
Abstract
In this endeavour, we study the statistical inference of multicomponent stress-strength reliability when components of the system have two paired elements experiencing common random stress. The k strength variables \((X_1,Y_1),\ldots ,(X_k,Y_k)\) follow a bivariate Topp-Leone distribution and the stress variable which follows a Topp-Leone distribution. This system is unfailing when at least \(s(1\le s\le k)\) out of k components simultaneously activate. The maximum likelihood estimate along with its asymptotic confidence interval, the uniformly minimum variance unbiased estimate, and the exact Bayes estimate of stress-strength reliability are derived. Further, we determined the Bayes estimates of the stress-strength reliability via different methods such as the Tierney and Kadane approximation, Lindley’s approximation, and the Markov Chain Monte Carlo (MCMC) method, to compare their performances with the exact Bayes estimate. Also, the highest probability density credible interval is obtained using the MCMC method. Monte Carlo simulations are implemented to compare the different suggested methods. Ultimately, the analysis of one real data is investigated for illustrative purposes.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The study of resistance of systems with random stress X and random strength Y in reliability literature is well-known as the stress-strength model, while the parameter \(R=P(X<Y)\) assesses the reliability of the system. This system fails if \(X>Y\). The problem of estimating the parameter R plays a significant role in reliability analysis. This has been discussed by a great number of authors. A comprehensive review of different stress-strength models up to 2003 has been presented in [1]. Recently, the reliability of multicomponent stress-strength models has attracted the attention of researchers. This model consists of the k independent and identical strength components and survives when at least \(s(1\le s\le k)\) components persist against a common stress. The stress-strength reliability for such a system is known as the s-out-of-k: G system and it is given by \(R_{s,k}\). The recent efforts in multicomponent stress-strength models are [2,3,4,5,6,7,8,9,10,11,12].
In most of the work related to the reliability of multicomponent stress-strength models, the system components have only one element, whereas in real-life each component may consist of more than one element. These types of situations may be seen in many real-life scenarios. For example, it can be used in the construction of suspended bridges, where the deck is sustained by a series of vertical cables which hang from the towers. Assume a suspension bridge is made of k pairs of vertical cables on either side of the deck. Here, each component consists of two dependent elements. The bridge will only stand when at least s number of vertical cables through the deck exceed the applied stresses such as heavy traffic, wind forces, corrosion, and so on.
In this paper, we assume that the strength variables \((X_1,Y_1),\ldots ,(X_k,Y_k)\) are independent and identically distributed random variables that following the bivariate Topp-Leone (BTL) distribution and are statistically independent with random stress that follows the Topp-Leone (TL) distribution. Recently, the estimation of multicomponent stress-strength reliability when the stress and strength variables follow Kumaraswamy and bivariate Kumaraswamy distributions, respectively, was studied in [13].
The TL distribution was first introduced by [14]. This is one of the distributions having finite support used to model percentage data, rates, and data extracted from some chemical processes. The main application of the TL distribution is when the reliability is assessed as the ratio of the number of successful experiments to the total number of experiments [15].
A random variable X has the TL distribution with the shape parameter \(\theta\) if its probability density function (PDF) is specified by
The cumulative distribution function (CDF) and survival function corresponding to Eq. (1), are
and
respectively. From here on, the TL distribution will be signified with the PDF in Eq. (1), by \(TL(\theta )\). Recently, the problem of \(R_{s,k}\) in the multicomponent stress-strength model when stress and strength variables are from TL distributions considered in [16]. In this study, the MLE of \(R_{s,k}\) was computed. Also, the Bayes estimates of the system reliability were determined by using the MCMC method and Lindley’s approximation. However, a UMVUE and an exact Bayes estimate of \(R_{s,k}\) were not taken into consideration.
The main goal of this paper is to discuss the classical and Bayesian inferences of \(R_{s,k}\) when strength variables follow the BTL distribution and the stress variable follows the TL distribution. The remainder of the paper is as follows. In Sect. 2, system reliability is determined. In Sect. 3, the MLE with the asymptotic confidence interval (ACI) and the UMVUE of \(R_{s,k}\) are investigated. In Sect. 4, the Bayes estimator of \(R_{s,k}\) is determined explicitly. Further, to compare other methods of the Bayesian estimates with the exact, the Tierney and Kadane method, Lindley’s approximation, and the MCMC method are used to obtain the Bayes estimates of \(R_{s,k}\). Also, the highest probability density credible interval (HPDCI) is provided in this section. In Sect. 5, the proposed methods are compared via MCMC simulations. In Sect. 6, a real data is given to demonstrate the suggested approaches. In Sect. 7, we extend the studied methods to a general family of distributions. Finally, we conclude the paper in Sect. 8.
2 System reliability
In this section, we first describe the BTL distribution and then obtain \(R_{s,k}\). Suppose \(V_1,V_2\), and \(V_3\) follow \(TL(\alpha _1)\), \(TL(\alpha _2)\), and \(TL(\alpha _3),\) respectively and all three random variables are mutually independent. Define the random variables X and Y as
where X and Y have a common random variable \(V_3\), making it clear that they are dependent. So the bivariate vector (X, Y) is the BTL distribution with the parameters \(\alpha _1,\alpha _2,\alpha _3\) and it is denoted by \(BTL(\alpha _1,\alpha _2,\alpha _3)\). Using the above definition, the following theorems can be easily proved.
Theorem 1
If \((X,Y)\sim BTL(\alpha _1,\alpha _2,\alpha _3)\), then their joint CDF is given by
where \(u=\min (x,y)\).
