
Abstract
Type-2 fuzzy sets (T2FSs) exhibit evident merits when it comes to representing the complex and high uncertainty, which has been encountered in fuzzy optimization and multiple criteria decision making (MCDM) problems. Since T2FSs theory was proposed by Zadeh in 1975, then a series of theories and methods were investigated by more scholars. Type-2 fuzzy aggregation operators, contributing to the fundamental information fusion theory, have been paid more attention and applied to different areas during the last two decades. In this paper, a survey of type-2 fuzzy aggregation and application for MCDM is carried out. We first review some basic knowledge including definitions, operations, type reduction and ranking methods of T2FSs. Then the definitions and properties of some main aggregation operators are introduced. Furthermore, some application categories under type-2 fuzzy environment are given. Finally, we identify some existing shortcomings and point at future research directions on this topic.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Decision making is a significant branch of management science, which includes the selection problem, outranking problem and sorting problem. Information fusion plays a vitally important role in the process of decision making, among which information aggregation operators are an effective and widely concerned research direction (Beliakov 2003; Eriz 2007; Calvo and Beliakov 2010; Mardani et al. 2018). It involves the fields including recommender system (Qin 2017), investment management (Ma et al. 2016) and supplier selection (Zhang 2018; Qin and Liu 2014). In order to handle the high complex uncertain problem, the type-2 fuzzy sets (T2FSs) was developed as an extension of type-1 fuzzy sets (T1FSs) (Zadeh 1975a; Zadeh 1975b; Zadeh 1975c). The notable difference between T2FSs and T1FSs lies in the two membership functions in T2FSs, i.e. the primary membership function (PMF) and the secondary membership function (SMF). In addition, since an interval type-2 fuzzy sets (IT2FSs) have the apparent merit in information representation and comprehensibility, many scholars paid more attention to the theory and application of IT2FSs. The former mainly includes the type reduction method (Karnik and Mendel 2001; Liu and Mendel 2011), ranking method (Wu and Mendel 2007a; Chen 2012; Sang and Liu 2016), aggregation operators and other knowledge (Mendel and John 2002; Mendel et al. 2006; Wu and Mendel 2007b), and the later mainly involves the multiple criteria decision making (MCDM) problems (Wu and Liu 2016; Kundu et al. 2017; Qin et al. 2017). Type-2 fuzzy aggregation operators, as a key technique, have been investigated by many scholars.
In the literature, we collect 61 references about this topic, the relationship between numbers of papers and year can be shown in Fig. 1. Several different families of type-2 fuzzy aggregation operators have been presented in Table 1 and the distribution of papers is displayed in Fig. 2. However, there is a lack in the previous studies concerning the systematic review of type-2 fuzzy aggregation operators. In this paper, we will handle this problem and further present the future research directions. Considering the situation, the weights and attributes represented by IT2FSs, the linguistic weighted average (LWA) operator was developed and have better application in hierarchical decision making (Wu and Mendel 2007b; John et al. 2018). Zhou et al. (Zhou et al. 2008; Zhou et al. 2010) proposed the T2FS ordered weighted averaging (OWA) operator, which can aggregate directly the linguistic preferences provided by decision makers (DMs). Based on triangle norm operations, triangle interval type-2 fuzzy Frank weighted averaging (TIT2FFWA) operator and triangle interval type-2 fuzzy Frank geometric average (TIT2FFWG) operator were developed (Qin and Liu 2014). Based on the non-negative trapezoidal IT2FNs, Wang et al. (Wang et al. 2015) put forward a family of information aggregation operators, i.e. trapezoidal interval type-2 fuzzy arithmetic averaging aggregation operator (TIT2AA), trapezoidal interval type-2 fuzzy ordered weighted averaging aggregation operator (TIT2OWA) and trapezoidal interval type-2 fuzzy hybrid weighted averaging aggregation operator (TIT2HWA). In order to describe the interaction between any two aggregated information, the Bonferroni mean was extended into different environments as a result of the characteristic of combining averaging and “anding” operator (Liu et al. 2017; Gou et al. 2017). Gong et al. (Gong et al. 2015) extended Bonferroni mean operator into the interval type-2 fuzzy environment and named them as trapezoidal interval type-2 fuzzy geometric Bonferroni mean (TIT2FGBM) operator and trapezoidal interval type-2 fuzzy weighted geometric Bonferroni mean (TIT2FWGBM) operator. Other type-2 fuzzy aggregation operators were presented such as interval type-2-dependent ordered weighted averaging (IT2DOWA) operator and interval type-2 power averaging (IT2PA) operator (Ma et al. 2016). Wu and Liu proposed interval type-2 fuzzy weighted geometric averaging (WGA) operator and interval type-2 fuzzy combined weighted geometric averaging (CWGA) operator (Wu and Liu 2016). Based on multi-granular linguistic environment, 2-dimension interval type-2 trapezoidal fuzzy ordered weighted average (2DIT2TFOWA) operator and quasi-2-dimension interval type-2 trapezoidal fuzzy ordered weighted average (quasi-2DIT2TFOWA) operator were developed (Wu et al. 2017). To consider the interaction among all the aggregated information, Qin presented the interval type-2 fuzzy Hamy mean (HM) operators, i.e. symmetric triangular interval type-2 fuzzy Hamy mean (STIT2FHM) operator and weighted symmetric triangular interval type-2 fuzzy Hamy mean (WSTIT2FHM) operator, which was applied to the tourism recommender system (Qin 2017). Zhang presented some trapezoidal interval type-2 fuzzy aggregation operators, such as trapezoidal interval type-2 fuzzy weighted averaging (TIT2FWA) operator, generalized trapezoidal interval type-2 fuzzy weighted averaging (GTIT2FWA) operator, trapezoidal interval type-2 fuzzy ordered weighted averaging (TIT2FOWA) operator, generalized trapezoidal interval type-2 fuzzy ordered weighted averaging (GTIT2FOWA) operator, trapezoidal interval type-2 fuzzy hybrid averaging (TIT2FHA) operator, and generalized trapezoidal interval type-2 fuzzy hybrid averaging (GTIT2FHA) operator (Zhang 2018). Except from these type-2 fuzzy operators, some operators were developed based on the fuzzy measures and fuzzy integrals, such as type-2 fuzzy Choquet integral and Sugeno integral (Havens et al. 2010; Bustince et al. 2013). More relevant type-2 fuzzy operators can refer to other literatures (Lee and Chen 2008; Andelkovic and Saletic 2012; Chen and Lee 2010; Wang et al. 2012; Li et al. 2018).

