
Abstract
A network of wireless sensors (WSN) is an outstanding technology that can aid in the various applications. Batteries run the sensor nodes those are used in WSN. The battery is impossible to charge or repair, so the most valuable resource for wireless sensor networks is power. Over the years, several strategies have been invented and used to preserve this precious WSN resource. One of the most successful approach for this purpose has turned out to be clustering. The aim of this paper is to suggest an effective technique for choosing cluster heads in WSNs to increase the lifetime of the network. To accomplish this task, Grey Wolf Optimizer (GWO) technique has been used. The general GWO was updated in this paper to meet the particular purpose of cluster head selection in WSNs. In this article, we have considered eleven attributes in the fitness function for the proposed algorithm. The simulation is carried out under different conditions. The results obtained show that the proposed protocol is superior in terms of energy consumption and network lifetime by evaluating the proposed protocol (i.e. CH-GWO protocol) with some well-existing cluster protocols. The suggested protocol forms energy-efficient and scalable clusters.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Facts have proved that a wireless sensor network (WSN) is one of the most promising reception mechanisms. WSN gives an opportunity to process and transmit data from the remote environment to the Base Station (BS) (Akyildiz et al. 2002). In WSN BS acts as a central node or central data processing node. They found use in various tasks such as forwarding of data, broadcasting of information, and routing of the network to transmit the information from one place to another. Typical WSN includes hundreds of less sized and fixed power battery sensor nodes and all the nodes are independent to other nodes for sensing and performing the operations over data. These sensor nodes are usually deployed in remote areas, so the battery cannot be easily replaced. So it is very difficult to recharge the batteries of the deployed sensor nodes in remote areas. In traditional WSNs all the nodes are directly connected to the BS node. When any nodes sensed information from their surroundings, forward this information to the BS node. This technique losses energy of the nodes very fast. This is where energy-saving work in wireless sensor networks plays an important role. To maintain WSN, it is important to decrease energy consumption in data transmission. To achieve low power consumption in data transmission, clustering gives an effective and simple enough way to maintain this. Clustering divides nodes into clusters and the representation of data transmission in WSN using clustering is shown in Fig. 1. In the past few decades, various hierarchical clustering algorithms for topology control have been proposed in the literature. Specifically, LEACH gets the best attention in all hierarchical clustering approaches for maintaining the best topology for data transmission (Senthil et al. 2014). LEACH focuses on randomly selecting cluster head nodes in a round-robin manner, and the energy load of the entire network is evenly distributed to each sensor node (Kaur and Seehra 2014). It also focuses on the improvement of the overall network life cycle. However, the randomness involved in the selection of cluster heads in LEACH leads to the imbalance of remaining energy between nodes, and also leads to the earlier death of some sensor nodes in the network (Noori and Khoshtarash 2013). In addition, a centralized LEACH (LEACH-C) is proposed as an extended version of LEACH, in which the selection of the best cluster head node is achieved by executing a simulated annealing algorithm (Gupta and Sharma 2014).

Clustering process in WSN
In essence, the cluster is to group multiple nodes of the WSN and inveterate transmission. Communication is carried out between the group and the BS node. In each group, there is one leader who communicates to the BS called the cluster head (CH) (Younis et al. 2006; Abbasi and Younis 2007). Clusters selection and the corresponding CH itself is an arduous and difficult task. Over the years, many approaches have been applied to the best choice of CHs selection. In past times, various approaches (Kulkarni et al. 2011) have been used to choose optimal combination CH groups over the randomly deployed network. Several optimization approaches give a better analysis in the selection of optimal CHs. These approaches contain various applications including IoT (Verma and Bhardwaj 2022), underwater sensors (Kumar et al. 2020), Energy-balanced hybrid depth-based routing protocol for underwater wireless sensor networks (Kumar et al. 2021), cloud computing (Kumar et al. 2022), and types of ant colony optimization (Ye and Mohamadian 2014), and so on.
This paper uses Grey Wolf Optimizer (GWO) approach (Mirjalili et al. 2014) to give the solution of the set of optimal cluster head selection problems. The solution of the cluster head selection problem is calculated by simulating the grey wolf itself. Alpha is the best solution; the rest is the subsequent level of the solution.
The rest of this article is organized as follows: Summarization of the related work done in the cluster field so far is discussed in Sect. 2. Section 3 contains a detailed explanation of the GWO approach. Section 4 contains information related to the radio model and assumptions about the network are described. Attributes used in the proposed fitness function detail discussion is in Sect. 5. The proposed approach analysis is discussed in Sect. 6. Section 7 introduces the simulation results. Section 8 contains the conclusion and future scope.
