
Abstract
Supervised multi-class classification (MCC) approach is widely being used for regional-level land use–land cover (LULC) mapping and monitoring. However, it becomes inefficient if the end user wants to map only one particular class. Therefore, an improved single-class classification (SCC) approach is required for quick and reliable map production purpose. In this regard, the current study attempts to evaluate the performance of MCC and SCC approaches for extracting mountain agriculture area using time-series normalized differential vegetation index (NDVI). At first, samples of eight LULC classes were acquired using Google Earth image, and corresponding temporal signatures (TS) were extracted from time-series NDVI to perform classification using minimum distance to mean (MDM) and spectral angle mapper (i.e., multi-class SAM—MCSAM) under MCC approach. Secondly, under SCC approach, the TS of three agriculture classes (i.e., agriculture, mixed agriculture and plantation) were utilized as a reference to extract agriculture extent using Euclidean distance (ED) and SAM (i.e., single-class SAM—SCSAM) algorithms. The area of all four maps (i.e., MDM—19.77% of total geographical area (TGA), MCSAM—21.07% of TGA, ED—15.23% of TGA, SCSAM—13.85% of TGA) was compared with reference agriculture area (14.54% of TGA) of global land cover product, and SCC-based maps were found to have close agreement. Also, the class-wise detection accuracy was evaluated using random sample point-based error matrix which reveals the better performance of ED-based map than rest three maps in terms of overall accuracy and kappa coefficient.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Consistent, accurate and timely agriculture information at the regional level is crucial for the policy maker, government and non-government agencies and researchers (Wardlow et al. 2007; Husak et al. 2008; Wu et al. 2014). Irrespective of scale, information about the extent and location of agriculture area is mainly used as a baseline for time-to-time resource assessment for addressing food security issues (Justice and Becker-Reshef 2007). With the regular availability and significant improvement in terms of spatiotemporal resolution of remote sensing-based satellite data product over the last four decades, agriculture mapping became feasible, especially in those areas where reliable agriculture information is inconsistent mainly due to the inaccessible complex terrain (Wu et al. 2008; Delrue et al. 2013).
Regional-level mapping using coarse resolution data has grown recently among remote sensing community, especially for mapping and monitoring of natural vegetation as well as agriculture (Hamandawana et al. 2005; Erasmi et al. 2006; Estel et al. 2015). The selection of a suitable classification algorithm also depends upon input data and application (Lu and Weng, 2007). The distance-based nonparametric classification algorithms such as Euclidean distance (ED), spectral angle mapper (SAM) and spectral correlation mapper (SCM) are well suited and established in the literature to classify vegetative classes using coarse resolution time-series data at regional scale (Lhermitte et al. 2011; Rodrigues et al. 2013). These algorithms are supervised in nature and work as a function of distance such that the most likely class for an unknown observation is determined through minimum distance. This can be termed as multi-class classification (MCC) approach, in which some predefined thematic class and a set of training sample (i.e., temporal signature) for each class of interest are a prerequisite (Foody 2010). However, the thematic map production is often determined by the interest of extracting the distribution of one particular class (i.e., agriculture class in the current study), where the user is interested in obtaining a highly accurate map of the target class. In the case of less number of input classes, the MCC approach resulted in higher uncertainty. Therefore, implementing MCC approach using single-class training data and obtaining a highly accurate map of the target class is tricky.
The objective of extracting one particular thematic class is termed as “single-class or one-class classification” (SCC or OCC) problem (Tax 2001). In SCC, the inclusion or exclusion of any unknown observation into the one predefined class is decided by the closeness or matching threshold. That means unknown observation will only be accepted if the distance with the target class is less than the closeness threshold. As a consequence, the classifier performance is highly dependent on the choice of threshold identification method and usefulness of any method in terms of minimum error rate is dependent on the specific application (Mack et al. 2014). Therefore, both threshold selection and resulted thematic class must be evaluated using a reference dataset.
