/10.1016/J.ENCONMAN.2019.112243 (2020).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evolut. Comput. 1(1), 67–82 (1997).
Abdel-Basset, M., El-Shahat, D., Jameel, M. & Abouhawwash, M. Exponential distribution optimizer (EDO): A novel math-inspired algorithm for global optimization and engineering problems. Artif. Intell. Rev. 56(9), 9329–9400. https://doi.org/10.1007/S10462-023-10403-9/METRICS (2023).
Tizhoosh, H. R. Opposition-based learning: A new scheme for machine intelligence. In Proceedings-International Conference on Computational Intelligence for Modelling, Control and Automation, CIMCA 2005 and International Conference on Intelligent Agents, Web Technologies and Internet, vol. 1 (695–701) 2005. https://doi.org/10.1109/cimca.2005.1631345.
Yousri, D., Allam, D., Eteiba, M. B. & Suganthan, P. N. Static and dynamic photovoltaic models’ parameters identification using chaotic heterogeneous comprehensive learning particle swarm optimizer variants. Energy Convers. Manag. 182, 546–563. https://doi.org/10.1016/j.enconman.2018.12.022 (2019).
Ćalasan, M., Abdel Aleem, S. H. E. & Zobaa, A. F. On the root mean square error (RMSE) calculation for parameter estimation of photovoltaic models: A novel exact analytical solution based on Lambert W function. Energy Convers. Manag. 210, 112716. https://doi.org/10.1016/j.enconman.2020.112716 (2020).
Muthuramalingam, L., Chandrasekaran, K. & Xavier, F. J. Electrical parameter computation of various photovoltaic models using an enhanced jumping spider optimization with chaotic drifts. J. Comput. Electron. 21(4), 905–941. https://doi.org/10.1007/S10825-022-01891-Z (2022).
Rasheed, M. S. & Shihab, S. Modelling and parameter extraction of PV cell using single-diode model. Adv. Energy Convers. Mater. https://doi.org/10.37256/aecm.122020550 (2020).
Premkumar, M., Sowmya, R., Umashankar, S. & Pradeep, J. An effective solar photovoltaic module parameter estimation technique for single-diode model. IOP Conf. Ser. Mater. Sci. Eng. https://doi.org/10.1088/1757-899X/937/1/012014 (2020).
Chen, Y., Sun, Y. & Meng, Z. An improved explicit double-diode model of solar cells: Fitness verification and parameter extraction. Energy Convers. Manag. 169, 345–358. https://doi.org/10.1016/J.ENCONMAN.2018.05.035 (2018).
Qais, M. H., Hasanien, H. M. & Alghuwainem, S. Parameters extraction of three-diode photovoltaic model using computation and Harris Hawks optimization. Energy 195, 117040. https://doi.org/10.1016/j.energy.2020.117040 (2020).
Premkumar, M. et al. Constraint estimation in three-diode solar photovoltaic model using Gaussian and Cauchy mutation-based hunger games search optimizer and enhanced Newton-Raphson method. IET Renew. Power Gener. 16(8), 1733–1772. https://doi.org/10.1049/RPG2.12475 (2022).
Zhao, X., Fang, Y., Liu, L., Li, J. & Xu, M. An improved moth-flame optimization algorithm with orthogonal opposition-based learning and modified position updating mechanism of moths for global optimization problems. Appl. Intell. https://doi.org/10.1007/s10489-020-01793-2 (2020).
Acknowledgements
The authors appreciate the anonymous reviewers for their valuable insights and constructive feedback, which significantly enhanced the paper's quality.
Funding
The authors did not obtain any financial or organizational assistance for the research presented in this submission.
Author information
Authors and Affiliations
Contributions
K.M.N.: Conceptualization, Methodology, Software, Data curation, Formal analysis, Investigation, Resources, Visualization, and Writing-original draft preparation. C.K.: Conceptualization, Software, Resources, Data curation, Validation, Visualization, Supervision, and Writing-original draft preparation. M.P.K.: Methodology, Software, Data curation, Formal analysis, Investigation, Validation, Visualization, and Writing-review and editing. B.D.: Formal analysis, Visualization, and Writing-review and editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent to publication
No consent for publication is required for this study.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kullampalayam Murugaiyan, N., Chandrasekaran, K., Manoharan, P. et al. Leveraging opposition-based learning for solar photovoltaic model parameter estimation with exponential distribution optimization algorithm. Sci Rep 14, 528 (2024). https://doi.org/10.1038/s41598-023-50890-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-50890-y
- Springer Nature Limited
This article is cited by
-
Parameter characterization of PEM fuel cell mathematical models using an orthogonal learning-based GOOSE algorithm
Scientific Reports (2024)
-
Probabilistic sunspot predictions with a gated recurrent units-based combined model guided by pinball loss
Scientific Reports (2024)
-
Parameter estimation of various PV cells and modules using an improved simultaneous heat transfer search algorithm
Journal of Computational Electronics (2024)
-
An efficient improved exponential distribution optimizer: application to the global, engineering and combinatorial optimization problems
Cluster Computing (2024)