
Abstract
The characteristics of residential environments that may affect health are posited to contribute to social and race/ethnic inequities in health through the differential allocation of health-promoting resources and health-harming conditions that stem from macro-level processes that systematically sort large groups of the American population into different neighborhoods. However, few studies have examined how exposure to these neighborhood conditions is inequitably experienced by individuals over adulthood. Longitudinal studies are well positioned to contribute to our understanding of the accumulation of neighborhood (dis)advantages and their impact on health throughout the life course but must first overcome the challenge of measuring differences in neighborhood context across time and between population groups. Using a longitudinal cohort of Black and white U.S. adults followed over a 25-year period with linked census tract data, we computed a Neighborhood Vulnerability Index (NVI) that combines multiple indicators of neighborhood risk into one composite score and tested the assumption of configural, metric, and scalar invariance both longitudinally and between race/gender groups. Using confirmatory factor analysis, we identified a two-dimensional model for neighborhood vulnerability and computed an index that demonstrated multiple levels of race, gender, and race-by-gender invariance (χ2 1000.48, df 15, RMSEA 0.07, SRMR 0.02, CFI 0.98, TLI 0.97, AIC 751,272). Inequities in exposure to neighborhood vulnerability between Black and white men and women at the neighborhood level has important implications for understanding the root of social, health, and economic disparities that have persisted in the U.S. over the past several decades.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Our understanding of neighborhood- and community-level factors and their influence on health and well-being has emerged as a result of the burgeoning interest in the contribution of contextual factors, over and above individual level factors, to health outcomes. The characteristics of residential environments that may affect health are posited to contribute to social and race/ethnic inequities in health through the differential allocation of health-promoting resources (e.g., safe recreational spaces, access to health care, employment opportunities) and health-harming conditions (poor housing and working conditions, food deserts, crime) that stem from macro-level processes that systematically sort large groups of the American population into different neighborhoods (Clarke & Nieuwenhuijsen, 2009; Mode et al., 2016; Waldstein et al., 2016). For example, many studies have documented significant associations between neighborhood socioeconomic conditions and various health outcomes including mortality, adverse mental health outcomes, incidence of cardiovascular disease, and diabetes using various methods of measuring exposure (Reijneveld et al., 2001; Diez Roux & Mair, 2010; Christine, et al. 2015; Schule and Bolte, 2015). However, few studies have examined how exposure to these neighborhood conditions is inequitably experienced by individuals over adulthood. Longitudinal studies are well positioned to contribute to our understanding of the accumulation of neighborhood (dis)advantages and their impact on health throughout the life course but must first overcome the challenge of measuring differences in neighborhood context across time and between population groups (Boen et. al. 2016; Vidourek et al., 2019).
Neighborhood indicators of (dis)advantage are often viewed as structural factors, defined as aspects of the economic and social environments that create the context in which risk production occurs (Freisthler & Maguire-Jack, 2015; Kolak et al., 2020). There are well-known structural risk factors that disproportionately impact population subgroups. For example, while all minoritized groups experience race-based oppression, it can be argued that very few groups, if any, have been exposed to this mistreatment as long as Black Americans, who stand on a socioeconomic and cultural base that is persistently undermined by larger society (Bailey et al., 2017; Brownlow et al., 2019; Hooks, 1981; Pager & Shepherd, 2008). Furthermore, Black women’s social context is drastically different from other racial/ethnic groups of women (Beauboeuf-Lafontant, 2007; Hooks, 2015). Black women experience misogynoir, a combination of sexism and racism that is unique to their identity (Bailey & Trudy, 2018). These perspectives suggest the need for measures of exposure to structural factors that capture differences in race and/or gender-based susceptibility.
Social factors such as race, gender, and class undergird environmental exposure to structural racism, sexism, and classism that can have consequences for health that shifts between places over sociohistorical time. The ways in which social systems interact with place and time to create exposure to harm and impact the ability to recover from harm can be viewed under a lens of vulnerability. The social systems embedded in the structure of America’s policies, institutions, and environments are unavoidable and chronically expose members of minoritized groups to an increased risk of issues related to mental health (chronic stress, anxiety, depression), physical health (chronic disease, chronic inflammation) and death (maternal mortality, lower life expectancy) (Carter et al., 2019; Chambers et al., 2018; Mitchell et al., 2020). The vulnerability created by these social systems exists regardless of variations in personality, perceptions, coping skills, and other individual level characteristics. Furthermore, this vulnerability is multifaceted and can be measured using aspects of identity within the socioeconomic context of the neighborhood environment and time (Krieger, 2020). While intersecting identities partially account for an individual’s exposure, the social, economic, and political characteristics of their location in time and place vary its intensity and potential impact on health outcomes.
The impact of neighborhoods on health is typically explored using two main spatial index measures. Disadvantage, defined as neighborhood deprivation that results from institutional practices such as redlining, segregation, and political divestment, is often measured using measures of concentrated poverty, public assistance recipients, residential instability, and racial composition (e.g., Barber et al., 2016; Bohlig, 2013; Ross & Mirowsky, 2001). Disadvantage is posited to influence health through its negative impact on access to and availability of health-promoting resources and local institutions that support neighborhood stability (Ross, 2000; Ross & Mirowsky, 2001). Affluence, a sociological construct distinct from disadvantage, is defined by the concentration of neighborhood resources that influence the viability of local institutions, maintain informal social control, and promote the health and economic infrastructure of a community (Browning & Cagney, 2003). Research exploring the effect of neighborhood structural context has shown disadvantage and affluence to be significant predictors of health outcomes regardless of individual characteristics (Browning & Cagney, 2003; Carpiano et al., 2009; Kane et al., 2017). These two constructs are posited to exist on a continuum, where less affluence means more disadvantage and vice versa.
Disadvantage measures those factors that negatively impact the community health-promoting capacity; thus, it is more commonly used to explore community disparities in health outcomes (Lillis, 2009; Schieman, 2005; Yakubovich et al., 2020). However, there is research to support the role of affluence as a key predictor. For example, affluence has been found to be more strongly associated with self-reported health, objectively measured health status and birth outcomes with an effect that persists when disadvantage and its related indicators are included (Browning & Cagney, 2003; Carpiano et al., 2009; Kane et al., 2017; Yourkavitch et al., 2018). Both indicators have a distinct impact on health outcomes at the individual level. Therefore, including disadvantage and affluence in a single multidimensional measure would add to the existing literature that has explored them as separate indicators.
Identity-based social and economic marginalization and its interaction with time and place combine to create Neighborhood Vulnerability. Neighborhood Vulnerability, a combination of social and economic vulnerability, is defined as the risk of harm due to a group or individual’s social identity within the places they inhabit and the time in which they inhabit them (Brennan, 2017; Adger, 2006). Social vulnerability is the risk of adverse life outcomes and experiences resulting from social stigma (stereotypes, prejudice and discrimination) that expose a group to potential harm based on perceived social characteristics (gender, race, age etc.); as such, it limits their ability to cope with and recover from this harm (Williams, 2016, Phelan and Link, 2015). Economic vulnerability is the risk of adverse life outcomes and experiences resulting from socioeconomic status (income, education, and occupation) that expose a group to potential harm based on their access to resources (money, wealth, social networks, education, healthcare, etc.) and limits their ability to cope with and recover from this harm (Brennan, 2017; Adger, 2006; Link & Phelan, 1995).
Neighborhood Vulnerability can be captured using a combination of social and economic characteristics of the population (i.e., education, income, poverty, race, gender). Previous studies have measured exposure to place-based risk using multiple definitions of neighborhood (i.e., census tract, community area, self-defined geographical community) to compute index measures that include various aspects of community context (i.e., income, education, employment, poverty, racial composition). Many indexes are computed by synthesizing decennial census data using different combinations of the following indicators: level of income, poverty, unemployment, public assistance, female-headed households, educational attainment, and employment in professional or managerial positions (Pickett & Pearl, 2001; Ponce et al., 2005; Chuang et al., 2005; Wang et al., 2007; Scott et al., 2009; Wen, 2009; Matthews & Yang, 2010; Yang & Matthews, 2010; Moore et al., 2013). Census tract measures are often combined using some method of summing or averaging, with limitations and sources of bias that are well documented (Song et al., 2013). Of the few studies that use factor analysis, most estimate a unidimensional construct measured at a single time point (Bird et al., 2010; Freedman et al., 2008; Morenoff et al., 2007). The dependence of Neighborhood Vulnerability on fluctuating social and economic factors across time and place means the most accurate measure quantifying exposure must be identity, place, and time specific. Neighborhood Vulnerability indicators are intended to represent perceptible manifestations of latent relationships between interacting neighborhood attributes shaped by differences in political power, concentration of resources, and structures of systemic marginalization that shape what opportunities and services people can access in the places they live (Berg et al., 2020).
