
Abstract
This paper is aimed at rectifying the numerical solution of linear Volterra–Fredholm integro-differential equations with the method of radial basis functions (RBFs). In this method, the spectral convergence rate can be acquired by infinitely smooth radial kernels such as Gaussian RBF (GA-RBF). These kernels are made by a free shape parameter, and the highest accuracy can often be achieved when this parameter is small, but herein the coefficient matrix of interpolation is ill-conditioned. Alternative bases can be used to improve the stability of method. One of them is based on the eigenfunction expansion for GA-RBFs which is utilized in this study. The Legendre–Gauss–Lobatto integration rule is applied to estimate the integral parts. Moreover, the error analysis is discussed. The results of numerical experiments are presented to demonstrate stable solutions with high accuracy compared to the standard GA-RBFs, the analytical solutions, and the other methods.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The study of integro-differential equations (IDEs) arises from its abundant applications in the real world, such as finance [46], ecology and evolutionary biology [37], medicine [20], mechanics and plasma physics [2, 23, 27] and other cases. Therefore, computational methods to solve these types of equations are noteworthy by many scientists. Some methods for solving these equations include: Bessel functions [50], Wavelets [11, 42], Adomian decomposition method [25, 29], compact finite difference method [51, 52], Galerkin method [7, 35], homotopy analysis method [24, 39] and radial basis functions method [12, 21, 28, 30, 45].
Recently, the radial basis functions (RBFs) meshless method has been used as an effective technique to interpolate and approximate the solution of differential equations (DEs), and integral equations (IEs). In the RBF method, we do not mesh the geometric space of the problem, but instead use some scattered points in the desired domain. Since the RBF method uses pairwise distances between points, so it is efficient for problems with high dimensions and irregular domains. First time, Hardy introduced MQ-RBF which was motivated by the cartographic problem [26], and later Kansa utilized it to solve parabolic, hyperbolic and elliptic partial differential equations [32]. Frank [18] examined about 30 two-dimensional approaches to interpolation and demonstrated that the best ones are MQ and TPS.
Radial basis functions are classified into two main classes [8, 33]:
Class 1. Infinitely smooth RBFs.
These basis functions are infinitely differentiable and depend on a parameter, called shape parameter \(\varepsilon\) (analogous Multiquadric(MQ), inverse multiquadric (IMQ) and Gaussian (GA)).
Class 2. Infinitely smooth (except at centers) RBFs.
These basis functions are not infinitely differentiable and are lacking the shape parameter. Also, these functions have less accurate than ones in Class 1. (analogous Thin Plate Splines (TPS)).
Selecting the optimal shape parameter is still an open problem. Some attempts have been made to overcome this problem. For MQ-RBF, Hardy [26] expressed \(\varepsilon =0.815d\) in which \(d=\frac{1}{N} \sum _{i=1}^{N} d_{i}\), N is the number of data and \(d_i\) is the distance between the \(i^{th}\) data point and its closest neighborhood. Franke [19] defined \(\varepsilon =\frac{1.25D}{\sqrt{N}}\) where D is the diameter of the smallest circle containing all data points. Carlson and Foley [5] declared that a good value of \(\varepsilon\) is independent of the number and position of the grid points. Furthermore, they employed the same value of \(\varepsilon\) for MQ and IMQ RBF interpolation. Rippa [43] showed that the optimal value depends on the number and position of grid points, the approximated function, the accuracy of calculation and the kind of RBF interpolation. Moreover, Rippa introduced an algorithm based on the Leave-One-Out Cross Validation (LOOCV) method for any RBF and any dimension by minimizing a cost function. In [3], Azarboni et al. presented the Leave-Two-Out Cross Validation (LTOCV) method which is more accurate than the LOOCV one. In RBFs, when the shape parameter is small and the basis function is near to be flat, the accuracy of method increases, but in this case, the system of equations is ill-conditioned. To overcome this problem, researchers have made many efforts that have led to the production of stable methods for small values of the shape parameter, like the Contour-Pade method [17], the RBF-QR method [15, 16, 34] and the Hilbert-Schmidt SVD method [6].
Fasshauer et al. established a new procedure to calculate and evaluate Gaussian radial basis function interpolants in a stable way with a concentration on small values of the shape parameter; see [14] and references therein. Using this, Rashidinia et al. introduced an effective stable method to estimate Gaussian radial basis function interpolants which has been performed by the eigenfunction expansion [41]. This approach is based on the properties of the orthogonal eigenfunctions and their zeros. They tested various interpolations and solved the boundary value problems in one and two dimensions by applying their method.
