
Abstract
This paper proposes a hybrid of Outer Block Boundary Matching Algorithm and Directional Interpolation Error Concealment Algorithm (DIECA) to recover the Motion Vectors (MVs) and the Disparity Vectors (DVs) of the lost color frames of the transmitted Three-Dimensional Video (3DV). For the lost 3DV depth frames, an Encoder-Independent Decoder-Dependent Depth-Assisted Error Concealment (EIDD-DAEC) algorithm is proposed. It exploits the recovered color MVs and DVs to estimate more additional concealment depth-assisted MVs and DVs. After that, the initially-estimated concealment candidate DVs and MVs are selected from all previously-predicted ones using the DIECA and the Decoder Motion Vector Estimation Algorithm (DMVEA). Finally, the proposed Bayesian Kalman Filtering (BKF) scheme is efficiently employed to filter out the inherent errors inside the selected concealment candidate color-plus-depth MVs and DVs to achieve better 3DV quality. Extensive experimental results on different standardized 3DV sequences demonstrate that the proposed color-plus-depth schemes are more robust against heavy losses and they achieve high 3DV quality performance with an improved average Peak Signal-to-Noise Ratio (PSNR) gain. They objectively and subjectively outperform the state-of-the-art error recovery techniques, especially at severe Packet Loss Rates (PLRs).
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The 3DV consists of different video streams captured for the same object with multiple cameras. The 3DV is predicted to rapidly take place of 2DV in different applications [1,2,3,4,5]. Recently, the 3DV communication through Internet or wireless networks has increased, dramatically [6]. Thence, highly efficient compression mechanisms must be introduced, whilst preserving a high reception quality for transmitting the 3DV over bounded-resources networks. For adaptive 3DV transmission, the 3DV structure must exploit the merit of the time and space matching between frames in the same stream in addition to the inter-view matching within the different 3DV streams to enhance the encoding performance. On the other hand, the extremely compressed 3DV is more sensitive to wireless channel errors.
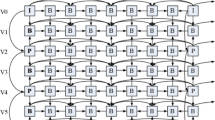
The 3DV communication over severe-packet-erasure wireless networks is servile to burst and random mistakes [7, 8]. So, it is a serious problem because of the bounded available bandwidth and the difficulty of re-transmitting the lost Macro-Blocks (MBs). Thus, it is an imperative assignment to achieve efficient encoding to adapt future bandwidth constraints, whilst preserving an increasing 3DV reception quality. The predictive 3D Multi-view Video Coding (MVC) framework is presented in Fig. 1 [9]. It comprises the inter- and intra-frames. So, the transmission errors might propagate to the adjacent views or to the subsequent frames leading to an impecunious video quality. In the case of real-time video transmission, it is difficult to re-transmit the whole lost or corrupted frames. Therefore, the post-processing Error Concealment (EC) techniques are utilized at the decoder to deal with the channel propagation errors [10,11,12]. They have the merit of minimizing the channel erasures without raising the latency or demanding encoder alterations.