The objective of this paper is to compute a Neighborhood Vulnerability Index (NVI) that combines multiple indicators of neighborhood risk into one composite score that is specific to race, gender, time and place using census tract data linked to a longitudinal sample of U.S. adults over a 25-year period. Since this is the one of the first papers to combine disadvantage and affluence into one composite measure, this paper will test two alternative measurement models for the NVI. While previous analyses have created neighborhood disadvantage and affluence indices at a national level, they have not been estimated specifically for race and gender subgroups of the population followed prospectively over time. This paper contributes to our understanding of which groups of the population are systematically exposed to neighborhood vulnerability by computing race/gender specific NVI for a national sample of over 3,000 Black and white Americans followed over adulthood (1986–2010). We hypothesize there will be more exposure to neighborhood vulnerability among racial and gender minorities, with disparities that persist over time.
Previous studies using index measures computed using factor analysis assume the relationships between variables among different groups are similar and scores are unbiased, or that the measure is invariant (Wodtke et al., 2011; Clarke et al., 2014; Berger et al., 2017; Li et al., 2019). Factorial invariance refers to the equivalence of the relationships between indicators used to define a theoretical construct such as neighborhood vulnerability and can inform whether comparisons of mean differences in scores between groups are valid and unbiased (Putnick & Bornstein, 2016). The estimation of the NVI in this study, therefore, includes an assessment of factorial invariance tested longitudinally and between race/gender groups. We then examine changes in Neighborhood Vulnerability over time and identify stark race and gender inequities in which Americans are persistently exposed to neighborhood vulnerability over a 25-year period.
Methods
Data come from the American’s Changing Lives (ACL) survey (House et al., 1990; 1994; 2005), a stratified, multi-stage area probability sample of non-institutionalized adults age 25 and older, living in the coterminous United States, and followed over a 25-year period. Black Americans and adults over age 60 were oversampled. The first wave of the study was conducted in 1986 with 3,617 adults (68% sample response rate for individuals). Surviving respondents were re-interviewed in 1989, 1994, 2001–2002, and 2011–2012. A sixth wave of data collection is currently in the field. This analysis focuses on the 3497 respondents who self-reported their race as Black (34%) or White (66%). We exclude 130 respondents of other racial identifications (e.g., Asian, Native American, and Hispanic) due to small sample size. The ACL data are appropriately weighted to adjust for (a) differential initial selection probabilities, (b) survey non-response, and (c) post-stratification adjustments to the 1986 age-race-sex-region-specific Census Bureau estimates of the U.S. population. For each later wave, additional weights adjust for panel non-response using predictor variables from prior waves (Lepkowski & Couper 2002). These weights make the ACL sample representative of the age, gender, and race distribution of the U.S. population in 1986. Except for differences due to post-1986 immigration and outmigration, the sample is also representative of American residents in the originally sampled age cohorts as they aged over 25 years (House et al., 1990).
Each respondent’s address at each wave was geocoded and linked to data from the U.S. Decennial Census and the American Community Survey for each year. Because census tract boundaries can change over time, tract boundaries were normalized to the 2010 tract boundaries using the Longitudinal Tract Database (Logan et al., 2014). With these five waves of data, a composite measure of exposure to Neighborhood Vulnerability was estimated for all respondents using confirmatory factor analysis, and scores were compared by gender and race subgroups over time.
Measures
The ACL dataset contains U.S. Census Bureau data on the social and economic characteristics of U.S. census tracts linked to each participant at each wave. Census tracts have on average about 4000 people and are designed to capture homogenous areas that roughly map to neighborhoods. For Wave 1, the value of each tract variable was interpolated based on the 1980 and 1990 Census data to estimate values for 1986. The same process was used to estimate Wave 3 (1994) values using the 1990 and 2000 census. Wave 2 (1989) and Wave 4 (2001) values correspond to the 1990 and 2000 U.S. Census survey data, respectively. Wave 5 (2011) tract data come from the 2010 American Community Survey.
A set of nine tract-level sociodemographic variables were selected a priori as indicators of three subconstructs of neighborhood vulnerability: affluence (AF), disadvantage (DA), and social vulnerability (SV). Distinct from simply being the absence of neighborhood disadvantage, neighborhood affluence is associated with higher levels of socioeconomic advantages and leverage over local institutions that can foster neighborhood environments with more opportunities for health and well-being (Browning & Cagney, 2003). Disadvantage represents the co-absence of economic, social, and employment resources in the neighborhood (Ross & Mirowsky, 2001). Social vulnerability captures the susceptibility of a neighborhood to marginalization and disinvestment based on the presence of race and gender minorities (Zha, 2019).
Affluence
Affluence is measured using tract-level proportions of (a) adults with 16 or more years of education (EDU), (b) households with income greater than or equal to $75,000 per year (INC), and (c) workers in professional employment (PRF). Professional employment is defined as those occupations in the executive, managerial, technology, and professional industries that require a high degree of expertise and training. Categories for professional employment are based on the U.S. Bureau of Labor Statistics six-digit Standard Occupation Code system used for the decennial census (1990, 2000) and ACS (2010) (Scopp, 2003).
Disadvantage
Disadvantage is measured using tract-level proportions of (a) adult unemployment (UNE), (b) adults in receipt of public assistance income (PBA), and (c) households in poverty (POV). Unemployment is defined as not working, currently looking for work and available to accept a job. Public Assistance is defined as financial resources (direct cash assistance and/or vendor payments) given to persons contingent upon their need from a government-operated welfare program. Households in poverty are defined as those who fall below federal income thresholds determined by household size and composition.
Social Vulnerability
Social vulnerability is measured using tract-level proportions of non-Hispanic Black residents (NHB), female-headed households (FHH), and female-headed households with kids (FHK). Female-headed households with kids are defined as those with an unmarried female head of household and children. These variables were chosen to account for gender and race as social indicators of exposure to neighborhood vulnerability.
All observed sociodemographic variables were continuously measured and represent census tract percentages ranging from 0 to 100%.
Analysis
Measuring Neighborhood Vulnerability
Maximum likelihood (ML) estimation assumptions in confirmatory factor analysis (CFA) include independence of observations, normally distributed indicator variables, and correct specification of the model (Kline, 2005, Hoyle, 2012). Due to moderate normality violations and missing data, models were estimated using a robust version of maximum likelihood estimation (MLR) which provides parameter estimates with corrections to standard errors and fit indices that are robust to non-normality and equivalent to maximum likelihood (Brown, 2014; Yuan & Bentler, 2000; Satorra & Bentler, 1994; Curran, 1996).
Confirmatory factor analysis was used to estimate the three latent subconstructs describing neighborhood vulnerability (disadvantage, affluence, social vulnerability) in R (version 3.6.6) lavaan package. CFA model identification requires the selection of a scaling variable to identify the mean and variance of each latent variable. The lavaan package automatically constrains the intercept and factor loading of the first indicator variable specified; models were respecified for scaling to be based on the indicator with the highest factor loading (Little et al., 2006). Each CFA model estimates (1) a matrix of factor loadings for the relationship between each observed variable and corresponding latent construct; (2) a vector of intercepts for each observed variable; (3) a vector of means of each latent variable; (4) a matrix of variances and covariances of each latent variable; and (5) a matrix of residual variances and covariances for the observed variables.
Three measurement models estimating the three subconstructs of NVI were compared and a final model was selected based on established thresholds for multiple indicators of absolute (standardized root-mean-square residual (SRMR) < 0.08, akaike information criterion (AIC)), parsimonious (root-mean-square error of approximation (RMSEA) < 0.08) and comparative fit (Comparative Fit Index (CFI) > 0.95, Tucker–Lewis Index (TLI) > 0.95) (Brown, 2014). Chi-square tests were also reported but not used to assess model fit due to the large sample size (West et al., 2012). Modification indices and residuals were examined in conjunction with theoretical and practical interpretation to guide model modification (Hayduk, 1990; Kaplan, 1989; 1991). In the final model building step, neighborhood vulnerability was added as a second-order latent variable and factor scores for neighborhood vulnerability were estimated for each participant at each wave.
Testing Measurement Invariance
The first level of invariance is configural invariance, which tests whether structure, or the set of census tract variables used to measure the NVI, is the same between groups. If configural invariance holds, the stability of metric invariance, or whether each census tract indicator corresponds to the NVI to a similar magnitude across groups, can be assessed. If the NVI demonstrates configural and metric invariance, scalar invariance, or whether mean differences in census tract indicators are captured by the NVI, can be assessed (Steenkamp & Baumgartner, 1998; Rudnev et al., 2018). If the NVI demonstrates full scalar invariance, it can be meaningfully compared across timepoints and race/gender groups with less concern for false conclusions due to biased scores.