The primary objective of this study is to test the potentiality of MCC and SCC approaches to extract the mountain agriculture extent of Himachal Pradesh, India, using 250-m time-series MODIS NDVI. In this regard, two nonparametric algorithms, i.e., minimum distance to mean (MDM) and spectral angle mapper (SAM), have been used in MCC approach, and Euclidean distance (ED) and SAM have been used in SCC approach. Finally, the accuracy of the extracted agriculture maps has been evaluated using random sample point verified with Google Earth (GE) image and using already available high-resolution agriculture map through binary error matrix.
Methodology
Study Area and Data
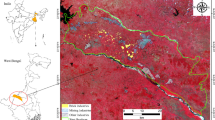
Himachal Pradesh, one of the mountain states situated in northern India, was chosen as a study site. Total geographical area of Himachal Pradesh is 55,673 Sq. km and extends between 33°23′N to 33°15′N latitude and 75°15′E to 79°00′E longitude (Fig. 1). Despite the mountainous location, strong altitudinal variability, topographic complexity and climatic diversity, Himachal Pradesh is the third fastest economically growing state of the country. Agriculture is one of the major contributing sectors after hydroelectric and tourism toward total state gross domestic product, and about 16.9% of the total geographical area (TGA) of the state is under agriculture practice (12.9% of TGA under cultivated area and 4% of TGA under horticulture area) (DES 2015). However, despite great importance, the agriculture growth of the state is under stress (Basannagari and Kala 2013; Singh et al. 2016) and, therefore, an efficient and timely monitoring approach is required.

Location map of the study area
MODIS Terra (MOD13Q1 Version 5) NDVI having 250-m spatial and 16-day temporal resolution is used as a primary input data in the study. The study was carried out in 1-year (2012) time-series dataset, and therefore, a total of 23 composites of the h24v05 grid were acquired from the LP-DAAC Web site. Though MODIS provides the best-quality product at the 16-day interval through maximum value compositing technique, it is not 100% error free and additional filtering is required to clean the inherited noise. Therefore, a temporal moving window-based gap-filling filter was applied to remove unwanted drops and then smoothed using discrete Fourier transform to reduce high temporal variability (Jakubauskas et al. 2001; Jeganathan et al. 2010). DFT is advantageous over other competitive technique due to the requirement of less number of model parameters (Atkinson et al. 2012).
The high-resolution (30 m) land use–land cover data (i.e., global land cover [GLC]-30 m) over Himachal Pradesh were downloaded from www.globallandcover.com (Chen et al. 2015). The cultivated land class extracted from GLC-30 m data has been used as reference data. The cultivated land class covers lands used for agriculture, horticulture and gardens, including paddy fields, irrigated and dry farmland, vegetation and fruit gardens. ASTER global digital elevation model (GDEM) having 30-m spatial resolution was used to extract elevation information of Himachal Pradesh.
The current study is mainly focused on agriculture land use mapping of Himachal Pradesh. From the initial analysis using GLC-30 m agriculture area and ASTER DEM, it was observed that region above 2700 meters of elevation covers about 54% of TGA, but contains a negligible amount of agriculture area (0.34% of TGA). Therefore, all the pixels above 2700 m elevation in MODIS NDVI composite were masked out to save computation and analysis time of the study and all the further processing was carried out on a region below 2700 m elevation.
Methods
The methodology of the study has three main components, i.e., (1) multi-class classification, (2) single-class classification and (3) validation and comparative evaluation. The schematic illustration of the overall methodology is shown in Fig. 2. In MCC approach, eight different land use–land cover classes were predefined, i.e., (1) agriculture, (2) mixed agriculture, (3) plantation, (4) dense forest, (5) degraded forest, (6) alpine forest (coniferous), (7) grassland and (8) waterbody, whereas only three agriculture-related classes were selected in the SCC approach. As the study was mainly focused on agriculture area mapping, validation and evaluation of all the output maps were carried out on three agriculture-related classes only.