Proof
Substituting Eq. (3) into the above equation, the proof is obtained. Note that the random variable X and Y are independent iff \(\alpha _3=0\). \(\square\)
Theorem 2
If \((X,Y)\sim \text {BTL}(\alpha _1,\alpha _2,\alpha _3)\), then
-
(a)
\(X\sim \text {TL}(\alpha _1)\) and \(Y\sim \text {TL}(\alpha _2+\alpha _3)\).
-
(b)
\(\max (X,Y)\sim \text {TL}(\alpha )\), where \(\alpha =\alpha _1+\alpha _2+\alpha _3\).
Proof
(a)
Substituting Eq. (3) into the above equation, we get \(X\sim TL\left( {{\alpha }_{1}}+{{\alpha }_{3}} \right)\). Similarly, \(Y\sim TL\left( {{\alpha }_{2}}+{{\alpha }_{3}} \right)\) is proved.
(b)
Now, we consider a system having k identical and independent strength components, creating a parallel system of dependent elements experiencing common stress. Here, the strength vectors \((X_1,Y_1),\ldots ,(X_k,Y_k)\) follow \(BTL(\alpha _1,\alpha _2,\alpha _3)\) and a common stress variable T follows \(TL(\beta )\). Hence the reliability in a multicomponent stress-strength model is given by
Let \(Z_i=\max (X_i,Y_i),i=1,\ldots ,k\), therefore, according to Theorem 2(b), \({{Z}_{i}}\sim TL\left( \alpha \right)\) and then \(R_{s,k}=P(T<Z_i),i=1,\ldots ,k\). The system works if at least s out of \(k(1\le s\le k)\) of the \(Z_i\) strength variables simultaneously survive. Suppose k strength \((Z_1,\ldots ,Z_k)\) components are independent and identically distributed random variables with CDF F(z) and the stress T is a random variable with the CDF F(t). Hence, the reliability of \(R_{s,k}\) introduced by [17], can be obtained as
Note that the potential data are as follows
but the actual observations can be constructed as
where \(z_{ij}=\max (x_{ij},y_{ij})\), \(i=1,\ldots ,n\), and \(j=1,\ldots ,k\). \(\square\)
3 Classical estimates of \(R_{s,k}\)
In this section, we investigate the MLE of \(R_{s,k}\) along with its ACI. Also, we obtain the UMVUE of \(R_{s,k}\).
3.1 MLE of \(R_{s,k}\)
To find the MLE of \(R_{s,k}\), we need to determine the MLEs of \(\alpha\) and \(\beta\). The likelihood function based on Eq. (7) is
and the log-likelihood function is
where c is constant. So, the MLEs of \(\alpha\) and \(\beta\) can be computed as the solution of the following equations
Thus,
where \(P=\sum _{i=1}^{n}\sum _{j=1}^{k}\ln \bigl [z_{ij}(2-z_{ij})\bigr ]\) and \(Q=-\sum _{i=1}^{n}\ln \bigl [t_i(2-t_i)\bigr ]\).
It should be noted that, since \(0<t<1\), then \(0<t(2-t)=1-(t-1)^2<1\) and \(\ln \bigl [t(2-t)\bigr ]<0\), so we always have \(Q>0\). In a similar process \(P>0\). Therefore, \({\hat{\alpha }}\) and \({\hat{\beta }}\) are indeed the MLEs of \(\alpha\) and \(\beta\), respectively. Also, it can be shown that If \({{X}_{1}},...,{{X}_{n}}\sim TL\left( \alpha \right) ,\) then \(-\sum \nolimits _{i=1}^{n}{\ln \left[ {{X}_{i}}\left( 2-{{X}_{i}} \right) \right] }\sim Gamma\left( n,\alpha \right) .\) For this, it is sufficient to show that \(-\ln \bigl [X(2-X)\bigr ]\) has an exponential distribution with parameter \(\alpha\). To find the PDF for \(Y=g(X)=-\ln \bigl [X(2-X)\bigr ]\), we first find \(g^{-1}(x)\). Since \(y=g\left( x \right) =\ln \left[ x\left( 2-x \right) \right]\), then \(x={{g}^{-1}}\left( y \right) =1-\sqrt{1-{{e}^{y}}}.\) So, by using the change of variable technique, we have
Thus, it can be concluded that \(P\sim Gamma( nk,\alpha )\) and \(Q\sim Gamma( n,\beta )\).
In the following, the MLE of \(R_{s,k}\) is computed from Eq. (6) by the invariant property of MLEs:
Now, the ACI of \(R_{s,k}\) can be obtained using the asymptotic distribution of \(\theta =(\alpha ,\beta )\). The expected Fisher information matrix of \(\theta\) is defined as
where \(a_{11}=\frac{nk}{\alpha ^2},a_{22}=\frac{n}{\beta ^2},\) and \(a_{12}=a_{21}=0\).
The MLE of \(R_{s,k}\) is asymptotically normal with the mean \(R_{s,k}\) and variance
where \(A^{-1}_{ij}\) is the (i, j) th element of the inverse of A.
Also,
Hence, using the delta method, the asymptotic variance is given by
Therefore, the \(100(1-\delta )\%\) ACI of \(R_{s,k}\) is obtained as follows:
where, \(Z_{\delta /2}\) is the upper \(\delta /2\)th quantile of the standard normal distribution.