Measurement invariance was assessed to test the configural, metric, and scalar invariance of the NVI. Invariance was tested between waves (time invariance), race (Black American and white), gender (men and women), and race-by-gender groups using the standard iterative method comparing constrained models (Millsap, 2011). Since full scalar invariance of the measure is necessary for meaningful comparison of scores between groups (and/or across time) partial measurement invariance was not assessed (Brown, et al., 2017; Edwards et al., 2018; Steinmetz, 2013). Invariance at the configural level means that the structural organization of the latent variables (i.e., number of loadings on affluence and social disadvantage) is applicable to each group. At the metric level, invariance means each census tract indicator contributes to the latent variable (affluence or social disadvantage) to a similar magnitude across groups. Scalar invariance means that mean differences in the latent variables capture all mean differences in the shared variance of the indicators for affluence and social disadvantage (Millsap, 2011).
Configural invariance was tested using a multi-group CFA, which simultaneously estimates the model separately in each group. Invariance at the configural level was assessed by examining the overall fit of the multi-group model. If configural invariance was upheld, metric invariance was tested by adding equality constraints on the factor loadings of the census tract indicators to the multi-group model. If both configural and metric invariance were upheld, scalar invariance was tested by additionally imposing equality constraints on the indicator intercepts while retaining the factor loading constraints. Model fit indices and CFI ≥ 0.95 were used to determine whether conditions for configural invariance were met. For metric and scalar invariance, comparisons of nested models using likelihood ratio tests and a change in CFI less than 0.02 were used to determine whether invariance was upheld (Pentz and Chou, 1994; Putnick & Bornstein, 2016).
Results
Descriptives
Table 1 shows baseline descriptive characteristics of all ACL participants by gender and race. The analytic sample consisted of all 3497 participants at baseline residing in 412 U.S. census tracts. Of them, 2185 (62%) were women and 1,129 (32%) were Black. In the overall sample, most had at least a high school diploma (62%), were married (54%) and employed at least part time (51%). Table 2 shows means and standard deviations of each indicator variable at each wave. Census tract social disadvantage indicators appear to remain stable between 1986 and 1994, and then decreased in 2000 followed by an increase in 2012. Mean values of affluence indicators increased gradually throughout the course of the study.
Measuring Exposure to Neighborhood Vulnerability
The process of identifying the best measurement model for NVI involved estimating a set of two theoretically alternative CFA models (Fig. 1) in which fit indices are detailed in Table 3. The initial estimation of Model A showed a negative variance for Female-Headed Households, indicating high multicollinearity between this and other indicators of social vulnerability (Kolenikov & Bollen, 2012, Heywood, 1931). Model B represents the re-specification of Model A to include social disadvantage, a new latent variable combining the indicators of social vulnerability, and disadvantage after removing female-headed households due to high correlation with female-headed households with kids. Model B was selected as the final best-fitting model based on fit indices (χ2 1000.48, df 15, RMSEA 0.07, SRMR 0.02, CFI 0.98, TLI 0.97, AIC 751,272), factor loadings, and standardized variances.

Alternative measurement models for neighborhood vulnerability. Two and three factor theoretical models for the measurement of neighborhood vulnerability. PV Proportion of census tract residents living in poverty, UE proportion of census tract residents who are unemployed, PA proportion of census tract resident receiving public assistance, NB proportion of census tract residents who are non-Hispanic Black, FK proportion of census tract female-headed households with kids, IN proportion of census tract residents with annual income greater than or equal to $75,000, ED proportion of census tract residents with 16 or more completed years of education, EM proportion of census tract residents with professional employment
All factor loadings for tract indicators fell within an acceptable range (> 0.5), indicating a moderate to strong influence of each observed variable on the variation of each latent construct (Harrington, 2008). The final measurement model is presented in Fig. 2. Factor loadings for public assistance (0.90) and poverty (0.90) were especially high, indicating a strong influence on the variance in exposure to social disadvantage between tracts. The loadings for unemployment and female-headed households with kids were also relatively strong (0.82 and 0.79, respectively) while the proportion of non-Hispanic Black residents (0.65) had the lowest loading of the five indicators. The three indicators of affluence had very similar loadings, with education (0.94) and professional employment (0.93) explaining more of the common variance in census tract affluence than income (0.83).

Measurement model for neighborhood vulnerability, American’s Changing Lives Study (1986–2011). Fit indices: χ2 1000.48 (p < 0.001), df 15, CFI 0.98, TLI 0.97, RMSEA 0.07 (CI 0.06, 0.07), SRMR 0.02, χ2 Chi-square, df degrees of freedom, RMSEA root-mean-square error of approximation, SRMR standardized root-mean-square residual, CFI comparative fit index, TLI Tucker–Lewis Index. All factor loadings are standardized. Indicators: POV proportion of census tract residents living in poverty, UNE proportion of census tract residents who are unemployed, PBA proportion of census tract resident receiving public assistance, NHB proportion of census tract residents who are non-Hispanic Black, FHK proportion of census tract female-headed households with kids, INC proportion of census tract residents with annual income greater than or equal to $75,000, EDU proportion of census tract residents with 16 or more completed years of education, PRF proportion of census tract residents with professional employment
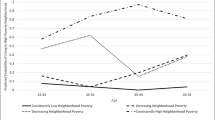
To estimate NVI scores, both lower-order constructs (affluence and social disadvantage) were loaded onto a higher-order factor, neighborhood vulnerability. As expected, affluence was negatively correlated with exposure to neighborhood vulnerability while social disadvantage was positively correlated. Results show that indicators of affluence have a stronger influence on the variance in exposure to neighborhood vulnerability compared to social disadvantage with factor loadings of − 0.96 and 0.59, respectively. The addition of neighborhood vulnerability as a higher-order latent variable resulted in minor changes to model fit (χ2 1000.48, df 15, RMSEA 0.07, SRMR 0.02, CFI 0.98, TLI 0.97, AIC 751,272), and factor scores for the NVI were estimated for each ACL respondent based on this model. Neighborhood Vulnerability Index scores ranged from 19.9 to -36.2 with lower, more negative scores indicating less exposure to vulnerability. Men had lower NVI scores across all waves compared to women in the overall sample and within racial groups. Fig. 3 shows cross-wave trajectories of NVI scores by gender, race, and race-by-gender subgroups in the ACL study. Overall, exposure to neighborhood vulnerability decreased for the full ACL sample and for each gender and racial group between 1986 and 2011. Table 4 shows NVI scores for each ACL subgroup at each wave. Disparities remained persistent between race and gender groups, with women and Black Americans having consistently higher scores compared to their race/gender counterparts at every wave.

Neighborhood vulnerability index trajectories by group, American’s Changing Lives Study (1986–2011). BW black women, BM black men, WW white women, WM white women. Trajectories based on the mean of model estimated neighborhood vulnerability index scores for each group at each wave. ACL American’s Changing Lives Study analytic sample
Testing Measurement Invariance
Measurement invariance tests were conducted between waves, race, gender, and race-by-gender subgroups to assess whether the relationships among census tract variables were influenced by group membership or time. Table 5 shows each series of models, where the fit of model 1 testing configural invariance was compared to model 2 testing metric invariance. If conditions for invariance were met, the fit of model 2 was compared to model 3 testing scalar invariance. Configural (CFI 0.986), metric (ΔCFI = 0, LRT, p < 0.01), and scalar (ΔCFI = 0, LRT p < 0.001) invariance were upheld between gender groups. Race invariance was validated at the configural (CFI: 0969, LRT p < 0.001) and metric (ΔCFI = 0.002, LRT p < 0.001) levels, but scalar invariance (pertaining to item intercepts) was not upheld (ΔCFI = 0.038, LRT p < 0.001). Similarly, race-by-gender group invariance was upheld at the configural (CFI 0.975) and metric (ΔCFI = 0.01) levels only. The NVI did not meet conditions for any level of time invariance.