2 Literature survey
To provide a powerful businesslike approach towards a WSN is a difficult task in the current environment. So there is a need for such an approach that gives a long duration to the WSN network in the data collection or communication. Because in traditional network data communication is done by the direct, which is not efficient direct communication limits the lifetime of the WSN because it consumes more energy to transmit the data to the Base Station (BS). To overcome this limitation clustering approaches give a better understanding. Various clustering approaches are suggested by many researchers (Heinzelman et al. 2002; Younis and Fahmy 2004a; Baker et al. 1984). Several work has been done to aggregate data on a wireless sensor network, which reduces power consumption. Clustering in WSN is an efficient procedure for reducing the power consumption of sensor nodes. In cluster routing algorithms for wireless networks, LEACH is known for its simplicity and efficiency. In LEACH, CHs are randomly selected and all non-CHs are generated based on the received signal strength from the CHs. In LEACH, every node can become a CH, there is no CH selection scheme, and all nodes have the same chance of becoming a CH, so LEACH is ineffective. The CHs are chosen at random, and the energy is distributed equally among all the nodes. CHs collect all sensed information from its cluster (Heinzelman et al. 2002). LEACH protocol used clustering for exchanging the information from one sensor to another. It makes a cluster by considering the signal strength of the sensors. In LEACH every cluster send the data to BS after performing aggregation over the data. CH is selected periodically among the cluster nodes. It forms a cluster based on individual perception of the nodes and this type of clustering is belongs to distributed category. In this approach, every CH has a direct link to the sink. In LEACH protocol some limitations are that CHs distribution are not uniformly and according to this theory energy consumption of each CHs are equal so the nonuniform distribution of CHs limits the lifetime of the network. To overcome this limitation another protocol low energy adaptive clustering hierarchy- centralized (LEACH-C) is given by another researcher. LEACH-C (Heinzelman et al. 2002) selects CHs based on the residual energy of the nodes and average energy of the network, suggest better clustering as compare to the LEACH. In LEACH-C a node is only eligible for acts as a CHs if its remaining energy is higher than the average residual energy of the whole network.
All existing approaches require either knowledge of network density or uniform dispersion of nodes in the field. An article (Younis and Fahmy 2004b) offers hybrid energy-efficient distributed clustering (HEED). HEED makes no assumptions about the network, such as density and size. Each node operates individually in HEED protocol. At the end of the process, each node becomes either a cluster head or a child with respect to the cluster head. The residual energy of the node is the first parameter when choosing the cluster header, and the proximity to its neighbors or the degree of the node is the second. HEED generates a single-level hierarchical clustering structure for intra-cluster communication. HEED is also not giving the guarantee that the selected number of elected CHs would be optimum. In (Lee 1995; Sakya 2020), a hybrid approach to aggregation based on clusters is presented, which adaptively selects the appropriate data aggregation function. This document shows the improvement in power consumption versus target speed. Dynamic clustering shows the best performance at high target speeds. Energy-Efficient Hierarchical Clustering Protocol (DWEHC) (Ding et al. 2005) based on distributed weights is an improvement of HEED. Even if there are some similarities, such as the density and size independent of WSN, the remaining energy is used as the main parameter, but it will The size of the generated CH balance does not overlap. HEED also has some disadvantages. However, HEED provides a good CH distribution, but because the tentative CH is not selected as the CH in the end, there are some undiscovered nodes. According to the implementation of HEED, these nodes are forced to become CH, so it may not be any associated node or maybe in the area of other CHs, resulting in higher CH generation and consuming unbalanced energy. Since a large number of control messages are generated in the iterative process, both HEED and DWEHC will generate a lot of overhead. In (Demirbas et al. 2004) another approach is suggested, gives the approximately equal size and non-overlapped clusters are called Fast LOCal Clustering (FLOC). This condition is met: a node with a distance greater than m hops from the CH cannot be connected to the CH, and a node with a one-hop distance from the CH is always connected to the CH.
In heuristic clustering approaches another algorithm is added by the one researcher, which oversees the unbalanced energy consumption in WSN is called energy-efficient clustering algorithms (EECS) (Ye et al. 2005). To determine CH, three functions and a weighted cost factor are required. Another modified variant of EECS is energy efficiency unequal clustering (EEUC) (Yuan et al. 2011), which takes into account certain restrictions of EECS, for example, for computing the CH cost each node should be entertain. Since the CH needs to transmit control packets through high transmission power, and the node needs to maintain information about the CH, the CH and the node have a reason for wasting energy. In article (Kumar et al. 2009) another heuristic clustering approach is discussed is called the energy-efficient heterogeneous clustering scheme of the wireless sensor network (EEHC). In this approach weighted potential probability can be decided on the basis of the residual energy of each node. The Super Heterogeneous Protocol for Balanced Energy Saving Network Integration (BEENISH) (Qureshi et al. 2013) gives clustering by considering the remaining power level of specific sensors. In the BEENISH protocol, four power levels are considered to provide efficient clustering in WSNs. In article (Yi et al. 2007) power-efficient and adaptive clustering hierarchy (PEACH) is introduced by researchers, which supports location-aware as well as location unaware WSNs and also gives the facility to do multi-level clustering. Using some of the attributes in Table 1, some heuristic algorithms have been compared with the proposed algorithm.
