
Abstract
Wireless sensor network (WSN) is a cost-effective networking solution for information updating in the coverage radius or in the sensing region. To record a real-time event, a large number of sensor nodes (SNs) need to be arranged systematically, such that information collection is possible for a longer span of time. But, the hurdle faced by WSN is the limited resources of SNs. Hence, there is a high demand to design and implement an energy-efficient scheme to prolong the performance parameters of WSN. Clustering-based routing is the most suitable approach to support for load balancing, fault tolerance, and reliable communication to prolong performance parameters of WSN. These performance parameters are achieved at the cost of reduced lifetime of cluster head (CH). To overcome such limitations in clustering based hierarchical approach, efficient CH selection algorithm, and optimized routing algorithm are essential to design efficient solution for larger scale networks. In this paper, fuzzy extended grey wolf optimization algorithm based threshold-sensitive energy-efficient clustering protocol is proposed to prolong the stability period of the network. Analysis and simulation results show that the proposed algorithm significantly outperforms competitive clustering algorithms in the context of energy consumption, stability period and system lifetime.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Wireless sensor network (WSN), which combines the technology of sensors, embedded computing, and wireless communications, is the most important element in the Internet of Things (IoT). The growing popularity of IoT systems such as the smart grid, Body Area Networks (BANs), and the Intelligent Transportation System (ITS) is driving WSN systems to the limit in terms of abilities and performance. WSNs were initially designed for low power, low data rate, and latency-tolerant applications [1]. However, this paradigm is changing because of the nature of the new applications. Examples of IoT applications include Body Area Networks (BANs), disaster discovery, object movement detection, battlefield surveillance, Intelligent Transportation Systems (ITSs) and security systems. WSNs are popular because of the wide range of IoT applications they can be used in. In effect, WSNs are being implemented in almost all IoT applications due to their effectiveness in transmitting many monitoring many events. WSNs are built from small SNs that can monitor and collect data, process it, and communicate it wirelessly to a sink node or a Base Station (BS).
In the literature, there are numerous studies that examined different areas of WSN technologies and their applications [2,3,4,5]. SNs are battery-powered and usually deployed in environments that have the least human supervision (like forests, battlefields, etc.). As such, replacing or recharging SNs batteries is not practical. In order to avoid any disruption in the services of the WSN due to battery drainage, two approaches are followed. From one side, SNs are deployed in abundance (WSNs can be constituted by thousands of SNs) in order to guarantee redundancy in the data reported by SNs. That is, if certain SNs deplete their batteries, other nodes are already covering for them and serious disruption in services is mitigated. On the other side, any communication protocol or algorithm to be ported on the SN platform should not pose any processing burden. The early phases of design, development, and deployment of WSNs focused on conserving the power resources of the SNs [6,7,8].
Due to scarce resources in WSN, direct communication of SN with BS or multi-hop communication of SNs towards BS is not practical as energy consumption is high which results in the early expiry of nodes. Direct communication or single-tier communication is not feasible for large scale networks as WSN cannot support long-haul communication. Direct communication has its disadvantages such as high energy consumption, duplication of data (SNs that were close to each other, sending data with very small variation), and farthest nodes dying quickly. To overcome these problems, two-tier communication through a hierarchical approach is used where nodes are grouped into clusters. The leader node also called cluster head (CH) is responsible for aggregating the data and then forwarding it to the BS. Hierarchical network structure often makes a two-level hierarchy, in which the CHs are placed at the upper level, and the lower level is for member nodes. The lower level nodes periodically send data to their respective CH. The CH then aggregates that data and forwards it to BS. The CH node spends more energy than member nodes, like all the time CH node is sending data over long distances. Moreover, after certain rounds, the selected CH may be unable to perform or perish due to high energy consumption. In order to ensure load balancing among SNs, the role of CH is changed periodically to balance energy consumption [6]. Communication within a cluster (intra-cluster) is usually single-hop and between clusters (inter-cluster) may be single-hop or multi-hop.
The prime objectives of cluster-based routing protocols are saving the dissipated energy, ensuring the network connectivity, and prolonging the lifetime of WSNs. These objectives can be achieved by finding the optimal head nodes in WSNs. This is a difficult problem and can be considered as a Nondeterministic Polynomial (NP) optimization problem. In order to solve and find optimal solutions for this problem, researchers have developed some robust cluster-based routing protocols based on evolutionary algorithms.
Optimization algorithms used for the CH selection in recent past are genetic algorithm (GA) [9,10,11,12], differential evolution (DE) [13, 14], artificial bee colony (ABC) algorithm [15], harmony search algorithm (HSA) [16, 17], spider monkey optimization (SMO) [18], moth flame optimization (MFO) [19] and others. These optimization algorithms are competitive but they suffer from certain weaknesses like slow convergence and premature convergence. Grey wolf optimization (GWO) is a recently developed nature-inspired global optimization method [20] that mimics the social behavior and hunting mechanism of Grey wolves. The algorithm though is very competitive and has been applied to various fields of research, but this algorithm suffers from the problem of local optima stagnation and poor exploration. This is because a new solution is generated by evaluating the mean of the three best solutions from the entire population and the other members don’t participate in the evolution process. Hence, extended grey wolf optimization (EGWO) has been proposed to overcome the limitation of the GWO. In present work, EGWO has been exploited along with FIS to the best of its potential for solving the above load balancing problem in the clustering algorithm.
The rest of this paper is organized as follows: In Sect. 2, the relevant works are presented. In Sect. 3, the extended grey wolf optimization algorithm is outlined. Sections 4 and 5 focused on the radio energy dissipation model and network model respectively in detail. In Sect. 6, the proposed methodology and strategy are described. The performance analysis of our work is depicted in Sect. 7. Finally, in Sect. 8 the conclusions of our work are presented.
2 Related work
As pointed out earlier, the nodes are tiny and energy-constrained. In this context, it is desirable to form a group of devices and these groups of devices communicate among themselves through a group leader that ensures the minimum communication overhead and energy-efficient execution using clustering. In literature, various attempts have been made to improve the energy efficiency through different clustering techniques by addressing the problems of efficient cluster formation, even distribution of load, CH selection and reselection, and cluster reformation; few of them are discussed here.