Discussion
This analysis is one of the first to examine race/gender inequities in exposure to neighborhood vulnerability over time and one of very few studies to assess invariance of a tract-based measure. Using an index derived from contextual aspects of U.S. census tracts at five timepoints between 1986 and 2011, the findings highlight stark inequities in which groups are exposed to neighborhood vulnerability in this national sample of U.S. adults. Exposure to neighborhood vulnerability is disproportionately experienced by Black Americans compared to whites across all time points. While results show exposure to neighborhood vulnerability decreased over time in the sample overall, the rates of decline were attenuated for census tracts where Blacks lived compared to whites (and to a lesser extent for women compared to men), resulting in widening disparities in exposure to neighborhood vulnerability across this 25-year period. Furthermore, race-by-gender trajectories show the compounding effect of race and gender on neighborhood vulnerability, where Black women navigate the most vulnerable environments. The results highlight the persistent and reinforcing pattern of inequitable neighborhood conditions along racial and gender lines in the United States.
The Neighborhood Vulnerability Index (NVI) consists of 8 indicators of social disadvantage and affluence using data from a nationally representative longitudinal population-based sample. Study results show a two-dimensional model of neighborhood vulnerability is a good fit for this sample of U.S. adults ages 25 and older at baseline. The final model for NVI measures this construct based on two underlying dimensions—affluence and social disadvantage. As expected, affluence and social disadvantage have opposite influences on exposure to neighborhood vulnerability. In addition, affluence accounts for a higher amount of variance in neighborhood vulnerability compared to social disadvantage. This is supported by research on the social and economic capital of affluent communities, specifically how they have the ability to generate exclusive resources in ways that spatially segregated impoverished communities do not (Reardon & Bischoff, 2011). For example, a study relocating low-income families to more affluent neighborhoods showed those who lived in well-resourced areas for a longer period had better employment, education, and health outcomes (Ludwig, et al., 2008). On the contrary, when groups of affluent individuals move into disadvantaged neighborhoods, they are unlikely to lose their affluence, in fact, it is more likely their presence will shift the makeup of the neighborhood towards their own interests and income through processes such as cultural displacement, political displacement, and gentrification (Golding, 2016; Hyra, 2014). These observations suggest the strong longitudinal influence of living in a “high opportunity” area given its ability to reverse the impact of prolonged exposure to disadvantage over time.
Based on invariance tests, the NVI measured the same theoretical construct in each group (configural invariance) and the tract indicators had a similar contribution to its variance at each timepoint (metric invariance). However, the NVI did not meet conditions for scalar invariance by race or race-by-gender groups. However, these violations are more informative than invalidating and serve as a guide to practical interpretation of the NVI. Scalar non-invariance (pertaining to factor intercepts) may be indicative of the impact of racial segregation on exposure to neighborhood vulnerability, and the combined impact of race and gender for Black women. In other words, NVI intercepts are heavily influenced by racial group membership while this effect was not observed in the gender invariance tests. This pattern of results is consistent with the well-established influence of race on the type of neighborhood in which people live and a negligible influence of gender alone. These results are also consistent with previous research as scalar invariance is often unachievable and rare in large-scale studies (Marsh et al., 2017). Similarly, longitudinal non-invariance is common in assessments of tract-based indexes as context is expected to shift over time (Berg et al., 2020; Miles et al., 2015).
The NVI can be interpreted as a measure of exposure to health risks based on neighborhood socioeconomic status (education, income, employment), social characteristics (racial composition, gender dynamics), and time. Based on the distribution of NVI scores, there were differences in exposure to neighborhood vulnerability by group at each timepoint. Both gender- and race-impacted levels of vulnerability at each timepoint. Neighborhood vulnerability is decreasing overall, but a persistent gap exists between the decrease for men and women, with the gap widening after 2000. A significant dip occurred between 1986 and 1990 followed by another dip between 1995 and 2000. Score trajectories also show a gap in exposure to neighborhood vulnerability between non-Hispanic Black and white Americans, with a disparity that widens over the course of the study. There is a more dramatic decrease for non-Hispanic whites than Blacks, with similar significant drops from 1986 to 1990 and 1995 to 2000. The race-by-gender trajectories show a similar trend, with the disparity in exposure to neighborhood vulnerability between Black men and women being wider than the gap between white men and women, and Black women being exposed to the highest levels of vulnerability. Despite progress towards less vulnerability overall, these trends are indicative of worsening neighborhood inequities at the local neighborhood level between gender and race groups.
The decreases in exposure to neighborhood vulnerability parallel the period of economic expansion in the U.S. between 1991 and 2001, when there were consistent advancements in median household income, homeownership, poverty, and educational attainment (Sasson, 2016; Anthony, 2018; Marotta, 2020, Stiglitz, 2002). However, U.S. trends in socioeconomic gains did not equitably benefit all groups. The racial disparities in NVI scores that widen during this period are consistent with inequities in income, unemployment and poverty rates between Black and White Americans in the U.S. over the past several decades (Assari, 2017; Caliendo, 2018; Herring & Henderson, 2016; Lichter, 1989; Mason, 2011).
While overall exposure to neighborhood vulnerability declined, the health and well-being of Black Americans remained more vulnerable at all timepoints. This finding would suggest Black Americans continue to reside in distinct neighborhood contexts via residential racial segregation, which somewhat conflicts with segregation trends that show sharp declines in black segregation that overlap with this period (1960–2000) (Fischer et al., 2004). However, research has shown racial segregation has persisted over the past several decades (1990–2016) despite increases in integration in some areas (Stroub & Richards, 2013; Williams et al., 2018). In addition, affluent families have become increasingly more segregated, a trend that likely resulted in separation of socially mobile Black Americans from their less affluent counterparts. Since studies also show Black Americans who socioeconomically advance don’t always experience the same health and mortality protections as their white counterparts (Turner et al., 2017; Assari et al., 2018; Assari, 2018), further exploration of the health impacts of residential racial integration during this time would be an informative future direction.
The NVI is comparable to other indexes using census tract indicators to describe community health risks. For example, the Neighborhood Socioeconomic Status (NSES) index, a time-invariant measure of longitudinal exposure to census tract socioeconomic factors, was created using a unidimensional CFA model and similar variables (Miles et. al, 2015). The NVI builds on the NSES by including variables that capture additional aspects of the neighborhood risk environment, suggesting two dimensions (social disadvantage and affluence) that influence exposure in opposite directions. In addition, linking the NVI to a nationally representative longitudinal sample of U.S. adults allows for describing exposure to neighborhood vulnerability by race and gender at different time points to show inequities in exposure to neighborhood vulnerability over time.
The NVI also corresponds to other community-based indexes that have been used for various purposes in health research, public health prevention and urban planning. For example, the Child Opportunity Index (COI) was developed to identify communities with limited educational, health, environmental and socioeconomic resources (Noelke et al., 2020). Similarly, the Community Vulnerability Index (CVI) is used to measure the potential impact of infectious disease outbreaks to advise public health resource allocation both in the U.S and abroad (Surgo Foundation, 2020). While these indexes incorporate a variety of neighborhood characteristics (transportation, food access and healthcare availability, etc.), their comparability to the NVI demonstrates the ways in which neighborhood factors can be used to characterize and quantify the underlying factors that contribute to susceptibility to health risks at the environmental level.
Strengths and Limitations
This analysis has many strengths. The use of factor analysis (compared to summing or averaging indicators) to estimate the NVI limits measurement bias and allows each indicator to make a unique contribution to the variance of the overall measure. In addition, the use of a longitudinal nationally representative dataset allows for a description of the history of exposure to neighborhood vulnerability among U.S. adults at the local level. The trends in exposure to neighborhood vulnerability between groups replicate previous findings on the differences in exposure to neighborhood context by race and gender (Browning et al., 2013; Dozier, 2010; Karriker-Jaffe et al., 2012; Schieman, 2005), while adding additional evidence to support moving beyond disadvantage to include affluence in analyses of neighborhood effects (Browning & Cagney, 2003). Finally, invariance tests of the NVI met conditions for race (configural, metric) and gender (configural, metric, scalar) invariance, validating the use of the measure to describe between group NVI inequities at any time point.
Some limitations should also be noted. Census tract indexes are limited to variables available in publicly accessible census data, and all limitations of the source of the data will persist throughout the NVI. While these data are the most feasible to use for longitudinal measures of environmental characteristics, census tracts are arbitrary boundaries that may not fully represent socio-spatial exposures (Kramer, et al., 2010). Furthermore, census tract indicators were interpolated for intercensal years; however, in the neighborhood literature, these data are consistently used (Merkin et al., 2009; Cerdá et al., 2010; Clarke et al., 2014).
