
Abstract
This paper presents an improved continuous genetic algorithm (CGA) to optimize the reliability redundancy allocation problem (RRAP) which determines the best redundancy strategies, the number of components, and levels of each subsystem to maximize the system reliability. In this system, both active and cold-standby redundancies can be chosen for individual subsystems. The RRAP belongs to NP-hard problems in the computational complexity theory that is the main reason for employing CGA to solve it. In addition, the response surface methodology (RSM) is used to increase the performance of CGA considering the design of experiments. This algorithm employs a new chromosome so that frees offspring to repair during the evolution process. Considering several numerical examples, the proposed algorithm presents better solutions than the previous studies based on the system reliability. Finally, the conclusion and future research are considered.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
System reliability is one of the most important issues to design various types of electrical and mechanical systems. In the reliability theory, redundancy is applied to improve system reliability. In addition, reliability redundancy allocation problem (RRAP) is an important class in modeling reliability systems so that belongs to NP-hard problems. In the RRAP literature, there are several considered RRAPs such as series, parallel, series–parallel [1–4], and k-out-of-n [5]. Hence, Fig. 1 shows a series–parallel system in which includes s subsystems and n redundant machines.

Graphical representation of series–parallel system
There are two categories of RRAPs. The first class is a system including component mixing. The second category is a system without component mixing, which meant that the components allocated in the same subsystem in which should be the same type [6]. Furthermore, active and standby approaches are two main classifications for the redundancy strategies. The situation that all components are operated simultaneously from the time zero is called active redundancy versus standby redundancy that the redundant components are used sequentially during component failure times [7]. Moreover, standby redundancy is categorized into three different types, namely, cold [8–10], hot [11, 12], and warm [13–15] so that frees the component to fail before it operates in the cold standby redundancy versus warm standby that components are more likely to be failed before operating. Further, the failure pattern of components is freed from the idleness or the operation of the components with respect to the hot standby redundancy. In the majority of studies in the RRAP literature, it is assumed that only one type of redundancy can be used to investigate systems: active or cold standby. In the real world, both the redundancy strategies are applied simultaneously in the design of systems. Therefore, this paper studies redundancy strategy with respect to active and cold standby components.
In system-reliability optimization, Kuo and Prasad [16] provided a good overview. However, there are several studies in the scope of cold standby redundancy so that Tillman et al. [17] evidenced in their research; on the other hand, they investigate 100 papers relating to the reliability optimization researches with different types of redundancy. According to strictly cold standby redundancy, Coit [5] discussed a problem that considered imperfect switching and k-Erlang distributed time-to-failures, and then presented an integer programming solution to optimize the RRAP. To consider problems of active and cold standby redundancy is near to real-world situations in which there are few studies because of its computational complexity. Considering multiple k-out-of-n subsystems in the series, Coit and Liu [18] provided a solution methodology to optimize a RRAP for systems so that they assumed that the redundancy strategy is predetermined for each subsystem. Regarding zero–one integer programming method, Coit [19] extended another methodology to maximize system reliability with respect to either active or cold-standby redundancy can be selectively chosen for individual subsystems. Thus, he developed the previous solution methodology by adding several decision variables. Next, Tavakkoli-Moghaddam et al. [20] improved the system reliability the RRAP [19] by employing the genetic algorithm (GA). Tian, et al. [21] extended an approach to optimize systems with multi-sate components with respect to the factors that influence system reliability and system life cycle cost. Moreover, Sharma, et al. [22] proposed an efficient algorithm to find a near-optimal solution to minimize the configuration cost of heterogeneous multistate series–parallel systems while a desired reliability index should be satisfied.
With these explanations, the purpose of this article is to develop a better solution methodology to improve the RRAP optimization. In other words, this paper illustrates a continuous GA (CGA) for series–parallel RRAP used in Tavakkoli-Moghaddam et al. [20]. Since the meta-heuristics are impressed by their parameters, we utilize the response surface methodology (RSM) in the design of experiments to tune parameters of the proposed algorithm. As innovations, we can point to CGA that applies a new chromosome so that free offspring from reparation during the generation; in addition, employing RSM to calibrate parameters of CGA is another contribution. Table 1 provides several studies relevant to GA in the literature.