Heinzelman et al. [6] presented LEACH which is one of the first energy-efficient routing protocols and is still used as a state-of-the-art protocol in WSN. The basic idea of LEACH is to select CH among a number of nodes by rotation so that energy dissipation from communication can be spread to all nodes in a network. LEACH has some disadvantages such as probabilistic approach using the random number for CH selection, which might result in suboptimal CH node thus resulting in high energy consumption. Furthermore, the dynamic clustering overhead and non-uniform distribution of CH will consume more energy and lead to poor network performance. A number of variants to LEACH are stated based on heterogeneity [21,22,23,24,25,26], distance-based thresholds [24], multi-hopping [26, 27], deterministic CH selection [28] and reactive protocol [8, 29,30,31].
Manjeshwar and Agrawal [8] proposed an event-driven clustering approach called TEEN. In this approach, the sensed data is forwarded to the BS only if some event occurs, which is based on two thresholds, that is, soft and hard. Later, this approach has been enhanced and proposed as an adaptive TEEN (APTEEN) [31]. APTEEN combines the event-driven approach of TEEN and periodic approach of LEACH to address the problems occurring in TEEN. APTEEN is good for periodic applications, but the complexity of the approach increases due to the inclusion of extra threshold function and count time.
Smaragdakis et al. [21] introduced Stable Elections Protocol (SEP) to enhance the stability and lifetime of heterogeneous WSN (HWSN). Two-level energy nodes are introduced in this protocol namely, normal and advanced nodes. The advanced node has more chance to get selected as CH than normal node. In the study, an increasing the percentage of advanced nodes and hence the probability of CH selection improves performance in the form of network lifetime, which also improves the throughput of the network. Enhanced SEP (E-SEP) [22] has introduced the three-level communication hierarchy. E-SEP distributes SNs into three categories: normal, intermediate, and advanced nodes, where advance nodes have higher energy followed by intermediate and normal nodes respectively. By using an extra level of heterogeneity as compared to SEP [21], up to some extent energy dissipation is reduced.
Kumar et al. [25] suggested EEHC protocol in that nodes in the network are categorized into three levels according to their initial energy. Mittal and Singh presented a reactive clustering protocol named DRESEP which is optimal for event-driven applications like forest fire detection [29]. Mittal et al. [30] also proposed a protocol called SEECP in which CHs are nominated in deterministic fashion based on the remaining energy of nodes to balance the load effectively among sensors.
Researchers have combined the clustering scheme with the biologically inspired routing scheme to achieve a longer lifetime [32]. Evolutionary algorithms (EAs) are used to handle the cluster-based problem to minimize energy consumption and prolong the lifetime of network with heterogeneity. Evolutionary based clustered routing protocol (ERP) [9], energy-aware ERP (EAERP) [10], stable-aware ERP (SAERP) [11] and stable threshold-sensitive energy-efficient routing protocols (STERP) using DE [13], HSA [17] and SMO [18] are some of the recently developed EA based clustering algorithms. EAERP redesigned some significant features of EAs, which can assure a longer stable period and extend the lifetime with efficient energy dissipation. ERP overcame the shortcomings of hierarchical cluster-based routing (HCR) algorithm [33] by uniting the clustering aspects of cohesion and separation error. SAERP combined the main idea of SEP and EAs with an aim to increase the network stability period. In STERP, an energy-aware heuristics is integrated into cluster-based protocols as a parameter for CH selection so that a better stability period of the network is achieved. Each of these routing schemes (DESTERP, HSSTERP, SMSTERP, and GASTERP) demonstrated their advantages in prolonging the lifetime of HWSNs [13, 16, 18, 34].
Gupta et al. [35] introduced a centralized approach for CH election using fuzzy logic by considering fuzzy variables: residual energy, node degree, and node centrality. LEACH-FL [36] utilizes fuzzy logics based on three metrics: residual energy level, density and distance from the sink for CH election. CHEF [37] utilizes two fuzzy descriptors: residual energy and local distance for CH election. Sert et al. [38] proposed MOFCA protocol in which CHs are selected using a fuzzy logic approach. The main objective of MOFCA is to overcome the hotspot problem, which arises due to multi-hop communication. MOFCA is used for both stationary and mobile environments.
Tomar et al. [39] presented a clustering algorithm with a fuzzy inference system (FIS). The aim is to provide an alternative solution to probabilistic CH selection. In this approach, fuzzy-logic along with ACO is used for CH selection and to determine an optimal path between node and BS. Tamandani et al. [40] introduced a clustering protocol named SEP based on fuzzy logic (SEPFL). To enhance the CH selection process in SEP, three variables namely distance of SNs from BS, residual energy and density of nodes are used with fuzzy logic control.
Obaidy and Ayesh [41] proposed an intelligent GA-PSO based hybrid protocol to increase the lifetime of mobile WSNs. In this protocol, GA is used to form optimum clusters that reduce the energy consumption of the network by minimizing the distance between nodes and BS. PSO is used to provide distance management which makes the WSN self-organized. Simulation results showed that this approach minimizes the distance effectively in mobile WSNs.
Mittal et al. [42] presented a stable threshold-sensitive energy-efficient cluster-based routing protocol called FESTERP suitable for event-driven applications such as forest fire detection. The protocol considers the remaining energy, node centrality and the distance to BS to elect appropriate CHs. CHs are selected using a simple FIS as a fitness function for EFPA. An energy-based heuristics is applied to have longer stability period for WSNs.
Armin et al. [43] presented a fuzzy multi cluster-based routing with a constant threshold (FMCR-CT) algorithm for WSN. FMCR-CT avoids clustering in each round by trusting the selected CHs from the previous rounds. Random selection of CHs in some clustering algorithms reduces the likelihood of considering the best node as the CH. The algorithm chooses the node with the best fuzzy parameters as the CH, and reduces the number of sent control messages and collision.
Radhika and Rangarajan [44] proposed a clustering algorithm that minimizes the loss of energy of nodes by lowering the overhead on message transmission and to simplify the construction and update processes of clusters thus increasing the network lifetime. The primary idea of the algorithm is to form suitable clusters and re-cluster them based on the update cycle calculated using the FIS. This method significantly reduces data transmission by identifying similar sensed data readings using machine learning. Possibility of failure of CH nodes is likewise considered for performance improvement.