In this paper, we focus on high-order Volterra–Fredholm integro-differential equations in the following general form
with initial-boundary conditions
, where \(r_{j k}, s_{j k}, q_{j}, \theta _{1}, \theta _{2}, a\) and b are real constants, \(m\in \mathbb {N}\), \(l_1,l_2\) are two non-negative integers, \(y^{(0)}(x)=y(x)\) is an unknown function, \(p_{k}\) and f are known and continuous functions on [a, b] and the kernels \(k_{1}\) and \(k_{2}\) are known and analytical functions that have suitable derivatives on \([a, b] \times [a, b]\). With the help of Legendre–Gauss–Lobatto approximation for integrals and collocation points, we intend to develop the eigenfunction expansion method to solve (1) under the conditions (2).
The method proposed in this work transforms the main problem to a system of linear algebraic equations. By solving the resulting system, the coefficients of expansion for the solution are found. In illustrative examples, very small values for the shape parameter are employed. Numerical results show stable solutions with high accuracy and appropriate condition number compared to the standard GA-RBF method.
This paper is arranged as follows: In Sect. 2, a review of previous studies about standard RBFs interpolation and eigenfunction expansions are mentioned. The Legendre–Gauss–Lobatto nodes and weights are described in Sect. 3. In Sect. 4, the present method is explained. Section 5 is assigned to a discussion on the residual error. Numerical examples are included in Sect. 6.
The preliminaries and basic definitions
In this section, we briefly describe some basic definitions and items required in this work.
Standard RBFs interpolation method
Definition 1
[48] A function \(\varPhi : \mathbb {R}^{d} \rightarrow \mathbb {R}\) is called radial basis whenever there exists a univariate function \(\varphi :[0, \infty ) \rightarrow \mathbb {R}\) such that \(\varPhi (x)=\varphi (r)\), where \(r=\Vert x\Vert\) and \(\Vert \cdot \Vert\) is usual Euclidean norm.
Definition 2
A real-valued continuous function \(\varPhi : \mathbb {R}^{d} \rightarrow \mathbb {R}\) is called positive definite whenever for any N distinct points \(\{x_i\}_{i=1} ^{N} \in \mathbb {R}^{d}\) and \(\mathbf {G}={(g_1,g_2,\dots ,g_N)}^T \in \mathbb {R}^{N},\) we have
The function \(\varPhi\) is called strictly positive definite if unequal in (3) becomes equal only for \(\mathbf {G}=0\).
Definition 3
(Scattered data interpolation problem [13, 38, 47]). For given data \(f_{i} \in \mathbb {R}\) at scattered data \(\{x_i\}_{i=1} ^{N} \in {\mathbb {R}}^d\), we find a continuous function W such that
One of the efficient methods for interpolating scattered points is the RBF method. An RBF approximation is presented as follows:
To interpolate the given values \(\{f_i\}_{i=1} ^{N}\) at scattered data set \(\mathbf {x}=\{x_i\}_{i=1} ^{N},\), namely center nodes, where \(\varphi \left( r\right)\) is a radial kernel.
In order to acquire unknown coefficients \(\mathbf {C}={(c_1,c_2,\ldots ,c_N)}^T\), we apply the interpolation conditions (4) which is equivalent to solving the following system
so that \(\mathbf {A}_{ij}=\varphi \left( \left\| x_i-x_j\right\| \right)\) and \(\mathbf {F}={(f_1,f_2,\dots ,f_N)}^T\) .
If the function \(\varphi\) is strictly positive definite, then the matrix \(\mathbf {A}\) is positive definite and so non-singular. Therefore, the system of equations corresponding to the interpolation problem has a unique solution. Some popular choices of radial kernels are summarized in Table 1.
The following theorem is related to the convergence of RBFs interpolation:
Theorem 1
If \(\left\{ x_{i}\right\} _{i=1}^{N}\) are N nodes in the convex space \(\varOmega \subset \mathbb {R}^{d}\) and
when \(\hat{\phi }(\eta )<c(1+|\eta |)^{-2 l+d} \text{ for } \text{ any } y(x) { \text{ satisfies } \text{ in } } \int (\hat{y}(\eta ))^{2} /\hat{ \phi }(\eta ) d \eta <\infty ,\) then
in which \(\phi\) refers to RBFs and the constant c depends on RBFs, \(\hat{\phi }\) and \(\hat{y}\) are supposed to be the Fourier transforms of \(\phi\) and y respectively, \(y^{(\alpha )}\) denotes the \(\alpha ^{th}\) derivative of \(y, y_{N}\) is the RBFs approximation of y, d is space dimension, l and \(\alpha\) are non-negative integers.