In recent studies, optimization approaches give good performance in clustering (Camilo, et al. 2006; Zeng and Dong 2016). Particle Swarm Optimization (PSO) is a way to increase the lifetime of the network. The algorithm proposes to construct paths and distribute routing data through clusters near base stations or the heads of gateway nodes to maximize the network time axis.
Genetic Algorithm (GA) belongs to optimization (Jin et al. 2003), which can be used for clustering to provide an efficient solution in CHs selection. The algorithm can be changed by selecting many other attributes in the function (Ferentinos et al. 2005), as selecting a single of the two signal ranges from normal sensors, the state of the sensor node, and selecting the appropriate channel. GA (Lee et al. 2007) can be select best topology management to obtain less power consumption and achieve balance.
A GWO-based protocol is proposed, which is called Improved Gray Wolf Optimization Based on Fitness Value (FIGWO) (Zhao et al. 2018). CHs are selected on the basis of the fitness function value. In the FIGWO approach, CHs are selected based on the fitness function value of each node, nodes have the highest energy and nearest to the BS get a chance to become a CHs. In addition, the distance to sending data is recalculated every time when a new CH is selected. However, it suffers from load balancing between CHs.
The suggested model (Yadav et al. 2023a) employs a modified secure routing protocol and cluster-based method to reduce network load and overhead while enhancing network security and performance. The method of re-selection for cluster head is minimized by using two key variables as the contribution level and stability factor for the selection of the cluster head. The network’s security is increased by adding nodes while utilizing authentication and the Modified Secure Routing Protocol. With the aid of fuzzy logic, this work (Yadav et al. 2023b) proposes the Stable On-Demand Multiple-Path Routing Protocol (SODRP) for MANET, which is an efficient yet lightweight protocol. The suggested protocols offer a fresh approach for getting around stability on demand by improving the performance and efficiency of packet delivery ratio, delay, and control overhead.
In this article, the protocol is proposed to provide efficient clustering in the WSNs using GWO. There are certain reasons for selecting the GWO instead of another heuristic as well as metaheuristic approaches. Primary objective: GWO converges faster; Secondary objective is: Fewer decision variables and it avoids local optima.
3 Grey wolf optimizer
GWO is a meta-heuristic algorithm that can solve many optimization problems. GWO drew inspiration from the leadership that naturally exists in the hunting mechanism of gray wolves. It is the most studied algorithm (Mirjalili et al. 2014) and a new optimization method compared to other optimization methods. In terms of implementation and use, the algorithm is similar to the genetic algorithm. In this article (Mirjalili et al. 2014), algorithm mathematical equations have come from the pack hunting mechanisms observed patterns. Then, adapt the equation to the current problem to find an optimal feasible solution.
Candidate solutions can also be categorized based on gray Wolves’ social dominance hierarchy. Therefore, alpha (α) contains the best and most optimized solution, where beta (β) and delta (δ) form the second and third best solutions, accordingly (Mirjalili et al. 2014). All other solutions are omega (Ω) solutions and are the most unsuitable solutions. Alpha (α) solutions are those solutions that are the best optimized and fittest in the pack. Beta (β) solutions are the second most appropriate solution in the pack, and delta (δ) solutions are the third most suitable solution. All the remaining solutions from the alpha (α), beta (β), and delta (δ) come in the omega (Ω) solutions in the pack. The optimization process is based on the hunting process, and it works over the guidance of α, β, δ, and Ω parameters.
During the hunt, the gray wolf surrounds its prey (Mirjalili et al. 2014). This enclosed behaviour of wolves can be described mathematically as:
where \(\overrightarrow{A}\) and \(\overrightarrow{K}\) are coefficient vectors and calculated by using Eq. 3 and 4 respectively, current iteration is denoted by t, \({\overrightarrow{Y}}_{p}\) represents prey vector position, \(\overrightarrow{Y}\) represents grey wolf vector position.
where \(\overrightarrow{{r}_{1}}\) and \(\overrightarrow{{r}_{2}}\) denotes two random vectors and the value of these two random vectors should be in between 0 and 1, \(\overrightarrow{b}\) components decreases its value from 2 to 0 when iteration is repeated.
where \(\overrightarrow{A}\) and \(\overrightarrow{K}\) are coefficient vectors and calculated by using Eq. 3 and 4 respectively, current iteration is denoted by t, \({\overrightarrow{Y}}_{p}\) represents prey vector position, \(\overrightarrow{Y}\) represents grey wolf vector position, \(\overrightarrow{{r}_{1}}\) and \(\overrightarrow{{r}_{2}}\) denotes two random vectors and the value of these two random vectors should be in between 0 and 1, \(\overrightarrow{b}\) components decreases its value from 2 to 0 when iteration is repeated.