Thangaramya et al. [45] proposed a protocol called neuro-fuzzy based cluster formation protocol (FBCFP). The protocol performs learning of the network by considering four important components namely current energy level of the CH, distance of the CH from the sink node, change in area between the nodes present in the cluster and the CH due to mobility and the degree of the CH. For this purpose, the network is trained with convolutional neural network with fuzzy rules for weight adjustment. Fuzzy reasoning approach is used for powerful cluster formation and to perform cluster based routing.
3 Extended grey wolf optimization
GWO [20] algorithm is inspired by the social behavior and hunting mechanism of the grey wolves. These animals live in groups and in each group, the population is divided into four levels. Topmost position in a group is occupied by the alpha wolf followed by beta, then delta wolves and the lowest level is occupied by omega wolves. The main phases of group hunting of grey wolf are as follows:
-
Encircling
-
Hunting
-
Attacking the prey
The above-discussed hunting mechanism and the social hierarchy of grey wolves can be modelled mathematically in the GWO algorithm with the help of the following equations [20].
where t denotes the current iteration, \(\vec{A}\) and \(\vec{C}\) are coefficient vectors, \(\overrightarrow {Xp} \left( t \right)\) is vector which denotes the position of prey and \(\vec{X}\)(t) is vector which denotes the position of grey wolf. In this element of \(\vec{a}\) are linearly decreased from 2 to 0 over the course of iteration, \(\overrightarrow {{r_{1} }}\) and \(\overrightarrow {{r_{2} }}\) are random vectors in the range of [0 1].
Though GWO has been used to solve various optimization problems (like flow shop scheduling problem [46], economic load dispatch problem [47], hyper-spectral band selection [48] and many more) but it still has some limitations. Here because of the local optima stagnation problem, the algorithm doesn’t guaranty a global solution.
Thus to improve the performance, the EGWO algorithm has been implemented and used to solve the load balancing problem of WSN. The new algorithm employs two modifications in the original GWO algorithm. Firstly, for the value of \(\left| {\vec{A}} \right| > 1\), different positions to the best members have been applied for switching to different areas of search space. This is done to enhance exploration and get rid of the local optima stagnation problem. Secondly, in order to bring diversity among the search agents during the initial iterations, the opposition based learning approach has been used to find the global minima.
3.1 Modification 1
Why the condition of |A| >1? The first modification added is the condition of \(\left| A \right| > 1\), this means that when the wolves are getting closer to the prey, the range of \(\vec{A}\) is reduced and this reduction is followed by linearly reducing the value of \(\vec{a}\) in the range of 2–0. This means that the value of \(\vec{A}\) actually shifts between [\(- 2a, 2a\)] and is same as given by Eq. (3). Here if we keep the value of \(\vec{A}\) between [− 1, 1], the step size will be small and then updated position of agents will be around the prey’s and is given in Fig. 1. This eventually means that \(\vec{A}\) makes the wolves move in the direction of their prey and hence helping in exploitation. Now correspondingly, if the value of \(\vec{A}\) is greater than 1 or less than − 1, the next position of the search agents will be very far from the prey’s (best) position. Thus for present case, the values of \(\vec{A}\) will be very far away from each other and hence help in exploration of the search space.

Behaviour of wolves [40]
In basic GWO algorithm, all the search agents move with respect to the alpha, beta and delta wolves. This movement is with respect to the omega wolves and has been clearly shown in Fig. 2. Here omega wolves are always following the best particles with in the search space making the algorithm fall in some local optimal solution. So from here we can conclude that the value of \(\vec{A}\) controls the total amount of exploration and exploitation required for optimal functioning of the algorithm. So in order to enhance the exploration capability of the search agents in GWO algorithm, new improvements have been added in the basic algorithms and major change is based on the value of the \(\vec{A}\).

Updating Positions of omega (ω) wolf [20]
How new condition is imposed in EGWO? The major problem which is required to be dealt with for any optimization algorithm is the local optima stagnation. For present case we are using a new criteria based on \(\left| {\vec{A}} \right| > 1\), to find the positions of alpha, beta and delta wolves. Here the population is divided into three groups and correspondingly α score which is the best value for the current group is assigned a new position namely α2. Similarly for the second and third group, β2 and δ2 are the best solutions. The rest of the wolves or members of the population update their positions with respect to Eqs. (5)–(11) with in the search space. In the exploitation phase \(\left( \left| {\vec{A}} \right| < 1\right)\), alpha, beta, and delta agents are the top three fittest members from the population and remaining wolves follow them to exploit the prey using equations from 5 to 11.
Why division of the population into three groups? It can be seen from Fig. 2 that the basic GWO algorithm uses the three best members of the whole population to update the positions of other members of the group. By following this procedure, the best members within the group makes the algorithm to perform intensive exploitation with in the search space and hence leading to the problem of local optima stagnation as given by Fig. 3. In this figure circle denotes the whole search space, \(x_{best}\) shows the position of best particle and \(x_{1} ,x_{2} , \ldots ,x_{n}\) shows the position of remaining search particles with respect to the best. From Fig. 3(a) it is clear that the search agents update their position according to the best particle i.e. they are moving in some particular direction while other areas remain unexplored. Hence, it leads to exploitation. From Fig. 3(b), it can be inferred that search agents always follow the best particle even if it gets stuck at some local solution and is far away from the global solution. Under this scenario, the algorithm fails to reach global optima and leads to premature convergence.

a Movement of random solutions toward the best; b movement of random solutions toward the best and away from the global optima
Now in order to address this problem, the algorithm should generate diversified solutions. Hence in order to promote diversification, the population is divided into three as stated earlier and each best member namely α2, β2 and δ2 of the group is selected. The rest of the wolves are then updated according to the newly generated values of alpha, beta and delta using Eq. (11). Thus helping the algorithm in exploring the search space using new search regions and it is expected that the new algorithm will provide much better result when compared with the existing GWO algorithm.
3.1.1 Using different random numbers
Using multiple random numbers can also be considered as another modification to the basic algorithm. From Eqs. (8–10), it can be inferred that the vector \(\vec{A}1\) provides a random weight between the current and the best (α) position and correspondingly \(\vec{A}2\) and \(\vec{A}3\) are used to find random weights between current, beta and delta positions respectively. The random number generated in this case is calculated with the help of Eq. (3). So here three random numbers are generated using different values of alpha and beta and delta wolves and hence overall randomness is increased in the algorithm. This new property helps the algorithm in improving the diversification or simply the exploration properties of the algorithm with in the search space.