Papers related to type-2 fuzzy sets

The distribution of papers of type-2 fuzzy aggregation operators across journals
This paper is organized as follows: in Section 2, we introduce some basic knowledge on I2FSs, which are comprised of the definitions, operations, type reduction method and ranking method. Section 3 summarizes type-2 fuzzy aggregation operators and their advantages and disadvantages. Furthermore, some application fields with regard to type-2 fuzzy aggregation operations are reviewed in Section 4. Finally, Section 5 discusses the current challenges and outlines future research directions on type-2 fuzzy aggregation operations.
2 Type-2 fuzzy sets and basic knowledge
In this section, we first introduce some basic knowledge about information aggregation function. Then type-2 fuzzy sets, operations, type reduction approaches and ranking methods are reviewed. The basic theories are shown in Fig. 3.

The graphical representation of type-2 fuzzy basic theories
2.1 Information aggregation function
Definition 1
(Eriz 2007) The information aggregation function f : [0, 1]n → [0, 1] (n > 1) should satisfy the following properties:
-
(1)
f(0, 0, ⋯, 0) = 0 and f(1, 1, ⋯, 1) = 1;
-
(2)
If x ≤ y, then f(x) ≤ f(y) for ∀x, y ∈ [0, 1]n
wherex, yare two inputs vectors. The above aggregation function can deal with the problem of the same input components. In order to handle any number of arguments, the extended aggregation function is defined as follows:
Definition 2
(Eriz 2007) The extended aggregation function, as a mapping, is defined as follows:
The aggregation functions are divided into four categories: averaging, conjunctive, disjunctive, and mixed ones. Let us introduce the corresponding definitions.
Definition 3
(Eriz 2007) An averaging aggregation function f should satisfy the following relationship for any x:
Definition 4
(Eriz 2007) A conjunctive aggregation function f should satisfy the following relationship for any x:
Definition 5
(Eriz 2007) A disjunctive aggregation function f should satisfy the following relationship for any x:
The mixed aggregation function is not the above any one, which includes the different behavior types for different parts of the domain.
In general, some aggregation operators could satisfy the following properties (Eriz 2007):
Property 1
(Idempotency) If the input information is the same, viz. x = (t, t, ⋯, t), t ∈ [0, 1], then the aggregated result is the same as the input information f(t, t, ⋯, t) = t. We call this aggregation function f idempotent.
Property 2
(Symmetry) There is a collection of input information. If we exchange the position of input information in a permutation, then the aggregated result is left unchanged. The aggregation function f is symmetric if it satisfies the following relationship:
Where the P(1), P(2), ⋯, P(n) is some other permutation of 1, 2, ⋯, n.
Property 3
(Monotonicity) If the input information is monotonically increasing (decreasing), then the aggregated result is also monotonically increasing (decreasing).. The aggregation function f is monotonicity if it satisfies the following relationship:
Property 4
(Boundness) The aggregated result is bigger than the minimum of all the input information and smaller than the maximum all the input information. The aggregation function f is bounded if it satisfies the following relationship:
2.2 Definitions of Type-2 fuzzy sets
For the definitions of type-2 fuzzy sets, some scholars presented their individual opinions, see Table 2. Next, we introduce a representative one.
Definition 6
(Mendel and John 2002) For a given type-2 fuzzy set A associated with universe of discourse X and Jx ⊆ [0, 1], A is defined as follows:
The other representation is shown as follows:
where Jx is denoted as the primary membership at x, and \( {\int}_{u\in {J}_x}{\mu}_A\left(x,u\right)/\left(x,u\right) \) means the secondary membership at x. ∬represents the union over all admissible xand u. ∫can be replaced by ∑when dealing with discrete spaces. The graphical representation is shown in Fig. 4.

A general type-2 fuzzy sets
Based on the idea of set theory, Mo and Wang proposed discrete T2FS, as a special representation (Mo and Wang 2017). The definition on discrete T2FS is given as follows:
Definition 7
(Mo and Wang 2017) Assuming ω is a discrete T2FS, for X = {x1, x2, ⋯, xK}, then ω and associated with its primary membership function Lx and secondary membership function are represented by
and
and
The graphical representation is shown in Fig. 5.

The discrete T2FS
Definition 8
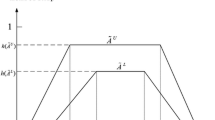
(Mendel and John 2002) Let \( \tilde{A} \) be a type-2 fuzzy set in the universe of discourse X represented by a type-2 membership function μA(x, u). If all μA(x, u) = 1 holds, then it is denoted as an interval type-2 fuzzy set (IT2FS) in Fig. 6. It is a special case of type-2 fuzzy set, which can be described as follows:
where Jx is denoted as the primary membership at x, and \( {\int}_{u\in {J}_x}1/\left(x,u\right) \) means the secondary membership at x.

The FOU of an IT2FS \( \tilde{A} \)
Definition 8
(Mendel and John 2002) For given an IT2FS \( \tilde{A} \) with a universe of discourse X shown in Fig. 5, the footprint of uncertainty (FOU) is defined as follows:
where Jx is denoted as the primary membership at x.
2.3 Operations of type-2 fuzzy sets
In this section, we introduce some operations of T2FSs.
Definition 9
(Karnik and Mendel 2001) Let \( \tilde{A} \) and \( \tilde{B} \) be two T2FSs defined on the universe of discourse X, their primary membership functions are defined as:
where u, w ∈ Jx, then the union and intersection operations are defined as:
when \( \tilde{A} \) and \( \tilde{B} \) are two IT2FSs, the above two operations can be simplified as follows:
Obviously, the results shown above can be easy extended to the case of multiple T2FSs.
Regarding to complementary operation, it is defined as:
Definition 10
(Karnik and Mendel 2001) The operations of T2FSs satisfy the following properties:
It is noted that the operations of T2FSs do not satisfy absorption, distribution and identity.
