
Abstract
A new three-parameter lifetime distribution based on compounding Pareto and Poisson distributions is introduced and discussed. Various statistical and reliability properties of the proposed distribution including: quantiles, ordinary moments, median, mode, quartiles, mean deviations, cumulants, generating functions, entropies, mean residual life, order statistics and stress-strength reliability are obtained. In presence of data collected under Type-II censoring, from frequentist and Bayesian points of view, the model parameters are estimated. Using independent gamma priors, Bayes estimators against the squared-error, linear-exponential and general-entropy loss functions are developed. Based on asymptotic properties of the classical estimators, asymptotic confidence intervals of the unknown parameters are constructed using observed Fisher’s information. Since the Bayes estimators cannot be obtained in closed-form, Markov chain Monte Carlo techniques are considered to approximate the Bayes estimates and to construct the highest posterior density intervals. A Monte Carlo simulation study is conducted to examine the performance of the proposed methods using various choices of effective sample size. To highlight the perspectives of the utility and flexibility of the new distribution, two numerical applications using real engineering data sets are investigated and showed that the proposed model fits well compared to other eleven lifetime models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Modeling of lifetime data is an important issue for statisticians in a wide range of scientific and technological fields such as medicine, engineering, biology, actuarial science, industrial reliability, etc. The basic idea behind compounding is that the lifetime of a system with N(a discrete random variable) components and the lifetime of ith component (say Xi), independent of N, follow several lifetime distributions. Then the maximum (or minimum) time of failures of components of the system depending on the condition whether they are parallel (or in series), see Adamidis and Loukas (1998). By compounding some continuous distributions (such as the exponential, gamma or Weibull distribution) with some discrete distributions (such as binomial, geometric or zero-truncated Poisson), several new distributions were introduced in the literature, for example see Maurya and Nadarajah (2021).
Pareto’s distribution was first proposed for modeling the income data, and then used to analyze the size of city’s population and the firms size. It has also been an appropriate fit to numerous data in many scientific fields such as physics, technology, biology etc., whenever the Pareto’s law is found, for details see Nadarajah (2005). To generate a distribution that has the ability to model lifetimes data with a heavy tail, based on the composition of the Pareto distribution with the class of discrete distributions power series, De Morais (2009) introduced a class of continuous distributions called Pareto power series (PPS). He also discussed various of its statistical properties along with its reliability features. Three special cases of the PPS, called; Pareto-Poisson, Pareto-geometric and Pareto-logarithmic distributions have also been investigated. Moreover, several lifetime distributions have been introduced as an extension of the Pareto distribution, for example, Asgharzadeh et al. (2013) introduced the Pareto Poisson-Lindley distribution and studied several of its properties. Nassar and Nada (2013) presented the beta Pareto-geometric distribution. Elbatal et al. (2017) proposed the exponential Pareto power series distributions.
To the best of our knowledge, we have not encountered any work related to discussing any statistical properties of the Pareto-Poisson (PP) distribution and/or estimating its parameters under complete (or incomplete) sampling. So, by demonstrating that the PP distribution may be used as a survival model utilizing complete and Type-II censored samples, the purpose of this study is to close this gap. The objectives of the present study are three-fold. First, we shall exclusively focus on discussing some several characteristics of the PP distribution such as: quantile function, median, mode, quartiles, mean deviations, moments, generating functions, entropies, mean residual life, order statistics and stress-strength reliability. Second objective aimed to derive both point and interval estimators of the PP parameters, when the scale Pareto parameter is known, using likelihood and Bayesian estimation methods. Two-sided approximate confidence intervals for the unknown parameters, using asymptotic normal approximation of the frequentist estimators, are constructed. Using independent gamma priors, the Bayes estimators of the PP parameters are developed against symmetric and asymmetric loss functions. Since Bayes estimators cannot be obtained analytically, Markov chain Monte Carlo (MCMC) techniques are considered to compute the Bayes estimates and to construct associated highest posterior density intervals are computed. To check the convergence of MCMC chains, Gelman and Rubin’s convergence diagnostic statistic is used. A comparison between the proposed methodologies is made through a simulation study in terms of their root mean squared-error (RMSE), relative absolute bias (RAB), average confidence lengths (ACLs) and coverage probabilities (CPs). Lastly, two real data sets of different features; the first includes the failure times of some mechanical components and the other represents the active repair times for airborne communication transceiver, are discussed to show how the proposed methods can be applied in real practice. Some specific recommendations are also drawn from the numerical findings.
The rest of the paper is organized as follows: In Section 2, we define the PP distribution and its statistical properties. Frequentist and Bayes estimators for parameter estimation are developed in Sections 3 and 4, respectively. The simulation results are reported in Section 5. Section 6 presents two real applications of the proposed distribution. Some conclusions are addressed in Section 7.
2 The Pareto–Poisson Distribution
In this section, we introduce the PP distribution, which is a member of the Pareto power series family of distributions, and investigate some of its useful mathematical and statistical properties such as: moments, entropies, generation function, reliability function, failure rate function, mean residual-life function stress-strength reliability and order statistics.
First suppose that Y1,Y2,...,YN are independent random variables (rv)s following the Pareto distribution whose probability density function (PDF), \(g\left (y;\alpha ,\lambda \right )=\alpha {{\lambda }^{\alpha }}{{y}^{-\left (\alpha +1 \right )}},\ y\geqslant \lambda \), with shape parameter α > 0 and scale parameter λ > 0. Following De Morais (2009), suppose that the index N is a rv follows a distribution in the power series class whose the following probability mass function
where an > 0 (depends only on n) and \( C(\beta )=\sum \nolimits _{n=1}^{\infty }{{{a}_{n}}}{{\beta }^{n}},\ \beta >0 \) is finite.