The paper is organized as follows. Section 2 defines the assumptions and the mathematical model. The proposed algorithm is presented in Section 3. Parameter tuning and the comparison of CGA are elaborated in Sections 4 and 5, respectively. Finally, Section 6 provides the conclusion and future research.
2 Mathematical model
This section presents a RRAP without component mixing for the series–parallel redundant reliability system considering S subsystem so that individual subsystems can select either active or cold standby redundancy strategy. In addition, two separable linear constraints are considered. Several typical assumptions are,
-
a.
The failed components, which are not repaired, do not damage to the system.
-
b.
Failures of individual components are statistically-independent.
-
c.
The states of the elements and the system are either good or have failed (and no other states are considered).
Nomenclatures used in this paper are as follows.
- S :
-
Number of subsystems
- i :
-
An index used for a subsystem; i = 1, 2, 3, …, S
- n i :
-
Number of components used in subsystem; n i ∈ {1, 2, …, n max,i }
- n :
-
(n 1, n 2, …, n s )
- m i :
-
Number of available component choices for a subsystem i
- z i :
-
Index of component choice used for a subsystem i; z i ∈ {1, 2, …, m i }
- Z :
-
(z 1, z 2, …, z S )
- A :
-
Set of all subsystems using active redundancy
- CS :
-
Set of all subsystems using cold standby redundancy
- n max,i :
-
Upper bound for n i (n i ≤ n max,i )
- \( {r}_{i{z}_i}(t) \) :
-
Reliability at time t for z th i available component for subsystem i
- \( {\lambda}_{i{z}_i},{k}_{i{z}_i} \) :
-
Scale and shape parameters the Gamma distribution for z th i available component for subsystem i
- \( {f}_{i{z}_i}^{(j)}(t) \) :
-
pdf of z th i failure arrival for subsystem i, where is the sum of jiid component failure times
- W :
-
System-level constraint limit for weight
- c ij , w ij :
-
Cost and weight of the j th available component for the subsystem i, respectively
- ρ i (t):
-
Failure-detection / switching reliability at time t (scenario 1; continual sensing)
- ρ i :
-
Failure-detection/switching reliability success probability (scenario 2; active only in response to a failure state)
- R(t; z, n):
-
System reliability at time t for designing vectors z and n
- \( \tilde{R}\left(t;z,n\right) \) :
-
Approximation of R(t; z, n)
- t :
-
Mission time (fixed)
Where the decision variables are: redundancy strategies, selected components, and the number of components for each subsystem.
According to the mentioned nomenclature, the mathematical model of RRAP can be written as follows.
s.t,
Equation (3) presents the overall reliability system; in addition, Eqs. (4) and (5) satisfy the constraints on the available cost and weight, respectively. Then, Eqs. (7) and (8) obtain the system reliability as two scenarios [5]:
-
Scenario 1:
continual detector/switch operation,
-
Scenario 2:
switch active only in response to a failure,
In the CS, the subsystem reliability is the sum of the n i mutually exclusive probabilities. Just after the product for CS, the first term in Eq. (6) is \( {r}_{i{z}_i}(t) \) that represents the probability that no cold standby redundant components are required during the mission interval. Other subsequent terms represent n i − 1 mutually exclusion probabilities that there are between one and n i − 1 failures. Note that the switch is available to perform its function at the time of the failure, and a redundant component is always operating at time t.
2.1 Approximation of reliability
Regarding Eqs. (7) and (9) obtains the system reliability approximation in which only one difference can be seen in the product term for CS.
Where \( {\delta}_i\left(t,{n}_i\right)=\left\{\begin{array}{l}{\rho}_i(t)\\ {}{\rho}_i^{n_i-1}\end{array}\right. \), as a probability function to determine the probability of the switch at hours for each subsystem, which it is considered 0.99 in this paper.
A specified form of Eq. (9) shall be determined if k-Erlang distribution is considered for component time-to-failure. The k-Erlang distribution as a special form of Gama distribution can model diverse constant and increase hazard functions. According to k-Erlang distribution, the approximation of the system reliability can be calculated as follows.
3 Solution algorithm: Continuous genetic algorithm (CGA)
There are several methods to optimize NP-hard problems such as dynamic programming [26], integer programming [27], and meta-heuristics like GA [20, 28–30], particle swarm optimization [31–33], the cuckoo search (CS) algorithm [34], the bee algorithm [35]. Thus, we employ an improved meta-heuristic to optimize the model.
GA has been developed as a robust and powerful stochastic search algorithm and works based on Darwin’s theory of evolution [36]. CGA or real-coded GA, which its chromosomes are considered as a floating point number, is a special forming of GAs so that acts better than GA based on a binary method for function optimization problems [37]. There are several superior features of CGA versus the binary GA such as working quickly because of the designed chromosomes, and storing computational less space to run the algorithm. Figure 2 shows the flowchart of the proposed algorithm, which is described as follows.

