
Abstract
The basis and reliability for timely diagnosis of cardiovascular diseases depend on the robust and accurate detection of QRS complexes along with the fiducial points in the electrocardiogram (ECG) signal. Despite, the several QRS detection algorithms reported in the literature, the development of an efficient QRS detector remains a challenge in the clinical environment. Therefore, this article summarizes the performance analysis of various QRS detection techniques depending upon three assessment factors which include robustness to noise, computational load, and sensitivity validated on the benchmark MIT-BIH arrhythmia database. Moreover, the limitations of these algorithms are discussed and compared with the standard signal processing algorithms, followed by the future suggestions to develop a reliable and efficient QRS methodology. Further, the suggested method can be implemented on suitable hardware platforms to develop smart health monitoring systems for continuous and long-term ECG assessment for real-time applications.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The report of World Health Organization (WHO) places the cardiovascular diseases (CVDs) as the leading cause of mortalities across the globe and will remain in the near future [1]. In 2008, the CVDs caused 17.3 million deaths, representing 30% of the mortalities worldwide [1]. In 2018, the deaths in United States alone has increased to 836546 (with an average of one death in every 38 s) [1, 2]. By 2030, the expected number of deaths can increase up to 23.3 million globally [3]. As a consequence of the increased rate in mortalities due to CVD’s, cardiac health research has gained significant importance by the researchers. The most common clinical technique utilized for cardiac disorder analysis is an electrocardiogram (ECG). An ECG is a simple, reliable, low-cost and non-invasive tool commonly used to diagnose cardiac disorders [4]. An ECG records the electrical signals originating from the myocardium by placing the electrodes on the surface of the body which is later analyzed by a cardiologist. The term ECG was introduced by Augustus D. Waller (a British physiologist) in 1887 when he recorded the first human ECG using a capillary electrometer [5]. In 1893, Einthoven used an improved electrometer and a correction formula to distinguish five deflections later named as P, Q, R, S and T [5] waves. These waves are generated by heart that undergoes three processes, namely atrial depolarization, ventricular depolarization and ventricular repolarization resulting in the generation of P wave, QRS complex, and T wave respectively. These different waves comprising the standard ECG cycle are depicted in Fig. 1 while their clinical significance is summarized in Table 1. In Fig. 1, the U wave is shown, however it is seen occasionally. It is a positive wave occurring after T-wave having an amplitude of one-fourth of the T wave. The U wave is found in subjects having more prominent T waves and slow heart rates (most frequently seen in leads V2–V4). Therefore, the genesis of U wave is elusive. All of these waves exhibit specific characteristics (such as in time, amplitude or morphology) and carry sufficient amount of information for diagnosing CVDs. Further, various other features such as frequency, entropy distribution and energy, event intervals (like the RR-interval) are also extracted for reliable diagnosis. Any change in either of the features of these P, QRS, T waves may indicate cardiac abnormalities or arrhythmias leading to stroke or sudden cardiac death. Therefore, an efficient diagnosis of these waves is clinically essential for reliable analysis of heart health, such as arrhythmia classification [6,7,8,9,10,11,12,13,14,15], diagnosing breathing disorders [16, 17], study of cardiac functioning during sleep and hypertension [18, 19], epilepsy [20] and for examining various other heart disorders [21].

Cardiac cycle representing the waves
Among these waves, the QRS wave exhibits the most striking feature in terms of morphology, amplitude and time of occurrence and therefore, plays a significant role in an efficient analysis of ECG recordings of subjects. In the past few decades, the detection of QRS complexes has been thoroughly studied by various researchers. In fact, the study of P and T wave detection is not explored much in comparison to QRS complex detection due to the factors including low signal-to-noise ratio (SNR), variation in amplitude and morphology, and overlapping nature of P and T wave. In spite of various studies and research works in the domain of QRS complexes detection, the development of a reliable universal solution is still a challenge. These challenges mainly arise due to low SNR, variability (i.e. inter and intra) in the morphology of QRS complex and the rest of the waves as well as the artifacts inherent in the ECG signal. The most commonly used database for validating the research works has been the benchmark Massachusetts Institute of Technology—Boston’s Beth Israel Hospital (MIT-BIH) arrhythmia database [22] (described in detail in “MIT-BIH arrhythmia database” section). However, detailed analysis of the cardiac events is possible only if the QRS event is detected efficiently. Therefore, the development of fast, robust, efficient and reliable QRS detector becomes clinically important for timely diagnosis of CVDs.
The objective of this review article lies in the thorough analysis of QRS detection algorithms available in the literature. In order to prepare this manuscript, the literature are searched and reported using the databases such as Google Scholar, Scopus, web of science and the keywords searched is QRS and detection. The analysis is divided in two stages, i.e., the pre-processing stage and the QRS detection stage. In the preprocessing stage, the QRS complex feature is made more prominent or emphasized with respect to the rest of the waves. The output of this stage is followed by the QRS detection stage where the onset and offset points are demarcated and the corresponding R-peak is located in the ECG signal. The contribution of this study is to evaluate the performance of algorithms or techniques depending upon three criteria, i.e., (a) sensitivity towards the noise, (b) computational load and (c) accuracy for both the stages. Further, the current study also provide suggestions to develop a fast, efficient and robust QRS detector methodology for real-time applications.
The rest of the article is summarized as follows. “MIT-BIH arrhythmia database” section briefly describes the most commonly used ECG database studied in the literature. “Pre-processing stage” section presents the evaluation of the preprocessing algorithms while “QRS detection techniques” section presents the evaluation of the QRS detection algorithms. “Performance evaluation and discussion” section presents a brief discusses the challenges of the evaluated pre-processing and QRS detection stages on together followed by future suggestions to develop an efficient QRS methodology. Final section presents the conclusion of the study.
MIT-BIH arrhythmia database
Most of the research works are evaluated and validated on the benchmark Massachusetts Institute of Technology—Boston’s Beth Israel Hospital (MIT-BIH) arrhythmia database [22] developed during 1975 and 1979 by the BIH arrhythmia laboratory. The database contains two channel ambulatory ECG recordings of 47 different subjects comprising 48 records. A modified limb lead II (MLII) is the lead A signal in 45 recordings; a modified lead V1 (often V2 or V5, and V4 in one excerpt) is the lead B. Whereas V5 is the lead A signal in the other three excerpts and V2 is the lead B (two excerpts) or MLII (one excerpt). The heartbeats signal in lead A have more prominent peaks than lead B signal. The database includes 110109 beat labels while the data is band-pass filtered at 0.1 H–100 Hz. The excerpts are digitized with a sampling frequency of 360 samples per second and acquired with 11-bit resolution over 10 mV range. The database is open-access available on-line that can be accessed for performing the experiments.
Pre-processing stage
In this stage, the acquired raw ECG signal is pre-processed to remove various kinds of noise and artifacts [23] associated with them. These various kinds of noise include the baseline wander, artifacts due to muscle contraction, electrode movement and power-line interference. The pre-processing stage improves the SNR of the ECG signals. Hence, the pre-processing of the ECG signal is highly instrumental for an efficient QRS detection. Otherwise, it results in the generation of false alarms and degraded performance of the QRS detector. This section presents the performance evaluation of the various pre-processing techniques based on two factors, i.e. computational load and robustness to noise. A summary of the evaluation done is presented in Table 2 at the end of this section.
For reader’s point of view, this section uses two variables, i.e. A[m] which refers to the raw input ECG signal and B[m] refers to the output filtered signal.
Amplitude technique
The amplitude technique is one of the commonly used algorithms used for the R-peak detection within the ECG signals. Initially, a differentiation step is applied to suppress the P and T event influence in order to highlight the QRS complex, which is followed by the amplitude threshold. Later, this algorithm is used by Sufi et al. [24] to detect the heart rate on mobiles. Moreover, the amplitude threshold followed by the first derivative to make the slope of QRS complex more prominent. The amplitude threshold for a fragment of the ECG signal is determined as:
where \(\alpha\) is the amount of ECG signal eliminated in percentage whose value vary from \(0< \alpha < 1\). Moreover, the value of \(\alpha\) is optimized once before the pre-processing while the thresholds are kept constant throughout the analysis. Various amplitude thresholds are employed for subsequent QRS detection. Morizet et al. [25] introduced a QRS scheme using \(A{\text{th}} = 0.3\max \{ A[m]\},\) where below 30% of the peak amplitude of the signal is truncated for A[m], whereas Fraden [26] employed \(A{\text{th}}=0.4\max \{A[m]\}\).
The main advantage of this technique is that it involves less computational load among all the existing pre-processing techniques which is due to smaller length of ECG signal used for processing. The disadvantage being the length of ECG segments processed are fixed and determined empirically [25,26,27]. If the length of ECG is longer, the performance may degrade until it divided into shorter lengths but the ECG segment may lose the starting and end of ECG beats.