Here, the confidence interval obtained for \(R_{s,k}\) may be outside the domain (0, 1), so it is better to use the logit transformation \(f(R_{s,k})=\ln \bigl [R_{s,k}/(1-R_{s,k})\bigr ]\) and then change it again to the original scale [18]. Therefore, the \(100(1-\delta )\%\) ACI for \(f(R_{s,k})\) is specified by
Finally, the \(100(1-\delta )\%\) ACI for \(R_{s,k}\) is derived by
3.2 UMVUE of \(R_{s,k}\)
In this subsection, we derive the UMVUE of \(R_{s,k}\) by using an unbiased estimator of \(\gamma (\alpha ,\beta )=\frac{(-1)^j\beta }{\alpha (k+j-i)+\beta }\) and a complete sufficient statistic of \(\left( \alpha ,\beta \right)\). We observe from Eq. (10) that \((P,Q)=\left( -\sum _{i=1}^{n}\sum _{j=1}^{k}\ln [z_{ij}(2-z_{ij})],-\sum _{i=1}^{n}\ln \left[ t_i(2-t_i)\right] \right)\) is the complete sufficient statistic of \((\alpha ,\beta )\). In addition, as mentioned in Sect. 3.1, P and Q follow Gamma distributions with parameters \((nk,\alpha )\) and \((n,\beta )\), respectively. Let \(P^*=-\ln \left[ Z_{11}(2-Z_{11})\right]\) and \(Q^*=-\ln \left[ T_1(2-T_1)\right]\). It is obvious that \({{P}^{*}}\) and \({{Q}^{*}}\) are exponentially distributed with mean \({1}/{\alpha }\;\) and \({1}/{\beta },\) respectively. Hence,
is an unbiased estimator of \(\gamma (\alpha ,\beta )\), and so the UMVUE of \(\gamma (\alpha ,\beta )\) can be derived by using the Lehmann-Scheffe Theorem. Therefore,
where \(\omega =\{(p^*,q^*):0<p^*<p,0<q^*<q,p^*>(k+j-i)q^*\}\). This double integral can be discussed with regards to \(h\le 1\) and \(h>1\), where \(h=\frac{(k+j-i)q}{p}\). When \(h\le 1\), the integral in Eq. (16) reduces to
where \(\nu =\frac{\tilde{q}}{q}\). When \(h>1\), the integral in Eq. (16) reduces to
where \(\nu =\frac{p^*}{p}\). Thus, the \({\hat{\gamma }}_{UM}(\alpha ,\beta )\) is obtained from Eqs. (17) and (18). Finally, the UMVUE of \(R_{s,k}\) is determined by applying the linearity property of UMVUE as follows
4 Bayes estimation of \(R_{s,k}\)
In this section, we provide the Bayesian inference of \(R_{s,k}\) under the squared error (SE) loss function. Assume that the parameters \(\alpha\) and \(\beta\) are independent random variables and have Gamma prior distributions with parameters \((a_1,b_1)\) and \((a_2,b_2)\), respectively, where \(a_i,b_i>0, i=1,2\). Based on the observations, the joint posterior density function is
where P and Q are shown in Eq. (10). Then, the Bayes estimate of \(R_{s,k}\) is calculated by
Now using the computational process provided by [12], the Bayes estimate of \(R_{s,k}\) can be rewritten as
where \(u=nk+n+a_1+a_2\) and \(\nu =1-\frac{(b_2+Q)(k+j-i)}{b_1+P}\). Notice that
is the hypergeometric series, which is available in standard software such as R. Therefore, for this example, the Bayes estimate is derived in the closed form. However, for comparison purposes, we provide the Bayes estimate by using other techniques such as the Tierney and Kadane approximation, Lindley’s approximation, and the MCMC method.
4.1 Tierney and Kadane approximation
In this subsection, we obtain the Bayes estimator of \(R_{s,k}\) via the Tierney and Kadane approximation [19]. This technique is used for the posterior expectation of the function \(u(\theta )\) as follows:
where \(\varphi (\theta )=\frac{\log {\pi }(\theta ,data)}{n}\), and \(\varphi ^*(\theta )=\varphi (\theta )+\frac{\log {u}(\theta )}{n}\). Suppose \({\hat{\theta }}=({\hat{\alpha }},{\hat{\beta }})\) and \({\hat{\theta }}^*=({{\hat{\alpha }}}^*,{\hat{\beta }}^*)\) maximize the functions \(\varphi (\theta )\) and \(\varphi ^*(\theta )\), respectively. By employing the Tierney and Kadane approximation, Eq. (21) approximates the following expression:
where \(\vert H^*\vert\) and \(\vert H\vert\) are the inverse determinant of the negative hessian of \(\varphi (\theta )\) and \(\varphi ^*(\theta )\), respectively, computed at \({\hat{\theta }}\) and \({\hat{\theta }}^*\). In our case, we have
Then, we compute \({\hat{\theta }}\) by solving following equations
thus, \(\varphi _{11}=\frac{nk+a_1-1}{n{\hat{\alpha }}^2}\), \(\varphi _{12}=\varphi _{21}=0\), \(\varphi _{22}=\frac{n+a_2-1}{n{\hat{\beta }}^2}\), and \(\vert H\vert =\frac{n^2{\hat{\alpha }}^2{\hat{\beta }}^2}{(nk+a_1-1)(n+a_2-1)}\). Now, we obtain \(\vert H^*\vert\) following the same arguments with \(u(\theta )=\sum _{i=s}^{k}\sum _{j=0}^{i} \left( {\begin{array}{c}k\\ i\end{array}}\right) \frac{(-1)^j\beta }{\alpha (k+j-i)+\beta }\) in \({\hat{\theta }}^*\). Finally, the Bayes estimate of \(R_{s,k}\) based on the Tierney and Kadane approximation is obtained as
4.2 Lindley’s approximation
Lindley [20] presented an approximate technique for the determination of the ratio of two integrals. Similar to the Tierney and Kadane approximation, this technique is also used to derive the posterior expectation from a function such as \(u(\theta )\) as follows:
