
Abstract
This research paper presents a novel approach to predicting the surface roughness of polylactic acid (PLA) specimens manufactured using the additive manufacturing process known as fused deposition modeling (FDM). The study introduces a unique coupling of genetic algorithm (GA) with four prominent machine learning algorithms, namely decision tree (DT), random forest (RF), artificial neural network (ANN), and gradient boosting regressor (GBR). The goal of this coupling is to enhance the accuracy and efficiency of surface roughness prediction, which is a critical aspect of FDM-based manufacturing. The proposed hybrid methodology explores the synergistic effect of GA and machine learning algorithms by optimizing the algorithmic parameters and feature selection. A comprehensive dataset was collected from the PLA specimens, and various performance metrics were employed to evaluate the effectiveness of the coupled algorithms. The results indicate that the GA–DT model outperforms the other coupled models, achieving an impressive R2 value of 0.9378. This high R2 value demonstrates the robustness of the GA–DT model in predicting surface roughness and highlights its potential applicability in the additive manufacturing domain.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Additive manufacturing (AM) represents a revolutionary shift in the landscape of fabrication technologies, offering unparalleled advantages and opportunities across various industries. As opposed to traditional subtractive methods, which involve the removal of material to achieve the desired shape, AM builds objects layer-by-layer, directly from digital 3D models. This advanced fabrication technique enables the creation of intricate geometries, customizable products, and reduced material waste, all of which contribute to increased manufacturing efficiency and sustainability (Ref 1,2,3,4,5).
The rapid development and adoption of AM technologies have had a transformative impact on numerous sectors, including aerospace, automotive, medical, and consumer goods. The flexibility offered by AM allows for the production of lightweight, high-strength components, driving innovation in aerospace and automotive design. In the medical field, AM facilitates the development of patient-specific implants and prosthetics, enhancing the quality of patient care. Furthermore, consumer goods manufacturers benefit from accelerated product development cycles and greater design freedom, enabling them to deliver tailored solutions to their customers (Ref 6,7,8,9).
Despite the numerous advantages, AM techniques often face challenges related to the quality and consistency of the final products. One such critical challenge is the accurate prediction and control of surface roughness, which plays a vital role in determining the functionality and aesthetics of the manufactured parts. Surface roughness affects properties such as friction, wear, and adhesion, and thus has a significant impact on the performance and longevity of AM-produced components. Surface roughness is a critical factor influencing the performance of additive manufactured specimens, as it directly affects various material properties and functional attributes. Surface roughness influences the mechanical behavior of AM-produced parts, including their fatigue life, tensile strength, and fracture toughness. Rough surfaces can introduce stress concentrations and micro-cracks, which can act as initiation sites for crack propagation, leading to premature failure of the component. The surface roughness of additive manufactured specimens plays a significant role in determining their wear and friction characteristics (Ref 10,11,12,13). Rough surfaces increase the contact area between interacting components, resulting in higher friction and wear rates. This can adversely affect the energy efficiency, performance, and durability of the moving parts in various applications, such as bearings, gears, and sliding components. Surface roughness affects the adhesion and bonding performance of AM-produced components, which is crucial in applications like coatings, adhesive joints, and biomedical implants. A rough surface can provide increased surface area and mechanical interlocking, improving the bond strength between the materials. However, excessive surface roughness may lead to weak bonding due to voids and trapped air, reducing the overall performance of the component. Surface roughness can impact the thermal properties of AM-produced specimens, such as heat transfer and thermal conductivity. Rough surfaces may exhibit increased heat transfer rates due to enhanced surface area and turbulence, which can be advantageous in applications like heat exchangers. Conversely, excessive surface roughness may lead to localized hotspots and thermal stress, potentially compromising the component's integrity. Surface roughness directly affects the aesthetic appeal and surface finish of additive manufactured components. Rough surfaces may require additional post-processing steps like polishing, grinding, or chemical etching to achieve the desired surface finish, increasing the production time and cost. In biomedical applications, surface roughness can influence the biocompatibility and osseointegration of AM-produced implants. A controlled level of surface roughness can promote better cell adhesion and tissue integration, improving the long-term success of the implant. However, excessive roughness may cause adverse reactions and compromise the implant's performance (Ref 14,15,16,17,18).