First order derivative
Generally, a differentiator of first-order is utilized as a high-pass filter which removes unwanted low-frequency noise and the baseline wander of A[m]. Moreover, it creates zero crossings at the R-peak location and modifies the phase in the ECG signals. Several algorithms implemented the first derivative by the following equation [28]:
Moreover, Holsinger et al. [29] used a central finite-difference approach as:
while Okada et al. used a backward difference scheme [30]:
An optimal threshold is chosen and applied to B[m] along with the first-order derivative technique for subsequent QRS complex detection within the ECG signals. The length of ECG signal processed and the thresholds applied during the ECG analysis are fixed. The main advantage being this technique involves less computational load. The disadvantage being the technique is not able to remove high-frequency noise completely.
First and second derivative
The first and second order derivatives are calculated separately for A[m] (i.e. input ECG signal) in the QRS enhancement algorithms. These derivatives magnitudes are linearly combined to highlight the QRS wave region with respect to other ECG features. The first and second order derivatives computed by Balda et al. [31] are defined as:
Here, \(B_{0}[m]\) is the first while \(B_{1}[m]\) is the second order derivatives of A[m]. Further, both of these derivatives are linearly combined as:
In [32], Ahlstrom et al. computed the first derivative as:
Thenafter, the rectified first derivative is smoothed as:
A rectified second derivative is then calculated:
At last, this smoothed rectified first and second derivative are combined together as:
These linear combinations of derivatives are followed by a proper threshold criterion for the subsequent QRS detection.
The advantage of this technique is that it involves less computational load. However, the computational load is more than first derivative algorithms. The disadvantage being the noise is not reduced significantly. The length of ECG signal processed and the parameters utilized are fixed. However, the usage of several differentiators (i.e the advantage of each step) for pre-processing is not justified in literature.
Digital filters
In the literature, the digital filter techniques are efficiently utilized for pre-processing the ECG signals [33,34,35,36,37,38,39,40,41,42]. Several algorithms are implemented to realize complex digital filters [30, 33, 43,44,45,46,47,48,49,50,51,52,53,54]. Among them, the most cited are highlighted here.
Engelse et al. [33] applied a differentiator initially to process the input ECG A[m] as
Further, a digital low-pass filter (LPF) is applied to \(B_{0}[m]\) as:
Another technique based on the digital filters has been proposed by Okada [30] in which a three-point moving average filter is used to smoothen A[m] as:
Further, a LPF is applied to \(B_{0}[m]\)
The input and output of this LPF are subtracted and squared, to remove waves of low amplitude with respect to R peak as:
Thenafter, filtering is applied to this square of difference which makes the QRS area enlarged relative to another ECG features:
Suppappola [55] proposed another digital filter based on the multiplication of backward difference (MOBD) [6, 55, 56] which consists of AND-combination (i.e multiplication operation) of the adjacent derivative values. A MOBD of Mth order is defined as:
where C[m] represents the QRS features extracted that can be detected by the use of an proper threshold.
Dokur et al. [36] used two different band-pass filters and multiplied the outputs X[m] and Y[m] as:
where C[m] carries the extracted features of the QRS complex. This procedure assumes that for each filter the occurrence of frequency components within the pass-bands characterizes each of the QRS wave. Here, the AND-combination executes the multiplication operation. Particularly, if the outputs of both the band-pass filters are ’high’ and the feature output (i.e AND combination) is ‘true’, then only a QRS event is detected and the maximum amplitude is the R wave location.
In fact, Pan et al. [34] applied a band-pass digital filter followed by derivative to filter and measure the slope of ECG signals. A high-pass filter (\(B_{2}[m]\)) is used after a low-pass filter (\(Y_{1}[n]\)) to constitute a band-pass filter given as:
The band-pass filter output is followed by the first derivative which is given by:
Differentiation is followed by the band-pass filtered signal (\(Y_2[n]\)) to emphasize QRS slope, suppress the baseline wander and smoothing ECG signals.
However, the MOBD algorithm is more suitable for real-time implementation due to its better trade-off between computational load and accuracy. The squaring operation amplifies the smaller differences less than the larger differences in an exponential fashion.
The advantage of the digital filter based technique is that it is able to reduce noise properly. However, its computational load more than derivative based algorithms. The length of ECG processed and parameters utilized are fixed.
Wavelet transform (WT)
The wavelet transform (WT) [57] is a mathematical tool for analyzing non-stationary signal localized in both time and scale representation.
The continuous wavelet transform (CWT) provides a variable resolution in both the time and frequency domains for various frequency bands by using a set of analyzing functions which bears an advantage on Fourier transform (FT) and short-time Fourier transform (STFT).
However, the CWT is more redundant than the discrete wavelet transform (DWT) that can be deduced by discretizing the scale and translation parameters. It is usually implemented using the high-pass and low-pass filters as shown in Fig. 2. This choice of scale (\(a=2^k\)) and translation parameters (\(b=m(2^k)\)) leads to the dyadic WT (DyWT) as:
where j and n are integers. The DyWT is implemented using a dyadic filter bank, in which the filter coefficients are obtained from the mother wavelet function employed for analysis of non-stationary signals [58,59,60,61,62,63,64,65,66] like an ECG.

Block diagram of DWT implementation
The choice of the mother wavelet (like Haar, Daubechesis, Mexican hat and many more), length of processed ECG segment and wavelet scale varies in the literature [68,69,70,71]. However, the selection of mother wavelet depends upon the similarity to the QRS complex. The ECG signals are divided into 2.4 s and 11 s segments by Ahmed et al. [68] and Xiuyu et al. [69] respectively. The scales vary from \(2^3\) to \(2^4\) and \(2^2\) to \(2^4\), which is used by Szilagyi [70] and Xu et al. [71] to detect the QRS complexes. Moreover, the input ECG signal is re-sampled at 250 Hz by Martinez et al. [72].
The advantage of WT is that it improves the signal quality by choosing the coefficients of high amplitude. The disadvantage of this technique is that it involves high computational load.
Matched filters
The matched filter provides an optimal SNR and more essentially, a symmetrical output pulse waveform. Digital filtering is used prior to the use of matched filters [73, 74]. The matched filter output for the filter impulse response of length \(M=128\) is computed as
where q(t) is an output sample and \(r(t-j)\) are input samples of the matched filter. For every patient, the filter coefficients \(p_j\) are selected to optimize the matched filter impulse response. The filter output coefficients are chosen in such a way that resembles to the bandpass-filtered QRS complex. Further, the dc component of sampled QRS complex is removed and windowed and normalized to have a gain of one for the matched filter used as an impulse response. Basically, the matched filter impulse response is the time-reversed version of a template QRS complex. In matched filters, the length of the template processed is fixed; while the type of filter utilized and length of the template is determined empirically. However, its efficient implementation is available in [75]. The disadvantage of this technique is that the analysis of ECG requires more complexity than the derivative based algorithms.
Filter banks (FB)
A FB typically contains a set of analysis filters. It decomposes the signal bandwidth into sub-band signals having uniform frequency bands of constant length. These sub-bands provide information for processing the input signal in both the time and frequency domain from different frequency ranges [76]. The analysis filters \(H_{j}(z)\) bandpass the input ECG signal A(z) [76] to produce the subband signals \(v_{j}(z)\) as:
where \(j=0,\,1, \ldots ,\,N-1\). The effective bandwidth of subband \(v_{j}(z)\) can be downsampled to decrease the total rate which is \(\pi /N\). One sample is kept out from the N samples by utilizing this downsampling process \(N \downarrow\). Hence, downsampled signal \(d_{j}(z)\) is given by:
where \(X=e^{-k(2\pi /N)}.\) The sub-band \(v_{j}(z)\) has a higher sampling rate than \(d_{j}(z)\). The process of filtering is done using downsampling at 1 / N of the input rate. This technique reduces the computational load of filter bank algorithms [76] and referred as polyphase implementation. The sub-bands of interest are combined to form a variety features that represent the QRS complexes [76]. For example, a sum-of-absolute values feature can be computed using sub-bands, \(j=1, \ldots , 4\) in the range of [5.6, 22.5] Hz. Six features (\(a_1\), \(a_2\), \(a_3\), \(a_4\), \(a_5\), and \(a_6\)) are derived from these sub-bands as:
These features contain a range of values being proportional to QRS wave energy. Ultimately, heuristic beat-detection logic [76] is utilized to incorporate some above features representing the QRS wave.
This technique significantly increases the SNR, which can be considered as an advantage. The computational load of filter banks depends on four parameters, i.e. the filter length, transition-band width, number of sub-bands and the stop-band attenuation having fixed values and are determined experimentally [77]. It involves high computational load which is more than the derivative based techniques. Afonso et al. [78] introduced finite impulse response (FIR) filters having fixed length i.e. 32. The filters are employed to decompose the noisy input ECG into eight constant sub-band frequencies. A sub-band signal within the range of 0–12.5 Hz is not changed, while in the range of (12.5–25 Hz) the sub-band signal is removed outside the region of QRS wave. The high-frequency components outside the QRS region are considered as noise. The sub-band signal within the rest of six bands of range (25–100 Hz) is considered as zero. The main challenge is the selection of combination of optimal filter banks to highlight the QRS wave.