3D video prediction coding model
The EC techniques exploit the intra-view and inter-view correlations within the 3DV content to recover the corrupted MBs. Also, they are neither imposing encoder modifications nor rising the transmission bit rate or propagation delay. The EC methods proposed for 1D or 2D video transmission can be employed to restore the corrupted 3D video frames [13,14,15,16,17]. They are expected to work more efficaciously in concealing the 3DV frame errors due to the availability of the inter-view correlations [9, 10]. The 3DV-plus-Depth (3DV+D) is another format of 3D video representation that has recently been discussed, intensively. They have data about the scene-per-pixel geometry [5, 6, 10]. The depth data is very essential and it is beneficial of adaptive depth conception to harmonize various 3D displays. Because the whole object pixels must have identical depth values, the depth information can be used to recognize the object boundaries that may help the concealment process [18]. Furthermore, the depth data optimizes the 3DV stored bits compared to the traditional 2DV applications.
The state-of-the-art EC techniques [10,11,12,13,14,15,16,17] exploit the availability of the neighboring space, time, and inter-view correlations among the 3DV views and frames to reconstruct the DVs and MVs of the corrupted MBs. Unfortunately, in the state of heavy transmission errors, these EC algorithms are mostly unfaithful and might present inaccurate 3DV quality and their concealment efficiency will be close to that of the straightforward Frame Temporal Replacement Algorithm (FTRA) [13]. To handle the case of heavy MBs losses, we propose improved hybrid post-processing EC algorithms for the color-plus-depth 3DV transmission over unreliable error-prone wireless channels. The suitable EC algorithm is selected depending on the corrupted frame and view types. For the lost depth frames, the EIDD-DAEC is proposed. It comes different from what were introduced in the literature works [19,20,21,22,23,24,25], which require the depth maps to be encoded and transmitted through the network. In this paper, the depth maps are estimated at the decoder rather than being calculated at the encoder. For further enhancement of the decoded 3DV quality, the proposed BKF is utilized on the predicted color and depth MVs and DVs to improve the overall performance of the proposed concealment algorithms.
The Kalman Filter (KF) is a recursive Bayesian filtering technique, which is used for predicting unsteady indiscriminate operations from a set of noisy experiments [19]. Based on this similarity, the KF model can be applied to the received heavily-corrupted-depth 3DV. The process of MVs and DVs estimation is considered as a set of noisy observations because the restoration of the lost boundary MBs from their neighboring correlated MBs does not depend on the corrupted MBs themselves. Therefore, an enhanced BKF based EC (BKF-EC) mechanism is proposed for the MVs and DVs prediction. It alleviates the burst transmission errors by refining the predicted candidate color and depth MVs and DVs that are firstly estimated by the proposed OBBMA and DIECA. Consequently, the immanent errors among the OBBMA-estimated MVs and the DIECA-estimated DVs could be removed, and thus the erroneous color and depth frames can be concealed with further precision. It is noticed that the KF was used previously in 2D H.264/AVC video concealment [19,20,21]. The proposed work in this paper is different from what were introduced in the previous works. Our proposed scheme refines the corruptly-received 3D H.264/MVC color-plus-depth videos with erroneous MBs at high PLRs. The proposed BKF-EC scheme in this paper outperforms what were presented in the literature works by up to 5 dB PSNR.
In the following sections, the proposed schemes with the experimental results will be introduced with more details. The rest of this paper is organized as follows. Section 2 presents the 3D MVC prediction coding framework, the basic error concealment methods, the related works on the depth-aided EC methods, and the conventional KF model. In Sect. 3, we introduce the proposed color-plus-depth EC algorithms. Simulation results are discussed in Sect. 4. The concluding remarks are given in Sect. 5.
2 Related Works
2.1 3D MVC Prediction Structure (3D MVC-PS)
The 2DV coding differs greatly from the 3DV coding, which benefits from the high inter-view matching between different views, and also from the space-temporal correlations among frames within the self-same view video [26]. The Disparity Compensation Prediction (DCP) and Motion Compensation Prediction (MCP) are used at the encoder to achieve high 3DV compression. They are also used at the decoder for performing an efficient concealment mechanism [13]. In the 3D MVC-PS shown in Fig. 1, the MCP is utilized to determine the MVs among different frames in the same video view, and the DCP is used to estimate the DVs among various frames of contiguous views. So, each frame in the 3D MVC-PS can be estimated through temporally-neighboring frames and/or through various view frames.
The 3D MVC-PS has an efficacious encoding/decoding achievement. It introduces a Group Of Pictures (GOPs) that contains eight different time pictures. The vertical direction represents multiple camera views and the horizontal direction represents the temporal axis. For example, the V0 view is encoded only via time correlation depending on the MCP. The other even V2, V4, and V6 views are likewise encoded based on the MCP. On the other hand, the prime key frames are encoded via the inter-view predictions depending on the DCP. In the V1, V3, and V5 odd views, the inter-view and temporal estimations (DCP + MCP) are simultaneously used for enhancing the encoding performance. In this work, the 3DV view is referred to considering its elementary locality 3DV frame. Therefore, as presented in Fig. 1, the odd views are called B-views, the even views are referred to as P-views, and the V0 view is symbolized as I-view. The final view might be even or odd based on the suggested 3DV GOPs. In this paper, it is proposed to be a P-view.
The 3D MVC-PS presents two encoded frame types, which are the P and B inter-frames and the I intra-frames. The inter-frames in the B-views are estimated via the intra-frames inside the I-view, and also from the inter-frames within the P-views. Thence, if an error occurs in the I frames or in the P frames, it propagates to the relative inter-view frames and furthermore to the adjacent temporal frames in the same video view. In this paper, we suggest different cases of EC hypothesis for the color and depth inter- and intra-frames in the B, I, and P views. Therefore, the suitable EC hypothesis is efficiently exploited depending on the lost view and frame types to recover the corrupted color and depth MBs.
2.2 Error Concealment (EC) Algorithms
The 3DV transmission through unreliable channels may encounter huge challenges due to unavoidable bit errors or packet loss that deteriorate the decoded 3DV quality. Thus, it is a promising solution to perform the EC for credible 3DV transmission. The EC is an efficacious methodology to resolve the errors through substituting the lost 3DV MBs by correctly-decoded and recovered MBs of the video stream to reduce or eliminate the bit-stream erasures. The EC techniques utilized in 2D video to compensate for broadcasting errors can be employed with particular modifications to deal with the corrupted 3DV frames [13,14,15,16,17,18,19,20,21]. They are expected to be more valuable for hiding errors in the 3DV system as they exploit the inter-view correlations among the different 3DV views. The FTRA is a straightforward time concealment algorithm that replaces the lost MBs by their spatial relative MBs in the correlated frame. The DMVEA and the OBBMA are more advanced time concealment techniques [13].
The OBBMA estimates the MVs amongst the external outlines of the substituted MB pixels and the same outer outlines of the corrupted MB pixels. It utilizes only the reference MB external borders to set the most correlated adjacent MVs as presented in Fig. 2a. The DMVEA determines the MVs of the erroneously-received MBs by employing a complete search in their relative 3DV frames. It is beneficial in characterizing the exchange of MBs that reduces the error distortion limit as illustrated in Fig. 2b. The DMVEA introduces more effective EC performance than that of the OBBMA with approximately the same computational complexity. The DIECA and the Weight Pixel Averaging Interpolation (WPAI) algorithm are used for the inter-view and spatial EC [14]. The WPAI algorithm restores the lost pixels by employing the horizontal and vertical pixels in the adjacent MBs as indicated in Fig. 3a. The DIECA conceals the lost MBs by searching on the neighboring MBs to determine the object boundary direction, where the largest value of the object boundary orientation is selected to conceal the corrupted MBs as illustrated in Fig. 3b.

