
Abstract
This paper presents a novel approach to Lyapunov stability theory-based adaptive filter (LAF) design. The proposed design is based on the minimization of the Euclidean norm of the difference weight vector under negative definiteness constraint defined over a novel linear Lyapunov function. The proposed fixed step size LAF (FSS-LAF) algorithm is first obtained by using the method of Lagrangian multipliers. The FSS-LAF satisfying asymptotic stability in the sense of Lyapunov provides a significant performance gain in the presence of a measurement noise. The stability of the FSS-LAF algorithm is also statistically analyzed in this study. Moreover, gradient variable step size (VSS) algorithms are adapted to the FSS-LAF algorithm to further enhance the performance for the first time in this paper. These VSS algorithms are Benveniste (BVSS), Mathews and Farhang–Ang (FVSS) algorithms. Simulation results on system identification problems show that the bounds of step size for the FSS-LAF algorithm are verified, and especially, the BVSS-LAF and FVSS-LAF algorithms provide a better trade-off between steady-state mean square deviation error and convergence rate than other proposed algorithms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Adaptive filters have been used in many applications such as prediction, noise cancellation and system identification [1]. Recently, the LAF algorithms are the most widely used adaptive filter algorithms [2,3,4,5,6,7,8], because they are designed to construct an energy surface having a single global minimum point in contrast to the gradient descent-based algorithms [2]. Furthermore, they always guarantee asymptotic stability according to the Lyapunov stability theory (LST) due to the fact that their error signals can converge to zero asymptotically [2,3,4,5,6,7,8]. However, since these LAF algorithms are designed without considering measurement noise effects, they cannot estimate optimal weight vector coefficients of an unknown system. To overcome many of the limitations on existing LAF algorithms [2,3,4,5,6,7,8], we proposed an LAF algorithm with a fixed step size for the noisy desired signal in [9]. The proposed algorithm in [9] has provided the distinct advantages over the conventional LAF algorithm [2] by controlling the fixed step size parameter. However, there are conflicting requirements between the convergence rate and the steady-state MSD error for the proposed LAF algorithm in [9]. Also, the analysis of the proposed algorithm in terms of convergence in the mean has not been investigated in [9], and hence, the lower and upper bounds for the step size parameter have not been statistically determined yet.
In this paper, we propose a novel LAF algorithm and its some VSS versions. A novel Lyapunov function is first determined as \(V(k) = \left| {e(k)} \right| \), and then, the proposed filter design is expressed as a constrained optimization problem by considering LST. As a result of the solution of the optimization problem, we obtain the FSS-LAF algorithm. Thus, the proposed FSS-LAF algorithm, which ensures negative definiteness in the sense of Lyapunov, iteratively updates the weight vector coefficients of the adaptive filter. Use of the step size parameter in the proposed algorithm improves the convergence capability, provides the estimation of the optimal weight vector coefficients of the unknown system and controls both steady-state and transient MSD errors. Furthermore, we present the convergence analysis of the proposed FSS-LAF algorithm for the first time in this paper. However, the selection of the step size parameter plays a critical role in the convergence performance of the proposed algorithm. Hence, the step size parameter in the FSS-LAF needs to be optimized and adaptively controlled during the filtering process.
To deal with this problem, a number of widely used gradient VSS algorithms are also adapted to the proposed FSS-LAF algorithm to further improve the performance for the first time in this paper. These VSS algorithms adjusting the step size parameter are the BVSS [10], MVSS [11] and FVSS [12] algorithms. To iteratively update and optimize the step size in the FSS-LAF algorithm, similar to studies in [10,11,12,13], the BVSS-LAF algorithm is rigorously derived without considering the independence assumptions, whereas the MVSS-LAF algorithm uses instantaneous gradients. The FVSS-LAF algorithm is also proposed to reduce the computational complexity of the BVSS-LAF algorithm. Furthermore, computational complexities of the proposed VSS algorithms are analyzed in this study. Finally, the performances of the proposed algorithms are comparatively illustrated on benchmark system identification problems.