Hilbert transform (HT)
Zhou et al. [79] and Nygards et al. [80] used Hilbert transform (HT) for QRS detection. In the time domain, the HT of the input signal A is:
In the frequency domain, the input signal can be transformed with a filter of response:
where \(\otimes\) denotes the convolution operator and the transfer function of the Hilbert transform \(H(j\omega )\) is given by:
The use of fast Fourier transform (FFT) reduces the computational load of Hilbert transform. The HT i.e. \(A_{H}[m]\) of the ECG signal A[m] is used to compute the signal envelope [80] for band-limited signals which is given by:
Further, the envelope [80] is approximated which involves less computational load as:
Then after, the envelope is low-pass filtered [80] to eliminate the ripples and to avoid uncertainty in peak detection. Moreover, a waveform adaptive scheme is proposed to remove ECG components of low frequencies. Zhou et al. [79] proposed a method to approximate the envelope of input signal based on HT given as:
where \(B_{1}[m]\) and \(B_{2}[m]\) are orthogonal filter outputs given as:
Further, the noise is removed from the envelope signal \(B_{e}[m]\) by using a four-tap moving average filter. A few works [81,82,83] have reported the use of a first derivative before applying the HT. The ECG is differentiated which modifies the phase and creates zero crossings the R-peak location. Hence, it requires a transformation which rectifies the phase to mark the true R-peak location in a signal. In [84], the output of Hilbert transform is followed by adaptive Fourier decomposition for enhancing the QRS complex in the ECG signal.
This technique involves high computational load and does not able to reduce noise by itself. The use of FFT for the calculation of HT makes the envelope independent of the frame width. During experiments moving average and digital filters are utilized whose selection is done empirically while the length of ECG signal processed are constant.
Empirical mode decomposition (EMD)
EMD technique is widely used for nonlinear and non-stationary signal analysis [85]. It decomposes a signal into a sum of intrinsic mode functions (IMFs). The EMD process can also be utilized for adaptive filtering. As such, the combination of number of the IMFs obtained after decomposing the ECG signal generates more prominent QRS wave. The EMD can be explained by sifting process. J modes \(w_{p}\)[m] and a residual term g[m] [86,87,88] are obtained and given by:
The various steps involved in EMD algorithm are as follows:
-
1.
Given a signal \(w_{p=1}[m]=r[m]\); with the sifting \(r_k[m]=w_{p}[m]\), \(k=0\).
-
2.
Detect all extrema of input \(r_{k}[m]\).
-
3.
Calculate the lower and upper envelopes from the maxima and minima by using cubic spline interpolation.
-
4.
Compute the mean of upper and lower envelopes, \(n[m]=\frac{1}{2}(EnvMax[m]+EnvMin[m])\).
-
5.
Extract the detail \(r_{k+1}[m]=r_{k}[m]-n[m]\).
-
6.
If \(r_{k+1}[m]\) is an IMF, go to step 7; otherwise, iterate steps 2–5 on the signal \(r_{k+1}[m]\), \(k=k+1\). (An IMF satisfies two conditions i.e (a) the number of the extrema equals the number of zeros and (b) the upper and lower envelopes should have the same absolute value.)
-
7.
Extract the mode \(w_{p}[m]=r_{k+1}[m]\).
-
8.
Calculate the residual \(g_{p}[m]=r[m]-w_{p}[m]\).
-
9.
The extraction is finished \(g[m]=g_{p}[m]\) if \(g_{p}[m]\) has less than two extrema, otherwise, the algorithm is iterated from step 1 on the residual \(g_{p}[m]\), \(p=p+1\). The two conditions must be satisfied for an IMF: (a) The mean value of the envelopes defined by maxima and minima should be zero at every point. (b) The difference between number of zero crossings and number of extrema should be zero or one.
The length of ECG signals processed is fixed which generates the IMF’s i.e. the number of IMF’s is proportional to the length of ECG. The selection of number IMF’s is selected empirically. An ensemble empirical mode decomposition (EEMD), an advanced EMD is also used to pre-process the ECG signal. This technique involves high computational load and reduces noise significantly.
Mathematical morphology
Chu et al. [89] proposed an enhancement technique, namely mathematical morphology for removing the noise associated with the ECG signal and latter used by Trahanias et al. [90] for QRS detection. It depends on the idea of dilation and erosion. Assume that u : \(U \rightarrow K\) and \(p : P \rightarrow K\) represent discrete functions, where U and P sets are denoted by \(U=0,\,1, \ldots ,\,M-1\) and \(P=0,\,1, \ldots ,\,N-1\). K represents a set of integers here. Erosion of a function u [89] can be defined in terms of function p as:
where p refers to a structuring element also, and defined as \(n=0, \ldots , M-N\). The values of u are always smaller than function (\(u\ominus p\)). Dilation of a function u [89] is defined in terms of function p as:
where in this case \(n=N-1,\,N, \ldots ,\,M-1\). Values of u are always less than function (\(u\oplus p\)). Additional steps are performed by combining the dilation and erosion operations. Closing, (indicated as \(\bullet\)) is defined as dilation after erosion operation while Opening (indicated as \(\circ\)) is defined as erosion after dilation operations. These operators exploits the input signals, comparatively in such a way that for a sequence u, opening eliminates the peaks while closing eliminates the negative peaks with the structuring element p. Chu and Delp [89] used these opening and closing operations [90] to suppress noise given as:
where p is the structuring element. The features are generated for the QRS wave as
Zhang et al. [91] utilized the first derivative (Okada’s equation [30]) after multi-scale mathematical morphology filtering to remove base-line drifts and artifacts associated with the A[m].
During experiments, the length of ECG segments processed are fixed and equal [25, 26, 31,32,33, 92]. The fixed length of the structuring element is used for the analysis of A[m] i.e 3. This structuring element length is determined empirically and shorter than the multiplication of sampling frequency and the length of A[m] [93]. The advantage of the multiplication operations used in literature [25, 26, 31,32,33, 92] is not discussed. The use of low-pass filter along with this approach increases the SNR significantly.
Sparsity filtering
The sparse representation (SR) model for a time-domain input signal \(a\in \mathfrak {R}^n\) can be approximated as \(a\approx D\alpha\). Here, \(D\in Re^{n\times m}\) is a dictionary matrix \(\alpha \in \mathfrak {R}^m\) that provides coefficients representing the input signal. In SR, the input signal is approximated as a weighted sum of each columns of the dictionary matrix \({{\varvec{D}}}\) known as atoms and their weights (as given by the coefficients in \(\alpha\)). Generally, the dictionary \({{\varvec{D}}}\) is redundant, where the number of atoms in the dictionary is greater than the length of the input signals. The coefficients \(\alpha\) are sparse i.e. there are only few non-zero weights (coefficients) in \(\alpha\). Hence, the SR of the input signal a is approximated using only few atoms (with corresponding weights that are not equal to zero) from the dictionary matrix \({\varvec{{D}}}\).
In [94], second and third order derivatives of the input signal were computed to smoothen the ECG signal. To reduce the artifacts by solving a convex \(\ell _1\) optimization problem where the clean input signal is modeled as a sum of two signals whose second and third-order derivatives (differences) are sparse respectively. In [95], \(\ell _1\)-sparsity filter with overcomplete hybrid dictionaries is used to emphasize the QRS complex and suppress the baseline drifts, power-line interference and large P/T waves. In [96], the input signal is modeled as superposition of atoms which is learned from a training set plus additive random noise to remove noise and other artifacts such as baseline wandering.
Among all the pre-processing algorithms discussed in this section, none of them are completely efficient when all kinds of noise are considered [27] for analyzing the ECG signals. The amplitude and slope based techniques have a significant advantage over electromyogram (EMG) noise (i.e muscle noise) and are sensitive to changes in the baseline of A[m]. However, the performance of these algorithms is degraded if they are applied to composite noise. Rather, a higher performance is reported by the high-pass and cubic spline approaches used to correct the baseline wander. The filtering of the signal to remove EMG noise is more difficult as the frequency spectrum overlaps the QRS wave. As such, pre-processing algorithms based on filtering based algorithms are sensitive to high-frequency noise but insensitive to baseline changes. Further, the amplitude and derivative based techniques involve less computational load in their implementation, despite being noise sensitive. However, the various stages involved in the amplitude and derivative based algorithms are not justified for pre-processing the ECG signal for their validation on the MIT-BIH arrhythmia database. As such, the parameters of these techniques employed are purely data dependent and may yield varying results, if analyzed on a different database (or on data of different patients). A brief comparison of these pre-processing techniques is summarized in Table 2 in terms of computational load and noise sensitivity. From Table 2, it is concluded that the amplitude and derivative based techniques should be developed properly for pre-processing the ECG signals. Once A[m] is filtered, it is passed through the detection stage for reliable QRS detection.
QRS detection techniques
The filtered ECG signal is passed through the QRS detection stage. This section presents a brief description of the QRS detection techniques used for the localization of the R-peak in the input ECG signal. Among several detection algorithms include the thresholding [50, 117,118,119,120], syntactic methods [121,122,123], neural networks [105, 124,125,126], zero-crossing [127], hidden Markov model [128], matched filters [129, 130], and singularity techniques [131,132,133]. These detection algorithms are also evaluated on the basis of two parameters, i.e. computational load and robustness to noise which is summarized in Table 3.