3.2 Modification 2
In order to enhance the exploration of the algorithm, search agents need to explore more search areas in the initial generations to find the global solution and then later converge to exploit the global solution. This has been done using the opposition based learning (OBL) technique in the initial iterations. The concept of OBL was introduced by Tizhoosh [49]. The main idea behind this theory is the use of a random solution and its oppositely generated number in order to find a global solution. The concept of opposite generated number is defined as:
Let \(\varvec{X}_{\varvec{i}}\) be a solution in space with dp-dimension given as \(\varvec{X}_{\varvec{i}} = \left\{ {x_{i,1} , x_{i,2} , x_{i,3} , \ldots , x_{i,dp} } \right\}\). The opposite point \(\left(X_{i}^{{\prime }} = \left\{ {x_{i.1}^{{\prime }} ,x_{i.2}^{{\prime }} , \ldots , x_{i,dp}^{{\prime }} } \right\} \right)\) to this approximated solution can be calculated by relation
Why opposition based learning technique? Positions of grey wolves in the search space is extremely important in grey wolf optimization. It affects the final solution and convergence speed. In this article, the initial set of the population is generated using random initialization. This population consists of ‘n’ solutions, where each solution consists of dp-dimension. Random solutions can be generated by the following equation:
where \(x_{\hbox{max} ,j} \;{\text{and}}\;x_{\hbox{min} ,j}\) are the upper and lower bound of the problem, j denotes the dimensionality of vector (j = 1, 2, 3, …, dp), i is the number of solution (i = 1, 2, 3, …, n). Here, dp is the dimensions of the problem under consideration.
The random selection of the solution has a chance of revisiting some search areas again and again. Hence, it reduces the diversity among the solutions. Thus, to enhance the diversity in the randomly generated population, the concept of OBL has been used. Using this method, some dimensions of the solution can become opposite to the estimated solution. Therefore, the new combination of the population will have diverse solutions [50]. Thus, the idea of OBL will help in enhancing the exploration of the GWO.
How OBL is applied? OBL is a very important property which help any algorithm to diversify the solutions. For present case, the population is divided into two equal halves. The first half of the population employs the basic initialization step as used by original GWO whereas for the second half of the population, partial opposition is followed. By partial opposition we mean that some of the solutions of the search space are replaced randomly by their opposite numbers. Here the division of population is done without sorting to take advantage of randomness which enhances the diversity and results in better exploration ability of GWO. This more exploration in the initial iterations helps in moving toward the global solution which will be further exploited by other wolves. The pseudo-code for the proposed algorithm is given in Algorithm 1. Note that the procedure of OBL is followed only for first half of the iterations.

4 Radio energy dissipation model
The energy consumption of WSNs is generally composed of many parts, such as monitoring, data storing, and data transmitting. However, the energy used for data transmission takes up a large proportion of the total energy consumption. The network energy is consumed on both sides of the communication (sender and receiver) according to a wireless energy consumption model as shown in Fig. 4. The model consists of two parts reflecting transmission and reception as shown in Eqs. 14 and 15 respectively. SN needs to consume energy \(E_{TX}\) to run the transmitter circuit and \(E_{amp}\) to activate the transmitter amplifier, whereas a receiver consumes \(E_{RX}\) power for running the receiver circuit. Energy consumption in wireless communication also depends on message length (\(l\)). Thus, the transmission cost for an \(l\)-bit message having transmitter–receiver distance \(d\), is calculated as:
where \(d_{0}\) is crossover distance and is given by:

Radio energy dissipation model [30]
The term \(E_{elec}\) represents the per-bit energy consumed for transmission. The parameters \(\varepsilon_{friis\_amp}\) and \(\varepsilon_{two\_ray\_amp}\) denote energy consumed by transmitting node to run radio amplifier in free space and two ray ground propagation models, respectively.
The reception cost for the \(l\)-bit data message is given by:
where \(E_{elec}\) is the per-bit energy consumption for the reception.
5 Network model
A three-level node energy heterogeneity is used in the proposed network model. The network model consists of N randomly deployed sensor nodes on a M × M sensing layout. BS is at the center of the network field. Communication links between each other are assumed to be symmetric [22]. Nodes namely normal, advanced, and super with increasing order of energy level as presented in [22]. Hence, in the proposed protocol, we have a three-level energy value of heterogeneity as \(E_{0}\), \(E_{Adv}\), and \(E_{Super}\) for the energy of normal, advanced, and super nodes, respectively. Nodes with percentage population factor as \(a\) for advanced nodes with total N nodes, which is equipped with an energy factor greater than \(m\) times than normal node. Super nodes are equipped with energy incrementing factor as \(m_{0}\), with percentage population factor \(a_{0}\) with respect to total N nodes. Individual node details in the form of the equation are presented as follows.
Initial energy for normal nodes is \(E_{0}\) with population count as \(N(1 - a - a_{0} )\). Subsequently, advanced and super node populations are \(na\) and \(na_{0}\), respectively. The energy available with advanced and super node is \(E_{Adv}\), and \(E_{Super}\), respectively. Energy calculations for respective nodes are as follows:
Above equations present energy available with all three types of nodes, i.e. normal, advanced and super nodes respectively. Total initial energy proposed in the network model is calculated as \(E_{Total}\):
Hence, from (16), we hereby conclude that if we add heterogeneity level up to level-2, available energy increased by a factor \(\left( {1 + ma} \right)\), and if it is increased to level 3, then energy increased by a factor \(\left( {1 + ma + m_{0} a_{0} } \right)\).
6 Proposed protocol
In hierarchical routing protocols, sensor nodes perform different tasks such as sensing, processing, transmitting, and receiving. Some of these sensor nodes called CHs or parent nodes, are responsible for collecting and processing data and then forwarding it to sink. The task of other nodes called member nodes sense the sensor field and transmit the sensing data to the head nodes. Hierarchical based routing is a two-layer architecture, where head nodes selection is performed in the first layer and the second layer is responsible for routing.