Definition 11
Let \( \tilde{\tilde{A}}=\left({\tilde{A}}^{+},{\tilde{A}}^{-}\right) \) and \( \tilde{\tilde{B}}=\left({\tilde{B}}^{+},{\tilde{B}}^{-}\right) \) be two TraIT2FSs, the graphic representation of a TraIT2FS \( \tilde{\tilde{A}} \) is contained in Fig. 7. The arithmetic operations are defined as follows:
-
1.
Addition operation (Chen 2012)

The graphic representation of a TraIT2FS \( \tilde{\tilde{A}} \)
-
2.
Subtraction operation (Lee and Chen 2008)
-
3.
Multiplication operation (Lee and Chen 2008)
-
4.
Multiplication by real number operation (Chen 2012)
-
5.
Power operation (Chen 2012)
-
6.
Radical operation (Kahraman et al. 2014)
2.4 Type reduction of type-2 fuzzy sets
Calculating the centroid of a type-2 fuzzy sets and reducing a type-2 fuzzy sets to a type-1 fuzzy sets are operations that must be taken into consideration. From the representation theorem for IT2FSs, we introduce the Karnik–Mendel (KM) algorithms for type reduction of type-2 fuzzy sets.
Definition 12
(Karnik and Mendel 2001) The centroid of IT2FSs \( \tilde{A} \) is the union of the centroids of all its embedded T1FSs c(Ae), which is defined as:
where
\( {c}_l\left(\tilde{A}\right) \) and \( {c}_r\left(\tilde{A}\right) \)can be computed by the iterative KM algorithm presented in Table 3.
Liu and Mendel (Liu and Mendel 2011) proposed a continuous KM for the direct centroid computation of IT2FSs, which can transform the centroid computation into the Root-Finding problems shown in Fig. 8.

KM algorithm and Newton–Raphson method. (a) and (b) Computation of cl = ξ4. (c) and (d) Computation of cr = ξ4
Assume that all the xi are different, and they are bounded in [a, b], where\( a=\underset{1\le i\le N}{\min}\left\{{x}_i\right\},b=\underset{1\le i\le N}{\max}\left\{{x}_i\right\} \), which denote the smallest and the largest sampled values of x, respectively. Then, the continuous versions of (20) and (21) are:
Theorem 1
(Liu and Mendel 2011) (a) Let cl = cl(ξ∗) be the unique minimum value of (22), and ξ∗ is the unique simple root of the monotonic increasing convex function:
Furthermore, ξ∗ is the fixed point of cl(ξ) with ξ∗ = cl(ξ∗), so that
(b) Let cr = cr(ξ∗) be the unique maximum value of (23), and ξ∗ is the unique simple root of the monotonic decreasing convex function:
Furthermore, ξ∗ is the fixed point of cr(ξ) with ξ∗ = cr(ξ∗), so that
2.5 Ranking methods for type-2 fuzzy sets
The ranking of type-2 fuzzy sets is another basic topic on the agenda of computing with type-2 fuzzy sets. Not surprising, there have been a number of different ranking methods. Wu and Mendel proposed the KM centroid ranking method, which is the common ranking method associated with low computation complexity (Wu and Mendel 2007a). Chen presented the signed-based distance ranking method in virtue of directed distance, i.e. signed distance (Chen 2012). Sang and Liu developed a new ranking method based on the possibilistic mean and variation coefficient, which is more effective in terms of comparing symmetric IT2FSs (Sang and Liu 2016). In what follows, we present the KM centroid ranking method and signed-based distance ranking method.
Definition 13
(Wu and Mendel 2007a) For given an IT2FS \( \tilde{A} \), we obtain the ranking value \( C\left(\tilde{A}\right) \) using the following expression:
For any two IT2FSs \( \tilde{A} \) and \( \tilde{B} \), we can employ the ranking value to compare them:
-
1)
If \( c\left(\tilde{A}\right)>c\left(\tilde{B}\right) \), then\( \tilde{A}\succ \tilde{B} \);
-
2)
If \( c\left(\tilde{A}\right)=c\left(\tilde{B}\right) \), then\( \tilde{A}\sim \tilde{B} \);
-
3)
If \( c\left(\tilde{A}\right)<c\left(\tilde{B}\right) \), then\( \tilde{A}\prec \tilde{B} \).
Definition 14
(Chen 2012) Let \( \tilde{A} \) be a non-negative IT2FS defined on the universe of discourseXand \( \tilde{A}=\left[{A}^L,{A}^U\right]=\left[\left({a}_1^L,{a}_2^L,{a}_3^L,{a}_4^L;{h}_A^L\right),\left({a}_1^U,{a}_2^U,{a}_3^U,{a}_4^U;{h}_A^U\right)\right] \)(\( {h}_A^U\ne 0 \)), the signed distance from \( \tilde{A} \) to 0˜ is expressed as follows:
where 0˜ is a reference point map onto the y-axis at x = 0.
For any two IT2FSs \( \tilde{A} \) and \( \tilde{B} \), we have the following order relationship:
-
1)
If \( d\left(A,\tilde{0}\right)>d\left(B,\tilde{0}\right) \), then \( \tilde{A} \) is better than or preferred to \( \tilde{B} \), denoted by\( \tilde{A}\succ \tilde{B} \);
-
2)
If \( d\left(A,\tilde{0}\right)=d\left(B,\tilde{0}\right) \), then the preference relation between \( \tilde{A} \) and \( \tilde{B} \) is indifferent, denoted by\( \tilde{A}\sim \tilde{B} \);
-
3)
\( d\left(A,\tilde{0}\right)<d\left(B,\tilde{0}\right) \), then \( \tilde{A} \) is worse than or less preferred to \( \tilde{B} \), denoted by\( \tilde{A}\prec \tilde{B} \).