If one set \(X_{(1)}={\min \limits } \left [ {{Y}_{1}},{{Y}_{2}},...,{{Y}_{N}} \right ]\), then the conditional distribution of X(1) given N = n follows the Pareto density with shape parameter nα and scale parameter λ. Then, the cumulative distribution function (CDF) of X(1)|N = n (say G(⋅)) can be defined as
and the joint PDF of X(1) and N (say g(⋅)) is given by
Setting n = 1 in Eqs. 2.2 and 2.1, the PDF and CDF of the PPS distribution are given by
and
respectively.
As a result, by setting C(β) = eβ − 1 and \( {C}^{\prime }(\beta )={{e}^{\beta }} \) in Eqs. 2.3 and 2.4, the PDF and CDF of three-parameter PP distribution are given respectively by
and
where α is the shape parameter and (β,λ) are the scale parameters. Moreover, when \( \beta \rightarrow {0^{+}} \), the Pareto distribution can be obtained as a special case from the PP distribution.
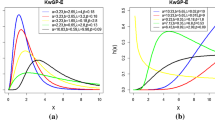
Using some specified values of α, λ and β, some shapes of the PP density function (2.5) are displayed in Fig. 1. It shows that the PP density has a heavy tail. Also, from Eqs. 2.3 and 2.4, one can be easily seen that \( \lim _{x\rightarrow {\infty }} F(t+x)/({{1-{F}(x)}}) = 1 \), which means that the PP distribution has also a long right tail.

Several shapes of the PP density using some specific parameter values
2.1 Quantile, Median and Mode
To generate random samples from the PP distribution, suppose that U is a rv of standard uniform distribution. From Eq. 2.6, it can be shown that the following transformation of U has a PP distribution. Thus, the quantile function x = Q(p) = F− 1(p), for 0 < p < 1, of the PP distribution is given by
In particular, the first, second (median) and third quartiles of the PP distribution (say Q1(⋅), Q2(⋅) and Q3(⋅)) can be obtained by putting p = 0.25, 0.50 and = 0.75 in Eq. 2.7, respectively.
The mode of the PP distribution, x0, is obtained by finding the first derivative of its logarithm PDF, \(\log f\left (x \right )\) with respect to x and equating it to zero. Hence, the mode of the PP distribution is defined by
is always exists and unique.
2.2 Moments
Moments used to describe the characteristics of a distribution, so they are necessary and important in any statistical analysis. So, in this section, the r − th moment about zero of PP distribution is derived. However, the r − th moment \( ({{{\mu }}^{\prime }_{r}}) \) of a rv X has density function (2.5) is given by
using the following Taylor’s series expansion
then, from Eqs. 2.8 and 2.9, the r − th moment of PP distribution for r = 1,2,3,... can be expressed as
Setting r = 1, the mean of X, where \(X\sim \text {PP}{(\alpha ,\lambda ,\beta )}\), is
Similarly, setting r = 1 and r = 2, the variance of X is given by \(V(X)={{{\mu }}^{\prime }_{2}}-{{\left ({{{{\mu }}^{\prime }}_{1}} \right )}^{2}}\) where
Using the cumulants, denoted by \({\mathcal {C}_{r}}\), the coefficient of skewness and kurtosis can be calculated from the ordinary moments of X. As \(X\sim \text {PP}{(\alpha ,\lambda ,\beta )}\), the first four cumulants of a rv X are given by
Putting r = 1,2,3,4 into (2.12), then one gets the four cumulants \( \mathcal {C}_{r},\ r=1,2,3,4 \) as
Once the cumulants \( \mathcal {C}_{2} \), \( \mathcal {C}_{3} \) and \( \mathcal {C}_{3} \) of the PP distribution obtained, the corresponding coefficients of skewness (denoted by κ1), and kurtosis (denoted by κ2), of PP distribution can easily be evaluated, respectively, as \({{\kappa }_{1}}={{\mathcal {C}_{3}}}/{\mathcal {C}_{2}^{{3}/{2}}}\) and \({{\kappa }_{2}}={{\mathcal {C}_{4}}}/{\mathcal {C}_{2}^{2}} \).
2.3 Moment Generating Function
The moment generating (MG) function of X provides the basis of an alternative route to analytic results compared with working directly with the CDF (or PDF) of X. However, the MG function denoted by MX(t), is given by
Applying the Maclaurin series expansion for etx, we get \( {{e}^{tx}}=\sum \nolimits _{r=0}^{\infty }{\frac {{{(tx)}^{r}}}{r!}} \). If X is a non-negative rv follows the PP distribution, then (2.13) can be rewritten as
However, substituting (2.10) in (2.14), the MG function of the PP distribution can be expressed as
Practically, it is easier to work with the logarithm of the MG function which is called the cumulant generating function. Using the MG function for |t| < 1, the cumulant generating function, \({{C}_{X}}\left (t \right )\), of a rv X follows the PP distribution is given by
From Eqs. 2.10 and 2.15, the cumulant generating function of PP distribution is given by
2.4 Mean Deviation
The mean deviation about the mean and the median are useful measures of variation for a population. Let μ and M be the mean and median of the PP distribution respectively. The mean deviations about the mean μ (say \({\mathcal {D}_{1}}(X)\)) and about the median M(say \({\mathcal {D}_{2}}(X)\)) can be calculated respectively as
and
For short, set \( \eta =\left (\mu \text { or }M \right ) \), using (2.5), one gets
Using the Taylor’s series expansion (2.9), based on some algebraic manipulations, Eq. 2.18 can be rewritten as
Substituting (2.19) into (2.16) and (2.17), the mean deviations about the mean μ and about the median M of PP distribution are given, respectively, by
and
where φ(μ) and φ(M) can be easily obtained from Eq. 2.19 by replacing η by μ or M, respectively.