Artificial Intelligence (AI) has shown immense potential in optimizing and enhancing the quality of additive manufactured specimens, particularly in the determination of mechanical properties (Ref 19,20,21,22). Machine learning algorithms, a subset of AI, can be employed to analyze and predict the mechanical properties of these specimens by correlating various process parameters, such as layer thickness, print speed, and material composition. This enables manufacturers to fine-tune the printing process and produce parts with desired mechanical characteristics.
Given the importance of surface roughness in AM, there is a growing need for innovative methodologies to predict and optimize this attribute during the fabrication process. This study focuses on the development of a novel coupled Genetic Algorithm–Machine Learning approach to accurately predicting the surface roughness of polyactic acid specimens manufactured using fused deposition modeling. The findings of this research aim to contribute to the enhancement of AM processes, leading to improved product quality and increased manufacturing efficiency across various industries.
2 Problem Statement
The rapid advancement of additive manufacturing techniques, such as fused deposition modeling (FDM), has enabled the production of complex and customized components across a wide range of industries. However, the quality and performance of FDM-produced parts are often influenced by surface roughness, which affects various material properties and functional attributes. Accurate prediction and control of surface roughness are essential to optimize the manufacturing process, enhance product quality, and improve overall efficiency.
Traditional methods for surface roughness prediction often rely on empirical models, which may not account for the complex interactions between various process parameters and material properties. Moreover, these methods may lack the flexibility and adaptability required to address the evolving demands of additive manufacturing technologies. As a result, there is a need for innovative, accurate, and efficient methodologies to predict surface roughness in FDM-produced polylactic acid (PLA) specimens.
The problem statement for this research work can be articulated as follows:
-
Developing a novel, coupled Genetic Algorithm–Machine Learning approach for predicting surface roughness in FDM-produced PLA specimens, which can effectively account for the complex interdependencies between process parameters and material properties, while ensuring high accuracy, efficiency, and adaptability to various manufacturing conditions.
-
To address this problem, the research aims to investigate the integration of Genetic Algorithm with four prominent machine learning algorithms (decision tree, random forest, artificial neural network, and gradient boosting regressor) to optimize the algorithmic parameters and feature selection. The effectiveness of the coupled algorithms will be evaluated using a comprehensive dataset collected from PLA specimens, and their performance will be compared based on various metrics, such as R2 value, to identify the most suitable approach for surface roughness prediction in additive manufacturing processes.
3 Materials and Methods
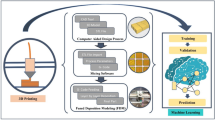
To maintain uniformity in the model, the geometry outlined in the ASTM E8 standard was used as a reference, with dimensions reduced by 50% to decrease print size and minimize both material consumption and time. The response surface methodology (RSM) design of experiment was implemented to create 30 distinct trial conditions (see Figure 1), with each having three levels of input parameters. Based on the literature review, machine capability and pilot study, the levels of 3D printing parameters were selected. The CAD model (see Figure 2) was sliced using the Ultimaker Cura software, generating the G-code. The experimental investigation was conducted using the Creality 3D FDM printer (see Figure 3). Each print was allocated a unique combination of settings that varied in layer height, infill density, infill pattern, bed temperature, and nozzle temperature to produce Polylactic Acid (PLA) specimens. An input parameter datasheet was compiled, and the length discrepancies between each model and the original CAD file were measured using a digital Vernier caliper.

Additive manufactured PLA specimens

Design of the PLA specimens

Setup for 3D printing the specimens
The experimental data obtained is transformed into a CSV file and then imported to the Google Colab platform to implement coupled GA–ML algorithms developed using Python programming. The framework employed in this study is illustrated in Figure 4. The Pandas library is utilized for data manipulation and analysis, offering efficient data structures for managing and accessing large datasets. Widely employed in machine learning, Pandas supports tasks like data pre-processing, cleaning, and transformation, handling missing values, merging and grouping datasets, and filtering and sorting data. NumPy, another library extensively used in machine learning, caters to large multi-dimensional arrays and matrices and includes a suite of high-level mathematical functions. It is valuable for linear algebra, numerical computing, and scientific computing tasks within machine learning. The Seaborn library is employed for data visualization, offering a high-level interface for crafting visually appealing and informative statistical graphics. In machine learning, Seaborn is beneficial for visualizing data distributions, identifying patterns, and exploring variable relationships. Another Python library, Matplotlib, is used for data visualization, providing a comprehensive set of graphical tools for generating high-quality visualizations. It is valuable in machine learning for tasks such as data visualization, model evaluation, and result presentation.