where \(l(\theta )\) and \(\varphi (\theta )\) are the logarithms of the likelihood function and the prior density of \(\theta\), respectively. Thus, Eq. (23) can be written as follows:
where \(\theta =(\theta _1,\ldots ,\theta _n),i,j,k,l=1,\ldots ,n, {\hat{\theta }}\) is the MLE of \(\theta , u=u(\theta ), u_i=\frac{\partial u}{\partial \theta _i}, u_{ij}=\frac{\partial ^2u}{\partial \theta _i\partial \theta _j}, {{L_i}_j}_k=\frac{\partial ^3\,l}{\partial \theta _i}\partial \theta _j\partial \theta _k, \varphi _j=\frac{\partial \varphi }{\partial \varphi _j}\), and \(\tau _{ij}=(i,j)\)th element in the inverse of the matrix \([-L_{ij}]\) are all calculated at the MLEs of the parameters. In this case, Lindley’s approximation lead to
Here, \(\theta =(\alpha ,\beta )\) and \(u=u(\alpha ,\beta )=R_{s,k}\). therefore,
and the other \(L_{ijk}=0\). Moreover \(u_1\) and \(u_2\) are presented in Eqs. (12) and (13), respectively. Also,
Therefore,
Hence, the Bayes estimator of \(R_{s,k}\) based on Lindley’s approximation is obtained as
4.3 MCMC method
In this subsection, we use the Gibbs sampling method to determine the Bayes estimate and to establish the credible interval for \(R_{s,k}\). The posterior conditional density of \(\alpha\) and \(\beta\) can be derived as
respectively. We observe from Eqs. (25) and (26) that the conditional densities of \(\alpha\) and \(\beta\) have Gamma distributions with parameters \((nk+a_1,b_1+P)\) and \((n+a_2,b_2+Q),\) respectively. Therefore, we can to use the Gibbs sampling algorithm steps as follows.

.
The Bayes estimate of \(R_{s,k}\) based on the MCMC method is calculated by
Also, the highest probability density \(100(1-\delta )\%\) credible interval for \(R_{s,k}\) can be computed by method of [21], minimizing
where, the values of \(R_{s,k}\) are ranked in ascending order from 1 to N.
5 Simulation study
In this section, we performed MCMC simulations to compare the performances of the point and interval estimates of \(R_{s,k}\) by using the classical and Bayesian methods for different sample sizes and different choices of parameter values. The performances of the point estimators are compared in terms of their mean squared errors (MSEs). The performances of the interval estimators are compared by the average lengths (ALs) of intervals and coverage probabilities (CPs). We have generated random samples from strength and stress populations based on different sample sizes, \(n=5(10)45\), and different parameter values, \((\alpha ,\beta )=(0.5,1), (0.5,1.5), (2.5,2), (3,2)\). The true values of \(R_{s,k}\) with the given \((\alpha ,\beta )\) for \((s,k)=(1,3)\) are 0.6, 0.5, 0.7895, 0.8182 and for \((s,k)=(2,4)\) are 0.4, 0.2857, 0.6579, 0.7013, respectively. To investigate the Bayes estimate, both non-informative and informative priors are considered and have been dubbed Prior 1 and Prior 2, respectively. Prior 1 is \((a_i,b_i)=(0.0001,0.0001), i=1,2\) and Prior 2 is \((a_i,b_i)=(3,1), i=1,2\). All of the calculations are obtained by using R 3.4.4 based on 50,000 replications. Further, the Bayes estimate along with its credible interval are calculated using 1000 sampling. For comparison purposes, we have considered three approximate methods of Bayes estimates, namely Lindley’s approximation, the Tierney and Kadane approximation, and the MCMC method. In Tables 1 and 2, the point estimates and the MSEs of \(R_{s,k}\) are reported based on classical and Bayesian estimates. According to Tables 1 and 2, the MSEs for the estimates decrease as the sample size increases for all cases, as expected. The Bayes estimates of \(R_{s,k}\) under Prior 2 have a smaller MSE than the other estimates, especially for small sample size \(n=5\). Also, the MSEs of the ML estimates are smaller than the UMVUE estimates. Moreover, these MSEs are near each other as the sample size increases. According to Tables 3 and 4, the interval estimates of \(R_{s,k}\) are reported based on the classical and Bayesian estimates and their ALs and CPs. As expected, the ALs of the intervals decrease as the sample size increases. The ALs of the HPDCIs are smaller than ACIs, but the CPs of ACIs are generally nearer to the nominal level of \(95\%\) compared to HPDCIs. In Tables 5 and 6, the different Bayes estimates of \(R_{s,k}\) and their corresponding MSEs are listed. From these tables, we observed that the MSEs in the MCMC method are generally larger than those computed from other Bayes methods for small sample sizes of \(n=5\). However, as the sample size increases, all Bayes estimates and their corresponding MSEs are very close to each other.