2 The proposed FSS-LAF algorithm formulation
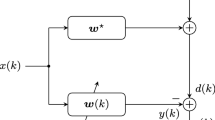
In the classical structure of a system identification problem, the desired signal consists of the following model:
where \(s(k) = {\mathbf{w }_o}^\mathrm{T}\mathbf{x }(k)\) represents the unknown system output, \(\mathbf{x }(k) = {[x(k),x(k - 1),\ldots ,x(k - M + 1)]^\mathrm{T}}\) is the input vector, \({\mathbf{w }_o} = {[{w_0},{w_1},\ldots ,{w_{M - 1}}]^\mathrm{T}}\) is the optimal weight vector of the unknown system to be estimated, n(k) is the measurement noise, and M is the filter order.
The filter output y(k) and the error signal e(k) are defined in (2) and (3), respectively.
For the design of the proposed adaptive filter, a candidate Lyapunov function should be determined after the error signal e(k) is defined in (3). According to LST, the Lyapunov function in our design is selected as \(V(k) = \left| {e(k)} \right| \) to construct a linear inequality constraint in our optimization problem. In order to ensure the asymptotic stability of the proposed algorithm in the sense of Lyapunov, the determined Lyapunov function V(k) should also provide the negative definiteness condition as \(\Delta V(k) = V(k) - V(k - 1) < 0\), \(\forall \,k\). Therefore, this condition is integrated into the constraint part of the proposed optimization problem as follows:
where \(\delta \mathbf{w } = \mathbf{w }(k) - \mathbf{w }(k - 1)\) and \(\Delta V(k) = \left| {e(k)} \right| -\left| {e(k-1)} \right| \).
In order to solve the optimization problem having the quadratic cost function and the linear inequality constraint, we use the method of Lagrange multipliers. We primarily define the Lagrangian function \(F(\mathbf{w }(k),\lambda )\) as follows:
where \(\lambda \) is the Lagrange multiplier.
Then, the derivative of \(F(\mathbf{w }(k),\lambda )\) is taken with respect to \(\mathbf{w }\) and \(\lambda \) and these results are equal to zero. Thus, we obtain the two optimality conditions as follows.
By implementing optimality Condition 1, (8) is obtained as follows:
In order to obtain the Lagrange multiplier \(\lambda \) from (8), we can multiply both sides of (8) by \({\mathbf{x }^\mathrm{T}}(k)\). Thus, we can get the Lagrange multiplier \(\lambda \) in (9) after rearrangement of terms.
where \(\alpha (k)\) represents the a priori estimation error given by:
Finally, Condition 2 in (7) is obtained as follows:
Here, Condition 2 is obtained as \(\left| {e(k)} \right| = \left| {e(k - 1)} \right| \) under the optimum conditions. However, this result does not ensure the negative definiteness of the Lyapunov function, \(\Delta V(k) < 0\). Therefore, in order to ensure \(\Delta V(k)\) \(= \left| {e(k)} \right| - \left| {e(k-1)} \right| < 0\) in all cases, we modify the error signal \(\left| {e(k)} \right| \) by using adaptation gain rate \(\kappa \in [0,1)\), as follows:
Thus, the asymptotic stability of the proposed algorithm in the sense of Lyapunov, that is, \(\Delta V(k) = \kappa \left| {e(k - 1)} \right| - \left| {e(k - 1)} \right| < 0\) is ensured for \(\kappa \in [0,1)\). Therefore, the error function \(\left| {e(k)} \right| \) for \(\kappa \in [0,1)\) asymptotically converges to zero when the time index k approaches to infinity. This case can easily be verified by using (12) as follows:
Remark
The use of the adaptation gain rate parameter \(\kappa \) in the proposed algorithm controls and improves the transient response of the adaptive filter. If \(\kappa \) is set to a small value, the proposed algorithm can achieve a faster convergence rate.
The Lagrange multiplier defined in (9) is rewritten in (14) by using (12).
Finally, substituting (14) into (8), the proposed weight vector updates law is obtained as follows:
The weight vector update law of the proposed algorithm in (15) can be multiplied by a positive constant step size \(\mu \) in order to govern the steady-state and transient behaviors of the proposed algorithm. In addition, (15) can be modified in order to avoid singularity by adding a small positive constant \(\epsilon \). Consequently, the weight vector update law of the generalized FSS-LAF algorithm is given as in (16).