2.5 Hazard and Reversed Hazard Functions
The hazard h(⋅) and reverse hazard r(⋅) functions of the PP distribution are given respectively by
and
where F(⋅), f(⋅) and R(⋅) are obtained in Eqs. 2.1, 2.2 and 2.23, respectively.
To show that h(⋅) is monotonically decreasing function depending on the PP parameters, the Glaser’s theorem is used, see Glaser (1980). First, define the following function
where \( {f}^{\prime }(x) \) is the first derivative of f(x) with respect to x.
From Eq. 2.5, Eq. 2.21 is equivalent straightforward to
then its first derivative will be
From Eq. 2.22, it can be easily seen that the hazard function of PP distribution, for 0 < α < 1, is decreasing function for all given x > 0 values. Plots of hazard function (2.20) for various values of the model parameters α, β and λ are displayed in Fig. 2. It shows that the hazard rate plots of the PP distribution have decreasing shape in x for all given values of α, β and λ.

Hazard rate of the PP distribution using some specific parameter values
2.6 Reliability and Mean Residual Life
The reliability (or survival) R(⋅) function of PP distribution is given by
In the context of reliability studies, the mean-residual-life mR(⋅) function is known as the average remaining life span, which is a component survived up to distinct time t is defined as
where R(t) and \( {{{\mu }}^{\prime }_{1}} \) are defined in Eqs. 2.23 and 2.11, respectively.
However, let X be a PP lifetime rv, then the mean-residual-life of X is given by
2.7 Entropies
Entropy is an important metric used to measure the amount of uncertainty associated with a rv X. It has been used in many fields such as survival analysis, information theory, computer science and econometrics. So, this section deals with two well-known entropies namely Rényi and δ-entropies. Recently, the considered entropies have also been discussed by Amigó et al. (2018) and Elshahhat et al. (2021).
The Rényi entropy of ζth order, say ρζ, is defined as
If \( X\sim \text {PP}(\alpha ,\beta ,\lambda ) \), using the Taylor’s series expansion (2.9), we get
where \( {{J}^{*}}=1-\zeta \left (\alpha +1 \right )-\alpha J. \)
Hence, from Eq. 2.25, the Rényi entropy of X becomes
Thus, the δ-entropy, denoted by \( {{I}_{\delta }}\left (X \right ) \), of a lifetime rv X follows PP(α,β, λ) is given by
and then it follows the Rényi entropy given by Eq. 2.26.
2.8 Order Statistics
In this subsection, closed-form expressions for the PDF and CDF of the rth order statistic of the PP distribution are obtained. In particular, the distribution of the smallest X(1) and largest X(n) order statistics are also obtained. Suppose \({{X}_{(1)}}\leqslant {{X}_{(2)}}\leqslant \cdots \leqslant {{X}_{(n)}}\) represent the order statistics of a random sample of size n obtained from Eqs. 2.5 and 2.6.
Thus, the PDF and CDF of \({{X}_{(r)}},\ r=1,2,\dots ,n,\) denoted by f(r)(x) and F(r)(x) are given respectively by
and
where \({{C}_{r}}=B\left (r,n-r+1 \right )\).
Substituting (2.) and (2.6) into (2.27) and (2.28), the PDF of the rth order statistic from PP distribution is given by
and
In particular, by setting r = 1 and r = n in Eqs. 2.29 and 2.30, the PDFs of smallest X(1) and largest X(n) order statistics are given, respectively, by
and
2.9 Stress-Strength Reliability
Stress-strength model describes the life of a component which has a random strength (say X1) that is subjected to a random stress (say X2). The component fails when the stress applied to it exceeds the strength and it continues to operate satisfactorily whenever X1 > X2.
Suppose X1 and X2 have independent PP rv s such as \( {{X}_{1}}\sim {\text {PP}}\left ({{\alpha }_{1}}, \lambda ,{{\beta }_{1}} \right ) \) and \( {{X}_{2}}\sim {\text {PP}}\left ({{\alpha }_{2}}, \lambda ,{{\beta }_{2}} \right ) \). Then the stress-strength parameter, say \( \mathcal {R} \), where \( \mathcal {R}=\Pr \left ({{X}_{1}}>{{X}_{2}} \right ) \), is defined as
However, using Eqs. 2.5 and 2.6, the PDF and CDF of X1 and X2 can be expressed, respectively, as
and
where α1 and α2 are the shape parameters and β1,β2 and λ are the scale parameters.
Substituting (2.32) and (2.33) into (2.31), the stress-strength parameter \( \mathcal {R} \) becomes
For the integral term in Eq. 2.34 (say \( \mathcal {G} \)), using the Taylor’s series expansion (2.9), after some algebraic manipulations, we get
Thus, using (2.35), the stress-strength parameter \( \mathcal {R} \) of PP distribution is given by
where \( {{\psi }_{J}}\left (\lambda ,{{\alpha }_{1}},{{\beta }_{1}},{{\beta }_{2}} \right )=\frac {{\beta _{1}^{J}}{{\lambda }^{-{{\alpha }_{1}}}}{{e}^{{{\beta }_{2}}}}}{{{\alpha }_{1}}(J+1){\Gamma } (J+1)} \) and \( {{\psi }_{J,s}}\left (\lambda ,{{\alpha }_{1}},{{\alpha }_{2}},{{\beta }_{1}},{{\beta }_{2}} \right )=\) \(\frac {{\beta _{1}^{J}}{\beta _{2}^{s}}{{\lambda }^{-{{\alpha }_{1}}}}}{\left ({{\alpha }_{1}}(J+1)+{{\alpha }_{2}}s \right ){\Gamma } (J+1){\Gamma } (s+1)} \).