The flowchart of the CGA algorithm
3.1 Initialization
To begin the CGA, the parameters of the algorithm should be assigned an initial value. The parameters that have important roles in CGA are: (i) It: Number of iterations of CGA or the number of the generations; (ii) Npop: Number of the individual population; (iii) P c : Crossover operator ratio; (iv) P m : Mutation operator ratio. Where these parameters are tuned by RSM in Section 4.
3.2 Encoding structure
Encoding solution is the vital component to effective search in the solution area; therefore, we present a new encoding to CGA. Note that a possible solution consists of redundancy strategies, selected components, and the number of components for each subsystem. The proposed encoding presents a feasible solution that does not need to repair during the CGA process. There are three parts in the encoding of solution in which showed in Fig. 3.

The proposed chromosome
Here, the rows, which are a random number between (0 ∼ 1), are a 1 × S vector so that S denotes number of the subsystem. Thus, these rows obtain a feasible solution after decoding process. The initial population is created randomly considering Npop.
3.3 Decoding structure
In order to evaluate the fitness function, it is necessary to decode the encoded solutions. Thus, the decoding process is elaborated considering an example with these explanations:
S Number of subsystem (S = 6)
m i Number of available component for a subsystem (m i = 3)
n max,i Constraint on the number of components used in each subsystem (n max,i = 6)
a i Two redundancy strategies including active and cold standby for each subsystem (a i = 2)
The following steps describe decoding process.
-
Step 1:
Generate randomly a chromosome, (see Fig. 4).
Fig. 4 
A graphical representation of the chromosome
-
Step 2:
Select the redundancy strategy for each subsystem between active or cold standby by rounding numbers obtained from the first row to nearest integer like this ⌊r i × a i + 1⌋. Such, active and cold strategies are chosen by 1 and 2, respectively, (see the first row in Fig. 5).
Fig. 5 
Decoded the chromosome
-
Step 3:
Calculate ⌊m i × c i + 1⌋ to allocate available component for subsystem i so that 1, 2, and 3 are their number, (see the second row in Fig. 5).
-
Step 4:
Obtain ⌊n max,i × n i + 1⌋ to select the number of the components used in subsystem i, (see the third row in Fig. 5).


3.4 CGA operators
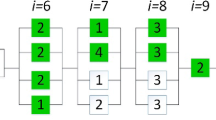
In order to satisfy the constraints described in Eqs. (4) and (5), we employ one of the penalty methods, called the death penalty [36]. Moreover, individuals with higher qualification should have a greater chance of selection than those with lower fitness. Hence, we apply the roulette wheel selection to select the chromosomes. GA generates a new population with crossover and mutation operators. This paper utilizes a specific version of the continuous uniform crossover used by Radcliffe [38] as follows. Two chromosomes, which called parents, are selected between the populations. Next, a row similar to one of the parent is generated, namely β (with values between zero and one). Afterwards, offspring are created considering Eqs. (11) and (12). Figure 6 elaborates the process of the crossover operator for the 1th row of chromosomes.

An example of crossover operator
The second operator in GA, which called mutation, prevents the algorithm to converge on a local optimal solution. The uniform mutation operator of Radcliff [38] is used in this paper. Figure 7 explains mutation operator; such, a chromosome is selected randomly, and then exchanged one of its cells with a random number between zero and one.

