
Abstract
Collapsible soils, particularly loessial soils, present significant geotechnical engineering hazards that should be carefully investigated before any construction can commence. However, it is generally difficult to estimate the collapse potential of soils based on the relative contributions of each of the numerous influencing factors. Therefore, the main objective of this study is to find a reliable method for predicting the collapse potential of loessial soils by using machine learning-based tools. In this regard, details of 766 performed oedometer test were gathered from the published literature containing six variables for each data point including dry unit weight of soil, plasticity index, void ratio, degree of saturation, inundation stress at which the oedometer test was conducted, and the collapse potential. Then, prediction for the degree of collapsibility of loess was performed by employing three well-known supervised machine learning tools, namely Multi-Layer Perceptron Neural Network (MLPNN), Radial Basis Function Network (RBFN), and Naïve Bayesian Classifier (NBC), and outcomes were analyzed based on a comparative view. Simulation results indicate the superiority of MLPNN in estimating the degree of collapsibility of loess against other models in terms of performance error metrics and precision criterion.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Loess is a widely-abundant collapsible soil with a microstructure of meta-stable characteristic (Pye 1984; Jefferson et al. 2005). Typically composed of wind-borne sediment, silt-sized particles, this type of soil has some unique physical and chemical characteristics (Smalley 1995; Bell 2013).
In general, loess is highly porous, which results in a low dry density as well as low permeability (Kim & Kang 2013; Liu et al. 2016; Yates et al. 2018). Due to its relatively low shear strength, loess is susceptible to slope failure and other types of failure in construction. Unless properly managed, loess is highly erodible and is susceptible to erosion and gullying. Combined with other factors, such as climate, these properties can greatly influence the behavior of loessial soils in construction and other applications.
Loess is most commonly found in arid and semi-arid regions with low to moderate precipitation rates and strong winds, as these conditions are conducive to the formation and preservation of loess deposits (Li et al. 2020). Russia, the United States, China, Libya, Argentina, Australia and Iran are all known to have this type of soil (Follmer 1996; Zárate 2003; Zhangjian et al. 2007; Nouaouria et al. 2008; Karimi et al. 2009; Yates et al. 2018). Approximately 10 percent of the surface of the earth is covered by loess (Li et al. 2020).
Having a macro-porous characteristic, loess possesses collapsing behavior especially under loading or water inundation which results in construction problems (Yang 1989; Fredlund & Gan 1995; Munoz-Castelblanco et al. 2011). Loess can also collapse when it becomes inundated due to the breakdown of particle connections (Giménez et al. 2012; Wang et al. 2020). As a collapsible soil, construction on loess may make the foundation of the buildings extremely vulnerable to abrupt settlements, absolute and differential, upon saturation of the underlying soil.
As reported in the literature, construction on the base of loess layers have frequently ended in collapsing events in many residential, commercial, and infrastructural projects (Houston et al. 1988; Derbyshire 2001; Jefferson et al. 2003; Sakr et al. 2008; Rabbi et al. 2014).
In general, the potential of collapse refers to the change in the bulk volume of the soil under water inundation, and an experimental approach is used to evaluate this characteristic by compressing and inundating undisturbed soil samples using an oedometer (ASTM 1996).
A number of studies have been dedicated to the effect of different soil parameters on the collapse potential. In general, it can be inferred from the reported results that numerous physical properties of the soil can affect its collapsibility. These parameters include the soil texture and its water content as well as dry density, Atterberg limits and void ratio (Mansour et al. 2008; Bell 2013; Langroudi & Jefferson 2013; Garakani et al. 2015). Regarding the soil micro-structure, the mineral constituents and the number of macro and mini pores along with the bonding material between them can significantly influence the collapse potential (Giménez et al. 2012; Liu et al. 2016; Ma et al. 2017; Xie et al. 2018).
2 Background Review
Within the last two decade, several research papers have been published on the use of modern computational techniques such as artificial neural networks and machine learning methods to solve the problems related to the estimation of collapse potential of collapsible soils.
As one of the earliest studies in this field, Juang & Elton (1997) applied neural network techniques on a dataset composed of the property and collapse potential data for a total of 1044 soil samples. Also, their approach for training employed three main techniques, namely Naïve back-propagation (NBP), backpropagation with momentum and adaptive learning rate, and Levenberg- Marquardt algorithm (LM). The results indicate that their trained network is capable of estimating the collapse potential of soils but since they did not focus on a particular soil type and their dataset contained different types of collapsible soil, the results of their research cannot be applied to a special soil type such as loess.