Thresholding
The thresholds are fixed values that are used to determine a boundary above which a R-peak is detected in A[m]. The thresholds may be fixed or adaptive depending on the approach employed. Numerous works have been reported in which the threshold based approach is utilized that is determined experimentally in [28, 31, 33, 34] to detect the R-peak. A peak is defined as a local maximum when the signal changes its direction within a pre-defined time interval, i.e. to be signal peak, the peak should exceed the threshold. The approach is considered as simple while the choice of optimal threshold is quite difficult. If the input ECG signal contains maximum SNR, then it is possible to utilize the lower thresholds. In Pan et al. [34] improved the SNR by using bandpass filter and used the adaptive thresholds. The thresholds are allowed to float over the noise. The two types of thresholds are applied to the R-peak i.e higher and lower thresholds. The higher thresholds among them are allowed to first analyze the signal. While the lower threshold is used when the no QRS complex is detected within a certain time which is followed by a search back technique to find the QRS complexes back in time. The main advantage of this approach is that it involves less computational load in comparison to all the detection techniques utilized. However, this method requires specification and adjustment of numerous parameters for adequate detection accuracy remains a challenge.
Neural networks (NN’s)
Neural networks have the ability to learn patterns in response to newly input patterns. Those learning and self-organizing abilities are appropriate for QRS-wave recognition [134], because the QRS-wave will change its shape according to the patient’s physical condition. Suzuki et al. [135] used an ART2 (adaptive resonance theory) network employed in this self-organizing neural-network system to detect the QRS complex. In this approach, the category of neural networks should be selected and modified during analysis. The architecture of an ART2 newtwork is shown in Fig. 3, where LTM is the long-term memory, F1 and F2 are layers connecting the neurons and \(w_i\), \(x_i\), \(u_i\), \(q_i\), \(p_i\) \(q_i\) are the nodes that characterize the F1 layer. A neural network with N number of inputs is developed, where the sample taken from the window is fixed for each input [136]. Garcia-Berdone’s et al. [136] utilized 20 samples as input, thereby emphasizing that the input for NN’s should be chosen within a range of samples. In the NN hidden layer, the choice of optimal number of neurons is difficult and determined empirically. A typical neural network architecture is depicted in Fig. 3.
The disadvantage of the technique is that involves high computational load and is highly noise sensitive. The average accuracy of this technique is also lesser than the thresholding based techniques.

Neural network models for QRS detection
Hidden Markov model (HMM’s)
A hidden Markov model (HMM) characterizes an observed data sequence by a probability density function which varies according to the state of an underlying Markov chain. In this approach the output function, a number of states and transition probabilities are determined empirically. The HMM parameters are fixed and cannot be approximated from training data by employing maximum likelihood methods due to the fact that data produced from the state sequence remains unknown [137]. The parameters of a hidden Markov model are not directly estimated when the data is unknown. A hidden Markov model is depicted in Fig.4, where \(q_1,\,q_2,\,q_3, \ldots ,\,q_6\) are the number of sets of states. The model consists of two Markov sub-sources, i.e. one for non-QRS segments and one for QRS segments.
The advantage of this technique is that it provides automatic estimation of all the parameters in the decision rule stage from each ECG file undergoing analysis. However, the search for parameters involves huge computational load. The accuracy results show that a simple HMM detector achieves accuracy which is very close to adaptive threshold based detection techniques.

HMM model for QRS detection [137]
Syntactic techniques
The syntactic approach is applied after the digital derivative operator [121]. The method utilizes a very simple look-up table for coding. The sequences of energy peaks of the derivatives of ECG waveforms corresponding to different leads are coded into the string of messages. For each lead waveform, the strings which correspond to QRS complexes are considered as a sample of positive information and are processed by a grammatical inference algorithm. Analogously the strings which correspond to non-QRS complexes are saved and considered as a negative information, sample to be eventually used in a further generalization step. Consequently, two grammars are built [121]; the first one generates only positive sequences (corresponding to QRS events) while the second one generates sequences corresponding to hypotheses that may or may not correspond to a QRS complex. This learning algorithm infers linear grammars based upon formal derivatives.
The syntactic method enables the detection of the QRS wave of an ECG signal by itself [121,122,123]. The ECG fragments length processed are uniform throughout the analysis. Belforte et al. [121] used segment of 30-s. The syntactic method [122] utilizes four attributes, i.e. the chord length, arc symmetry, arc length and degree of curvature that are computed empirically.
The disadvantage of the technique is that involves high computational load and is highly noise sensitive. However, it yields a comparable accuracy with the rest of the detecting techniques.
Singularity methods
Most of the ECG signal information is carried by its irregular morphology and singular points (fiducial points). In mathematics, a singularity is often considered as the opposite of smoothness and can be measured by Lipschitz exponent. Using the nth derivative of a so-called smoothing function, the singular points can be detected by modulus maxima of the wavelet. In this approach thresholding is employed on individual modulus maxima of WT to reduce the white noise from ECG signals. The wavelet scales are chosen experimentally to search for singular points [138, 139]. The use of thresholds per ECG fragment is constant [138] and computed empirically.
The disadvantage of the technique is that involves high computational load due to searching the singular points and is highly noise sensitive. However, it yields an accuracy (i.e. 99.22% [139]) which is approaching to the thresholding based techniques.
Zero-crossing (ZC)
Zero crossing methods are robust against noise and are particularly useful for finite precision arithmetic. This detection method inherits the robustness and provides a high degree of detection performance even in very noisy ECG signals. In this technique, the beginning of an event is identified when the features of the signal (i.e. number of zero crossings per segment) fall below a signal adaptive threshold while the end is identified when the signal rises above the threshold [127, 140]. This beginning and end of the event determine the boundaries of the search interval for the temporal localization of the R-wave. If adjacent events are temporally very close (multiple events), they will be combined into one single event. The beginning of the combined event is the beginning of the first event and the end of the combined event is the end of the last event. The threshold per segment employed for determining the number of zero crossings is fixed [127] and calculated empirically. In literature [127, 141], the search for zero-crossings depend on the choice of wavelet scale.
The disadvantage of the technique is that involves high computational load and is highly noise sensitive. However, it yields an accuracy (i.e. 99.70%) which is approximately same with those achieved by the thresholding based techniques.
The different algorithms involved in the detection of QRS complexes are summarized in Table 3. Among all the algorithms presented, the thresholding approach involve low computational load. Since, the study aims to highlight the development of efficient algorithms for a robust and reliable QRS detector, the use of threshold based technique is suggested because of its simplicity and efficiency. These thresholds are used in time [25, 26, 153] and time-frequency domain both [154,155,156]. There are two types of thresholds used to detect the QRS complexes which include the fixed and adaptive thresholds. The use of fixed threshold is simple and efficient for stationary input signals only having similar morphologies. In fact, movement of patients, baseline drift and variation in morphology of ECG signals results in highly inaccurate detection of QRS complexes using fixed thresholds. Rather, the usage of adaptive thresholding [71, 157,158,159], increases the correct detection of QRS complexes; however, the adjustment of multiple thresholds chosen empirically is a drawback. Most of the QRS detection presented in Table 3 perform well on the clean or filtered signals. Rather, their performance degrades in the noisy environment or signals containing arrhythmias. Therefore, these QRS detection techniques lacks in providing a generalized solution.
Performance evaluation and discussion
The R-peak detection is followed by the performance evaluation of the subsequent algorithms. The performance evaluation of various algorithms discussed in the earlier sections is estimated on the basis of two statistical parameters i.e. sensitivity and positive predictivity. The sensitivity is defined as the rate of correctly detected events among the total number of events detected by the algorithm, while positive predictivity refers to the rate of correctly classified events in all detected events which can be represented as:
where TP (true positives) is termed as the number of correctly classified events into a particular class, FN (false negatives) refers to events of a particular class which have not been detected, and FP (false positives) refers to the number of events of another class detected in a particular class. The overall performance of the existing QRS detection algorithms reported in the current study have not been analyzed relative to computational load and noise sensitivity. Further, a standard database is not used for testing these QRS detection algorithms which makes the analysis difficult to evaluate and compare i.e. some of works utilized different databases or signals from patients demanding the development of an efficient QRS detector algorithm. An algorithm or technique can be termed as efficient, if it satisfies the following factors such as low computational load, evaluated on common standards of data and high accuracy. As such, the QRS detection algorithms reporting high classification performance in terms of accuracy, computational load along with the other factors responsible are summarized in Table 4 and discussed subsequently to develop a fast and robust QRS detector.
A high overall performance is reported by Li et al. [160] (records 214 and 215 are excluded) achieving a sensitivity of 99.89% and specificity of 99.94% respectively, evaluated on the benchmark MIT-BIH arrhythmia database [22]. The features of the different waves are extracted using wavelet-based approach and singularity technique for classification of these features. However, this technique involves high computational load and hence cannot be considered superior in terms of performance. Moreover, the experiments are performed by excluding some of the records from the MIT-BIH arrhythmia database [22] to reduce the noise in the processed ECG signals and reported an improved performance in the detection of QRS complexes. While several investigators also performed their experiments by excluding paced beats [139] and ventricular flutter beats [72] from the patient’s data. Rather, such kind of evaluation of algorithms based on the variability in the utilization of data cannot be justified. Thus, a reliable algorithm is needed for the analysis of ECG signals yielding better overall performance on the overall dataset (i.e. without excluding any fragments of ECG).