Schematic illustration of the overall methodology of the study
Multi-Class Classification (MCC) Approach
In the MCC approach, selection of training samples is the first important requirement. The surface pattern of each class is visible in the high-resolution GE image and helpful for reference data collection (Clark et al. 2010; Adhikari and de Beurs 2016), and hence, well-distributed sample clusters for each of the eight predefined classes were collected using GE image. As 250-m MODIS NDVI is the main input data, the edge or boundary of each cluster (or polygon) may be affected by the class-mixing problem in coarse resolution pixel. Therefore, each training polygon was converted into a set of points and points falling at the edge of the polygon were removed. Then, randomly 75% of a total number of points in each class was selected as training point set to classification purpose, and the remaining 25% was retained as test point set for accuracy evaluation purpose. The training point set was further used to extract the temporal signatures from Fourier smoothed NDVI stack. Finally, minimum distance to mean (MDM) and spectral angle mapper (MCSAM, i.e., multi-class SAM) classification algorithms were performed using ERDAS Imagine software. The test point set was used to calculate the classification accuracy of both of the algorithms. Four accuracy metrics such as user accuracy (UA), producer accuracy (PA), overall accuracy (OA) and kappa coefficient were computed using a confusion matrix.
Single-Class Classification (SCC) Approach
In the SCC approach, the temporal signatures of each agriculture class were used as reference and two different distances or similarity measures, i.e., Euclidean distance (ED—Eq. 1) (Lambin and Strahlers 1994) and spectral angle mapper (SCSAM, i.e., single-class SAM—Eq. 2) (Kruse et al. 1993), have been used to compute the distance or similarity between reference and unknown observation.
where N is the maximum number of the temporal bands (i.e., 23), r and o are the reference and observed signatures, respectively, and a is the angle (in radian) between the reference and observed signatures in N-dimensional feature space.
At first, the pixel-wise calculation was performed using ED and SCSAM to compute distance maps (\( \delta 1,\delta 2, \ldots \delta n \)) corresponding to each reference signature \( \left( {s_{1} , s_{2} , \ldots s_{n} } \right) \) for an agriculture class (ACi), where n is the maximum number of signatures in that class. Further, a minimum distance map \( \left( {{\text{MDM}}_{{{\text{AC}}_{i} }} } \right) \) was computed for the respective agriculture class (ACi) to identify the distance of most likely reference sample in a pixel as follows:
The class having the lowest or minimum distance is generally considered as most likely in MCC approach using nonparametric similarity measure (Rodrigues et al. 2013). However, in the SCC approach (i.e., in the absence of other LULC class), the accurate detection of an individual class largely depends on the proper distance boundary or closeness threshold. Therefore, an inflection point (IP)-based approach was used to determine the closeness threshold (Kaivanto 2008; Frazier and Wang 2011). To identify the IP, a cumulative matching area was calculated between MDM of a class (i.e., \( {\text{MDM}}_{{{\text{AC}}_{i} }} \)) and reference agriculture mask (extracted from GLC-30 m) at multiple threshold level. Under an iterative approach, incremental distance threshold was applied on MDM at each iteration to extract the area below the threshold, and the common area with reference agriculture mask was recorded. The distance threshold of the first iteration was set to 0 and increased by 0.005 in each iteration. The total number of iterations was determined as the maximum value of MDM divided by the threshold increment. Finally, a cumulative common area curve or cumulative distribution function (CDF) curve was generated and IP or closeness threshold was identified as the position on CDF curve where the rate of change in curvature reaches to its maxima. In this regard, first derivative of CDF curve was calculated using the cumulative common area curve to identify the maximum rate of change.
Class-wise closeness threshold was then applied to the MDM to get binary agriculture class mask. The same process was iteratively applied to compute MDM of each agriculture class under consideration, and binary class mask of each class was obtained. All three masks were merged to get a final agriculture extent map. However, if a pixel was detected as agriculture in more than one class during the merging process, then the most likely class was identified based on minimum distance criteria.
