
Abstract
Accurate, efficient and stable prediction of thermal displacements generated during spindle machining is essential for improving machining quality, increasing economic efficiency and ensuring production safety. Aiming at the existing thermal displacement prediction models with low precision and poor robustness, this paper put forward a prediction model based on the Bald Eagle Search (BES) algorithm optimized Least Squares Support Vector Machine (LSSVM). Firstly, the experimental platform was built to carry out the spindle thermal deformation experiment and collect the experimental data. Then use K-means clustering method to classify the temperature measurement points, and combine with gray correlation analysis to calculate the size of the correlation between each point and thermal displacement, comprehensive analysis of the classification results and the size of the correlation, from the 10 points preferred 4 points. After that, the BES algorithm, which has strong searching ability in the global range, is chosen to optimize the internal parameters of LSSVM, and the prediction model based on BES-LSSVM is constructed by learning the nonlinear correlation characteristics between the spindle temperature and axial thermal displacement. Finally, it is compared with the prediction model using BES algorithm to optimize support vector machine and the prediction model using sparrow search algorithm to optimize LSSVM respectively. The comparison reveals that the predictions output from the BES-LSSVM model have better accuracy and stability. The results of the study can provide a certain knowledge base and technical support for the effective prediction of spindle thermal displacement changes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the continuous improvement of production requirements, production and processing are constantly in need of new machining technology to improve processing efficiency and reduce production costs [1]. CNC machine tools are the main equipment in the industrial manufacturing process [2] and play an important role in precision manufacturing [3]. Electric spindle is a new technology product in the field of CNC machine tools, which creatively combines the machine tool spindle and high-speed motor into one, and then enhance the machining condition, which helps to improve productivity and machining quality [4]. Conventional spindles generally use pulley drives [5] and gear drives, which complicate the structure of the drive system of CNC machine tools. Compared with the traditional spindle, the electric spindle built-in motor, eliminating the transmission mechanism and has the advantages of low noise, low vibration, to avoid excessive noise on the working environment which causes serious impact [6], and also can realize the rapid start and quasi-stop.
In actual machining, the speed and power of high-speed electric spindle application is very large, the maximum speed can reach 180,000rpm, and the corresponding motor power can reach 1KW, for example, ISA’s A/C double-axis rotary milling head, the spindle rated torque is more than 3,000N•m, and the maximal clamping torque is up to 15,000N•m [7], so that there will be a not-insignificant amount of heat generated inside the electric spindle. In the structural design of the spindle, in order to reduce the volume, its internal parts and components of the compact structure, high degree of centralization, and good sealing, which also leads to the actual machining of the spindle in the heat dissipation is more difficult. Due to the high amount of heat generation and the difficulty in dissipating heat, the spindle is therefore thermally displaced, leading to an increase in thermal error. According to relevant statistics, among all sources of errors in machine tools, geometric and thermal errors have the largest proportion, with thermal errors taking up more than 40% of the total error [8, 9].
As production technology continues to advance, both the speed and power required by machine tools continue to increase [10], which also leads to an increase in the amount of thermal displacement of the spindle. In an effort to minimize thermal displacements and improve product accuracy, thermal error compensation technology can be applied, which compensates for errors by continuously correcting the position of the spindle during operation. When using this technology, first of all, according to the characteristics of heat generation when the spindle is working, the temperature measuring equipment is arranged in a suitable position on the spindle. During the experiments, data acquisition equipment was utilized for experimental data collection. Then the optimization of temperature measurement points is carried out and suitable temperature measurement points are selected. The optimized experimental data is used to build a prediction model, and the compensation value calculated by the prediction model is input to the CNC system for compensation.
When collecting temperature data, increasing the number of temperature measurement points can provide a more comprehensive description of the temperature change of the spindle system during operation, but at the same time, each temperature measurement point also carries some errors. If the prediction model uses temperature data from too many temperature measurement points, it may lead to redundancy in the input data, which not only reduces the computational speed of the model, but also affects the prediction effect of the model, so the appropriate temperature measurement points need to be selected. Many scholars have carried out in-depth studies on optimizing the spindle temperature measurement points, providing many valuable references. Lee et al. [11] proposed an evaluation method to extract the temperature measurement points that have a large influence on thermal deformation by independent component analysis. Wang et al. [12] used a hidden variable modeling approach as an alternative to existing modeling methods and used this algorithm to propose a method for determining the optimal number of temperature measurement points. Han et al. [13] proposed a fuzzy clustering model and used the proposed model to classify the input data and the validity criteria were based on cluster analysis. Li et al. [14] used the optimal approximation law to improve the binary grasshopper optimization algorithm to select suitable temperature measurement points, which improved the model prediction accuracy compared to the fuzzy C-mean clustering method. Liao et al. [15] used the pearson correlation coefficient method to select three crucial temperature measurement points from 15 measurement points. The above measurement point optimization method provides a reference for the screening of temperature measurement points in this paper, and a simple and accurate method can be used to select temperature measurement points with higher correlation with spindle thermal displacement.
