
Abstract
The present study used time-series Landsat-8 and 9 satellite datasets of June to February 2016–2017 and 2021–2022 to classify and detect the changes in vegetation covers. The studied Akole region of Ahmednagar district of Maharashtra, India, is vulnerable to drought conditions in a diverse environment. The spectral features based on the Normalized Difference Vegetation Index (NDVI) were calculated. Machine learning algorithms such as k-means clustering and Iterative Self-Organizing Data Analysis (ISODATA) clustering have also been applied to time-series NDVI images to classify the vegetation cover and detect the changes in vegetation. Furthermore, to identify different drought clusters. The results of the NDVI values ranged from 0 0.25 to 0.99 and 0.31 to 0.75 for 2016–2017 and 2021–2022, respectively. The classification results show that most of the areas were occupied by healthy vegetation in 2021–2022. In 2016–2017, the vegetations were less due to low rainfall. Regional planners and decision makers can use the present study to identify vegetation, assess and monitor drought severity, and predict future scenarios.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Agricultural drought is becoming a natural hazard due to the unavailability of regular rainfall. Drought produces changes in the external appearance of vegetation. Therefore, it is necessary to monitor the agricultural drought. However, satellite sensors and vegetation indices can detect and monitor agricultural drought conditions in near real-time. Recently, remote sensing datasets have played an essential role in identifying and tracking drought episodes. The remote sensing data provides real-time vegetation status information over the sizeable spatial coverage [1, 2].
Consequently, the NDVI-based spectral feature extraction method has been recommended by the World Meteorological Organization (WMO) to identify and monitor vegetation health [3]. Therefore, vegetation classification is gaining global relevance and has a considerable role in the global frame of change.
Several methodologies have been applied for vegetation cover classification and are utilized all over the globe. For instance, the vegetation cover classifications have been done by [4] to detect the changes at the ecosystem level based on a temporal scale (seasonal, gradual, and abrupt changes). The factors used for change detection were seasonal ecological constraints, inter-annual environment inconsistency, land management, and disturbances (deforestation, fires, and floods). The study [5] used Landsat satellite images and the NDVI index to detect vegetation changes. The simulation findings disclose that the NDVI is exceptionally effective in recognizing surface features of the viewable area, which is tremendously valuable in decision-making.
Similarly, the NDVI and K-means clustering has been used in the study [6, 7] for vegetation cover classification and agricultural change detection. Conversely, the web-GIS-based system was developed for vegetation status monitoring using Landsat-8 and NDVI methods [8]. However, supervised-based approaches like support vector machine [9], K-Nearest Neighbor [10], and random forests [2] have also been used for the classification. The deep learning-based convolutional neural network (CNN) method has recently been popular due to its high accuracy. Since CNN are not interpretable enough to describe image semantics [11]. Therefore, we employ unsupervised methods for detecting vegetation classes in this paper.
On the other hand, many researchers have demonstrated vegetation analysis using various datasets and methods. The previous studies either use Landsat-8 or earlier versions with NDVI and k-means clustering or other methods. However, the governments use the recent Landsat-9 satellite data for multiple applications like agriculture, planning, natural resource data collection, homeland security, and other purposes [12]. The data driven from the Landsat supports government applications and civilian services, military operations, and a few industries are also using the data recently to collect multiple resources and planning details. It has a wide application in the education field throughout the world. As per the current evaluation, Landsat can gather up to 750 scenes daily, and Landsat can collect 1500 HQ images of the earth in a day, which repeats every 8 days on average [13]. The resolution of Landsat-9 is the same as Landsat-8. It has been designed using four visible spectral bands. The spatial resolution of visual, near-infrared, shortwave and cirrus spectral bands are 30 m, the panchromatic band is 15 m, and the thermal bands are 100 m [14].