The NVI also did not meet conditions for full scalar invariance by race or race-by-gender groups or time invariance. Small deviations from invariance do not necessarily preclude subsequent group analyses, and there is no clear consensus on standards for the cutoffs for small violations (Putnick & Bornstein, 2016; Reise et al., 1993). Consequently, future cross-race or -gender analyses using NVI may still be valid, but longitudinal applications should be limited. Finally, the decreases in exposure to neighborhood vulnerability could be partially due to the survival of those who were less vulnerable at baseline. If study attrition did result in systematic differences in the tracts represented in the model, this may have had an impact on the distribution of the NVI and conclusions drawn from this analysis (Halamová et al., 2019). Replication of this analysis in other nationally representative samples and further exploration of invariance are needed to address the limitations within this study.
Conclusions and Future Research
This analysis has expanded the literature on measuring neighborhood exposure to risk and vulnerability in a number of ways. Based on the final model, exposure to neighborhood vulnerability is declining in the overall sample and between race and gender groups. However, we observe a persistent racial and gender disparity in exposure at each time point. Results support the experience of distinct socio-structural contexts for marginalized groups of U.S. adults over time, which has implications for the persistence of health and socioeconomic disparities (Williams & Collins, 2001; Do et al., 2008; Wen and Kowalski-Jones, 2012; White et al., 2012; Kravitz-Wirtz, 2016). The differences in access to neighborhood resources and opportunities between race and gender groups are reflected in the clustering of minoritized groups in socially disadvantaged environments. Moreover, the lack of affluence (a combination of education, income, and professional employment) is a stronger driver of neighborhood vulnerability, indicating the potential benefit of equitable resource allocation in vulnerable communities. Black and White Americans live in vastly different census tracts, which speaks to the potential power of neighborhood equity in reducing health inequities in society more broadly (Ioana et. al, 2018). The impact of racial and income segregation is compounded by race and gender, as evidenced by the NVI disparities between men and women in all groups. Measures such as the NVI provide a new method of accounting for structural exposure to health risks that is otherwise unaccounted for by focusing on the individual.
Future studies should seek to validate the NVI in other population-based samples. In addition, repeated analyses in more diverse samples would allow for additional racial/ethnic group comparisons and provide the ability to further examine patterns of exposure to neighborhood vulnerability among U.S. adults over time. Assessing whether the NVI is a significant predictor of health outcomes could provide evidence of a direct link between structural factors and health, further supporting the need to shift local policies, systems, and environments to reduce racial health inequities. There is also a need to explore approaches to addressing neighborhood vulnerability, such as local advocacy to shift the socio-structural environment through civic engagement and political action. Addressing the upstream social determinants of health at the neighborhood level may prove to be more effective than interventions at the individual level in addressing health inequities.
Data Availability
The Americans’ Changing Lives data are publicly available through the Inter-university Consortium for Political and Social Research (www.icpsr.umich.edu). The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code Availability
The code used during the current study is available from the corresponding author on reasonable request.
References
Adger, W. N. (2006). Vulnerability. Global Environmental Change 16(3), 268–281. https://doi.org/10.1016/j.gloenvcha.2006.02.006
Anthony, J. (2018). Economic prosperity and housing affordability in the United States: Lessons from the booming. (1990). Housing Policy Debate, 28(3), 325–341. U-M Articles Search. https://doi.org/10.1080/10511482.2017.1393689
Assari, S. (2017). Unequal gain of equal resources across racial groups. International Journal of Health Policy and Management, 7(1), 1–9. https://doi.org/10.15171/ijhpm.2017.90
Assari, S. (2018). Blacks’ diminished return of education attainment on subjective health; Mediating effect of income. Brain Sciences, 8(9), 176. https://doi.org/10.3390/brainsci8090176
Assari, S., Lapeyrouse, L. M., & Neighbors, H. W. (2018). Income and self-rated mental health: Diminished returns for high income Black Americans. Behavioral Sciences, 8(5), 50. https://doi.org/10.3390/bs8050050
Bailey, M., & Trudy. (2018). On misogynoir: Citation, erasure, and plagiarism. Feminist Media Studies, 18(4), 762–768. https://doi.org/10.1080/14680777.2018.1447395
Bailey, Z. D., Krieger, N., Agénor, M., Graves, J., Linos, N., & Bassett, M. T. (2017). Structural racism and health inequities in the USA: Evidence and interventions. The Lancet (british Edition), 389(10077), 1453–1463. https://doi.org/10.1016/S0140-6736(17)30569-X
Barber, S., Hickson, D. A., Kawachi, I., Subramanian, S. V., & Earls, F. (2016). Neighborhood disadvantage and cumulative biological risk among a socioeconomically diverse sample of African American adults: An examination in the Jackson Heart Study. Journal of Racial and Ethnic Health Disparities, 3(3), 444. https://doi.org/10.1007/s40615-015-0157-0
Beauboeuf-Lafontant, T. (2007). “You Have to Show Strength”: An Exploration of Gender, Race, and Depression. Gender and Society, 21(1), 28–51
Berg, K. A., Dalton, J. E., Gunzler, D. D., Coulton, C. J., Freedman, D. A., Krieger, N. I., Perzynski, A. T. (2020, September 11). The ADI-3: A revised neighborhood risk index of the social determinants of health over time and place. https://doi.org/10.31235/osf.io/8zajb
Berger, N., Kaufman, T., Bader, M., Sheehan, D., Mooney, S., Neckerman, K., Rundle, A., & Lovasi, G. (2017). P27|Can we better capture longitudinal exposure to the neighbourhood environment? A latent class growth analysis of the obesogenic environment in New York City, 1990–2010. Journal of Epidemiology and Community Health, 71(Suppl 1), A63. https://doi.org/10.1136/jech-2017-SSMAbstracts.129
Bird, C. E., Seeman, T., Escarce, J. J., Basurto-Dávila, R., Finch, B. K., Dubowitz, T., Heron, M., Hale, L., Merkin, S. S., Weden, M., & Lurie, N. (2010). Neighbourhood socioeconomic status and biological ‘wear and tear’ in a nationally representative sample of US adults. Journal of Epidemiology and Community Health (1979), 64(10), 860–865. https://doi.org/10.1136/jech.2008.084814
Boen, C. (2016). The role of socioeconomic factors in Black-White health inequities across the life course: Point-in-time measures, long-term exposures, and differential health returns. Social Science & Medicine, 1982(170), 63–76. https://doi.org/10.1016/j.socscimed.2016.10.008
Bohlig, A. J. (2013). The effect of neighborhood disadvantage, stability, and ethnic homogeneity on depressive symptoms: A multilevel analysis of a predominantly latino sample [Ph.D., The University of Wisconsin - Madison]. http://search.proquest.com/docview/1432193023/abstract/14A42867C1AF4FA6PQ/1
Brennan, V. M. (2017). Vulnerability. Journal of Health Care for the Poor and Underserved, 28(3), viii–xii. U-M Articles Search. https://doi.org/10.1353/hpu.2017.0080
Brown, G. T. L., Harris, L. R., O’Quin, C., & Lane, K. E. (2017). Using multi-group confirmatory factor analysis to evaluate cross-cultural research: Identifying and understanding non-invariance. International Journal of Research & Method in Education, 40(1), 66–90. https://doi.org/10.1080/1743727X.2015.1070823
Brown, T. A. (2014). Confirmatory factor analysis for applied research, 2nd edn, Guilford Publications, 2015. ProQuest Ebook Central. Retrieved From https://ebookcentral-proquest-com.proxy.lib.umich.edu/lib/umichigan/detail.action?docID=1768752.