The likelihood estimation method is the most widely-used in statistical inference and the associated estimators included various desirable properties such as efficiency, consistency, invariance property and convergence properties as well as its intuitive appeal. When the prior information of test items exists, the Bayesian procedure provide some advantages compared with the traditional likelihood technique. One of the most common censoring plans in reliability experiments is termed as Type-II censoring. This censoring has several advantages, for example; (i) reducing the test cost, (ii) reaching a test decision in shorter time and/or with fewer observations, and (iii) the remaining units removed early can be used for other tests. Therefore, in the next two sections, we shall be considering the maximum likelihood and Bayesian estimation methods to derive both point and interval estimators of the unknown PP parameters in presence of data collected under Type-II censoring. Following De Morais (2009), we assume that the PP distribution involves only two unknown parameters α and β, while the scale λ parameter is assumed known.
3 Maximum Likelihood Estimators
Under Type-II (or failure) censoring, the life-test terminated after a specified number of failures (say k) is reached. Suppose that \( \underline {\mathbf {x}}=({{X}_{(1)}},{{X}_{(2)}},...,\) X(k)) is Type-II censored sample of size k obtained from a life-test of n independent units (put on a test at time) taken from a continuous population. Hence, following Lawless (2003), the likelihood function of Type-II censored sample, \( X_{(i)},\ i=1,2,\dots ,k \), is defined as
If one setting k = n in Eq. 3.1, the Type-II censoring returned to the complete sampling. However, suppose that \( \underline {\mathbf {x}} \) lifetimes being identically distributed having PDF and CDF of PP distribution as defined in Eqs. 2.5 and 2.6, respectively, then the likelihood function (3.1) can be written (up to proportional) as
The corresponding log-likelihood function, \( \ell (\cdot )\propto \log L(\cdot ) \), of Eq. 3.2 becomes
Upon differentiating (3.3) partially with respect to α and β, we have two likelihood equations as
and
It can be seen that, from Eqs. 3.4 and 3.5, the MLEs \(\hat {\alpha }\) and \( \hat {\beta } \) have been derived in a system of two nonlinear equations, respectively. Thus, a very simple iterative method like Newton-Raphson (N-R) procedure may be used to maximize Eqs. 3.4 and 3.5 to obtain the desired MLEs of α and β. Unfortunately, due to the MLEs of \(\hat {\alpha }\) and \( \hat {\beta } \) cannot be obtained in closed form, then the corresponding exact distribution (or exact confidence intervals) of α and β is also not available. Numerically, we suggest to apply the ’maxLik’ package for any given data set \( x_{(i)},\ i = 1,2,\dots ,k, \) proposed by Henningsen and Toomet (2011). This package utilizes the N-R iterative method via ‘maxNR()’ function to implement the maximum likelihood calculations of \(\hat {\alpha }\) and \( \hat {\beta } \). On the other hand, the EM algorithm can also be easily incorporated to estimate the target parameters.
To construct the 100(1 − γ)% two-sided asymptotic confidence intervals (ACIs) of α and β, the Fisher’s information matrix, Iij(⋅), i,j = 1,2, of their MLEs must be obtained as
Clearly, the exact solutions of the expectation in Eq. 3.6 is tedious to obtain. Hence, by dropping E in Eq. 3.6, the approximated variances and covariances of \(\hat {\alpha }\) and \( \hat {\beta } \) are given by
Taking the second-partial derivative of Eq. 3.3 with respect to α and β, the Fisher’s elements of Eq. 3.7, locally at their MLEs \(\hat {\alpha }\) and \( \hat {\beta } \), are given by
and
To evaluate the MLEs \( \hat \alpha \) and \( \hat \beta \) for any given data set (X(1),X(2),...,X(k)), the ‘maxLik’ package that utilizes the N-R iterative method in computations, proposed by Henningsen and Toomet (2011), is recommended. In N-R iterative, from the parameter space limits, the initial value of each unknown parameter is taken.
Under some regularity conditions, the asymptotic normality of MLEs \( \hat {\Theta } \) is approximately bivariate normal as \( \hat {\Theta }\sim N({\Theta } ,\mathbf {I}^{-1}(\hat {\Theta })) \). Hence, using the large sample theory, the 100(1 − γ)% two-sided ACIs for α and β can be obtained, respectively, by
where zγ/2 is an upper (γ/2)% of the standard normal distribution.
4 Bayes Estimators
Bayes’ procedure has been grown to become the most popular approach in many fields; including but not limited to engineering, clinical, biology, etc. In this section, we consider the Bayesian estimation method to obtian the point and interval estimates of α and β when the data sampled from Type-II censoring.
4.1 Prior Information and Loss Functions
The selection of prior distribution of an unknown parameter is an significant issue in Bayesian inference. A conjugate prior distribution is established when a member of a family of distributions is selected such that the posterior distribution also belongs to the same family. Gamma distribution, depending on its parameter values, can provide variety of shapes. Thus, it also can be considered as suitable prior of model parameter than other complex prior distributions, see Kundu (2008). Therefore, the gamma density priors are considered to adapt support of the PP parameters. Under the assumption of α and β are assumed to be stochastically independent gamma distributed as \( \alpha \sim Gamma({{a}_{1}},{{b}_{1}}) \) and \( \beta \sim Gamma({{a}_{2}},{{b}_{2}}) \), the joint prior PDF of α and β is given by
where ai and bi for i = 1,2 are the shape and scale hyperparameters, respectively. They have been chosen to represent prior knowledge about α and β. Improper gamma prior of α and β can be obtained from Eq. 4.1 by setting ai = bi = 0, i = 1,2.