Temporal EC algorithms: a outer block boundary matching, and b decoder motion vector estimation

Spatial/inter-view EC algorithms: a weight pixel averaging interpolation, and b directional interpolation
2.3 Depth-Based EC Techniques
Several depth-assisted EC techniques have been extensively explored for the 2D H.264/AVC standard. Recently, the depth-based EC algorithms for 3DV transmission have gained increasing attention. Yan [18] introduced a Depth-aided Boundary Matching Algorithm (DBMA) for color-plus-depth sequences. In addition to the zero MV and other MVs of the collocated MBs and neighboring spatial MBs, another MV estimated through depth map motion calculations is appended to the group of estimated candidate MVs. Wen et al. [22] proposed an EC technique for 3DV transmission in color and depth format by making use of the correlation among 2D texture video and its congruous depth data.
Liu et al. [23] proposed a Depth-dependent Time Error Concealment (DTEC) technique for the color streams. In addition to the MVs of the MBs surrounding a corrupted MB, the corresponding MV of the depth-map MB is added into the candidate group of the former MVs. Furthermore, the MB depth identical to a corrupted color MB is classified into homogeneous or boundary type. A homogeneous MB can be recovered as a whole. On the other hand, a boundary MB may be divided into background and foreground, and after that, they are separately recovered. The DTEC method can differentiate between the background and foreground, but it fails to allow adequate outcomes when the depth information is absent at the identical corresponding positions of the color sequence. In [24], Chung et al. presented a frame damage concealment scheme, where precise calculations for the corrupted color MVs are carried out with the assistance of depth data. Hong et al. [25] proposed an object-dependent EC technique. It is called the True Motion Estimation (TME) scheme that employs the depth data to estimate and extract the MVs for every object.
It is noticed that most of the previously-proposed works extract the depth data at the encoder and allow the depth maps to be coded and transported through the network to the decoder. So, they increase the complexity and bit rate of the transmission system, which does not meet the future bandwidth constraints of wireless transmission networks. Therefore, the efficient proposed depth-assisted EC contribution comes from estimating the depth information of the erroneous MBs at the decoder side rather than performing estimation at the encoder side. So, the proposed algorithm can achieve more efficient objective and subjective qualities compared to prior depth-based EC works, while saving the transmission bit rate and presenting minimal computational complexity. It neither requires difficult encoder operations nor increases the transmission latency.
2.4 Conventional Kalman Filter Model
The KF is a recursive Bayesian filtering mechanism that describes the mathematical model of the discrete-time observed process [19]. It is used to predict the discrete-time problem events s ( k ) that are observed through the stochastic linear difference formula from a series of calculated measurements y ( k ). The mathematical BKF model is expressed in Eq. (1) and (2).
In Eqs. (1) and (2), s ( k ) = [s 1 ( k ), s 2 ( k ) , …., s N ( k )]T, y ( k ) is an Mx1 measurement vector, r ( k ) is an Mx1 measurement noise vector with \(N\left( {0,\sigma_{r}^{2} } \right)\), H ( k ) is an MxM measurement matrix, w ( k ) is an Nx1 white noise vector with \(N\left( {0,\sigma_{w}^{2} } \right)\), and A ( k - 1 ) illustrates an NxN transition matrix. In this work, we assumed that the process w ( k ) and measurement r ( k ) noises follow independent and normal distributions.
In this paper, the BKF is employed in the MVs and DVs prediction processes. We assumed that the MVs and DVs estimation of the lost MBs from their neighboring reference MBs follows a Markov model. Thus, the BKF can manage their prediction for recovering the corrupted MBs. The BKF is an optimum recursive method that follows two steps in the estimation process, which are the time update and measurement update as depicted in Fig. 4. The \(\hat{s}_{{\bar{k}}} ,p_{k}^{ - } ,p_{k}^{ - } ,\hat{s}_{k} ,\mathop p\nolimits_{k} \;{\text{and}}\;\mathop K\nolimits_{k}\) refer to a priori state estimate, a priori estimate error covariance, a posteriori state estimate, a posteriori estimate error covariance, and KF gain, respectively. The KF is used to estimate the filtered events s ( k ) from a set of noisy states y ( k ) [20], where it exploits the predestined state from the prior step time and measurement at the immediate step time to predict the current state.

Bayesian Kalman filter (BKF) prediction process
3 The Proposed Color and Depth 3D Video Error Concealment Schemes
In this section, the proposed color-plus-depth EC schemes at the decoder are introduced for concealing the erroneously-recevied 3DV inter- and intra-frames. We present the proposed BKF-EC scheme for reconstructing the corrupted color frames and also introduce the suggested EIDD-DAEC algorithm for concealing the lost depth frames. A full framework diagram of the proposed color-plus-depth 3DV wireless transmission system is presented in Fig. 5.

