
Abstract
The failure mode and effect analysis (FMEA) employing the risk priority numbers (RPN) have been used extensively for identifying and prioritizing failure modes with a view of mitigating their impact on equipment failure. However, in its traditional form, the prioritization approach through the RPN lacks the objectivity required for robust risk assessment, more so, where maintenance data is available, which could enhance such objectivity. This paper extends a quantitative approach for prioritizing failure modes and component failures in facilities, and more specifically, leverages on maintenance data often recorded in such facilities. To enhance the objectivity of the risk prioritization process, the proposed approach integrates three objective measures—the cost of failure, failure occurrence rate and percentage downtime effects of equipment failure. The integrated measures are demonstrated as more robust for prioritizing risks as opposed to ordinal indices as the case in the conventional FMEA approach. Using historical maintenance records, a three-step ranking approach is proposed for prioritizing critical failure modes in a thermal power plant where a case study is discussed. Moreover, the study compares the results derived from the prioritization approach with that derived utilizing the conventional RPN method. The comparative study demonstrates the added value of a more objective and quantitative prioritization approach for maintenance decision support. Ultimately, the critical failure modes are evaluated using a decision scheme to allocate appropriate maintenance strategies as the final step of risk assessment (i.e. risk treatment). The proposed approach is viewed as generalizable, intuitive and offering insights to the maintenance practitioners.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The failure mode and effect analysis (FMEA) is a well-known prioritization approach for risk assessment and consequently assisting in maintenance decision making. The analysis is embedded in the Reliability Centered Maintenance and provides decision-makers with a logical, structured framework for identifying, analyzing and prioritizing failure modes and component failures in technical assets/equipment. Moreover, the FMEA aids the decision-makers to analyze the possible causes and consequences of equipment failure at the plant/system, subsystem or component level in technical assets (Cameron et al. 2017). In addition, the FMEA allows the classification, or prioritisation, of each potential failure mode in accordance with the seriousness or severity of its effect. Therefore, critical failure modes are better identified, which provides maintenance practitioners with the basis of formulating more effective and robust mitigation measures—through implementing more effective maintenance actions targeted at the critical failure modes.
1.1 Failure prioritization using FMEA
The Failure Modes and Effect Criticality Analysis (FMECA) has been used for long, to predict the consequences of failures in systems and assists to identify failures in advance so that failure effects can be reduced, if not eliminated from the system (Karthikeyan et al. 2017). On one hand, the criticality analysis (CA) is used to prioritize the failure modes in terms of importance, quantified based on combined severity and frequency of failure. While ranking based on the CA, the process utilizes historical failure data or based on expert assessment well versed with the technical system (Sahoo et al. 2014).
Hence, by prioritizing failure modes according to their level of severity, more robust maintenance strategies can be implemented in assets, therefore enhancing the reliability of the asset. In this context, reliability looks at the ability of the asset to undertake its intended function to support manufacturing or to provide a service (Pintelon and Van Puyvelde 2013). Improving asset reliability is essential to the profitability and existence of any organization, especially to its operation and maintenance activities. Importantly, by implementing robust maintenance strategies, the organization is in a better position of minimising the operation and maintenance cost. This is attributed to the fact that the failure of a critical component may portend significant operation and maintenance cost impacts, for instance, production loss, need for spare parts, loss of plant efficiency, etc. (Chemweno et al. 2016a; Linnéusson et al. 2016; Castro-Santos et al. 2016; Wakiru et al. 2018; Fakher et al. 2018).
The need for implementing robust maintenance strategies extends to thermal power plants, which in developing countries like Kenya, performs an essential role in bridging power generation and supply deficiencies. The power plants are often fuel-driven and are set up both for long-term and as emergency power plants. To this end, the power plants are required to operate with high availability and manage the often-high operation and maintenance costs, an essential need experienced by power plant operators. Distinctly, maintenance costs represent very often a salient cost aspect in which, depending on the operating context, it often constitutes a substantial proportion of the total cost of ownership (Wakiru et al. 2019a). Moreover, in thermal power plants, any downtime due to the failure of critical components frequently affects plant economics significantly.
In installed thermal power plant facilities in Kenya, condition-based maintenance strategies (CBM) such as used oil analysis, vibration analysis, or thermography, Use-based Maintenance (UBM) and preventive maintenance are implemented as the key strategies (Wakiru 2015). However, despite implementing such strategies, power plants continue experiencing failures, incurring high downtime and maintenance costs, implying the existing strategies are sub-optimal, hence the need for developing more robust strategies(Wakiru et al. 2019a). Nonetheless, formulating such strategies is not straightforward and requires a structured framework for decision-makers to be able to select the most appropriate strategies tailored for recurrent critical failure modes and component failures. Significantly since the power plant consists of several inter-linked equipment types prone to failure, there is a need for prioritizing the critical subsystem. In this case, if their respective failure modes are addressed, a significant contribution to plant downtime will have been mitigated. However, many thermal power plants in developing countries lack such a structured methodology for formulating appropriate maintenance strategies which mitigate recurrent critical failures (Wakiru 2015). Significantly, the proposed structured methodology would firstly, assist the maintenance practitioners in prioritizing the subsystems systematically. Ultimately, for the critical subsystems, prioritize their respective failure modes and mitigate them through targeted maintenance strategies of which depending on the failure mode criticality, differentiated maintenance strategies are assigned to equipment failures observed at the plant. This aspect further motivates the need for a risk-based maintenance approach of which equipment failures are prioritized and ranked according to their level of criticality.
Thus, given the challenges, this research proposes a risk-based structured methodology for prioritizing equipment failures as per the level of associated risks. The research integrates a cost-based prioritization approach for ranking critical failures alongside the failure occurrence rate and equipment downtime. The study further advances a maintenance strategy selection framework to mitigate the critical failure modes identified. Finally, a comparison between the advanced cost-based FMEA and RPN FMEA approaches is undertaken based on the empirical maintenance data used in the research. The other sections of this paper are as follows. Section 2 presents a recent literature review that is relevant to the research discussed in this paper. In Sect. 3, the proposed methodology is outlined, and the specific steps further discussed. Section 4 discusses the application of the methodology using the case study of a thermal power plant facility in Kenya. Section 5 presents the managerial implications of the methodology proposed where the novelty of the same approach is further discussed. Section 6 presents the conclusion and directions for future research.
2 Review of related literature
2.1 Risk identification and prioritization
Risk management entails four key steps, risk identification, risk assessment, risk management and finally monitoring, where different studies (e.g. Ríos et al. 2019) conclude that the first two steps (i.e. risk identification and assessment) are critical for performing successful risk management. Diverse methods have been utilized in literature for specific types of risk identification such as checklists, what-if analysis, task analysis, questionnaires, Delphi method, operability and risk studies, brainstorming, decomposition techniques and semi-structured interviews (Ríos et al. 2019).
The criticality of failure of equipment in the conventional FMEA is assessed by computing the risk priority number (RPN), which represent a product of three risk metrics: occurrence (O), severity (S) and detectability (D), as depicted in Eq. 1 below:
In the RPN formulation, the occurrence metric evaluates the probability/likelihood of a failure occurring, the severity metric indicates the intensity of failure, and finally, detectability metric indicates the likelihood of discovering a developing or commencing failure mode before its occurrence (Chemweno et al. 2016b). Nonetheless, several reasons have been raised criticizing conventional FMEA as follows:
-
The importance of each of the metrics O, S and D are not taken into consideration (Zammori and Gabbrielli 2012; Sharma and Sharma 2012; Liu et al. 2015). For instance, failure modes of varying failure severities (S) may yield the same risk priority number computed through Eq. 1. Consequently, this may lead to the erroneous conclusion of the failure criticality ranking even though high failure severity metric (e.g. severity of 10) would imply high failure criticality, as opposed to low assigned failure severity (e.g. severity of 1).