Browning, C. R., & Cagney, K. A. (2003). Moving beyond poverty: Neighborhood structure, social processes, and health. Journal of Health and Social Behavior, 44(4), 552–571. JSTOR. https://doi.org/10.2307/1519799
Browning, C. R., Soller, B., Gardner, M., & Brooks-Gunn, J. (2013). “Feeling disorder” as a comparative and contingent process: Gender, neighborhood conditions, and adolescent mental health. Journal of Health and Social Behavior, 54(3), 296–314. https://doi.org/10.1177/0022146513498510
Brownlow, B. N., Sosoo, E. E., Long, R. N., Hoggard, L. S., Burford, T. I., & Hill, L. K. (2019). Sex differences in the impact of racial discrimination on mental health among Black Americans. Current Psychiatry Reports, 21(11), 1–14. https://doi.org/10.1007/s11920-019-1098-9
Caliendo, S. (2018). Inequality in America: Race, poverty, and fulfilling democracy’s promise. Routledge. https://doi.org/10.4324/9780429495540
Carpiano, R. M., Lloyd, J. E. V., & Hertzman, C. (2009). Concentrated affluence, concentrated disadvantage, and children’s readiness for school: A population-based, multi-level investigation. Social Science & Medicine (1982), 69(3), 420–432. https://doi.org/10.1016/j.socscimed.2009.05.028
Carter, R. T., Johnson, V. E., Kirkinis, K., Roberson, K., Muchow, C., & Galgay, C. (2019). A meta-analytic review of racial discrimination: Relationships to health and culture. Race and Social Problems, 11(1), 15–32. https://doi.org/10.1007/s12552-018-9256-y
Cerdá, M., Diez-Roux, A. V., Tchetgen Tchetgen, E., Gordon-Larsen, P., & Kiefe, C. (2010). The relationship between neighborhood poverty and alcohol use: Estimation by marginal structural models. Epidemiology (Cambridge, MA), 21(4), 482–489. https://doi.org/10.1097/ede.0b013e3181e13539
Chambers, B. D., Baer, R. J., McLemore, M. R., & Jelliffe-Pawlowski, L. L. (2018). Using index of concentration at the extremes as indicators of structural racism to evaluate the association with preterm birth and infant mortality—California, 2011–2012. Journal of Urban Health, 96(2), 159–170. https://doi.org/10.1007/s11524-018-0272-4
Christine, P. J., Auchincloss, A. H., Bertoni, A. G., Carnethon, M. R., Sánchez, B. N., Moore, K., Adar, S. D., Horwich, T. B., Watson, K. E., & Diez Roux, A. V. (2015). Longitudinal associations between neighborhood physical and social environments and incident type 2 diabetes mellitus: The multi-ethnic study of atherosclerosis (MESA). JAMA Internal Medicine, 175(8), 1311–1320. https://doi.org/10.1001/jamainternmed.2015.2691
Chuang, Y.-C., Cubbin, C., Ahn, D., & Winkleby, M. A. (2005). Effects of neighbourhood socioeconomic status and convenience store concentration on individual level smoking. Journal of Epidemiology and Community Health (1979), 59(7), 568–573. https://doi.org/10.1136/jech.2004.029041
Clarke, P., Morenoff, J., Debbink, M., Golberstein, E., Elliott, M. R., & Lantz, P. M. (2014). Cumulative exposure to neighborhood context. Research on Aging, 36(1), 115–142. https://doi.org/10.1177/0164027512470702
Clarke, P., & Nieuwenhuijsen, E. R. (2009). Environments for healthy ageing: A critical review. Maturitas, 64(1), 14–19. https://doi.org/10.1016/j.maturitas.2009.07.011
Curran, P. J., West, S. G., & Finch, J. F. (1996). The robustness of test statistics to nonnormality and specification error in confirmatory factor analysis. Psychological Methods, 1(1), 16–29. https://doi.org/10.1037/1082-989X.1.1.16
Diez Roux, A. V., & Mair, C. (2010). Neighborhoods and health. Annals of the New York Academy of Sciences, 1186(1), 125–145. https://doi.org/10.1111/j.1749-6632.2009.05333.x
Do, D. P., Finch, B. K., Basurto-Davila, R., Bird, C., Escarce, J., & Lurie, N. (2008). Does place explain racial health disparities? Quantifying the contribution of residential context to the Black/white health gap in the United States. Social Science & Medicine (1982), 67(8), 1258–1268. https://doi.org/10.1016/j.socscimed.2008.06.018
Dozier, R. (2010). Accumulating disadvantage: The growth in the black-white wage gap among women. Journal of African American Studies, 14(3), 279–301. https://doi.org/10.1007/s12111-010-9122-5
Edwards, M. C., Houts, C. R., & Wirth, R. J. (2018). Measurement invariance, the lack thereof, and modeling change. Quality of Life Research, 27(7), 1735–1743. https://doi.org/10.1007/s11136-017-1673-7
Fischer, C. S., Stockmayer, G., Stiles, J., & Hout, M. (2004). Distinguishing the geographic levels and social dimensions of U.S. Metropolitan Segregation, 1960–2000. Demography, 41(1), 37–59. https://doi.org/10.1353/dem.2004.0002
Surgo Foundation. (2020). The COVID - 19 Community Vulnerability Index. https://precisionforcovid.org/ccvi
Freedman, V. A., Grafova, I. B., Schoeni, R. F., & Rogowski, J. (2008). Neighborhoods and disability in later life. Social Science & Medicine (1982), 66(11), 2253–2267. https://doi.org/10.1016/j.socscimed.2008.01.013
Freisthler, B., & Maguire-Jack, K. (2015). Understanding the interplay between neighborhood structural factors, social processes, and alcohol outlets on child physical abuse. Child Maltreatment, 20(4), 268–277. https://doi.org/10.1177/1077559515598000
Golding, S. A. (2016). Gentrification and segregated wealth in rural America: Home value sorting in destination counties. Population Research and Policy Review, 35(1), 127–146. https://doi.org/10.1007/s11113-015-9374-9
Halamová, J., Kanovský, M., Gilbert, P., Troop, N. A., Zuroff, D. C., Petrocchi, N., Hermanto, N., Krieger, T., Kirby, J. N., Asano, K., & Matos, M. (2019). Multiple group IRT measurement invariance analysis of the forms of self-criticising/attacking and self-reassuring scale in thirteen international samples. J Rat-Emo Cognitive-Behav Ther, 37, 411–444. https://doi.org/10.1007/s10942-019-00319-1
Harrington, D. (2008). Confirmatory factor analysis. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780195339888.001.0001
Hayduk, L. A. (1990). Should model modifications be oriented toward improving data fit or encouraging creative and analytical thinking? Multivariate Behavioral Research, 25(2), 193–196. https://doi.org/10.1207/s15327906mbr2502_7
Herring, C., & Henderson, L. (2016). Wealth inequality in black and white: Cultural and structural sources of the racial wealth gap. Race and Social Problems, 8(1), 4–17. https://doi.org/10.1007/s12552-016-9159-8
Heywood, H.B. (1931). On finite sequences of real numbers. Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 134(824), 486–501. https://doi.org/10.1098/rspa.1931.0209
Hooks, B., 1952-. (1981). Ain’t I a woman: Black women and feminism. In Ain’t I a woman: Black women and feminism (Vol. 1–205). South End Press
Hooks, B. (2015). Ain’t I a woman: Black women and feminism. Routledge. https://mirlyn.lib.umich.edu/Record/013539783
House, J. S., Kessler, R. C., & Herzog, A. R. (1990). Age, socioeconomic status, and health. The Milbank Quarterly, 68(3), 383–411. https://doi.org/10.2307/3350111
House, J. S., Lantz, P. M., & Herd, P. (2005). Continuity and change in the social stratification of aging and health over the life course: Evidence from a nationally representative longitudinal study from 1986 to 2001/2002 (Americans’ Changing Lives Study). The Journals of Gerontology. Series B, Psychological Sciences and Social Sciences, 60(Special_Issue_2), S15–S26. https://doi.org/10.1093/geronb/60.special_issue_2.s15
House, J. S., Lepkowski, J. M., Kinney, A. M., Mero, R. P., Kessler, R. C., & Herzog, A. R. (1994). The social stratification of aging and health. Journal of Health and Social Behavior, 35(3), 213–234. https://doi.org/10.2307/2137277
Hoyle, R. H. (2012). Handbook of structural equation modeling. The Guilford Press; ProQuest Ebook Central, https://ebookcentral-proquest.com.proxy.lib.umich.edu/lib/umichigan/detail.action?docID=922196.
Hyra, D. (2014). The back-to-the-city movement: Neighbourhood redevelopment and processes of political and cultural displacement. Urban Studies (edinburgh, Scotland), 52(10), 1753–1773. https://doi.org/10.1177/0042098014539403
Ioana, P., Duffy, E., Mendelsohn, J., Escarce, J. J., & Bowen, M. (2018). Racial residential segregation socioeconomic disparities and the White-Black survival gap. PLOS ONE 13(2), e0193222. https://doi.org/10.1371/journal.pone.0193222
Kane, J. B., Miles, G., Yourkavitch, J., & King, K. (2017). Neighborhood context and birth outcomes: Going beyond neighborhood disadvantage, incorporating affluence. SSM - Population Health, 3(C), 699–712. https://doi.org/10.1016/j.ssmph.2017.08.003
Kaplan, D. (1989). Model modification in covariance structure analysis: Application of the expected parameter change statistic. Multivariate Behavioral Research, 24(3), 285–305. https://doi.org/10.1207/s15327906mbr2403_2
Kaplan, D. (1991). On the modification and predictive validity of covariance structure models. Quality & Quantity, 25(3), 307–314. https://doi.org/10.1007/BF00167535
Karriker-Jaffe, K. J., Zemore, S. E., Mulia, N., Jones-Webb, R., Bond, J., & Greenfield, T. K. (2012). Neighborhood disadvantage and adult alcohol outcomes: Differential risk by race and gender. Journal of Studies on Alcohol and Drugs, 73(6), 865–873. https://doi.org/10.15288/jsad.2012.73.865
Kline, R. B. (2005). Principles and practice of structural equation modeling, 2nd ed. (pp. xviii, 366). Guilford Press.