In Table 4, each of the QRS detection algorithm is categorized as low, medium or high in terms of its computational load. The computational load of the algorithm is determined by computing the total number of operations involved (in terms of addition, multiplication and differentiation) and the number of iterations. The algorithms with more number of operations (i.e., higher computational load) is categorized as high while the algorithms with lesser number of operations is termed as low. The algorithms having low computational load are faster and vice-versa. Therefore, faster algorithm is more suitable for hardware implementation and can be used in real-time monitoring of ECG signals. Table 4 shows that the Christov [157], Chiarugi et al. [162] and Elgendi [166] algorithms involve low computational load. In the preprocessing stage, the application of first order derivative is promising, particularly if it is followed by a suitable detection stage [167] such as dynamic and/or moving average threshold. The computational load of a first order derivative is O(m) i.e. for m length of ECG data, O(m) number of operations are required, i.e. of linear order. Similarly, the computational load for second order derivative require additional O(m) operations. In fact, the sole application of first order derivative in the preprocessing stage is noise sensitive, and hence, it must be followed by an efficient detection scheme [27]. However, the implementation of the first and second order derivative schemes used for preprocessing the signal is slower than the amplitude based schemes. Rather, a faster (or simple) technique cannot be considered as efficient for QRS detection.
Prior to the development of a fast and robust QRS detector, these efficient algorithms are evaluated on the performance parameters such as noise sensitivity, computational load and accuracy as mentioned in each of the earlier sections. In addition, these efficient algorithms are required to be implemented on the suitable hardware platforms such as microcontrollers or field programmable gate arrays (FPGA). However, the processing speed of the algorithms depends on the operating frequency of these hardware platforms. It is to note that the higher is the processing speed of the hardware platforms, faster is the processing and vice-versa. Some of the works reported usage of mobile phones [24] to evaluate the performance of the three QRS detection techniques. Here, the QRS pre-processing stage consists of amplitude, first and second order derivative algorithms, whereas the detection stage consists of a thresholds only. The simplicity of the combination of these methodologies can be confirmed from Table 4 in terms of computational load. It is concluded from Table 4, the combination of first derivative with threshold can be considered as efficient in terms of computational load for detecting the QRS complexes.
While processing the ECG signals, the consumption of power [166] will be a limitation in battery operated devices. The case of classical Pan–Tompkins technique [34] is an example which shows a significant power utility [167], though it uses first order derivative. The total computational load of Pan–Tompkins algorithm is O(mkn) where ‘n’ is the number of stages through which the ECG signal is passed, ‘k’ is the order of the individual filters (in this case it is 1) and m is the length of the ECG signal. When n and k are very small compared to m, the total complexity would be O(m). Due to more stages involved in the Pan–Tompkins algorithm, more power is required in the detection of QRS complexes. In this study, the standard Pan–Tompkins algorithm is suggested as a ready made solution that can be implemented on suitable hardware platforms to develop an efficient QRS detector. The experiments are validated on the benchmark of the MIT-BIH arrhythmia database and performed using the MATLAB software package with hardware configuration of Intel CoreTM i5-processor CPU 3.30 GHz and 4.00 GB of RAM. The different stages involved in the Pan–Tompkins algorithm is depicted in Fig. 5.

Plot of R-peak detection within B[m] using Pan–Tompkins algorithm [34]
The complete analysis of the QRS detection algorithms depending on the factors such as noise sensitivity, computational load and accuracy is presented in this study prior to their implementation. The algorithms employed in real-time analysis should be simple (in terms of computational load) without resulting in degraded performance i.e., accuracy. If the algorithm is simple, the processing of larger databases is faster and requires less hardware leading to low-power consumption and reduced cost. It is also suggested to process the input data at higher operating frequencies as it can be helpful to process larger databases within the less amount of time. From Table 4, it can be concluded that the combination of first derivative and threshold are efficient if developed properly. Moreover, the Pan–Tompkins can be considered as a complete ready-made solution in the efficient detection of QRS complexes which satisfies all the factors like noise sensitivity, computational load and accuracy which is evaluated on all the records (without excluding of any segment) of the MIT-BIH arrhythmia database. An efficient QRS detector can be integrated with the feature extraction and the classification algorithms for arrhythmia classification [12, 168, 169]. Moreover, a fast and robust detector can easily be employed for breathing disorders and various other cardiac disorders to enhance the lifestyle of patients for CVDs.
Despite of the several algorithms reported in literature their clinical utility is not discussed. It is however difficult for an algorithm that mentions its significance and utility from a clinical point of view. It is best of the author’s knowledge that none of the discussed algorithms are implemented and verified in a clinical environment or hospitals. Hence, it is also suggested that the new algorithms developed for robust and reliable QRS detector based on the factors (i.e. as mentioned in the aim of the study) must be implemented and verified in the clinical environment.
Conclusion
This article presents a brief study of QRS complex detection algorithms based on the literature, to figure out the best-suited algorithm for cardiac analysis based on the factors like robustness to noise, computational load and sensitivity. For pre-processing the filtered ECG, the first-order derivative is suggested because it involves less computational load with high accuracy. However, this approach is noise sensitive and therefore, the approach should be followed by a suitable detection algorithm such as adaptive thresholding. Both these techniques can be developed firmly for detecting the QRS waves because the combination involves less computational load and achieves higher accuracy suitable real-time applications. However, the classical Pan–Tompkins approach is also a good ready-made alternative which is employed in most of the works in arrhythmia classification and implemented in this study. The developed QRS detectors based on the suggested algorithms can be helpful for detecting several cardiac disorders to lead a healthy and secure lifestyle.
References
Alwan A (2014) Global status report on noncommunicable diseases 2014. World Health Organization, Geneva
Benjamin EJ (2018) Heart disease and stroke statistics update: a report from the American Heart Association. AHA statistical update. Circulation 137:e67–e492
Goss J (2008) Projection of Australian health care expenditure by disease, 2003 to 2033. Australian Institute of Health and Welfare, Canberra
Dilaveris P, Gialafos E, Sideris S, Theopistou A, Andrikopoulos GK (1998) Simple electrocardiographic markers for the prediction of paroxysmal idiopathic atrial fibrillation. Am Heart J 135(5):733–738
Jenkins D (2009) A (not so) brief history of electrocardiography. http://www.ecglibrary.com/ecghist.html
Benali R, Reguig FB, Slimane ZH (2012) Automatic classification of heartbeats using wavelet neural network. J Med Syst 36(2):883–892
Tsipouras M, Fotiadis D, Sideris D (2002) Arrhythmia classification using the RR-interval duration signal. In: Computer in cardiology, pp 485–488
Thong T, McNames J, Aboy M, Goldstein B (2004) Prediction of paroxysmal atrial fibrillation by analysis of atrial premature complexes. IEEE Trans Biomed Eng 51(4):561–569
Bashour C, Visinescu M, Gopakumaran B, Wazni O, Carangio F (2004) Characterization of premature atrial contraction activity prior to the onset of postoperative atrial fibrillation in cardiac surgery patients. Chest 126(4):831S
de Chazal P, O’Dwyer M, Reilly R (2004) Automatic classification of heartbeats using ecg morphology and heartbeat interval features. IEEE Trans Biomed Eng 51(7):1196–1206