-
The RPN metrics, i.e. Occurrence (O), Severity (S), and Detection (D) are usually ordinal numbers, ranging from 1 to 10, hence challenging to evaluate precisely (Kutlu 2012; Zammori and Gabbrielli 2012). Moreover, the ordinal indices are assigned based on expert experience or judgment and seldom linked to the empirical failure event. As an example, assigning an occurrence metric of 10 delinks from empirical evidence of the failure occurrence which may be observable through objective reliability metrics, for instance, time to failure or failure frequency (Chemweno et al. 2016a).
-
The formula for computing RPN is contentious (Chin et al. 2009; Kutlu 2012; Du et al. 2014). For the reason that multiplying ordinal numbers for the RPN leads to criticality index, which ranges from 1 to 1000, hence deriving precise equipment failure criticality is not straightforward.
Nonetheless, the RPN approach has been widely studied by different authors Feili et al. (2013), Du et al. (2014), Gaula and Sharma (2015), Sinha and Mukhopadhyay (2015), Li et al. (2016), Karthikeyan et al. (2017).
Therefore, to address the limitations of the RPN, several indices are advanced and utilized while prioritizing failures by different authors. Some authors have proposed employing production outage (Bhangu et al. 2017), the frequency of failures and downtime (Vala et al. 2018), consequences of missed fault detection (Panchal and Kumar 2017) or considering causes of equipment failure (Panchal and Kumar 2017). Other authors (e.g. Bhangu et al. 2017), propose using the expected cost of failure as an intuitive measure of risk in technical assets. The authors here argue the cost measure is ideal for prioritizing equipment failure modes and thereby assigning appropriate maintenance strategies. The cost-based FMEA methodology offers several advantages compared to conventional RPN-FMEA. For instance, the use of cost is an alternative and promising approach compared to RPN since the cost is quantifiable, computable and directly correlated with failure severity or seriousness. Moreover, it enables identification of potential and critical failures, which directly reduces the exposure by the system or plant to the failures and associated effects (Bhangu et al. 2017). Consequently, this makes the cost based FMEA a credible tool for failure analysis of divergent facilities such as power plants. The subsequent section briefly summarizes several studies which employed cost-based FMEA prioritization metric.
2.2 Cost-based FMEA
Several authors have advocated the significance of the cost aspect while undertaking FMEA programs. Gaula and Sharma (2015) advanced a hybrid framework adopting qualitative and quantitative techniques to model and analyze the failure aspects of flexible manufacturing cells. The study concluded that cost of maintenance should be taken into consideration. However, ‘life cost-based FMEA’ was proposed by Gilchrist (1993) and further enhanced by Rhee and Ishii (2003). Their paper (i.e. Rhee and Ishii), advanced a cost-Based FMEA approach which relies on empirical data to enhance the reliability, maintainability and life cycle cost of complex systems. However, the study employed the probability of specific failure occurring; which in real life is unknown a priori and may change due to equipment operational and environmental aspects. Moreover, the study disregarded the evaluation of failure risk consequences, hence no prioritization of the failures is made. Furthermore, the study did not consider inherent expertise knowledge in FMEA, which can be used to address the challenge of unavailable data experienced in many industrial set-ups.
Kmenta and Ishii (2005) proposed the use of probability and cost FMEA in decision making and failure scenario analysis. In this case, they utilized the expected costs and the probability of failure observed and detected at various points in the life cycle of a product. Despite their paper reviewing risk prioritization using both RPN and expected cost, it, however, did not utilize expert knowledge in quantifying the expected failure costs. The latter, an integral aspect of ensuring the validity of the prioritization approach.
Dong (2007) proposed a tool for cost based FMEA, which focuses on quantifying the utility cost. They employed the utility theory and fuzzy membership functions for the assessment of severity, occurrence, and detection. Their approach further embedded a fuzzy utility cost estimation approach for dealing with the shortcomings of the conventional FMEA. The study considered fuzzy triangular membership functions, which were defuzzified to compute the Risk Priority Index (RPI) while considering team opinions. The research did not apply actual empirical maintenance costs associated with equipment failure modes which may offer more intuitive insights in cost intensive facilities like power plants. Moreover, the failure cost metric is clearly unexplained in their study.
von Ahsen (2008) advanced an approach that incorporated the cost of defects or faults discovered by the customer. The costs found within the company and due to flaws in inspection while evaluating the impact of potential failures. The study considered failure cost as the sole criteria for prioritization and did not apply actual empirical maintenance costs, an approach that may yield suboptimal decision support. This is contrary to the expectations in facilities like power plants, where other aspects such as opportunity or production loss, availability and failure frequency are equally significant in evaluating the impact of failures. In a similar fashion, the research did not attempt to review the critical failure modes using a prioritization criterion.
Bradley et al. (2011) suggested using a data elicitation technique aiming to prioritize Failure Modes while employing Yager’s (1981) method. In their solution, three criteria were assigned a weighting factor to address the challenge of varying importance between different risk prioritization cost metrics. However, their approach suffers two disadvantages; in the first place, they increase the difficulty of performing the FMEA, as one requires an in-depth understanding of mathematical concepts to involve their proposed fuzzy logic solutions. Such intuitiveness present oftentimes a critical challenge amongst practitioners in practice. Secondly, they employ the probability of detection for functional failure, as an input variable. This aspect increases uncertainty, especially where the detection metric is estimated subjectively. Wang (2011) proposed a revised format for FMEA analysis by replacing occurrence, severity, and detection using quality cost factors alluding to their ambiguousness. Their research was based on a manufacturing set up, which specifically addressed the manufacturing process and not the maintenance of the equipment. However, despite integrating the quality cost with the conventional RPN approach, the research overlooks the need of expert knowledge. Furthermore, various empirical maintenance cost factors, for instance, the cost of spare parts which are significant constituents addressing maintenance of industrial facilities like power plants, are not applied.
Hassan et al. (2010) incorporated cost-based FMEA in a quality/cost-based conceptual process planning (QCCPP). The study undertook cost-based FMEA analysis to assess the failure modes due to the manufacturing process and to estimate the failure cost. However, the study did not utilize actual empirical maintenance data, for instance, the quantification of the failure cost disregarded cost elements such as spares which are significant in operations like power plants. Moreover, the study disregarded the use of expert knowledge and did not prioritize the failure modes systematically based from the system to equipment level.
Liu et al. (2013) addressed the limitations of RPN metric in their review of risk evaluation approaches for prioritizing equipment failures in the FMEA. The study recommends alternative prioritization criterion based on methods like fuzzy approaches, linear programming and multi-criteria decision-making approaches. However, the proposed methods are limited to providing intuitive decision support to practitioners, for instance, in many power plants in developing countries, hence, their use for a wholesome decision support is questionable. Moreover, their application may require tools and some level of expertise or in-depth understanding of the concepts, which may not be available for the practitioners.
Jahangoshai Rezaee et al. (2017) employed cost-based FMEA and data envelopment analysis by imposing costs related to any failure in the system to prioritize failures. The study primarily computed the cost based on the opportunity lost by the failure of the equipment (e.g. production loss), and did not explicitly apply empirical maintenance related costs like spares among others. However, despite the study being involved in the stone processing sector, it did not follow a systematic approach while prioritizing the failures. Due to numerous equipment in such facilities as power plants, addressing them concertedly would be arduous and may not offer robust decision support with palpable insights. Moreover, the employment of expert knowledge was disregarded, an aspect which would offer more insights in failure quantification and prioritization and ensure applicability of the approach in real life.
In more recent studies, several authors address the deficiency of which the RPN delinks the failure prioritization to the observed empirical failure modes, through enhanced data-driven FMEA approaches. For instance, Chemweno et al. (2016b) proposed a dynamic FMEA approach which leverages on both expert knowledge and sparse equipment reliability or maintenance data. They propose an approach based on a Bayesian inferencing framework for addressing concerns of data availability. Their approach combines elicited expert knowledge and empirical maintenance data. They also propose a data mining framework which allows maintenance practitioners to prioritize equipment failures, hence assist the performance of root cause analysis (Chemweno et al. 2016a). A considerable flaw of their proposed methodologies represents the need to adopt statistical and mathematical modelling approaches. These approaches are limited by the available data, and often not intuitive to maintenance practitioners. For instance, the hierarchical Bayesian approach and multivariate and cluster analysis, may not be clearly used by many practitioners. Moreover, the data mining approach presumes the availability of large structured datasets, which in practice remain ordinarily not the case.