In this process, the location of the prey is presumed to be unknown. The search process is led by the best alpha and beta candidate solutions and the least relevant member (i.e., omegas updates its position based on the information provided by the best search agent) (Mirjalili et al. 2014) alpha and beta. The mathematical description is modelled in Eqs. 5–11 for this purpose.
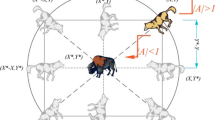
The attack is the final step in the hunting process. The above operators can be used to mathematically define the attacking process. This is accomplished by lowering the value of \(\overrightarrow{Z}\) and lowering the range of variation of \(\overrightarrow{A}\) to [− 2a, 2a], while `a` is reduced from 2 to 0 over iterations. The position of the search agent will be between the current position and the prey’s position if the values of \(\overrightarrow{A}\) are in the range [− 1, 1]. The wolves attack the prey if |A| is 1. As can be seen, the search agents adjust their positions based on the positions of the alpha, beta, and delta members using the GWO algorithm.
4 Energy model and presuppositions
4.1 System model
In WSN, the sensor nodes senses the environment near to it and sends data to the corresponding CH, and the CH sends the aggregated information to the receiver after collecting the information. For this kind of transmission, to adjust the power consumption, we need representation. As shown in Fig. 2, we have adopted an ordinary model of hardware energy consumption and required assumptions for simulation is described in Table 2.

Energy model
We assume that fading is in multipath and free-space for experimental purposes, and depends on the distance from the transmitter to the receiver node. For example, if the transmission distance is smaller than the threshold d0, the power amplifier can decrease the power loss and control the power, only the free space model is used, and if its value is larger than the threshold, then multipath model is used for data transmission. To transmit p bit data at distance d, required energy is:
Energy consumption to transmit the p bit data at transmitter end:
Energy consumption to receive the p bit data at receiver end:
Optimal number of CHs are calculated for the simulation is as (Heinzelman et al. 2002) by Eq. 15:
4.2 Presuppositions
-
1.
Nodes are distributed randomly in a 2 dimensional space.
-
2.
All nodes become stationary after a deployment.
-
3.
All nodes are homogeneous.
-
4.
Sensor nodes sense the data from its surrounding and communicate the sensed information to the respective CHs.
-
5.
BS has infinite energy for communication.
-
6.
Sensor nodes can change their mode from active to sleep and sleep to active.
5 Attributes used in fitness function
In WSN, there are several attributes those are useful in data collection. We’re looking at 11 attributes. Among these, few in nature are beneficiaries and few are non-beneficiaries. Beneficiary criteria need a higher value for energy conservation, but a lower value for non-beneficiary criteria is good for having the best solution. In Table 3 definition of the attributes is located.
5.1 Coverage_of_CHs
This indicates the percentage of sensor nodes whose distance from the corresponding CH is less than or equal to d0. Its maximum value confirms that a large number of nodes are nearer to the respective CH. This confirms that the demand of electricity will be decreased. The formula for the estimation is:
where \({d}_{0}=\sqrt{\frac{{\varepsilon }_{fs}}{{\varepsilon }_{mp}}}\), \({Distance}_{\left({Node}_{v}-CHs\right)}\) shows distance in between nodes and CHs & \({Count\_Nodes}_{v}\) count number of nodes \(v\).
5.2 CH_BS_Bearing
This indicate that how many CHs in total have a distance less than d0 from the BS. A higher value indicates that the distance from the selected CH to the receiver is shorter, which means that the less power is required for data transmission from CH to BS. The formula for the estimation is:
where \(\left({Distance}_{{(CH}_{v}-BS)}\right)\) indicates CH ‘\(v\)’ to BS distance, \(Count\_{CHs}_{v}\) indicate count number of CHs, \(Tot\_Optimal\_CHs\) shows optimal number of CHs.
5.3 Avg_Eresidual
This indicate the average value of the remaining power of CHs. The larger value of this attribute indicates that the selected CHs have higher remaining energy, which means that more information can be collected and sent to the BS by using these CHs. The calculation formula is:
where \(Eresidual\_{CH}_{v}\) shows selected CH remaining energy.