Proposed framework in the present work
The coupled GA–ML model aims to enhance the prediction accuracy and efficiency of surface roughness by integrating the powerful search and optimization capabilities of Genetic Algorithms with the learning and generalization abilities of Machine Learning algorithms.
The first step involves using the Genetic Algorithm to optimize the feature selection process and algorithmic parameters of the chosen ML models. The GA searches for the optimal combination of input features (e.g. layer height, infill density, infill pattern, bed temperature, and nozzle temperature) and ML algorithm parameters (e.g. learning rate, depth of the tree, number of estimators, etc.) that contribute to the best surface roughness prediction performance. During the optimization process, each chromosome in the GA population represents a potential solution, consisting of the selected features and ML algorithm parameters. The fitness function evaluates the performance of each chromosome based on the prediction accuracy of the corresponding ML model, such as the R2 or mean squared error. Through iterative selection, crossover, and mutation, the GA evolves the population towards an optimal or near-optimal solution, identifying the best combination of input features and ML algorithm parameters for surface roughness prediction.
Once the optimal feature set and algorithm parameters have been identified using the GA, the selected ML models (decision tree, random forest, artificial neural network, and gradient boosting regressor) are trained using the optimized settings. The training process involves using a dataset of PLA specimens, where each specimen has a set of input features and a corresponding surface roughness value. The ML models learn the complex relationships between the input features and surface roughness by minimizing the prediction error on the training data. The models' generalization performance is assessed using validation or testing datasets, which were not used during the training process.
After training the ML models with the optimized GA settings, their performance is evaluated using various metrics such as R-squared value, mean squared error, and mean absolute error. The performance of each coupled GA–ML model is compared to determine the most suitable approach for predicting surface roughness in FDM-produced PLA specimens.
The present work utilizes the population size of 50 and number of generations equal to 200. By integrating the Genetic Algorithm with Machine Learning algorithms, the coupled GA–ML model offers a robust and accurate method for surface roughness prediction in additive manufacturing processes. This approach addresses the challenges of feature selection, parameter optimization, and model complexity, contributing to the advancement of surface roughness prediction methodologies in the field of additive manufacturing.
In this study, mean absolute error (MAE), mean square error (MSE), and coefficient of determination (R2) are employed as metric features to assess the performance of the coupled GA–ML models. MAE is a widely used metric for evaluating regression model performance. It calculates the average of the absolute differences between predicted and actual values. A lower MAE value indicates better model performance. MAE is advantageous because it offers an easily interpretable measure of the average error magnitude in predicted values. MSE is another commonly used metric for assessing regression model performance. It calculates the average of the squared differences between predicted and actual values. MSE is advantageous because it more heavily penalizes larger errors compared to smaller ones, which is crucial for accurately assessing model performance. R2 is a statistical measure representing the proportion of variance in the dependent variable explained by the independent variables in the model. R2 values range from 0 to 1, with higher values signifying a better model fit to the data. R2 is a valuable metric for evaluating regression models, as it provides insight into the model's capacity to account for data variation.
4 Results and Discussion
Table 1 shows the obtained results for Surface roughness by the combination of different input parameters.
Figure 5 displays the Confusion Heat Map matrix obtained in this study. The correlation matrix heatmap is a vital tool in machine learning, as it helps determine the relationship strength and direction between various variables. It offers a quick visual representation of the connections between different variables. This information is crucial for feature selection, as highly correlated variables can cause overfitting, and it is essential to eliminate redundant variables to enhance the model's performance.

Obtained correlation matrix heatmap
The correlation matrix heatmap is color-coded, with the color intensity indicating the correlation strength. Positive correlations are represented by shades of blue, while negative correlations are denoted by shades of red. The darker the shade, the stronger the correlation. A neutral correlation is depicted by shades of white or gray. Variables with high correlation appear as dark squares on the heatmap, which can lead to overfitting and should be removed. Variables with low or no correlation appear as light squares on the heatmap. A negative correlation between two variables is indicated by a shade of red. When variables exhibit a strong negative correlation, they move in opposite directions. A positive correlation between two variables is denoted by a shade of blue. When variables display a strong positive correlation, they move in the same direction.