Validation
The accuracy assessment of thematic product is generally carried out using reference samples either collected through a ground survey or existing reference data. In this study, an approach similar to Clark et al. (2010) was adopted (based on independent random sample point) for accuracy assessment of agriculture classes obtained from MCC and SCC approaches. A grid map as per MODIS pixel size was generated and exported to Google Earth engine for the ground (proxy) verification purpose. The random grid was selected as a sample and labeled according to agriculture type and coverage within corresponding grids and priority given to majority class (Clark et al. 2010). Grids covering more than 20% of the agriculture pattern were considered. Finally, pixel-based information was extracted from each agriculture map using labeled samples and UA, PA, overall accuracy and Kappa coefficient were computed from the error matrix.
Results and Discussion
Identifying Best Sample Set in MCC Approach
The classification using each of the two algorithms, i.e., MDM and MCSAM, was performed 10 times (i.e., 10 iterations chosen arbitrarily) using 10 different training (i.e., 75% random point) and test (i.e., remaining 25% point) point sets to identify the best training and test sample set. Totally, 1600 points (i.e., 200 points per class) were used for the final classification purpose. That means, a total of 1200 points were used as training signatures and the remaining 400 test points were used for accuracy evaluation for each iteration. The mean temporal NDVI signature of eight LULC classes extracted using the training sample set of third iteration is presented in Fig. 3. The error matrix-based accuracy statistics of each iteration (i.e., the total number of correctly classified samples, overall accuracy and kappa coefficient) computed using all eight classes and only for agriculture-related classes are presented in Fig. 4. The highest overall accuracy and Kappa have been obtained in eighth and third iterations for MDM (Fig. 4a) and MCSAM (Fig. 4b), respectively, when all eight classes were considered. The accuracy results considering only three agriculture classes (i.e., agriculture, mixed agriculture and plantation) showed that sample set 3 (corresponding to third iteration) provided the best classification accuracy (Fig. 4c, d) in both classifiers. So, the classified agriculture area (for three classes) obtained using sample set 3 was considered for further comparative analysis with the results from the single-class approach.

Temporal NDVI signature of eight LULC classes. Training sample set of third iteration was used to compute the mean profile of each class. Error bar is showing the sample variation (i.e., standard deviation) in each NDVI composite

Graphical illustration of statistical parameters obtained from the classification map of each iteration. The parameters were estimated using all eight classes of a MDM-based map and b MCSAM-based map, and using only three agriculture-related classes (i.e., agriculture, mixed agriculture and plantation) of c MDM-based map and d MCSAM-based map
Threshold Specification of SCC Approach
Figure 5 represents an example of inflection point-based threshold identification concept. In general practice, the cross section point (i.e., point “b” in Fig. 5) of omission and commission error curves is considered as an optimum threshold (Yang et al. 2015; Jiménez-Valverde 2012; Lobo et al. 2008). However, in this study, the cross section point (i.e., point “a” in Fig. 5) of cumulative common area curve and cumulative commission area curve is selected as an inflection point (IP) or optimum closeness threshold as rate of change is maximum in corresponding derivative curve (i.e., point “c” in Fig. 5). Here, the IP is representing the trade-off or balanced threshold position between the common area and committed area of a class. That means, if we choose threshold above the IP location, spatial matching will increase at decreasing rate and commission error will increase at increasing rate. Here, it is important to note that higher distance between training and observe signature increases the possibility of dissimilarity. Therefore, any distance threshold higher than IP may classify other land cover features as target class leading to higher commission error. So in the current study, consideration of the next theoretical point (i.e., point “b”) as optimum threshold will be misleading since it will yield higher commission error.