General framework of the proposed 3DV transmission system
3.1 The Proposed BKF-EC Algorithm for the Lost Color Frames
In this section, the proposed BKF-EC algorithm is explained. It is employed for refining the previously-estimated color MVs and DVs by the OBBMA and DIECA. In this work, the 3DV coding prediction framework presented in Fig. 1 is utilized due to its effective performance. It presents the space-temporal correlations between different frames within the same video view in addition to the inter-view matching between different views. As it was discussed in Sect. 2.1, the DCP and MCP processes can be employed at the encoder to achieve more 3DV compression and also at the decoder for an efficient EC process. Therefore, in order to efficiently estimate the MVs and DVs of the corrupted MBs, we exploit the advantage of the 3DV inter-view, spatial, and temporal matching among the 3D MVC-PS views and frames.
The proposed BKF EC algorithm adaptively chooses the suitable EC scheme (OBBMA or DIECA or both) depending on the corrupted view and lost frame types to recover the heavily-corrupted color blocks. After that, to eliminate the immanent errors among the OBBMA-estimated MVs and the DIECA-estimated DVs, the proposed BKF is used as a second step to improve the 3DV visual quality with more accuracy. Figure 6 shows the flow structure of the suggested BKF-EC technique for the corrupted color frames.

Complete structure of the proposed BKF-EC algorithm for the lost color frames
In Fig. 6, the BKF scheme is used as a correction prediction mechanism compensating for the estimated measurement errors of the OBBMA-estimated MVs and the DIECA-estimated DVs. We assumed that the desired predicted MV or DV is defined by the state vector s = [s n , s m ], and we also assumed that the previously-recovered measurement MV or DV is given by y = [y n , y m ], where m and n represent respectively the height and width of the MB. The desirable outcome s ( k ) of a frame k is presumed to be elicited from that case at frame k-1 using Eq. (3). Likewise, the observation measurement state y ( k ) of the state vector s ( k ) is calculated by Eq. (4). So, the state and measurement model for MV or DV prediction can be described as in (3) and (4). In the proposed algorithm, we assume constant process w ( k ) and observation r ( k ) noises that follow zero-mean Gaussian white noise distributions, where they are set with constant covariance of \(\sigma^{2}_{w} = \sigma_{r}^{2} 0.5I_{2}\) (I 2 is the unity matrix of size two). Also, we adopted constant transition A ( k ) and measurement H ( k ) matrixes as two-dimension unity matrices, where it is assumed that there are high correlations between horizontally and vertically neighboring MBs.
The proposed BKF-EC prediction process can be characterized by the prediction and updating steps as discussed in Sect. 2.4. The detailed proposed BKF refinement mechanism can be summarized as in the following three phases:
3.1.1 Phase (1): Initialization Phase
-
1.
Define the previously-measured noisy OBBMA-estimated MVs or/and DIECA-estimated DVs.
-
2.
Set the initial state and covariance vectors as in Eq. (5).
3.1.2 Phase (2): Prediction Phase
-
1.
Calculate the predicted a priori estimate state (MV or DV) \(\hat{s}_{{\bar{k}}}\) for frame k using the previous (MV or DV of the MB) updated state \(\hat{s}_{k - 1}\) of frame k-1 as introduced in Eq. (6).
-
2.
Calculate the estimated a priori predicted error covariance \(p_{k}^{ - }\) utilizing the updated estimate covariance \(p_{k - 1}\) and the noise covariance process \(\sigma^{2}_{w}\) as presented in Eq. (7).
3.1.3 Phase (3): Updating Phase
-
1.
Calculate the updated estimate state (finally estimated candidate MV or DV) vector \(\hat{s}_{k}\) employing the measurement state \(\mathop y\nolimits_{{_{k} }}\)(the initially OBBMA-estimated MVs or/and DIECA-estimated DVs) and the observation noise covariance \(\sigma_{r}^{2}\) as shown at Eq. (8).
-
2.
Calculate the updated filtered error covariance \(\mathop p\nolimits_{k}\) via the predicted estimate covariance \(p_{k}^{ - }\) and the noise covariance observation \(\sigma_{r}^{2}\) as in Eq. (9), where the KF gain \(\mathop K\nolimits_{k}\) is given by Eq. (10).
For each lossy color MB indexed according to its position in the corrupted color frame and view, the above prediction and updating phases are applied as refinement processes. The BKF-EC steps are repeated for all the corrupted color MBs until we get the finally-estimated candidate MVs or/and DVs as given in Eq. (8). Such a mechanism repeats until all corrupted color MBs are concealed. Thus, if the initially-estimated MVs and DVs are not reliable for optimum EC due to heavy error occurrence and low available surrounding and boundary pixels information, they are then enhanced by the finally-predicted candidate MVs and DVs via employing the proposed BKF to fulfill high objective and subjective 3DV quality for the transmitted color frames.
3.2 The Proposed EIDD-DAEC Algorithm for the Corrupted Depth Frames
In this section, the suggested EIDD-DAEC algorithm is introduced for concealing the 3DV depth intra-frames and inter-frames. A full schematic chart of the suggested EIDD-DAEC algorithm at the decoder is illustrated in Fig. 7. Since the MVs and DVs are calculated at the encoder, and then they are transmitted to the decoder, we may instantly use them at the decoder to calculate the depth maps of the received MBs in their reference frames. The MB depth maps of the correctly received MBs within their reference frames depend on the correctly received neighboring matched left/right MVs and up/down DVs, and they can be calculated by (11) and (12) [18].