Furthermore, Basma & Kallas (2004) developed an artificial neural network-based model capable of soil collapsibility behavior prediction. Their proposed network was able to estimate the collapse potential of different soil types with different arrangements and pressure levels. This network includes six neurons as inputs consisting of six main soil properties of the samples.
Also, Habibagahi & Taherian (2004) utilized several neural networks including Generalized Regression Neural Network (GRNN), Recurrent Neural Network (RNN) and Back-Propagation Neural Network (BPNN) for collapse potential estimation. Their findings indicate the significant influence of soil dry density on the collapse potential.
GRNN was also used, along with RBFN, to predict collapsibility potential of different types of soil (Zhang 2011). In comparison with RBFN and the experimental results, GRNN was found to have higher accuracy in estimating the collapse potential of soil.
The use of Multivariate Adaptive Regression Spline (MARS) and BPNN methods in collapse potential estimation were also examined by W. Zhang (2020). Both of these methods exhibit acceptable collapsibility estimation capabilities.
Similarly, Salehi et al. (2015) studied the collapse potential of loess using MLPNN, RBFN and Adaptive Neuro-Fuzzy Inference Systems (ANFIS). The MLPNN was shown to have high prediction capability through LM backpropagation technique. RBFN was also found to be closely accurate but estimations by ANFIS were not just as promising.
Further, Uysal (2020) employed Gene Expression Programming (GEP) technique to estimate collapsibility based on six soil parameters, namely the water content, dry unit weight, inundation stress, sand and clay contents, and the uniformity coefficient. The study also drew a comparison between the GEP-based model and the previously-proposed regression-based models.
In our opinion, the existing models proposed so far in the literature have two major flaws. The first problem is that most of the models were presented based on limited datasets, which usually pertain to a specific geographical area. The second issue is that the models are often presented based on data related to a wide range of collapsible soils, while the different types of collapsible soils possess different characteristics and the results cannot be generalized to them all. Thus, loessial soils have received insufficient attention in this case.
Hence, the purpose of this study is to represent a comparative perspective on well-known supervised machine learning tools including MLPNN, RBFN, and NBC and find a reliable model for estimating the collapse potential of loessial soils.
3 Analysis Methods
This section presents customizations of three supervised machine learning tools including MLPNN, RBFN, and NBC for estimating loess collapse potential. By considering the complexity of data points’ distribution and features of their behaviors, the tools named above were selected to investigate the effect of different classifier properties on results.
With the help of MLPNN, linear separation can be achieved in functions such as AND/OR. However, some of the functions, such as Exclusively-OR (XOR), are not linearly separable. Thus, RBFN was chosen to handle such situations, employing radial functions. In fact, RBFN transforms the input values into a form, which can then be incorporated into the network to achieve linear separability. The reason for studying NBC’s performance in current research, is to employ its high precision classification capability, considering conditional independency and the probabilistic nature of the values of the features.
3.1 MLPNN
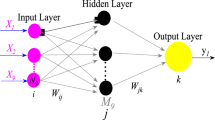
As a multi-layer perceptron neural network, MLPNN is categorized as a feed-forward network with activation thresholds. It is formed by at least three layers of processing nodes including an input layer, a hidden layer, and an output layer. Figure 1 illustrates a simplified MLPNN structure. Using this network, historical data are used for supervised learning aimed at mapping known inputs to outputs (Du & Swamy 2013). It is important to note that, the trained network can then be used to estimate the unknown output through any set of given inputs.

A simple structure of MLPNN (Du & Swamy 2013)
In this model, each neuron calculates the weighted sum of all entries. This value is then subtracted from the neuron’s threshold value. The result is passed to an activation function, and finally, the neuron’s outcome is achieved according to Eq. (1) for n neurons (Du & Swamy 2013).
where i denotes the identification number of the input feature, which ranges from 1 to n, X and W are the value and weight of the input feature, respectively. A brief scheme of neuron is shown in Fig. 2.

A brief scheme of a neuron (Du & Swamy 2013)
MLPNN uses the well-known learning algorithm, backpropagation, which was introduced in the 1980s. Backpropagation learns the set of weights iteratively using gradient descent technique to reduce errors and to enhance class prediction precision of the samples.