Kolak, M., Bhatt, J., Park, Y. H., Padrón, N. A., & Molefe, A. (2020). Quantification of neighborhood-level social determinants of health in the continental United States. JAMA Network Open, 3(1), e1919928–e1919928. https://doi.org/10.1001/jamanetworkopen.2019.19928
Kolenikov, S., & Bollen, K. A. (2012). Testing negative error variances: Is a Heywood case a symptom of misspecification? Sociological Methods & Research, 41(1), 124–167. https://doi.org/10.1177/0049124112442138
Kramer, M. R., Cooper, H. L., Drews-Botsch, C. D., Waller, L. A., & Hogue, C. R. (2010). Do measures matter? Comparing surface-density-derived and census-tract-derived measures of racial residential segregation. International Journal of Health Geographics, 9, 29. https://doi.org/10.1186/1476-072X-9-29
Kravitz-Wirtz, N. (2016). Cumulative effects of growing up in separate and unequal neighborhoods on racial disparities in self-rated health in early adulthood. Journal of Health and Social Behavior, 57(4), 453–470. https://doi.org/10.1177/0022146516671568
Krieger, N. (2020). Measures of racism, sexism, heterosexism, and gender binarism for health equity research: From structural injustice to embodied harm-an ecosocial analysis. Annual Review of Public Health, 41(1), 37–62. https://doi.org/10.1146/annurev-publhealth-040119-094017
Lepkowski, J. M., & Couper, M. P. (2002). Nonresponse in the second wave of longitudinal household surveys. Survey Nonresponse, 259–272.
Li, M., Johnson, S. B., Newman, S., & Riley, A. W. (2019). Residential mobility and long-term exposure to neighborhood poverty among children born in poor families: A U.S. longitudinal cohort study. Social Science & Medicine (1982), 226, 69–76. https://doi.org/10.1016/j.socscimed.2019.02.042
Lichter, D. T. (1989). Race, employment hardship, and inequality in the American Nonmetropolitan South. American Sociological Review, 54(3), 436–446. https://doi.org/10.2307/2095615
Lillis, J. P. (2009). Living with stress: Neighborhood disadvantage, social capital, and depression. ProQuest Dissertations Publishing
Link, B. & Phelan, J. (1995) Social Conditions As Fundamental Causes of Disease. Journal of Health and Social Behavior 35:80. https://doi.org/10.2307/2626958
Little, T. D., Slegers, D. W., & Card, N. A. (2006). A non-arbitrary method of identifying and scaling latent variables in SEM and MACS Models. Structural Equation Modeling, 13(1), 59–72. https://doi.org/10.1207/s15328007sem1301_3
Logan, J. R., Xu, Z., & Stults, B. J. (2014). Interpolating U.S. decennial census tract data from as early as 1970 to 2010: A longitudinal tract database. The Professional Geographer, 66(3), 412–420. https://doi.org/10.1080/00330124.2014.905156
Ludwig, J., Liebman, J. B., Kling, J. R., Duncan, G. J., Katz, L. F., Kessler, R. C., & Sanbonmatsu, L. (2008). What can we learn about neighborhood effects from the moving to opportunity experiment? The American Journal of Sociology, 114(1), 144–188. https://doi.org/10.1086/588741
Marotta, D. J. (2020). Longest Economic Expansion In United States History. Forbes. https://www.forbes.com/sites/davidmarotta/2020/01/21/longest-economic-expansion-in-united-states-history/?sh=529e13bf62a2
Marsh, H., Guo, J., Parker, P., Nagengast, B., Asparouhov, T., Muthén, B., & Dicke, T. (2017). What to do When Scalar Invariance Fails: The Extended Alignment Method for Multi-Group Factor Analysis Comparison of Latent Means Across Many Groups. Psychological Methods, 23. https://doi.org/10.1037/met0000113
Mason, P. L. (2011). Moments of disparate peaks: Race-gender wage gaps among mature persons, 1965–2007. Review of Black Political Economy, 38(1), 1–25. https://doi.org/10.1007/s12114-010-9059-x
Matthews, S. A., & Yang, T.-C. (2010). Exploring the role of the built and social neighborhood environment in moderating stress and health. Annals of Behavioral Medicine, 39(2), 170–183. https://doi.org/10.1007/s12160-010-9175-7
Merkin, S. S., Basurto-Dávila, R., Karlamangla, A., Bird, C. E., Lurie, N., Escarce, J., & Seeman, T. (2009). Neighborhoods and cumulative biological risk profiles by race/ethnicity in a national sample of U.S. Adults: NHANES III. Annals of Epidemiology, 19(3), 194–201. https://doi.org/10.1016/j.annepidem.2008.12.006
Miles, J. N., Weden, M. M., Lavery, D., Escarce, J. J., Cagney, K. A., & Shih, R. A. (2015). Constructing a time-invariant measure of the socio-economic status of U.S. Census Tracts. Journal of Urban Health, 93(1), 213–232. https://doi.org/10.1007/s11524-015-9959-y
Millsap, R. E. (2011). Statistical approaches to measurement invariance. Routledge; ProQuest Ebook Central. Retrieved from https://ebookcentral-proquest-com.proxy.lib.umich.edu/lib/umichigan/detail.action?docID=692401.
Mitchell, F. M., Sangalang, C., Lechuga-Peña, S., Lopez, K., & Beccera, D. (2020). Health inequities in historical context: A critical race theory analysis of diabetes among African Americans and American Indians. Race and Social Problems, 12(4), 289–299. https://doi.org/10.1007/s12552-020-09301-4
Mode, N. A., Evans, M. K., & Zonderman, A. B. (2016). Race, neighborhood economic status, income inequality and mortality. PLoS ONE, 11(5), e0154535. https://doi.org/10.1371/journal.pone.0154535
Moore, K., Diez Roux, A. V., Auchincloss, A., Evenson, K. R., Kaufman, J., Mujahid, M., & Williams, K. (2013). Home and work neighbourhood environments in relation to body mass index: The Multi-Ethnic Study of Atherosclerosis (MESA). Journal of Epidemiology and Community Health, 67(10), 846–853. https://doi.org/10.1136/jech-2013-202682
Morenoff, J. D., House, J. S., Hansen, B. B., Williams, D. R., Kaplan, G. A., & Hunte, H. E. (2007). Understanding social disparities in hypertension prevalence, awareness, treatment, and control: The role of neighborhood context. Social Science & Medicine (1982), 65(9), 1853–1866. https://doi.org/10.1016/j.socscimed.2007.05.038
Noelke, C., McArdle, N., Baek, M., Huntington, N., Huber, R., Hardy, E., & Acevedo-Garcia, D. (2020). Child Oportunity Index 2.0 Technical Documentation. The Heller School for Social Policy and Management, Brandeis University. https://diversitydatakids.org/researchlibrary/research-brief/how-we-built-it.
Pager, D., & Shepherd, H. (2008). The sociology of discrimination: racial discrimination in employment, housing, credit, and consumer markets. Annual Review of Sociology, 34(1), 181–209. https://doi.org/10.1146/annurev.soc.33.040406.131740
Pentz, M. A., & Chou, C.-P. (1994). Measurement invariance in longitudinal clinical research assuming change from development and intervention. Journal of Consulting and Clinical Psychology 62(3), 450–462. https://doi.org/10.1037/0022-006X.62.3.450
Phelan, J. C., & Link, B. G. (2015). Is racism a fundamental cause of inequalities in health? Annual Review of Sociology, 41(1), 311–330. https://doi.org/10.1146/annurev-soc-073014-112305
Pickett, K. E., & Pearl, M. (2001). Multilevel analyses of neighbourhood socioeconomic context and health outcomes: A critical review. Journal of Epidemiology and Community Health (1979), 55(2), 111–122. https://doi.org/10.1136/jech.55.2.111
Ponce, N. A., Hoggatt, K. J., Wilhelm, M., & Ritz, B. (2005). Preterm birth: The interaction of traffic-related air pollution with economic hardship in Los Angeles Neighborhoods. American Journal of Epidemiology, 162(2), 140–148. https://doi.org/10.1093/aje/kwi173
Putnick, D. L., & Bornstein, M. H. (2016). Measurement invariance conventions and reporting: The state of the art and future directions for psychological research. Developmental Review, 41, 71–90. https://doi.org/10.1016/j.dr.2016.06.004
Reardon, S. F., & Bischoff, K. (2011). Income inequality and income segregation. The American Journal of Sociology, 116(4), 1092–1153. https://doi.org/10.1086/657114
Sijmen A. Reijneveld, Michelle Pearl, & Kate E. Pickett. (2001). Explanations for Differences in Health Outcomes between Neighbourhoods of Varying Socioeconomic Level [with Reply]. Journal of Epidemiology and Community Health (1979), 55(11), 847–847. https://doi.org/10.1136/jech.55.11.847
Reise, Steven P, Widaman, Keith F, & Pugh, Robin H. (11/1993). Confirmatory Factor Analysis and Item Response Theory. Psychological Bulletin, 114(3), 552–566
Ross, C. E. (2000). Neighborhood disadvantage and adult depression. Journal of Health and Social Behavior, 41(2), 177–187. https://doi.org/10.2307/2676304
Ross, C. E., & Mirowsky, J. (2001). Neighborhood disadvantage, disorder, and health. Journal of Health and Social Behavior, 42(3), 258–276.