Complete flow structure of the suggested EIDD-DAEC algorithm for the lost depth frames
where the \(MV(m,n)\) and \(DV(m,n)\) are the motion and disparity vectors, respectively, at the location \((m,n)\), the \(k\) is a calibration factor, and the subscripts x and y demonstrate the MB horizontal and vertical components, respectively. After that, we determine the spatio-temporal and inter-view (MVs and DVs) depth values of the lost MBs inside their correlated and reference neighboring left/right and up/down frames as introduced in Fig. 8 by (13) and (14) [18].

3DV frames prediction structure
where the subscripts F+1, F−1, S+1, S−1 refer to the right, left, up, and down reference frames, respectively, as shown in Fig. 8. The calculation of motion and disparity depth values for the erroneous MBs is performed using their collocated adjacent MBs. Thus, the DCP and MCP are employed on the previously-estimated depth maps, which are calculated by (13) and (14) to take out the depth DVs and depth MVs, respectively. The Sum of Absolute Difference (SAD) [24] is used as the estimation measure to collect the candidate depth MVs as given in (15) and (16), and to determine the candidate depth DVs that can be found by (17) and (18).
where the \(D_{i} (m,n)\) signifies the amount of depth at position \((m,n)\) of frame i, and the R is the search domain. In these formulas above, we suppose that the MBs within frame F are corrupted. Therefore, the \(D_{F} (m,n)\) is estimated by (13) or (14). The \(D_{F - 1} (m,n)\) and \(D_{F + 1} (m,n)\) are calculated by (11). By the way, the \(D_{S - 1} (m,n)\) and \(D_{S + 1} (m,n)\) are determined by (12).
To improve the EC efficiency, we also gather the set of candidate texture color MVs and DVs for the lost MBs in their reference frames. The texture color MVs and DVs are those associated with the immediate MBs and the collocated MBs of their reference frames, which are estimated by the same criteria used to calculate the depth MVs and DVs. The depth MVs and DVs of the lost MBs are derived from the depth data maps with the selfsame locations as the texture color MVs and DVs. However, we combine the depth MVs and DVs associated with the received corrected MBs, whose depth is estimated by (11) and (12). At this stage, we have a lot of texture candidate color MVs and DVs in addition to the estimated candidate depth MVs and DVs from the correctly-received and the lost MBs. Thus, finally, the DMVEA is employed to select the optimum concealed MVs and apply the DIECA to select the best concealed DVs for concealing the lost color-plus-depth MBs of the received 3DV sequences.
4 Experimental Results
So as to assess the performance of the suggested combined color-plus-depth (BKF-EC/EIDD-DAEC) schemes, we have carried out several test simulations on standard well-known 3DV + D (Ballet, Kendo, and Balloons) sequences [27]. The three 3DV sequences have different characteristics. The Ballet video is a fast-moving sequence, the Kendo stream is a moderate animated video, and the Balloons sequence is an intermediate slow-moving video. For each sequence, the encoded 3D H.264/MVC bitstreams are produced, and after that they are transported through the wireless channel with different PLRs of 20, 30, 40, 50, and 60%. The received bitstreams are then subsequently concealed and decoded via the proposed schemes at the decoder, without embracing error propagation. In our simulation results, the reference JMVC codec [28] is employed, depending on the 2D video codec [26]. The encoding simulation parameters utilized in this work are selected depending on the well-known JVT experiment [27]. The PSNR is utilized as the measured objective quantity of the concealed and recovered MBs to appraise the efficiency of the suggested algorithms.
To clarify the influence of employing the suggested algorithms for recovering and concealing the corrupted transmitted color-plus-depth 3DV over heavily-erroneous channels, we compare their performance with the case of utilizing the state-of-the-art EC techniques without applying the BKF-EC and the EIDD-DAEC schemes (Color-assisted EC + No Depth-assisted EC + No BKF), compare also with the case when utilizing the EIDD-DAEC algorithm only and without the BKF-EC algorithm (Color-assisted EC + Depth-assisted EC + No BKF), compare also with the case of using the BKF-EC technique only and without the EIDD-DAEC algorithm (Color-assisted EC + No Depth-assisted EC + BKF), and compare also with the case when no EC is applied (No Color-assisted EC + No Depth-assisted EC + No BKF). In the introduced simulation results, the BKF-EC + EIDD-DAEC (Color-assisted EC + Depth-assisted EC + BKF) gives high-quality results.
Figures 9 to 14 present the color-plus-depth subjective comparison results at different Quantization Parameters (QPs) (37, 32 and 27) and at different severe PLRs (40, 50, and 60%) for the color-plus-depth inter- and intra-frames of the selected three 3DV (Ballet, Balloons, and Kendo) sequences. For each sequence, miscellaneous erroneous frame positions and types (I- or B- or P-frame) are chosen inside different view locations (I- or B- or P-view) to show the effectiveness of the proposed BKF-EC + EIDD-DAEC schemes on ameliorating different positions and types of the lost color-plus-depth MBs at various PLRs.