However, the use of Landsat-9 time-series datasets was less in earlier studies. Therefore, the present study proposes vegetation cover classification and seasonal change detection using Landsat-9 and Landsat-8 data. The primary objectives were (1) to use Landsat-8 and 9 time-series datasets, (2) to extract the spectral vegetation feature using the NDVI method, (3) to implement machine learning algorithms such as k-means clustering and ISODATA on NDVI resulting from images, (4) to identify and group vegetation cover classes, and (5) to detect the vegetation health and seasonal change in vegetation cover.
The details of the present study are presented in four sections. “Introduction” offers the related studies and current improvements of the study. “Introduction” also gives the previous studies’ limitations and the recent research objectives. The studied region used datasets, and implemented methodology is provided in “Materials and Methods”. Results are discussed in “Results and Discussions”. The last section concludes the present study.
Materials and Methods
Study Area
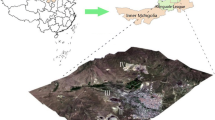
The present study has been conducted in the Akole Tehsil of Ahmednagar district of Maharashtra, India. It is located at 19° 32′ 32.06″ North Latitude and 74° 0′ 19.88″ East Longitude [15]. The Ahmednagar district is surrounded by Beed district to the East, Thane district to the North-West, Osmanabad, Solapur to the South, Pune district to the West, and Aurangabad district to the North-East and Nashik district to the North. The district covers an area of 17,412 km2. This region is generally drought-prone due to an annual rainfall of 568.7 mm, less than an average of 750 mm. Agricultural operations mainly depend on the South-West monsoon, but this region has less rainfall. Over recent years, the intensity and frequency have increased. There has been a big drying trend over many parts of the region [15]. Figure 1 depicts the considered study area for the present study.

The geolocation of the study area
The Used Datasets
The present study used time-series Landsat-8 and Landsat-9 OLI/TIRS satellite temporal datasets corresponding to June 2016 to February 2017 (total 9 month-images) and June 2021 to February 2022 (total 9 month-images) to classify and detect the changes in agricultural regions. The complete satellite images were eighteen for the Kharif and Rabi seasons for 2016 and 2021 (Table 1). The Landsat datasets were acquired from the USGS official website [16]. Landsat datasets are equipped with two science instruments: the OLI-2 (Operational Land Imager 2) and the TIRS-2 (Thermal Infrared Sensor 2), which have a moderate spatial resolution of 15 m, 30 m, or 100 m, depending on the spectral band. The OLI-2 will give information for nine spectral bands with a higher ground sampling distance (GSD), both in-track and cross-track, of 30 m for all bands, excluding the panchromatic band, which has a 15 m GSD. The TIRS-2 offers two spectral bands with 100 m for each band [17]. Table 1 depicts the year-wise information of Landsat 8 and 9 satellite datasets used in the present study.
Though infrared images are also used in many applications like pedestrian detection [18], night vision, and surveillance. On the other hand, the meteorological data for the academic years 2016–2017 and 2021–2022 were also used for validating our results. The monthly rainfall statistics (figure) for the similar period of satellite overpass for the year 2026–2017 and 2021–2022 were downloaded from the “Rainfall Recording and Analysis, Department of Agriculture Maharashtra State” department (https://maharain.maharashtra.gov.in/).
The Methodology
The implemented methodology is demonstrated in Fig. 2, consisting of Landsat data acquisition, pre-processing, NDVI-based spectral feature extraction, and unsupervised classification. Additionally, we used rainfall statistics (Fig. 8) to input the NDVI calculation and validate the results. The detailed methodology is explained in this section. The acquired datasets were input into the ArcMap to create a standard false-color composite image for better visual interpretation. Figure 3 depicts the standard color composite image of the study region generated from Landsat images.