3.2 RBFN
As a feedforward neural network, RBFN is comprised of three main layers (Haykin 2010):
-
Input layer consisting of sensory or source nodes acquiring data from the environment,
-
Hidden layer which performs a nonlinear transformation on the inputs to obtain the feature space. In general, this layer is of high dimensions making it suitable only for unsupervised learning,
-
Output layer trained in a linear supervised approach which ultimately conveys the network response to the input pattern.
In MLPNN, only linear separability is feasible whereas a function such as XOR is not linearly separable. RBFN uses the radial basis function as an activation function. Neurons’ outputs are inversely proportional to the distance from a location, e.g., the neuron center. The distance metric is usually a Euclidian norm; however, other metrics such as Minkowski and Manhattan are commonly used. The output of the RBFN is a mapping approximation between input and output using a linear combination of radially symmetric functions.
Accordingly, the kth output is given by Eq. (2) (Du & Swamy 2013):
where n is the number of inputs, \(k=\mathrm{1,2},\dots ,\) m and m is the number of outputs. Additionally, the Gaussian function \({\Phi }_{i}\left(X\right)\) is defined as Eq. (3) (Haykin 2010).
where \({C}_{i}\) and \({\sigma }_{i}\ge 0\) are selected centers and widths, and \({r}_{i}\ge 0\).
3.3 NBC
NBC is a probabilistic mathematical classification tool based on the Bayes Theorem and the hypothesis of maximum posteriori. In this method, the values of attributes are assumed to be mutually independent known as “Class Conditional Independence”. This method is considered as “Naïve” as it is used to simplify the calculation task. Class membership of the input pattern can be estimated using this method in a probabilistic way.
Consider a vector \(X=\left({x}_{1},\dots ,{x}_{n}\right)\) is a problem instance with n independent variables. NBC assigns probability depicted in Eq. (4) to this instance for each class \({C}_{k}\) (Murty and Devi 2011):
In such a case, conditional probability based on the Bayes theorem can be decomposed as Eq. (5) (Murty and Devi 2011):
3.4 Advantages and limitation of the considered models
Advantages and limitations of MLPNN, RBFN, and NBC are thoroughly examined and summarized in detail within Table 1. This table sheds light on the distinctive features and potential drawbacks of each model.
4 Data collection
In order to prepare the dataset, the results of 766 oedometer tests conducted on undisturbed loess samples have been collected from the published literature as primitive raw data. Aside from the measured collapse potential and the inundation stress at which the test was conducted, 4 main soil parameters were collected for each sample including plasticity index, dry unit weight, void ratio, and degree of saturation. Listed in Table A-1 are the details of the compiled dataset, including references, sampling locations, and soil type for each reference based on the USCS.
Figure 3 illustrates the soil type distribution of all samples based on the USCS in the compiled dataset. As shown, the dataset contains four types of soil including CL (clay with low plasticity), ML (silt with low plasticity), SM (silty sand), and ML-CL (clay with low plasticity combined with silt). As can be seen CL is the dominant soil type in the compiled dataset.

Soil type classification of the dataset (Based on the USCS)
In addition, Fig. 4 provides a visual representation of the data, illustrating general trends. It is observed that as the degree of saturation and dry unit weight of the samples increase, the collapse potential of the samples decreases. Conversely, with an increase in the void ratio of the samples, the collapse potential shows an upward trend. However, when considering inundation stress and plasticity index, no clear correlation can be identified.

Influence of a Dry unit weight, b Void ratio, c Degree of saturation, d Plasticity index, e Inundation stress on collapse potential of the studied soil samples
These findings highlight the complex nature of the collapse potential, indicating the need for more advanced tools and methodologies for analysis. Therefore, in this study, machine learning tools were used to provide a deeper understanding and improved prediction of collapse potential.
A summary of basic statistics is presented in Table 2, including maximum, minimum, average, standard deviation (SD), and coefficient of variation (CV) of the considered variables.
Based on the information presented in the table, it can be inferred that a majority of the samples exhibit a low dry unit weight. Additionally, the majority of the samples have a comparatively high void ratio as a result of the elevated average value of this parameter (0.76), which can be attributed to the porous characteristics of loess. The table also indicates that the degree of saturation is relatively low, which is expected for loess deposits found in arid areas. The table also demonstrates that the samples are composed of soils with low plasticity, as indicated by the low value of the plasticity index.