Figure 6 presents the feature importance plot generated in this study. The feature importance plot is a visual tool employed in machine learning to ascertain the significance of each feature within a dataset. It aids in identifying the most relevant features for the target variable and those that can be removed. The feature importance plot can also help detect irrelevant features that do not contribute to the model's accuracy. Eliminating these features during feature selection can enhance the model's performance. It is observed that Layer Height has the greatest impact on the output parameter, i.e., Surface Roughness, while Wall Thickness, Bed Temperature, and Fan Speed parameters exert a negligible effect on Surface Roughness.

Feature importance plot
Figure 7 shows the convergence curve of the GA–ML coupled algorithms. The convergence curve of the GA–ML coupled algorithm is an essential aspect of understanding and evaluating the performance of the combined optimization approach. The convergence curve illustrates the progress of the Genetic Algorithm (GA) throughout its iterations (generations). By plotting the best fitness values found in each generation, the curve provides a visual representation of how the optimization process evolves over time. This allows researchers to observe the gradual improvement of the solutions as the GA progresses towards an optimal or near-optimal solution. The convergence curve helps assess the speed at which the GA–ML coupled algorithm converges to an optimal or near-optimal solution. A rapid convergence indicates that the algorithm efficiently navigates the search space, while a slower convergence suggests that more iterations or adjustments to the algorithm's parameters may be required. Evaluating the convergence speed is crucial for comparing different algorithms or parameter settings and ensuring that the optimization process is effective and efficient. The convergence curve can also provide insights into the stability of the GA–ML coupled algorithm. A smooth curve indicates a stable optimization process, where the algorithm consistently improves the solutions. In contrast, a curve with sudden fluctuations or oscillations may signal instability in the algorithm, possibly due to issues like premature convergence or inadequate exploration of the search space. Analyzing the stability of the algorithm is critical for ensuring that the optimization process reliably converges to the best possible solution. By examining the convergence curve, researchers can determine appropriate termination criteria for the GA–ML coupled algorithm. The curve can reveal when the algorithm has reached a plateau, suggesting that further iterations are unlikely to yield significant improvements in the solution quality. Identifying the point of diminishing returns allows for the termination of the optimization process at an appropriate time, saving computational resources and time.

Convergence curves of (a) GA–gradient boosting regressor, (b) GA–random forest, (c) GA–decision tree, and (d) GA–artificial neural network
Table 2 shows the comparison of the performance of implemented GA–ML coupled algorithms on the basis of metric features such as MSE, MAE, and R2 value.
Figure 8 shows the visualization of the obtained results for MSE, MAE, and R2 value.

Visualization of the metric features results
Figure 9 shows the plot between original surface roughness values and predicted surface roughness value for the implemented algorithms.

Original vs. predicted values plot of (a) GA–gradient boosting regressor, (b) GA–decision tree, (c) GA–random forest, and (d) GA–artificial neural network
The results obtained for the four coupled GA–ML algorithms highlight their varying performances in predicting the surface roughness of the polyactic acid specimens manufactured by the fused deposition modeling (FDM) process. The GA–gradient boosting regressor algorithm achieved a moderately high R2 value of 0.7627, indicating a reasonable fit of the model to the data. However, the relatively higher MSE and MAE values suggest that the model's predictions deviate more from the actual values compared to the GA–Decision Tree and GA–Random Forest algorithms. The GA–Decision Tree algorithm displayed the highest performance among the four algorithms, with the lowest MSE and MAE values and the highest R2 value. An R2 value of 0.9378 indicates a very strong fit between the predicted and actual values, suggesting that the GA–Decision Tree model can effectively explain the variation in the data. The low MSE and MAE values further confirm the model's high accuracy in predicting surface roughness. The GA–Random Forest algorithm performed relatively well, with an R2 value of 0.8987, indicating a good fit between the predicted and actual values. However, its MSE and MAE values are higher compared to the GA–Decision Tree algorithm, suggesting slightly less accurate predictions. The GA–Artificial Neural Network algorithm performed poorly in predicting surface roughness, as evidenced by its negative R2 value and substantially higher MSE and MAE values. The negative R2 value suggests that the model does not explain the variation in the data well and may not be suitable for this specific problem.