From the Bayesian point of view, the main focus of this article is on estimating system reliability based on the SE loss function. The mentioned loss function is symmetric, which means that the same penalty is imposed for overestimation and underestimation. However, if we want to consider a higher penalty for overestimation or underestimation, we must use an asymmetric loss function. Here, we briefly examine the performance of Bayes estimation under SE loss with an asymmetric loss. The most well-known asymmetric loss function is the linear-exponential (LINEX) loss, which is defined as follows
where \(\nu \ne 0\) and \({\hat{\sigma }}\) is an estimate of \(\sigma\). The magnitude and sign of \(\nu\) represents the degree and direction of asymmetry, respectively. When \(\nu\) is close to zero, LINEX and SE losses are approximately equal. For \(\nu <0\), underestimation is more important than overestimation, and vice versa. Calculation of Bayes estimation based on LINEX loss function is performed in a process similar to that described in Sect. 4.3, that due to the article’s length, it will not be shown here. In Table 7, the Bayes estimates of \(R_{s,k}\) and their corresponding MSEs are reported based on LINEX loss function for \(v=-2\) and \(v=1\) as well as for both \((s,k)=(1,3)\) and (2, 4). Based on the results of Table 7 and its comparison with Tables 5 and 6, we conclude that when \(\nu =1\) the performance of the Bayes estimator under LINEX loss is better than SE loss and when \(\nu =-2\) the opposite is true.
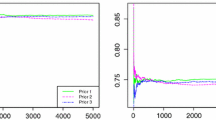
We also used graphs to compare the performances of the competing estimators when \(R_{s,k}\) changes from 0.05 to 0.95. For this aim, we considered the different values of the parameters along with the different sets of hyperparameters and then calculated the MSEs of \(R_{s,k}\), followed by the computation of the CPs and ALs of the interval estimates of \(R_{s,k}\). Figure 1 shows the MSEs of \({\hat{R}}_{s,k}^{MLE}, {\hat{R}}_{s,k}^{UM}\), and \({\hat{R}}_{s,k}^B\) for different sample sizes, \(n=5(10)35\) and \((s,k)=(1,3)\). According to Fig. 1, when \(R_{s,k}\) is about 0.5, we observed that
where \({\hat{R}}_{s,k}^{B-P1}\) and \({\hat{R}}_{s,k}^{B-P2}\) are Bayes estimates under non-informative and informative priors, respectively. When \(R_{s,k}\) approaches the extreme values, we observed that
Also, the MSEs are large when \(R_{s,k}\) is about 0.5 and they are small for the extreme values of \(R_{s,k}\). Some of the results extracted from this figure are quite clear. It was found that the estimates obtained based on greater sample sizes have lower MSEs. Also, as the sample sizes increase, the MSEs of are near each other for all types of estimates. Figure 2 shows the ALs of interval estimates for different sample sizes, \(n=5(10)35\). According to Fig. 2, we observed that the ALs of the HPDCIs under non-informative priors are almost identical with ACIs. Also, based on ALs, the performances of the HPDCIs with informative priors are the best. Furthermore, the ALs of the intervals decrease as the sample size increases, as expected. Figure 3 presents the CPs of interval estimates for different sample sizes, \(n=5(10)35\). According to Fig. 3, we observed that the HPDCIs with informative priors are preferable to the ACIs in terms of CPs for case \(n=5\), but as sample sizes increase, the ML estimates are nearer to the predetermined nominal level.

The MSEs of estimates of \(R_{1,3}\) for sample sizes \(n=5\) (a), \(n=15\) (b), \(n=25\) (c) and \(n=35\) (d)

The ALs of interval estimates of \(R_{1,3}\) for sample sizes \(n=5\) (a), \(n=15\) (b), \(n=25\) (c) and \(n=35\) (d)

The CPs of interval estimates of \(R_{1,3}\) for sample sizes \(n=5\) (a), \(n=15\) (b), \(n=25\) (c) and \(n=\)35 (d)
6 Data analysis
In this section, we conduct the analysis of real data for illustrative purposes. The issue of excessive drought is very important in agriculture because it causes a lot of damage to crops, so it needs to be managed. The following scenario is useful to understand in case of an excessive drought. In a five-year period, if at least two times, the maximum water capacity of a reservoir in August and September is more than the volume of water achieved on December of the previous year, it can be claimed that there will not be any excessive drought afterwards. Therefore, the multicomponent stress-strength reliability is the probability of non-occurrence drought. The data are taken for the months of August, September, and December from 1980 to 2015. This data was studied in [12], previously. Assuming, \(k=5\) and \(s=2\), \(x_{11},x_{12},\ldots ,x_{15}\) and \(y_{11},y_{12},\ldots ,y_{15}\) are the capacities of August and September from 1981 to 1985. \(x_{21},x_{22},\ldots ,x_{25}\) and \(y_{21},y_{22},\ldots ,y_{25}\) are the capacities of August and September from 1987 to 1991 and continues until \(x_{61},x_{62},\ldots ,x_{65}\) and \(y_{61},y_{62},\ldots ,y_{65}\) are the capacities of August and September from 2011 to 2015. Also, \(t_1\) is the capacity of December 1980, \(t_2\) is the capacity of December 1986 and continues until \(t_6\) is the capacity of December 2010. Hence, the reliability of multicomponent can be represented as 2-out-of-5: G system. Since the support of the TL distribution is defined for \(0<x<1\), we divide all the values by the total capacity of the Shasta reservoir, which is 4,552,000 acre-foot. The transformed data are as follows:
