
Abstract
Due to its distinct production paradigm, additive manufacturing (AM) is positioned to bring about a revolution. It presents the possibility of on-demand, decentralized, and mass-customizable manufacturing. However, several issues related to design principles, standardization, and quality control arise from not only the complexity of production systems but also the need for increasingly complicated and high-quality goods. Artificial Intelligence (AI)-based algorithms, which can effectively monitor quality, optimize processes, model complex systems, and manage energy, is essential in addressing the difficulties. In the present work, we have used three supervised machine learning regression-based algorithms, i.e., XG Boost, Random Forest, and Decision Trees, to determine the Flexural Strength of the Fused Deposition Modeling specimen. The results showed that the XG Boost algorithm resulted in the highest coefficient of determination value of 0.77. Supervised machine learning classification-based algorithms such as the Stochastic Gradient Descent (SGD) algorithm, Decision Tree, and Random Forest algorithm is used to determine good and bad flexural strength specimens. The result showed that the SGD algorithm achieved the highest F1 score of 0.85.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Producing an object layer by layer is known as additive manufacturing. It is the reverse of subtractive manufacturing, which involves removing small amounts of a solid block of material until the finished item is produced. Technically, the term “additive manufacturing” can apply to any procedure involving building up a product, like molding, but it references 3-D printing. In the 1980s, prototypes made using additive manufacturing for the first time were typically non-functional. Because it allowed for the creation of a scale replica of the finished product quickly and without the usual setup time and expense associated with producing a prototype, this method was referred to as rapid prototyping [1,2,3,4,5]. Rapid tooling was employed to make molds for finished items and was added to additive manufacturing as it advanced. Early in the new millennium, practical products were being made via additive manufacturing. Recently, organizations like Boeing and General Electric have started integrating additive manufacturing into their operational procedures. Automation and digitization are the keys to further advancement of additive manufacturing for many businesses [6,7,8]. To fully utilize the capabilities of the technology, an increasing number of manufacturers are depending on cloud-based solutions and incorporating different algorithms into their 3D printing solutions. 3D printing is an integral aspect of an era where artificial intelligence, such as machine learning, is being employed to optimize the value chain because it is a digital process in and of itself. Industry 4.0. Artificial intelligence (AI) is taking on more significance as a decision-making tool since it can quickly process a significant amount of complex data [6, 9,10,11,12]. To create medium and large-scale metal parts with a high deposition rate and level of automation, wire arc additive manufacturing (WAAM) has emerged as a feasible alternative. However, the production quality may suffer because of the subpar surface quality of the deposited layer. For WAAM, Xia et al. [13] created a laser sensor-based surface roughness measurement technique. Various machine learning models, including ANFIS, ELM, and SVR, were created to forecast the surface roughness to improve the surface integrity of layers that WAAM deposited. To identify the best process parameter to regulate the final deposition geometry, Xiao, et al. [14] presented a unique machine learning framework to quantitatively assess the correlated connection between the process variables and deposition shape. In contrast to traditional machine learning techniques that only qualitatively predict deposition shape, the proposed artificial intelligence framework can anticipate the deposition shape quantitatively and systematically. The prediction model can show the complex process-quality relationships, and the WAAM can be guided to be more prognostic and dependable by determining the quality of the deposition. Experiments will be used to validate the accuracy and efficacy of the suggested quantitative process-quality analysis. Machine learning algorithms were used by Gor et al. [15] to forecast the density of PBF-AM. The most important factor in determining the overall performance of an AM manufacturing part is density. A model for estimating the density of the stainless steel (SS) 316L construction part is developed using the machine learning (ML) approaches artificial neural network (ANN), K-nearest neighbor (KNN), support vector machine (SVM), and linear regression (LR). The projected outcome for these four approaches is compared using R-squared scores and various error functions. With R-square values for the density estimation of 0.95 and 0.923 for the ANN and SVM models, respectively, they both did well. The estimation of the process variables would benefit from using ML models. Based on the information gathered from the WAAM process, Qin et al. [16] suggested a deep learning-based technique for controlling the droplet transfer mode. The primary transfer mode classification model used a long short-term memory neural network. Arc voltage time-series data was gathered, and analytical and frequency features, including 11 pertinent variables, were retrieved to use as the classification model’s inputs. Then, based on the identified transfer mode, the spacing between the melted pool and the melted wire was modified to maintain the required process stability. In the present work, Supervised Machine Learning based algorithms are implemented to determine the flexural strength of the Fused Deposition Modeling specimens. As defined by science, flexural strength is a material’s resistance to breaking or fracture. Flexural strength reveals the force needed to fracture a test sample with a certain measurement diameter. When this limit is reached, the test specimen cracks. The material can endure more impact forces the higher the value. However, the measurement technique and sample surface preparation, such as whether the material is cleaned or ground, significantly impact the flexural strength discovered during a test.
2 Materials and methods
The following steps in the FDM process: CAD models are created for stereolithography and then turned into STL files. This file depicts three-dimensional surfaces as a collection of planar triangles. The accuracy will be better the more triangles there are. After the STL file has been translated, the slicing procedure entails processes like 3D component description, slice separation, support material selection, tool path selection, and tool angle selection. Numerous parameters are defined in the STL file to indicate how the machines will function across several layers. The Creality Ender 3 machine, which has a bed size of 220 × 220 × 250 mm, is used to produce the FDM samples. The pieces are designed using CATIA software. The Repetier software’s Cura engine slices the converted STL file into machine-readable g-code files. As indicated in Fig. 1, the flexural specimen’s dimensions, 125 mm × 12.7 mm × 3.2 mm, are in accordance with ASTM D790 specifications.