Establishing an efficient, stable and accurate prediction model is the most critical step in the thermal error compensation technology, and the accuracy and stability of the prediction model determine the final effect of the compensation work. Currently, the empirical thermal error modeling method is mainly used to build prediction models. Using the actual measured experimental data and comprehensively analyzing the mathematical relationship that exists between the input data and the output data in the data, a prediction model is then established. Currently, the main models that are used more and with better accuracy are least squares, regression analysis model, gray model, neural network model and so on. Ramesh et al. [16] devised an SVM-Bayesian error model. The model first utilizes a Bayesian model to classify the measured experimental data and then an SVM model to reflect the potential relationship that exists between the measured spindle temperature and the thermal error. Zhang et al. [17] proposed a new gray neural network prediction model by combining gray system theory and neural network, which can better combine the advantages of the two. Wei et al. [18] introduced a new prediction model on the basis of gaussian process regression (GPR). Shi et al. [19] and others proposed a prediction model on the basis of Bayesian neural network to greatly reduce the thermal error of the feed system, while experimental validation yielded that the model can show its excellent prediction performance under different operating conditions. Li et al. [20] used the ISPO algorithm to optimize the parameters of the BP neural network and thus build a prediction model, which is better compared to the traditional genetic algorithm (GA). Abdulshahed et al. [21] utilized the adaptive neuro fuzzy inference system to develop the prediction model with good prediction performance. Li et al. [22] chose the BAS algorithm to perform optimization of the internal parameters of the BP neural network, and then established the prediction method of BAS-BP, and compared the prediction effect of this method with that of the BP method and the GA-BP method, and concluded that the prediction effect of BAS-BP is better. Abdulshahed et al. [23] combined the advantages of artificial neural networks and gray system models to propose a modeling approach based on gray system theory and the learning ability of artificial neural networks in a single system. Through reading numerous references in related fields, it is found that there are more scholars researching on prediction models and the proposed models also have better prediction performance, but generally require more sample data. To ameliorate this problem, this paper proposes an LSSVM model, which retains the advantage that SVM can handle the small sample data problem well, while also reducing the computational complexity. In order to further improve the prediction performance of the models, some scholars combine the models with bionic optimization algorithms, and then build prediction models, which can be used for optimization in dynamic and uncertain environments, providing diversity options for the establishment of prediction models. Considering that the BES algorithm has better searching ability in the global range, the BES algorithm is chosen to optimize the internal parameters of the LSSVM model and establish the BES-LSSVM prediction model. After outputting the predicted values using the prediction model, the compensation work, i.e., the process of adjusting the position between the tool and the workpiece, can be started [24]. Compensation work can be embarked upon at every stage of machine tool design or manufacture, even if the structure has already been determined, with the advantages of efficiency and economy [25]. Currently, the commonly used spindle compensation method is mainly the origin offset compensation method [26], and the working principle is shown in Fig. 1.

Principal diagram of origin offset compensation
In summary, in order to realize the accurate compensation of spindle working position, it is necessary to choose the appropriate optimization algorithm and model, and then establish the spindle thermal displacement prediction model, which accurately and stably outputs the predicted value of spindle thermal displacement.
The research process of this paper is shown in Fig. 2. Firstly, the thermal deformation experiment is carried out by building an experimental platform, and the experimental data are collected under different working conditions of the spindle. Then the K-means clustering method is used to classify the temperature measurement points on the main axis, and the gray correlation method is used to screen out four temperature measurement points with large correlation with thermal displacement, so as to reduce the influence of multiple colinearity between temperature data on the performance of the prediction model. The LSSVM model has a fast learning speed and can better adapt to the sample data under different experimental working conditions. Meanwhile, the BES algorithm has a strong ability to search in the global range, which can effectively target all kinds of numerical optimization problems, and can improve the prediction precision and smoothness of the LSSVM model, therefore, the BES-LSSVM prediction model is proposed, and the optimized experimental data are used to train the model. Finally, the BES-LSSVM model are compared with the BES-SVM and SSA-LSSVM models, respectively. The comparison results revealed that the BES-LSSVM prediction model predicted better results compared to the other two models. The results of the above research can provide a certain theoretical basis and technical support for the accurate prediction of spindle thermal displacement changes, which is of great significance in promoting the accurate operation of the electric spindle system and the precision work of machine tools.

The research process of this paper
2 Experimental Study of Heat Deformation
2.1 Heat Deformation Experimental Design
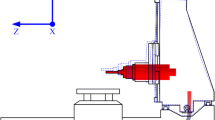
In order to fully describe the temperature changes during high-speed rotation of the electric spindle, 10 temperature measurement points, code-named T1, T2, …, T10, were arranged in the spindle system during the thermal deformation experiments. When the high-speed electric spindle works, its internal stator, rotor, front and rear bearings generate heat more seriously, which makes the axial temperature of the spindle system varies greatly, so in order to improve the accuracy of the measured temperature data, the temperature sensors are arranged along the axial direction of the spindle. The location of the measurement points is illustrated in Fig. 3, in which the temperature sensors code named T1 and T2 are arranged at the front end face of the spindle, the rest of the temperature sensors code named T3, T4, T6, T7, T8, and T9 are fixed at the spindle shell in turn, and the temperature sensors code named T5 and T10 are arranged inside the spindle near the front bearing and the back bearing, respectively.

Arrangement of temperature measurement points
At the same time, arrangement of the displacement sensor is carried out to collect thermal displacement data. The magnetic suction base is used to fix the sensor bracket on the experimental platform, and then the position of the eddy current probe on the bracket is adjusted to align the eddy current probe to the center of the front end of the spindle and adjust the distance between the probe and the front end face of the spindle. Although the spindle generates two radial thermal displacements and one axial thermal displacement during the working works, the two radial thermal displacements are negligible because they are much smaller than the axial thermal displacements [13]. Therefore, the size of the change in axial thermal displacement in this thermal deformation experiment can be approximated as the thermal error generated by the spindle.