The adopted methodology for vegetation change detection

Standard false-color composite data of the study area
The Pre-processing
The geometric, radiometric, and atmospheric corrections [19] are required for pre-processing Landsat images. Radiometric corrections consist of correcting sensor anomalies and unwanted or atmospheric noise and converting the data to correctly represent the reflected or emitted radiation detected by the sensor. In contrast, converting images into geographic coordinates is known as geometric correction [20]. However, the first seven spectral bands of Landsat 8–9 data are corrected images (Level 2) by the USGS Earth Explorer. Thus, no further pre-processing is required. It should be noted that the specific processing levels of the images are currently provided as “ready products,” which means that these datasets can be directly retrieved from earth data engines like the USGS Earth Explorer platform without any pre-processing [21]. Nevertheless, the ATCOR-3 method has been used by several researchers [20] for atmospheric correction. The present study uses corrected images; thus, no further pre-processing is required for the acquired satellite imagery.
NDVI-Based Spectral Feature Extraction
The NDVI is used globally to assist in fire zone forecasting, monitoring the drought regions, agriculture production forecasting, and many more applications related to the agriculture sector [6, 22, 23]. It is widely used in vegetation monitoring as it compensates for lighting, exposures, and other factors. Equation 1 [22, 24] has been used to calculate and examine the vegetation change:
where NIR is the reflection in the near-infrared spectrum and RED is the reflection in the red range of the spectrum.
NDVI computations produce a number ranging from negative one (− 1) to plus one (+ 1) for any given pixel. Several zero implies that vegetation is unavailable, whereas a value of about one, i.e., 0.8–0.9, indicates that green foliage is primarily present. Empty sand, rocks, and snow areas have values less than or equal to 0.1. Meadows and shrubs often have moderate values, such as 0.2 to 0.3. Tropical woods and temperature are represented by values 0.6 to 0.8. NDVI is susceptible to factors such as soil backdrop, especially in sparse vegetation [25].
We have used ArcGIS software to compute the NDVI using bands 4 and 5 as input, as they resemble red and near-infrared images. The NDVI algorithm has created 7 clusters used in classification to observe the change detection for the time-series profile of the studied region. Pixels with high NDVI values suggest high vegetation or chlorophyll in the area. Whereas low NDVI levels usually indicate a lack of vegetation. Furthermore, negative NDVI readings suggest that the substance is categorized as water.
Unsupervised Classification
The present study uses an unsupervised-based machine learning classification approach that does not require previous knowledge. It obtains the values from pixels and assigns spectral classes to them. Clusters with comparable spectral qualities are grouped. The unsupervised approach is based on clustering algorithms and discrimination space selection. In this study, we have used the K-means clustering and ISODATA method for the classification. The k-means clustering method creates a cluster of images with comparable spectral values. It uses iterations to generate sets and begins intra-groups by determining the slightest squared distance among data values and the cluster’s centroid [26,27,28].
Alternatively, the ISODATA approach uses the minimal distance center method based on item meta-clustering. This technique chooses the preliminary class grouping center based on particular criteria and then calculates the standard deviation of each cluster with their distances [29, 30].
In the present study, the K-means clustering was implemented using QGIS software, and the ISODATA method was implemented using ArcGIS software. The ISODATA and k-means clustering algorithms have automatically identified clusters in images and produced a classified image by considering the NDVI image as an input.
Results and Discussions
Spectral Feature Extraction
Satellite imagery acquired from the Kharif and Rabi seasons from year June 2016 to February 2017 and June 2021 to February 2022 (Table 1) is considered for vegetation classification for the studied region. The provider has already pre-processed the satellite images. The pre-processed images were used in the NDVI calculation. The NDVI has been frequently utilized to investigate the relationship between spectral inconsistency and variations in the pace of vegetation growth [22]. It can also figure out how much green vegetation is produced and spot vegetation changes.