3 Stability of the FSS-LAF algorithm
In this section, we will represent the stability of the proposed FSS-LAF algorithm in terms of the convergence in the mean. The convergence analysis of the proposed algorithm can be done mathematically tractable if we use independence assumptions given in [1, 13, 14]. The desired signal first can be defined without loss of generality as follows:
where n(k) is zero-mean white Gaussian noise with variance \(\sigma _n^2\) which is uncorrelated with the input signal \(\mathbf{x }(k)\) [1, 13, 14].
Then, the a priori estimation error \(\alpha (k)\) is expressed by using (17) as follows:
Thus, using (18), (16) can be rewritten for \(\epsilon =0\) as:
After subtracting \({\mathbf{w }_o}\) from both sides of (19) [1, 13, 14], the weight error vector \(\mathbf{c }(k) = \mathbf{w }(k) - {\mathbf{w }_o}\) can be obtained by using (13), as follows:
The statistical expectation operator is employed to both sides of (20), and then, the error signal vanishes in (20) (that is, \(\kappa \left| {e(k - 1)} \right| = {\kappa ^k}\left| {e(0)} \right| = 0\)) if the time index k approaches to infinity. Thus, (20) is easily obtained again under these assumptions as follows:
Using the unitary transformation similar to [1, 13, 14], we can define the correlation matrix \(\mathbf{R }\) as \(\mathbf{R }=\mathbf{Q }{\varvec{\varLambda }}\mathbf{Q }^\mathrm{T}\). Thus, we have:
where \({\varvec{\varLambda }}\) is the diagonal matrix which has diagonal elements of \(\mathbf{R }\), \(\mathbf{Q }\) is the unitary matrix of transformation, \(\lambda _{\max }\) is the maximum eigenvalue of \(\mathbf{R }\), and \(\mathbf{v }(k)=\mathbf{Q }^\mathrm{T}\mathbf{c }(k)\).
If the nth natural mode of (22) is solved by considering the initial condition, we obtain the following solution:
where \(\lambda _n\) is the nth eigenvalue of \(\mathbf{R }\).
If the step size \(\mu \) in (23) is chosen as \( 0< \mu < 2\), \(\mathbf{w }(k)\) converges to \(\mathbf{w }_o\) when the time index k approaches infinity. In addition to this, assume that the error signal e(k) is equal to a priori estimation error \(\alpha (k)\) when the weight vector of the adaptive filter is close to the optimal weight vector.
4 Variable step size algorithms
In this section, we will design a number of widely used gradient VSS algorithms for the FSS-LAF algorithm. A gradient variable step size \(\mu (k)\) can be derived based on the following equation:
where the parameter \(\rho \) is the learning rate.
Using the cost function \(J(k) = \frac{1}{2}{\alpha ^2}(k)\), the gradient \(\nabla _\mu J(k)\) is calculated as [10]:
Assuming \(\mu (k - 1) \approx \mu (k)\) for a small step size value [10], we obtain the following equation:
where \({\varvec{\psi }} (k)\) represents the sensitivity term [13].
Thus, a general update rule for the step size is obtained by using the sensitivity term \({\varvec{\psi }} (k)\), as follows:
In the subsections, the design of VSS algorithms will be presented by evaluating the sensitivity term \({\varvec{\psi }} (k)\).
4.1 BVSS-LAF algorithm
In this algorithm, the sensitivity term \({\varvec{\psi }} (k)\) is rigorously evaluated based on (16) as follows:
The last term in (28) equals to zero because the input \(\mathbf{x }(k - 1)\) is independent of the step size \(\mu (k - 1)\). Therefore, only the terms \(\partial \left| {\alpha (k - 1)} \right| /\partial \mu (k - 1)\) and \(\partial \left| {e(k - 2)} \right| /\partial \mu (k - 1)\) are obtained as follows:
Using (29) and (30), (28) is rewritten as follows:
Thus, the sensitivity term \({\varvec{\psi }} (k)\) is expressed as follows:
where \(\varvec{\varLambda }(k-1)\) is a time-varying adaptive filter that enables low-pass filtering of instantaneous gradients. Thus, the BVSS-LAF algorithm exhibits more accurate and robust behaviors against uncertainties resulted from the noisy instantaneous gradients [13].