Visual subjective results of the chosen color 16th intra I frame in the I view (V0) of the “Ballet” video: a error-free original I16 color frame, b erroneous I16 color frame with PLR = 40% and QP = 37, c concealed I16 color frame without depth-assisted EC and without BKF-EC, d concealed I16 color frame with depth-assisted EC and without BKF-EC, e concealed I16 color frame without depth-assisted EC and with BKF-EC, f concealed I16 color frame with depth-assisted EC and BKF-EC
Figure 9 demonstrates the color frames subjective visual results of the 3DV Ballet sequence at PLR = 40% and QP = 37 of the selected 16th intra-coded color I frame as a test frame inside the V0 view. We recovered the tested 16th color I intra-frame (depending on indexed lossy MB position in the corrupted frame and view) with the appropriate color-assisted EC algorithms without using the depth-assisted EC and without the BKF algorithm as introduced in Fig. 9c, when employing the depth-assisted EC algorithm without the BKF algorithm as shown in Fig. 9d, with the state of not utilizing the depth-assisted EC algorithm with the BKF algorithm as shown in Fig. 9e, and finally with both the depth-assisted EC and the BKF-EC algorithms as given in Fig. 9f. It is observed that the subjective results given in Fig. 9f of the color frames of the suggested full BKF-EC + EIDD-DAEC schemes outperform those of the color-assisted OBBMA + DIECA algorithms only, those of the EIDD-DAEC scheme only, and those of the BKF-EC algorithm only, which are introduced respectively in Fig. 9c to 9e. By the way, the depth frames subjective results of the comparison on the Ballet 3DV sequence at PLR = 40% and QP = 37 for the selected 16th intra depth I frame as a test frame within the V0 view are presented in Fig. 10. We observe that the subjective depth frame visual result given in Fig. 10f for the proposed BKF-EC + EIDD-DAEC schemes outperform those with depth algorithms only, those of the EIDD-DAEC scheme only, and those of the BKF-EC algorithm only, which are introduced in Fig. 10c to 10e.

Visual subjective results of the chosen depth 16th intra I frame in the I view (V0) of the “Ballet” video: a error-free original I16 depth frame, b erroneous I16 depth frame with PLR = 40% and QP = 37, c concealed I16 depth frame without color-assisted EC and without BKF-EC, d concealed I16 depth frame with color-assisted EC and without BKF-EC, e concealed I16 depth frame without color-assisted EC and with BKF-EC, f concealed I16 depth frame with color-assisted EC and BKF-EC
Figure 11 shows the color frames visual results, and Fig. 12 offers their typically depth frames visual results of the 3DV Balloons sequence at channel PLR = 50% and QP = 32. We have chosen the 73rd inter-encoded color-plus-depth B frames within the V1 view. From the shown concealed color frame result in Fig. 11f compared to that offered in Figs. 11c, 10d, e, and from the presented reconstructed depth frame result given in Fig. 12f compared to that introduced in Fig. 12c to 12e, it is noticed that the full suggested BKF-EC + EIDD-DAEC schemes for recovering the corrupted color-plus-depth MBs achieves good results in the case of heavily-erroneous channels as in the case of PLR = 50%. By similarity, Fig. 13 introduces the color frames subjective visual results and Fig. 14 presents their depth frames subjective visual results of the 3DV Kendo sequence at channel PLR = 60%, and QP = 27 for the tested chosen 24th inter-encoded color-plus-depth P frame inside P view V2. From both introduced color frames results in Fig. 13f compared to those introduced in Fig. 13c–e, and also from the depth frames visual results given in Fig. 14f compared to those shown in Fig. 14c to 14e; we observe that the subjective visual results of the full proposed BKF-EC + EIDD-DAEC (Color-based EC + Depth-based EC + BKF-EC) schemes outperform those of the (Color-based EC + No Depth-based EC + No BKF-EC), the (Color-based EC + Depth-based EC + No BKF-EC), and the (Color-based EC + No Depth-based EC + BKF-EC) algorithms. Thus, the utilization of the full proposed BKF-EC + EIDD-DAEC schemes is attractive for concealing the lost color-plus-depth MBs, efficiently, especially in the case of heavily-erroneous channels such as the case with PLR = 60%.

Visual subjective results of the chosen color 73rd inter B frame in the B view (V1) of the “Balloons” video: a error-free original B73 color frame, b erroneous B73 color frame with PLR = 50% and QP = 32, c concealed B73 color frame without depth-assisted EC and without BKF-EC, d concealed B73 color frame with depth-assisted EC and without BKF-EC, e concealed B73 color frame without depth-assisted EC and with BKF-EC, f concealed B73 color frame with depth-assisted EC and BKF-EC

Visual subjective results of the chosen depth 73rd inter B frame in the B view (V1) of the “Balloons” video, a error-free original B73 depth frame, b erroneous B73 depth frame with PLR = 50% and QP = 32, c concealed B73 depth frame without color-assisted EC and without BKF-EC, d concealed B73 depth frame with color-assisted EC and without BKF-EC, e concealed B73 depth frame without color-assisted EC and with BKF-EC, f concealed B73 depth frame with color-assisted EC and BKF-EC