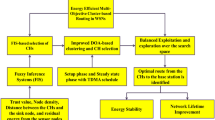
In this work, in order to deal with uncertainties during CH selection, FIS has been adopted along with EGWO to provide the chance value for each node. The process of the proposed protocol named Fuzzy GWO based stable threshold-sensitive energy-efficient cluster-based routing protocol (FGWSTERP), is divided into rounds consisting of set-up and steady-state phase as shown in Fig. 5.

Operation of proposed FGWSTERP protocol
The selection of CHs, in the set-up phase, is performed by BS using FIS based EGWO from the alive SNs having residual energy more than a threshold energy level as shown in Fig. 6. EGWO handles a population of several individual solutions and an answer is shown by each individual. A complete solution is represented in such a way that each individual solution indicates the complete assignment of all SNs. It determines where the CHs and their members are located in WSN. The phase begins by generating the initial population. Let \(X_{i} = \left( {X_{i1} , X_{i2} , \ldots , X_{iN} } \right)\) denote the ith population vector of a WSN with \(d_{p} = N\) sensors, where \(X_{i} \left( j \right) \in \left\{ {0, 1} \right\}\). Alive SNs and CH nodes are represented by 0 and 1 respectively.

CH election algorithm using EGWO with FIS
The grey wolf search agents are used as vectors to represent an answer to the low-energy clustering problem. Every solution might depict a number of arbitrarily chosen CH nodes. The low-energy clustering problem is transformed into finding out a CH node-set in the prospect solution space using the EGWO. In this way, a potential solution will be shown as a string. Therefore, binary encoding is used on every individual. Every single SN within the system contains Binary factors denoting whether the corresponding SN is selected as the CH node or not. For instance, assuming a solution is X = (0, 0, 1, 0, 0, 0, 1, 0, 0, 0). There are 10 sensors in the region and Nos. 3 and 7 nodes are selected as CH nodes. Such encoding is adequate and powerful since it contains the whole searching region.
The initial population of grey wolves is given by
where p is the desired percentage of CHs, and rand is a uniform random number. \(E_{avg} \left( r \right)\) is the average energy of the whole network in current round r, and \(E\left( {node_{j} } \right)\) is the current energy of sensor \(j\) [34].
The fitness value of each individual is evaluated to quantify the effectiveness of that individual in the routing optimization problem using FIS (in the next section). The individual vectors are evolved over time to improve the quality of the individual vectors. The population goes through various operators (see Eqs. 1–13) to create an evolved population.
Finally, the fittest vector is used to seed the next phase where the non-CH nodes are associated with their CHs to form clusters. This process is repeated iteratively until the termination condition occurs.
6.1 CH selection using FIS
In a centralized CH selection method, the energy consumption of WSN is huge since the sink node needs to transmit the information of selected CHs to all the nodes in each round. Moreover, the lifetime of the whole network depends on the energy consumption related to the distance and residual energy of each node. It is hard to describe the exact mathematical model of the relationship between the network lifetime and the node’s parameters. The FIS does not need an exact mathematical model of the system as well, and it can make decisions even if there is insufficient data. Thus, the FIS is strongly recommended for WSN due to its low computational complexity and its easy application in a distributed way with low cost compared to other methods. Therefore, we develop FIS to select the CHs.
Initially, BS announces a small communication to wake up and to demand the identifications, locations and energy level and type of the node (advanced or normal) of every sensor in the sensor arrangement. Each node computes the chance value using FIS. Depending on the responded data from sensors, BS utilizes EGWO to elect CHs based on the chance value of each node. The node that has chance larger than chance values from the others is selected as a CH. The whole process for CH selection is demonstrated in Fig. 6. Also, BS allocates the associated sensors of every CH on the basis of minimum Euclidean distance. When CHs are elected and their associate members are assigned, the BS launches a small communication to notify the sensor network about CH and associated members. Time Division Multiple Access (TDMA) schedules are formed by CH for accompanying member nodes in the cluster. Member nodes communicate with CH in the allotted time slots and remain in sleeping mode during unallocated time slots.
As shown in Fig. 7, residual energy (RE), node centrality (NC), and distance to BS (D) are three input variables for the FIS and the CH selection probability of a node is the only output parameter, named chance. The possibility of a node to be nominated as a CH is more for higher values of chance.

FIS-based probabilistic model for CH selection
The universal of a discourse of the variables RE, NC, D, and fit are [0…1], [0…1], [0…1], and [0…1], respectively. Based on the application scenario considered, the FIS input set of values include RE, NC and D. The linguistic variables of the input values are considered as very low, low, medium, high and very high for RE, close, rather close, reachable, rather distant and distant for NC, and close, nearby, average, far and farthest for distance to BS as shown in Fig. 8(a–c). Applying these characteristics to fuzzy logic the resulting proposed FIS includes the following set of input fuzzy variables:
and the probability of a CH candidate selection chance is the resulting output, shown in Fig. 8(d).

Fuzzy sets for input and output variables
A complete set of the fundamental rules (for each input the total number of rules are 5 × 5 × 5 = 125) has been extracted and defined so as to train the proposed FIS (Table 1). The following set of rules represent all the possible combinations of the input linguistic variables.
A node that holds higher residual energy, closer node centrality and nearer to BS has a higher probability of CH selection. An optimistic illustration of this is rule 101 in Table 1, while the contradictory one is rule 25.
Steady-state phase The steady-state or transmission phase represents the actual communication of environmental reports from the network field. The proposed protocol adopts a unique data transmission phase in order to achieve the goal of energy efficiency, reliability, and minimum delay transmission. For intra-cluster communication, the protocol adopts event-based reactive short-range single-hop transmissions, while multi-hopping is implemented for inter-cluster communications.
Intra-cluster data transmission phase During this data transmission phase, the energy of active nodes will be modified according to the dissipated energy required for sensing, packets transmission, receiving, and aggregation. Energy is dissipated in sensing and to transmit the message packets from non-CH to their associated CHs when threshold conditions are satisfied and, hence, the energy of the CMs will be modified. For CH nodes, energy is modified while performing packets receiving and aggregation. Thus, in this phase, the energy of the CM and CH nodes can be formally modified according to the following:
where \(E\left( {node_{j} } \right)\) and \(E\left( {CH_{k} } \right)\) denote current energy of sensor \(j\) and CH \(k\) respectively, \(E_{{TX_{{node_{a} ,node_{b} }} }}\) is energy expenditure for transmitting data from \(node_{a}\) to \(node_{b}\), \(E_{RX}\) is energy dissipated for the reception of data and \(E_{DA}\) is the energy dissipation in data aggregation.