Krasteva V, Jekova I, Christov I (2004) Automatic detection of premature atrial contractions in the electrocardiogram. Electrotech Electron E E 3(2):132–137
Raj S, Chand GP, Ray KC (2015) Arm-based arrhythmia beat monitoring system. Microprocess Microsyst 39(7):504–511
Raj S, Ray KC (2017) ECG signal analysis using DCT-based DOST and PSO optimized SVM. IEEE Trans Instrum Meas 66(3):470–478
Raj S, Ray KC, Shankar O (2016) Cardiac arrhythmia beat classification using DOST and PSO tuned SVM. Comput Methods Programs Biomed 136:163–177
Raj S, Ray KC (2018) Sparse representation of ECG signals for automated recognition of cardiac arrhythmias. Expert Syst Appl 105:49–64
Zapanta L, Poon CS, White D, Marcus C, Katz E (2004) Heart rate chaos in obstructive sleep apnea in children. In: 26th Annual international conference of the IEEE Engineering in Medicine and Biology Society (IEMBS), vol 2, pp 3889–3892
Shouldice R, Brien LO, Brien CO, de Chazal P, Gozal D (2004) Detection of obstructive sleep apnea in pediatric subjects using surface lead electrocardiogram features. Sleep 27(4):784–792
Scholz U, Bianchi A, Cerutti S, Kubicki S (1997) Vegetative background of sleep: spectral analysis of the heart rate variability. Physiol Behav 62(5):1037–1043
Trinder J, Kleiman J, Carrington M, Smith S, Breen S (2001) Autonomic activity during human sleep as a function of time and sleep stage. J Sleep Res 10(4):253–264
Jeppsen J, Beniczky S, Fuglsang FA, Sidenius P, Johansen P (2017) Modified automatic R-peak detection algorithm for patients with epilepsy using a portable electrocardiogram recorder. In: 39th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp 4082-4085
Song J, Yan H, Xu Z, Yu X, Zhu R (2011) Myocardial ischemia analysis based on electrocardiogram QRS complex. Australas Phys Eng Sci Med 34(4):515–521
Moody G, Mark R (2001) The impact of the MIT-BIH arrhythmia database. IEEE Eng Med Biol Mag 20(3):45–50
Luo S, Johnston P (2010) A review of electrocardiogram filtering. J Electrocardiol 43(6):486–496
Sufi F, Fang Q, Cosic I (2007) ECG R-R peak detection on mobile phones. In: 29th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBS), pp 3697–3700
Morizet-Mahoudeaux P, Moreau C, Moreau D, Quarante JJ (1981) Simple microprocessor based system for on-line ECG arrhythmia analysis. Med Biol Eng Comput 19(4):l497–500
Fraden J, Neuman M (1980) QRS wave detection. Med Biol Eng Comput 18(2):125–132
Friesen G, Jannett T, Jadallah M, Yates S, Quint S, Nagle H (1990) A comparison of the noise sensitivity of nine QRS detection algorithms. IEEE Trans Biomed Eng 37(1):85–98
Menrad A (1981) Dual microprocessor system for cardiovascular data acquisition, processing and recording. In: Proceedings of the 1981 IEEE international conference on industrial electronics, control and instrumentation, pp 64–69
Holsinger WP, Kempner KM, Miller MH (1971) A QRS preprocessor based on digital differentiation. IEEE Trans Biomed Eng 18(3):212–217
Okada M (1979) A digital filter for the QRS complex detection. IEEE Trans Biomed Eng 26(12):700–703
Balda R, Diller G, Deardorff E, Doue J, Hsieh P (1977) The HP ECG analysis program. In: van Bemmel JH, Willems JL (eds) Trends in computer-processed electrocardiograms. North-Holland Publishing, Amsterdam, pp 197–205
Ahlstrom ML, Tompkins WJ (1983) Automated high-speed analysis of Holter tapes with microcomputers. IEEE Trans Biomed Eng 30(10):651–657
Engelse W, Zeelenberg C (1979) A single scan algorithm for QRS-detection and feature extraction. In: IEEE proceedings of computers in cardiology
Pan J, Tompkins WJ (1985) A real-time QRS detection algorithm. IEEE Trans Biomed Eng 32(3):230–236
Ligtenberg A, Kunt M (1983) A robust-digital QRS-detection algorithm for arrhythmia monitoring. Comput Biomed Res 16(3):273–286
Dokur Z, Olmez T, Yazgan E, Ersoy O (1997) Detection of ECG waveforms by neural networks. Med Eng Phys 19(8):738–741
Borjesson P, Pahlm O, Sornmo L, Nygards ME (1982) Adaptive QRS detection based on maximum a posteriori estimation. IEEE Trans Biomed Eng 29(5):341–351
Fancott T, Wong DH (1980) A minicomputer system for direct high speed analysis of cardiac arrhythmia in 24 h ambulatory ECG tape recordings. IEEE Trans Biomed Eng 27(12):685–693
Keselbrener L, Keselbrener M, Akselrod S (1997) Nonlinear high pass filter for R-wave detection in ECG signal. Med Eng Phys 19(5):481–484
Leski J, Tkacz E (1992) A new parallel concept for QRS complex detector. In: 14th Annual international conference of the IEEE Engineering in Medicine and Biology Society, vol 2, pp 555–556
Nygards M, Hulting J (1979) An automated system for ECG monitoring. Comput Biomed Res 12(2):181–202
Srnmo L, Pahlm O, Nygards M (1982) Adaptive QRS detection in ambulatory ECG monitoring: a study of performance. In: Proceedings of IEEE computers in cardiology
Christov I, Dotsinsky I, Daskalov I (1992) High-pass filtering of ECG signals using QRS elimination. Med Biol Eng Comput 30(2):253–256
Laguna P, Thakor N, Caminal P, Jane R (1990) Low-pass differentiators for biological signals with known spectra: application to ECG signal processing. IEEE Trans Biomed Eng 37(4):420–425
Thakor N, Webster J, Tompkins WJ (1984) Estimation of QRS complex power spectra for design of a QRS filter. IEEE Trans Biomed Eng 31(11):702–706
Thakor N, Zhu Y-S (1991) Applications of adaptive filtering to ECG analysis: noise cancellation and arrhythmia detection. IEEE Trans Biomed Eng 38(8):785–794
Bayasi N, Saleh H, Mohammad B, Ismail M (2014) 65-nm ASIC implementation of QRS detector based on Pan and Tompkins algorithm. In: 10th International conference on innovations in information technology (INNOVATIONS), pp 84–87
Deepu C, Lian Y (2015) A joint QRS detection and data compression scheme for wearable sensors. IEEE Trans Biomed Eng 62(1):165–175
Chen H, Chen S (2003) A moving average based filtering system with its application to real-time QRS detection. In: Computers in cardiology, pp 585–588
Phukpattaranont P (2015) QRS detection algorithm based on the quadratic filter. Expert Syst Appl 42(11):4867–4877
Kumar S, Mohan N, Prabaharan P, Soman KP (2016) Total variation denoising based approach for R-peak detection in ECG signals. In: 6th International conference on advances in computing & communications (ICACC), Cochin, India, pp 697–705
Gliner V, Behar J, Yaniv Y (2018) Novel method to efficiently create an mHealth App: implementation of a real-time electrocardiogram R peak detector. JMIR mHealth uHealth 6(5):e118
Jain S, Ahirwal MK, Kumar A, Bajaj V, Singh GK (2017) QRS detection using adaptive filters: a comparative study. ISA Trans 66:362–375
Sharma T, Sharma KK (2017) QRS complex detection in ECG signals using locally adaptive weighted total variation denoising. Comput Biol Med 87:187–199
Suppappola S, Ying S (1994) Nonlinear transforms of ECG signals for digital QRS detection: a quantitative analysis. IEEE Trans Biomed Eng 41(4):397–400
Sun Y, Suppappola S, Wrublewski T (1992) Microcontroller-based real-time QRS detection. Biomed Instrum Technol 26(6):477–84
Doyle T, Dugan E, Humphries B, Newton R (2004) Discriminating between elderly and young using a fractal dimension analysis of centre of pressure. Int J Med Sci 1(1):11–20
Burrus C, Gopinath R, Guo H (1998) Introduction to wavelets and wavelet transforms. Prentice Hall, New Jersey
Strang G, Nguyen T (1996) Wavelets and filter banks. Wellesley-Cambridge Press, Wellesley
Elgendi M, Jonkman M, De Boer F (2009) R wave detection using Coiflets wavelets. In: 35th Annual Northeast IEEE bioengineering conference, pp 1–2
Ghaffari A, Mollakazemi M (2015) Robust fetal QRS detection from noninvasive abdominal electrocardiogram based on channel selection and simultaneous multichannel processing. Australas Phys Eng Sci Med 38(4):581–592
Dinh H, Kumar D, Pah N, Burton P (2001) Wavelets for QRS detection. Australas Phys Eng Sci Med 24(4):207–211
Song J, Yan H, Li Y, Mu K (2010) Research on electrocardiogram baseline wandering correction based on wavelet transform, QRS barycenter fitting, and regional method. Australas Phys Eng Sci Med 33(3):279–283
Yochum M, Renaud C, Jacquir S (2016) Automatic detection of P, QRS and T patterns in 12 leads ECG signal based on CWT. Biomed Signal Process Control 25:46–52
Qin Q, Li J, Yue Y, Liu C (2017) An adaptive and time-efficient ECG R-peak detection algorithm. J Healthc Eng. https://doi.org/10.1155/2017/5980541
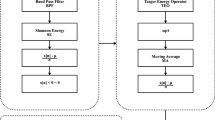
Park J, Lee S, Park U (2017) R peak detection method using wavelet transform and modified Shannon energy envelope. J Healthc Eng. https://doi.org/10.1155/2017/4901017
Singh O, Sunkaria R (2017) ECG signal denoising via empirical wavelet transform. Australas Phys Eng Sci Med 40(1):219–229
Ahmed S, Al-Shrouf A, Abo-Zahhad M (2000) ECG data compression using optimal nonorthogonal wavelet transform. Med Eng Phys 22(1):39–46