2.2 Establishment of Heat Deformation Experimental Platform
Firstly, the temperature sensor arrangement was carried out. The temperature sensors were fixed on the front end face of the spindle, at the front and back bearings inside the spindle system, as well as on the surface housing of the electrical spindle, respectively. The model of the temperature sensor used this time is PT100, which is the contact temperature sensor with good reproducibility and stability, and its temperature measurement range is from − 200 to 850 °C with an accuracy of ± 0.3 °C and a resolution of 0.1 °C. The temperature sensors are connected to the DH5922-1 temperature data collector and then the temperature data collector is connected to the computer through the conversion cable. Then, the collection software on the computer matched with the temperature data collector is used to save the collected temperature data.
After that, the arrangement of the displacement sensor is carried out, and the position of the probe of the eddy current displacement sensor is constantly adjusted to make it aligned with the center of the front end of the spindle and keep it at a certain distance. The model of eddy current displacement sensor used this time is AEC-5503, which is a non-contact displacement sensor with an accuracy of 1 μm, a resolution of 0.3 μm, and a measurement range of 0 ~ 300 μm, which has the advantages of high detection accuracy, wide range of applicable occasions, and strong anti-jamming ability. The eddy current displacement sensor is powered by the switching power supply and outputs the voltage signal to the PCI-1710 thermal displacement data collector. The thermal displacement data collector is connected to the computer through the conversion cable. Finally, the collection software on the computer matched with the thermal displacement data collector is used to save the collected thermal displacement data. The experimental platform is constructed as shown in Fig. 4.

Construction of heat deformation experiment
2.3 Heat Deformation Experiment Working Condition Setting
This thermal deformation experiment was carried out on a certain model of electric spindle produced by a domestic enterprise, which has a rated speed of 10,000 rpm and a maximum speed of 14,000 rpm. During the experiments, constant temperature air conditioning was utilized to keep the temperature of the laboratory at about 22 °C, while industrial water cooling systems were used to cool the stator and bearings of the electric spindle to dissipate heat. The spindle is at rest for 24 h prior to the test to bring the spindle temperature in line with the room temperature.
This experiment was carried out at three different spindle speeds respectively, in each test, the spindle speed starts from 0, reaches a certain speed and continues to rotate for a period of time, and then continues to increase the speed until it reaches the speed of the final experiment, so that the temperature and axial thermal displacement data measured during the idling of the spindle are more in line with the actual machining situation. The final rotational speeds set for this heat distortion experiment were 2000 rpm, 4000 rpm and 6000 rpm, respectively, and were run continuously for 180 min. The required experimental data were collected in real time, with an interval of 1 min each time, and measured samples of experimental data, for a total of 180 samples of data.
3 Analysis of Experimental Results
3.1 Analyze Temperature Data Collection Results
During the experiment, 180 temperature data were collected at each set of rotational speeds, respectively. The temperature change curves of each temperature measurement point on the spindle at different rotational speeds are displayed in Fig. 5.

Temperature variation curve at different rotational speeds
Analyzing the graphs of temperature rise under different rotational speeds, it is evident that after the spindle has been working under the final rotational speed for a period of time, the temperatures at different measurement points are on an upward trend. The refrigerating characteristic of the industrial water cooler is that when the temperature of the cooling water does not exceed a certain value, the refrigeration machine in the water cooler does not work and does not cool the cooling water. When more heat is absorbed the temperature of the cooling water starts to rise, and when it exceeds a certain value, the chiller starts to work to cool down the cooling water. As the temperature of the cooling water fluctuates, the cooling effect to the spindle also fluctuates, thus leading to certain fluctuations in the measured temperature data. Moreover, when the spindle system is in operation, the state of heat generation is different at different locations, so the speed of temperature change measured at the temperature measurement points at different locations is also somewhat different. As can be seen from Fig. 6, when the spindle rotates at high speed, the temperature rise at the front and back bearings inside the spindle system is large, while the spindle shell is cooled by the cooling effect of the stator cooling water jacket, resulting in a smaller temperature rise measured at the temperature measurement point on the spindle shell. At the same time, the temperature rise of the front bearing and the rear bearing inside the spindle system are different, the temperature rise of the front bearing is smaller, which is mainly due to the design of circulating cooling waterway inside the spindle, the cooling water is injected from the front end of the spindle and outflowed from the rear end, which has a more significant cooling effect on the front bearing.

Axial thermal displacement variation curve at different rotational speeds
3.2 Axial Thermal Displacement Data Acquisition Results and Analysis
When spindle temperature data collection was performed, the measurement of spindle thermal displacement data was also conducted. The spindle will produce two radial thermal displacements and one axial thermal displacement in the working engineering, but since the two radial thermal displacements are far shorter than the axial thermal displacement, this paper focuses on the axial thermal displacement of the spindle, and the change curve of the axial thermal displacement is shown in Fig. 6.
Analysis of Fig. 6 revealed that at the beginning of the experiment, the curve rose faster, and gradually stabilized after a period of time, and the trend of change was almost identical to that of the temperature curve. Combined with the temperature and thermal displacement trend can be obtained, the electric spindle in the working process, with the temperature rise, caused by the spindle axial thermal displacement increase.