Inflection point (i.e., point a)-based threshold identification concept. All the parameters were extracted using the ED-based agriculture class. The first-derivative curve is representing the rate of change in common area between two successive iterations
The closeness threshold was computed for all the three classes for ED and SCSAM and is presented in Table 1. The significant variation in the closeness threshold represents that variation present in the temporal pattern (i.e., annual NDVI profile) of each class is different in the study, and hence these three classes cannot be treated as one class. The higher threshold in agriculture class in both ED and SCSAM is mainly due to the higher variation in signature pattern.
Evaluation of Extracted Agriculture Maps
The agriculture maps of Himachal Pradesh from four algorithms are presented in Fig. 6 [MDM (Fig. 6a), MCSAM (Fig. 6b), ED (Fig. 6c) and SCSAM (Fig. 6d)] and GLC-30 m-based agriculture class (Fig. 6e). District-wise agriculture area extracted from four extracted agriculture map is presented in Fig. 6f. The agriculture class of GLC-30 m data was upscaled to MODIS pixel size to compare the area statistics at same spatial scale (Vintrou et al. 2012). The total agriculture area extracted using MDM [19.77% of the total geographical area (TGA)] and MCSAM (21.07% of TGA) in MCC approach was considerably higher than GLC-30 m-based agriculture area (14.54% of TGA), whereas a close estimate was obtained from ED (15.23% of TGA) and SCSAM (13.85% of TGA). Figure 6f shows the consistency among all five maps in Bilaspur, Hamirpur and Una districts. However, MDM and MCSAM provide a considerable overestimation than ED and SCSAM in Chamba, Kullu, Mandi and Shimla districts in which the concentration of plantation or mixed agriculture class is high, whereas an underestimation was observed, irrespective of the algorithm, in Sirmaur and Solan districts mainly due to the minimal size of agriculture cluster in these two districts.

Agriculture map of Himachal Pradesh extracted using multi-class [i.e., a MDM, b MCSAM] and single-class [i.e., c ED, d SCSAM] classification approach. e The GLC-30 m-based agriculture map was used as a reference to compare f the district-wise agriculture area of four extracted agriculture maps
Random Sample-Based Evaluation
Table 2 shows the district-wise class detection accuracy statistics computed using random sample-based error matrix. Overall, the class detection accuracy of the algorithm used in the SCC approach has been better than the MCC approach. However, in both MCC and SCC approaches, SAM algorithm performed poorly than MDM and ED (Table 2). For agriculture class, SCSAM produces higher UA in the majority of the districts, but no one algorithm was able to provide consistent higher PA and varied district to district. However, ED produces higher UA and PA for mixed agriculture class extraction, whereas both UA and PA varied algorithm to algorithm in different districts in case of plantation class. Considerably lower PA value (than UA) shows poor detection of plantation class irrespective of the algorithm. This is mainly due to the similar temporal signature pattern between plantation (Fig. 3c) and alpine forest (i.e., coniferous) (Fig. 3f). Snowfall during the winter season in higher elevation region reduces the NDVI value, and therefore, sharp valley occurs during the winter time (i.e., between day 33 and day 97 in Fig. 3c, f). Though minor variation exists between two temporal patterns, differentiability is very less in terms of distance and resulted in false detection of plantation class. Overall, the class detection accuracy of ED under SCC approach was found better in terms of overall accuracy and Kappa coefficient in the majority of the districts, except Bilaspur, Chamba and Shimla.
Conclusion
This study examined multi-class and single-class classification approaches for agriculture area mapping on complex mountain terrain of Himachal Pradesh using 250-m time-series MODIS NDVI data. At first, MDM- and SAM-based multi-class classifiers are used to generate eight class-based LULC map. Then, two single-class classifiers (ED and SCSAM) were utilized to extract only agriculture-related class based on similarity computation. The district-wise agriculture area from both approaches was compared with agriculture area from reference global land cover product. It was found that two SCC-based classifiers performed better than MCC-based classifiers in the majority of the districts of Himachal Pradesh. Also, a class-wise assessment carried out using random sample-based error matrix revealed the better performance (i.e., higher overall accuracy and Kappa value among four algorithms) of ED algorithm under the SCC approach. Our study recommends that coarse resolution (250 m) time-series imagery can be successfully used for regional or large area agriculture monitoring.