Proof
A complete proof is presented in [49, 53]. \(\square\)
It can be seen that not only RBFs itself but also its any order derivative has a good convergence.
An eigenfunction expansion for Gaussian RBFs
Let the Gaussian kernel be a positive definite function. So, the coefficient matrix in the system (6) is non-singular but often ill-condition. Using Mercer’s theorem, a decomposition of the matrix \(\mathbf {A}\) is found which overcomes the ill-conditioning of system.
Theorem 2
(Mercer). If \(X\subseteq {\mathbb {R}}^d\) be closed, then a continuous positive definite kernel \(K:X\times X \rightarrow \mathbb {R}\) has an eigenfunction expansion
so that \(\lambda _{n}\) are positive eigenvalues, \(\varphi _{n}\) are orthogonal eigenfunctions in \(L_{2}(X)\) and the series converges absolutely and uniformly. Moreover,
Proof
A complete explanation is given in [36, 40, 41]. \(\square\)
So, GA-RBFs can be written by
The eigenfunctions \(\varphi _{n}\) are orthogonal with respect to the weight function \(\rho (x)=\frac{\alpha }{\sqrt{\pi }} e^{-\alpha ^{2} x^{2}}\), and
where \(H_{n-1}\) are Hermite polynomials of degree \(n-1\) defined by the following recursion relation
In addition,
and
Also, by applying (8) and (9) we get
The parameters \(\varepsilon\) and \(\alpha\) are called the shape and the global scale parameters, respectively. Although they are freely chosen, but they have an important effect on the accuracy of the method. For GA-RBFs, if \(\alpha\) is fixed and \(\varepsilon \rightarrow 0,\) then \(\beta \rightarrow 1\), \(\delta \rightarrow 0,\) the eigenfunctions \(\varphi _{n}\) converge to the normalized Hermite polynomials \(\widetilde{H}_{n}(x)= \frac{1}{\sqrt{2^{n-1} \varGamma (n)}} H_{n-1}(\alpha x)\) and the eigenvalues behave similarly \(\left( \frac{\varepsilon ^{2}}{\alpha ^{2}}\right) ^{n-1} \cdot\) This content indicates that one of the sources of ill-conditioning is the eigenvalues \(\lambda _{n}\) [6, 14].
The stable method for Gaussian RBF interpolation in one dimension space
By applying the assumptions mentioned before, we now interpret the interpolation by the Gaussian RBF using Mercer’s series. According to Eq. (5), the Gaussian RBF approximation is as the following form
To use Mercer’s series, we have to truncate the expansion at the finite length L. If L is selected large enough, then interpolation by the truncated expansion converges to the one based on the full series [22, 41]. So, the Gaussian kernel can be approximated as follows
, where \(\varPhi _{1}^{T}(x)=\left( \varphi _{1}(x), \ldots , \varphi _{N}(x)\right) , \mathbf {C}=\left( c_{1}, \ldots , c_{N}\right) ^{T},\)
To obtain unknown coefficients \(c_{i}\), the linear system of Eqs. (6) is written as follows
then
By substituting (13) into (12) we achieve
This stable interpolation function is called “interpolant with the cardinal basis” which lacks the matrix \(\varLambda\) as one of the sources of ill-conditioning.
Theorem 3
[41] Let
and \(W_{L}\) be in the form of Eq. (12). Then,
when \(L \rightarrow \infty\) then \(\left| W(x)-W_{L}(x)\right| \rightarrow 0,\) , where \(C= \max \lbrace |c_{j}|, j=1,\ldots , N \rbrace\), and
Legendre–Gauss–Lobatto nodes and weights
Let \(\{P_{i}\}_{i\ge 1}\) be Legendre polynomial functions of order i which are orthogonal with respect to the weight function \(\omega (x)=1\), on the interval \([-1,1]\). These polynomials satisfy in the following formulas
The Legendre–Gauss–Lobatto nodes can be found as follows
, where \(P_{i}^{\prime }(x)\) is the derivative of \(P_{i}(x)\). No explicit formula for the nodes \(\{x_{j}\}_{j=2}^{N-1}\) is known, and so they are computed numerically using subroutines [9, 10]. The integral approximation of function f on the interval \([-1,1]\) is
, where \(w_{j}\) are Legendre–Gauss–Lobatto weights presented in [44]
and \(E_{f}\) is the error term specified by
Also, if f(x) is a polynomial of degree \(\le 2 N-3\) then the integration in Eq. (16) is exact.