5.4 BS_Max_Distance
It demonstrates the maximum distance to the sink from any selected CH. Its minimum value shows that all CHs are needed to transmit information below this distance. This implies that total power consumption is limited. It is determined as:
5.5 CHs_Avg_Distance
It demonstrate the mean value of the distances between all sensors and the respective CHs. Its smaller value means that the data packet requires a shorter distance to be transmitted. It also demonstrates the lower dissipation of electricity. It is determined as:
5.6 BS_Avg_Distance
The mean value of all the distances from the chosen CHs to the BS is shown. The lower value means the CHs are closer to the BS. It is determined by its value as:
5.7 Node_Energy
This demonstrates the energy needed by the sensors to transmit the data to the correspondence CHs. The lower value of this factor indicates that the maximum total number of nodes is closer to their correspondence CH. It is determined by its value as:
where \({E}_{T({Node}_{v}-CH)}\) shows energy required to transmit the data from node \(v\) to respective CHs.
5.8 CH_Energy
This demonstrates the energy needed by the CHs to transmit the data to the BS. The lower value of this factor indicates that the maximum total number of CHs is closer to the BS. It is determined by its value as:
where \({E}_{T({CH}_{v}-BS)}\) shows energy required to transmit the data from CH \(v\) to BS.
5.9 CHs_Avg_lifetime
The mean lifetime of CHs is shown. It illustrates how much time the CHs will continue the process of transmission. Large value means that more data can be processed by the CHs, meaning that CHs have more life. It is determined by its value as:
where \(Avg\_Transmission\_Energy\_required\) shows energy required to transmit the data from CH to BS.
5.10 Avg_Eres_of_Conn_CH
Connected CH is defined as the CHs those have a less distance from the BS. It measures the mean residual power of CHs those have a less distance to BS. The larger value of this factor indicates that the distances of the CHs to the BS is less than d0 and that the residual energy is higher. It is determined by its value as:
5.11 Avg_Eres_of_Disconn_CH
Disconnected CH is defined as the CHs those have a higher distance from the BS. It measures the mean residual power of CHs those have a higher distance to BS. The greater value of this factor means that the CHs that are far from the BS have higher energy, showing that CHs survival time will be longer. It is determined by its value as:
6 Proposed work
In this section, a detailed description of the proposed protocol is given. The process of clustering is divided into two parts: the selection step for CHs is the first segment, and the creation stage for clusters is the second segment.
6.1 CH selection
The selection of CH in the network is done through GWO technology. Usually, CHs are elected according to the parameters of the sensor network (such as distance from the BS, remaining energy of the sensor nodes and coverage of the sensor nodes). Choosing CHs through a single parameter will not be profitable for an effective communication process because the energy usage and lifetime of the entire network are also can influenced by several other competing factors. Therefore, certain other attributes considerations need to be addressed and there is also a need for cooperation between them. Eleven parameters as given in Table 4 are considered in this proposed protocol, i.e. CH-GWO, to elect the optimal CHs. All the sensor nodes sends their exact location and residual energy to the BS after the initialization of the network. BS runs a cluster protocol based on GWO. The fitness function is just established based on 11 considered attributes as given (Rajpoot and Dwivedi 2019), Coverage_of_CHs, CH_BS_Bearing, Avg_Eresidual, BS_Max_Distance, CHs_Avg_Distance, BS_Avg_Distance, Nodes_Energy, CH_Energy, CHs_Avg_lifetime, Avg_Eres_of_Conn_CH, Avg_Eres_of_Disconn_CH.
The primary aim of the CH-GWO is to select the CHs in the network to extend the life of the network. Eleven factors are considered to effectively select the CHs. The GWO approach (Mirjalili et al. 2014) is used to provide the optimal lifetime and balanced energy consumption by choosing the best set of CHs. The coordination between these factors verifies that the balance between conflicting attributes helps to create favorable conditions for optimal energy consumption. Instead of minimizing each fitness function Eq. (16–26) separately, minimize the combination of these considered factors by using fitness function Eq. 27.
where \({k}_{1}, {k}_{2}, {k}_{3}, {k}_{4}, {k}_{5, }{k}_{6}, {k}_{7}, {k}_{8}, {k}_{9}, {k}_{10}, {k}_{11}\) are constant weights of the considered attributes and \({k}_{1}+{k}_{2}+{k}_{3}+{k}_{4}+{k}_{5}+{k}_{6}+{k}_{7}+{k}_{8}+{k}_{9}+{k}_{10}+ {k}_{11}=1\) and weightage of each attribute for optimal CHs set selection is mentioned in Table 5. Based on specific observations and experimentation, we have given 72 percent weightage to the beneficial attributes, and the remaining 28 percent weightage is distributed among the non-beneficial attributes. The sum of the overall weights of the considered attributes should be one.