An example of mutation operator
4 Parameter tuning: Response Surface Methodology
There are two main approaches to calibrate the parameters used in meta-heuristics: a trial-and-error procedure, and the statistical methods. The parameters of meta-heuristics impress the quality of the solutions; hence, we employ one of the statistical methods in design of experiments, called the Response Surface Methodology (RSM). The RSM uses a collection of useful mathematical and statistical techniques to model and analysis of problems [39]. Considering a response that here is the system reliability, the RSM determines the best levels of variables in a problem. There are four variables in which are presented in Table 2 that shows their levels and coded factor.
In the beginning of RSM, a trial-and-error procedure is used to initialize the variables. Considering the obtained responses, a first-order model is fitted; and performed a test of lack of fit so that this test determines the sufficiency; otherwise, a second-order model is tested [40]. There are several the designs to fit a second-order model such as the central composite design (CCD) in which includes 2k factorial points, n c central points, and 2k axial points. The second-order model of CCD can be written as,
Where E(Y) is the expected value of the response variable in which is the system reliability, and β 0, β i and β ij are fixed coefficients of the second-order model. In addition, X i and X j are the input variables in k number.
4.1 Experiments
To perform RSM, we run 33 test problems in which have 14 subsystems with varying decreasingly weights W from 191 to 159, and the available budget restricted to 130 (C = 130).
Note that the values of −1, 0, and 1 are low, middle, and high levels of parameters, respectively. To remove the influence of results obtained from the test problems with different size, the mean ratio of the CGA solution (Y as the response) is defined as the performance index of the CGA. Table 3 shows the CCD that consists of eight factorial points, eight axial points, and four central points in twenty experiments. Considering the CCD, we run CGA to obtain the responses (Y). Since the proposed model belongs to the maximization models, a response (Y) with higher values presents better performances of the CGA. Regarding the analysis of variance (ANOVA) test for the response in Table 4, there is a statistically significant curvature on the response surfaces; therefore, a second order model is employed to analysis experiments. The responses in Table 3 are used to estimate the second order models.
The best values of parameters are given by solving a single objective problem in Eq. (12), which is obtained by the estimated regression coefficients in the second-order model.
Finally, the optimal values of parameters are illustrated in Table 5.
5 Numerical example
In this section, an example [5] is used to evaluate the performance of the proposed algorithm. There are 14 subsystems with three or four component selections; in addition, the maximum number of components is six (n max,i = 6). Moreover, it is considered 0.99 as the reliability of a switch at 100 h for each subsystem.
Thus, Table 6 illustrates the component cost, the weight and k-Erlang distribution parameters of the example. The aim of solving is to maximize system reliability considering two constraints of the system cost (C = 130) and the weight (W = 170) in 100 h. There are two redundancy strategies for each subsystem: active or cold standby. The switch operates and fails similar to Scenario 1 in the cold standby redundancy strategy. Therefore, a continuous decreasing function would be suggested for switch reliability.
Table 7 makes a comparison between three solution approaches. The results explain that the proposed algorithm optimizes better the problem versus four studies. The reliability (0.9872) presented by the proposed algorithm, for example, is better than the one presented by Coit [5].
In the second part of comparison, we resolve 33 problems used in Tavakkoli-Moghaddam et al. [20] considering varying the available weight from 191 to 159 and the constrained cost to 130. It can be understood from Table 8 that the proposed algorithm acts better than the solution algorithm of Tavakkoli-Moghaddam et al. [20] for all the problems. Figure 8 shows the domination of the proposed algorithm versus solution algorithm Tavakkoli-Moghaddam et al. [20].

Performance of CGA vs. Tavakkoli-Moghaddam et al. [20]
Figures 9 and 10 shows normal probability plots of the best results obtained (Table 8) using the proposed CGA and the GA [20], respectively, to statistically compare the results obtained. Table 9 presents the result of a t-test for the alternative “The proposed CGA < The GA [20]” as the null hypothesis. As a significant difference is not shown (p-value = 0.000 < 0.5), there is no presumption against the null hypothesis. Thus, the proposed CGA provides the better solution than the GA [20] on the average. Table 9 shows more details, in which SE Mean and StDev abbreviate the standard error of the mean and the standard deviation, respectively. Moreover, Fig. 11 presents the boxplot of comparison between the two methods, in which the reliability provided by the proposed algorithm is better than GA [20]. Note that the obtained solutions are the best among 20 runs of the algorithm. Notice also that a PC with 2.2 GHz Intel Core 2 Duo CPU, and 4 GB of RAM memory calculates all calculations in this paper; moreover, CGA is run in MATLAB 2009a.