Method of solution
The main aim of this section is to solve high-order linear Volterra–Fredholm integro-differential equations in the form (1) with the conditions (2). First of all, we consider the grid points \(\{x_{i}\}_{i=1}^{N}\) into integral domain [a, b]. Then, the unknown solution of equation can be approximated by GA-RBFs as follows
, where \(\mathbf {S}=\left( s(x_1), \ldots , s(x_N)\right) ^{T}\) is an unknown vector, \(\varPhi _{1}^{T}(x)\) and \(\varPhi _{1}\) are defined in the Sect. 2.3. By substituting Eq. (17) into Eqs. (1) and (2), we get
and
Now, by collocating Eq. (18) at interior points \(\{x_{i}\}_{i=1}^{N-m}\) we have
To use the Legendre–Gauss–Lobatto rule for Eq. (20), we apply the following transformations
So,
and by using (16) we write
, where \(\tau _{\beta j}\) and \(w_{\beta j}\), \((\beta =1,2)\) are the Legendre–Gauss–Lobatto nodes and weights into \([-1,1]\), respectively. Finally, an \(N\times N\) system of linear algebraic equations is produced such that the \(N-m\) first row is related to Eq. (21) and m remained row is related to Eq. (19). By use of the \(\mathtt {linsolve}\) command in MATLAB, the value of unknown vector \(\mathbf {S}\) and consequently the solution y(x) is obtained.
Error analysis
In this section, we try to find an upper bound for the residual error when the presented method is derived for (1). Suppose that y and \(\tilde{y}\) are the exact solution and the approximate one, respectively. Define
The main result of this section is formulated through the following theorem.
Theorem 4
Assume \(M_{p}, M, R_{1}, R_{2}, R'_{1}, R'_{2}\) are real positive numbers and
For the residual error function, that is RE(x) , we have the following bound
in which
Proof
Using (1) one can write
We define \(e(x)= y(x)-\tilde{y}(x)\). By utilizing (16), it is obvious
, where there exists an \(\zeta \in (-1,1)\) so that
Moreover, for each \(a\le x \le b\)
, where there exists an \(\eta \in (-1,1)\) so that
On the other hand, for every \(0\le k \le m\) one obtains
If \(c=\max \left\{ \left| c_{j} \right| : j=1,\ldots , N \right\}\) then we have
Since
we can write
Because of \(\frac{d}{dx}e^{-\delta ^2 x^2}=-2\delta ^2 x e^{-\delta ^2 x^2}\), for every \(0 \le i \le k\) there exists an \(M_{i}>0\) on the interval [a, b] such that
Putting \(M=\max \left\{ M_{i}:\ i=0,1, \ldots k\right\}\) enables one to conclude
According to the asymptotic expansion of Hermite polynomials [41],
, it is easy to see that
Let \(E=\frac{\varepsilon ^2}{\alpha ^2+\varepsilon ^2+\delta ^2}<1\). From (25), we determine
Subsequently, if we assume \(M'=\frac{cM\beta \alpha e^{\alpha ^2 b^2}}{\sqrt{\alpha ^2+\varepsilon ^2+\delta ^2}}\) it is acquired
The inequality (26) shows that when \(L \rightarrow \infty\) then \(e^{(k)}(x)\) converges to zero. Now, suppose that
By these notations and deriving (23), (24), we realize
If we set \(M_{p}=\max \left\{ \vert p_{k}(x)\vert :\ k=0,1,\ldots , m \right\}\), by applying (22), (23) and (27) the expected result is achieved. \(\square\)
Numerical examples
In this section, several examples are given to assess the performance of present method. A uniform data set from size N in one dimension is considered. The number of Legendre–Gauss–Lobatto nodes is denoted by M. Assume that y and \(\tilde{y}\) refer to the exact solution and the approximate one, respectively. The accuracy of method is measured by applying the absolute error, namely \(\left| e(x)\right|\), the maximum absolute error \((L_{\infty } \text{ error } )\) and the Root-Mean-Square error (RMS error) overall N data points as follows:
All of the numerical computations are performed in MATLAB R2015a, on a laptop with an Intel(R) Core(TM) i5-6200U, CPU 2.40GHz, 8GB(RAM).