Furthermore, the concept of ranking values of trapezoidal interval type-2 fuzzy sets is proposed by Lee and Chen as follows (Lee and Chen 2008):
Definition 15
(Lee and Chen 2008) Let \( {\tilde{\tilde{A}}}_i \) be an IT2FS, where \( {\tilde{\tilde{A}}}_i=\left[{\tilde{A}}_i^U,{\tilde{A}}_i^L\right]= \)\( \left[\left({a}_{i1}^U,{a}_{i2}^U,{a}_{i3}^U,{a}_{i4}^U;{H}_1\left({\tilde{A}}_i^U\right),{H}_2\left({\tilde{A}}_i^U\right)\right),\left({a}_{i1}^L,{a}_{i2}^L,{a}_{i3}^L,{a}_{i4}^L;{H}_1\left({\tilde{A}}_i^L\right),{H}_2\left({\tilde{A}}_i^L\right)\right)\right] \). The ranking value \( Rank\left({\tilde{\tilde{A}}}_i\right) \) of the TrIT2FS \( {\tilde{\tilde{A}}}_i \) is defined as follows:
where \( {M}_p\left({\tilde{A}}_i^j\right)=\left({a}_{ip}^j+{a}_{i\left(p+1\right)}^j\right)/2 \), 1 ≤ p ≤ 3; \( {S}_4\left({\tilde{A}}_i^j\right)=\sqrt{\frac{1}{4}{\sum}_{k=1}^4{\left({a}_{ik}^j-\frac{1}{4}{\sum}_{k=1}^4{a}_{ik}^j\right)}^2} \), \( {H}_p\left({\tilde{A}}_i^j\right) \) denotes the membership value of \( {a}_{i\left(p+1\right)}^j \) in the trapezoidal membership function \( {\tilde{A}}_i^j \), 1 ≤ p ≤ 2, j ∈ {U, L}, and 1 ≤ i ≤ n.
In Eq. (28), the sum of \( {M}_1\left({\tilde{A}}_i^U\right),{M}_1\left({\tilde{A}}_i^L\right),{M}_2\left({\tilde{A}}_i^U\right),{M}_2\left({\tilde{A}}_i^L\right),{M}_3\left({\tilde{A}}_i^U\right),{M}_3\left({\tilde{A}}_i^L\right), \)\( {H}_1\left({\tilde{A}}_i^U\right),{H}_1\left({\tilde{A}}_i^L\right),{H}_2\left({\tilde{A}}_i^U\right),{H}_2\left({\tilde{A}}_i^L\right) \)represent the basic ranking score, where we deduct the average of \( {S}_1\left({\tilde{A}}_i^U\right),{S}_1\left({\tilde{A}}_i^L\right),{S}_2\left({\tilde{A}}_i^U\right),{S}_2\left({\tilde{A}}_i^L\right),{S}_3\left({\tilde{A}}_i^U\right),{S}_3\left({\tilde{A}}_i^L\right),{S}_4\left({\tilde{A}}_i^U\right), \)\( {S}_4\left({\tilde{A}}_i^L\right) \) from the basic ranking score to give the dispersive IT2FS a penalty, where 1 ≤ i ≤ n.
3 Type-2 fuzzy information aggregation
In this section, we review some basic type-2 fuzzy information aggregation operators, such as interval type-2 FWA, interval type-2 fuzzy OWA, interval type-2 fuzzy BM, interval type-2 fuzzy MSM and interval type-2 fuzzy HM, respectively.
3.1 Interval type-2 fuzzy FWA
The fuzzy weighted average (FWA) has great influence on the type-2 fuzzy logic theory and multi-criteria decision making (Wu and Mendel 2007a; Liu et al. 2012; Liu and Wang 2013). Therefore, it is significant to have a grasp of the FWA.
Definition 16
(Dong and Wong 1987) For given fuzzy numbers Xi and Wi, the FWA is expressed as follows:
The computation methods for obtaining FWA were investigated by many scholars, which mainly include Dong and Wong’s algorithm based on α-cuts and an α-cut decomposition theorem (Dong and Wong 1987). In order to reduce the computational complexity, Liou and Wang proposed the improved FWA (IFWA) algorithm (Liou and Wang 1992). Lee and Park presented the efficient FWA (EFWA) algorithm to decrease the numbers of iterations (Lee and Park 1997). In addition, some literature focuses on Karnik Mendel (KM) algorithm and its extension, such as (Liu and Mendel 2008; Wu and Mendel 2009). In terms of analytical solution for the FWA, Kao and Liu (Kao and Liu 2001), Liu et al. (Liu et al. 2012) and Liu and Wang (Liu and Wang 2013) express their individual opinions, which have good structure and simple computation. In order to exploit the advantages of computing with words, Wu and Mendel proposed the LWA based on IT2FSs, which is an extension of the FWA (Wu and Mendel 2007b).
Definition 17
(Wu and Mendel 2007b) For given two IT2FSs \( {\tilde{X}}_i \) and \( {\tilde{W}}_i \), the LWA is defined as follows:
It is noteworthy that the aggregation result \( {\tilde{Y}}_{LWA} \) is an IT2FS, which can be computed using the LMF \( {\underset{\_}{Y}}_{LWA} \) and UMF \( {\overline{Y}}_{LWA} \).
In order to obtain the \( {\underset{\_}{Y}}_{LWA} \) and \( {\overline{Y}}_{LWA} \), we can adopt the α-cut based approach. The detail can refer to (Wu and Mendel 2007b; John et al. 2018).
3.2 Interval type-2 fuzzy OWA
Type-2 fuzzy sets provide an effective way to model uncertain information and experts’ preferences in soft decision making. And OWA operator is a kind of effective and applicable operator (Yager et al. 2011). The motivation for the type-2 OWA operator is suggested to aggregate linguistic variables modeled as type-2 fuzzy sets by the OWA mechanism.
Definition 18
(Zhou et al. 2008) Given IT2FSs \( {\left\{{\tilde{W}}_i\right\}}_{i=1}^n \) and \( {\left\{{\tilde{X}}_i\right\}}_{i=1}^n \), the membership function of an interval type-2 fuzzy ordered weighted averaging (IT2FOWA) is computed by:
where \( {W}_i^e \) and \( {X}_i^e \) are embedded T1FSs of \( {\tilde{W}}_i \) and \( {\tilde{X}}_i \), respectively, and σ: {1,…, n} → {1,…, n} is a permutation function such that {xσ(1), xσ(2), ⋯, xσ(n)}are in descending order.
Observe that the bracketed term is a T1FOWA, and the IT2FOWA is the union of all possible T1FOWAs calculated from the embedded T1FSs of \( {\tilde{X}}_i \) and \( {\tilde{W}}_i \). The Wavy Slice Representation Theorem (Mendel 2008) for IT2FSs is implicitly used in this definition.
3.3 Interval type-2 fuzzy Bonferroni mean
When the decision information is relevant, the BM can deal with this problem and has the good flexibility. Therefore, Gong et al. (Gong et al. 2015). proposed the TIT2FGBM operator and the TIT2FWGBM operator.