In real-life applications, exact information is not constantly available; it follows, uncertainty is retained in the analysis, and this could be countered by integrating fuzzy methodologies with the conventional FMEA techniques. Several authors have considered integrating fuzzy methodology to overcome the drawbacks of traditional FMEA approach in risk ranking. (Jamwal et al. 2018; Panchal and Srivastava 2018; Panchal et al. 2018) applied risk ranking fuzzy FMEA and grey relational analysis approaches within traditional RPN based FMEA for diverse applications. The studies sort to address the uncertainty or imprecision involved in the information collected from field experts and maintenance logbooks. The advanced fuzzy logic models retain several limitations despite rendering more straightforward and intuitive models from vague conditions, while managing uncertainty to provide robust predictions. They retain stagnant rules since any change in the variables necessitate a change in the decision logic; rule segregation is challenging because all rules have an influence on the output, thus may compromise model accuracy. Moreover, increased features employed could lead to a combinatorial challenge (Wakiru et al. 2019b).
2.3 Risk treatment strategies
The prioritized critical risks ultimately require to be mitigated to ensure plant operability and sustainability. Risk treatment as an aspect of mitigating and possibly eliminating recurrent prioritized failure modes, is significant towards achieving maximized plant availability. This is achieved through selecting optimal maintenance action or tactic/strategies. Several alternative strategies are proposed in this context for achieving this; Failure based maintenance (FBM) which is breakdown maintenance usually employed for non-critical or equipment characterized by constant failure rates (Kumar and Maiti 2012). Time or Use Based Maintenance (TBM/UBM) is employed after a specified calendar or usage time elapses, while Condition-based Maintenance (CBM) approach utilizes information derived through monitoring the condition of the equipment, from which maintenance intervention is carried out (Jardine and Tsang 2013). The Design out Maintenance (DOM) may be selected in instances where changes or modifications may be carried out on the equipment to eliminate a failure cause or to improve the equipment reliability. By applying DOM, practitioners hope to reduce their reliance on maintenance (Sondalini 2009). Design for Maintenance (DFM) considers the objective of reducing the likelihood of failures of the equipment or even better to eliminate the requirement of maintenance (Gupta and Gandhi 2014). DFM addresses design aspects that could reduce human or technical errors, prevent maintenance altogether, and if not, significantly reduce the frequency of maintenance intervention. Lastly, the Design out Reliability (DOR) represents an improvement that develops high-reliability components that seldom fail due to standard failure modes, hence ensures the durability of the asset (Gupta and Gandhi 2014). DOR activities can be employed in an existing component by re-engineering to significantly reduce failure modes in service. This can also be attained by using an alternative design where a prototype is produced and intentionally made to fail while analyzing failure modes with a view of designing-out such failures.
2.4 Summary and motivation of the study
All the studies reviewed so far in Sect. 2.2; however, suffer from several deficiencies hence drive the motivation of this study as discussed briefly:
-
Limited embeddedness of expert knowledge or empirical data in the failure prioritization step, which we view as significant where experts can augment missing data and information to derive prioritization index such as cost comprehensively and ultimately offer validation of the various data being utilized.
-
Lack of an empirical link to actual maintenance costs, like spare and labour costs. Moreover, complex algorithms for prioritizing failure modes fail to invoke the practitioner’s interest, understanding, and interpretability.
-
The studies do not go beyond prioritizing failure modes to review the critical failure modes and further suggest or align mitigating risk strategies to the critical failure modes.
The purpose of this study is to introduce a risk-based approach, where through cost-based FMEA, a structured approach for identifying critical failure modes is used. A comparison between the advanced approach and conventional RPN based on the empirical data used is further advanced. Additionally, the risks embedded in critical failure modes are evaluated and risk-mitigating maintenance strategies selected to address the risks. In the subsequent section, we expound in detail the methodology adopted in this study.
3 Methodology
3.1 Integrated cost-based FMEA framework
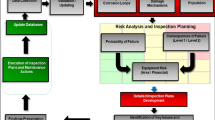
The proposed approach in this paper consists of five steps, as outlined in Fig. 1, which include; maintenance data collection, data consolidation, structuring and risk identification, risk quantification and prioritization/ranking. In the ultimate step of the methodology (i.e. risk treatment), the critical failure modes are assigned appropriate maintenance strategies using a decision scheme after the prioritization process.

Summary of research methodology
3.2 Research methodology
The methodology illustrated in Fig. 1, takes a five-step approach, as discussed in the following section.
Step 1 Data collection
The proposed methodology is applied in the case study of a thermal power plant that retains heavy fuel oil-driven engines generating electricity connected to the grid. The raw maintenance data was collected from maintenance records and intensive interviews with the maintenance staff. The data documented in maintenance records indicated failure dates, a description that retains both the failure modes and repair actions undertaken on the power plant engines. Other vital details like spare parts used, maintenance staff utilization and labour rates estimates were derived from the operations and supply chain department records. However, the critical cost aspects missing were augmented by estimates elicited through interviews with the maintenance staff. The data used in this research was initially unstructured, hence the need to re-structure, as discussed in the next section.
Table 1 illustrates a sample of the unstructured data, which details aspects such as; component failures, failure modes, date and time of occurrence of the failures, date and time of resumption type of repair done, spares used and the estimated downtime.
Step 2 Data consolidation, structuring, and risk identification
In this step, the data were restructured to satisfy the requirements of the methodology, of which maintenance cost aspects were extracted for purposes of prioritizing critical system, subsystem and component failures. For the structuring process, the plant was categorized to subsystems in consultation and discussions with the maintenance engineers. The data was further organized in a manner facilitating extraction of cost parameters required as input to the cost-based FMEA approach. The information here includes data on functional failures and other related data such as spare parts used and their respective quantity. This information was derived from maintenance records as well as responses from the informal interview sessions with maintenance staff as discussed before. New cost estimates were elicited through interviews with procurement and supply chain, for instance, cost estimates of spare parts used during repair activities. Maintenance schedules adopted by the plant were important for estimating diagnosis, isolation, repair and start-up times. The maintenance schedules were also insightful for estimating man-hour costs, which were linked to repairing times.
During the structuring process, 13 engine subsystems were identified and coded; SS1 to SS13 (subsystems). Additionally, a total of 86 failure modes was observed from the data and consequently linked to the 13 subsystems. The failure modes are indicated with the codes; FM1 …to FM86. A sample of the 21 failure modes discussed in the subsequent sections is detailed in “Appendix 1”, while the description of the 13 subsystems and their respective codes are detailed in “Appendix 2”.
Table 2 shows a sample of structured failure modes, where the first failure mode (FM1) in Table 1, is linked with subsystem 1 (SS1). On the other hand, FM26 is linked to subsystem SS3. Illustratively, for the latter, camshaft failure (FM 26) depicted in “Appendix 1” is observed as influencing the operational availability of the cam subsystem (SS3). The day and time of failure (stop) and at the (start) metrics in Table 2 were observed as useful for computing the unavailable time (UT). The UT is used for computing the percentage downtime, and outage production cost discussed in Step 3.
After the structuring process, the expected failure cost, percentage downtime, and failure occurrence rate were computed for each of the observation, depicting the impact while employing expert consultations to identify the risks based on the expected failure cost impact and capacity of the plant to recover from the failure. Moreover, task analysis in conjunction with brain storming was employed to identify all risks linked to each failure mode and subsystem. The objective of the computation is to facilitate prioritization of the failures modes grouped within each of the 13 engine subsystems. In the following sections, the risk quantification process is discussed.
Step 3 Risk quantification
In this step, the risk quantification follows two complimenting approaches, as indicated in Fig. 1, where the first involves computation of the expected failure cost, while the second involves computation of both the failure occurrence rate and percentage downtime, as enumerated in the following sections.