Also, let \(Z_{ik}=max{(X_{ik},Y_{ik})},i=1,\ldots ,6,k=1,\ldots ,5\). Then, the actual observed data are obtained as
We first check whether or not the BTL distribution can be used to analyze these data. Unfortunately, there is no satisfactory goodness of fit test for the bivariate distributions like in univariate distributions. In this case, we can perform goodness of fit tests for X, Y, and \(Z=\max (X,Y)\), separately. Also, we use goodness of fit test to validate whether the TL distribution can be used to make an acceptable inference for the T data. The MLE of unknown parameters, the Kolmogorov-Smirnov (K-S), Andeson-Darling (A), and Cramer-von Mises (W) statistics along with the P-values for each data are reported in Table 8. Based on these results, we conclude that the TL distribution provides a good fit for the X, Y, Z, and T data. The validity of the TL distribution is also supported by P-P plot shown in Fig. 4. Here, we obtain the estimates of \(R_{2,5}\) by using classical and Bayesian methods discussed in this article. First, from the above data, the ML estimates of \(\alpha\) and \(\beta\) are computed as \({\hat{\alpha }}=3.9496\) and \({\hat{\beta }}=6.2797\), respectively. Then, the MLE of \(R_{2,5}\) along with its ACI are obtained from Eqs. (11) and (14), respectively. Also, the UMVUE of \(R_{2,5}\) is determined from Eq. (19). To analyze the data from the Bayesian view, we have taken different parameters of the priors. The parameters \((a_i,b_i)=(0.0001,0.0001), i=1,2\) are selected for the non-informative prior case and the parameters \(a_1=4,a_2=6, b_1=b_2=1\) are selected for the informative prior by using the MLEs of unknown parameters. Tables 9 and 10 give point and interval estimates of \(R_{2,5}\). It is observed that the point estimates of \(R_{2,5}\) which are obtained by the Bayesian and classical methods are about the same, but the HPDCI of \(R_{2,5}\) based on the informative prior is remarkably smaller than the HPDCI based on the non-informative prior and the ACI. Therefore, if prior information is available, it should be used. Also, the estimates of \(R_{2,5}\) obtained from the approximate and exact Bayes methods are near each other except that which is obtained from Lindley’s approximation under the informative prior.

P-P plot for X, Y, Z, and T data
7 Extension of methods to a general family of distributions
In the previous sections, we studied different methods of estimating the reliability of \(R_{s,k}\) where the strength variables followed a BTL distribution and were subjected to a common random stress that had a TL distribution. Now, we extend our methods for a flexible family of distributions, namely proportional reversed hazard rate family (PRHRF) whose CDF and PDF are, respectively, defined as follows:
where \(\alpha\) is the shape paramete. Also, \(F_0(.)\) and \(f_0(.)\) are a baseline CDF and PDF, respectively. The model given in Eqs. (27) and (28) is also known with names such as exponentiated distributions and Lehmann alternatives. This family includes several well-known lifetime distributions such as generalized Rayleigh (Burr Type X), generalized exponential, generalized Lindley, exponentiated half logistic, generalized logistic, and so on. Some of the recently introduced flexible distributions from PRHRF are: exponentiated unit Lindley [22], exponentiated Teissier [23], exponentiated XGamma [24], and exponentiated Burr-Hatke [25]. Due to the importance of PRHRF distributions in the reliability literature, many studies have been done on their properties and applications. Some of the recent efforts pertaining to this family of distributions are [26,27,28,29,30].
Now, we describe the bivariate proportional reversed hazard rate family (BPRHRF). Suppose \(V_1,V_2\), and \(V_3\) follow \(PRHRF(\alpha _1), PRHRF(\alpha _2)\), and \(PRHRF(\alpha _3)\), respectively and all three random variables are mutually independent. Define the random variables X and Y as
where X and Y have a common random variable \(V_3\). So the bivariate vector (X, Y) is a bivariate distribution of BPRHRF with parameters \(\alpha _1,\alpha _2\), and \(\alpha _3\) and it is denoted by \(BPRHRF(\alpha _1,\alpha _2,\alpha _3)\). Using the above definition, the following theorems can be easily proved by applying the same argument used in Sect. 2.
Theorem 3
If \((X,Y)\sim \text {BPRHRF}(\alpha _1,\alpha _2,\alpha _3)\), then their joint CDF is given by
where \(u=\min (x,y)\).
Theorem 4
If \((X,Y)\sim \text {BPRHRF}(\alpha _1,\alpha _2,\alpha _3)\), then \(X\sim \text {PRHRF}(\alpha _1+\alpha _3)\) and \(Y\sim \text {PRHRF}(\alpha _2+\alpha _3)\). Also, \(\max (X,Y)\sim \text {PRHRF}(\alpha )\), where \(\alpha =\alpha _1+\alpha _2+\alpha _3\).
Now, we assume that the strength vectors \((X_1,Y_1),\ldots ,(X_k,Y_k)\) follow \(BPRHRF(\alpha _1,\alpha _2,\alpha _3)\) and a common stress variable T follows \(PRHRF(\beta )\). Hence the reliability in a multicomponent stress-strength model is given by
According to Theorem 4 and assuming \(Z_i=\max (X_i,Y_i), i=1,\ldots ,k,\) we have \(Z_i\sim PRHRF(\alpha )\) and then \(R_{s,k}=P(T<Z_i),i=1,\ldots ,k\). Suppose k strengths \((Z_1,\ldots ,Z_k)\) be a random sample from \(PRHRF(\alpha )\) and the stress T is a random sample from \(PRHRF(\beta )\). Therefore, the reliability of \(R_{s,k}\) is obtained as Eq. (6).