Example 1
Let us consider linear Volterra IDE of the first kind
with the initial conditions \(y(0)=y^{\prime }(0)=0\). The exact solution for this equation is \(y(x)=x^{2}\).
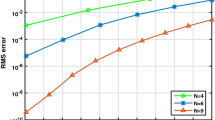
Put \(M=4\), \(\varepsilon =0.4\) and \(\alpha =0.1\). The comparison of RMS error, \(L_\infty\) error and condition number for different values of N between the present method and the standard GA-RBF one are given in Table 2. It indicates that the error values and condition numbers of present method are better than those of the standard one. Because the eigenfunctions \(\varphi _{n}\) are orthogonal, so the matrix \(\varPhi _{1}\) in Eq. (14) is relatively well behaved. Also, by removing the matrix \(\varLambda\) into (14), as one of the sources of ill-conditioning for the small values of \(\varepsilon\), the present method is more stable, and the condition number is significantly less than that of classical GA-RBF. Figure 1 displays the absolute error as a function of \(x\in [0,1]\) for \(N=\{4,6,11\}\) which decreases when the number of data points increases. The RMS error as a function of \(\varepsilon \in [0.01,1]\) for \(N=\{4,6,11\}\) is shown in Figure 2. It can be seen that for small \(\varepsilon\) the RMS error value is less for \(N=\{4,6\}\).

Absolute error of present method as a function of x for different values of N for Example 1

RMS error of present method as a function of \(\varepsilon\) for different values of N for Example 1
Example 2
Consider first-order Volterra IDE
The exact solution is \(y(x)=x \cos (x)\).
We use \(M=5\), \(\varepsilon =0.09\) and \(\alpha =1.9\). The comparison of RMS error for different values of N between the present method and the methods introduced by [4] are expressed in Table 3. It shows that the error values in the present method are better than those of [4]. Table 4 declares the RMS error results of present method, \(L_\infty\) error and condition number for different values of N. Figure 3 displays the absolute error as a function of \(x\in [0,1]\) for \(N=\{5,8,12\}\), which decreases by increasing the number of data points. The RMS error as a function of \(\varepsilon \in [0.01,2]\) for \(N=\{5,8,12\}\) is shown in Fig. 4.

Absolute error of present method as a function of x for different values of N for Example 2

RMS error of present method as a function of \(\varepsilon\) for different values of N for Example 2
Example 3
Let us consider linear Fredholm IDE
under the initial conditions \(y(0)=1\) and \(y^{\prime }(0)=1 .\) Here, the exact solution is \(y(x)=e^{x}\).
Assume \(M=4\), \(\varepsilon =0.01\) and \(\alpha =1.9\). The comparison of absolute errors on the interval \([-1,1]\) between the present method and the method described by [21] are expressed in Table 5. It indicates that the absolute error values of present method for \(N=13\) are better than those of described in [21] for \(N=1000\). The RMS error in [21] for \(N=1000\) is 2.87486e-08, whereas the RMS error of our method is 4.1029e-11 for \(N=13\). Table 6 presents the RMS error results, \(L_\infty\) error and condition number of present method for different values of N. Figure 5 displays the absolute error as a function of \(x\in [-1,1]\) for \(N=\{6,8,11,13\}\), which decreases by increasing the number of data points. The RMS error as a function of \(\varepsilon \in [0.01,1.5]\) for \(N=\{6,8,11,13\}\) is shown in Fig. 6.

Absolute error of present method as a function of x for different values of N for Example 3

RMS error of present method as a function of \(\varepsilon\) for different values of N for Example 3
Example 4
We consider eight-order Fredholm IDE with initial conditions as follows
The exact solution is \(y(x)=(1-x) e^{x} .\)
Let \(M=4\), \(\varepsilon =0.01\) and \(\alpha =0.9\). Table 7 announces the RMS error results, \(L_\infty\) error and condition number of present method for different values of N. Figure 7 portrays the absolute error as a function of \(x\in [0,1]\) for \(N=\{6,10,12,13\}\), which decreases by increasing the number of data points. The RMS error as a function of \(\varepsilon \in [0.001,1.5]\) for \(N=\{6,10,12,13\}\) is shown in Fig. 8.