Given the comprehensive information regarding soil parameters and inundation stresses, this dataset can be considered highly comprehensive and representative, as the values of different variables span across a wide range without being limited to specific ranges.
5 Model Preparation
In order to prepare the models, the primitive raw data were preprocessed before being fed as input to the models. During the preprocessing of the data, a number of different techniques were applied, including cleaning, integration, reduction, and transformation, based on necessity. These techniques were used to handle the following situations:
-
Noise removal, outlier handling, missing values, and inconsistencies correction,
-
Merging data gathered from various sources into a coherent data store,
-
Reducing data size by aggregating or eliminating redundancies,
-
Normalizing data in some specific ranges or intervals to enhance accuracy and overall performance.
Preprocessed data containing 634 samples were then ready for feeding into the models.
As part of the preparation of the MLPNN and RBFN, the data samples were randomly divided into three parts including 70% as training data, 11% as validation data, and 19% as test data. In order to prepare NBC, the first two parts were combined and fed into the model as training data (81% of the data), and the last part was kept as test data (19% of the data).
In order to prepare MLPNN, a two-hidden-layer feed-forward network with 10 sigmoid neurons in the hidden layer and linear output neurons was selected, and it was trained for 21 epochs. The MLPNN was trained with the Levenberg–Marquardt (LM) backpropagation algorithm except when there is not enough memory. In that case, scaled conjugate gradient backpropagation will be employed. It should be noted that, in the preparation of the model, 5 features (including plasticity index, dry unit weight, void ratio, degree of saturation, and inundation stress) were considered as input parameters while the collapse potential was considered as target or output parameter. In addition, the validation data was used to stop training process in case the network gets overfitted.
For the preparation of the RBFN, both input and output parameters were the same as those for MLPNN. Accordingly, a network with a maximum of 100 neurons was trained, and the spread of RBFs was set to 1.0. Additionally, during the training process, 10 neurons were incrementally added between displays.
To prepare the NBC, the collapse potential values of the samples were classified as targets into five different classes, 1–5, according to Table 3 (ASTM 1996).
After classifying the samples as inputs, NBC with normal (Gaussian) distribution parameters was defined for the train data. As a key point, NBC used the same input parameters as MLPNN and RBFN, but its output parameter was the labeled class of collapsibility rather than collapse potential. For the purpose of testing the performance of the model, the NBC was applied to the test data.
6 Evaluation of the Performance of the Proposed Models
In order to assess the performance of the models, it is important to note that the output of MLPNN and RBFN is the collapse potential of soil samples, which is a continuous variable ranging from 0 to more than 10. NBC, however, generates the degree of collapsibility of the samples (In accordance with Table 3), which is an integer ranging from 1 to 5.
Due to the fact that the outputs of the MLPNN and RBFN are continuous values, it is, therefore, necessary to use appropriate performance indices to evaluate their performances such as R2, RMSE, and MAE. The output of NBC, however, is not merely a number, but a class, which makes other criteria such as “Precision” more appropriate for evaluating its performance.
The performance indices are error functions generally defined as the absolute subtraction of targets and model outputs. Learning functions iteratively attempt to reduce error values through techniques such as gradient descent. In general, the closer the outputs are to the targets, the more accurate the model will be. Thus, for some indices, such as R2, high values indicate better performance of the model, while for other indices, such as RMSE and MAE, lower values indicate better performance. As mentioned previously, three popular error indices are R2, MAE, and RMSE as defined by Eqs. (6–8).
where n is the number of outputs, and \(output_{avg} = {1 \mathord{\left/ {\vphantom {1 n}} \right. \kern-0pt} n}\sum\nolimits_{i = 1}^{n} {output_{i} }\).
Based on the MLPNN and RBFN predictions, Fig. 5 shows the actual values of collapse potential as well as the predicted values for the test dataset (19% of data). Figure 5 illustrates that most of the predicted values of collapse potential by MLPNN and RBFN are in close agreement with the actual values of collapse potential.

Comparison of actual collapse potential values with predicted values based on MLPNN and RBFN models
Accordingly, Table 4 presents the calculated MAE, R2, and RMSE for all training, validation, and test datasets for the MLPNN and RBFN.