7.1 MLE of \(R_{s,k}\)
To find the MLE of \(R_{s,k}\), we need to determine the MLEs of \(\alpha\) and \(\beta\). The log-likelihood function is
where c is constant. So, the MLEs of \(\alpha\) and \(\beta\) can be easily obtained as follows
where \(P=-\sum _{i=1}^{n}\sum _{j=1}^{k}\ln [F_0(z_{ij})]\) and \(Q=-\sum _{i=1}^{n}\ln [F_0(t_i)]\). Since \(\ln [F_0(z)]\) and \(\ln [F_0(t)]\) are negative, so we always have \(P>0\) and \(Q>0\). Therefore, \({\hat{\alpha }}\) and \({\hat{\beta }}\) are indeed the MLEs of \(\alpha\) and \(\beta\), respectively. Also, similar to what was mentioned in Sect. 3.1, it can be shown that if \(X_1,\ldots ,X_n\sim PRHRF(\alpha )\), then \(-\sum _{i=1}^{n}\ln [X_i(2-X_i)]\sim Gamma(n,\alpha )\). In the following, the MLE of \(R_{s,k}\) is computed from Eq. (6) by the invariant property of MLEs:
7.2 UMVUE of \(R_{s,k}\)
Using same argument used in Sect. 3, the UMVUE of \(R_{s,k}\) is obtained as
where
\(p=-\sum _{i=1}^{n}\sum _{j=1}^{k}\ln [F_0(z_{ij})]\) and \(q=-\sum _{i=1}^{n}\ln [F_0(t_i)]\).
7.3 Bayes estimation of \(R_{s,k}\)
Assume that the parameters \(\alpha\) and \(\beta\) are independent random variables and have Gamma prior distributions with positive parameters \((a_1,b_1)\) and \((a_2,b_2)\), respectivel. The exact and approximate Bayesian estimates of \(R_{s,k}\) are obtained in a process quite similar to that mentioned in Sect. 4. It is enough to replace \(P=-\sum _{i=1}^{n}\sum _{j=1}^{k}\ln [z_{ij}(2-z_{ij})]\) with \(P=-\sum _{i=1}^{n}\sum _{j=1}^{k}\ln [F_0(z_{ij})]\) and \(Q=-\sum _{i=1}^{n}\ln [t_i(2-t_i)]\) with \(Q=-\sum _{i=1}^{n}\ln [F_0(t_i)]\).
8 Conclusions
In this endeavour, we have considered the inference of multicomponent stress-strength reliability under the bivariate Topp-Leone (BTL) distribution. Here, the strength variables follow a BTL distribution and are exposed to a common random stress that follows a Topp-Leone (TL) distribution. We have provided the MLE along with its ACI of \(R_{s,k}\). Also, the UMVUE and the exact Bayes estimates of \(R_{s,k}\) are computed. Moreover, we determined the Bayes estimate of \(R_{s,k}\) via three methods: the Tierney and Kadane approximation, Lindley’s approximation, and the MCMC method. Additionally, we established HPDCIs of \(R_{s,k}\).
The simulation results showed that the point and interval estimates of obtained from larger sample sizes have lower MSEs and lower ALs, respectively. According to the MSE and AL values, Bayesian estimators under the informative priors have the best performances among the estimators. Also, the MSEs and ALs of the all estimators are small when \(R_{s,k}\) tends to the extreme value and they are large when \(R_{s,k}\) tends to 0.5. Comparing the classical estimators showed that the MSEs of the UMVUE estimates are smaller than the ML estimates when \(R_{s,k}\) is near extreme values, and when \(R_{s,k}\) tends to 0.5, the ML estimators work better. According to the CP values, the HPDCIs with informative priors are better than ACIs for small sample sizes, but as the sample size increases, the ML estimates are nearer to the predetermined nominal level.
Comparing the different Bayesian estimation methods showed that all of the Bayes estimates and their corresponding MSEs are near each other for sample sizes of \(n\ge 15\). As a general conclusion, because Bayesian estimators under the informative priors often performed better than other estimators, they should be used if information on hyerparameters is available.