-
(a)
Computation of expected failure cost
The expected cost of failure (TC) for each identified failure mode includes the production loss due to downtime, labour cost, and spares cost, as illustrated by Eq. 2. The inclusion of such cost components is also corroborated by (Avontuur and van der Werff 2001). Equation 2 below depicts the calculation of the expected failure cost in dollar value terms.
where TC is the total failure cost for a specific failure mode, CP is the outage production loss cost, \(CM\) is the man-hour cost, CS is the spare parts or material cost
The Outage Production Cost (CP), also referred to as downtime cost or opportunity cost, is the cost associated with loss of production (value creation) due to the occurrence of a failure. It is described by Eq. 3:
where UM = Unavailable production, UT = Unavailable time/downtime, EO = Engine output, ES = Energy cost per MWh
The man-hour cost (CM) in Eq. 2, also referred to as Labour cost is the cost associated with the repairing the failure mode. Despite this aspect not recorded in many unstructured maintenance data such as for the case company, it can be derived from information contained maintenance schedules and in-depth interviews. This is arrived at by using the industrial power plant standard labour-rate as below equations shows:
where LR = Industry-standard labour-rate, TN =Number of technicians, TTR = Time to Repair, EST = Engine stopping time, ESP = engine start-up time, IST = Isolation time, RST = removal of isolation, commission and start time
TTR is computed by considering the unavailable time negating isolation time, commission and start times. TTR was also verified using the maintenance task or work plan schedules reviewed from the plant records. Finally, for the spares or material cost (CS) were associated with component replacement during repair, because of direct failure or due to secondary failure, and the material cost or spare part cost obtained by the Eq. 8:
where NC = Number of components replaced, CC = Component average cost
Several variables are treated as standard during the computation of expected total failure cost, which includes the engine output (7.5 MWh/h), labour-rate (LR) of 15$/h, Energy cost (ES) 48.23$/MWh which were retrieved from the engine data and service level agreements. An example of the total expected cost computation for the failure mode, FM 1 is briefly discussed.
While computing the production loss (CP) applying Eq. 3, the unavailable production (UM) is first derived by multiplying the unavailable time (UT) as observed in Table 2 with the standard engine output (EO). The unavailable production (UM), is computed using Eq. 4, where unavailable time (UT) is 487.53 h. while the engine output (EO) is 7.5 MWh/h, hence deriving from Eq. 4:
Thus, from Eq. 3:
\(CP = UM \times ES\), where UM was derived above, while the energy cost (ES) is 48.23$/MWh. Therefore, applying this equation, the outage production cost/loss is 3657 * 48.23 giving 176.35$K.
While computing man-hour cost (CM), following expert review concerning FM1, isolation and diagnosis time (IST) was 107 h, while removal of isolation, commissioning and starting (RST) was 67.53 h. (See Table 3). The number of technicians (TN) was 6, thus, the time to repair (TTR) was computed applying Eq. 6, as 313 h (487.53–107–67.53), hence one employs TTR, TN and standard labour-rate (LR) to derive CM. Finally computing the spare cost (SC), the number of components replaced (NC) was two units each with the average cost (CC) of 2031$ hence computed as below.
Using Eqs. 3, 5 and 8 and substitute to Eq. 2, the total cost is:
-
(b)
Computation of failure occurrence rate and percentage downtime
Apart from prioritizing based on failure cost, the subsystems and failure modes were similarly prioritized while considering the percentage failure occurrence, and percentage downtime associated with each respective failure modes. This section shows the computation of the failure occurrence rate and percentage downtime for the various failure modes categorized according to the different subsystems.
-
(i)
Failure occurrence rate
The failure occurrence rate for the subsystem was computed as the percentage of the total failure frequency of a subsystem to the total failure frequency of the power plant in the period of 3 years. The failure occurrence rate for failure modes represent the ratio of the number of failures of each failure mode to the total failures in a subsystem. See Eq. 9.
-
(ii)
Percentage Downtime
The percentage downtime for subsystem was measured as the percentage of the total downtime in hours of a subsystem to the total failure related downtime of the power plant. Similarly, that of the failure modes was computed as a percentage of downtime directly related to a failure mode as a proportion of the total downtime of the subsystem. This computation is depicted in Eq. 10.
To illustrate the computation of the failure occurrence rate and percentage downtime, again consider failure mode FM1 and FM2. From the structured records, of which a sample is indicated in Table 3, SS1 was observed as suffering a total of 17 failure modes. Out of these, FM1 was only observed once, while FM2 appeared twice in the records. Put differently, FM1 and FM2 had frequencies of one and two, respectively. Hence, using Eq. 9, FM1 and FM2 the failure occurrence rates of FM1 and FM2 are 6% (or 1 out of 17 failures) and 11.8% (or 2 out of 17 failures) respectively.
In a similar fashion, SS1 had a total downtime of 995.17 h from records, of which a sample of two failure modes FM1 and FM2 whose downtime are 487.53 h and 70.86 h (two similar failure modes are summed up 12.88 h and 57.98 h generating a total of 70.86 h) respectively, as indicated in Table 3. Hence, applying Eq. 10, the percentage downtime for FM1 is 49% (or 487.53/995.517), while that of FM2 is 7.1% (or 70.86/995.517).
Step 4 Ranking and prioritization
This step follows a three-tier risk analysis process, where the three indices, the expected failure cost, failure occurrence rate, and downtime contribution were employed in the evaluation for prioritizing and ranking the failure modes. The fundamental element of analysis is the failure modes; hence, each respective subsystem will be constituted with several failure modes.
-
Firstly, the total expected cost, failure occurrence rate and percentage downtime of each subsystem are summed up considering individual values for each failure mode. Prioritization and ranking of the subsystems are performed, where highly ranked (critical) subsystems based on the 80:20 Pareto rule were identified. The results of this step are indicated in Table 4.
Table 4 Computed prioritization indices for Power plant subsystems -
Secondly, failure modes constituting each of the identified critical subsystems from the previous step, are ranked with a view of identifying critical failure modes among each of the known critical subsystems. The result of this step is indicated in Table 5.
Table 5 Table illustrating computed prioritization indices for failure modes included in SS2 -
Finally, the highly ranked (using 80:20 rule) failure modes in each identified critical subsystem were summed and ranked/prioritized, hence constituting the most critical failure modes for the system.
Based on the prioritization process, several highly ranked failure modes were selected and considered for risk treatment where mitigation strategies were allocated according to step 6 discussed below.
Step 5 Risk treatment
For each of the critical failure modes identified, a risk mitigation maintenance strategy is selected using a decision tree scheme to address the risk depicted by the failure modes, where various maintenance strategies advanced considering the risks and root causes embedded in the failure modes.
The decision scheme illustrated in Fig. 2 represents an enhanced version from (Chemweno et al. 2016b), for selecting suitable maintenance strategies for the critical failure modes identified as risk treatment options.

Decision scheme for maintenance strategy selection
The first strategy, i.e. the failure-based maintenance (FBM), is selected for items of low urgency and can be repaired or replaced post-failure. For instance, items with minor failures that are addressed post occurrence are subjected to FBM. The second strategy i.e. Use or Time-based Maintenance (UBM/TBM), is selected for failures of components which deteriorate due to firstly the use (UBM). In this case, where observed use is quantified by time which can be from a meter reading like the engine hours. Secondly, (TBM) is advanced for failure of components which deteriorate due to time in use, where time is based on the calendar. This can be determined by the use of maintenance data of the component. The third strategy, i.e. Condition-based Maintenance (CBM) is proposed where the available component condition can trigger the failure mode, and right information on the component historical performance is available to enable one to determine its remaining life. Hence, maintenance intervention is made before failure occurrence. The fourth strategy i.e. design out maintenance (DOM) strategy, the modification is selected where partial or minor changes on the components being done in the plant are practical and attainable. An example would be, to include a bolt and nut on the flange of a coupling to ensure close tolerances required (Locke et al. 2013). Another DOM option, where the failure mode is done away with completely. This option, is used for components of which either minor or partial changes and repairs, still do not reduce failure rates and cost of carrying out adjustment require equipment builder expertise and cannot be done in the plant. This instance would require reference and advice from the original equipment manufacturer (OEM) on the modification to be done in practice. An example would replace the fasteners on the coupling which has to use special OEM fasteners to ensure more tight installations.