4 Optimization of Temperature Measurement Points
Too much temperature data will bring more errors and reduce the calculation speed of the model, so it is necessary to optimize the spindle temperature measurement points and select representative temperature measurement points. The K-means clustering algorithm is simple and efficient, and maintains scalability and high efficiency when dealing with datasets. The gray correlation analysis algorithm, on the other hand, is less computationally intensive and the quantitative results are generally the same as those of qualitative analysis. In this paper, the advantages of these two algorithms are utilized to pick the appropriate measurement points.
4.1 K-means Clustering
Cluster analysis is a method for generating effective groupings of data of different nature [27]. K-means is a classical and practical unsupervised algorithm that can realize the division of the unlabeled data and ensure that the data has a fixed class. The main steps are as described below:
The class cluster m of the dataset is first proposed.
Then m data points in the dataset are randomly designated as the center point ci (i = 1, 2, …, k) of the initial clustering of the m class clusters, where each of the center points also has the n-dimensional attribute, i.e., cij (j = 1, 2, …, n).
The distances of the remaining data points except the center point from the m center points are calculated, and based on the calculation results, the remaining data points are assigned to the category to which the nearest center point belongs, which ultimately results in the formation of m class clusters ci. This distance is calculated using the Euclidean distance formula, which is expressed as:
In the formula, dpi is the Euclidean distance, Xp is the pth element within the class cluster, Ci is the class cluster to which Xp belongs, Xpj is the pth dimensional coordinate of the jth point, and Cij is the ith center of mass of the jth class cluster.
The center points of the previous class clusters were randomly specified, so it is necessary to recalculate the n-dimensional mean value of all data points in Ci in each newly obtained class cluster, and assign the result of the calculation to the new center point. Repeat the above steps until the clustering objective function converges. Where the objective function is shown in Equation (2):
In the formula, S is the clustering objective function and d is the Euclidean distance between two points in the Euclidean space.
From the above, it can be seen that the K-means clustering algorithm in the application, first of all, the number of clusters m should be determined, and then randomly initialized and so on m clustering centers, if the initial clustering center is not selected appropriately, it will make the clustering results are not stable, so it is necessary to run the K-means clustering algorithm for many times, and the clustering outcomes are displayed in Table 1.
4.2 Gray Correlation Analysis
Although the spindle temperature measurement points can be classified using the cluster analysis method, it is not able to determine the correlation degree between the temperature measurement points at different locations on the spindle and the axial thermal displacement, so the key temperature measurement points are selected by combining the gray correlation analysis method with K-means clustering. The basic working concept of grey correlation analysis is to first normalize the data series under different factors and then output the value of correlation between the series. Compared to other correlation methods, gray correlation analysis can get results with higher prediction accuracy by using less data. The gray correlation equation is:
In the formula, α is the discrimination coefficient, S is the gray correlation coefficient, Yi is the variable subsequence, and the smaller the correlation degree of S(W,Yi), the smaller the effect on axial thermal displacement.
Taking the measured axial thermal displacement as the parent sequence (W) and the results of 10 sets of temperature data measured at 10 points as the subsequence (Yi), the gray correlation between the axial thermal displacement and the 10 sets of temperature data measured at each temperature measurement point was calculated. Combine the above categorization results to select the appropriate temperature measurement point. The calculated correlation degree values are shown in Table 2 and the correlation degree bar graph is shown in Fig. 7.

Bar chart of correlation degree
Analyzing Fig. 7 shows that the temperature measurement points arranged at the front and back bearings inside the spindle system have highest correlation degree and are higher than the other temperature measurement points. The results of correlation degree ranking are shown in Table 3. Combining the results of K-means clustering and correlation degree analysis, the temperature data of temperature measurement points T1, T5, T7, and T10 are selected as the input data of the model.
5 Data and Methodology
The Bald Eagle Search Algorithm (BES) was proposed by Malasian scholars Alsattar et al. [28]. It is an optimization algorithm that has been developed inspired by some of the behavioral patterns that arise during bald eagle hunting. The algorithm has a strong ability to search for prey in the global range and can highly efficiently handle numerous numerical optimization tasks. In this paper, the BES algorithm is used to optimize the internal important parameters of the LSSVM model to improve the prediction effect of the LSSVM model on the thermal displacement of the spindle.
5.1 Least Squares Support Vector Machine (LSSVM) Model
The LSSVM model is an improvement on the SVM model. The model learns faster and also adapts better to the sample data, thus avoiding the problem of long training time. The steps are as follows.
First select the training samples:
In the formula, xp is the pth input vector, yp is the pth output vector, n is the sample space dimension, and N is the sample size.
The LSSVM model is denoted by the following formula:
In the formula, ω is the weight vector, c the offset value, and φ(x) is the model mapping function.
Then the minimization problem of the desired function can be expressed as follows:
In the formula, ep is the slack variable, γ is the penalty factor, and J denotes the value of deviation.
This can be obtained by introducing the Lagrange multiplier λp again:
Equation (9) is transformed by the KKT (Karush Kuhn Tucker) condition:
The elimination of ω and ep by association and deduction yields:
where λ = (λ1, λ2, … λN)T, y = (y1, y2, … yN)T, and Z = (11, 12, … 1N)T.