Visual subjective results of the chosen color 24th inter P frame in the P view (V2) of the “Kendo” video, a error-free original P24 color frame, b erroneous P24 color frame with PLR = 60% and QP = 27, c concealed P24 color frame without depth-assisted EC and without BKF-EC, d concealed P24 color frame with depth-assisted EC and without BKF-EC, e concealed P24 color frame without depth-assisted EC and with BKF-EC, f concealed P24 color frame with depth-assisted EC and BKF-EC

Visual subjective results of the chosen depth 24th inter P frame in the P view (V2) of the “Kendo” video, a error-free original P24 depth frame, b erroneous P24 depth frame with PLR = 60% and QP = 27, c concealed P24 depth frame without color-assisted EC and without BKF-EC, d concealed P24 depth frame with color-assisted EC and without BKF-EC, e concealed P24 depth frame without color-assisted EC and with BKF-EC, f concealed P24 depth frame with color-assisted EC and BKF-EC
In Fig. 15, Table 1, and Fig. 16, we illustrate the objective PSNR values of the tested 3DV sequences at different PLRs and QPs of 27, 32, and 37. We show the PSNR results of the suggested BKF-EC + EIDD-DAEC schemes (Color-based EC/Depth-based EC/BKF) compared to those of the state-of-the-art EC techniques without applying the BKF-EC and the EIDD-DAEC schemes (Color-based EC/No-Depth-based EC/No-BKF), those of the EIDD-DAEC algorithm only without the BKF-EC algorithm (Color-based EC/Depth-based EC/No-BKF), those of the BKF-EC technique only without the EIDD-DAEC algorithm (Color-based EC/No-Depth-based EC/BKF), and those of no EC (No Color-based EC/No-Depth-based EC/No BKF). From all the tested 3DV sequences, it is perceived that the proposed BKF-EC + EIDD-DAEC schemes always consummate superior PSNR values. As well, it can be realized that the proposed Color-based EC/Depth-based EC/BKF schemes have a meaningful average gain in objective PSNR on all tested 3DV sequences of about 0.6–0.8, 1.3–1.6, and 2.03–2.35 dB at different QPs and PLRs over the case of harnessing the Color-based EC/No-Depth-based EC/BKF schemes, the case of applying the Color-based EC/Depth-based EC/No-BKF schemes, and the case of employing the Color-based EC/No-Depth-based EC/No-BKF schemes, respectively.

PSNR (dB) objective results of the three tested: a ballet, b balloons, and c kendo 3DV streams at different PLRs and QP = 27