The choice of the loss function is an important aspect of the Bayes paradigm. Here, we consider three different type of loss functions, called squared-error loss (SEL), linear-exponential loss (LL) and general-entropy loss (GEL) functions. The most commonly symmetric loss function is the SEL function (which is denoted by lS(⋅)) is defined as
Under SEL function (4.2), the Bayes estimate \( \tilde {\Theta }_{S} \) (say) of Θ, is the posterior mean and is given by
The LL function (which is denoted by lL(⋅)) and GEL function (which is denoted by lG(⋅)) are the most commonly asymmetric loss functions and are given, respectively, by
and
The direction and degree of symmetry using LL function are determined based on the sign and size of the shape parameter ν such as if ν > 0 means that overestimation is more serious than underestimation and ν < 0 means the opposite. When \( \nu \rightarrow 0\), the Bayes LL estimate will close to the Bayes SEL estimate. Under (4.3), the Bayes estimate \( \tilde {\Theta }_{L} \) of Θ is given by
provided the above exception exists, and is finite. Under (4.4), the minimum error occurs when \( \tilde {\Theta }={\Theta } \). For υ > 0, a positive error has a more serious effect than a negative error and opposite for υ < 0. Putting υ = − 1 in Eq. 4.4, the Bayes GEL estimate coincides with the Bayes SEL estimate.
Under (4.4), the Bayes estimate \( \tilde {\Theta }_{G} \) of Θ is given by
provided the above exception exists, and it is finite. For more discussion on Bayesian loss functions, the readers may refer to the recent excellent book presented by Berger (2013). Although we are interested to drive the Bayes estimates using the SEL and GEL functions, yet other loss functions can be easily considered.
4.2 Posterior Analysis
According to the continuous Bayes’ theorem, the joint posterior density (say Φ(⋅)) of α and β is given by
where \( C={\int \limits }_{0}^{\infty }{\int \limits }_{0}^{\infty }\pi \left (\alpha ,\beta \right )L\left (\left .\underline {\mathbf {x}} \right |\alpha ,\beta \right ) \text{d}\alpha \ \text {d}\beta \) is the normalizing constant.
Combining (3.2) and (4.1), the joint posterior density (4.5) of α and β is given by
Conspicuously, because of the nonlinear form of the likelihood function (3.2), the marginal posterior distributions corresponding to α and β cannot be obtained explicitly. Thus, we propose to use MCMC techniques to generate samples from Eq. 4.6 and use them to compute the Bayes estimators of α and β and to construct their highest posterior density (HPD) intervals. To implement MCMC methodology, from Eq. 4.6, the full conditionals \( {\Phi }_{\alpha }^{*}(\cdot ) \) and \( {\Phi }_{\beta }^{*}(\cdot ) \) of α and β are given, respectively, by
and
where \( b_{1}^{*}=({{b}_{1}}+\sum \nolimits _{i=1}^{k}{\log ({{x}_{(i)}} )} ) \) and \( b_{2}^{*}(\alpha )=({{b}_{2}}-\sum \nolimits _{i=1}^{k}{{{(\lambda x_{(i)}^{-1} )}^{\alpha }}}) \).
From Eqs. 4.7 and 4.8, the conditional posterior distributions of α and β, respectively, cannot be reduced to any familiar distributions. Via R version 4.0.4, the diagram plot of the posterior distributions \( {\Phi }_{\alpha }^{*}(\cdot ) \) and \( {\Phi }_{\beta }^{*}(\cdot ) \) of α and β (when (α,λ,β) = (2,1,2)), respectively, Fig. 3 shows that the distributions (4.7) and (4.8) behave similarly to the normal distribution. Therefore, the Metropolis-Hasting (M-H) algorithm with normal proposal distribution is proposed to simulate MCMC samples, see for example Gelman et al. (2004).

Diagram plot of the conditional PDFs of α and β
To compute the Bayes MCMC estimates (or constructing associated HPD intervals) of α and β, do the below steps of M-H algorithm for sample generation process:
- Step 1: :
-
Start with an initial guess \( {{\alpha }^{(0)}=\hat {\alpha }} \) and \( {{\beta }^{(0)}=\hat {\beta }} \).
- Step 2: :
-
Set j = 1.
- Step 3: :
-
Generate α∗ and β∗ from normal proposal distributions \( N(\hat \alpha ,\hat \sigma _{\hat \alpha }^{2}) \) and \( N(\hat \beta ,\hat \sigma _{\hat \beta }^{2}) \), respectively.
- Step 4: :
-
Calculate τ1 and τ2 as \( \tau _{1} = \frac {{{\Phi }_{\alpha }^{*}\left ({\left . {\alpha ^{*} } \right |\beta ^{(j-1)} ,\underline {\mathbf {x}}} \right )}}{{{\Phi }_{\alpha }^{*}\left ({\left . {\alpha ^{(j - 1)} } \right |\beta ^{(j-1)} ,\underline {\mathbf {x}}} \right )}}\) and \( \tau _{2} = \frac {{{\Phi }_{\beta }^{*}\left ({\left . {\beta ^{*} } \right |\alpha ^{(j)} ,\underline {\mathbf {x}}} \right )}}{{{\Phi }_{\beta }^{*}\left ({\left . {\beta ^{(j - 1)} } \right |\alpha ^{(j)} ,\underline {\mathbf {x}}} \right )}}. \)
- Step 5: :
-
Generate u1 and u2 from uniform U(0,1) distribution.
- Step 6: :
-
If \( u_{1} \leqslant \min \limits \{1,\tau _{1}\} \), set α(j) = α∗ else set α(j) = α(j− 1). Similarly if \( u_{2} \leqslant \min \limits \{1,\tau _{2}\} \), set β(j) = β∗ else set β(j) = β(j− 1).
- Step 7: :
-
Put j = j + 1.
- Step 8: :
-
Redo Steps 2-7 \( {\mathscr{B}} \) times to get \( {\mathscr{B}} \) draws of α and β.