This study calculates the NDVI from time-series data for June 2016 to February 2017 and June 2021 to February 2022 using 4 and 5 bands of Landsat images. The spatial distribution of the NDVI is divided into seven classes shown in Figs. 6 and 7 for 2016–2017 and 2021–2022, respectively. The results are well related to the land cover types spread over the studied region. The NDVI-derived classes and the NDVI scales are given in Tables 2 and 3 for 2016–2017 and 2021–2022, respectively. The water body class has ranged from − 0.07 to 0.09 and − 0.07 to 0.09 for 2016–2017 and 2021–2022, respectively. However, all vegetation classes ranged from 0.26 to 0.99. The shrubs and grasslands were detected in rowan, heathland, alder, wetland, and other similar types of grasses. Dense vegetation was located in the forest resigns.
It was seen from Tables 2 and 3 and Figs. 4 and 5 that satellite images had produced results for dense vegetation between 0.25 to 0.99 and 0.31 to 0.75 for 2016–2017 and 2021–2022, respectively. The peak of NDVI for dense vegetation was highest in July, October, November, December and January 2016–2017. However, the values for sparse and low vegetation ranged between 0.18 to 0.47 for 2016–2017. On the other hand, the NDVI values were good for sparse and low vegetation in 2021–2022 (Tables 2 and 3 and Figs. 4 and 5). The lowest values are seen on more minor vegetated soils, likely because soil reflection is significant, producing common NIR band values and high red band values, resulting in common NDVI values.

The comparison of NDVI values for June 2016 to February 2017

The comparison of NDVI values for June 2021 to February 2022
Figure 4 shows that the dense and sparse vegetation was more (NDVI = 0.99 and 0.47) in 2016–2017. However, the highest dense vegetation was also observed in July, August, and February 2021–2022. Furthermore, the chosen location is covered with multiple hills layered with dense trees, indicating dense vegetation. For December and February, the accessible land and a fraction of land parcels with vegetative cover are replaced by evolved concrete structures more concentrated in the city zone. Hence, there was a noteworthy reduction in the vegetation. The green vegetation cover was increased in both the years for the Kharif season compared to Rabi due to a change in significant environment.
We classified the vegetation or crop covers based on NDVI values and identified the vegetation changes with the NDVI profile. The NDVI has depicted the amount of vegetation [31]. Many researchers have reported using NDVI for crop cover evaluation, monitoring various droughts [2], and assessing agricultural drought at the national and international levels. The NDVI is a straightforward and efficient measuring parameter used to show vegetation growth and plant cover on the earth’s surface [5]. The ability to compare images from multiple dates for different plots on different scenes is a crucial step in applying satellite data to monitor change [32].
The NDVI maps of 2016–2017 and 2021–2022 (Figs. 6 and 7, respectively) are computed to classify and analyze the studied region’s seasonal and spatial vegetation changes. Healthy vegetation was observed in July, December and February 2016–2017 (Fig. 6). However, healthy vegetation was observed in the Rabi season (Fig. 7) of the average year 2021–2022 due to sufficient rainfall in Kharif and Rabi seasons (Fig. 8). Areas which are colored blue are water surfaces, and they correspond to negative values. All the green shades in the NDVI maps are vegetations and correspond to positive values between 0.2 and 1. The healthy, dense vegetation canopy is above 0.5 because good rainfall is necessary for Kharif crops. In 2016–2017 and 2021–2022, the crops’ yield was influenced by the timing and volume of rain. The suitable time to plant Rabi crops is in the middle of November, ideally after the monsoon season. Either irrigation is used, or rainfall that has seeped into the ground is used to grow the crops. Changes in vegetation classes have occurred in July, October, November, December and January of 2016–2017 and in July, August and February 2021–2022. However, the vegetation remains green (high NDVI values) due to water availability in the soil after rainfall. While seeded in the winter, Rabi crops are harvested in the spring. The green vegetation tends to vanish for the rest of the months, and the NDVI values drop when soil water availability falls for any environmental reason (stress from water shortage). The relationship between spectral variability and changes in vegetation growth rate has been extensively studied using the NDVI.