6.2 Cluster formation
After receiving the notification of the CHs, the member node selects the nearest CH and uses the CSMA MAC protocol to reply the Join packet to the corresponding CH. It also measures the distance between the member node and the respective CH.
The sensors can be scheduled to sense the atmosphere at various samples or time intervals at the sensor node level and sleep as much as possible to save power of the batteries. Although some information may be lost, this is an efficient way of maximizing the lifetime of the sensor nodes (Sridhar et al. 2008). If the distance between the member node and the CH is greater than the distance between it and the BS, the member node can interact directly with the BS at a fixed time slice. Otherwise, to form a cluster, it will join the cluster based on the closest distance (Euclidean distance). Use the distance matrix MD (m × n) to re-cluster nodes according to the distance of the selected cluster head, as Eq. 28.
where d is a Euclidean distance between a node location and a CH location. If a (x, y) and b (x, y) are two nodes then Euclidean distance between these nodes are calculated by using Eq. 29:
Each value di, j in MD matrix is a distance value of the ith cluster head and the jth node. The column containing the minimum value indicates the cluster number to be joined by the corresponding node. For example, if dCh1, y2 is the minimum value in the second column, then in this case, node y2 will associated with that cluster whose cluster head is Ch1.
Working model or framework of proposed clustering protocol is as Fig. 3:

Proposed energy efficient clustering protocol working model
Once a cluster is created, CH assigns a time slot for each member after receiving all CH join emails from all nodes. The responsibility for collecting data from all nodes in the cluster are of respective CHS. The CH sends the frames to the base station after applying data aggregation while collecting data frames from all members. While the cluster member nodes can enter sleep mode when those have not any data to sense, the CH must remain in active condition. It should be noted that in the LEACH protocol, the re-clustering technique is often followed where CHs are chosen using the probabilistic approach instead of a deterministic method. The re-clustering and data transfer process will continue for several rounds until all the nodes not get die.
6.3 Algorithm
GWO technique gives faster convergence and it also uses few variables and avoids to stick in local minima. On the basis of these properties we used this algorithm in warless sensor network to select the optimal CHs. The pseudo code of the proposed CH-GWO algorithm is described below:
Input: Number of alive sensor nodes in each round.
Number of groups: Ng.
Number of CHs in a group: Calculated based on equation 15 from the alive nodes whose remaining energy is higher than the average remaining energy of the all nodes.
Output: Optimal CHs set

7 Simulation and results
The experimentation of proposed CH-GWO based CH selection in WSN is carried out using MATLAB, which can provide practicality and effective modeling of WSN. As specified in Heinzelman et al. (2002), it uses the same operating model and round operation method. Each round covers two things, the primary is clustering, and secondary one is data transmission. GWO approach selects CHs in the clustering phase from the active sensor nodes, and in the data transmission, cluster members transmit their sensed data to respective CHs. Finally, the CHs send that information to the sink node after conducting the aggregation.
In this type of modeling, the number of rounds is a parameter to compare the network’s performance. The first_N_dead means at which round the first sensor nodes get to die. The Half_N_dead means that round 50 percent of the sensor nodes die. The Net_dead implies that 90 percent of the sensors die. Network dead means that WSN eventually runs out of the data collection process when this condition is satisfied. Here, using the three parameters mentioned, the suggested approach is compared with several existing methods. At the start of the network, all nodes have sufficient energy to transmit data to the respective CHs, but as a number of rounds pass, the power of the nodes falls. After passing some rounds, all nodes have less remaining energy than the starting rounds of the operation, so the numbers of dead nodes after passing some rounds are more compared to the starting round of the process. When the network executes last rounds, numbers of dead nodes are larger as compare to first_N_dead and Half_N_dead comes under Net_dead. So based on these parameters values deviation occurs in ‘first_N_dead and Half_N_dead’, ‘Half_N_dead and Net_dead’. We also compare the outcomes produced in WSN by various existing CHs selection approaches. Comparing the first_N_dead, Half_N_dead, and Net_dead values for different algorithms, first_N_dead means that the first node dies at what round, while the Half_N_dead and Net_dead round values show the round when half of the network nodes die and the round when the whole network dies.
The comparisons were made between five algorithms for scenario numbers 1–6. These scenarios are described in Table 6. Table 7 shows the algorithms and corresponding simulation abbreviations, and the generated results are shown using Figs. 4, 5, 6, 7, 8, 9.