Definition 19
(Gong et al. 2015) For given a collection of trapezoidal interval type-2 fuzzy numbers (IT2FNs) \( {\tilde{A}}_i=\left({\tilde{A}}_i^U,{\tilde{A}}_i^L\right)=\left(\left({a}_{i1}^U,{a}_{i2}^U,{a}_{i3}^U,{a}_{i4}^U\right),\left({a}_{i1}^L,{a}_{i2}^L,{a}_{i3}^L,{a}_{i4}^L\right)\right)\left(i=1,2,\cdots, n\right) \) and the parameter p, q ≥ 0, the TIT2FGBM is defined as follows:
The TIT2FGBM can be employed to aggregate the IT2FNs the result is also an IT2FN. This operator maintains the properties of idempotency, boundedness, monotonicity and commutativity. When p and q are equal to 1, the TIT2FGBM can be reduced to trapezoidal interval type-2 fuzzy interrelated square geometric mean operator. In consideration of different weight of aggregated information, the TIT2FWGBM is presented.
Based on the above definition, we have:
where
and
Definition 20
(Gong et al. 2015) For given a collection of IT2FNs \( {\tilde{A}}_i=\left({\tilde{A}}_i^U,{\tilde{A}}_i^L\right)=\left(\left({a}_{i1}^U,{a}_{i2}^U,{a}_{i3}^U,{a}_{i4}^U\right),\left({a}_{i1}^L,{a}_{i2}^L,{a}_{i3}^L,{a}_{i4}^L\right)\right)\left(i=1,2,\cdots, n\right) \) with corresponding weight vector w = (w1, w2, ⋯, wn)T, where wi ∈ [0, 1] and \( {\sum}_{i=1}^n{w}_i=1 \) should be satisfied, andp, q ≥ 0, the TIT2FWGBM can be described as follows:
Similarly, we can obtain the same properties as TIT2FGBM, for the detail referring to (Gong et al. 2015).
3.4 Interval type-2 fuzzy Maclaurin symmetric mean
The Maclaurin symmetric mean (MSM) is a classical generalized symmetric mean that is an extended Bonferroni mean. It can aggregate multiple related elements and overcome the shortcomings of the relationship between each two elements in Bonferroni mean (Xu and Yager 2011; Zhu and Xu 2013; Zhu et al. 2012), which can solve the problem of related information aggregation to some extent.
The definition of the interval type-2 fuzzy Maclaurin symmetric mean (IT2FMSM) is as follows:
Definition 21
Let \( {A}_i=\left({A}_i^U,{A}_i^L\right)=\left(\left({a}_{i1}^U,{a}_{i2}^U,{a}_{i3}^U,{a}_{i4}^U;{h}_i^U\right),\left({a}_{i1}^L,{a}_{i2}^L,{a}_{i3}^L,{a}_{i4}^L;{h}_i^L\right)\right)\left(i=1,2,\cdots, n\right) \) be a collection of interval type-2 fuzzy set, and k = 1, 2, ⋯, n, then the IT2FMSM can be defined as
Based on the above definition, we have
where
and
In the process of information aggregation, we usually need to consider the importance of every element, i.e. weight information. Therefore, we give the definition of weighted interval type-2 fuzzy Maclaurin symmetric mean (WIT2FMSM).
Definition 22
Let Ai(i = 1, 2, ⋯, n) be a collection of type-2 fuzzy number, w = (w1, w2, ⋯, wn)T represents the weight vector, where wi is the importance of Ai satisfying wi ∈ [0, 1] and \( {\sum}_{i=1}^n{w}_i=1 \). If
\( \mathrm{WIT}2{\mathrm{FMSM}}_w^{(k)} \) is an interval weighted type-2 fuzzy Maclaurin symmetric mean. Obviously, when w = (1/n, 1/n, ⋯, 1/n)T, WIT2FMSM is reduced to the IT2FMSM.
It should be noted that the WIT2FMSM satisfies the idempotency property when the function of WIT2FMSM is represented by using piecewise function, which is remarkable feature difference between WIT2FMSM and other operators.
3.5 Type-2 fuzzy fuzzy Hamy mean
In order to represent the interrelationship among integrated information, Qin proposed the interval type-2 fuzzy HM, which is comprised of STIT2FHM operator and WSTIT2FHM operator (Qin 2017). Compared with interval type-2 FWA and interval type-2 fuzzy BM, the computing complexity of interval type-2 fuzzy HM is lower than the complexity of these two operators.
Definition 23
(Qin 2017) For given a collection of symmetric triangular interval type-2 fuzzy numbers (STIT2FNs) \( {\tilde{A}}_i=\left({c}_{{\tilde{A}}_i},{\delta}_{{\tilde{A}}_i},{\underset{\_}{h}}_{{\tilde{A}}_i},{\overline{h}}_{{\tilde{A}}_i}\right)\left(i=1,2,\cdots, n\right) \) and parameter k = 1, 2, ⋯, n, the STIT2FHM can be represented as follows:
The aggregation result is still a STIT2FN by using STIT2FHM, and the STIT2FHM satisfies the properties of idempotency, commutativity and monotonicity. For the details, the reader can refer to (Qin 2017). With regard to different values of the parameter k, the STIT2FHM is called as different operators, such as k = 1 named symmetric triangular interval type-2 fuzzy averaging (STIT2FA) operator and k = n named symmetric triangular interval type-2 fuzzy geometric (STIT2FG) operator. Considering that the weight of information has a significant influence for aggregation, Qin defined the WSTIT2FHM operator (Qin 2017).
Definition 24
(Qin 2017) For given a collection of STIT2FNs \( {\tilde{A}}_i\left(i=1,2,\cdots, n\right) \) associated with the corresponding weight vector w = (w1, w2, ⋯, wn)T, where the relationships wi ∈ [0, 1] and \( {\sum}_{i=1}^n{w}_i=1 \) hold, the WSTIT2FHM is defined as follows:
Similarly, the aggregation consequence is still a STIT2FN by using WSTIT2FHM operator. The relationship between STIT2FHM and WSTIT2FHM is that the WSTIT2FHM is a special case of STIT2FHM.