Comparison of the proposed FSS-LAF algorithm in terms of MSD (dB) for correlated input at different fixed step sizes, a SNR \(=\) 0 dB, b SNR \(=\) 10 dB
4.2 FVSS-LAF algorithm
In order to simplify the BVSS-LAF algorithm, the time-varying term \(\varvec{\varLambda }(k-1)\) is replaced by a constant \(0< a < 1\). Thus, \({\varvec{\psi }}(k)\) can be written as follows:
As seen from (33), the FVSS-LAF algorithm has a low-pass filter with a fixed coefficient a and thus provides the filtering of the noisy instantaneous gradients [13].
4.3 MVSS-LAF algorithm
By setting \(a=0\) in (33), the calculation of the sensitivity term can be further simplified as follows:
As seen from (34), the MVSS-LAF algorithm only uses the noisy instantaneous gradient estimates [13].
5 Computational complexities
As seen from Table 1, the BVSS-LAF algorithm has a higher computational complexity than the other VSS algorithms because of the detailed evaluation of \({\varvec{\psi }} (k)\). However, since the MVSS-LAF algorithm does not contain the information of the past values of \({\varvec{\psi }}(k)\), its computational complexity is less than those of the BVSS-LAF and FVSS-LAF algorithms.
6 Simulation results and discussion
In this section, the performance of the proposed algorithms is illustrated on identification scenarios. The unknown system H(z) including ten coefficients is randomly generated, and it has the same number of coefficients with the adaptive filter. The unknown system and the adaptive filter are fed by two Gaussian input signals [15] which are generated by filtering zero-mean white Gaussian random sequence through a first-order system (correlated input) \({G_1}(z) = {1}/({1 - 0.9{z^{ - 1}}})\) or a third-order system (nonwhite Gaussian input) \({G_2}(z) = {0.44}/({1 - 1.5{z^{ - 1}} + {z^{ - 2}}-0.25}{z^{ - 3}})\). The unknown system output s(k) is corrupted by the measurement noise n(k) with 0 and 10 dB signal-to-noise ratio (SNR) levels. To measure the performance of the proposed algorithms, the MSD is used as \(\text {MSD} = E{{{\left\| {{\mathbf{w }_o}-\mathbf{w }(k)} \right\| }^2}}\) [16]. All the following simulation results are obtained by ensemble averaging over 50 independent trials. The adaptation gain rate parameter of the proposed algorithms is chosen as \(\kappa =0.01\) in all the simulations to satisfy stability in the sense of Lyapunov. Also, \(\epsilon \) is chosen as 0.001.

Comparison of the proposed FSS-LAF algorithm in terms of MSD (dB) for nonwhite Gaussian input at different fixed step sizes, a SNR \(=\) 0 dB, b SNR \(=\) 10 dB

a Comparison of the algorithms in terms of MSD (dB) for correlated input when SNR \(=\) 0 dB. b Variation of step sizes of the proposed VSS algorithms for correlated input when SNR \(=\) 0 dB

a Comparison of the algorithms in terms of MSD (dB) for correlated input when SNR \(=\) 10 dB. b Variation of step sizes of the proposed VSS algorithms for correlated input when SNR \(=\) 10 dB

a Comparison of the algorithms in terms of MSD (dB) for nonwhite Gaussian input when SNR \(=\) 0 dB. b Variation of step sizes of the proposed VSS algorithms for nonwhite Gaussian input when SNR \(=\) 0 dB

a Comparison of the algorithms in terms of MSD (dB) for nonwhite Gaussian input when SNR \(=\) 10 dB. b Variation of step sizes of the proposed VSS algorithms for nonwhite Gaussian input when SNR \(=\) 10 dB