The use of the fifth and sixth strategies, i.e. design for maintenance (DFM) and design-out reliability (DOR) respectively, ensures risk information is cascaded to the OEM to design the components, while addressing the risks identified in practice, to reduce instances that introduce or aggravate risks. DFM will ensure either maintenance is avoided or is significantly reduced, while DOR is used where maintenance cannot be eliminated. Hence, the component is designed to avoid the failure mode identified, while if not re-designable, then DFM is employed. DOR, retain the objective to maximize the lifetime of a component and its durability. To achieve this objective, requires comprehensive knowledge on potential failure modes and reliability characteristics which this study advances in prioritizing the failure modes and further root cause analysis would ideally enable the advancement of the program.
4 Case study results
The results were organized following the methodology Steps 4, where ranking/prioritization is performed and Step 5, which involve risk treatment as discussed in the following section.
4.1 Ranking and prioritization
-
(a)
Subsystem prioritization
Table 4 illustrates the failure frequency, downtime, failure occurrence rate, percentage downtime, total failure cost, percentage failure cost and cumulative failure cost (%) of the plant subsystems ranked based on total failure cost. As depicted using 80:20 Pareto rule, subsystem SS1 had the highest percentage failure cost (29%) in the plant, followed by the SS2 (19%), SS3 and SS4 at (9%), while SS5 and SS6 (8%) which cumulatively account for over 82%.
Subsystems SS13 and SS12 bore the most minimal costs of failure at 2% and 1% respectively. The SS1 had the most significant percentage of downtime (25%), followed by SS2 (18%) and SS6 at 13%, while SS9 had the lowest at 1%. The SS4 showed the highest failure occurrence rate at 23%, followed by the SS7 at 13%, then the SS3 at 12%. SS8 had the least failure occurrence rate of 1% which translates to only one failure occurrence of the 154-failures recorded in the last 3 years. The analysis of the total failure cost, failure occurrence rate and downtime in Table 4, is based on the 80:20 rules. It is clearly observed that from both, a failure occurrence rate and failure cost perspectives, that SS1 is the most critical subsystem followed by the SS2, SS3, SS4, SS5 and the SS6.
The least critical subsystems are SS13, SS12 and SS11. However, for brevity, we will focus on the first three ranked subsystems (i.e. SS1, SS2, and SS3). In the subsequent section, the failure modes under the three identified critical subsystems (SS1, SS2, and SS3) are evaluated and prioritized. The quantitative risk matrix shown in “Appendix 3” is based on the risk levels that were judged acceptable for the Case study plant subsystems by the researcher and the maintenance engineers.
-
(b)
Failure mode prioritization
Failure modes for each of the identified critical subsystems identified in Sect. 5.1, were analyzed. Due to space constraint, we illustrate an extract of the failure modes in subsystem 2 (SS2), where Table 5 illustrates the computed parameters. From Table 5, analyzing failure modes for subsystem SS2, FM15 and FM16 both had the highest failure occurrence rate (each failure mode had occurred twice out of the total 13 failures on the subsystem). FM15 exhibited the highest percentage downtime of 49% of all the failures in the subsystem, cost (26% of all costs on the failure mode) and occurrence rate of 15% as compared to the other failure modes.
This was followed by FM17 and FM 18 both with a percentage downtime (10% of total downtime on the subsystem), cost (11% of all costs on SS2) and occurrence rate of 8% as compared to the other failure modes. FM 15, FM16 and FM 17 were picked as the critical failure mode for the subsystem. Selection of FM16 as one of the critical failure modes could be controversial here; however, following the methodology, whose basis is the cost of failure of respective failure mode, it could be selected over FM18. However, following 80:20 rule FM15, FM16, FM17, FM18, FM19, and FM20 are selected for the final ranking process.
The consequent analysis was conducted considering other highly ranked subsystems i.e. SS1, SS3, SS4, SS5 and SS6 to prioritize/rank failure modes for each of the subsystems. In this case, the resulting highly ranked 25 failure modes (total from the six subsystems) were ranked based on total failure cost, failure occurrence rate and percentage downtime as seen in Table 6.
4.2 Selection of critical failure modes
From the analysis depicted in Table 6, which follows the 80:20 Pareto rule, indicate FM1, FM2, FM15, FM3, FM4, FM26, FM56, FM5, FM27, FM46, FM61, FM16, FM17, and FM18 as the critical failure modes. The 14 failure modes contribute over 79% of total failure cost, 58% of occurrence rate and 82% of downtime of the 25 highly ranked failure modes.
4.3 Selection process of the risk treatment strategies
In this study, the 14 critical failure modes as indicated in Sect. 4.2, were subjected to the risk mitigation strategy selection process. The process involved expert’s discussion (both maintenance engineers and OEM specialists) following the scheme illustrated in Fig. 2 in the same Sect. 4.2. For brevity, we evaluate the three highly ranked failure modes (i.e. FM1 “secondary failure on turbocharger due to broken intake valve”, FM2 “Thermal fatigue of the turbine wheel” and FM15 “Stress fatigue on cylinder head studs”), whose results are illustrated in Table 7.
For FM1, CBM option, for instance, employing vibration analysis would address the failure mode if the occurrence is gradual. Detecting deviations in the vibration signals would potentially signal the need for intervention through more inspection. However, this would be limited if the process of the valve breakage was instantaneous, whereby DOR was proposed as the second option when the use of CBM would not comprehensively address the risk exposed by the failure mode. This is predominantly if the valve design contains a metallurgical defect leading to the breakage. However, this failure had no recurrence characteristics; hence, it was viewed as performing diagnosis, which is a reactive approach. While evaluating FM2, the strict use of TBM for preventive replacement of the turbine wheel is proposed as the primary strategy. Condition monitoring techniques like thermography combined with other inspection techniques like dye penetrant inspection would abate such failure modes. The use of dye penetrant would offer information about the crack existence and or propagation status, while thermography would indicate stressed or hot points which would enhance inspection and further investigation before such failure modes occur. In closing, FM15 evaluation elucidated the use of CBM where vibration analysis could expose cyclic stress while material stress fatigue could invoke DOM where a change of the studs in consultation with original equipment builder (OEM) or equipment builder (EB) could address the risk. This would entail modification, which can be done in-house to mitigate the recurrence of failure. Decidedly, DOR could be invoked if the studs design modification under DOM cannot reduce the failures. The information on the failure mode could be exchanged with the OEM/EB who would re-design the future components (studs) of the equipment incorporating new reliability measures to prevent the recurrence of the failure mode. This process is expected to be interactive with the OEM carrying out field tests of the newly designed studs with the client or under their test engines under research and development (R&D).
4.4 Comparison of proposed cost-based FMEA with conventional RPN approach
This research equally did a comparison study using RPN and cost based FMEA as discussed in this section. This is meaningful as it demonstrated how the results while implementing the two approaches differed. The same structured data as presented in Table 2, under the second step of the methodology in Sect. 3.2, was utilized for this exercise. Scales ranging from one to ten were applied, this means RPN’s range from 1 to 1000. Both the subsystems and Failure Mode, with the highest RPN, were considered for comparison purposes. While calculating the RPN, severity refers to the magnitude of the impact or effect caused by a failure. Hence, when severity rate 10 is tagged failure, it means the failure can cause extensive damage. Likewise, occurrence refers to the likeliness of a failure to take place or eventuate, and detection refers to the prospect or chance of observing or spotting failure before eventuation (Feili et al. 2013). This research adopted the rating scales from (Towler and Sinnott 2012).