It is noteworthy that the most significant difference between type-2 MSM operator and type-2 HM operator lies in the emphasized element. The former stresses the importance of the whole element, but the later pays attention to the importance of each element.
3.6 Type-2 fuzzy Choquet integral and Sugeno integral
As another research direction in aggregation operators, fuzzy measures and fuzzy integrals have been extended into different environments, which can capture the interaction among provided information and uncertainty present in the information sources. The fuzzy integrals of interest are Choquet integral and Sugeno integral. Next, we introduce type-2 fuzzy Choquet integral and Sugeno integral aggregation operators.
Definition 25
(Havens et al. 2010). Based on the idea, i.e. Choquet integral with an IT2FN-valued integrand \( \tilde{H} \) producing an IT2FN, the FOU of \( {C}_g\left(\tilde{H}\right) \) as the union of all \( {C}_g\left({H}_e^j\right) \) can be defined as follows:
where \( {H}_e^j\in FOU\left(\tilde{H}\left({x}_i\right)\right), for\forall i,j \) is embedded T1FN-valued functions. Then we obtain
The type-2 fuzzy Choquet integral satisfies the proposition that the UMF and LMF of \( FOU\left({C}_g\left(\tilde{H}\right)\right) \) can be derived by the Choquet integral on the individual functions on UMFs and LMFs of the set \( \tilde{H} \). The other proposition is that level-cut \( {}^{\alpha}\left({\cup}_j{C}_g\left({H}_e^j\right)\right) \) consists of two closed intervals between theUMF and LMF of \( FOU\left({C}_g\left(\tilde{H}\right)\right) \).
Definition 26
(Bustince et al. 2013). For given information source set X associated with its fuzzy measure μc, a IT2FS [μL, μR] defined on X, the interval type-2 Sugeno integral for μc is defined as follows:
where 0 ≤ σL(xi) ≤ σL(xi + 1) ≤ ⋯ ≤ σL(xn) ≤ 1 and 0 ≤ σR(xi) ≤ σR(xi + 1) ≤ ⋯ ≤ σR(xn) ≤ 1.
4 Applications of type-2 fuzzy aggregation operations
As a flexible tool in representing human qualitative and subjective cognitive aspects, the aggregation operations have gained success in practical applications. Table 4 lists the recent applications of these operations.
From Table 4, we can see that many type-2 fuzzy aggregation operations have been implemented addressing various aspects of management in our daily life. Especially, this concerns supplier selection and investment management. For example, the TIT2FHA, TIT2FGBM, TIT2FWGBM, TIT2FFWA, TIT2FFWG and IT2FWA operators have been applied to supplier selection problem. The IT2PA, IT2DOWA, TIT2OWA, TITHWA WIFMSM operators are widely used in investment management. The OWA, CWGA, STIT2FHM, 2DIT2TFOWA, LWA operators were applied to employment and hiring management, tourism recommender system and others. It seems that numerous evaluation problems with qualitative assessment information can be solved by the fuzzy decision-making approaches. With the promotion and development of the research in type-2 fuzzy aggregation operations, more and more practical problems could be solved by this comprehensively qualitative tool.
Compared with application of type-2 fuzzy multiple criteria decision making, the application range of type-2 fuzzy aggregation operations is somewhat narrow. Considering the application of type-2 fuzzy multiple criteria decision making, we should extend type-2 fuzzy aggregation operations into these MCDM fields, such as green supplier selection (Qin et al. 2015), human resource management (Abdullah and Zulkifli 2015), clustering (Yang and Lin 2009) and medical diagnosis (Own 2009). In general, these type-2 fuzzy aggregation operations are directly applied to group decision making, which do not pay attention to combining with other multiple criteria decision making methods or ranking methods. Therefore, we can exploit the advantages of type-2 fuzzy aggregation operations and multiple criteria decision making methods or ranking methods to make decision.
5 Summary and future research directions
Type-2 fuzzy sets exhibit merits in terms of describing higher degree of ambiguity and uncertainty. In this paper, we review type-2 fuzzy information aggregation operators and some applications to multiple criteria decision making. We have summarized some essential fundamentals of type-2 fuzzy sets and information aggregation function. The former is comprised of the definitions, operations, type reduction and ranking methods, and the later includes the characteristics, categories and properties of information aggregation function. Next, some representative type-2 fuzzy information aggregation operators have been reviewed, such as interval type-2 fuzzy FWA, interval type-2 fuzzy OWA, interval type-2 fuzzy BM, interval type-2 fuzzy MSM, interval type-2 fuzzy HM along with its extensions and properties.
The existing research have developed some different type-2 fuzzy operators, which have been applied to many fields such as supplier selection, investment management and recommender systems. The existing challenges and future research directions are summarized as follows:
-
(1)
The existing research focus on the aggregation operations of IT2FSs, but the general T2FSs has been paid little attention. The zSlices method is adopted to deal with the general T2FSs (Wagner and Hagras 2008; Wagner and Hagras 2010; Bilgin et al. 2013; Kumbasar and Hagras 2015). However, the research on information aggregation operators of general T2FSs still constitutes a big challenge. In addition, one can develop and propose some interaction information aggregations which can integrate the Choquet integral into the process of information aggregation. It will be a better information fusion in multiple criteria decision making.
-
(2)
Owing to the accuracy and lower computation complexity, Liu et al. presented the analytical method to compute the FWA (Liu et al. 2012). But there are no the analytical solutions of IT2FSs aggregation. Therefore, this is a noteworthy direction for the information aggregation in the context of IT2FSs. If the interaction information were proposed, we could present analytical solutions of these operators.
-
(3)
The existing aggregation operators on T2FSs do not consider the problem of data driven. In order to aggregate objectively information, some IT2FSs aggregation operators based on data driven should be developed. For instance, we should pay attention the integration the information aggregation and granular computing (Pedrycz and Song 2012; Yao et al. 2013; Cabrerizo et al. 2013). We can establish the optimization model to maximize the product of coverage and specificity to obtain the consequence of information aggregation.
-
(4)
Type-2 fuzzy information aggregation involves complex uncertain information, as a powerful tool for dealing with uncertain optimization, robust optimization should be paid more attention (Ben 1998). In the future, the theory about linear, non-linear, distributionally robust optimization, and robust optimal regression should be applied to type-2 fuzzy information aggregation to obtain the analytical solution associated with good analytical properties, which can further enrich and improve the type-2 fuzzy information aggregation theory. Other open questions and potential research directions in type-2 fuzzy aggregation area are worthy to be discussed in future research.