Absolute error of present method as a function of x for different values of N for Example 4

RMS error of present method as a function of \(\varepsilon\) for different values of N for Example 4
Example 5
[31] Consider linear Fredholm–Volterra IDE
with the initial condition \(y(0)=1 .\) The exact solution of this equation is \(y(x)=(x+1)^{3}\).
Put \(M=5\), \(\varepsilon =0.01\) and \(\alpha =1.9\). Table 8 gives the RMS error results, \(L_\infty\) error and condition number of present method for different values of N. Figure 9 displays the absolute error as a function of \(x\in [-1,1]\) for \(N=\{5,7,9,10\}\), which decreases by increasing the number of data points. The RMS error as a function of \(\varepsilon \in [0.01,1.5]\) for \(N=\{5,7,9,10\}\) is shown in Fig. 10.

Absolute error of the presented method as a function of x for different values of N for Example 5

RMS error of present method as a function of \(\varepsilon\) for different values of N for Example 5
Example 6
Consider fifth-order linear Fredholm–Volterra IDE with initial conditions given by
The exact solution of the above equation is \(y(x)=e^{-x}\).
Suppose \(M=4\), \(\varepsilon =0.01\) and \(\alpha =1.9\). Table 9 declares the RMS error results, \(L_\infty\) error and condition number of present method for different values of N. Figure 11 displays the absolute error as a function of \(x\in [0,1]\) for \(N=\{10,11,12,13\}\), which decreases when the number of data points increases. The RMS error as a function of \(\varepsilon \in [0.01,2]\) for \(N=\{10,11,12,13\}\) is demonstrated in Fig. 12.

Absolute error of present method as a function of x for different values of N for Example 6

RMS error of present method as a function of \(\varepsilon\) for different values of N for Example 6
Conclusion
We described an improved approach of Gaussian RBFs to solve high-order linear Volterra–Fredholm integro-differential equations. The small values of \(\varepsilon\) were well known to make highly accurate results, but the coefficient matrix of interpolation became ill-conditioned. We used very small values for \(\varepsilon\) and employed the eigenfunction expansion for GA-RBFs. The standard RBF did not work for illustrative examples except for the first one. We did not mention the numerical results of standard RBF for those examples. In those cases, the impression of present version of RBF was seen. Generally, in Figures attributed to RMS error as a function of \(\varepsilon\) for fixed N, the RMS error increased by increasing \(\varepsilon\). Also, according to Figures corresponding to the absolute error as a function of x, by increasing N the absolute error rate decreased. Besides, the condition number in the present method was small and acceptable compared to the standard GA-RBF one. These were reasons for the efficiency of present method.
References
Abramowitz, M., Stegun, I.A.: Handbook of mathematical functions: with formulas, graphs, and mathematical tables. Courier Corporation, vol. 55. SIAM (1964)
Avazzadeh, Z., Heydari, M.H., Cattani, C.: Legendre wavelets for fractional partial integro-differential viscoelastic equations with weakly singular kernels. Eur. Phys. J. Plus 134(7), 368 (2019)
Azarboni, H.R., Keyanpour, M., Yaghouti, M.: Leave-Two-Out Cross Validation to optimal shape parameter in radial basis functions. Eng. Anal. Bound. Elements 100, 204–210 (2019)
Biazar, J., Asadi, M.A.: Galerkin RBF for integro-differential equations. British J. Math. Comput. Sci. 11(2), 1–9 (2015)
Carlson, R.E., Foley, T.A.: The parameter \({R}^2\) in multiquadric interpolation. Comput. Math. Appl. 21(9), 29–42 (1991)
Cavoretto, R., Fasshauer, G.E., McCourt, M.: An introduction to the Hilbert-Schmidt SVD using iterated Brownian bridge kernels. Numer. Algorithms 68(2), 393–422 (2015)
Chen, J., He, M., Zeng, T.: A multiscale Galerkin method for second-order boundary value problems of Fredholm integro-differential equation II: Efficient algorithm for the discrete linear system. J. Visual Commun. Image Represent. 58, 112–118 (2019)