Table 8 illustrates the comparison of results using the two approaches RPN vis-a-vis expected failure cost, downtime, and failure occurrence rate. RPN was calculated using the ordinal indices S, O and D as discussed in Sect. 2.1 while the expected cost computed as discussed in Sect. 3.4.3. The final two columns indicate the ranking for each subsystem as demonstrated by RPN and cost-based FMEA approaches, respectively.
Figure 3 illustrates the comparison of failure modes ranked utilizing RPN in comparison to cost-based FMEA performance, where nine failure modes are illustrated. From Table 8 and Fig. 3, it clearly shows that when using the proposed method of cost-based FMEA and RPN, the results are different. SS1, which is ranked first when using Cost based FMEA, is ranked fourth using RPN. This subsystem had high severity whose failure would result in non-functionality of the system, while detectability of the defect obtained a moderate score of 5 (see Table 8). Using the cost-based FMEA, the SS1 subsystem accounts for 25% of downtime experienced by the power plant and 27% of the failure costs incurred by the plant. Comparing the two methods, it clearly shows RPN ranking in terms of criticality is limited and not comprehensive.

Failure modes prioritized based on RPN compared with cost-based FMEA approach
With the most significant contribution of 27% of total failure costs and 25% of total downtime, the subsystem SS1 clearly should be ranked higher in terms of criticality in the power plant, which by contrast, the RPN indicates otherwise. SS3 is ranked third using cost-based FMEA while sixth using RPN. The subsystem had high severity whose failure would result in non-functionality of the system and a remote probability that the defect will be detected with a score of 3. Using the cost-based FMEA, the subsystem accounts to 12% of the combined number of failures in the plant, 7% of downtime experienced by the power plant and 9% of the failure costs incurred by the plant. SS4 is ranked fourth using cost-based FMEA and eighth using RPN. The subsystem had low severity, a significant probability of occurrence over 20% and detectability of the defect indicated a reasonable probability. Using cost-based FMEA, the subsystem accounts for 23% of the combined number of failures in the plant, no downtime and 8% of the failure costs incurred by the power plant.
Similarly, failure mode FM 15 was ranked first using RPN while cost-based FMEA of all failure modes of the plant is ranked third. The severity indicated that the failure resulted in causing non-functionality of the plant. The downtime was the highest for the whole plant of 358 h. This is likely the reason for a high ranking using RPN. The occurrence rate was also rated high since it was 15% of the total failures of the subsystem SS2.
5 Discussion
Many plants such as the case study power plant generate maintenance data, often unstructured and undoubtedly require pre-processing and structuring to be able to derive information. This information can further be analyzed and ultimately offer knowledge that assists in maintenance decision support. This step makes distinct the extent to which meaningful data for the FMEA program was retrieved, the significance of expert assessment and records to offering valid information. Significantly, an interactive engagement is developed between the stakeholders in cases where data requires structuring and further lacks information on key variables required for analysis, to ensure the validity of the outcome of the results is achieved. This study demonstrated this aspect, by employing experts in all data verification and validation process, as well as consolidating various aspects such as labour costs and carrying out RPN computations.
In this study, the methodology advanced follows a three-step prioritization process where, the first step involved performing criticality analysis of subsystems following the 80:20 Pareto rule. In this first step, SS1, SS2, SS3, SS4, SS5, and SS6 were derived as critical subsystems. In the second step, failure modes for each of the six highly ranked subsystems were prioritized, while the ultimate step the highly ranked failure modes from each of the critical subsystem were evaluated to prioritize the failure modes. This evaluation approach demonstrates the potential of offering critical insights especially for maintenance managers that desire to identify critical failure modes in a plant. For instance, evaluating Table 4; the plant can identify the six critical subsystems contributing to over 80% of the total cost of failure in the plant. Sizeable plants with many subsystems could harness this potential benefit, while this may bare a limitation for small plants. The limitation may be attributed to the fact that, while prioritizing subsystems, highly intensive subsystems in terms of failure costs will dominate, and this may lead to the sub-optimal outcome as some critical failure modes may go unnoticed. However, this framework offers insight into the critical failure modes the maintenance function should focus on and address. If these critical failure modes are dealt with, significant plant performance improvement will be derived. In contrast to the conventional FMEA programs, this approach utilizes multiple indices (failure cost, downtime, and failure occurrence rate) while undertaking prioritization task. This combination of findings provides some support for the conceptual premise, that the consideration of more than one index could represent a significant factor. This factor would ensure reliability of the prioritization process as evidenced in the results derived in Sect. 4.2. This case reveals, where failure modes had approximately same value in terms of failure cost, other indices can be used to prioritize between the two failure modes. Nonetheless, the present results are significant in at least two significant respects, firstly, the approach while prioritizing the subsystems offers the first criticality analysis, which conclusively adds insight and focus to the maintenance function. For instance, identifying the critical subsystems will undoubtedly reduce effort and time in the preceding or future prioritization process, which we believe will ensure timely interventions and maintenance plans. This further offers a potential benefit to the plant, ensuring an objective and targeted resource allocation and scheduling program that considers the critical subsystems. In the second aspect, employing the cost of failure as a basis for prioritization, a quantitative index eliminates bias while offering an objective decision support framework. The elicited cost aspects were retrieved from the supply chain and verified, e.g. checking the cost of similar parts from the OEM or part suppliers which offers validity to the process. Cost represents a generalizable objective aspect that is well understood and related to. Hence, due to its quantitative characteristics; its application in the prioritization process will eliminate subjectivity and bias as evidenced in other conventional FMEA approaches such as RPN. Sensitivity analysis was utilized for predicting the outcome of a decision if a situation turns out to be different (considering downtime, spare cost and labour rate) compared to the key predictions. The results of the sensitivity analysis for the expected failure cost, sample (downtime and spare cost as independent variables) presented in “Appendix 4”, demonstrates that with an average change between 2% and 12% of the downtime, spare parts cost and labour rate, the expected cost of failure increases between 1.8% and 10.3%. The spare parts cost is identified as the variable with significant influence or impact on the expected cost of failure.
The three-step prioritization using RPN and cost-based FMEA approaches, for comparison produced altogether distinct sets of results. This is because, from the onset, the two ranking approaches are not exactly similar, because cost-based FMEA is quantitative while RPN approach is qualitative. Hence the prioritized subsystems were different when RPN or cost-based FMEA is employed. However, the conventional RPN approach is principally used in practice where all the failure modes of a plant are evaluated together. This is in contrast to our three-step ranking approach using cost-based FMEA, where we first rank the subsystems, followed by the failure modes of the critical subsystems and finally the failure modes from the highly ranked subsystems are prioritized. These two aspects, consideration of quantitative indices and 3-step prioritization process, we view offers a more realistic differentiation between the conventional RPN and our proposed cost-based FMEA approach. Consistent with the literature, this research found that utilizing RPN lacks the objectivity required for robust risk assessment, more so, where maintenance data is available which could enhance such objectivity and validity of failure prioritization outcomes.
While undertaking risk treatment, which represents the ultimate process that is supported by the developed framework, options considered include unconventional maintenance strategies. The unconventional strategies included Design of Maintenance (DOM), Design of Reliability (DOR) and Design for Maintenance (DFM). These strategies were utilized in addition to the conventional FBM, UBM/TBM, and CBM. While strategies employed by the end-user or the maintenance team might be limited to the application context of the equipment under study, the involvement of the equipment builder or original equipment manufacturers (OEM) becomes significant to address inherent risks. This decision scheme would offer support to a broad range of industries and addresses not only the in-house strategies but also engages the OEM or supplier of the technology. This is an aspect that is significant for capital assets that plants strive to lengthen or extend their life beyond the end of life. This finding considers significant implications for selecting maintenance strategies in cases where a plant is faced with the challenge like obsolete technology. In this case, equipment and or spares are no longer available due to technological advancement or equipment builder interruptions such as close-out or acquisition. Hence, the requirement to employ unconventional strategies like DOM and DOR is recommended.