To ignore the effect of choosing the initial guess value, the first simulated varieties with size \( {{\mathscr{B}}_{0}} \) are removed. Then, the remaining samples, α(j) and β(j) for \( j={\mathscr{B}}_{0}+1,\dots ,{\mathscr{B}} \), of the unknown parameters α and β, respectively, can be further utilized to develop the Bayesian inference. Thus, the approximate Bayes estimates of α or β (say 𝜗) based on SEL, LL and GEL functions are given, respectively, by
where \( {\mathscr{B}}_{0} \) is burn-in. Bayes point estimates of α and β based on various loss functions can be easily obtained via useful ’coda’ package which proposed by Plummer et al. (2006).
According to the procedure proposed by Chen and Shao (1999), the HPD intervals of α and β under Type-II censored data are constructed. First, one must be ordered the simulated MCMC samples of 𝜗(j) for \( j=1,\dots ,{\mathscr{B}}, \) after burn-in as \( \vartheta _{({\mathscr{B}}_{0}+1)},\dots ,\vartheta _{({\mathscr{B}})} \). Thus, the 100(1 − γ)% two-sided HPD interval of 𝜗 is given by
where \( {{j}^{*}}={{{\mathscr{B}}}_{0}}+1,\dots ,{\mathscr{B}} \) is chosen such that
5 Simulation Study
To evaluate the performance of the proposed estimation methods, an intensive Monte Carlo simulation study is conducted. For fixed λ = 0.1, by considering two different sets of parametric values, namely (α,β) = (0.25,0.75) and (0.5,0.9), a large 1,000 Type-II censored samples for different combinations of n(complete sample size) and k(Type-II censored sample size ) are generated from the PP model such as n = 60, 100 and 200 where the failure percentage k is taken as (k/n)% = 50, 75 and 100% for each n. When (k/n)% = 100%, it means that the simulated Type-II censored sampling has been extended to the complete sampling. However, based on 1,000 replications, the MLEs and their ACIs of α and β are calculated.
To see the impacts of the priors on the PP parameters, two informative sets of hyperparameters of α and β are used, namely Prior 1: (a1,a2) = (1,3), bi = 4 and Prior 2: (a1,a2) = (2.5,7.5), bi = 10 when (α,β) = (0.25,0.75) as well as Prior 1: (a1,a2) = (2.5,4.5), bi = 5 and Prior 2: (a1,a2) = (5,9), bi = 10 when (α,β) = (0.5,0.9). In this numerical study, the hyperparameters (ai,bi), i = 1,2 are chosen in such a way that the prior average fits the expected value of the associated target parameter, see Kundu (2008). Practically, it is preferable to use MLEs rather than the Bayesian estimates, whenever the improper gamma prior information is available, due to the latter is more computationally costly.
Using the M-H algorithm proposed in Section 4, 12,000 MCMC samples (with discarded the first 2,000 samples as burn-in) are generated. Then, based on 10,000 MCMC samples, the average of Bayes MCMC estimates and 95% HPD interval estimates are calculated. In this study, the shape parameter values of LL and GEL functions are taken as ν = υ = (− 5,5). To monitor whether MCMC simulated sample is sufficiently close to the target posterior, we purpose to consider the Gelman and Rubin’s convergence diagnostic statistic. Similar to a classical analysis of variance, this diagnostic measures whether there is a significant difference between the variance-within chains and the variance-between chains. When MCMC outputs are far from 1, this indicates a lack of convergence, for more details see Gelman and Rubin (1992). Figure 4, by running two chains corresponding to both given sets of (α,β) when (n,k) = (100,50), shows that the MCMC iterations reach 1 after about the first 2,000 iterations and thus the proposed simulations converged well. It also presents that the burn-in sample size is a good size to ignore the effect of initial guesses.

Gelman and Rubin’s statistic for MCMC iterations of α and β
For each test setup, the average estimates of the unknown PP parameters α and β (say 𝜗) with their RMSEs and RABs are calculated using the following formulae, respectively, as:
where M is the amount of generated sequence data and \( \hat \vartheta ^{(j)} \) is the calculated maximum likelihood (or Bayes) estimate at the jth sample of α or β.
Further, the corresponding ACLs and CPs related to the ACIs (or HPD intervals) of α and β are obtained, respectively, as
and
where 1(⋅) is the indicator function, L(⋅) and U(⋅) denote the lower and upper bounds, respectively, of (1 − γ)% asymptotic (or HPD) interval of 𝜗. Performance of the point estimates is judged based on their RMSE and RAB values. Also, the performance of the intervals estimates is judged using their ACLs and CPs. The average point estimates of α and β, RMSEs, and RABs are reported in Tables 1 and 2, respectively. In addition, the ACLs of 95% asymptotic and HPD interval estimates of α and β are listed in Table 3. All numerical computations were performed using R software version 4.0.4 with two recommended packages namely ‘maxLik’ and ‘coda’ packages. All R-environment scripts that support the findings of this study are available from the corresponding author upon reasonable request.
From Tables 1 and 2, we observe that the proposed estimates of the parameters α and β have very good performance in terms of minimum RMSEs and RABs. Also, as n is large, various estimates of α and β are quite close to the corresponding true parameter values. As n (or k) increases, the performance of both classical and Bayes estimates becomes better. Due to the simulated random normal variates using M-H algorithm, it is observed that the Bayes estimates of α and β become even better compared to the other method. Moreover, using gamma conjugate priors, the Bayesian estimates performed better than the frequentist estimates. Since the variance of prior 2 is lower than prior 1, the Bayesian estimates based on prior 2 have performed superior than those obtained from the other in terms of the smallest RMSEs, RABs and ACLs and highest CPs.
Furthermore, from Table 3, the ACLs of both of 95% ACI/HPD intervals for α and β narrowed down while the corresponding CPs increase when (k/n)% increases. Also, in respect of shortest ACLs and highest CPs, the HPD intervals of α and β performed better than the asymptotic intervals due to the gamma prior information.