PSNR (dB) objective results of the three tested: a ballet, b balloons, c kendo 3DV streams at different PLRs and QP = 37
We can also pay attention to the fact that the proposed Color-based EC/Depth-based EC/BKF algorithms are crucial as they provide about 15.35 ~ 24.25 dB average PSNR gain at different QPs and PLRs compared to the case of not bestowing any recovering algorithms (No-Color-based EC/No-Depth-based EC/No-BKF). From all the presented objective and subjective results, it is recognized that exploiting the proposed Color-based EC/Depth-based EC/BKF schemes is more appreciated in the case of heavily-erroneous channels. They have preferable objective and visual simulation results compared to the Color-based EC/No-Depth-based EC/BKF, the Color-based EC/Depth-based EC/No-BKF, and the Color-based EC/No-Depth-based EC/No-BKF algorithms. The simulation results show that there is a PSNR amelioration achieved by the proposed schemes over those achieved by other EC algorithms that do not use the depth-assisted correlations or the BKF. They become significant while increasing the PLR or QP values. Furthermore, it is noticed that the suggested BKF-EC + EIDD-DAEC algorithms present good experimental results for 3DV streams with different characteristics, and they can recover erroneous frames in any view position with high efficiency.
5 Conclusions
This paper proposed enhanced EC schemes at the decoder for lossy color-plus-depth frames of the 3DV transmission over erroneous wireless networks. One of the main important strengths of this work is the inclusion of depth MVs and DVs without encoding and transmitting the depth maps to avoid sophisticated depth calculations at the encoder. Moreover, the appropriate EC scheme is adaptively selected depnding on the corrupted color or depth faulty frame and view. Furthermore, the proposed algorithms proved that they are more desirable and reliable in the case of lossy channel conditions. Experimental results manifest the heartening achievements of the proposed algorithms on concealing heavily-corrupted color-plus-depth 3DV sequences at high PLRs. They expound the prominence of deploying the BKF-EC and depth-assisted MVs and DVs to reinforce the 3DV subjective quality and likewise acquire appreciated objective PSNR values. We elucidated that the suggested algorithms can deal with various 3DV characteristics efficiently with high 3DV quality.
References
Xiang, W., Gao, P., & Peng, Q. (2015). Robust multiview three-dimensional video communications based on distributed video coding. IEEE Systems Journal, 99, 1–11.
Cagri, O., Erhan, E., Janko, C., & Ahmet, K. (2016). Adaptive delivery of immersive 3D multi-view video over the Internet. Journal of Multimedia Tools and Applications, 75(20), 12431–12461.
Huanqiang, Z., Xiaolan, W., Canhui, C., Jing, C., & Yan, Z. (2014). Fast multiview video coding using adaptive prediction structure and hierarchical mode decision. IEEE Transactions on Circuits and Systems for Video Technology, 24(9), 1566–1578.
Ying, C., & Vetro, A. (2014). Next generation 3D formats with depth map support. IEEE Multimedia, 21(2), 90–94.
Purica, A., Mora, E., Pesquet, P. B., Cagnazzo, M., & Ionescu, B. (2016). Multiview plus depth video coding with temporal prediction view synthesis. IEEE Transactions on Circuits and Systems for Video Technology, 26(2), 360–374.
Abreu, A. D., Frossard, P., & Pereira, F. (2015). Optimizing multiview video plus depth prediction structures for interactive multiview video streaming. IEEE Journal of Selected Topics in Signal Processing, 9(3), 487–500.
Hewage, C. T. E. R., & Martini, M. G. (2013). Quality of experience for 3D video streaming. IEEE Communications Magazine, 51(5), 101–107.
Liu, Z., Cheung, G., & Ji, Y. (2013). Optimizing distributed source coding for interactive multiview video streaming over lossy networks. IEEE Transactions on Circuits and Systems for Video Technology, 23(10), 1781–1794.
El-Shafai, W. (2015). Pixel-level matching based multi-hypothesis error concealment modes for wireless 3D H.264/MVC communication. 3D Research, 6(3), 31.
Khattak, S., Maugey, T., Hamzaoui, R., Ahmad, S., & Frossard, P. (2016). Temporal and inter-view consistent error concealment technique for multiview plus depth video. IEEE Transactions on Circuits and Systems for Video Technology, 26(5), 829–840.
Zhou, Y., Xiang, W., & Wang, G. (2015). Frame loss concealment for multiview video transmission over wireless multimedia sensor networks. IEEE Sensors Journal, 15(3), 1892–1901.
Lee, P. J., Kuo, K. T., & Chi, C. Y. (2014). An adaptive error concealment method based on fuzzy reasoning for multi-view video coding. Journal of Display Technology, 10(7), 560–567.
Xiang, X., Zhao, D., Wang, Q., Ji, X., & Gao, W. (2007). A novel error concealment method for stereoscopic video coding. In Proceedings 2007 IEEE international conference on image processing (ICIP) (pp. 101–104).
Hwang, M., & Ko, S. (2008). Hybrid temporal error concealment methods for block-based compressed video transmission. IEEE Transactions on Broadcasting, 54(2), 198–207.
Lie, W. N., Lee, C. M., Yeh, C. H., & Gao, Z. W. (2014). Motion vector recovery for video error concealment by using iterative dynamic-programming optimization. IEEE Transactions on Multimedia, 16(1), 216–227.
Gadgil, N., Li H., & Delp, E. J. (2015). Spatial subsampling-based multiple description video coding with adaptive temporal-spatial error concealment. In Proceedings 2015 IEEE picture coding symposium (PCS) (pp. 90–94).
Ebdelli, M., Le-Meur, O., & Guillemot, C. (2015). Video inpainting with short-term windows: application to object removal and error concealment. IEEE Transactions on Image Processing, 24(10), 3034–3047.
Yan, B., & Jie, Z. (2012). Efficient frame concealment for depth image-based 3-D video transmission. IEEE Transactions on Multimedia, 14(3), 936–941.
Gao, Z. W., & Lie, W. N. (2004). Video error concealment by using Kalman-filtering technique. In Proceedings of the international symposium on circuits and systems (pp. 69–72).
Mochn, J., Marchevsk, S., & Gamec, J. (2009). Kalman filter based error concealment algorithm. In Proceedings of 54th Internationales Wissenchaftliches Kolloquium (pp. 1–4).
Shihua, C., Cui, H., & Tang, K. (2014). An effective error concealment scheme for heavily corrupted H.264/AVC videos based on Kalman filtering. Signal, Image and Video Processing, 8(8), 1533–1542.
Wen, N. L., & Guan, H. L. (2013). Error concealment for 3D video transmission. In Proceedings of IEEE international symposium on circuits and systems (ISCAS) (pp. 2856–2559).
Liu, Y., Wang, J., & Zhang, H. (2010). Depth image-based temporal error concealment for 3-D video transmission. IEEE Transactions on Circuits and Systems for Video Technology, 20(4), 600–604.
Chung, T. Y., Sull, S., & Kim, C. S. (2011). Frame loss concealment for stereoscopic video plus depth sequences. IEEE Transactions on Consumer Electronics, 57(3), 1336–1344.
Hong, C. S., Wang, C. C., Tai, S. C., & Luo, Y. C. (2011). Object-based error concealment in 3D video. In Proceedings of IEEE fifth international conference on genetic and evolutionary computing (ICGEC) (pp. 5–8).
H.264/AVC codec reference software. http://iphome.hhi.de/suehring/tml/. Accessed 28 September 2014.
ISO/IEC JTC1/SC29/WG11. (2006). Common test conditions for multiview video coding. JVT-U207, Hangzhou, China.
WD 4 reference software for multiview video coding (MVC). http://wftp3.itu.int/av-arch/jvt-site/2009_01_Geneva/JVT-AD207.zip. Accessed 25 October 2015.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
El-Shafai, W., El-Rabaie, S., El-Halawany, M. et al. Enhancement of Wireless 3D Video Communication Using Color-Plus-Depth Error Restoration Algorithms and Bayesian Kalman Filtering. Wireless Pers Commun 97, 245–268 (2017). https://doi.org/10.1007/s11277-017-4503-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-017-4503-x