Zheng X, Li Z, Shen L, Ji Z (2008) Detection of QRS complexes based on biorthogonal spline wavelet. In: International symposium on information science and engineering (ISISE), vol 2, pp 502–506
Szilagyi S, Szilagyi L (2000) Wavelet transform and neural-network-based adaptive filtering for QRS detection. In: Proceedings of the 22nd annual international conference of the IEEE Engineering in Medicine and Biology Society, vol 2, pp 1267–1270
Xiaomin X, Ying L (2005) Adaptive threshold for QRS complex detection based on wavelet transform. In: 27th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBS), pp 7281–7284
Martinez J, Almeida R, Olmos S, Rocha A, Laguna P (2004) A wavelet-based ECG delineator: evaluation on standard databases. IEEE Trans Biomed Eng 51(4):570–581
Ruha A, Sallinen S, Nissila S (1997) A real-time microprocessor QRS detector system with a 1-ms timing accuracy for the measurement of ambulatory HRV. IEEE Trans Biomed Eng 44(3):159–167
Li Y, Yan H, Hong F (2012) A new approach of QRS complex detection based on matched filtering and triangle character analysis. Australas Phys Eng Sci Med 35(3):341–356
Eskofier B, Kornhuber J, Hornegger J (2008) Embedded QRS detection for noisy ECG sensor data using a matched filter and directed graph search. In: Proceedings of the 4th Russian-Bavarian conference on Biomedical Engineering, Zelenograd, Moscow, Russia
Afonso V, Tompkins WJ, Nguyen T, Luo S (1999) ECG beat detection using filter banks. IEEE Trans Biomed Eng 46(2):192–202
Mengda L, Vinod A, Samson S (2011) A new flexible filter bank for low complexity spectrum sensing in cognitive radios. J Signal Process Syst 62(2):205–215
Afonso V, Tompkins WJ, Nguyen T, Trautmann S, Luo S (1995) Filter bank-based processing of the stress ECG. In: 17th IEEE annual engineering conference in Medicine and Biology Society, vol 2, pp 887–888
Song-Kai Z, Jian-Tao W, Jun-Rong X (1988) The real-time detection of QRS-complex using the envelope of ECG. In: Proceedings of the annual international conference on IEEE Engineering in Medicine and Biology Society
Nygards M, Sornmo L (1983) Delineation of the QRS complex using the envelope of the ECG. Med Biol Eng Comput 21(5):538–547
Arzeno N, Deng Z-D, Poon C-S (2008) Analysis of first-derivative based QRS detection algorithms. IEEE Trans Biomed Eng 55(2):478–484
Benitez D, Gaydecki P, Zaidi A, Fitzpatrick A (2000) A new QRS detection algorithm based on the Hilbert transform. In: Computers in cardiology, pp 379–382
Arzeno N, Poon C-S, Deng Z-D (2006) Quantitative analysis of QRS detection algorithms based on the first derivative of the ECG. In: 28th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBS), pp 1788–1791
Wang Z, Wong CM, Wan F (2017) Adaptive Fourier decomposition based R-peak detection for noisy ECG signals. In: 39th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBS), pp 987–990
Huang N, Shen Z, Long S, Wu M, Shih H (1998) The empirical mode decomposition and Hilbert spectrum for nonlinear and nonstationary time series analysis. In: Proceedings of the Royal Society of London
Oukhellou L, Aknin P, Delechelle E (2006) Railway infrastructure system diagnosis using empirical mode decomposition and Hilbert transform. In: Proceedings of IEEE international conference on acoustics, speech and signal processing (ICASSP), vol 3
Damerval C, Meignen S, Perrier V (2005) A fast algorithm for bidimensional EMD. IEEE Signal Process Lett 12(10):701–704
Safari A, Hesar H, Mohebbi M, Faradji F (2016) A novel method for R-peak detection in noisy ECG signals using EEMD and ICA. In: 23rd Iranian conference on biomedical engineering, pp 155–158
Chu C-H, Delp E (1989) Impulsive noise suppression and background normalization of electrocardiogram signals using morphological operators. IEEE Trans Biomed Eng 36(2):262–273
Trahanias P (1993) An approach to QRS complex detection using mathematical morphology. IEEE Trans Biomed Eng 40(2):201–205
Zhang F, Lian Y (2007) Novel QRS detection by CWT for ECG sensor. In: IEEE biomedical circuits and systems conference (BIOCAS), pp 211–214
Gustafson D (1977) Automated VCG interpretation studies using signal analysis techniques, technical report R-1044. Charles Stark Draper Laboratory, Cambridge
Chen Y, Duan H (2005) A QRS complex detection algorithm based on mathematical morphology and envelope. In: 27th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBS), pp 4654–4657
NingIvan X, Selesnick W (2013) ECG enhancement and QRS detection based on sparse derivatives. Biomed Signal Process Control 8(6):713–723
Manikandan MS, Ramkumar B (2014) Straightforward and robust QRS detection algorithm for wearable cardiac monitor. Healthc Technol Lett 1(1):40–44
Zhou Y, Hu X, Tang Z, Ahn AC (2016) Sparse representation-based ECG signal enhancement and QRS detection. Physiol Meas 37(12):2093–2110
Arteaga-Falconi J, Al Osman H, El Saddik A (2015) R-peak detection algorithm based on differentiation. In: IEEE 9th International symposium on intelligent signal processing (WISP), pp 1–4
Zhang F, Lian Y (2007) Electrocardiogram QRS detection using multiscale filtering based on mathematical morphology. In: 29th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBS), pp 3196–3199
Ulusar U, Govindan R, Wilson J, Lowery C, Preissl H, Eswaran H (2009) Adaptive rule based fetal QRS complex detection using Hilbert transform. In: Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp 4666–4669
Lin C, Hu W, Chen C, Weng C (2008) Heart rate detection in highly noisy handgrip electrocardiogram. In: Computers in cardiology, pp 477–480
Zhang F, Wei Y, Lian Y (2009) Frequency-response masking based filter bank for QRS dection in wearable biomedical devices. In: IEEE international symposium on circuits and systems (ISCAS), pp 1473–1476
Vai M-I, Zhou L-G (2004) Beat-to-beat ECG ventricular late potentials variance detection by filter bank and wavelet transform as beat-sequence filter. IEEE Trans Biomed Eng 51(8):1407–1413
Kaplan D (1990) Simultaneous QRS detection and feature extraction using simple matched filter basis functions. In: Proceedings of computers in cardiology, pp 503–506
Hamilton P, Tompkins W (1988) Adaptive matched filtering for QRS detection. In: Proceedings of annual international conference of the IEEE Engineering in Medicine and Biology Society, pp 147–148
Xue Q, Hu Y, Tompkins WJ (1992) Neural-network-based adaptive matched filtering for QRS detection. IEEE Trans Biomed Eng 39(4):317–329
Lu Y, Xian Y, Chen J, Zheng Z (2008) A comparative study to extract the diaphragmatic electromyogram signal. In: International conference on BioMedical Engineering and Informatics (BMEI), vol 2, pp 315–319
Dinh H, Kumar D, Pah N, Burton P (2001) Wavelets for QRS detection. In: Proceedings of 23rd annual international conference of the IEEE Engineering in Medicine and Biology Society, vol 2, pp 1883–1887
Szilagyi L (1999) Wavelet-transform-based QRS complex detection in on-line Holter systems. In: 21st Annual conference and the 1999 annual fall meeting of the Biomedical Engineering Society Engineering in Medicine and Biology, BMES/EMBS, conference, proceedings of the first joint, vol 1
Shyu L-Y, Wu Y-H, Hu W (2004) Using wavelet transform and fuzzy neural network for VPC detection from the Holter ECG. IEEE Trans Biomed Eng 51(7):1269–1273
Alesanco A, Olmos S, Istepanian R, Garcia J (2003) A novel real-time multilead ECG compression and de-noising method based on the wavelet transform. In: Computers in cardiology, pp 593–596
Bothe H (1997) Neuro-fuzzy-methoden. Springer, Berlin
Zhang F, Lian Y (2009) Wavelet and Hilbert transforms based QRS complexes detection algorithm for wearable ECG devices in wireless body sensor networks. In: IEEE biomedical circuits and systems conference (BioCAS), pp 225–228
Zhou H-Y, Hou K-M (2008) Embedded real-time QRS detection algorithm for pervasive cardiac care system. In: 9th International conference on signal processing (ICSP), pp 2150–2153
Tang J, Yang X, Xu J, Tang Y, Zou Q, Zhang X (2008) The algorithm of R peak detection in ECG based on empirical mode decomposition. In: 4th International conference on natural computation (ICNC), vol 5, pp 624–627
Hongyan X, Minsong H (2008) A new QRS detection algorithm based on empirical mode decomposition. In: 2nd International conference on bioinformatics and biomedical engineering (ICBBE), pp 693–696
Arafat A, Hasan T (2009) Automatic detection of ECG wave boundaries using empirical mode decomposition. In: IEEE international conference on acoustics, speech, and signal processing (ICASSP), pp 461–464
Kew H-P, Jeong D-U (2011) Variable threshold method for ECG R-peak detection. J Med Syst 35(5):1085–1094
Zidelmal Z, Amirou A, Abdeslam DO, Moukadem A, Dieterlen A (2014) QRS detection using S-transform and Shannon energy. Comput Methods Programs Biomed 116(1):1–9