The outstanding performance of the GA–Decision Tree algorithm can be ascribed to multiple aspects. Decision trees possess an innate ability to be easily interpreted and efficiently manage intricate relationships among variables. This makes them particularly adept at handling challenges like predicting surface roughness, where numerous parameters may exhibit nonlinear influences. Moreover, the genetic algorithm's fine-tuning of the decision tree's parameters could have resulted in a more precise model, culminating in the algorithm's exceptional performance in this research.
An experimental determination/validation of the modeling results using actual experimental measurements of the surface roughness is shown in Table 3 for which the GA–DT model accuracy is 92%.
The rationale for adopting machine learning approaches, even when traditional experimental determination methods are prevalent, stems from the unique benefits provided by machine learning techniques when predicting surface roughness in Fused Deposition Modeling (FDM) processes. Machine learning algorithms have the capacity to establish intricate connections between input variables and the target outcome, potentially resulting in enhanced accuracy in surface roughness prediction. This is evidenced by the noteworthy R2 value of 0.9378 achieved by the GA–DT model in this study. Additionally, predictions based on machine learning can considerably decrease the time and resources required for experimental testing, promoting more effective resource use. By leveraging these techniques, surface roughness can be accurately and efficiently estimated, eliminating the need for costly and time-consuming trial-and-error experiments. Furthermore, the combination of genetic algorithm (GA) with machine learning algorithms enables improved optimization of algorithmic parameters and feature selection, which can contribute to a streamlined and optimized FDM process, superior product quality, and a reduction in manufacturing defects.
Machine learning models also possess scalability and adaptability, as they can be readily updated with new data as it becomes accessible. This allows the models to adapt to changing manufacturing conditions and continuously enhance their predictive abilities. Such adaptability is especially valuable in the fast-paced and ever-evolving additive manufacturing industry.
5 Conclusion
In conclusion, this research successfully demonstrated the application of coupling genetic algorithm (GA) with four machine learning algorithms, namely decision tree, random forest, artificial neural network, and gradient boosting regressor, for predicting the surface roughness of polyactic acid specimens manufactured through the fused deposition modeling (FDM) process. The study's results indicated that the GA–Decision Tree algorithm outperformed the other algorithms in terms of Mean Square Error (MSE), Mean Absolute Error (MAE), and R2 value, showcasing its potential as an effective and accurate model for surface roughness prediction in additive manufacturing.
The superior performance of the GA–Decision Tree model can be attributed to the decision tree's inherent interpretability and ability to handle complex interactions between variables effectively. Furthermore, the optimization of the decision tree's parameters by the genetic algorithm contributed to the enhanced accuracy of the model.
The current research has laid the foundation for further advancements in the additive manufacturing domain. As a future scope, this work can be extended to include other machine learning algorithms and optimization techniques to explore the possibility of achieving even better prediction accuracy.
References
X. Zhang and F. Liou, Introduction to Additive Manufacturing, Additive Manufacturing. Elsevier, 2021, p 1–31
D. Bourell and T. Wohlers, Introduction to Additive Manufacturing, Addit. Manuf., 2020, 2020, p 24.
S. Ford, L. Mortara, and T. Minshall, The Emergence of Additive Manufacturing: Introduction to the Special Issue (2016)
T.H.J. Vaneker, The Role of Design for Additive Manufacturing in the Successful Economical Introduction of AM, Procedia CIRP, 2017, 60, p 181–186.
C. Greer, A. Nycz, M. Noakes, B. Richardson, B. Post, T. Kurfess, and L. Love, Introduction to the Design Rules for Metal Big Area Additive Manufacturing, Addit. Manuf., 2019, 27, p 159–166.
A. Haleem and M. Javaid, Additive Manufacturing Applications in Industry 4.0: A Review, J. Ind. Integr. Manag., 2019, 4(04), p 1930001.
S.K. Adapa, Prospects of Natural Fiber-Reinforced Polymer Composites for Additive Manufacturing Applications: A Review, JOM, 2023, 2023, p 1–21.
A. Nazir, O. Gokcekaya, K.M.M. Billah, O. Ertugrul, J. Jiang, J. Sun, and S. Hussain, Multi-material Additive Manufacturing: A Systematic Review of Design, Properties, Applications, Challenges, and 3D Printing of Materials and Cellular Metamaterials, Mater. Des., 2023, 2023, p 111661.