According to Mercer conditions:
In the formula p = 1, 2, …, N, k = 1, 2, … N.
Solution of γ and c by solving the system of equations yields the regression function of the LSSVM as:
where H(xp,xk) is the kernel function for the low-dimensional to high-dimensional mapping.
In this paper, radial basis kernel function (RBF) is used as the kernel function of the model, which has the characteristics of simple structure and strong generalization ability, and is described by the formula:
where σ represents the width parameter of the kernel function, which can effectively reflect the distributional characteristics of the predicted data.
The penalty factor γ mentioned in Equation (8) reflects the model’s ability to adapt to the sample data. From the above analysis, it can be obtained that σ and γ are two important parameters affecting the model prediction performance, so intelligent algorithms can be chosen to perform optimization of these two parameters in order to improve the model prediction performance.
5.2 Bald Eagle Search (BES) Algorithm
The BES algorithm is divided into 3 main phases, which are determining the space in which to search for the prey, searching for the prey in the determined space, and swooping to capture the prey after determining the target.
-
(1)
Determine the space to search for prey: Bald eagles determine the optimal hunting zone within the search area according to the amount of food, change the position according to the observation, and finally perform the hunting operation in the selected space. Expressed in a mathematical formula as:
$$p_{k,new} = p_{best} + \beta \times D(p_{mean} - p_{k} )$$(15)
In the formula, Pk,new denotes the updated position of the kth bald eagle while searching the capture space, Pbest denotes the currently determined optimal search position, β denotes the parameter controlling the change of the bald eagle’s position during the search process, D represents a random number in the interval (0,1), Pmean denotes the average distribution position of the bald eagle while searching the capture space, and Pk denotes the position of the kth bald eagle during the search of the capture space.
-
(2)
Searching for prey in the space determined in the first stage: The bald eagle uses spiral flight to find the best position to swoop down and capture prey in the determined hunting space. At the same time the bald eagle adjusts the search speed by controlling the spiral trajectory of the flight. The spiral flight trajectory is expressed using polar coordinate equations as:
$$\left\{ \begin{gathered} xr(k) = r(k) \times \sin (\theta (k)) \hfill \\ yr(k) = r(k) \times \cos (\theta (k)) \hfill \\ x(k) = \frac{xr(k)}{{\max (\left| {xr} \right|)}} \hfill \\ y(k) = \frac{yr(k)}{{\max (\left| {yr} \right|)}} \hfill \\ \theta (k) = b \times \pi \times D \hfill \\ r(k) = \theta (k) + R \times D \hfill \\ \end{gathered} \right.$$(16)
In the formula, x(k) and y(k) denote the position of the condor during flight, θ(k) and r(k) denote the polar angle and polar diameter of the polar coordinate equation, and b and R denote the parameters controlling the trajectory equation of the condor during flight.
The formula for updating the position of a bald eagle in spiral flight is expressed as:
Pk+1 in the formula denotes the next position of the kth bald eagle in spiral flight.
-
(3)
Swooping to capture prey after determining position: Bald eagles swoop down to capture prey from the optimal swooping capture position. Other bald eagles individuals in the population also begin to move toward the target prey and swoop down to capture it. The subduction equation is also described by using polar coordinates:
$$\left\{ \begin{gathered} xr(k) = r(k) \times \sinh (\theta (k)) \hfill \\ yr(k) = r(k) \times \cosh (\theta (k)) \hfill \\ x_{1} (k) = \frac{xr(k)}{{\max (\left| {xr} \right|)}} \hfill \\ y_{1} (k) = \frac{yr(i)}{{\max (\left| {yr} \right|)}} \hfill \\ \theta (k) = b \times \pi \times D \hfill \\ r(k) = \theta (k) \hfill \\ \end{gathered} \right.$$(18)
The formula that describes the position of a bald eagle during a downward swoop is:
In the formula, t1 and t2 denote the intensity coefficients of the bald eagle moving towards the center position in the space and the best position in the space, respectively, and the magnitude of their values ranges from (1,2).
5.3 BES-LSSVM Prediction Model
The theoretical analysis of the LSSVM model shows that the internal parameters γ and σ in this model have a large impact on the predictive performance of the model. In order to accurately, efficiently and stably predict the thermal displacement changes during spindle operation, the BES algorithm is used to perform parameter optimization. The main steps are shown below:
Step 1: Initialize the parameters of the BES algorithm, set the number of populations and the number of iterations.
Step 2: Randomly form the initial population and calculate the initial bald eagle individual fitness values.
Step 3: Determine the space in which to search for prey and perform location updates.
Step 4: Search for space prey for location updates.
Step 5: Swoop to capture prey for position update.
Step 6: Update the optimal individual position and determine whether the output requirements are met. If yes, output the best parameters and substitute them into the prediction model for calculation.
The workflow of the BES-LSSVM prediction model is shown in Fig. 8.