Flexural specimen design
Polylactic Acid (PLA), frequently utilized for FDM-processed parts, was used to make the specimen. In the present work, Infill Percentage, Layer Height (mm), Print Speed (mm/s), and Extrusion Temp (°C) are input parameters, while Flexural Strength is an output parameter, as shown in Table 1.
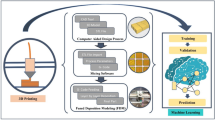
The infill percentage indicates the quantity of material within the manufactured part. It displays the part’s density. The part required determines the infill percentage. The numbers chosen for the infill percentage are 10, 33, 55, 78, and 100%. The layer thickness in FDM is the thickness of a single layer deposited by the nozzle. The paper thickness is determined by the type of nozzle used. The nozzle size in this instance is 0.4 mm. The layer height is set at 0.08 mm, 0.16 mm, 0.24 mm, 0.32 mm, and 0.4 mm. Print speed is the term used to describe how quickly the material will be deposited from the nozzle. Extremely rapid printing will damage mechanical components and lead to an uneven distribution of materials. Low printing speeds are unrealistic because they will lengthen the time needed to print a single specimen. As a result, the print speed values are set at 20, 35, 50, 65, and 80 mm/s. The temperature at which the substance is extruded from the nozzle is known as the extrusion temperature. A heater within the extruder warms the substance to a semi-liquid state. The viscosity of the substance increases with warmth. As a result, the extruder temperature must be regulated to remain within the range where semi-liquid materials can be maintained. The heating system’s capacity determines the temperatures at which components are extruded. There are five temperature settings: 190, 200, 210, 220, and 230 °C. Figure 2 shows the methodology for subjecting the above-obtained data to machine learning algorithms. The first step is to prepare the obtained experimental data in a CSV file format which is further imported to our Python environment. The second step is to perform exploratory data analysis (EDA) on our imported dataset. The third step is to divide our dataset into training and testing set into 80–20 ratio, where 80% of the data is used for training purposes and 20 percent for testing purposes. The fourth step is to subject this machine learning regression and classification algorithms to these sets. For classification-based purposes, “0” is assigned to the specimen with poor flexural strength and “1” is assigned to the specimen with good flexural strength. The last step is to measure the performance of these algorithms based on R2, F1-Score, and AUC Score values.