References
Beliakov G (2003) How to build aggregation operators from data. Int J Intell Syst 18(8):903–923
Eriz M (2007) Aggregation functions: a guide for practitioners. Springer, Berlin Heidelberg
Calvo T, Beliakov G (2010) Aggregation functions based on penalties. Fuzzy Sets Syst 161(10):1420–1436
Mardani A, Nilashi M, Zavadskas EK, Awang SR, Zare H, Jamal NM (2018) Decision making methods based on fuzzy aggregation operators: three decades review from 1986 to 2017. Int J Inf Tech Dec Making 17(02):391–466
Qin JD (2017) Interval type-2 fuzzy Hamy Mean operators and their application in multiple criteria decision making. Gran Comput 2(7):1–21
Ma X, Wu P, Zhou L, Chen H, Zheng T, Ge J (2016) Approaches based on interval type-2 fuzzy aggregation operators for multiple attribute group decision making. Inter J Fuzzy Syst 18(4):697–715
Zhang Z (2018) Trapezoidal interval type-2 fuzzy aggregation operators and their application to multiple attribute group decision making. Neural Comput Appl 29(4):1039–1054
Qin JD, Liu XW (2014) Frank aggregation operators for triangular interval type-2 fuzzy set and its application in multiple attribute group decision making. J Appl Math 2014:1–24
Zadeh LA (1975a) The concept of a linguistic variable and its application to approximate reasoning-I. Inf Sci 8:199–249
Zadeh LA (1975b) The concept of a linguistic variable and its application to approximate reasoning-ii. Inf Sci 8(4):301–357
Zadeh LA (1975c) The concept of a linguistic variable and its application to approximate reason-III. Inf Sci 8(3):43–80
Karnik NN, Mendel JM (2001) Centroid of a type-2 fuzzy set. Inf Sci 132(1):195–220
Liu X, Mendel JM (2011) Connect Karnik-Mendel algorithms to root-finding for computing the centroid of an interval type-2 fuzzy set. IEEE Trans Fuzzy Syst 19(4):652–665
Wu D, Mendel JM (2007a) Uncertainty measures for interval type-2 fuzzy sets. Inf Sci 177(23):5378–5393
Chen T (2012) Multiple criteria group decision-making with generalized interval-valued fuzzy numbers based on signed distances and incomplete weights. Appl Math Model 36(7):3029–3052
Sang X, Liu X (2016) Possibility mean and variation coefficient based ranking methods for type-1 fuzzy numbers and interval type-2 fuzzy numbers. J Intel Fuzzy Syst 30(4):2157–2168
Mendel JM, John RIB (2002) Type-2 fuzzy sets made simple. IEEE Trans Fuzzy Syst 10(2):117–127
Mendel JM, John RI, Liu F (2006) Interval type-2 fuzzy logic systems made simple. IEEE Trans Fuzzy Syst 14(6):808–821
Wu D, Mendel JM (2007b) Aggregation using the linguistic weighted average and interval type-2 fuzzy sets. IEEE Trans Fuzzy Syst 15(6):1145–1161
Wu T, Liu X (2016) An interval type-2 fuzzy clustering solution for large-scale multiple-criteria group decision-making problems. Knowl-Based Syst 114:118–127
Kundu P, Kar S, Maiti M (2017) A fuzzy multi-criteria group decision making based on ranking interval type-2 fuzzy variables and an application to transportation mode selection problem. Soft Comput 21(11):3051–3062
Qin JD, Liu XW, Pedrycz W (2017) An extended TODIM multi-criteria group decision making method for green supplier selection in interval type-2 fuzzy environment. Eur J Oper Res 258(2):626–638
John R, Hagras Hani, Castillo O (2018) Type-2 fuzzy logic and systems. doi: https://doi.org/10.1007/978-3-319- 72892-6_1
Zhou S, Chiclana F, John RI, Garibaldi JM (2008) Type-2 OWA operators - aggregating type-2 fuzzy sets in soft decision making. IEEE international conference on fuzzy systems
Zhou S, John RI, Chiclana F, Garibaldi JM (2010) On aggregating uncertain information by type-2 OWA operators for soft decision making. Int J Intel Syst 25(6)
Wang J, Yu S, Wang J, Chen Q, Zhang H, Chen X (2015) An interval type-2 fuzzy number based approach for multi-criteria group decision-making problems. Int. J. Uncertainty Fuzziness Knowl. Based Syst. 23(04):565–588
Liu X, Tao Z, Chen H, Zhou L (2017) A new interval-valued 2-tuple linguistic Bonferroni mean operator and its application to multiattribute group decision making. Int J Fuzzy Syst 19(1):86–108
Gou X, Xu Z, Liao H (2017) Multiple criteria decision making based on Bonferroni means with hesitant fuzzy linguistic information. Soft Comput 21(21):6515–6529
Gong Y, Hu N, Zhang J, Liu G, Deng J (2015) Multi-attribute group decision making method based on geometric Bonferroni mean operator of trapezoidal interval type-2 fuzzy numbers. Comput Ind Eng 81(C):167–176
Wu Q, Wang F, Zhou L, Chen H (2017) Method of multiple attribute group decision making based on 2-dimension interval type-2 fuzzy aggregation operators with multi-granularity linguistic information. Int. J. Fuzzy Syst. 19(6):1880–1903
Havens TC, Anderson DT, Keller JM (2010) A fuzzy Choquet integral with an interval type-2 fuzzy number-valued integrand, IEEE International Conference on Fuzzy Systems 1–8
Bustince H, Galar M, Bedregal B, Kolesarova A, Mesiar R (2013) A new approach to interval-valued Choquet integrals and the problem of ordering in interval-valued fuzzy set applications. IEEE Trans Fuzzy Syst 21(6):1150–1162
Lee L, Chen S (2008) A new method for fuzzy multiple attributes group decision-making based on the arithmetic operations of interval type-2 fuzzy sets. Proceedings of the seventh international conference on machine learning and cybernetics 12–15
Andelkovic M, Saletic DZ (2012) A novel approach for generalizing weighted averages for trapezoidal interval type-2 fuzzy sets. IEEE Jubilee International symposium on intelligent systems & informatics