Dehghan, M., Shokri, A.: A meshless method for numerical solution of the one-dimensional wave equation with an integral condition using radial basis functions. Numer. Algorithms 52(3), 461 (2009)
Elnagar, G.N., Kazemi, M.A.: Pseudospectral Legendre-based optimal computation of nonlinear constrained variational problems. J. Comput. Appl. Math. 88(2), 363–375 (1998)
Elnagar, G.N., Razzaghi, M.: A collocation-type method for linear quadratic optimal control problems. Opt. Control Appl. Methods 18(3), 227–235 (1997)
Erfanian, M., Mansoori, A.: Solving the nonlinear integro-differential equation in complex plane with rationalized Haar wavelet. Math. Comput. Simul. 165, 223–237 (2019)
Fakhr Kazemi, B., Jafari, H.: Error estimate of the MQ-RBF collocation method for fractional differential equations with Caputo-Fabrizio derivative. Math. Sci. 11(4), 297–305 (2017)
Fasshauer, G.E.: Meshfree Approximation Methods with MATLAB, vol. 6. World Scientific, Singapore (2007)
Fasshauer, G.E., McCourt, M.J.: Stable evaluation of Gaussian radial basis function interpolants. SIAM J. Sci. Comput. 34(2), A737–A762 (2012)
Fornberg, B., Larsson, E., Flyer, N.: Stable computations with Gaussian radial basis functions. SIAM J. Sci. Comput. 33(2), 869–892 (2011)
Fornberg, B., Piret, C.: A stable algorithm for flat radial basis functions on a sphere. SIAM J. Sci. Comput. 30(1), 60–80 (2008)
Fornberg, B., Wright, G.: Stable computation of multiquadric interpolants for all values of the shape parameter. Comput. Math. Appl. 48(5–6), 853–867 (2004)
Franke, R.: A critical comparison of some methods for interpolation of scattered data. Tech. rep, Naval Postgraduate School Monterey (1979)
Franke, R.: Scattered data interpolation: tests of some methods. Math. Comput. 38(157), 181–200 (1982)
Gallas, B., Barrett, H.H.: Modeling all orders of scatter in nuclear medicine. In: 1998 IEEE Nuclear Science Symposium Conference Record. 1998 IEEE Nuclear Science Symposium and Medical Imaging Conference (Cat. No. 98CH36255), vol. 3, pp. 1964–1968. IEEE (1998)
Golbabai, A., Seifollahi, S.: Radial basis function networks in the numerical solution of linear integro-differential equations. Appl. Math. Comput. 188(1), 427–432 (2007)
Griebel, M., Rieger, C., Zwicknagl, B.: Multiscale approximation and reproducing kernel Hilbert space methods. SIAM J. Numer. Anal. 53(2), 852–873 (2015)
Grigoriev, Y.N., Kovalev, V.F., Meleshko, S.V., Ibragimov, N.H.: Symmetries of Integro-Differential Equations: With Applications in Mechanics and Plasma Physics. Springer, Berlin (2010)
Hamoud, A., Ghadle, K.: Homotopy analysis method for the first order fuzzy Volterra-Fredholm integro-differential equations. Ind. J. Electr. Eng. Comput. Sci. 11(3), 857–867 (2018)
Hamoud, A.A., Ghadle, K.P.: The combined Modified Laplace with Adomian decomposition method for Solving the nonlinear Volterra-Fredholm Integro Differential Equations. J. Korean Soc. Ind. Appl. Math. 21(1), 17–28 (2017)
Hardy, R.L.: Multiquadric equations of topography and other irregular surfaces. J. Geophys. Res. 76(8), 1905–1915 (1971)
Heydari, M.H., Laeli Dastjerdi, H., Nili Ahmadabadi, M.: An efficient method for the numerical solution of a class of nonlinear fractional fredholm integro-differential equations. Int. J. Nonlinear Sci. Numer. Simul. 19(2), 165–173 (2018)
Heydari, M.H., Hosseininia, M.: A new variable-order fractional derivative with non-singular Mittag-Leffler kernel: application to variable-order fractional version of the 2D Richard equation. Eng. Comput. 1–12 (2020)
Hendi, F., Al-Qarni, M.: The variational Adomian decomposition method for solving nonlinear two-dimensional Volterra-Fredholm integro-differential equation. J. King Saud Univ. Sci. 31(1), 110–113 (2019)
Hosseininia, M., Heydari, M.H., Avazzadeh, Z., Maalek Ghaini, F.M.: A hybrid method based on the orthogonal Bernoulli polynomials and radial basis functions for variable order fractional reaction-advection-diffusion equation. Eng. Anal. Bound. Elements 127, 18–28 (2021)
İşler Acar, N., Daşcıoğlu, A.: A projection method for linear Fredholm-Volterra integro-differential equations. J. Taibah Univ. Sci. 13(1), 644–650 (2019)