NDVI profiles of a June 2016, b July 2016, c August 2016, d September 2016, e October 2016, f November 2016, g December 2016, h January 2017, and i February 2017

NDVI profiles of a June 2021, b July 2021, c August 2021, d September 2021, e October 2021, f November 2021, g December 2021, h January 2022, and i February 2022

Monthly average rainfall for the study area during 2016–2017 and 2021–2022
Image Classification
The seven classes NDVI map (Figs. 6 and 7) was given as an input to the classification step. The visual interpretation of seven NDVI classes has been made to reconstruct the possible deficits. Because the single peak of NDVI could not be detected, thus, visual performance has been constructed of seven classes of NDVI. On the other hand, the NDVI-generated maps (Figs. 6 and 7) consist of different land patterns due to the region's complexity and the low spatial resolution of data [33].
Figures 9, 10, 11, and 12 show that the spectral reflectance qualities of various objects on the earth's surface are reflected in the high degree of distinguishability in classes of land cover types employed in a landscape setting. The resulting NDVI images for Kharif and Rabi seasons were input to the ISODATA and k-means clustering methods. The computation of the ISODATA method has been done in ArcGIS software. The sample interval set to 10 indicates that one cell is used in the cluster calculations instead of a block of cells. Conversely, the k-means clustering method has been implemented in QGIS software. The Hill climbing method has been used to group the classes. The land cover types were clustered into seven categories, as indicated in Figs. 9, 10, 11, and 12. It is observed in Figs. 9, 10, 11, and 12 that the methods used delimited different extensions of the coverage area for vegetation and non-vegetations. The spatial variations in vegetation classes were observed for July, September, December, and February 2016–2017 (Figs. 9 and 11). The vegetation cover has changed during the study tenure. The obtained results were more precise, objective, and independent in analyzing vegetation cover types than supervised classification methods. The complex and heterogeneous landscapes were classified accurately using k-means clustering and the ISODATA method implemented in advanced ArcGIS and QGIS software versions.

Classified output based on the ISODATA method for a June 2016, b July 2016, c August 2016, d September 2016, e October 2016, f November 2016, g December 2016, h January 2017, and i February 2017

Classified output based on ISODATA method for a June 2021, b July 2021, c August 2021, d September 2021, e October 2021, f November 2021, g December 2021, h January 2022, and i February 2022

Classified output based on the k-means clustering method for a June 2016, b July 2016, c August 2016, d September 2016, e October 2016, f November 2016, g December 2016, h January 2017, and i February 2017

Classified output based on the k-means clustering method for a June 2021, b July 2021, c August 2021, d September 2021, e October 2021, f November 2021, g December 2021, h January 2022, and i February 2022
Tables 4 and 5 and Figs. 13 and 14 highlight the spatial distributions of the land cover types derived from ISODATA and k-means clustering methods. Both the clustering methods have resulted from similar values for both years. Therefore, we calculated average values for 2016–2017 and 2021–2022 for both the clustering methods and added Tables 4 and 5. It is seen from Tables 4 and 5 and Figs. 13 and 14 that there is a minor change in water bodies degraded in January and February 2017 and 2022. The vegetation classes increased slightly in the Rabi season of 2021–2022. At the same time, water bodies increased in February 2022 compared to December 2021 and January 2022. The vegetation classes were raised in the Rabi season of 2021–2022 due to sufficient rainfall in Kharif (Fig. 14). The studied area is generally drought-prone due to low annual rainfall in 2016–2017 (Fig. 13). However, wet drought conditions occurred in December 2021, January, and February 2022 due to rain. Hence, vegetations were more. Nevertheless, assessing and monitoring the agriculture drought is critical for district administration and mitigation strategy. Therefore, in the current investigation, we have done vegetation cover classification and detected spatial variations in agricultural sectors, which can be used in assessing agrarian droughts.