In Table 4, it can be seen that the models perform differently for training and validation datasets due to the random subdivision process. Based on this table, the prediction performance is better for validation set than the training set in terms of the predefined indices. In the context of the test and validation dataset, the high performance of the models can be considered as an indication of their generalization capabilities, as discussed by Cabalar et al. (2012). Regarding the comparison between MLPNN and RBFN, it is evident that MLPNN performs better across all datasets.
In order to compare the performance of RBFN and MLPNN with NBC, the outputs had to be homogenized. Accordingly, Table 3 was once more used to classify the output values of collapse potential for each sample predicted by MLPNN and RBFN.
After classifying the predicted collapse potential values by MLPNN and RBFN, the actual class of soil samples (degree of collapsibility) as well as the predicted class based on MLPNN, RBFN, and NBC are shown in Fig. 6.

Comparison of the predicted class of collapsibility by MLPNN, RBFN, and NBC with the actual class for the test dataset
Table 5 shows confusion matrix of predicted classes performed by the used models. A confusion matrix is a widely common performance measurement for machine learning techniques which summarizes a table of the number of actual and predicted classes yielded by a prediction model. The rows in this table indicate the number of samples predicted in each class using three different models, including MLPNN, RBFN, and NBC. Additionally, the columns indicate the amount of data for each actual class. The diagonal cells in the confusion matrix were bolded to visually indicate where the model's predictions aligned with the actual classes.
In the next step, the Precision criterion was selected as an appropriate criterion to compare the performance of the three mentioned models in predicting the degree of collapsibility of samples.
Precision is a machine learning evaluation metric that measures the proportion of correct predictions among all predictions made by a model. In other words, it is an indicator of how accurate a model is at making correct predictions. Alternatively, precision is the percentage of correct predictions that are actually borne out by the model. Precision can be calculated by knowing the number of true positive predictions (TP) and false positive predictions (FP) made by the model. It is then possible to calculate Precision in the following manner (Powers 2020):
In order to evaluate the performance of the mentioned models using Precision, the actual degree of collapsibility was compared to the predicted degree of collapsibility by MLPNN, RBFN, and NBC, and if the predictions matched, the prediction was considered TP, whereas if not, they were considered FP. Figure 7 shows the calculated Precision values for each model.

Measured values of Precision for MLPNN, NBC, and RBFN model
In this figure, it can be seen that the MLPNN correctly predicted the degree of collapsibility of loess in 86.6% of samples (104 samples from 120) which is a high accuracy level.
7 Conclusion
In this paper, a comparative classification and prediction of the collapse potential of loessial soils was conducted using three well-known supervised machine learning approaches, namely MLPNN, RBFN, and NBC. The preprocessed data utilized in this study comprised 634 samples with 5 input features including dry unit weight, plasticity index, void ratio, degree of saturation, and inundation stress, along with an output parameter named collapse potential. By using the same train, validation, and test data for the MLPNN and RBFN, it was determined that both models are capable of predicting the collapse potential of loess when considering the aforementioned input parameters. MLPNN, however, had better performance than RBFN in predicting collapse potential of loess based on low calculated performance indices (RMSE, MAE, and R2). Furthermore, by utilizing the Precision criterion and confusion matrix, MLPNN was proven to be more accurate than RBFN and NBC in predicting the degree of collapsibility of loessial soils. To conclude, MLPNN performed well when used to predict the level of collapsibility of loess, or in other words when classifying the level of potential collapse risk of loess based on ASTM (1996).
Data Availability
No new data were generated during this study.
References
Abd El Aal AK, Rouaiguia A (2020) Determination of the geotechnical parameters of soils behavior for safe future urban development, Najran Area, Saudi Arabia: implications for settlements mitigation. Geotech Geol Eng 38(1):695–712. https://doi.org/10.1007/s10706-019-01058-x
Al-Harthi AA, Bankher KA (1999) Collapsing loess-like soil in western Saudi Arabia. J Arid Environ 41(4):383–399. https://doi.org/10.1006/jare.1999.0494
Assallay AM, Rogers CDF, Smalley IJ (1996) Engineering properties of loess in Libya. J Arid Environ 32(4):373–386. https://doi.org/10.1006/jare.1996.0031
ASTM, D5333 (1996) Standard test method for measurement of collapse potential of soils. ASTM International. https://doi.org/10.1520/D5333-92R96.