One of the main issues in Bayesian analysis is assessing the convergence of a MCMC chain. Therefore, the trace and autocorrelation plots of the simulated MCMC draws of the unknown PP parameters α and β are displayed (when (n,k) = (100,75)) in Fig. 5. The trace plots of MCMC outputs look like random noise and also when the autocorrelation values close to zero, the lag value increases. It also indicates that the MCMC draws are mixed adequately and thus the estimation results are reasonable.

Trace (left-pandel) and Autocorrelation (right-panel) for MCMC outputs of α and β
To sum up, simulation results pointed out that the proposed estimation methodologies work well in terms of their RMSEs and RABs (for point estimates) and in terms of their ACLs and CPs (for interval estimates). Finally, Bayesian estimation method utilizing the M-H algorithm sampler to estimate the PP distribution parameters is recommended.
6 Engineering Applications
In real practice, based on complete sampling, we aim to demonstrate the usefulness of the proposed model compared to other common lifetime models in the literature. For this purpose, we shall analyze two real data sets obtained from an engineering field. First data (Data-I) consists of the failure times of twenty mechanical components, see Murthy et al. (2004). Other data (say Data-II) consists of 40 records of the active repair times (in hours) for airborne communication transceiver, see Jorgensen (2012). For computational convenience we multiply each original data unit in Data-I and -II by one hundred. The new transformed datasets are presented in Table 4.
Practically, to identify the failure rate shapes based on both observed data sets I and II, the scaled Total Time on Test (TTT) plot is used. According to Aarset (1987), the scaled TTT transform is defined as
where \( G^{-1}(u)={\int \limits }_{0}^{F^{-1}(u)}R(t)dt \). The corresponding empirical version of Eq. 6.1 is given by
where x(i) represents the ith order statistic of the observed data. Graphically, the scaled TTT transform is displayed by plotting (k/n,Kn(k/n)).
Using both data sets I and II in Table 4, plots of the empirical and estimated scaled TTT transforms of the PP distribution are provided in Fig. 6. It shows that the scaled TTT transform is concave and convex. It also indicates that an increasing failure rate function for the fitting PP lifetime model is suitable for Data-I, whereas a decreasing failure rate function is suitable for Data-II. Also, plots in Fig. 6 support our same findings as shown in Fig. 2.

Empirical and estimated scaled TTT-Transform plot of the PP distribution
Using data sets I and II, we examine goodness-of-fit of the PP distribution and compare the fit results with common flexible distributions that exhibit various failure rates, namely: Weibull (W), gamma (G), exponentiated-exponential (EE), exponentiated Pareto (EPr), alpha power exponential (APE), exponential Poisson (EP), Weibull–Poisson (WP), exponentiated-exponential Poisson (EEP), generalized exponential Poisson (GEP), geometric exponential Poisson (GoEP) and quasi xgamma-Poisson (QXgP) distributions. The corresponding PDFs of these distributions (for x > 0 and α,β,λ > 0) are reported in Table 5.
Several criteria of model selection such as: negative log-likelihood (NL), Akaike information (AI), Bayesian information (BI), consistent Akaike information (CAI), Hannan-Quinn information (HQI), Kolmogorov-Smirnov (KS) with its P-value, Anderson-Darling (AD) and Cramér von Mises (CvM) statistics are used. Using ‘AdequacyModel’ package, the maximum likelihood estimates with their standard errors (SEs) of unknown model parameters along with their goodness measures are calculated and provided in Table 6, for details see Marinho et al. (2019). It is evident that the PP distribution has the smallest values of all fitted selection criteria with the highest P-value than the comparative distributions. It also implies that the PP distribution fits both given data sets well satisfactorily and gives the best fit with respect to all given criteria. If one needs to compare two (or more) statistical models based on the Bayes approach, it is preferable to consider the Watanabe-Akaike information criterion.
For more exploration, to assess the goodness-of-fit of the proposed model compared to other models, the probability–probability plots of all competitive distributions are displayed in Fig. 7. It shows that all fitted points of the PP distribution from data sets I and II are almost close to the straight line, thus the PP distribution gives a better fit than other distributions.

The probability–probability plots of the competitive distributions
Moreover, the relative histograms of both data sets and the fitted densities as well as the plot of fitted and empirical reliability functions are displayed in Fig. 8. It is clear that the PP life distribution appears to capture the general pattern of the histograms best. Likewise, the fitted survival function of the PP model fits the empirical function for both given data sets quite well.

Fitted densities (left-panel), fitted survival functions (right-panel) of the competitive distributions
7 Conclusions
By compounding the Pareto and Poisson distributions, we have presented the three-parameter Pareto-Poisson distribution. Various properties of the proposed distribution such as: moments, percentile function, stress-strength measure, entropies and order statistics have been obtained. Under Type-II censored data, when λ known, the model parameters have been estimated using the maximum likelihood and Bayesian estimation methods. To assess the convergence of MCMC chains, the Gelman and Rubin’s diagnostic has been used. Simulation results showed that the performance of the proposed estimators is satisfactory. Two engineering applications from mechanical and communication fields have been analyzed to provide the usefulness of the proposed distribution, showing that it provides a better fits than eleven competitive lifetime distributions namely: Weibull, gamma, exponentiated-exponential, exponentiated Pareto, alpha power exponential, exponential Poisson, Weibull–Poisson, exponentiated-exponential Poisson, generalized exponential Poisson, geometric exponential Poisson and quasi xgamma-Poisson distributions. We can also say that the Pareto-Poisson distribution is high flexible and is the most suitable model for the both real data sets among others. Finally, we recommend to utilize the proposed distribution as a survival model to utility of its ability to model lifetimes data with a heavy tail shaped. As a future research, it is useful to compare the proposed model with some other literature lifetime models in presence of data collected under Type-II censored sampling.