Flowchart of the BES-LSSVM prediction model
6 Results and Discussion
In order to verify that the proposed BES-LSSVM model has superior prediction capabilities, the prediction results output from this model are compared with other models (BES-SVM and BES-SVM). Accuracy (η), goodness of fit (R2), root mean square error (RMSE), and mean absolute error (MAE) were chosen as evaluation metrics for the three models. η denotes the prediction preciseness of the model, and the more its value converges to 1, the more precise the prediction result of the model is. R2 denotes the goodness of fit of the prediction model, ranging between (0,1), the larger R2 indicates a higher degree of model fit. The formula is as follows:
RMSE represents the root mean square error of the prediction model and the range of values is [0, + ∞), the output RMSE value is smaller, the model’s prediction performance is more excellent. The formula is as follows:
MAE represents the mean absolute error of the model and takes the same range of values as RMSE, the output MAE value is smaller, then the model’s prediction performance is better. The calculation formula is as follows:
where M is the sample number, is the model predicted value, \(k_{p}\) is the actual value of thermal displacement, and is the average value of thermal displacement.
In order to continuously train the established prediction model to improve the prediction performance, this time, the experimental data of 4000 rpm is divided into the training set, and the data of 2000 rpm and 6000 rpm are divided into the validation data set to train the BES-SVM model, the SSA-LSSVM model and the BES-LSSVM model, respectively. The data sets all take the four sets of temperature data measured at the temperature measurement points T1, T5, T7, and T10 as inputs and the measured axial thermal displacements at the corresponding rotational speeds as outputs. Comparative evaluation of three prediction models at different rotational speeds are illustrated in Figs. 9 and 10, respectively. Maximum and minimum of residual values of each prediction model at different rotational speeds are displayed in Tables 4 and 5. Evaluation results of three models at different rotational speeds and changes in evaluation results are presented in Tables 6, 7 and 8.

Comparative evaluation of three prediction models at 2000 rpm

Comparative evaluation of three prediction models at 6000 rpm
It can be seen from (a) of Figs. 9 and 10 that the forecast value curves of the BES-LSSVM model are more similar to the true value curves as compared to the BES-SVM prediction model. It can be concluded that that the LSSVM model can better predict the thermal displacement variation during spindle operation. As can be seen from (b) of Figs. 9 and 10, the prediction curves of the BES-LSSVM model are also more similar to the true value curves compared to the SSA-LSSVM prediction model. As can be concluded that the selection of the BES algorithm to improve the internal factors of the LSSVM model can largely enhance the prediction effect of the LSSVM model. It can be confirmed that the spindle thermal displacement can be effectively predicted by establishing the BES-LSSVM prediction model.
The residual of the model indicates the difference between the prediction values and the real values, the smaller the residual, the nearest the predicted value curve of the model is to the real value curve, and the better the prediction effect of the model is. As can be seen from (c) of Figs. 9 and 10, the residual distributions of three prediction models are relatively uniform, but the residuals of the BES-LSSVM prediction model fluctuate less, while the residuals of the BES-SVM and SSA-LSSVM prediction models fluctuate up and down more. Combining the maximum and minimum of residual values in Tables 4 and 5, it can be seen that the BES-LSSVM prediction model has the smallest range of residuals at different operating speeds of the spindle, and both the maximum residual value and the minimum residual value are also the smallest. It can be concluded that that the BES-LSSVM prediction model has better prediction performance under different working conditions of the spindle.
Although the predictive effect of the model can be visualized from the predictive value curve and the range of fluctuation of the residuals of the model, in order to better verify the predictive performance of the model, it is also necessary to analyze evaluation results of models. By analyzing Table 6, Table 7, and Table 8, it can be seen that the BES-LSSVM model has a large improvement in η and R2 relative to the BES-SVM and SSA-LSSVM models, indicating that the BES-LSSVM model has a better prediction accuracy and fitting effect. Also, the BES-LSSVM model has smaller values of RMSE and MAE relative to the BES-SVM and SSA-LSSVM models, indicating better robustness of the BES-LSSVM model. In a comprehensive analysis, compared to the other two prediction models, the BES-LSSVM model has much better prediction precision and robustness, and thus better prediction performance. By collecting experimental data at different rotational speeds of the spindle and using the optimized experimental data to train and test the established prediction model, which also makes the prediction model have a good generalization performance and adapt well to new sample data. It is obtained that the BES-LSSVM model is suitable to be used for the prediction of spindle thermal displacement, and it is hoped that it can be effectively applied in the field of spindle thermal displacement prediction in the future.
7 Conclusions
In this paper, the experimental data of spindles at three different rotational speeds are collected through thermal deformation experiments; then optimizes the experimental data; establishes the BES-LSSVM spindle prediction model based on the optimized experimental data; and compares it with the BES-SVM and SSA-LSSVM prediction models respectively to come up with the following main conclusions:
-
(1)
The K-means clustering method was used to classify the 10 temperature measurement points on the main axis; then the gray correlation method was used to calculate the magnitude of the correlation degree between each point and thermal displacement. Combining these two methods, four representative points were selected. It can effectively avoid the covariance phenomenon of temperature data, and at the same time, simplify the model and improve the computational efficiency of the model.
-
(2)
The parameters inside the LSSVM model affect the prediction performance of the model, to improve the prediction effect of the LSSVM model on the thermal displacement of the spindle, BES algorithm is chosen to seek the optimization of the internal parameters of the LSSVM model and output the optimal parameters to establish the BES-LSSVM thermal displacement prediction model of the spindle. According to the different experimental working conditions, the optimized experimental data are classified into two sets: training set and test set, and the BES-LSSVM model is trained, which can enhance the prediction capability of the model.