References
Adhikari, P., & de Beurs, K. M. (2016). An evaluation of multiple land-cover data sets to estimate cropland area in West Africa. International Journal of Remote Sensing, 37(22), 5344–5364.
Atkinson, P. M., Jeganathan, C., Dash, J., & Atzberger, C. (2012). Inter-comparison of four models for smoothing satellite sensor time-series data to estimate vegetation phenology. Remote Sensing of Environment, 123, 400–417.
Basannagari, B., & Kala, C. P. (2013). Climate change and apple farming in the Indian Himalayas: A study of local perceptions and responses. PLoS ONE, 8(10), e77976.
Chen, J., Chen, J., Liao, A., Cao, X., Chen, L., Chen, X., et al. (2015). Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing, 103, 7–27.
Clark, M. L., Aide, T. M., Grau, H. R., & Riner, G. (2010). A scalable approach to mapping annual land cover at 250 m using MODIS time series data: A case study in the Dry Chaco ecoregion of South America. Remote Sensing of Environment, 114(11), 2816–2832.
Delrue, J., Bydekerke, L., Eerens, H., Gilliams, S., Piccard, I., & Swinnen, E. (2013). Crop mapping in countries with small-scale farming: A case study for West Shewa, Ethiopia. International Journal of Remote Sensing, 34(7), 2566–2582.
DES. (2015). Statistical abstract of Himachal Pradesh 2014–2015 (pp. 1–189). Shimla: Department of Economics and Statistics, The Government of Himachal Pradesh.
Erasmi, S., Bothe, M., & Petta, R. A. (2006). Enhanced filtering of MODIS time series data for the analysis of desertification process in northeast Brazil. In Proceedings of the ISPRS/ITC-midterm symposium—remote sensing: From pixels to processes, Enschede, The Netherlands (Vol. 34, No. 30, pp. 8–11).
Estel, S., Kuemmerle, T., Alcántara, C., Levers, C., Prishchepov, A., & Hostert, P. (2015). Mapping farmland abandonment and recultivation across Europe using MODIS NDVI time series. Remote Sensing of Environment, 163, 312–325.
Foody, G. M. (2010). Assessing the accuracy of remotely sensed data: Principles and practices. The Photogrammetric Record, 25(130), 204–205.
Frazier, A. E. & Wang, L. (2011). Optimal Ranges to evaluate sub-pixel classifications for landscape metrics. In ASPRS 2011 annual conference, Milwaukee, Wisconsin (pp. 1–12).
Hamandawana, H., Eckardt, F., & Chanda, R. (2005). Linking archival and remotely sensed data for long-term environmental monitoring. International Journal of Applied Earth Observation and Geoinformation, 7(4), 284–298.
Husak, G. J., Marshall, M. T., Michaelsen, J., Pedreros, D., Funk, C., & Galu, G. (2008). Crop area estimation using high and medium resolution satellite imagery in areas with complex topography. Journal of Geophysical Research: Atmospheres, 113(D14112), 1–8.
Jakubauskas, M. E., Legates, D. R., & Kastens, J. H. (2001). Harmonic analysis of time-series AVHRR NDVI data. Photogrammetric Engineering and Remote Sensing, 67(4), 461–470.
Jeganathan, C., Dash, J., & Atkinson, P. M. (2010). Mapping the phenology of natural vegetation in India using a remote sensing-derived chlorophyll index. International Journal of Remote Sensing, 31(22), 5777–5796.
Jiménez-Valverde, A. (2012). Insights into the area under the receiver operating characteristic curve (AUC) as a discrimination measure in species distribution modelling. Global Ecology and Biogeography, 21(4), 498–507.
Justice, C., & Becker-Reshef, I. (2007). Developing a strategy for global agricultural monitoring in the framework of the Group on Earth Observations (GEO) Workshop Report (p. 67). Rome: Group on Earth Observations.