Inter-cluster data transmission phase During this phase, the energy of CHs in the network will be consumed according to the dissipated energy required for packets transmission to BS. Energy is also dissipated for relay CHs to receive the message packets from distant CHs and data aggregation, and transmission to BS. Thus, in this phase, the energy of the CH nodes can be formally modified according to the following:
where \(CH_{R}\) is the relay CH that lie within the radius \(R\) centered on BS.
7 Simulation results
MATLAB is used for designing the network scenario which executes the Fuzzy based EGWO algorithm to form clusters and selecting CHs in order to reduce energy conservation of SNs. The simulation results of FGWSTERP protocol have been analyzed with respect to the performance metrics such as energy efficiency, total network residual energy and network lifetime against the competitive protocols such as LEACH, SEP, HCR, ERP, DRESEP, SEECP, HSSTERP DESTERP, and FESTERP. The network characteristics used for the protocol simulations are summarized in Table 2.
Simulation results are produced by deploying 100 nodes randomly within a 100 m × 100 m area and BS is located at (50, 50). In homogeneous setup, the network consists of nodes having initial energy \(E_{0}\). For heterogeneous setup, advanced and super nodes are set to 20% and 10% of the total nodes and have initial energy 2 times and 3 times greater than normal nodes (having initial energy \(E_{0}\)) respectively. The parameters setting for simulated protocols are given in Table 3.
The simulation results of competitive protocols for homogeneous setup with initial energy \(E_{0} = 1\;{\text{J}}\) are shown in Fig. 9. It shows the relation between alive nodes and number of rounds, from which it is obvious that FGWSTERP enhances the entire network lifetime to some extent. The main reason for this result is that FGWSTERP considers the remaining energy of nodes for CH selection. In FGWSTERP, the node with the highest residual energy and shortest distance to BS has the best chance to become the CH. Therefore the nodes transmission radius decreases as its distance to BS decreases, which leads to creating smaller cluster sizes with shorter sensors chain length than those farther away from the BS. Hence, the energy consumed due to intra-cluster data processing and long distances to respective CHs will be reduced. In addition, the dual-hop routing in inter-cluster is adopted in an optimum manner on the basis of distance of CH to BS as a factor. These measures reduce and balance the energy consumption of the whole network in comparison to HSSTERP and DESTERP. From the point of view of the individual, it further minimizes the communication cost for inter-cluster data transmission.

Number of alive nodes per round for homogeneous setup for \(E_{0} = 1\;{\text{J}}\)
The average energy remaining in the network per round for homogeneous setup is shown in Fig. 10. Energy analysis determines that FGWSTERP consumes less energy at each round in comparison to competitive protocols. The reason for this phenomenon is that the uniform distribution of the clusters is ensured in FGWSTERP, which is conducive to balancing the energy depletion of the entire network. Furthermore, FGWSTERP consumes less energy than other algorithms at each round. This is because the dual-hop routing is used for data transmission that avoids CH to send data to BS at longer distances.

Average energy per round for homogeneous setup for \(E_{0} = 1\;{\text{J}}\)
The simulations are performed to check the performance of the proposed protocol with a varying initial energy of nodes. Tables 4, 5 and 6 present the round history of dead nodes for homogeneous setup for \(E_{0} = 0.25\;{\text{J}}\), 0.5 J and 1 J respectively. For the total network lifetime (i.e., the time until last node dead (LND)) and the stability period [i.e., the time until first node dead (FND)], the proposed protocol proves very favorable against all other protocols.
The behavior of FGWSTERP for heterogeneous setup is shown in Figs. 11 and 12, and the statistics are given in Tables 7, 8 and 9.

Number of alive nodes per round for heterogeneous setup for \(E_{0} = 1\;{\text{J}}\)

Average energy per round for heterogeneous setup for \(E_{0} = 1\;{\text{J}}\)
Table 10 presents the number of rounds taken for FND, HND, and LND together with stability and instability periods of competitive algorithms for \(E_{0} = 1\;{\text{J}}\). There is an improvement of 158.32%, 181.76%, 1327.3%, 18.71% and 1.16% in stability period for FGWSTECP as against LEACH, HCR, ERP, DRESEP and FESTERP respectively. Also, the instability period reduces to 2.54%, 47.92%, 23.27% and 57.61% in comparison with LEACH, HCR, ERP, and DRESEP respectively for homogeneous setup. Similarly, for heterogeneous setup, there is significant progress in stability period for FGWSTERP as compared to competitive protocols.
To evaluate the effect of node density in each approach, the number of nodes is varied from 100 to 500 with initial energy 1 J. The same parameters as that in 100 nodes scene are used to create the simulation model, and the results are demonstrated as given in Tables 11 and 12 for homogeneous and heterogeneous setups respectively. In dense networks, more CHs help to maximize the network lifetime. The performance of FGWSTERP is much better than other approaches for varying node density. By increasing the node density, the resulting network has a better lifetime as the dual-hop communication in inter-cluster is utilized in an optimum manner. The performance of FGWSTERP denotes that the reliability, the stability, and the scalability of the proposed algorithm is especially excellent and is suitable to large scale WSNs.
Though improvements are made in several performance metrics, there are certain limitations in using this algorithm. FGWSTERP belongs to the reactive routing algorithm so that this protocol is most appropriate when an event or threshold-based monitoring by the sensor network is needed. Another limitation of FGWSTERP is that delay in generating the data transmission process from a node to BS is a bit higher in comparison to competitive algorithms. This is because data fusion is implemented at each CH in the path toward BS.