Basma AA, Kallas N (2004) Modeling soil collapse by artificial neural networks. Geotech Geol Eng 22(3):427–438. https://doi.org/10.1023/B:GEGE.0000025044.72718.db
Bell FG (2013) Engineering properties of soils and rocks. Elsevier
Bell FG, Culshaw MG, Northmore KJ (2003) The metastability of some gull-fill materials from Allington, Kent, UK. Q J Eng GeolHydrogeol 36(3):217–229. https://doi.org/10.1144/1470-9236/02-005
Bishop CM, Nasrabadi NM (2006) Pattern recognition and machine learning. Springer, Berlin
Bolouri Bazzaz J, Marouf MA (2012) Identification and evaluation of mechanical behavior collapsible soil (case study in north eastern of Iran. Sci Q J Iran Assoc Eng Geol 5(1 & 2):27–40
Cabalar AF, Cevik A, Gokceoglu C (2012) Some applications of adaptive neuro-fuzzy inference system (ANFIS) in geotechnical engineering. Comput Geotech 40:14–33
Delage, P., Cui, Y.-J., & Antoine, P. (2008). Geotechnical problems related with loess deposits in Northern France. ArXiv Preprint arXiv:0803.1435. https://doi.org/10.48550/arXiv.0803.1435.
Derbyshire E (2001) Geological hazards in loess terrain, with particular reference to the loess regions of China. Earth Sci Rev 54(1–3):231–260. https://doi.org/10.1016/S0012-8252(01)00050-2
Du K-L, Swamy MN (2013) Neural networks and statistical learning. Springer, Berlin
Dušan B, Zoran B, Čebašek V, Šušić N (2014) Characterization of collapsing loess by seismic dilatometer. Eng Geol 181:180–189
Follmer LR (1996) Loess studies in central United States: evolution of concepts. Eng Geol 45(1–4):287–304. https://doi.org/10.1016/j.enggeo.2014.07.011
Fredlund DG, Gan JK (1995) The collapse mechanism of a soil subjected to one-dimensional loading and wetting. Genesis and properties of collapsible soils. Springer, Dordrecht, pp 173–205
Garakani AA, Haeri SM, Khosravi A, Habibagahi G (2015) Hydro-mechanical behavior of undisturbed collapsible loessial soils under different stress state conditions. Eng Geol 195:28–41. https://doi.org/10.1016/j.enggeo.2015.05.026
Giménez RG, de la Villa RV, Martín JG (2012) Characterization of loess in central Spain: a microstructural study. Environ Earth Sci 65(7):2125–2137. https://doi.org/10.1007/s12665-011-1193-7
Habibagahi G (2004) Prediction of collapse potential for compacted soils using artificial neural networks. Sci Iran 11(1):1–20
Haeri SM, Zamani A, Garakani AA (2012) Collapse potential and permeability of undisturbed and remolded loessial soil samples. Unsaturated soils: Research and applications. Springer, Berlin, pp 301–308
Hafezi Moghaddas N, Nikudel M, Bahrami K (2011) Evaluation of collapsibility of loess deposits of Gharnaveh catchment in north of Kalale, Golestan province. Sci Q J Iran Assoc Eng Geol 4(1 & 2):39–46
Haykin S (2010) Neural networks and learning machines, 3/E. Pearson Education India.