Figures 1 and 2 show the effect of the step size on the MSD error of the proposed FSS-LAF algorithm at 0 and 10 dB SNRs for the correlated and nonwhite input signals. As seen from Figs. 1 and 2, a small step size slows down the convergence rate but provides a lower steady-state MSD error. On the other hand, a large step size accelerates the convergence but produces a higher steady-state MSD error. When \(\mu = 2\), the proposed algorithm demonstrates an unstable behavior because the step size \(\mu \) must be chosen less than 2 to ensure the stability of the proposed FSS-LAF algorithm. Note that the FSS-LAF algorithm for \(\mu = 1\) is equivalent to the classical LAF algorithm [2] which does not find the optimal weight vector coefficients as seen from Figs. 1 and 2. However, the proposed algorithm with a small step size value can estimate the optimal weight vector of the unknown system. Furthermore, Table 2 shows steady-state MSE performance of the proposed FSS-LAF algorithm for the correlated and nonwhite Gaussian inputs at different step sizes and SNR levels. As can be observed from both Figs. 1, 2 and Table 2, the proposed FSS-LAF algorithm provides a lower steady-state MSD and MSE errors for \(\mu = 0.05\). Therefore, its step size is chosen to be \(\mu = 0.05\) in the following simulations. For a fair comparison, while the initial values of the step sizes of the proposed VSS algorithms are initialized a small value such that as \(\mu (0) = 0.01\), other parameters of them for each simulation are chosen experimentally to achieve both the best convergence rate and the minimum level of the MSD (dB) error. In our simulations, we also compare the proposed algorithms with the recursive least square (RLS) algorithm, where the forgetting factor \(\lambda \) and the parameter \(\delta \) for initializing the inverse autocorrelation matrix \(\mathbf P (0)\) are chosen as 0.999 and 0.01, respectively.
Figure 3a shows the convergence performances of the algorithms in terms of the MSD (dB) for the uncorrelated input signal when SNR \(=\) 0 dB. As seen from Fig. 3a, proposed BVSS-LAF and FVSS-LAF algorithms provide a good trade-off between the convergence rate and the steady-state MSD error due to the use of a low-pass filter for the noisy instantaneous gradients when compared to the other two proposed algorithms. As seen from Fig. 3a, the RLS algorithm exhibits a faster convergence rate than the proposed algorithms but achieves the same steady-state MSD error with the FVSS-LAF algorithm. Note that the faster convergence rate of the RLS algorithm comes at the cost of high computational complexity which is \(3(M+1)^2 + 2(M+1)\) [14]. The variations of step sizes of the corresponding VSS algorithms for the uncorrelated input signal and SNR \(=\) 0 dB are also shown in Fig. 3b. As seen from Fig. 3b, the step sizes \(\mu (k)\) of the BVSS-LAF and FVSS-LAF algorithms, unlike the MVSS-LAF algorithm, go up to higher values initially and then come down very fast to lower values. Thus, the BVSS-LAF and FVSS-LAF algorithms exhibit a faster initial convergence behavior and then improve the identification of the unknown system in order to obtain a lower MSD error in the steady state. For SNR \(=\) 10 dB, results similar to those in Fig. 3a, b are observed in Fig. 4a, b, respectively.
Figure 5a shows the convergence performances of the algorithms in terms of MSD (dB) for the nonwhite Gaussian input signal when SNR \(=\) 0 dB. As seen from Fig. 5a, the BVSS-LAF and FVSS-LAF algorithms outperform the FSS-LAF and MVSS-LAF algorithms in terms of the convergence rate and steady-state MSD error. Also, in Fig. 5a, although RLS algorithm for nonwhite Gaussian input shows a faster convergence rate, it produces a higher steady-state MSD error when compared to the proposed algorithms. In Fig. 5b, for the nonwhite Gaussian input signal at SNR \(=\) 0 dB, the step sizes \(\mu (k)\) of the BVSS-LAF and FVSS-LAF algorithms quickly converge to high values and then very fast descend to small values, unlike the MVSS-LAF algorithm. Also, in Fig. 6a, b, results similar to those in Fig. 5a, b are observed for 10 dB SNR. Moreover, Tables 3 and 4 summarize the coefficients of the unknown system obtained by the algorithms for the correlated and nonwhite Gaussian input signals at 0 and 10 dB SNR levels. Tables 3 and 4 show that, in the steady-state, all the algorithms approximately converge to the optimal weight vector coefficients.