Scenario 1 comparison graph

Scenario 2 comparison graph

Scenario 3 comparison graph

Scenario 4 comparison graph

Scenario 5 comparison graph

Scenario 6 comparison graph
The results show that with CHGWO, the algorithm has certain advantages when considering 11 attributes. CHGWO always gives the best result for the scenario when we see the results produced by the proposed CHGWO algorithm for scenario (1–6). Current approaches in some cases have decent performance for few comparison parameters, but overall proposed algorithm gives better results for each scenario.
The FIRST-N-DEAD value in one existing algorithm is better than the proposed algorithm in scenario 5, but the values of the other two comparison parameters HALF_N_DEAD and NET_DEAD are worse. In this scenario, the CHs are chosen in a way that, they have the shortest distance from the node but according to the other parameters they are not fine. Our aim is to balance the overall consumption of energy, so we focus in a combined way on all the parameters. For all three FIRST N DEAD, HALF N DEAD and NET DEAD comparison parameters, we need the optimal value. Finally, we can assume that, by using GWO, the proposed algorithm is better in all aspects.
The detailed results review as well as the use of simulation has proven this proposed CHGWO approach gives better results in all aspects. This also decreases the downside of data missing from such specific areas because of the dead nodes. Proposed CHGWO provides balanced energy consumption at all areas, thereby it reduces the probability of dead nodes from one specific area, but other algorithms may encounters with this problem.
8 Conclusion
The GWO is a relatively new technique with a wide variety of possibilities open for its improvement. CHs election and cluster formation approach is discussed in this article. A proper fitness function is built that takes into account important network parameters. For the six typical scenarios of the BS case, the results were compared, and the GWO was found to produce consistently better results compared to the existing GWO-C, FIGWO, LEACH and LEACH-C. Three basic metrics of FIRST_N_DEAD, HALF_N_DEAD, and NET_DEAD were checked for the performance for all six scenarios. In all the cases and in all the metrics, the GWO was able to have better performance. The suggested work for the WSNs with static sensor nodes was idealized, implemented, and evaluated. Furthermore, the work can be applied to networks with mobile sensor nodes, i.e. sensors that can alter their real-time locations.
References
Abbasi AA, Younis M (2007) A survey on clustering algorithms for wireless sensor networks. Comput Commun 30(14–15):28262841
Agrawal D, Wasim Qureshi MH, Pincha P, Srivastava P, Agarwal S, Tiwari V, Pandey S (2020) GWO-C: grey wolf optimizer-based clustering scheme for WSNs. Int J Commun Syst 33(8):e4344
Akyildiz IF, Su W, Sankarasubramaniam Y, Cayirci E (2002) Wireless sensor networks: a survey. Comput Netw 38(4):393–422
Baker D, Ephremides A, Flynn J (1984) The design and simulation of a mobile radio network with distributed control. IEEE J Sel Areas Commun 2(1):226–237
Camilo T, et al (2006) An energy-efficient ant-based routing algorithm for wireless sensor networks. In: International workshop on ant colony optimization and swarm intelligence. Springer Berlin Heidelberg
Demirbas M, Arora A, Mittal V (2004) FLOC: a fast local clustering service for wireless sensor networks. Workshop on dependability issues in wireless ad hoc networks and sensor networks (DIWANS/DSN 2004), pp 1–6
Ding P, Holliday JA, Celik A (2005) Distributed energy-efficient hierarchical clustering for wireless sensor networks, distributed computing in sensor systems. Springer, Berlin, pp 466–467
Ferentinos KP, Tsiligiridis TA, Arvanitis KG (2005) Energy optimization of wirless sensor networks for environmental measurements. In: Proceedings of the international conference on computational intelligence for measurement systems and applicatons (CIMSA), vol 51, pp 1031–1051
Gupta V, Sharma SK (2014) Cluster head selection using modified ACO. Adv Intell Syst Comput 1(1):11–20
Heinzelman WB, Chandrakasan AP, Balakrishnan H (2002) An application-specific protocol architecture for wireless microsensor networks. IEEE Trans Wireless Commun 1(4):660–670
Jin S, Zhou M, Wu AS (2003) Sensor network optimization using a genetic algorithm. In: Proceedings of the 7th world multiconference on systemics, cybernetics and informatics, pp 109–116
Kaur H, Seehra A (2014) Performance evaluation of energy efficient clustering protocol for cluster head selection in wireless sensor network. Int J Peer to Peer Netw 5(3):1–13