Availability of data and materials
Not applicable
References
Kotz, S., Lumelskii, Y., Pensky, M.: The Stress-strength Model and Its Generalizations: Theory and Applications. World Scientific, Singapore (2003)
Rao, G.S., Kantam, R., Rosaiah, K., Reddy, J.P.: Estimation of reliability in multicomponent stress-strength based on inverse Rayleigh distribution. J. Stat. Appl. Probab. 2(3), 261 (2013)
Nadar, M., Kızılaslan, F.: Estimation of reliability in a multicomponent stress-strength model based on a Marshall-Olkin bivariate Weibull distribution. IEEE Trans. Reliab. 65(1), 370–380 (2015)
Dey, S., Mazucheli, J., Anis, M.: Estimation of reliability of multicomponent stress-strength for a Kumaraswamy distribution. Commun. Statist.-Theory Methods 46(4), 1560–1572 (2017)
Pandit, P.V., Joshi, S.: Reliability estimation in multicomponent stress-strength model based on generalized Pareto distribution. Am. J. Appl. Math. Stat. 6(5), 210–217 (2018)
Kohansal, A.: On estimation of reliability in a multicomponent stress-strength model for a Kumaraswamy distribution based on progressively censored sample. Stat. Pap. 60, 2185–2224 (2019)
Kohansal, A., Shoaee, S.: Bayesian and classical estimation of reliability in a multicomponent stress-strength model under adaptive hybrid progressive censored data. Stat. Pap. 62(1), 309–359 (2021)
Ahmadi, K., Ghafouri, S.: Reliability estimation in a multicomponent stress-strength model under generalized half-normal distribution based on progressive type-II censoring. J. Stat. Comput. Simul. 89(13), 2505–2548 (2019)
Rasekhi, M., Saber, M.M., Yousof, H.M.: Bayesian and classical inference of reliability in multicomponent stress-strength under the generalized logistic model. Commun. Stat.-Theory Methods 50(21), 5114–5125 (2020)
Kayal, T., Tripathi, Y.M., Dey, S., Wu, S.-J.: On estimating the reliability in a multicomponent stress-strength model based on Chen distribution. Commun. Stat.-Theory Methods 49(10), 2429–2447 (2020)
Kızılaslan, F.: Classical and bayesian estimation of reliability in a multicomponent stress-strength model based on the proportional reversed hazard rate mode. Math. Comput. Simul. 136, 36–62 (2017)
Sauer, L., Lio, Y., Tsai, T.-R.: Reliability inference for the multicomponent system based on progressively type II censored samples from generalized pareto distributions. Mathematics 8(7), 1176 (2020)
Kızılaslan, F., Nadar, M.: Estimation of reliability in a multicomponent stress-strength model based on a bivariate Kumaraswamy distribution. Stat. Pap. 59, 307–340 (2018)
Topp, C.W., Leone, F.C.: A family of J-shaped frequency functions. J. Am. Stat. Assoc. 50(269), 209–219 (1955)
Genç, A.I.: Estimation of \(P(X>Y)\) with Topp-Leone distribution. J. Stat. Comput. Simul. 83(2), 326–339 (2013)
Akgül, F.G.: Reliability estimation in multicomponent stress-strength model for Topp-Leone distribution. J. Stat. Comput. Simul. 89(15), 2914–2929 (2019)
Bhattacharyya, G., Johnson, R.A.: Estimation of reliability in a multicomponent stress-strength model. J. Am. Stat. Assoc. 69(348), 966–970 (1974)
Ghitany, M., Al-Mutairi, D.K., Aboukhamseen, S.: Estimation of the reliability of a stress-strength system from power Lindley distributions. Commun. Stat.-Simul. Comput. 44(1), 118–136 (2015)
Tierney, L., Kadane, J.B.: Accurate approximations for posterior moments and marginal densities. J. Am. Stat. Assoc. 81(393), 82–86 (1986)
Lindley, D.V.: Approximate bayesian methods. Trabajos de estadísticay de investigación operativa 31, 223–245 (1980)
Chen, M.-H., Shao, Q.-M.: Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 8(1), 69–92 (1999)
Irshad, M., D’cruz, V., Maya, R.: The exponentiated unit Lindley distribution: properties and applications. Ricerche di Matematica, 1–23 (2021)
Sharma, V.K., Singh, S.V., Shekhawat, K.: Exponentiated teissier distribution with increasing, decreasing and bathtub hazard functions. J. Appl. Stat. 49(2), 371–393 (2022)
Yadav, A.S., Saha, M., Tripathi, H., Kumar, S.: The exponentiated XGamma distribution: a new monotone failure rate model and its applications to lifetime data. Statistica 81(3), 303–334 (2021)
El-Morshedy, M., Aljohani, H.M., Eliwa, M.S., Nassar, M., Shakhatreh, M.K., Afify, A.Z.: The exponentiated Burr-Hatke distribution and its discrete version: reliability properties with csalt model, inference and applications. Mathematics 9(18), 2277 (2021)
Pal, A., Samanta, D., Mitra, S., Kundu, D.: A simple step-stress model for Lehmann family of distributions. Adv. Stat.-Theory Appl.: Honoring Contributions Barry C. Arnold Stat. Sci., 315–343 (2021)
Demiray, D., Kızılaslan, F.: Stress-strength reliability estimation of a consecutive k-out-of-n system based on proportional hazard rate family. J. Stat. Comput. Simul. 92(1), 159–190 (2022)
Seo, J.I., Kim, Y.: Note on the family of proportional reversed hazard distributions. Commun. Stat.-Simul. Comput. 51(10), 5832–5844 (2022)
Demiray, D., Kızılaslan, F.: Reliability estimation of a consecutive k-out-of-n system for non-identical strength components with applications to wind speed data. Qual. Technol. Quant. Manag., 1–36 (2023)
Sadeghpour, A., Nezakati, A., Salehi, M.: Comparison of two sampling schemes in estimating the stress-strength reliability under the proportional reversed hazard rate model. Stat. Optim. Inform. Comput. 9(1), 82–98 (2021)
Funding
This work was supported by the Khorramshahr university of marine science and technology with Grant Number 1401.
Author information
Authors and Affiliations
Contributions
HP-Z: Methodology, conceptualization, writing, methodology and simulation.
Corresponding author
Ethics declarations
Conflict of interest
I have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Pasha-Zanoosi, H. Estimation of multicomponent stress-strength reliability based on a bivariate Topp-Leone distribution. OPSEARCH 61, 570–602 (2024). https://doi.org/10.1007/s12597-023-00713-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12597-023-00713-5