The normal probability plot of the best costs provided by the proposed CGA

The normal probability plot of the best costs provided by GA [20]

The Boxplot of Proposed Algorithm and GA [18]
6 Conclusion
This paper has considered the optimization of a series–parallel reliability redundancy allocation problem (RRAP) in which subsystems can select active or cold standby strategies. The aim of this problem was to choose the best redundancy strategies, components, and levels for each subsystem for maximizing the system reliability. Since the RRAP is an NP-hard problem, we employed a continuous genetic algorithm (CGA), which applied a new method in the production of chromosomes, to solve the model. In addition, the performance of CGA was improved by parameter tuning that one of statistical methods namely the response surface methodology (RSM) was used. According to the comparison of the proposed algorithm with the last solution algorithms, it can be concluded that the CGA has an efficient performance to optimize the RRAP problems. In other words, the presented method can probably be the best available algorithms in the literature to solve the considered problem. Finally, the future works of this study are as follows. (1) Investigate fuzzy condition in modeling. (2) Develop the objectives to consider the cost. (3) Study other redundancy strategies as decision variables.
References
Yalaoui, A., Chu, C., Châtelet, E.: Reliability allocation problem in a series–parallel system. Reliab. Eng. Syst. Saf. 90, 55–61 (2005)
Yalaoui, A., Chatelet, E., Chengbin, C.: A new dynamic programming method for reliability & redundancy allocation in a parallel–series system. IEEE Trans. Reliab. 54, 254–261 (2005)
Yeh, W.-C.: Orthogonal simplified swarm optimization for the series–parallel redundancy allocation problem with a mix of components. Knowl.-Based Syst. 64, 1–12 (2014)
Huang, C.-L.: A particle-based simplified swarm optimization algorithm for reliability redundancy allocation problems. Reliab. Eng. Syst. Saf. 142, 221–230 (2015)
Coit, D.W.: Cold-standby redundancy optimization for nonrepairable systems. IIE Trans. 33, 471–478 (2001)
Fyffe, D.E., Hines, W.W., Lee, N.K.: System reliability allocation and a computational algorithm. IEEE Trans. Reliab. 17, 64–69 (1968)
Ebeling, C. E. :An introduction to reliability and maintainability engineering: McGraw Hill (1997)
Franko, C., Ozkut, M., Kan, C.: Reliability of coherent systems with a single cold standby component. J. Comput. Appl. Math. 281, 230–238 (2015)
Grabski, F.: 6 - SM models of renewable cold standby system. In: Grabski, F., (ed.). Semi-Markov Processes: Applications in System Reliability and Maintenance, pp. 99–118. Elsevier, (2015)
Levitin, G., Xing, L., Dai, Y.: Optimal component loading in 1-out-of-N cold standby systems. Reliab. Eng. Syst. Saf. 127, 58–64 (2014)
Levitin, G., Xing, L., Dai, Y.: Cold vs. hot standby mission operation cost minimization for 1-out-of-N systems. Eur. J. Oper. Res. 234, 155–162 (2014)
Mukherjee, A., Dhar, A.S.: Real-time fault-tolerance with hot-standby topology for conditional sum adder. Microelectron. Reliab. 55, 704–712 (2015)
Huang, W., Loman, J., Song, T.: A reliability model of a warm standby configuration with two identical sets of units. Reliab. Eng. Syst. Saf. 133, 237–245 (2015)
Wells, C.E.: Reliability analysis of a single warm-standby system subject to repairable and nonrepairable failures. Eur. J. Oper. Res. 235, 180–186 (2014)
Levitin, G., Xing, L., Dai, Y.: Optimal sequencing of warm standby elements. Comput. Ind. Eng. 65, 570–576 (2013)
Kuo, W., Prasad, V.R.: An annotated overview of system-reliability optimization. IEEE Trans. Reliab. 49, 176–187 (2000)
Tillman, F.A., Hwang, C.-L., Kuo, W.: Optimization techniques for system reliability with redundancy: a review. IEEE Trans. Reliab. 26, 148–155 (1977)
Coit, D.W., Liu, J.C.: System reliability optimization with k-out-of-n subsystems. Int. J. Reliab. Qual. Saf. Eng. 07, 129–142 (2000)
Coit, D.W.: Maximization of system reliability with a choice of redundancy strategies. IIE Trans. 35, 535–543 (2003)