7 Conclusion
In this paper, we have proposed a generalized FSS-LAF algorithm and its VSS versions. The proposed FSS-LAF algorithm ensuring asymptotic stability has improved the performance in the presence of the measurement noise. Furthermore, three VSS algorithms have been adapted to the FSS-LAF algorithm to further improve the performance. The performances of the proposed algorithms have been tested on system identification problems in terms of the MSD (dB) and the convergence rate. The simulation results have shown that the derived bounds of step size for the FSS-LAF algorithm are justified, and especially, the BVSS-LAF and FVSS-LAF algorithms provide a better trade-off between the steady-state MSD (dB) error and the convergence rate.
References
Haykin, S.: Adaptive Filter Theory. Prentice-Hall, Englewood Cliffs (1996)
Seng, K.P., Man, Z., Wu, H.R.: Lyapunov-theory-based radial basis function networks for adaptive filtering. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 49(8), 1215–1220 (2002)
Sakrani, S., Sayadi, M. and Fnaiech, F.: A new 2D adaptive nonlinear filter based on the Lyapunov stability theory. In: Proceedings of 3rd International Symposium on Image and Signal Processing and Analysis, vol. 2, pp. 1102–1105 (2003)
Phooi, S.K., Ang, L.M.: Adaptive RBF neural network training algorithm for nonlinear and nonstationary signal. In: Proceedings of International Conference on Computational Intelligence and Security, vol. 1, pp. 433–436 (2006)
Zhao, H., Zhang, J.: Filtered-X Lyapunov algorithm for nonlinear active noise control using second-order Volterra filter. In: Proceedings of 11th IEEE International Conference on Communication Technology, pp. 497–500 (2008)
Caiyun, W.: Active noise control based on adaptive bilinear F-L algorithm. In: Proceedings of International Conference on Computer Distributed Control and Intelligent Environmental Monitoring (CDCIEM), pp. 89–92 (2012)
Mengüç, E.C., Acır, N.: A novel adaptive filter algorithm for tracking of chaotic time series. In: Proceedings of IEEE 19th Conference on Signal Processing and Communications Applications (SIU), pp. 490–493 (2011)
Mengüç, E.C., Acır, N.: A novel adaptive filter design using Lyapunov stability theory. Turk. J. Electr. Eng. Comput. Sci. 23(8), 719–728 (2015)
Mengüç, E.C., Acır, N.: Lyapunov stability theory based adaptive filter algorithm for noisy measurements. In: Proceedings of 15th International Conference on Computer Modelling and Simulation (UKSim), pp. 451–454 (2013)
Benveniste, A., Metivier, M., Priouret, P.: Adaptive Algorithms and Stochastic Approximation. Springer, Berlin (1990)
Mathews, V.J., Xie, Z.: A stochastic gradient adaptive filter with gradient adaptive step size. IEEE Trans. Signal Process. 41(6), 2075–2087 (1993)
Ang, W.-P., Farhang-Boroujeny, B.: A new class of gradient adaptive step-size LMS algorithms. IEEE Trans. Signal Process. 49(4), 805–810 (2001)
Mandic, D.P., Goh, V.S.L.: Complex Valued Nonlinear Adaptive Filters: Noncircularity, Widely Linear and Neural Models. Wiley, New York (2009)
Hayes, M.: Statistical Digital Signal Processing and Modelling. Wiley, New York (1999)
Hwang, J.-K., Li, Y.-P.: Variable step-size LMS algorithm with a gradient-based weighted average. IEEE Signal Process. Lett. 16(126), 1043–1046 (2009)
Aliyu, M.L., Alkassim, M.A., Salman, M.S.: A p-norm variable step-size LMS algorithm for sparse system identification. Signal Video Image Process. 9(7), 1559–1565 (2016)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mengüç, E.C., Acır, N. A generalized Lyapunov stability theory-based adaptive FIR filter algorithm with variable step sizes. SIViP 11, 1567–1575 (2017). https://doi.org/10.1007/s11760-017-1121-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-017-1121-8