Class-wise area distributions of vegetation classes for 2016–2017

Class-wise area distributions of vegetation classes for 2021–2022
The vegetation and other classes of 2016–2022 showed that there had been remarkable changes in vegetation during the study period. The area around the central water bodies and streams in the watershed has changed from other land covers to agricultural land cover due to this increasing trend in land cover/land use change. It is noted that the built-up or settled areas are primarily surrounded by agricultural land, particularly in the catchment area.
According to results from 2021–2022 (Fig. 14), water features, barren regions, shrubs, and grasslands were ranked highest. Built-up areas with sparse, low, and dense vegetation comprised the remainder of the land use for 2016–2017 (Fig. 13). However, the top three categories were water bodies, built-up areas, and arid lands in 2016–2017 due to misclassification. Shrub and grassland, low, sparse, and dense vegetation, comprised the rest of the land uses.
It is noted that the ISODATA and k-means clustering methods provided similar results when observing the spatial distribution values for all the classes. The results are satisfactory and confirmed via field observations, rainfall statistics, Google maps, and Google Earth.
Conclusions
The NDVI has provided satisfactory output to access vegetation changes with unsupervised-based classification methods. The retrieved values of the NDVI maps were used to determine influential variables on vegetation cover classes. In this study, the Landsat-8 and 9 datasets have been used to analyze the changes in the vegetation cover for June to February 2016–2017 and 2021–2022. The study’s findings indicate that the vegetation areas increased in 2021–2022. In contrast, the vegetation was diminished in 2016–2017 due to low rainfall. It is concluded that the time-series Landsat datasets could be effectively used in vegetation cover classification and change detection. The present study emphasizes the importance of maintaining harmony between permeable and impermeable zones in the planning and development of the studied region.
Data availability
The authors have downloaded the publicacly available data via USGS website: https://earthexplorer.usgs.gov/.
References
Gaikwad SV, Kale KV, Kulkarni SB, Varpe AB, Pathare GN. Agricultural drought severity assessment using remotely sensed data: a review. Int J Adv Remote Sens GIS. 2015;4(1):1195–203.
Gaikwad SV, Vibhute AD, Kale KV. Assessing meteorological drought and detecting LULC dynamics at a regional scale using SPI, NDVI, and random forest methods. SN Comput Sci. 2022;3(6):458.
Choubin B, Soleimani F, Pirnia A, Sajedi-Hosseini F, Alilou H, Rahmati O, et al. Chapter 17 - Effects of drought on vegetative cover changes: investigating spatiotemporal patterns. In: Melesse AM, Abtew W, Senay G, editors. Extreme hydrology and climate variability. Amsterdam: Elsevier; 2019. p. 213–22.
Verbesselt J, Hyndman R, Newnham G, Culvenor D. Detecting trend and seasonal changes in satellite image time series. Remote Sens Environ. 2010;114:106–15.
Gandhi GM, Parthiban S, Thummalu N, Christy A. Ndvi: vegetation change detection using remote sensing and Gis—a case study of Vellore District. Procedia Comput Sci. 2015;57:1199–210. https://doi.org/10.1016/j.procs.2015.07.415.
Gaikwad SV, Vibhute AD, Kale KV, Mane AV. Vegetation cover classification using Sentinal-2 time-series images and K-Means clustering. In: 2021 IEEE Bombay section signature conference (IBSSC), Gwalior, India. IEEE; 2021. p. 1–6. https://doi.org/10.1109/IBSSC53889.2021.9673181.
Liyantono YA, Adillah Y, Maulana Yusuf M, Reza Mahbub MN, Fatikhunnada A. Analysis of paddy productivity using NDVI and K-means clustering in Cibarusah Jaya, Bekasi Regency. In: IOP conference series: materials science and engineering, vol. 557(1); 2019. p. 0–7. https://doi.org/10.1088/1757-899X/557/1/012085
Gaikwad SV, Vibhute AD, Kale KV. Design and implementation of a web-GIS platform for monitoring of vegetation status. ICTACT J Image Video Process. 2021;11(3):2373–7.