Machine learning framework used in the present work
3 Results and discussion
Figure 3 shows the specimen after the flexural strength test. Figure 4 shows the results of feature importance. The primary reason feature selection is so crucial in machine learning is that it acts as a key strategy to focus variables on what is most successful and efficient for a particular machine learning system. It is observed that the Infill percentage has the highest contribution towards the output parameter, i.e., flexural strength, which is further followed by layer height and print speed. It is also observed that the extrusion temperature has no contribution toward flexural strength. So, this parameter is dropped when subjected to machine learning algorithms.

Specimen after flexural strength test

Feature importance results
Figure 5 shows the obtained result obtained from EDA. EDA is a method of data exploration that helps you comprehend the different facets of the data. EDA is frequently used to learn more about the parameters in a data collection and their interactions and investigate what data might reveal outside of formal modeling. It might also assist us in determining the suitability of the statistical techniques we are investigating for data analysis. It provides an understanding of all the data and the numerous interactions between data parts prior to modeling the data. Figure 6 shows the heat map analysis on our dataset. Correlation matrix coefficients are displayed as a heat map to show the degree of association between various factors. It helps identify traits that are ideal for creating machine learning models. The correlation matrix is converted into color labeling via the heat map.

Exploratory data analysis results

Heat map analysis
Table 2 shows the metrics features obtained from the supervised machine learning algorithms. Metric features such as Mean Square Error (MSE), Mean Absolute Error (MAE), and coefficient of determination (R2) are used for measuring the performance of the employed supervised machine learning algorithms. Equations (1), (2), and (3) are used for calculating these metrics features.
where \({y}_{i}\) and \(\widehat{{y}_{i}}\) are actual and predicted values.
It is observed from the results that coefficient of determination value for XG Boost is higher in comparison to other algorithms. XGBoost is a tree-based ensemble machine learning technique that improves on the Gradient Boosting framework by incorporating certain precise approximation algorithms. It has improved prediction power and performance. While evaluating the performance of classification-based algorithms, the F1-Score and AUC scores of each algorithm are evaluated. Equation (1) is used for the calculation of the F1-Score value. Table 3 shows the obtained result for classification-based algorithms.
It is clearly observed from the results that the SGD algorithm has the highest F1 score of 0.86 in comparison to the other algorithms. On a specific dataset, one pass of SGD is statistically (minimax) ideal. In other words, no other method can outperform it in terms of the predicted loss throughout the entire range of data distributions. Furthermore, stochastic gradient descent can converge more quickly on large datasets because it updates more frequently. Additionally, rather than training on a single data point, the stochastic nature of online/minibatch training uses vectorized operations to handle the mini-batch all at once. Figure 7 shows the confusion matrix for the classification-based algorithms, while Fig. 8 shows the obtained AUC curve for the subjected classification-based algorithms. In the Decision Tree classification-based algorithm, entropy is used as a criterion calculated by Eq. (5). Entropy is a unit of measurement for information that depicts the unpredictability of the target’s features. The feature with the lowest entropy selects the optimal split, just like the Gini Index does. A node is pure when the entropy has its lowest value, zero, and it reaches its largest value when the probabilities of the two classes are equal. Figure 9 represents the obtained Decision Tree plot of the present work.
where \({p}_{j}\) stands for class j probability.