-
(3)
To verify that the BES-LSSVM model has better prediction capability, the BES-LSSVM model are compared with the BES-SVM model and the SSA-LSSVM model, respectively. The results show that the BES-LSSVM model has a smaller range of residuals and residual fluctuations, as well as higher η and R2 and smaller RMSE and MAE. In summary, the BES-LSSVM model has better prediction capability, higher accuracy and robustness of the output results, and has better adaptability to different sample data with strong generalization ability.
The BES-LSSVM prediction model introduced in this paper has better prediction accuracy and robustness, and is able to accurately and stably predict the thermal displacement changes during spindle rotation for subsequent accurate compensation. The results of the study can provide some reference for the development of spindle thermal displacement prediction modeling techniques. Due to the limitation of experimental conditions and experimental time, this thermal deformation experiment is only carried out in the spindle at low and medium rotational speeds to collect experimental data, and then train and test the BES-LSSVM model. In the subsequent study, the prediction results of the BES-LSSVM model for thermal displacement at high spindle speed condition will be verified to demonstrate its general applicability. At the same time, in order to make the measured experimental data as close as possible to the actual machining conditions, the study will be based on the original heat deformation experiments, adding part of the cutting experiments, which will be favorable to promote the promotion and application of the BES-LSSVM prediction model in the actual machining process.
Abbreviations
- BES:
-
Bald eagle search
- LSSVM:
-
Least squares support vector machine
- SSA:
-
Sparrow search algorithm
- SVM:
-
Support vector machine
- CNC:
-
Computer numerical control
- GPR:
-
Gaussian process regression
- ISPO:
-
Intelligent Single Particle Optimizer
- GA:
-
Genetic algorithm
- BP:
-
Back propagation
- BAS:
-
Beetle antennae search
- RMSE:
-
Root mean square error
- MAE:
-
Mean absolute error
References
Aydin, G., Kaya, S., & Karakurt, I. (2019). Effect of abrasive type on marble cutting performance of abrasive waterjet. Arabian Journal of Geosciences, 12(11), 1–8. https://doi.org/10.1007/s12517-019-4475-0
Li, B., Tian, X. T., & Zhang, M. (2021). Modeling and multi-objective optimization method of machine tool energy consumption considering tool wear. International Journal of Precision Engineering and Manufacturing-Green Technology, 9(1), 127–141. https://doi.org/10.1007/S40684-021-00320-Z
Wang, S. M., Lee, C. Y., & Gunawan, H. (2022). On-line error-matching measurement and compensation method for a precision machining production line. International Journal of Precision Engineering and Manufacturing-Green Technology, 9(2), 493–505. https://doi.org/10.1007/s40684-021-00336-5
Sim, B., & Lee, W. (2023). Digital twin based machining condition optimization for CNC machining center. International Journal of Precision Engineering and Manufacturing-Smart Technology, 1(2), 115–123. https://doi.org/10.57062/ijpem-st.2023.0010
Chen, E. P., Li, S. H., Wu, F. H., & Jiang, C. M. (2014). Structure design of biaxial rotary milling head with high-torque, high-precision and mechanical spindle. Key Engineering Materials, 3351(621621), 337–345. https://doi.org/10.4028/www.scientific.net/KEM.621.337
Karakurt, I., Aydin, G., & Aydiner, K. (2013). Predictive modelling of noise level generated during sawing of rocks by circular diamond sawblades. Sadhana: Academy Proceedings in Engineering Science, 38(3), 491–511. https://doi.org/10.1007/s12046-013-0117-5
Abele, E., Altintas, Y., & Brecher, C. (2010). Machine tool spindle units. CIRP Annals - Manufacturing Technology, 59(2), 781–802. https://doi.org/10.1016/j.cirp.2010.05.002
Mayr, J., Jedrzejewski, J., Uhlmann, E., Alkan Donmez, M., Knapp, W., Härtig, F., Wendt, K., Moriwaki, T., Shore, P., Schmitt, R., Brecher, C., Würz, T., & Wegener, K. (2012). Thermal issues in machine tools. CIRP Annals - Manufacturing Technology, 61(2), 771–791. https://doi.org/10.1016/j.cirp.2012.05.008
Li, Y., Zhao, W. H., Lan, S. H., Ni, J., Wu, W. W., & Lu, B. H. (2015). A review on spindle thermal error compensation in machine tools. International Journal of Machine Tools and Manufacture, 95, 20–38. https://doi.org/10.1016/j.ijmachtools.2015.04.008
Sy, T. D., Byung-Sub, K., & Seung-Kook, R. (2021). An analysis of a thermally affected high-speed spindle with angular contact ball bearings. Tribology International. https://doi.org/10.1016/J.TRIBOINT.2021.106881
Lee, D. S., Choi, J. Y., & Choi, D.-H. (2003). ICA based thermal source extraction and thermal distortion compensation method for a machine tool. International Journal of Machine Tools and Manufacture, 43(6), 589–597. https://doi.org/10.1016/S0890-6955(03)00017-8
Wang, H., & Huang, Q. (2006). In-line statistical monitoring of machine tool thermal error through latent variable modeling. Journal of Manufacturing Systems, 25(4), 279–292. https://doi.org/10.1016/S0278-6125(06)80240-2