Change history
12 January 2023
A Correction to this paper has been published: https://doi.org/10.1007/s13171-022-00306-2
References
Aarset, M.V. (1987). How to identify a bathtub hazard rate. IEEE Trans. Reliab. 36, 1, 106–108.
Adamidis, K. and Loukas, S. (1998). A lifetime distribution with decreasing failure rate. Stat. Probab. Lett. 39, 35–42.
Amigó, J.M., Balogh, S.G. and Hernández, S. (2018). A brief review of generalized entropies. Entropy 20, 11, 813.
Asgharzadeh, A., Bakouch, H.S. and Esmaeili, L. (2013). Pareto Poisson–Lindley distribution with applications. J. Appl. Stat. 40, 8, 1717–1734.
Barreto-Souza, W. and Cribari-Neto, F. (2009). A generalization of the exponential-Poisson distribution. Stat. Probab. Lett. 79, 24, 2493–2500.
Berger, J.O. (2013). Statistical Decision Theory and Bayesian Analysis. Springer Science and Business Media.
Chen, M.H. and Shao, Q.M. (1999). Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 8, 69–92.
De Morais, A.L. (2009). A Class of Generalized Beta Distributions, Pareto Power Series and Weibull Power Series. Dissertação de mestrado–Universidade Federal de Pernambuco. CCEN.
Elbatal, I., Zayed, M., Rasekhi, M. and Butt, N.S. (2017). The exponential Pareto power series distribution: Theory and applications. Pak. J. Stat. Oper. Res., 603–615.
Elshahhat, A., Aljohani, H.M. and Afify, A.Z. (2021). Bayesian and classical inference under type-II censored samples of the extended inverse Gompertz distribution with engineering applications. Entropy 23, 12, 1578.
Gelman, A. and Rubin, D.B. (1992). Inference from iterative simulation using multiple sequence. Stat. Sci. 7, 457–511.
Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., Vehtari, A. and Rubin, D.B. (2004). Bayesian Data Analysis, 2nd edn. Chapman and Hall/CRC, USA.
Glaser, R.E. (1980). Bathtub and related failure rate characterizations. J. Amer. Stat. Assoc. 75, 667–672.
Gupta, R.C., Gupta, R.D. and Gupta, P.L. (1998). Modeling failure time data by Lehman alternatives. Commun. Stat.-Theory Methods 27, 4, 887–904.
Gupta, R.D. and Kundu, D. (2001). Generalized exponential distribution: different method of estimations. J. Stat. Comput. Simul. 69, 4, 315–337.
Henningsen, A. and Toomet, O. (2011). maxlik: A package for maximum likelihood estimation in R. Comput. Stat. 26, 3, 443–458.
Johnson, N., Kotz, S. and Balakrishnan, N. (1994). Continuous Univariate Distributions, 2nd edn. Wiley, New York.
Jorgensen, B. (2012). Statistical Properties of the Generalized Inverse Gaussian Distribution. Springer, New York.
Kundu, D. (2008). Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics 50, 2, 144–154.
Lawless, J.F. (2003). Statistical Models and Methods For Lifetime Data, 2nd edn. Wiley, New Jersey.
Kuş, C. (2007). A new lifetime distribution. Comput. Stat. Data Anal.51, 9, 4497–4509.
Lu, W. and Shi, D. (2012). A new compounding life distribution: The Weibull–Poisson distribution. J. Appl. Stat. 39, 1, 21–38.
Mahdavi, A. and Kundu, D. (2017). A new method for generating distributions with an application to exponential distribution. Commun. Stat.-Theory Methods46, 13, 6543–6557.
Marinho, P.R.D., Silva, R.B., Bourguignon, M., Cordeiro, G.M. and Nadarajah, S. (2019). AdequacyModel: an R package for probability distributions and general purpose optimization. PLoS ONE. https://doi.org/10.1371/journal.pone.0221487.
Maurya, S.K. and Nadarajah, S. (2021). Poisson generated family of distributions: A review. Sankhya B 83, 2, 484–540.
Murthy, D.N.P., Xie, M. and Jiang, R. (2004). Weibull models Wiley series in probability and statistics. Wiley, Hoboken.
Nadarajah, S. (2005). Exponentiated Pareto distributions. Statistics39, 255–260.
Nadarajah, S., Cancho, V.G. and Ortega, E.M. (2013). The geometric exponential Poisson distribution. JISS 22, 3, 355–380.
Nassar, M. and Nada, N. (2013). A new generalization of the Pareto–geometric distribution. J. Egypt. Math. Soc. 21, 2, 148–155.
Plummer, M., Best, N., Cowles, K. and Vines, K. (2006). CODA: Convergence diagnosis and output analysis for MCMC. R news. 6, 7–11.
Ristić, M.M. and Nadarajah, S. (2014). A new lifetime distribution. J. Stat. Comput. Simul. 84, 1, 135–150.
Subhradev, S.E.N., Korkmaz, M.C. and Yousof, H.M. (2018). The quasi xgamma-Poisson distribution: Properties and Application. Istatistik Journal of The Turkish Statistical Association 11, 3, 65–76.
Weibull, W. (1951). A statistical distribution function of wide applicability. J. Appl. Mech. 18, 3, 293–297.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original version of this article was revised: This article was originally published with misplaced figures.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Elshahhat, A., El-Sherpieny, ES.A. & Hassan, A.S. The Pareto–Poisson Distribution: Characteristics, Estimations and Engineering Applications. Sankhya A 85, 1058–1099 (2023). https://doi.org/10.1007/s13171-022-00302-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13171-022-00302-6
Keywords and phrases
- Pareto-Poisson distribution
- classical and Bayesian estimators
- Gelman and Rubin’s diagnostic
- hazard rate function
- type-II censoring
- Metropolis-Hasting algorithm.