8 Conclusion
The major design issues in the research of clustering protocols for WSNs are energy management, stability period and network lifetime optimization. This work focuses on energy conservation in each SN by using EGWO based CH selection energy optimization clustering algorithm. The CH is selected using Fuzzy based EGWO based on sensor parameters such as residual energy, node centrality and distance to BS. To increase the lifetime of the WSN, a threshold-based data transmission algorithm is employed in inter-cluster communication. Also, dual-hop communication is utilized to improve the load balancing and to minimize the energy consumption of the distant CHs. The performance metrics such as network lifetime, residual energy and total energy consumption are evaluated and compared with competitive clustering methodology. The simulation outcome shows that FGWSTERP gives improved performance in terms of the total energy expenditure and network lifetime of WSN.
The proposed algorithm opens a quantum of opportunities for research aspirants. Further research can be carried out to make the network framework adaptive that automatically optimizes the number of clusters, lower and upper bound for a specified number of senor nodes and terrain area. Further work can be done to improvise the selection and reselection process of CH in order to increase efficiency and to prolong the network lifetime. It would also be interesting to see the impact of newly proposed evolutionary algorithms in the proposed technique. The above-said algorithms can be used to monitor forest fires based on temperature and communicate the real-time data for optimum management of forest fires and various other applications.
References
Afsar, M. M., & Tayarani-N, M. (2014). Clustering in sensor networks: A literature survey. Journal of Network and Computer Applications, 46, 198–226.
Anisi, M. H., Abdul-Salaam, G., Idris, M. Y. I., Wahab, A. W. A., & Ahmedy, I. (2017). Energy harvesting and battery power based routing in wireless sensor networks. Wireless Networks, 23(1), 249–266.
Pantazis, N. A., Nikolidakis, S. A., & Vergados, D. D. (2013). Energy-efficient routing protocols in wireless sensor networks: A survey. IEEE Communications, Surveys and Tutorials, 15(2), 551–591.
Halawani, S., & Khan, A. W. (2010). Sensors lifetime enhancement techniques in wireless sensor networks—A survey. Journal of Computing, 2(5), 34–47.
Idris, M. Y. I., Znaid, A. M. A., Wahab, A. W. A., Qabajeh, L. K., & Mahdi, O. A. (2017). Low communication cost (LCC) scheme for localizing mobile wireless sensor networks. Wireless Networks, 23(3), 737–747.
Heinzelman, W. B., Chandrakasan, A., & Balakrishnan, H. (2000). Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd annual Hawaii International Conference on System Siences (HICSS-33) (p. 223). IEEE, https://doi.org/10.1109/hicss.2000.926982.
Younis, O., & Fahmy, S. (2004). HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Transactions on Mobile Computing, 3(4), 366–379.
Manjeshwar, A., & Agrawal, D. P. (2001). TEEN: A routing protocol for enhanced efficiency in wireless sensor networks. In 15th International Parallel and Distributed Processing Symposium (IPDPS’01) Workshops, USA, California (pp. 2009–2015).
Attea, B. A., & Khalil, E. A. (2012). A new evolutionary based routing protocol for clustered heterogeneous wireless sensor networks. Applied Soft Computing, 12, 1950–1957. https://doi.org/10.1016/j.asoc.2011.04.007.
Khalil, E. A., & Attea, B. A. (2011). Energy-aware evolutionary routing protocol for dynamic clustering of wireless sensor networks. Swarm and Evolutionary Computation, 1, 195–203. https://doi.org/10.1016/j.swevo.2011.06.004.
Khalil, E. A., & Attea, B. A. (2013). Stable-aware evolutionary routing protocol for wireless sensor networks. Wireless Personal Communications, 69(4), 1799–1817.
Hussain, S., Matin, A. W., & Islam, O. (2007). Genetic algorithm for hierarchical wireless sensor networks. Journal of Networking, 2, 87–97.
Mittal, N., Singh, U., & Sohi, B. S. (2017). A novel energy efficient stable clustering approach for wireless sensor networks. Wireless Personal Communications, 95(3), 2947–2971.
Kuila, P., & Jana, P. K. (2014). A novel differential evolution based clustering algorithm for wireless sensor networks. Applied Soft Computing, 25, 414–425.
Karaboga, D., Okdem, S., & Ozturk, C. (2012). Cluster based wireless sensor network routing using artificial bee colony algorithm. Wireless Networks, 18, 847–860.
Mittal, N., Singh, U., & Sohi, B. S. (2016). Harmony search algorithm based threshold-sensitive energy-efficient clustering protocols for WSNs. Adhoc and Sensor Wireless Networks, 36(1–4), 149–174.
Hoang, D. C., Yadav, P., Kumar, R., & Panda, S. K. (2014). Real-time implementation of a harmony search algorithm-based clustering protocol for energy-efficient wireless sensor networks. IEEE Transactions on Industrial Informatics, 10(1), 774–783.
Mittal, N., Singh, U., & Sohi, B. S. (2018). A boolean spider monkey optimization based energy efficient clustering approach for WSNs. Wireless Networks, 24(6), 2093–2109.
Mittal, N. (2018). Moth flame optimization based energy efficient stable clustered routing approach for wireless sensor networks. Wireless Personal Communications, 104, 677–694. https://doi.org/10.1007/s11277-018-6043-4.
Mirjalili, S., Mirjalili, S. M., & Lewis, A. (2014). Grey wolf optimizer. Advances in Engineering Software, 69, 46–61.
Smaragdakis, G., Matta, I., & Bestavros, A. (2004). SEP: A stable election protocol for clustered heterogeneous wireless sensor networks. In Proceedings of the international workshop on SANPA. http://open.bu.edu/xmlui/bitstream/handle/2144/1548/2004-022-sep.pdf?sequence=1. Accessed 5 Sept 2018.
Aderohunmu, F. A., Deng, J. D., & Purvis, M. K. (2011). Enhancing clustering in wireless sensor networks with energy heterogeneity. International Journal of Business Data Communications and Networking, 7(4), 18–32.
Qing, L., Zhu, Q., & Wang, M. (2006). Design of a distributed energy-efficient clustering algorithm for heterogeneous wireless sensor network. Computer Communications, 29, 2230–2237. https://doi.org/10.1016/j.comcom.2006.02.017.
Kang, S. H., & Nguyen, T. (2012). Distance based thresholds for cluster head selection in wireless sensor networks. IEEE Communications Letters, 16(9), 1396–1399. https://doi.org/10.1109/LCOMM.2012.073112.120450.