Dohare AK, Kumar V, Kumar R (2014) An efficient new method for the detection of QRS in electrocardiogram. Comput Electr Eng 40(5):1717–1730
Lin Z, Wang B, Chen H, Zhang Y, Wang X (2017) Design and implementation of a high quality R-peak detection algorithm. In: China semiconductor technology international conference (CSTIC), pp 1–3
Belforte G, De Mori R, Ferraris E (1979) A contribution to the automatic processing of electrocardiograms using syntactic methods. IEEE Trans Biomed Eng 26(3):125–136
Ciaccio E, Dunn S, Akay M (1993) Biosignal pattern recognition and interpretation systems. 2. Methods for feature extraction and selection. IEEE Eng Med Biol Mag 12(4):106–113
Trahanias P, Skordalakis E (1990) Syntactic pattern recognition of the ECG. IEEE Trans Pattern Anal Mach Intell 12(7):648–657
Vijaya G, Kumar V, Verma H (1998) ANN-based QRS-complex analysis of ECG. J Med Eng Technol 22(4):160–167
Hu YH, Tompkins WJ, Urrusti JL, Afonso VX (1993) Applications of artificial neural networks for ECG signal detection and classification. J Electrocardiol 26:66–73
Strintzis M, Stalidis G, Magnisalis X, Maglaveras N (1992) Use of neural networks for electrocardiogram (ECG) feature extraction recognition and classification. Neural Network World 3:313–328
Kohler B, Hennig C, Orglmeister R (2003) QRS detection using zero crossing counts. Appl Genomics Proteomics 2:138–145
Coast D, Stern R, Cano G, Briller S (1990) An approach to cardiac arrhythmia analysis using hidden Markov models. IEEE Trans Biomed Eng 37(9):826–836
Dobbs S, Schmitt N, Ozemek H (1984) QRS detection by template matching using real-time correlation on a microcomputer. J Clin Eng 9:197–212
Ebenezer D, Krishnamurthy V (1993) Wave digital matched filter for electrocardiogram preprocessing. J Biomed Eng 15(2):132–134
Di Virgilio V, Francaiancia C, Lino S, Cerutti S (1995) ECG fiducial points detection through wavelet transform. In: 17th Annual conference of the IEEE Engineering in Medicine and Biology Society, vol 2, pp 1051–1052
Rao K (1997) DWT based detection of R-peaks and data compression of ECG signals. IETE J Res 43(5):345–349
Kadambe S, Murray R, Boudreaux-Bartels G (1999) Wavelet transform-based QRS complex detector. IEEE Trans Biomed Eng 46(7):838–848
Abibullaev B, Seo H (2011) A new QRS detection method using wavelets and artificial neural networks. J Med Syst 35(4):683–691
Suzuki Y (1995) Self-organizing QRS-wave recognition in ECG using neural networks. IEEE Trans Neural Network 6(6):1469–1477
Garca-Berdons C, Narvez J, Fernndez U, Sandovalm F (1997) A new QRS detector based on neural network. IWANN: biological and artificial computation: from neuroscience to technology. Springer, Heidelberg, pp 1260–1269
Cost A, Cano G (1989) QRS detection based on hidden Markov modeling. In: Proceedings of annual international conference on IEEE Engineering in Medicine and Biology Society, images of the twenty-first century, pp 34–35
Ayat M, Shamsollahi M, Mozaffari B, Kharabian S (2009) ECG denoising using modulus maxima of wavelet transform. In: Annual international conference of IEEE Engineering in Medicine and Biology Society (EMBC), pp 416–419
Moraes J, Freitas M, Vilani F, Costa E (2002) A QRS complex detection algorithm using electrocardiogram leads. In: Computers in cardiology, pp 205–208
Manikandan MS, Soman KP (2012) A novel method for detecting R-peaks in electrocardiogram (ECG) signal. Biomed Signal Process Control 7(2):118–128
Mallat S, Hwang W (1992) Singularity detection and processing with wavelets. IEEE Trans Inf Theory 38(2):617–643
Ravanshad N, Rezaee-Dehsorkh H, Lotfi R, Lian Y (2014) A level-crossing based QRS-detection algorithm for wearable ECG sensors. IEEE J Biomed Health Inform 18(1):183–192
Varon C, Caicedo A, Testelmans D, Buyse B, Huffel S (2015) A novel algorithm for the automatic detection of sleep apnea from single-lead ECG. IEEE Trans Biomed Eng 62(9):2269–78
Zhang X, Lian Y (2014) A 300-mv 220-nw event-driven ADC with real-time QRS detection for wearable ECG sensors. IEEE Trans Biomed Circuits Syst 8(6):834–843
Alavi S, Saadatmand-Tarzjan M (2013) A new combinatorial algorithm for QRS detection. In: 3rd International conference on computer and knowledge engineering (ICCKE), pp 396–399
Bouaziz F, Boutana D, Benidir M (2014) Multiresolution wavelet-based QRS complex detection algorithm suited to several abnormal morphologies. IET Signal Process 8(7):774–782
Krimi S, Ouni K, Ellouze N (2008) An approach combining wavelet transform and hidden Markov models for ECG segmentation. In: 3rd International conference on information and communication technologies: from theory to applications (ICTTA), pp 1–6
Clifford G, Azuaje F, McSharry P (2006) Advanced methods and tools for ECG data analysis. Artech House, Inc, Norwood
Dokur Z, Imez T (2001) ECG beat classification by a novel hybrid neural network. Comput Methods Programs Biomed 66(2–3):167–81
Cheng W, Chan K (1998) Classification of electrocardiogram using hidden Markov models. In: Proceedings of the 20th annual international conference of the IEEE Engineering in Medicine and Biology Society, vol 1, pp 143–146
Coast D (1993) Segmentation of high-resolution ECGs using hidden Markov models. In: IEEE international conference on acoustics, speech, and signal processing (ICASSP), vol 1, pp 67–70
Poli R, Cagnoni S, Valli G (1995) Genetic design of optimum linear and nonlinear QRS detectors. IEEE Trans Biomed Eng 42(11):1137–1141
Chen H, Chan H (2006) A real-time QRS detection method based on moving-averaging incorporating with wavelet denoising. Comput Methods Programs Biomed 82(3):187–195
Ghaffari A, Golbayani H, Ghasemi M (2008) A new mathematical based QRS detector using continuous wavelet transform. Comput Electr Eng 34(2):81–91
Zheng H, Wu J (2008) Real-time QRS detection method. In: 10th International conference on e-health networking, applications and services (HealthCom), pp 169–170
Fard P, Moradi M, Tajvidi M (2008) A novel approach in R peak detection using hybrid complex wavelet (HCW). Int J Cardiol 124(2):250–253
Christov II (2004) Real time electrocardiogram QRS detection using combined adaptive threshold. Biomed Eng Online 3(1):28
Elgendi M, Mahalingam S, Jonkman M, de Boer F (2008) A robust QRS complex detection algorithm using dynamic thresholds. In: International symposium on computer science and its applications (CSA), pp 153–158
Elgendi M, Jonkman M, De Boer F (2009) Improved QRS detection algorithm using dynamic thresholds. Int J hybrid Inf Technol 2:65–80
Li C, Zheng C, Tai C (1995) Detection of ECG characteristic points using wavelet transforms. IEEE Trans Biomed Eng 42(1):21–28
Afonso V, Tompkins WJ, Nguyen T, Luo S (1996) Filter bank-based ECG beat detection. In: Proceedings of the 18th annual international conference of the IEEE Engineering in Medicine and Biology Society, bridging disciplines for biomedicine, vol 3, pp 1037–1038
Chiarugi F, Sakkalis V, Emmanouilidou D, Krontiris T, Varanini M, Tollis I (2007) Adaptive threshold QRS detector with best channel selection based on a noise rating system. In: Computers in cardiology, pp 157–160
Chouhan V, Mehta S (2008) Detection of QRS complexes in 12-lead ECG using adaptive quantized threshold. Int J Comput Sci Network Secur 8:155–163
Chouakri S, Bereksi-Reguig F, Taleb-Ahmed A (2011) QRS complex detection based on multi wavelet packet decomposition. Appl Math Comput 217(23):9508–9525
Zidelmal Z, Amirou A, Adnane M, Belouchrani A (2012) QRS detection based on wavelet coefficients. Comput Methods Programs Biomed 107(3):490–496
Elgendi M (2013) Fast QRS detection with an optimized knowledge-based method: evaluation on 11 standard ECR databases. PLoS ONE 8(9):e73557
Elgendi M, Eskofier B, Dokos S, Abbott D (2014) Revisiting QRS detection methodologies for portable, wearable, battery-operated, and wireless ECG systems. PLoS ONE 9(1):1–18
Raj S, Luthra S, Ray KC (2015) Development of handheld cardiac event monitoring system. IFAC-PapersOnLine 48(4):71–76
Raj S, Ray KC (2018) A personalized arrhythmia monitoring platform. Sci Rep 8(11395):1–11. https://doi.org/10.1038/s41598-018-29690-2
Acknowledgements
The authors acknowledge the Department of Science and Technology, Government of India for sponsoring this research work (IF 120841) under DST-INSPIRE Fellowship Scheme.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no conflicts of interest to declare.
Research involving human and animal participants
This article does not contain any studies with human participants or animals performed by any of the authors.
Rights and permissions
About this article

Cite this article
Raj, S., Ray, K.C. & Shankar, O. Development of robust, fast and efficient QRS complex detector: a methodological review. Australas Phys Eng Sci Med 41, 581–600 (2018). https://doi.org/10.1007/s13246-018-0670-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13246-018-0670-7