Kulkarni RV, Forster A, Venayagamoorthy GK (2011) Computational intelligence in wireless sensor networks: a survey. IEEE Commun Surv Tutor 13(1):68–96
Kumar D, Aseri TC, Patel RB (2009) EEHC: energy efficient heterogeneous clustered scheme for wireless sensor networks. Comput Commun 32(4):662–667
Kumar R, Bhardwaj D, Mishra MK (2021) EBH-DBR: energy-balanced hybrid depth-based routing protocol for underwater wireless sensor networks. Mod Phys Lett B 35(03):2150061
Kumar R, Bhardwaj D, Mishra MK (2020) Enhance the lifespan of underwater sensor network through energy efficient hybrid data communication scheme. In: 2020 International conference on power electronics and IoT applications in renewable energy and its control (PARC), IEEE, pp 355–359
Kumar R, Bhardwaj D, Joshi R (2022) Adaptive bat optimization algorithm for efficient load balancing in cloud computing environment. In: Advances in computational intelligence and communication technology: proceedings of CICT 2021. Singapore, Springer Singapore, pp 357–369
Lee WC (1995) Mobile Cellular Telecommunications. McGraw Hill, NY
Lee D, Lee W, Kim J (2007) Genetic algorithmic topology control for two-tiered wireless sensor networks. Computational Science-ICCS 2007, Springer, pp 385–392
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Noori M, Khoshtarash A (2013) BSDCH: new chain routing protocol with best selection double cluster head in wireless sensor networks. Wirel Sens Netw 05(02):9–13
Qureshi TN, Javaid N, Khan AH, Iqbal A, Akhtar E, Ishfaq M (2013) BEENISH: balanced energy efficient network integrated super heterogeneous protocol for wireless sensor networks. Proced Comput Sci 19:920–925
Rajpoot P, Dwivedi P (2019) Multiple parameter based energy balanced and optimized clustering for WSN to enhance the Lifetime using MADM approaches. Wireless Pers Commun 106(2):829–877
Sakya S (2020) Design of hybrid energy management system for wireless sensor networks in remote areas. J Electr Eng Autom (EEA) 2(01):13–24
Senthil M, Rajamani V, Kanagachid G (2014) Energy-efficient cluster head selection for life time enhancement of wireless sensor networks. Inf Technol J 13(4):676–682
Sridhar P, Madni AM, Jamshidi MM (2008) Multi-criteria decision making in sensor networks. IEEE Instrum Meas Mag 11(1):24–29
Verma U, Bhardwaj D (2022) A secure lightweight anonymous elliptic curve cryptography-based authentication and key agreement scheme for fog assisted-Internet of things enabled networks. Concurr Comput: Pract Exp 34(23):e7172
Yadav AS, Singh A, Vidyarthi A, Barik RK, Kushwaha DS (2023a) Performance of optimized security overhead using clustering technique based on fuzzy logic for mobile ad hoc network. Cybern Inf Technol 23(1):94–109
Yadav AS, Rakesh N, Vidyarthi A, Barik RK, Singhal A, Kushwaha DS (2023b) Restoration and fuzzy logic-based formation of multipath routing protocol in MANET. Int J Syst Assur Eng Manag 14(Suppl 1):117–132
Ye M, Li C, Chen G, Wu J (2005) EECS: An energy efficient clustering scheme in wireless sensor networks. In: 24th IEEE international performance, computing, and communications conference IPCCC 2005, IEEE, pp 535–540
Ye Z, Mohamadian H (2014) Adaptive clustering based dynamic routing of wireless sensor networks via generalized ant colony optimization. Ieri Procedia 10:2–10
Yi S, Heo J, Cho Y, Hong J (2007) PEACH: power-efficient and adaptive clustering hierarchy protocol for wireless sensor networks. Comput Commun 30(14):2842–2852
Younis O, Fahmy S (2004a) HEED: a hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans Mob Comput 3(4):366–379
Younis O, Krunz M, Ramasubramanian S (2006) Node clustering in wireless sensor networks: recent developments and deployment challenges. IEEE Netw 20(3):20–25
Younis, O., & Fahmy, S. (2004). Distributed clustering in ad-hoc sensor networks: A hybrid, energy-efficient approach. In IEEE INFOCOM 2004 (Vol. 1). IEEE
Yuan HY, Yang SQ, Yi YQ (2011) An energy-efficient unequal clustering method for wireless sensor networks. In: 2011 International conference on computer and management (CAMAN), IEEE, pp 1–4
Zeng B, Dong Y (2016) An improved harmony search based energy-efficient routing algorithm for wireless sensor networks. Appl Soft Comput 41:135–147
Zhao X, Zhu H, Aleksic S, Gao Q (2018) Energy-efficient routing protocol for wireless sensor networks based on improved grey wolf optimizer. KSII Trans Internet Inf Syst 12(6):4
Funding
No funding fron any agencies.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lekhraj, Kumar, A. & Kumar, A. Load balanced and optimal clustering in WSNs using grey wolf optimizer. Int J Syst Assur Eng Manag 15, 2950–2964 (2024). https://doi.org/10.1007/s13198-024-02306-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-024-02306-x