Kaivanto, K. (2008). Maximization of the sum of sensitivity and specificity as a diagnostic cutpoint criterion. Journal of Clinical Epidemiology, 61(5), 517.
Kruse, F., Lefkoff, A., Boardman, J., Heidebrecht, K., Shapiro, A., Barloon, P., et al. (1993). The spectral image processing system (SIPS)—Interactive visualization and analysis of imaging spectrometer data. Remote Sensing of Environment, 44, 145–163.
Lambin, E. F., & Strahlers, A. H. (1994). Change-vector analysis in multitemporal space: A tool to detect and categorize land-cover change processes using high temporal-resolution satellite data. Remote Sensing of Environment, 48(2), 231–244.
Lhermitte, S., Verbesselt, J., Verstraeten, W. W., & Coppin, P. (2011). A comparison of time series similarity measures for classification and change detection of ecosystem dynamics. Remote Sensing of Environment, 115(12), 3129–3152.
Lobo, J. M., Jiménez-Valverde, A., & Real, R. (2008). AUC: A misleading measure of the performance of predictive distribution models. Global Ecology and Biogeography, 17(2), 145–151.
Lu, D., & Weng, Q. (2007). A survey of image classification methods and techniques for improving classification performance. International Journal of Remote Sensing, 28(5), 823–870.
Mack, B., Roscher, R., & Waske, B. (2014). Can I trust my one-class classification? Remote Sensing, 6(9), 8779–8802.
Rodrigues, A., Marçal, A. R., & Cunha, M. (2013). Identification of potential land cover changes on a continental scale using NDVI time-series from SPOT-VEGETATION. International Journal of Remote Sensing, 34(22), 8028–8050.
Singh, N., Sharma, D., & Chand, H. (2016). Impact of climate change on apple production in India: A review. Current World Environment, 11(1), 251–259.
Tax, D. M. J. (2001). One-class classification: Concept-learning in the absence of counterexamples. Ph.D. thesis, Delft University of Technology.
Vintrou, E., Desbrosse, A., Bégué, A., Traoré, S., Baron, C., & Seen, D. L. (2012). Crop area mapping in West Africa using landscape stratification of MODIS time series and comparison with existing global land products. International Journal of Applied Earth Observation and Geoinformation, 14(1), 83–93.
Wardlow, B. D., Egbert, S. L., & Kastens, J. H. (2007). Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sensing of Environment, 108(3), 290–310.
Wu, W., Shibasaki, R., Yang, P., Zhou, Q., & Tang, H. (2008). Remotely sensed estimation of cropland in China: A comparison of the maps derived from four global land cover datasets. Canadian Journal of Remote Sensing, 34(5), 467–479.
Wu, Z., Thenkabail, P. S., Mueller, R., Zakzeski, A., Melton, F., Johnson, L., et al. (2014). Seasonal cultivated and fallow cropland mapping using the MODIS-based automated cropland classification algorithm. Journal of Applied Remote Sensing, 8(1), 083685.
Yang, Y., Liu, Y., Zhou, M., Zhang, S., Zhan, W., Sun, C., et al. (2015). Landsat 8 OLI image based terrestrial water extraction from heterogeneous backgrounds using a reflectance homogenization approach. Remote Sensing of Environment, 171, 14–32.
Acknowledgements
We would like to acknowledge NASA MODIS team and National Geomatics Center of China for making MODIS NDVI product and GLC-30 m data freely available.
Author information
Authors and Affiliations
Corresponding author
About this article

Cite this article
Mondal, S., Jeganathan, C. Evaluating the Performance of Multi-Class and Single-Class Classification Approaches for Mountain Agriculture Extraction Using Time-Series NDVI. J Indian Soc Remote Sens 46, 2045–2055 (2018). https://doi.org/10.1007/s12524-018-0852-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12524-018-0852-5