R. Agrawal, Sustainable Design Guidelines for Additive Manufacturing Applications. Rapid Prototyp. J. (2022)
P. Kumar and N.K. Jain, Surface Roughness Prediction in Micro-plasma Transferred Arc Metal Additive Manufacturing Process using K-Nearest Neighbors Algorithm, Int. J. Adv. Manuf. Technol., 2022, 119(5–6), p 2985–2997.
F. Lavecchia, M.G. Guerra, and L.M. Galantucci, Chemical Vapor Treatment to Improve Surface Finish of 3D Printed Polylactic Acid (PLA) Parts Realized by Fused Filament Fabrication, Prog. Addit. Manuf., 2022, 2022, p 1–11.
W. Macek, R.F. Martins, R. Branco, Z. Marciniak, M. Szala, and S. Wroński, Fatigue Fracture Morphology of AISI H13 Steel Obtained by Additive Manufacturing, Int. J. Fract., 2022, 235(1), p 79–98.
J.C. Pereira, F. Zubiri, M.J. Garmendia, M. Tena, H. Gonzalez, and L.N. López de Lacalle, Study of Laser Metal Deposition Additive Manufacturing, CNC Milling, and NDT Ultrasonic Inspection of IN718 Alloy Preforms, Int. J. Adv. Manuf. Technol., 2022, 120(3–4), p 2385–2406.
H. Fayazfar, J. Sharifi, M.K. Keshavarz, and M. Ansari, An Overview of Surface Roughness Enhancement of Additively Manufactured Metal Parts: A Path Towards Removing the Post-print Bottleneck for Complex Geometries, Int. J. Adv. Manuf. Technol., 2023, 2023, p 1–53.
B. Whip, L. Sheridan, and J. Gockel, The Effect of Primary Processing Parameters on Surface Roughness in Laser Powder Bed Additive Manufacturing, Int. J. Adv. Manuf. Technol., 2019, 103, p 4411–4422.
U.M. Dilberoglu, B. Gharehpapagh, U. Yaman, and M. Dolen, Current Trends and Research Opportunities in Hybrid Additive Manufacturing, Int. J. Adv. Manuf. Technol., 2021, 113, p 623–648.
P. Tyagi, T. Goulet, C. Riso, and F. Garcia-Moreno, Reducing Surface Roughness by Chemical Polishing of Additively Manufactured 3D Printed 316 Stainless Steel Components, Int. J. Adv. Manuf. Technol., 2019, 100, p 2895–2900.
A.S. Shastri, A. Nargundkar, A.J. Kulkarni, and K.K. Sharma, Multi-cohort Intelligence Algorithm for Solving Advanced Manufacturing Process Problems, Neural Comput. Appl., 2020, 32, p 15055–15075.
R. Mamedipaka and S. Thapliyal, Data-Driven Model for Predicting Tensile Properties of Wire Arc Additive Manufactured 316L Steels and Its Validation, J. Mater. Eng. Perform., 2023 https://doi.org/10.1007/s11665-023-08071-5
N. Ranjan, R. Kumar, R. Kumar et al., Investigation of Fused Filament Fabrication-Based Manufacturing of ABS-Al Composite Structures: Prediction by Machine Learning and Optimization, J. Mater. Eng. Perform., 2022 https://doi.org/10.1007/s11665-022-07431-x
P. Charalampous, N. Kladovasilakis, I. Kostavelis et al., Machine Learning-Based Mechanical Behavior Optimization of 3D Print Constructs Manufactured Via the FFF Process, J. Mater. Eng. Perform., 2022, 31, p 4697–4706. https://doi.org/10.1007/s11665-021-06535-0
K.L. Raju, S. Thapliyal, S. Sigatapu et al., Process Parameter Dependent Machine Learning Model for Densification Prediction of Selective Laser Melted Al-50Si Alloy and Its Validation, J. Mater. Eng. Perform., 2022, 31, p 8451–8458. https://doi.org/10.1007/s11665-022-06831-3
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mishra, A., Jatti, V.S. Novel Coupled Genetic Algorithm–Machine Learning Approach for Predicting Surface Roughness in Fused Deposition Modeling of Polylactic Acid Specimens. J. of Materi Eng and Perform 33, 6136–6145 (2024). https://doi.org/10.1007/s11665-023-08379-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11665-023-08379-2