Kumar, D., Aseri, T. C., & Patel, R. B. (2009). EEHC: Energy efficient heterogeneous clustered scheme for wireless sensor networks. Computer Communications, 32, 662–667. https://doi.org/10.1016/j.comcom.2008.11.025.
Kumar, D. (2014). Performance analysis of energy efficient clustering protocols for maximising lifetime of wireless sensor networks. IET Wireless Sensor Systems, 4(1), 9–16. https://doi.org/10.1049/iet-wss.2012.0150.
Tarhani, M., Kavian, Y. S., & Siavoshi, S. (2014). SEECH: Scalable energy efficient clustering hierarchy protocol in wireless sensor networks. IEEE Sensors Journal, 14(11), 3944–3954. https://doi.org/10.1109/JSEN.2014.2358567.
Aderohunmu, F. A., Deng, J. D., & Purvis, M. K. (2011). A deterministic energy-efficient clustering protocol for wireless sensor networks. In Proceedings of the 7th international conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP ‘11) (pp. 341–346). IEEE, https://doi.org/10.1109/issnip.2011.6146592.
Mittal, N., & Singh, U. (2015). Distance-based residual energy-efficient stable election protocol for WSNs. Arabian Journal of Science and Engineering, 40(6), 1637–1646. https://doi.org/10.1007/s13369-015-1641-x.
Mittal, N., Singh, U., & Sohi, B. S. (2016). A stable energy efficient clustering protocol for wireless sensor networks. Wireless Networks, 23, 1809–1821. https://doi.org/10.1007/s11276-016-1255-6.
Manjeshwar, A., Agrawal, D. P. (2002). APTEEN: A hybrid protocol for efficient routing and comprehensive information retrieval in wireless sensor networks. In International parallel and distributed processing symposium, Florida (pp. 195–202).
Adnan, Md. A., Razzaque, M. A., Ahmed, I., & Isnin, I. F. (2014). Bio-mimic optimization strategies in wireless sensor networks: A survey. Sensors, 14, 299–345. https://doi.org/10.3390/s140100299.
Hussain, S., & Matin, A. W. (2006). Hierarchical cluster-based routing in wireless sensor networks. In IEEE/ACM International conference on Information Processing in Sensor Networks, IPSN.
Mittal, N., Singh, U., & Sohi, B. S. (2018). An energy aware cluster-based stable protocol for wireless sensor networks. Neural Computing and Applications. https://doi.org/10.1007/s00521-018-3542-x.
Gupta, I., Riordan, D., & Sampalli, S. (2005). Cluster-head election using fuzzy logic for wireless sensor networks. In 3rd Annual communication networks and services research conference (pp. 255–260).
Ran, G., Zhang, H., & Gong, S. (2010). Improving on LEACH protocol of wireless sensor networks using fuzzy logic. Journal of Information and Computational Science, 7(3), 767–775.
Kim, J. M., Park, S. H., Han, Y. J., & Chung, T. M. (2008). CHEF: Cluster head election mechanism using fuzzy logic in wireless sensor networks. In 10th International conference on advanced communication technology, Vol. 1 (pp. 654–659).
Sert, S. A., Bagci, H., & Yazici, A. (2015). MOFCA: Multi-objective fuzzy clustering algorithm for wireless sensor networks. Applied Soft Computing, 30, 151–165.
Tomar, G. S., Sharma, T., & Kumar, B. (2015). Fuzzy based ant colony optimization approach for wireless sensor network. Wireless Personal Communication, 84, 361–375.
Tamandani, Y. K., & Bokhari, M. U. (2015). SEPFL routing protocol based on fuzzy logic control to extend the lifetime and throughput of the wireless sensor network. Wireless Networks, 22(2), 647–653.
Obaidy, M. Al., & Ayesh, A. (2015). Energy efficient algorithm for swarmed sensors networks. Sustainable Computing: Informatics and Systems, 5, 54–63.
Mittal, N., Singh, U., Salgotra, R., & Bansal, M. (2019). An energy efficient stable clustering approach using fuzzy enhanced flower pollination algorithm for WSNs. Neural Computing and Applications. https://doi.org/10.1007/s00521-019-04251-4.
Armin, M., Sayyed, M. M., & Mostafa, M. (2019). FMCR-CT: An energy-efficient fuzzy multi cluster-based routing with a constant threshold in wireless sensor network. Alexandria Engineering Journal, 58(1), 127–141.
Radhika, S., & Rangarajan, P. (2019). On improving the lifespan of wireless sensor networks with fuzzy based clustering and machine learning based data reduction. Applied Soft Computing Journal, 83, 1–9.
Thangaramya, K., Kulothungan, K., Logambigai, R., Selvi, M., Ganapathy, S., & Kannan, A. (2019). Energy aware cluster and neuro-fuzzy based routing algorithm for wireless sensor networks in IoT. Computer Networks. https://doi.org/10.1016/j.comnet.2019.01.024.
Komaki, G. M., & Kayvanfar, V. (2015). Grey Wolf Optimizer algorithm for the two-stage assembly flow shop scheduling problem with release time. Journal of Computational Science, 8, 109–120.
Kamboj, V. K., Bath, S. K., & Dhillon, J. S. (2016). Solution of non-convex economic load dispatch problem using Grey Wolf Optimizer. Neural Computing and Applications, 27(5), 1301–1316.
Medjahed, S. A., Saadi, T. A., Benyettou, A., & Ouali, M. (2016). Gray Wolf Optimizer for hyperspectral band selection. Applied Soft Computing, 40, 178–186.
Tizhoosh, H. R. (2005). Opposition-based learning: a new scheme for machine intelligence. In Computational intelligence for modelling, control and automation, 2005 and international conference on intelligent agents, web technologies and internet commerce, Vol. 1 (pp. 695–701).
Yusof, Y., & Mustaffa, Z. (2015). Time series forecasting of energy commodity using grey wolf optimizer. In Proceedings of the international multi-conference of engineers and computer scientists, Vol. 1 (pp. 18–20).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interests regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mittal, N., Singh, U., Salgotra, R. et al. An energy efficient stable clustering approach using fuzzy extended grey wolf optimization algorithm for WSNs. Wireless Netw 25, 5151–5172 (2019). https://doi.org/10.1007/s11276-019-02123-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-019-02123-2