Han, J., Wang, L. P., Wang, H. T., & Cheng, N. B. (2012). A new thermal error modeling method for CNC machine tools. The International Journal of Advanced Manufacturing Technology, 62(14), 205–212. https://doi.org/10.1007/s00170-011-3796-2
Li, G. L., Tang, X. D., Li, Z. Y., Xu, K., & Li, C. Z. (2022). The temperature-sensitive point screening for spindle thermal error modeling based on IBGOA-feature selection. Precision Engineering, 73, 140–152. https://doi.org/10.1016/J.PRECISIONENG.2021.08.021
Liao, Q. H., Wang, L., Yin, M., & Xie, L. F. (2022). Obtaining more appropriate temperature sensor locations for thermal error modeling: Reduction, classification, and selection. The International Journal of Advanced Manufacturing Technology, 120(78), 5175–5192. https://doi.org/10.1007/S00170-022-09052-Z
Ramesh, R., Mannan, M. A., & Poo, A. N. (2002). Support vector machines model for classification of thermal error in machine tools. International Journal of Advanced Manufacturing Technology, 20(2), 114–120. https://doi.org/10.1007/s001700200132
Zhang, Y., Yang, J. G., & Jiang, H. (2012). Machine tool thermal error modeling and prediction by grey neural network. The International Journal of Advanced Manufacturing Technology, 59(912), 1065–1072. https://doi.org/10.1007/s00170-011-3564-3
Wei, X. Y., Ye, H. H., & Miao, E. M. (2022). Thermal error modeling and compensation based on Gaussian process regression for CNC machine tools. Precision Engineering, 77, 65–76. https://doi.org/10.1016/J.PRECISIONENG.2022.05.008
Shi, H., Jiang, C. P., Yan, Z. Z., Tao, T., & Mei, X. S. (2020). Bayesian neural network–based thermal error modeling of feed drive system of CNC machine tool. The International Journal of Advanced Manufacturing Technology, 108(14), 3031–3044. https://doi.org/10.1007/s00170-020-05541-1
Li, B., Tian, X. T., & Zhang, M. (2019). Thermal error modeling of machine tool spindle based on the improved algorithm optimized BP neural network. The International Journal of Advanced Manufacturing Technology, 105(14), 1497–1505. https://doi.org/10.1007/s00170-019-04375-w
Abdulshahed, A. M., Longstaff, A. P., & Fletcher, S. (2015). The application of ANFIS prediction models for thermal error compensation on CNC machine tools. Applied Soft Computing Journal, 27, 158–168. https://doi.org/10.1016/j.asoc.2014.11.012
Li, Z. L., Zhu, B., Dai, Y., Zhu, W. M., Wang, Q. H., & Wang, B. D. (2021). Research on thermal error modeling of motorized spindle based on BP neural network optimized by beetle antennae search algorithm. Machines, 9(11), 286–286. https://doi.org/10.3390/MACHINES9110286
Abdulshahed, A. M., Longstaff, A. P., Fletcher, S., & Potdar, A. (2016). Thermal error modelling of a gantry-type 5-axis machine tool using a Grey Neural Network Model. Journal of Manufacturing Systems, 41, 130–142. https://doi.org/10.1016/j.jmsy.2016.08.006
Postlethwaite, S. R., Allen, J. P., & Ford, D. G. (1998). The use of thermal imaging, temperature and distortion models for machine tool thermal error reduction. Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture, 212(8), 671–679. https://doi.org/10.1243/0954405981515932
Wei, X. Y., Miao, E. M., Liu, H., & Liu, S. L. (2019). Two-dimensional thermal error compensation modeling for worktable of CNC machine tools. The International Journal of Advanced Manufacturing Technology, 101(14), 501–509. https://doi.org/10.1007/s00170-018-2918-5
Cui, G. W., Lu, J., Gu, Y. F., Gao, D., & Wang, H. C. (2011). Research on real-time synthetic error compensation principle for CNC machine tool. Advanced Materials Research, 1379(314316), 2454–2457. https://doi.org/10.4028/www.scientific.net/AMR.314-316.2454
Li, Y., Zhao, J., Ji, S. J., & Liang, F. S. (2019). The selection of temperature-sensitivity points based on K-harmonic means clustering and thermal positioning error modeling of machine tools. The International Journal of Advanced Manufacturing Technology, 100(912), 2333–2348. https://doi.org/10.1007/s00170-018-2793-0
Alsattar, H. A., Zaidan, A. A., & Zaidan, B. B. (2020). Novel meta-heuristic bald eagle search optimisation algorithm. Artificial Intelligence Review: An International Science and Engineering Journal, 53(8), 2237–2264. https://doi.org/10.1007/s10462-019-09732-5
Acknowledgements
This work was supported by the Opening Project of the Key Laboratory of Advanced Manufacturing and Intelligent Technology (Ministry of Education), Harbin University of Science and Technology, grant number: KFKT202204. Besides, the authors are grateful to the anonymous reviewers for valuable comments and suggestions, which helped to improve this study.
Funding
This work was supported by the Opening Project of the Key Laboratory of Advanced Manufacturing and Intelligent Technology (Ministry of Education), Harbin University of Science and Technology, grant number: KFKT202204.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by Yaonan Cheng, Shenhua Jin, Kezhi Qiao, Shilong Zhou, Jing Xue. The first draft of the manuscript was written by Yaonan Cheng, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Cheng, Y., Jin, S., Qiao, K. et al. Predictive Modeling of Thermal Displacement for High-Speed Electric Spindle. Int. J. Precis. Eng. Manuf. (2024). https://doi.org/10.1007/s12541-024-01101-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12541-024-01101-9