6 Conclusion
This research was designed to develop a methodology to identify critical failure modes and their mitigation strategies. This was derived from the use of the cost-based FMEA to generate the anticipated costs and consequent prioritization of the subsystems and failure modes. This additionally incorporated failure occurrence rate and downtime contribution of the subject subsystem and failure modes. It was noted that the prioritization of failures using frequency alone would lead to erroneous maintenance actions prioritization. Analysis of the variables used in the research exposed that the downtime in terms of time the equipment is unavailable, and the cost, contributes significantly to the failure cost. This could also be dealt with by maintaining a redundant unit on standby, which would present an extra challenge of high inventory holding costs in the spares inventory. Despite the downtime cost contributing to the failure costs, most power plants secure contractual agreements to supply up to a thresh hold capacity, failure to which a hefty penalty is imposed. The methodology exposed the magnitude in size/value of a failure mode that needs to be identified and seen by the maintenance engineers, an aspect unconsidered by other conventional FMEA approaches. With the identification of the critical subsystems and failure modes, the plant can implement an optimal allocation of maintenance policies and targeted maintenance actions that will reduce failure, consequent downtime, and cost of failure. This directly positively affects the plant reliability and cost of operations, improving profitability. Further research on root cause analysis of the critical failure modes would ideally enable comprehensive maintenance strategy selection.
The research also compared the risk prioritization of the proposed method of cost-based FMEA with the conventional RPN method. The two methods produced altogether conflicting results with cost-based FMEA producing more comprehensive results. The developed cost-based FMEA method employed in this research addressed most of the RPN limitations outlined earlier. The research showed a comprehensive prioritization of critical subsystems and failure modes, should not be subjective as using ordinal values as the case of RPN represent; but should use discrete values with actual implications or exposure which cost-based FMEA utilized. The use of costs (generated from actual impact and through expert assessment hence reducing subjectivity), failure occurrence rate and downtime for the subject failure modes offer an objective method for risk prioritization. This integrated approach will enhance the accuracy and exactness of FMEA results in the field of risk assessment. Finally, the incorporation of design for maintenance and design for reliability as risk treatment options involving both the OEM and equipment user, illustrate the significance of collaboration in learning the equipment risks and improving the designs. Further research on the OEM-user framework towards enhanced equipment design for maintenance and reliability optimization is proposed. Finally, due to extensive failures experienced and the need for plants to extend operations of the equipment beyond their end of life, a study linking maintenance and other equipment life extension strategies could be advanced.
Abbreviations
- FMEA:
-
Failure mode and effect analysis
- RPN:
-
Risk priority number
- FMECA:
-
Failure modes and effect criticality analysis
- TBM:
-
Time based maintenance
- UBM:
-
Use based maintenance
- CA:
-
Criticality analysis
- FM:
-
Failure mode
- SS:
-
Subsystem
- FBM:
-
Failure based maintenance
- CBM:
-
Condition-based maintenance
- DOM:
-
Design out maintenance
- DFM:
-
Design for maintenance
- DOR:
-
Design out reliability
References
Avontuur GC, van der Werff K (2001) An implementation of reliability analysis in the conceptual design phase of drive trains. Reliab Eng Syst Saf 73:155–165. https://doi.org/10.1016/S0951-8320(01)00041-2
Bhangu NS, Pahuja GL, Singh R (2017) Enhancing reliability of thermal power plant by implementing RCM policy and developing reliability prediction model: a case study. Int J Syst Assur Eng Manag 8:1923–1936. https://doi.org/10.1007/s13198-016-0542-z
Bradley JR, Guerrero H, H Ector (2011) An alternative FMEA method for simple and accurate ranking of failure modes. Decis Sci 42:743–772
Cameron I, Mannan S, Németh E et al (2017) Process hazard analysis, hazard identification and scenario definition: are the conventional tools sufficient, or should and can we do much better? Process Saf Environ Prot 110:53–70. https://doi.org/10.1016/j.psep.2017.01.025
Castro-Santos L, Martins E, Guedes Soares C (2016) Cost assessment methodology for combined wind and wave floating offshore renewable energy systems. Renew Energy 97:866–880. https://doi.org/10.1016/J.RENENE.2016.06.016
Chemweno P, Morag I, Sheikhalishahi M et al (2016a) Development of a novel methodology for root cause analysis and selection of maintenance strategy for a thermal power plant: a data exploration approach. Eng Fail Anal 66:19–34. https://doi.org/10.1016/j.engfailanal.2016.04.001
Chemweno P, Pintelon L, Wakiru J et al (2016b) A dynamic risk assessment methodology for maintenance decision support. Qual Reliab Eng Int 33:551–564. https://doi.org/10.1002/qre.2040
Chin K-S, Wang Y-M, Poon GKK, Yang J-B (2009) Failure mode and effects analysis by data envelopment analysis. Decis Support Syst 48:246–256. https://doi.org/10.1016/j.dss.2009.08.005
Dong C (2007) Failure mode and effects analysis based on fuzzy utility cost estimation. Int J Qual Reliab Manag 24:958–971. https://doi.org/10.1108/02656710710826216
Du Y, Mo H, Deng X et al (2014) A new method in failure mode and effects analysis based on evidential reasoning. Int J Syst Assur Eng Manag 5:1–10. https://doi.org/10.1007/s13198-014-0218-5
Fakher HB, Nourelfath M, Gendreau M (2018) Integrating production, maintenance and quality: a multi-period multi-product profit-maximization model. Reliab Eng Syst Saf 170:191–201. https://doi.org/10.1016/j.ress.2017.10.024
Feili HR, Akar N, Lotfizadeh H et al (2013) Risk analysis of geothermal power plants using failure modes and effects analysis (FMEA) technique. Energy Convers Manag 72:69–76. https://doi.org/10.1016/j.enconman.2012.10.027
Gaula AK, Sharma RK (2015) Analyzing the effect of maintenance strategies on throughput of a typical FMC (3-M, 1-R). Int J Syst Assur Eng Manag 6:183–190. https://doi.org/10.1007/s13198-014-0268-8
Gilchrist W (1993) Modelling failure modes and effects analysis. Int J Qual Reliab Manag 10:16–23. https://doi.org/10.1108/02656719310040105
Gupta P, Gandhi OP (2014) Equipment redesign feasibility through maintenance-work-order records using fuzzy cognitive maps. Int J Syst Assur Eng Manag 5:21–31. https://doi.org/10.1007/s13198-013-0214-1
Hassan A, Siadat A, Dantan JY, Martin P (2010) Conceptual process planning an improvement approach using QFD, FMEA, and ABC methods. Robot Comput Integr Manuf 26:392–401. https://doi.org/10.1016/j.rcim.2009.12.002
Jahangoshai Rezaee M, Salimi A, Yousefi S (2017) Identifying and managing failures in stone processing industry using cost-based FMEA. Int J Adv Manuf Technol 88:3329–3342. https://doi.org/10.1007/s00170-016-9019-0
Jamwal U, Kamboj K, Srivastava P et al (2018) Fuzzy methodology application for failure analysis of transmission system. Int J Math Oper Res 12:220. https://doi.org/10.1504/ijmor.2018.10010217
Jardine AK, Tsang AH (2013) Maintenance, replacement, and reliability, vol Second. CRC Press, Boca Ranton