Dhumal RK, Vibhute AD, Nagne AD, Solankar MM, Gaikwad SV, Kale KV, Mehrotra SC. A spatial and spectral feature based approach for classification of crops using techniques based on GLCM and SVM. In: Panda G, Satapathy S, Biswal B, Bansal R, editors. Microelectronics, electromagnetics and telecommunications. Lecture notes in electrical engineering, vol. 521. Singapore: Springer; 2019. https://doi.org/10.1007/978-981-13-1906-8_5
Vajda S, Santosh KC. A fast k-nearest neighbor classifier using unsupervised clustering. In: Recent trends in image processing and pattern recognition: first international conference, RTIP2R 2016, Bidar, India, December 16–17, 2016, revised selected papers 1. Singapore: Springer; 2017. p. 185–93.
Do TH, Anh NT, Dat NT, Santosh KC. Can we understand image semantics from conventional neural networks? In: Recent trends in image processing and pattern recognition: second international conference, RTIP2R 2018, Solapur, India, December 21–22, 2018, revised selected papers, part I 2. Singapore: Springer; 2019. p. 509–19.
Showstack R. Landsat 9 satellite continues half-century of earth observations: eyes in the sky serve as a valuable tool for stewardship. Bioscience. 2022;72(3):226–32. https://doi.org/10.1093/biosci/biab145.
https://www.usgs.gov/landsat-missions/landsat-9. Accessed 29 Jan 2022.
Lulla K, Nellis MD, Rundquist B, Srivastava PK, Szabo S. Mission to earth: LANDSAT 9 will continue to view the world. Geocarto Int. 2021;36(20):2261–3. https://doi.org/10.1080/10106049.2021.1991634.
Sasane MS (2016) Assessment of drought severity for understanding climate change in Ahmednagar District, Maharashtra. In: International conference on global environment: issues, challenges and solutions, Aurangabad, Maharashtra, India, vol. 2.
https://earthexplorer.usgs.gov/. Accessed 05 Mar 2022.
Khan A, Vibhute AD, Mali S, Patil CH. A systematic review on hyperspectral imaging technology with a machine and deep learning methodology for agricultural applications. Ecol Inform. 2022;69: https://doi.org/10.1016/j.ecoinf.2022.101678.
Soundrapandiyan R, Santosh KC, Chandra Mouli PVSSR. Infrared image pedestrian detection techniques with quantitative analysis. In: Recent trends in image processing and pattern recognition: second international conference, RTIP2R 2018, Solapur, India, December 21–22, 2018, revised selected papers, part III 2. Singapore: Springer; 2019. p. 406–15.
Vibhute AD, Kale KV, Dhumal RK, Mehrotra SC. Hyperspectral imaging data atmospheric correction challenges and solutions using QUAC and FLAASH algorithms. In: 2015 International conference on man and machine interfacing (MAMI). Bhubaneswar: IEEE; 2015. p. 1–6. https://doi.org/10.1109/MAMI.2015.7456604.
Gaikwad SV, Vibhute AD, Kale KV, Dhumal RK, Nagne AD, Mehrotra SC, et al. Drought severity identification and classification of the land pattern using Landsat 8 data based on spectral indices and maximum likelihood algorithm. In: Panda G, Satapathy S, Biswal B, Bansal R, editors. Microelectronics, electromagnetics and telecommunications, vol. 521., Lecture notes in electrical engineering. Singapore: Springer; 2019. https://doi.org/10.1007/978-981-13-1906-8_53.
Agapiou A. Evaluation of Landsat 8 OLI/TIRS level-2 and sentinel 2 level-1C fusion techniques intended for image segmentation of archaeological landscapes and proxies. Remote Sens. 2020. https://doi.org/10.3390/rs12030579.