Rudnev, M., Lytkina, E., Davidov, E., Schmidt, P., & Zick, A. (2018). Testing measurement invariance for a second-order factor. A cross-national test of the Alienation Scale. Methoden, Daten, Analysen. https://doi.org/10.12758/mda.2017.11
Sasson, I. (2016). Trends in life expectancy and lifespan variation by educational attainment: United States, 1990–2010. Demography, 53(2), 269–293. https://doi.org/10.1007/s13524-015-0453-7
Satorra, A., & Bentler, P. M. (1994). Corrections to test statistics and standard errors in covariance structure analysis. Latent Variables Analysis: Applications for Developmental Research, 399–419.
Schieman, S. (2005). Residential stability and the social impact of neighborhood disadvantage: A study of gender- and race-contingent effects. Social Forces, 83(3), 1031–1064.
Schüle, S. A., & Bolte, G. (2015). Interactive and independent associations between the socioeconomic and objective built environment on the neighbourhood level and individual health: A systematic review of multilevel studies. PLoS ONE, 10(4), e0123456. https://doi.org/10.1371/journal.pone.0123456
Scopp, T. (2003). The Relationship Between The 1990 Census and Census 2000 Industry and Occupation Classification Systems (Technical Paper No. 65). U.S. Census Bureau. The Relationship Between The 1990 Census and Census 2000 Industry and Occupation Classification Systems
Scott, M. M., Dubowitz, T., & Cohen, D. A. (2009). Regional differences in walking frequency and BMI: What role does the built environment play for Blacks and Whites? Health & Place, 15(3), 897–902. https://doi.org/10.1016/j.healthplace.2009.02.010
Song, M.-K., Lin, F.-C., Ward, S. E., & Fine, J. P. (2013). Composite variables: When and how. Nursing Research (new York), 62(1), 45–49. https://doi.org/10.1097/NNR.0b013e3182741948
Steenkamp, J. E. M., & Baumgartner, H. (1998). Assessing measurement invariance in cross-national consumer research. The Journal of Consumer Research, 25(1), 78–107. https://doi.org/10.1086/209528
Steinmetz, H. (2011). Analyzing observed composite differences across groups. Methodology, 9(1), 1–12. https://doi.org/10.1027/1614-2241/a000049
Stiglitz, J. (2002). The Roaring Nineties—The Atlantic. The Atlantic. https://www.theatlantic.com/magazine/archive/2002/10/the-roaring-nineties/302604/
Stroub, K. J., & Richards, M. P. (2013). From resegregation to reintegration: Trends in the racial/ethnic segregation of metropolitan public schools, 1993–2009. American Educational Research Journal, 50(3), 497–531. https://doi.org/10.3102/0002831213478462
Turner, R. J., Brown, T. N., & Hale, W. B. (2017). Race, socioeconomic position, and physical health: A descriptive analysis. Journal of Health and Social Behavior, 58(1), 23–36. https://doi.org/10.1177/0022146516687008
Vidourek, R. A., King, K. A., & Yockey, R. A. (2019). Do neighborhood characteristics contribute to anxiety? A national study of 12 to 17-year-olds. American Journal of Health Education, 50(4), 245–250. https://doi.org/10.1080/19325037.2019.1616016
Waldstein, S. R., Moody, D. L. B., McNeely, J. M., Allen, A. J., Sprung, M. R., Shah, M. T., Al’Najjar, E., Evans, M. K., & Zonderman, A. B. (2016). Cross-sectional relations of race and poverty status to cardiovascular risk factors in the Healthy Aging in Neighborhoods of Diversity across the Lifespan (HANDLS) study. BMC Public Health, 16(1), 258–311. https://doi.org/10.1186/s12889-016-2945-9
Wang, M. C., Kim, S., Gonzalez, A. A., MacLeod, K. E., & Winkleby, M. A. (2007). Socioeconomic and food-related physical characteristics of the neighbourhood environment are associated with body mass index. Journal of Epidemiology and Community Health, 61(6), 491–498. https://doi.org/10.1136/jech.2006.051680
Wen, M., & Kowaleski-Jones, L. (2012). The built environment and risk of obesity in the United States: Racial–ethnic disparities. Health & Place, 18(6), 1314–1322. https://doi.org/10.1016/j.healthplace.2012.09.002
Wen, M., & Zhang, X. (2009). Contextual effects of built and social environments of urban neighborhoods on exercise: A multilevel study in Chicago. American Journal of Health Promotion, 23(4), 247–254. https://doi.org/10.4278/ajhp.07052448
West, S. G., Taylor, A. B., & Wu, W. (2012). Model fit and model selection in structural equation modeling. Handbook of Structural Equation Modeling, 209–231.
White, K., Haas, J. S., & Williams, D. R. (2012). Elucidating the role of place in health care disparities: The example of racial/ethnic residential segregation. Health Services Research, 47(3pt2), 1278–1299. https://doi.org/10.1111/j.1475-6773.2012.01410.x
Williams, A., Emamdjomeh, A., Keating, D., Mellnik, T., & Karklis, L. (2018). America is more diverse than ever—But still segregated. The Washington Post. https://www.washingtonpost.com/graphics/2018/national/segregation-us-cities/
Williams, D. R., & Collins, C. (2001). Racial residential segregation: A fundamental cause of racial disparities in health. Public Health Reports (1974), 116(5), 404–416. https://doi.org/10.1016/s0033-3549(04)50068-7
Williams, D. R. (2016). Measuring Discrimination Resource. 24.
Wodtke, G. T., Harding, D. J., & Elwert, F. (2011). Neighborhood effects in temporal perspective: The impact of long-term exposure to concentrated disadvantage on high school graduation. American Sociological Review, 76(5), 713–736. https://doi.org/10.1177/0003122411420816
Yakubovich, A. R., Heron, J., & Humphreys, D. K. (2020). How do perceived and objective measures of neighbourhood disadvantage vary over time? Results from a prospective-longitudinal study in the UK with implications for longitudinal research on neighbourhood effects on health. PLoS ONE, 15(4), e0231779. https://doi.org/10.1371/journal.pone.0231779
Yang, T.-C., & Matthews, S. A. (2010). The role of social and built environments in predicting self-rated stress: A multilevel analysis in Philadelphia. Health & Place, 16(5), 803–810. https://doi.org/10.1016/j.healthplace.2010.04.005
Yourkavitch, J., Kane, J. B., & Miles, G. (2018). Neighborhood disadvantage and neighborhood affluence: Associations with breastfeeding practices in urban areas. Maternal and Child Health Journal, 22(4), 546–555. https://doi.org/10.1007/s10995-017-2423-8
Yuan, K.-H., & Bentler, P. M. (2000). Three likelihood-based methods for mean and covariance structure analysis with nonnormal missing data. Sociological Methodology, 30(1), 165–200. https://doi.org/10.1111/0081-1750.00078
Zha, P. (2019). Social epidemiology. In D. Pacquiao & M. Douglas (Eds.), Social pathways to health vulnerability. Cham: Springer.
Funding
This research was supported by the University of Michigan Rackham Graduate School; funding for the Americans’ Changing Lives study came from the National Institutes of Health (NIA R01AG018418).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare no conflicts of interest.
Informed Consent
Informed consent was obtained from all individual participants included in the original study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Battle, S., Clarke, P. Inequities in Exposure to Neighborhood Vulnerability over Time: Findings from a National Sample of U.S. Adults. Race Soc Probl 14, 53–68 (2022). https://doi.org/10.1007/s12552-021-09343-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12552-021-09343-2