Karthikeyan M, Naikan VNA, Narayan R (2017) Root cause analysis and reliability improvement methods for orbital TIG welding process for propulsion feed system of satellites. Int J Syst Assur Eng Manag 8:910–924. https://doi.org/10.1007/s13198-016-0549-5
Kmenta S, Ishii K (2005) Scenario-based failure modes and effects analysis using expected cost. J Mech Des 126:1027–1035. https://doi.org/10.1115/1.1799614
Kumar G, Maiti J (2012) Modeling risk based maintenance using fuzzy analytic network process. Expert Syst Appl 39:9946–9954. https://doi.org/10.1016/j.eswa.2012.01.004
Kutlu AC (2012) Expert systems with applications fuzzy failure modes and effects analysis by using fuzzy TOPSIS-based fuzzy AHP. Expert Syst Appl 39:61–63. https://doi.org/10.1016/j.eswa.2011.06.044
Li Y-F, Huang H-Z, Zhang H et al (2013) Fuzzy Sets Method of Reliability Prediction and Its Application to a Turbocharger of Diesel Engines. Adv Mech Eng 2013:7. https://doi.org/10.1155/2013/216192
Linnéusson G, Galar D, Wickelgren M (2016) In need for better maintenance cost modelling to support the partnership with manufacturing á shift in mind. In: Kumar U, Ahmadi A, Verma A, Varde P (eds) Current trends in reliability, availability, maintainability and safety. Lecture notes in mechanical engineering. Springer, Cham
Liu H-C, Liu L, Liu N (2013) Risk evaluation approaches in failure mode and effects analysis: a literature review. Expert Syst Appl 40:828–838. https://doi.org/10.1016/j.eswa.2012.08.010
Liu H-C, Li P, You J-X, Chen Y-Z (2015) A novel approach for FMEA: combination of interval 2-tuple linguistic variables and gray relational analysis. Qual Reliab Eng Int 31:761–772. https://doi.org/10.1002/qre.1633
Locke S, Corcoran J, Burgess M et al (2013) Coupling credible failure modes and owner options to intervene. Turbo Mach Symp 42:1–30
Panchal D, Kumar D (2017) Stochastic behaviour analysis of real industrial system. Int J Syst Assur Eng Manag 8:1126–1142. https://doi.org/10.1007/s13198-017-0579-7
Panchal D, Srivastava P (2018) Qualitative analysis of CNG dispensing system using fuzzy FMEA–GRA integrated approach. Int J Syst Assur Eng Manag 10:44–56. https://doi.org/10.1007/s13198-018-0750-9
Panchal D, Mangla SK, Tyagi M, Ram M (2018) Risk analysis for clean and sustainable production in a urea fertilizer industry. Int J Qual Reliab Manag 35:1459–1476. https://doi.org/10.1108/IJQRM-03-2017-0038
Pintelon L, Van Puyvelde F (2013) Asset management: the maintenance perspective. ACCO, Leuven
Rhee SJ, Ishii K (2003) Using cost based FMEA to enhance reliability and serviceability. Adv Eng Inf 17:179–188. https://doi.org/10.1016/j.aei.2004.07.002
Ríos J, Duque D, Gómez J (2019) Operational supply chain risk identification and prioritization using the Identification and priorization using SCOR model. Ing Univ 23:1–18. https://doi.org/10.11144/Javeriana.iyu23
Sahoo T, Sarkar PK, Sarkar AK (2014) Maintenance optimization for critical equipments in process industries based on FMECA method. Int J Eng Innov Technol 3:107–112
Sharma RK, Sharma P (2012) Integrated framework to optimize RAM and cost decisions in a process plant. J Loss Prev Process Ind 25:883–904. https://doi.org/10.1016/j.jlp.2012.04.013
Sinha RS, Mukhopadhyay AK (2015) Reliability centered maintenance of cone crusher: a case study. Int J Syst Assur Eng Manag 6:32–35. https://doi.org/10.1007/s13198-014-0240-7
Sondalini M (2009) Plant and equipment wellness. Engineers Media, Riverwood
Towler G, Sinnott R (2012) Chemical engineering design, safety and loss prevention. Elseiver, Massachusetts
Vala S, Chemweno P, Pintelon L, Muchiri P (2018) A risk-based maintenance approach for critical care medical devices: a case study application for a large hospital in a developing country. Int J Syst Assur Eng Manag. https://doi.org/10.1007/s13198-018-0705-1
von Ahsen A (2008) Cost-oriented failure mode and effects analysis. Int J Qual Reliab Manag 25:466–476. https://doi.org/10.1108/02656710810873871
Wakiru J (2015) Development of a maintenance strategy for a thermal power plant: a case study. Dedan Kimathi University of Technology, Mechanical Engineering, Nyeri
Wakiru J, Pintelon L, Muchiri P, Chemweno P (2018) Maintenance optimization: application of remanufacturing and repair strategies. Proc CIRP 69:899–904. https://doi.org/10.1016/j.procir.2017.11.008
Wakiru J, Pintelon L, Muchiri P, Chemweno P (2019a) Maintenance objective selection framework applicable to designing and improving maintenance programs. Int J Eng Res Af 43:127–144. https://doi.org/10.4028/www.scientific.net/JERA.43.127
Wakiru J, Pintelon L, Muchiri PN, Chemweno PK (2019b) A review on lubricant condition monitoring information analysis for maintenance decision support. Mech Syst Signal Process 118:108–132. https://doi.org/10.1016/j.ymssp.2018.08.039
Wang MH (2011) A cost-based FMEA decision tool for product quality design and management. In: Proceedings of 2011 IEEE international conference on intelligence and security informatics. IEEE, pp 297–302
Yager RR (1981) A new methodology for ordinal multiobjective decisions based on fuzzy sets. Decis Sci 12:589–600. https://doi.org/10.1111/j.1540-5915.1981.tb00111.x
Zammori F, Gabbrielli R (2012) ANP/RPN: a multi criteria evaluation of the risk priority number. Qual Reliab Eng Int 28:85–104. https://doi.org/10.1002/qre.1217
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Failure modes codes and description
Code | Failure mode | Code | Failure mode |
|---|---|---|---|
FM1 | Secondary failure—broken intake valve | FM26 | Cam failure |
FM2 | Thermal fatigue—turbine wheel | FM27 | Thermal fatigue on cam |
FM3 | Secondary failure—broken exhaust valve | FM28 | Material failure causing high exhaust temp |
FM4 | Thermal erosion—turbine blades | FM46 | Injector cracked |
FM5 | Axial displacement—Bearing failure | FM47 | Cam roller failure |
FM6 | Broken valve cone | FM48 | Fuel oil leak |
FM15 | Stress fatigue on cylinder head studs | FM49 | Abrasive wear on injector nozzle and push rod |
FM16 | Cracked cylinder head | FM50 | Injector leaking |
FM17 | Thermal fatigue—inlet valve | FM56 | High LO inlet temp- governor fail |
FM18 | Stress fatigue on barring bearings | FM57 | Sheared driveshaft |
FM19 | Piston cracked -lack of lubrication | FM58 | Impact fatigue-governor over speed |
FM20 | Thermal stress on the cylinder | FM61 | Sheared governor bolts |
FM21 | Low water jacket pressure—Misaligned sleeve | FM62 | Low LO pressure-secondary contaminant |
Appendix 2: Subsystems codes and description
Subsystem description | Subsystem |
|---|---|
Turbocharger | SS1 |
Cylinder | SS2 |
Cam | SS3 |
Fuel system | SS4 |
Governor | SS5 |
LO pump | SS6 |
Lubrication system | SS7 |
Main bearings | SS8 |
Water jacket | SS9 |
Valves | SS10 |
Cooler | SS11 |
Exhaust | SS12 |
Inlet fuel pipe | SS13 |
Appendix 3: Risk matrix employed for risk assessment of case study subsystems

Appendix 4: Sensitivity analysis of expected failure cost (US$)
Δ in average spare cost | |||||
|---|---|---|---|---|---|
19.404 | 2% | 4% | 6% | 8% | 10% |
Δ in average downtime | |||||
2% | 19.767 | 19.945 | 20.122 | 19.109 | 20.478 |
5% | 20.045 | 20.223 | 20.400 | 19.387 | 20.756 |
7% | 20.230 | 20.408 | 20.586 | 19.572 | 20.941 |
9% | 20.416 | 20.593 | 20.771 | 19.758 | 21.126 |
12% | 20.694 | 20.871 | 21.049 | 20.036 | 21.404 |
Rights and permissions
About this article

Cite this article
Wakiru, J., Muchiri, P.N., Pintelon, L. et al. A cost-based failure prioritization approach for selecting maintenance strategies for thermal power plants: a case study context of developing countries. Int J Syst Assur Eng Manag 10, 1369–1387 (2019). https://doi.org/10.1007/s13198-019-00864-z
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-019-00864-z