Confusion matrix for classification-based algorithms

Obtained AUC curve for classification based algorithms

Decision tree plot obtained in the present work
4 Conclusion
There is no denying that artificial intelligence (AI) will advance additive manufacturing (AM). There are simply too many factors to evaluate for each and every possible element that a user could want to print in a laser powder bed fusion construct, including laser power, hatch distance, gas flow, and others. When it comes to processing discovery, it makes more sense to digitize, simulate, and outsource the “thinking” to a computer than to dedicate human minds and material resources. In the present work, three types of machine learning-based regression and classification-based algorithms were used to determine the flexural strength of the Fusion Deposition Modeling specimen. The obtained results showed that in the regression-based approach XG Boost algorithm resulted in the highest coefficient of determination, while in a classification-based approach, the Stochastic Gradient Descent resulted in the highest F1-Score. The future of this study can be the coupling of nature-based optimization algorithms with machine learning-based algorithms to improve the performance of the obtained results.
Data availability
Not applicable.
References
Dilberoglu UM, Gharehpapagh B, Yaman U, Dolen M (2017) The role of additive manufacturing in the era of industry 4.0. Proc Manuf 11:545–554. https://doi.org/10.1016/j.promfg.2017.07.148
Herzog D, Seyda V, Wycisk E, Emmelmann C (2016) Additive manufacturing of metals. Acta Mater 117:371–392. https://doi.org/10.1016/j.actamat.2016.07.019
Dörfler K et al (2022) Additive manufacturing using mobile robots: opportunities and challenges for building construction. Cement Concrete Res 158:106772. https://doi.org/10.1016/j.cemconres.2022.106772
Sefene EM (2022) State-of-the-art of selective laser melting process: a comprehensive review. J Manuf Syst 63:250–274. https://doi.org/10.1016/j.jmsy.2022.04.002
Sefene EM, Hailu YM, Tsegaw AA (2022) Metal hybrid additive manufacturing: state-of-the-art. Prog Addti Manuf. https://doi.org/10.1007/s40964-022-00262-1
Shidnal S, Latte MV, Kapoor A (2021) Crop yield prediction: two-tiered machine learning model approach. Int J Inf Technol 13(5):1983–1991. https://doi.org/10.1007/s41870-019-00375-x
Verma KK, Singh BM, Dixit A (2022) A review of supervised and unsupervised machine learning techniques for suspicious behavior recognition in intelligent surveillance system. Int J Inf Technol 14(1):397–410. https://doi.org/10.1007/s41870-019-00364-0
Sarkar A, Sharma HS, Singh MM (2022) A supervised machine learning-based solution for efficient network intrusion detection using ensemble learning based on hyperparameter optimization. Int J Inf Technol. https://doi.org/10.1007/s41870-022-01115-4
Qin J et al (2022) Research and application of machine learning for additive manufacturing. Addi Manuf 52:102691. https://doi.org/10.1016/j.addma.2022.102691
Guo S et al (2022) Machine learning for metal additive manufacturing: towards a physics-informed data-driven paradigm. J Manuf Syst 62:145–163. https://doi.org/10.1016/j.jmsy.2021.11.003
Fu Y, Downey ARJ, Yuan L, Zhang T, Pratt A, Balogun Y (2022) Machine learning algorithms for defect detection in metal laser-based additive manufacturing: a review. J Manuf Process 75:693–710. https://doi.org/10.1016/j.jmapro.2021.12.061
Barrionuevo GO, Sequeira-Almeida PM, Ríos S, Ramos-Grez JA, Williams SW (2022) A machine learning approach for the prediction of melting efficiency in wire arc additive manufacturing. Int J Adv Manuf Technol 120(5):3123–3133. https://doi.org/10.1007/s00170-022-08966-y
Xia C, Pan Z, Polden J, Li H, Xu Y, Chen S (2022) Modelling and prediction of surface roughness in wire arc additive manufacturing using machine learning. J Intell Manuf 33(5):1467–1482. https://doi.org/10.1007/s10845-020-01725-4
Xiao X, Waddell C, Hamilton C, Xiao H (2022) Quality prediction and control in wire arc additive manufacturing via novel machine learning framework. Micromachines 13(1):137
Gor M et al (2022) Density prediction in powder bed fusion additive manufacturing: machine learning-based techniques. Appl Sci 12(14):7271
Qin J, Wang Y, Ding J, Williams S (2022) Optimal droplet transfer mode maintenance for wire + arc additive manufacturing (WAAM) based on deep learning. J Intell Manuf 33(7):2179–2191. https://doi.org/10.1007/s10845-022-01986-1
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
VSJ, EMS, AVJ, AM, RDD: conceptualization, methodology, writing an original draft, making simulation, review and editing the whole paper. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing personal and financial interests.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jatti, V.S., Jatti, A.V., Mishra, A. et al. Optimizing flexural strength of fused deposition modelling using supervised machine learning algorithms. Int. j. inf. tecnol. 15, 2759–2766 (2023). https://doi.org/10.1007/s41870-023-01329-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41870-023-01329-0