Chen S, Lee L (2010) Fuzzy multiple attributes group decision-making based on the ranking values and the arithmetic operations of interval type-2 fuzzy sets. Expert Syst Appl 37(1):824–833
Wang W, Liu X, Qin Y (2012) Multi-attribute group decision making models under interval type-2 fuzzy environment. Knowl-Based Syst 30:121–128
Li J, John R, Coupland S, Kendall G (2018) On Nie-tan operator and type-reduction of interval type-2 fuzzy sets. IEEE Trans Fuzzy Syst 26(2):1036–1039
Mo H, Wang FY, Zhou M, Li R, Xiao Z (2014) Footprint of uncertainty for type-2 fuzzy sets. Inf Sci 272:96–110
Mendel JM, Rajati MR, Sussner P (2016) On clarifying some definitions and notations used for type-2 fuzzy sets as well as some recommended changes. Inf Sci 340:337–345
Mo H, Wang FY (2017) Representation for general type-2 fuzzy sets. International Conference on Information, Cybernetics and Computational Social Systems:389–394
Kahraman C, Öztayşi B, Uçal Sİ, Turanoğlu E (2014) Fuzzy analytic hierarchy process with interval type-2 fuzzy sets. Knowl-Based Syst 59:48–57
Liu XW, Mendel JM, Wu D (2012) Analytical solution methods for the fuzzy weighted average. Infor Sci 187:151–170
Liu XW, Wang YM (2013) An analytical solution method for the generalized fuzzy weighted average problem. Int J Uncertainty Fuzziness Knowl Based Syst 21(3):455–480
Dong WM, Wong FS (1987) Fuzzy weighted averages and implementation of the extension principle. Fuzzy Sets Syst 21(2):183–199
Liou TS, Wang MJJ (1992) Fuzzy weighted average: an improved algorithm. Fuzzy Sets Syst 49:307–315
Lee DH, Park D (1997) An efficient algorithm for fuzzy weighted average. Fuzzy Sets Syst 87:39–45
Liu F, Mendel JM (2008) Aggregation using the fuzzy weighted average as computed by the Karnik–Mendel algorithms. IEEE Trans Fuzzy Syst 16(1):1–12
Wu D, Mendel JM (2009) Enhanced Karnik-Mendel algorithms. IEEE Trans Fuzzy Syst 17(4):923–934
Kao C, Liu ST (2001) Fractional programming approach to fuzzy weighted average. Fuzzy Sets Syst 120(3):435–444
Yager RR, Kacprzyk J, Beliakov G (2011) Recent developments in the ordered weighted averaging operators: theory and practice, Springer
Mendel JM (2008) Tutorial on the uses of the interval type-2 fuzzy set’s wavy slice representation theorem. Fuzzy Information Processing Society, Nafips Meeting of the North American 1–6
Xu Z, Yager RR (2011) Intuitionistic fuzzy Bonferroni means. IEEE Trans Syst Man Cyber Part B 41(2):568–578
Zhu B, Xu ZS (2013) Hesitant fuzzy Bonferroni means for multi-criteria decision making. J Oper Res Soc 64(12):1831–1840
Zhu B, Xu Z, Xia M (2012) Hesitant fuzzy geometric Bonferroni means. Inf Sci 205:72–85
Chen S, Kuo L (2017) Autocratic decision making using group recommendations based on interval type-2 fuzzy sets, enhanced Karnik–Mendel algorithms, and the ordered weighted aggregation operator. Info Sci 412-413:174–193
Chen TY (2017) Multiple criteria decision analysis using prioritised interval type-2 fuzzy aggregation operators and its application to site selection. Technol Econ Dev Eco 23(1):1–21
Qin JD, Liu XW, Pedrycz W (2015) An extended VIKOR method based on prospect theory for multiple attribute decision making under interval type-2 fuzzy environment. Knowl-Based Syst 86:116–130
Abdullah L, Zulkifli N (2015) Integration of fuzzy AHP and interval type-2 fuzzy DEATEL: an application to human resource management. Expert Syst Appl 42(9):4397–4409
Yang MS, Lin DC (2009) On similarity and inclusion measures between type-2 fuzzy sets with an application to clustering. Comput Math Appl 57(6):896–907
Own CM (2009) Switching between type-2 fuzzy sets and intuitionistic fuzzy sets: an application in medical diagnosis. Appl Intell 31(3):283
Wagner C, Hagras H (2008) zSlices — towards bridging the gap between interval and general type-2 fuzzy logic. IEEE International Conference on Fuzzy Systems 489–497
Wagner C, Hagras H (2010) Toward general type-2 fuzzy logic systems based on zslices. IEEE Trans Fuzzy Syst 18(4):637–660
Bilgin A, Hagras H, Malibari A, Alhaddad MJ, Alghazzawi D (2013) Towards a linear general type-2 fuzzy logic based approach for computing with words. Soft Comput 17(12):2203–2222
Kumbasar T, Hagras H (2015) A self-tuning zslices-based general type-2 fuzzy pi controller. IEEE Trans Fuzzy Syst 23(4):991–1013
Pedrycz W, Song M (2012) Granular fuzzy models: a study in knowledge management in fuzzy modeling. Int J Approx Reason 53(7):1061–1079
Yao J, Vasilakos AV, Pedrycz W (2013) Granular computing: perspectives and challenges. IEEE Trans Cybern 43(6):1977–1989
Cabrerizo FJ, Herrera-Viedma E, Pedrycz W (2013) A method based on PSO and granular computing of linguistic information to solve group decision making problems defined in heterogeneous contexts. Eur J Oper Res 230(3):624–633
Ben TN (1998) Robust convex optimization. Math Oper Res 23(4):769–805
Acknowledgements
We thank Professor Witold Pedrycz very much for his valuable suggestions and comments. The work was supported by the National Natural Science Foundation of China (NSFC) under Project 71701158, MOE (Ministry of Education in China) Project of Humanities and Social Sciences (Project No. 17YJC630114) and the Fundamental Research Funds for the Central Universities 2018IVB036.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Qin, J. A survey of type-2 fuzzy aggregation and application for multiple criteria decision making. J. of Data, Inf. and Manag. 1, 17–32 (2019). https://doi.org/10.1007/s42488-019-00002-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42488-019-00002-1