Kansa, E.J.: Multiquadrics-a scattered data approximation scheme with applications to computational fluid-dynamics-i surface approximations and partial derivative estimates. Comput. Math. Appl. 19(8–9), 127–145 (1990)
Khattak, A.J., Tirmizi, S., et al.: Application of meshfree collocation method to a class of nonlinear partial differential equations. Eng. Anal. Bound. Elements 33(5), 661–667 (2009)
Larsson, E., Lehto, E., Heryudono, A., Fornberg, B.: Stable computation of differentiation matrices and scattered node stencils based on Gaussian radial basis functions. SIAM J. Sci. Comput. 35(4), A2096–A2119 (2013)
Merad, A., Martín-Vaquero, J.: A Galerkin method for two-dimensional hyperbolic integro-differential equation with purely integral conditions. Appl. Math. Comput. 291, 386–394 (2016)
Mercer, J.: Functions of positive and negative type, and their connection with the theory of integral equations. Philosophical Transactions of the Royal Society of London. Ser. A, Containing Pap. Math. Phys. Charact. 209(441–458), 415–446 (1909)
Mirrahimi, S.: Integro-differential models from ecology and evolutionary biology. Ph.D. thesis, Université Paul Sabatier (Toulouse 3) (2019)
Mirzaee, F., Samadyar, N.: Using radial basis functions to solve two dimensional linear stochastic integral equations on non-rectangular domains. Eng. Anal. Bound. Elements 92, 180–195 (2018)
Mohamed, M.S., Gepreel, K.A., Alharthi, M.R., Alotabi, R.A.: Homotopy analysis transform method for integro-differential equations. General Math. Notes 32(1), 32 (2016)
Pazouki, M., Schaback, R.: Bases for kernel-based spaces. J. Comput. Appl. Math. 236(4), 575–588 (2011)
Rashidinia, J., Fasshauer, G.E., Khasi, M.: A stable method for the evaluation of Gaussian radial basis function solutions of interpolation and collocation problems. Comput. Math. Appl. 72(1), 178–193 (2016)
Ray, S.S., Behera, S.: Two-dimensional wavelets operational method for solving Volterra weakly singular partial integro-differential equations. J. Comput. Appl. Math. 366, 112411 (2020)
Rippa, S.: An algorithm for selecting a good value for the parameter c in radial basis function interpolation. Adv. Comput. Math. 11(2–3), 193–210 (1999)
Shen, J., Tang, T.: High order numerical methods and algorithms. Chinese Science Press, Abstract and Applied Analysis (2005)
Uddin, M., Ullah, N., Shah, S.I.A.: Rbf Based Localized Method for Solving Nonlinear Partial Integro-Differential Equations. Comput. Model. Eng. Sci. 123(3), 955–970 (2020)
Wang, W., Chen, Y., Fang, H.: On the variable two-step IMEX BDF method for parabolic integro-differential equations with nonsmooth initial data arising in finance. SIAM J. Numer. Anal. 57(3), 1289–1317 (2019)
Wendland, H.: Scattered Data Approximation, vol. 17. Cambridge University Press, Cambridge (2004)
Wendland, H.: Scattered data approximation (2005)
Wu, Z.M., Schaback, R.: Local error estimates for radial basis function interpolation of scattered data. IMA J. Numer. Anal. 13(1), 13–27 (1993)
Yüzbaşı, Ş, Şahın, N., Sezer, M.: Bessel polynomial solutions of high-order linear Volterra integro-differential equations. Comput. Math. Appl. 62(4), 1940–1956 (2011)
Zhao, J., Corless, R.M.: Compact finite difference method for integro-differential equations. Appl. Math. Comput. 177(1), 271–288 (2006)
Zheng, X., Qiu, W., Chen, H.: Three semi-implicit compact finite difference schemes for the nonlinear partial integro-differential equation arising from viscoelasticity. Int. J. Model. Simul. 41(3), 234–242 (2020)
Zong-Min, W.: Radial basis function scattered data interpolation and the meshless method of numerical solution of PDEs. Chin. J. Eng. Math. 2 (2002)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Farshadmoghadam, F., Deilami Azodi, H. & Yaghouti, M.R. An improved radial basis functions method for the high-order Volterra–Fredholm integro-differential equations. Math Sci 16, 445–458 (2022). https://doi.org/10.1007/s40096-021-00432-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-021-00432-2
Keywords
- Volterra–Fredholm integro-differential equation
- Gaussian radial basis function
- Legendre–Gauss–Lobatto quadrature
- Eigenfunction expansion
- Collocation method