Mullapudi A, Vibhute AD, Mali S, Patil CH. A review of agricultural drought assessment with remote sensing data: methods, issues, challenges and opportunities. Appl Geomat. 2022. https://doi.org/10.1007/s12518-022-00484-6.
Gaikwad SV, Vibhute AD, Kale KV. Estimation of area sown and sowing dates of in-season rabi crops using sentinel-2 time series data. J Res ANGRAU. 2021;49(1):69–81.
Vibhute AD, Kale KV, Gaikwad SV, Dhumal RK, Nagne AD, Varpe AB, et al. Classification of complex environments using pixel level fusion of satellite data. Multimedia Tools Appl. 2020;79(47):34737–69.
Guliyeva SH. Land cover/land use monitoring for agriculture features classification. Int Arch Photogramm Remote Sens Spat Inf Sci ISPRS Arch. 2020;43(B3):61–5. https://doi.org/10.5194/isprs-archives-XLIII-B3-2020-61-2020.
Sinaga KP, Yang MS. Unsupervised K-means clustering algorithm. IEEE Access. 2020;8:80716–27. https://doi.org/10.1109/ACCESS.2020.2988796.
Vibhute AD, Gawali BW. Analysis and modeling of agricultural land use using remote sensing and geographic information system: a review. Int J Eng Res Appl. 2013;3(3):081–91.
Li B, Zhao H, Lv Z. Parallel ISODATA clustering of remote sensing images based on MapReduce. In: 2010 International conference on cyber-enabled distributed computing and knowledge discovery. IEEE; 2010. p. 380–83. https://doi.org/10.1109/CyberC.2010.75.
Li XC, Liu LL, Huang LK. Comparison of several remote sensing image classification methods based on Envi. Int Arch Photogramm Remote Sens Spat Inf Sci. 2020;42:605–11.
Abbas AW, Minallh N, Ahmad N, Abid SAR, Khan MAA. K-Means and ISODATA clustering algorithms for landcover classification using remote sensing. Sindh Univ Res J (Sci Ser). 2016;48(2):315–8.
Zaitunah A, Samsuri S, Ahmad AG, Safitri RA. Normalized difference vegetation index (NDVI) analysis for land cover types using Landsat 8 oli in besitang watershed, Indonesia. IOP Conf Ser: Earth Environ Sci. 2018. https://doi.org/10.1088/1755-1315/126/1/012112.
Bid S, Bengal W. Change detection of vegetation cover by NDVI technique on catchment area of the Panchet Hill Dam, India. Int J Res Geogr. 2016;2(3):11–20. https://doi.org/10.20431/2454-8685.0203002.
De Bie CAJM, Khan MR, Smakhtin VU, Venus V, Weir MJC, Smaling EMA. Analysis of multi-temporal SPOT NDVI images for small-scale land-use mapping. Int J Remote Sens. 2011;32(21):6673–93.
Acknowledgements
The authors would like to thank USGS for providing Landsat satellite data for this research. The authors would also like to thank anonymous reviewers and editors for reviewing the manuscript and for their scientific and valuable comments and suggestions that have improved the quality of this manuscript.
Author information
Authors and Affiliations
Contributions
AM: conceptualization, data curation, methodology, experiments, writing draft. ADV: scientific analysis, investigation, methodology, experiments, validation, technical assistance, writing—review and final editing. SM: formal analysis. CHP: formal analysis, edited the manuscript, correction, evaluation. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
All the authors declare that he/she has no conflict of interest.
Ethical approval
This article does not contain any studies with animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Advances in Applied Image Processing and Pattern Recognition” guest edited by K C Santosh.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mullapudi, A., Vibhute, A.D., Mali, S. et al. Spatial and Seasonal Change Detection in Vegetation Cover Using Time-Series Landsat Satellite Images and Machine Learning Methods. SN COMPUT. SCI. 4, 254 (2023). https://doi.org/10.1007/s42979-023-01710-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-023-01710-7