Tavakkoli-Moghaddam, R., Safari, J., Sassani, F.: Reliability optimization of series–parallel systems with a choice of redundancy strategies using a genetic algorithm. Reliab. Eng. Syst. Saf. 93, 550–556 (2008)
Tian, Z., Levitin, G., Zuo, M.J.: A joint reliability–redundancy optimization approach for multi-state series–parallel systems. Reliab. Eng. Syst. Saf. 94, 1568–1576 (2009)
Sharma, V.K., Agarwal, M., Sen, K.: Reliability evaluation and optimal design in heterogeneous multi-state series–parallel systems. Inf. Sci. 181, 362–378 (2011)
Pasandideh, S.H.R., Niaki, S.T.A., Nia, A.R.: A genetic algorithm for vendor managed inventory control system of multi-product multi-constraint economic order quantity model. Expert. Syst. Appl. 38, 2708–2716 (2011)
Sadeghi, J., Sadeghi, A., Saidi-Mehrabad, M.: A parameter-tuned genetic algorithm for vendor managed inventory model for a case single-vendor single-retailer with multi-product and multi-constraint. J Optim. Ind. Eng. 4, 57–67 (2011)
Nachiappan, S.P., Jawahar, N.: A genetic algorithm for optimal operating parameters of VMI system in a two-echelon supply chain. Eur. J. Oper. Res. 182, 1433–1452 (2007)
Ng, K.Y.K., Sancho, N.G.F.: A hybrid ‘dynamic programming/depth-first search’ algorithm, with an application to redundancy allocation. IIE Trans. 33, 1047–1058 (2001)
Gen, M., Ida, K., Lee, J.-U.: A computational algorithm for solving 0–1 goal programming with GUB structures and its application for optimization problems in system reliability, Electron. Commun. Jpn. (Part III: Fundam Electron Sci), 73, 88–96, (1990).
Sahoo, L., Bhunia, A.K., Kapur, P.K.: Genetic algorithm based multi-objective reliability optimization in interval environment. Comput. Ind. Eng. 62, 152–160 (2012)
Sadeghi, J., Sadeghi, S., Niaki, S.T.A.: A hybrid vendor managed inventory and redundancy allocation optimization problem in supply chain management: an NSGA-II with tuned parameters. Comput. Oper. Res. 41, 53–64 (2014)
Paul, R.J., Chanev, T.S.: Optimising a complex discrete event simulation model using a genetic algorithm. Neural Comput. & Applic. 6, 229–237 (1997)
Pereira, C.M.N.A., Lapa, C.M.F., Mol, A.C.A., da Luz, A.F.: A Particle Swarm Optimization (PSO) approach for non-periodic preventive maintenance scheduling programming. Prog. Nucl. Energy 52, 710–714 (2010)
Pai, P.-F., Chen, C.-T., Hung, Y.-M., Hung, W.-Z., Chang, Y.-C.: A group decision classifier with particle swarm optimization and decision tree for analyzing achievements in mathematics and science, Neural Comput. Applic., 1–13, (2014)
Jiang, S., Yi, D., Ju, X., Wang, L. Liu, Y.: An approach for test data generation using program slicing and particle swarm optimization. Neural Comput. Applic. 1–9 (2014)
Ouaarab, A., Ahiod, B., Yang, X.-S.: Discrete cuckoo search algorithm for the travelling salesman problem. Neural Comput. & Applic. 24, 1659–1669 (2014)
Tsai, H.-C.: Integrating artificial bee colony and bees algorithm for solving numerical function optimization. Neural Comput. & Applic. 25, 635–651 (2014)
Gen, M., Cheng, R.: Genetic algorithms and engineering design, 1st edn. Wiley, New York (2000)
Randy, S.E.H., Haupt, L.: Practical genetic algorithms. Wiley & Sons, New York (2004)
Reeves, C.R.: Genetic algorithms and grouping problems. IEEE J. Magazines 5, 297–298 (2001)
Raymond, D.C.M., Myers, H., Anderson-Cook, C.M.: Response surface methodology: process and product optimization using designed experiments. John Wiley & Sons, New York (2009)
Montgomery, D.C.: Design and analysis of experiments, 5th edn. John Wiley and Sons, New York (2001)
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(RAR 4 kb)
Rights and permissions
About this article

Cite this article
Chambari, A., Sadeghi, J., Bakhtiari, F. et al. A note on a reliability redundancy allocation problem using a tuned parameter genetic algorithm. OPSEARCH 53, 426–442 (2016). https://doi.org/10.1007/s12597-015-0230-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12597-015-0230-9