Houston SL, Houston WN, Spadola DJ (1988) Prediction of field collapse of soils due to wetting. J Geotech Eng 114(1):40–58. https://doi.org/10.1061/(ASCE)0733-9410(1988)114:1(40)
Iranpour B (2016) The influence of nanomaterials on collapsible soil treatment. Eng Geol 205:40–53. https://doi.org/10.1016/j.enggeo.2016.02.015
Jefferson I, Smalley I, Northmore K (2003) Consequence of a modest loess fall over southern and midland England. Mercian Geol 15(4):199–208
Jefferson I, Rogers C, Evstatiev D, Karastanev D (2005) Treatment of metastable loess soils Lessons from Eastern Europe. Elsevier geo-engineering book series. Elsevier, London, pp 723–762
Juang CH, Elton DJ (1997) Predicting collapse potential of soils with neural networks. Trans Res Rec J Trans Res Board 1582(1):22–28. https://doi.org/10.3141/1582-04
Karimi A, Khademi H, Kehl M, Jalalian A (2009) Distribution, lithology and provenance of peridesert loess deposits in northeastern Iran. Geoderma 148(3–4):241–250. https://doi.org/10.1016/j.geoderma.2008.10.008
Khodabandeh MA, Nokande S, Besharatinezhad A, Sadeghi B, Hosseini SM (2020) The effect of acidic and alkaline chemical solutions on the behavior of collapsible soils. Period Polytech Civ Eng 64(3):939–950. https://doi.org/10.3311/PPci.15643
Kim D, Kang S-S (2013) Engineering properties of compacted loesses as construction materials. KSCE J Civ Eng 17(2):335–341. https://doi.org/10.1007/s12205-013-0872-1
Langroudi AA, Jefferson I (2013) Collapsibility in calcareous clayey loess: A factor of stress-hydraulic history. Int J Geomate Geotech Constr Mater Environ 5(1):620–626
Li Y, Shi W, Aydin A, Beroya-Eitner MA, Gao G (2020) Loess genesis and worldwide distribution. Earth Sci Rev 201:102947. https://doi.org/10.1016/j.earscirev.2019.102947
Liu Z, Liu F, Ma F, Wang M, Bai X, Zheng Y, Yin H, Zhang G (2016) Collapsibility, composition, and microstructure of loess in China. Can Geotech J 53(4):673–686. https://doi.org/10.1139/cgj-2015-0285
Ma F, Yang J, Bai X (2017) Water sensitivity and microstructure of compacted loess. Trans Geotech 11:41–56. https://doi.org/10.1016/j.trgeo.2017.03.003
Mansour ZM, Chik Z, Taha MR (2008) On the procedures of soil collapse potential evaluation. J Appl Sci 8(23):4434–4439. https://doi.org/10.3923/jas.2008.4434.4439
Meier, C., Boley, C., & Zou, Y. (2009). Practical relevance of collapse behavior and microstructure of loess soils in Afghanistan. In: Proceedings of the 17th International Conference on Soil Mechanics and Geotechnical Engineering (Volumes 1, 2, 3 and 4), 738–741. https://doi.org/10.3233/978-1-60750-031-5-738.
Munoz-Castelblanco J, Delage P, Pereira J-M, Cui Y-J (2011) Some aspects of the compression and collapse behavior of an unsaturated natural loess. Géotechnique Letters 1(2):17–22. https://doi.org/10.1680/geolett.11.00003
Murty MN, Devi VS (2011) Pattern recognition: An algorithmic approach. Springer, Berlin
Nouaouria MS, Guenfoud M, Lafifi B (2008) Engineering properties of loess in Algeria. Eng Geol 99(1–2):85–90. https://doi.org/10.1016/j.enggeo.2008.01.013
Owens RL (1990) Collapsible soil hazard map for the southern Wasatch Front [PhD Thesis]. Brigham Young University. Department of Civil Engineering.
Pan L, Zhu J-G, Zhang Y-F (2021) Evaluation of structural strength and parameters of collapsible loess. Int J Geomech 21(6):04021066. https://doi.org/10.1061/(ASCE)GM.1943-5622.0001978
Phien-Wej N, Pientong T, Balasubramaniam AS (1992) Collapse and strength characteristics of loess in Thailand. Eng Geol 32(1–2):59–72. https://doi.org/10.1016/0013-7952(92)90018-T
Powers, D. M. (2020). Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. ArXiv Preprint arXiv:2010.16061. https://doi.org/10.48550/arXiv.2010.16061.
Pye K (1984) Loess. Prog Phys Geogr 8(2):176–217
Qian Z, Lu X, Yang W, Cui Q (2014) Behaviour of micropiles in collapsible loess under tension or compression load. Geomech Eng. https://doi.org/10.12989/GAE.2014.7.5.477
Rabbi A, Cameron DA, Rahman MM (2014) Role of matric suction on wetting-induced collapse settlement of silty sand. Unsat Soil Res Appl. https://doi.org/10.1201/b17034-17
Rezaei M, Ajalloeian R, Ghafoori M (2012) Geotechnical properties of problematic soils emphasis on collapsible cases. Int J Geosci 3(1):105–110. https://doi.org/10.4236/ijg.2012.31012
Rouaiguia A, Dahim MA (2021) Geotechnical properties of najran soil, Kingdom of Saudi Arabia. Yanbu J Eng Sci 5(1):64–76
Sakr M, Mashhour M, Hanna A (2008) Egyptian collapsible soils and their improvement. In: GeoCongress 2008 Geosustainability and Geohazard Mitigation (pp. 654–661). https://doi.org/10.1061/40971(310)81.
Salehi T, Shokrian M, Modirrousta A, Khodabandeh M, Heidari M (2015) Estimation of the collapse potential of loess soils in Golestan Province using neural networks and neuro-fuzzy systems. Arab J Geosci 8(11):9557–9567. https://doi.org/10.1007/s12517-015-1894-4
Shafiei A, Dusseault MB, Heidari M (2008) Engineering properties of loess from NE Iran. GeoEdmonton 8:61
Smalley I (1995) Making the material: The formation of silt sized primary mineral particles for loess deposits. Quatern Sci Rev 14(7–8):645–651. https://doi.org/10.1016/0277-3791(95)00046-1
Uysal F (2020) Prediction of collapse potential of soils using gene expression programming and parametric study. Arab J Geosci 13(19):1–13. https://doi.org/10.1007/s12517-020-06050-x
Wang L, Li X-A, Li L-C, Hong B, Yao W, Lei H, Zhang C (2020) Characterization of the collapsible mechanisms of Malan loess on the Chinese Loess Plateau and their effects on eroded loess landforms. Hum Ecol Risk Assess Int J 26(9):2541–2566. https://doi.org/10.1080/10807039.2020.1721265
Xie W, Li P, Zhang M, Cheng T, Wang Y (2018) Collapse behavior and microstructural evolution of loess soils from the Loess Plateau of China. J Mt Sci 15(8):1642–1657. https://doi.org/10.1007/s11629-018-5006-2
Xing Y, Gao D, Jin S, Zhang A, Guo M (2019) Study on mechanical behaviors of unsaturated loess in terms of moistening level. KSCE J Civ Eng 23(3):1055–1063. https://doi.org/10.1007/s12205-019-0848-x
Yang Y (1989) Study of the mechanism of loess collapse. Sci Chin Ser B Chem Life Sci Earth Sci 32(5):604–617
Yates K, Fenton CH, Bell DH (2018) A review of the geotechnical characteristics of loess and loess-derived soils from Canterbury, South Island, New Zealand. Eng Geol 236:11–21. https://doi.org/10.1016/j.enggeo.2017.08.001
Zárate MA (2003) Loess of southern south America. Quatern Sci Rev 22(18–19):1987–2006. https://doi.org/10.1016/S0277-3791(03)00165-3
Zhang S (2011) Assessment of loess collapsibility with GRNN. In: Ma Ming (ed) Communication Systems and Information Technology. Springer, Berlin, pp 745–752
Zhang W (2020) MARS use in prediction of collapse potential for compacted soils. In: Zhang Wengang (ed) MARS applications in geotechnical engineering systems. Springer, Singapore, pp 27–46
Zhang Y, Hu Z, Chen H, Xue T (2018a) Experimental investigation of the behavior of collapsible loess treated with the acid-addition pre-soaking method. KSCE J Civ Eng 22(11):4373–4384. https://doi.org/10.1007/s12205-017-0170-4
Zhang Y, Hu Z, Xue Z (2018b) A new method of assessing the collapse sensitivity of loess. Bull Eng Geol Env 77(4):1287–1298. https://doi.org/10.1007/s10064-018-1372-9
Zhang W, Sun Y, Chen W, Song Y, Zhang J (2019) Collapsibility, composition, and microfabric of the coastal zone loess around the Bohai Sea China. Eng Geol 257:105142. https://doi.org/10.1016/j.enggeo.2019.05.019
Zhangjian XU, Zaiguan LIN, Zhang M (2007) Loess in China and loess landslides. Chin J Rock Mech Eng 26(7):1297–1312
Funding
The authors have not disclosed any funding
Author information
Authors and Affiliations
Contributions
SM: conceptualization, methodology, supervision, data curation, formal analysis, validation, writing – original draft, writing–review & editing. FR: methodology, data curation, writing–original draft. SF: formal analysis, methodology, software, validation, writing–original draft, writing–review & editing. AS: conceptualization, project administration, methodology, writing–review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Motameni, S., Rostami, F., Farzai, S. et al. A Comparative Analysis of Machine Learning Models for Predicting Loess Collapse Potential. Geotech Geol Eng 42, 881–894 (2024). https://doi.org/10.1007/s10706-023-02593-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10706-023-02593-4